Entropy-操作示范
熵权法excel -回复

熵权法excel -回复熵权法Excel(熵值权重法):一个简单有效的多指标综合评价方法【引言】在现代社会中,我们经常需要对各种事物进行评估、比较和排序,无论是项目选址、产品购买还是人才选拔,都离不开多个指标的综合评价。
然而,在众多指标中,各个指标的重要性不同,如何确定每个指标的权重就成为了至关重要的问题。
本文将介绍一种简单有效的评价方法——熵权法(熵值权重法),并使用Excel软件进行具体操作,以帮助读者了解和应用该方法,提高决策的科学性和精确性。
【第一步:收集和整理数据】在使用熵权法进行评价之前,我们首先需要收集相关的数据,并对其进行整理和准备。
以我们需要对某城市的教育、医疗、环境和交通等多个指标进行评价为例,我们可以将这些指标列为表格的列标题,不同城市的数据作为行,将其填写到Excel中的工作表中。
【第二步:归一化处理】在多个指标的评价中,有些指标的数据可能是以不同的单位或量纲表示的,为了能够进行比较和综合评价,我们需要对指标数据进行归一化处理。
常用的方法有线性标准化法、对比标准化法等,这里我们以线性标准化法为例进行说明。
在Excel中,我们选择一个合适的单元格,输入“=(数值-最小值)/(最大值-最小值)”的公式,然后将公式拖拽复制到其他单元格中,即可实现数据的线性标准化处理。
【第三步:计算信息熵】信息熵是一种用于衡量指标数据离散程度和分散程度的指标,计算一个指标的信息熵前,我们需要先根据归一化后的数据计算对应的概率。
在Excel中,我们可以利用“COUNTIF”函数和“SUM”函数来计算概率和信息熵。
具体操作如下:1. 首先,在工作表中选择一个合适的单元格,输入“=COUNTIF(数据区域, ">0")/COUNT(数据区域)”的公式,表示计算大于0的数据的概率。
其中,“数据区域”表示选取数据进行计算的区域,可以使用Excel的“SUMPRODUCT”函数来实现。
python计算熵权法

python计算熵权法熵权法是一种多属性决策方法,用于确定多个属性对于决策目标的重要性。
在Python中,我们可以使用一些库来计算熵权法,比如numpy和pandas。
下面我将从多个角度介绍如何在Python中计算熵权法。
首先,我们需要导入所需的库,即numpy和pandas。
我们可以使用以下代码进行导入:python.import numpy as np.import pandas as pd.接下来,我们需要准备数据。
假设我们有一个包含多个属性的数据集,我们可以将数据集存储在一个pandas的DataFrame中。
然后,我们可以使用pandas提供的函数来进行数据处理和计算。
下面是一个示例数据集和如何将其存储在DataFrame中的代码:python.data = {'Attribute1': [1, 2, 3, 4],。
'Attribute2': [4, 3, 2, 1],。
'Attribute3': [2, 3, 1, 4]}。
df = pd.DataFrame(data)。
接下来,我们可以使用numpy和pandas来计算熵权法。
首先,我们需要计算每个属性的权重。
可以按照以下步骤进行计算:1. 计算每个属性的熵值。
可以使用numpy的熵函数来计算。
2. 计算每个属性的权重。
可以根据每个属性的熵值来计算。
下面是一个示例代码,演示如何计算熵权法:python.# 计算每个属性的熵值。
entropy_attribute1 = (df['Attribute1'] /df['Attribute1'].sum() np.log(df['Attribute1'] /df['Attribute1'].sum())).sum()。
entropy_attribute2 = (df['Attribute2'] /df['Attribute2'].sum() np.log(df['Attribute2'] /df['Attribute2'].sum())).sum()。
熵值法计算过程

熵值法计算过程熵值法(Entropy Method)是一种多指标综合评价方法,通过计算指标的熵值来确定其权重,从而进行综合评价。
下面将详细介绍熵值法的计算过程。
一、确定评价指标和数据我们需要明确评价的目标和指标体系。
评价指标应该能够全面反映被评价对象的特点和性能,且指标之间应具有一定的相关性。
接下来,收集相关数据。
根据评价指标,收集被评价对象的相关数据,确保数据的准确性和完整性。
二、数据标准化由于不同指标的量纲和量级可能不同,为了消除这种差异,需要对数据进行标准化处理。
常用的标准化方法有线性标准化和区间标准化。
线性标准化将数据映射到0到1之间,而区间标准化将数据映射到指定的区间内。
三、计算熵值根据标准化后的数据,计算每个指标的熵值。
熵值是信息论中的概念,用于衡量信息的混乱程度。
在熵值法中,熵值越大表示指标的信息越混乱,即对评价对象的特点和性能的判断越困难。
计算熵值的步骤如下:1. 计算每个指标的权重。
权重可以根据主观判断或者专家意见确定,也可以通过层次分析法等方法计算得到。
2. 计算每个指标的信息熵。
使用以下公式计算:熵值 = -Σ(Pi * log(Pi))其中,Pi表示指标的标准化值。
3. 计算每个指标的熵值权重。
使用以下公式计算:熵值权重 = 熵值/ Σ(熵值)熵值权重表示每个指标在综合评价中的重要程度。
四、综合评价根据指标的熵值权重,计算综合评价值。
将每个指标的标准化值乘以对应的熵值权重,并求和得到综合评价值。
综合评价值可以用于对不同对象进行比较,也可以用于对同一对象在不同时间或不同条件下的评价。
需要注意的是,熵值法的计算结果只能作为辅助决策的参考,不能作为唯一的依据。
在实际应用中,还需要考虑其他因素,如经济性、可行性等。
熵值法是一种基于信息熵的多指标综合评价方法。
通过计算指标的熵值,确定其权重,从而进行综合评价。
该方法可以较好地解决指标权重确定的问题,对于决策和评价具有一定的指导意义。
熵值法matlab

熵值法matlab熵值法是一种常用的多指标决策方法,因为它可以很好地处理不同指标之间的相互影响。
熵值法的基本思想是建立一个标准化的权重向量,使得不同指标的权重相互独立,且能够体现出各指标重要性之间的差异。
熵值法的原理是基于熵值理论,它假设一个完全随机的参照状态,该状态拥有各指标取值的最大熵值。
熵值法通过度量各指标离参照状态的距离来计算各指标的权重,并利用熵值最小化原则来确定最终的权重向量。
熵值法的优点在于它能够避免传统评价方法中的主观性,可以有效地处理多指标的评价问题。
熵值法的具体步骤如下:1. 设定评价指标集合,同时确定每个指标的正向或反向性质。
2. 构建决策矩阵,包括不同指标下的样本点。
3. 标准化决策矩阵,使得不同指标的取值范围相同。
4. 计算每个指标的熵值,通过度量样本点的离散程度来描述该指标的重要性。
5. 计算每个指标的权重,根据熵值最小化原则,使得各指标的权重相互独立,且能够体现出各指标重要性之间的差异。
6. 计算各样本点的分值,利用指标权重对标准化决策矩阵进行加权求和操作。
7. 选择最优方案,可以选取分值最高的样本点作为最优方案,也可以对各样本点进行排序,选取排名靠前的方案。
在MATLAB中,可以使用entropy函数来计算熵值和权重向量。
具体实现步骤如下:1. 导入评价指标和决策矩阵数据,通过xlsread函数读取Excel文件中的数据。
2. 对决策矩阵进行标准化操作,可以使用zscore函数或者min-max标准化方法。
3. 计算每个指标的熵值,可以使用entropy函数,其中输入参数为决策矩阵。
4. 计算每个指标的权重,可以使用熵值最小化原则,先将熵值进行归一化操作,再利用线性规划方法求解。
总之,熵值法是一种简单有效的多指标决策方法,在MATLAB中的实现也非常简单,可以很好地应用于各种评价问题中。
熵权法 python代码

熵权法 python代码熵权法 Python代码熵权法是一种多指标综合评价方法,可以用于解决多个指标之间相互独立且权重不确定的问题。
本文将介绍熵权法的原理及其在Python中的实现代码。
一、熵权法原理熵权法是基于信息熵和权重分配原则的方法。
在熵权法中,首先需要对每个指标的数据进行标准化处理,以消除指标之间的量纲和数量级差异。
然后,计算每个指标的信息熵,熵值越大表示指标的波动性越大,对整体评价的贡献也越大。
接下来,根据信息熵的大小,计算每个指标的权重,权重越大表示指标对整体评价的重要性越高。
最后,将标准化后的指标值与相应的权重相乘,得到每个指标的加权值,再对所有指标的加权值求和,即可得到最终的综合评价结果。
二、Python实现代码下面是使用Python实现熵权法的代码:```pythonimport numpy as npdef entropy_weight(X):# 对数据进行标准化处理X = (X - np.min(X, axis=0)) / (np.max(X, axis=0) -np.min(X, axis=0))# 计算每个指标的信息熵entropy = -np.sum(X * np.log(X), axis=0)# 计算每个指标的权重weight = (1 - entropy) / np.sum(1 - entropy)return weight# 示例数据data = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])# 计算权重weight = entropy_weight(data)# 输出权重print("指标的权重为:", weight)```以上代码首先导入了必要的库,然后定义了一个名为`entropy_weight`的函数,该函数接受一个数据矩阵作为输入,并返回每个指标的权重。
在函数内部,我们首先对数据进行标准化处理,然后计算每个指标的信息熵,最后根据信息熵的大小计算权重。
熵权法excel

熵权法excel熵权法(Entropy method)是一种常用的多指标权重确定方法。
该方法通过计算每个指标的熵值,得到指标的权重。
熵值越大,表示指标的不确定性越高,权重越小。
下面是使用Excel进行熵权法计算的步骤:1. 准备数据:将各指标的原始数据录入Excel表格。
假设有n 个指标,m个样本,数据放在A2到R(m+1)单元格范围内。
2. 标准化数据:在S2单元格输入公式"=(A2-AVERAGE(A2:A2))/STDEV.P(A2:A2)",将其填充到S2到T(m+1)单元格范围内,用于计算标准化后的数据。
其中AVERAGE函数用于计算平均值,STDEV.P函数用于计算标准差。
3. 计算指标权重:a. 在U2单元格输入公式"=EXP(SUM(S2:T2*LN(S2:T2)))",将其填充到U2到U(m+1)单元格范围内,用于计算熵值。
其中EXP函数用于计算指数值,SUM函数用于求和,LN函数用于计算自然对数。
b. 在V2单元格输入公式"=(1-U2)/(n-EXP(SUM(LN(U2:UU(m+1))+LN((n-1)*(U2:UU(m+1)))))",将其填充到V2到V(m+1)单元格范围内,用于计算权重。
其中EXP函数用于计算指数值,SUM函数用于求和,LN函数用于计算自然对数。
4. 归一化权重:将V2到V(m+1)单元格范围内的数据进行归一化处理。
在W2单元格输入公式"=V2/SUM(V2:VU(m+1))",然后将其填充到W2到W(m+1)单元格范围内。
现在,W2到W(m+1)单元格范围内的数据就是各指标的权重值,可以用于多指标决策分析。
Entropy介绍(newhospital)解读
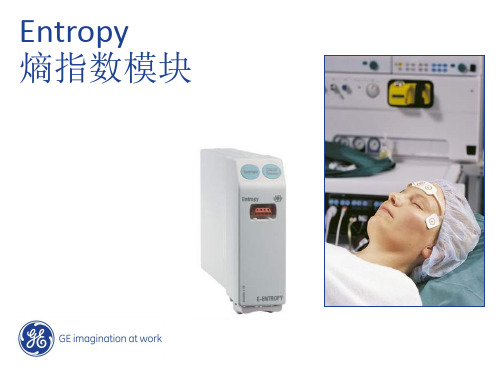
BIS Titrated
快速苏醒
(Gan, 1997)
缩短了PACU 的停留时间
(White, 2004)
Standard Practice
BIS-Titrated
Standard Practice
BIS-Titrated
30 / GE /
累积深度催眠时间
大多数时间 麻醉深度 < 45
1年内相关病死率风险
26 / GE /
EEG 的四个特征波形
Beta (13-30 Hz) 精神集中, 小剂量镇静 Alpha (8-13Hz) 清醒,放松, 浅麻醉 Theta (4-8Hz) 全麻
Delta (<4Hz)
深麻醉 缺血 用药过量
27 / GE /
ASA实践建议白皮书
对于术中知晓和脑功能监测的临床操作建 议
37 / GE /
阿芬太尼 150 ng/ml 100
80 60
熵 40 20
A B
C
A: 放喉镜 B: 插管 C: 切皮
0
0
异丙酚 5µg/ml
20
40
60
80
100 120 140
34 / GE /
时间 (min)
Billard, Anesthesiology, 87(3A) A313, 1997
影响麻醉深度的因素
17 / GE /
皮肤处理准备
• 用蘸有酒精的纱布轻轻 擦拭皮肤 • 让皮肤干燥
18 / GE /
连接电极及电缆
•顺序固定电极2号的位置
•然后在固定编号3的电极 在太阳穴的位置
• 确认电极贴好后,连接 传感器和电缆
19 / GE /
基于熵的数据排序离散化方法

基于熵的数据排序离散化方法基于熵(entropy)的数据排序离散化方法是一种常用的数据分析技术,旨在将连续变量划分为若干个有序的离散区间。
该方法通过最小化不确定性和最大化区分度来确定合适的区间划分点,以便更好地分析数据。
熵是信息论中的概念,用来度量随机变量的不确定性。
在数据离散化中,熵用来评估每个划分点的好坏程度。
具体来说,对于给定的连续变量,我们可以尝试将其划分为若干个区间,并计算每个划分点的熵。
然后,我们选择熵值最小的划分点作为最优划分点,将数据离散化为有序的区间。
以下是基于熵的数据排序离散化方法的具体步骤:1.数据排序:首先,对于给定的连续变量,将其数据值按照大小进行排序。
2.初始划分点确定:在排序后的数据值中,选择多个初始划分点。
通常选择的方法有等间隔划分和等频划分。
等间隔划分是将数据值划分为若干个相等的间隔,而等频划分是将数据值划分为若干个拥有相同观测频率的区间。
3.区间划分及熵计算:根据初始划分点,将数据划分为多个区间。
对于每个划分点,计算划分后的熵值。
熵的计算通常使用信息熵公式或基尼指数公式。
4.最优划分点选择:选择具有最小熵值的划分点作为最优划分点。
这意味着该划分点使得数据的不确定性最小,具有最大的区分度。
5.区间合并和划分点更新:根据最优划分点,将相邻的区间进行合并,并将合并后的区间作为新的划分点。
然后,重新计算新的划分点所对应的熵值。
6.重复步骤4和5,直到满足停止准则。
停止准则可以是熵值的变化小于一些阈值,或者达到了预定的划分点数量。
7.最终离散化:根据最终计算得到的划分点,将数据离散化为有序的区间。
可以根据需要将区间编号或者使用区间的边界值来表示离散化结果。
1.不依赖任何先验知识:该方法不依赖任何关于数据的领域知识。
只需给定连续变量的数据,就可以自动选择最优划分点进行离散化。
2.考虑数据的分布特点:通过最小化熵值,该方法能够更好地考虑数据的分布特点。
这有助于提高数据离散化的准确性和可解释性。
熵值法 excel 计算过程

熵值法 excel 计算过程1.打开Excel软件,新建一个表格。
Open Excel software and create a new spreadsheet.2.在第一列依次输入各个选项的名称。
Enter the names of the options in the first column.3.在接下来的列中,依次输入各个选项的相关数据。
Enter the relevant data for each option in the following columns.4.在Excel中选择一个空白单元格,输入以下函数:=ENTROPY (A2:A52)Select a blank cell in Excel and enter the following function: =ENTROPY(A2:A52)5.按下回车键,Excel会自动计算出这些选项的熵值。
Press Enter, and Excel will automatically calculate the entropy of the options.6.熵值法是一种用来度量不确定性的方法。
The entropy method is a way to measure uncertainty.7.它可以帮助我们对各个选项之间的差异进行量化评估。
It can help us quantitatively evaluate the differences between the options.8.在excel中使用熵值法可以方便快捷地进行大量数据的计算。
Using the entropy method in Excel can quickly and easily calculate large amounts of data.9.通过比较不同选项的熵值,我们可以找出最优的选择。
By comparing the entropy of different options, we can find the optimal choice.10.熵值法在决策分析和风险评估中有着广泛的应用。
化学反应的熵变计算

化学反应的熵变计算熵(entropy)是描述系统无序程度或混乱程度的物理量,在化学反应中起着重要的作用。
熵变(ΔS)是指化学反应发生后系统总的熵的变化。
通过计算熵变可以了解反应过程中的熵变化情况,从而得出反应是否倾向于发生或者反应速度的大小。
计算熵变的方法主要包括以下几个步骤:确定化学反应方程式、查找反应物和生成物的标准摩尔熵、计算熵变。
1. 确定化学反应方程式首先,我们需要确定化学反应的方程式。
以A和B反应生成C和D为例,反应方程式可以表示为:A +B →C + D2. 查找反应物和生成物的标准摩尔熵在计算熵变之前,我们需要查找反应物和生成物的标准摩尔熵(S°)。
标准摩尔熵是在标准状态下,物质的摩尔熵值。
这个值可以通过参考资料或者热力学手册获得。
假设反应物A和B的标准摩尔熵分别为S°(A)和S°(B),生成物C 和D的标准摩尔熵分别为S°(C)和S°(D)。
3. 计算熵变熵变的计算公式为:ΔS = ΣS°(生成物) - ΣS°(反应物)根据上述公式,我们可以得到反应的熵变。
例如,假设反应物A和B的标准摩尔熵分别为100 J/mol·K和150J/mol·K,生成物C和D的标准摩尔熵分别为200 J/mol·K和250J/mol·K,则反应的熵变为:ΔS = (S°(C) + S°(D)) - (S°(A) + S°(B))= (200 + 250) - (100 + 150)= 200 J/mol·K通过计算可以得知,在该化学反应中,系统的熵增加了200 J/mol·K。
熵变的正负也可以表明反应的方向性。
如果ΔS > 0,则表示反应过程中系统的熵增加,即反应是自发进行的;如果ΔS < 0,则表示反应过程中系统的熵减少,即反应是不可逆进行的;如果ΔS = 0,则表示反应过程中系统的熵不发生变化,即反应处于平衡状态。
熵的计算问题

熵的计算问题熵(entropy)是分子动力学或者热力学中最重要的概念之一,它可以用来衡量一个系统的焓,也可以作为一种指标来描述系统的混沌程度。
熵的计算是物理学和化学研究的基础,它在计算中需要考虑到很多细节,因此被称为一个复杂的问题。
本文将介绍熵的计算问题,以及如何使用计算机程序解决这个问题。
熵的定义及计算熵定义为某系统内可能出现的状态数之和,也就是所有状态的可能性的总和。
它可以用来衡量一个系统的不确定性,即一个系统的熵越大,该系统的变化越多,也就是说,就熵的角度来看,系统越混沌。
计算熵需要考虑到很多细节。
根据热力学定律,熵的值由热力学函数计算得出。
热力学函数通常由系统的压强和温度定义,因此,计算熵就需要计算系统的压强和温度,这一步可以使用数值计算技术来实现。
此外,熵的计算还受到系统中的元素的影响,因此必须具体分析系统中的元素,根据系统中的元素确定系统的全部状态。
计算机模拟熵的计算熵的计算复杂,不可能用简单的计算方法实现,因此,大多数科学家会使用计算机模拟来解决这一问题。
计算机模拟熵的计算,其基本思想是通过模拟系统内某一体系的热力学特性,从而得到系统的熵。
具体来说,首先需要使用计算机模拟计算系统内某一体系的特性,即系统的温度、压强和元素组成,以及其他影响熵的因素。
接着,计算机将计算出的系统温度、压强和元素组成输入到一个数据库中,然后计算出系统内可能存在的状态数,最后由此得出熵的值。
熵的计算在物理学和化学中的应用熵的计算在物理学和化学中有广泛的应用,主要用于研究物质性质以及其在各种热力学条件下的变化。
熵的计算可以帮助科学家们理解以下重要概念:体系的稳定性,即系统在特定温度和压强条件下的变化程度;亚稳定态的可能性,即系统在特定温度和压强条件下存在的可能形态;以及热力学特性的变化,即热力学函数可能具有的局限性及变化。
此外,熵的计算还可以帮助科学家们解答一些重要的实际问题,如水中溶液平衡、化学反应平衡等。
Entropy 介绍 (new hospital)
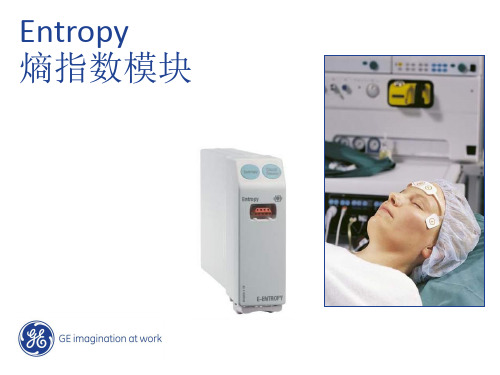
4 / GE /
Entropy 和麻醉
当病人进入无意识状态时,EEG 也 从不规律变到规律的模式
脑电的熵 减少
RE 100 SE 90 RE 42 SE 40
5 / GE /
熵指数Entropy™-麻醉深度监测新方法
多频率信号
熵指数高
单一频率信号
熵指数低
2 种 Entropy™ 指数
SE状态熵:麻醉过程中大脑皮层的受 抑制程度
RE反应熵:复苏阶段前额骨骼肌兴奋 程度及大脑皮层的受抑制程度
6 / GE /
熵监测的标准是什么?
1通道波形, 有脑电(EEG)和前额肌电 (FEMG)的趋 势 2个Entropy 参数 • 快速反应的 Response Entropy (RE) = 快速反 应是由前额肌电变化激活 • 稳定提示的 State Entropy (SE) = 评估麻醉 药物在大脑中的催眠效果 提供了手术期间,麻醉药物引起的催眠意识连续 变化的状态
过深麻醉
适宜的/最佳的
麻醉深度
麻醉不足
23 / GE /
传统的麻醉管理
• 根据推荐的药物剂量给药
• 根据血流动力学及体动反应判断麻醉深度
血液动力学和意识
“硫喷妥钠或异丙酚麻醉后的意识恢复”1
Blood Pressure (MAP)
Entropy 100 80 60
意识恢复*
180
140
100 8 8 60 0
28 / GE /
的临床建议报告
中华医学会08年发布指南:
如果病人有发生知晓的危险因素:
(1)应告之病人术中有发生知晓的可能 性; (2)提倡用脑功能监测设备监测麻醉 (镇静)深度,如熵指数(Entropy)监 测仪,以确保麻醉中<60。
计算熵 非负处理python

熵(Entropy)是一个衡量随机变量不确定性的度量,通常在信息论和统计中使用。
对于离散随机变量,熵的定义如下:H(X) = - Σ_i p(x_i) * log_2(p(x_i))其中,X 是一个离散随机变量,p(x_i) 是X 取值为x_i 的概率。
在Python中,你可以使用NumPy库来计算熵。
但是,如果你的数据中包含非负值(即概率为0),你需要先对它们进行处理,因为对0取对数会导致无穷大或未定义的值。
通常,你可以通过给这些值为0的概率一个小的正数(例如epsilon)来避免这个问题。
以下是一个简单的Python函数,用于计算离散随机变量的熵,并处理了概率为0的情况:pythonimport numpy as npdef calculate_entropy(probabilities, epsilon=1e-10):"""计算离散随机变量的熵。
参数:probabilities (list or np.array): 随机变量取各个值的概率。
epsilon (float): 用于处理概率为0的小正数。
返回:float: 熵的值。
"""# 将概率转换为numpy数组probs = np.array(probabilities)# 处理概率为0的情况probs = probs + epsilon * (1 - probs.sum())probs /= probs.sum()# 计算熵entropy = -np.sum(probs * np.log2(probs))return entropy你可以使用这个函数来计算任何离散随机变量的熵,只要你知道它取各个值的概率。
例如:pythonprobabilities = [0.1, 0.2, 0.7] # 假设的随机变量概率分布entropy = calculate_entropy(probabilities)print("Entropy:", entropy)1。
python entropy用法

python entropy用法Entropy 是一个用于计算数据集的随机性或不确定性的度量方式。
在信息论中,熵描述了一个随机变量的不确定性,也可以被解释为信息的度量。
在机器学习和数据挖掘中,熵通常被用于构建决策树等模型,作为一个能够量化数据集不确定性的指标。
在Python 中,可以使用`scipy.stats.entropy`函数来计算熵。
这个函数接受一个概率分布作为输入,并返回相应的熵。
首先,需要导入`scipy.stats`模块来使用`entropy`函数:pythonfrom scipy.stats import entropy然后,可以使用`entropy`函数来计算熵。
这个函数接受一个概率分布作为输入,概率分布可以表示为一个列表或一维数组。
例如,假设有一个包含以下元素的列表:pythondata = [0.2, 0.3, 0.1, 0.4]这个列表表示一个概率分布,对应的元素分别表示不同事件发生的概率。
可以使用`entropy`函数来计算其熵:pythonresult = entropy(data)print(result)输出结果将是一个浮点数,表示熵的值。
熵的值越大,表示数据集的不确定性越高。
除了计算整个概率分布的熵之外,还可以计算条件熵。
条件熵是在给定某些条件下,对数据集的不确定性进行量化。
可以使用`scipy.stats.entropy`函数的`base`参数来指定熵的基数,即对数的底数,默认为2。
这个参数在计算条件熵时非常有用。
假设有两个概率分布`p`和`q`,可以使用`entropy`函数来计算这两个分布的交叉熵。
交叉熵是比较两个分布之间差异的一种度量方式。
可以使用以下代码来计算交叉熵:pythoncross_entropy = entropy(p, q)print(cross_entropy)其中,`p`和`q`分别表示两个概率分布。
除了`scipy.stats.entropy`函数之外,还可以使用`numpy`库中的`numpy.sum`和`numpy.log2`函数来计算熵。
stata截面数据熵权法

在Stata中使用熵权法(Entropy Weight)进行截面数据分析,可以按照以下步骤进行操作:1. 导入数据:首先,使用`import delimited`命令导入包含截面数据的CSV文件。
假设文件名为`data.csv`,变量名称为`var1`、`var2`、`var3`等。
```stataimport delimited "data.csv", clear```2. 计算熵权:接下来,使用`egen`命令计算每个变量的熵权。
假设你要计算`var1`、`var2`和`var3`的熵权,并将结果存储在新的变量`entropy_var1`、`entropy_var2`和`entropy_var3`中。
```stataegen entropy_var1 = entropy(var1)egen entropy_var2 = entropy(var2)egen entropy_var3 = entropy(var3)```3. 计算综合得分:最后,使用`summarize`命令计算每个观测值的综合得分。
将熵权与原始变量值相乘,然后对乘积进行加总,得到综合得分。
假设综合得分的变量名称为`composite_score`。
```statagen composite_score = entropy_var1*var1 + entropy_var2*var2 + entropy_var3*var3summarize composite_score, meanonly```通过以上步骤,你可以在Stata中使用熵权法进行截面数据分析并计算综合得分。
请注意,这只是一个基本的示例,实际情况可能需要根据具体的数据和研究需求进行适当的调整。
entropy函数

entropy函数
Entropy(熵)是一个 thermodynamic 概念,表示一个混乱系统中的无序程度,它也可以被定义为系统的不确定性程度。
在信息理论中,熵被使用来衡量信息的不确定性或信息量。
在信息理论中,熵是一个概率分布的函数,它度量了对该分布进行编码所需要的最小平均比特数。
因此,熵通常用比特或者纳特作为单位来度量信息量的多少。
对于一个随机变量X,它的熵可以表示为:H(X) = - Σ P(x)log2P(x)
其中,Σ指的是对所有可能的x值求和,P(x)是随机变量X取值为x的概率,log2是以2为底的对数。
可以发现,当概率分布中一个事件的概率越高,那么该事件所带来的信息量就越少,相反的,当概率分布中一个事件的概率越小,那么该事件所带来的信息量就越多。
因此,熵表示了随机变量X的平均信息量。
除此之外,熵也可以用于度量两个概率分布的相似度。
例如,当两个概率分布相同时,它们的熵就相同。
另一方面,如果两个概率分布的差异越大,它们的熵就越大。
总之,在信息理论中,熵是一个非常重要的概念,它不仅可以用于度量信息的不确定性和信息量的多少,还可以用于比较不同概率分布之间的相似程度。
torchentropy函数

torchentropy函数参数说明:- input:输入的tensor,包含了概率分布的概率值。
- base:熵计算的基数,可以是2、e或10,默认为e(自然对数的底数)。
- dim:指定计算熵的维度。
如果给定,将在指定维度上计算熵。
如果未给定,将在整个tensor上计算熵。
- keepdim:设置为True时,计算的结果tensor具有与输入相同的维度。
返回值:- 返回一个tensor,包含了输入tensor的熵值。
下面是一些示例,以说明如何使用torch.entropy(函数。
示例1:计算一维概率分布的熵``` pythonimport torchprobs = torch.tensor([0.2, 0.5, 0.3])entropy = torch.entropy(probs)print(entropy)```输出结果:``` pythontensor(1.0297)```在这个示例中,我们计算了一个包含3个概率值的一维概率分布的熵。
概率分布为[0.2,0.5,0.3],该分布的熵为1.0297示例2:计算二维概率分布的熵``` pythonimport torchprobs = torch.tensor([[0.1, 0.2, 0.3],[0.3,0.5,0.2]])entropy = torch.entropy(probs, base=2, dim=1)print(entropy)```输出结果:``` pythontensor([1.4855, 1.4855])```概率分布为[0.1, 0.2, 0.3],第二个概率分布为[0.3, 0.5, 0.2]。
我们通过指定base=2,计算了以2为基数的熵,并通过指定dim=1,在每行上计算熵。
结果为[1.4855, 1.4855]。
示例3:计算三维概率分布的熵``` pythonimport torchprobs = torch.tensor([[[0.25, 0.25],[0.25,0.25]],[[0.2,0.3],[0.4,0.1]]])entropy = torch.entropy(probs, base=10, dim=(1,2),keepdim=True)print(entropy)```输出结果:``` pythontensor([[[0.3010]],[[0.0559]]])```概率分布为[[0.25, 0.25], [0.25, 0.25]],第二个概率分布为[[0.2, 0.3], [0.4, 0.1]]。
py计算分桶熵

py计算分桶熵【原创版】目录1.分桶熵的概念2.Py 计算分桶熵的方法3.实际应用案例正文1.分桶熵的概念分桶熵(Bucket Entropy)是一种衡量数据分布均匀性的指标,用于描述数据在多个分桶(如区间、类别等)中的分布情况。
在数据挖掘、机器学习等领域中,分桶熵被广泛应用于数据预处理和特征选择等任务,以提高模型的性能和准确性。
2.Py 计算分桶熵的方法在 Python 中,我们可以使用熵(entropy)的相关公式来计算分桶熵。
熵的计算公式为:H(X) = -ΣP(x) * log2(P(x)),其中 X 表示数据集,P(x) 表示数据集 X 中元素 x 出现的概率。
对于分桶熵,我们首先需要将数据集划分为多个分桶,然后计算每个分桶中的熵,最后求得分桶熵的平均值。
以下是一个使用 Python 计算分桶熵的示例:```pythonimport numpy as npdef bucket_entropy(data, bucket_count):# 对数据进行分桶buckets = [[] for _ in range(bucket_count)]for x in data:buckets[np.argmin(np.abs(x -buckets[-1]))].append(x)entropy = 0for bucket in buckets:if len(bucket) > 0:entropy -= np.sum([np.log2(np.array(bucket) / len(bucket)) for bucket in zip(*bucket)])return entropy / len(data)# 示例数据data = [1, 2, 2, 3, 3, 3, 4, 4, 4, 4, 4]# 计算分桶熵bucket_count = 4entropy = bucket_entropy(data, bucket_count)print("分桶熵:", entropy)```3.实际应用案例假设我们有一组用户的年龄数据,希望根据年龄将用户划分为不同的年龄段,以便进行进一步的数据分析。
熵权法excel

熵权法excel熵权法是一种多指标综合评价方法,它在决策分析中被广泛应用。
该方法是基于信息熵的概念,通过计算各指标的信息熵来确定指标的权重,从而实现对多指标的有效评价和比较。
在使用熵权法进行多指标评价时,首先需要确定评价指标集合。
这些指标可以是定量的也可以是定性的,它们涵盖了要评价的对象的各个方面。
然后,根据评价指标的数据,计算每个指标的信息熵。
信息熵是评价指标的离散程度的度量,离散程度越大,信息熵越大。
通过计算信息熵,我们可以得到各个指标的权重,也就是各个指标对决策结果的重要程度。
熵权法的核心思想是,指标的权重应该与其信息熵成负相关。
也就是说,离散程度越大的指标对决策结果的影响越小,权重越低;离散程度越小的指标对决策结果的影响越大,权重越高。
通过计算信息熵与指标的相关性,可以得到各个指标的权重。
具体操作上,使用熵权法可以分为以下几个步骤:第一步,收集相关数据并计算指标值。
根据评价对象的不同,可以使用不同的数据源和方法来获取评价指标的数据。
第二步,计算每个指标的信息熵。
信息熵的计算需要用到指标数据的概率分布。
对于离散型指标,可以直接根据不同取值的频率计算概率分布;对于连续型指标,可以先将数据离散化,再计算概率分布。
第三步,计算指标的权重。
通过信息熵的计算结果,可以得到各个指标的权重。
计算权重的方法可以有多种,常用的方法是除以所有指标信息熵的总和。
第四步,进行多指标评价。
根据指标的权重,对评价指标进行加权求和,得到每个评价对象的得分。
根据得分的大小,可以对不同对象进行排序或排名,得到最终的评价结果。
熵权法的优点是可以处理多指标的评价问题,并且能够考虑指标之间的相关性。
它可以帮助决策者在面对多个因素时,更加客观地进行决策分析。
然而,熵权法也有一些限制,比如对指标的数据要求较高,需要有准确的数据支持;此外,熵权法假设各个评价指标之间是相互独立的,但在实际应用中,指标之间可能存在相互关联的情况。
总的来说,熵权法是一种有效的多指标综合评价方法,能够帮助决策者进行决策分析。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
GE En0 •收费:578
•增加经济收入
11 / GE Title or job number / 6/6/2016
为什么使用熵指数测量?
确保更快和更多的预见觉 醒和去除导管 改进麻药管理 帮助避免不必要的深度麻 醉并阻止意外苏醒
12 / GE Title or job number / 6/6/2016
6/ GE Title or job number / 6/6/2016
使用指导
麻醉前 麻醉中
苏醒期
仅用于全身麻醉
成人和儿童患者(2岁或以上)
AAI,BIS,Entropy– 哪个更常用
1.目前临床上用来检测麻醉深度的有AAI, BIS,Entropy。 2.AAI使用环境要求高, 抗干扰能力差, 并且 要求患者听力正常, 还要不断有声音刺激, 再 者儿童的听阈不同于成人的听阈, 鉴于上述 因素其临床应用仍有一定限制。
熵指数检测在全麻中的应用
恰当的麻醉监护 (Adequacy of Anesthesia,AOA)
2/ GE Title or job number / 6/6/2016
AOA 监护的好处
1.更好的理解麻醉的不同组成成分 – 更安全的
入睡,更快的苏醒
2.确保高风险病人处于无意识状态
3/ GE Title or job number / 6/6/2016
AAI,BIS,Entropy– 哪个更常用
3.Entropy麻醉深度的算法涵盖了时域、频域和信号复杂性
(熵)三个方面,避免了单一研究信号的某一方面造成的信息
缺失。 4.熵指数与BIS不同的是不但分析了自发脑电熵而且加增了 额肌电熵从而可以提前预测唤醒, 也许也可以预测对疼痛刺 激的反应,有可能使脑电监测跳出只能监测催眠成分的局限, 因此具有广阔的发展前景。
Thank you !
13 / GE Title or job number / 6/6/2016
AOA 监护的好处
3.根据个体需要实施麻醉
• 避免过量麻醉
– 缩短苏醒时间
– 副作用最小化
• 检测病人需要剂量超过平均量
– 使用癫痫药物或精神类药物的病人
4/ GE Title or job number / 6/6/2016
Entropy(熵指数)
1.熵是一个物理范畴概念, 是定量随机信号(如EEG) 不 规则性的概念。
2.新近的熵指数监测仪通过分析脑电信号, 并将脑电信
号的不规则性量化成无量纲的标准化指数, 其包括两部 分指数, 状态熵( SE) 0-91, 反应熵( RE) 0-100。
5/ GE Title or job number / 6/6/2016
熵指数范围指导
RE 100 60 40 0
SE 解释 90 完全觉醒并作出响应 60 有临床意义的麻醉, 40 记忆的概率很低 0 大脑皮层电活动抑制