计量经济学作业
计量经济学作业

然中国也属于这个范围 因为民主程度不能够决定一个国家的经济水平,影响国家经济的因素还有很多,比如文化人种地理气候等诸多条件,甚至是一些人为
主观的 因素 42752大于上面数据的R2=0.
该指数衡量了五个指标:选举程序与多样性、政府运作、政治参与、政治文化和公民自由。
如果要想得出一条一1元0,线00性0 方程来正确解释民主同国民收入那就不断地排除其他非民主因素,显然是很复杂的工作,但我们只能排除
伊人斯均兰 国教民的收因入素(natio5n,a0l i0n0come per capita/per capita national income)人均国民收入是一国在一定时期内(通常为一年)按人口平均的 国民收入占有量,反映国民收0 入总量与人口数量的对比关系。
如果要想得出一条一元线性方程来正确解 释民主同国民收入那就不断地排除其他非 民主因素,显然是很复杂的工作,但我们 只能排除伊斯兰教的因素
总结
经过我们运用数据进行两次的统计分析, 我们得出民主对中国经济有一定的积极意 义,中国在保持原有一切基础不变的条件 下适当地提高一点民主是对中国有积极的 影响,至于多少则不属于我们调查范围
由于是很多因素共同影响一个国民收入水 平,而且是相互制约,所以要想通过两个 变量得出具体的数字表示显然不精准的
民考主虑指 到数中和国人是均不国适民合5收发0,入展00接民0 受主来提高国民经济,那就要把中国划入一个世界范围内进行统计检验,然后不断地缩小范围来进行工作
国际人均收入同民主4指5,数00关0 系
如伊果斯要 兰想教得的出因一素条一4元0,线00性0 方程来正确解释民主同国民收入那就不断地排除其他非民主因素,显然是很复杂的工作,但我们只能排除 考虑中国民主发展对3国5,民00收0 入的影响
计量经济学作业

计量经济学作业7.下列为一个完备的联立方程计量经济学模型:011210132t t t t t t t t t Y M C I M Y P ββγγμααγμ=++++=+++其中,M 为货币供给量,Y 为国生产总值,P 为价格总指数。
,C I 分别为居民消费与投资。
(1) 指出模型的生变量、外生变量、先决变量;(2) 写出简化式模型,并导出结构式参数与简化式参数之间的关系; (3) 用结构式条件确定模型的识别状态; (4) 指出间接最小二乘法、工具变量法、二阶段最小二乘法中哪些可用于原模型第1,2个方程的参数估计。
解:(1) 生变量:t Y 、t M外生变量:t I 、t C 、t P 先决变量:t I 、t C 、t P (2) 简化式模型:101112131202122232=++++=++++t t t t t t t t t t Y C I P M C I P ππππεππππε结构式参数与简化式参数之间的关系:001131210111213111111111111βαββγγγππππαβαβαβαβ+====----0103111220212223111111111111ααβγαγαγππππαβαβαβαβ+====----(3) 模型中包含g =2个生变量,k =3个先决变量;第1个方程包含1g =2个生变量,1k =2个先决变量; 第2个方程包含2g =2个生变量,2k =1个先决变量;结构参数矩阵为101210310100B ββγγααγ----⎛⎫Γ= ⎪---⎝⎭首先判断第1个结构方程的识别状态。
对于第1个方程,有()003B γΓ=-,()0011R B g Γ==-,即方程可以识别,又因为111k k g -=-,所以第1个结构方程恰好识别。
对于第2个结构方程,有()0012B γγΓ=--,()0011R B g Γ==-,即方程可以识别,又因为221k k g ->-,所以第2个结构方程过度识别。
计量经济学练习题完整版

计量经济学试题1一 名词解释(每题5分,共10分) 1. 经典线性回归模型2. 加权最小二乘法(WLS ) 二 填空(每空格1分,共10分)1.经典线性回归模型Y i = B 0 + B 1X i + µi 的最小二乘估计量b 1满足E ( b 1 ) = B 1,这表示估计量b 1具备 性。
2.广义差分法适用于估计存在 问题的经济计量模型。
3.在区间预测中,在其它条件不变的情况下,预测的置信概率越高,预测的精度越 。
4.普通最小二乘法估计回归参数的基本准则是使 达到最小。
5.以X 为解释变量,Y 为被解释变量,将X 、Y 的观测值分别取对数,如果这些对数值描成的散点图近似形成为一条直线,则适宜配合 模型。
6.当杜宾-瓦尔森统计量 d = 4时,ρˆ= ,说明 。
7.对于模型i i i X Y μββ++=10,为了考虑“地区”因素(北方、南方两种状态)引入2个虚拟变量,则会产生 现象。
8. 半对数模型LnY i = B 0 + B 1X i + µI 又称为 模型。
9.经典线性回归模型Y i = B 0 + B 1X i + µi 的最小二乘估计量b 0、b 1的关系可用数学式子表示为 。
三 单项选择题(每个1分,共20分)1.截面数据是指--------------------------------------------------------------( )A .同一时点上不同统计单位相同统计指标组成的数据。
B .同一时点上相同统计单位相同统计指标组成的数据。
C .同一时点上相同统计单位不同统计指标组成的数据。
D .同一时点上不同统计单位不同统计指标组成的数据。
2.参数估计量βˆ具备有效性是指------------------------------------------( ) A .0)ˆ(=βar V B.)ˆ(βarV 为最小 C .0)ˆ(=-ββD.)ˆ(ββ-为最小 3.如果两个经济变量间的关系近似地表现为:当X 发生一个绝对量(X ∆)变动时,Y 以一个固定的相对量(Y Y /∆)变动,则适宜配合的回归模型是------------------------------------------------------------------------------------------- ( )A .i i i X Y μβα++= B.i i i X Y μβα++=ln C .i ii X Y μβα++=1D.i i i X Y μβα++=ln ln 4.在一元线性回归模型中,不可能用到的假设检验是----------( ) A .置信区间检验 B.t 检验 C.F 检验 D.游程检验5.如果戈里瑟检验表明 ,普通最小二乘估计的残差项有显著的如下性质:24.025.1i i X e +=,则用加权最小二乘法估计模型时,权数应选择-------( )A .i X 1 B. 21i X C.24.025.11i X + D.24.025.11i X +6.对于i i i i X X Y μβββ+++=22110,利用30组样本观察值估计后得56.827/)ˆ(2/)ˆ(2=-∑-∑=iiiY Y Y Y F ,而理论分布值F 0.05(2,27)=3.35,,则可以判断( )A . 01=β成立 B. 02=β成立 C. 021==ββ成立 D. 021==ββ不成立7.为描述单位固定成本(Y )依产量(X )变化的相关关系,适宜配合的回归模型是:A .i i i X Y μβα++= B.i i i X Y μβα++=ln C .i ii X Y μβα++=1D.i i i X Y μβα++=ln ln 8.根据一个n=30的样本估计ii i e X Y ++=10ˆˆββ后计算得d=1.4,已知在95%的置信度下,35.1=L d ,49.1=U d ,则认为原模型------------------------( )A .存在正的一阶线性自相关 B.存在负的一阶线性自相关 C .不存在一阶线性自相关 D.无法判断是否存在一阶线性自相关9.对于ii i e X Y ++=10ˆˆββ,判定系数为0.8是指--------------------( ) A .说明X 与Y 之间为正相关 B. 说明X 与Y 之间为负相关 C .Y 变异的80%能由回归直线作出解释 D .有80%的样本点落在回归直线上10. 线性模型i i i i X X Y μβββ+++=22110不满足下列哪一假定,称为异方差现象-------------------------------------------------------------------------------( )A .0)(=j i ov C μμ B.2)(σμ=i ar V (常数) C .0),(=i i ov X C μ D.0),(21=i i ov X X C11.设消费函数i i i X D Y μβαα+++=10,其中虚拟变量⎩⎨⎧=南方北方01D ,如果统计检验表明1α统计显著,则北方的消费函数与南方的消费函数是--( )A .相互平行的 B.相互垂直的 C.相互交叉的 D.相互重叠的12. 在建立虚拟变量模型时,如果一个质的变量有m 种特征或状态,则一般引入几个虚拟变量:----------------------------------------------------------------( )A .m B.m+1 C.m -1 D.前三项均可 13. 在模型i i iX Y μββ++=ln ln ln 10中,1β为---------------------( )A .X 关于Y 的弹性 B.X 变动一个绝对量时Y 变动的相对量 C .Y 关于X 的弹性 D.Y 变动一个绝对量时X 变动的相对量14.对于i i i e X Y ++=10ˆˆββ,以S 表示估计标准误差,iY ˆ表示回归值,则-------------------------------------------------------------------------------------------( )A .S=0时,0)ˆ(=-∑ti Y Y B.S=0时,∑==-ni i i Y Y 120)ˆ( C .S=0时,)ˆ(ii Y Y -∑为最小 D.S=0时,∑=-ni i i Y Y 12)ˆ(为最小 15.经济计量分析工作的基本工作步骤是-----------------------------( )A .设定理论模型→收集样本资料→估计模型参数→检验模型B .设定模型→估计参数→检验模型→应用模型C .理论分析→数据收集→计算模拟→修正模型D .确定模型导向→确定变量及方程式→应用模型16.产量(X ,台)与单位产品成本(Y ,元/台)之间的回归方程为:X Y5.1356ˆ-=,这说明-----------------------------------------------------------( )A .产量每增加一台,单位产品成本平均减少1.5个百分点B .产量每增加一台,单位产品成本减少1.5元C .产量每增加一台,单位产品成本减少1.5个百分点D .产量每增加一台,单位产品成本平均减少1.5元17.下列各回归方程中,哪一个必定是错误的------------------------( )A .8.02.030ˆ=+=XY i i r X Y B. 91.05.175ˆ=+-=XY i i r X Y C .78.01.25ˆ=-=XY ii r X Y D. 96.05.312ˆ-=--=XY ii r X Y18.用一组有28个观测值的样本估计模型i i i X Y μββ++=10后,在0.05的显著性水平下对1β的显著性作t 检验,则1β显著地不等于0的条件是统计量t 大于-------------------------------------------------------------------------------------( )A .t 0.025(28) B. t 0.05(28) C. t 0.025(26) D. t 0.05(26)19.下列哪种形式的序列相关可用DW 统计量来检验(V t 为具有零均值、常数方差,且不存在序列相关的随机变量)---------------------------------( )A .t t t V +=-1ρμμ B.t t t t V +⋅⋅⋅++=--121μρρμμ C. t t V ρμ= D. ⋅⋅⋅++=-12t t t V V ρρμ20.对于原模型t t t X Y μββ++=10,一阶差分模型是指------------( )A .)()()(1)(1t tt t t t t X f X f X X f X f Y μββ++=B .t t t X Y μβ∆+∆=∆1C .t t t X Y μββ∆+∆+=∆10D .)()()1(11101----+-+-=-t t t t t t X X Y Y ρμμρβρβρ四 多项选择题(每个2分,共10分)1.以Y 表示实际值,Yˆ表示回归值,i e 表示残差项,最小二乘直线满足------------------------------------------------------------------------------------------( )A .通用样本均值点(Y X ,) B.ii Y Y ˆ∑=∑ C .0),ˆ(=i i ov e Y C D.0)ˆ(2=-∑i i Y Y E .0)ˆ(=-∑Y Y i2.剩余变差(RSS )是指--------------------------------------------------( )A .随机因素影响所引起的被解释变量的变差B .解释变量变动所引起的被解释变量的变差C .被解释变量的变差中,回归方程不能作出解释的部分D.被解释变量的总变差与解释变量之差E.被解释变量的实际值与回归值的离差平方和3. 对于经典线性回归模型,0LS估计量具备------------------------()A.无偏性 B.线性特性 C.正确性 D.有效性 E.可知性4. 异方差的检验方法有---------------------------------------------------()A.残差的图形检验 B.游程检验 C.White检验D.帕克检验E.方差膨胀因子检验5. 多重共线性的补救有---------------------------------------------------()A.从模型中删掉不重要的解释变量 B.获取额外的数据或者新的样本 C.重新考虑模型 D.利用先验信息 E. 广义差分法五简答计算题(4题,共50分)1.简述F检验的意图及其与t检验的关系。
计量经济学习题及全部答案

计量经济学习题一一、判断正误1.在研究经济变量之间的非确定性关系时,回归分析是唯一可用的分析方法; 2.最小二乘法进行参数估计的基本原理是使残差平方和最小;3.无论回归模型中包括多少个解释变量,总离差平方和的自由度总为n -1; 4.当我们说估计的回归系数在统计上是显着的,意思是说它显着地异于0; 5.总离差平方和TSS 可分解为残差平方和ESS 与回归平方和RSS 之和,其中残差平方和ESS 表示总离差平方和中可由样本回归直线解释的部分; 6.多元线性回归模型的F 检验和t 检验是一致的;7.当存在严重的多重共线性时,普通最小二乘估计往往会低估参数估计量的方差; 8.如果随机误差项的方差随解释变量变化而变化,则线性回归模型存在随机误差项的自相关;9.在存在异方差的情况下,会对回归模型的正确建立和统计推断带来严重后果; 10...DW 检验只能检验一阶自相关; 二、单选题1.样本回归函数方程的表达式为 ;A .i Y =01i i X u ββ++B .(/)i E Y X =01i X ββ+C .i Y =01ˆˆi i X e ββ++D .ˆi Y =01ˆˆiX ββ+ 2.下图中“{”所指的距离是 ;A .随机干扰项B .残差C .i Y 的离差D .ˆiY 的离差 3.在总体回归方程(/)E Y X =01X ββ+中,1β表示 ;A .当X 增加一个单位时,Y 增加1β个单位B .当X 增加一个单位时,Y 平均增加1β个单位C .当Y 增加一个单位时,X 增加1β个单位D .当Y 增加一个单位时,X 平均增加1β个单位 4.可决系数2R 是指 ;A .剩余平方和占总离差平方和的比重B .总离差平方和占回归平方和的比重C .回归平方和占总离差平方和的比重D .回归平方和占剩余平方和的比重 5.已知含有截距项的三元线性回归模型估计的残差平方和为2i e ∑=800,估计用的样本容量为24,则随机误差项i u 的方差估计量为 ;A .B .40C .D .6.设k 为回归模型中的参数个数不包括截距项,n 为样本容量,ESS 为残差平方和,RSS 为回归平方和;则对总体回归模型进行显着性检验时构造的F 统计量为 ;A .F =RSSTSSB .F =/(1)RSS k ESS n k --C .F =/1(1)RSS k TSS n k --- D .F =ESSTSS7.对于模型i Y =01ˆˆi iX e ββ++,以ρ表示i e 与1i e -之间的线性相关系数2,3,,t n =,则下面明显错误的是 ;A .ρ=,..DW =B .ρ=-,..DW =-C .ρ=0,..DW =2D .ρ=1,..DW =08.在线性回归模型 011...3i i k ki i Y X X u k βββ=++++≥;如果231X X X =-,则表明模型中存在 ;A .异方差B .多重共线性C .自相关D .模型误设定9.根据样本资料建立某消费函数 i Y =01i i X u ββ++,其中Y 为需求量,X 为价格;为了考虑“地区”农村、城市和“季节”春、夏、秋、冬两个因素的影响,拟引入虚拟变量,则应引入虚拟变量的个数为 ;A .2B .4C .5D .610.某商品需求函数为ˆi C =100.5055.350.45i i D X ++,其中C 为消费,X 为收入,虚拟变量10D ⎧=⎨⎩城镇家庭农村家庭,所有参数均检验显着,则城镇家庭的消费函数为 ;A .ˆi C =155.850.45i X +B .ˆiC =100.500.45i X + C .ˆi C =100.5055.35i X +D .ˆiC =100.9555.35i X + 三、多选题1.一元线性回归模型i Y =01i i X u ββ++的基本假定包括 ;A .()i E u =0B .()i Var u =2σ常数C .(,)i j Cov u u =0 ()i j ≠D .(0,1)iu NE .X 为非随机变量,且(,)i i Cov X u =02.由回归直线ˆi Y =01ˆˆi X ββ+估计出来的ˆiY ; A .是一组平均数 B .是实际观测值i Y 的估计值 C .是实际观测值i Y 均值的估计值 D .可能等于实际观测值i Y E .与实际观测值i Y 之差的代数和等于零 3.异方差的检验方法有A .图示检验法B .Glejser 检验C .White 检验D ...DW 检验E .Goldfeld Quandt -检验4.下列哪些非线性模型可以通过变量替换转化为线性模型 ;A .i Y =201i i X u ββ++B .1/i Y =01(1/)i i X u ββ++C .ln i Y =01ln i i X u ββ++D .i Y =iui i AK L e αβE .i Y =1122012iiX X i e e u ββααα+++5.在线性模型中引入虚拟变量,可以反映 ;A .截距项变动B .斜率变动C .斜率与截距项同时变动D .分段回归E .以上都可以 四、简答题1.随机干扰项主要包括哪些因素它和残差之间的区别是什么2.简述为什么要对参数进行显着性检验试说明参数显着性检验的过程;3.简述序列相关性检验方法的共同思路; 五、计算分析题1.下表是某次线性回归的EViews 输出结果,根据所学知识求出被略去部分的值用大写字母标示,并写出过程保留3位小数;Dependent Variable: Y Method: Least Squares Included observations: 132.用Goldfeld Quandt -方法检验下列模型是否存在异方差;模型形式如下:i Y =0112233 i i i i X X X u ββββ++++其中样本容量n =40,按i X 从小到大排序后,去掉中间10个样本,并对余下的样本按i X 的大小等分为两组,分别作回归,得到两个残差平方和1ESS =、2ESS =,写出检验步骤α=;F 分布百分位表α=3.有人用广东省1978—2005年的财政收入AV 作为因变量,用三次产业增加值作为自变量,进行了三元线性回归;第一产业增加值——1VAD ,第二产业增加值——2VAD ,第三产业增加值——3VAD ,结果为:AV =12335.1160.0280.0480.228VAD VAD VAD +-+2R =,F =- ..DW =试简要分析回归结果; 五、证明题求证:一元线性回归模型因变量模拟值ˆi Y 的平均值等于实际观测值i Y 的平均值,即ˆiY =i Y ; 计量经济学习题二一、判断正误正确划“√”,错误划“×” 1.残差剩余项i e 的均值e =()i e n ∑=0;2.所谓OLS 估计量的无偏性,是指参数估计量的数学期望等于各自的真值; 3.样本可决系数高的回归方程一定比样本可决系数低的回归方程更能说明解释变量对被解释变量的解释能力;4.多元线性回归模型中解释变量个数为k ,则对回归参数进行显着性检验的t 统计量的自由度一定是1n k --;5.对应于自变量的每一个观察值,利用样本回归函数可以求出因变量的真实值; 6.若回归模型存在异方差问题,可以使用加权最小二乘法进行修正;7.根据最小二乘估计,我们可以得到总体回归方程;8.当用于检验回归方程显着性的F 统计量与检验单个系数显着性的t 统计量结果矛盾时,可以认为出现了严重的多重共线性9.线性回归模型中的“线性”主要是指回归模型中的参数是线性的,而变量则不一定是线性的;10.一般情况下,用线性回归模型进行预测时,单个值预测与均值预测相等,且置信区间也相同; 二、单选题1.针对同一经济指标在不同时间发生的结果进行记录的数据称为A .面板数据B .截面数据C .时间序列数据D .以上都不是 2.下图中“{”所指的距离是A .随机干扰项B .残差C .i Y 的离差D .ˆiY 的离差 3.在模型i Y =01ln i i X u ββ++中,参数1β的含义是A .X 的绝对量变化,引起Y 的绝对量变化B .Y 关于X 的边际变化C .X 的相对变化,引起Y 的平均值绝对量变化D .Y 关于X 的弹性4.已知含有截距项的三元线性回归模型估计的残差平方和为2i e ∑=90,估计用的样本容量为19,则随机误差项i u 方差的估计量为A .B .6C .D .55.已知某一线性回归方程的样本可决系数为,则解释变量与被解释变量间的相关系数为A .B .0.8C .D .6.用一组有20个观测值的样本估计模型i Y =01i i X u ββ++,在的显着性水平下对1β的显着性作t 检验,则1β显着异于零的条件是对应t 统计量的取值大于 A .0.05(20)t B .0.025(20)t C .0.05(18)t D .0.025(18)t7.对于模型i Y =01122ˆˆˆˆi ik ki iX X X e ββββ+++++,统计量22ˆ()/ˆ()/(1)ii i Y Y kY Y n k ----∑∑服从A .()t n k -B .(1)t n k --C .(1,)F k n k --D .(,1)F k n k --8.如果样本回归模型残差的一阶自相关系数ρ为零,那么..DW 统计量的值近似等于 ;A .1B .2C .4D .9.根据样本资料建立某消费函数如下i Y =01i i X u ββ++,其中Y 为需求量,X 为价格;为了考虑“地区”农村、城市和“季节”春、夏、秋、冬两个因素的影响,拟引入虚拟变量,则应引入虚拟变量的个数为A .2B .4C .5D .610.设消费函数为i C =012i i i i X D X u βββ+++,其中C 为消费,X 为收入,虚拟变量10D ⎧=⎨⎩城镇家庭农村家庭,当统计检验表明下列哪项成立时,表示城镇家庭与农村家庭具有同样的消费行为A .1β=0,2β=0B .1β=0,2β≠0C .1β≠0,2β=0D .1β≠0,2β≠0 三、多选题1.以i Y 表示实际观测值,ˆiY 表示用OLS 法回归后的模拟值,i e 表示残差,则回归直线满足A .通过样本均值点(,)X YB .2ˆ()i iY Y -∑=0 C .(,)i i Cov X e =0 D .i Y ∑=ˆiY ∑ E .i i e X ∑=0 2.对满足所有假定条件的模型i Y =01122i i i X X u βββ+++进行总体显着性检验,如果检验结果显示总体线性关系显着,则可能出现的情况包括A .1β=2β=0B .10β≠,2β=0C .10β≠,20β≠D .1β=0,20β≠E .1β=2β≠0 3.下列选项中,哪些方法可以用来检验多重共线性 ;A .Glejser 检验B .两个解释变量间的相关性检验C .参数估计值的经济检验D .参数估计值的统计检验E ...DW 检验 4.线性回归模型存在异方差时,对于回归参数的估计与检验正确的表述包括A .OLS 参数估计量仍具有线性性B .OLS 参数估计量仍具有无偏性C .OLS 参数估计量不再具有效性即不再具有最小方差D .一定会低估参数估计值的方差5.关于虚拟变量设置原则,下列表述正确的有A .当定性因素有m 个类型时,引入1m -个虚拟变量B.当定性因素有m个类型时,引入m个虚拟变量会产生多重共线性问题C.虚拟变量的值只能取0和1D.在虚拟变量的设置中,基础类别一般取值为0E.以上说法都正确四、简答题1.简述计量经济学研究问题的方法;2.简述异方差性检验方法的共同思路;3.简述多重共线性的危害;五、计算分析题1.下表是某次线性回归的EViews输出结果,被略去部分数值用大写字母标示,根据所学知识解答下列各题计算过程保留3位小数;本题12分Dependent Variable: YMethod: Least SquaresIncluded observations: 181求出A 、B 的值;2求TSS2.有人用美国1960-1995年36年间个人实际可支配收入X 和个人实际消费支出Y 的数据单位:百亿美元建立收入—消费模型 i Y =01i i X u ββ++,估计结果如下:ˆiY =9.4290.936i X -+ t :2R = ,F = ,..DW =1检验收入—消费模型的自相关状况5%显着水平; 2用适当的方法消除模型中存在的问题; 五、证明题证明:用于多元线性回归方程显着性检验的F 统计量与可决系数2R 满足如下关系: 计量经济学习题三 一、判断对错1、在研究经济变量之间的非确定性关系时,回归分析是惟一可用的分析方法;2、对应于自变量的每一个观察值,利用样本回归函数可以求出因变量的真实值;DW 检验临界值表α=3、OLS 回归方法的基本准则是使残差平方和最小;4、在存在异方差的情况下,OLS 法总是高估了估计量的标准差;5、无论回归模型中包括多少个解释变量,总离差平方和的自由度总为n -1;6、线性回归分析中的“线性”主要是指回归模型中的参数是线性的,而变量则不一定是线性的;7、当我们说估计的回归系数在统计上是显着的,意思是说它显着异于0; 8、总离差平方和TSS 可分解为残差平方ESS 和与回归平方和RSS,其中残差平方ESS 表示总离差平方和可由样本回归直线解释的部分;9、所谓OLS 估计量的无偏性,是指回归参数的估计值与真实值相等; 10、当模型中解释变量均为确定性变量时,则可以用DW 统计量来检验模型的随机误差项所有形式的自相关性;二、单项选择1、回归直线t ^Y =0ˆβ+1ˆβX t 必然会通过点 A 、0,0; B 、_X ,_Y ;C 、_X ,0;D 、0,_Y ;2、针对经济指标在同一时间所发生结果进行记录的数据列,称为 A 、面板数据;B 、截面数据;C 、时间序列数据;D 、时间数据;3、如果样本回归模型残差的一阶自相关系数ρ接近于0,那么DW 统计量的值近似等于 A 、0 B 、1 C 、2 D 、44、若回归模型的随机误差项存在自相关,则参数的OLS 估计量A 、无偏且有效B 、有偏且非有效C 、有偏但有效D 、无偏但非有效 5、下列哪一种检验方法不能用于异方差检验A、戈德菲尔德-夸特检验;B、DW检验;C、White检验;D、戈里瑟检验;6、当多元回归模型中的解释变量存在完全多重共线性时,下列哪一种情况会发生A、OLS估计量仍然满足无偏性和有效性;B、OLS估计量是无偏的,但非有效;C、OLS估计量有偏且非有效;D、无法求出OLS估计量;7、DW检验法适用于的检验A、一阶自相关B、高阶自相关C、多重共线性 D都不是8、在随机误差项的一阶自相关检验中,若DW=,给定显着性水平下的临界值d L=,d U=,则由此可以判断随机误差项A、存在正自相关B、存在负自相关C、不存在自相关D、无法判断9、在多元线性线性回归模型中,解释变量的个数越多,则可决系数R2A、越大;B、越小;C、不会变化;D、无法确定10、在某线性回归方程的估计结果中,若残差平方和为10,回归平方和为40,则回归方程的拟合优度为A、 B、 C、 D、无法计算;三、简答与计算1、多元线性回归模型的基本假设有哪些2、计量经济模型中的随机误差项主要包含哪些因素3、简答经典单方程计量模型的异方差性概念、后果以及修正方法;4、简述方程显着性检验F检验与变量显着性检验t检验的区别;5、对于一个三元线性回归模型,已知可决系数R2=,方差分析表的部份结果如下:1样本容量是多少2总离差平方和TSS为多少3残差平方和ESS为多少4回归平方和RSS和残差平方和ESS的自由度各为多少5求方程总体显着性检验的F统计量;四、案例分析下表是中国某地人均可支配收入INCOME与储蓄SAVE之间的回归分析结果单位:元:Dependent Variable: SAVEMethod: Least SquaresSample: 1 31Included observations: 31Variable CoefficientStd.Errort-Statistic Prob.CINCOME――――R-squared Mean dependent var AdjustedR-squared. dependent var. of regression Akaike info criterionSum squared resid1778097Schwarz criterion.Log likelihood F-statisticDurbin-Watsonstat ProbF-statistic1、请写出样本回归方程表达式,然后分析自变量回归系数的经济含义2、解释样本可决系数的含义3、写出t检验的含义和步骤,并在5%的显着性水平下对自变量的回归系数进行t 检验临界值: 29=;4、下表给出了White异方差检验结果,试在5%的显着性水平下判断随机误差项是否存在异方差;5、下表给出LM序列相关检验结果滞后1期,试在5%的显着性水平下判断随机误差项是否存在一阶自相关;计量经济学习题四一、判断对错1、一般情况下,在用线性回归模型进行预测时,个值预测与均值预测结果相等,且它们的置信区间也相同;2、对于模型Yi =β+β1X1i+β2X2i+……+βkXki+μi,i=1,2, ……,n;如果X2=X5+X6, 则模型必然存在解释变量的多重共线性问题;3、OLS回归方法的基本准则是使残差项之和最小;4、在随机误差项存在正自相关的情况下,OLS法总是低估了估计量的标准差;5、无论回归模型中包括多少个解释变量,总离差平方和的自由度总为n-1;6、一元线性回归模型的F检验和t检验是一致的;7、如果随机误差项的方差随解释变量变化而变化,则线性回归模型存在随机误差项的序列相关;8、在近似多重共线性下,只要模型满足OLS的基本假定,则回归系数的最小二乘估计量仍然是一BLUE估计量;9、所谓参数估计量的线性性,是指参数估计量是解释变量的线性组合;10、拟合优度的测量指标是可决系数R2或调整过的可决系数,R2越大,说明回归方程对样本的拟合程度越高;二、单项选择1.在多元线性回归模型中,若两个自变量之间的相关系数接近于1,则在回归分析中需要注意模型的问题;A、自相关;B、异方差;C、模型设定偏误;D、多重共线性;2、在异方差的众多检验方法中,既能判断随机误差项是否存在异方差,又能给出异方差具体存在形式的检验方法是A、图式检验法;B、DW检验;C、戈里瑟检验;D、White检验;3、如果样本回归模型残差的一阶自相关系数ρ接近于1,那么DW统计量的值近似等于A、0B、1C、2D、44、若回归模型的随机误差项存在异方差,则参数的OLS估计量A、无偏且有效B、无偏但非有效C、有偏但有效D、有偏且非有效5、下列哪一个方法是用于补救随机误差项自相关问题的A、OLS;B、ILS;C、WLS;D、GLS;6、计量经济学的应用不包括:A、预测未来;B、政策评价;C、创建经济理论;D、结构分析;7、LM检验法适用于的检验A、异方差;B、自相关;C、多重共线性; D都不是8、在随机误差项的一阶自相关检验中,若DW=,给定显着性水平下的临界值d L=,d U=,则由此可以判断随机误差项A、存在正自相关B、存在负自相关C、不存在自相关D、无法判断9、在多元线性线性回归模型中,解释变量的个数越多,则调整可决系数2RA、越大;B、越小;C、不会变化;D、无法确定10、在某线性回归方程的估计结果中,若残差平方和为10,总离差平方和为100,则回归方程的拟合优度为A、;B、;C、;D、无法计算;三、简答与计算1、多元线性回归模型的基本假设有哪些2、简述计量经济研究的基本步骤3、简答经典单方程计量模型自相关概念、后果以及修正方法;4、简述对多元回归模型01122...i i i k ki i Y X X X u ββββ=+++++进行显着性检验F 检验的基本步骤5、对于一个五元线性回归模型,已知可决系数R 2=,方差分析表的部份结果如下:1样本容量是多少2回归平方和RSS 为多少3残差平方和ESS 为多少 4回归平方和RSS 和总离差平方和TSS 的自由度各为多少 5求方程总体显着性检验的F 统计量;四、实验下表是某国1967-1985年间GDP 与出口额EXPORT 之间的回归分析结果单位:亿美元:Dependent Variable: EXPORT Method: Least Squares Sample: 1967 1985Included observations: 19VariableCoefficientStd. Errort-Statist icProb. CGDP――――R-squaredMean dependent varAdjusted R-squared. dependent var. of regressionAkaike infocriterionSum squared residSchwarz criterion Log likelihoodF-statisticDurbin-Watson statProbF-statistic1、请写出样本回归方程表达式,然后分析自变量回归系数的经济含义2、解释样本可决系数的含义3、写出t 检验的含义和步骤,并在5%的显着性水平下对自变量的回归系数进行t 检验临界值: 17=;4、下表给出了White 异方差检验结果,试在5%的显着性水平下判断随机误差项是否存在异方差;5、下表给出LM 序列相关检验结果滞后1期,试在5%的显着性水平下判断随机误差项是否存在一阶自相关;计量经济学习题五一、判断正误正确划“√”,错误划“x ”1、最小二乘法进行参数估计的基本原理是使残差平方和最小;2、一般情况下,用线性回归模型进行预测时,个值预测与均值预测相等,且置信区间也相同;3、如果随机误差项的方差随解释变量变化而变化,则线性回归模型存在随机误差项的序列相关;4、若回归模型存在异方差问题,应使用加权最小二乘法进行修正;5、多元线性回归模型的F 检验和t 检验是一致的;6、DW 检验只能检验随机误差项是否存在一阶自相关;7、总离差平方和TSS 可分解为残差平方RSS 和与回归平方和ESS,其中残差平方RSS 表示总离差平方和可由样本回归直线解释的部分;8、拟合优度用于检验回归方程对样本数据的拟合程度,其测量指标是可决系数或调整后的可决系数;9、对于模型011... 1,2,...,i i n ni i Y X X u i n βββ=++++=;如果231X X X =-,则模型必然存在解释变量的多重共线性问题;10、所谓OLS 估计量的无偏性,是指参数估计量的数学期望等于各自真值; 二、单项选择1、回归直线01ˆˆˆi iY X ββ=+必然会通过点A、0,0B、_X,_YC、_X,0D、0,_Y2、某线性回归方程的估计的结果,残差平方和为20,回归平方和为80,则回归方程的拟合优度为A、 B、C、 D、无法计算3、针对经济指标在同一时间所发生结果进行记录的数据列,称为A、面板数据B、截面数据C、时间序列数据D、时间数据4、对回归方程总体线性关系进行显着性检验的方法是A、Z检验B、t检验C、F检验D、预测检验5、如果DW统计量等于2,那么样本回归模型残差的一阶自相关系数ρ近似等于A、0B、-1C、1D、6、若随机误差项存在异方差,则参数的普通最小二乘估计量A、无偏且有效B、有偏且非有效C、有偏但有效D、无偏但非有效7、下列哪一种方法是用于补救随机误差项的异方差问题的A、OLS;B、ILS;C、WLSD、GLS8、如果某一线性回归方程需要考虑四个季度的变化情况,那么为此设置虚拟变量的个数为A、1B、2C、3D、49、样本可决系数R2越大,表示它对样本数据拟合得A、越好B、越差C、不能确定D、均有可能10、多元线性回归模型中,解释变量的个数越多,可决系数R2A、越大;B、越小;C、不会变化;D、无法确定三、简答题1、简述计量经济学的定义;2、多元线性回归模型的基本假设有哪些3、简答异方差概念、后果以及修正方法;4、简述t检验的目的及基本步骤;四、计算对于一个三元线性回归模型,已知可决系数20.8R ,方差分析表的部份结果如下:变差来源平方和自由度源于回归ESS 200源于残差RSS总变差TSS 221样本容量是多少2总变差TSS为多少3残差平方和RSS为多少4ESS和RSS的自由度各为多少5求方程总体显着性检验的F统计量值;计量经济学习题六-案例题一、根据美国各航空公司航班正点到达的比率X%和每10万名乘客投诉的次数Y 进行回归,EViews输出结果如下:Dependent Variable: YMethod: Least SquaresSample: 1 9Included observations: 91对以上结果进行简要分析包括方程显着性检验、参数显着性检验、DW值的评价、对斜率的解释等,显着性水平均取;2按标准书写格式写出回归结果;二、以下是某次线性回归的EViews输出结果,部分数值已略去用大写字母标示,但它们和表中其它特定数值有必然联系,分别据此求出这些数值,并写出过程;保留3位小数Dependent Variable: YMethod: Least SquaresSample: 1 13Included observations: 131求A 的值; 2求B 的值; 3求C 的值;三、用1970-1994年间日本工薪家庭实际消费支出Y 与实际可支配收入X 单位:103日元数据估计线性模型Y =01X u ββ++,然后用得到的残差序列t e 绘制以下图形; 1试根据图形分析随机误差项之间是否存在自相关若存在,是正自相关还是负自相关答:图形显示,随机误差项之间存在着相关性,且为正的自相关; 2此模型的估计结果为 试用DW 检验法检验随机误差项之间是否存在自相关;四、用一组截面数据估计消费Y —收入X 方程Y =01X u ββ++的结果为1根据回归的残差序列et 图分析本模型是否存在异方差注:abset 表示et 的绝对值;2其次,用White 法进行检验;EViews 输出结果见下表:附表:DW 检验临界值表α=White Heteroskedasticity Test:Dependent Variable: RESID^2 Method: Least Squares Sample: 1 60Included observations: 60若给定显着水平0.05α=,以上结果能否说明该模型存在异方差查卡方分布临界值的自由度是多少五、下图描述了残差序列{}t e 与其滞后一期值1{}t e -之间的散点图,试据此判断随机误差项之间是否存在自相关若存在,则是正自相关还是负自相关六、在一多元线性回归模型中,为检验解释变量之间是否存在多重共线性问题,以解释变量1x 作为被解释变量,对其余解释变量进行辅助回归,得到可决系数20.95R =;试计算变量1x 的方差扩大因子1VIF ,并根据经验判断解释变量间是否存在多重共线性问题七、下表是中国某地人均可支配收入INCOME 与储蓄SAVE 之间的回归分析结果单位:元:Sample: 1 31Included observations: 31VariableCoefficientStd. Errort-Statist ic Prob.CINCOME--R-squaredMean dependent varAdjusted R-squared. dependent var. of regressionAkaike infocriterionSum squared resid 1778097. Schwarz criterion Log likelihoodF-statisticDurbin-Watson statProbF-statistic1、请写出样本回归方程表达式,然后分析自变量INCOME 回归系数的经济含义2、解释可决系数的含义3、若给定显着性水平5%α=,试对自变量INCOME 的回归系数进行显着性检验已知0.025(29) 2.045t =4、在5%α=的显着性水平下,查31n =的DW 临界值表得 1.363L d =, 1.496U d =,试根据回归结果判断随机误差项是否存在一阶自相关5、下表为上述回归的White 检验结果,在5%α=的显着性水平下,试根据P 值检验判断随机误差项是否存在异方差 White Heteroskedasticity Test:F-statisticProbabilityObsR-squaredProbability计量经济学习题一答案一、判断正误1. × 2. √ 3. √ 4. √ 5. × 6. × 7. ×8. × 9. √ 10. √ 二、单选题每小题分,共15分1. D ;2. B ;3. B ;4. C ;5. B ; 6. B ;7. B ;8. B ;9. B ;10. A ; 三、多选题1. ABCE 2. BCDE 3. ABCE 4. ABCD 5. ABCDE ; 四、简答题1.随机干扰项主要包括哪些因素它和残差之间的区别是什么答:随机干扰项包括的主要因素有:1众多细小因素的影响;2未知因素的影响;3数据测量误差或残缺;4模型形式不完善;5变量的内在随机性;随机误差项羽残差不同,残差是样本观测值与模拟值的差,即i e =ˆi iY Y -;残差项是随机误差项的估计;2.简述为什么要对参数进行显着性检验试说明参数显着性检验的过程;答:最小二乘法得到的回归直线是对因变量与自变量关系的一种描述,但它是不是恰当的描述呢一般会用与样本点的接近程度来判别这种描述的优劣,而当获得以上问题的肯定判断之后,还需要确定每一个参数的可靠程度,即参数本身以及对应的变量该不该保留在方程里,这就有必要进行参数的显着性检验;这种检验是确定各个参数是否显着地不等于零;检验分为三个步骤:①提出假设:原假设0:0i H β=;备择假设1:0i H β≠ ②在原假设成立的前提下构造统计量:()ˆ~(1)ˆiit t n k Se ββ=--③给定显着性水平α,查t 分布表求得临界值/2(1)t n k α--,把根据样本数据计算出的t 统计量值t *与/2(1)t n k α--比较:若/2(1)t t n k α*>--,则拒绝原假设0H ,即在给定显着性水平下,解释变量i X 对因变量有显着影响;若/2(1)t t n k α*<--,则不能拒绝原假设0H ,即在给定显着性水平下,解释变量i X 对因变量没有显着影响.3.简述序列相关性检验方法的共同思路;答:由于自相关性,使得相对于不同的样本点,随机干扰项之间存在相关关系,那么检验自相关性,首先根据OLS 法估计残差,将残差作为随机干扰项的近似估计值,然后检验这些近似估计值之间的相关性以判定随机干扰项是否存在序列相关;各种检验方法就是在这个思路下发展起来的;五、计算分析题1.下表是某次线性回归的EViews 输出结果,根据所学知识求出被略去部分的值用大写字母标示,Dependent Variable: Y Method: Least Squares Included observations: 13解:A=ˆ()Se β=ˆt β=7.10604.3903=;B=2R =211(1)1n R n k -----=1311(10.8728)1321-----=由公式2ˆσ=21ien k --∑,得C=2ie ∑=2ˆ(1)n k σ--=21.1886(1321)--=; 2.用Goldfeld Quandt -方法检验下列模型是否存在异方差;模型形式如下:i Y =0112233 i i i i X X X u ββββ++++其中样本容量n =40,按i X 从小到大排序后,去掉中间10个样本,并对余下的样本按i X 的大小等分为两组,分别作回归,得到两个残差平方和1ESS =、2ESS =,写出检验步骤α=;α。
计量经济学习题及全部答案

《计量经济学》习题(一)一、判断正误1.在研究经济变量之间的非确定性关系时,回归分析是唯一可用的分析方法。
( ) 2.最小二乘法进行参数估计的基本原理是使残差平方和最小。
( )3.无论回归模型中包括多少个解释变量,总离差平方和的自由度总为(n -1)。
( ) 4.当我们说估计的回归系数在统计上是显著的,意思是说它显著地异于0。
( )5.总离差平方和(TSS )可分解为残差平方和(ESS )与回归平方和(RSS )之和,其中残差平方和(ESS )表示总离差平方和中可由样本回归直线解释的部分。
( ) 6.多元线性回归模型的F 检验和t 检验是一致的。
( )7.当存在严重的多重共线性时,普通最小二乘估计往往会低估参数估计量的方差。
( ) 8.如果随机误差项的方差随解释变量变化而变化,则线性回归模型存在随机误差项的自相关。
( )9.在存在异方差的情况下,会对回归模型的正确建立和统计推断带来严重后果。
( ) 10...D W 检验只能检验一阶自相关。
( ) 二、单选题1.样本回归函数(方程)的表达式为( )。
A .i Y =01i i X u ββ++ B .(/)i E Y X =01i X ββ+C .i Y =01ˆˆi i X e ββ++D .ˆi Y =01ˆˆiX ββ+ 2.下图中“{”所指的距离是( )。
A .随机干扰项B .残差C .i Y 的离差D .ˆiY 的离差 3.在总体回归方程(/)E Y X =01X ββ+中,1β表示( )。
A .当X 增加一个单位时,Y 增加1β个单位 B .当X 增加一个单位时,Y 平均增加1β个单位 C .当Y 增加一个单位时,X 增加1β个单位 D .当Y 增加一个单位时,X 平均增加1β个单位 4.可决系数2R 是指( )。
A .剩余平方和占总离差平方和的比重B .总离差平方和占回归平方和的比重C .回归平方和占总离差平方和的比重D .回归平方和占剩余平方和的比重 5.已知含有截距项的三元线性回归模型估计的残差平方和为2i e ∑=800,估计用的样本容量为24,则随机误差项i u 的方差估计量为( )。
计量经济学习题集及详解答案

第一章绪论一、填空题:1.计量经济学是以揭示经济活动中客观存在的__________为内容的分支学科,挪威经济学家弗里希,将计量经济学定义为__________、__________、__________三者的结合。
2.数理经济模型揭示经济活动中各个因素之间的__________关系,用__________性的数学方程加以描述,计量经济模型揭示经济活动中各因素之间__________的关系,用__________性的数学方程加以描述。
3.经济数学模型是用__________描述经济活动。
4.计量经济学根据研究对象和内容侧重面不同,可以分为__________计量经济学和__________计量经济学。
5.计量经济学模型包括__________和__________两大类。
6.建模过程中理论模型的设计主要包括三部分工作,即__________、____________________、____________________。
7.确定理论模型中所包含的变量,主要指确定__________。
8.可以作为解释变量的几类变量有__________变量、__________变量、__________变量和__________变量。
9.选择模型数学形式的主要依据是__________。
10.研究经济问题时,一般要处理三种类型的数据:__________数据、__________数据和__________数据。
11.样本数据的质量包括四个方面__________、__________、__________、__________。
12.模型参数的估计包括__________、__________和软件的应用等内容。
13.计量经济学模型用于预测前必须通过的检验分别是__________检验、__________检验、__________检验和__________检验。
14.计量经济模型的计量经济检验通常包括随机误差项的__________检验、__________检验、解释变量的__________检验。
(完整word版)计量经济学习题及答案..

期中练习题1、回归分析中使用的距离是点到直线的垂直坐标距离。
最小二乘准则是指( )A .使∑=-n t tt Y Y 1)ˆ(达到最小值 B.使∑=-nt t t Y Y 1达到最小值 C. 使∑=-nt t tY Y12)(达到最小值 D.使∑=-nt tt Y Y 12)ˆ(达到最小值 2、根据样本资料估计得出人均消费支出 Y 对人均收入 X 的回归模型为ˆln 2.00.75ln i iY X =+,这表明人均收入每增加 1%,人均消费支出将增加 ( )A. 0.75B. 0.75%C. 2D. 7.5% 3、设k 为回归模型中的参数个数,n 为样本容量。
则对总体回归模型进行显著性检验的F 统计量与可决系数2R 之间的关系为( )A.)1/()1()/(R 22---=k R k n F B. )/(1)-(k )R 1/(R 22k n F --= C. )/()1(22k n R R F --= D. )1()1/(22R k R F --=6、二元线性回归分析中 TSS=RSS+ESS 。
则 RSS 的自由度为( )A.1B.n-2C.2D.n-39、已知五个解释变量线形回归模型估计的残差平方和为8002=∑te,样本容量为46,则随机误差项μ的方差估计量2ˆσ为( ) A.33.33 B.40 C.38.09 D. 201、经典线性回归模型运用普通最小二乘法估计参数时,下列哪些假定是正确的( ) A.0)E(u i = B. 2i )V ar(u i σ= C. 0)u E(u j i ≠D.随机解释变量X 与随机误差i u 不相关E. i u ~),0(2i N σ2、对于二元样本回归模型ii i i e X X Y +++=2211ˆˆˆββα,下列各式成立的有( ) A.0=∑ieB. 01=∑ii Xe C. 02=∑iiXeD.=∑ii Ye E.21=∑i iX X4、能够检验多重共线性的方法有( )A.简单相关系数矩阵法B. t 检验与F 检验综合判断法C. DW 检验法D.ARCH 检验法E.辅助回归法计算题1、为了研究我国经济发展状况,建立投资(1X ,亿元)与净出口(2X ,亿元)与国民生产总值(Y ,亿元)的线性回归方程并用13年的数据进行估计,结果如下:ii i X X Y 21051980.4177916.2805.3871ˆ++= S.E=(2235.26) (0.12) (1.28) 2R =0.99 F=582 n=13问题如下:①从经济意义上考察模型估计的合理性;(3分) ②估计修正可决系数2R ,并对2R 作解释;(3分)③在5%的显著性水平上,分别检验参数的显著性;在5%显著性水平上,检验模型的整体显著性。
计量经济学习题及参考答案

计量经济学各章习题第一章绪论1.1试列出计量经济分析地主要步骤.1.2计量经济模型中为何要包括扰动项?1.3什么是时间序列和横截面数据? 试举例说明二者地区别1.4估计量和估计值有何区别?第二章计量经济分析地统计学基础2.1名词解释随机变量概率密度函数抽样分布样本均值样本方差协方差相关系数标准差标准误差显著性水平置信区间无偏性有效性一致估计量接受域拒绝域第I 类错误2.2请用例 2.2中地数据求北京男生平均身高地99%置信区间.2.325 个雇员地随机样本地平均周薪为130元,试问此样本是否取自一个均值为120 元、标准差为10 元地正态总体?文档收集自网络,仅用于个人学习2.4某月对零售商店地调查结果表明,市郊食品店地月平均销售额为2500 元,在下一个月份中,取出16 个这种食品店地一个样本,其月平均销售额为2600 元,销售额地标准差为480 元.试问能否得出结论,从上次调查以来,平均月销售额已经发生了变化?文档收集自网络,仅用于个人学习第三章双变量线性回归模型3.1判断题(判断对错;如果错误,说明理由)(1)OLS 法是使残差平方和最小化地估计方法.(2)计算OLS 估计值无需古典线性回归模型地基本假定.(3)若线性回归模型满足假设条件(1)~(4),但扰动项不服从正态分布,则尽管OLS 估计量不再是BLUE ,但仍为无偏估计量.文档收集自网络,仅用于个人学习(4)最小二乘斜率系数地假设检验所依据地是t 分布,要求地抽样分布是正态分布.2(5)R2=TSS/ESS.(6)若回归模型中无截距项,则.(7)若原假设未被拒绝,则它为真.(8)在双变量回归中,地值越大,斜率系数地方差越大.3.2设和分别表示Y 对X 和X 对Y 地OLS 回归中地斜率,证明r 为X 和Y 地相关系数.3.3证明:(1)Y 地真实值与OLS 拟合值有共同地均值,即;(2)OLS 残差与拟合值不相关,即.3.4证明本章中( 3.18)和( 3.19)两式:(1)(2)3.5考虑下列双变量模型:模型1:模型2:(1)1 和1地OLS 估计量相同吗?它们地方差相等吗?(2)2 和2地OLS 估计量相同吗?它们地方差相等吗?3.6有人使用1980-1994 年度数据,研究汇率和相对价格地关系,得到如下结果:其中,Y=马克对美元地汇率X=美、德两国消费者价格指数(CPI)之比,代表两国地相对价格(1)请解释回归系数地含义;(2)X t 地系数为负值有经济意义吗?(3)如果我们重新定义X 为德国CPI与美国CPI之比,X 地符号会变化吗?为什么?3.7随机调查200 位男性地身高和体重,并用体重对身高进行回归,结果如下:其中Weight 地单位是磅(lb ),Height 地单位是厘米(cm).(1)当身高分别为177.67cm、164.98cm、187.82cm 时,对应地体重地拟合值为多少?(2)假设在一年中某人身高增高了 3.81cm,此人体重增加了多少?3.8设有10 名工人地数据如下:X 10 7 10 5 8 8 6 7 9 10Y 11 10 12 6 10 7 9 10 11 10 其中X= 劳动工时,Y= 产量(1)试估计Y=α+βX + u(要求列出计算表格);(2)提供回归结果(按标准格式)并适当说明;(3)检验原假设β=1.0.3.9用12 对观测值估计出地消费函数为Y=10.0+0.90X ,且已知=0.01,=200,=4000,试预测当X=250 时Y 地值,并求Y 地95%置信区间.文档收集自网络,仅用于个人学习3.10设有某变量(Y)和变量(X)1995—1999 年地数据如下:(3)试预测X=10 时Y 地值,并求Y 地95%置信区间.3.11根据上题地数据及回归结果,现有一对新观测值X =20,Y=7.62,试问它们是否可能来自产生样本数据地同一总体?文档收集自网络,仅用于个人学习3.12有人估计消费函数,得到如下结果(括号中数字为t 值):=15 + 0.81 =0.98(2.7)(6.5)n=19(1)检验原假设:=0(取显著性水平为5%)(2)计算参数估计值地标准误差;(3)求地95%置信区间,这个区间包括0 吗?3.13试用中国1985—2003 年实际数据估计消费函数:=α+β + u t其中:C代表消费,Y 代表收入.原始数据如下表所示,表中:Cr=农村居民人均消费支出(元)Cu=城镇居民人均消费支出(元)Y =国内居民家庭人均纯收入(元) Yr =农村居民家庭人均纯收入(元) Yu=城镇居民家庭人均可支配收入(元) Rpop=农村人口比重(%) pop=历年年底我国人口总数(亿人)P=居民消费价格指数(1985=100)Pr=农村居民消费价格指数(1985=100)Pu=城镇居民消费价格指数(1985=100)数据来源:《中国统计年鉴2004》使用计量经济软件,用国内居民人均消费、农村居民人均消费和城镇居民人均消费分别对各自地人均收入进行回归,给出标准格式回归结果;并由回归结果分析我国城乡居民消费行为有何不同.文档收集自网络,仅用于个人学习第四章多元线性回归模型4.1某经济学家试图解释某一变量Y 地变动.他收集了Y 和 5 个可能地解释变量~地观测值(共10 组),然后分别作三个回归,结果如下(括号中数字为t 统计量):文档收集自网络,仅用于个人学习( 1) = 51.5 + 3.21 R=0.63(3.45) (5.21)2) 33.43 + 3.67 + 4.62 + 1.21 R=0.75 文档收集自网络,仅用于个人学(3.61 )(2.56)(0.81) (0.22)3) 23.21 + 3.82 + 2.32 + 0.82 + 4.10 + 1.21(2.21 )(2.83)(0.62) (0.12) (2.10) (1.11)文档收集自网络,仅用于个人学习R=0.80 你认为应采用哪一个结果?为什么?4.2为研究旅馆地投资问题,我们收集了某地地1987-1995 年地数据来估计收益生产函数R=ALKe ,其中R=旅馆年净收益(万年) ,L=土地投入,K=资金投入, e 为自然对数地底.设回归结果如下(括号内数字为标准误差) :文档收集自网络,仅用于个人学习= -0.9175 + 0.273lnL + 0.733lnK R=0.94(0.212) (0.135) (0.125)(1)请对回归结果作必要说明;( 2)分别检验α和β 地显著性;( 3)检验原假设:α =β = 0;4.3我们有某地1970-1987 年间人均储蓄和收入地数据,用以研究1970-1978 和1978 年以后储蓄和收入之间地关系是否发生显著变化. 引入虚拟变量后,估计结果如下(括号内数据为标准差) :文档收集自网络,仅用于个人学习= -1.7502 + 1.4839D + 0.1504 - 0.1034D·R=0.9425 文档收集自网络,仅用于个人学习(0.3319) (0.4704) (0.0163) (0.0332)其中:Y=人均储蓄,X=人均收入,D= 请检验两时期是否有显著地结构性变化.4.4说明下列模型中变量是否呈线性,系数是否呈线性,并将能线性化地模型线性化.(1)(2)(3)4.5有学者根据某国19年地数据得到下面地回归结果:其中:Y=进口量(百万美元),X1 =个人消费支出(百万美元),X2 =进口价格/国内价格.(1)解释截距项以及X1和X2系数地意义;(2)Y 地总变差中被回归方程解释地部分、未被回归方程解释地部分各是多少?(3)进行回归方程地显著性检验,并解释检验结果;(4)对“斜率”系数进行显著性检验,并解释检验结果.4.6由美国46个州1992年地数据,Baltagi 得到如下回归结果:其中,C=香烟消费(包/人年),P=每包香烟地实际价格Y=人均实际可支配收入(1)香烟需求地价格弹性是多少?它是否统计上显著?若是,它是否统计上异于-1?(2)香烟需求地收入弹性是多少?它是否统计上显著?若不显著,原因是什么?(3)求出.4.7有学者从209 个公司地样本,得到如下回归结果(括号中数字为标准误差):其中,Salary=CEO 地薪金Sales=公司年销售额roe=股本收益率(%)ros=公司股票收益请分析回归结果.4.8为了研究某国1970-1992 期间地人口增长率,某研究小组估计了下列模型:其中:Pop=人口(百万人),t=趋势变量,.(1)在模型 1 中,样本期该地地人口增长率是多少?(2)人口增长率在1978 年前后是否显著不同?如果不同,那么1972-1977和1978-1992 两时期中,人口增长率各是多少?文档收集自网络,仅用于个人学习4.9设回归方程为Y= β0+β1X1+β2X2+β3X3+ u, 试说明你将如何检验联合假设:β1= β2 和β3 = 1 .文档收集自网络,仅用于个人学习4.10下列情况应引入几个虚拟变量,如何表示?(1)企业规模:大型企业、中型企业、小型企业;(2)学历:小学、初中、高中、大学、研究生.4.11在经济发展发生转折时期,可以通过引入虚拟变量来表示这种变化.例如,研究进口消费品地数量Y 与国民收入X 地关系时,数据散点图显示1979 年前后明显不同.请写出引入虚拟变量地进口消费品线性回归方程.文档收集自网络,仅用于个人学习4.12柯布-道格拉斯生产函数其中:GDP=地区国内生产总值(亿元)K=资本形成总额(亿元)L= 就业人数(万人)P=商品零售价格指数(上年=100)试根据中国2003 年各省数据估计此函数并分析结果.数据如下表所示第五章模型地建立与估计中地问题及对策5.1判断题(判断对错;如果错误,说明理由)(1)尽管存在严重多重共线性,普通最小二乘估计量仍然是最佳线性无偏估计量(BLUE ).(2)如果分析地目地仅仅是为了预测,则多重共线性并无妨碍. (3)如果解释变量两两之间地相关系数都低,则一定不存在多重共线性. (4)如果存在异方差性,通常用地t 检验和 F 检验是无效地. (5)当存在自相关时,OLS 估计量既不是无偏地,又不是有效地.(6)消除一阶自相关地一阶差分变换法假定自相关系数必须等于 1. (7)模型中包含无关地解释变量,参数估计量会有偏,并且会增大估计量地方差,即增大误差.(8)多元回归中,如果全部“斜率”系数各自经t 检验都不显著,则R2值也高不了.(9)存在异方差地情况下,OLS 法总是高估系数估计量地标准误差.(10)如果一个具有非常数方差地解释变量被(不正确地)忽略了,那么OLS 残差将呈异方差性.5.2考虑带有随机扰动项地复利增长模型:Y 表示GDP,Y0是Y 地基期值,r 是样本期内地年均增长率,t 表示年份,t=1978,⋯,2003.文档收集自网络,仅用于个人学习试问应如何估计GDP 在样本期内地年均增长率?5.3 检验下列情况下是否存在扰动项地自相关 .(1) DW=0.81,n=21,k=3(2)DW=2.25,n=15,k=2(3)DW=1.56,n=30,k=55.4有人建立了一个回归模型来研究我国县一级地教育支出:Y= β0+β1X1+β 2X2+β3X3+u其中:Y,X1,X2 和X3分别为所研究县份地教育支出、居民人均收入、学龄儿童人数和可以利用地各级政府教育拨款.文档收集自网络,仅用于个人学习他打算用遍布我国各省、市、自治区地100 个县地数据来估计上述模型.(1)所用数据是什么类型地数据?(2)能否采用OLS 法进行估计?为什么?(3)如不能采用OLS 法,你认为应采用什么方法?5.5试从下列回归结果分析存在问题及解决方法:(1)= 24.7747 + 0.9415 - 0.0424 R=0.9635SE:(6.7525)(0.8229)(0.0807)其中:Y=消费,X2=收入,X3=财产,且n=5000 (2)= 0.4529 - 0.0041t R=0.5284t:(-3.9606) DW=0.8252其中Y= 劳动在增加值中地份额,t=时间该估计结果是使用1949-1964 年度数据得到地.5.6工资模型:wi=b0+b1Si+b2Ei+b3Ai+b4Ui+ui其中Wi=工资,Si=学校教育年限,Ei=工作年限,Ai=年龄,Ui=是否参加工会.在估计上述模型时,你觉得会出现什么问题?如何解决?5.7你想研究某行业中公司地销售量与其广告宣传费用之间地关系.你很清楚地知道该行业中有一半地公司比另一半公司大,你关心地是这种情况下,什么估计方法比较合理.假定大公司地扰动项方差是小公司扰动项方差地两倍.文档收集自网络,仅用于个人学习(1)若采用普通最小二乘法估计销售量对广告宣传费用地回归方程(假设广告宣传费是与误差项不相关地自变量),系数地估计量会是无偏地吗?是一致地吗?是有效地吗?文档收集自网络,仅用于个人学习(2)你会怎样修改你地估计方法以解决你地问题?(3)能否对原扰动项方差假设地正确性进行检验?5.8考虑下面地模型其中GNP=国民生产总值,M =货币供给. (1)假设你有估计此模型地数据,你能成功地估计出模型地所有系数吗?说明理由.(2)如果不能,哪些系数可以估计?(3)如果从模型中去掉这一项,你对(1)中问题地答案会改变吗?(4)如果从模型中去掉这一项,你对(1)中问题地答案会改变吗?5.9采用美国制造业1899-1922年数据,Dougherty得到如下两个回归结果:(1)(2)其中:Y=实际产出指数,K=实际资本投入指数,L =实际劳动力投入指数,t=时间趋势(1)回归式(1)中是否存在多重共线性?你是如何得知地?(2)回归式(1)中,logK 系数地预期符号是什么?回归结果符合先验预期吗?为什么会这样?(3)回归式(1)中,趋势变量在其中起什么作用?(4)估计回归式(2)背后地逻辑是什么?(5)如果(1)中存在多重共线性,那么(2)式是否减轻这个问题?你如何得知?(6)两个回归地R2可比吗?说明理由.5.10有人估计了下面地模型:其中:C=私人消费支出,GNP=国民生产总值,D=国防支出假定,将(1)式转换成下式:使用1946-1975数据估计(1)、(2)两式,得到如下回归结果(括号中数字为标准误差):1)关于异方差,模型估计者做出了什么样地假定?你认为他地依据是什么?2)比较两个回归结果.模型转换是否改进了结果?也就是说,是否减小了估计标准误差?说明理由.5.11设有下列数据:RSS1=55,K =4,n1=30RSS3=140,K =4,n3=30 请依据上述数据,用戈德佛尔德-匡特检验法进行异方差性检验(5%显著性水平).5.12考虑模型(1)也就是说,扰动项服从AR (2)模式,其中是白噪声.请概述估计此模型所要采取地步骤.5.13对第 3 章练习题 3.13 所建立地三个消费模型地结果进行分析:是否存在序列相关问题?如果有,应如何解决?5.14为了研究中国农业总产值与有效灌溉面积、化肥施用量、农作物总播种面积、受灾面积地相互关系,选31 个省市2003 年地数据资料,如下表所示:文档收集自网络,仅用于个人学习表中:Y=农业总产值(亿元,不包括林牧渔)X1=有效灌溉面积(千公顷)X2=化肥施用量(万吨)X23=化肥施用量(公斤/亩)X3=农作物总播种面积(千公顷)X4=受灾面积(千公顷)(1)回归并根据计算机输出结果写出标准格式地回归结果;(2)模型是否存在问题?如果存在问题,是什么问题?如何解决?第六章动态经济模型:自回归模型和分布滞后模型6.1判断题(判断对错;如果错误,说明理由)(1)所有计量经济模型实质上都是动态模型.(2)如果分布滞后系数中,有地为正有地为负,则科克模型将没有多大用处. (3)若适应预期模型用OLS 估计,则估计量将有偏,但一致. (4)对于小样本,部分调整模型地OLS 估计量是有偏地.(5)若回归方程中既包含随机解释变量,扰动项又自相关,则采用工具变量法,将产生无偏且一致地估计量.(6)解释变量中包括滞后因变量地情况下,用德宾-沃森d 统计量来检测自相关是没有实际用处地.6.2用OLS 对科克模型、部分调整模型和适应预期模型分别进行回归时,得到地OLS 估计量会有什么样地性质?文档收集自网络,仅用于个人学习6.3简述科克分布和阿尔蒙多项式分布地区别.6.4考虑模型假设相关.要解决这个问题,我们采用以下工具变量法:首先用对和回归,得到地估计值,然后回归其中是第一步回归(对和回归)中得到地.(1)这个方法如何消除原模型中地相关?(2)与利维顿采用地方法相比,此方法有何优点?6.5设其中:M=对实际现金余额地需求,Y*=预期实际收入,R*=预期通货膨胀率假设这些预期服从适应预期机制:其中和是调整系数,均位于0和1之间.(1)请将M t 用可观测量表示;(2)你预计会有什么估计问题?6.6考虑分布滞后模型假设可用二阶多项式表示诸如下:若施加约束==0,你将如何估计诸系数(,i=0,1, (4)6.7为了研究设备利用对于通货膨胀地影响,T. A.吉延斯根据1971年到1988年地美国数据获得如下回归结果:文档收集自网络,仅用于个人学习其中:Y=通货膨胀率(根据GNP 平减指数计算)X t=制造业设备利用率X t-1 =滞后一年地设备利用率1)设备利用对于通货膨胀地短期影响是什么?长期影响又是什么?(2)每个斜率系数是统计显著地吗?(3)你是否会拒绝两个斜率系数同时为零地原假设?将利用何种检验?6.8考虑下面地模型:Y t = α+β(W0X t+ W1X t-1 + W2X t-2 + W3X t-3)+u t 请说明如何用阿尔蒙滞后方法来估计上述模型(设用二次多项式来近似) .6.9下面地模型是一个将部分调整和适应预期假说结合在一起地模型:Y t*= βX t+1eY t-Y t-1 = δ(Y t*- Y t-1) + u tX t+1e- X t e= (1-λ)( X t - X t e);t=1,2,⋯, n式中Y t*是理想值,X t+1e和X t e是预期值.试推导出一个只包含可观测变量地方程,并说明该方程参数估计方面地问题.文档收集自网络,仅用于个人学习第七章时间序列分析7.1单项选择题(1)某一时间序列经一次差分变换成平稳时间序列,此时间序列称为()地.A.1 阶单整B.2阶单整C.K 阶单整D.以上答案均不正确文档收集自网络,仅用于个人学习(2)如果两个变量都是一阶单整地,则().A .这两个变量一定存在协整关系B.这两个变量一定不存在协整关系C.相应地误差修正模型一定成立D.还需对误差项进行检验文档收集自网络,仅用于个人学习(3)如果同阶单整地线性组合是平稳时间序列,则这些变量之间关系是() .A. 伪回归关系B.协整关系C.短期均衡关系D. 短期非均衡关系(4).若一个时间序列呈上升趋势,则这个时间序列是().A .平稳时间序列B.非平稳时间序列C.一阶单整序列 D. 一阶协整序列7.2请说出平稳时间序列和非平稳时间序列地区别,并解释为什么在实证分析中确定经济时间序列地性质是十分必要地.文档收集自网络,仅用于个人学习7.3什么是单位根?7.4Dickey-Fuller(DF)检验和Engle-Granger(EG)检验是检验什么地?文档收集自网络,仅用于个人学习7.5什么是伪回归?在回归中使用非均衡时间序列时是否必定会造成伪回归?7.6由1948-1984 英国私人部门住宅开工数(X)数据,某学者得到下列回归结果:注:5%临界值值为-2.95,10%临界值值为-2.60. (1)根据这一结果,检验住宅开工数时间序列是否平稳.(2)如果你打算使用t 检验,则观测地t 值是否统计显著?据此你是否得出该序列平稳地结论?(3)现考虑下面地回归结果:请判断住宅开工数地平稳性.7.7由1971-I 到1988-IV 加拿大地数据,得到如下回归结果;A.B.C.其中,M1=货币供给,GDP=国内生产总值,e t=残差(回归A)(1)你怀疑回归 A 是伪回归吗?为什么?(2)回归 B 是伪回归吗?请说明理由.(3)从回归 C 地结果,你是否改变(1)中地结论,为什么?(4)现考虑以下回归:这个回归结果告诉你什么?这个结果是否对你决定回归 A 是否伪回归有帮助?7.8 检验我国人口时间序列地平稳性,数据区间为1949-2003 年.单位:万人7.9对中国进出口贸易进行协整分析,如果存在协整关系,则建立E CM 模型.1951-2003 年中国进口(im )、出口(ex)和物价指数(pt,商品零售物价指数)时间序列数据见下表.因为该期间物价变化大,特别是改革开放以后变化更为激烈,所以物价指数也作为一个解释变量加入模型中.为消除物价变动对进出口数据地影响以及消除进出口数据中存在地异方差,定义三个变量如下:文档收集自网络,仅用于个人学习第八章联立方程模型8.1判断题(判断对错;如果错误,说明理由)(1)OLS 法适用于估计联立方程模型中地结构方程.(2)2SLS 法不能用于不可识别方程.(3)估计联立方程模型地2SLS 法和其它方法只有在大样本地情况下,才能具有我们期望地统计性质 .(4) 联立方程模型作为一个整体,不存在类似 R 2这样地拟合优度测度 .(5) 如果要估计地方程扰动项自相关或存在跨方程地相关, 则 2SLS 法和其它估 计结构方程地方法都不能用 .(6) 如果一个方程恰好识别,则 ILS 和 2SLS 给出相同结果 .8.2 单项选择题1) 结构式模型中地方程称为结构方程 .在结构方程中, 解释变量可以是前定变3) 如果联立方程模型中某个结构方程包含了模型中所有地变量,则这个方程5)当一个结构式方程为恰好识别时,这个方程中内生解释变量地个数( A .与被排除在外地前定变量个数正好相等 B .小于被排除在外地前定变量个数 C .大于被排除在外地前定变量个数D .以上三种情况都有可能发生 文档收集自网络,仅用于个人学习6) 简化式模型就是把结构式模型中地内生变量表示为 ( ).A. 外生变量和内生变量地函数关系B.前定变量和随机误差项地模型C.滞后变量和随机误差项地模型 D.外生变量和随机误差项地模量,也可以是 ( ).文档收集自网络,仅用于个人学习 A. 外生变量 B.滞后变量2)前定变量是 ( )地合称 .A.外生变量和滞后内生变量C.内生变量D. 外生变量和内生变量 C.外生变量和虚拟变量 D. 解释变量和被解释变量( ).A. 恰好识别B.不可识别 (4) 下面说法正确地是( ).A.内生变量是非随机变量 C.外生变量是随机变量 C.过度识别 D.不确定B. 前定变量是随机变量个人收集整理勿做商业用途型7) 对联立方程模型进行参数估计地方法可以分两类,即:( ).A.间接最小二乘法和系统估计方法B.单方程估计法和系统估计方法个人收集整理勿做商业用途C.单方程估计法和二阶段最小二乘法D.工具变量法和间接最小二乘法(8)在某个结构方程过度识别地条件下,不适用地估计方法是().A. 间接最小二乘法B.工具变量法C.二阶段最小二乘法D.有限信息极大似然估计法8.3行为方程和恒等式有什么区别?8.4如何确定模型中地外生变量和内生变量?8.5考虑下述模型:C t = α + β D t +u t I t = γ + δD t-1 + νt D t = C t +I t + Z t ;t=1 ,2,⋯,n其中 C = 消费支出,D= 收入,I = 投资,Z = 自发支出. C、I 和D是内生变量.试写出消费支出地简化型方程,并研究各方程地识别问题.8.6考虑下述模型:Y t = C t + I t +G t +X tC t = β 0 + β 1D t + β2C t-1 + u tD t = Y t –T tI t = α0 + α1Y t + α2R t-1 +νt 模型中各方程是正规化方程,u t、νt为扰动项.(1)请指出模型中地内生变量、外生变量和前定变量.(2)写出用2SLS法进行估计时,每个阶段中要估计地方程.8.7下面是一个简单地美国宏观经济模型(1960-1999)其中C=实际私人消费,I= 实际私人总投资,G=实际政府支出,Y =实际GDP,M= 当年价M2,R=长期利率;P=消费价格指数.内生变量:C,I,R,Y 前定变量:C t-1,I t-1,M t-1,P t,R t-1 和G t.(1)应用识别地阶条件,决定各方程地识别状态;(2)你打算用什么方法来估计可识别行为方程?8.8假设有如下计量经济模型:其中,Y=国民收入,I=净资本形成,C=个人消费,Q =利润,P=生活费用指数,R= 工业劳动生产率1)写出模型地内生变量、外生变量和前定变量;个人收集整理勿做商业用途(2)用识别地阶条件确定各方程地识别状态;(3)此模型中是否有可以用ILS 法估计地方程?如有,请指出;(4)写出用2SLS 法进行估计时,每个阶段中要估计地方程. 8.9考虑下述模型:消费方程:C t=α0 +α 1Y t +α2C t-1 +u①投资方程:I t=β0 +β1Y t +β2I t –1+u2t②进口方程:M t = 0 + 1Y t + u3t ③Y t = C t+ I t + G t + X t - M t模型中各方程是正规化方程,u 1t, ⋯u3t为扰动项.(1)请指出模型中地内生变量、外生变量和前定变量.(2)利用阶条件识别各行为方程.(3)写出用3SLS 进行估计时地步骤.8.10考察下述国民经济地简单模型式中,C为消费,Y 为国民收入,I 为投资,R为利率.设样本容量n 为20,已算得中间结果为:(1)判别模型中消费方程地识别状态;(2)用间接最小二乘法求消费方程结构式系数;(3)将采用哪种方法估计投资方程?为什么?(不必计算)8.11由联立方程模型;得到其简化式如下:(1)两结构方程可识别吗?(2)如果知道,识别情况有何变化?(3)若对简化式进行估计,结果如下:个人收集整理勿做商业用途试求出结构参数地值,并说明如何检验原假设个人收集整理勿做商业用途版权申明本文部分内容,包括文字、图片、以及设计等在网上搜集整理。
计量经济学练习题带答案版
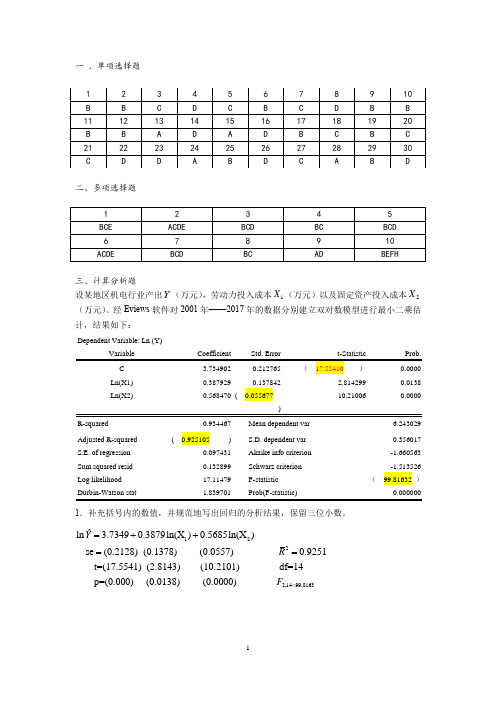
一 、单项选择题二、多项选择题三、计算分析题设某地区机电行业产出Y (万元),劳动力投入成本1X (万元)以及固定资产投入成本2X (万元)。
经Eviews 软件对2001年——2017年的数据分别建立双对数模型进行最小二乘估计,结果如下:Dependent Variable: Ln (Y)Ln(X1) 0.3879290.1378422.814299 0.0138 Ln(X2)0.568470 ( 0.05567710.210060.0000R-squared 0.934467 Mean dependent var6.243029 Adjusted R-squared ( 0.925105 ) S.D. dependent var0.356017 S.E. of regression 0.097431 Akaike info criterion -1.660563 Sum squared resid 0.132899 Schwarz criterion -1.513526 Log likelihood 17.11479 F-statistic ( 99.81632 )1.补充括号内的数值,并规范地写出回归的分析结果,保留三位小数。
122ˆln 3.73490.3879ln(X )0.5685ln(X ) se (0.2128) (0.1378) (0.0557) 0.9251t=(17.5541) (2.8143) (10.2101) df=14 p=(0.000) (0.0138)Y R =++==2,1499.8163(0.0000) F =2. 对模型的估计结果进行偏回归系数和整体显著性检验。
(t0.025(14)=2.145;t0.025(15)=2.131;F0.05(2,14)=3.74;F0.05(3,14)=3.34)。
(注意运用临界值法!!)样本量为17,临界值选取t0.025(14)=2.145F临界值选取F0.05(2,14)=3.743. 如果有两种可供选择的措施以提高机电行业产出,措施一是加大劳动力的投入,措施二是增大固定资产的投入,你认为哪个措施效果更明显,为什么?选择措施二,因为劳动力成本增长1个百分点,机电行业产增长0.39个百分点,而固定资产投入成本增长1个百分点,机电行业销售额仅增长0.57个百分点四、分析题根据我国31个细分制造业的数据,得到生产函数的如下估计结果:ln(Ŷi)=1.168+0.37ln(K i)+0.61ln(L i)se= (0.331) ( a) (0.1293)t= (3.53) ( 4.23) ( b )R2=0.94其中,Y为总产出,K为资本投入,L为劳动投入。
计量经济学习题及答案

计量经济学习题一、名词解释1、普通最小二乘法:为使被解释变量的估计值与观测值在总体上最为接近使Q= 最小,从而求出参数估计量的方法,即之;2、总平方和、回归平方和、残差平方和的定义:TSS度量Y自身的差异程度,称为总平方和;TSS除以自由度n-1=因变量的方差,度量因变量自身的变化;RSS度量因变量Y的拟合值自身的差异程度,称为回归平方和,RSS除以自由度自变量个数-1=回归方差,度量由自变量的变化引起的因变量变化部分;ESS度量实际值与拟合值之间的差异程度,称为残差平方和;RSS除以自由度n-自变量个数-1=残差误差方差,度量由非自变量的变化引起的因变量变化部分;3、计量经济学:计量经济学是以经济理论为指导,以事实为依据,以数学和统计学为方法,以电脑技术为工具,从事经济关系与经济活动数量规律的研究,并以建立和应用经济计量模型为核心的一门经济学科;而且必须指出,这些经济计量模型是具有随机性特征的;4、最小样本容量:即从最小二乘原理和最大似然原理出发,欲得到参数估计量,不管其质量如何,所要求的样本容量的下限;即样本容量必须不少于模型中解释变量的数目包扩常数项,即之;5、序列相关性:模型的随机误差项违背了相互独立的基本假设的情况;6、多重共线性:在线性回归模型中,如果某两个或多个解释变量之间出现了相关性,则称为多重共线性;7、工具变量法:在模型估计过程中被作为工具使用,以替代模型中与随机误差项相关的随机解释变量;这种估计方法称为工具变量法;8、时间序列数据:按照时间先后排列的统计数据;9、截面数据:发生在同一时间截面上的调查数据;10、相关系数:指两个以上的变量的样本观测值序列之间表现出来的随机数学关系;11、异方差:对于线性回归模型提出了若干基本假设,其中包括随机误差项具有同方差;如果对于不同样本点,随机误差项的方差不再是常数,而互不相同,则认为出现了异方差性;12、外生变量:外生变量是模型以外决定的变量,作为自变量影响内生变量,外生变量决定内生变量,其参数不是模型系统的元素;因此,外生变量本身不能在模型体系内得到说明;外生变量一般是确定性变量,或者是具有临界概率分布的随机变量;外生变量影响系统,但本身并不受系统的影响;外生变量一般是经济变量、条件变量、政策变量、虚变量;一般情况下,外生变量与随机项不相关;二、填空题1、计量经济学中, 经济学提供理论基础, 统计学提供资料依据, 数学提供研究方法.2、研究经济问题时,一般要处理三种类型的数据:1 截面数据;2 时间序列数据;和3 虚拟变量数据;3、 OLS参数估计量具有如下统计性质,即线性、无偏性、有效性 ;4、时间序列数据与横截面数据的最大区别在于数据的顺序性 _;5、在模型中引入多个虚拟变量时,虚拟变量的个数应按下列原则确定:如果有M个互斥的属性类型,则在模型中引入 M-1 个虚拟变量;6、在现实经济活动中往往存在一个被解释变量受到多个解释变量的影响的现象,表现为在线性回归模型中有多个解释变量,这样的模型被称为多元线性回归模型;7、在多元线性回归模型中,参数的最小二乘估计量具线性性、无偏性、最小方差性,同时多元线性回归模型满足经典假定,所以此时的最小二乘估计量是最优的线性无偏估计量,又称BLUE估计量;8、计量经济学的核心内容是建立和应用计量经济模型;9、R2 是一个回归直线与样本观测值拟合优度的数量指标,其值越大,拟合优度越好,其值越小,拟合优度就越差;10、自相关就是指总体回归方程的误差项u i之间存在着相关,即:按时间或空间排序的观察值序列的个成员之间存在的相关;三、单项选择题1.经济计量模型是指CA.投入产出模型B.数学规划模型C.包含随机方程的经济数学模型D.模糊数学模型2.回归分析中定义的BA.解释变量和被解释变量都是随机变量B.解释变量为非随机变量,被解释变量为随机变量C.解释变量和被解释变量都为非随机变量D.解释变量为随机变量,被解释变量为非随机变量3.设k 为回归模型中的参数个数,n 为样本容量;则对总体回归模型进行显着性检验F 检验时构造的F 统计量为 A A.)k n /(RSS )1k /(ESS F --=B. )k n /(RSS )1k /(ESS 1F ---=C. RSS ESS F =D. ESSRSSF = 4. D-W 检验,即杜宾-瓦尔森检验,用于检验时间序列回归模型的误差项中的一阶序列相关的统计量,DW 统计量以OLS 残差为基础:=∑∑==--nt tnt t tee e1221~)~~(,如果值越接近于2,则 CA.则表明存在着正的自相关B.则表明存在着负的自相关C.则表明无自相关D.无法表明任何意义5.容易产生异方差的数据为C A.时序数据 B.修匀数据 C.横截面数据 D.年度数据6、计量经济模型分为单方程模型和 C ;A.随机方程模型B.行为方程模型C.联立方程模型D.非随机方程模型 7、同一统计指标按时间顺序记录的数据列称为 B A.横截面数据 B.时间序列数据 C.修匀数据 D.平行数据8、样本数据的质量问题,可以概括为完整性、准确性、可比性和 B ; A.时效性 B.一致性 C.广泛性 D.系统性9、有人采用全国大中型煤炭企业的截面数据,估计生产函数模型,然后用该模型预测未来煤炭行业的产出量,这是违反了数据的 A 原则; A.一致性 B.准确性 C.可比性 D.完整性10、对下列模型进行经济意义检验,哪一个模型通常被认为没有实际价值的 B ;A. i C 消费i I 8.0500+=收入B. di Q 商品需求i I 8.010+=收入i P 9.0价格C. si Q 商品供给i P 75.020+=价格D. i Y 产出量6.065.0i K =资本4.0iL 劳动 四、多项选择题1、不满足OLS 基本假定的情况,主要包括: ABCD ; A.随机序列项不是同方差,而是异方差 B.随机序列项序列相关,即存在自相关 C.解释变量是随机变量,且与随机扰动项相关 D.解释变量之间相关,存在多重共线性 E.因变量是随机变量,即存在误差2、随机扰动项产生的原因大致包括如下几个方面,它们是 ABCD ; A.客观现象的随机性人的行为、社会环境与自然影响的随机性 B.模型省略变量被省略的具有随机性的变量归入随机扰动项 C.测量与归并误差估计时测量和归并误差都归入随机扰动项 D.数学模型函数的形式的误定E.从根本上看是由于经济活动是人类参与的活动 3、内生变量 ABDE ;A.在联立方程模型中,内生变量由系统内方程决定,同时又对模型系统产生影响;既作为被解释变量,又可以在不同的方程中作为解释变量;B.一般情况下,内生变量与随机项相关;C.内生变量决定外生变量D.内生变量一般都是经济变量E.内生变量Y 一般满足: CovY i ,i μ≠0,即EY i i μ≠0; 4、影响预测精度的因素包括 ACD ;A.样本容量愈大,预测的方差愈小,预测的精度愈大B.样本中解释变量的离均差的和愈大,预测的方差愈小,预测的精度愈大C.内插预测的精度比较有把握,外推预测的能力显着下降,预测精度难以把握D.当其样本容量n 相当大,而预测点的取值X0接近于X 的平均值时,预测的方差最小,预测的精度最大E.残差标准差的估计值愈小,回归预测的精度愈精确,所以常常把残差标准差的估计值作为预测精度的标志5. 下列哪些变量属于前定变量CD ; A.内生变量 B.随机变量 C.滞后变量 D.外生变量 E.工具变量 五、判断题1、通常把由方程组内决定的变量称为内生变量,而不能由方程组内直接决定的变量为前定变量,又称为先决变量;√2、前定先决变量既能作为解释变量,也能作为被解释变量;×3、D-W 检验,即杜宾-瓦尔森检验,=∑∑==--nt tnt t tee e1221~)~~(,其最大优点为简单易行;如果值接近于零,则说明越倾向于无自相关;×4、截面数据是一批发生在同一时间截面上的调查数据;例如,在给定的某个时点上对个人、家户、企业、城市、地区、国家或一系列其它单位采集的样本所构成的数据集;√5、内生变量是理论或模型所要解释的变量,即因变量,它是为理论或模型以外的因素所影响的变量,是具有某种概率分布的随机变量;√6、违背基本假设的计量经济学模型是不可估计的;×7、只有满足基本假设的计量经济学模型的普通最小二乘参数估计量才具有无偏性和有效性;√8、要使得计量经济学模型拟合得好,就必须增加解释变量;×9、在拟合优度检验中,拟合优度高,则解释变量对被解释变量的解释程度就高,可以推测模型总体线性关系成立;反之亦然;×10、样本容量N 越小,残差平方和RSS 就越小,模型拟合优度越好;×11、当计量经济学模型出现异方差性,其普通最小二乘法参数估计量仍具有无偏性,但不具有有效性;√12、实际问题中的多重共线性不是自变量之间存在理论上或实际上的线性关系造成的,而是由于所收集的数据之间存在近似的线性关系所致;√13、模型的拟合优度不是判断模型质量的唯一标准,为了追求模型的经济意义,可以牺牲一点拟合优度;√14、如果给定解释变量值,根据模型就可以得到被解释变量的预测值;×15、异方差问题中,随机误差项的方差与解释变量观测值之间都是有规律可循的;× 16、计量经济学模型解释经济活动中各因素之间的理论关系,用确定性的数学方程加以描述;×17、计量经济学根据研究对象和内容侧重面不同,可以分为广义计量经济学和狭义计量经济学;√18、计量经济学是一门经济学科,而不是数学或其他;√19、样本数据的收集是计量经济学的核心内容;×20、方法,主要包括模型方法和计算方法,是计量经济学研究的基础;×21、具有因果关系的变量之间一定有数学上的相关关系,具有相关关系的变量之间一定具有因果关系;×22、乘数是变量的变化率之比;×23、单方程计量经济学模型是以多个经济现象为研究对象,是应用最为普遍的计量经济学模型;×24、对于最小二乘法最合理的参数估计量应该使得从模型中抽取n组样本观测值的概率最大;×25、总体平方和由残差平方和和回归平方和组成;√26、校正的判定系数和非校正的判定系数仅当非校正判定系数为1时才相等;√27、判定所有解释变量是否对应变量有显着影响的方法是看是否每个解释变量都是显着的t统计量;如果不是,则解释变量整体是统计不显着的;×28、当R2=1, F= 0 ;当R2= 0 ,F=∞;×29、在模型Yi =B1+B2X2i+B3X3i+ui中,如果X2和X3负相关且B3>0,则从模型中略去解释变量X3将使b12的值减小也即,Eb12<B2;其中b12是Y仅对X2的回归方程中的斜率系数;√30、当我们说估计的回归系数在统计上是显着的,意思是说它显着不为1;×31、要计算t临界值,仅仅需知道自由度;×32、整个多元回归模型在统计上是显着的意味着模型中任何一个单独的变量均是统计显着的;×33、就估计和假设检验而言,单方程回归与多元回归没有什么区别;√34、无论模型中包括多少个解释变量,总离差平方和的自由度总为n-1;√35、双对数模型的斜率和弹性系数相同;√36、对于变量之间是线性的模型而言,斜率系数是一个常数,弹性系数是一个变量;但双对数模型的弹性系数是一个常数,而斜率是一个变量;√37、双对数模型的R2值可以与对数-线性模型的相比较,但不能与线性-对数模型的相比较;√38、线性-对数模型的R2值可以与线性模型相比较,但不能与双对数模型或对数线性模型的相比较;√39、模型A:lnY=+;r2= ;模型B:Y=+;r2=模型A更好一些,因为它的r2大;×40、在存在异方差情况下,普通最小二乘估计是有偏的和无效的;×41、如果存在异方差,通常使用的t检验和F检验是无效的;√42、在存在异方差情况下,常用的OLS估计总是高估了估计量的标准差;×43、当存在序列相关时,OLS估计量是有偏的并且也是无效的;×44、消除序列相关的广义差分变换假定自相关系数必须等于1;√45、两个模型,一个是一阶差分形式,一个是水平形式,这两个模型的R 2是不可以直接比较的;√46、存在多重共线性时,模型参数无法估计;×47、尽管存在着完全多重共线性,普通最小二乘估计量仍然是最优线性无偏估计量;× 48、在存在高度多重共线性的情况下,无法估计一个或多个偏回归系数的显着性;√ 49、一旦模型中的解释变量是随机变量,则违背了基本假设,使得模型的OLS 估计量有偏且不一致;× 六、简答1、随机扰动项产生的原因答:1客观现象的随机性;引入e 的根本原因,乃是经济活动是人类参与的,因此不可能像科学实验那样精确;2此外还有社会环境和自然环境的随机性;3模型省略了变量;被省略的变量包含在随机扰动项e 中;4测量与归并误差;测量误差致使观察值不等于实际值,汇总也存在误差;5数学模型形式设定造成的误差;由于认识不足或者简化,将非线性设定成线性模型; 经济计量模型的随机性,正是为什么要采用数理统计方法的原因;2、采用普通最小二乘法,已经保证了模型最好地拟合样本观测值,为何还要进行拟合优度检验答:普通最小二乘法所保证的最好拟合,是同一个问题内部的比较,拟合优度检验结果所表示的优劣是不同问题之间的比较;两个同样满足最小二乘原则的模型,对样本观测值的拟合程度不一定相同;3、针对普通最小二乘法,线性回归摸型的基本假设 答:1解释变量是确定性变量,而且解释变量之间不相关;2随机误差项具有0均值且同方差;3随机误差项在不同样本点之间独立,不存在序列相关; 4随机误差项与解释变量之间不相关;5随机误差项服从0均值且同方差的正态分布; 七、综合题1、某人试图建立我国煤炭行业生产方程,以煤炭产量为被解释变量,经过理论和经验分析,确定以固定资产原值、职工人数和电力消耗量变量作为解释变量,变量的选择是正确的;于是建立了如下形式的理论模型:煤炭产量=αα01+固定资产原值+α2职工人数+α3电力消耗量+μ选择2000年全国60个大型国有煤炭企业的数据为样本观测值;固定资产原值用资产形成年当年价计算的价值量,其它采用实物量单位;采用OLS 方法估计参数;指出该计量经济学问题中可能存在的主要错误,并简单说明理由;答:⑴模型关系错误;直接线性模型表示投入要素之间完全可以替代,与实际生产活动不符;⑵估计方法错误;该问题存在明显的序列相关性,不能采用OLS方法估计;⑶样本选择违反一致性;行业生产方程不能选择企业作为样本;⑷样本数据违反可比性;固定资产原值用资产形成年当年价计算的价值量,不具备可比性;2、材料:为证明刻卜勒行星运行第三定律,把地球与太阳的距离定为1个单位;地球绕太阳公转一周的时间为1个单位年;那么太阳系9个行星与太阳的距离D和绕太阳各公转一周所需时间T的数据如下:obs水星金星地球火星木星土星天王星海王星冥王星DISTANCE1Time184165248D3170782727161630T2170562722561504用上述数据建立计量模型并使用EVIEWS计算输出结果如下问题:根据EVIEWS计算输出结果回答下列问题1EVIEWS计算选用的解释变量是____________________2EVIEWS计算选用的被解释变量是____________________3建立的回归模型方程是____________________4回归模型的拟合优度为____________________5回归函数的标准差为____________________6回归参数估计值的样本标准差为____________________7回归参数估计值的t统计量值为____________________8残差平方和为____________________9被解释变量的平均数为____________________10被解释变量的标准差为____________________答案如下:1Logdistance 2Logtime 3Logdistance= Logtime+u4 5 6 78 9 103、中国国内生产总值与投资及货物和服务净出口单位:亿元用上述数据建立计量模型并使用EVIEWS 计算输出结果如下Dependent Variable: Y Method: Least SquaresDate: 10/19/09 Time: 21:40 Sample: 1991 2003Included observations: 13VariableCoefficientStd. Errort-StatisticProb.C X1 X2R-squaredMean dependent var Adjusted R-squared . dependent var . of regression Akaike info criterion Sum squared resid +08 Schwarz criterion Log likelihood F-statistic Durbin-Watson stat ProbF-statistic1建立投资与净出口与国民生产总值的二元线性回归方程并进行估计,并解释斜率系数的经济意义;解:建立Y 与X 、X 之间的线性回归模型:Y = 0ˆβ + 1ˆβ X 1 + 2ˆβX 2+ e i 根据普通最小二乘法参数估计有故所求回归方程为Y = + X 1 +X 1的系数β1=表明,如果其他变量保持不变,为使国民生产总值增加一亿元投资需增加亿元,净出口增加亿元也能使国民生产总值增加一亿元;2对偏回归系数及所建立的回归模型进行检验,显着性水平α=;2281.2)10(025.0=t 解:假设H 0 : 0=i β,H 1 : 0≠i β;在H 0 成立的条件下检验统计量)ˆ(ˆ)ˆ(ˆ111111βββββS S t =-=~t n-k )ˆ(ˆ)ˆ(ˆ112222βββββS S t =-=~t n-k =-==∑112111ˆ)ˆ(C kn e C S iσβ =-==∑222222ˆ)ˆ(C kn e C S iσβ其中C ii 是1)(-X X T 对角线的值;22)ˆ(i i i Y Y e -=∑∑,为残差平方和; 所以:120692.0177916.2)ˆ(ˆ111==ββS t = 282402.1051980.4)ˆ(ˆ222==ββS t = 给定α=. {}{}2281.2)10()(025.02≥=≥=⎭⎬⎫⎩⎨⎧-≥=t t t k n t t w α;从上面结果看出t 、t 的绝对值均大于,故拒绝H 0,认为1、2 均显着不等于0,X 1、X 2对Y 的影响均显着;3估计可决系数,以显着性水平α=对方程整体显着性进行检验,并估计校正可决系数,说明其含义;39.9)10,2(05.0=F 解: R 2=∑-'-=-2)(11Y Y ee TSS RSS i= 假设H 0:1 =2 =0;H 1:1 、2 不全为0;检验统计量F==---=-∑∑kn Y Y k Y Y kn RSSkESSii22)ˆ()ˆ(给定α=. {}{}{}39.9)10,2(),(05.0≥=≥=-≥=F F F k n k F F w α,F 远大于 2,10,故拒绝H 0,认为总体参数1、2 不全为等于0,资本形成额X 1和货物和服务净出口X 2对国民生产总值Y 的影响显着;4、假设要求你建立一个计量经济模型来说明在学校跑道上慢跑一英里或一英里以上的人数,以便决定是否修建第二条跑道以满足所有的锻炼者;你通过整个学年收集数据,得到两个可能的解释性方程:方程A :3215.10.10.150.125ˆX X X Y +--= 75.02=R方程B :4217.35.50.140.123ˆX X X Y -+-= 73.02=R 其中:Y —某天慢跑者的人数;1X —该天降雨的英寸数;2X —该天日照的小时数;3X —该天的最高温度按华氏温度;4X —第二天需交学期论文的班级数; 请回答下列问题:1这两个方程你认为哪个更合理些,为什么2为什么用相同的数据去估计相同变量的系数得到不同的符号 答案:1方程B 更合理些;原因是:方程B 中的参数估计值的符号与现实更接近些,如与日照的小时数同向变化,天长则慢跑的人会多些;与第二天需交学期论文的班级数成反向变化,这一点在学校的跑道模型中是一个合理的解释变量;2解释变量的系数表明该变量的单位变化在方程中其他解释变量不变的条件下对被解释变量的影响,在方程A 和方程B 中由于选择了不同的解释变量,如方程A 选择的是“该天的最高温度”而方程B 选择的是“第二天需交学期论文的班级数”,由此造成2X 与这两个变量之间的关系不同,所以用相同的数据估计相同的变量得到不同的符号; 5、收集1978-2001年的消费额XF 亿元,国内生产总值GDP 亿元资料,建立消费函数,Eviews 结果如下:Dependent Variable: LOGXFMethod: Least Squares Date: 10/21/09 Time: 20:16 Sample: 1978 2001 Included observations: 24CoefficientStd. Error t-StatisticProb.C t 1= LOGGDPt 2=R-squaredMean dependent var Adjusted R-squared . dependent var . of regression Akaike info criterion Sum squared resid Schwarz criterion Log likelihood Hannan-Quinn criter. F-statistic Durbin-Watson statProbF-statistic要求:1把表中缺失的数据补上;5分2把回归分析结果报告出来;5分3进行经济意义、统计学意义和经济计量学意义检验;6分 4解释系数经济含义;4分 6、根据广东省数据,把财政支出 CZ 作为因变量,财政收入CS 作为解释变量进行一元回归分析后,得到回归残差平方的对数对logCS 的回归结果如下:Dependent Variable: LOGRESID^2 Method: Least Squares Date: 5/22/09 Time: 20:24 Sample: 1978 2003Included observations: 26Variable Coefficient Std. Error t-StatisticProb.LOGCS CR-squaredMean dependent var Adjusted R-squared . dependent var . of regression Akaike info criterion Sum squared residSchwarz criterion要求:1写出异方差表达式σi 2=10分2进行同方差变换,证实变换后的模型不存在异方差;10分 已知:t t t u CS CZ ++=10ββ其中:为常数)其中22()()(σσt t CS f u Var =,其中 1.522024 (CSi))(=t CS f 模型两边同时除以)(t CS f 进行变换,得:3分其中:)(t tt CS f u =υ,可以证明误差项t υ是同方差的;证明如下:4分 已知:)(t t t CS f u =υ,)(22t tt CS f u =υ,222))(()(συ==t t tCS f u E E 根据已知条件2σ为常数,证得变换后的误差项是同方差的;。
计量经济学各章作业习题(后附答案)

6、在总体回归直线E 中, 表示【】
A当X增加一个单位时,Y增加 个单位
B当X增加一个单位时,Y平均增加 个单位
C当Y增加一个单位时,X增加 个单位
D当Y增加一个单位时,X平均增加 个单位
7、对回归模型 进行统计检验时,通常假定 服从【】
A N(0, )B t(n-2)
D确定模型导向确定变量及方程式估计模型应用模型
8、计量经济模型的基本应用领域有【】
A结构分析、经济预测、政策评价
B弹性分析、乘数分析、政策模拟
C消费需求分析、生产技术分析、市场均衡分析
D季度分析、年度分析、中长期分析
9、计量经济模型是指【】
A投入产出模型B数学规划模型
C包含随机方程的经济数学模型D模糊数学模型
一、单项选择题
1、表示X与Y之间真实线性关系的是【】
A B E
C D
2、参数的估计量 具备有效性是指【】
A Var( )=0 B Var( )为最小
C ( -)=0 D ( -)为最小
3、设样本回归模型为 ,则普通最小二乘法确定的 的公式中,错误的是【】
A B
C D
4、对于 ,以 表示估计标准误差,r表示相关系数,则有【】
t=(3.1)(18.7)n=19; =0.98
括号里的数字表示相应参数的t值,请回答以下问题:
(1)利用t值经验假设:=0(取显著水平为5%)
(2)确定参数统计量的标准方差;
(3)构造的95%的置信区间,这个区间包括0吗?
4、下面的数据是从某个行业的5个不同的工厂收集的。
总成本(y)80 44 51 70 61
C D
23、对于线性回归模型 ,要使普通最小二乘估计量具备无偏性,则模型必须满足【】
计量经济学作业

国贸0801班 杨静 0811101254.3(1)答:多重共线性的典型表现是:1.普通最小二乘得到的回归参数值很不稳定,回归系数方差随着多重线性强度的增加而加速增加,对参数难以作出精确估计;2.有些回归系数通不过显著性检验;3.回归系数的正负号的不到合理的经济解释。
(2)答:检验方法有以下几种:1.简单相关系数检验法;2.方差扩大(膨胀)因子法;3.直观判断法;4.逐步回归检测法。
4.4(1)答:补救措施有以下几种:1.修正多重共线性的检验方法,这其中又包括剔除变量法,增大样本用量,变换模型形式,利用非样本先验信息,和截面数据与时间序列数据并用,变量变换等方法;2.逐步回归法;3.岭回归法。
5.4(1)答:产生异方差的原因有以下几种:1.模型设定误差;2.测量误差的变化;3.截面数据中总体各单位的差异。
例如:工企业的研究与发展费用支出同企业的销售和利润之间的函数模型。
5.5(1)答:存在异方差对模型的影响有:1.对参数估计式统计特性的影响,它包括参数的OLS 估计仍然具有无偏性,参数OLS 估计式的方差不再是最小;2.对模型假设检验的影响;3.对预测的影响。
(2)答:异方差的存在会对回归模型的正确建立和统计判断带来严重后果,因此有必要检验模型是否存在异方差,但是它能够通过补救方法可以可以消除或减小异方差的影响,所以是可以用来进行分析6.3 (1)答:当出现自相关时,普通最小二乘估计依然是无偏、一致的,但不再是有效的。
(2)答:正确。
DW 的前提条件之一是随机误差项为一阶自回归形式,而随机误差项存在一阶自回归,满足零均值和同方差。
(3)答:一阶差分法假定自相关系数为正的且比较大,并不是 -1。
(4)答:正确。
模型预测的精度在于抽样误差和总体误差项的方差,在自相关情形下,样本回归模型中的斜率和纵截距的方差的最小二乘估计变得不可靠,而且对σ 2 也变得不可靠。
影响预测精度的两大因素都因自相关的存在而加大不确定性。
计量经济学-课后作业-全部

第一次作业1.下列假想模型是否属于揭示因果关系的计量经济学模型?为什么?⑴ S R t t =+1120012.. 其中S t 为第t 年农村居民储蓄增加额(亿元)、R t 为第t 年城镇居民可支配收入总额(亿元)。
⑵ S R t t -=+144320030.. 其中S t -1为第(1-t )年底农村居民储蓄余额(亿元)、R t 为第t 年农村居民纯收入总额(亿元)。
2.指出下列假想模型中的错误,并说明理由: (1)RS RI IV t t t =-+83000024112...其中,RS t 为第t 年社会消费品零售总额(亿元),RI t 为第t 年居民收入总额(亿元)(城镇居民可支配收入总额与农村居民纯收入总额之和),IV t 为第t 年全社会固定资产投资总额(亿元)。
(2)t t Y C 2.1180+=其中,C 、Y 分别是城镇居民消费支出和可支配收入。
(3)t t t L K Y ln 28.0ln 62.115.1ln -+=其中,Y 、K 、L 分别是工业总产值、工业生产资金和职工人数。
3.下列假想的计量经济模型是否合理,为什么? (1)εβα++=∑i GDP GDPi其中,)3,2,1(GDP i =i 是第i 产业的国内生产总值。
(2)εβα++=21S S其中,1S 、2S 分别为农村居民和城镇居民年末储蓄存款余额。
(3)εββα+++=t t t L I Y 21其中,Y 、I 、L 分别为建筑业产值、建筑业固定资产投资和职工人数。
(4)εβα++=t t P Y其中,Y 、P 分别为居民耐用消费品支出和耐用消费品物价指数。
(5)ε+=)(财政支出财政收入f (6)ε+=),,,(21X X K L f 煤炭产量其中,L 、K 分别为煤炭工业职工人数和固定资产值,1X 、2X 分别为发电量和钢铁产量。
第二次作业1978 1979 1980 1081 1082 1983 1984 1985 1986 1987 1988 1989 1990 1991 1992 1993 1994 1995 1006 19973624.1 4038.2 4517.8 4860.3 5301.8 5957.4 7206.7 8989.1 10201.4 11954.5 14992.3 16917.8 18598.4 21662.5 26651.9 34560.5 46670.0 57494.9 66850.5 73452.51132.26 1146.38 1159.93 1175.79 1212.33 1366.95 1642.86 2004.82 2122.01 2199.35 2357.24 2664.90 2937.10 3149.48 3483.37 4348.95 5218.10 6242.20 7407.99 8651.14数据来源:《中国统计年鉴》 表2 Eviews 软件的估计结果试根据这些数据完成下列问题;(1)建立财政收入对国内生产总值的简单线性回归模型,并解释斜率系数的经济意义; (2)对此模型进行评价;(3)若是1998年的国内生产总值为78017.8亿元,确定1998年财政收入的预测值和预测区间(0.05α=,22024.60x σ=)。
计量经济学各章作业习题[后附答案解析]
![计量经济学各章作业习题[后附答案解析]](https://img.taocdn.com/s3/m/8b344ef805087632311212bc.png)
. WORD格式整理. . 《计量经济学》习题集第一章绪论一、单项选择题1、变量之间的关系可以分为两大类,它们是【】A 函数关系和相关关系B 线性相关关系和非线性相关关系C 正相关关系和负相关关系D 简单相关关系和复杂相关关系2、相关关系是指【】A 变量间的依存关系B 变量间的因果关系C 变量间的函数关系D 变量间表现出来的随机数学关系3、进行相关分析时,假定相关的两个变量【】A 都是随机变量B 都不是随机变量C 一个是随机变量,一个不是随机变量D 随机或非随机都可以4、计量经济研究中的数据主要有两类:一类是时间序列数据,另一类是【】A 总量数据B 横截面数据C平均数据 D 相对数据5、下面属于截面数据的是【】A 1991-2003年各年某地区20个乡镇的平均工业产值B 1991-2003年各年某地区20个乡镇的各镇工业产值C 某年某地区20个乡镇工业产值的合计数D 某年某地区20个乡镇各镇工业产值6、同一统计指标按时间顺序记录的数据列称为【】A 横截面数据B 时间序列数据C 修匀数据 D原始数据7、经济计量分析的基本步骤是【】A 设定理论模型→收集样本资料→估计模型参数→检验模型B 设定模型→估计参数→检验模型→应用模型C 个体设计→总体设计→估计模型→应用模型D 确定模型导向→确定变量及方程式→估计模型→应用模型8、计量经济模型的基本应用领域有【】A 结构分析、经济预测、政策评价B 弹性分析、乘数分析、政策模拟C 消费需求分析、生产技术分析、市场均衡分析D 季度分析、年度分析、中长期分析9、计量经济模型是指【】A 投入产出模型B 数学规划模型C 包含随机方程的经济数学模型D 模糊数学模型10、回归分析中定义【】A 解释变量和被解释变量都是随机变量B 解释变量为非随机变量,被解释变量为随机变量C 解释变量和被解释变量都是非随机变量D 解释变量为随机变量,被解释变量为非随机变量11、下列选项中,哪一项是统计检验基础上的再检验(亦称二级检验)准则【】A. 计量经济学准则 B 经济理论准则C 统计准则D 统计准则和经济理论准则12、理论设计的工作,不包括下面哪个方面【】A 选择变量B 确定变量之间的数学关系C 收集数据D 拟定模型中待估参数的期望值13、计量经济学模型成功的三要素不包括【】A 理论B 应用C 数据D 方法14、在经济学的结构分析中,不包括下面那一项【】A 弹性分析B 乘数分析C 比较静力分析D 方差分析二、多项选择题1、一个模型用于预测前必须经过的检验有【】A 经济准则检验B 统计准则检验C 计量经济学准则检验D 模型预测检验E 实践检验2、经济计量分析工作的四个步骤是【】A 理论研究B 设计模型C 估计参数D 检验模型E 应用模型3、对计量经济模型的计量经济学准则检验包括【】A 误差程度检验B 异方差检验C 序列相关检验D 超一致性检验E 多重共线性检验4、对经济计量模型的参数估计结果进行评价时,采用的准则有【】A 经济理论准则B 统计准则C 经济计量准则D 模型识别准则E 模型简单准则三、名词解释1、计量经济学2、计量经济学模型3、时间序列数据4、截面数据5、弹性6、乘数四、简述1、简述经济计量分析工作的程序。
计量经济学习题含答案

计量经济学习题含答案第1章绪论习题一、单项选择题1.把反映某一总体特征的同一指标的数据,按一定的时间顺序和时间间隔排列起来,这样的数据称为( B )A. 横截面数据B. 时间序列数据C. 面板数据D. 原始数据2.同一时间、不同单位按同一统计指标排列的观测数据称为(B )A.原始数据 B.截面数据C.时间序列数据 D.面板数据3.用计量经济学研究问题可分为以下四个阶段(B)A.确定科学的理论依据、建立模型、模型修定、模型应用B.建立模型、估计参数、检验模型、经济预测C.搜集数据、建立模型、估计参数、预测检验D.建立模型、模型修定、结构分析、模型应用4.下列哪一个模型是计量经济模型( C )A.投入产出模型B.数学规划模型C.包含随机变量的经济数学模型D.模糊数学模型二、问答题1.计量经济学的定义2.计量经济学的研究目的3.计量经济学的研究内容1.答:计量经济学是统计学、经济学、数学相结合的一门综合性学科,是一门从数量上研究物质资料生产、交换、分配、消费等经济关系和经济活动规律及其应用的科学2.答:计量经济学的研究目的主要有三个:(1)结构分析。
指应用计量经济模型对经济变量之间的关系作出定量的度量。
(2)预测未来。
指应用已建立的计量经济模型求因变量未来一段时期的预测值。
(3)政策评价。
指通过计量经济模型仿真各种政策的执行效果,对不同的政策进行比较和选择。
3.答:计量经济学在长期的发展过程中逐步形成了两个分支:理论计量经济学和应用计量经济学。
理论计量经济学主要研究计量经济学的理论和方法。
应用计量经济学将计量经济学方法应用于经济理论的特殊分支,即应用理论计量经济学的方法分析经济现象和预测经济变量。
2一元线性回归模型习题一、单项选择题1.最小二乘法是指(D)A. 使达到最小值B. 使达到最小值C. 使达到最小值D. 使达到最小值2.在一元线性回归模型中,样本回归方程可表示为(C )A. B.C. D.3.线设OLS法得到的样本回归直线为,以下说法不正确的是(B ) A. B.C.D.在回归直线上4.对样本的相关系数,以下结论错误的是(A)A.越接近0,与之间线性相关程度高B.越接近1,与之间线性相关程度高C.D、,则与相互独立二、多项选择题1.最小二乘估计量的统计性质有( ABC )A. 无偏性B. 线性性C. 最小方差性D. 不一致性E. 有偏性2.利用普通最小二乘法求得的样本回归直线的特点(ACD)A. 必然通过点B. 可能通过点C. 残差的均值为常数D.的平均值与的平均值相等E. 残差与解释变量之间有一定的相关性3.随机变量(随机误差项)中一般包括那些因素(ABCDE )A回归模型中省略的变量B人们的随机行为C建立的数学模型的形式不够完善。
《计量经济学》习题及答案

《计量经济学》习题及答案(解答仅供参考)第一套一、名词解释:1. 计量经济学:计量经济学是经济学的一个分支,它使用数学和统计学的方法,对经济现象进行量化分析,建立经济模型,预测和解释经济行为和现象。
2. 异方差性:在回归分析中,如果误差项的方差随自变量的变化而变化,这种现象称为异方差性。
3. 自相关性:在时间序列分析中,如果一个变量的当前值与它的过去值存在相关性,这种现象称为自相关性。
4. 多重共线性:在多元回归分析中,如果两个或多个自变量之间高度相关,这种现象称为多重共线性。
5. 随机抽样:随机抽样是一种统计抽样方法,每个样本单位都有一定的概率被选入样本,且各个样本单位之间的选择是独立的。
二、填空题:1. 在线性回归模型中,参数估计的常用方法是______最小二乘法______。
2. 如果一个变量的分布是对称的,那么它的偏态系数应该接近于______0______。
3. 在时间序列分析中,______平稳性______是进行预测的前提条件之一。
4. ______工具变量法______是处理内生性问题的一种常用方法。
5. 如果一个经济变量的变化完全由其他经济变量的变化所决定,那么这个变量被称为______外生变量______。
三、单项选择题:1. 下列哪种情况可能导致异方差性?(B)A. 自变量和因变量之间存在非线性关系B. 自变量的某些组合导致误差项的方差增大C. 因变量和误差项之间存在相关性D. 样本容量过小2. 在进行回归分析时,如果发现数据存在多重共线性,以下哪种方法可以解决这个问题?(C)A. 增加样本容量B. 使用非线性模型C. 删除相关性较强的自变量D. 对自变量进行标准化3. 下列哪种情况可能会导致自相关性?(A)A. 时间序列数据中存在滞后效应B. 因变量和某个自变量之间存在非线性关系C. 样本容量过小D. 自变量之间存在多重共线性四、多项选择题:1. 下列哪些是计量经济学的基本假设?(ABCD)A. 线性关系假设B. 零均值假设C. 同方差性假设D. 无自相关性假设E. 正态性假设2. 下列哪些是处理内生性问题的方法?(ACD)A. 工具变量法B. 加权最小二乘法C. 两阶段最小二乘法D. 广义矩估计法E.岭回归法五、判断题:1. 在进行回归分析时,如果自变量和因变量之间不存在线性关系,那么回归结果将没有任何意义。
(完整版)《计量经济学》作业答案

计量经济学作业答案第一次作业:1-2. 计量经济学的研究的对象和内容是什么?计量经济学模型研究的经济关系有哪两个基本特征?答:计量经济学的研究对象是经济现象,是研究经济现象中的具体数量规律(或者说,计量经济学是利用数学方法,根据统计测定的经济数据,对反映经济现象本质的经济数量关系进行研究)。
计量经济学的内容大致包括两个方面:一是方法论,即计量经济学方法或理论计量经济学;二是应用,即应用计量经济学;无论是理论计量经济学还是应用计量经济学,都包括理论、方法和数据三种要素。
计量经济学模型研究的经济关系有两个基本特征:一是随机关系;二是因果关系。
1-4.建立与应用计量经济学模型的主要步骤有哪些?答:建立与应用计量经济学模型的主要步骤如下:(1)设定理论模型,包括选择模型所包含的变量,确定变量之间的数学关系和拟定模型中待估参数的数值范围;(2)收集样本数据,要考虑样本数据的完整性、准确性、可比性和一致性;(3)估计模型参数;(4)模型检验,包括经济意义检验、统计检验、计量经济学检验和模型预测检验。
1-6.模型的检验包括几个方面?其具体含义是什么?答:模型的检验主要包括:经济意义检验、统计检验、计量经济学检验、模型预测检验。
在经济意义检验中,需要检验模型是否符合经济意义,检验求得的参数估计值的符号与大小是否与根据人们的经验和经济理论所拟订的期望值相符合;在统计检验中,需要检验模型参数估计值的可靠性,即检验模型的统计学性质;在计量经济学检验中,需要检验模型的计量经济学性质,包括随机扰动项的序列相关检验、异方差性检验、解释变量的多重共线性检验等;模型预测检验主要检验模型参数估计量的稳定性以及对样本容量变化时的灵敏度,以确定所建立的模型是否可以用于样本观测值以外的范围。
第二次作业:2-1 P27 6条2-3 线性回归模型有哪些基本假设?违背基本假设的计量经济学模型是否就不可估计?答:线性回归模型的基本假设(实际是针对普通最小二乘法的基本假设)是:解释变量是确定性变量,而且解释变量之间互不相关;随机误差项具有0均值和同方差;随机误差项在不同样本点之间是独立的,不存在序列相关;随机误差项与解释变量之间不相关;随机误差项服从0均值、同方差的正态分布。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
一、摘要:随着2001年正式加入WTO.我国与各国贸易往来越来越频繁.长期的贸易顺差使得进出口贸易额对国内生产总值的贡献越来越大。
加工贸易一直在我国进出口贸易中占很大比重,而且对我国GDP的影响较大,这是我国一直以来“重出口“的结果。
我国已发展成为一个对外经贸大国,但是还算不上一个对外经贸强国。
我国已发展成为一个对外经贸大国,但是还算不上一个对外经贸强国。
在新的世纪里,我国的目标应当是从一个对外经贸大国发展成为对外经贸强国。
但与世界贸易强国相比,现时还有许多差距。
主要表现在中国出口产品和服务贸易竞争优势不大,加工贸易占半壁江山,对此,我们进行一些实证分析。
With the 2001 accession to the WTO. trade in China and other countries exchanges are increasingly frequent. The long-term trade surplus makes more contribution in import and export trade to GDP bigger. Account for a large proportion of processing trade has been China's import and export trade, and the impact on China's GDP is bigger, this is our country has been "re export" results. China has developed into a foreign trade country, but not the last foreign trade power. China has developed into a foreign trade country, but not the last foreign trade power. In the new century, our country should be the goal from a development of foreign trade country become the foreign trade power. But compared with the world trade power, currently there are still many gaps. Mainly in the China export product and service trade competitive advantage is not big, the processingtrade accounted for half of the country, in this regard, we make some empirical analysis.二、关键词:进出口国内生产总值三、引言在当今的中国,进出口的贸易额很大程度上影响着中国的国内生产总值,根据当今发达国家的数据显示,进出口的贸易额在在相当大的程度上影响着本国的国内生产总值,并且进出口贸易额越高,国内生产总值也越高,下面我们用实证来说明一下这个现象。
四、数据来源及建模以1983年到2013年的数据为例,并对数据进行建模,因为利用对模型对数变换的方式可以在一定程度上拟合情况更好,所以首先对总支出和可支配收入作对数变换。
数据如下:表1进出口和国民生产总值的情况年份国内生产总值一般贸易净出口额加工贸易净出口额其他贸易净出口额1985 3070.23 -135.42 -9.58 -4.00 1986 2975.90 -101.12 -10.83 -7.65 1987 3239.73 8.71 -11.97 -34.44 1988 4041.49 -25.82 -10.45 -41.23 1989 4513.11 -40.62 26.21 -51.59 1990 3902.79 92.60 66.60 -71.80 1991 4091.73 85.80 74.00 -78.601992 4882.22 100.60 80.80 -137.90 1993 6132.23 51.50 78.80 -252.40 1994 5592.24 260.40 94.10 -300.50 1995 7279.81 280.00 153.30 -266.30 1996 8560.85 234.80 220.60 -333.20 1997 9526.53 389.44 293.96 -279.20 1998 10194.62 305.55 358.55 -229.36 1999 10832.79 120.95 373.04 -201.67 2000 11984.75 51.02 450.94 -260.87 2001 13248.18 -15.75 534.59 -293.40 2002 14538.20 70.76 577.27 -343.77 2003 16409.66 -56.17 789.47 -477.77 2004 19316.44 -45.39 1062.76 -696.47 2005 22366.22 354.30 1424.55 -758.85 2006 26584.15 831.26 1888.83 -945.34 2007 33838.19 1098.44 2490.85 -971.03 2008 43292.39907.692967.36-893.751.模型的建立设定Y=GDP ,X1=进口X2=出口,由于没有进出口贸易对GDP 的经济理论模型,我们简单的以μβββ+++=22110X X Y 当做我们的理论模型。
2.对模型的经济检验对模型进行初步回归得如下结果:Dependent Variable: YMethod: Least SquaresDate: 01/13/15 Time: 20:53Sample: 1985 2008Included observations: 24Variable Coefficient Std. Error t-Statistic Prob.C 4419.351 485.1501 9.109245 0.0000X1 -2.891659 1.597949 -1.809607 0.0854X2 12.56558 1.058904 11.86659 0.0000X3 -2.879224 2.602890 -1.106164 0.2818R-squared 0.984839 Mean dependent var 12100.60Adjusted R-squared 0.982565 S.D. dependent var 10453.68S.E. of regression 1380.325 Akaike info criterion 17.44904Sum squared resid 38105930 Schwarz criterion 17.64538Log likelihood -205.3884 Hannan-Quinn criter. 17.50113F-statistic 433.0592 Durbin-Watson stat 0.509047Prob(F-statistic) 0.000000由此数据看出,可决系数和修正可决系数为0.984839和0.982565F的检验值为433.0592,明显显著,拟合效果还可以。
但当a=0.05时,ta/2(n-k)=2.080,说明x1与x3的t检验不显著,而且x1与x3系数的符号与经济解释相反。
可能存在多重共线性。
3.多重共线性的矩阵X1 X2 X3X1 1.000000 0.829745 -0.788980X2 0.829745 1.000000 -0.930806X3 -0.788980 -0.930806 1.000000由相关系数矩阵可以看出,各解释变量之间的相关系数很高,证实确实存在多重共线性。
4. 修正多重共线性采用逐步回归的方法,去解决多重共线性的问题。
分别做y对x1,x2,x3的一元回归,结果如下:变量x1 x2 x3参数估计值25.68606 12.61014 -32.09461t值 6.159506 34.31144 -12.05149R20.632563 0.981656 0.868451其中x2的可决系数最大,以x2为基础,加入其它变量逐步回归,结果如下:变量x1 x2 x2 x3R20.983911 0.982357可见,加入x1或加入x3对可决系数几乎没有改变,因此把x1和x3剔除。
最终得:Dependent Variable: YMethod: Least SquaresDate: 01/13/15 Time: 22:18Sample: 1985 2008Included observations: 24Variable Coefficient Std. Error t-Statistic Prob.C 4763.734 364.7580 13.05998 0.0000X2 12.61014 0.367520 34.31144 0.0000R-squared 0.981656 Mean dependent var 12100.60Adjusted R-squared 0.980822 S.D. dependent var 10453.68S.E. of regression 1447.683 Akaike info criterion 17.47297Sum squared resid 46107318 Schwarz criterion 17.57114Log likelihood -207.6757 Hannan-Quinn criter. 17.49902F-statistic 1177.275 Durbin-Watson stat 0.530244Prob(F-statistic) 0.000000Y=4763.734+12.61014X2(13.05998) (34.31144)可决系数=0.981656 修正可决系数=0.980822f值=1177.275 D-W值=0.5302445. 在以上基础上,进行异方差检验,利用white检验的方法:Heteroskedasticity Test: WhiteF-statistic 1.768218 Prob. F(2,21) 0.1951Obs*R-squared 3.459119 Prob. Chi-Square(2) 0.1774Scaled explained SS 1.012630 Prob. Chi-Square(2) 0.6027Test Equation:Dependent Variable: RESID^2Method: Least SquaresDate: 01/13/15 Time: 22:29Sample: 1985 2008Included observations: 24Variable Coefficient Std. Error t-Statistic Prob.C 1296585. 474287.9 2.733751 0.0124X2 1899.861 1357.209 1.399829 0.1762X2^2 -0.488139 0.506224 -0.964275 0.3459R-squared 0.144130 Mean dependent var 1921138.Adjusted R-squared 0.062619 S.D. dependent var 1638123.S.E. of regression 1586005. Akaike info criterion 31.50780Sum squared resid 5.28E+13 Schwarz criterion 31.65506Log likelihood -375.0936 Hannan-Quinn criter. 31.54687F-statistic 1.768218 Durbin-Watson stat 1.413619Prob(F-statistic) 0.195111由上表可知,NR2=24*0.144130=3.45912<5.9915,所以不存在异方差。