实验三虚拟变量及模型诊断与检验案例分析
《计量经济学》上机实验答案过程步骤
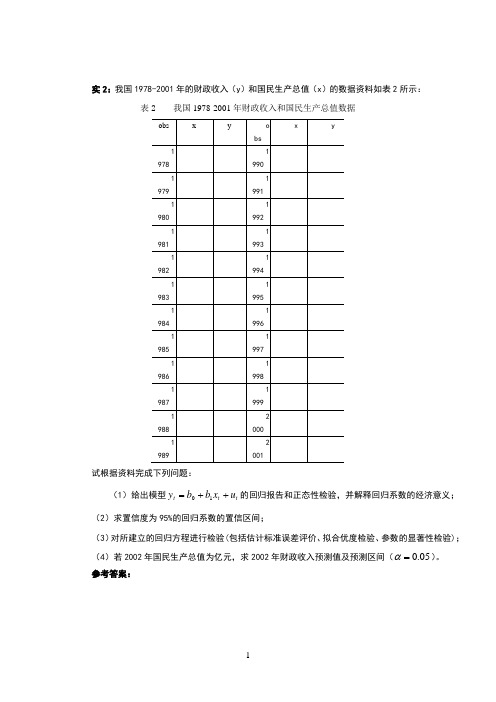
实2:我国1978-2001年的财政收入(y )和国民生产总值(x )的数据资料如表2所示:表2 我国1978-2001年财政收入和国民生产总值数据试根据资料完成下列问题:(1)给出模型t t t u x b b y ++=10的回归报告和正态性检验,并解释回归系数的经济意义; (2)求置信度为95%的回归系数的置信区间;(3)对所建立的回归方程进行检验(包括估计标准误差评价、拟合优度检验、参数的显著性检验); (4)若2002年国民生产总值为亿元,求2002年财政收入预测值及预测区间(05.0=α)。
参考答案:(1) t t x y133561.06844.324ˆ+= =)ˆ(i b s =)ˆ(ib t 941946.02=R 056.1065ˆ==σSE 30991.0=DW 9607.356=F 133561.0ˆ1=b ,说明GNP 每增加1亿元,财政收入将平均增加万元。
(2))ˆ()2(ˆ02/00b s n t b b ⋅-±=α=±⨯ )ˆ()2(ˆ12/11b s n t b b ⋅-±=α=±⨯ (3)①经济意义检验:从经济意义上看,0133561.0ˆ1〉=b ,符合经济理论中财政收入随着GNP 增加而增加,表明GNP 每增加1亿元,财政收入将平均增加万元。
②估计标准误差评价: 056.1065ˆ==σSE ,即估计标准误差为亿元,它代表我国财政收入估计值与实际值之间的平均误差为亿元。
③拟合优度检验:941946.02=R ,这说明样本回归直线的解释能力为%,它代表我国财政收入变动中,由解释变量GNP 解释的部分占%,说明模型的拟合优度较高。
④参数显著性检验:=)ˆ(1b t 〉0739.2)22(025.0=t ,说明国民生产总值对财政收入的影响是显著的。
(4)6.1035532002=x , 41.141556.103553133561.06844.324ˆ2002=⨯+=y根据此表可计算如下结果:102221027.223)47.32735()1()(⨯=⨯=-⋅=-∑n x x x tσ92220021002.5)47.327356.103553()(⨯=-=-x x ,109222/1027.21002.52411506.10650739.241.14155)()(11ˆ)2(ˆ⨯⨯++⨯⨯±=--++⋅⋅-±∑x x x x n n t yt f f σα=实验内容与数据3:表3给出某地区职工平均消费水平t y ,职工平均收入t x 1和生活费用价格指数t x 2,试根据模型t t t t u x b x b b y +++=22110作回归分析报告。
计量经济学案例分析报告

《计量经济学》实验报告实验课题:各章节案列分析姓名:茆汉成班级:会计学12-2班学号: 2012213572指导老师:蒋翠侠报告日期: 2015.06.18目录第二章简单线性回归模型案例 01 问题引入 02 模型设定 03 估计参数 (2)4 模型检验 (2)第三章多元线性回归模型案例 (4)1 问题引入 (4)2 模型设定 (4)3 估计参数 (5)4 模型检验 (5)第四章多重线性案例 (7)1 问题引入 (7)2 模型设定 (7)3 参数估计 (7)4 对多重共线性的处理 (8)第五章异方差性案例 (10)1 问题引入 (10)2 模型设定 (10)3 参数估计 (10)4 异方差检验 (11)5 异方差性的修正 (13)第六章自相关案例 (14)1 问题引入 (14)2 模型设定 (14)3 用OLS估计 (14)4 自相关其他检验 (15)5 消除自相关 (16)第七章分布滞后模型与自回归模型案例 (18)7.2案例1 (18)1 问题引入 (18)2 模型设定 (18)3 参数估计 (18)7.3案例2 (20)1 问题引入 (20)2 模型设定 (20)3、回归分析 (20)4模型检验 (22)第八章虚拟变量回归案例 (23)1 问题引入 (23)2 模型设定 (23)3 参数估计 (25)4 模型检验 (26)第二章简单线性回归模型案例1、问题引入居民消费在社会经济的持续发展中有着重要的作用。
适度的居民消费规模和合理的消费模型是人民生活水平的具体体现,有利于经济持续健康的增长。
随着社会信息化程度和居民的收入水平的提高,计算机的运用越来越普及,作为居民耐用消费品重要代表的计算机已经为众多的城镇居民家庭所拥有。
研究中国各地区城镇居民计算机拥有量与居民收入水平的数量关系。
影响居民计算机拥有量的因素有多种,但从理论和经验分析,最主要的影响因素应是居民收入水平。
从理论上说居民收入水平越高,居民计算机拥有量越多。
计量经济学虚拟变量实验报告
第七章虚拟变量实验报告一、研究目的改革开放以来,我国经济保持了长期较快发展,与此同时,我国对外贸易规模也日益增长。
尤其是2002年中国加入世界贸易组织之后,我国对外贸易迅速扩张。
2012年,我国进出口总值38667.6亿美元,与上年同期相比增长6.2%。
至此,我国贸易总额首次超过美国,成为世界贸易规模最大的国家。
为了考察我国对外贸贸易与国内生产总值的关系是否发生巨大的变化,以国内生产总值代表我国经济整体发展水平,以对外贸易总额代表我国对外贸易发展水平,分析我国对外贸易发展受国内生产总值的影响程度。
二、模型设定为研究我国对外贸易发展规模受我国经济发展程度影响,引入国内生产总值为自变量。
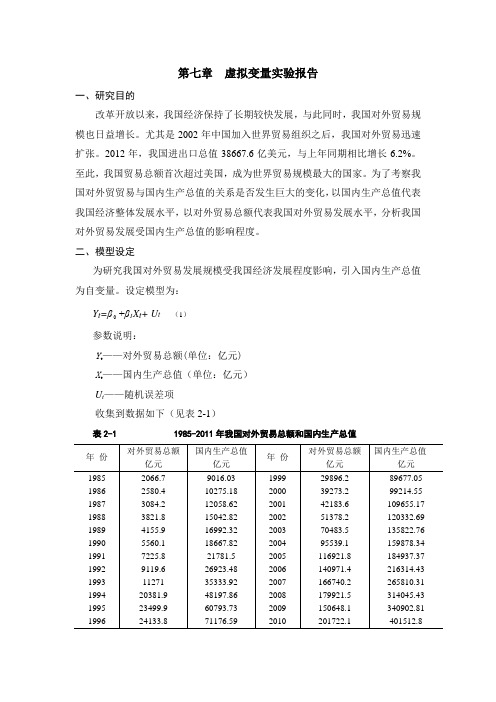
设定模型为:+β1X t+ U t (1)Y t=β参数说明:Y t——对外贸易总额(单位:亿元)X t——国内生产总值(单位:亿元)U t——随机误差项收集到数据如下(见表2-1)表2-1 1985-2011年我国对外贸易总额和国内生产总值注:资料来源于《中国统计年鉴》1986-2012。
为了研究1985-2011年期间我国对外贸易总额随国内生产总值的变化规律是否有显著不同,考证对外贸易与国内生产总值随时间变化情况,如下图所示。
图2.1 对外贸易总额(Y)与国内生产总值(X)随时间变化趋势图从图2.1中,可以看出对外贸易总额明显表现出了阶段特征:在2002年、2007年和2009年有明显的转折点。
为了分析对外贸易总额在2002年前后、2007年前后及2009年前后几个阶段的数量关系,引入虚拟变量D1、D2、D3。
这三个年度对应的GDP分别为120332.69亿元、265810.31亿元和340902.81亿元。
据此,设定以下以加法和乘法两种方式同时引入虚拟变量的模型:Y t=β0+β1Xt+β2(Xt-120332.69)D1+β3(Xt-265810.31)D2+β4(Xt-340902.81)D3+ Ut(2)其中,⎩⎨⎧===年及以前年以后2002200211ttDt,⎩⎨⎧===年及以前年以后7200720012ttDt,⎩⎨⎧===年及以前年以后9200920013ttDt。
虚拟变量 实验报告

虚拟变量实验报告引言虚拟变量(dummy variable)是在统计学中常用的一种技术,用于表示分类变量。
通过将分类变量转换为二进制数值变量,虚拟变量可以在回归分析、方差分析以及其他统计模型中发挥重要作用。
本实验报告旨在介绍虚拟变量的概念、用法以及在实际应用中的一些注意事项。
虚拟变量的定义虚拟变量是一种二元变量,用于表示某个特征是否存在。
通常情况下,虚拟变量的取值为0或1。
虚拟变量可以用于将分类变量转换为数值变量,使其适用于各种统计模型。
虚拟变量的应用虚拟变量主要用于以下两个方面的统计模型:1. 回归分析在回归分析中,虚拟变量被用于表示一个分类变量的不同水平。
例如,在研究某产品的销售量时,可以引入虚拟变量表示该产品是否进行了促销活动。
这样,回归模型就可以分析促销活动对销售量的影响。
2. 方差分析方差分析是一种用于比较不同组之间差异的统计方法。
虚拟变量可以用于表示不同组的存在与否。
例如,在研究不同药物对某种疾病治疗效果时,可以引入虚拟变量表示不同药物的使用与否,进而进行方差分析。
如何创建虚拟变量创建虚拟变量的方法通常有两种:1. 单变量编码单变量编码是最常见的创建虚拟变量的方法。
对于具有k个水平的分类变量,单变量编码将该变量转换为k-1个虚拟变量。
其中,k-1个虚拟变量分别表示k个水平的存在与否。
例如,在研究不同颜色对产品销售量的影响时,可以使用单变量编码将颜色变量转换为两个虚拟变量,分别表示是否为蓝色和是否为红色。
2. 二进制编码二进制编码是一种使用更少虚拟变量的方法。
对于具有k个水平的分类变量,二进制编码将该变量转换为log2(k)个虚拟变量。
其中,每个虚拟变量都表示一个水平的存在与否。
例如,在研究不同国家对某项政策的支持时,可以使用二进制编码将国家变量转换为几个虚拟变量,每个虚拟变量表示一个国家的存在与否。
虚拟变量的注意事项在使用虚拟变量时需要注意以下几点:1.避免虚拟变量陷阱:虚拟变量陷阱是指多个虚拟变量之间存在完全共线性的情况,这会导致回归模型的多重共线性。
虚拟变量的分析
虚拟变量(dummy variable )在实际建模过程中,被解释变量不但受定量变量影响,同时还受定性变量影响。
例如需要考虑性别、民族、不同历史时期、季节差异、企业所有制性质不同等因素的影响。
这些因素也应该包括在模型中。
由于定性变量通常表示的是某种特征的有和无,所以量化方法可采用取值为1或0。
这种变量称作虚拟变量,用D 表示。
虚拟变量应用于模型中,对其回归系数的估计与检验方法与定量变量相同。
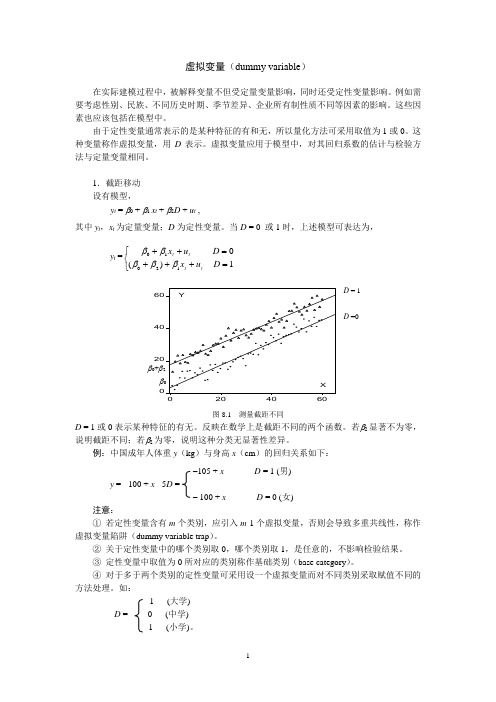
1.截距移动 设有模型,y t = β0 + β1 x t + β2D + u t ,其中y t ,x t 为定量变量;D 为定性变量。
当D = 0 或1时,上述模型可表达为,y t =⎩⎨⎧=+++=++1)(012010D u x D u x tt t t βββββ0204060204060X Y图8.1 测量截距不同D = 1或0表示某种特征的有无。
反映在数学上是截距不同的两个函数。
若β2显著不为零,说明截距不同;若β2为零,说明这种分类无显著性差异。
例:中国成年人体重y (kg )与身高x (cm )的回归关系如下: –105 + x D = 1 (男)y = - 100 + x - 5D =– 100 + x D = 0 (女) 注意:① 若定性变量含有m 个类别,应引入m -1个虚拟变量,否则会导致多重共线性,称作虚拟变量陷阱(dummy variable trap )。
② 关于定性变量中的哪个类别取0,哪个类别取1,是任意的,不影响检验结果。
③ 定性变量中取值为0所对应的类别称作基础类别(base category )。
④ 对于多于两个类别的定性变量可采用设一个虚拟变量而对不同类别采取赋值不同的方法处理。
如:1 (大学) D = 0 (中学) -1 (小学)。
β0β0+β2D = 1 D =0例1:市场用煤销售量模型(file: Dummy1) 我国市场用煤销量的季节性数据(1982-1988,《中国统计年鉴》1987,1989)见下图与表。
(3)案例:虚拟变量20140416
案例分析(3):虚拟变量模型改革开放以来,随着经济的发展中国城乡居民的收入快速增长,同时城乡居民的储蓄存款也迅速增长。
经济学界的一种观点认为,20世纪90年代以后由于经济体制、住房、医疗、养老等社会保障体制的变化,使居民的储蓄行为发生了明显改变。
为了考察改革开放以来中国居民的储蓄存款与收入的关系是否已发生变化,以城乡居民人民币储蓄存款年底余额代表居民储蓄(Y),以国民总收入GNI代表城乡居民收入,分析居民收入对储蓄存款影响的数量关系。
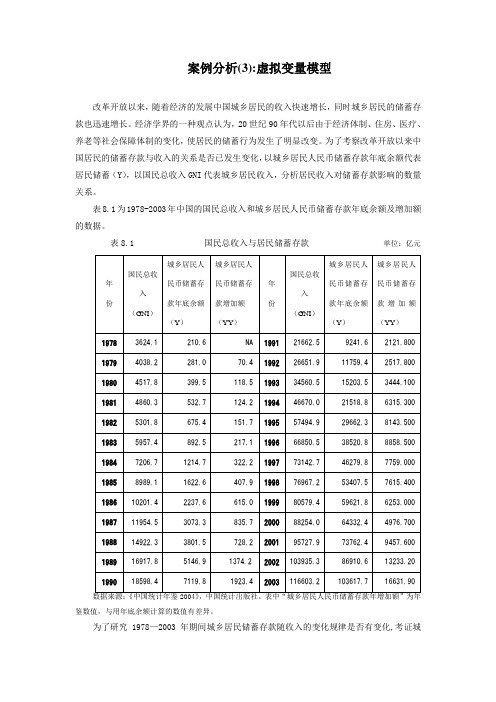
表8.1为1978-2003年中国的国民总收入和城乡居民人民币储蓄存款年底余额及增加额的数据。
表8.1 国民总收入与居民储蓄存款单位:亿元鉴数值,与用年底余额计算的数值有差异。
为了研究1978—2003年期间城乡居民储蓄存款随收入的变化规律是否有变化,考证城乡居民储蓄存款、国民总收入随时间的变化情况,如下图所示:图8.5从图8.5中,尚无法得到居民的储蓄行为发生明显改变的详尽信息。
若取居民储蓄的增量(YY ),并作时序图(见图8.6)图8.6 图8.7从居民储蓄增量图可以看出,城乡居民的储蓄行为表现出了明显的阶段特征:在1996年和2000年有两个明显的转折点。
再从城乡居民储蓄存款增量与国民总收入之间关系的散布图看(见图8.7),也呈现出了相同的阶段性特征。
为了分析居民储蓄行为在1996年前后和2000年前后三个阶段的数量关系,引入虚拟变量D 1和D 2。
D 1和D 2的选择,是以1996、2000年两个转折点作为依据,1996年的GNI 为66850.50亿元,2000年的GNI 为国为民8254.00亿元,并设定了如下以加法和乘法两种方式同时引入虚拟变量的的模型:()()12314266850.5088254.00t t t t t t tYY = +GNI GNI D + GNI D u ββββ+--+其中:11199601996t t D t =⎧=⎨=⎩年以后 年及以前 21200002000t t D t =⎧=⎨=⎩年以后年及以前 对上式进行回归后,有:Dependent Variable: YY Method: Least Squares Date: 06/16/05 Time: 23:27Sample (adjusted): 1979 2003Included observations: 25 after adjustmentsVariableCoefficientStd. Errort-StatisticProb.C -830.4045 172.1626 -4.823374 0.0001 GNI0.144486 0.005740 25.17001 0.0000 (GNI-66850.50)*DUM1 -0.291371 0.027182 -10.71920 0.0000 (GNI-88254.00)*DUM20.5602190.04013613.958100.0000R-squared 0.989498 Mean dependent var 4168.652 Adjusted R-squared 0.987998 S.D. dependent var 4581.447 S.E. of regression 501.9182 Akaike info criterion 15.42040 Sum squared resid 5290359. Schwarz criterion 15.61542 Log likelihood -188.7550 F-statistic 659.5450 Durbin-Watson stat1.677712 Prob(F-statistic)0.000000即有:()()12t = -830.4045 + 0.1445 - 0.2914-66850.50 + 0.5602-88254.00t t t t t YY GNI GNI D GNI D se =(172.1626)(0.0057) (0.0272) (0.0401)t = (-4.8234) (25.1700) (-10.7192) (13.9581) 20.9895R = 20.9880R = 659.545F = 1.6777DW = 由于各个系数的t 检验均大于2,表明各解释变量的系数显著地不等于0,居民人民币储蓄存款年增加额的回归模型分别为:1t2t3t = -830.4045 + 0.1445+1996= 18649.8312- 0.1469+1996<2000 =- 30790.0596 + 0.4133+2000t t t t t t t YY GNI t YY YY GNI t YY GNI t εεε≤⎧⎪=≤⎨⎪>⎩这表明三个时期居民储蓄增加额的回归方程在统计意义上确实是不相同的。
虚拟变量与检验演示文稿

值太少,那么可能无法用其估计子模型。此时可以考虑采用
Chow预测检验。 • Chow预测检验同样需要将全部样本分为两个部分,检验
的步骤为:
– 利用全部样本估计模型,得到RSSr; – 利用第一个子样本(假定容量为T1)估计模型,得到RSSu ; – 用估计的模型预测第二个子样本(假定容量为T2)的因变量;
虚拟变量与检验演示文稿
第1页,共37页。
(优选)虚拟变量与检验
第2页,共37页。
一、虚拟变量的定义
根据属性类型,构造只取“0”或“1”的人工变量,称为虚拟变 量(Dummy Variable)。通常记为 D。
1男 D= 0 女
含有虚拟变量的模型称为虚拟变量模型。
二、虚拟变量的引入
虚拟变量在模型中可以作解释变量,也可以作被解释变量。一般 是作解释变量。虚拟变量的引入有两种基本方式:加法方式和乘法方 式。
,得到残差平方和SSR1和
– 用全部数据做回归(即参数受限制的情况),得到残差平方和SSR;
– 计算F统计值
– 检验其显著性。F SSR SSR1 SSR2 • T 2K
• 用全部数据做回归等同于加S上SRk1个约SS束R2条件,即两K个方程的所有参数
都相同;
• 用两组数据分别做回归则得到两套不同的截距和斜率系数,因而相应
第20页,共37页。
五、Chow检验
• 在现实生活中,有时会由于某些重大的政策和制度变化或 偶发事件,导致经济运行机制或行为改变。
– 不同的经济体制 – 不同的生产条件
• 对于计量经济学研究工作来说,这种情况表现为模型的参数发生 改变。
• 如果在样本资料所涉及的期间内发生过这样的情况,那么就有 必要检验模型参数的稳定性。
计量经济学实验报告(虚拟变量)

计量经济学实验报告实验三:虚拟变量模型姓名:上善若水班级:序号:学号:中国人均消费影响因素一、理论基础及数据1. 研究目的本文在现代消费理论的基础,分析建立计量模型,通过对1979——2008 年全国城镇居民的人均消费支出做时间序列分析和对2004—2008年各地区(31个省市)城镇居民的人均消费支出做面板数据分析,比较分析了人均可支配收入、消费者物价指数和银行一年期存款利率等变量对居民消费的不同影响。
2. 模型理论西方消费经济学者们认为,收入是影响消费者消费的主要因素,消费是需求的函数。
消费经济学有关收入与消费的关系,即消费函数理论有:(1)凯恩斯的绝对收入理论。
他认为消费主要取决于消费者的净收入,边际消费倾向小于平均消费倾向。
他假定,人们的现期消费,取决于他们现期收入的绝对量。
(2)杜森贝利的相对收入消费理论。
他认为消费者会受自己过去的消费习惯以及周围消费水准来决定消费,从而消费是相对的决定的。
当期消费主要决定于当期收入和过去的消费支出水平。
(3)弗朗科•莫迪利安的生命周期的消费理论。
这种理论把人生分为三个阶段:少年、壮年和老年;在少年与老年阶段,消费大于收入;在壮年阶段,收入大于消费,壮年阶段多余的收入用于偿还少年时期的债务或储蓄起来用来防老。
(4)弗里德曼的永久收入消费理论。
他认为消费者的消费支出主要不是由他的现期收入来决定,而是由他的永久收入来决定的。
这些理论都强调了收入对消费的影响。
除此之外,还有其他一些因素也会对消费行为产生影响。
(1)利率。
传统的看法认为,提高利率会刺激储蓄,从而减少消费。
当然现代经济学家也有不同意见,他们认为利率对储蓄的影响要视其对储蓄的替代效应和收入效应而定,具体问题具体分析。
(2)价格指数。
价格的变动可以使得实际收入发生变化,从而改变消费。
基于上述这些经济理论,我找到中国1979-2008年全国城镇居民人均消费以及城镇居民人均可支配收入、城镇居民消费者物价指数和2004—2008年各地区城镇居民人均消费以及城镇居民人均可支配收入、城镇居民消费者物价指数、以及银行一年期存款利率的官方数据。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
实验三虚拟变量及模型诊断与检验案例分析
一、实验目的
利掌握虚拟变量的基本原理,对虚拟变量的设定和模型的估计与检验;掌握模型约束条件的F检验、LR检验、LM检验,以及相关的EViews软件操作方法。
二、实验要求
了解并掌握对虚拟变量参数估计和模型约束条件检验的操作方法。
三、实验原理与内容
影响因变量的因素除了定量变量外还有定性变量,因此需要对包含有虚拟变量模型的估计方法熟练掌握。
当对模型施加约束时,如何检验约束条件是否成立。
本节实验要完成以下内容:
1、熟悉用GENR命令产生新序列。
2、熟悉如何在模型中加入定性变量。
3、了解包含有定性变量的模型的估计方法。
4、掌握线束条件检验的F检验、似然比(LR)检验、Wald检验。
四、实验内容和步骤
1、虚拟变量案例分析(以教材202页练习题8.9为例)
(1)、构建虚拟变量。
季度虚拟变量数据生成,在工作文件窗口点击Quick/Generate Series,在弹出的由方程生成序列的窗口,输入命令D1= @seas(4)。
用相似的方法生成D2和D3。
得到建模数据。
(2)、利用最小二乘法估计加入虚拟变量的模型。
(3)、进一步检验回归方程的斜率是否有变化,在包含虚拟变量的回归模型中加入t D。
2、模型约束条件检验(以教材254页案例11.1为例)
(1)用OLS方法估计模型。
(2)检验回归系数
430
ββ
==的约束条件是否成立:运用F检验、LR检验、Wald检验。