如何求解参数的矩估与极大似然估计
数理统计7:矩法估计(MM)、极大似然估计(MLE),定时截尾实验

数理统计7:矩法估计(MM)、极⼤似然估计(MLE),定时截尾实验在上⼀篇⽂章的最后,我们指出,参数估计是不可能穷尽讨论的,要想对各种各样的参数作出估计,就需要⼀定的参数估计⽅法。
今天我们将讨论常⽤的点估计⽅法:矩估计、极⼤似然估计,它们各有优劣,但都很重要。
由于本系列为我独⾃完成的,缺少审阅,如果有任何错误,欢迎在评论区中指出,谢谢!⽬录Part 1:矩法估计矩法估计的重点就在于“矩”字,我们知道矩是概率分布的⼀种数字特征,可以分为原点矩和中⼼矩两种。
对于随机变量X⽽⾔,其k阶原点矩和k阶中⼼矩为a_k=\mathbb{E}(X^k),\quad m_k=\mathbb{E}[X-\mathbb{E}(X)]^k,特别地,⼀阶原点矩就是随机变量的期望,⼆阶中⼼矩就是随机变量的⽅差,由于\mathbb{E}(X-\mathbb{E}(X))=0,所以我们不定义⼀阶中⼼矩。
实际⽣活中,我们不可能了解X的全貌,也就不可能通过积分来求X的矩,因⽽需要通过样本(X_1,\cdots,X_n)来估计总体矩。
⼀般地,由n个样本计算出的样本k阶原点矩和样本k阶中⼼矩分别是a_{n,k}=\frac{1}{n}\sum_{j=1}^{n}X_j^k,\quad m_{n,k}=\frac{1}{n}\sum_{j=1}^{n}(X_j-\bar X)^k.显然,它们都是统计量,因为给出样本之后它们都是可计算的。
形式上,样本矩是对总体矩中元素的直接替换后求平均,因此总是⽐较容易计算的。
容易验证,a_{n,k}是a_k的⽆偏估计,但m_{n,k}则不是。
特别地,a_{n,1}=\bar X,m_{n,2}=\frac{1}{n}\sum_{j=1}^{n}(X_j-\bar X)^2=\frac{n-1}{n}S^2\xlongequal{def}S_n^2,⼀阶样本原点矩就是样本均值,⼆阶样本中⼼矩却不是样本⽅差,⽽需要经过⼀定的调整,这点务必注意。
第六章参数估计

113第六章 参数估计一、 知识点1. 点估计的基本概念2. 点估计的常用方法(1) 矩估计法① 基本思想:以样本矩作为相应的总体矩的估计,以样本矩的函数作为相应的总体矩的同一函数的估计。
(2) 极大似然估计法设总体X 的分布形式已知,其中),,,(21k θθθθΛ=为未知参数,),,(21n X X X Λ为简单随机样本,相应的),,,(21n x x x Λ为它的一组观测值.极大似然估计法的步骤如下:① 按总体X 的分布律或概率密度写出似然函数∏==ni i n x p x x x L 121);();,,,(θθΛ (离散型)∏==ni i n x f x x x L 121);();,,,(θθΛ (连续型)若有),,,(ˆ21nx x x Λθ使得);,,,(max )ˆ;,,,(2121θθθn n x x x L x x x L ΛΛΘ∈=,则称这个θˆ为参数θ的极大似然估计值。
称统计量),,,(ˆ21nX X X Λθ为参数θ的极大似然估计量。
② 通常似然函数是l θ的可微函数,利用高等数学知识在k θθθ,,,21Λ可能的取值范围内求出参数的极大似然估计k l x x x nl l ,,2,1),,,,(ˆˆ21ΛΛ==θθ 将i x 换成i X 得到相应的极大似然估计量k l X X X nl l ,,2,1),,,,(ˆˆ21ΛΛ==θθ 注:当);,,,(21θn x x x L Λ不可微时,求似然函数的最大值要从定义出发。
3. 估计量的评选标准(1) 无偏性:设),,(ˆˆ21nX X X Λθθ=是参数θ的估计量,如果θθ=)ˆ(E ,则称θˆ为θ的无偏估计量。
(2) 有效性:设1ˆθ,2ˆθ是θ的两个无偏估计,如果)ˆ()ˆ(21θθD D ≤,则称1ˆθ较2ˆθ更有效。
4. 区间估计114 (1) 定义 设总体X 的分布函数族为{}Θ∈θθ),;(x F .对于给定值)10(<<αα,如果有两个统计量),,(ˆˆ111n X X Λθθ=和),,(ˆˆ122n X X Λθθ=,使得{}αθθθ-≥<<1ˆˆ21P 对一切Θ∈θ成立,则称随机区间)ˆ,ˆ(21θθ是θ的双侧α-1置信区间,称α-1为置信度;分别称1ˆθ和2ˆθ为双侧置信下限和双侧置信上限. (2) 单侧置信区间(3) 一个正态总体下未知参数的双侧置信区间(置信度为α-1)二、 习题 1. 选择题(1) 设n X X X ,,,21Λ是来自总体X 的一个样本,则以下统计量①)(211n X X + ②)2(14321n X X X X X n ++++-Λ ③)2332(101121n n X X X X +++-作为总体均值μ的估计量,其中是μ的无偏估计的个数是A.0B.1C.2D.3(2) 设321,,X X X 是来自正态总体)1,(μN 的样本,现有μ的三个无偏估计量321332123211216131ˆ;1254131ˆ;2110351ˆX X X X X X X X X ++=++=++=μμμ其中方差最小的估计量是A.1ˆμB.2ˆμC. 3ˆμD.以上都不是 (3) 设0,1,0,1,1为来自0-1分布总体B(1,p)的样本观察值,则p 的矩估计值为 。
五种估计参数的方法

五种估计参数的方法在统计学和数据分析中,参数估计是一种用于估计总体的未知参数的方法。
参数估计的目标是通过样本数据来推断总体参数的值。
下面将介绍五种常用的参数估计方法。
一、点估计点估计是最常见的参数估计方法之一。
它通过使用样本数据计算出一个单一的数值作为总体参数的估计值。
点估计的核心思想是选择一个最佳的估计量,使得该估计量在某种准则下达到最优。
常见的点估计方法有最大似然估计和矩估计。
最大似然估计(Maximum Likelihood Estimation,简称MLE)是一种常用的点估计方法。
它的核心思想是选择使得样本观测值出现的概率最大的参数值作为估计值。
最大似然估计通常基于对总体分布的假设,通过最大化似然函数来寻找最优参数估计。
矩估计(Method of Moments,简称MoM)是另一种常用的点估计方法。
它的核心思想是使用样本矩和总体矩之间的差异来估计参数值。
矩估计首先计算样本矩,然后通过解方程组来求解参数的估计值。
二、区间估计点估计只给出了一个参数的估计值,而没有给出该估计值的不确定性范围。
为了更全面地描述参数的估计结果,我们需要使用区间估计。
区间估计是指在一定的置信水平下,给出一个区间范围,该范围内包含了真实参数值的可能取值。
常见的区间估计方法有置信区间和预测区间。
置信区间是对总体参数的一个区间估计,表示我们对该参数的估计值的置信程度。
置信区间的计算依赖于样本数据的统计量和分布假设。
一般来说,置信区间的宽度与样本大小和置信水平有关,较大的样本和较高的置信水平可以得到更准确的估计。
预测区间是对未来观测值的一个区间估计,表示我们对未来观测值的可能取值范围的估计。
预测区间的计算依赖于样本数据的统计量、分布假设和预测误差的方差。
与置信区间类似,预测区间的宽度也与样本大小和置信水平有关。
三、贝叶斯估计贝叶斯估计是一种基于贝叶斯理论的参数估计方法。
它将参数看作是一个随机变量,并给出参数的后验分布。
贝叶斯估计的核心思想是根据样本数据和先验知识来更新参数的分布,从而得到参数的后验分布。
2.2 矩估计和最大似然估计

求未知参数 ( , 2 ) 的矩估计量. 解 分别用样本均值 X 和二阶中心矩(未修正样本方
差) M 2* 估计 EX 和 DX ,得 和 2 的联立方程组:
1 2 X exp , 2 M * (e 1) exp2 2 . 2
于是,得 和 2 的矩估计量:
* 2 X M 2 2 , ˆ ln ˆ . ln 1 2 M* X 2 X 2
* 2 2
1 2
.
二、最大似然估计法
1、最大似然原理 一个试验有若干个可能的结果 A,B,C, ,若在一次 试验中结果 A 出现, 则一般认为试验条件对结果 A 出现有利, 也即 A 出现的概率最大。
2
关于 和 2 解方程组:
1 ln X 2, ln X 2 2 2 , 2
* ln M 2 ln(e 1) 2 2 ln(e 1) ln X 2;
2 2
ln(e
2
* * M2 M2 2 1) ln 2 , e 1 2 , X X * M2 2 ˆ ln 1 2 ; X
第 3 页 共 13 页
2.2 矩估计和最大似然估计
* ˆ X 3M2 a 所以 a , b 的矩估计为 * ˆ b X 3M 2
参数估计

(2)再用样本k阶矩代替相应的总体k阶矩
上一页
下一页
返回
设 总 体X ~ N ( , 2 ), , 2 未 知 , 设 例1: ( X 1 , X 2 ,..., X n )为 来 自 总 体 的 样 本 , 求 X 与 2的 矩 估 计 量 。
解:先建立待估参数与总体矩的关系
维随机变量,样本的联合概率密度为:
f ( x1 , x2 ,, xn ) f X 1 ( x1 ) f X 2 ( x2 ) f X n ( xn )
f ( x1 , ) f ( x2 , ) f ( xn , ) f ( xi , )
i 1
n
显然上式也为θ的函数,记作 L( ),即
L( ) f ( xi , )
i 1 n
我们称 L( ) 为似然函数。
小结:
似然函数
n p( x i ; ) i 1 L( ) n f ( x i ; ) i 1
由上可知,求极大似然估计值就是求使 L( ) 取最大的θ值。 下面我们用例子来说明求解极大似然估计值的步骤。
6
3
[ x dx x dx]
2 3 0 0
2
用样本k阶矩代替相应的总体k阶矩,得θ的矩估计量:
ˆ 2X
2)将数据代入,得θ的矩估计值为:
ˆ 2x 2 1 xi 8.9 8 i 1
8
计 算 器 的 使 用
例3:设总体X在区间[a,b]上服从均匀分布, a , b
实为 发生的概率。
根据极大似然原理,
概率大的事件在一次观测中更容易发生。
现在只做一次抽样, 事件 { X 1 x1 , X 2 x2 ,, X n xn } 故 认为其概率较大。 认为其概率较大。 也即我们应选择 使 L( ) 取最大值。 我们把使 L( ) 取最大值的 值称为 的极大 竟然发生了,
矩估计和极大似然估计
^ 2
1 n
n i1
Xi2
2
X .
14/22
即
ˆ X ,
ˆ 2
1 n
n i 1
(Xi
X )2.
故,均值,方差2的矩估计为
ˆ ˆ
X, 2 1
n
n
(X
i1
i
X )2
即
n 1S2. n
15/22
如:正态总体N(, 2) 中和2的矩估计为
)2
i1 2
(2 ) e , 2
n 2
1
2
2
n i1
( xi )2
对数似然函数为
ln
L(,
2
)
n 2
ln( 2
)
n 2
ln
2
1
2
2
n
( xi
i1
)2,
35/22
似然方程组为
ln L(, 2 ) 1 2
ln L(, 2 )
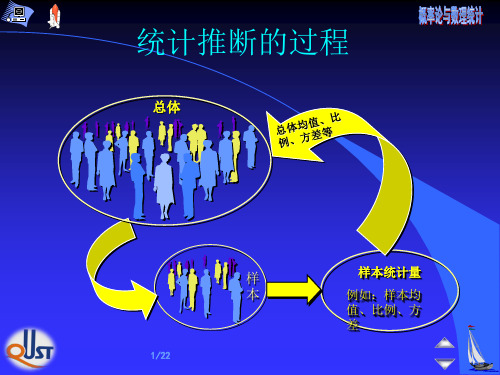
X1, X2 , … , Xn . 依样本对参数θ 做出估计,或估计参数θ 的 某个已知函数 g(θ ) 。 这类问题称为参数估计。
参数估计包括:点估计和区间估计。
4/22
为估计参数 µ,需要构造适当的统计量 T( X1, X2 , … , Xn ),
一旦当有了样本,就将样本值代入到该统计 量中,算出一个值作为µ的估计, 称该计算 值为 µ的一个点估计。
7/22
总体 k 阶原点矩 ak E(X k ),
样本 k 阶原点距
Ak
1 n
工程随机数学20117

无偏性
定义:若参数的估计量ˆ ˆ X1, X2, , Xn ,满足E ˆ ,
则称ˆ是的一个无偏估计量。
若E ˆ ,那么 E ˆ 称为估计量ˆ的偏差 若lim E ˆ ,则称ˆ是的渐近无偏估计量
n
1。无偏性只有在大量重复抽样时才有意义,它只保证无系统误差,只涉 及一阶矩 2。无偏性并非给出准确无误的估计,只是讲平均误差为零 3。误差可以分为系统误差和随机误差 4。无偏性不保证在一次具体使用时无误差
0 其它
故 参数的似然函数为:L 1n
由于
dln
d
n
0, 不能用微分法求ˆL
0
0 x1, x2 , 其它
, xn
以下从定义出发求ˆL :
因为 0 xi ,故的取值范围最小为xn maxx1, x2, , xn
又L
1
n
对
xn的 是减函数, 越小,L越大,故ˆL
xn时,L最大;
所以的极大似然估计量为ˆL Xn maxx1, x2, , xn
2 矩估计
由
E
X
0
1
xdx
2
X
ˆ 2X
例6:设总体X的概率分布率为:1
2
2
3
1- 3
二、 极大似然估计法(Fisher)
极大似然估计原理: 一个随机事件,可能有A、B、C诸个结果,若在一次实验
中,A发生,则认为A出现的概率最大; 又如,一个事件发生的概率,可能是0.1或0.3,若在一次试 验中,该事件发生,就认为它发生的概率为0.3 极大似然估计基本思想:
均匀分布的矩估计和极大似然估计

一、概述矩估计和极大似然估计是统计学中常用的两种参数估计方法,它们在众多领域中都有着重要的应用。
本文将对均匀分布的矩估计和极大似然估计进行深入探讨,分析它们的特点和适用范围,并对两种方法的优缺点进行比较和总结。
二、均匀分布的矩估计1. 均匀分布的概念和特点均匀分布是概率论中常见的一种离散型随机变量分布,它具有概率密度函数f(x) = 1/(b-a),其中a和b分别为分布的起始值和终止值。
均匀分布的特点是在[a, b]区间内各个数值出现的概率相等。
2. 均匀分布的矩估计方法均匀分布的参数估计通常采用矩估计方法。
矩估计是利用样本矩来估计总体矩,其基本思想是将样本矩与总体矩相等,通过方程求解得到参数的估计值。
对于均匀分布而言,可以通过样本均值和样本方差来进行参数估计,具体的计算过程可以通过数学推导来进行详细阐述。
三、均匀分布的极大似然估计1. 极大似然估计的基本原理极大似然估计是统计学中另一种常用的参数估计方法,其基本思想是在给定样本条件下,寻找最大化似然函数的参数值作为估计值。
对于均匀分布而言,可以通过求解似然函数的一阶导数为0的方程来得到参数的极大似然估计值,具体的推导过程也需要进行详细的分析和阐述。
2. 极大似然估计与矩估计的比较极大似然估计与矩估计在参数估计的方法和理论基础上存在着一定的差异,它们在不同情况下各有优劣。
通过比较两种方法在均匀分布参数估计中的应用,可以得出它们在精确度、稳定性和有效性等方面的优缺点,为使用者提供更多的参考依据。
四、实例分析通过实际的数据样本和模拟实验,可以对均匀分布的矩估计和极大似然估计进行对比分析。
选择适当的参数和样本规模,比较两种方法得到的参数估计值与真实值之间的偏差情况,从而验证两种方法的可靠性和有效性。
五、结论通过对均匀分布的矩估计和极大似然估计的深入研究和分析,可以得出它们在不同情况下各有优劣,适用范围也有所不同。
在实际应用中,需要根据具体问题的特点选择合适的参数估计方法,以保证估计结果的准确性和可靠性。
极大似然估计和广义矩估计

05
案例分析
极大似然估计的案例
线性回归模型
在回归分析中,极大似然估计常用于估计线性回归模型的参数。通过最大化似然 函数,可以得到最佳线性无偏估计,使得预测值与实际观测值之间的误差最小。
正态分布参数估计
极大似然估计在正态分布的参数估计中也有广泛应用。例如,假设一组数据来自 正态分布,我们可以通过极大似然估计来估计均值和方差。
极大似然估计和广义矩估 计
• 引言 • 极大似然估计 • 广义矩估计 • 极大似然估计与广义矩估计的比较 • 案例分析 • 总结与展望
01
引言
主题简介
极大似然估计
极大似然估计是一种参数估计方 法,基于观测数据的概率分布模 型,通过最大化似然函数来估计 未知参数。
广义矩估计
广义矩估计是一种非参数估计方 法,通过最小化一系列矩(如一 阶矩、二阶矩等)的离差来估计 未知参数。
唯一性
在某些条件下,极大似然估计具有唯一性,即真实参 数值是极大似然函数的唯一最大值。
极大似然估计的步骤和实现
1 2
定义似然函数
根据数据分布和模型假设,定义似然函数。
求导并求解
对似然函数求导,并使用优化算法求解导数为零 的点,得到参数的极大似然估计值。
3
验证估计值
使用验证数据集验证估计值的准确性和有效性。
3. 优化目标函数
实现
使用优化算法(如牛顿法、拟牛顿法等) 最小化目标函数,以找到最优的模型参数 。
在编程语言(如Python、R等)中,可以 使用相应的统计库(如statsmodels、 EMMA等)来方便地实现广义矩估计。
04
极大似然估计与广义矩估计的比较
相似之处
理论基础
01
矩估计与极大似然估计的典型例题

关于矩估计与极大似然估计的典型例题例1,设总体X 具有分布律⎟⎟⎠⎞⎜⎜⎝⎛−−22)1()1(2321~θθθθX 其中10<<θ为未知参数。
已经取得了样本值1,2,1321===x x x ,试求参数θ的矩估计与极大似然估计。
解:(i )求矩估计量,列矩方程(只有一个未知参数)XX E =−=−×+−×+=θθθθθ23)1(3)1(22)(22得6523432x 32X 3=−=−=−=矩θ(ii ii)求极大似然估计,写出似然函数,即样本出现的概率)求极大似然估计,写出似然函数,即样本出现的概率),,()(332211x X x X x X P L ====θ)1,2,1(321====X X X P )1()2()1(321=×=×==X P X P X P )1(2)1(2522θθθθθθ−=×−×=对数似然)1ln(ln 52ln )(ln θθθ−++=L 0115)(ln =−−=θθθθd L d 得极大似然估计为65ˆ=极θ例2,某种电子元件的寿命某种电子元件的寿命((以h 记)X 服从双参数指数分布服从双参数指数分布,,其概率密度为⎪⎩⎪⎨⎧≥−−=其他,0],/)(exp[1)(µθµθx x x f 其中0>µθ,均为未知参数,自一批这种零件中随机抽取n 件进行寿命试验,设它们的失效时间分别为.,,2,1n x x x L (1)求µθ,的最大似然估计量;(2)求µθ,的矩估计量。
解:(1)似然函数,记样本的联合概率密度为∏===ni i n x f x x x f L 12,1)();,,()(µθµθ,,L ⎪⎩⎪⎨⎧≥−−=∏=其他,0,,,]/)(exp[12,11µθµθn n i i x x x x L ⎪⎩⎪⎨⎧>≤−−=∑=)1()1(1,0),/)(exp(1xx n x ni i n µµθµθ在求极大似然估计时在求极大似然估计时,,0)(=µθ,L 肯定不是最大值的似然函数值,不考虑这部分,只考虑另一部分。
第二章1-矩估计和极大似然估计

0
解法二
E
X
x
1
x
e dx
1
x
x e dx (2)
2
0
即 E|X|
1 n
用 n i1 X i
替换
EX
即得的另一矩估计量为
ˆ 1
n
n i 1
Xi
16
• 矩估计的优点 – 不依赖总体的分布,简便易行 – 只要n充分大,精确度也很高。
• 矩估计的缺点 – 矩估计的精度较差; – 要求总体的某个k阶矩存在; – 要求未知参数能写为总体的原点矩的函数形 式
得和2的估计值分别为13(mm)和 0.133(mm)2
12
例2 设总体X的概率密度为
f
( x;
)
x 1 ,
0,
0 x 1 其它
X1,X2,,Xn为来自于总体X的样本,x1,x2, ,xn 为样本值,求参数的矩估计。
解: 先求总体矩
1
1
E( X ) x x 1dx x dx
x 1 1
ˆ2 (x1, x2 ,, xn )
数值
ˆk (x1, x2 ,, xn )
称数ˆ1,ˆ2 ,,ˆk 为未知参数1,2 ,,k 的估计值 对应的统计量为未知参数1,2 ,,k 的估计量
问题 如何构造统计量?
6
二.点估计的方法
1、矩方法;(矩估计) 2、极大似然函数法(极大似然估计).
1. 矩方法
• 极大似然估计的缺点 要求必须知道总体的 分布函数形式
29
多参数情形的极大似然估计
若总体X的概率密度为:f (x;1,2 , ,k )
其中
1
,
2
,,
概率论与数理统计课件第7章参数估计

一、矩估计
4
A B
一、矩估计 例1
5
01
OPTION
02
OPTION
一、矩估计 解
6
一、矩估计
7
一、矩估计
8
解(1)
一、矩估计
9
解(2)
一、矩估计 例3
10
一、矩估计 解
11
一、矩估计
12
关于矩估计量有下列结论:
一、矩估计
13
例4
解
一、矩估计
14
01
OPTION
02
OPTION
一、无偏性 定义1
51
ˆ lim E θ 如果 n+ X1 ,
, X n θ
一、无偏性
52
例1
试求 1 3 2
解
(1)由矩估计定义可知
一、无偏性
53
故
一、无偏性
54
一、无偏性 例2
55
一、无偏性
56
解
一、无偏性 定理 1
57
则有
因此, 样本均值是总体均值的无偏估计, 样本
二、极大似然估计
48
极大似然估计求解
似然函数 对数似然求导法
直接法
49
目录/Contents
7.1 7.2
点估计 点估计的优良性评判标 准 置信区间 单正态总体下未知参数的置信区间 两个正态总体下未知参数的置信区间
7.3
7.4 7.5
50
目录/Contents
7.2
点估计的优良性评判标准 一、无偏性 二、有效性 三、相合性
置信区间
69
置信区间
70
置信区间
极大似然估计和广义矩估计

这里用到了矩阵微分的以下两条规则: (1)ab/ba (2) ( b A b ) / b ( A + A ) b 2 A b ,第二个等号成立 的条件是A为对称矩阵。
在(4.19)式中,a是 YX ,A是 XX 。 由(4.19)式的结果,使对数似然函数(4.17)达到 极大的一阶条件为
lnL(β,2) 2XY2XXβ β 22 0
为了得到 的无偏估计量的Cramèr-Rao下界,需要 先计算信息矩阵
I(β , 2 ) E 2 2l ln n L L / / β 2 β β 2 l2 n ln L L / /β 2 22 (4 .2 2 )
信息矩阵是按 β 和 2分块对角的,这是扰动项为正态
ln L (β 2 ,2) (Y X β 2 ) (Y 4 X β ) 2 n 2 0
解此二正规方程,得: βˆML(XX)-1XY
ˆM 2 L (Y X β ) n (Y X β ) R S S /n e e /n
因此,在随机扰动项满足标准假设条件的情况下 ,β 的极大似然估计量与普通最小二乘估计量相同 ,方差 2 的ML估计量与OLS估计量则不同。
消费方程设定为:
t c t 0 1 g d p t 2 p t u t t 1 9 8 8 , 1 9 8 9 , . . . , 2 0 0 7
偏估计量中方差最小。假设多一些(CLR模型加上正
态性),得到的也多一些(MVU而不仅仅是BLUE)。
例4.2 以简单的消费函数为例,说明极大似然估计 法的估计过程。
根据经济理论,消费和收入与价格密切相关,因此 建立以国内生产总值gdp和消费价格指数p 为解释 变量,国内总消费tc为被解释变量的消费方程。数 据区间为1988—2007年。
参数估计-矩法和极大似然法

(4) 在最大值点的表达式中, 用样本值代入就 得参数的最大似然估计值 .
可靠性数学基础
例 设总体 X ~N( μ , σ )2 ,
2 μ , σ未知 .
x1 ,
, xn
是来自 X 的样本值 , 试求 μ , σ 2的最大似然估计量 . 解 X 的概率密度为
f ( x) 1 2 e
( x )2 2 2
Fisher
可靠性数学基础
最大似然法的基本思想
先看一个简单例子: 某位同学与一位猎人一起外 出打猎 . 一只野兔从前方窜过 .
只听一声枪响,野兔应声倒下 . 如果要你推测,是谁打中的呢? 你会如何想呢?
可靠性数学基础
你就会想,只发一枪便打中, 猎人命中的概率 一般大于这位同学命中的概率 . 看来这一枪是猎人 射中的 . 这个例子所作的推断已经体现了极大似然法的 基本思想 .
1
n
可靠性数学基础
且是的增函数
取其它值时,L( , ) 0.
故使 L( , )达到最大的 , 即 的MLE 是
min xi
* 1 i n
于是
n 1 * xi * n i 1 即 * , *为 , 的MLE .
可靠性数学基础
1 ( x ) e , x X ~ f ( x ) , 为未知参数 其它 0,
其中 >0,求 , 的最大似然估计. 解:似然函数为
1 ( xi ) , xi e L( , ) i 1 其它 0,
可靠性数学基础
最大似然估计原理:
设X1,X2,…Xn是取自总体X的一个样本,样本 的联合密度(连续型)或联合分布律 (离散型)为 f (x1,x2,… ,xn ; ) . 当给定样本X1,X2,…Xn时,定义似然函数为:
点估计中两种方法的分析和比较

点估计中两种常用方法的比较与分析楚尚坤河南理工大学数学与信息科学学院信息与计算科学专业2005级3班摘 要:本文首先介绍矩估计法和极大似然估计法,然后对于同一分布和同一参数,用这两种不同的方法求出矩估计量和极大似然估计量,利用估计量的三条评选标准:无偏性、有效性和一致性来判断哪个估计量在这种情况下与该参数的真实值更相近,从而选择相应的点估计法。
关键词:矩估计 极大似然估计 无偏性 有效性 一致性§1 引言当我们碰到这样的问题:假设总体分布函数的形式已知(它可由理论分析和过去经验得到,或者从抽样数据的直方图和概率纸描点初步估计出),但它的一个或多个参数未知,借助于总体的一个样本值,构造适当的样本函数来估计总体未知参数的问题,我们称之为点估计问题。
点估计是数理统计学中内容很丰富的一个分支,其中两种最常用的构造的估计量的方法是矩估计法和极大似然估计法。
当对于同一分布和同一参数时,先用矩估计法和极大似然估计法分别求得矩估计量和极大似然估计量,然后用无偏性、有效性和一致性对这两个估计量进行衡量,当样本容量足够大时,从而选出一个估计量使得这个估计量既在未知参数的真实值附近,又与未知参数真实值的偏离程度很小,而且随着样本容量n 的增大估计量与被估计参数的偏差越来越小,进而选择相应的点估计法。
§2 相关概念2.1 参数估计所谓参数估计,是指从样本),,,(21n X X X 中提取有关总体X 的信息,即构造样本的函数——统计量),,,(21n X X X g ,然后用样本值代入,求出统计量的观测值12(,,,)n g x x x ,用该值来作为相应待估参数的值。
此时,把统计量),,,(21n X X X g 称为参数的估计量,把),,(,21n x x x g 称为参数的估计值。
2.2 参数估计的类型参数估计问题常有两类:点估计和区间估计。
(1) 点估计:指对总体分布中的参数θ,根据样本),,,(21n X X X 及样本值),,,(21n x x x ,构造一统计量),,,(21n X X X g ,将),,(,21n x x x g 作为θ的估计值,则称),,,(21n X X X g 为θ的点估计量,简称点估计,记为∧θ=),,,(21n X X X g 。
矩估计和极大似然估计

=θ2+(θ+μ)2
注意到 令 θ μ X , 2 θ M 2 . DX = E ( X2 )-( EX )2=θ2
2 1 ˆ M2 (Xi X ) , n i 1 ˆ X M . μ n
2
14
第二节
极大似然估计
第七章
极大似然估计
15
极大似然估计法: 定义7.1 设 是
1, 第i次取到不合格品; Xi i 1, 2, , n. 0, 第i次取到合格品.
解 因 p=EX, 故 p 的矩估计量为
1 ˆ X X i f n ( A) p n i 1
(即出现不合格产品的频率).
9
n
例5
设总体X ~ U [a, b], a, b未知;X 1 , , X n
1100
可用两种方法:矩法估计 和极大似然估计.
28
1 x e , x0 X : p( x; ) ( 0) 0 , other
1)矩法估计
令 X
1 EX x e dx 0 则可得 的矩法估计量为:ˆ X .
x
1 n A1 X i X n i 1
1 ˆ 则 x (0 75 1 90 6 1) 1.22 250
ˆ 1.22。 所以 X 估计 下面我们通过几个例子说明利用矩估计法求 未知参数的过程。
6
例2
22
令
即
所以参数
的极大似然估计量为
23
例3
解
设 X1, X2, …, Xn 是取自总体X 的一个样本,
,求参数λ的极大似然估计值。
似然函数为:
参数的矩估计量

参数的矩估计量摘要:I.引言- 介绍参数估计量的概念- 矩估计量的定义和重要性II.矩估计量的性质- 矩的定义和性质- 矩估计量的性质和特点III.矩估计量的求解方法- 最大似然估计法- 矩估计量的求解步骤IV.矩估计量的应用- 常见参数的矩估计量- 矩估计量在实际问题中的应用V.结论- 总结矩估计量的重要性和应用- 提出进一步研究的方向正文:I.引言参数估计量是统计学中一个重要的概念,它用于估计未知参数的值。
矩估计量是参数估计量的一种,它具有许多优良的性质,因此在实际应用中得到广泛的应用。
本文将介绍参数的矩估计量的概念、性质、求解方法和应用。
II.矩估计量的性质矩估计量是基于样本数据来估计总体参数的一种方法,它的核心思想是利用样本数据的某些性质(如均值、方差等)来估计总体参数。
矩估计量的性质主要体现在以下几个方面:1.矩估计量具有良好的无偏性,即估计量的期望值等于被估计参数的真实值。
2.矩估计量具有较小的方差,即估计量的方差较小,说明估计量具有较高的精度。
3.矩估计量具有较好的稳健性,即对于样本数据的某些变化,矩估计量的值具有较好的稳定性。
III.矩估计量的求解方法矩估计量的求解方法主要有最大似然估计法,该方法的基本思想是寻找一个使得样本数据出现的概率最大的参数值。
矩估计量的求解步骤如下:1.确定待估计参数的分布;2.计算参数的矩;3.求解矩的极大似然函数;4.求解极大似然函数的临界点;5.根据临界点求解参数的矩估计量。
IV.矩估计量的应用矩估计量在实际问题中有着广泛的应用,例如在经济学、生物学、医学等领域。
以下列举一些常见参数的矩估计量及其应用:1.均值的矩估计量:用于估计总体均值,如在产品质量控制中,通过抽样检测来估计产品的平均质量水平。
2.方差的矩估计量:用于估计总体方差,如在农业研究中,通过抽样调查来估计农作物产量的方差。
3.比例的矩估计量:用于估计总体比例,如在市场调查中,通过抽样调查来估计某种产品的市场份额。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
如何求解参数的矩估与极大似然估计
一、矩估计
若统计量T作为总体参数θ(或g(θ ))的估计时,T就称为θ(或g(θ ))的估计量。
定义 6.1矩估计量 设n X X X ,,,21 是总体X的样本,X的分布函数),,:(1k x F θθ 依赖于参数k θθ,,1 ,假定X 的r 阶矩为),,,(1k r r EX θθα =
,,,1k r =(或r 阶中心矩)相应的样本矩记为),,,(1n r X X A 如下的k 个议程
k r a X X A k r n r ,,1),,,(),,(11 ==θθ (6.1) 的解,称为未知参数k θθ,,:1 的矩估计。
二、最(极)大似然估计
设总体X的密度函数θθ),,(x f 是参数或参数向量,n X X X ,,,21 是该总体的样本,对给定的一组观测值n x x x ,,,21 ,其联合密度是θ的函数,又称似然函数,记为:
∏=∈==n
k k n x f x x L L 11),,(),,,()(Θθθθθ
其中Θ为参数集,若存在,),,(ˆˆ1Θθθ∈=n x x 使Θθθθ∈≥),()ˆ(L L 就称 ),,(ˆ1n x x θ是θ的最大似然估计值,而),,(ˆ1n
X X θ是θ的最大似然估计量。
注:1)对给定的观测值,)(θL 是θ的函数,最大似然估计的原理是选择使观测值
n x x x ,,,21 出现的“概率”达到最大的θˆ作为θ的估计。
2)最大似然估计具有不变性,即若θ
ˆ是θ的最大似然估计,则)(θg 的最大似然估计为)ˆ(θ
g 。
但是,矩估计不具有不变性,例如假定θ是X 的矩估计,一般情形下,2θ的矩估计不是2
X 。
1. 设总体ξ服从指数分布,其概率密度函数为⎪⎩⎪⎨⎧<≤=-0
01)(1
x x e
x f x θ
θ
,(θ>0)
试求参数θ的矩估计和极大似然估计.
解:ξ的概率密度为()1,0
;,00,0x
e x
f x x θ
θθθ-⎧≥⎪=>⎨⎪<⎩
似然函数为: ()11i x n i L e
θ
θθ
-=⎛⎫=⋅ ⎪⎝⎭
∏ 1
1
1
1
1
n
i
i
i x n
x n
n
i e
e
θ
θ
θ
θ
=--
=∑=
⋅=⋅∏
而
1
1
ln ln n
i i L n x θθ
==-⋅-
∑
令
2
1
ln 11
0n
i
i d L n x
d θθθ
==-⋅+=∑
得到:1
1ˆn
i i x n θ==∑=X
因此得到参数θ的极大似然估计量为:1
1ˆn i i X n θ==∑
矩估计求法如下: 因为1E μξθ==
令111n
i i A x n θ===∑
则1
1ˆn i i x n θ==∑
从而θ的矩估计量为1
1ˆn i i X n θ==∑=X
2. 设母体ξ具有指数分布,密度函数为⎩⎨
⎧<≤=-0
0),(x x
e x
f x
λλλ,(λ>0) 试求参数λ的矩估计和极大似然估计. 解:参数λ的矩估计求法为:因为
11
E μξλ
==
令:
111
1n
i i A x n λ===∑ 则λ的矩估计量为:1
1
1ˆn
i
i n
A X
λ
===∑
极大似然估计求法如下:
ξ的概率密度为(),0
,0,0x e x f x x λλλ-⎧≥=⎨<⎩
似然函数为: ()1,0i
n
x i L e x λ
λλ-==
≥∏
而1
ln ln n
i
i L n x
λλ
==-∑
令
1
ln 0n
i i d L n x d λλ==-=∑ 解得λ的极大似然估计量为:1
ˆn
i
i n
x
λ
==∑
3. 设总体X ~N(μ,1), ),,(1n X X 为来自X 的一个样本,试求参数μ的矩估计和最大似然估计.
解:矩估计求法为:
()1E X μμ==
令111n
i i A x n μ===∑
则1
1ˆn
i i x n μ
==∑ 极大似然估计求法为:
X 的概率密度为: (
)()2
2
;x f x μμ--
=
似然函数为:
(
)()2
2
1
i x n
i L μμ--==
()()21
1
22
2n
i i x n e
μπ=-
--∑
=
而
()()2
1
1ln ln 222n i i n L x πμ==---∑
令
()1
ln 1202n
i i d L x d μμ==-=∑ 即
()1
0n
i
i x μ=-=∑
解得μ的极大似然估计量为:1
1ˆn
i i x n μ
==∑。