Spark1.2集群环境搭建(StandaloneHA)4G内存5个节点也是蛮拼的
spark集群三种部署模式的区别

Spark三种集群部署模式的比较目前Apache Spark支持三种分布式部署方式,分别是standalone、spark on mesos和spark on YARN,其中,第一种类似于MapReduce 1.0所采用的模式,内部实现了容错性和资源管理,后两种则是未来发展的趋势,部分容错性和资源管理交由统一的资源管理系统完成:让Spark运行在一个通用的资源管理系统之上,这样可以与其他计算框架,比如MapReduce,公用一个集群资源,最大的好处是降低运维成本和提高资源利用率(资源按需分配)。
本文将介绍这三种部署方式,并比较其优缺点。
1. standalone模式,即独立模式,自带完整的服务,可单独部署到一个集群中,无需依赖任何其他资源管理系统。
从一定程度上说,该模式是其他两种的基础。
借鉴Spark开发模式,我们可以得到一种开发新型计算框架的一般思路:先设计出它的standalone模式,为了快速开发,起初不需要考虑服务(比如master/slave)的容错性,之后再开发相应的wrapper,将stanlone模式下的服务原封不动的部署到资源管理系统yarn或者mesos上,由资源管理系统负责服务本身的容错。
目前Spark在standalone模式下是没有任何单点故障问题的,这是借助zookeeper实现的,思想类似于Hbase master单点故障解决方案。
将Spark standalone与MapReduce比较,会发现它们两个在架构上是完全一致的:1) 都是由master/slaves服务组成的,且起初master均存在单点故障,后来均通过zookeeper解决(Apache MRv1的JobTracker仍存在单点问题,但CDH版本得到了解决);2) 各个节点上的资源被抽象成粗粒度的slot,有多少slot就能同时运行多少task。
不同的是,MapReduce将slot分为map slot和reduce slot,它们分别只能供Map Task和Reduce Task使用,而不能共享,这是MapReduce资源利率低效的原因之一,而Spark则更优化一些,它不区分slot类型,只有一种slot,可以供各种类型的Task使用,这种方式可以提高资源利用率,但是不够灵活,不能为不同类型的Task定制slot资源。
Hadoop-Spark集群部署手册
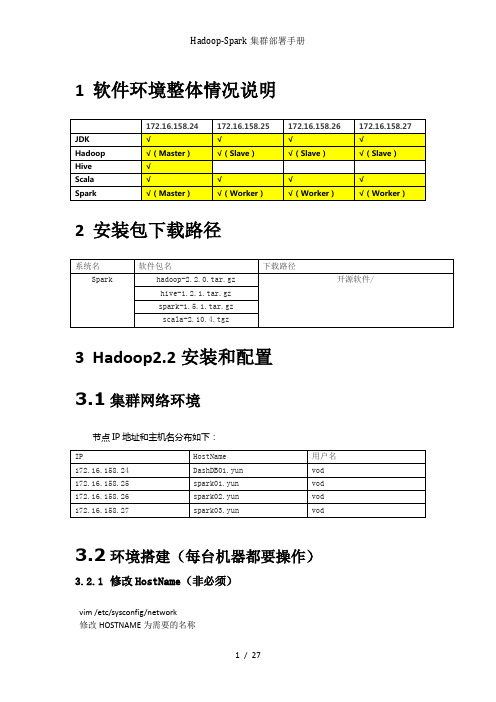
1软件环境整体情况说明2安装包下载路径3Hadoop2.2安装和配置3.1集群网络环境节点IP地址和主机名分布如下:3.2环境搭建(每台机器都要操作)3.2.1修改HostName(非必须)vim /etc/sysconfig/network修改HOSTNAME为需要的名称重启服务器,进行生效reboot3.2.2设置Host映射文件1.使用root身份编辑/etc/hosts映射文件,设置IP地址与机器名的映射,设置信息如下:vim /etc/hosts172.16.158.24 DashDB01.yun172.16.158.25 spark01.yun172.16.158.26 spark02.yun172.16.158.27 spark03.yun2.使用如下命令对网络设置进行重启/etc/init.d/network restart3.验证设置是否成功3.2.3设置操作系统环境3.2.3.1关闭防火墙在Hadoop安装过程中需要关闭防火墙和SElinux,否则会出现异常1.service iptables status查看防火墙状态,如下所示表示iptables已经开启2.以root用户使用如下命令关闭iptableschkconfig iptables off3.2.3.2关闭SElinux1.使用getenforce命令查看是否关闭2.修改/etc/selinux/config 文件将SELINUX=enforcing改为SELINUX=disabled,执行该命令后重启机器生效3.2.3.3JDK安装及配置赋予vod用户/usr/lib/java目录可读写权限,使用命令如下:sudo chmod -R 777 /usr/lib/java把下载的安装包,上传到/usr/lib/java 目录下,使用如下命令进行解压tar -zxvf jdk-7u55-linux-x64.tar.gz解压后目录如下图所示:使用root用户配置 /etc/profile,该设置对所有用户均生效vim /etc/profile添加以下信息:export JAVA_HOME=/usr/lib/java/jdk1.7.0_55export PATH=$PATH:$JAVA_HOME/bin:$JAVA_HOME/jre/binexport CLASSPATH=.:$CLASSPATH:$JAVA_HOME/lib:$JAVA_HOME/jre/lib修改完毕后,使用source /etc/profilejava -version3.2.3.4更新OpenSSLyum update openssl3.2.3.5无密码验证配置1.以root用户使用vim /etc/ssh/sshd_config,打开sshd_config配置文件,开放4个配置,如下图所示:RSAAuthentication yesPubkeyAuthentication yesAuthorizedKeysStrictModes no2.配置后重启服务service sshd restart3.使用root用户登录在4个节点,在/home/common目录下,执行命令mkdir .ssh4.使用vod用户登录在4个节点中使用如下命令生成私钥和公钥;sudo chown -R vod .sshssh-keygen -t rsa5.进入/home/common/.ssh目录在4个节点中分别使用如下命令cp id_rsa.pub authorized_keys_DashDB01.yun把公钥命名authorized_keys_DashDB01.yunauthorized_keys_spark01.yunauthorized_keys_spark02.yunauthorized_keys_spark03.yun6.把3个从节点(spark01,spark02,spark03)的公钥使用scp命令传送到DashDB01.yun节点的/home/common/.ssh文件夹中;scp authorized_keys_spark01.yun :/home/common/.ssh最终DashDB01.yun节点中文件如下7.把4个节点的公钥信息保存到authorized_key文件中使用cat authorized_keys_DashDB01.yun >> authorized_keys 命令8.把该文件分发到其他两个从节点上使用scp authorized_keys :/home/common/.ssh把密码文件分发出其余三台机器的.ssh文件包含如下:9.在4台机器中使用如下设置authorized_keys读写权限chmod 775 authorized_keys10.测试ssh免密码登录是否生效3.3配置Hadooop设置3.3.1准备hadoop文件1.把hadoop-2.2.0目录移到/usr/local目录下cd /home/hadoop/Downloads/sudo cp hadoop-2.2.0 /usr/local2.使用chown命令遍历修改hadoop-1.1.2目录所有者为hadoopsudo chown -R vod /usr/local/hadoop-2.2.0chmod 775 -R /usr/local/hadoop-2.2.0/3.3.2在Hadoop目录下创建子目录使用vod用户在hadoop-2.2.0目录下创建tmp、name和data目录,保证目录所有者为vodcd /usr/local/hadoop-2.2.0mkdir tmpmkdir namemkdir datals3.3.3配置/etc/profilesudo vim /etc/profile添加以下内容export HADOOP_HOME=/usr/local/hadoop-2.2.0export PATH=$PATH:$HADOOP_HOME/binexport YARN_HOME=$HADOOP_HOMEexport HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop export YARN_CONF_DIR=$HADOOP_HOMR/etc/hadoop使用命令使其生效source /etc/profile3.3.4配置hadoop-env.sh1.打开配置文件hadoop-env.shcd /usr/local/hadoop-2.2.0/etc/hadoopsudo vim hadoop-env.sh2.加入配置内容,设置了hadoop中jdk和hadoop/bin路径export JAVA_HOME=/usr/lib/java/jdk1.7.0_55export PATH=$PATH:/usr/local/hadoop-2.2.0/bin3.编译配置文件hadoop-env.sh,并确认生效source hadoop-env.sh3.3.5配置yarn-env.sh1.在/usr/local/hadoop-2.2.0/etc/hadoop打开配置文件yarn-env.sh cd /usr/local/hadoop-2.2.0/etc/hadoopsudo vim yarn-env.sh2.加入配置内容,设置了hadoop中jdk和hadoop/bin路径export JAVA_HOME=/usr/lib/java/jdk1.7.0_553.编译配置文件yarn-env.sh,并确认生效source yarn-env.sh3.3.6配置core-site.xml1.使用如下命令打开core-site.xml配置文件sudo vim core-site.xml2.在配置文件中,按照如下内容进行配置<configuration><property><name></name><value>hdfs://172.16.158.24:9000</value></property><property><name>fs.defaultFS</name><value>hdfs://172.16.158.24:9000</value></property><property><name>io.</name><value>131072</value></property><property><name>hadoop.tmp.dir</name><value></value><description>Abase for other temporary directories.</description> </property><property><name>hadoop.proxyuser.hduser.hosts</name><value>*</value></property><property><name>hadoop.proxyuser.hduser.groups</name><value>*</value></property></configuration>3.3.7配置hdfs-site.xml1.使用如下命令打开hdfs-site.xml配置文件sudo vim hdfs-site.xml2.在配置文件中,按照如下内容进行配置<configuration><property><name>node.secondary.http-address</name><value>172.16.158.24:9001</value></property><property><name>.dir</name><value></value></property><property><name>dfs.datanode.data.dir</name><value></value></property><property><name>dfs.replication</name><value>2</value></property><property><name>dfs.webhdfs.enabled</name><value>true</value></property><property><name>dfs.permissions</name><value>false</value></property></configuration>3.3.8配置mapred-site.xml1.默认情况下不存在mapred-site.xml文件,可以从模板拷贝一份cp mapred-site.xml.template mapred-site.xml2.使用如下命令打开mapred-site.xml配置文件sudo vim mapred-site.xml3.在配置文件中,按照如下内容进行配置<configuration><property><name></name><value>yarn</value></property><property><name>mapreduce.jobhistory.address</name><value>172.16.158.24:10020</value></property><property><name>mapreduce.jobhistory.webapp.address</name><value>172.16.158.24:19888</value></property></configuration>3.3.9配置yarn-site.xml1.使用如下命令打开yarn-site.xml配置文件sudo vim yarn-site.xml2.在配置文件中,按照如下内容进行配置<configuration><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><property><name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandler</value></property><property><name>yarn.resourcemanager.address</name><value>172.16.158.24:8032</value></property><property><name>yarn.resourcemanager.scheduler.address</name><value>172.16.158.24:8030</value></property><property><name>yarn.resourcemanager.resource-tracker.address</name><value>172.16.158.24:8031</value></property><property><name>yarn.resourcemanager.admin.address</name><value>172.16.158.24:8033</value></property><property><name>yarn.resourcemanager.webapp.address</name><value>172.16.158.24:8088</value></property></configuration>3.3.10配置slaves文件1.设置从节点sudo vim slaves修改为spark01.yunspark02.yunspark03.yun3.3.11向各节点分发hadoop程序1.在spark01.yun spark02.yun spark03.yun 机器中创建/usr/local/hadoop-2.2.0目录,然后修改该目录所有权限sudo mkdir /usr/local/hadoop-2.2.0sudo chown -R vod /usr/local/hadoop-2.2.0sudo chmod 775 -R /usr/local/hadoop-2.2.0/2.在DashDB01.yun机器上进入/usr/local/hadoop-2.2.0目录,使用如下命令把hadoop文件夹复制到其他3台使用命令cd /usr/local/hadoop-2.2.0scp -r * :/usr/local/hadoop-2.2.0scp -r * :/usr/local/hadoop-2.2.0scp -r * :/usr/local/hadoop-2.2.03.在从节点查看是否复制成功执行chmod 775 -R /usr/local/hadoop-2.2.0/4.每个节点配置/etc/profilesudo vim /etc/profile添加以下内容export HADOOP_HOME=/usr/local/hadoop-2.2.0export PATH=$PATH:$HADOOP_HOME/binexport YARN_HOME=$HADOOP_HOMEexport HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoopexport YARN_CONF_DIR=$HADOOP_HOMR/etc/hadoop使用命令使其生效source /etc/profile3.4启动hadoop 3.4.1格式化namenode./bin/hdfs namenode -format3.4.2启动hadoopcd /usr/local/hadoop-2.2.0/sbin ./start-all.sh3.4.3验证当前进行此时执行jps命令在DashDB01.yun上运行的进程有:namenode,secondarynamenode,resourcemanagerspark01.yun spark02.yun 和spark03.yun上面运行的进程有:datanode,nodemanager 4Hive1.2.1安装和配置4.1拷贝项目sudo cp -r /home/common/Downloads/hive-1.2.1/ hive-1.2.1更改文件夹所属sudo chown -R vod /usr/local/hive-1.2.1sudo chmod 775 -R /usr/local/hive-1.2.14.2配置/etc/profilesudo vim /etc/profileexport HIVE_HOME=/usr/local/hive-1.2.1export PATH=$HIVE_HOME/bin:$PATHexport HIVE_CONF_DIR=$HIVE_HOME/confsource /etc/profile4.3配置hive(使用mysql数据源)前提条件:在mysql数据库建立hive用户并赋予相关权限mysql> CREATE USER 'hive' IDENTIFIED BY 'mysql';mysql> GRANT ALL PRIVILEGES ON *.* TO 'hive'@'%' WITH GRANT OPTION;mysql> flush privileges;cd $HIVE_CONF_DIR/cp hive-default.xml.template hive-site.xmlvim hive-site.xml修改下列参数:<name>javax.jdo.option.ConnectionURL</name><value>jdbc:mysql://192.168.15.150:3306/hive?createDatabaseIfNotExist=true</value><name>javax.jdo.option.ConnectionDriverName</name><value>com.mysql.jdbc.Driver</value><name>javax.jdo.option.ConnectionUserName</name><value>hive</value><name>javax.jdo.option.ConnectionPassword</name><value>hive</value>执行命令chmod 775 -R /usr/local/hive-1.2.1/4.4启动HiveServer2(后台启动)cd $HIVE_HOME/binnohup hive --service hiveserver2 &测试:netstat -an|grep 10000 或者使用jdbc连接测试4.5测试输入hive命令,启动hivehive> show tables;OKTime taken: 4.824 secondshive> create table hwz(id int, name string);OKTime taken: 0.566 secondshive> select * from hwz;OKTime taken: 0.361 seconds$ hadoop dfs -lsr /user/hiveWarning: $HADOOP_HOME is deprecated.drwxr-xr-x - hadoop supergroup 0 2012-03-22 12:36 /user/hive/warehouse drwxr-xr-x - hadoop supergroup 0 2012-03-22 12:36 /user/hive/warehouse/hwz5Scala安装和配置5.1拷贝安装包cd /usr/libsudo cp /home/common/Downloads/scala-2.10.4.tgz scala-2.10.4.tgz5.2解压安装包sudo tar -xvf scala-2.10.4.tgzsudo rm scala-2.10.4.tgz给scala文件夹赋予相应的权限sudo chown -R vod /usr/lib/scala-2.10.4 sudo chmod 775 -R /usr/lib/scala-2.10.4 5.3配置/etc/profile sudo vim /etc/profileexport SCALA_HOME=/usr/lib/scala-2.10.4 export PATH=$PATH:$SCALA_HOME/bin source /etc/profile5.4向每台机器分发cd /usr/libsudo mkdir scala-2.10.4sudo chown -R vod /usr/lib/scala-2.10.4 sudo chmod 775 -R /usr/lib/scala-2.10.4 scp -r * :/usr/lib/scala-2.10.45.5配置/etc/profile sudo vim /etc/profileexport SCALA_HOME=/usr/lib/scala-2.10.4 export PATH=$PATH:$SCALA_HOME/binsource /etc/profile5.6检测scala -version6Spark安装和配置6.1在master上安装并配置Sparksudo cp -r /home/common/Downloads/spark-1.5.1/ spark-1.5.1sudo chown -R vod /usr/local/spark-1.5.1sudo chmod 775 -R /usr/local/spark-1.5.1●设置SPARK_EXAMPLES_JAR 环境变量sudo vim /etc/profileexport SPARK_HOME=/usr/local/spark-1.5.1export PATH=$PATH:$SPARK_HOME/binexportSPARK_EXAMPLES_JAR=$SPARK_HOME/lib/spark-assembly-1.5.1-hadoop2.2.0.jarsource /etc/profile●在conf/spark-env.sh 中设置cd $SPARK_HOME/confmv spark-env.sh.template spark-env.shsudo vim spark-env.shexport JAVA_HOME=/usr/lib/java/jdk1.7.0_55export SCALA_HOME=/usr/lib/scala-2.10.4export SPARK_MASTER_IP=172.16.158.24export SPARK_MASTER_PORT=7077export MASTER=spark://${SPARK_MASTER_IP}:${SPARK_MASTER_PORT} export SPARK_MEM=16gexport SPARK_WORKER_MEMORY=32gexport SPARK_WORKER_CORES=12source spark-env.sh●在conf/slaves, 添加Spark worker的hostname, 一行一个。
spark standalone集群安装步骤总结

经过这两天的详细安装过程,总结Spark Standalone集群安装步骤如下:环境准备:1、⼀一台物理笔记本mac,8G内存;安装三个虚拟机(Virtualbox),虚拟机操作系统ubuntu12-64bit;2、三个虚拟机名称(修改主机名: vim /etc/hostname; 增加主机名与IP映射: vim /etc/hosts):10.0.2.9 master10.0.2.10 slave110.0.2.11 slave2注意,Virtualbox虚拟机,在NAT模式下,三个节点的IP都是⼀一样的,能够访问mac主机(mac主机访问不了虚拟机节点);如果想将三个节点作为集群,必须将⺴⽹网络模式设置为:内部模式(intnet),linux情况下,⼿手⼯工设置IP 地址和⼦子⺴⽹网掩码3、为了避免权限⿇麻烦,⽤用户使⽤用root登录和使⽤用Ubuntu系统,⽽而Ubuntu在默认情况下并没有开启root ⽤用户,需要做如下设置:sudo -s 进⼊入root⽤用户权限模式vim /etc/lightdm/lightdm.conf增加:[SeatDefaults]greeter-session=unity-greeteruser-session=ubuntugreeter-show-manual-login=true #⼿手⼯工输⼊入登录系统的⽤用户名和密码allow-guest=false #不允许guest登录sudo passwd root(⼀一)JDK安装配置:1、下载JDK,并创建home⺫⽬目录,将安装包解压到home⺫⽬目录:mkdir /usr/lib/javatar zxf jdk-7u51-linux-x64.tar 根据你的操作系统选择jdk版本2、设置环境变量:vim ~/.bashrc增加:export JAVA_HOME=/usr/lib/java/jdk1.7.0_51export JRE_HOME=${JAVA_HOME}/jreexport CLASS_PATH=.:${JAVA_HOME}/lib:${JRE_HOME}/libexport PATH=${JAVA_HOME}/bin:${PATH}使变量⽣生效:source ~/.bashrc3、监测java运⾏行:java -version(⼆二)hadoop2.6.0安装脚本:(2.1) 安装SSH1、安装sshhadoop/spark是采⽤用ssh进⾏行通信的,此时我们需要设置密码为空,即不需要密码登录,这样免去每次通信时都输⼊入密码。
spark环境搭建流程

spark环境搭建流程下载温馨提示:该文档是我店铺精心编制而成,希望大家下载以后,能够帮助大家解决实际的问题。
文档下载后可定制随意修改,请根据实际需要进行相应的调整和使用,谢谢!并且,本店铺为大家提供各种各样类型的实用资料,如教育随笔、日记赏析、句子摘抄、古诗大全、经典美文、话题作文、工作总结、词语解析、文案摘录、其他资料等等,如想了解不同资料格式和写法,敬请关注!Download tips: This document is carefully compiled by theeditor. I hope that after you download them,they can help yousolve practical problems. The document can be customized andmodified after downloading,please adjust and use it according toactual needs, thank you!In addition, our shop provides you with various types ofpractical materials,such as educational essays, diaryappreciation,sentence excerpts,ancient poems,classic articles,topic composition,work summary,word parsing,copy excerpts,other materials and so on,want to know different data formats andwriting methods,please pay attention!1. 安装 Java检查系统是否已安装 Java,如果没有则需要安装。
Spark环境搭建(下)——Spark安装

Spark环境搭建(下)——Spark安装1. 下载Spark1.1 官⽹下载Spark打开上述链接,进⼊到下图,点击红框下载Spark-2.2.0-bin-hadoop2.7.tgz,如下图所⽰:2. 安装SparkSpark安装,分为:准备,包括上传到主节点,解压缩并迁移到/opt/app/⽬录;Spark配置集群,配置/etc/profile、conf/slaves以及confg/spark-env.sh,共3个⽂件,配置完成需要向集群其他机器节点分发spark程序,直接启动验证,通过jps和宿主机浏览器验证启动spark-shell客户端,通过宿主机浏览器验证2.1 上传并解压Spark安装包1. 把spark-2.2.0-bin-hadoop2.7.tgz通过Xftp⼯具上传到主节点的/opt/uploads⽬录下2. 在主节点上解压缩# cd /opt/uploads/# tar -zxvf spark-2.2.0-bin-hadoop2.7.tgz有时解压出来的⽂件夹,使⽤命令 ll 查看⽤户和⽤户组有可能不是hadoop时,即上图绿框显⽰,则需要使⽤如下命令更换为hadoop⽤户和⽤户组:# sudo chown hadoop:hadoop spark-2.2.0-bin-hadoop2.73. 把spark-2.2.0-bin-hadoop2.7移到/opt/app/⽬录下# mv spark-2.2.0-bin-hadoop2.7 /opt/app/# cd /opt/app && ll2.2 配置⽂件与分发程序2.2.1 配置/etc/profile1. 以hadoop⽤户打开配置⽂件/etc/profile# sudo vi /etc/profile2. 定义SPARK_HOME并把spark路径加⼊到PATH参数中export SPARK_HOME=/opt/app/spark-2.2.0-bin-hadoop2.7export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin2.2.2 配置conf/slaves1. 打开配置⽂件conf/slaves,默认情况下没有slaves,需要使⽤cp命令复制slaves.template# cd /opt/app/spark-2.2.0-bin-hadoop2.7/conf 如果不在/opt/app/spark-2.2.0-bin-hadoop2.7⽬录下,则使⽤该命令# cp slaves.template slaves# sudo vi slaves2. 加⼊slaves配置节点hadoop1hadoop2hadoop32.2.3 配置conf/spark-env.sh1. 以hadoop⽤户,使⽤如下命令,打开配置⽂件spark-env.sh# cd /opt/app/spark-2.2.0-bin-hadoop2.7 如果不在/opt/app/spark-2.2.0-bin-hadoop2.7⽬录下,则使⽤该命令# cp spark-env.sh.template spark-env.sh# vi spark-env.sh2. 加⼊如下环境配置内容,设置hadoop1为Master节点:export JAVA_HOME=/usr/lib/java/jdk1.8.0_151export SPARK_MASTER_IP=hadoop1export SPARK_MASTER_PORT=7077export SPARK_WORKER_CORES=1export SPARK_WORKER_INSTANCES=1export SPARK_WORKER_MEMORY=900M【注意】:SPARK_WORKER_MEMORY为计算时使⽤的内存,设置的值越低,计算越慢,反之亦然。
Spark1.2_搭建过程

Spark1.2.0 on yarn搭建过程1.搭建Hadoop2.6.0的集群,内容见《Hadoop2.6.0搭建过程》。
2.安装Scala(用户需要根据Spark官方规定的Scala版本进行下载和安装)2.1下载Scala官网提供各个版本的Scala,直接到下载页面/download/进行下载需要的版本。
本次搭建过程以Scala2.10.4为例。
2.2解压$ sudo tar -vxzf scala-2.10.4.tgz -C /usr/local/2.3配置环境变量$ vim /etc/profile添加以下内容:# set scala homeexport SCALA_HOME=/usr/local/scala-2.10.4export PATH=${SCALA_HOME}/bin:$PATH2.4使profile文件生效$ source /etc/profile3.安装Spark3.1下载进入官方网站下载页面/downloads.html下载对应Hadoop版本的Spark,本次搭建以Spark1.2.0为例。
下载的时候只需要主要下载的版本是否需要自己编译。
我介绍的过程下载的是预编译版本。
3.2解压$ sudo tar -vxzf spark-1.2.0-bin-hadoop2.4.tgz -C /usr/local/$ cd /usr/local/$ sudo mv spark-1.2.0-bin-hadoop2.4 spark1.2$ sudo chown -R hadoop:hadoop spark1.2最后一步就是将这个文件授权给hadoop用户,因为我解压到的路径是root用户拥有的,当然你也可以将所有的路径都设置再hadoop用户下。
3.3修改配置文件$ cd /usr/local/spark1.2/$ vim conf/spark-env.sh没有这个文件可以直接重命名spark-env.sh.template文件,或者复制它再修改名称,都可以添加如下内容:#配置Scala的路径export SCALA_HOME=/usr/local/scala-2.10.4#配置每个worker的最大工作内存,增加这个数值可以在内存中缓存更多的数据,但一定#要给slave节点留有足够的内存运行其他服务,具体情况根据自己的集群实际情况而定。
大数据集群配置过程_spark篇

大数据集群配置过程_spark篇JDDC_SEED_BIGDATA 2015-01-151.概述本篇文档主要讲解spark集群的部署过程。
如果是基于yarn模式的spark部署,必须在部署spark之前完成Hadoop集群的部署工作,并确保Hadoop可以正常工作。
1.1Spark的部置模式整理▪standalone模式:即独立模式,自带完整的服务,可单独部署到一个集群中,无需依赖任何其他资源管理系统。
从一定程度上说,该模式是spark on mesos和 spark on YARN的基础。
▪Spark On Mesos模式:这是很多公司采用的模式,官方推荐这种模式(当然,原因之一是血缘关系)。
正是由于Spark开发之初就考虑到支持Mesos,因此,目前而言,Spark运行在Mesos上会比运行在YARN上更加灵活,更加自然。
▪Spark On YARN模式:这是一种最有前景的部署模式。
但限于YARN自身的发展,目前仅支持粗粒度模式(Coarse-grained Mode)。
如之前所述,些种模式下需要部署hadoop集群。
总体分析:根据网上的资源的描述,目前来看YARN这种模式,是比较流行的方式。
因为YARN拥有强大的社区支持,且逐步已经成为资源管理系统中的标准。
本次检证采用的是Spark on YARN这种模式。
1.2Spark部置所需要软件由于本次采用的是Spark on YARN这种模式,所以需要的软件如下:说明:如果采用预编译的方式进spark的布署,还需要安装maven。
本次没有采用预编译的方式而是采用包邦定的方式(所以下使用spark-1.0.2-bin-hadoop**.tar这样的安装包),因为预编译的方式部置需要联网,而且速度慢,步骤复杂,但有一个好处—不需要单独安装scala。
另外需要注意的是,采用包邦定的方式部署时,要使用与hadoop相兼容的spark版本。
2.正文本次spark集群规模以及分布如下:2.1JDK安装请参考《大数据集群配置过程_hadoop篇.docx》2.2Hadoop集群安装请参考《大数据集群配置过程_hadoop篇.docx》2.3Scala安装在spark mastar(hadoop02)节点进行进行scala案装1.将scala-2.10.4.gz文件放置到/home/hadoop/source/目录下2.执行tar –zvxf /home/hadoop/source/scala-2.10.4.gz命令3.执行vi /etc/profile对环境配置文件进行内容追加,追加内容如下export SCALA_HOME=/home/hadoop/source/scala-2.10.4export PATH=$PATH:$SCALA_HOME/bin2.4Spark安装在spark mastar(hadoop02)节点进行进行spark案装1.将spark-1.0.2-bin-hadoop2.tar文件放置到/home/hadoop/source/目录下2.执行tar –zvxf /home/hadoop/source/spark-1.0.2-bin-hadoop2.tar命令3.执行vi /etc/profile对环境配置文件进行内容追加,追加内容如下export SPARK_HOME=/home/hadoop/source/spark-1.0.2-bin-hadoop2export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin4.执行以下各命令进入到/home/hadoop/source/spark-1.0.2-bin-hadoop2/confcd /home/hadoop/source/spark-1.0.2-bin-hadoop2/conf5.执行cp spark-env.sh.template spark-env.sh命令,生成一个spark-env.sh文件6.执行vi spark-env.sh命令向spark-env.sh文件中追加以下内容export SCALA_HOME=/home/hadoop/source/scala-2.10.4export JAVA_HOME=/usr/java/jdk1.8.0_25export HADOOP_HOME=/home/hadoop/source/hadoop-2.2.0export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoopexport SPARK_MASTER_IP=hadoop02export SPARK_WORKER_MEMORY=1gexport SPARK_MASTER_PORT=7077export SPARK_MASTER_WEBUI_PORT=8080注意:export SPARK_MASTER_IP=hadoop02中的hadoop02是master节点的主机名。
如何运行Spark集群的Standalone模式

如何运⾏Spark集群的Standalone模式之前看了很多中⽂资料,看得云⾥雾⾥,还不如直接看官⽹呢!既权威⼜简洁明了。
Spark集群有三种运⾏模式:Standalone、Mesos和YARN模式。
现在说Standalone模式。
这是最简单的模式,Spark靠⾃⼰就能运⾏这个模式(不依靠其它集群管理⼯具)。
⽅法⼀:⼿动运⾏Standalone模式。
前提:Spark各个⽂件都不做任何修改。
1、在master机器上运⾏ ./sbin/start-master/sh运⾏完之后,会打印出url: spark://HOST:PORT ,这个就是当前master的Spark URL。
2、在slave机器上运⾏ ./sbin/start-slave.sh <master-spark-url>然后在Master的管理界⾯上查看http://master-ip:8080,查看slave是否已上线。
⽅法⼆:使⽤集群运⾏脚本运⾏Standalone模式。
前提:master节点去访问slave节点需要使⽤ssh⽆密码登录,因此需要提前配置⽆密码登录。
1、在master的conf⽂件夹下新增slaves⽂件。
slaves⽂件⾥存放着每⼀个slave节点的hostname,每⾏⼀个。
2、在master节点上运⾏如下脚本即可:sbin/start-master.sh - 在本机上运⾏master节点sbin/start-slaves.sh - 根据slaves⽂件在每台机器上运⾏slave节点sbin/start-slave.sh - 在本机上运⾏slave节点sbin/start-all.sh - 运⾏所有的master和slave节点sbin/stop-master.sh - 关闭本机上运⾏的master节点sbin/stop-slaves.sh - 关闭slaves⽂件⾥设定的每⼀个slave节点sbin/stop-all.sh - 关闭所有的master和slave节点完毕。
Spark集群环境搭建——部署Spark集群

Spark集群环境搭建——部署Spark集群在前⾯我们已经准备了三台服务器,并做好初始化,配置好jdk与免密登录等。
并且已经安装好了hadoop集群。
如果还没有配置好的,参考我前⾯两篇博客:Spark集群环境搭建——服务器环境初始化:Spark集群环境搭建——Hadoop集群环境搭建:集群规划:搭建Spark集群1、下载:官⽹地址:下载地址:cd /data/apps/shell/softwarewget https:///spark/spark-3.1.2/spark-3.1.2-bin-hadoop3.2.tgz --no-check-certificate2、解压安装:tar xf spark-3.1.2-bin-hadoop3.2.tgzmv spark-3.1.2-bin-hadoop3.2 /data/apps/spark-3.1.2编辑环境变量:vim /etc/profile## SPARK_HOMEexport SPARK_HOME=/data/apps/spark-3.1.2export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin加载使⽣效:source /etc/profile3、修改配置:进⼊conf⽬录:cd /data/apps/spark-3.1.2/confmv spark-defaults.conf.template spark-defaults.confmv spark-env.sh.template spark-env.shmv log4j.properties.template log4j.properties修改slaves⽂件,添加从机vim slavesdev-spark-master-206dev-spark-slave-171dev-spark-slave-172修改spark-defaults.confvim spark-defaults.confspark.master spark://dev-spark-master-206:7077spark.serializer org.apache.spark.serializer.KryoSerializerspark.driver.memory 1g修改spark-env.shvim spark-env.shexport JAVA_HOME=/usr/java/jdk1.8.0_162export HADOOP_HOME=/data/apps/hadoop-3.2.2/export HADOOP_CONF_DIR=/data/apps/hadoop-3.2.2/etc/hadoopexport SPARK_DIST_CLASSPATH=$(/data/apps/hadoop-3.2.2/bin/hadoop classpath)export SPARK_MASTER_HOST=dev-spark-master-206export SPARK_MASTER_PORT=70774、解决与Hadoop冲突这⾥要注意,备注:在$HADOOP_HOME/sbin 及 $SPARK_HOME/sbin 下都有 start-all.sh 和 stop-all.sh ⽂件,如果同时加载到环境变量,会有冲突,我们选择改掉其中⼀个:在输⼊ start-all.sh / stop-all.sh 命令时,谁的搜索路径在前⾯就先执⾏谁,此时会产⽣冲突。
spark搭建手册

H a d o o p+S p a r k大数据集群环境1.配置集群的准备,文件包如下图:分布式机器如下:SparkMasterSparkWorker1SparkWorker 22.配置linux 环境1.1配置linux登录时可以使用root账户1.2配置/etc/hostname,修改主机名SparkMaster,工作机为SparkWorker1、SparkWorker2,重启生效1.3配置/etc/hosts ,如下图1.4配置三台机器SSH无密码登录3.安装java环境,安装到/usr/lib/java目录,配置环境变量,验证成功,如下图4.安装hadoop1.1将hadoop安装到 /usr/local/hadoop目录,配置环境变量1.2在$HADOOP_HOME 下,按照下图操作创建目录,如下图1.3进入$HADOOP_HOME目录,对配置文件进行如下图配置,如下图首先,修改,JAVA_HOME=我们java安装目录,如下图然后,修改, JAVA_HOME=我们java安装目录,如下图然后,修改, JAVA_HOME=我们java安装目录,如下图然后,修改slaves文件,将客户机填写到文件中,如下图然后,修改,填写如图配置,如下图然后,修改,填写如图配置,如下图然后,复制一份为,如下图然后,修改,填写如图配置,如下图最后,将SparkMaster操作,同步到SparkWorker1和SparkWorker2上1.4启动hadoop首先,收入hadoop namenode –format,如下图然后,启动hdfs文件系统,如下图可以验证是否成功,使用jps命令,master有3个进程,worker2有两个进程,如下图同时登录hdfs文件系统web界面查看配置情况,如下图然后,启动yarn集群,如下图进行验证,使用jps命令,如下图最后,验证hadoop分布式集群在hdfs上,创建两个文件夹,如下图登录,hdfs的web界面,进行查看,如下图5.安装scala安装到 /usr/lib/scala目录下,配置环境变量,验证如下图所有分布式集群都需要安装。
spark作业运行流程

spark作业运行流程
Spark作业运行流程简述如下:
1. 创建SparkContext:在应用中初始化Spark环境,连接到集群资源管理器(如Standalone、YARN或Mesos)。
2. 提交作业:通过spark-submit命令提交打包好的应用程序给Master节点。
3. 申请资源:SparkContext向资源管理器请求Executor资源,资源管理器分配资源并在Worker节点上启动Executor进程。
4. DAG构建与优化:根据用户代码生成DAG(有向无环图),表示任务的执行计划。
DAGScheduler将DAG划分为Stage(阶段),每个Stage包含多个可以并行执行的Task。
5. 任务调度:DAGScheduler将TaskSet提交给TaskScheduler,后者负责在Executor之间调度和分配任务。
6. 执行任务:Executor执行任务,任务可能涉及数据加载、转换操作和行动操作,结果写回存储系统或输出到控制台。
7. 反馈与容错:Driver监控所有任务的执行状态,并处理失败任务的重试,确保作业最终成功完成。
spark之Standalone模式部署配置详解

spark之Standalone模式部署配置详解spark运⾏模式Spark 有很多种模式,最简单就是单机本地模式,还有单机伪分布式模式,复杂的则运⾏在集群中,⽬前能很好的运⾏在Yarn和 Mesos 中,当然 Spark 还有⾃带的 Standalone 模式,对于⼤多数情况 Standalone 模式就⾜够了,如果企业已经有Yarn 或者 Mesos 环境,也是很⽅便部署的。
1.local(本地模式):常⽤于本地开发测试,本地还分为local单线程和local-cluster多线程;2.standalone(集群模式):典型的Mater/slave模式,不过也能看出Master是有单点故障的;Spark⽀持ZooKeeper来实现HA3.on yarn(集群模式):运⾏在 yarn 资源管理器框架之上,由 yarn 负责资源管理,Spark 负责任务调度和计算4.on mesos(集群模式):运⾏在 mesos 资源管理器框架之上,由 mesos 负责资源管理,Spark 负责任务调度和计算5.on cloud(集群模式):⽐如 AWS 的 EC2,使⽤这个模式能很⽅便的访问 Amazon的 S3;Spark ⽀持多种分布式存储系统:HDFS 和 S3Spark Standalone集群部署准备⼯作1.这⾥我下载的是Spark的编译版本,否则需要事先⾃⾏编译2.Spark需要Hadoop的HDFS作为持久化层,所以在安装Spark之前需要安装Hadoop,这⾥Hadoop的安装就不介绍了,给出⼀个教程3.实现创建hadoop⽤户,Hadoop、Spark等程序都在该⽤户下进⾏安装4.ssh⽆密码登录,Spark集群中各节点的通信需要通过ssh协议进⾏,这需要事先进⾏配置。
通过在hadoop⽤户的.ssh⽬录下将其他⽤户的id_rsa.pub公钥⽂件内容拷贝的本机的authorized_keys⽂件中,即可事先⽆登录通信的功能5.Java环境的安装,同时将JAVA_HOME、CLASSPATH等环境变量放到主⽬录的.bashrc,执⾏source .bashrc使之⽣效部署配置这⾥配置⼯作需要以下⼏个步骤:1.解压Spark⼆进制压缩包2.配置conf/spark-env.sh⽂件3.配置conf/slave⽂件下⾯具体说明⼀下:配置Spark的运⾏环境,将spark-env.sh.template模板⽂件复制成spark-env.sh,然后填写相应需要的配置内容:export SPARK_MASTER_IP=hadoop1export SPARK_MASTER_PORT=7077export SPARK_WORKER_CORES=1export SPARK_WORDER_INSTANCES=1export SPARK_WORKER_MEMORY=3g其他选项内容请参照下⾯的选项说明:# Options for the daemons used in the standalone deploy mode:# - SPARK_MASTER_IP, to bind the master to a different IP address or hostname# - SPARK_MASTER_PORT / SPARK_MASTER_WEBUI_PORT, to use non-default ports for the master# - SPARK_MASTER_OPTS, to set config properties only for the master (e.g. "-Dx=y")# - SPARK_WORKER_CORES, to set the number of cores to use on this machine# - SPARK_WORKER_MEMORY, to set how much total memory workers have to give executors (e.g. 1000m, 2g)# - SPARK_WORKER_PORT / SPARK_WORKER_WEBUI_PORT, to use non-default ports for the worker# - SPARK_WORKER_INSTANCES, to set the number of worker processes per node# - SPARK_WORKER_DIR, to set the working directory of worker processes# - SPARK_WORKER_OPTS, to set config properties only for the worker (e.g. "-Dx=y")# - SPARK_HISTORY_OPTS, to set config properties only for the history server (e.g. "-Dx=y")conf/slave⽂件⽤户分布式节点的配置,这⾥只需要在slave⽂件中写⼊该节点的主机名即可将以上内容都配置好了,将这个spark⽬录拷贝到各个节点scp -r spark hadoop@hadoop2:~接下来就可以启动集群了,在Spark⽬录中执⾏sbin/start-all.sh,然后可以通过netstat -nat命令查看端⼝7077的进程,还可以通过浏览器访问hadoop1:8080了解集群的概况Spark Client部署Spark Client的作⽤是,事先搭建起Spark集群,然后再物理机上部署客户端,然后通过该客户端提交任务给Spark集群。
Spark环境搭建手册

Spark集群搭建手册1.在各个节点安装spark,推荐从官网下载最新的稳定版本:a.创建spark安装目录:mkdir/usr/local/sparkb.把下载的spark拷贝到安装目录并解压(安装了VMware tools后,可以直接将下载的安装包拖拉到安装目录中):tar-xzvf spark-2.0.0-bin-hadoop2.6.tgzc.为了可以在任意目录下使用spark命令,需要将spark的bin和sbin目录配置到.bashrc中,vim~/.bashrc:export SPARK_HOME=/usr/local/spark-2.0.0-bin-hadoop2.6ExportPATH=$JAVA_HOME/bin:$JRE_HOME/bin:$SCALA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$SPARK_HOME/bin:$SPARK_HOME/sbin:$PATHd.使用source命令使更改生效:source~/.bashrc2.在各个节点配置spark一下,配置文件都是在$SPARK_HOME/conf目录下:a.修改slaves文件,(若没有slaves文件可以cp slaves.template slaves创建),添加worker节点的Hostname,修改后内容如下:b.配置spark-env.sh,(若没有该文件可以cp spark-env.sh.template spark-env.sh创建),添加如下内容:export JAVA_HOME=/usr/lib/javaexport SCALA_HOME=/usr/lib/scala-2.12.0-M5export HADOOP_HOME=/usr/local/hadoopexport HADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoopexport SPARK_MASTER_IP=masterexport SPARK_WORKER_MEMORY=1g新版的:(旧版的)修改后的内容如下:更详细的配置说明,请参考官方文档:/docs/latest/spark-standalone.html#cluster-launch-scriptsc.(可选)配置spark-defaults.sh:d.将主节点中的Spark目录复制到从节点的家目录中3.启动并验证spark集群:Spark只是一个计算框架,并不提供文件系统功能,故我们需要首先启动文件系统hdfs;在standalone模式下,我们并不需要启动yarn功能,故不需要启动yarn.a.用start-dfs.sh启动hdfsb.在hadoop集群启动成功的基础上,启动spark集群,常见的做法是在master节点上start-all.sh:c.使用jps在master和worker节点上验证spark集群是否正确启动:d.通过webui查看spark集群是否启动成功:http://master:8080。
(一)从零开始搭建SparkStandalone集群环境搭建

(⼀)从零开始搭建SparkStandalone集群环境搭建本⽂主要讲解spark 环境的搭建主机配置 4核8线程,主频3.4G,16G内存虚拟环境: VMWare虚拟环境系统:Ubuntu 14.10虚拟机运⾏环境:jdk-1.7.0_79(64bit)hadoop-2.6.0.tar.gzscala-2.10.4.tarspark-1.5.0-bin -hadoop-2.6.0.tgz(⼀)样本虚拟机的搭建1)虚拟机安装ubuntu,每个分配3G内存,完成后后输⼊如下命令来获得root权限: #sudo passwd 2)ubuntu下源的更改: #sudo gedit /etc/apt/sources.list 找到⼀个还⽤的源替换掉 /etc/apt/sources.list中原来的内容 执⾏更新: #sudo apt-get update3)安装ssh,以便远程登录 ssh-client :本机作为客户机通过ssh链接远程的服务器 ssh-server:本机作为远程服务器,可以被客户机链接 #sudo apt-get install ssh-client 注意上述命令可能出现问题 “依赖:openssh-client (= 1:6.6p1-2ubuntu1)” 使⽤这条命令即可解决: #sudo apt-get install ssh-client= 1:6.6p1-2ubuntu1 接下来安装#sudo apt-get install ssh-server (或者 apt-get install openssh-server)4)查看ssh服务是否启动 #ps -e |grep ssh 显现出sshd 则说明安装成功5)更新vim #sudo apt-get remove vim #sudo apt-get install vim6)修改/etc/ssh/sshd_config ⽂件,使得本机允许远程连接,现在即可通过putty,xshell等连接该机 # Authentication: LoginGraceTime 120 PermitRootLogin yes StrictModes yes7)修改host主机名 #vi /etc/hostname 将该⽂件该为spark1 然后 #vi /ect/hosts 改成与上述⽂件相同的名字 重启 #hostname 查看是否⽣效8)注意虚拟机的⽹络设置为桥接 #ifconfig 可来查看⽹络状态9)根据求查看是否需要固定IP 设置静态IP⽅法如下: #sudo vim /etc/network/interfaces #修改如下部分: auto eth0 iface eth0 inet static address 192.168.0.117 gateway 192.168.0.1 #这个地址你要确认下⽹关是不是这个地址 netmask 255.255.255.0 network 192.168.0.0 broadcast 192.168.0.255 因为以前是dhcp解析,所以会⾃动分配dns服务器地址,⽽⼀旦设置为静态ip后就没有⾃动获取到的dns服务器了,设置静态IP地址后,再重启后就⽆法解析域名。
Spark集群-Standalone模式

Spark集群-Standalone模式Spark 集群相关来源于官⽅, 可以理解为是官⽅译⽂, 外加⼀点⾃⼰的理解. 版本是2.4.4本篇⽂章涉及到:集群概述master, worker, driver, executor的理解打包提交,发布 Spark applicationstandalone模式SparkCluster 启动及相关配置资源, executor分配开放⽹络端⼝⾼可⽤(Zookeeper)名词解释Term(术语) | Meaning(含义)| - | -Application | ⽤户构建在 Spark 上的程序。
由集群上的⼀个 driver 程序和多个 executor 组成。
Driver program | 该进程运⾏应⽤的 main() ⽅法并且创建了 SparkContext。
Cluster manager | ⼀个外部的⽤于获取集群上资源的服务。
(例如,Standlone Manager,Mesos,YARN)Worker node | 任何在集群中可以运⾏应⽤代码的节点。
Executor | ⼀个为了在 worker 节点上的应⽤⽽启动的进程,它运⾏ task 并且将数据保持在内存中或者硬盘存储。
每个应⽤有它⾃⼰的Executor。
Task | ⼀个将要被发送到 Executor 中的⼯作单元。
Job | ⼀个由多个任务组成的并⾏计算,并且能从 Spark action 中获取响应(例如 save,collect); 您将在 driver 的⽇志中看到这个术语。
Stage | 每个 Job 被拆分成更⼩的被称作 stage(阶段)的 task(任务)组,stage 彼此之间是相互依赖的(与 MapReduce 中的 map 和 reduce stage 相似)。
您将在 driver 的⽇志中看到这个术语。
概述参考链接:中⽂链接:Spark Application 在集群上作为独⽴的进程组来运⾏,在 main程序(称之为 driver 程序)中通过 SparkContext 来协调。
spark集群环境搭建基本步骤

spark集 群 环 境 搭 建 基 本 步 骤
1 准备环境 2 安装JDK 3 上传 spark安装包 4 解压 spark并修改配置文件(两个配置文件,第一个配置文件添加了3个配置参数) 5 将配置好的 spark安装程序拷贝给其他机器 for i in{5..8}; do scp-r/ biodata/ spark-2.2.0-bin-hadoop2. 7/ node-$i:/biodata:done 6 启动 spark(sbin/ start-all.sh) 问题:Worker怎么知道 Master在嘟里嗯? 7 通过web页面访问 spark管理页面( master所在机器的地址+8088端口)
该方案仍存在单点故障问题,需要引入备用master,但需要结合zookeeper部署,
Hale Waihona Puke
Spark集群搭建

Spark集群搭建一、前提1、安装hadoop集群2、安装scala3、假设三个节点:master、slave1、slave2二、Spark集群搭建1、建立文件夹存放spark压缩包2、在本文件夹下解压3、将解压得到的文件夹名重命名4、进入spark-2.20\conf文件夹,修改spark-env.sh.template为spark-env.sh5、在spark-env.sh中添加以下内容:export JAVA_HOME=/opt/softWare/java/jdk1.8.0_141export SCALA_HOME=/opt/software/scala/scala-2.12.4export HADOOP_HOME=/opt/software/hadoop/hadoop-2.7.3exportHADOOP_CONF_DIR=/opt/softWare/hadoop/hadoop-2.7.3/etc/hadoopexport SPARK_MASTER_IP=192.168.XXX.XX#export SPARK_WORKER_INSTANCES=1 //每个Slave中启动几个Worker实例export SPARK_WORKER_MEMORY=1g#exportSPARK_DIST_CLASSPATH=$(/home/hadoop/hadoop-2.7.2/bin/hadoop classpath)注意:前面有#的可以不用添加6、进入spark-2.20\conf文件夹,修改slaves.template为slave,添加如下内容:masterslave1slave27、赋权限chmod 777 /opt/software/spark/spark-2.20/bin/*chmod 777 /opt/software/spark/spark-2.20/sbin/*8、scp到其他两台机器。
scp -r /opt/software/spark slave1:/opt/software/sparkscp -r /opt/software/spark slave2:/opt/software/spark9、在每台主机配置/etc/profile中配置环境变量#sparkexport SPARK_HOME=/opt/software/spark/spark-2.20 PATH=$SPARK_HOME/bin:$PATH然后:source /etc/profile10、启动sparkcd /opt/software/spark/spark-2.20/sbin/./start-all.sh11、查看jps12、查看spark Webip:8080。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Spark1.2集群环境搭建(Standalone+HA) 4G内存5个节点也是蛮拼的准备工作:1、笔记本4G内存,操作系统WIN7 (屌丝的配置)2、工具VMware Workstation3、虚拟机:CentOS6.4共五台4、搭建好Hadoop集群( 方便Spark可从HDSF上读取文件,进行实验测试)实验环境:Hadoop HA集群:Ip hostname role192.168.249.130 SY-0130 ActiveNameNode192.168.249.131 SY-0131 StandByNameNode192.168.249.132 SY-0132 DataNode1192.168.249.133 SY-0133 DataNode2Spark HA集群:Ip hostname role192.168.249.134 SY-0134 Master192.168.249.130 SY-0130 StandBy Master192.168.249.131 SY-0131 worker192.168.249.132 SY-0132 worker192.168.249.133 SY-0133 worker实验环境仅作学习用,4G内存确实蛮拼的,资源非常有限。
下周换上几台台式机作集群。
上述SY-0134是新克隆的虚拟机,作为Spark的环境中的Master,原属于Hadoop集群中的4个节点分别作为StandByMaster 和Worker角色。
关于虚拟机环境设置、网络配置、Hadoop集群搭建参见XXX 。
本文重点关注Spark1.2环境、Zookeeper环境简易搭建,仅作学习与实验原型,且不涉及太多理论知识。
软件安装:(注:用户hadoop登录SY-0134)1、在节点SY-0134,hadoop用户目录创建toolkit 文件夹,用来保存所有软件安装包,建立labsp文件作为本次实验环境目录。
[hadoop@SY-0134 ~]$ mkdir labsp[hadoop@SY-0134~]$ mkdir toolkit我将下载的软件包存放在toolkit中如下[hadoop@SY-0134 toolkit]$ lshadoop-2.5.2.tar.gz hadoop-2.6.0.tar.gz jdk-7u71-linux-i586.gz scala-2.10.3.tgzspark-1.2.0-bin-hadoop2.3.tgz zookeeper-3.4.6.tar.gz2、这次实验我下载的Spark包是spark-1.2.0-bin-hadoop2.3.tgz ,Scala版本是 2.10.3,Zookeeper是3.4.6。
这里需要注意的是,Spark和Scala有版本对应关系,可在Spark官网介绍中找到Spark版本支持的Scala版本。
3、JDK安装及环境变量设置[hadoop@SY-0134 ~]$ mkdir lab#我将jdk7安装在lab目录[hadoop@SY-0134 jdk1.7.0_71]$ pwd/home/hadoop/lab/jdk1.7.0_71#环境变量设置:[hadoop@SY-0134 ~]$ vi .bash_profile# User specific environment and startup programsexport JA VA_HOME=/home/hadoop/lab/jdk1.7.0_71PATH=$JA V A_HOME/bin:$PATH:$HOME/binexport PATHexport CLASSPA TH=.:$JA V A_HOME/lib/dt.jar:$JA V A_HOME/lib/tools.jar#设置生效[hadoop@SY-0130 ~]$ source .bash_profile4、Scala安装及环境变量设置我将scala解压到/home/hadoop/labsp/scala-2.10.3位置。
修改.bash_profile文件增加:export SCALA_HOME=/home/hadoop/labsp/scala-2.10.3修改:PATH=$JA V A_HOME/bin:$PA TH:$HOME/bin:$SCALA_HOME/bin#设置生效[hadoop@SY-0130 ~]$ source .bash_profile检验Scala是否安装好:[hadoop@SY-0134 ~]$ scalaWelcome to Scala version 2.10.3 (Java HotSpot(TM) Client VM, Java 1.7.0_71).上述显示安装成功。
5、Spark安装及环境配置我将spark解压到/home/hadoop/labsp/spark1.2_hadoop2.3位置。
下载的这个包是预编译包。
修改.bash_profile文件增加:export SPARK_HOME=/home/hadoop/labsp/spark1.2_hadoop2.3修改PATH=$JA V A_HOME/bin:$PATH:$HOME/bin:$SCALA_HOME/bin:$SPARK_HOME/bin #设置生效[hadoop@SY-0130 ~]$ source .bash_profile#修改spark-env.sh[hadoop@SY-0134 conf]$ pwd/home/hadoop/labsp/spark1.2_hadoop2.3/conf[hadoop@SY-0134 conf]$vi spark-env.sh核心配置:export JA VA_HOME=/home/hadoop/lab/jdk1.7.0_71export SCALA_HOME=/home/hadoop/labsp/scala-2.10.3export SPARK_DAEMON_JA V A_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=SY-0134:2181,SY-0130:2181,SY-0131:2181,SY-0132:2181,SY-013 3:2181 -Dspark.deploy.zookeeper.dir=/spark"至此JDK,Scala,Spark 安装及环境变量设置好,当然上述配置步骤也可一次修改完成。
6、Zookeeper安装我将zookeeper解压到/home/hadoop/labsp/zookeeper-3.4.6位置。
#配置zoo.cfg文件[hadoop@SY-0134 zookeeper-3.4.6]$ pwd/home/hadoop/labsp/zookeeper-3.4.6[hadoop@SY-0134 zookeeper-3.4.6]$ mkdir data[hadoop@SY-0134 zookeeper-3.4.6]$ mkdir datalog[hadoop@SY-0134 zookeeper-3.4.6]$ cd conf[hadoop@SY-0134 conf]$ cp zoo_sample.cfg zoo.cfg[hadoop@SY-0134 conf]$ vi zoo.cfg# The number of milliseconds of each ticktickTime=2000# The number of ticks that the initial# synchronization phase can takeinitLimit=10# The number of ticks that can pass between# sending a request and getting an acknowledgementsyncLimit=5# the directory where the snapshot is stored.# do not use /tmp for storage, /tmp here is just# example sakes.dataDir=/home/hadoop/labsp/zookeeper-3.4.6/datadataLogDir=/home/hadoop/labsp/zookeeper-3.4.6/datalog# the port at which the clients will connectclientPort=2181# the maximum number of client connections.# increase this if you need to handle more clients#maxClientCnxns=60## Be sure to read the maintenance section of the# administrator guide before turning on autopurge.## /doc/current/zookeeperAdmin.html#sc_maintenance## The number of snapshots to retain in dataDir#autopurge.snapRetainCount=3# Purge task interval in hours# Set to "0" to disable auto purge feature#autopurge.purgeInterval=1server.1=SY-0134:2888:3888server.2=SY-0130:2888:3888server.3=SY-0131:2888:3888server.4=SY-0132:2888:3888server.5=SY-0133:2888:3888#配置myid文件[hadoop@SY-0134 data]$ pwd/home/hadoop/labsp/zookeeper-3.4.6/data输入1进入SY-0134的zookeeper中的myid文件echo "1"> home/hadoop/labsp/zookeeper-3.4.6/data/myid7、SSH免密码登录虽然在Hadoop集群中,SY-0130,能够免密码登录到SY-0131,SY-0132,SY-0133 。
但是在本次Spark集群中,Master为SY-0134 ,他需要能够免密码登录到SY-0130,SY-0131,SY-0132,SY-0133。