oracle执行计划和日常注意事项36页PPT
oracle执行计划解释

oracle执行计划解释一.相关概念1·rowid,伪列:就是系统自己给加上的,每个表都有一个伪列,并不是物理存在。
它不能被修改,删除,和添加,rowid在该行的生命周期是唯一的,如果向数据库插入一列,只会引起行的变化,但是rowid并不会变。
2·recursive sql概念:当用户执行一些SQL语句时,会自动执行一些额外的语句,我们把这些额外的SQL语句称为“recursive calls” 或者是“recursive sql statement”,当在执行一个DDL语句时,Oracle总会隐含的发出一些Recursiv sql语句,用于修改数据字典,如果数据字典没有在共享内存中,则就执行“resursive calls”,它会把数据字典从物理读取到共享内存。
当然DML和select语句都可能引起recursive SQL。
3·row source 行源:在查询中,由上一操作返回的符合条件的数据集,它可能是整个表,也可能是部分,当然也可以对2个表进行连接操作(join)最后得到的数据集4·predicate:一个查询中的where限制条件5·driving table 驱动表:该表又成为外层表,这个感念用于内嵌和HASH连接中,如果返回数据较大,会有负面影响,返回行数据较小的适合做驱动表6·probed table 被探查表:该表又称为内层表,我们在外层表中取得一条数据,在该表中寻找符合连接的条件的行。
7·组合索引(concatenated index)由多个列组成的索引,在组合索引中有一个重要的概念,就是引导索引,create index idx_tab on tab(col1,col2,col3),indx_tab则称为组合索引,col1则称为引导列在查询条件where后,必须使用引导索引,才会使用该组合索引8.可选择性(selectivity)比较一下列中唯一键的数量和表中的行数,就可以判断该列的可选择性。
Oracle培训ppt课件

游标、异常处理及事务控制
2024/1/24
游标
01
游标是用于处理查询结果的一种数据结构,可以逐行访问查询
结果集中的数据。
异常处理
02
PL/SQL提供了异常处理机制,可以捕获和处理程序运行过程中
的错误或异常情况。
事务控制
03
PL/SQL支持事务控制语句,如COMMIT、ROLLBACK和
SAVEPOINT,用于管理数据库事务的提交和回滚。
22
Oracle SQL增强功能介绍
Oracle SQL扩展
Oracle数据库为SQL语言提供了许多扩展功能, 如PL/SQL编程、分区表、物化视图等。这些功能 可以提高数据库的性能、可维护性和灵活性。
数据完整性保障
Oracle数据库提供了ACID事务特性、约束( constraint)和触发器(trigger)等机制,确保 数据的完整性和一致性。这些功能可以防止脏读 、不可重复读和幻读等问题。
2024/1/24
9
物理存储结构
数据文件
存储数据的物理文件, 如表数据和索引数据。
2024/1/24
控制文件
记录数据库的物理结构 的文件,包括数据文件 和日志文件的位置和状
态信息。
重做日志文件
归档日志文件
记录数据库所有更改的 文件,用于在故障时恢
复数据。
10
当重做日志文件满时, 可将其转移到归档日志 文件中,以释放空间。
运行测试查询
执行一些简单的SQL查询,验证数据库是否正常工作。
检查日志文件
查看Oracle数据库的日志文件,确保没有错误或警告信 息。
2024/1/24
监控数据库性能
使用Oracle Enterprise Manager (OEM) 或其他性能监 控工具监控数据库的性能指标,如CPU利用率、内存使用 情况等。
oracle基础知识(十三)----执行计划
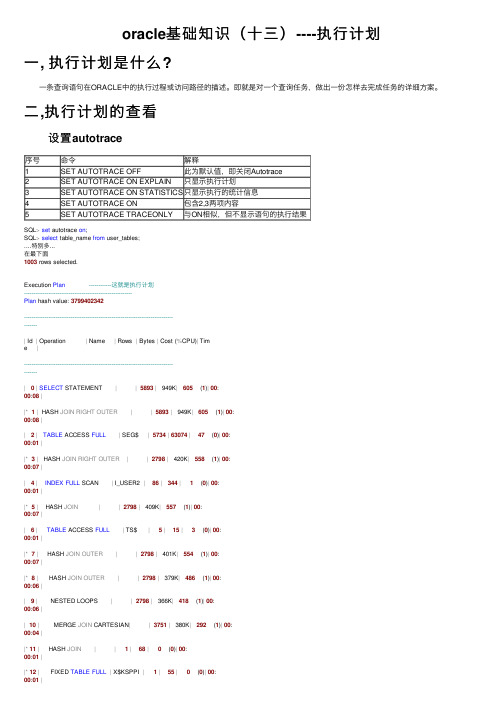
oracle基础知识(⼗三)----执⾏计划⼀, 执⾏计划是什么? ⼀条查询语句在ORACLE中的执⾏过程或访问路径的描述。
即就是对⼀个查询任务,做出⼀份怎样去完成任务的详细⽅案。
⼆,执⾏计划的查看 设置autotrace序号命令解释1SET AUTOTRACE OFF此为默认值,即关闭Autotrace2SET AUTOTRACE ON EXPLAIN只显⽰执⾏计划3SET AUTOTRACE ON STATISTICS只显⽰执⾏的统计信息4SET AUTOTRACE ON包含2,3两项内容5SET AUTOTRACE TRACEONLY与ON相似,但不显⽰语句的执⾏结果SQL>set autotrace on;SQL>select table_name from user_tables;....特别多...在最下⾯1003 rows selected.Execution Plan------------这就是执⾏计划----------------------------------------------------------Plan hash value: 3799402342---------------------------------------------------------------------------------------| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |---------------------------------------------------------------------------------------|0|SELECT STATEMENT ||5893| 949K|605 (1)|00:00:08||*1| HASH JOIN RIGHT OUTER||5893| 949K|605 (1)|00:00:08||2|TABLE ACCESS FULL| SEG$ |5734|63074|47 (0)|00:00:01||*3| HASH JOIN RIGHT OUTER||2798| 420K|558 (1)|00:00:07||4|INDEX FULL SCAN | I_USER2 |86|344|1 (0)|00:00:01||*5| HASH JOIN||2798| 409K|557 (1)|00:00:07||6|TABLE ACCESS FULL| TS$ |5|15|3 (0)|00:00:01||*7| HASH JOIN OUTER||2798| 401K|554 (1)|00:00:07||*8| HASH JOIN OUTER||2798| 379K|486 (1)|00:00:06||9| NESTED LOOPS ||2798| 366K|418 (1)|00:00:06||10| MERGE JOIN CARTESIAN||3751| 380K|292 (1)|00:00:04||*11| HASH JOIN||1|68|0 (0)|00:00:01||*12| FIXED TABLE FULL| X$KSPPI |1|55|0 (0)|00:00:01||13| FIXED TABLE FULL| X$KSPPCV |100|1300|0 (0)|00:00:01||14| BUFFER SORT ||3751| 131K|292 (1)|00:00:04||*15|TABLE ACCESS FULL| OBJ$ |3751| 131K|292 (1)|00:00:04||*16|TABLE ACCESS CLUSTER| TAB$ |1|30|1 (0)|00:00:01||*17|INDEX UNIQUE SCAN | I_OBJ# |1||0 (0)|00:00:01||18|INDEX FAST FULL SCAN | I_OBJ1 |86281| 421K|68 (0)|00:00:01||19|INDEX FAST FULL SCAN | I_OBJ1 |86281| 674K|68 (0)|00:00:01|---------------------------------------------------------------------------------------Predicate Information (identified by operation id):---------------------------------------------------1- access("T"."FILE#"="S"."FILE#"(+) AND "T"."BLOCK#"="S"."BLOCK#"(+) AND"T"."TS#"="S"."TS#"(+))3- access("CX"."OWNER#"="CU"."USER#"(+))5- access("T"."TS#"="TS"."TS#")7- access("T"."DATAOBJ#"="CX"."OBJ#"(+))8- access("T"."BOBJ#"="CO"."OBJ#"(+))11- access("KSPPI"."INDX"="KSPPCV"."INDX")12- filter("KSPPI"."KSPPINM"='_dml_monitoring_enabled')15- filter("O"."OWNER#"=USERENV('SCHEMAID') AND BITAND("O"."FLAGS",128)=0) 16- filter(BITAND("T"."PROPERTY",1)=0)17- access("O"."OBJ#"="T"."OBJ#")Statistics-----这⾥是统计信息----------------------------------------------------------8 recursive calls0 db block gets8809 consistent gets0 physical reads0 redo size31347 bytes sent via SQL*Net to client1250 bytes received via SQL*Net from client68 SQL*Net roundtrips to/from client1 sorts (memory)0 sorts (disk)1003 rows processed 使⽤sql查看SQL>set autotrace off;SQL> explain plan for select*from WRI$_DBU_FEATURE_METADATA;Explained.SQL>SELECT plan_table_output FROM TABLE(DBMS_XPLAN.DISPLAY('PLAN_TABLE')); PLAN_TABLE_OUTPUT--------------------------------------------------------------------------------Plan hash value: 563503327-----------------------------------------------------------------------------------------------| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |-----------------------------------------------------------------------------------------------PLAN_TABLE_OUTPUT--------------------------------------------------------------------------------|0|SELECT STATEMENT ||176|91344|5(0)|00:00:01||1|TABLE ACCESS FULL| WRI$_DBU_FEATURE_METADATA |176|91344|5(0)|00:00:01|-----------------------------------------------------------------------------------------------8 rows selected.SQL>select*from table(dbms_xplan.display);PLAN_TABLE_OUTPUT--------------------------------------------------------------------------------Plan hash value: 563503327-----------------------------------------------------------------------------------------------| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |-----------------------------------------------------------------------------------------------PLAN_TABLE_OUTPUT--------------------------------------------------------------------------------|0|SELECT STATEMENT ||176|91344|5(0)|00:00:01||1|TABLE ACCESS FULL| WRI$_DBU_FEATURE_METADATA |176|91344|5(0)|00:00:01|-----------------------------------------------------------------------------------------------8 rows selected.SQL> 客户端的话界⾯有解释选项⾃⼰找找三,执⾏计划解释 01.执⾏顺序的原则 执⾏顺序的原则是:由上⾄下,从右向左 由上⾄下:在执⾏计划中⼀般含有多个节点,相同级别(或并列)的节点,靠上的优先执⾏,靠下的后执⾏ 从右向左:在某个节点下还存在多个⼦节点,先从最靠右的⼦节点开始执⾏。
2024版oracle系列培训ppt课件

Oracle PaaS服务为企业提供数据库、应用开发和集成、大数据分析等云平台,加速企业数字 化转型。
Oracle Cloud软件即服务(SaaS)
Oracle提供丰富的SaaS应用,如ERP、CRM、HCM等,满足企业不同业务需求,降低企业 运营成本。
Oracle在大数据处理中的应用实践
数据库安全管理
安全管理策略Leabharlann 阐述Oracle数据库的安全管理策略,包括用户权限管理、 角色管理、数据加密和安全审计等方面的内容。
数据加密与传输安全
讲解Oracle数据库的数据加密技术和传输安全机制,包括 透明数据加密(TDE)、SSL/TLS加密通信等,保障数据的 机密性和完整性。
用户与权限管理
详细介绍如何管理Oracle数据库的用户和权限,包括用户 的创建、授权和撤销等操作,确保只有授权用户才能访问数 据库资源。
TKPROF等,帮助管理员及时发 现和定位性能问题。
SQL优化
详细讲解SQL优化的方法和技巧, 包括SQL语句的编写规范、索引 设计原则、执行计划分析和优化 等,提高SQL语句的执行效率。
系统优化
提供系统层面的优化建议,包括 内存分配、磁盘I/O优化、网络 配置调整等,提升整个数据库系
统的性能表现。
的集合,是数据管理的高级阶段。
数据库的发展历程
02
从文件系统到层次、网状数据库,再到关系数据库和非关系数
据库。
Oracle数据库的特点与优势
03
高性能、高可用性、可扩展性、安全性等。
Oracle数据库体系结构
01
02
03
04
物理存储结构
数据文件、控制文件、重做日 志文件等。
Oracle定时执行计划任务

Oracle定时执行计划任务Oracle在10g版本以前,计划任务用的是DBMS_JOB包,10g版本引入DBMS_SCHEDULER 来替代先前的DBMS_JOB,在功能方面,它比DBMS_JOB提供了更强大的功能和更灵活的机制管理,但DBMS_JOB包的使用相对比较简单,也基本能够满足定时执行计划任务的需求,故接下来就先看看DBMS_JOB包的使用方法。
1.DBMS_JOB我们可以在命令窗口输入show parameter job_queue_processes查看数据库中定时任务的最多并发数,一般设置为10(设置方法:alter system set job_queue_processes=10),如果设为0,那么数据库定时作业是不会运行的。
oracle定时执行job queue 的后台进程是SNP,要启动snp,首先看系统模式是否支持sql> alter system enable restricted session;或sql> alter system disenable restricted session;利用上面的命令更改系统的会话方式为disenable restricted,为snp的启动创建条件.接下来我们尝试实现以下功能:每隔一分钟自动向job_test表中插入当前的系统时间。
1、创测试表create table job_test(updatetime date);2、创建JOBvariable v_job_no number;begindbms_job.submit(:v_job_no, 'insert into job_test values(sysdate);', sysdate, 'sysdate+1/1440');end;/其中最后一个参数'sysdate+1/1440'表示时间间隔为每分钟。
其它常用的时间间隔的设置如下:(1)如果想每天凌晨1点执行,则此参数可设置为'trunc(sysdate)+25/24';(2)如果想每周一凌晨1点执行,则此参数可设置为'trunc(next_day(sysdate,1))+25/24';(3)如果想每月1号凌晨1点执行,则此参数可设置为'trunc(last_day(sysdate))+25/24';(4)如果想每季度执行一次,则此参数可设置为'trunc(add_months(sysdate,3),'Q')+1/24';(5)如果想每半年执行一次,则此参数可设置为'add_months(trunc(sysdate,'yyyy'),6)+1/24';(6)如果想每年执行一次,则此参数可设置为'add_months(trunc(sysdate,'yyyy'),12)+1/24'。
Oracle课件 第1章

实例后台进程
实例的后台进程共同实现对Oracle数据库的管理功能,每 个后台进程只完成一项单一的任务,主要后台进程包括: 数据库写入进程(DBWR):负责将SGA数据库缓冲区 缓存中的脏数据块写入数据文件。DBWR在下面条件下执 行写入操作:服务器进程找不到足够数量的可用干净缓冲 区,或者数据库系统执行检查点时。一个实例可启动的 DBWR数量由初始化参数DB_WRITER_PROCESSES指 定; 日志写入进程(LGWR):负责把日志缓冲区内的重做 日志写入联机重做日志文件; 归档进程(ARCH):发生日志文件切换时,如果数据 库运行在归档模式下,归档进程将把填写过的联机重做日 志文件复制到指定位置进行归档 ;
Oracle数据库中的其它文件
除以上三种Oracle数据库文件之外,Oracle数据库管理系 统在管理数据库时还使用其它一些辅助文件,其中包括 : 参数文件:记录Oracle数据库的初始化参数设置,如实 例使用的内存量、控制文件的数量及其存储路径等。它相 当于实例的属性文件,实例启动时首先打开并读取它; 口令文件:用于存储被授予SYSDBA、SYSOPER和 SYSASM权限的数据库用户及口令,以便在数据库还未打 开时用于验证具有这些特殊权限的数据库管理员的身份 ; 警告日志文件:这是一个文本文件,其名称是 alertdb_name.log(db_name是数据库名),它相当于一 个数据库的“编年体”日志,按照时间的先后顺序完整记 录从数据库创建开始,直到删除之前发生的重大事项,如 可能出现的内部错误或警告,数据库的启动与关闭操作, 表空间的创建、联机和脱机操作等信息;
oracle执行计划怎么看

oracle执行计划怎么看Oracle执行计划怎么看。
Oracle数据库系统是当今世界上应用最广泛的关系型数据库管理系统之一,它的执行计划对于数据库性能的优化和调优起着至关重要的作用。
执行计划是Oracle数据库在执行SQL语句时生成的一种执行策略,它告诉我们数据库是如何执行SQL语句的,通过分析执行计划,我们可以了解SQL语句的执行效率,找到优化的空间,提高数据库的性能。
本文将介绍如何查看Oracle执行计划,以及如何解读执行计划,帮助大家更好地理解和优化SQL语句的执行效率。
一、查看执行计划的方法。
1. 使用EXPLAIN PLAN语句。
在Oracle中,我们可以使用EXPLAIN PLAN语句来获取SQL语句的执行计划。
具体的语法如下:EXPLAIN PLAN FOR。
SQL语句;然后可以使用如下语句来查看执行计划:SELECT FROM TABLE(DBMS_XPLAN.DISPLAY);2. 使用AUTOTRACE。
在SQLPlus或者SQL Developer中,我们可以使用AUTOTRACE功能来查看SQL语句的执行计划。
在SQLPlus中,可以使用如下语句开启AUTOTRACE功能:SET AUTOTRACE ON;然后执行需要查看执行计划的SQL语句即可。
3. 使用SQL Developer。
对于Oracle数据库开发人员来说,SQL Developer是一个非常常用的工具,它提供了直观的图形界面来查看SQL语句的执行计划。
在SQL Developer中,执行SQL语句后,可以通过右键菜单选择“Explain Plan”来查看执行计划。
二、执行计划的解读。
1. 表的访问方式。
在执行计划中,我们可以看到表的访问方式,包括全表扫描、索引扫描、唯一索引扫描等。
全表扫描意味着数据库将会扫描整张表,而索引扫描则表示数据库将会利用索引来快速定位数据,不同的访问方式对于SQL语句的性能影响很大。
Oracle优化之执行计划解析

Oracle应用优化
SQL语句的解析过程 什么是SQL执行计划 了解RBO和CBO 如何解读执行计划 NC SQL规范
什么是SQL执行计划
所谓执行计划,就是对一个DML SQL做出一份怎样去 完成任务的执行路径。基于不同的优化方式,执行计划可能 有很大的差异。
什么是SQL执行计划
Oracle应用优化
NC SQL规范
6、避免在索引列上使用计算
使用substr字符串函数的,如: select * from staff_member where substr(last_name,1,4)=’FRED’; ‘%’通配符在第一个字符的,如: select * from staff_member where first_name like ‘%DON’; 字符串连接(||)的,如: select * from staff_member where first_name||’’=’DONALD’
QA
NC SQL规范
8、避免使用IS NULL
设计中尽量避免字段为NULL,不能用NULL代表业 务意义。 例:总帐 凭证的记帐标示等 NC系统里常见(col1=’’ or colx is null)造成诸多效 率问题
NC SQL规范
9、将产生排他锁的操作放到事务的最后
锁等待的避免 死锁产生及其避免
Oracle应用优化
SQL语句的解析过程 什么是SQL执行计划 了解RBO和CBO 如何解读执行计划 NC SQL规范
如何解读执行计划
执行计划阅读方法 执行方法描述 术语解释
执行计划阅读方法
以树状格式进行读取,通过递归进入最底层 ,然后再返回该树的父(第一)。
实际演示
执行方法描述
oracle执行计划详解

oracle执⾏计划详解⼀:什么是Oracle执⾏计划?执⾏计划是⼀条查询语句在Oracle中的执⾏过程或访问路径的描述⼆:怎样查看Oracle执⾏计划?因为我⼀直⽤的PLSQL远程连接的公司数据库,所以这⾥以PLSQL为例:①:配置执⾏计划需要显⽰的项:⼯具 —> ⾸选项 —> 窗⼝类型 —> 计划窗⼝ —> 根据需要配置要显⽰在执⾏计划中的列执⾏计划的常⽤列字段解释:基数(Rows):Oracle估计的当前操作的返回结果集⾏数字节(Bytes):执⾏该步骤后返回的字节数耗费(COST)、CPU耗费:Oracle估计的该步骤的执⾏成本,⽤于说明SQL执⾏的代价,理论上越⼩越好(该值可能与实际有出⼊)时间(Time):Oracle估计的当前操作所需的时间②:打开执⾏计划:在SQL窗⼝执⾏完⼀条select语句后按 F5 即可查看刚刚执⾏的这条查询语句的执⾏计划注:在PLSQL中使⽤SQL命令查看执⾏计划的话,某些SQL*PLUS命令PLSQL⽆法⽀持,⽐如SET AUTOTRACE ON三:看懂Oracle执⾏计划①:执⾏顺序:根据Operation缩进来判断,缩进最多的最先执⾏;(缩进相同时,最上⾯的最先执⾏)例:上图中 INDEX RANGE SCAN 和 INDEX UNIQUE SCAN 两个动作缩进最多,最上⾯的 INDEX RANGE SCAN 先执⾏;同⼀级如果某个动作没有⼦ID就最先执⾏同⼀级的动作执⾏时遵循最上最右先执⾏的原则例:上图中 TABLE ACCESS BY GLOBAL INDEX ROWID 和 TABLE ACCESS BY INDEX ROWID 两个动作缩进都在同⼀级,则位于上⾯的 TABLE ACCESS BY GLOBAL INDEX ROWID 这个动作先执⾏;这个动作⼜包含⼀个⼦动作 INDEX RANGE SCAN,则位于右边的⼦动作 INDEX RANGE SCAN 先执⾏;图⽰中的SQL执⾏顺序即为:INDEX RANGE SCAN —> TABLE ACCESS BY GLOBAL INDEX ROWID —> INDEX UNIQUE SCAN —> TABLE ACCESS BY INDEX ROWID —> NESTED LOOPS OUTER —> SORT GROUP BY —> SELECT STATEMENT, GOAL = ALL_ROWS(注:PLSQL提供了查看执⾏顺序的功能按钮(上图中的红框部分) )②:对图中动作的⼀些说明:1. 上图中 TABLE ACCESS BY … 即描述的是该动作执⾏时表访问(或者说Oracle访问数据)的⽅式;表访问的⼏种⽅式:(⾮全部)TABLE ACCESS FULL(全表扫描)TABLE ACCESS BY ROWID(通过ROWID的表存取)TABLE ACCESS BY INDEX SCAN(索引扫描)(1) TABLE ACCESS FULL(全表扫描):Oracle会读取表中所有的⾏,并检查每⼀⾏是否满⾜SQL语句中的 Where 限制条件;全表扫描时可以使⽤多块读(即⼀次I/O读取多块数据块)操作,提升吞吐量;使⽤建议:数据量太⼤的表不建议使⽤全表扫描,除⾮本⾝需要取出的数据较多,占到表数据总量的 5% ~ 10% 或以上(2) TABLE ACCESS BY ROWID(通过ROWID的表存取) :先说⼀下什么是ROWID?ROWID是由Oracle⾃动加在表中每⾏最后的⼀列伪列,既然是伪列,就说明表中并不会物理存储ROWID的值;你可以像使⽤其它列⼀样使⽤它,只是不能对该列的值进⾏增、删、改操作;⼀旦⼀⾏数据插⼊后,则其对应的ROWID在该⾏的⽣命周期内是唯⼀的,即使发⽣⾏迁移,该⾏的ROWID值也不变。
oracle执行计划

oracle执行计划Oracle执行计划。
Oracle执行计划是数据库系统中非常重要的一个概念,它指的是Oracle数据库在执行SQL语句时所选择的最优执行路径。
通过执行计划,我们可以了解到Oracle是如何执行SQL语句的,从而可以对SQL语句进行优化,提高数据库的性能。
在本文中,我们将深入探讨Oracle执行计划的相关内容,包括执行计划的基本概念、执行计划的生成方式、执行计划的解读和优化等方面。
首先,我们来了解一下执行计划的基本概念。
执行计划是Oracle数据库优化器根据SQL语句和数据库对象的统计信息,通过优化算法生成的一种执行路径。
这个执行路径包括了SQL语句的执行顺序、访问方法、连接方式等信息。
通过执行计划,我们可以知道数据库是如何执行SQL语句的,从而可以对SQL语句进行优化,提高数据库的性能。
接下来,我们将介绍执行计划是如何生成的。
在Oracle数据库中,执行计划是由优化器根据SQL语句和数据库对象的统计信息生成的。
优化器会根据SQL语句的复杂度、表的大小、索引的选择等因素,选择最优的执行路径。
在生成执行计划时,优化器会考虑多种执行路径,并选择成本最低的执行路径作为最终的执行计划。
然后,我们将讨论如何解读执行计划。
执行计划通常以树状结构的方式呈现,包括了SQL语句的执行顺序、访问方法、连接方式等信息。
我们可以通过执行计划了解到SQL语句的执行路径,从而可以对SQL语句进行优化。
例如,我们可以通过执行计划了解到是否使用了索引、是否进行了全表扫描等信息,从而可以对SQL语句进行优化,提高数据库的性能。
最后,我们将介绍如何优化执行计划。
通过执行计划,我们可以了解到SQL语句的执行路径,从而可以对SQL语句进行优化。
例如,我们可以通过执行计划了解到是否使用了索引、是否进行了全表扫描等信息,从而可以对SQL语句进行优化,提高数据库的性能。
在优化执行计划时,我们可以考虑对SQL语句进行重写、创建索引、收集统计信息等方式,从而提高数据库的性能。
ORACLE的执行计划

更多oracl e资料下载,可以访问我的收藏页/forum-160286-1.htmlSQL语句性能调整之ORACLE的执行计划【内容导航】∙第1页:背景知识∙第2页:Rowid的概念∙第3页:可选择性∙第4页:执行计划的步骤∙第5页:访问路径(方法) -- access path∙第6页:4种类型的索引扫描∙第7页:表之间的连接∙第8页:嵌套循环(Nested Loops, NL)∙第9页:如何产生执行计划∙第10页:如何分析执行计划∙第11页:对于RBO优化器∙第12页:对于CBO优化器∙第13页:如何干预执行计划 - - 使用hints提示∙第14页:使用全套的hints∙第15页:具体案例分析文本Tag:Oracle数据库Oracle数据库开发背景知识:为了更好的进行下面的内容我们必须了解一些概念性的术语:共享sql语句为了不重复解析相同的SQL语句(因为解析操作比较费资源,会导致性能下降),在第一次解析之后,ORACLE将SQL语句及解析后得到的执行计划存放在内存中。
这块位于系统全局区域SGA(system global area)的共享池(shared buffer pool)中的内存可以被所有的数据库用户共享。
因此,当你执行一个SQL语句(有时被称为一个游标)时,如果该语句和之前的执行过的某一语句完全相同,并且之前执行的该语句与其执行计划仍然在内存中存在,则ORACLE就不需要再进行分析,直接得到该语句的执行路径。
ORACLE的这个功能大大地提高了SQL的执行性能并大大节省了内存的使用。
使用这个功能的关键是将执行过的语句尽可能放到内存中,所以这要求有大的共享池(通过设置shared buffer pool参数值)和尽可能的使用绑定变量的方法执行SQL语句。
当你向ORACLE 提交一个SQL语句,ORACLE会首先在共享内存中查找是否有相同的语句。
这里需要注明的是,ORACLE对两者采取的是一种严格匹配,要达成共享,SQL语句必须完全相同(包括空格,换行等)。
Oracle里的执行计划

Oracle⾥的执⾏计划第⼆章:Oracle⾥的执⾏计划2.1 什么是执⾏计划Oracle⽤来执⾏⽬标SQL语句的这些步骤的组合就被称为执⾏计划。
执⾏计划可以分为如下三个部分:1、⽬标SQL的正⽂、SQL ID和其执⾏计划所对应的的PLAN HASH VALUE。
2、执⾏计划的主体部分。
可以看到Oracle在执⾏⽬标SQL时所⽤的内部执⾏步骤,这些步骤的执⾏顺序,所对应的的谓词信息、列信息,优化器评估出来执⾏这些步骤后返回结果集的Cardinality、成本等内容。
执⾏计划⾏前*字符指执⾏步骤有对应的驱动或者过滤查询条件,这个星号对应的具体的驱动或过滤查询条件可以从执⾏计划的“Predicate Information(identified y operation id)”中找到。
实际上,这部分内饿哦那个就是上述执⾏步骤所对应的谓词信息。
access表⽰驱动查询条件。
3、执⾏计划的额外补充信息。
是否使⽤动态采样(dynamic sampling)是否使⽤Cardinality Feedback(Oracle 11g中引⼊的修正执⾏计划中返回结果集的Cardinality的⼀种技术⼿段)是否使⽤SQL Profile(Oracle 10g中引⼊的调整、稳定执⾏计划的⼀种⽅法)。
2.2 如何查看执⾏计划(1)、explain plan命令按F5,PL/SQL Developer就调⽤explain plan命令,F5只是explain plan命令上的⼀层封装⽽已。
语法:explain plan for + ⽬标SQLselect * from table(dbms_xplan.display)执⾏explain plan命令,则Oracle就将解析⽬标SQL所产⽣的执⾏计划的具体执⾏步骤写⼊PLAN_TABLE$,随后执⾏的select * from table(dbms_xplan.display)只是从PLAN_TABLE$中将这些具体执⾏步骤以格式化的⽅式显⽰出来。
Oracle执行计划详解

索引唯一扫描(index unique scan)
索引范围扫描(index range scan)
索引全扫描(index full scan)
索引快速扫描(index fast full scan)
(1) 索引唯一扫描(index unique scan)
SQL> explain plan for select empno, ename from emp
where empno > 7876 order by empno;
Query Plan
--------------------------------------------------------------------------------
Oracle执行计划详解
简介:
本文全面详细介绍oracle执行计划的相关的概念,访问数据的存取方法,表之间的连接等内容。
并有总结和概述,便于理解与记忆!
+++
目录
---
一.相关的概念
Rowid的概念
RecursiveSql概念
Predicate(谓词)
DRiving Table(驱动表)
SELECT STATEMENT[CHOOSE] Cost=
TABLE ACCESS FULL DUAL
2) 通过ROWID的表存取(Table Access by ROWID或rowid lookup)
行的ROWID指出了该行所在的数据文件、数据块以及行在该块中的位置,所以通过ROWID来存取数据可以快速定位到目标数据上,是Oracle存取单行数据的最快方法。
oracle--如何分析执行计划

oracle--如何分析执⾏计划例1:假设LARGE_TABLE是⼀个较⼤的表,且username列上没有索引,则运⾏下⾯的语句:SQL> SELECT * FROM LARGE_TABLE where USERNAME = ‘TEST’;Query Plan-----------------------------------------SELECT STATEMENT Optimizer=CHOOSE (Cost=1234 Card=1 Bytes=14)TABLE ACCESS FULL LARGE_TABLE [:Q65001] [ANALYZED]在这个例⼦中,TABLE ACCESS FULL LARGE_TABLE是第⼀个操作,意思是在LARGE_TABLE表上做全表扫描。
当这个操作完成之后,产⽣的row source中的数据被送往下⼀步骤进⾏处理,在此例中,SELECT STATEMENT操作是这个查询语句的最后⼀步。
ptimizer=CHOOSE 指明这个查询的optimizer_mode,即optimizer_mode初始化参数指定的值,它并不是指语句执⾏时真的使⽤了该优化器。
决定该语句使⽤何种优化器的唯⼀⽅法是看后⾯的cost部分。
例如,如果给出的是下⾯的形式,则表明使⽤的是CBO优化器,此处的cost表⽰优化器认为该执⾏计划的代价:SELECT STATEMENT Optimizer=CHOOSE (Cost=1234 Card=1 Bytes=14)然⽽假如执⾏计划中给出的是类似下⾯的信息,则表明是使⽤RBO优化器,因为cost部分的值为空,或者压根就没有cost部分。
SELECT STATEMENT Optimizer=CHOOSE Cost=SELECT STATEMENT Optimizer=CHOOSE这样我们从Optimizer后⾯的信息中可以得出执⾏该语句时到底⽤了什么样的优化器。
oracle 固定执行计划

oracle 固定执行计划Oracle数据库是目前应用最广泛的关系型数据库管理系统之一,它不仅具有丰富的高级功能和应用程序,还具备了极高的安全性能和稳定性,被广泛应用于企业级互联网应用、商业应用等领域。
其中固定执行计划是Oracle数据库中的一个重要概念之一,本文将为您详细介绍。
一、什么是固定执行计划顾名思义,固定执行计划就是一种在Oracle数据库中对SQL语句执行计划进行指定和固定的方法。
当数据库在执行一条SQL语句时,通常会根据优化器的分析结果自动确定最优执行计划,但有时候由于各种因素,这个最优的执行计划并不一定是我们想要的结果。
因此,我们可以通过固定执行计划的方式来指定SQL语句执行时的具体执行计划,从而达到所需的效果。
下面是一些使用固定执行计划的场景:1. 如果一条SQL语句的扫描方式受到了Oracle版本升级、系统参数修改等因素的影响,那么它的执行计划可能会发生变化,如果我们想保证其性能稳定,就需要使用固定执行计划的方式来避免由于自动计划变化而导致性能问题的发生。
2. 对于一些关键业务系统,其响应时间和吞吐量非常敏感,任何微小的变化都可能引起系统性能下降或者响应延迟。
此时我们可以通过固定执行计划来保证SQL语句的性能稳定,从而保证整个系统的正常运行。
3. 在数据库中,同一个SQL语句可能会被不同的应用程序或者用户调用,不同的调用方式需要使用不同的执行计划来保证最佳性能。
如果我们对一条SQL语句的执行计划进行了优化,那么将它固定下来可以确保所有的调用者都使用相同的执行计划,避免性能的波动。
Oracle数据库提供了多种方式来实现固定执行计划:1. 使用dbms_sqltune包该方法需要使用dbms_sqltune包中的create_sql_profile方法来创建一个SQL语句的profile,然后将其与该SQL语句相关联。
当SQL语句执行时,数据库会根据该profile 中指定的执行计划进行执行。
oracle关于执行计划的字段解释说明

oracle关于执⾏计划的字段解释说明1create table dw_object as select*from dba_objects;2CREATE INDEX IDX_DW ON DW_OBJECT(OBJECT_ID);3exec dbms_stats.gather_table_stats(ownname=>'SCOTT',TABNAME=>'DW_OBJECT',CASCADE=>TRUE);---收集统计信息4SELECT*FROM DW_OBJECT WHERE OBJECT_ID IN (12,14);5select sql_text, sql_id,a.hash_value,child_number from v$sql a where sql_text like'%SELECT * FROM DW_OBJECT WHERE OBJECT_ID%';--获取sql_id6 SQL>SELECT*FROM TABLE(DBMS_XPLAN.DISPLAY_CURSOR(NULL,NULL,'advanced'));7 PLAN_TABLE_OUTPUT8--------------------------------------------------------------------------------9 SQL_ID 9m7787camwh4m, child number010begin :id := sys.dbms_transaction.local_transaction_id; end;11 NOTE: cannot fetch plan for SQL_ID: 9m7787camwh4m, CHILD_NUMBER: 012 Please verify value of SQL_ID and CHILD_NUMBER;13 It could also be that the plan is no longer in cursor cache (check v$sql_p148 rows selected1516 SQL>SELECT*FROM TABLE(DBMS_XPLAN.DISPLAY_CURSOR('271x26x15yk3b',0,'advanced'))172 ;18 PLAN_TABLE_OUTPUT19--------------------------------------------------------------------------------20 SQL_ID 271x26x15yk3b, child number021-------------------------------------22SELECT*FROM DW_OBJECT WHERE OBJECT_ID IN (12,14)23Plan hash value: 155755626924--------------------------------------------------------------------------------25| Id | Operation | Name | Rows | Bytes | Cost (%CPU)|26--------------------------------------------------------------------------------27|0|SELECT STATEMENT ||||4 (100)|28|1| INLIST ITERATOR |||||29|2|TABLE ACCESS BY INDEX ROWID| DW_OBJECT |2|194|4 (0)|30|*3|INDEX RANGE SCAN | IDX_DW |2||3 (0)|31--------------------------------------------------------------------------------32 Query Block Name / Object Alias (identified by operation id):33-------------------------------------------------------------341- SEL$1352- SEL$1/ DW_OBJECT@SEL$136 PLAN_TABLE_OUTPUT37--------------------------------------------------------------------------------383- SEL$1/ DW_OBJECT@SEL$139 Outline Data40-------------41/*+42 BEGIN_OUTLINE_DATA43 IGNORE_OPTIM_EMBEDDED_HINTS44 OPTIMIZER_FEATURES_ENABLE('11.2.0.1')45 DB_VERSION('11.2.0.1')46 ALL_ROWS47 OUTLINE_LEAF(@"SEL$1")48 INDEX_RS_ASC(@"SEL$1" "DW_OBJECT"@"SEL$1" ("DW_OBJECT"."OBJECT_ID"))49 END_OUTLINE_DATA50*/51 Predicate Information (identified by operation id):52---------------------------------------------------533- access(("OBJECT_ID"=12OR "OBJECT_ID"=14))54 PLAN_TABLE_OUTPUT55--------------------------------------------------------------------------------56Column Projection Information (identified by operation id):57-----------------------------------------------------------581- "DW_OBJECT"."OWNER"[VARCHAR2,30], "DW_OBJECT"."OBJECT_NAME"[VARCHAR2,128]59 "DW_OBJECT"."SUBOBJECT_NAME"[VARCHAR2,30], "OBJECT_ID"[NUMBER,22],60 "DW_OBJECT"."DATA_OBJECT_ID"[NUMBER,22], "DW_OBJECT"."OBJECT_TYPE"[VARCHA61 "DW_OBJECT"."CREATED"[DATE,7], "DW_OBJECT"."LAST_DDL_TIME"[DATE,7],62 "DW_OBJECT"."TIMESTAMP"[VARCHAR2,19], "DW_OBJECT"."STATUS"[VARCHAR2,7],63 "DW_OBJECT"."TEMPORARY"[VARCHAR2,1], "DW_OBJECT"."GENERATED"[VARCHAR2,1],64 "DW_OBJECT"."SECONDARY"[VARCHAR2,1], "DW_OBJECT"."NAMESPACE"[NUMBER,22],65 "DW_OBJECT"."EDITION_NAME"[VARCHAR2,30]662- "DW_OBJECT"."OWNER"[VARCHAR2,30], "DW_OBJECT"."OBJECT_NAME"[VARCHAR2,128]67 "DW_OBJECT"."SUBOBJECT_NAME"[VARCHAR2,30], "OBJECT_ID"[NUMBER,22],68 "DW_OBJECT"."DATA_OBJECT_ID"[NUMBER,22], "DW_OBJECT"."OBJECT_TYPE"[VARCHA69 "DW_OBJECT"."CREATED"[DATE,7], "DW_OBJECT"."LAST_DDL_TIME"[DATE,7],70 "DW_OBJECT"."TIMESTAMP"[VARCHAR2,19], "DW_OBJECT"."STATUS"[VARCHAR2,7],71 "DW_OBJECT"."TEMPORARY"[VARCHAR2,1], "DW_OBJECT"."GENERATED"[VARCHAR2,1],72 "DW_OBJECT"."SECONDARY"[VARCHAR2,1], "DW_OBJECT"."NAMESPACE"[NUMBER,22],73 "DW_OBJECT"."EDITION_NAME"[VARCHAR2,30]743- "DW_OBJECT".ROWID[ROWID,10], "OBJECT_ID"[NUMBER,22]7562 rows selected⼀、执⾏计划中字段说明ID:⼀个序号,但不是执⾏的先后顺序,执⾏的先后顺序是根据缩进来判断,最右最上的原则。
怎样看懂Oracle的执行计划

一、什么是执行计划An explain plan is a representation of the access path that is taken when a query is executed within Oracle.二、如何访问数据At the physical level Oracle reads blocks of data. The smallest amount of data read is a single Oracle block, the largest is constrained by operating system limits (and multiblock i/o). Logically Oracle finds the data to read by using the following methods: Full Table Scan (FTS) --全表扫描Index Lookup (unique & non-unique) --索引扫描(唯一和非唯一)Rowid --物理行id三、执行计划层次关系When looking at a plan, the rightmost (ie most inndented) uppermost operation is the first thing that is executed. --采用最右最上最先执行的原则看层次关系,在同一级如果某个动作没有子ID就最先执行1、看一个简单的例子:Query Plan-----------------------------------------SELECT STATEMENT [CHOOSE] Cost=1234**TABLE ACCESS FULL LARGE [:Q65001] [ANALYZED]--[:Q65001]表示是并行方式,[ANALYZED]表示该对象已经分析过了优化模式是CHOOSE的情况下,看Cost参数是否有值来决定采用CBO还是RBO:SELECT STATEMENT [CHOOSE] Cost=1234 --Cost有值,采用CBOSELECT STATEMENT [CHOOSE] Cost= --Cost为空,采用RBO2、层次的父子关系,看比较复杂的例子:PARENT1**FIRST CHILD****FIRST GRANDCHILD**SECOND CHILDHere the same principles apply, the FIRST GRANDCHILD is the initial operation then the FIRST CHILD followed by the SECOND CHILD and finally the PARENT collates the output.四、例子解说Execution Plan----------------------------------------------------------0 **SELECT STATEMENT ptimizer=CHOOSE (Cost=3 Card=8 Bytes=248)1 0 **HASH JOIN (Cost=3 Card=8 Bytes=248)2 1 ****TABLE ACCESS (FULL) OF 'DEPT' (Cost=1 Card=3 Bytes=36)3 1 ****TABLE ACCESS (FULL) OF 'EMP' (Cost=1 Card=16 Bytes=304)左侧的两排数据,前面的是序列号ID,后面的是对应的PID(父ID)。
Oracle数据库的用户和权限管理PPT课件

第11页/共53页
使用IDENTIFIED BY子句为用户设置口令,这时用户将通过数据库来进行身份认 证 。 如 果 要 通 过 操 作 系 统 来 对 用 户 进 行 身 份 认 证 , 则 必 须 使 用 IDENTIFIED EXTERNAL BY子句。
第24页/共53页
5.2.2 创建角色
使用CREATE ROLE语句可以创建一个新的角色,执行该语句的用户必须具 有CREATE ROLE系统权限。
在角色刚刚创建时,它并不具有任何权限,这时的角色是没有用处的。因此, 在创建角色之后,通常会立即为它授予权限。例如:利用下面的语句创建了一个名 为OPT_ROLE的角色,并且为它授予了一些对象权限和系统权限:
第28页/共53页
2.授予对象权限 Oracle对象权限指用户在指定的表上进行特殊操作的权利。 在GRANT关键字之后指定对象权限的名称,然后在ON关键字后指定对象名
称,最后在TO关键字之后指定接受权限的用户名,即可将指定对象的对象权限 授予指定的用户。
使用一条GRANT语句可以同时授予用户多个对象权限,各个权限名称之间用 逗号分隔。
CREATE ROLE OPT_ROLE; GRANT SELECT ON sal_history TO OPT_ROLE; GRANT INSERT,UPDATE ON mount_entry TO OPT_ROLE; GRANT CREATE VIEW TO OPT_ROLE;