R实战学习笔记
R语言教程笔记

R 编程笔记2简介1.突出特点:【多领域的统计资源】目前在R 网站上约有2400个程序包,涵盖了基础统计学、社会学、经济学、生态学、空 间分析、系统发冇分析、生物信息学等诸多方而。
【免费】2.缺点:【占用内存】所有的数据处理在内存中进行,不适于处理超大规模的数据。
【运行速度稍慢】即时编译,约相当于C 语言的1/20。
3. CRAN :全称 The Comprehensive R Archive Networks由世界几十个镜像网站组成网络.提供F 载安装程序和相向软件包。
0镜像更新频率一般为天。
推荐镜像: 中国的镜像:数学所:即时更新的CRAN 源:界而下如下(版本)4.R 程序包(R packages )什么是R 程序包R 程序包是多个函数的集合,具有详细的说明和示例。
每个程序包包含R 函数、数据、帮助文件、描述 文件等window 下是zip 形式,安装时不要解压缩,R 程序包是R 功能扩展,特定的分析功能,需要用相 应的程序包实现。
例如:系统发冇分析,常用到ape 程序包,群落生态学vegan 包等。
4.2常用R 程序包ade4 adephylo ape利用欧几里得方法进行生态学数据分析 系统进化数据挖掘与比较方法系统发育与进化分析apTreeshape boot cluster ecodist FD进化树分析Bootstrap 检验聚类分析生态学数据相异性分析 功能多样性分析geiger 物种形成速率f j 进化分析Graphics lattice 栅格图绘图maptools空间对象的读取和处理R Console7PJ2S1R version Z.L1.1 (2010-05-31)Copyrlght IC) 2010 The R FouDd^t-aon £oc C OBDU S DJTSE« 3-M0OSL-07-DD 是自由恢件,不带任何担佩・在菓些条件下你可以梓我口由散布.用'llcerwe |) *或,licenced *来希阪布的库融*件.P •是个合作tt 划,利许多入为NiS 出丁贡献・•contcibut.ora I),来石合作吉的i#细用会警诉你如何在出版樹中正礎也引用卩戒口性序包・ffi'derrcO 1来着一些示范徑序,ffl* heLp (I •M 文件,戏用'lielp.atatcd '迪过时血列觅密隶薈?ft 助gf4. 用51 ■退出R ・(處来滋存的工隹空间已圧胆】> hlflLotry(|> rate<-c(2D z 22, 2今.26, 2B, 30, 32. 3" 36, 3B Z 40, 121> tmpMrLty <-c(0.4z 9・» 11.0z 10.^f 15.3, 14・6 13 2/ X4.7Z 15.4Z 10.5r 1D.9J > ploi | impxiif Lty^6ca| >rca<-(xnpurit ?-e)ceg<-1 tn (in pur it 产 rat e) J 1 -r.u : M .;, • . •« c«r ■] 丈再施9(蔑他tfffsva 屯in-nix)rate<-c(ZD, ZZ, 2仇 ZC r Z0z 、0, 32, 3G Z 3 0z 今 impMtLCy <-C(8.4, 9・5, 11.8Z 10.13・3, L4・8, 13 plot | Uiputlty-totcl6LXlft(lornula - lrwpurlty - cate) JSecidMala:XlhiQ Ftedlan 如 Soxs\unrar7(recj) ^ve.m,gerFrVi^习筋料X 救梧井桁黃花宝典\\R 语专 hiatocycimgev mvpart nlme ouch pgirmessphangorn picante广义加性模型相关 多变量分解线性及非线性混合效应模型 系统发弃比较 生态学数据分析系统发育分析群落系统发育多样性分析raster ffi 格数据分析与处理 seqinrDNA 序列分析sp空间数据处理spatstat spla ncs stats SDMTools vegan CRAN Task Views空间点格局分析,模型拟合与检验 空间与时空点格局分析R 统计学包物种分布模型工具植物与植物群落的排序,生物多样性计算中有对程序包的分类介绍4.3 R 程序包安装1.用函数(),如果已经连接到互联网,在括号中输入要安装的程序包洛称,选择镜像后,程序将自动下载并安装程序 包。
R语言笔记

安装包install.packages(pkgs,depend=TRUE)SVMLibrary(e1071)fit.svm=svm(AL~.,data=train)fit.svmsvm.pred=predict(fit.svm,data=train)ROC曲线Library(pROC)roc1 <- roc(myData$label, myData$score) roc2 <- roc(myData2$label, myData2$score) plot(roc1, col="blue")plot.roc(roc2, add=TRUE, col="red")nomogram语言> require(rms)> w<-read.table("abc.prn",header=T)> attach(w)> ddist <- datadist(T,C)> options(datadist='ddist')> f <- lrm(AL~ T + C )> nom <- nomogram(f, fun=plogis, fun.at=c(.001, .01, .05, seq(.1,.9, by=.1), .95, .99, .999), lp=F, funlabel="Risk for AL")> plot(nom)输出结果> x<-svm.pred> write.table(x,"C:\\Users\\admin\\Desktop\\x.csv",sep=",")校正曲线(示例)library(rms)ddist<-datadist(BMIc, location_c2, thickc, Tc, N, histc, dif, CA199c)options(datadist='ddist')f<-lrm(PM~ BMIc + location_c2 + thickc + Tc + N + histc + dif + CA199c,x=T,y=T)nom<-nomogram(f,fun=plogis,fun.at=c(.001,.01,.1,.3,.5,.7,.9,.99,.999),funlabel="Probabili ty",lp=F)plot(nom,cex.axis=1.0)validate(f,method="boot",B=1000,dxy=T)cal<-calibrate(f,method="boot",B=1000)plot(cal,scat1d.opts=list(nhistSpike=240,side=1,frac=0.08,lwd=1,nint=50))导入数据w=read.table("clipboard",header=T,fill=TRUE)index计算fp <- predict(f)validate(f,method="boot",B=1000,dxy=T)rcorrcens(AL~predict(f),data=w)外部验证f2=lrm(A~predict(f,newdata=data2),x=T,y=T,data=data2)validate(f2,method="boot",B=1000,dxy=T)rcorrcens(A~predict(f2),data=data2)Decision curvelibrary(rmda)simple<- decision_curve(AL~collagenscore+location,data = data3, family = binomial(link ='logit'),thresholds= seq(0,1, by = 0.01), confidence.intervals =0.95,study.design ='case-control',population.prevalence = 0.16)> plot_decision_curve(List,s= c('Model'),cost.benefit.axis =T,col =c('red'),confidence.intervals =FALSE,standardize = FALSE)plot_clinical_impact(simple,population.size = 1000,cost.benefit.axis = T, n.cost.benefits= 8,col = c('red','blue'), confidence.intervals= T)柱状图library(ggthemes)library(ggplot2)w=read.table("clipboard",header=T,fill=TRUE)p1=ggplot(data=w,mapping=aes(x=G,y=C,fill=A,group=A))+geom_bar(stat="identity",widt h=1)p1 <- p1 + labs(x="",y="Collagen score")p1 <- p1 + theme(axis.title.y = element_text(size = 12*1.33, angle = 90))p1=p1+theme(panel.background = element_rect(fill = "transparent",colour = NA), panel.grid.minor = element_blank(), panel.grid.major = element_blank(),plot.background = element_rect(fill = "transparent",colour = NA))p1=p1+ylim(-2,5)data<-read.table("clipboard",header=F,fill=TRUE)df<-data[-1]library(e1071)fit.svm<-svm(V2~.,data=df)svm.pred<-predict(fit.svm,data=df)svm.predSVMdata<-read.table("clipboard",header=F,fill=TRUE)df<-data[-1]set.seed(1234)train<-sample(nrow(df),0.7*nrow(df))df.train<-df[train,]df.validata<-df[-train,]library(e1071)set.seed(1234)fit.svm<-svm(V2~.,data=df.train)fit.svmsvm.pred<-predict(fit.svm,data=df.train)svm.predtuned<-tune.svm(V2~.,data=df.train,gamma=10^(-6:1),cost=10^(-10:10)) tunedfit.svm<-svm(V2~.,data=df.train,gamma=,cost=)svm.pred<-predict(fit.svm,data=df.train)svm.predx<-svm.predwrite.table(x,"C:\\Users\\admin\\Desktop\\x.csv",sep=",")lassodata<-read.table("clipboard",header=F,fill=TRUE)data<-as.matrix(data)x<-data[,1:11]y<-data[,12]library("glmnet")cv.fit=cv.glmnet(x,y,family='binomial',type.measure="auc",nfolds=10) plot(cv.fit,xlab="log(λ)")cv.fit$lambda.mincv.fit$lambda.1sefit<-glmnet(x,y,family="binomial")plot(fit, xvar = "lambda",label="TRUE",xlab="log(λ)")coefficients<-coef(fit,s=cv.fit$lambda.1se)>Active.Index<-which(coefficients!=0) #系数不为0的特征索引>Active.coefficients<-coefficients[Active.Index] #系数不为0的特征系library(pROC)library(ggplot2)data(aSAH)rocobj1 <- roc(aSAH$outcome, aSAH$s100b)auc(rocobj1)plot(rocobj1)plot(rocobj1, print.auc=TRUE, auc.polygon=T, max.auc.polygon=F,auc.polygon.col="skyblue", print.thres=F)热图library(pheatmap)pheatmap(data1,cluster_row = T, cluster_col = F,cellwidth = 5,cellheight = 5,fontsize = 4,border_color=F)。
R实战笔记..

R实战笔记(转载)1.R的使用1.3.基础命令函数说明example(‘foo’)查看函数示例data() 查看已加载可用的数据集vignette(‘foo’)查看主题为foo可用的vignette文档getwd() 显示当前工作目录setwd() 修改工作目录ls() 显示工作空间的对象rm(list=ls()) 删除全部的对象options() 显示或设置当前选项history(n) 显示最近的n个命令save.image(‘myfile’)保存工作空间到myfile中,默认是.RData load(‘myfile’)读取一个工作空间到当前会话source(‘file_name’)在当前会话中执行一个脚本sink(‘file_name’)重定向输出到文件,append是否追加,split=T 则同时输出到屏幕和文件中object.size(x)/1000000 查看变量占用的内存空间,M srirage.mode(x) 改变变量的存储类型storage.mode(x)<- “integer”改为整数型,可以看到该对象的大小会变为原来的一半memory.size() 查看现在的work space的内存使用memory.limit() 查看系统规定的内存使用上限,注意,在32位的R中,封顶上限为4G,无法在一个程序上使用超过4G (数位上限)。
这种时候,可以考虑使用64位的版本rm(object) 删除变量gc() 做Garbage collection,否则内存是不会自动释放的,相当于你没做rm.rm(list=ls()) 删除全部变量图像输出pdf(‘filename.pdf’) #重定向到图像输出png(‘filename.png’)jpeg(‘filename.jpeg’)dev.off() #将输出返回到终端2.数据结构2.2.2.矩阵matrix(vector, nrow=n, ncol=m, byrow=TRUE, dianames=list(rname, cname))2.2.4.数据框数据框绑定attach()detach()with()attach(mtcars)plot(mpg, wt)mpgdetach(mtcars)with(mtcars, {summary(mpg, disp, wt)plot(mpg, disp)plot(mpg, wt)})∙ 1∙ 2∙ 3∙ 4∙ 5∙ 6∙7∙8∙9∙10 2.2.6.列表的引用list[[n]]4.数据管理1.data.frame(col1,col2…,stringAsFactors=FALSE)创建数据框的时候,不要将字符串转成因子2.创建新变量mydata = transform(mydata,sumx = x1+x2,meanx = (x1+x2)/2)library(dplyr)mutate(mydata, sumx = x1+x2, meanx = (x1+x2)/2)∙ 1∙ 2∙ 3∙ 4∙ 5∙ 64.3.变量重编码!x:非xx|y:或x&y:与,和isTRUE(x):测试x是否为truemydata$age[mydata$age == 99] <-NAmydata$agecat[mydata$age >=55 & mydata$age <=75] <- 'middle aged' mydata = with(mydata, {agecat <- NAagecat[age>75] <-'elder'agecat[age>=55 & age <=75] <- 'middle aged'agecat[age<55] <- 'young' })#epicalc包的recode函数#看看有哪些因子水平,或者说不重复的取值list = unique(data3$arpu)#构建old 列表old <-c("(50,80)","(10,20]","0","(20,50]","(0,5]","(100,150]","(150,200]","(200, 300]","(5,10]","[80,100]","300以上" )#构建new 列表new <- c("低值","低值","低值","低值","低值","高值","高值","高值","低值","高值","高值")library(epicalc)recode(vars = "arpu",old,new,dataframe)#recode 函数其实是用new替换原来的old,所以建议先复制一列,然后在复制的列上进行recode 操作#R的cut函数aaa <- c(1,2,3,4,5,2,3,4,5,6,7)cut(aaa, 3, b = 4, ordered = TRUE)∙ 1∙ 2∙ 3∙ 4∙ 5∙ 6∙7∙8∙9∙10∙11∙12∙13∙14∙15∙16∙17∙18∙19∙20∙21∙22∙23∙24∙25∙26∙27∙284.4.变量重命名#1fit(mydata) #交互式修改`#2library(reshape)mydata = rename(mydata,c(old_name1 = 'new_name1', old_name2 = 'new_name2',...))#3names(mydata)[2]='new_name'∙ 1∙ 2∙ 3∙ 4∙ 5∙ 6∙7∙8∙9∙104.5.缺失值删除含有缺失值的行na.omit(mydata)4.6.日期符号含义示例%d 01-31天%a 缩写的星期Mon%A 非缩写的星期Monday%m 月份00-12%b 缩写的月份Jan%B 非缩写的月份January%y 两位数的年份07%Y 4位数的年份2007as.Data(c('2007-06-22','2004-02-13'))#系统日期Sys.Date()date()format(Sys.Date(), format='%Y%m%d')#日期加减end_date - start_datediff(today, that_day, units='weeks')#lubridate包∙ 1∙ 2∙ 3∙ 4∙ 5∙ 6∙7∙8∙9∙10∙11∙12∙13 4.8.排序mydata = mydata[order[mydata$age),]attach(mydata)newdata = mydata[order(gender, -age),]detach(mydata) ∙ 1∙ 2∙ 3∙ 4∙ 54.9.合并数据集# merge,一种内连接,innder jointotal = merge(data1, data2, by=c('id','country'))rbind()cbind()∙ 1∙ 2∙ 3∙ 4∙ 54.10.子集mydata[, c(6:10)]mydata[, c(var1,var2,...)]#丢弃变量vars = names(mydata) %in% c('q3','q4')mydata[!vars]mydata[c(-8,-9)]#删除变量mydata$q4 <- NULL∙ 1∙ 2∙ 3∙ 4∙ 5∙ 6∙7∙8∙9∙10∙11∙124.10.进入观测mydata = mydata[,1:3]mydata[ which(mydata$gender == 'M' & mydata$age>30),] attach(mydata)mydata[which(gender == 'M' & age>30),]detach(mydata) ∙ 1∙ 2∙ 3∙ 4∙ 5∙ 6subset(mydata,age>=35 | age<24, select=c(q1,q2,q3,q4)) subset(mydata, gender =='M' & age >25, select =gender:q4) ∙ 1∙ 2∙ 34.11.随机抽样# 无放回随机抽样,抽10个样本mydata[sample(1:nrow(mydata),10, replace=FALSE), ] ∙ 1∙ 24.12.sql语句library(sqldf)newdata = sqldf('select * from mydata where carb=1 order by mpg', s=TRUE)new_data = sqldf('select avg(mpg), avg(disp) as avg_disp, gear from mtcars where cyl in (4,6) group by gear')∙ 1∙ 2∙ 3∙ 45.高级数据管理5.2.数值与字符处理函数5.2.1.数学函数函数描述abs(x) 绝对值sqrt(x) 平方根x^2 平方ceiling(x) 向上取整floor(x) 向下取整trunc(x) 向零取整round(x, digits=n) 直接截断保留n位小数signif(x) 四舍五入保留n位小数cos(x),sin(x),tan(x) 余弦,正弦,正切acos(x),asin(x),atan(x) 反余弦,反正弦,反正切cosh(x),sinh(x),tanh(x) 双曲余弦,双曲正弦,双曲正切acosh(x),asinh(x),atanh(x) 反双曲余弦,反双曲正弦,反双曲正切log(x,base=n) n为底的对数,log(x)为自然对数,log10(x)为10常用对数exp(x) 指数5.2.2.统计函数函数描述mean(x) 平均数median(x) 中位数sd(x) 标准差var(x) 方差mad(x) 绝对中位差quantile(x,probs=c(0.3,0.84)) 分位数range(x) 范围sum(x) 求和diff(x,lag=n) 滞后差分min(x),max(x) 最小最大值scale(x,center=T, scale=T) 中心化(center=T)或标准化(center=T, scale=T)其他均值和方差的标准化scale(mydata)*sd+mean5.2.3.概率函数d=密度函数p=分布函数q=分位数函数r=生产随机数(随机偏差)分布名称缩写分布名称缩写正态分布norm 非中心卡方分布chisq Beta分布beta logistic分布logis二项分布binom 多项分布multinom 柯西分布cauchy 负二项分布nbinom 指数分布exp 泊松分布poisF分布 f Wilcoxon符号秩分布signrank Gamma分布gamma t分布t几何分布geom 均匀分布unif超几何分布hyper Weibull分布weibull分布名称缩写分布名称缩写对数正态分布lnorm Wilcoxon秩和分布wilcox设定随机数种子set.seed(1234)5.2.4.字符串处理函函数描述nchar(x)x的字符数量,注意和length(x)的区别substr(x,start,stop)提取或替换子字符串,substr(‘abcde’,2,4)<-‘22222’grep(pattern,x,ignore.case=F,fixed=F)正则表达式搜索,返回值为匹配的下标sub(pattern,replacement,x,ignore.case=F,fixed=F)搜索并替换,如果fixed=T,则pattern是一个文本字符串strsplit(x,split,fixed=F)在split处分割字符串,返回一个列表,用unlist()变成向量paste(x,sep=”)连接字符串,指定分隔符toupper(x) 转大写tolower(x) 转小写5.2.5.其他实用函数函数说明length(x) 长度seq(from,to,by) 生产序列rep(x,n,each=n) 将x重复n次,指定each将会排序cut(x,n) 分割成n水平的因子pretty(x,n)创建美观的分割点,在绘图中常用cat(…,file=’myfile’,append=T)|连接…中的对象,并将其输出到屏幕或者文件中5.3.apply-by系列5.3.1.apply# 1=对每行操作,2=对每列操作apply(mydata, margin=1, fun=myfunc)∙ 1∙ 25.3.2.by,分组汇总操作# 针对1:4列,根据species因子分组,求均值by(iris[,1:4],Species,mean)∙ 1∙ 2pplyl=list(a=1:10,b=11:20)lapply(l,mean)∙ 1∙ 25.3.4.sapplylapply返回的是一个含有两个元素a和b的list,而sapply返回的是一个含有元素**“a”++和**“b”++的vector,或者列名为a和b的矩阵。
《r语言实战》菜鸟学习笔记(一)

《r语⾔实战》菜鸟学习笔记(⼀)打算学习⼀下r语⾔(windows),不知道从什么地⽅开始学习,加上本⼈的数理统计基础⽐较薄弱,所以就漫⽆⽬的的从⽹上找教程。
其实我逛的最多的⽹站还是知乎,读了好多很好的答案后,我选择了两本书,《153分钟学会r》《》。
前者⼤概扫了⼀眼,不太适合边看书边敲代码(我个⼈⽐较喜欢这种),所以后者就⽐较适合我,这套书还是⽐较适合菜鸟看的,我还看过《集体智慧编程》,很不错。
下⾯开始了第⼀段程序。
(博客园没有r语⾔选项,只好⽤plain txt了)age <- c(1,3,5,2,11,9,3,9,12,3)weight <- c(4.4,5.3,7.2,5.2,8.5,7.3,6.0,10.4,10.2,6.1)mean(weight)plot(age,weight)q()代码很简单,不多说了。
这段代码要注意的地⽅有:正斜杠,⼩数点后三位,均匀分布。
setwd("F:/R Code") #如果不存在需要使⽤dir.create()创建⽬录options()options(digits=3)x<-runif(20)#摘要统计量summary(x)#直⽅图hist(x)savehistory()save.image()q()接下来就要讨论r语⾔的数据结构了r语⾔包含了4中数据结构:向量,矩阵,数组和数据框。
1.向量是⼀维的a <- c(1,2,5,3,6,-2,4)2.矩阵是⼆维的cells <- c(1,26,24,68)rnames <- c("R1","R2")cnames <- c("C1", "C2")mymatrix <- matrix(cells,nrow=2, ncol=2, byrow=TRUE,dimnames=lilst(rnames,cnames)) #按⾏填充3.数组可以是多维的dim1 <-c("A1","A2")dim2 <- c("B1","B2","B3")dim3 <- c("C1","C2","C3","C4")#array(vector, dimanesions,dimnames)z <- array(1:24, c(2,3,4), dimnames=list(dim1,dim2,dim3))4.数据框这个就是⼤杂烩了patientID <- c(1,2,3,4)age <- c(25,34,28,52)diabetes <- c("Type1", "Type2", "Type1", "Type1")status <- c("Poor","Improved", "Excellent", "Poor")patientdata <- data.frame(patientID, age, diabetes, status)取数据框中的某⼀个元素:patientdata age,如果不想每⼀次都输⼊patientdata,可以使⽤attach() detach()或者单独使⽤函数with()来简化代码。
社会网络分析方法+R实战(自学笔记2)

社会网络分析方法+R实战(自学笔记2)每个网络可视化的基础是关于关系的数据。
这些关系可以观察或模拟(即假设)。
在分析一组关系时,我们通常会使用两种不同的数据结构之一: 边表或邻接矩阵。
1.边表表示图的一个简单方法是列出边,我们称之为边列表。
对于每条边,我们只列出对应于这条边的对象。
所以边列表是两列的矩阵,直接告诉计算机每个边绑定了哪些参与者。
在有向图中,A列中的参与者是边的来源,B列中的参与者接收关系。
在无向图中,顺序并不重要。
在R中,我们可以使用vector和data.frames创建一个例子边列表。
我用向量指定边缘列表的每一列,然后将它们赋值为data.frame的列。
我们可以用它来形象化边缘列表应该是什么样子。
#install.packages("igraph")library(igraph)#R显示没有该包时使用上面一行代码进行安装personA<-c("Mark","Mark","Peter","Peter","Bob","Jill")personB<-c("Peter","Jill","Bob","Aaron","Jill","Aaron")edgelist <-data.frame(PersonA=personA,PersonB=personB,stringsAsFa ctors=F)print(edgelist)PersonA PersonB1 Mark Peter2 Mark Jill3 PeterBob4 Peter Aaron5 Bob Jill6 Jill Aaron在边列表中,行数与网络中的边数一致,因为每一行都详细说明了特定关系中的参与者。
R语言学习过程各种笔记

数据挖掘与数据分析的主要区别是什么?数据分析就是为了处理原有计算方法、统计方法,着重点就是数据、算法、统计、数值。
数据挖掘是从庞大的数据库中分析出有目标数据群,筛选出利于决策的有效信息简单来说就是数据分析是针对以往取得的成绩,比如说哪方面做得好,哪方面需要改进;数据挖掘就是通过以前的成绩预测未来的发展的趋势,并且为决策者提供建议。
读excel时可以先复制再运行data <- ("clipboard", header = T, sep = '\t')在R语言中,使用“=”和“<-”到底有什么不同?就是等号和箭头号有什么区别,是完全一样还是局部不同?R里通常用符号”<-”代替其它语言里的”=”来作赋值符号。
因为前者敲起来比等号要麻烦,且大部分情况下两者是等价的,所以通常就愉懒依旧用”=”来赋值。
但要切记两者在某些时候是有区别的。
字面上的解释,可以认为”<-”是赋值,”=”是传值。
在函数调用中,func(x=1)与func(x<-1)是有区别的,前者调用完后变量x不会被保留,而后者会在工作区里保留变量x=1。
再如length(x=seq(1,10))计算完成后x不会被保留,而length(x<-seq(1,10))计算完后你会在工作区里发现x这个变量。
矩阵知识:1_矩阵的生成2_矩阵的四则运算3_矩阵的矩阵运算4_矩阵的分解1_1将向量定义成数组向量只有定义了维数向量(dim属性)后才能被看作是数组.比如:> z=1:12;> dim(z)=c(3,4);> z;[,1] [,2] [,3] [,4][1,] 1 4 7 10[2,] 2 5 8 11[3,] 3 6 9 12注意:生成矩阵是按列排列的。
1_2用array ( )函数构造多维数组用法为:array(data=NA,dim=length(data),dimnames=NULL)参数描述:data:是一个向量数据。
赖江山老师讲授R语言课程个人笔记

一、非对称分析(回归)做回归分析的前提条件:方差齐次性、独立、数据满足正态分布如果数据不正态,导致的后果平均值95%置信区间,两边不对称如果方差不等,某一边的标准差、置信区间大,有重叠回归Y定性时,整个式子叫做“分类排序”;X定性又定量时,整个方程叫“协方差分析”二、单因素方差分析(1)验证数据的正态性,零假设:均值相等,一组一组地验证:tapply(df$yield,df$Treat,shapiro.test),正态分析函数(shapiro.test),当结果P>0.05,则是一种自然分布(2)合并检验正态性:shapiro.test(resid(lm(yield~Treat,df)))(3)方差齐性检验,零假设:方差相等:bartlett.test(yield~Treat,df)(4)方差分析:fit <- aov(yield ~ Treat, df) 【“~”表示回归,aov是单因素方差分析ANOVA函数】(5)小知识:范函数:[summary.] /[plot.](6)P=1-pf(value组间方差-即组间变异幅度,Df-treat, Df-Residuals)Treat-Meansq/Treat-Value=Residuals-MeansqDf Sum Sq Mean Sq F value Pr(>F)Treat 4 301.2 75.30 11.18 0.000209 ***Residuals 15 101.0 6.73---Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘’ 1(7)多重比较:安装赖老师的写的包(NEwR2),library(NEwR2),LSD多重比较:Least Significance Difference;多个t检验Install.package(‘agricolae’)(8)(9)结果P值,犯“1类错误,拒接真的原假设”的概率,正常我们说的P=0.05,就是:我们可以接受犯这个错误的概率。
统计R学习笔记
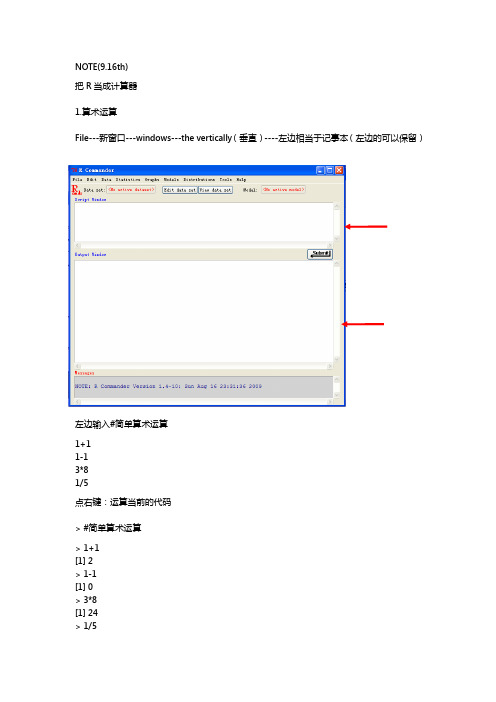
NOTE(9.16th)把R当成计算器1.算术运算File---新窗口---windows---the vertically(垂直)----左边相当于记事本(左边的可以保留)左边输入#简单算术运算1+11-13*81/5点右键:运算当前的代码> #简单算术运算> 1+1[1] 2> 1-1[1] 0> 3*8[1] 24> 1/5[1] 0.2(R中#是提示作用)平方根:sqrt(?)1+sqrt(1+sqrt(1+sqrt(2))) 立方:4^(1/3)(多少次幂)二.#建立简单的对象1.先赋值(学习赋值语句)<-表示等于x<-2Y=35->zobjects() #查看现有对象[1] "x" "Y" "z"rm(x)----移除电脑建立所有对象rm(list=ls())#慎用,移除所有对象再运算x+Y+z(x/Y)^(1/3)w<-x+2*Y+10*z^2(赋予新的值)注意:一定要区别大小写三#建立向量matrixv<-c(1,2,3)C---把1,2,3连成向量h<-c(x,y,z,w)-----把x,y,z,w变成向量k<-c(v,h)-----可以不断运算#向量的算术运算v*2向量的乘法(对应的元素相乘)h<-c(4,5,6)v*h再另h1<-c(3,5)> h1[1] 3 5> v[1] 1 2 3> v*h1[1] 3 10 9警告信息:In v * h1 : 长的对象长度不是短的对象长度的整倍数因为v的3没有对应的数,所以再把v中的3和h1中的第一个3乘一次四.#向量元素的索引只取向量元素中的一部分向量h[3]----取第三个元素h[2]---取第二个元素h[1:2]---取第一个到第二个元素h[c(1,3)]---取第一个,第三个五.#rep(),seq()函数Rep---repeatRep(2,8)---把2重复8次rep(c(2,3),c(3,4))----向量重复Seq----序列seq(from=0,to=1,length=10)----0-1产生10个数,9个间隔产生等差序列KEY OF R----HELP在后边输入> help("seq")或?seqstarting httpd help server ... Done产生向量2,4,6,8,10seq(from=0,to=1,length=11)2*(1:5)----:表示从1到5的数Attention:一定要注意是用英文的符号!!2013.10.14th画图----直方图x<-rnorm(100)----从标准正态分布里产生随机数数> x<-rnorm(100)> x[1] 0.341019718 0.232379800 -1.156626786 -0.013856883 -0.079887867[6] 0.105013772 -1.122563463 0.141311078 -1.203527506 1.617024288[11] 1.882750286 1.787700346 -0.094190399 0.344903331 -0.703671085[16] -0.450606133 0.242303165 1.238181966 1.066555721 0.494756905[21] 0.685797591 -2.736760356 -0.089690631 -1.666324609 0.223574925[26] -1.525330731 1.405092774 1.259759907 1.304417029 0.043141531[31] 0.388122525 -0.043076269 -0.160404380 -0.271311951 1.119678989[36] -0.090459611 -1.046401794 -0.221043437 0.098923434 -0.542525595[41] -0.032062588 -0.720217246 0.339581709 1.007299430 -0.021627639[46] 1.214776541 -0.424784206 -1.249418227 0.791781085 -0.770785046[51] 0.374259448 -0.522112542 -1.002355477 1.473828173 -1.163678070[56] 0.051130757 -0.006516286 1.215113429 0.285956584 -0.238135538[61] 0.914600607 0.291277244 2.540533053 1.526002529 0.792335698[66] -0.310752916 0.499751815 -0.698590551 -0.204159783 1.079188693[71] 0.836828566 0.722438863 0.088398640 -0.912404063 3.105980352[76] 0.370655484 -1.545378507 2.260279793 0.261019588 0.169971020[81] -1.017774240 2.689896807 0.874411838 -0.894351550 -0.551249948[86] 1.378679481 -0.068646910 0.551432663 1.172866188 -2.035676088[91] 0.656948321 0.445607324 -1.642623913 0.550977676 -0.028277642[96] -1.937337915 1.577919383 -0.190344210 -1.225727248 -0.340590751X是向量,列向量查询第一个数----x【1】sum(x>0)---大于0的数有多少次(在50中间徘徊)Sum----求和,true---1 false---0X>0----逻辑判断> x>0[1] TRUE TRUE FALSE FALSE FALSE TRUE FALSE TRUE FALSE TRUE TRUE TRUE[13] FALSE TRUE FALSE FALSE TRUE TRUE TRUE TRUE TRUE FALSE FALSE FALSE[25] TRUE FALSE TRUE TRUE TRUE TRUE TRUE FALSE FALSE FALSE TRUE FALSE[37] FALSE FALSE TRUE FALSE FALSE FALSE TRUE TRUE FALSE TRUE FALSE FALSE[49] TRUE FALSE TRUE FALSE FALSE TRUE FALSE TRUE FALSE TRUETRUE FALSE[61] TRUE TRUE TRUE TRUE TRUE FALSE TRUE FALSE FALSE TRUE TRUE TRUE[73] TRUE FALSE TRUE TRUE FALSE TRUE TRUE TRUE FALSE TRUE TRUE FALSE[85] FALSE TRUE FALSE TRUE TRUE FALSE TRUE TRUE FALSE TRUE FALSE FALSE[97] TRUE FALSE FALSE FALSE>下面把我的数值做成直方图hist(x)#histogramHistogram of xx F r e q u e n c y-3-2-1012340510*******求帮助----在右边方框里输入?Hist 回车怎么把数据导入R 里面新建需要的数据的excel 保存csv 格式Csv---标点符号分割的格式数据read.csv("D:\\x.csv")读取 #导入数据population<-read.csv("D:\\population.csv")最好存在D 盘,而且路径不要有中文的,不好读出来而且excel 要标准,第一列是英文名称---如population ,并且只有一列。
【RNotebook】R学习笔记

【RNotebook】R学习笔记IntroR为数据分析提供了⽅便的统计功能,可⽤于创建⾼级数据可视化。
查看这些资源以了解有关 R 的更多信息::下载 R、⽂档和帮助的⽹站:R 核⼼团队⼿册的链接,包括介绍、管理和帮助:R 的编码教程集合:帮助您在 R 中处理数据、图形和统计数据Python是⼀种通⽤语⾔,可⽤于创建数据分析所需的内容。
以下是开始学习 Python 的⼀些资源::⼀个⽹站,提供帮助您⼊门的指南:来⾃ PSF 站点的 Python 3 教程:Python 的编码教程合集RStudio: This web page explains some of the reasons why RStudio is many analysts’ preferred choice for interfacing with R. You’ll learn about the advantages of using RStudio for data analysis, from ease of use to accessibility of graphics and more.: This online introduction to data analysis and R programming is a good starting point for R and RStudio users. It also includes a list of detailed explanations about the advantages of using R and RStudio. You’ll also find a helpful guide for getting set up with RStudio. Online communitiesOnline communities allow you to connect with other R users no matter where you live. This list includes forums and discussion channels where you can join the conversation. It also includes social media tags you can use on your existing social media platforms to connect with other data analysts.The RStudio Community forum is a great place to get help and find solutions to challenges you have with R–and maybe helpsomeone else out, too!: The R language subreddit is an active online community on the social media platform Reddit, where R users go to discuss R, ask questions, and share tips.: rOpenSci has a community forum where R users can ask questions and search for solutions. It also includes links to their Best Practices guide and support pages.This is a community with another Slack channel where R learners and mentors can gather and connect. This is a great place to chat about using R for data science.: If you use Twitter, you can connect with other R users using the hashtag #rstats; a lot of R developers and analysts are active on Twitter.Use Kaggle to ask a questionCheck out websites like R for Data Science Online Learning Community and RStudio Community.let's talk about some specific situations when you might use it for data analysis. Here's three scenarios: reproducing your analysis, processing lots of data, and creating data visualizations.Basic计算Addition: +Subtraction: -Multiplication: *Division: /Exponentiation: ^Modulo: %%Notice from the last expression that R is case sensitive: "R" is not equal to "r".数据类型Decimal values like 4.5 are called numerics.Whole numbers like 4 are called integers. Integers are also numerics.To create a vector of integers using the c() function, you must place an L directly after each number. c(1L, 5L, 15L)Boolean values (TRUE or FALSE) are called logical.Text (or string) values are called characters.The most common data structures in the R programming language include:VectorsData framesMatricesArraysYou can determine what type of vector you are working with by using the typeof() function.typeof(c(“a” , “b”))#> [1] "character"R语⾔中=和<-功能基本相同,有时候=会出错,所以⽤<-。
那些年倒腾的R语言学习笔记,全都在这里了~

那些年倒腾的R语言学习笔记,全都在这里了~今天这一篇整理一下我以往推送过的所有R语言相关文章,一来是方便大家的检索,二来也是阶段性学习的一次总结。
关于内容分类,我分成了学习心得篇、R语言基础、数据可视化、网络数据爬取,然后各自类别进行详细的再分类。
-----------------------------R语言学习心得篇:R语言基础:数据可视化:•ggplot2语法入门•R语言商务图表•信息图•地理信息可视化•动态可视化网络数据爬取:----------------------------------R语言学习心得篇:给R语言初学者的几个建议~学习R语言我都做了那些有趣的事情R语言基础入门:R:R语言笔记之——常用数据导入方式简介R语言数据重塑及导出操作R语言数据处理——数据合并与追加R VS Python:左右用R右手Python系列——字符串格式化输出左手用R右手Python系列——数据合并与追加左手用R右手Python系列——数据塑型与长宽转换左手用R右手Python系列——因子变量与分类重编码数据可视化:基础部分:R语言信息可视化——文字云R语言数据可视化之——TreeMapR语言学习笔记——柱形图R语言可视化——柱形图美化(簇状、堆积、百分比)R语言可视化——多系列柱形图(条形图)与分面组图美化技巧!R语言可视化——散点图及其美化技巧!R语言可视化——直方图及其美化技巧!R语言可视化——密度曲线图及其美化!R语言可视化——折线图、平滑曲线及路径图R语言可视化——面积(区域)图及其美化R语言可视化——箱线图及其美化技巧R语言可视化——极坐标变换与衍生图表类型R语言可视化——多边形与数据地图填充R语言可视化——用ggplot构造期待已久的雷达图当PowerBI遇到R语言配色与版式优化:R预设配色系统及自定义色板R语言颜色综合运用与色彩方案共享一个神奇的配色网站~R语言可视化——ggplot图表中的线条R语言可视化——图表美化与套用主题(上)R语言可视化——图表美化与套用主题(下)R语言可视化——ggplot图表配色技巧R语言可视化——图表嵌套(母子图)R语言可视化——ggplot携手plotly,让你的图表灵动起来!R语言可视化——图表排版之一页多图R语言可视化——ggplot的theme订制R语言可视化——ggplot图表系统中的形状R语言可视化——ggplot图表系统中的辅助线不经意间又发现了一个有趣又炫酷的包~用优雅的配色来缔造图表专业主义~R语言图表美化——巧用分面表达优化图表布局,做出堪比杂志级视觉体验的商务图表ggplot2又添新神器——ggthemr助你制作惊艳美图地图部分(ggplot2)一篇文章教你搞定JSON素材,从此告别SHP时代~大道至简——论如何最优雅的操纵json地图数据关于美国地图中的两个海外州坐标平移与原始投影问题~R语言可视化——关于ggplot所支持的数据地图素材类型一篇小短文助你打开数据可视化的任督二脉!数据地图多图层对象的颜色标度重叠问题解决方案ggplot2中如何自定义数据地图版面范围~关于数据地图的几个遗留问题解决方案R语言数据地图——美国地图R语言数据地图——全球填色地图数据地图系列7|R语言版(上)数据地图系列8|R语言版数据地图(下)R语言可视化——数据地图应用(东三省)R语言可视化——数据地图离散百分比填充(环渤海)R语言可视化——地图填充与散点图图层叠加R语言可视化——多图层叠加(离散颜色填充与气泡图综合运用)R语言可视化——地图与气泡图结合应用用R语言复盘美国总统大选结果~R语言可视化——ggplot绘制中心密度辐射图R语言可视化——中心放射状路径图你绝对想不到,数据地图还能这么玩~玩转数据地图系列之——地图上的迷你条形图一个小案例,教你如何从数据抓取、数据清洗到数据可视化一篇全是代码的数据可视化案例小魔方不想跟你说话,并向你扔了一堆代码~~~地图可视化之——移花接木REmap地图:R语言可视化——REmap动态地图R语言可视化——REmap(路径图)R语言可视化——REmapB函数R语言可视化——REmapC(填充地图)R语言可视化——REmapH(中心热度图)leaflet地图:动态地理信息可视化——leaflet在线地图简介动态地理信息可视化——散点地图系列动态地理信息可视化——leaflet构造路径图动态地理信息可视化——leaflet填充地图Leaflet在线地图进阶宝典——json素材操纵与图层面板控制leaflet在线地图进阶宝典之——高级辅助特性leaflet在线地图进阶宝典——高级交互特性leaflet的小搭档leaflet.minicharts来了,从此动态地图又多了一些乐趣~~~商务图表进阶:超强脑洞第二弹之——ggplot构造漏斗图超强脑洞第三弹之——ggplot构造瀑布图超强脑洞第四弹——ggplot构造甘特图超强脑洞第五弹——ggplot 构造连环饼图用R语言制作商务图表,让你的图表美出新高度~一场用R语言打造的商务图表视觉盛宴~流量结构分布图——桑基图(Sankey)流量结构分布图——炫酷和弦图Word天呀,气泡图居然还有这种操作~这么牛X的包,一般人我不告诉他信息图高仿:信息图表高仿——R语言仿一财经典线条比较图用ggplot轻松搞定太极图用ggplot来挑战数据可视化的上限~ggplot系列之脑洞大开鱼缸百分比信息图~ggplot制作分析仪表盘用ggplot2制作静态数据可视化报告!R语言数据可视化——仿网易数独圆环条形图重要的是图表思维,而不是工具让执着成为一种习惯——仿网易数独玫瑰气泡图是时候展现真正的技术了——让你的图表舞动起来~上帝视角——给世界一个特写~像电影一样记录数据可视化shiny仪表盘:用R-Shiny打造一个美美的在线Appshiny动态仪表盘——360度全空间无死角拖拉换肤功能的旋转地球shiny仪表盘应用——2016年美国大选数据可视化案例爬虫及数据可视化:用R语言抓取网页图片——从此高效存图告别手工时代经历过绝望之后,选择去知乎爬了几张图~一言不合就爬虫系列之——爬取小姐姐的秒拍MV教你如何优雅的用R语言调用有道翻译2017年的第一周,你吸了多少雾霾?用数据来聊聊国产电影~当大家都在讨论金刚狼3的时候,他们到底在说些什么~一篇文章揭开office配色模板的的神秘面纱~你知道经管类的核心期刊都分布在那里吗?这是一篇很务正业的可视化推送~(上篇)下篇(续)大连市2016年空气质量数据可视化~北京历史空气质量数据可视化~挑战不可能之——ggplot环形字体地图用emoji表情包来可视化北京市历史天气状况!实习僧招聘网爬虫数据可视化我也不敢相信自己竟然写过这么多代码,不过都是过去的事情了,以后要往前看,不断地优化代码,学习新东西的同时不断巩固旧知识,抱着一种归零的心态,总结、凝练、提升、创新~~~R语言学习笔记精华汇总!。
R语言实战(第2版)——第2章-2.3数据的输入

R语言实战(第2版)——第2章-2.3数据的输入•使用键盘输入小数据#P31 2.3.1 使用键盘输入数据(小数据集)mydata <-data.frame(age=numeric(0),gender=character(0),weight=numeric(0)) #创建一个数据框mydata <- edit(mydata) #调用数据文本编辑器mydatatxt <- "age gender weight25 m 16630 f 11518 f 120"mydata <- read.table(header = TRUE,text=mydatatxt)•从带分隔符的文本文件导入数据setwd("E:/2-science_learning/R_learning_20/Rcode/R_in_Action_v2_011121")grades <-read.table("studentgrades.csv", header =TRUE, s = "StudentID", sep=",")str(grades)容易出现这样的错误这是因为输入名字时O'Leary未加引号,导致R系统认为单引号隔开的是两个不同的value,故只需将O'Leary加个引号即可。
•导入excel数据读取excel最好的方式是将其另存为csv文件,以read.table的方式读入直接导入需要安装xlsx包,需要xlsxjars和rJava包,以及一个正常工作的Java安装•导入xml数据XML包•从网页抓取数据readLines()读取网页上的文字,grep()和gsub()处理•导入spss数据foreign包的read.spss()Hmisc包的spss.get()•导入SAS数据foreign包的read.ssd()Hmisc包的sas.get()sas7bdat包的read.sas7bdat():不要求sas程序•导入stata数据foreign包的read.dta()•导入NetCDF数据ncdf包和ncdf4包•导入HDF5数据rhdf5包•访问数据库管理系统ODBC包DBI包•通过Stat/Transfer导入数据可在34种数据格式之间转换的独立应用程序。
R语言笔记完整版

R语⾔笔记完整版R语⾔与数据挖掘:公式;数据;⽅法R语⾔特征1. 对⼤⼩写敏感2. 通常,数字,字母,. 和 _都是允许的(在⼀些国家还包括重⾳字母)。
不过,⼀个命名必须以 . 或者字母开头,并且如果以 . 开头,第⼆个字符不允许是数字。
3. 基本命令要么是表达式(expressions)要么就是赋值(assignments)。
4. 命令可以被 (;)隔开,或者另起⼀⾏。
5. 基本命令可以通过⼤括弧({和}) 放在⼀起构成⼀个复合表达式(compound expression)。
6. ⼀⾏中,从井号(#)开始到句⼦收尾之间的语句就是是注释。
7. R是动态类型、强类型的语⾔。
8. R的基本数据类型有数值型(numeric)、字符型(character)、复数型(complex)和逻辑型(logical),对象类型有向量、因⼦、数组、矩阵、数据框、列表、时间序列。
基础指令程序辅助性操作:运⾏q()——退出R程序tab——⾃动补全ctrl+L——清空consoleESC——中断当前计算调试查错browser() 和debug()——设置断点进⾏,运⾏到此可以进⾏浏览查看(具体调试看browser()帮助⽂档(c,n,Q))stop('your message here.')——输⼊参数不正确时,停⽌程序执⾏cat()——查看变量?帮助help(solve) 和 ?solve 等同solve——检索所有与solve相关的信息help("[[") 对于特殊含义字符,加上双引号或者单引号变成字符串,也适⽤于有语法涵义的关键字 if,for 和 functionhelp(package="rpart")——查看某个包help.start()——得到html格式帮助help.search()——允许以任何⽅式(话题)搜索帮助⽂档example(topic)——查看某个帮助主题⽰例apropos("keyword")——查找关键词keyword相关的函数RSiteSearch("onlinekey", restrict=fuction)——⽤来搜索邮件列表⽂档、R⼿册和R帮助页⾯中的关键词或短语(互联⽹)RSiteSearch('neural networks')准备⽂件⽬录设置setwd(<dir>)——设置⼯作⽂件⽬录getwd()——获取当前⼯作⽂件⽬录list.files()——查看当前⽂件⽬录中的⽂件加载资源search()——通过search()函数,可以查看到R启动时默认加载7个核⼼包。
R语言学习笔记 内附实例及代码
R语言入门R是开源的统计绘图软件,也是一种脚本语言,有大量的程序包可以利用。
R中的向量、列表、数组、函数等都是对象,可以方便的查询和引用,并进行条件筛选。
R具有精确控制的绘图功能,生成的图可以另存为多种格式。
R编写函数无需声明变量的类型,能利用循环、条件语句,控制程序的流程。
R网络资源:R主页: R资源列表NCEAS /scicomp/software/rR Graphical Manual http://bm2.genes.nig.ac.jp/RGM2/index.php统计之都: /QuikR /丁国徽的R文档: /R/R-doc/R语言中文论坛/Rbbs/forums/list.page一、用函数install.packages(),[直接输入就可以联网,第一次的话之后选择镜像,然后选择包下载即可]如果已经连接到互联网,在括号中输入要安装的程序包名称,选择镜像后,程序将自动下载并安装程序包。
例如:要安装picante包,在控制台中输入install.packages("picante")已经安装了?二. 安装本地zip包路径:Packages>install packages from local files选择本地磁盘上存储zip包的文件夹。
(文件,运行R的脚本,选择所在文档)三.调用程序包在控制台中输入如下命令library(“picnate”)程序包内的函数的用法与R内置的基本函数用法一样。
四.程序包内部都有哪些函数?分别有什么功能?查询程序包内容最常用的方法:1 菜单帮助>Html帮助;2 查看pdf帮助文档五.查看函数的帮助文件函数的默认值是什么?怎么使用?使用时需要注意什么问题?需要查询函数的帮助。
1 ?t.test 直接打开相关函数的说明和使用模板。
2 RGui>Help>Html help 同样的效果,同上3 apropos("t.test")合理使用T 检验,五种模式的T 检验4 help("t.test")帮助同1-25 help.search("t.test")有关T 检验的一切东西都可以查出来。
R语言笔记 常用函数、统计分析、数据类型、数据操作、帮助、安装程序包、R绘图

eigen( matrix ),特征值和特征向量 svd(matrix),奇异值分解,返回 X 包含属性 U、d、V 工作空间对象 ls() 列举所有对象 rm() 删除对象
数据框
创建数据框 data.frame(x1,x2,…)或带上列的名称 data.frame(=x1,=x2,…) 在创建数据框的时候,字符串的列会自动的转换成因子,以方便统计 数据框取值 data[x,y](取单个值) data[x](取第 x 列的数据组成的数据框) data[x,](取第 x 行的数据) data[,y](取第 y 列的数据) data[a:b,y](取 a-b 行的第 y 列的数据) data[c(“colName1”,” colName1”,””,…)] ,根据列名进行访问 注意:data[x]与 data[,y]的不同,data[,y]取值后返回的是一个一维向量 限定取值 可以通过限制列的范围来取子集,但此时同时一定要指定取哪些列,如 data[data$col>k,c(“col1”,”col2”,…)],用 attach(data)可以简化这一步 操作, 即在 attach 之后可以直接访问列 (所有) , data[data$col>k], 用 detach 可以解除。
4、序列模式
常用的包: arulesSequences SPADE 算法: cSPADE
5、时间序列
常用的包: timsac 时间序列构建函数: ts 成分分解: decomp, decompose, stl, tsr
6、统计
常用的包: Base R, nlme 方差分析: aov, anova 密度分析: density 假设检验: t.test, prop.test, anova, aov 线性混合模型:lme 主成分分析和因子分析:princomp
【数据分析R语言实战】学习笔记第十一章对应分析

【数据分析R语⾔实战】学习笔记第⼗⼀章对应分析11.2对应分析在很多情况下,我们所关⼼的不仅仅是⾏或列变量本⾝,⽽是⾏变量和列变量的相互关系,这就是因⼦分析等⽅法⽆法解释的了。
1970年法国统计学家J.P.Benzenci提出对应分析,也称关联分析、R-Q型因⼦分析,其是⼀种多元相依变量统计分析技术。
它通过分析由定性变量构成的交互汇总表,来揭⽰同⼀变量各类别之间的差异,以及不同变量各类别之间的对应关系,这是⼀种⾮常好的分析调查问卷的⼿段。
对应分析是⼀种视觉化的数据分析⽅法,其基⽊思想是将⼀个联列表的⾏和列中各元素的⽐例结构以点的形式在较低维的空间中表⽰出来,优点在于能够将⼏组看不出任何联系的数据,通过视觉上可以接受的定位图展现出来,使⽤起来直观、简单、⽅便,因此⼴泛应⽤于市场细分、产品定位、地质研究以及计算机⼯程等领域。
11.2.1理论基础对应分析是寻求样⽊(⾏)与指标(列)之间联系的低维图⽰法,其关键是利⽤⼀种数据变换⽅法,使含有n个样本观测值和m个变量的原始数据矩阵x变成另⼀个矩阵z, z是⼀个过渡知阵,在接下来的计算中使⽤。
通过z将样本和变量结合起来。
11.2.2 R语⾔实现R中的程序包MASS提供了两个函数,corresp()⽤于做简单⼀的对应分析,mca()⽤于计算多重对应分析,通常使⽤前者,其调⽤格式为corresp(x,nf=1,……)x是数据矩阵:nf表⽰因⼦分析中计算因⼦的个数,通常取2.【例】> ch=data.frame(A=c(47,22,10),B=c(31,32,11),C=c(2,21,25),D=c(1,10,20))> rownames(ch)=c("Pure-Chinese","Semi-Chinese","Pure-English")> library(MASS)> ch.ca=corresp(ch,nf=2)> options(digits=4)> ch.caFirst canonical correlation(s): 0.5521 0.1409Row scores:[,1] [,2]Pure-Chinese 1.2069 0.6383Semi-Chinese -0.1368 -1.3079Pure-English -1.3051 0.9010Column scores:[,1] [,2]A 0.9325 0.9196B 0.4573 -1.1655C -1.2486 -0.5417D -1.5346 1.2773分析结果给出了两个因⼦对应⾏变量、列变量的载荷系数。
R语言数据分析实战指南

R语言数据分析实战指南R语言是一种功能强大的开源编程语言,广泛应用于数据分析和统计建模领域。
本文将为大家介绍如何使用R语言进行数据分析,并提供一些实战指南,帮助读者快速上手和应用R语言进行各种数据分析任务。
一、R语言基础在开始数据分析之前,首先需要了解R语言的基本语法和数据结构。
R语言提供了丰富而强大的函数库,可以进行各种数据处理和可视化操作。
以下是一些常用的R语言基础知识:1. 数据类型:R语言支持多种数据类型,包括向量、矩阵、数组、数据框等。
不同的数据类型适用于不同的数据分析任务。
2. 数据操作:R语言提供了丰富的数据操作函数,如数据的载入与保存、数据的合并与拆分、变量的选择与筛选等。
3. 统计函数:R语言内置了大量的统计函数,可以进行描述性统计、假设检验、回归分析等。
4. 数据可视化:R语言的数据可视化功能十分强大,可以绘制各种统计图表,如柱状图、散点图、线图等。
二、数据处理与清洗在实际的数据分析过程中,数据往往会存在各种问题,如缺失值、异常值、重复值等。
因此,数据处理与清洗是数据分析的关键步骤。
以下是一些常用的数据处理与清洗技巧:1. 缺失值处理:当数据中出现缺失值时,可以使用R语言的函数或者包来处理缺失值,如na.omit和mice包。
2. 异常值检测与处理:异常值会对数据分析结果产生不良影响,可以使用R语言的函数或者包来检测和处理异常值,如outliers包和z-score方法。
3. 数据转换与标准化:某些数据分析方法要求数据满足一定的条件,可以使用R语言的函数或者包进行数据转换和标准化,如log变换和z-score标准化。
4. 数据合并与拆分:当需要将多个数据源进行合并或者从一个数据源中提取特定的数据时,可以使用R语言提供的函数进行数据的合并与拆分,如merge和subset函数。
三、统计分析与建模R语言作为一种统计分析工具,提供了丰富的统计函数和建模方法,可以应用于各种数据分析任务。
用R语言做非参数和半参数回归笔记.docx

由詹鹏整理 ,仅供交流和学习根据南京财经大学统计系孙瑞博副教授的课件修改 ,在此感谢孙老师的辛勤付出!教材为:Luke Keele: Semiparametric Regression for the Social Sciences. John Wiley & Sons, Ltd. 2008.-------------------------------------------------------------------------第一章 introduction: Global versus Local Statistic一、主要参考书目及说明1、Hardle(1994). Applied Nonparametic Regresstion. 较早的经典书2、Hardle etc (2004). Nonparametric and semiparametric models: an introduction. Springer. 结构清晰3、Li and Racine(2007). Nonparametric econometrics: Theory and Practice. Princeton. 较全面和深入的介绍 ,偏难4、Pagan and Ullah (1999). Nonparametric Econometrics. 经典5、Yatchew(2003). Semiparametric Regression for the Applied Econometrician. 例子不错6、高铁梅(2009). 计量经济分析方法与建模:EVIEWS应用及实例(第二版). 清华大学出版社. (P127/143)7、李雪松(2008). 高级计量经济学. 中国社会科学出版社. (P45 ch3)8、陈强(2010). 高级计量经济学及Stata应用. 高教出版社. (ch23/24)【其他参看原ppt第一章】二、内容简介方法:——移动平均(moving average)——核光滑(Kernel smoothing)——K近邻光滑(K-NN)——局部多项式回归(Local Polynormal)——Loesss and Lowess——样条光滑(Smoothing Spline)——B-spline——Friedman Supersmoother模型:——非参数密度估计——非参数回归模型——非参数回归模型——时间序列的半参数模型——Panel data 的半参数模型——Quantile Regression三、不同的模型形式1、线性模型linear models2、Nonlinear in variables3、Nonlinear in parameters四、数据转换 Power transformation(对参数方法)In the GLM framework, models are equally prone(倾向于) to some misspecification (不规范) from an incorrect functional form.It would be prudent(谨慎的) to test that the effect of any independent variable of a model does not have a nonlinear effect. If it does have a nonlinear effect, analysts in the social science usually rely on Power Transformations to address nonlinearity.[ADD: 检验方法见Sanford Weisberg. Applied Linear Regression (Third Edition). A John Wiley & Sons, Inc., Publication.(本科的应用回归分析课教材)]----------------------------------------------------------------------------第二章Nonparametric Density Estimation非参数密度估计一、三种方法1、直方图 Hiatogram2、Kernel density estimate3、K nearest-neighbors estimate二、Histogram 对直方图的一个数值解释Suppose x1,…xN – f(x), the density function f(x) is unknown.One can use the following function to estimate f(x)【与x的距离小于h的所有点的个数】三、Kernel density estimateBandwidth: h; Window width: 2h.1、Kernel function的条件The kernel function K(.) is a continuous function, symmetric(对称的) around zero, that integrates(积分) to unity and satisfies additional bounded conditions:(1) K() is symmetric around 0 and is continuous;(2) ,,;(3) Either(a) K(z)=0 if |z|>=z0 for z0Or(b) |z|K(z) à0 as;(4) , where is a constant.2、主要函数形式3、置信区间其中 ,4、窗宽的选择实际应用中 ,。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
内置数据结构:元组:元组由不同元素构成,每个元素可以存储不同类型的数据,如字符串、数值、元组。
元组是写保护的,元组创建后不能再做任何修改。
reload()函数将以前导入过的模块再加载一次。
重新加载(reload)包括最初导入模块时应用的分析过程和初始化过程。
这样就允许在不退出解释器的情况下重新加载已更改的Python模块。
Pow(n,2)对某数求平方pow(4.5-4,2)记(4.5−4)2Sqrt()求平方根欧几里得距离sqrt(pow(4.5-4)+pow(2-1,2))Deepcopy()深拷贝,能拷贝对象内部所有数据和引用。
若A深拷贝数据B,则A变,B 不变。
Copy()浅拷贝,只是复制数据。
若A浅拷贝数据B,则A变,B也变。
+表示连接%系统一、入门R区分大小写字母1获取帮助help.start()help(foo) 或者?fooexample(foo)data() 列出加载包中所有可用示例数据集2工作空间工作空间是R用来读取文件和保存结果的默认目录。
getwd()setwd(“D:/rworkspace”) D:/rworkspace必须存或者用dir.create()创建新目录load()从上一次会话结束地方开始3输入source(”myscript.R”)将执行包含在文件myscript.R中的R语句集合4输出sink(“myoutput”,append=TRUE,split=TRUE) 默认情况下,有一样名字文件,会被覆盖原文件。
append将文本追加到文件后,而不是覆盖,split将文件发送至屏幕并且输出文件。
不加参数的sink()仅向屏幕输出结果。
图形输出Pdf(“mygraphs.pdf”)输出结果作为输入5包包是函数、数据、预编译代码以一种定义完善的格式组成的集合。
存包的目录称为库函数.libpath()显示库所在位置library()显示库位置以及有哪些包第一次安装一个包用:install.packages(“gclus”)包(引号是必须的)gclus提供了创建增强型散点图的函数。
包只需安装一次,但作者可能更新它update.packages(“包名”)查看已经安装的包installed.packages()列出安装包的版本和依赖关系包的载入:包安装时从cran镜像站点下载它加入库的过程需用到时还得library(gclus)包带有示例,help(package=”包名”)可以输出包的简短描述以及包中函数和数据集名称的列表。
选中全部代码再按run 否则编译器只会运行最后一行代码二、数据集对象是可以赋值给变量的任何事物。
x<-mtcars[order(mpg),]不加,系统分不清向量矩阵数组数据框data.frame() patientid$age 用来选取一个给定数据框中的某个特定变量attach(mtcars)//可以将数据框添加到R的搜索路径,plot(disp,mpg)//此时若有其他名称相同对象,比如也叫disp则原始对象取得优先权。
若长度不匹配则报错,要注意detach(mtcars)否则得plot(mtcar s$disp,mtcars$mpg)with ({只写半边括号,r中命令就能按enter后自动换行命令<<-按上下键可以使用历史命令列表(向量、数组、数据框、列表)因子:因子(factors) 提供了一种处理分类数据的更简介的方式。
levels=c(“poor”,””,”improved”,”excellent”) 可以通过level将类别变量排序列联表table(patientdata$diabete,patientdata$status)str(patientdata)显示数据框patientdata的结构,如哪些列,多少个变量与观测,具体值是。
Summary(patient)显示统计概要#注释无多行注释三、图形初阶如何创建多个图形并随时查看每一个呢方法一dev.new()创建图语句dev.new()创建图语句··dev.off()将输出返回到终端修改图形参数> dose<-c(20,30,40,45,60)> drugA<-c(16,20,27,40,60)> drugB<-c(15,18,25,31,40)> plot(dose,drugA,type="b")复制当前图形参数opar<-par(no.readonly=TRUE)par(lty=2,pch=17) #设置图形参数,此时应用于所有之后创建图形plot(dose,drugA,type="b")#查看修改参数后图片效果> par(opar)> plot(dose,drugA,type="b")#图片又变回原来参数了> plot(dose,drugA,type="b",lty=2,pch=17)#仅应用于该图像绘制点的符号R中查看已经安装的包路径和包名library()pchAxis坐标轴font字体类型:1 常规2 粗体3 斜体 4 粗斜体图形前景色与背景色图形尺寸:代码应该提前,不要等到图已经做出来了再写该代码Par(pin=c(4,3),m,mar=c(1,.5,1,.2))pin长宽Mar 指边界大小par(mar=(5,4,4,8)+0.1)下开始,逆时针转注意:某些高级绘图函数已经包含了默认的标题和标签。
你可以通过在plot()语句或者单独的par()中添加ann=FALSE来移除它们announcement通告坐标轴yaxt="n" xaxt=”n”将分别禁用x轴、y轴(会留下框架,只是禁用了刻度)参考线Abline图例Legend文本标注Text mtexttext(wt,mpg,s(mtcars),cex=.6,pos=4,col="red")直接点的位置,再加上标注向量text(3,3,”exzample”)单独点加标注图形组合Par(mfrow=c(2,2)) 2行2列按行填充4个图layout(matrix(c(1,1,2,3),2,2,byrow=TRUE),widths=c(3,1),heights=c(1,2))c()为矩阵元素2,2 为2行2列layout(matrix(c(1,2,3,0,2,3,0,0,3),nr=3)) matrix有9个元素,具有这样的形式: [,1] [,2] [,3][1,] 1 0 0[2,] 2 2 0[3,] 3 3 3把这个矩阵传入layout函数,我们就能得到这样的output devicepar(fig=c(0,0.8,0,0.8))> plot(wt,mpg,xlab="mile",ylab="weight")par(fig=c(0,0.8,0.55,1),new=TRUE)boxplot(wt,horizontal=TRUE,axes=FALSE)opar<-par(no.readonly=TRUE)par(fig=c(0,0.8,0,0.8))plot(wt,mpg,xlab="mile",ylab="weight")par(fig=c(0,0.8,0.55,1),new=TRUE)boxplot(wt,horizontal=TRUE,axes=FALSE)六、基本图形:条形图barplot() 一个数值堆砌条形图分组条形图均值条形图可以使用数据整合函数并将结果传递给barplot()条形图的微调棘状图棘状图对堆砌条形图进行了重缩放,这样每个条形的高度均为1,每一段高度表示比例。
library(vcd)attach(Arthritis)counts<-table(Treatment,Improved)spine(counts,main="Spinogram Example")#spine属于vcd包中detach(Arthritis)饼图opar <- par(no.readonly=TRUE)par(mfrow=c(2,2))x <- c(10, 12.9, 4, 16, 8)lbls <- c("US", "France", "Germany", "Australia", "UK")pie(x, lbls, main="简单饼图")lbls <- paste(lbls, " ", round(x/sum(x)*100,2), "%", sep="")#paste()实现字符串连接pie(x, lbls, main="使用百分比标签的饼图",col=rainbow(length(lbls)))install.packages("plotrix")library(plotrix)pie3D(x, labels=lbls, explode=0.1,main="3D饼图")mytable <- table(state.region)lbls <- paste(names(mytable), "\n", mytable, sep="")pie(mytable, labels=lbls,main="列表数据饼图\n (一个简单的)")扇形图比较各个部分大小par(mfrow=c(1,1))lbls <- c("US", "France", "Germany", "Australia", "UK")#lbls label listfan.plot(x, labels=lbls, main="扇形图")直方图histogrambreaks=12, 表示分组数hist(x)hist(mtcars$mpg,breaks=12,col="red",xlab="miles per gallon",main="colored histogram with 12 bins")分成12组# 根据概率密度画图# 增加轴须图hist(mpg,freq=FALSE,# fre=FALSE表示根据概率密度而不是频数绘制图形breaks=12,# # breaks用于控制组的数量col="red",main="直方图、轴须图、概率密度曲线",xlab="Miles Per Gallon", ylab="概率密度")rug(jitter(mpg))增加轴须图# rug(jitter(mpg, amount=0.01))如果数据中有许多结(数据中相同的值),可以使用该代码将轴须图的数据打散lines(density(mpg), col="blue", lwd=2)#概率密度曲线核密度曲线轴须图:是实际数据值的一种一维呈现方式x <- mpgh <- hist(x,breaks=12,col="red",main="添加正态密度曲线和外框的直方图",xlab="Miles Per Gallon", ylab="频数")xfit <- seq(min(x), max(x), length=40)#生成一个序列,最小最大值为···长度为40个yfit <- dnorm(xfit, mean=mean(x), sd=sd(x))#生成一个yfit <- yfit*diff(h$mids[1:2])*length(x) 不理解lines(xfit, yfit, col="blue", lwd=2)box()# 外框detach(mtcars)par(opar)核密度图核密度估计是用于估计随机变量概率密度函数的一种非参数方法。