Visualizing and Classifying Odors Using a Similarity Matrix
琼脂糖凝胶电泳(Agarose gel electrophoresis)
You may also like... Restriction Digest of Plasmid DNA Purifying DNA from an Agarose Gel DNA Ligation This website uses cookies to ensure you get the best experience. By continuing to use this site, you agree to the use of cookies. Addgene is open and shipping orders.•Pending order? We will email to confirm that your organization can accept shipments.•Conducting coronavirus or COVID-19 research? Email us at help@ with your order or deposit number so we can prioritize it.Learn more about our current shipping status and COVID-19 resources .Agarose Gel Electrophoresis IntroductionGel electrophoresis is the standard lab procedure for separating DNA by size (e.g., length in base pairs) forvisualization and purification. Electrophoresis uses an electrical field to move the negatively charged DNA throughan agarose gel matrix toward a positive electrode. Shorter DNA fragments migrate through the gel more quickly thanlonger ones. Thus, you can determine the approximate length of a DNA fragment by running it on an agarose gelalongside a DNA ladder (a collection of DNA fragments of known lengths).Last Update: Feb. 20, 2018EquipmentReagentsProcedurePouring a Standard 1% Agarose Gel:1.Measure 1 g of agarose.2.Mix agarose powder with 100 mL 1xTAE in a microwavable flask. See TAE Recipe .Note: Make sure to use the same buffer as the one in the gel box(do not mix different buffers and do not use water).3.Microwave for 1-3 min until the agarose is completely dissolved (but donot overboil the solution, as some of the buffer will evaporate and thusalter the final percentage of agarose in the gel. Many people prefer tomicrowave in pulses, swirling the flask occasionally as the solutionheats up.).CAUTION:HOT! Be careful stirring, eruptive boiling can occur.4.Close •Casting tray •Well combs •Voltage source •Gel box•UV light source •Microwave•TAE (recipe here )•Agarose•Ethidum bromide (stock concentration of 10 mg/mL)*Pro-Tip* Agarose gels are commonly used in concentrations of 0.7% to 2% depending on the size of bands needed to beseparated - see FAQs below . Simply adjust the mass of agarose in a given volume to make gels of other agaroseconcentrations (e.g., 2 g of agarose in 100 mL of TAE will make a 2% gel).*Pro-Tip* TBE can be used instead of TAE, labsusually use one or the other, but there is very littledifference between the two.Let agarose solution cool down to about 50 °C (about when you can comfortably keep your hand on the flask), about 5 mins.5.(Optional) Add ethidium bromide (EtBr) to a final concentration of approximately 0.2-0.5 μg/mL (usually about 2-3 μl of lab stock solution per100 mL gel). EtBr binds to the DNA and allows you to visualize the DNA under ultraviolet (UV) light.CAUTION: EtBr is a known mutagen. Wear a lab coat, eye protection and gloves when working with this chemical.Note: If you add EtBr to your gel, you will also want to add it to the running buffer when you run the gel. If you do not add EtBr to the gel and running buffer, you will need to soak the gel in EtBr solution and then rinse it in water before you can image the gel.6.Pour the agarose into a gel tray with the well comb in place.7.Place newly poured gel at 4 °C for 10-15 mins OR let sit at room temperature for 20-30 mins, until it has completely solidified.Loading Samples and Running an Agarose Gel:1.Add loading buffer to each of your DNA samples.Note: Loading buffer serves two purposes: 1) it provides a visible dye thathelps with gel loading and allows you to gauge how far the DNA hasmigrated; 2) it contains a high percentage of glycerol that increases thedensity of your DNA sample causing it settle to the bottom of the gel well,instead of diffusing in the buffer.2.Once solidified, place the agarose gel into the gel box (electrophoresis unit).3.Fill gel box with 1xTAE (or TBE) until the gel is covered.4.Carefully load a molecular weight ladder into the first lane of the gel.Note: When loading the sample in the well, maintain positivepressure on the sample to prevent bubbles or buffer from enteringthe tip. Place the very top of the tip of the pipette into the buffer justabove the well. Very slowly and steadily, push the sample out andwatch as the sample fills the well. After all of the sample is unloaded,push the pipettor to the second stop and carefully raise the pipettestraight out of the buffer.5.Carefully load your samples into the additional wells of the gel.6.Run the gel at 80-150 V until the dye line is approximately 75-80% of theway down the gel. A typical run time is about 1-1.5 hours, depending onthe gel concentration and voltage.Note: Black is negative, red is positive. The DNA is negatively charged and will run towards the positive electrode. Always Run to Red.7.Turn OFF power, disconnect the electrodes from the power source, and then carefully remove the gel from the gel box.8.(Optional) If you did not add EtBr to the gel and buffer, place the gel into a container filled with 100 mL of TAE running buffer and 5 μL of EtBr,place on a rocker for 20-30 mins, replace EtBr solution with water and destain for 5 mins.ing any device that has UV light, visualize your DNA fragments. The fragments of DNA are usually referred to as ‘bands’ due to theirappearance on the gel.Note: When using UV light, protect your skin by wearing safety goggles or a face shield, gloves and a lab coat.Analyzing Your Gel:Using the DNA ladder in the first lane as a guide (the manufacturer's instruction will tell you the size of each band), you can infer the size of the DNA in your sample lanes. For more details on doing diagnostic digests and how to interpret them please see the Diagnostic Digest page.*Pro-Tip* It is a good idea to microwave for 30-45 sec, stop and swirl, and then continue towards a boil. Keep an eye on itthe solution has a tendancy to boil over. Placing saran wrap over the top of the flask can help with this, but is not necessaryif you pay close attention.*Pro-Tip* Pour slowly to avoid bubbles which will disrupt the gel. Any bubbles can be pushed away from the well comb ortowards the sides/edges of the gel with a pipette tip.*Pro-Tip* If you are in a hurry, the gel will set more quickly if you place the gel tray at 4 °C earlier so that it is already coldwhen the gel is poured into it.*Pro-Tip* Remember, if you added EtBr to your gel, add some to the buffer as well. EtBr is positively charged and will run theopposite direction from the DNA. So if you run the gel without EtBr in the buffer you will reach a point where the DNA will bein the bottom portion of the gel, but all of the EtBr will be in the top portion and your bands will be differentially intense. Ifthis happens, you can just soak the gel in EtBr solution and rinse with water to even out the staining after the gel has beenrun, just as you would if you had not added EtBr to the gel in the first place.*Pro-Tip* If you will be purifying the DNA for later use, use long-wavelength UV and expose for as little time as possible tominimize damage to the DNA.Purifying DNA from Your Gel:If you are conducting certain procedures, such as molecular cloning, you will need to purify the DNA away from the agarose gel. For instructions on how to do this, visit the Gel Purification page.Tips and FAQ•How do you get better resolution of bands?A few simple ways to increase the resolution (crispness) of your DNA bands include: a) running the gel at a lower voltage for a longer period oftime; b) using a wider/thinner gel comb; or c) loading less DNA into the well. Another method for visualizing very short DNA fragments ispolyacrylamide gel electrophoresis (PAGE), which is typically used to separate 5 - 500 bp fragments.•How do you get better separation of bands?If you have similarly sized bands that are running too close together, you can adjust the agarose percentage of the gel to get better separation. A higher percentage agarose gel will help resolve smaller bands from each other, and a lower percentage gel will help separate larger bands.•10% Rule:For each sample you want to load on a gel, make 10% more volume than needed because several microliters can be lost in pipetting. Forexample, if you want to load 1.0 μg in 10 μL, make 1.1 μg in 11 μL.Reference Page | Top | Index。
我们正在研究的各种英文表述

: glen_almond@W e are currently establishing methods to characterize porcine T-lymphocyte subpopulations for two different studies. One involves evaluation of the T cells in weaned pigs following vaccination with a novel adjuvant; the other focuses on the influence of stress on T-lymphocyte populations and immunity in young pigs. Lymphocyte trapping is associated with stress, and we plan to explore this perturbation of the immune system. In addition, other studies focus on understanding the physiological roles of tumor necrosis factor and prostaglandin-E prior to and after the initiation of luteolysis. We are examining the significance of vascular endothelial growth factor (VEGF) and hypoxia-induc ible factor (HIF) in porcine corpus luteum. We utilize RT-PCR and additional genomic methodologies to characterize the expression of the factors and their receptors. We anticipate that future studies will determine the respective signal transduction pathways and re-visit the influence of the cytokines and the immune system on corpus luteum function.Birkenheuer, Adam, DVM, PhDDepartment of Clinical SciencesNCSU College of V eterinary Medicine, Campus Box 84014700 Hillsborough StRaleigh, NC 27606Phone: (919) 513-8288E-mail: ajbirken@My research is focused on companion animal infectious diseases. Tick-transmitted protozoan parasites are emerging infectious diseases causing substantial morbidity and mortality worldwide. Our studies address discovery and characterization of novel pathogens, development of improved diagnostic assays, enhanced understanding of the epidemiology of tick-transmitted protozoan parasites, and identification of treatment strategies resulting in significantly improved survival rates.Breitschwerdt, Ed, DVMDepartment of Clinical SciencesNCSU College of V eterinary Medicine, Campus Box 84014700 Hillsborough StRaleigh, NC 27606Phone: (919) 919-513-8277E-mail: ed_breitschwerdt@My research interests are focused in the area of infectious diseases, with a particular emphasis on diagnostic, therapeutic, and immunopathologic aspects of zoonotic vector-transmitted bacterial and rickettsial diseases. The laboratory has contributed substantially to current understanding of Rickettsia rickettsii, Ehrlichia canis, and Bartonella vinsonii infection in dogs and Bartonella henselae in cats. We are currently capable of handling biosafety P3-level. It is increasingly obvious that vector borne pathogens contribute to a substantial quantity of animal and humandisease and suffering. In most instances the immunopathologic consequences of infection with one or simultaneous infection with multiple vector-transmitted infectious agents remains unknown. It is our goal to better define the clinical consequences of chronic infection with these organisms. Dean, Gregg, DVM, PhDDepartment of Molecular Biomedical SciencesNCSU College of V eterinary Medicine, Campus Box 84014700 Hillsborough StRaleigh, NC 27606Phone: (919) 513-2819E-mail: gregg_dean@My research focuses on the immunopathogenesis and prevention of human and feline immunodefic iency virus infection (HIV and FIV, respectively). FIV is a valuable model of human immunodeficiency virus infection in people and represents a significant health threat to the feline population world-wide. We are investigating the role of innate immune defects induced by HIV/FIV infection. These studies focus on the function of dendritic cells, natural killer cells, and Toll-like receptors in the immunopathogenesis of opportunistic infections during chronic retroviral infection. Ongoing vaccine studies seek to employ recombinant bacteria as vaccine vectors. We are evaluating recombinant Lactobacillus spp. engineered to express FIV/HIV Gag and consensus Env genes as a means to provide effective mucosal and systemic immune responses through oral immunization.Fogle, Jonathan, DVM, PhDDepartment of Population Health and PathobiologyNCSU College of V eterinary Medicine, Campus Box 84014700 Hillsborough StRaleigh, NC 27606Phone: (919) 513-6304E-mail: jonathan_fogle@Using the FIV model for HIV, we have shown that CD4+CD25+ T regulatory cells are constitutively activated and suppress CD4+CD25- T helper cell immune responses during the acute phase and chronic phase of infection. Results of our recent experiments indicate that CD4+CD25+ T regulatory cells suppress the CD8+ immune response during the acute and chronic stages of FIV infection. We are currently investigating the mechanism(s) of CD8+ cell mediated suppression and the intracellular signaling events that occur in CD8+ targets, following their interaction with activated CD4+CD25+ cell from FIV+ cats.Gilmour, Ian, BSc, PhDCardiopulmonary and Immunotoxicology BranchEnvironmental Public Health DivisionNational Health and Environmental Effects Research LaboratoryU.S. Environmental Protection AgencyResearch Triangle Park, NC 27711Phone: (919) 541-0015E-mail: Gilmour.Ian@We study the effect of air pollutant exposure on pulmonary immunity and subsequent development of allergic and infectious lung disease. Air pollutants are generated in the inhalation exposure facility at the EPA which has the capability to aerosolize simple gases and vapors, various particles including nanomaterials, as well as fossil fuel combustion emissions. The staff also operates mobile field sampling laboratories that collect size-fractionated particles from various locations across the country. The relative toxicity of various air pollutants are compared and then applied in animal models of asthma, influenza, or cardiac dysfunction. Parallel studies are conducted with in vitro systems in order to extrapolate between cell based and whole body responses for the purposes of predicting potential effects in humans. Hammerberg, Bruce, DVM, PhDDepartment of Population Health and PathobiologyNCSU College of V eterinary Medicine, Campus Box 84014700 Hillsborough StRaleigh, NC 27606Phone: (919) 513-7712E-mail: bruce_hammerberg@My current research expertise is in allergic diseases and nematode biology. Regarding allergic disease research, we have developed canine x murine heterohybridomas. One of these produces canine monoclonal IgE specific for a filarial nematode antigen. Another produces canine IgG antibody specific for canine IgE. Using these tools, I have developed mouse monoclonal antibodies against heat stable epitopes of canine IgE and have the opportunity to make canine monoclonal antibodies against canine IgE epitopes that will be useful in preventing allergic disease in the dog. The unlimited supply of canine IgE of known antigen specificity has directed my research toward characterizing inherited differences in mast cell function in the dog, and at this time I am investigating the role of stem cell factor in inherited canine atopic dermatitis.My work with filarial nematodes over the last 25 years has recently turned to investigating how fatty acid binding proteins function in nematode physiology.Havell, Edward, PhDDepartment of Population Health and PathobiologyNCSU College V eterinary Medicine, Campus Box 84014700 Hillsborough StRaleigh, NC 27606Phone: (919) 515-6184E-mail: ed_havell@The major objective of our research is to determine the roles that tumor necrosis factor (TNF), interferon-gamma (IFN-gamma) and host cells play in both innate and adaptive immunity toenteric bacterial pathogens. To study possible roles of cytokines and host cells in anti-bacterial resistance, specific inhibitors (e.g., anti-cytokine antibodies) that block the actions of a given cytokine or host cell are administered before or at progressive times during bacterial infection in mice. The subsequent course of infection is monitored to determine the effect of such treatment on bacterial pathogenesis. The long-range goal of our research is to acquire an understanding of how TNF, IFN-gamma, and host cells having anti-bacterial function interact in the defense of the host against bacterial pathogens. Studies are underway to develop a reproducible model of inflammatory bowel disease that will enable the study of the roles of cytokines and host cells in chronic inflammatory intestinal disease. Finally, we have generated an avirulent Listeria monocytogenes mutant that does not translocate from the intestinal lumen but induces very strong protective T cell-mediated anti-listerial immunity. We plan to evaluate this avirulent mutant as an orally administered vaccine platform to present secreted recombinant tuberculosis antigens to the intestinal immune system in order to elicit protective anti-TB T cell immunityHess, Paul, DVM, PhDDepartment of Clinical SciencesNCSU, College of V eterinary Medicine, Campus Box 84014700 Hillsborough StRaleigh, NC 27606Phone: (919) 513-6183E-mail: paul_hess@My principal interests are CD8-positive T cell immunology and immunotherapy. One focus of the laboratory is examining how the interaction of the MHC class I molecule and the T cell receptor can be manipulated to induce stable tolerance in animal models of autoimmunity and allotransplantation. The second focus is the discovery of new peptide epitopes in viral diseases. Lastly, we are investigating novel clinical predictors of chemotherapy-induced toxicity in the dog. Hudson, Lola C., DVM, PhDDepartment of Molecular Biomedical SciencesNCSU College V eterinary Medicine, Campus Box 84014700 Hillsborough StRaleigh, NC 27606Phone: (919) 513-6306E-mail: lola_hudson@Research in this laboratory focuses on the study of viral neuropathogenesis and blood-brain barrier (BBB) function. We are currently investigating feline immunodeficiency virus (FIV), which has divergent mechanisms of CNS entry, as a model for AIDS neuropathogenesis. We have developed an in vitro feline blood-brain barrier model system to determine the conditions under which immune cells in normal and FIV-infected animals are capable of penetrating the BBB. Additional studies focus on characteristics of attaching cells and mechanisms of attachment to the barrier such as up-regulation of specific adhesion molecules. Additionally, in vivo studies parallel in vitro studies with the aim of increasing detection of neural infection during the early stages ofdisease. We are currently focusing on various cognitive-motor behavioral tests in normal and infected cats to determine acute losses in neurologic function. Such tests can then be used to assess the efficacy of various therapeutics to delay or prevent CNS infection.Jones, Samuel L., DVM, PhDDepartment of Clinical SciencesNCSU College of V eterinary Medicine, Campus Box 84014700 Hillsborough StRaleigh NC 27606Phone: (919) 513-7722E-mail: sam_jones@My research interests focus on how inflammation is triggered and regulated and how inflammation contributes to the pathophysiology of diseases such as colitis, equine colic, sepsis, and endotoxemia. A primary objective of our work is to understand the cellular and molecular details of cell migration with a focus on the key innate immune cell, the neutrophil. We are particularly interested in how the signaling molecules protein kinase A, phosphatidylinositol 3-kinase, and p38 and the actin binding proteins MARCKS, V ASP, and L-plastin regulate the actin cytoskeleton, integrin function, and signaling during migration of neutrophils and other cell types. We use human and equine primary cells, cell lines, and in vivo models including mice and zebrafish for these studies. We are also studying how inflammation is triggered and how pro-inflammatory genes, particularly genes in the prostaglandin synthesis cascade that encode cyclooxygenase-2 and prostaglandin synthase-1, are upregulated in equine leukocytes. In collaborative work, we are studying the effects of neutrophils and inflammatory mediators on intestinal mucosal repair following ischemic injury that occurs in some forms of equine colic. Koci, Matt, PhDDepartment of Poultry ScienceNCSU Scott Hall, Campus Box 7608Raleigh, NC 27695Phone: (919) 515-5388E-mail: mdkoci@The overall focus of my research is to understand how the immune system responds to viral challenges. The majority of our work focuses on the innate aspects of host resistance to viral infection, particularly addressing how the innate immune system recognizes and responds to infection and thus can have profound affects on the adaptive immune response and ultimately the outcome of the infection. Understanding how stimulation of the innate immune system leads to different clinical outcomes is critical to understanding the genetic basis of disease resistance. Laster, Scott M., PhD- Immunology Program DirectorDepartment of MicrobiologyNCSU Gardner Hall, Campus Box 7615Raleigh, NC 27695Phone: (919) 515-7958E-mail: scott_laster@Research in my laboratory focuses on the anti-viral immune response. One aspect of this response currently under investigation is the apoptosis-inducing activity of tumor necrosis factor (TNF). TNF is a product of many cells, including macrophages and monocytes, and is released by these cells during infection. TNF is able to act in an anti-viral manner by causing the death of infected cells before virus replication is complete, thereby reducing the number of infectious virions that are produced. The apoptosis-inducing activity of TNF is selective for infected cells because these cells are unable to transcribe appropriate levels of NF-kB-dependent, anti-apoptotic gene products. The virus under investigation in my laboratory is the human adenovirus. While not a major human pathogen, the adenovirus represents an excellent model system for studies of molecular and cellular immunology. Recent studies from my laboratory suggest that adenovirus induces susceptibility to TNF by preventing the expression of a tyrosine or dual specificity phosphatase, leading us to propose that this phosphatase normally acts in an anti-apoptotic manner by inhibiting apoptotic signal transduction through the dephosphorylation of cytosolic phospholipase A2.Miller, Jennifer, PhDDepartment of MicrobiologyNCSU Gardner Hall, Campus Box 7615Raleigh, NC 27695Phone: (919) 515-7867E-mail: jen_miller@My research focuses on the interaction between the tick-borne spirochete Borrelia burgdorferi and the innate immune system. B. burgdorferi is the causative agent of Lyme disease, a multi-system disorder whose symptoms include the development of subacute arthritis within both a large joint of afflicted humans and the rear ankle joints of susceptible inbred mouse strains. This subacute arthritis is associated with the presence of B. burgdorferi within the joints. My laboratory utilizes tissue culture and mouse models to examine both the bacterial and host-derived mechanisms driving the induction of Lyme arthritis. We are currently focusing on a novel and previously unappreciated role for Type I interferon (IFN) in the development of severe Lyme arthritis. The goal of these studies is to identify additional bacterial effectors, innate immune components, and mechanistic pathways that drive both Type I IFN production and the development of Lyme arthritis.Nordone, Shila, PhDDepartment of Molecular Biomedical SciencesNCSU College V eterinary Medicine, Campus Box 84014700 Hillsborough StRaleigh, NC 27606Phone: (919) 515-7410E-mail: shila_nordone@My research involves studying the mechanisms and consequences of the molecular interactions between pathogenic organisms and the innate immune system. Pathogen-mediated modulation of innate immunity can dictate the pathological consequences of infection, the duration of survival of the pathogen in the host, and ultimately, the ability of the adaptive immune response to evolve and clear infection. At the center of my research is the role of Toll-like receptor (TLR) and Triggering Receptor Expressed on Myeloid Cells-1 (TREM-1) activation in pathogen-immune system interactions. We are currently engaged in the following research areas: 1) Modulation of TLR-mediated responses by HIV-1 infection and 2) TREM-1 mediated inflammation during canine sepsis. The overall aim of both areas of research is to increase our understanding of the basic mechanisms of pathogen-innate immune cell crosstalk and to identify new therapeutic targets for treating HIV and sepsis.Olivry, Thierry, DrV et, PhDDepartment of Clinical SciencesNCSU, College of V eterinary Medicine, Campus Box 84014700 Hillsborough StRaleigh, NC 27606Phone: (919) 513-6276E-mail: thierry_olivry@My principal research interests involve investigating the pathogenesis and therapy of canine atopic dermatitis and autoimmune skin diseases. Current projects on atopic dermatitis include clinical trials on the pharmacotherapy of this disease, modeling skin lesions experimentally, researching novel methods for immunotherapy as well as investigating the genetics of this trait in West Highland White Terriers. My research on autoimmune skin diseases involves the characterization of clinical signs, histopathology and immunological aspects of novel pathological entities of dogs, cats and horses. Additionally, we are investigating the autoantibody response in the blistering disease pemphigus foliaceus in dogs.Selgrade, Mary Jane, PhDImmunotoxicology BranchU.S. Environmental Protection AgencyResearch Triangle Park, NC 27711Phone: (919) 541-1821E-mail: selgrade.maryjane@My research interests center around the interactions between xenobiotic compounds (ambient and indoor air pollutants) and the immune system and consequent effects on susceptibility to infectious and allergic disease. The laboratory has developed several infectivity and allergy models in laboratory rodents. The focus is to understand the effects that exposure to environmental agents may have on both local and systemic immune responses, the underlying mechanisms associated with these effects, and the consequent impact on susceptibility to disease.Sherry, Barbara, PhDDepartment of Molecular Biomedical SciencesNCSU College V eterinary Medicine, Campus Box 84014700 Hillsborough StRaleigh, NC 27606Phone; (919) 515-4480E-mail: barbara_sherry@We study reovirus-induced myocarditis (cardiac inflammation and tissue damage) in mice as a model for this important human disease. Recently, we have focused on the cardiac response to viral infection, with particular emphasis on viral induction of the anti-viral cytokine interferon-beta in cardiac cells. We are interested in both the viral genes that stimulate this response, and the cardiac transcription factors and anti-viral proteins that are central to protection against disease. Our approaches, using primarily molecular techniques, include the use of transgenic mice and primary cardiac myocyte cell cultures.Sikes, Michael, PhDDepartment of MicrobiologyNCSU Gardner Hall, Campus Box 7615Raleigh, NC 27695Phone: (919) 513-0528E-mail: mike_sikes@As different cells in the body develop, they selectively use specific genes while ignoring others. In fact, development of multicellular organisms is absolutely dependent on differential gene regulation. But how genes are programmed to be activated or silenced at the right time remains a mystery. The research in our laboratory investigates the epigenetic changes that govern selective gene usage during lymphocyte development. Unlike other tissues, lymphocytes develop in discreet stages that can be easily followed using cell surface marker proteins, and for which individual cell line models exist. Specifically, we study the epigenetic programs that regulate the developmentally-timed activation and inactivation of the genes that encode the antibody and T cell receptor molecules. These genes are unique in the body in that they undergo a process of genetic recombination. We believe that transcriptional promoters positioned throughout each gene serve as nucleation points for transcription factors and histone modifiers that work together to shape local windows of accessible chromatin in response to developmental cues. Work is underway to test this hypothesis and to define the protein factors involved.Suter, Steven, VMD, MS, PhDDepartment of Clinical SciencesNCSU College of V eterinary Medicine, Campus Box 84014700 Hillsborough StRaleigh, NC 27606Phone: (919) 513-0813E-mail: steven_suter@My research interests focus primarily on hematologic malignancies in companion animals, specifically canine and feline lymphoma. Elucidating the underlying molecular abnormalities associated with these diseases, as well as the development of novel therapeutics is the main thrust of my research. Although canine lymphoma is phenotypically and biologically similar to human non-Hodgkin’s diffuse large B-cell lymphoma, it is not known if these diseases share similar genetic perturbations. We aim to begin to elucidate these perturbations in dogs with lymphoma to both enhance dog lymphoma as a pertinent large animal model of human non-Hodgkin’s lymphoma and develop more targeted therapeutics for this disease.Tompkins, Mary, DVM, PhDDepartment of Population Health and PathobiologyNCSU College of V eterinary Medicine, Campus Box 84014700 Hillsborough StRaleigh, NC 27606(919) 513-6255E-mail: mary_tompkins@The research in my laboratory is directed towards understanding the immunopathogenesis of feline retrovirus infection. In particular, we are examining mechanisms of virus-induced immunosuppression and persistence, especially alterations in cytokine regulation and cell-mediated immunity. We have been studying the immunopathogenesis of feline immunodefic iency virus (FIV), which is one of the best animal models for HIV infection. Our early studies described alterations in peripheral blood lymphocyte subset numbers, in vivo virus tropism, and disease progression. More recently we have described in detail cytokine dysregulation associated with FIV infection that leads to the inability of the infected cat to mount a successful cell mediated immune response to a secondary intracellular pathogen.Tompkins, Wayne, PhDDepartment of Population Health and PathobiologyNCSU College of V eterinary Medicine, Campus Box 84014700 Hillsborough StRaleigh, NC 27606Phone: (919) 515-7394E-mail: wayne_tompkins@The focus of my research is immunopathogenesis of FIV infection in the cat: a model for human HIV infection. We are studying the cellular and molecular basis of T cell dysfunction and progression to AIDS in FIV-infected cats, utilizing RT-qcPCR and multi-color flow cytometry to define the receptor phenotype and cytokine profiles of CD4-positive and CD8-positive T cells. We are specifically exploring the role of B7 co-stimulatory molecules and the cytokines IL-10 and TGF-beta in mediating T cell anergy and apoptosis.Tonkonogy, Susan, PhDDepartment of Population Health and PathobiologyNCSU College of V eterinary Medicine, Campus Box 84014700 Hillsborough StRaleigh, NC 27606Phone: (919) 513-6252E-mail: sue_tonkonogy@The overall goal of my research is to identify the molecular mechanisms that regulate the intestinal immune response. Our current approach is to determine the patterns of cytokines produced by T cells, B cells, macrophages, and dendritic cells isolated from mucosal lymphoid tissue of genetically manipulated rodents that spontaneously develop chronic intestinal inflammation when maintained in specific pathogen free housing. Germ-free rodents with identical genetic alterations do not develop inflammation, implicating the microorganisms that colonize the intestinal tract in the initiation of disease. The long-range goal of these studies is to provide a basis for designing therapeutic strategies aimed towards down-regulating the intestinal immune response that we postulate to be an underlying cause of the chronic inflammation that occurs in inflammatory bowel diseases.Ward, Marsha, PhDImmunotoxicology BranchU.S. Environmental Protection AgencyResearch Triangle Park, NC 27711Phone: (919) 541-1193E-mail: ward.marsha@My research interests involve the assessment of indoor environmental contaminants, particularly fungi for the potential to cause allergy/asthma using laboratory rodent models. The focus of our studies is hazard identification including 1) the identification and characterization of the allergenic proteins and 2) the identification of potential biomarkers that differentiate an allergic response from a non-allergic inflammatory response. Additionally, we are interested in the area of food allergies that could occur due to the introduction of genetically modified crops.Y oder, Jeffrey, PhDDepartment of Molecular Biomedical SciencesNCSU College of V eterinary Medicine, Campus Box 84014700 Hillsborough StRaleigh, NC 27606Phone: (919)-515-7406E-mail: jeff_yoder@Web site: /~jayoder/。
管理学英语试题及答案

管理学英语试题及答案一、选择题(每题2分,共20分)1. The term "management" refers to the process of:A. Making decisionsB. Organizing resourcesC. Directing and controlling activitiesD. All of the above答案:D2. Which of the following is NOT a function of management?A. PlanningB. StaffingC. MotivatingD. Selling答案:D3. The process of setting goals and deciding on actions to achieve these goals is known as:A. OrganizingB. LeadingC. PlanningD. Controlling答案:C4. Which of the following is an example of a managementprinciple?A. Division of laborB. CentralizationC. DelegationD. All of the above答案:D5. In the context of management, "controlling" refers to:A. The process of ensuring that things are done as plannedB. The process of making plansC. The process of organizing resourcesD. The process of motivating employees答案:A6. The concept of "span of control" is related to:A. The number of employees a manager can effectively superviseB. The range of activities a manager is responsible forC. The level of authority a manager hasD. The type of control systems a manager uses答案:A7. The management function that involves influencing people to work towards organizational goals is:A. OrganizingB. LeadingC. PlanningD. Controlling答案:B8. Which of the following is a characteristic of effective communication?A. ClarityB. AmbiguityC. DisorganizationD. Lack of feedback答案:A9. The "scientific management" theory was developed by:A. Henri FayolB. Max WeberC. Frederick TaylorD. Abraham Maslow答案:C10. In the context of management, "empowerment" means:A. Giving employees the authority to make decisionsB. Centralizing all decision-making powerC. Reducing the role of employees in decision-makingD. Ignoring employee input in decision-making答案:A二、填空题(每题1分,共10分)1. The four basic functions of management are planning, organizing, leading, and ________.答案:controlling2. The management principle that suggests that there is an optimal span of control for each manager is known as ________.答案:span of control3. The management approach that focuses on the social needsof employees is known as the ________ approach.答案:human relations4. The process of identifying, selecting, orienting, training, and compensating employees is known as ________.答案:staffing5. A management style that involves a high level of task orientation and a low level of relationship orientation is known as ________ leadership.答案:autocratic6. The concept of "management by objectives" was developed by ________.答案:Peter Drucker7. The "Maslow's hierarchy of needs" theory suggests that people are motivated by a series of needs, starting with physiological needs and ending with ________ needs.答案:self-actualization8. In a ________ structure, there is a clear chain of command and a narrow span of control.答案:hierarchical9. The process of comparing actual performance with planned performance is known as ________.答案:budgeting10. The management function that involves setting goals and determining the sequence of actions needed to achieve them is known as ________.答案:strategic planning三、简答题(每题5分,共30分)1. What are the three key characteristics of an effective organizational structure?答案:An effective organizational structure should havethe following characteristics: clarity of roles and responsibilities, a clear chain of command, and a balance between centralization and decentralization.2. Explain the difference between leadership and management.答案:Leadership is the process of influencing, motivating, and directing individuals towards the achievement of organizational goals. Management, on the other hand, is a broader concept that includes planning, organizing, leading, and controlling organizational resources to achieve goals.3. What are the main principles of scientific management according to Frederick Taylor?答案:The main principles of scientific management includethe scientific selection and training of workers, the scientific selection of tasks and tools, the scientific determination of work methods, and the scientific scheduling of work and rest periods.4. Describe the four stages of the control process.。
融合多尺度通道注意力的开放词汇语义分割模型SAN
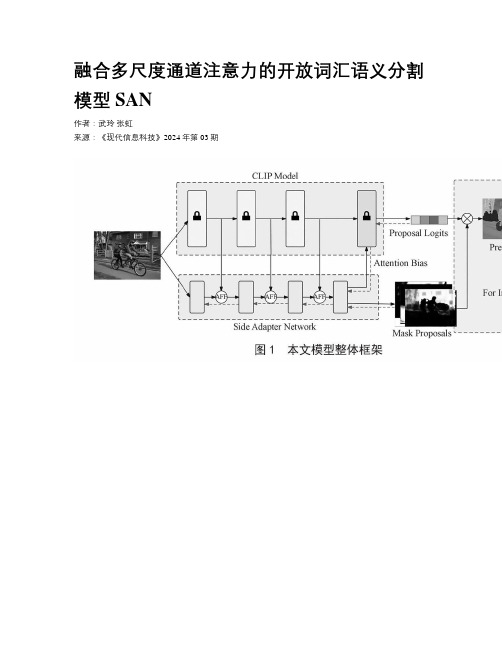
融合多尺度通道注意力的开放词汇语义分割模型SAN作者:武玲张虹来源:《现代信息科技》2024年第03期收稿日期:2023-11-29基金项目:太原师范学院研究生教育教学改革研究课题(SYYJSJG-2154)DOI:10.19850/ki.2096-4706.2024.03.035摘要:随着视觉语言模型的发展,开放词汇方法在识别带注释的标签空间之外的类别方面具有广泛应用。
相比于弱监督和零样本方法,开放词汇方法被证明更加通用和有效。
文章研究的目标是改进面向开放词汇分割的轻量化模型SAN,即引入基于多尺度通道注意力的特征融合机制AFF来改进该模型,并改进原始SAN结构中的双分支特征融合方法。
然后在多个语义分割基准上评估了该改进算法,结果显示在几乎不改变参数量的情况下,模型表现有所提升。
这一改进方案有助于简化未来开放词汇语义分割的研究。
关键词:开放词汇;语义分割;SAN;CLIP;多尺度通道注意力中图分类号:TP391.4;TP18 文献标识码:A 文章编号:2096-4706(2024)03-0164-06An Open Vocabulary Semantic Segmentation Model SAN Integrating Multi Scale Channel AttentionWU Ling, ZHANG Hong(Taiyuan Normal University, Jinzhong 030619, China)Abstract: With the development of visual language models, open vocabulary methods have been widely used in identifying categories outside the annotated label. Compared with the weakly supervised and zero sample method, the open vocabulary method is proved to be more versatile and effective. The goal of this study is to improve the lightweight model SAN for open vocabularysegmentation, which introduces a feature fusion mechanism AFF based on multi scale channel attention to improve the model, and improve the dual branch feature fusion method in the original SAN structure. Then, the improved algorithm is evaluated based on multiple semantic segmentation benchmarks, and the results show that the model performance has certain improvement with almost no change in the number of parameters. This improvement plan will help simplify future research on open vocabulary semantic segmentation.Keywords: open vocabulary; semantic segmentation; SAN; CLIP; multi scale channel attention 0 引言識别和分割任何类别的视觉元素是图像语义分割的追求。
外研版高一上学期英语试题及答案指导

外研版英语高一上学期复习试题及答案指导一、听力第一节(本大题有5小题,每小题1.5分,共7.5分)1、Listen to the following conversation and answer the question.A: Hi, John! How was your weekend?B: Hi, Mary! It was great! I went hiking with a group of friends.A: That sounds fun! Where did you go?B: We went to the mountains near our town.A: Oh, I wish I could have gone with you.Question: What did John do over the weekend?A) He went shopping.B) He went hiking.C) He stayed at home.Answer: B) He went hiking.Explanation: The listener can determi ne from John’s response that he went hiking with friends over the weekend.2、Listen to the following dialogue and choose the best answer to the question.M: Excuse me, could you tell me the way to the nearest post office?W: Sure, it’s not far from here. W alk straight down this street until you see the bank on your left. Then turn left at the traffic lights and the postoffice will be on your right.Question: Which building is on the right after the traffic lights?A) The bank.B) The post office.C) A supermarket.Answer: B) The post office.Explanation: The woman gives clear directions to the post office, indicating that it is on the right after turning left at the traffic lights.3.You hear a student saying, “I think the school library is the best place t o study. It’s quiet and has a wide range of books.”Question: Where does the student prefer to study?A) At homeB) In a caféC) At the school libraryD) In a classroomAnswer: C) At the school libraryExplanation: The student explicitly mentions that they think the school library is the best place to study, which indicates their preference.4.You hear a conversation between two students.Student 1: “Have you heard about the upcoming school trip to the museum?”Student 2: “Yes, I have. I’m really excited. It’s a great opportunity to learn about history.”Question: What are the two students discussing?A) A movie night at schoolB) A school trip to the museumC) A sports eventD) A school partyAnswer: B) A school trip to the museumExplanation: The conversation revolves around the topic of a school trip to the museum, which is directly mentioned by Student 2.5.You will hear a conversation between two students, Alice and Bob, discussing their study plans for the upcoming semester. Listen to the conversation and answer the following question.Question: How many courses are Alice and Bob planning to take in the upcoming semester?A. 6 coursesB. 7 coursesC. 8 coursesD. 9 coursesAnswer: B. 7 coursesExplanation: In the conversation, Alice mentions that she is planning to take five courses, and Bob says he is planning to take two more. Therefore, the total number of courses they are planning to take is seven.二、听力第二节(本大题有15小题,每小题1.5分,共22.5分)1、Listen to the conversation and choose the best answer to the question you’ve just heard.Q: What is the man planning to do this weekend?A) Go to a movie.B) Visit a friend.C) Go hiking.D) Attend a concert.Answer: C) Go hiking.Explanation: In the conversation, the man mentions that he has a free weekend and is thinking of going hiking, which indicates that he plans to go hiking.2、Listen to the dialogue and answer the question.Q: Why does the woman refuse to lend her book to the man?A) She needs it for a class project.B) She has already lent it to someone else.C) She forgot to bring it with her.D) She doesn’t like the man.Answer: A) She needs it for a class project.Explanation: The woman explicitly states that she cannot lend her book to the man because she needs it for an upcoming class project, which is why she refuses.3、You will hear a conversation between two friends discussing their weekendplans. Listen to the conversation and answer the following question.Question: What does Mark suggest they do for their weekend trip?A. Go to the beach.B. Visit the museum.C. Go hiking in the mountains.D. Stay in town and relax.Answer: CExplanation: In the conversation, Mark mentions, “Let’s go hiking in the mountains this weekend, it’ll be great exercise and we can enjoy the fresh air.” This indicates that he suggests going hiking in the mountains for their weekend trip.4、You will hear a short talk about the importance of healthy eating habits. Listen to the talk and answer the following question.Question: According to the speaker, which of the following is NOT a benefit of a balanced diet?A. Improved physical health.B. Better concentration at work or school.C. Increased risk of heart disease.D. Enhanced mood and emotional well-being.Answer: CExplanation: The speaker discusses the various benefits of a balanced diet, such as improved physical health, better concentration, and enhanced mood. However,they do not mention an increased risk of heart disease as a benefit of a balanced diet. In fact, the speaker implies that a balanced diet can help prevent heart disease, making option C the correct answer.5.You’re listening to a conversation between a student and a teacher.Student: Professor, I was wondering if you could explain the difference betw een “affect” and “effect” one more time?Teacher: Of course, let me put it this way. “Affect” is a verb that means to influence or cause a change. “Effect” is a noun that refers to the result of that influence or change.Student: Okay, so in a sentence like “The rain affected the crops,” “affect” is the verb, right?Teacher: Exactly. And in a sentence like “The effect of the rain on the crops was devastating,” “effect” is the noun.Question: What is the main difference bet ween “affect” and “effect” as explained by the teacher?A) Affect is a verb, and effect is a noun.B) Affect is the result, and effect is the cause.C) Affect is the cause, and effect is the result.D) Affect is a noun, and effect is a verb.Answer: A) Affect is a verb, and effect is a noun.解析:根据老师的解释,“affect” 是动词,表示影响或引起变化,而“effect” 是名词,表示这种影响或变化的结果。
八年级英语议论文论证方法单选题40题

八年级英语议论文论证方法单选题40题1. In the essay, the author mentions a story about a famous scientist to support his idea. This is an example of _____.A.analogyB.exampleparisonD.metaphor答案:B。
本题主要考查论证方法的辨析。
选项A“analogy”是类比;选项B“example”是举例;选项C“comparison”是比较;选项D“metaphor”是隐喻。
文中提到一个关于著名科学家的故事来支持观点,这是举例论证。
2. The writer uses the experience of his own life to prove his point. This kind of method is called _____.A.personal storyB.example givingC.case studyD.reference答案:B。
选项A“personal story”个人故事范围较窄;选项B“example giving”举例;选项C“case study”案例分析;选项D“reference”参考。
作者用自己的生活经历来证明观点,这是举例论证。
3. The author cites several historical events to strengthen his argument. What is this method?A.citing factsB.giving examplesC.making comparisonsing analogies答案:B。
选项A“citing facts”引用事实,历史事件可以作为例子,所以是举例论证;选项B“giving examples”举例;选项C“making comparisons”比较;选项D“using analogies”使用类比。
当代研究生英语 第七单元 B课文翻译

价格的利润生物公司正在吞噬可改变动物DNA序列的所有专利。
这是对阻碍医学研究发展的一种冲击。
木匠认为他们的贸易工具是理所当然的。
他们买木材和锤子后,他们可以使用木材和锤子去制作任何他们所选择的东西。
多年之后来自木材厂和工具储藏室的人并没有任何进展,也没有索要利润份额。
对于那些打造明日药物的科学家们来说,这种独立性是一种罕见的奢侈品。
发展或是发现这些生物技术贸易中的工具和稀有材料的公司,对那些其他也用这些工具和材料的人进行了严格的监控。
这些工具包括关键基因的DNA序列,人类、动物植物和一些病毒的基因的部分片段,例如,HIV,克隆细胞,酶,删除基因和用于快速扫描DNA样品的DNA 芯片。
为了将他们这些关键的资源得到手,医学研究人员进场不得不签署协议,这些协议可以制约他们如何使用这些资源或是保证发现这些的公司可以得到最终结果中的部分利益。
许多学者称这抑制了了解和治愈疾病的进程。
这些建议使Harold得到了警示,Harold是华盛顿附近的美国国家卫生研究院的院长,在同年早期,他建立了一个工作小组去调查此事。
由于他的提早的调查,下个月出就能发布初步的报告。
来自安阿伯密歇根大学的法律教授,该工作组的主席Rebecea Eisenberg说,她们的工作组已经听到了好多研究者的抱怨,在它们中有一份由美国联合大学技术管理组提交的重量级的卷宗。
为了帮助收集证据,NIH建立了一个网站,在这个网站上研究者们可以匿名举报一些案件,这些案件他们相信他们的工作已经被这些限制性许可证严重阻碍了。
迫使研究人员在出版之前需要将他们的手稿展示给公司的这一保密条款和协议是投诉中最常见的原因之一。
另一个问题是一些公司坚持保有自动许可证的权利,该许可证是有关利用他们物质所生产的任何未来将被发现的产品,并且这些赋予他们对任何利用他们的工具所赚取的利润的支配权利的条款也有保有的权利。
Eisenberg说:“如果你不得不签署了许多这样的条款的话,那真的是一个大麻烦”。
《2024年面向专家示例的StackOverflow本体构造和推理研究》范文

《面向专家示例的StackOverflow本体构造和推理研究》篇一一、引言随着互联网技术的快速发展,知识问答平台如StackOverflow 已经成为专家和开发者获取知识和解决问题的首选途径。
在这些平台上,本体(Ontology)的构造和推理研究对于提升信息检索的准确性和效率至关重要。
本文旨在深入探讨面向专家示例的StackOverflow本体构造和推理研究,为相关领域的研究和实践提供有价值的参考。
二、StackOverflow本体构造(一)本体定义与构建StackOverflow本体是指基于StackOverflow平台的知识领域和概念体系。
本体的构建需要从知识抽取、概念分类、关系定义等方面入手,形成层次清晰、结构合理的知识体系。
在构建过程中,需要充分利用StackOverflow平台的用户问答数据,通过自然语言处理技术进行知识抽取,构建出包含实体、属性、关系等要素的本体结构。
(二)实体与关系定义在StackOverflow本体的构建中,实体主要包括问题、答案、用户、标签等要素。
这些实体之间存在着复杂的关系,如问答关系、用户与答案的关联关系、标签与问题的关联关系等。
通过定义这些实体及其关系,可以形成完整的知识网络,为后续的推理研究提供基础。
(三)本体优化与扩展随着StackOverflow平台的发展和用户需求的不断变化,本体的构建需要不断进行优化和扩展。
这包括对已有知识的整合、新知识的引入、关系调整等方面的工作。
通过持续的优化和扩展,可以保证本体的时效性和准确性,提高信息检索的效率和准确性。
三、StackOverflow本体推理研究(一)推理技术与方法本体推理是指利用本体中的知识进行推理和推断的过程。
在StackOverflow本体的推理研究中,主要采用基于规则的推理、基于语义的推理等方法。
这些方法可以充分利用本体的结构化知识,进行逻辑推理和语义分析,从而得出有用的结论和信息。
(二)推理应用场景StackOverflow本体的推理研究可以应用于多个场景,如问题推荐、答案评估、知识图谱构建等。
Measuring Visual Clutter

Measuring visual clutterDepartment of Brain &Cognitive Sciences,MIT,Cambridge,MA,USA RuthRosenholtz Department of Brain &Cognitive Sciences,MIT,Cambridge,MA,USA YuanzhenLi Department of Brain &Cognitive Sciences,MIT,Cambridge,MA,USALisaNakanoVisual clutter concerns designers of user interfaces and information visualizations.This should not surprise visual perception researchers because excess and/or disorganized display items can cause crowding,masking,decreased recognition performance due to occlusion,greater dif ficulty at both segmenting a scene and performing visual search,and so on.Given a reliable measure of the visual clutter in a display,designers could optimize display clutter.Furthermore,a measure of visual clutter could help generalize models like Guided Search (J.M.Wolfe,1994)by providing a substitute for “set size ”more easily computable on more complex and natural imagery.In this article,we present and test several measures of visual clutter,which operate on arbitrary images as input.The first is a new version of the Feature Congestion measure of visual clutter presented in R.Rosenholtz,Y .Li,S.Mans field,and Z.Jin (2005).This Feature Congestion measure of visual clutter is based on the analogy that the more cluttered a display or scene is,the more dif ficult it would be to add a new item that would reliably draw attention.A second measure of visual clutter,Subband Entropy,is based on the notion that clutter is related to the visual information in the display.Finally,we test a third measure,Edge Density,used by M.L.Mack and A.Oliva (2004)as a measure of subjective visual complexity.We explore the use of these measures as stand-ins for set size in visual search models and demonstrate that they correlate well with search performance in complex imagery.This includes the search-in-clutter displays of J.M.Wolfe,A.Oliva,T.S.Horowitz,S.Butcher,and A.Bompas (2002)and Bravo and Farid (2004),as well as new search experiments.An additional experiment suggests that color variability,accounted for by Feature Congestion but not the Edge Density measure or the Subband Entropy measure,does matter for visual clutter.Keywords:clutter,visual search,set size,Feature Congestion,Subband EntropyCitation:Rosenholtz,R.,Li,Y .,&Nakano,L.(2007).Measuring visual clutter.Journal of Vision,7(2):17,1–22,/7/2/17/,doi:10.1167/7.2.17.Clutter is an important phenomenon in our lives and an important consideration in the design of user interfaces and information visualizations.It can interfere with searching for an important item,for example,a threat in a baggage X-ray,a document on our desktop,or a vehicle or pedestrian while driving.Clutter can interfere with quickly and veridically gathering visual information and making decisions.However,we lack a clear understanding of what clutter is;what features,attributes,and factors are relevant;why it presents a problem;and how to identify it.In practical applications,a computational measure of clutter could help either by allowing optimization of the level of clutter in displays over which we have control or by providing system alerts when clutter might impair task performance,for example,when road clutter might impair driving performance.In addition,a measure of visual clutter would also be useful for basic research in visual search.Most visualsearch research has used simple displays like that shown in Figure 1A .Researchers interested in search in more complex,naturalistic displays,however,need to be able to perform experiments on images more like that in Figure 1B and to generalize models of visual search to such images.This introduces numerous difficulties.Researchers have begun to address some of these difficulties,for example,by generalizing models of visual saliency to more complex imagery (Itti,Koch,&Niebur,1998;Rosenholtz &Jin,2005)and by exploring the influence of top–down information in more natural tasks and images (Torralba,Oliva,Castelhano,&Henderson,2006).One of the remaining difficulties in generalizing models to more complex and natural images concerns the notion of “set size,”that is,the number of “items”in the display.Research on visual search has focused a great deal on reaction time (RT)versus set-size functions as a measure of search difficulty,and set size accounts for a significant proportion of the variance in simple search experiments.Furthermore,models such as Wolfe’s (1994)Guided Search use the set size of the display to set aJournal of Vision (2007)7(2):17,1–22/7/2/17/1doi:10.1167/7.2.17Received July 15,2006;published August 6,2007ISSN 1534-7362*ARVOcriterion for when to stop looking when the observer has not found the target.However,even in complex displays generated by the experimenter,the set size of the display is often unclear.In the map shown in Figure 2,is a mountain range an item or multiple items?Does a single raindrop constitute an item?The outline of a state?In natural images,where the experimenter does not control the display,determining the number of items in the display becomes extremely difficult even given a reason-able definition of what constitutes an “item.”We propose that visual search research requires,for complex imagery,a concept of visual clutter as a stand-infor the standard concept of set size.In the following section,we discuss what one might want from a measure of clutter.Then,we suggest a broad operational definition,followed by more specific candidate definitions,which will allow us to derive several measures of the level of clutter in a display.One such measure,the Feature Congestion measure of clutter,makes use of extensive modeling of what makes items in a display visually salient.Another is based on the notion that visual clutter is related to the amount of visual information in a display.Finally,we test Edge Density measure of clutter,suggested by Mack and Oliva (2004),as a measure of subjective image complexity.In general,these clutter measures correlate well with the influence of a complex background on search performance both in previous search results from other researchers and in our own experiments.Visual search is a common subtask in many real-world visual tasks.A user must find buttons or other components of a user interface.An alert system must draw attention to a relevant part of a display so that the user can find it prehending information visualizations also has a significant visual search component.By having an understanding of how clutter plays a role in visual search,we take a significant step toward understanding the role of clutter in many real-world visual tasks.Clutter as a stand-in for set sizeIn substituting a notion of clutter for one of set size,we do not merely want to try to count the number of items in more complex displays.In the first place,this is currently unrealistic,given the state of computer vision algorithms.Furthermore,as mentioned in the previous section,items are ill-defined.What is an item in a natural scene such as that in Figure 1B :Is it a person?A shirt?A cup in a stack of cups?A branch on a tree?Furthermore,Bravo and Farid (2004)have argued that items are not even the unit of relevance,suggesting instead that the number of “parts”is more relevant to search performance.By analogy with the notion of set size,we should not expect a measure of clutter to predict,by itself,search performance.In standard RT versus set-size performance curves,as in Figure 3,set size interacts with something like target–distractor discriminability to determine search difficulty.(Here,we may not mean target–distractor discriminability in exactly the sense of threshold in a single-item discriminability experiment because we may need to take into account greater search inefficiency in spatial-configuration or conjunction search situations,which may not entirely be captured by traditional discriminability.We use the term “discriminability”here more loosely.)In a simple view of visual search,target–distractor discriminability determines whichcurveFigure 1.(A)Typical display for visual search experiments versus (B)a more complex,natural image.describes search performance.Set size determines essen-tially where a stimulus lies on a particular performance curve;that is,it determines the x -value.Together,the two (curve plus x -value)predict the performance,for example,RT.Similarly,we would expect clutter to interact with discriminability to predict search performance in complex imagery.Additional factors also influence search performance.Of particular importance for the issues of clutter and set size is the effect of top–down information on visual search.When a cue indicates that the target will appear at a subset of possible locations in a display,RTs are a function of the relevant (cued)rather than the nominal set size (Palmer,1994;Palmer,Ames,&Lindsey,1993).Features of the target may also cue a subset of potential items as possible targets,again effectively reducing set size.Furthermore,researchers have shown that in complex natural scenes,expertise such as prior knowledge about regions likely to contain a target,such as a pedestrian,can limit eye movements during search to those regions (Torralba et al.,2006).In testing our measure of visual clutter,we propose to initially minimize these top–down effects by focusing on search for categorical targets in situations that minimize prior knowledge about likely target locations.(If one were trying to determine whether set size is relevant for search performance,one would not first perform experiments in which relevant set size is unknown and differed from nominal set size.)Once we have confidence in a measure of visual clutter,such a measure can help us better evaluate experimental resultsinvolving more complex stimuli and search tasks,includ-ing those with significant top–down components.Our goals for this article are to derive,implement,and test several initial measures of visual clutter.These measures should be able to operate on arbitrary images,rather than requiring a list of the items in the display and their properties (e.g.,“green tree at location (5,2.6)”).The measures should behave sensibly on standard simple psychophysical displays.Furthermore,they should corre-late well with performance in search experiments,at least when one (approximately)controls for target–distractor discriminability and when such experiments have a minimal top–down component to the visual search task.None of the candidate clutter measures explicitly deal with objects,but they will be a function of the number of objects in the display,as well as of their appearance and organization.Furthermore,the measures may be applied to any static display because they take an image as input and do not require a list of items in the display.What is clutter?Clutter is the state in which excess items,or their representation or organization,lead to a degradation of performance at some task.Excess and/or disorganized display items can cause crowding (Stuart &Burian,1962),masking (Legge &Foley,1980),decreased object recog-nition performance due to occlusion,and impaired visual search performance (see Wolfe,1998,for a review).More items can also stretch or exceed the limits of short-term memory (Miller,1994).In the case of short-term memory,the relevant factor seems not to be merely the number of objects,but their features (color,orientation,etc.);theFigure 2.A portion of an information visualization:a map.What counts as an “item ”in a display likethis?Figure 3.RT versus set-size (or clutter)curves.Set size (clutter)and target –distractor discriminability interact to predict perfor-mance.Target –distractor discriminability select which curve describes the RT data;for example,a dif ficult feature search might put performance on the green curve.Set size (clutter)selects location on this curve (circle or triangle),to predict RT.capacity for certain simple features is higher than for more complex features(Alvarez&Cavanagh,2004). Sometimes,more items lead to performance benefits. This tends to occur when the items are low entropy, meaning that the appearance of one item is easily predicted from its neighbors.Under such conditions,it can be easier,for instance,to spot a trend in data when there are a larger number of points contributing to that trend or to notice a grouping of items with similar characteristics.Given a consistent trend or group of items, more items can aid detection of a deviation V an outlier with features or trend different from the group,or a boundary between two differing groups.Because clutter is a state when excess items lead to performance degradation,ideally,a measure of visual clutter should be modulated by low-entropy conditions in which additional items may actually lead to performance benefits.It should also capture the various phenomena in which additional or disorganized items degrade perfor-mance.However,although all of these phenomena have been studied extensively,many lack adequate models. There exist a number of models of visual search,and in the next section,wefirst suggest a measure of visual clutter based on such a model.When is a desk cluttered?In deriving a measure of visual clutter,consider a situation in which one wants to leave a note on a colleague’s desk,with the hope that it will draw attention and the colleague will act upon it.If the colleague’s desk is uncluttered,it seems easy to place a note such that one is confident that the colleague will notice it.If the colleague’s desk is cluttered,one cannot be confident of drawing attention,and often,one leaves a note on an uncluttered chair instead of the desk.This analogy suggests that the level of visual clutter in a display or scene is related to the ease of adding an attention-drawing target to that display or scene.How-ever,predicting,given a background image,the difficulty of adding an attention-grabbing target is not a usual task for a visual search model.Most such models are instead built to predict the ease of searching for a particular target among particular distractors and would need to be run iteratively to predict the difficulty of adding an item that would draw attention.Luckily,one of the authors (Rosenholtz,1999,2001a,2001b;Rosenholtz&Jin, 2005)has,for some time now,been developing the Statistical Saliency Model.Rosenholtz’model tries to capture human performance at a functional rather than biological level,utilizing the notion that the visual system is designed to characterize various statistical aspects of the visual display.This statistical framework leads to easier intuitions for why a target in a display is or is not salient and can suggest features for a salient target or predict the ease of selecting features to create a salient target.Furthermore, this model has recently been implemented so it can run on arbitrary images(Rosenholtz&Jin,2005).In the following subsection,we describe the Statistical Saliency Model for visual search and show how it can predict the ease with which one can add an attention-grabbing target to a display.Then,we will develop our measure of visual clutter and describe its implementation. The Statistical Saliency ModelRosenholtz begins with the premise that the visual system has an interest in detecting“unusual”items.She suggests that an item is unusual and,thus,salient if its features are outliers to the local distribution of features in the display.Following a long line of visual search researchers,these features are likely to include such things as contrast,color,orientation,and motion(see Wolfe,1998,for a review).Rosenholtz suggests a measure like a z-score for the degree to which a feature vector,T,is an outlier to the local distribution of feature vectors,represented by their mean,2D,and covariance, @D.The saliency,$,is given by the following equation: $¼ffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiðT j2DÞV@D j1ðT j2DÞqð1ÞwhereðT j2DÞV indicates a vector transpose.The higher the target saliency,the easier the predicted search.The saliency,$,can be thought of as a formalization of Duncan and Humphreys’(1989)notion of the different roles of target–distractor versus distractor–distractor similarity in search performance.Rosenholtz’s model predicts the results of a wide range of search experiments involving basic features such as those mentioned above(Rosenholtz, 1999,2001a,2001b;Rosenholtz,Nagy,&Bell,2004), including experiments that were previously thought to involve search asymmetries(Rosenholtz,2001a).More recently,this model has been implemented to run on arbitrary images and shown to be predictive of eye movement data(Rosenholtz&Jin,2005).Consider the graphical interpretation in Figure4.The Statistical Saliency Model essentially represents the local distribution of features by a set of covariance ellipsoids in the appropriate feature space,as shown.The local covariance,@D,specifies the size,aspect ratio,and orientation of the covariance ellipsoids.The innermost, 1A,ellipsoid indicates feature vectors1SD away from the mean feature vector,2D.The2A ellipsoid indicates feature vectors that are2SD away from the mean,and so on.A target with a feature vector on the n A ellipsoid will have saliency$=n.The farther out the target featurevector lies on these nested ellipsoids,the easier the predicted search.One can also use this model to choose attention-drawing features for an item in the display.If a designer wants to add an item to a given portion of the display,such that the saliency of that item is at least d,then any features outside of the local d A covariance ellipse will suffice.The Statistical Saliency Model can indicate the diffi-culty of adding a new,salient item to a local area of a display.Figure 5demonstrates this.Figure 5A depicts a number of lines with identical orientation and variable luminance.Figure 5B shows a cartoon of the associated covariance ellipse,assuming an (orientation,luminance)feature space.The display in Figure 5A has high variance in the luminance direction and low variance in the orientation direction (its only variance is due to observa-tion noise).Thus,the ellipsoid has low area,and it would be easy to draw attention to a target simply by giving it a significantly different orientation,as shown in Figure 5C .On the other hand,the display in Figure 5D has high variance in both orientation and luminance,as shown by the covariance ellipse in Figure 5E ,which has a relatively high area.It would be difficult to draw attention to a target in this display using only orientation or luminance as features.The volume of the local covariance ellipsoid repre-sented by @D therefore gives a measure of the local clutter in a display,that is,of the difficulty of adding a new,salient item to a local area of a display.Locally measuring the ellipsoid size and pooling over the relevant display area gives a measure of clutter for the whole display.We call this the Feature Congestion measure of visual clutter.Displays with high clutter,according to this measure,are cluttered because feature space is already “congested”(filled by the covariance ellipsoid),so that there is little room for a new feature to draw attention.Too many colors,sizes,shapes,and/or motions are already clamor-ing for attention.The Feature Congestion measure of visual clutterOur discussion leads us to a surprisingly simple measure of clutter V The clutter in a local part of a display is related to the local variability in certain key features.Implementation of the Feature Congestion clutter measure involves four stages:(1)compute local feature (co)variance at multiple scales and compute the volume of the local covariance ellipsoid,(2)combine clutter across scale,(3)combine clutter across feature types,and (4)pool over space to get a single measure of clutter for each input image.In the current implementation,we use color,orientation,and luminance contrast as features.Color,luminance contrast,and orientation have been used to model a number of perceptual phenomena,for example,pattern discriminability (Watson,2000)and preattentive texture segmentation (Malik &Perona,1990).Color naturally seems important to our sense of clutter.Contrast-energy feature detectors are known to exist early in the visual system and can not only detect simple luminance contrast but also serve as a measure of size and shape (see Rosenholtz,2000,for a review of evidence that such detectors may mediate preattentive processing of shape in the human visual system).Future implementations might include other features believed to be basic features in visual search and attention,for example,features sug-gested by the work of Treisman and Gelade (1980).Below,we briefly describe our implementation.See Rosenholtz (2000)for more details on the feature covariance stage of processing because similar steps are used to segment an image into regions of different texture V a process thought to have much in common with visual search in the human brain.Feature covarianceThe Feature Congestion measure of visual clutter depends upon being able to estimate the perceptual distance between feature vectors.Therefore,we start by converting the input image into the perceptually based CIELab color space (C.I.E.,1978).We then process the image at multiple scales (currently,three)by creating a Gaussian pyramid by alternately smoothing and subsam-pling the image (Burt &Adelson,1983).Next,we find features at each scale.For luminance contrast,we compute a form of “contrast energy”by filtering the luminance band by a center-surround filter formed from the difference of two Gaussians and squaring the outputs.ForFigure 4.Graphical depiction of the Statistical Saliency Model.X s represent the actual local distribution of features.Ellipses represent the mean and covariance of this distribution.Ellipses correspond to points of equal saliency.Outer ellipses correspond to greater saliency and easier search;thus,the model predicts that a target with a feature vector represented by the open circle ())is easier to search for than a target with a feature vector represented by the closed circle (&).color,we extract a local mean color at each scale by pooling with a Gaussian filter.For orientation,we compute oriented opponent energy,a la Bergen and Landy (1991),which gives usatwo-vector,(k cos(2E ),k sin(2E )),at each image location and scale,where E is the local orientation and k is related to the extent to which there is a single strong orientation at the given scale and location.Then,for each feature,we compute the local (co)variance for each feature.This may be done efficiently,and in a biologically plausible way,through a combina-tion of linear filtering (to average over a local area)and point-wise nonlinear operations (to compute the variance).From a covariance matrix,it is straightforward to compute the volume (area)of the covariance ellipsoid,our local measure of color (orientation)feature congestion,that is,clutter.The contrast feature congestion is simply the square root of the contrast variance.Combine across scalesFor each feature,we combine feature congestion across scale by taking the maximum at each pixel.We reason that a feature is locally congested if it is congested at any scale.Little has been done to examine the interaction of multiple scales in determining target saliency or the influence of clutter,and more basic research needs to be done to have a better understanding of how information combines across scale.Combine across featuresAt this point,we have three clutter maps for the image,representing the “color congestion,”“texture congestion,”and “orientation congestion.”Next,we combine color,contrast,and orientation clutter at each point.We first take the cube root of color clutter (a volume)and the square root of orientation clutter (an area)to make these more comparable to contrast energy clutter (a scalar).Even so,the three clutter measures are not scaled equivalently.The true measure of how congested a feature space is is how much of feature space is taken up by the covariance ellipsoid relative to how much feature space is available.Therefore,it is appropriate to scale the clutter value in each feature dimension by essentially the range of possible clutter values for that feature.Currently,we approximate that range by normalizing by the standard deviation of clutter values for a given feature over a wide range of input images.We then combine the scaled color,contrast,and orientation clutter at each point by taking their sum.A final model of clutter will almost certainly involve a more complicated combination rule than that used here.The features might,for instance,be combined into a single large feature vector prior to computation of the covariance,as might be suggested by the search results and modelling of Eckstein,Thomas,Palmer,and Shimozaki (2000).Some features might have priority over other features;for example,Callaghan (1989)has suggested that color dominates over geometric form in texture segregation.Much basic research needs to be done to adequately model feature interaction.In the absence of such research,our aim was to see how far we could go with a simple measure.Early attempts to allow a general linear combination of clutter across features did not greatly improve performance of this cluttermeasure.Figure 5.(A)High luminance variability,low orientation variability,as indicated in Panel (B).(C)One easily notices an item with an unusual orientation.(D)High variability in both luminance and orientation,as indicated in Panel (E).It would be dif ficult to draw attention to an item in this display using only the features of luminance and orientation.Combine across spaceFinally,we pool over space to get a single measure of clutter for each display by taking the average clutter value over the entire image.For a given number of objects in a scene,the scene will appear less cluttered the more“organized”it an-ization may involve grouping similar objects together; aligning them;and making many of the objects a similar hue,luminance,size,and so forth.This principle is well known in the literature on decluttering one’s home,and research has shown that perceptual organization of this sort affects search performance(Treisman,1982)and other visual tasks.The degree of organization of a scene can be thought of in terms of the extent to which each part of the scene is predictable from the rest of the scene,or in terms of the amount of redundancy in the scene.The Feature Congestion measure of clutter captures this concept of“organization”to some extent implicitly;by looking at feature covariance,it essentially captures some measure of the grouping by similarity+proximity in the display.To the extent that an image contains redundancy,it can be represented,either in the brain or in a computer,with a more efficient code.If,for example,a region of the image forms a single homogeneous group,then that region can be encoded by noting its group characteristics and location instead of encoding each point within that region. Similarly,if a number of objects repeat regularly,they can be efficiently encoded by representing the object and its repetition pattern.Therefore,the less cluttered an image is,the more it is redundant and the more efficiently it can be encoded.We propose a second measure of clutter based on attempts to measure the efficiency with which the image can be encoded while maintaining perceptual image quality.For this purpose,one would ideally like an encoder that detects the sorts of redundancies exploited by the visual system.Both low-level visual processing and mid-level visual processing seem aimed at capturing redundancies in natural images.Earlyfiltering by V1 receptivefields can be thought of as capturing low-level redundancies in the input.Researchers have suggested that a way to achieve efficient coding of natural scenes is to choose earlyfiltering operations that maximize sparse representation and that this principle leads to receptive fields like that in V1(Olshausen&Field,1996).Mid-level perceptual organization captures higher level redun-dancies in images by encoding groupings,symmetry,and so on.However,although one would ideally like to know how efficiently one can encode an image by making use of the same sorts of redundancies as the visual system,this is difficult to do given the current state of understanding and modeling of perceptual organization and mid-level pro-cessing.Therefore,for our purposes,we initially suggest using encoding efficiency of current,highly successful subband image coding methods such as JPEG2000.Our Subband Entropy clutter measure is based on the notion that clutter is related to the number of bits required for subband(wavelet)image coding.A wavelet coderfirst decomposes the image into a set of subbands with different orientations and spatial frequencies,which is analogous to the decomposition that occurs early in human vision.Thus,it captures some of the same redundancy in images as early vision.We use steerable pyramids as the basis for our Subband Entropy measure (Simoncelli&Freeman,1995).A number of effective image coders such as JPEG and JPEG2000follow a subband transform of the image with entropy encoding.Similarly,in our Subband Entropy measure of clutter,we next compute the Shannon entropy within each subband.Shannon entropy is defined as~ij p i logðp iÞ:ð2ÞHere,p is the probability distribution of coefficients in each subband and is estimated by binning(i.e.,quanti-zing)the subband coefficients into bins indexed by i and computing a histogram.This Shannon entropy essentially captures the bits required to encode the subband,for a given level offidelity,as specified by the coarseness of the bins(quantization).Higherfidelity,that is,finer bins, requires more bits to encode.In our computations,the number of bins is equal to the square root of the number of coefficients,meaning that bands with fewer coefficients also have,on average,fewer coefficients per bin.This implicitly says that it is more important to faithfully reproduce lower frequencies than high frequencies;at lower frequencies,a wavelet transform has fewer coef-ficients,and thus,this strategy leads tofiner bins,more bits required,and more faithful encoding.The clutter measure is computed as a sum of these subband entropies.The algorithm is as follows:1.Convert the RGB image into CIELab.2.Decompose the luminance(L)and the chrominance(a,b)into wavelet subbands using a steerable pyramid.3.Bin the wavelet coefficients within each subband andcompute the Shannon entropy within each subband according to Equation2.。
2024年江苏新高考一卷英语试题.doc

2024年江苏新高考一卷英语试题2024年江苏新高考一卷英语试题及答案例:How much is the shirt?A.E19.15.B.E9.18.C.E9.15.答案是C.1.What is Kate doing?A.Boarding a flight.B.Arranging a tripC.Seeing a friend off.2.What are the speakers talking about?A.pop star.B.An old songC.A radio program3.What will the speakers do today?A.Goto an art show.B.Meet the mans aunt.C.Eat out with Mark4.What does the man want to do?A.Cancel an order.B.Ask for a receipt.C.Reschedule a delivery5.When will the next train to Bedford leave?A.At 9:45.B.At 10:15C.At 11:00.第二节 (共15小题;每小题1.5分,满分22.5分)听下面5段对话或独白。
每段对话或独白后有几个小题,从题中所给的 A 、B 、C 三个选项中选出最佳选项。
听每段对话或独白前,你将有时间阅读各个小题,每小题5秒钟;听完后,各小题将给出5秒钟的作答时间。
每段对话或独白读两遍。
听第6段材料,回答第6、7题。
6.What will the weather be like today?A.StormyB.SunnyC.Foggy7.What is the man going to do?A.Plant a tree.B.Move his carC.Check the map听第7段材料,回答第8至10题。
人工智能专业英语Unit3

Exercises I. Read the following statements carefully, and decide whether they are true (T) or false (F) according to the text.
Section A: Reasoning with Uncertainty
II. Choose the best answer to each of the following questions according to the text.
1. When was Thomas Bayes born? A. In 1936 B. In 1702 C. In 1761 D. In 1985
Contents
• Part 1 Reading and Translating
人教版高一英语上册Welcome unit Reading for Writing 分层练习

Welcome unit Reading for Writing分层练习语言知识一、(2024·高一课时练习)根据汉语提示完成句子1.____ _____ ________ ______, you'll achieve what you want.如果你努力,你会获得你想要的。
2. It is children's nature______ _______ _________ ______the people and things around them.对周围的人和事物感到好奇是孩子们的天性。
3. I wish_______ _________what was going to happen.但愿我(能)知道要发生什么事。
4. ______ _____ _______ ___________to keep me running every day, I think.我认为每天坚持跑步对于我来说是非常重要的。
5._____ _____ ________ _________,you must be calm.无论发生什么事,你都必须镇定。
【答案】1. If you work hard2. to be curious about3. I knew4. It is very important5. No matter what happens二、(2024·高一课时练习)根据汉语提示完成句子1. ____ ____ we moved the sofa over there? Would that look better?把沙发搬到那边怎么样?看上去会更好些吗?2. We find_____ _____to finish the work on time.我们发现我们按时完成工作有困难。
3. The new teacher____ _____ _____ ______on the students by her rich knowledge and humorous talk.那位新老师以她丰富的知识和幽默的语言给同学们留下了好的印象。
图形化编程工具辅助程序设计学习_刘芳芳

126信息化教学2009年11月下 第30期(总第183期)1 研究概述我国自1982年开始中小学计算机普及教育,以学习计算机原理和程序设计为主,当时受到硬件设备的限制,开设的主要是Basic和logo的程序设计。
考虑到中小学生的心理与学习特点,1985年受在美国召开的“第四届世界计算机教育会议”影响,我国计算机教育开始重新审视教学内容,将单一的Basic语言教学逐步转向计算机应用的教学上来,于是程序教学开始遭到摒弃,教学内容和模式开始转向应用软件的使用操作。
1994年,联合国教科文组织(UNESCO)委托国际信息处理学会(IFIP),编写指导世界各国计算机课程设置的文件《中学信息学课程》[1],其中指出:“这里所指的程序设计是非技术性的程序设计,更确切地说应该是把‘你自己做的事情’转变成‘别人能做的事情’。
这就要求能详尽地描述完成任务的过程,以便其他的人或其他的设备能准确地重复这一项工作。
”其中“能详尽地描述完成任务的过程”通俗一点讲,就是程序教学并不是要培养“程序员”,而是想通过教给学生详细的过程,来培养学生设计程序的思维方式,从而学会用这种思维来分析、解决问题。
因此,程序设计是培养学生创造力的有效手段和途径,应让学生适当参与。
随着计算机技术的大发展,中小学信息技术课程教学开始从“单一的技能训练”逐步转向“信息素养的培养”,开始注重中小学生的创新思维的训练。
尤其是2003年国家教育部颁布的中小学信息技术标准,其中将程序设计又作为选修模块开始出现。
从高中的新课标把算法与程序设计作为一个选修模块,到义务教育阶段慢慢把程序设计作为一项必修内容,程序设计又慢慢地回到信息技术教材中[2]。
让中小学生运用所学的语句自己组合程序来解决数学问题、设计小游戏等,这个过程对学生来说是一种创造设计的过程,也是一种培养分析、解决问题以及创造能力的过程,由此可见程序设计课在中小学开设是非常必要的。
2 研究的问题2.1 问题的提出 随着网络技术的发展,计算机语言也跟随10.3969/j.issn.1671-489X.2009.30.126图形化编程工具辅助程序设计学习刘芳芳上海师范大学教育技术系 上海 200234摘 要 随着技术的进步,思维可视化成为教学关注的一个焦点。
2023年3月六级真题第一套

2023年3月大学英语六级考试真题(第1套)Part I Writing (30 minutes) Directions:For this part, you are allowed 30 minutes to write an essay that begins with the sentence “People are now increasingly aware of the danger of ‘appearance anxiety’ or beingobsessed with one’s looks.” You can make comments, cite examples or use your personalexperiences to develop your essay. You should write at least 150 words but no more than 200words._____________________________________________________________________________________ _____________________________________________________________________________________ _____________________________________________________________________________________ _____________________________________________________________________________________ _____________________________________________________________________________________ Part II Listening Comprehension (30 minutes) Section ADirections:In this section, you will hear two long conversations. At the end of each conversation, you will hear four questions. Both the conversation and the questions will be spoken only once.After you hear a question, you must choose the best answer from the four choices marked A),B), C), and D). Then mark the corresponding letter on Answer Sheet 1with a single linethrough the centre.Questions 1 to 4 are based on the conversation you have just heard.1. A. In a kitchen. B. In a restaurant.C. In a food store.D. In a supermarket.2. A. She eats meat occasionally. B. She enjoys cheeseburgers.C. She is a partial vegetarian.D. She is allergic to seafood.3. A. Changing one’s eating habit. B. Dealing with one’s colleagues.C. Following the same diet for years.D. Keeping awake at morning meetings.4. A. They are both animal lovers. B. They enjoy perfect health.C. They only eat organic food.D. They are cutting back on coffee.Questions 5 to 8 are based on the conversation you have just heard.5. A. The man had an attitude problem.B. The man made little contribution to the company.C. The man paid attention to trivial things.D. The man got a poor evaluation from his colleagues.6. A. They make unhelpful decisions for solving problems.B. They favor some employees’ suggestions over others’.C. They reject employees’ reasonable arguments for work efficiency.D. They use manipulative language to mask their irrational choices.7. A. It is a must for rational judgment. B. It is more important now than ever.C. It is a good quality in the workplace.D. It is more of a sin than a virtue.8. A. Smoothing relationships in the workplace.B. Making rational and productive decisions.C. Preserving their power and prestige.D. Focusing on employees’ carcer growth.Section BDirections:In this section, you will hear two passages. At the end of each passage, you will hear three or four questions. Both the passage and the questions will be spoken only once. After you hear aquestion, you must choose the best answer from the four choices marked A), B), C) and D).Then mark the corresponding letter on Answer Sheet 1 with a single line through the centre. Questions 9 to 11 are based on the passage you have just heard.9. A. They show genius which defies description.B. They create very high commercial value.C. They accomplish feats many of us cannot.D. They bring great honor to their country.10. A. They try to be positive role models to children.B. They work in spare time to teach children sports.C. They take part in kids’ extra-curricular activities.D. They serve as spokespersons for luxury goods.11. A. Being super sports stars without appearing arrogant.B. Preventing certain athletes from getting in trouble with the law.C. Keeping athletes away from drug or alcohol problems.D. Separating an athlete’s professional life from their personal life.Questions 12 to 15 are based on the passage you have just heard.12. A. They are dreams coming true to the brides.B. They are joyous and exciting occasions.C. They should be paid up by the attendees.D. They always cost more than expected.13. A. It was cancelled. B. It cost $60,000.C. It had eight guests only.D. It was held in Las Vegas.14. A. Postpone her wedding. B. Ask her friends for help.C. Keep to her budget.D. Invite more guests.15. A. She called it romantic. B. She rejected it flatly.C. She said she would think about it.D. She welcomed it with open arms.Section CDirections: In this section, you will hear three recordings of lectures or talks followed by three or four questions. The recordings will be played only once. After you hear a question, you mustchoose the best answer from the four choices marked A), B), C) and D). Then mark thecorresponding letter on Answer Sheet 1 with a single line through the centre.Questions 16 to 18 are based on the recording you have just heard.16. A. It determines people’s moods.B. It can impact people’s wellbeing.C. It can influence peop le’s personalities.D. It is closely related to people’s emotions.17. A. They make people more reproductive. B. They tend to produce positive feelings.C. They increase people’s life expectancy.D. They may alter people’s genes gradually.18. A. The Americans are apparently more outgoing than the Chinese.B. People share many personality traits despite their nationalities.C. People in the same geographical area may differ in personality.D. The link between temperature and personality is fairly weak.Questions 19 to 21 are based on the recording you have just heard.19. A. The number of older Americans living alone is on the rise.B. Correlations have been found between loneliness and ill health.C. Chronic loneliness does harm to senior citizens in particular.D. A growing number of US seniors face the risk of early mortality.20. A. Loneliness is probably reversible.B. Loneliness rarely results from living alone.C. Being busy helps fight loneliness.D. Medication is available for treating loneliness.21. A. Living with one’s children. B. Meaningful social contact.C. Meeting social expectations.D. Timely medical intervention.Questions 22 to 25 are based on the recording you have just heard.22. A. She had a successful career in finance.B. She wrote stories about women travelers.C. She made regular trips to Asian countries.D. She invested in several private companies.23. A. Buy a ranch. B. Set up a travel agency.C. Travel round the world.D. Start a blog.24. A. Create something unique to enter the industry.B. Gain support from travel advertising companies.C. Try to find a full-time job in the travel business.D. Work hard to attract attention from publishers.25. A. Attracting sufficient investment. B. Avoiding too much advertising early on.C. Creating an exotic corporate culture.D. Refraining from promoting similar products.Part III R eading Comprehension (40 minutes) Section ADirections:In this section, there is a passage with ten blanks. You are required to select one word for each blank from a list of choices given in a word bank following the passage. Read thepassage through carefully before making your choices. Each choice in the bank is identifiedby a letter. Please mark the corresponding letter for each item on Answer Sheet 2with asingle line through the centre. You may not use any of the words in the bank more than once. Questions 26 to 35 are based on the following passage.Unthinkable as it may be, humanity, every last person, could someday be wiped from the face of the Earth. We’ve learned to worry about asteroids (小行星) and super volcanoes, but the more likely 26 , according to Nick Bostrom, a professor of philosophy at Oxford, is that we humans will destroy ourselves.Professor Bostrom, who directs Oxford’s Future of Humanity Institute, has argued over the course of several papers that human 27 risks are poorly understood and, worse sill, 28 underestimated by society. Some of these existential risks are fairly well known, especially the natural ones. But others are 29 or even exotic. Most worrying to Bostrom is the subset of existential risks that 30 from human technology, a subset that he expects to grow in number and potency over the next century.Despite his concerns about the risks 31 to humans by technological progress, Bostrom is no luddite(科技进步反对者). In fact, he is a longtime 32 of transhumanism—the effort to improve the human condition, and even human nature itself, through technological means. In the long run he sees technology as a bridge, a bridge we humans must cross with great care, in order to reach new and better modes of being. In his work, Bostrom uses the tools of philosophy and mathematics, in 33 , probability theory, to try and determine how we as a 34 might achieve this safe passage. What follows is my conversation with Bostrom about some of the most interesting and worrying existential risks that humanity might 35 in the decades and centuries to come, and about what we can do to make sure we outlast them.Section BDirections:In this section, you are going to read a passage with ten statements attached to it. Each statement contains information given in one of the paragraphs. Identify the paragraph fromwhich the information is derived. You may choose a paragraph more than once. Eachparagraph is marked with a letter. Answer the question by marking the corresponding letteron Answer Sheet 2.San Francisco Has Become One Huge Metaphor for Economic Inequality in AmericaA) The fog still chills the morning air and the cable cars still climb halfway to the stars. Yet on theground, the Bay Area has changed greatly since Tony Bennett left his heart here. Silicon Valley and the tech industry have led the region into a period of unprecedented wealth and innovation. But existing political and land limits have caused an alarming housing crisis and astronomical rise in social and economic difference.B) While the residents of most cities display pride and support for their home industries, drastic marketdistortions in the San Francisco Bay Area have created a boiling resentment in the region towards the tech industry. A vocal minority is even calling on officials to punish those who are benefitting from the economic and housing boom. If this boom and its consequences are not resolved, a drastic increase in social and economic difference may have a profound impact on the region for generations.A history and analysis of this transformation may hold invaluable insights about the opportunities.Perils of tech cities are currently being cultivated across the US, and indeed around the world.C) According to a recent study, San Francisco ranks first in California for economic difference. Theaverage income of the top 1% of households in the city averages $3.6 million. This is 44 times the average income of those at the bottom, which stands at $81,094. The top 1% of the San Francisco peninsula’s share of total income now extends to 30.8% of the region’s income. This was a dramatic jump from 1989, where it stood at 15.8%.D) The region’s economy has been fundamentally transformed by the technology industry springingfrom Silicon Valley. Policies pushed by Mayor Ed Lee provided tax breaks for tech companies to set up shop along the city’s long-neglected Mid-Market area. The city is now home to Twitter, Uber, Airbnb, Pinterest, Dropbox and others. In short, the Bay Area has become a global magnet for those with specialized skills, which has in turn helped fuel economic enthusiasm, and this economic growth has reduced unemployment to 3.4%, an admirable feat.E) In spite of all that, the strength of recent job growth, combined with policies that have traditionallylimited housing development in the city and throughout the peninsula, did not help ease the affordability crisis. In 2015 alone, the Bay Area added 64,000 in jobs. In the same year, only 5,000 new homes were built.F) With the average house in the city costing over $1.25 million and average flat prices over $1.11million, the minimum qualifying income to purchase a house has increased to $254,000. Considering that the average household income in the city currently stands at around $80,000, it is not an exaggeration to say that the dream of home ownership is now beyond the grasp of the vast majority of today’s people who rent.G) For generations, the stability and prosperity of the American middle class has been anchored by homeownership. Studies have consistently shown that the value of land has overtaken overall income growth, thus providing a huge advantage to property owners as a vehicle of wealth building. When home prices soar above the reach of most households, the gap between the rich and the poor dramatically increases.H) If contributing factors leading to housing becoming less than affordable are not resolved overmultiple generatio ns, a small elite control a vast share of the country’s total wealth. The result? A society where the threat of class warfare would loom large. A society’s level of happiness is tied less to measures of quantitative wealth and more to measures of qualitative wealth. This means that how a person judges their security in comparison to their neighbors’ has more of an impact on their happiness than their objective standard of living. At the same time, when a system no longer provides opportunities for the majority to participate in wealth building, it not only robs those who are excluded from opportunities, but also deprives them of their dignity.I) San Francisco and the Bay Area have long been committed to values which embrace inclusion andrejection of mainstream culture. To see these values coming apart so publicly adds insult to injury fora region once defined by its progressive social fabric. In the face of resentment, it is human to wantrevenge. But deteriorating policies such as heavily taxing technology companies or real estate developers are not likely to shift the balance.J) The housing crisis is caused by two primary factors: the growing desirability of the Bay Area as a place to live due to its excellent economy, and our limited housing stock. Although the city is experiencing an unprecedented boom in new housing, more units are sorely needed. Protection policies were originally designed to suppress bad development and boost historic preservation in our urban areas. Now too many developers are experiencing excessive delays. Meanwhile, there are the land limitations of the Bay Area to consider. The region is surrounded by water and mountains. Local governments need to aid development as well. This means increasing housing density throughout theregion and building upwards while streamlining the approval process.K) Real estate alone will not solve the problem, of course. Transportation, too, needs to be updated and infrastructure extended to link distant regions to Silicon Valley and the city. We need to build an effective high-speed commuting system linking the high-priced and crowed Bay Area with the low-priced and low-density Central Valley. This would dramatically reduce travel times. And based on the operating speeds of hovering trains used in countries such as Japan or Spain, high-speed rail could shorten the time to travel between San Francisco and California’s capitol, Sacramento, or from Stockton to San Jose, to under 30 minutes. This system would bring once distant regions within reasonable commute to heavy job centers. The city also needs to update existing transportation routes combined with smart home-building policies that dramatically increase housing density in areas surrounding high-speed rail stations. By doing so, we will be able to build affordable housing within acceptable commuting distances for a significant bulk of the workforce.L) Our threatening housing crisis forces the difficult question of what type of society we would like to be. Will it be one where elites command the vast bulk of wealth and regional culture is defined by a aggressive business world? We were recently treated to a taste of the latter, when local tech employee Justin Keller wrote an open letter to the city complaining about having to see homeless people on his way to work.M) It doesn’t have to be this way. But solutions need to be implemented now, before angry crowds grow from a nuisance to serious concern. It may take less than you might think. And in fact, the solutions to our housing crisis are already fairly clear. We need to increase the density of housing units. We need to use existing technology to shorten travel times and break the land limits. There is a way to solve complex social and economic problems without abandoning social responsibility. This is the Bay Area’s opportunity to prove that it can innovate more than just technology.36. S an Francisco city government offered tax benefits to attract tech companies to establish operationsin a less developed area.37. T he fast rise in the prices of land and houses increases the economic inequality among people.38. S an Francisco has been found to have the biggest income gap in California between the rich and thepoor.39. T he higher rate of employment, combined with limited housing supply, did not make it any easier tobuy a house.40. W hen people compare their own living standard with others’, it has a greater impact on their sense ofcontentment.41. I mproved transport networks connecting the city to distant outlying areas will also help solve thehousing crisis.42. A verage incomes in the Bay Area make it virtually impossible for most tenant families to buy ahome.43. I nnovative solutions to social and economic problems should be introduced before it is too late.44. R esidents of the San Francisco Bay Area strongly resent the tech industry because of the economicinequality it has contributed to.45. O ne way to deal with the housing crisis is for the government to simplify the approval procedures forhousing projects.Section CDirections:There are 2 passages in this section. Each passage is followed by some questions or unfinished statements. For each of them there are four choices marked A), B), C) and D). Youshould decide on the best choice and mark the corresponding letter on Answer Sheet 2 with asingle line through the centre.Passage OneQuestions 46 to 50 are based on the following passage.The suggestion that people should aim for dietary diversity by trying to eat a variety of foods has been a basic public health recommendation for decades in the United States everywhere. Now, however, experts are warning that aiming for a diverse diet may actually lead to just eating more calories, and, thus, to obesity. One issue is that people may not interpret "variety” the way nutritionists intend. This problem is highlighted by new research conducted by the American Heart Association. Researchers reviewed all the evidence published related to dietary diversity and saw a correlation between dietary diversity and a greater intake of both healthy and unhealthy foods. This had implications for obesity, as researchers found a greater prevalence of obesity amongst people with a greater dietary diversity.One author of the new study explained that their findings contradict standard dietary advice, as most dietary guidelines around the world include a statement of eating a variety of foods. But this advice does not seem to be supported by science, possibly because there is little agreement about the meaning of “dietary diversity,” which is not clearly and consistently defined. Some experts measure dietary diversity by counting the number of food groups eaten, while others look at the distribution of calories across individual foods, and still others measure how different foods eaten are from each other.Although the findings of this new study contradict standard dietary advice, they do not come as a surprise to all of the researchers involved. Dr. Rao, one of the study authors, noted that after 20 years of experience in the field of obesity, he has observed that people who have a regimented lifestyle and diet tend to be thinner and healthier than people with a wide variety of consumption. This anecdotal evidence matches the conclusions of the study, which found no evidence that dietary diversity promotes healthy body weight or optimal eating patterns, and limited evidence shows that eating a variety of foods is actually associated with consuming more calories, poor eating patterns and weight gain. Further, there is some evidence that a greater variety of f ood options in a single meal may delay people’s feeling of fullness and actually increase how much they eat.Based on their findings, the researchers endorse a diet consisting of a limited number of healthy foods such as vegetables, fruits, grains, and poultry. They also recommend that people simultaneously endeavor to restrict consumption of sweets, sugar and red meat. The researchers stress, however, that their dietary recommendations do not imply dietary diversity is never positive, and that, in the past, diversity in diets of whole, unprocessed food may have actually been very beneficial.46. What has been a standard piece of dietary advice for decades?A. People should diversify what they eat.B. People should have a well-balanced diet.C. People should cultivate a healthy eating habit.D. People should limit calorie intake to avoid obesity.47. What did the new research by the American Heart Association find?A. Unhealthy food makes people gain weight more easily.B. Dietary diversity is positively related to good health.C. People seeking dietary diversity tend to eat more.D. Big eaters are more likely to become overweight.48. What could help to explain the contradiction between the new findings and the common public healthrecommendation?A. There is little consensus on the definition of dietary diversity.B. The methods researchers use to measure nutrition vary greatly.C. Conventional wisdom about diet is seldom supported by science.D. Most dietary guidelines around the world contradict one another.49. What did Dr. Rao find after 20 years of research on obesity?A. There is no clear definition of optimal eating patterns.B. Diversified food intake may not contribute to health.C. Eating patterns and weight gain go hand in hand.D. Dietary diversity promotes healthy body weight.50. What does the passage say about people who eat a great variety of food?A. They are more likely to eat foods beneficial to their health.B. They don’t have any problems getting sufficient nutrition.C. They don’t feel they have had enough until they overeat.D. They tend to consume more sweets, sugar and red meat.Passage TwoQuestions 51 to 55 are based on the following passage.The ability to make inferences from same and different, once thought to be unique to humans, is viewed as a cornerstone of abstract intelligent thought. A new study, however, has shown that what psychologists call same-different discrimination is present in creatures generally seen as unintelligent: newborn ducklings (小鸭).The study, published Thursday in Science, challenges our idea of what it means to have a birdbrain, said Edward Wasserman, an experimental psychologist at the University of Iowa who wrote an independent review of the study.“In fact, birds are extremely intelligent and our problem pretty much lies in figuring out how to get them to ‘talk’ to us, or tell us how smart they really are,” he said.Antone Martinho and Alex Kacelnik, co-authors of the new paper, devised a clever experiment to better test bird intelligence.First, they took 1-day-old ducklings and exposed them to a pair of moving objects. The two objects were either the same or different in shape or color. Then they exposed each duckling to two entirely new pairs of moving objects.The researchers found that about 70 percent of the ducklings preferred to move toward the pair of objects that had the same shape or color relationship as the first objects they saw. A duckling that was first shown two green spheres, in other words, was more likely to move toward a pair of blue spheres than a mismatched pair of orange and purple spheres.Ducklings go through a rapid learning process called imprinting shortly after birth—it’s what allows them to identify and follow their mothers.These findings suggest that ducklings use abstract relationships between sensory inputs like color, shape, sounds and odor to recognize their mothers, said Dr. Kacelnik.By studying imprinting, the authors of this study have shown for the first time that an animal can learn relationships between concepts without training, said Jeffrey Katz, an experimental psychologist at Auburn University who was not involved in the study.Previous studies have suggested that other animals, including pigeons, dolphins, honeybees and some primates (灵长类动物), can discern same from different, but only after extensive training.Adding ducklings to the list—particularly untrained newborn ducklings—suggests that the ability to compare abstra ct concepts “is far more necessary to a wider variety of animals’ survival than we previously thought,” Dr Martinho said. He believes the ability is so crucial because it helps animals consider context when identifying objects in their environment.It’s clear from this study and others like it that “animals process and appreciate far more of the intricacies in their world than we’ve ever understood,” Dr. Wasserman said. “We are in a revolutionary phase in terms of our ability to understand the minds of othe r animals.”51. In what way were humans thought to be unique?A. Being capable of same-different discrimination.B. Being able to distinguish abstract from concrete.C. Being a major source of animal intelligence.D. Being the cornerstone of the creative world.52. What do we learn from the study published in Science?A. Our understanding of the bird world was biased.B. Our communication with birds was far from adequate.C. Our knowledge about bird psychology needs updating.D. Our conception of birds’ intelligence was wrong.53. What did the researchers discover about most ducklings from their experiment?A. They could associate shape with color.B. They could tell whether the objects were the same.C. They preferred colored objects to colorless ones.D. They reacted quickly to moving objects.54. What was novel about the experiment in the study reported in Science?A. The ducklings were compared with other animals.B. It was conducted by experimental psychologists.C. The animals used received no training.D. It used a number of colors and shapes.55. What do we learn from Dr. Wasserman’s comment on the study of animal minds at the end of thepassage?A. Research methods are being updated.B. It is getting more and more intricate.C. It is attracting more public attention.D. Remarkable progress is being made.Part IV T ranslation (30 minutes) Directions: For this part, you are allowed 30 minutes to translate a passage from Chinese into English.You should write your answer on Answer Sheet 2.徐霞客是中国明代的著名地理学家,他花费了三十多年的时间游遍了大半个中国。
视觉语法下的多模态研究

视觉语法下的多模态研究作者:朱泽浩来源:《青年时代》2019年第20期摘要:本文以Kress&Van Leeuwen提出的视觉语法框架为理论依据,以《江西全球推介会宣传片》为多模态研究语料,从再现意义、互动意义和构图意义三个层面着手,不仅从语言文字和翻译艺术的角度分析了宣传片的交际效果,还从图像、构图等视觉非语言符号为切入点探究宣传片取得成功的原因。
关键词:视觉语法,宣传片,多模态以语言和非语言符号相结合的传媒的发展促使文化交流從传统的单一模式向“多模态”模式转变。
“多模态话语”是运用听觉、视觉等多种感觉,通过语言、图像、声音、动作等多种手段和符号来进行交际。
本文试以Kress & Van Leeuwen的视觉语法理论为基础,从再现意义、互动意义和构图意义三个层面对《江西全球推介会宣传片》这一“视觉名片”进行多模态分析。
一、视觉语法理论概述视觉语法理论是Kress &Van Leeuwen以韩礼德的系统功能理论为基础提出的。
系统功能将语言分为概念功能、人际功能和语篇功能。
Kress &Van Leeuwen基于这三大元功能在视觉模式中以怎样的方式传递什么意义出发,构建出了一个以再现意义、互动意义和构图意义为中心的视觉语法框架。
视觉语法中,再现意义通过图像中人物、环境、地点事件的关系来体现,分为叙事再现和概念再现。
叙事再现主要关注动作,受参与者行动、言语等影响。
概念再现表示参与者稳定、持久的状态,受分类、分析以及象征过程的影响。
互动意义解释图像如何与观众产生互动,并通过接触、视点、距离、情态体现相互之间的关系。
接触反映参与者与观众之间的关系,分为索取和提供。
视点也叫视角,通过角度来表现互动意义。
距离通过参与者之间位置的远近体现关系的亲疏。
情态反映客观的世界形态。
构图意义分析图像中元素如何通过构图来表达意义,体现多模态语篇构建的整体性。
构图再现有三个部分:信息值、显著性和取景。
What is Scientific Visualization

Visualization is not only looking into a pretty picture…
– understanding of the data – been able to analyze and interpret data
Applications
Used in: – Engineering – Computational Fluid Dynamics – Simulation – Medical Imaging – Geospatial – Ground Water Modeling – Oil and Gas Exploration and Production – and more…
Scientific Visualization
By: Jesus Caban and Chi Chau
What is Scientific Visualization?
Visualization for scientific computing, shortened to scientific visualization, was coined in 1987 and refers to the science or methodology of quickly and effectively displaying scientific data.
●
Motivation
In computational science we can use distributed computers and powerful clusters to simulate complex and realistic problems. It is difficult for the human brain to make sense out of the large volume of numbers Can we enhance and improve scientific productivity by utilizing human visual perception and computer graphics techniques? What can we do with the resulting numbers, formulas and data?
博士考试试题及答案英语

博士考试试题及答案英语一、选择题(每题2分,共20分)1. The correct spelling of the word "phenomenon" is:A. fenomenonB. phenomonC. phenominonD. phenomenon答案:D2. Which of the following is not a verb?A. to runB. to jumpC. to flyD. flight答案:D3. The phrase "break the ice" means:A. to start a conversationB. to stop a conversationC. to make a decisionD. to end a conversation答案:A4. The opposite of "positive" is:A. negativeB. optimisticC. pessimisticD. positive答案:A5. Which of the following is not a preposition?A. inB. onC. atD. is答案:D6. The word "perspective" can be used to describe:A. a point of viewB. a physical locationC. a mathematical calculationD. a scientific experiment答案:A7. The phrase "a piece of cake" is used to describe something that is:A. difficultB. boringC. easyD. expensive答案:C8. The verb "to accommodate" means:A. to refuseB. to ignoreC. to provide space or servicesD. to argue答案:C9. The word "meticulous" is an adjective that describes someone who is:A. lazyB. carelessC. very careful and preciseD. confused答案:C10. The phrase "to go viral" refers to:A. to become sickB. to spread quickly on the internetC. to travel by planeD. to become extinct答案:B二、填空题(每题2分,共20分)1. The word "____" means a sudden loud noise.答案:bang2. "____" is the term used to describe a person who is very knowledgeable.答案:savant3. The phrase "to turn a blind eye" means to ____.答案:ignore4. The word "____" is used to describe a situation that is very difficult to understand.答案:enigmatic5. "____" is a term used to describe a person who is very good at remembering things.答案:eidetic6. The word "____" is used to describe a person who is very talkative.答案:loquacious7. The phrase "to ____" means to make something more complex. 答案:complicate8. The word "____" is used to describe a person who is very organized and efficient.答案:methodical9. The phrase "to ____" means to make a plan or to decide ona course of action.答案:strategize10. The word "____" is used to describe a person who is verycurious and eager to learn.答案:inquisitive三、阅读理解(每题4分,共20分)阅读以下短文,然后回答问题。
英语作文如何快速记住时间

When it comes to memorizing dates and times, many students find themselves struggling with the sheer volume of information they need to retain. From historical events to scientific discoveries, the ability to recall specific dates can be crucial for academic success. Heres my personal journey and some strategies that Ive found effective in quickly memorizing times.Embracing the Power of AssociationOne of the first things I learned was the power of association. By linking dates to personal experiences or familiar events, I could anchor them in my memory more effectively. For instance, remembering the date of a friends birthday that falls close to a historical event can serve as a mnemonic device. This method not only makes the process less tedious but also more enjoyable.Utilizing Visual AidsVisual aids have been a gamechanger for me. Creating timelines or mind maps with dates and related events can help in visualizing the sequence of events. This method is particularly useful for understanding the chronology of historical periods. By seeing the flow of time visually, I could better grasp the context and significance of each date.Engaging in Regular PracticeConsistent practice is the key to retention. I made it a habit to review thedates I needed to memorize daily. Repetition is a powerful tool in the learning process. By revisiting the information regularly, I was able to move it from my shortterm to longterm memory.Employing the Method of LociThe method of loci, also known as the memory palace technique, is an ancient memorization strategy that I found incredibly useful. By associating dates with specific locations in a familiar place, such as my home or school, I could recall them more easily. Walking through this mental space helped me to retrieve the dates as I mentally navigated through the familiar environment.Using Acronyms and AcrosticsFor sequences of dates or events, acronyms and acrostics are a clever way to condense information. By creating a word or sentence from the first letters of the dates or related terms, I could recall the entire sequence with ease. This method is particularly effective for remembering lists or sequences of events in a specific order.Incorporating Dates into Daily LifeI tried to incorporate the dates I was learning into my daily life. For example, setting reminders or alarms for certain dates on my phone not only helped me remember them but also made the process feel more integrated into my routine.Engaging with Interactive ToolsTechnology has provided us with numerous interactive tools that can make memorizing dates more engaging. Apps and online games that involve quizzes or challenges related to dates have been a fun way for me to test my knowledge and reinforce my memory.Reflecting on the Importance of DatesUnderstanding the why behind the dates is as important as remembering the when. By reflecting on the significance of each date, I could create a deeper connection with the information, making it easier to remember. This approach also helped me to appreciate the relevance of the dates in the broader context of history or science.Group Study SessionsStudying with peers can be incredibly beneficial. During group study sessions, we would quiz each other on dates, share mnemonic devices, and discuss the significance of events. This collaborative approach not only made the process more enjoyable but also helped to solidify the information in my memory.ConclusionMemorizing dates and times doesnt have to be a daunting task. Byemploying a variety of strategies and making the process interactive and meaningful, I was able to improve my ability to recall specific times with ease. The key is to find the methods that work best for you and to integrate them into your study routine. With practice and persistence, anyone can become adept at quickly memorizing dates and times.。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Department of Computer Science and Applied Mathematics The Weizmann Institute of Science, Rehovot 76100, Israel {liran,yehuda,harel}@wisdom.weizmann.ac.il Abstract The Lorentzian model is an analytic expression that describes the time response of electronic nose sensors. We show how this model can be utilized to calculate a normalized similarity index between any two measurements. The set of similarity indices is then used for two purposes: visualization of the data, and classification of new samples. The visualization is carried out using graph drawing tools, and the results are shown to bear some desired properties. The classification is done using a majority-decision type algorithm, and is demonstrated to have very low error rate. Keywords electronic noses, similarity index, feature extraction, Lorentzian model, graph drawing, visualization, classification INTRODUCTION Visualization and classification are among the most addressed issues in the data analysis of electronic noses (eNoses). Classification, which is the task of determining the identity of incoming samples, is by far the most popular form of analysis. It is realized by a variety of supervised learning algorithms, details of which can be found in, e.g., [2] or [3]. Visualization is the task of representing the eNose measurements as points in two-dimensional (and in some occasions three-dimensional) space, in a way that faithfully captures their inter-relationships. Undoubtedly, principal component analysis (PCA) is the most widely used visualization algorithm. Whatever algorithm is used, would it be for visualization or for classifications, it requires feature vectors as input. A feature set is a small set of parameters that somehow describe the entire time response of a certain sensor in a certain measurement. The feature vector is comprised of the collection of the feature sets of all the sensors in a particular measurement. Typically, the height of the signal is taken as a single feature per sensor (see, e.g., [3]), resulting in feature vectors, to be hereinafter called the height feature vectors, whose length is the number of sensors in the eNose. The feature vectors serve well for many applications, but might introduce unavoidable difficulties for others. One problem is that the eNose sensors might be scaled differently, even if they are made of the same technology. Consequently, the various features must be preprocessed, so as to bring them onto common grounds. This is typically done by standardizing the features or by normalizing the feature vectors. Another problem is that many of the algorithms assume some metric for the feature space. For example, the popular K-nearest-neighbors (KNN) algorithm calculates the Euclidean distance between pairs of feature vectors, and PCA can be interpreted as a projection in an Euclidean space. Yet, there is no a priori reason to associate any specific metric with a particular feature space. We suggest a different approach, which enables visualization and classification without having to use directly the feature vectors. Instead, we propose a simple method for measuring the amount of similarity between any two measurements, in a way that allows for natural comparison between differently scaled signals. We further support this approach by introducing two algorithms, one for visualization and one for classification, which take these similarities as their input. We show that the resulting visualization is of high quality and often contains information not present in standard approaches, and that the probability of classification errors is very low. Experimental We have tested our algorithms against a large dataset that we have collected using the MOSESII eNose [6] with two sensor modules: an eight-sensor quartz-microbalance (QMB) module, and an eight-sensor metal-oxide (MOX) module. (Reviews on these technologies can be found in, e.g., [2] or [7].) The samples were put in 20-ml vials in HP7694 headspace sampler, which heated them to 40ºC and injected the headspace content into the eNose. There, the analyte was first introduced into the QMB chamber, whence it followed to the 300ºC heated MOS chamber. The injection lasts for 30 seconds, and is followed by a 15 minute purging stage using synthetic air. The dataset includes 30 volatile odorous pure chemicals listed alphabetically in Table 1. These chemicals were intentionally chosen from many different families, so that they would represent a broad range of possible stimuli. Each chemical was measured in batches, with a single batch containing at least seven successive measurements. Different batches of the same chemical were usually taken in totally different dates. In total, we have performed 300 measurements, with an average of ten per chemical. The Similarity Matrix For n measurements, the similarity matrix S is an n × n matrix, with Sij measuring the similarity between measurements i and j. Preferably, the similarity values should be