统计学第五版第八章课后习题答案.ppt
统计学概论课后答案第8章统计指数习题解答.

167第八章 对比分析与统计指数思考与练习4. 指出下列哪一个数量加权算术平均数指数,恒等于综合指数形式的拉 氏数量指标指数(C )。
C. d.6. 编制数量指标综合指数所采用的同度量因素是( a ) a .质量指标b .数量指标C •综合指标d •相对指标7. 空间价格指数一般可以采用( C )指数形式来编制。
a .拉氏指数 b.帕氏指数 C.马埃公式d.平均指数二、问答题:1.报告期与基期相比,某城一、选择题:1.某企业计划要求本月每万元产值能源消耗率指标比去年同期下降 实际降低了2.5%,则该项计划的计划完成百分比为( d )。
d. 102.6%5%a. 50.0%b. 97.4%c. 97.6% 2. 下列指标中属于强度相对指标的是(a..产值利润率 C.恩格尔系数3. 编制综合指数时, a .指数化指标 b. b. d.应固定的因素是( b基尼系数 人均消费支出C )。
个体指数c.同度量因素 d.被测定的因素S k q q 。
P 1 」2k q q 1 p 1S k q q o P 0 」 S k q q t p o;b. --------- ; c. -------- ; d. -------- a .S q 。
P 1送 q i P i S q o P o Z q i P o 5.之所以称为同度量因素,是因为:它可使得不同度量单位的现象总体转化为数量上可以加总; 客观上体现它在实际经济现象或过程中的份额 ;是我们所要测定的那个因素; 它必须固定在相同的时期。
(a )。
a .市居民消费价格指数为110%,居民可支配收入增加了20 %,试问居民的实际收入水平提高了多少?解:(1+20% /110%-100%=109.10%-100%=9.10%2.某公司报告期能源消耗总额为28.8万元,与去年同期相比,所耗能源的价格平均上升了20%那么按去年同期的能源价格计算,该公司报告期能源消耗总额应为多少?解:28.8 -(1+20%)=24 万元3.编制综合指数时,同度量因素的选择与指数化指标有什么关系?同度量因素为什么又称为权数?它与平均指数中的权数是否一致?解:(略)4.结构影响指数的数值越小,是否说明总体结构的变动程度越小?一般说来,当总体结构发生什么样的变动时,结构影响指数就会大于1。
统计学第八章课后题及答案解析

第八章一、单项选择题1.时间数列的构成要素是()A.变量和次数 B.时间和指标数值C.时间和次数 D.主词和时间2.编制时间数列的基本原则是保证数列中各个指标值具有()A.可加性 B.连续性C.一致性 D.可比性3.相邻两个累积增长量之差,等于相应时期的()A.累积增长量 B.平均增长量C.逐期增长量 D.年距增长量4.统计工作中,为了消除季节变动的影响可以计算()A.逐期增长量 B.累积增长量C.平均增长量 D.年距增长量5.基期均为前一期水平的发展速度是()A.定基发展速度 B.环比发展速度C.年距发展速度 D.平均发展速度6.某企业2003年产值比1996年增长了1倍,比2001年增长了50%,则2001年比1996年增长了()A.33% B.50%C.75% D.100%7.关于增长速度以下表述正确的有()A.增长速度是增长量与基期水平之比 B.增长速度是发展速度减1C.增长速度有环比和定基之分 D.增长速度只能取正值8.如果时间数列环比发展速度大体相同,可配合()A.直线趋势方程 B.抛物线趋势方程C.指数曲线方程 D.二次曲线方程二、多项选择题1.编制时间数列的原则有()A.时期长短应一致 B.总体范围应该统一C.计算方法应该统一 D.计算价格应该统一E.经济内容应该统一2.发展水平有()A.最初水平 B.最末水平C.中间水平 D.报告期水平E.基期水平3.时间数列水平分析指标有()A.发展速度 B.发展水平C.增长量 D.平均发展水平E.平均增长量4.测定长期趋势的方法有()A.时距扩大法 B.移动平均法C.序时平均法 D.分割平均法E.最小平方法三、填空题1.保证数列中各个指标值的_______是编制时间数列的最主要规则。
2.根据采用的基期不同,增长量可以分为逐期增长量和_______增长量两种。
3.累积增长量等于相应的_______之和。
两个相邻的_______之差,等于相应时期的逐期增长量。
统计学人教版第五版7,8,10,11,13,14章课后题答案

统计学复习笔记第七章 参数估计一、 思考题1. 解释估计量和估计值在参数估计中,用来估计总体参数的统计量称为估计量。
估计量也是随机变量。
如样本均值,样本比例、样本方差等。
根据一个具体的样本计算出来的估计量的数值称为估计值。
2. 简述评价估计量好坏的标准(1)无偏性:是指估计量抽样分布的期望值等于被估计的总体参数。
(2)有效性:是指估计量的方差尽可能小。
对同一总体参数的两个无偏估计量,有更小方差的估计量更有效。
(3)一致性:是指随着样本量的增大,点估计量的值越来越接近被估总体的参数。
3. 怎样理解置信区间在区间估计中,由样本统计量所构造的总体参数的估计区间称为置信区间。
置信区间的论述是由区间和置信度两部分组成。
有些新闻媒体报道一些调查结果只给出百分比和误差(即置信区间),并不说明置信度,也不给出被调查的人数,这是不负责的表现。
因为降低置信度可以使置信区间变窄(显得“精确”),有误导读者之嫌。
在公布调查结果时给出被调查人数是负责任的表现。
这样则可以由此推算出置信度(由后面给出的公式),反之亦然。
4. 解释95%的置信区间的含义是什么置信区间95%仅仅描述用来构造该区间上下界的统计量(是随机的)覆盖总体参数的概率。
也就是说,无穷次重复抽样所得到的所有区间中有95%(的区间)包含参数。
不要认为由某一样本数据得到总体参数的某一个95%置信区间,就以为该区间以0.95的概率覆盖总体参数。
5. 简述样本量与置信水平、总体方差、估计误差的关系。
1. 估计总体均值时样本量n 为2. 样本量n 与置信水平1-α、总体方差、估计误差E 之间的关系为 其中: 2222α2222)(E z n σα=n z E σα2=▪ 与置信水平成正比,在其他条件不变的情况下,置信水平越大,所需要的样本量越大;▪ 与总体方差成正比,总体的差异越大,所要求的样本量也越大;▪ 与与总体方差成正比,样本量与估计误差的平方成反比,即可以接受的估计误差的平方越大,所需的样本量越小。
统计学第五版课后习题答案(完整版)

统计学(第五版)课后习题答案(完整版)第一章思考题1.1什么是统计学统计学是关于数据的一门学科,它收集,处理,分析,解释来自各个领域的数据并从中得出结论。
1.2解释描述统计和推断统计描述统计;它研究的是数据收集,处理,汇总,图表描述,概括与分析等统计方法。
推断统计;它是研究如何利用样本数据来推断总体特征的统计方法。
1.3统计学的类型和不同类型的特点统计数据;按所采用的计量尺度不同分;(定性数据)分类数据:只能归于某一类别的非数字型数据,它是对事物进行分类的结果,数据表现为类别,用文字来表述;(定性数据)顺序数据:只能归于某一有序类别的非数字型数据。
它也是有类别的,但这些类别是有序的。
(定量数据)数值型数据:按数字尺度测量的观察值,其结果表现为具体的数值。
统计数据;按统计数据都收集方法分;观测数据:是通过调查或观测而收集到的数据,这类数据是在没有对事物人为控制的条件下得到的。
实验数据:在实验中控制实验对象而收集到的数据。
统计数据;按被描述的现象与实践的关系分;截面数据:在相同或相似的时间点收集到的数据,也叫静态数据。
时间序列数据:按时间顺序收集到的,用于描述现象随时间变化的情况,也叫动态数据。
1.4解释分类数据,顺序数据和数值型数据答案同1.31.5举例说明总体,样本,参数,统计量,变量这几个概念对一千灯泡进行寿命测试,那么这千个灯泡就是总体,从中抽取一百个进行检测,这一百个灯泡的集合就是样本,这一千个灯泡的寿命的平均值和标准差还有合格率等描述特征的数值就是参数,这一百个灯泡的寿命的平均值和标准差还有合格率等描述特征的数值就是统计量,变量就是说明现象某种特征的概念,比如说灯泡的寿命。
1.6变量的分类变量可以分为分类变量,顺序变量,数值型变量。
变量也可以分为随机变量和非随机变量。
经验变量和理论变量。
1.7举例说明离散型变量和连续性变量离散型变量,只能取有限个值,取值以整数位断开,比如“企业数”连续型变量,取之连续不断,不能一一列举,比如“温度”。
统计学第五版(贾俊平)课后思考题答案(完整版)

第8章思考题8.1假设检验和参数估计有什么相同点和不同点?答:参数估计和假设检验是统计推断的两个组成部分,它们都是利用样本对总体进行某种推断,然而推断的角度不同。
参数估计讨论的是用样本统计量估计总体参数的方法,总体参数μ在估计前是未知的。
而在参数假设检验中,则是先对μ的值提出一个假设,然后利用样本信息去检验这个假设是否成立。
8.2什么是假设检验中的显著性水平?统计显著是什么意思?答:显著性水平是一个统计专有名词,在假设检验中,它的含义是当原假设正确时却被拒绝的概率和风险。
统计显著等价拒绝H0,指求出的值落在小概率的区间上,一般是落在0.05或比0.05更小的显著水平上。
8.3什么是假设检验中的两类错误?答:假设检验的结果可能是错误的,所犯的错误有两种类型,一类错误是原假设H0为真却被我们拒绝了,犯这种错误的概率用α表示,所以也称α错误或弃真错误;另一类错误是原假设为伪我们却没有拒绝,犯这种错误的概论用β表示,所以也称β错误或取伪错误。
8.4两类错误之间存在什么样的数量关系?答:在假设检验中,α与β是此消彼长的关系。
如果减小α错误,就会增大犯β错误的机会,若减小β错误,也会增大犯α错误的机会。
8.5解释假设检验中的P值答:P值就是当原假设为真时所得到的样本观察结果或更极端结果出现的概率。
(它的大小取决于三个因素,一个是样本数据与原假设之间的差异,一个是样本量,再一个是被假设参数的总体分布。
)8.6显著性水平与P值有何区别答:显著性水平是原假设为真时,拒绝原假设的概率,是一个概率值,被称为抽样分布的拒绝域,大小由研究者事先确定,一般为0.05。
而P只是原假设为真时所得到的样本观察结果或更极端结果出现的概率,被称为观察到的(或实测的)显著性水平8.7假设检验依据的基本原理是什么?答:假设检验依据的基本原理是“小概率原理”,即发生概率很小的随机事件在一次试验中是几乎不可能发生的。
根据这一原理,可以作出是否拒绝原假设的决定。
大学统计学第八章课后题答案
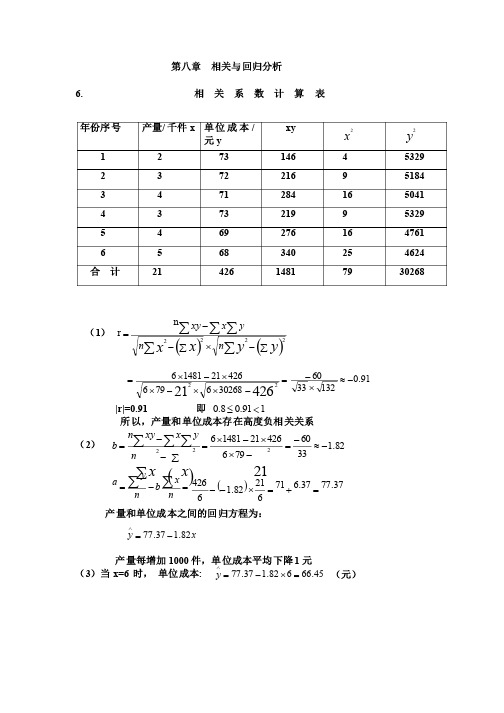
第八章 相关与回归分析 6. 相 关 系 数 计 算 表 (1) ()()åååååå-´å--=y yx x n n yx xy 2222nr 91.0132336030268679642621148164262122-»´-=-´´-´´-´= |r|=0.91 即 191.08.0<£ 所以,产量和单位成本存在高度负相关关系(2) ()82.133********211481621222-»-=-´´-´=å--=ååååx x n y x xy n b =-=åånx b ny a ()37.7737.67162182.16426=+=´-- 产量和单位成本之间的回归方程为: x y 82.137.77-=Ù 产量每增加1000件,单位成本平均下降1元 (3)当x=6 时, 单位成本: 45.66682.137.77=´-=Ùy (元) 年份序号 产量/千件x 单位成本/元y xy x 2 y 2 1 2 73 146 4 5329 2 3 72 216 9 5184 3 4 71 284 16 5041 4 3 73 219 9 5329 5 4 69 276 16 4761 6 5 68 340 25 4624 合 计 21 426 1481 79 30268 7. 相 关 系 数 计 算 表 序号 汽车使用年限/年x 年维修费用/元y xy x 2 y 2 1 2 400 800 4 160000 2 2 540 1080 4 291600 3 3 520 1560 9 270400 4 4 640 2560 16 409600 5 4 740 2960 16 547600 65 600 3000 25 360000 7 5 800 4000 25 640000 86 700 4200 36 490000 9 6 760 4560 36 577600 10 6 900 5400 36 810000 11 8 840 6720 64 705600 12 9 1080 9720 81 1166400 合 计 608520465603526428800()()åååååå-´å--=y yx x n n yx xy 2222n r=89.045552006244752064288001235212852060465601285206022»´=-´´-´´-´|r|=0.89 即 189.08.0<£所以,汽车使用年限与其维修费用间存在高度正相关关系(2) ()15.766244752035212852060465601260222==-´´-´=å--=ååååxx n y x xy n b =-=åån x b n y a 25.32975.380710126015.76128520=-=´- 汽车使用年限与其维修费用的回归方程为: x y 15.7625.329+=Ù(3) 当x=15时, 维修费用为: 5.14711515.7625.329=´+=Ùy8. (1) 相 关 系 数 计 算 表 序号 母亲身高/厘米x 女儿身高/厘米y xy x 2y 21 158 159 25122 24964 25281 2 159 160 25440 25281 256003 160 160 25600 25600 256004 161 163 26243 25921 265695 161 159 25599 25921 252816 155 154 23870 24025 237167 162 159 25758 26244 25281 8 157 158 24806 24649 24964 9 162 160 25920 26244 25600 10 150 157 23550 22500 24649 合计1585 1589251908251349252541()()åååååå-´å--=yy x x n n y x xy 2222nr=158915852225254110251349101589158525190810-´´-´´-´655.0»|r|=0.655 所以,母亲与女儿之间的关系为显著正相关(2) ()41.012655152513491015891585251908101585222»=-´´-´=å--=ååååxx n y x xy n b =-=åånx b n y a 915.93985.649.15810158541.0101589=-=´- 母亲与女儿之间的回归方程为: x y 41.0915.93+=Ù(3) 当x=170时, 女儿的身高为: 615.16317041.0915.93=´+=Ùy 9.(1) 由题知 n=9 å=546x å=260y å=16918xy 343622=åx()92.01114210302343629260546169189546222»=-´´-´=å--=ååååx x n yx xy n b =-=åånx b ny a 92.26954692.09260-=´-银行存款余额的直线回归方程: x y 92.092.26+-=Ù(2) 当x=400时,银行存款余额08.34140092.092.26=´+-=Ùy。
统计分析与SPSS的应用(第五版)课后练习答案(第8章)

《统计分析与SPSS的应用(第五版)》(薛薇)课后练习答案第8章SPSS的相关分析1、对15家商业企业进行客户满意度调查,同时聘请相关专家对这15家企业的综合竞争力进行评分,结果如下表。
编号客户满意度得分综合竞争力得分编号客户满意度得分综合竞争力得分1 90 70 9 10 602 100 80 10 20 303 150 150 11 80 1004 130 140 12 70 1105 120 90 13 30 106 110 120 14 50 407 40 20 15 60 508 140 130请问,这些数据能否说明企业的客户满意度与其综合竞争力存在较强的正相关,为什么?能。
步骤:(1)图形→旧对话框→散点/点状→简单分布→进行相应设置→确定;(2)再双击图形→元素→总计拟合线→拟合线→线性→确定(3)分析→相关→双变量→进行相关项设置→确定相关性客户满意度得分综合竞争力得分客户满意度得分Pearson 相关性 1 .864**显著性(双尾).000N 16 15 综合竞争力得分Pearson 相关性.864** 1显著性(双尾).000N 15 15 **. 在置信度(双测)为时,相关性是显著的。
两者的简单相关系数为,说明存在正的强相关性。
2、为研究香烟消耗量与肺癌死亡率的关系,收集下表数据。
(说明:1930年左右几乎极少国家1930年人均香烟消耗量1950年每百万男子中死于肺癌的人数澳大利亚480 180加拿大500 150丹麦380 170芬兰1100 350英国1100 460荷兰490 240冰岛230 60挪威250 90瑞典300 110瑞士510 250美国1300 200绘制上述数据的散点图,并计算相关系数,说明香烟消耗量与肺癌死亡率之间是否存在显著的相关关系。
香烟消耗量与肺癌死亡率的散点图(操作方法与第1题相同)相关性人均香烟消耗死于肺癌人数人均香烟消耗Pearson 相关性 1 .737**显著性(双尾).010N 11 11死于肺癌人数Pearson 相关性.737** 1显著性(双尾).010N 11 11**. 在置信度(双测)为时,相关性是显著的。
演示文稿统计学第五版第八章课后习题答案

8.6 某厂家在广告中声称,该厂生产的汽车轮胎在正常行驶条件下寿命 超过25000公里的目前平均水平。对一个由15个轮胎组成的随机样本做 了试验,得到样本均值和标准差分别为27000和5000公里。假定轮胎 寿命服从正态分布,问该厂的广告是否真实? (α=0.05)
解:N=15,x=27000,S=5000 小样本正态分布,σ未知,用t统计量计算。
x 解:已知 =241.5,S=98.726,N=16
小样本正态分布,σ未知,t统计量
右侧检验,α=0.05,自由度N-1=15,即 =1.75t3
HH
:μ≤225
0:μ>225
1
t x - 241.5 - 225 0.67
S/ n 98.726/ 16
结决论策::因有为证t据值落表入明接,受元域件,平所均以接寿受命与2,2拒5小绝 时H无0 。显著性H差1异,不能认为元件的
=n2134
p1=20.98%, p=2 9.7%
ZZ=11.218.6%4/50.028=4.03>1.645
决结论策::调在查α数=据0.能05支的持水“平吸上烟拒绝者容。易H 0患慢性气管炎”
这种观点。
第20页,共23页。
8.12 为了控制贷款规模,某商业银行有个内部要求,平均每项贷款数额不 能超过60万元。随着经济的发展,贷款规模有增大的趋势。银行经理想了 解在同样项目条件 下,贷款的平均规模是否明显地超过60万元,还是维持
,
2 A
632
。从B2 A厂5生7产2的材料中随机抽取81个样品,测
得 x A 1070kg/cm2 ;从B厂生产的材料中随机抽取64个样品,测
得 xB 1020kg/cm2 。根据以上调查结果,能否认为A、B两厂生产的材料平均
统计学第五版第八章课后习题答案

Z 1.645
8.12 为了控制贷款规模,某商业银行有个内部要求,平均每项贷款 数额不能超过60万元。随着经济的发展,贷款规模有增大的趋势。 银行经理想了解在同样项目条件 下,贷款的平均规模是否明显地超 过60万元,还是维持着原来的水平。 一个n=144的随机样本被抽出,测得 x=68.1万元,s=45。用 α=0.01的显著性水平,采用p值进行检验。 解: H 0 : μ≤60 H1 : μ>60 α= 0.01,n = 144, x =68.1,s=45 临界值(s):1%
2 2
0.5 1.96
nB
决策:在α= 0.05的水平上接受 H 0 。 结论:可以认为A、B两厂生产的材料平均抗压强度相同。
8.10 装配一个部件时可以采用不同的方法,所关心的问题是哪一个方 法的效率更高。劳动 效率可以用平均装配时间反映。现从不同的装配 方法中各抽取12件产品,记录下各自的装 配时间(分钟)如下:
决策: ∵Z值落入拒绝域, ∴在α=0.05的显著水平上拒绝 H 0,接受 H 1 。 结论: 有证据表明这批灯泡的使用寿命低于700小时,为不合格产品。
8.3 某地区小麦的一般生产水平为亩产250公斤,其标准差为30 公斤。现用一种化肥进行试验,从25个小区抽样,平均产量为 270公斤。这种化肥是否使小麦明显增产(α=0.05)?
H0 :
8.9 A、B两厂生产同样材料。已知其抗压强度服从正态分布, 2 2 2 2 且 A 63 , B 57 。从A厂生产的材料中随机抽取81个样品,测 2 得 x A 1070kg/cm ;从B厂生产的材料中随机抽取64个样品,测 得 x B 1020kg/cm 2 。根据以上调查结果,能否认为A、B两厂生产的材料平均 抗压强度相同(α=0.05)?
统计学第八章课后习题答案

8.1解:建立假设: H0:μ=4.55;H1:μ≠4.55这是双侧检验,并且方差已知,检验的统计量 Z 值为:=-1.833而=1.96>|-1.833|,因此不能拒绝原假设,即可认为现在生产的铁水平均含碳量为 4.558.2解:建立假设: H0:μ≥700;H1:μ<700这是左侧检验,并且方差已知,检验统计量 Z 为:Z==-2而-=-1.645>-2,因此拒绝原假设,即在显著性水平 0.05 下这批元件是不合格的。
8.3解:建立假设: H0:μ≤250;H1:μ>250这是右侧检验,并且方差已知,检验的统计量 Z 值为:Z==3.33 而=1.645<3.33,因此拒绝原假设,即这种化肥使小麦明显增产。
8.4解:建立假设: H0:μ=100;H1:μ≠1009/108.055.4484.4−=Z Z 025.036/60700680−Z 05.025/30250270−Z05.0由样本数据可得: ==99.978S===1.212这是双侧检验,并且方差未知,又是小样本,故采用 t 统计量,检验统计量的值为: t==-0.054而(8)=2.306>|-0.054|,因此不拒绝原假设,即该日打包机工作正常8.5、由题意先建立假设,显然不符合标准的比例越小越好,由于采用的是产品质量抽查,即使总体不合标准的比例没有超过5%,属于合格范围,采用右单侧检验。
P=6/50=12%属于单侧检验,当α=0.05时,有,因此拒绝原假设,即认为该批食品不能出厂n X ni ix∑==195.100....7.983.99+++1)(12−−∑=n x ni i x 8)978.995.100(...978.99-7.98978.99-3.99222−+++)()(9/2122.1100-978.99t025.0%5:%,5:1>≤ππH H o 27.250%)51(%5%5%12=−−−=Z 27.2645.105.0<=Z8.6、由题意建立假设:单侧检验,并且方差未知,n=15,属于小样本,故采用t 统计量,检验统计量的值为:α=0.05,,因此不能拒绝原假设,认为该厂家的广告不真实8.7、建立假设:,由样本数据可以得出,这是单侧检验,并且方差未知,是小样本,因此采用t 检验量,检验统计量的值为25000:,25000:10>≤μμH H 549.115/50002500027000/0=−=−=n s x t μ549.1761.1)14(05.0>=t 225,22510>≤H H 5.24116170485 (2121012801591)=++++++==∑=nxx ni i7.9815)5.241170(....)5.241280()5.241159(12221=−++−+−=−=∑=n xs ni in s x t /μ−=669.016/7.982255.241=−=通过查表可得出,,因此不能拒绝原假设,没有理由认为元件的平均寿命显著地大于225小时。
《统计学概论》第八章课后练习题答案

《统计学概论》第八章课后练习答案一、思考题1.什么是相关系数它与函数关系有什么不同P237- P2382.什么是正相关、负相关、无线性相关试举例说明。
P238- P2393.相关系数r的意义是什么如何根据相关系数来判定变量之间的相关系数P2454.简述等级相关系数的含义及其作用P2505.配合回归直线方程有什么要求回归方程中参数a、b的经济含义是什么P2566.回归系数b与相关系数r之间有何关系P2587.回归分析与相关分析有什么联系与区别P2548.什么是估计标准误差这个指标有什么作用P261【9.估计标准误差与相关系数的关系如何P258-P26410.解释判定系数的意义和作用。
P261二、单项选择题1.从变量之间相互关系的方向来看,相关关系可以分为()。
A.正相关和负相关B.直线关系与曲线关系C.单相关和复相关D.完全相关和不完全相关2.相关分析和回归分析相比较,对变量的要求是不同的。
回归分析中要求()。
A.因变量是随机的,自变量是给定的B.两个变量都是随机的C.两个变量都不是随机的D.以上三个答案都不对3.如果变量x与变量y之间的相关系数为-1,这说明两个变量之间是()。
'A.低度相关关系B.完全相关关系C.高度相关关系D.完全不相关4.初学打字时练习的次数越多,出现错误的量就越少,这里“练习次数”与“错误量”之间的相关关系为()。
A.正相关B.高相关C.负相关D.低相关5.假设两变量呈线性关系,且两变量均为顺序变量,那么表现两变量相关关系时应选用()。
A.简单相关系数r B.等级相关系数r sC.回归系数b D.估计标准误差S yx6.变量之间的相关程度越低,则相关系数的数值()。
A.越大B.越接近0…C.越接近-1 D.越接近17.下列各组中,两个变量之间的相关程度最高的是()。
A.商品销售额和商品销售量的相关系数是0.9B.商品销售额和商品利润率的相关系数是0.84C.产量与单位成本之间的相关系数为-0.94D.商品销售价格与销售量的相关系数为-0.918.相关系数r的取值范围是()。
统计学第五版第八章课后习题答案王永

n1 n2 11000
合并比例 x1 x 2 293 p 0.0133 n1 n2 22000
p1=0.95%, p2=1.72% 临界值(s):
Z =) ( 1 2 ) 1 1) P (1 P ) n n 2 1
解:已知μ =250,σ =30,N=25, x =270,α =0.05 右侧检验 ∵小样本,σ 已知 ∴采用Z统计量 Z ∵α =0.05,∴ =1.645 H 0 :μ ≤250 H1 :μ >250 计算统计量:
x / n
Z
=(270-250)/(30/5)=3.33
结论: Z统计量落入拒绝域,在α=0.05的显著性水平上,拒绝 H 0 ,接 受 H1 。
决策:有证据表明,这种化肥可以使小麦明显增产。
8.4 糖厂用自动打包机打包,每包标准重量是100千克。每天开工后需要检验 一次打包机工作是否正常。某日开工后测得9包重量(单位:千克)如下: 99.3,98.7,100.5,101.2,98.3,99.7,99.5,102.1,100.5 已知包重服从正态分布,试检验该日打包机工作是否正常 (α=0.05) 。
甲法: 31 34 29 32 35 38 34 30 29 32 31 26 乙法: 26 24 28 29 30 29 32 26 31 29 32 28 两总体为正态总体,且方差相同。问两种方法的装配时 间有无显著差别(α =0.05)? 解: 正态总体,小样本,σ²未知但相同,独立样本t检验 0 : 甲 - = 0 H 乙 甲 H1 : - 乙≠ 0
2 2
5 1.96
nB
决策:在α = 0.05的水平上拒绝 H 0 。 结论:可以认为A、B两厂生产的材料平均抗压强度不相同。
统计学(贾俊平)第五版课后习题答案(完整版)

统计学(第五版)贾俊平课后习题答案(完整版)第一章思考题1.1什么是统计学统计学是关于数据的一门学科,它收集,处理,分析,解释来自各个领域的数据并从中得出结论。
1.2解释描述统计和推断统计描述统计;它研究的是数据收集,处理,汇总,图表描述,概括与分析等统计方法。
推断统计;它是研究如何利用样本数据来推断总体特征的统计方法。
1.3统计学的类型和不同类型的特点统计数据;按所采用的计量尺度不同分;(定性数据)分类数据:只能归于某一类别的非数字型数据,它是对事物进行分类的结果,数据表现为类别,用文字来表述;(定性数据)顺序数据:只能归于某一有序类别的非数字型数据。
它也是有类别的,但这些类别是有序的。
(定量数据)数值型数据:按数字尺度测量的观察值,其结果表现为具体的数值。
统计数据;按统计数据都收集方法分;观测数据:是通过调查或观测而收集到的数据,这类数据是在没有对事物人为控制的条件下得到的。
实验数据:在实验中控制实验对象而收集到的数据。
统计数据;按被描述的现象与实践的关系分;截面数据:在相同或相似的时间点收集到的数据,也叫静态数据。
时间序列数据:按时间顺序收集到的,用于描述现象随时间变化的情况,也叫动态数据。
1.4解释分类数据,顺序数据和数值型数据答案同1.31.5举例说明总体,样本,参数,统计量,变量这几个概念对一千灯泡进行寿命测试,那么这千个灯泡就是总体,从中抽取一百个进行检测,这一百个灯泡的集合就是样本,这一千个灯泡的寿命的平均值和标准差还有合格率等描述特征的数值就是参数,这一百个灯泡的寿命的平均值和标准差还有合格率等描述特征的数值就是统计量,变量就是说明现象某种特征的概念,比如说灯泡的寿命。
1.6变量的分类变量可以分为分类变量,顺序变量,数值型变量。
变量也可以分为随机变量和非随机变量。
经验变量和理论变量。
1.7举例说明离散型变量和连续性变量离散型变量,只能取有限个值,取值以整数位断开,比如“企业数”连续型变量,取之连续不断,不能一一列举,比如“温度”。
统计学人教版第五版7,8,10,11,13,14章课后题答案

统计学人教版第五版7,8,10,11,13,14章课后题答案第七章 参数估计7.1 (1)79.0405===nx σσ (2)由于1-α=95% α=5% 96.12=αZ所以 估计误差55.140596.12≈⨯=nZ σα7.2 (1)14.24915===nx σσ (2)因为96.12=αZ 所以20.4491596.12≈⨯=nZ σα(3)μ的置信区间为20.41202±=±nZ x σα7.3 由于96.12=αZ 104560=x 85414=σ n=100所以μ的95%置信区间为14.167411045601008541496.11045602±=⨯±=±nZ x σα7.4(1)μ的90%置信区间为97.18110012645.1812±=⨯±=±n s Z x α(2)μ的95%置信区间为35.2811001296.1812±=⨯±=±n s Z x α(3)μ的99%置信区间为096.3811001258.2812±=⨯±=±n s Z x α7.5 (1)89.025605.396.1252±=⨯±=±nZ x σα(2)416.66.1197589.23326.26.1192±=⨯±=±n s Z x α(3)283.0419.332974.0645.1419.32±=⨯±=±n s Z x α7.6 (1)035.25389001550096.189002±=⨯±=±nZ x σα(2)650.16589003550096.189002±=⨯±=±nZ x σα(3)028.139890035500645.189002±=⨯±=±n s Z x α(4)583.196890035500326.289002±=⨯±=±n s Z x α7.7 317.31==∑i x nx ()609.1113612=--=∑=i ix x n s 90%置信区间为441.0317.336609.1645.1317.32±=⨯±=±n s Z x α95%置信区间为526.0317.336609.196.1317.32±=⨯±=±n s Z x α99%置信区间为6908.0317.336609.1576.2317.32±=⨯±=±n s Z x α7.8 101==∑i x nx ()464.311812=--=∑=i ix x n s 所以95%置信区间为()896.2108464.33646.21012±=⨯±=±-n s t x n α7.9 375.91==∑i x n x 由于()131.2)15(025.012==-t t n α ()113.4112=--=∑x x n s i 所以95%置信区间为()191.2375.916113.4131.2375.912±=⨯±=±-n s t x n α7.10 (1)63.05.1493693.196.15.1492±=⨯±=±n s Z x α(2)中心极限定理 7.11 (1)132.10150665011=⨯==∑i x nx ()641.188.131491112=⨯=--=∑x x n s i 455.032.10150641.196.132.1012±=⨯±=±n s Z x α(2)由于9.05045==p 所以 合格率的95%置信区间为()083.09.0501.09.096.19.012±=⨯⨯±=-±n p p Z p α7.12 由于128.161==∑i x n x ()745.3)24(005.012==-t t n α ()8706.0112=--=∑x x n s i所以99%置信区间为653.028.161258706.0745.328.161)1(2±=⨯±=-±n s n t x α 7.13 7396.1)17()1(05.02==-t n t α 556.131==∑i x nx ()800.7112=--=∑x x n s i所以90%置信区间为198.3556.13188.77396.1556.13)1(2±=⨯±=-±n s n t x α 7.14(1)()194.051.04449.051.0576.251.012±=⨯⨯±=-±n p p Z p α(2)()0435.082.030018.082.096.182.012±=⨯⨯±=-±n p p Z p α(3)()024.048.0115052.048.0645.148.012±=⨯⨯±=-±n p p Z p α7.15(1)90%置信区间为()049.023.020077.023.0645.123.012±=⨯⨯±=-±n p p Z p α(2)95%置信区间为()058.023.020077.023.096.123.012±=⨯⨯±=-±n p p Z p α7.16 89.1652001000576.222222222=⨯=⎪⎪⎭⎫ ⎝⎛=⇒=E Z n nZ E σδαα所以n 为166 7.17(1)()13.25302.06.04.0054.2122222=⨯⨯=-⎪⎪⎭⎫⎝⎛=E Z n ππα 所以n 为254 (2)()0625.15004.05.05.096.1122222=⨯⨯=-⎪⎪⎭⎫⎝⎛=E Z n ππα 所以n 为151(3)()89.26705.045.055.0645.1122222=⨯⨯=-⎪⎪⎭⎫⎝⎛=E Z n ππα 所以n 为268 7.18(1)64.05032==p (2)()46.611.02.08.096.1122222=⨯⨯=-⎪⎪⎭⎫⎝⎛=E Z n ππα 所以n 为62 7.19(1)()()339.661501205.022=-=-χχαn()()930.331501295.0221=-=--χχαn ()()2212222211ααχσχ--≤≤-s n s n所以()()40.272.1293.33492339.66491122122≤≤⇒⨯≤≤⨯⇒-≤≤--σσχσχααs n s n(2)()()6848.231151205.022=-=-χχαn()()5706.61151295.0221=-=--χχαn()()043.0015.002.05.61470602.06848.23141122122≤≤⇒⨯≤≤⨯⇒-≤≤--σσχσχααs n s n (3)()()6706.321221205.022=-=-χχαn()()5913.111221295.0221=-=--χχαn ()()725.4185.24315913.112131706.36211122122≤≤⇒⨯≤≤⨯⇒-≤≤--σσχσχααs n s n 7.20(1)15.71==∑i x n x ()4767.0112=--=∑x x n s i ()()0228.1911012025.022=-=-χχαn ()()7004.211012975.0221=-=--χχαn ()()87.0328.04767.07004.294767.00228.1991122122≤≤⇒⨯≤≤⨯⇒-≤≤--σσχσχααs n s n(2)()()326.3253.1822.17004.29822.10228.1991122122≤≤⇒⨯≤≤⨯⇒-≤≤--σσχσχααs n s n7.21 2)1()1(212222112-+-+-=n n s n s n s p=442.981910268.9613≈⨯+⨯ (1)21μμ-的90%置信区间为: 212122111)2()(n n s n n t x x p+-+±-α=⨯⨯±442.98729.18.971141+ =9411.78.9± (2)21μμ-的95%置信区间为: 212122111)2()(n n s n n t x x p+-+±-α=⨯⨯±442.9893.028.971141+ =13.698.9± (3)21μμ-的99%置信区间为: ⨯⨯±442.98609.828.971141+=40.1138.9± 7.22(1)2122121221)(n s n s z x x +±-α=36.096.12⨯±=176.12±(2)2)1()1(212222112-+-+-=n n s n s n s p=18209169⨯+⨯=18212122111)2()(n n s n n t x x p+-+±-α=5118.122⨯⨯±=8.932± (3)1)(1)()(222221212122122121-+-+=n n s n n s n s n s ν=17.78 2122121221)(t )(n s n s x x +±-να=6.31.22⨯±=98.32±(4)048.2)28(t 025.0=2)1()1(212222112-+-+-=n n s n s n s p=18.714 212122111)2()(n n s n n t x x p+-+±-α=20110114.71848.022+⨯⨯± =3.432±(5)1)(1)()(222221212122122121-+-+=n n s n n s n s n s ν1919.61)20201016(222++==20.05 086.2)(t =να2122121221)(t )(n s n s x x +±-να=1.61086.22+⨯±=64.332± 7.23(1)47d = 1)(2--=∑n d ds id =48332=917.6(2)n s n t d )1(d -±α=185.447± 7.24 6216.2)1(2=-n t α 11=d ,53197.6=d s d μ的置信区间为:ns n t d )1(d 2-±α=1053197.66216.211⨯±=4152.511±7.25(1)222111221)1()1()(p n p p n p p z p -+-±-α=25076.03.02506.04.0645.11.0⨯+⨯⨯±=0698.01.0± (2)222111221)1()1()(p n p p n p p z p -+-±-α=25076.03.02506.04.096.11.0⨯+⨯⨯±=0831.01.0± 7.26 241609.01=s 076457.02=s)1,1(21--n n F α=)20,20(025.0F =2.464 )20,20(975.0F =0.40576212221222122221αασσ-≤≤F s s F s s 40576.0986.9446.2986.92221≤≤σσ 611.240528.42221≤≤σσ7.27 222)1()(Ez n ππα-==2204.098.002.096.1⨯⨯=47.06 所以 n =487.282222)(E z n σα==2222012096.1⨯=138.30所以 n =139第8章 假设检验二、练习题(说明:为了便于查找书后正态分布表,本答案中,正态分布的分位点均采用了下侧分位点。
统计学(贾俊平)第五版课后习题答案(完整版)
统计学(第五版)贾俊平课后习题答案(完整版)第一章思考题1.1什么是统计学统计学是关于数据的一门学科,它收集,处理,分析,解释来自各个领域的数据并从中得出结论。
1.2解释描述统计和推断统计描述统计;它研究的是数据收集,处理,汇总,图表描述,概括与分析等统计方法。
推断统计;它是研究如何利用样本数据来推断总体特征的统计方法。
1.3统计学的类型和不同类型的特点统计数据;按所采用的计量尺度不同分;(定性数据)分类数据:只能归于某一类别的非数字型数据,它是对事物进行分类的结果,数据表现为类别,用文字来表述;(定性数据)顺序数据:只能归于某一有序类别的非数字型数据。
它也是有类别的,但这些类别是有序的。
(定量数据)数值型数据:按数字尺度测量的观察值,其结果表现为具体的数值。
统计数据;按统计数据都收集方法分;观测数据:是通过调查或观测而收集到的数据,这类数据是在没有对事物人为控制的条件下得到的。
实验数据:在实验中控制实验对象而收集到的数据。
统计数据;按被描述的现象与实践的关系分;截面数据:在相同或相似的时间点收集到的数据,也叫静态数据。
时间序列数据:按时间顺序收集到的,用于描述现象随时间变化的情况,也叫动态数据。
1.4解释分类数据,顺序数据和数值型数据答案同1.31.5举例说明总体,样本,参数,统计量,变量这几个概念对一千灯泡进行寿命测试,那么这千个灯泡就是总体,从中抽取一百个进行检测,这一百个灯泡的集合就是样本,这一千个灯泡的寿命的平均值和标准差还有合格率等描述特征的数值就是参数,这一百个灯泡的寿命的平均值和标准差还有合格率等描述特征的数值就是统计量,变量就是说明现象某种特征的概念,比如说灯泡的寿命。
1.6变量的分类变量可以分为分类变量,顺序变量,数值型变量。
变量也可以分为随机变量和非随机变量。
经验变量和理论变量。
1.7举例说明离散型变量和连续性变量离散型变量,只能取有限个值,取值以整数位断开,比如“企业数”连续型变量,取之连续不断,不能一一列举,比如“温度”。
统计学第五版(贾俊平)第八章课后习题答案

统计学第五版(贾俊平)第⼋章课后习题答案《统计学》第⼋章课后练习题8.4解:由题意知,µ=100,α=0.05,n=9<30,故选⽤t统计量。
经计算得:x =99.9778,s=1.2122,进⾏检验的过程为:H0:µ=100H1:µ≠100t=s n =1.21229=?0.0549当α= 0.05,⾃由度n-1= 8,查表得tα2(8)=2.3060,因为t< tα2,样本统计量落在接收域,所以接受原假设H0,即打包机正常⼯作。
⽤P值检测,这是双侧检验,故:P=2×1?0.5215=0.957,P值远远⼤于α,所以不能原假设H0。
8.7解:由题意知,µ=225,α=0.05,n=16<30,故选⽤t统计量。
经计算得:x =241.5,s=98.7259,进⾏检验的过程为:H0:µ≤225H1:µ>225t=s n =98.725916=0.6685当α= 0.05,⾃由度n-1= 15,查表得tα(15)=2.1314,这是⼀个右单侧检验,因为t即元件平均寿命没有显著⼤于225⼩时。
⽤P值检测,这是右单侧检验,故:P=1?0.743=0.257,P值远远⼤于α,所以不能拒绝原假设H0。
8.9,解:由题意得σA2=632,σB2=572,x A=1070,x B=1020,n A=81,n B=64,故选⽤z统计量。
进⾏检验的过程为:H0:µA?µB=0H1: µA?µB≠0Z=A B A BσA A +σBB=632+572=5当α=0.05时,zα2=1.96,因为Z>zα2,所以拒绝原假设H0,,即A、B两⼚⽣产的材料平均抗压强度不相同。
⽤P值检测,这是双侧检验,故:P=2×1?0.9999997=0.0000006,P值远远⼩于α,所以拒绝原假设H0,8.13解:建⽴假设为:H0: π1=π2H1: π1≠π2由题意得:p 1=10411000=0.00945,n 1=11000,p 2=18911000=0.01718,n 2=11000 p =p 1n 1+p 2n 2n 1+n 2=0.00945×11000+0.01718×1100011000+11000=0.01332 z =p ?p p (1?p )(n 1+n2) =0.00945?0.017180.01332×(1?0.01332)×(11000+11000)=?5 当α=0.05,z α/2=1.96,这是⼀个左单侧检验,因为 z > z α/2 ,样本统计量落⼊拒绝域,所以拒绝原假设H 0,接受备择假设H 1,即服⽤阿司匹林可以降低⼼脏病发⽣率。
《统计分析与SPSS的应用(第五版)》课后练习答案(第8章)

《统计分析与SPSS的应用〔第五版〕》〔薛薇〕课后练习答案第8章SPSS的相关分析1、对15家商业企业进行客户满意度调查,同时聘请相关专家对这15家企业的综合竞争力进行评分,结果如下表。
编号客户满意度得分综合竞争力得分编号客户满意度得分综合竞争力得分1 90 70 9 10 602 100 80 10 20 303 150 150 11 80 1004 130 140 12 70 1105 120 90 13 30 106 110 120 14 50 407 40 20 15 60 508 140 130请问,这些数据能否说明企业的客户满意度与其综合竞争力存在较强的正相关,为什么?能。
步骤:〔1〕图形→旧对话框→散点/点状→简单分布→进行相应设置→确定;〔2〕再双击图形→元素→总计拟合线→拟合线→线性→确定〔3〕分析→相关→双变量→进行相关项设置→确定相关性客户满意度得分综合竞争力得分客户满意度得分Pearson 相关性 1 .864**显著性〔双尾〕.000N 16 15 综合竞争力得分Pearson 相关性.864** 1显著性〔双尾〕.000N 15 15 **. 在置信度〔双测〕为 0.01 时,相关性是显著的。
两者的简单相关系数为0.864,说明存在正的强相关性。
2、为研究香烟消耗量与肺癌死亡率的关系,收集下表数据。
〔说明:1930年左右几乎极少的妇女吸烟;采用1950年的肺癌死亡率是考虑到吸烟的效果需要一段时间才可显现〕。
国家1930年人均香烟消耗量1950年每百万男子中死于肺癌的人数澳大利亚480 180加拿大500 150丹麦380 170芬兰1100 350英国1100 460荷兰490 240冰岛230 60挪威250 90瑞典300 110瑞士510 250美国1300 200绘制上述数据的散点图,并计算相关系数,说明香烟消耗量与肺癌死亡率之间是否存在显著的相关关系。
香烟消耗量与肺癌死亡率的散点图(操作方法与第1题相同)相关性人均香烟消耗死于肺癌人数人均香烟消耗Pearson 相关性 1 .737**显著性〔双尾〕.010N 11 11死于肺癌人数Pearson 相关性.737** 1显著性〔双尾〕.010N 11 11**. 在置信度〔双测〕为 0.01 时,相关性是显著的。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
8.6 某厂家在广告中声称,该厂生产的汽车轮胎在正常行驶条件下寿命 超过25000公里的目前平均水平。对一个由15个轮胎组成的随机样本做 了试验,得到样本均值和标准差分别为27000和5000公里。假定轮胎 寿命服从正态分布,问该厂的广告是否真实? (α =0.05)
解:N=15,
=27000,S=5000 x
∵Z值落入拒绝域,
∴在α=0.05的显著水平上拒绝 H 0 ,接受 H 1 。 结论:
有证据表明这批灯泡的使用寿命低于700小时,为不合格产品。
8.3 某地区小麦的一般生产水平为亩产250公斤,其标准差为30 公斤。现用一种化肥进行试验,从25个小区抽样,平均产量为 270公斤。这种化肥是否使小麦明显增产(α=0.05)?
结论: Z统计量落入拒绝域,在α=0.05的显著性水平上,拒绝 H 0 ,接 受 H 1。
决策:有证据表明,这种化肥可以使小麦明显增产。
8.4 糖厂用自动打包机打包,每包标准重量是100千克。每天开 工后需要检验一次打包机工作是否正常。某日开工后测得 9包重 量(单位:千克)如下: 99.3,98.7,100.5,101.2,98.3,99.7,99.5,102.1,100.5 已知包重服从正态分布,试检验该日打包机工作是否正常 (α=0.05) 。 解:
解:已知N=50,P=6/50=0.12, 大样本,右侧检验,采用Z统计量。α =0.05,Z =1.645
Байду номын сангаасH0
: P ≤5%
0
H1
: P >5%
0
Z
( p - p0 ) p0 (1- p0 ) n
=
0.12 - 0.05 =2.26 0.05* ( 1 - 0.05) 50
结论:因为Z值落入拒绝域,所以在α =0.05的显著水平上,拒绝 H 0 ,接 受 H 1。 决策:有证据表明该批食品合格率不符合标准,不能出厂。
如图所示: 本题采用单样本t检验。
H0 H1
:μ =100 :μ ≠100
基本统计量:
α =0.05,N=9, =99.978, Sx S=1.2122, =0.4041 检验结果: t=-0.005,自由度f=8, 双侧检验P=0.996,单侧检验P=0.498
解:已知N=36,σ =60, x =680,μ =700 左侧检验
∵是大样本,σ 已知
∴采用Z统计量计算
H0
H1
:μ ≥700 :μ <700
- Z 0.05
∵α =0.05∴
=-1.645
计算检验统计量:
Z x / n
=(680-700)/(60/6)=-2
决策:
统计学第八章假设检验 练习题作业
吕芽芽
8.1 已知某炼铁厂的含碳量服从正态分布N(4.55,0.108² ),现在测 定了9炉铁水,其平均含碳量为4.484。如果估计方差没有变化,可否 认为现在生产的铁水平均含碳量为4.55(α=0.05)?
x 解 : 已 知 : μ =4.55 , ,σ ²=0.108² , N=9 , =4.484
小样本正态分布,σ未知,用t统计量计算。
右侧检验,自由度N-1=14,
α=0.05,即 t :μ≤25000
0
=1.77
H
x 27000 25000 t 1 . 55 S / n 5000 / 15
H1
:μ>25000
结论: 因为t值落入接受域,所以接受 H 0,拒绝 H 1 。
解:已知μ =250,σ =30,N=25, x 右侧检验 ∵小样本,σ 已知 ∴采用Z统计量 ∵α =0.05,∴
H
0
=270,α =0.05
Z
=1.645
H1
:μ ≤250
:μ >250
计算统计量: x Z / n =(270-250)/(30/5)=3.33
双侧检验 H0 小样本, σ 已知,∴用Z统计量
H 1 :μ =4.55
:μ ≠4.55
Z 0.025
α =0.05 ,α /2=0.025,查表得: =1.96 (x ) Z 计算检验统计量: / n =(4.484-4.55)/(0.108/3)=-1.833
决策: ∵Z值落入接受域, ∴在α=0.05的显著水平上接受 H 0 。
结论:有证据表明现在生产的铁水平均含碳量与以前没有显著差 异,可以认为现在生产的铁水平均含碳量为4.55。
8.2 一种元件,要求其使用寿命不得低于700小时。现从一批这种 元件中随机抽取36件,测得其平均寿命为680小时。已知该元件寿 命服从正态分布,σ=60小时,试在显著性水平0.05下确定这批元 件是否合格。
小样本正态分布,σ未知,t统计量 右侧检验,α =0.05,自由度N-1=15,即 =1.753
x :μ ≤225
:μ >225
t
。
H0
t 0 . 67 S / n 98 . 726 / 16 决策:有证据表明,元件平均寿命与225小时无显著性差异,不能认为元
结论:因为 t值落入接受域,所以接受 ,拒绝 x 241 . 5 225 件的平均寿命显著地大于225小时。
决策:有证据证明,该厂家生产的轮胎在正常行驶 条件下使用寿命与目前平均水平25000公里无显著 性差异,该厂家广告不真实。
8.7 某种电子元件的寿命x(单位:小时)服从正态分布,现测得16只元 件的寿命如下: 问是否有理由认为这些元件的平均寿命大于225小时(α =0.05)? 159 280 101 212 224 379 179 264 222 解:已知 S=98.726 N=16485 170 362 =241.5 168 , 250 149 , 260
H0 结 论 : t 统 计 量 落 入 接 受 域 , 在 α =0.05 的 显 著 性 水 平 上 接 受 。
x
决策:有证据表明这天的打包机工作正常。
8.5 某种大量生产的袋装食品,按规定每袋不得少于250克。今 从一批该食品中任意抽取50袋,发现有6袋低于250克。若规定不 符合标准的比例超过5%就不得出厂,问该批食品能否出厂 (α=0.05)?