数学建模实验报告-统计回归模型
数学建模实验报告

湖南城市学院数学与计算科学学院《数学建模》实验报告专业:学号:姓名:指导教师:成绩:年月日目录实验一 初等模型........................................................................ 错误!未定义书签。
实验二 优化模型........................................................................ 错误!未定义书签。
实验三 微分方程模型................................................................ 错误!未定义书签。
实验四 稳定性模型.................................................................... 错误!未定义书签。
实验五 差分方程模型................................................................ 错误!未定义书签。
实验六 离散模型........................................................................ 错误!未定义书签。
实验七 数据处理........................................................................ 错误!未定义书签。
实验八 回归分析模型................................................................ 错误!未定义书签。
实验一 初等模型实验目的:掌握数学建模的基本步骤,会用初等数学知识分析和解决实际问题。
实验内容:A 、B 两题选作一题,撰写实验报告,包括问题分析、模型假设、模型构建、模型求解和结果分析与解释五个步骤。
数学建模与数学实验-回归分析

i1
i1
称 Qe 为残差平方和或剩余平方和.
2 的无偏估计为
ˆ
2 e
Qe
(n 2)
称ˆ
2 e
为剩余方差(残差的方差), ˆ
2 e
分别与ˆ0 、ˆ1
独立 。
ˆe 称为剩余标准差.
2019/10/19
返回 elecfans 电子发烧友
8
三、检验、预测与控制
1、回归方程的显著性检验
例1 测16名成年女子的身高与腿长所得数据如下:
身 高 1 4 31 4 51 4 61 4 71 4 91 5 01 5 31 5 41 5 51 5 61 5 71 5 81 5 91 6 01 6 21 6 4 腿 长 8 8 8 5 8 8 9 1 9 2 9 3 9 3 9 5 9 6 9 8 9 7 9 6 9 8 9 91 0 01 0 2
数 学 模 型 及 定 义
模 型 参 数 估 计
2019/10/19
检 验 、 预 测 与 控 制
性可 回线 归性 (化 曲的 线一 回元
数 学 模 型 及 定 义
模 型 参 数 估 计
归非
) 线elecfans 电子发烧友
检 验 与 预 测
多 元 线 性 回
归
中
的
逐 步 回 归 分 析
3
一、数学模型
15
11
10.5
10
9.5
9
8.5
8
7.5
7
6.5
6
2
4
6
8
10
12
14
16
散 点 图
此即非线性回归或曲线回归 问题(需要配曲线) 配曲线的一般方法是:
数学建模基础实验报告(3篇)

第1篇一、实验目的本次实验旨在让学生掌握数学建模的基本步骤,学会运用数学知识分析和解决实际问题。
通过本次实验,培养学生主动探索、努力进取的学风,增强学生的应用意识和创新能力,为今后从事科研工作打下初步的基础。
二、实验内容本次实验选取了一道实际问题进行建模与分析,具体如下:题目:某公司想用全行业的销售额作为自变量来预测公司的销售量。
表中给出了1977—1981年公司的销售额和行业销售额的分季度数据(单位:百万元)。
1. 数据准备:将数据整理成表格形式,并输入到计算机中。
2. 数据分析:观察数据分布情况,初步判断是否适合使用线性回归模型进行拟合。
3. 模型建立:利用统计软件(如MATLAB、SPSS等)进行线性回归分析,建立公司销售额对全行业的回归模型。
4. 模型检验:对模型进行检验,包括残差分析、DW检验等,以判断模型的拟合效果。
5. 结果分析:分析模型的拟合效果,并对公司销售量的预测进行评估。
三、实验步骤1. 数据准备将数据整理成表格形式,包括年份、季度、公司销售额和行业销售额。
将数据输入到计算机中,为后续分析做准备。
2. 数据分析观察数据分布情况,绘制散点图,初步判断是否适合使用线性回归模型进行拟合。
3. 模型建立利用统计软件进行线性回归分析,建立公司销售额对全行业的回归模型。
具体步骤如下:(1)选择合适的统计软件,如MATLAB。
(2)输入数据,进行数据预处理。
(3)编写线性回归分析程序,计算回归系数。
(4)输出回归系数、截距等参数。
4. 模型检验对模型进行检验,包括残差分析、DW检验等。
(1)残差分析:计算残差,绘制残差图,观察残差的分布情况。
(2)DW检验:计算DW值,判断随机误差项是否存在自相关性。
5. 结果分析分析模型的拟合效果,并对公司销售量的预测进行评估。
四、实验结果与分析1. 数据分析通过绘制散点图,观察数据分布情况,初步判断数据适合使用线性回归模型进行拟合。
2. 模型建立利用MATLAB进行线性回归分析,得到回归模型如下:公司销售额 = 0.9656 行业销售额 + 0.01143. 模型检验(1)残差分析:绘制残差图,观察残差的分布情况,发现残差基本呈随机分布,说明模型拟合效果较好。
统计回归模型

实验报告实验名称统计回归模型所属课程数学模型专业信息与计算科学2018年12月26日图1利用MATLAB 的统计工具箱可以得到回归系数及其置信区间(置信水平为0.05)、检验统计量2R ,F ,P 的结果。
见表2:参数参数估计值 参数置信区间 0β5.5863 [4.57436.5983] 1β-0.0031[-0.0056 -0.0006]20.819355R = 6.80359F = 0.0767782p =表2表2显示,20.819355R =指因变量y (单位成本)的81.93%可由模型确定,F 值超过F 检验的临界值,P 小于置信水平,因而模型从整体看是可用的。
表2的回归系数给出了模型中的0β,1β的估计值,则可得到一次线性关系式为y=5.5863-0.0031x (x ≤500)(2)对该模型做残差图:图2可以看出上面第二个点位异常点,去除第二个点后再进行拟合。
利用MATLAB 的统计工具箱可以得到回归系数及其置信区间(置信水平为0.05)、检验统计量2R ,F ,P 的结果。
见表3:参数参数估计值 参数置信区间 0β 5.5749 [5.0902 , 6.0596] 1β-0.0032[-0.0044 , -0.0020]20.976132R = F=40.8967 p=0.023882 表3表3显示,20.976132R =指因变量y (单位成本)的97.61%可由模型确定,F 值超过F 检验的临界值,P 小于置信水平,因而模型从整体看是可用的。
表3的回归系数给出了模型中的0β,1β的估计值,则可得到一次线性关系式为y=5.5749-0.0032x (x ≤500) (3)3.2模型二的建立与求解令生产批量为x ,单位成本为y 元,当x >500时,y 与x 满足一种线性关系,则可建立线性回归模型。
022y X ββε=++(4)其中0β,2β是待估计的回归系数,ε是随机误差。
数学建模与数学实验 回归分析

2、多项式回归
设变量 x、Y 的回归模型为 Y 0 1x 2 x2 ... p x p
其中 p 是已知的,i (i 1,2,, p) 是未知参数, 服从正态分布 N (0, 2 ) .
Y 0 1x 2 x2 ... k xk
腿长
88 85 88 91 92 93 93 95 96 98 97 96 98 99 100 102
以身高x为横坐标,以腿长y为纵坐标将这些数据点(xI,yi) 在平面直角坐标系上标出.
解答
102
100
98
y 0 1x
96
949290 Nhomakorabea88
86
84
140
145
150
155
160
165
2019/7/8
17
二、模型参数估计
1、对 i 和 2 作估计
用最小二乘法求0 ,..., k 的估计量:作离差平方和
n
Q yi 0 1xi1 ... k xik 2 i 1
选择 0 ,..., k 使 Q 达到最小。
解得估计值 ˆ
进行检验.
假设 H 0 : 1 0 被拒绝,则回归显著,认为 y 与 x 存在线性关 系,所求的线性回归方程有意义;否则回归不显著,y 与 x 的关系 不能用一元线性回归模型来描述,所得的回归方程也无意义.
2019/7/8
8
(Ⅰ)F检验法
当 H 0 成立时,
F
U
~F(1,n-2)
Qe /(n 2)
变量的值 x1* ,..., xk ,用 yˆ * ˆ0 ˆ1 x1* ... ˆk xk * 来预测
实验11_统计回归模型(4学时)要点
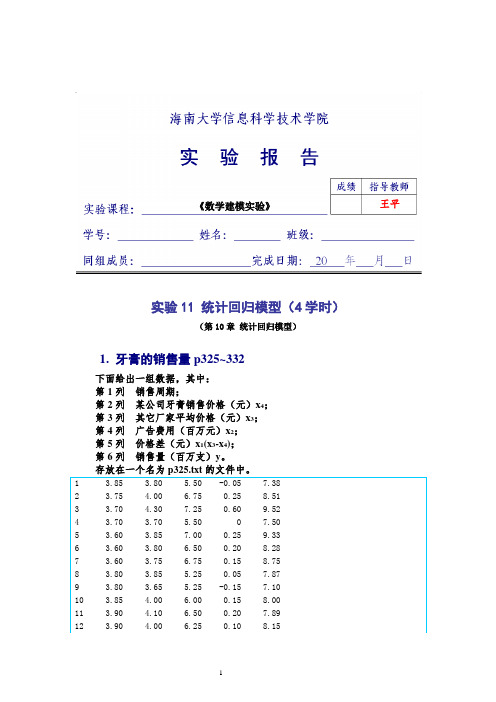
《数学建模实验》王平实验11 统计回归模型(4学时)(第10章统计回归模型)1. 牙膏的销售量p325~332下面给出一组数据,其中:第1列销售周期;第2列某公司牙膏销售价格(元)x4;第3列其它厂家平均价格(元)x3;第4列广告费用(百万元)x2;第5列价格差(元)x1(x3-x4);第6列销售量(百万支)y。
1.1(验证)基本模型p325~329先保存上面的p325.txt文件。
(1) 绘制y对x1的散点图[提示:dlmread将以ASCII码分隔的数值数据文件读入到矩阵(2) 确定y 对x 1的拟合,绘制散点图与拟合曲线组合图形从y 对x 1的散点图可以发现,可用线性模型(直线)011y x ββε=++(3) 绘制y对x2的散点图(4) 确定y 对x 2的的拟合,绘制散点图与拟合曲线组合图形从y 对x 2的散点图可以发现,可用二次函数模型201222y x x βββε=+++(5) y 对x 1, x 2的回归模型及其求解,销售量预测综上得回归模型20112232y x x x ββββε=++++变量x 1, x 2为回归变量,参数β0, β1, β2, β3为回归系数。
[提示:fprintf 输出到命令窗口或写数据到文本文件]见参考资料:MATLAB 函数和命令的用法。
1.2(验证,编程)模型改进p329~332仍使用题1的数据。
(1)(编程)y 对x 1, x 2的回归模型的改进和求解,销售量预测改进的模型20112232412y x x x x x βββββε=+++++参考题1(5)的程序,编写一个类似的程序,运行结果与教材p329~330的表3及相关结果相比较。
(2)(验证)完全二次多项式模型22011223124152y x x x x x x ββββββε=++++++用鼠标移动交互式画面中的十字线,或在图下方的窗口内输入,可改变x 1和x 2的数值。
改变x 1=0.2,x 2=6.5,观察窗口左边的y 估计值和预测区间。
回归模型实验报告

北京建筑大学理学院信息与计算科学教研室实验报告课程名称数学建模实验名称回归模型实验地点大兴机房日期2014.5.14姓名渠娅静班级计122 学号04 指导教师靳旭玲成绩【实验目的】1、了解回归分析的基本原理,掌握Matlab实现的方法;2、练习用回归分析解决实际问题;【实验要求】1、独立完成各个实验任务;2、实验的过程保存成.m 文件,以备检查;3、完成实验报告。
【实验内容】1、为了估计山上积雪融化后对下游灌溉的影响,在山上建立了一个观察站,测量了最大积雪深度(x)与当年灌溉面积(y),得到连续10年的数据如表所示。
20和25的灌溉面积。
2、水泥凝固时放出的热量y与水泥中4种化学成分x1、x2、x3、x4有关,今测得一组数据如下,试用逐【实验步骤】一、试建立灌溉面积对于最大积雪深度的回归模型,对模型和回归系数进行检验,并预测最大积雪深度是20和25的灌溉面积。
1、问题分析:求回归系数的点估计和区间估计、并检验回归模型: [b, bint,r,rint,stats]=regress(Y,X,alpha) Bint--回归系数的区间估计; r--残差; rint--置信区间; stats--用于检验回归模型的统计量,有三个数值:相关系数r 2、F 值、与F 对应的概率p; alpha--显著性水平(缺省时为0.05) 2 、求解过程:(1)输入数据,建立模型:x=[28.6 19.3 40.5 35.6 48.9 45.0 29.2 34.1 46.7 37.4 ]'; X=[ones(10,1) x];Y=[15.2 10.4 21.2 18.6 26.4 23.4 13.5 16.7 24.0 19.1]'; (2)、回归分析及检验:[b,bint,r,rint,stats]=regress(Y,X) b,bint,stats 3、实验结果:b = 2.3564 1.8129bint = -1.8587 6.5715 1.5962 2.0297stats = 0.9789 371.9453 0.0000 2.0133 4、结果分析:即01ˆˆ 2.3564 1.8129ββ==;0ˆβ的置信区间为[-1.8587,6.5715], 1ˆβ的置信区间为[1.5962,2.0297]; r2=0.9789, F=371.9453, p=0.0000,p<0.05, 可知回归模型 y=2.3564+1.8129x 成立.预测最大积雪深度是20和25的灌溉面积: X=20时,y =38.6144 X=25时,y = 47.6789 残差分析,作残差图: rcoplot(r,rint)预测及作图:z=b(1)+b(2)*xplot(x,Y,'k+',x,z,'r')二、水泥凝固时放出的热量y与水泥中4种化学成分x1、x2、x3、 x4有关,今测得一组数据如下,试用逐步回归法确定一个线性模型.1、问题分析:○1逐步回归的命令是: stepwise(x,y,inmodel,alpha)X--自变量数据, 阶矩阵; y--因变量数据, 阶矩阵; inmodel--矩阵的列数的指标,给出初始模型中包括的子集(缺省时设定为全部自变量); alpha--显著性水平(缺省时为0.5).○2运行stepwise命令时产生三个图形窗口:Stepwise Plot,Stepwise Table,Stepwise History.2、求解过程及结果:(1)输入数据,建立模型:x1=[7 1 11 11 7 11 3 1 2 21 1 11 10]';x2=[26 29 56 31 52 55 71 31 54 47 40 66 68]';x3=[6 15 8 8 6 9 17 22 18 4 23 9 8]';x4=[60 52 20 47 33 22 6 44 22 26 34 12 12]';y=[78.5 74.3 104.3 87.6 95.9 109.2 102.7 72.5 93.1 115.9 83.8 113.3 109.4]';(2)逐步回归:先在初始模型中取全部自变量x=[x1 x2 x3 x4];stepwise(x,y)(2)对变量y和x1、x2、x3、x4作线性回归X=[ones(13,1) x1 x2 x3 x4];b=regress(y,X)结果:b = 62.40541.55110.51020.1019-0.14413、结果分析:故最终模型为:y=62.4054+1.5511x1+0.5102x2+0.1019x3-0.1441x4【实验小结】心得体会:根据题目建立数学模型来求解,熟悉掌握MATLAB中线性规划的命令,注意自变量是X还是Y;总之多多练习、多多交流来不断提高自己应用MATLAB的能力。
数学建模 回归分析模型

非线性回归模型的实际应用
预测人口增长
非线性回归模型可以用来描述人口增长的动态变 化,预测未来人口数量。
医学研究
在医学研究中,非线性回归模型可以用来分析药 物对病人体内生理指标的影响。
经济预测
在经济领域,非线性回归模型可以用来预测经济 增长、通货膨胀等经济指标。
多元回归模型的实际应用
01
社会学研究
模型检验
对模型进行检验,包括残差分析、拟 合优度检验等,以确保模型的有效性 和可靠性。
非线性回归模型的参数估计
最小二乘法
梯度下降法
通过最小化预测值与实际值之间的平方误 差,求解出模型中的未知参数。
通过迭代计算,不断调整参数值,以最小 化预测值与实际值之间的误差。
牛顿法
拟牛顿法
基于泰勒级数展开,通过迭代计算,求解 出模型中的未知参数。
线性回归模型的评估与检验
残差分析
分析残差分布情况,检查是否 存在异常值、离群点等。
拟合优度检验
通过计算判定系数、调整判定 系数等指标,评估模型的拟合 优度。
显著性检验
对模型参数进行显著性检验, 判断每个自变量对因变量的影 响是否显著。
预测能力评估
利用模型进行预测,比较预测 值与实际值的差异,评估模型
基于牛顿法的改进,通过迭代计算,求解 出模型中的未知参数,同时避免计算高阶 导数。
非线性回归模型的评估与检验
残差分析
对模型的残差进行统计分析,包括残差 的分布、自相关性、异方差性等,以评
估模型的可靠性。
预测能力评估
使用模型进行预测,比较预测值与实 际值的误差,评估模型的预测能力。
拟合优度检验
通过比较实际值与预测值的相关系数 、决定系数等指标,评估模型的拟合 优度。
数学建模实验报告第十六章回归分析

数学建模实验报告第⼗六章回归分析实验名称:第⼗六章回归分析⼀、实验内容与要求1、⽤Matlab语⾔编写程序调⽤线性回归进⾏回归系数的估计、残差分析、求置信区间等各种常规运算。
2、能够熟练掌握Matlab编程中线性回归语句的调⽤格式,学会⽤Matlab对数据样本进⾏回归分析。
对实际问题,能够进⾏数据样本的分析,依该回归进⾏预测。
⼆、实验软件MA TLAB6.5三、实验内容1、考察温度x对产量y的影响,测得下列10组数据:求y关于x的线性回归⽅程,检验回归效果是否显著,并预测x=42℃时产量的估值及预测区间(置信度95%).程序:x =[ 20 25 30 35 40 45 50 55 60 65 ]’;X =[ones(10,1) x];Y =[13.2 15.1 16.4 17.1 17.9 18.7 19.6 21.2 22.5 24.3]’; [b,bint,r,rint,stats]=regress(Y,X);B,bint,stats实验结果:图像:2、某零件上有⼀段曲线,为了在程序控制机床上加⼯这⼀零件,需要求这段曲线的解析表达式,在曲线横坐标x i处测得纵坐标yi共11对数据如下:求这段曲线的纵坐标y关于横坐标x的⼆次多项式回归⽅程程序:x=0:2:20;y=[0.6 2.0 4.4 7.5 11.8 17.1 23.3 31.2 39.6 49.7 61.7]; [p,S]=polyfit(x,s,2)结果:p = 0.1403 0.1971 1.0105s = R: [3x3 double]df: 8normr: 1.1097结论:线性回归模型为y=0.1403x^2+0.1971x+1.0105程序Y=polyconf(p,x,S)plot(x,y,'k+',x,Y,'r')实验结果:四、实验体会。
数学建模统计回归模型

统计回归模型姓名:姚敏俊 班级:08数学(1)班 学号 08070210025摘要随着社会经济的飞速发展,社会人员更关心的是自己的社会福利和工资待遇问题。
在这里我们就中学教师的工资待遇问题建立了模型,并对模型作出了一系列讨论。
如:教师的薪金与他们的工作时间1x 、性别2x 、学历4x 、以及培训情况6x 等因素之间的关系。
我们首先利用MATLAB(程序见附录五)软件作出薪金与老师工作时间的散点图,如图(二),然后假设工作时间与教师薪金为线性关系,其关系式如模型(一);再运用统计回归模型分别从各个方面特别考虑了中学女教师的工资待遇是否受她们的婚姻状况3x 的影响。
经过对模型的各个变量的逐步回归和作残差图,详见图我们从众多变量中挑选出了对教师薪金y 影响最大的变量4x 及1x ,各个变量对教师的薪金的影响的回归系数如图(三),程序见附录(二)。
从影响系数的表图中我们得出了学历对教师的薪金的影响最大。
经过对模型的分析、讨论和进一步的优化,此模型还可以运用到市场调查、教师调研、影响农作物生长的的因素等等相关问题上。
模型(一):ε+*+*+*+*+*+*+*+=776655443322110x a x a x a x a x a x a x a a y 模型(二):44110x a x a a y *+*+=关键词:散点图 线性关系 统计回归模性 回归系数 逐步回归一、问题重述每地人事部门研究中学教师的薪金与他们的资历、性别、教育程度、及培训情况等因素之间的关系,要建立一个数学模型,分析人事策略的合理性,特别是考察女教师是否受到不公正的待遇,以及她们的婚姻状况是否会影响收入。
为此,从当地教师中随机选中3414位进行观察,然后从中保留了90个观察对象,得到关键数据。
二、问题分析与假设分析:本题要求我们分析教师薪金与他们的资历、性别、教育程度及培训情况等因素之间的关系。
按到日常生活中的常识,教师薪金应该与他们的资历、受教育程度有密切关系,资历高、受教育程度高其薪金也应该相应的要高,与其性别、婚姻状况应该没有必然的联系。
数学建模方法之统计回归总结

统计回归总结由于客观事物内部规律的复杂及人们认识程度的限制,无法分析实际对象内在的因果关系,建立合乎机理规律的数学模型。
所以我们通过对数据的统计分析,找出与数据拟合最好的模型。
我们通过实例讨论如何选择不同类型的模型,对软件得到的结果进行分析,对模型进行改进:回归分析步骤如下:●收集一组因变量和自变量的数据●选定因变量和自变量之间的模型,利用数据最小二乘准则计算模型中的系数●利用统计分析方法对不同的模型进行比较找出与数据拟合得最好的模型●判断这组模型是否适合于这组数据诊断有无不适合回归模型的异常数据●利用模型对因变量做出预测与解释实例分析一、牙膏的销售量题目:收集了30个销售周期本公司牙膏销售量、价格、广告费用,及同期其它厂家同类牙膏的平均售价,请根据对数据的处理建立牙膏销售量与价格、广告投入之间的模型预测在不同价格和广告费用下的牙膏销售量。
分析与假设根据对题目中数据进行处理,作散点图分析(MATLAB )应用格式Plot(x,y,’’)Plotfit(x,y,1),其中x 表示y 模型建立与求解假设y ~公司牙膏销售量,x 1~其它厂家与本公司价格差(1)x 2~公司广告费用(2)将(1)、(2)式子联立可以得到εββ++=110x y εβββ+++=222210x x y εββββ++++=22322110x x x y(3)y~被解释变量(因变量)x1,x2~解释变量(回归变量,自变量)β0,β1,β2,β3~回归系数ε~随机误差(均值为零的正态分布随机变量)利用MATLAB工具求解可以得到。
格式如下[b,bint,r,rint,stats]=regress(y,x,alpha)输入:y~n维数据向量x=[1 x1 x2 x22 ]~n×4数据矩阵,第一列为全1向量alpha(置信水平,0.05)输出:b~β的估计值bint~b的置信区间r ~残差向量y-xbrint~r的置信区间Stats~检验统计回归模型;检验统计量:R2,F,p注:其中R2越接近1越好,F远超过F检验的临界值,p远小于α=0.05则可行假如R 2,F,p 满足条件,则我们说模型从整体上看成立 结果分析判断出 R 2,F,p 均成立,则模型可用,但因为β2的置信区间通过0点,则说明此项对模型的影响不显著所以要对模型进行改进。
统计回归模型实验报告(3篇)

第1篇一、实验背景与目的随着社会科学和自然科学研究的深入,统计分析方法在各个领域得到了广泛应用。
回归分析作为统计学中一种重要的预测和描述方法,在经济学、医学、心理学等领域发挥着重要作用。
本次实验旨在通过EViews软件,对统计回归模型进行实践操作,掌握回归分析的原理和方法,并验证模型在实际问题中的应用效果。
二、实验内容与步骤1. 数据准备(1)收集实验所需数据:选取某地区近五年居民消费支出与居民收入作为实验数据。
(2)数据整理:将数据录入EViews软件,并进行必要的预处理,如剔除异常值、缺失值等。
2. 模型设定(1)根据实验目的,设定回归模型为:消费支出= β0 + β1 居民收入+ ε,其中β0为截距项,β1为居民收入对消费支出的影响系数,ε为误差项。
(2)选择合适的回归模型:根据实验数据特点,选择线性回归模型进行建模。
3. 模型估计(1)在EViews软件中,输入数据并选择线性回归模型。
(2)进行参数估计:利用最小二乘法(OLS)估计模型参数,得到β0和β1的估计值。
4. 模型检验(1)检验模型的整体拟合优度:计算R²、F统计量等指标,判断模型是否显著。
(2)检验参数估计的显著性:进行t检验,判断β0和β1是否显著异于零。
(3)检验误差项的正态性:进行正态性检验,判断误差项是否符合正态分布。
5. 模型应用(1)预测居民消费支出:利用估计出的模型,预测居民收入在一定范围内的消费支出。
(2)分析居民收入对消费支出的影响:根据β1的估计值,分析居民收入对消费支出的影响程度。
三、实验结果与分析1. 模型整体拟合优度根据实验数据,计算R²为0.9,F统计量为35.12,表明模型整体拟合优度较好,可以用于预测和描述居民消费支出与居民收入之间的关系。
2. 参数估计的显著性t检验结果显示,β0和β1的t值分别为2.12和3.45,均大于临界值,表明β0和β1在统计上显著异于零,居民收入对消费支出有显著影响。
数学建模案例分析第十章统计回归模型

岭回归原理及步骤
• 原理:岭回归是一种专用于共线性数据分析的有偏估计回归方 法,实质上是一种改良的最小二乘估计法,通过放弃最小二乘 法的无偏性,以损失部分信息、降低精度为代价获得回归系数 更为符合实际、更可靠的回归方法,对病态数据的拟合要强于 最小二乘法。
岭回归原理及步骤
• 原理:岭回归是一种专用于共线性数据分析的有偏估计回归方 法,实质上是一种改良的最小二乘估计法,通过放弃最小二乘 法的无偏性,以损失部分信息、降低精度为代价获得回归系数 更为符合实际、更可靠的回归方法,对病态数据的拟合要强于 最小二乘法。
一元线性回归
01
02
03
模型建立
一元线性回归模型用于描 述两个变量之间的线性关 系,通常形式为y=ax+b, 其中a和b为待估参数。
参数估计
通过最小二乘法等方法对 参数a和b进行估计,使得 预测值与实际观测值之间 的误差平方和最小。
假设检验
对模型进行假设检验,包 括检验模型的显著性、参 数的显著性等,以判断模 型是否有效。
线性回归模型检验
拟合优度检验
通过计算决定系数R^2等指标, 评估模型对数据的拟合程度。
残差分析
对模型的残差进行分析,包括残 差的分布、异方差性检验等,以
判断模型的合理性。
预测能力评估
通过计算预测误差、均方误差等 指标,评估模型的预测能力。同 时可以使用交叉验证等方法对模
型进行进一步的验证和评估。
线性回归模型检验
逐步回归原理及步骤
01
3. 对模型中已有的自变量进行检 验,如果不显著则将其从模型中 剔除。
02
4. 重复步骤2和3,直到没有新的 自变量可以进入模型,也没有不显 著的自变量可以从模型中剔除。
数学建模实验报告-统计回归模型
《数学建模与数学实验》实验报告实验2 统计回归模型先帝创业未半而中道崩殂,今天下三分,益州疲弊,此诚危急存亡之秋也。
然侍卫之臣不懈于内,忠志之士忘身于外者,盖追先帝之殊遇,欲报之于陛下也。
诚宜开张圣听,以光先帝遗德,恢弘志士之气,不宜妄自菲薄,引喻失义,以塞忠谏之路也。
宫中府中,俱为一体;陟罚臧否,不宜异同。
若有作奸犯科及为忠善者,宜付有司论其刑赏,以昭陛下平明之理;不宜偏私,使内外异法也。
侍中、侍郎郭攸之、费祎、董允等,此皆良实,志虑忠纯,是以先帝简拔以遗陛下:愚以为宫中之事,事无大小,悉以咨之,然后施行,必能裨补阙漏,有所广益。
将军向宠,性行淑均,晓畅军事,试用于昔日,先帝称之曰“能”,是以众议举宠为督:愚以为营中之事,悉以咨之,必能使行阵和睦,优劣得所。
亲贤臣,远小人,此先汉所以兴隆也;亲小人,远贤臣,此后汉所以倾颓也。
先帝在时,每与臣论此事,未尝不叹息痛恨于桓、灵也。
侍中、尚书、长史、参军,此悉贞良死节之臣,愿陛下亲之、信之,则汉室之隆,可计日而待也。
臣本布衣,躬耕于南阳,苟全性命于乱世,不求闻达于诸侯。
先帝不以臣卑鄙,猥自枉屈,三顾臣于草庐之中,咨臣以当世之事,由是感激,遂许先帝以驱驰。
后值倾覆,受任于败军之际,奉命于危难之间,尔来二十有一年矣。
先帝知臣谨慎,故临崩寄臣以大事也。
受命以来,夙夜忧叹,恐托付不效,以伤先帝之明;故五月渡泸,深入不毛。
今南方已定,兵甲已足,当奖率三军,北定中原,庶竭驽钝,攘除奸凶,兴复汉室,还于旧都。
此臣所以报先帝而忠陛下之职分也。
至于斟酌损益,进尽忠言,则攸之、祎、允之任也。
愿陛下托臣以讨贼兴复之效,不效,则治臣之罪,以告先帝之灵。
若无兴德之言,则责攸之、祎、允等之慢,以彰其咎;陛下亦宜自谋,以咨诹善道,察纳雅言,深追先帝遗诏。
臣不胜受恩感激。
今当远离,临表涕零,不知所言。
数学建模方法之统计回归总结

诡计回归总錯由子家观亨•畅内祁规律的复杂及人们认积程盛的限制,无廉分析宾际对隼内衣.的因糸关糸,建立合手机理规律的救学僕宴。
所以我们通过对數据的统计分析,我出与数据拟合录好的模型。
我们通过宾例讨论如何追择不同矣型的換型,对软件得到的姑果进行分析,对模矍进行改进J回归分析步腋如下:•收集一组阖变董和自变萤的数据• 选走因变量和令变量之间的栈型,利用數擁最小二泵准刘计算栈型中的糸救•创用统计分析方法对不同的栈4!进行比较找出与救据拟合得最好的模熨•判靳这俎栈熨是否追合于这俎數据诊斷有无不追合回归棋矍的异常數据•利用模晏对因变董做岀预測与解年卖例分析一、牙育的林a受题a :收集了30个4«@周期本心司牙青锚傅量.价格、Z4#用,A 同期其乞厂彖同典牙青的平的傳价,请根据对數据的处理建立牙育锚©董与价格、户告投入之间的棋熨预测虚不阿价格和/•告费用下的牙根据对题目中數据进行处理,作散点08分析fMATLAB;应用格PIot(x,yJ )Plotfit(x,y,1),其中x 表示y核熨建立与求解級4ty~心甸牙音補©量,冶~其它厂家与本公司价格左y = Q()+ Qz + £(1)X2~^<1广吿费用y = 0o + 0宀 + PiA + £(2)将fb. (2)或子朕立可以得到3)冷木2~解年雯受(回归变交■,角<4)00,九卩2屆~回归余数£~建机镁迸(拔值为奉的正杰分布随机iiJ刊用MATLAB工典求解可以得到。
格式如下[b,bint,r,rint,rtat$]» regress (y,x,alpha)输入:y~n推數据向董x・[1 XiX2X2?]~nX4數据矩阵,第一刃%全1向量alpha (JL 侑水平,0.05)输出:b~p的估计值bint~b的JL传区间r ~戎;M向董y-xbrint~r 的X^rfiL 间Stats~检絵疣计回归模型;检缺统计爻:2,F,p注:其中以越揍近1越好,F运起过F检絵的临界值,p运小于a・0.05 则可行假如R2,F,p满足条件,则我们说模熨从蔓体上看成立结系分析判靳出R2,F,p均成立,刘模熨可用,但因为卩2的置信区间通i±0点,则说明此项对模型的彩响不显著所以要对棋熨进行发遗。
数学建模实验三:统计回归模型Matlab求解

一、实验目的[1] 通过范例学习建立统计回归的数学模型以及求解全过程;[2] 熟悉MATLAB求解统计回归模型的过程。
二、实验内容(1) 一家技术公司人事部门为研究软件开发人员的薪金与他们的资历、管理责任、教育程度等因素之间的关系,要建立一个数学模型,以便分析公司人事策略的合理性,并作为新聘用人员薪金的参考。
他们认为目前公司人员的薪金总体上是合理的,可以作为建模的依据,于是调查来46名软件开发人员的档案资料,如表4,其中资历一列指从事专业工作的年数,管理一列中1表示管理人员,0表示非管理人员,教育一列中1表示中学程度,2表示大学程度,3表示更高程度(研究生)表1 软件开发人员的薪金与他们的资历、管理责任、教育程度之间的关系分析与假设按照常识,薪金自然随着资历的增长而增加,管理人员的薪金应高于非管理人员,教育程度越高薪金也越高。
薪金记作y ,资历记作x 1,为了表示是否管理人员,定义:210,x ⎧=⎨⎩,管理人员非管理人员.为了表示3种教育程度,定义:31,0,x ⎧=⎨⎩中学其它41,0,x ⎧=⎨⎩大学其它这样,中学用x 3=1,x 4=0表示,大学用x 3=0,x 4=1表示,研究生则用x 3=0,x 4=0表示。
假定资历对薪金的作用是线性的,即资历每加一年,薪金的增长是常数;管理责任、教育程度、资历诸因素之间没有交互作用,建立线性回归模型。
基本模型薪金y 与资历x 1, 管理责任x 2,教育程度x 3,x 4之间的多元线性回归模型为011223344y a a x a x a x a x ε=+++++(1)其中014,,a a a …,是待估计的回归系数,ε是随机误差。
利用MATLAB 编程计算可以得到回归系数及其置信区间(置信水平∝=0.05)、检验统计量R2,F,p结果,见表2:表2 模型(1)的计算结果具体MA TLAB代码如下所示:实际运行结果截图如下所示:结果分析: R 2=0.957,即因变量(薪金)的95.7%可由模型确定,F 值远远超过F 检验的临界值,p 远小于∝,因而模型(1)从整体来看是可用的。
数学模型之统计回归模型

下表列出了某城市18位35岁~44岁经理的年平均收入1x 千元,风险偏好度2x 和人寿保险额y 千元的数据,其中风险偏好度是根据发给每个经理的问卷调查表综合评估得到的,它的数值越大,就越偏爱高风险,研究人员想研究此年龄段中的经理所投保的人寿保险额与年收入及风险偏好度之间的关系。
研究者预计,经理的年均收入和人寿保险额之间存在着二次关系,并有把握地认为风险偏好度对人寿保险额有线性效应,但对风险偏好度对人寿保险额是否有二次效应以及两个自变量是否对人寿保险额有交互效应,心中没底。
请你通过表中的数据来建立一个合适的回归模型,验证上面的看法,并给出进一步的分析。
x1=[66.290 40.964 72.996 45.010 57.204 26.852 38.122 35.840 75.796 37.408 54.376 46.186 46.130 30.366 39.060 79.380 52.766 55.916];>> y1=[196 63 252 84 126 14 49 49 266 49 105 98 77 14 56 245 133 133]; >> p=polyfit(x1,y1,2) p =3.0246e-002 1.7886e+000 -6.0524e+001>> x2=0:0.01:85;y2=polyval(p,x2); plot(x1,y1,'o',x2,y2)1x y 对的散点图从图中可以发现,随着1x 的增加,y 的值有明显向上弯曲的二次增长趋势,图中的曲线是用二次函数模型εβββ+++=212110x x y (1)拟合的。
(其中ε是随机误差)>> x3=[7 5 10 6 4 5 4 6 9 5 2 7 4 3 5 1 8 6]; >> q=polyfit(x3,y1,1) q =1.3522e+001 3.8743e+001>> x4=0:0.01:15;y3=polyval(q,x4); plot(x3,y1,'o',x4,y3)的一次的散点图对2x y从图中可以发现,随着2x 的增加,y 的值比较明显的线性增长趋势,图中的曲线是用线性函数模型εββ++=210x y (2) 拟合的。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
二. 建立公司销售额对全行业的回归模型, 并用 DW 检验诊断随机误差项的 自相关性。
1.模型求解结果:
2
b= -1.4548 0.1763 bint = -1.9047 -1.0048 0.1732 0.1793 stats = 1.0e+004 * 0.0001 1.4888
0
0.0000
Residual Case Order Plot
%自相关性检验 Y=b0(1)+b0(2).*x0; Et=y0-Y; figure %模型残差
dw1=sum((Et(2:19,1)-Et(1:18,1)).^2); dw2=sum((Et(2:19,1)).^2); DW0=dw1/dw2
三. 建立消除了随机误差项自相关性之后的回归模型
1.广义差分变换 原模型: yt 0 1 xt t , t t 1 ut 变换:
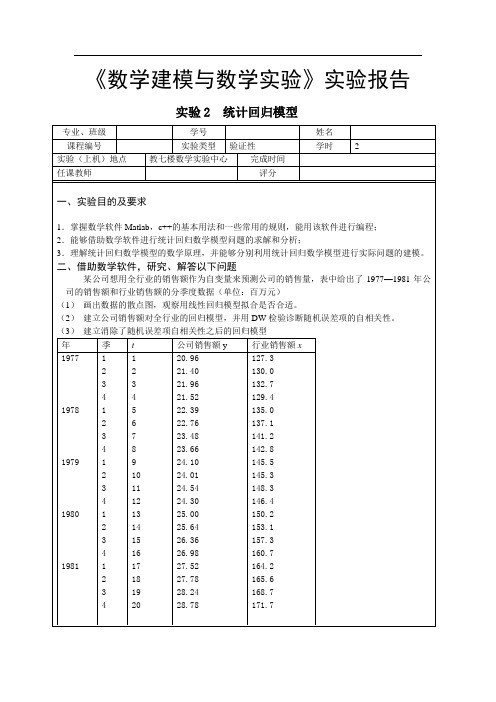
《数学建模与数学实验》实验报告
实验 2
专业、班级 课程编号 实验(上机)地点 任课教师 学号 实验类型 教七楼数学实验中心 验证性 完成时间 评分
统计回归模型
姓名 学时 2
一、实验目的及要求
1.掌握数学软件 Matlab,c++的基本用法和一些常用的规则,能用该软件进行编程; 2.能够借助数学软件进行统计回归数学模型问题的求解和分析; 3.理解统计回归数学模型的数学原理,并能够分别利用统计回归数学模型进行实际问题的建模。
DW
e
t 2
n
t
et 1 2
2 t
e
t 2
n
21
e e
t 2 n
n
t t 1
e
t 2
2 t
2 1
做矩阵运算(减法、乘法等)求得 DW 值。其中求和号可用函数 sum。
-0.1104
5
0.1691 stats1 = 1.0e+003 * 0.0010
0.1829
2.9374
0
0.0000
Residual Case Order Plot
0.2 0.15 0.1 0.05 0 -0.05 -0.1 -0.15 -0.2 2 4 6 8 10 Case Number 12 14 16 18
结果分析: y 的 100%可由模型确定, F=16752 远超过 F 检验的临界值, p 远小于 0.05 ,
0 , 1 的置信区间 bint 不包含零点,数据点的残差置信区间 rint 均包含零点,所以模型
4
yt -1.6093 0.1773xt ,从整体上看成立。
3.自相关性的定量诊断——DW 检验
结果分析: y 的 100%可由模型确定, F=2937.4 远超过 F 检验的临界值, p 远小于 0.05 ,
* 0 , 1 的置信区间不包含零点,但从图中看出,第 12 个点的残差的置信区间不包含零
点,应作为异常去掉。 代码:
%新模型求解 X1=[ones(18,1) x1]; [b1,bint1,r1,rint1,stats1]=regress(y1,X1); b1,bint1,stats1,rcoplot(r1,rint1)
2.广义差分法
关键是通过变换 yt* yt yt 1 , xt* xt xt 1 1 DW 得到新模型。 2
四、参考文献
[1] 姜启源,谢金星,叶俊.数学模型(第三版) ,高等教育出版社,2003 [2]邓薇.MATLAB 函数速查手册,人民邮电出版社,2010 DW 检验表
3.新模型的自相关性检验定量诊断——DW 检验
由 DW 值的大小确定自相关性:查 D-W 分布表,得到检验水平 0.05 ,样本容量 n=18,回归变 量数目 k=2 时,对应的检验临界值: d L 1.16, dU 1.39 。 因为结果求得 1.39 dU DW1 1.6537 4 - dU 2.61 ,所以新模型无自相关。
代码:
%新模型自相关性检验 Y1=b1(1)+b1(2).*x1;
6
Residuals
Et1=y1-Y1; %模型残差 Y1(:,1)=b1(1)+b1(2).*x1(:,1); Et1(:,1)=y1(:,1)-Y1(:,1); %模型残差 dw3=sum((Et1(2:18,1)-Et1(1:17,1)).^2); dw4=sum((Et1(2:18,1)).^2); DW1=dw3/dw4
7
由 DW 值的大小确定自相关性: 查 D-W 分布表, 得到检验水平 0.05 ,样本容量 n=19, 回归变量数目 k=2 时,对应的检验临界值: d L 1.18, dU 1.40 。 因为结果求得 DW 0 0.6412 d L 1.18 ,所以该模型存在正自相关。 代码:
yt* yt yt 1 , xt* xt xt 1
* * 新模型: yt* 0 1 xt* ut , 0 0 1
* * (新模型是以 0 , 1 为回归系数的普通回归模型,由数据 yt* , xt* 可估计系数 0 , 1 )
二、借助数学软件,研究、解答以下问题
某公司想用全行业的销售额作为自变量来预测公司的销售量,表中给出了 1977—1981 年公 司的销售额和行业销售额的分季度数据(单位:百万元) (1) 画出数据的散点图,观察用线性回归模型拟合是否合适。 (2) 建立公司销售额对全行业的回归模型,并用 DW 检验诊断随机误差项的自相关性。 (3) 建立消除了随机误差项自相关性之后的回归模型 年 1977 季 1 2 3 4 1 2 3 4 1 2 3 4 1 2 3 4 1 2 3 4 t 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 公司销售额 y 20.96 21.40 21.96 21.52 22.39 22.76 23.48 23.66 24.10 24.01 24.54 24.30 25.00 25.64 26.36 26.98 27.52 27.78 28.24 28.78 行业销售额 x 127.3 130.0 132.7 129.4 135.0 137.1 141.2 142.8 145.5 145.3 148.3 146.4 150.2 153.1 157.3 160.7 164.2 165.6 168.7 171.7
4.消除了随机误差项自相关性之后的回归模型:
yt 0.3948 0.1305yt 1 0.1738xt 0.1096xt 1
三、本次实验的难点分析 1.DW 检验——DW 的求解
(1)难点:DW 的求解不仅涉及模型残差,而且计算公式复杂,需要掌握数组及矩阵的相关运算, 并使用 FOR-END 循环。 (2)解决:先利用已求得的回归系数 0 , 1 写出模型,以此得估计值 y t ;然后做数组减法 y t y t 得 e t ,最后由以下公式:
170
175
代码:
x=[127.3,130.0,132.7,129.4,135.0,137.1,141.2,142.8,145.5,145.3,... 148.3,146.4,150.2,153.1,157.3,160.7,164.2,165.6,168.7,171.7]'; y=[20.96,21.40,21.96,21.52,22.39,22.76,23.48,23.66,24.10,24.01,... 24.54,24.30,25.00,25.64,26.36,26.98,27.52,27.78,28.24,28.78]'; plot(x,y,'.') title('数据散点图') xlabel('行业销售额 x'); ylabel('公司销售额 y')
0.3
0.2
0.1
Residuals
0
-0.1
-0.2
-0.3 2 4 6 8 10 12 Case Number 14 16 18 20
结果分析: y 的 100%可由模型确定, F=14888 远超过 F 检验的临界值, p 远小于 0.05 ,
0 , 1 的置信区间 bint 不包含零点,但是,从图中可以看出,第 4 个点的残差的置信区
1978
1979
1980
1981
1
一.画数据的散点图如下,观察发现用线性回归模型 yt 0 1 xt t 拟合 比较合适。
数据散点图 29 28 27 26
公司销售额y
25 24 23 22 21 20 125
130
135
140
145 150 155 行业销售额x
160
165
间 rint 不包含零点,应作为异常点去掉。 代码:
figure %模型求解 X=[ones(20,1) x]; [b,bint,r,rint,stats]=regress(y,X); b,bint,stats,rcoplot(r,rint)
2.去掉第 4 个异常点后的模型求解 结果:
3
b0 = -1.6093 0.1773 bint0 = -2.0403 -1.1783 0.1744 0.1802 stats0 = 1.0e+004 * 0.0001 1.6752
代码:
%广义差分变换 low=1-DW0/2; x1=zeros(18,1); y1=zeros(18,1); for t=2:19 y1(t-1,1)=y0(t)-low*y0(t-1); x1(t-1,1)=x0(t)-low*x0(t-1); end
2.新模型求解结果: