Eviews案例分析1
EVIEWS案例分析

学会分析计算结果!
பைடு நூலகம்
作图: 法1:单击“Quick/Graph”在出现的对话框上,键入 y x或 y x1 x2---/ok; 在出现的菜单中点击 Line Grap; 在下拉菜 单中选类型(如Scatter Diagram(散点图)/OK,出现图形;---)
Quick---Estimate Equation
Eviews主要操作步骤
一、启动软件包 ( 双击“Eviews”,进入Eviews主页) 二、创建工作文件(点击“File/New/Workfile/Ok”) 出现“Workfile Range”,目的: 1、选择数据频率(类型): Annual (年度) Quartely(季度) ┆ Undated or irrequar(未注明日期或不规则的) 2、确定Start date 和End date(如1980 1999或1 18 /ok)。 出现“Workfile对话框(子窗口)”中已有两个变量: c-----常数项 resid----模型将产生的残差项
(三) 检验模型 经济意义检验; 统计推断检验; 计量经济学检验; 预测检验; (计算机仿真技术判 断模型参数估计值 的可信度及模型的 功效等)。
(四) 应用模型 经济预测; 经济结构分析; 政策评价; (通过政策模拟提供制定 经济政策的依据)
二、案例分析
例 讨论家庭收入X对家庭消费支出Y的影响问题,通过 调查得到一组数据(百元)如下 :
注:在Equation框中,点击Resids,可以出 现Residual、Actual、Fitted的图形
计算描述统计量 点击: 1、“Quick/Group statistics/Descriptive statistics/Common Sample;
计量经济学Eviews操作案例集.

案例分析一关于计量经济学方法论的讨论问题:利用计量经济学建模的步骤,根据相关的消费理论,刻画我国改革开放以来的边际消费倾向。
第一步:相关经济理论。
首先了解经济理论在这一问题上的阐述,宏观经济学中,关于消费函数的理论有以下几种:①凯恩斯的绝对收入理论,认为家庭消费在收入中所占的比例取决于收入的绝对水平。
②相对收入理论,是由美国经济学家杜森贝提出的,认为人们的消费具有惯性,前期消费水平高,会影响下一期的消费水平,这告诉我们,除了当期收入外,前期消费也很可能是建立消费函数时应该考虑的因素。
关于消费函数的理论还有持久收入理论、生命周期理论,有兴趣的同学可以参考相应的参考书。
毋庸置疑,收入和消费之间是正相关的。
第二步:数据获得。
在这个例子中,被解释变量选择消费,用cs表示;解释变量为实际可支配收入,用inc表示(用GDP减去税收来近似,单位:亿元);变量均为剔除了价格因素的实际年度数据,样本区间为1978~2002年。
第三步:理论数学模型的设定。
为了讨论的方便,我们可以建立下面简单的线性模型:第四步:理论计量经济模型的设定。
根据第三步数学模型的形式,可得式中:cs=CS/P,inc=(1-t)*GDP/P,其中GDP是当年价格的国内生产总值,CS代表当年价格的居民消费值,P代表1978年为1的价格指数,t=TAX/GDP代表宏观税率,TAX是税收总额。
u t表示除收入以外其它影响消费的因素。
第五步:计量经济模型的参数估计根据最小二乘法,可得如下的估计结果:常数项为正说明,若inc为0,消费为414.88,也就是自发消费。
总收入变量的系数 为边际消费倾向,可以解释为城镇居民总收入增加1亿元导致居民消费平均增加0.51亿元。
另外,根据相对收入理论,我们可以得到下面的估计结果:上述结果表明加入消费的上期值以后,边际消费倾向的数据发生了明显的变化,究竟选择哪一个模型,可以在以后的案例讨论中进行说明。
第六步:假设检验。
Eviews多元回归模型案例分析

Eviews多元回归模型案例分析1. 引言本文将通过一个多元回归模型的案例分析来展示Eviews软件的应用。
多元回归模型是一种统计学方法,用于研究多个自变量对因变量的影响关系。
2. 数据集和变量2.1 数据集我们使用的数据集是一份包含多个变量的经济数据集,包括自变量和因变量。
2.2 变量在本案例中,我们选择了以下变量:- 因变量:Y- 自变量1:X1- 自变量2:X2- 自变量3:X33. 回归模型建立和参数估计3.1 建立模型我们根据选定的变量,建立了以下多元回归模型:Y = β0 + β1X1 + β2X2 + β3X3 + ε3.2 参数估计使用Eviews软件,我们对模型中的参数进行了估计。
具体估计结果如下:- β0的估计值为a- β1的估计值为b1- β2的估计值为b2- β3的估计值为b34. 模型拟合和统计检验4.1 拟合优度为了评估模型的拟合优度,我们计算了决定系数R^2。
结果显示,模型拟合效果良好,并能解释自变量对因变量的变异程度。
4.2 统计检验我们进行了一系列统计检验,包括回归系数的显著性检验、F 检验和残差分析等。
结果显示,模型的回归系数显著,并且F检验的p值足够小,支持多元回归模型的有效性。
5. 模型解释和预测5.1 模型解释我们分析了模型中每个自变量的系数和显著性水平,解释了它们对因变量的影响。
根据模型结果,可以得出每个自变量对因变量的贡献程度。
5.2 模型预测基于建立的多元回归模型,我们可以进行因变量的预测。
根据给定的自变量取值,我们可以通过模型预测出相应的因变量值。
6. 结论通过Eviews软件进行多元回归模型的案例分析,我们得出了一些结论。
多元回归模型在解释因变量和自变量之间关系方面具有一定的效果,并且可以用于因变量的预测。
然而,我们需要注意模型的限制和假设,并且在实际应用中进行进一步的验证和调整。
以上是对Eviews多元回归模型案例分析的简要介绍。
如有更详细的需求或其他问题,请随时联系。
eviews案例分析作业

eviews案例分析作业Eviews案例分析作业。
本次作业将使用Eviews软件进行一个实际案例的分析,以展示Eviews在实际经济数据分析中的应用。
我们选取了美国GDP(国内生产总值)和失业率的数据,来进行相关性分析和趋势预测。
首先,我们导入美国GDP和失业率的时间序列数据,并进行数据的初步观察和描述性统计分析。
通过Eviews的数据视图功能,我们可以直观地看到这两个变量的变化趋势和波动情况,从而为后续的分析提供基础。
接下来,我们将利用Eviews进行相关性分析,探讨美国GDP与失业率之间的关系。
通过Eviews的相关性分析功能,我们可以得到它们之间的相关系数,并利用散点图和回归分析来观察它们之间的线性关系。
通过这些分析,我们可以初步了解到美国GDP和失业率之间的关联程度,为后续的预测分析提供参考。
在完成相关性分析后,我们将利用Eviews进行趋势预测。
通过Eviews的时间序列分析功能,我们可以选择合适的模型对美国GDP和失业率的未来趋势进行预测。
在选择模型的过程中,我们将充分考虑数据的平稳性、季节性等特点,以确保模型的准确性和可靠性。
最终,我们将得到美国GDP和失业率未来的预测值,并进行可视化展示,以便更直观地观察它们的趋势变化。
通过本次Eviews案例分析作业,我们不仅对Eviews软件的使用有了更深入的了解,同时也对实际经济数据的分析方法有了更加清晰的认识。
Eviews作为一款专业的计量经济学软件,具有强大的数据分析和建模功能,可以帮助我们更好地理解和预测经济现象,为经济决策提供科学依据。
总之,Eviews案例分析作业不仅是对所学知识的巩固和实践,更是对实际问题的解决和预测。
通过本次作业,我们不仅提升了对Eviews软件的熟练度,更深入了解了经济数据分析的方法和技巧,为今后的学习和工作打下了坚实的基础。
希望通过这次作业的学习,能够更好地应用Eviews软件进行实际经济数据的分析和预测,为经济决策提供更加科学的支持。
计量经济学案例分析(Eviews操作)

美股行情对A股的影响性分析——标普500与沪深300相关性分析摘要:本文主要通过分析标准普尔500指数与沪深300指数的相关性,以标普500指数为解释变量,以沪深300指数为被解释变量,利用Eviews软件,使用其中的最小二乘法对其进行线性回归分析,最终得出方程。
并对其进行显著性检验(F,t)、异方差检验、自相关性检验来验证方程的可靠性。
然后解释方程的经济意义,并利用软件对未来指数变动进行预测。
最后在未来几天比较预测结果与实际两个指数的变化情况,验证实际应用情况。
关键词:标普500、沪深300、Eviews、显著性检验、异方差检验、自相关性检验。
一、研究背景1.全球化大环境在经济全球化不断深入发展的今天,全球资本市场,尤其是中美两个超级大国之间的资本流通,早已彼此嵌入,密不可分。
全世界早有不少学者对中美资本流通做了深入研究。
但美国股市发展早于中国十几年,其内部的资金也远远超过中国股市,美国股市的资本流动势必会对中国股市产生一定影响,这种影响不仅体现在情绪面,更反映在指数变动方向上。
2.对外开放资本市场的QFII政策Qualified Foreign Institutional Investor,作为一种过渡性制度安排,QFII制度是在资本项目尚未完全开放的国家和地区,实现有序、稳妥开放证券市场的特殊通道。
外资对中国股市的影响早已不可忽视,而美国市场的变动也一定程度会影响在中国股市外资的操作行为。
所以研究两个指数的变动是很有意义的。
二、数据1.数据选择沪深两个市场各自均有独立的综合指数和成份指数,这些指数不能用来反映沪深两市的整体情况,而沪深300指数则同时考虑了两市的交易情况,是中国A股市场的“晴雨表”。
标准普尔500指数英文简写为S&P 500 Index,是记录美国500家上市公司的一个股票指数。
与道琼斯指数等其他指数相比,标准普尔500指数包含的公司更多,因此风险更为分散,能够反映更广泛的市场变化。
Eviews案例解析
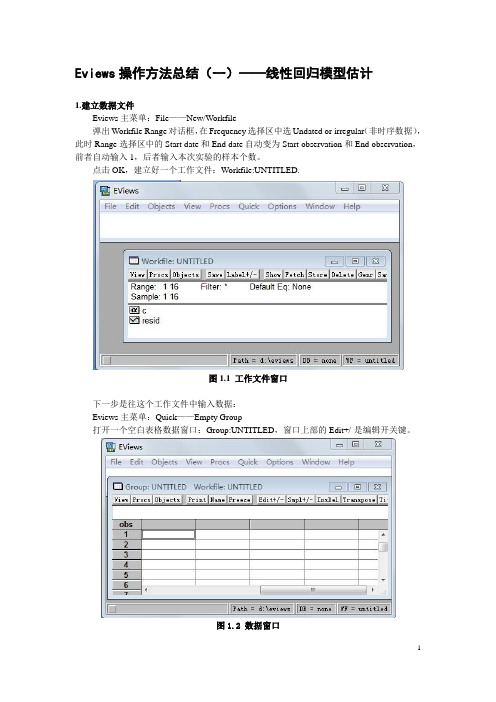
Eviews操作方法总结(一)——线性回归模型估计1.建立数据文件Eviews主菜单:File——New/Workfile弹出Workfile Range对话框,在Frequency选择区中选Undated or irregular(非时序数据),此时Range选择区中的Start date和End date自动变为Start observation和End observation,前者自动输入1,后者输入本次实验的样本个数。
点击OK,建立好一个工作文件:Workfile:UNTITLED.图1.1 工作文件窗口下一步是往这个工作文件中输入数据:Eviews主菜单:Quick——Empty Group打开一个空白表格数据窗口:Group:UNTITLED,窗口上部的Edit+/-是编辑开关键。
图1.2 数据窗口数据表的一行表示一个样本,一列代表一个变量,一般把被解释变量(如Y)放在第一列。
例子:图1.3 数据编辑状态2.画散点图Eviews主菜单:Quick——Graph/Scatter弹出Series List对话框,要求输入画图所用的变量名,对3.1以上版本,应先输入解释变量名,后输入被解释变量名,中间用空格隔开。
图1.4 作图变量输入窗口点OK,得散点图:图1.5 散点图3.OLS(普通最小二乘法)估计,以及线性回归模型的建立与检验Eviews主菜单:Quick——Estimate Equation弹出Equation Specification(方程设定)对话框,依次输入被解释变量Y,系数C(实际的方程中应该包括截距项和斜率项,而软件默认该变量的输出结果为截距项),解释变量X,中间用空格隔开。
在Estimation Setting(估计设定)选择框中,Method框选择LS-Least Squares(NLS and ARMA),Sample框默认为1 16(即样本个数)。
图1.6 方程设定窗口点OK,得方程的估计结果输出表:图1.7 估计结果输出表窗口对应的回归表达式:y i=−0.762928+0.40428x i(-0.624856)(12.11266)R2=0.91289, S.E.=2.036319 上式还可以从图1.7的V iew——Presentation得到:图1.8 回归方程窗口按Stats键可以还原回图1.7的估计结果输出表,按Estimate键可以随时改变估计模型的数学形式、样本范围和估计方法。
eviews面板数据实例分析

eviews⾯板数据实例分析1.已知 1996—2002年中国东北、华北、华东 15 个省级地区的居民家庭⼈均消费(cp ,不变价格)和⼈均收⼊(ip ,不变价格)居民,利⽤数据(1)建⽴⾯板数据( panel data )⼯作⽂件;( 2)定义序列名并输⼊数据;( 3)估计选择⾯板模型;( 4)⾯板单位根检验。
年⼈均消费(con sume )和⼈均收⼊(in come )数据以及消费者价格指数(p )分别见表 9.1,9.2 和 9.3。
表 9.1 1996— 2002 年中国东北、华北、华东 15 个省级地区的居民家庭⼈均消费(元)数据⼈均消费1996 1997 1998 1999 2000 2001 2002 CONSUMEAH 3607.43 3693.55 3777.41 3901.81 4232.98 4517.65 4736.52 CONSUMEBJ 5729.52 6531.81 6970.83 7498.48 8493.49 8922.72 10284.6 CONSUMEFJ 4248.47 4935.95 5181.45 5266.69 5638.74 6015.11 6631.68 CONSUMEHB 3424.35 4003.71 3834.43 4026.3 4348.47 4479.75 5069.28 CONSUMEHLJ 3110.92 3213.42 3303.15 3481.74 3824.44 4192.36 4462.08 CONSUMEJL 3037.32 3408.03 3449.74 3661.68 4020.87 4337.22 4973.88 CONSUMEJS 4057.5 4533.57 4889.43 5010.91 5323.18 5532.74 6042.6 CONSUMEJX 2942.11 3199.61 3266.81 3482.33 3623.56 3894.51 4549.32 CONSUMELN 3493.02 3719.91 3890.74 3989.93 4356.06 4654.42 5342.64 CONSUMENMG 2767.84 3032.3 3105.74 3468.99 3927.75 4195.62 4859.88 CONSUMESD 3770.99 4040.63 4143.96 4515.05 5022 5252.41 5596.32CONSUMESH 6763.12 6819.94 6866.41 8247.69 8868.19 9336.1 10464 CONSUMESX 3035.59 3228.71 3267.7 3492.98 3941.87 4123.01 4710.96 CONSUMETJ4679.61 5204.15 5471.01 5851.53 6121.04 6987.22 7191.96 CONSUMEZJ5764.276170.146217.936521.547020.227952.398713.08⼈均收⼊1996 1997 1998 1999 2000 2001 2002 INCOMEAH 4512.77 4599.27 4770.47 5064.6 5293.55 5668.8 6032.4 INCOMEBJ 7332.01 7813.16 8471.98 9182.76 10349.69 11577.78 12463.92 INCOMEFJ 5172.93 6143.64 6485.63 6859.81 7432.26 8313.08 9189.36 INCOMEHB 4442.81 4958.67 5084.64 5365.03 5661.16 5984.82 6679.68 INCOMEHLJ 3768.31 4090.72 4268.5 4595.14 4912.88 5425.87 6100.56 INCOMEJL 3805.53 4190.58 4206.64 4480.01 4810 5340.46 6260.16 INCOMEJS 5185.79 5765.2 6017.85 6538.2 6800.23 7375.1 8177.64 INCOMEJX 3780.2 4071.32 4251.42 4720.58 5103.58 5506.02 6335.64 INCOMELN4207.234518.1 4617.24 4898.61 5357.79 5797.01 6524.52 INCOMENMG3431.81 3944.67 4353.02 4770.53 5129.05 5535.89 6051 INCOMESD 4890.28 5190.79 5380.08 5808.96 6489.97 7101.08 7614.36 INCOMESH 8178.48 8438.89 8773.1 10931.64 11718.01 12883.46 13249.8 INCOMESX 3702.69 3989.92 4098.73 4342.61 4724.11 5391.05 6234.36 INCOMETJ 5967.71 6608.39 7110.54 7649.83 8140.5 8958.7 9337.56 INCOMEZJ6955.797358.727836.768427.959279.1610464.6711715.615 个省级地区的居民家庭⼈均收⼊(元)数据表 9.2 1996— 2002 年中国东北、华北、华东表9.3 1996 —2002年中国东北、华北、华东15个省级地区的消费者物价指数物价指数1996 1997 1998 1999 2000 2001 2002 PAH 109.9 101.3 100 97.8 100.7 100.5 99PBJ 111.6 105.3 102.4 100.6 103.5 103.1 98.2PFJ 105.9 101.7 99.7 99.1 102.1 98.7 99.5PHB 107.1 103.5 98.4 98.1 99.7 100.5 99PHLJ 107.1 104.4 100.4 96.8 98.3 100.8 99.3PJL 107.2 103.7 99.2 98 98.6 101.3 99.5PJS 109.3 101.7 99.4 98.7 100.1 100.8 99.2PJX 108.4 102 101 98.6 100.3 99.5 100.1PLN 107.9 103.1 99.3 98.6 99.9 100 98.9PNMG 107.6 104.5 99.3 99.8 101.3 100.6 100.2PSD 109.6 102.8 99.4 99.3 100.2 101.8 99.3PSH 109.2 102.8 100 101.5 102.5 100 100.5PSX 107.9 103.1 98.6 99.6 103.9 99.8 98.4PTJ 109 103.1 99.5 98.9 99.6 101.2 99.6PZJ 107.9 102.8 99.7 98.8 101 99.8 99.1(1)建⽴⾯板数据⼯作⽂件⾸先建⽴⼯作⽂件。
eviews面板数据实例分析(包会)-

eviews面板数据实例分析(包会)-Eviews是一种流行的面板数据分析软件,广泛用于经济学及财务学领域。
本文将以一个面板数据实例为例,介绍Eviews的一些基本功能及应用。
数据说明本数据集为横截面面板数据,共包含11个国家(美国、加拿大、英国、法国、德国、意大利、荷兰、比利时、奥地利、瑞典、日本)在1970年至1986年间的年度数据。
变量说明如下:- gdpercap:人均GDP- invest:投资/GDP比率- consump:消费/GDP比率- inflation:通货膨胀率- popgrowth:人口增长率- literacy:成年人识字率- female:女性劳动力占比数据导入及面板设置首先,在Eviews中新建一个工作文件,并将数据导入。
打开数据文件后,我们可以看到数据已经被正确读入。
然后,我们需要将数据设为面板数据。
在Eviews中,选择“View”菜单下的“Structure of Workfile”选项,可以进入工作文件结构设置。
在弹出的窗口中,选择“Panel Data”选项,并按照数据的属性设置面板变量。
在本例中,我们选择“Country”作为单位维度,“Year”作为时间维度。
设置完成后,Eviews会自动进行面板数据检测。
检测结果显示,数据格式符合面板数据要求。
面板数据描述及汇总统计接下来,我们可以对数据进行初步的描述性统计和汇总统计。
选择“Quick”菜单下的“Descriptive Stats”选项,Eviews会自动生成数据的描述性统计报告,展示各变量在不同国家和不同年份的均值、标准差、最小值、最大值等基本信息。
我们也可以手动计算其他统计量。
例如,选择“Proc”菜单下的“Panel Data”选项,可以对选定的变量进行面板数据汇总统计。
下面是在Eviews中计算人均GDP和消费/GDP比率两个变量的面板均值统计结果:面板数据变量之间的相关性分析在分析面板数据时,我们通常需要考虑不同变量之间的相关性。
基于EVIEWS软件的计量经济学建模检验案例解读

基于EVIEWS软件的计量经济学建模检验案例解读计量经济学是经济学领域的一个重要分支,它运用数理统计方法对经济学模型进行定量分析和预测。
而EVIEWS软件则是计量经济学常用的数据分析与建模工具。
本文将通过一个实例案例,解读基于EVIEWS软件的计量经济学建模检验的方法和过程。
首先,我们需要了解案例的背景和研究问题。
假设我们想研究某国家的经济增长与就业率之间的关系。
我们提出了一个假设:经济增长对就业率有积极的影响。
第一步是数据收集和准备。
我们需要收集与经济增长和就业率相关的数据。
以中国为例,我们可以从国家统计局等官方机构获取国内生产总值(GDP)和就业率的数据。
这些数据应该是时间序列数据,通常包括一定的时间跨度和频率(例如月度或年度数据)。
第二步是数据预处理。
我们需要对收集到的数据进行清洗和处理,以确保数据的质量。
具体来说,我们需要检查数据是否存在缺失值、异常值等,确保数据的连续性和一致性。
第三步是建立计量经济学模型。
在本案例中,我们使用一个简单的线性回归模型来研究经济增长对就业率的影响。
假设就业率(Y)是经济增长(X)的线性函数,即Y = β0 +β1X + ε,其中β0和β1是回归系数,ε是误差项。
第四步是模型检验。
在EVIEWS软件中,我们可以利用OLS(Ordinary Least Squares)方法进行模型的估计和检验。
OLS方法是最小二乘法的一种形式,用于估计回归系数的值。
此外,我们还可以通过检验模型的显著性和拟合优度来评估模型的质量。
具体来说,我们可以通过检验回归系数的t值和p值来判断是否存在统计显著性。
如果t值的绝对值较大且p值小于设定的显著性水平(通常是0.05),则可以认为回归系数是显著的,即具有统计意义。
此外,我们还可以计算回归方程的R-squared值来评估模型的拟合优度,R-squared值越接近1,说明模型的解释能力越强。
最后,我们需要进行模型诊断。
模型诊断用于检验回归模型的假设是否成立,以及模型是否满足统计方法的要求。
Eviews软件数据分析例文剖析

小学期作业影响财政收入的主要因素学院:经济学院班级:统计学班姓名:梁语丝学号:2011407036影响财政收入的主要因素摘要:财政收入是一国政府实现政府职能的基本保障,主要有资源配置、收入再分配和宏观经济调控三大职能。
财政收入的增长情况关系着一个国家经济的发展和社会的进步。
我国财政收入主要受国民经济发展、预算外资金收入、税收收入等因素的影响。
本文针对我国财政收入影响因素建立了计量经济模型,并利用Eviews软件对收集到的数据进行相关回归分析,排除简单多元回归模型存在的严重多重共线性等问题,建立财政收入影响因素更精确的模型,分析了影响财政收入主要因素及其影响程度,预测我国财政收入增长趋势。
二、模型设定研究财政收入的影响因素离不开一些基本的经济变量。
大多数相关的研究文献中都把总税收、国内生产总值这两个指标作为影响财政收入的基本因素,还有一些文献中也提出了其他一些变量, 比如其他收入、经济发展水平等。
影响财政收入的因素众多复杂, 但是通过研究经济理论对财政收入的解释以及对实践的观察, 对财政收入影响的因素主要是税收收入。
下面我们就以税收收入、能源消费总量、和预算外资金收入作为影响财政收入的主要研究因素。
从中国统计局网站上可以查询到1993年至2008年的相关数据,对其进行计算整理可得:4.、模型的建立根据1978—2008年每年的财政收入Y( 亿元) , 能源消费总量X1( 亿元),预算外资金收入X2( 亿元) ,税收收入X3( 亿元) 的统计数据,由E-views软件得到y,x1,x2,x3的线性图,如下:由图可知,y,x1, x3都是逐年增长的,但增长速率有所变动,而x2呈现水平波动,说明变量间不一定是线性关系,可探索将模型设定为以下形式:lnY=β0+β1lnX1+β2X2+β3lnX3+U三,模型估计与调整利用Eviews软件对模型进行最小二乘法全回归,结果如下:第一步,进行模型的检验。
(一),进行多重共线性的检验方程的修正后的R平方值很高,说明变量对因变量的拟合程度很好,但是应该注意到c,lnx1,x2三者的t值很低(在此选择置信度为0.05),未通过检验,因此怀疑其中存在变量之间的多重共线问题。
Eviews多元因子分析案例分析

Eviews多元因子分析案例分析
多元因子分析是一种常用的经济数据分析方法,它能够帮助我
们解释变量之间的关系以及其对观察数据的影响程度。
本文将以一
个案例为例,演示如何使用Eviews进行多元因子分析。
案例背景
在这个案例中,我们有一组经济数据,包括GDP增长率、通
货膨胀率、利率、失业率和投资增长率。
我们希望通过多元因子分析,找出这些变量之间的主要关系,并解释它们对经济发展的影响。
数据准备
在进行多元因子分析之前,我们首先需要准备好数据。
将数据
导入Eviews软件,并确保数据格式正确。
模型建立
在Eviews中,我们可以使用多元线性回归模型来进行因子分析。
通过选择适当的解释变量和因变量,我们可以建立一个能够解
释经济数据变动的模型。
数据分析
在模型建立完成后,我们可以进行数据分析。
通过观察回归结果,我们可以得出变量之间的关系以及各自的影响程度。
同时,我
们还可以进行统计检验,以评估模型的拟合程度和变量的显著性。
结论
通过Eviews多元因子分析,我们可以得出经济数据变量之间
的关系和影响程度。
这些结果可以帮助我们更好地理解经济的运行
规律,为决策提供参考。
以上就是Eviews多元因子分析的案例分析。
通过这个案例,
我们可以更好地掌握使用Eviews进行多元因子分析的方法和步骤。
希望本文对您有所帮助!。
eviews案例分析作业

eviews案例分析作业Eviews案例分析作业。
本次作业将通过Eviews软件对某公司销售数据进行分析,以便更好地理解和运用Eviews软件进行实际数据分析。
首先,我们需要导入销售数据,并对数据进行初步的描述性统计分析。
在Eviews软件中,我们可以通过导入数据文件,选取所需变量,并进行描述性统计分析,包括均值、标准差、最大最小值等。
通过这些统计指标,我们可以对销售数据的整体情况有一个初步的了解。
接下来,我们可以利用Eviews软件进行时间序列分析。
通过Eviews的时间序列分析功能,我们可以对销售数据的趋势、季节性和周期性进行分析,从而更好地了解销售数据的变化规律。
同时,我们还可以利用Eviews软件进行相关性分析,找出销售数据与其他变量之间的相关关系,帮助我们更好地理解销售数据的影响因素。
除了时间序列分析,Eviews软件还可以进行回归分析。
通过回归分析,我们可以建立销售数据与其他变量之间的数学模型,从而预测销售数据的变化趋势。
在Eviews软件中,我们可以选择合适的回归模型,并进行参数估计和显著性检验,以确定最优的回归模型,从而更准确地预测销售数据的变化。
最后,我们可以利用Eviews软件进行模型诊断和检验。
在建立了销售数据的数学模型之后,我们需要对模型进行诊断和检验,以验证模型的有效性和稳定性。
通过Eviews软件的模型诊断功能,我们可以对模型的残差进行分析,检验模型的拟合优度,并对模型进行修正和改进,以提高模型的预测能力和解释能力。
通过以上对Eviews软件在销售数据分析中的应用,我们可以更好地理解和运用Eviews软件进行实际数据分析。
Eviews软件提供了丰富的数据分析功能,可以帮助我们更好地理解数据的规律和特点,从而更准确地预测和分析数据的变化。
希望本次作业对大家能够有所帮助,更好地掌握Eviews软件的数据分析技能。
计量经济学案例eviews

案例分析1.问题的提出和模型的设定根据我国1978—1997年的财政收入Y 和国民生产总值X 的数据资料,分析财政收入和国民生产总值的关系建立财政收入和国民生产总值的回归模型。
假定财政收入和国民收入总值之间满足线性约束,则理论模型设定为i i i u X Y ++=21ββ其中i Y 表示财政收入,i X 表示国民生产总值。
表1我国1978—1997年财政收入和国民生产总值2.参数估计进入EViews 软件包,确定时间范围;编辑输入数据;选择估计方程菜单,估计样本回归函数如下表 2obsX Y 19783624.100 1132.260 19794038.200 1146.380 19804517.800 1159.930 19814860.300 1175.790 19825301.800 1212.330 19835957.400 1366.950 19847206.700 1624.860 19858989.100 2004.820 198610201.40 2122.010 198711954.50 2199.350 198814922.30 2357.240 198916917.80 2664.900 199018598.40 2937.100 199121662.50 3149.480 199226651.90 3483.370 199334560.50 4348.950 199446670.00 5218.100 199557494.90 6242.200 199666850.50 7407.990 1997 73452.50 8651.140估计结果为Y=858.3108 + 0.100031X(12.78768) (46.04788)R^2=0.991583 S.E.=208.508 F=2120.408括号内为t统计量值。
3.检验模型的异方差(一)图形法1、EViews软件操作。
eviews多元线性回归案例分析

一、研究的目的要求改革开放以来,随着经济体制的改革深化和经济的快速增长,中国的财政收支状况发生了很大的变化,中央和地方的税收收入1978年为亿元到2002年已增长到亿元25年间增长了33倍。
为了研究中国税收收入增长的主要原因,分析中央和地方税收收入的增长规律,预测中国税收未来的增长趋势,需要建立计量经济学模型。
影响中国税收收入增长的因素很多,但据分析主要的因素可能有:(1)从宏观经济看,经济整体增长是税收增长的基本源泉。
(2)公共财政的需求,税收收入是财政的主体,社会经济的发展和社会保障的完善等都对公共财政提出要求,因此对预算指出所表现的公共财政的需求对当年的税收收入可能有一定的影响。
(3)物价水平。
我国的税制结构以流转税为主,以现行价格计算的DGP等指标和和经营者收入水平都与物价水平有关。
(4)税收政策因素。
我国自1978年以来经历了两次大的税制改革,一次是1984—1985年的国有企业利改税,另一次是1994年的全国范围内的新税制改革。
税制改革对税收会产生影响,特别是1985年税收陡增%。
但是第二次税制改革对税收的增长速度的影响不是非常大。
因此可以从以上几个方面,分析各种因素对中国税收增长的具体影响。
二、模型设定为了反映中国税收增长的全貌,选择包括中央和地方税收的‘国家财政收入’中的“各项税收”(简称“税收收入”)作为被解释变量,以放映国家税收的增长;选择“国内生产总值(GDP)”作为经济整体增长水平的代表;选择中央和地方“财政支出”作为公共财政需求的代表;选择“商品零售物价指数”作为物价水平的代表。
由于税制改革难以量化,而且1985年以后财税体制改革对税收增长影响不是很大,可暂不考虑。
所以解释变量设定为可观测“国内生产总值(GDP)”、“财政支出”、“商品零售物价指数”从《中国统计年鉴》收集到以下数据年份财政收入(亿元)Y国内生产总值(亿元)X2财政支出(亿元)X3商品零售价格指数(%)X419781979102 198**** ****19821983198471711985198**** ****19881989199019911992199319941995199619971998199997 200020012002设定线性回归模型为:Y i=β0+β2X2+β3X3+β4X4+μ三、参数估计利用eviews软件可以得到Y关于X2的散点图:可以看出Y和X2成线性相关关系Y关于X3的散点图:可以看出Y和X3成线性相关关系Y关于X1的散点图:Dependent Variable: Y Method: Least SquaresDate: 12/01/09 Time: 13:16 Sample: 1978 2002Included observations: 25Variable Coefficient Std. Error t-Statistic Prob.C X2 X3 X4R-squaredMean dependent varAdjusted R-squared. dependent var. of regressionAkaike info criterionSum squared resid1463163.Schwarz criterion Log likelihood F-statisticDurbin-Watson statProb(F-statistic )模型估计的结果为:Y i=+++t={} {} {} {}R2= R2= F= df=21四、模型检验1.经济意义检验模型估计结果说明,在假定其他变量不变的情况下,当年GDP每增长1亿元,税收收入就会增长亿元;在假定其他变量不变的情况下,当年财政支出每增长1亿元,税收收入就会增长亿元;在假定其他变量不变的情况下,当零售商品物价指数上涨一个百分点,税收收入就会增长亿元。
计量经济学---EViews的基本操作案例

THANKS
利用Eviews的最小二乘法程序,输出的结果如下: Dependent Variable(从属变量):Y Method:Least Squares(最小二乘法) Sample:1985 2001 Included observations:17
(5)模型检验
可决系数检验:R² =1-ESS/TSS=0.9988
R² =0.998726
F=12952.03 n=17 DW=1.025082
(7)回归预测
点估计。假定预测出2002年、2003年的平均每人年收入分别为
X2002=6932.91元,X2003=7334.37元。预测Ŷ2002,Ŷ2003的值。
将X2002=6932.91,X2003=7334.37代入估计的回归方程的点估计值 Ŷ2002=132.0125+0.768761*6932.91=5461.76(元)
说明总离差平方和的99.88%被样本回归直线解释,仅有0.12%未被解释,因此,样
本回归直线对样本点的拟合优度很高。也即用人均年收入解释消费性支出变化效 果很好。
回归系数显著性检验(t检验)
提出原假设H0:β 1=0 备择假设H1:β 1≠0
取显著性水平α =0.05,在自由度为v=17-2=15下,查t分布表,得:t
Ŷ2003=132.0125+0.768761*7334.37=5770.389(元)
(8)作预测值曲线图
从图中可以看出,在样本区间内,城镇居民平均每人年消费 性支出样本值及其估计值非常接近,2002年、2003年预测 值的变化趋势也符合样本区间的变化趋势说明以上建立的先 行回归模型无论是结构分析、统计检验,还是预测效果,都 是比较好的。
Eviews软件数据分析例文剖析

小学期作业影响财政收入的主要因素学院:经济学院班级:统计学班**:***学号:**********影响财政收入的主要因素摘要:财政收入是一国政府实现政府职能的基本保障,主要有资源配置、收入再分配和宏观经济调控三大职能。
财政收入的增长情况关系着一个国家经济的发展和社会的进步。
我国财政收入主要受国民经济发展、预算外资金收入、税收收入等因素的影响。
本文针对我国财政收入影响因素建立了计量经济模型,并利用Eviews软件对收集到的数据进行相关回归分析,排除简单多元回归模型存在的严重多重共线性等问题,建立财政收入影响因素更精确的模型,分析了影响财政收入主要因素及其影响程度,预测我国财政收入增长趋势。
二、模型设定研究财政收入的影响因素离不开一些基本的经济变量。
大多数相关的研究文献中都把总税收、国内生产总值这两个指标作为影响财政收入的基本因素,还有一些文献中也提出了其他一些变量, 比如其他收入、经济发展水平等。
影响财政收入的因素众多复杂, 但是通过研究经济理论对财政收入的解释以及对实践的观察, 对财政收入影响的因素主要是税收收入。
下面我们就以税收收入、能源消费总量、和预算外资金收入作为影响财政收入的主要研究因素。
从中国统计局网站上可以查询到1993年至2008年的相关数据,对其进行计算整理可得:4.、模型的建立根据1978—2008年每年的财政收入Y( 亿元) , 能源消费总量X1( 亿元),预算外资金收入X2( 亿元) ,税收收入X3( 亿元) 的统计数据,由E-views软件得到y,x1,x2,x3的线性图,如下:由图可知,y,x1, x3都是逐年增长的,但增长速率有所变动,而x2呈现水平波动,说明变量间不一定是线性关系,可探索将模型设定为以下形式:lnY=β0+β1lnX1+β2X2+β3lnX3+U三,模型估计与调整利用Eviews软件对模型进行最小二乘法全回归,结果如下:第一步,进行模型的检验。
(一),进行多重共线性的检验方程的修正后的R平方值很高,说明变量对因变量的拟合程度很好,但是应该注意到c,lnx1,x2三者的t值很低(在此选择置信度为0.05),未通过检验,因此怀疑其中存在变量之间的多重共线问题。
用Eviews分析计量经济学问题

计量经济学案例分析一、问题背景高新区自开始设立至今短短十多年的时间,以其惊人的经济发展速度为世人所关注。
随着我国经济发展模式的逐步转变,高新区已经成为我国依靠科技进步和技术创新推动经济社会发展、走中国特色自主创新道路的一面旗帜。
“十二五”时期,面对新的机遇和挑战,国家高新区应注重提升五种能力,努力成为加快转变经济发展方式的排头兵。
为了探索高新经济发展的内在规律性,二、模型设定从高新区的投入来看,对产出有重要影响的因素主要包括以下几个方面:资本K ,劳动力L,技术投入T,此外,体制改革,管理模式创新也可以看作是投入的要素,但因其不可量化,因此归入模型的扰动项中。
这样,按照科布道格拉斯形式的生产函数,我们设定函数形式为:Y AK L T u 两边取自然对数得:lnY lnA lnK lnL lnT l nu其中,资本数据K我们利用的是当年的年末净资产来进行估计,即当年年末资产减去当年年末负债后得到的数据;用当年年末从业人员来估计劳动力L;用当年技术研发投入来估计技术投入T。
数据选用的是截面数据。
从《国家高新技术产业开发区十年发展报告(1991-2000年)》得到1999年全国53个高新区各项指标统计数据:三、模型估计用Eviews软件进行回归分析,得到如下结果:Dependent V ariable: Y Method: Least SquaresDate: 13/12/11 Time: 19:31 Sample: 1 53C LNK LNL R-squaredAdjusted R-squared S.E. of regression Sum squared resid Log likelihood0.664556 0.478131 0.367855 0.644854 0.171585 0.174496 1.030553 2.786560 2.108104 0.3078 0.0076 0.0402 0.740558 Mean dependent 6.280427var0.724674 S.D. dependent var 0.440805 0.231297 Akaike info criterion -0.0177552.621421 Schwarz criterion 0.130946 4.470508 F-statistic 46.62236从表可以看出,回归方程为:lnY 0.664556 0.478131lnK 0.367855lnL 0.140542lnTT= (1.030553) (2.786560) (2.109104) (1.520604)2R2 0.74055874 0.7246(1)经济意义检验从回归结果可以看出,模型估计的 , , 的参数值都为正、且小于1,与生产函数理论中, , 各数值的意义相符。
Eviews多元逻辑回归案例分析

Eviews多元逻辑回归案例分析
简介
本文档旨在使用Eviews软件进行多元逻辑回归分析的案例研究。
逻辑回归是一种常见的统计方法,被广泛应用于解答分类问题。
通过利用Eviews软件的功能,我们将对一个特定案例进行多元逻
辑回归分析并得出结论。
数据收集与准备
在进行多元逻辑回归分析之前,我们首先需要收集并准备相关
的数据。
这些数据应包括自变量和因变量,以及其他可能影响结果
的变量。
采集的数据应保证准确性和完整性。
Eviews多元逻辑回归分析步骤
1. 导入数据:使用Eviews软件将准备好的数据导入到程序中。
2. 数据清洗:对导入的数据进行清洗,包括缺失值处理、异常
值处理等。
3. 模型建立:根据研究的目的和问题,选择合适的自变量进行
建模。
4. 模型估计:使用Eviews软件对建立的模型进行估计,得出
模型的系数和显著性水平。
5. 模型评估与解释:对估计结果进行评估和解释,包括模型的
拟合程度和自变量的影响程度。
6. 结论与讨论:根据模型的结果,得出结论并进行相应的讨论。
结论
通过本次多元逻辑回归分析,在Eviews软件的辅助下,我们
对指定案例进行了深入的研究和分析。
通过清洗数据、建立模型、
估计和解释结果,我们得出了相关结论并进行了进一步的讨论。
这
些结果将为进一步研究和决策提供有价值的参考和指导。
参考文献
[1] Eviews软件官方文档. (访问日期:XXXX年XX月XX日)。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
案例分析一、研究的目的要求居民消费在社会经济的持续发展中有着重要的作用。
居民合理的消费模式和居民适度的消费规模有利于经济持续健康的增长,而且这也是人民生活水平的具体体现。
改革开放以来随着中国经济的快速发展,人民生活水平不断提高,居民的消费水平也不断增长。
但是在看到这个整体趋势的同时,还应看到全国各地区经济发展速度不同,居民消费水平也有明显差异。
例如,2002年全国城市居民家庭平均每人每年消费支出为6029.88元, 最低的黑龙江省仅为人均4462.08元,最高的上海市达人均10464元,上海是黑龙江的2.35倍。
为了研究全国居民消费水平及其变动的原因,需要作具体的分析。
影响各地区居民消费支出有明显差异的因素可能很多,例如,居民的收入水平、就业状况、零售物价指数、利率、居民财产、购物环境等等都可能对居民消费有影响。
为了分析什么是影响各地区居民消费支出有明显差异的最主要因素,并分析影响因素与消费水平的数量关系,可以建立相应的计量经济模型去研究。
二、模型设定我们研究的对象是各地区居民消费的差异。
居民消费可分为城市居民消费和农村居民消费,由于各地区的城市与农村人口比例及经济结构有较大差异,最具有直接对比可比性的是城市居民消费。
而且,由于各地区人口和经济总量不同,只能用“城市居民每人每年的平均消费支出”来比较,而这正是可从统计年鉴中获得数据的变量。
所以模型的被解释变量Y 选定为“城市居民每人每年的平均消费支出”。
因为研究的目的是各地区城市居民消费的差异,并不是城市居民消费在不同时间的变动,所以应选择同一时期各地区城市居民的消费支出来建立模型。
因此建立的是2002年截面数据模型。
影响各地区城市居民人均消费支出有明显差异的因素有多种,但从理论和经验分析,最主要的影响因素应是居民收入,其他因素虽然对居民消费也有影响,但有的不易取得数据,如“居民财产”和“购物环境”;有的与居民收入可能高度相关,如“就业状况”、“居民财产”;还有的因素在运用截面数据时在地区间的差异并不大,如“零售物价指数”、“利率”。
因此这些其他因素可以不列入模型,即便它们对居民消费有某些影响也可归入随即扰动项中。
为了与“城市居民人均消费支出”相对应,选择在统计年鉴中可以获得的“城市居民每人每年可支配收入”作为解释变量X。
从2002年《中国统计年鉴》中得到表2.5的数据:表2.52002年中国各地区城市居民人均年消费支出和可支配收入如图2.12:图2.12从散点图可以看出居民家庭平均每人每年消费支出(Y)和城市居民人均年可支配收入(X)大体呈现为线性关系,所以建立的计量经济模型为如下线性模型:12i i i Y X u ββ=++ 三、估计参数假定所建模型及随机扰动项i u 满足古典假定,可以用OLS 法估计其参数。
运用计算机软件EViews 作计量经济分析十分方便。
利用EViews 作简单线性回归分析的步骤如下: 1、建立工作文件首先,双击EViews 图标,进入EViews 主页。
在菜单一次点击File\New\Workfile ,出现对话框“Workfile Range ”。
在“Workfile frequency ”中选择数据频率:Annual (年度) Weekly ( 周数据 )Quartrly (季度) Daily (5 day week ) ( 每周5天日数据 ) Semi Annual (半年) Daily (7 day week ) ( 每周7天日数据 ) Monthly (月度) Undated or irreqular (未注明日期或不规则的) 在本例中是截面数据,选择“Undated or irreqular ”。
并在“Start date ”中输入开始时间或顺序号,如“1”在“end date ”中输入最后时间或顺序号,如“31”点击“ok ”出现“Workfile UNTITLED ”工作框。
其中已有变量:“c ”—截距项 “resid ”—剩余项。
在“Objects ”菜单中点击“New Objects”,在“New Objects”对话框中选“Group”,并在“Name for Objects”上定义文件名,点击“OK ”出现数据编辑窗口。
若要将工作文件存盘,点击窗口上方“Save ”,在“SaveAs ”对话框中给定路径和文件名,再点击“ok ”,文件即被保存。
4000600080001000012000400060008000100001200014000XY2、输入数据在数据编辑窗口中,首先按上行键“↑”,这时对应的“obs”字样的空格会自动上跳,在对应列的第二个“obs”有边框的空格键入变量名,如“Y ”,再按下行键“↓”,对因变量名下的列出现“NA ”字样,即可依顺序输入响应的数据。
其他变量的数据也可用类似方法输入。
也可以在EViews 命令框直接键入“data X Y ”(一元时) 或 “data Y 1X 2X … ”(多元时),回车出现“Group”窗口数据编辑框,在对应的Y 、X 下输入数据。
若要对数据存盘,点击 “fire/Save As”,出现“Save As ”对话框,在“Drives ”点所要存的盘,在“Directories ”点存入的路径(文件名),在“Fire Name ”对所存文件命名,或点已存的文件名,再点“ok ”。
若要读取已存盘数据,点击“fire/Open”,在对话框的“Drives”点所存的磁盘名,在“Directories”点文件路径,在“Fire Name”点文件名,点击“ok”即可。
3、估计参数方法一:在EViews 主页界面点击“Quick ”菜单,点击“Estimate Equation ”,出现“Equation specification ”对话框,选OLS 估计,即选击“Least Squares”,键入“Y C X ”,点“ok ”或按回车,即出现如表2.6那样的回归结果。
表2.6在本例中,参数估计的结果为:^282.24340.758511i i Y X =+ (287.2649) (0.036928) t=(0.982520) (20.54026)20.935685r = F=421.9023 df=29方法二:在EViews 命令框中直接键入“LS Y C X ”,按回车,即出现回归结果。
若要显示回归结果的图形,在“Equation ”框中,点击“Resids ”,即出现剩余项(Residual )、实际值(Actual )、拟合值(Fitted )的图形,如图2.13所示。
图2.13四、模型检验1、经济意义检验所估计的参数^20.758511β=,说明城市居民人均年可支配收入每相差1元,可导致居民消费支出相差0.758511元。
这与经济学中边际消费倾向的意义相符。
2、拟合优度和统计检验用EViews 得出回归模型参数估计结果的同时,已经给出了用于模型检验的相关数据。
拟合优度的度量:由表2.6中可以看出,本例中可决系数为0.935685,说明所建模型整体上对样本数据拟合较好,即解释变量“城市居民人均年可支配收入”对被解释变量“城市居民人均年消费支出”的绝大部分差异作出了解释。
对回归系数的t 检验:针对01:0H β=和02:0H β=,由表2.6中还可以看出,估计的回归系数^1β的标准误差和t 值分别为:^1()287.2649SE β=,^1()0.982520t β=;^2β的标准误差和t 值分别为:^2()0.036928SE β=,^2()20.54026t β=。
取0.05α=,查t 分布表得自由度为231229n -=-=的临界值0.025(29) 2.045t =。
因为^10.025()0.982520(29) 2.045t t β=<=,所以不能拒绝01:0H β=;因为^20.025()20.54026(29) 2.045t t β=>=,所以应拒绝02:0H β=。
这表明,城市人均年可支配收入对人均年消费支出有显著影响。
五、回归预测由表2.5中可看出,2002年中国西部地区城市居民人均年可支配收入除了西藏外均在8000以下,人均消费支出也都在7000元以下。
在西部大开发的推动下,如果西部地区的城市居民人均年可支配收入第一步争取达到1000美元(按现有汇率即人民币8270元),第二步再争取达到1500美元(即人民币12405元),利用所估计的模型可预测这时城市居民可能达到的人均年消费支出水平。
可以注意到,这里的预测是利用截面数据模型对被解释变量在不同空间状况的空间预测。
用EViews 作回归预测,首先在“Workfile ”窗口点击“Range ”,出现“Change Workfile Range ”窗口,将“End data”由“31”改为“33”,点“OK ”,将“Workfile ”中的“Range ”扩展为1—33。
在“Workfile ”窗口点击“sampl”,将“sampl”窗口中的“1 31”改为“1 33”,点“OK ”,将样本区也改为1—33。
为了输入18270f X =,212405f X =在EViews 命令框键入data x /回车, 在X 数据表中的“32”位置输入“8270”,在“33”的位置输入“12405”,将数据表最小化。
然后在“E quation ”框中,点击“Forecast ”,得对话框。
在对话框中的“Forecast name ”(预测值序列名)键入“fY ”, 回车即得到模型估计值及标准误差的图形。
双击“Workfile ”窗口中出现的“Yf ”,在“Yf ”数据表中的“32”位置出现预测值16555.132f Y =,在“33”位置出现29691.577f Y =。
这是当18270f X =和212405f X =时人均消费支出的点预测值。
为了作区间预测,在X 和Y 的数据表中,点击“View”选“Descriptive Stats\Cmmon Sample”,则得到X 和Y 的描述统计结果,见表2.7: 表2.7根据表2.7的数据可计算:222(1)2042.682(311)125176492.59i xx n σ=-=⨯-=∑221()(82707515.026)569985.74f X X -=-=222()(124057515.026)23911845.72f X X -=-= 取0.05α=,f Y平均值置信度95%的预测区间为:^^21f Y t n ασ18270f X =时6555.13 2.045413.1593⨯6555.13162.10=212405f X =时9691.58 2.045413.1593⨯ 9691.58499.25= 即是说,当18270f X =元时,1f Y 平均值置信度95%的预测区间为(6393.03,6717.23)元。