(BST) 举例存储结构typedef struct node { KeyType key; InfoType
阿里最新面试题(含部分答案解析)

•
return self.cache[key]
•
•
def put(self, key, value):
•
"""
•
:type key: int
•
:type value: int
•
:rtype: void
•
"""
•
if not key in self.cache:
•
if len(self.keys) == self.capacity:
•
m.erase(k);
•
}
•
}
•}
• 1.1.5 关于 epoll 和 select 的区别,哪些说法是正确的?(多选)
A. epoll 和 select 都是 I/O 多路复用的技术,都可以实现同时监听多个 I/O 事件的 状态。
B. epoll 相比 select 效率更高,主要是基于其操作系统支持的 I/O 事件通知机制,而 select 是基于轮询机制。
public int kthSmallest(TreeNode root, int k) { return kthSmallestHelper(root, k).val;
}
private ResultType kthSmallestHelper(TreeNode root, int k) { if (root == null) { return new ResultType(false, 0); }
•
self.elim_key()
•
self.cache[key] = value
•
self.visit_key(key)
CC++语法知识:typedefstruct用法详解

CC++语法知识:typedefstruct⽤法详解第⼀篇:typedef struct与struct的区别1. 基本解释typedef为C语⾔的关键字,作⽤是为⼀种数据类型定义⼀个新名字。
这⾥的数据类型包括内部数据类型(int,char等)和⾃定义的数据类型(struct等)。
在编程中使⽤typedef⽬的⼀般有两个,⼀个是给变量⼀个易记且意义明确的新名字,另⼀个是简化⼀些⽐较复杂的类型声明。
⾄于typedef有什么微妙之处,请你接着看下⾯对⼏个问题的具体阐述。
2. typedef & 结构的问题当⽤下⾯的代码定义⼀个结构时,编译器报了⼀个错误,为什么呢?莫⾮C语⾔不允许在结构中包含指向它⾃⼰的指针吗?请你先猜想⼀下,然后看下⽂说明:typedef struct tagNode{ char *pItem; pNode pNext;} *pNode;答案与分析:1、typedef的最简单使⽤typedef long byte_4;给已知数据类型long起个新名字,叫byte_4。
2、 typedef与结构结合使⽤typedef struct tagMyStruct{ int iNum; long lLength;} MyStruct;这语句实际上完成两个操作:1) 定义⼀个新的结构类型struct tagMyStruct{ int iNum; long lLength;};分析:tagMyStruct称为“tag”,即“标签”,实际上是⼀个临时名字,struct 关键字和tagMyStruct⼀起,构成了这个结构类型,不论是否有typedef,这个结构都存在。
我们可以⽤struct tagMyStruct varName来定义变量,但要注意,使⽤tagMyStruct varName来定义变量是不对的,因为struct 和tagMyStruct 合在⼀起才能表⽰⼀个结构类型。
2) typedef为这个新的结构起了⼀个名字,叫MyStruct。
数据结构复习题1

数据结构复习题2
一、选择题(30分)
1.设一维数组中有n个数组元素,则读取第i个数组元素的平均时间复杂度为()。
(A) O(n)(B) O(nlog2n)(C) O(1)(D) O(n2)
2.设一棵二叉树的深度为k,则该二叉树中最多有()个结点。
(A) 2k-1(B) 2k(C) 2k-1(D) 2k-1
5.设哈夫曼树中共有n个结点,则该哈夫曼树中有___0_____个度数为1的结点。
6.设有向图G中有n个顶点e条有向边,所有的顶点入度数之和为d,则e和d的关系为_________。
7.__________遍历二叉排序树中的结点可以得到一个递增的关键字序列(填先序、中序或后序)。
8.设查找表中有100个元素,如果用二分法查找方法查找数据元素X,则最多需要比较________次就可以断定数据元素X是否在查找表中。
typedef struct node {datatype data; struct node *lchild,*rchild;} bitree;
bitree *q[20]; int r=0,f=0,flag=0;
void preorder(bitree *bt, char x)
{
if (bt!=0 && flag==0)
int hashsqsearch(struct record hashtable[ ],int k)
{
int i,j; j=i=k % p;
while (hashtable[j].key!=k&&hashtable[j].flag!=0){j=(____) %m; if (i==j) return(-1);}
(C)判别栈元素的类型(D)对栈不作任何判别
数据结构试题及答案(免费)

数据结构试卷(十一)一、选择题(30分)1.设某无向图有n个顶点,则该无向图的邻接表中有()个表头结点。
(A) 2n (B) n (C) n/2 (D) n(n-1)2.设无向图G中有n个顶点,则该无向图的最小生成树上有()条边。
(A) n (B) n-1 (C) 2n (D) 2n-13.设一组初始记录关键字序列为(60,80,55,40,42,85),则以第一个关键字45为基准而得到的一趟快速排序结果是()。
(A) 40,42,60,55,80,85 (B) 42,45,55,60,85,80(C) 42,40,55,60,80,85 (D) 42,40,60,85,55,804.()二叉排序树可以得到一个从小到大的有序序列。
(A) 先序遍历(B) 中序遍历(C) 后序遍历(D) 层次遍历5.设按照从上到下、从左到右的顺序从1开始对完全二叉树进行顺序编号,则编号为i结点的左孩子结点的编号为()。
(A) 2i+1 (B) 2i (C) i/2 (D) 2i-16.程序段s=i=0;do {i=i+1;s=s+i;}while(i<=n);的时间复杂度为()。
(A) O(n) (B) O(nlog2n) (C) O(n2) (D) O(n3/2)7.设带有头结点的单向循环链表的头指针变量为head,则其判空条件是()。
(A) head==0 (B) head->next==0(C) head->next==head (D) head!=08.设某棵二叉树的高度为10,则该二叉树上叶子结点最多有()。
(A) 20 (B) 256 (C) 512 (D) 10249.设一组初始记录关键字序列为(13,18,24,35,47,50,62,83,90,115,134),则利用二分法查找关键字90需要比较的关键字个数为()。
(A) 1 (B) 2 (C) 3 (D) 410.设指针变量top指向当前链式栈的栈顶,则删除栈顶元素的操作序列为()。
2020年考研计算机数据结构模拟试题及答案(三)

2020年考研计算机数据结构模拟试题及答案(三)一、选择题(30分)1. 1. 字符串的长度是指( )。
(A) 串中不同字符的个数 (B) 串中不同字母的个数(C) 串中所含字符的个数 (D) 串中不同数字的个数2. 2. 建立一个长度为n的有序单链表的时间复杂度为( )(A) O(n) (B) O(1) (C) O(n2) (D) O(log2n)3. 3. 两个字符串相等的充要条件是( )。
(A) 两个字符串的长度相等 (B) 两个字符串中对应位置上的字符相等(C) 同时具备(A)和(B)两个条件 (D) 以上答案都不对4. 4. 设某散列表的长度为100,散列函数H(k)=k % P,则P通常情况下选择( )。
(A) 99 (B) 97 (C) 91 (D) 935. 5. 在二叉排序树中插入一个关键字值的平均时间复杂度为( )。
(A) O(n) (B) O(1og2n) (C) O(nlog2n) (D) O(n2)6. 6. 设一个顺序有序表A[1:14]中有14个元素,则采用二分法查找元素A[4]的过程中比较元素的顺序为( )。
(A) A[1],A[2],A[3],A[4] (B) A[1],A[14],A[7],A[4](C) A[7],A[3],A[5],A[4] (D) A[7],A[5] ,A[3],A[4]7. 7. 设一棵完全二叉树中有65个结点,则该完全二叉树的深度为( )。
(A) 8 (B) 7 (C) 6 (D) 58. 8. 设一棵三叉树中有2个度数为1的结点,2个度数为2的结点,2个度数为3的结点,则该三叉链权中有( )个度数为0的结点。
(A) 5 (B) 6 (C) 7 (D) 89. 9. 设无向图G中的边的集合E={(a,b),(a,e),(a,c),(b,e),(e,d),(d,f),(f,c)},则从顶点a出发实行深度优先遍历能够得到的一种顶点序列为( )。
大学计算机《数据结构》试卷及答案(八)

大学计算机《数据结构》试卷及答案一、选择题(30分)1.设一维数组中有n个数组元素,则读取第i个数组元素的平均时间复杂度为()。
(A) O(n) (B) O(nlog2n) (C) O(1) (D) O(n2)2.设一棵二叉树的深度为k,则该二叉树中最多有()个结点。
(A) 2k-1 (B) 2k(C) 2k-1(D) 2k-13.设某无向图中有n个顶点e条边,则该无向图中所有顶点的入度之和为()。
(A) n (B) e (C) 2n (D) 2e4.在二叉排序树中插入一个结点的时间复杂度为()。
(A) O(1) (B) O(n) (C) O(log2n) (D) O(n2)5.设某有向图的邻接表中有n个表头结点和m个表结点,则该图中有()条有向边。
(A) n (B) n-1 (C) m (D) m-16.设一组初始记录关键字序列为(345,253,674,924,627),则用基数排序需要进行()趟的分配和回收才能使得初始关键字序列变成有序序列。
(A) 3 (B) 4 (C) 5 (D) 87.设用链表作为栈的存储结构则退栈操作()。
(A) 必须判别栈是否为满(B) 必须判别栈是否为空(C) 判别栈元素的类型(D) 对栈不作任何判别8.下列四种排序中()的空间复杂度最大。
(A) 快速排序(B) 冒泡排序(C) 希尔排序(D) 堆9.设某二叉树中度数为0的结点数为N0,度数为1的结点数为N l,度数为2的结点数为N2,则下列等式成立的是()。
(A) N0=N1+1 (B) N0=N l+N2(C) N0=N2+1 (D) N0=2N1+l10.设有序顺序表中有n个数据元素,则利用二分查找法查找数据元素X的最多比较次数不超过()。
(A) log2n+1 (B) log2n-1 (C) log2n (D) log2(n+1)二、填空题(42分)1.设有n个无序的记录关键字,则直接插入排序的时间复杂度为________,快速排序的平均时间复杂度为_________。
c语言typedef语句结构

c语言typedef语句结构【原创版】目录1.C 语言 typedef 的作用2.typedef 语句的基本结构3.举例说明 typedef 的应用正文【1】C 语言 typedef 的作用在 C 语言编程中,typedef 是一种声明类型的方法,它可以为现有类型定义一个新的名字,使得程序的设计更加简洁和清晰。
通过使用typedef,我们可以创建用户自定义类型,从而简化代码的编写和阅读。
【2】typedef 语句的基本结构typedef 语句的基本结构如下:```typedef 原类型名新类型名;```其中,原类型名为已经存在的数据类型,如 int、float 等;新类型名是我们为原类型定义的新名字。
需要注意的是,typedef 声明的新类型并不是一个独立的类型,而是对原类型的一个别名。
【3】举例说明 typedef 的应用下面我们通过一个例子来说明 typedef 的应用:假设我们有一个程序需要频繁使用整数类型,但我们希望为整数类型定义一个新的名字,如`int32`。
通过 typedef,我们可以实现这个需求。
具体代码如下:```c#include <stdio.h>typedef int int32;int main() {int32 a = 100;int32 b = 200;printf("%d", a + b);return 0;}```在这个例子中,我们使用 typedef 为整数类型定义了一个新的名字`int32`,然后在程序中使用这个新名字。
这样做的好处是,我们可以在程序中使用更加直观和清晰的类型名,而不需要记住整数类型的具体名称。
typedef在c语言中的用法

typedef在c语言中的用法嘿,小伙伴们,今天咱们来聊聊C语言里头的一个神奇小工具——typedef,它啊,就像是编程世界里的魔法师,能让复杂的事情变得简单又有趣。
别看它名字听起来高深莫测,其实用起来,嘿,那叫一个顺手!想象一下,你正在厨房里忙碌,准备做一顿大餐。
锅碗瓢盆一大堆,每种工具都有它特定的用途,对吧?但有时候,为了方便,你可能会给某个常用的工具起个昵称,比如那把大铲子,你干脆叫它“翻云覆雨手”,听起来就带劲儿!这就是typedef干的活儿,它给复杂的数据类型起个简单易记的名字,让你的代码读起来像诗一样流畅。
首先,咱们得明白,为啥需要typedef呢?想象一下,如果你在写代码时,经常需要用到一种特别复杂的数据类型,比如一个指向函数的指针,这个函数又返回另一个指向另一个函数的指针,哎呀妈呀,这说起来都绕口。
每次写这么一串长长的类型声明,是不是感觉头都大了?这时候,typedef就像是个贴心的助手,它能帮你把这一大串复杂的东西简化成一个简短的、容易记住的名字。
比如,你可以这么写:```ctypedef int* IntPtr;```看,多简单!以后每当你想用指向int的指针时,直接写IntPtr就行了,再也不用担心记不住那长长的类型声明了。
再比如,咱们定义一个结构体,用来存储学生的信息:```cstruct Student {char name[50];int age;float score;};```每次使用这个结构体时,都得写`struct Student`,挺麻烦的。
有了typedef,咱们可以这么做:```ctypedef struct Student {char name[50];int age;float score;} Student;```注意看,这里有个小技巧,我们把`typedef`和`struct`放在了一起,这样定义之后,直接就可以用`Student`来声明变量了,省去了`struct`这个前缀,代码看起来更清爽。
c语言结构体定义typedef

c语言结构体定义typedefC语言结构体定义typedefC语言是一种非常流行的编程语言,广泛应用于嵌入式系统、操作系统以及各种应用程序的开发中。
在C语言中,结构体是一种非常重要的数据类型,它允许我们将不同的数据类型组合在一起,形成一个新的数据类型。
为了方便使用结构体,C语言提供了typedef关键字,使我们能够为结构体定义一个新的名称。
那么,下面就让我们一步一步地探讨typedef在C语言结构体定义中的作用和使用方法。
第一步:了解结构体的基本概念在开始使用typedef关键字定义结构体之前,我们首先需要了解结构体的基本概念。
结构体是由多个不同数据类型的变量组成的复合数据类型。
它允许我们将不同类型的数据组合在一起,形成一个整体,方便我们对这些数据进行统一管理和操作。
结构体的定义由关键字"struct"开始,后面跟着结构体的名称,再加上一对大括号,用于定义结构体的成员变量。
例如,我们可以定义一个包含学生信息的结构体如下:cstruct Student {int id;char name[20];int age;};上面的代码定义了一个名为Student的结构体,它包含了一个整型变量id、一个字符数组name和一个整型变量age。
第二步:使用typedef为结构体定义新的名称在上面的代码中,我们可以看到结构体的定义必须以struct关键字开头。
当我们想要使用这个结构体类型时,需要每次都写上struct关键字,这样显得比较冗长。
为了简化代码,C语言提供了typedef关键字,使我们能够为结构体定义一个新的名称。
使用typedef的语法如下:ctypedef struct {int id;char name[20];int age;} Student;在上面的代码中,我们使用typedef关键字为结构体定义了一个新的名为Student的名称。
这样,我们就可以直接使用Student作为结构体类型,而无需每次都写上struct关键字了。
第八章查找——精选推荐

查找一.选择题1.若查找每个元素的概率相等,则在长度为n 的顺序表上查找到表中任一元素的平均查找长度为_____________。
A. nB. n+1C. (n-1)/2D. (n+1)/2分析:本题主要考查顺序表的平均查长度的计算,在等概率下,ASLsucc=nP1+(n-1)P2+……+2Pn-1 +Pn=[n+(n-1)+ ……+1]/n = (n+1)/2,其中:Pi 为查找第i 个元素的概率。
所以答案为D。
2.折半查找的时间复杂度_____________。
A.O(n*n)B.O(n)C. O(nlog2n)D. O(log2n)分析:本题考查折半查找的基本思想和对应的判定树。
因为对n 个结点的线性表进行折半查找,对应的判定树的深度是 log2n +1,折半查找的过程就是走了一条从判定树的根到末端结点的路径,所以答案为D。
3.采用分块查找时,数据的组织方式为_____________。
A. 把数据分成若干块,每块内数据有序B. 把数据分成若干块,块内数据不必有序,但块间必须有序,每块内最大(或最小)的数据组成索引表C. 把数据分成若干块,每块内数据有序,每块内最大(或最小)的数据组成索引表D. 把数据分成若干块,每块(除最后一块外)中的数据个数相等分析:本题主要考查分块查找的数据组织方式特点。
在分块查找时,要求块间有序,块内或者有序或者无序。
这样,在查找记录所在的块时,可以采用折半查找。
所以答案为B。
4.二叉排序树的查找效率与二叉排序树的(1)有关,当(2)时,查找效率最低,其查找长度为n。
(1) A.高度B.结点的个数C.形状D.结点的位置(2) A.结点太多B.完全二叉树C.呈单叉树D.结点的结构太复杂分析:本题主要考查二叉排序树的查找效率与二叉排序树形存在一定的关系。
当二叉排序树的前 log2n 层是满二叉树时,其查找效率最高,其查找长度最大为 log2n +1;当二叉排序树呈单叉树时,其查找效率最低,其查找长度最大为n,此时相当于顺序查找。
南京林业大学2022年[数据结构]考研真题
![南京林业大学2022年[数据结构]考研真题](https://img.taocdn.com/s3/m/a209a922591b6bd97f192279168884868662b85e.png)
南京林业大学2022年[数据结构]考研真题一.是非题判断下列各题是否正确,正确的在括号内打 “√”,错的打“×”。
每小题2分,共20分。
1.数据的逻辑结构独立于计算机,物理结构依赖于计算机。
()2.线性表、栈和队列的逻辑结构完全相同。
()3.顺序存储方式只能用于存储线性结构。
()4.在单链表中,要取得某个元素,只要知道该元素的指针即可,因此,单链表是随机存取的存储结构。
()5.先根遍历树和先序遍历与该树对应的二叉树,其结果不同。
()6.外部排序与外部设备的特性无关。
()7.不使用递归,也可以实现二叉树的先序、中序和后序遍历。
()8.在哈夫曼编码中,当两个字符出现的频率相同时,其编码也相同,对于这种情况应作特殊处理。
()9. 有回路的图不能进行拓扑排序。
()10. 二叉排序树的查找和折半查找的时间性能相同。
()二.单项选择题A.规则B.集合C.结构D.运算2.对于顺序存储的线性表,设其长度为n,在任何位置上插入或删除操作都是等概率的。
插入一个元素时大约要移动表中的______个元素。
A.n/2B.(n+1)/2C.(n-1)/2D.n3.线性表采用链式存储时,其地址______。
A. 必须是连续的B. 部分地址必须是连续的C. 一定是不连续的D. 连续与否均可以4.设有一个空栈,栈顶指针为1000H(十六进制,下同,且设每个入栈元素需要1个单位存储空间),现有输入序列为1,2,3,4,5,经过PUSH,PUSH ,POP,PUSH,POP,PUSH,POP,PUSH后,栈顶指针是______。
A.1002HB.1003HC.1004HD.1005H5.将有关二叉树的概念推广到三叉树,则一棵有244个结点的完全三叉树的高度是______。
A. 4 B.5C.6 D.76.数组A[0..5,0..6]的每个元素占5个字节,将其按列优先次序存储在起始地址为1000的内存单元中,则元素A[5,5]的地址是______。
计算机数据结构复习题2
1解、采用遍历方式判断无向图G是否连通。若用深 度优先遍历方法,先给visited[]数组置初值0, 然后从0顶点开始遍历该图。在一次遍历后,若所 有顶点i的visited[i]均为1,则该图是连通的,否 则不连通。
1算法如下: int connect(AGraph *G) { int i,flag=1; for (i=0;i<G->n;i++) visited[i]=0; DFS(G,0); for (i=0;i<G->n;i++) if (visited[i]==0) flag=0; break; } return flag; }
D.(n-1)(m/2 -1)+1 解:根结点至少有一个关键字,其他n-1 个结点至少有(m/2 -1)个关键字,总共包 含.(n-1)(m/2 -1)+1
B. n D.(n-1)(m/2 -1)+1
三、算法设计题
1.假设图G采用邻接表存储,试设计一个算法,判断 无向图G是否连通。若连通则返回1,否则返回0.
5.树形如下:
A
B
C
G
H
D
E
F
I
L
J
K
先根遍历次序:ABCDEFGHIJKL
6.(1) 什么是递归程序? (2) 递归程序的优、缺点是什么? (3) 递归程序在执行时,应借助于什么来 完成? (4) 递归程序的入口语句、出口语句一般 用什么语句实现?
答案:
6.(1)一个函数在结束本函数之前,直接或
}
3.有一种简单的排序算法,叫做计数排序。这种排 序算法对一个待排序的表(用数组表示)进行排序, 并将排序结果存放到另一个新的表中。必须注意的 是,表中所有待排序的关键字互不相同,计数排序算 法针对表中的每个记录,扫描待排序的表一趟,统计 表中有多少个记录的关键字比该记录的关键字小。 假设对某一个记录,统计出数值为c,那么这个记录 在新的有序表中的合适的存放位置即为c。 (1)给出适用于计数排序的数据表定义。 (2)编写实现计数排序的算法。 (3)对于有n个记录的表,比较次数是多少? (4)与直接选择排序相比,这种方法是否更好?为什么?
数据结构练习题及答案

数据结构练习题(一)一、单选题1.栈和队列的共同特点是( )。
A.只允许在端点处插入和删除元素B.都是先进后出C.都是先进先出D.没有共同点2.用链接方式存储的队列,在进行插入运算时( )。
A. 仅修改头指针B. 头、尾指针都要修改C. 仅修改尾指针D.头、尾指针可能都要修改3.以下数据结构中( )是非线性结构。
A. 队列B. 栈C. 线性表D. 二叉树4.设有一个二维数组A[m][n],假设A[0][0]存放位置在644(10),A[2][2]存放位置在676(10),每个元素占一个空间,问A[3][3](10)存放在()位置。
脚注(10)表示用10进制表示。
A.688 B.678 C.692 D.6965.树最适合用来表示( )。
A.有序数据元素B.无序数据元素C.元素之间具有分支层次关系的数据D.元素之间无联系的数据6.二叉树的第k层的结点数最多为( )。
A.2k-1 B.2K+1 C.2K-1 D. 2k-17.若有18个元素的有序表存放在一维数组A[19]中,第一个元素放A[1]中,现进行二分查找,则查找A[3]的比较序列的下标依次为( )。
A. 1,2,3B. 9,5,2,3C. 9,5,3D. 9,4,2,38.对于线性表(7,34,55,25,64,46,20,10)进行散列存储时,若选用H(K)=K %9作为散列函数,则散列地址为1的元素有()个。
A.1 B.2 C.3 D.49.设有6个结点的无向图,该图至少应有( )条边才能确保是一个连通图。
A.5B.6C.7D.8二、填空题1.通常从四个方面评价算法的质量:_________、_________、_________和_________。
2.一个算法的时间复杂度为(n3+n2log2n+14n)/n2,其数量级表示为________。
3.假定一棵树的广义表表示为A(C,D(E,F,G),H(I,J)),则树中所含的结点数为__________个,树的深度为___________,树的度为_________。
结构体中typedef语句用法总结

结构体中typedef语句⽤法总结结构体中typedef语句⽤法总结typedef为的关键字,作⽤是为⼀种数据类型(这⾥仅讨论结构体数据类型)定义⼀个新名字。
在编程中使⽤typedef⽬的⼀般有两个:给变量⼀个易记且意义明确的新名字;简化⼀些⽐较复杂的类型声明。
1、typedef的最简单使⽤typedef int Data; //给已知数据类型int起个新名字---Data。
2、typedef ⽤法 & 结构体 typedef struct Node{ int info; char flag; } MyStruct;这语句实际上完成两个操作: 1) 定义⼀个新的结构类型 struct 关键字和Node⼀起构成了这个结构类型,不论是否有typedef,这个结构都存在。
我们可以⽤struct Node node来定义变量node,但要注意,使⽤Node node来定义变量不对的,因为struct 和Node合在⼀起才能表⽰⼀个结构类型。
2) typedef为这个新的结构起了⼀个名字,叫MyStruct。
因此,MyStruct实际上相当于struct Node,我们可以使⽤MyStruct node来定义变量node。
3、typedef & 结构体指针类型⽤法typedef struct Node { char flag; struct Node *Next; } *link;* * * ** * * * * * * * * * * * * * * * * *typedef struct Node *link; struct Node { char flag; link Next; }; 注意:在这个例⼦中,你⽤typedef给⼀个还未完全声明的类型起新名字。
C语⾔编译器⽀持这种做法。
数据结构期末复习试题

练习题:一、填空题1、元素项是数据的最小单位,数据元素是讨论数据结构时涉及的最小数据单位。
2、设一棵完全二叉树具有100个结点,则此完全二叉树有49个度为2的结点。
3、在用于表示有向图的邻接矩阵中,对第i列的元素进行累加,可得到第i个顶点的出度。
4、已知一棵度为3的树有2个度为1的结点,3个度为2的结点,4个度为3的结点,则该树中有12个叶子的结点。
n=n0+n1+n2+…+nm (1)又有除根结点外,树中其他结点都有双亲结点,且是唯一的(由树中的分支表示),所以,有双亲的结点数为:n-1=0*n0+1*n1+2*n2+…+m*nm (2)联立(1)(2)方程组可得:叶子数为:n0=1+0*n1+1*n2+2*n3+...+(m-1)*nm5、有一个长度为20的有序表采用二分查找方法进行查找,共有4个元素的查找长度为3。
6、对于双向链表,在两个结点之间插入一个新结点需要修改的指针共4个。
删除一个结点需要修改的指针共2个。
7、已知广义表LS=(a,(b,c,d),e),它的深度是2,长度是3。
8、循环队列的引入是为了克服假溢出。
9、表达式a*(b+c)-d/f的后缀表达式是abc+*df/-。
10、数据结构中评价算法的两个重要指标是时间复杂度和空间复杂度。
11、设r指向单链表的最后一个结点,要在最后一个结点之后插入s所指的结点,需执行的三条语句是r->next=s; r=s; r->next=null;12、设有一个空栈,栈顶指针为1000H(十六进制),现有输入序列为1,2,3,4,5,经过PUSH,PUSH,POP,PUSH,POP,PUSH,PUSH之后,输出序列是23,而栈顶指针值是1012_H。
设栈为顺序栈,每个元素占4个字节。
13、模式串P=‘abaabcac’的next函数值序列为01122312。
14、任意连通图的连通分量只有一个,即是自身。
15、栈的特性是先进后出。
16、串的长度是包含的元素个数。
实验报告 实验三 二叉排序树的建立和查找

实验三二叉排序树的建立和查找一、实验目的1.掌握二叉排序树的建立算法2.掌握二叉排序树查找算法。
二、实验环境操作系统和C语言系统三、预习要求复习二叉排序树的生成及查找算法,编写完整的程序。
四、实验内容实现二叉排序树上的查找算法。
具体实现要求:用二叉链表做存储结构,输入键值序列,建立一棵二叉排序树并在二叉排序树上实现查找算法。
五、参考算法#include <stdio.h>#include <stdlib.h>typedef int InfoType;typedef int KeyType; /*假定关键字类型为整数*/typedef struct node /*结点类型*/{KeyType key; /*关键字项*/InfoType otherinfo; /*其它数据域,InfoType视应用情况而定,下面不处理它*/struct node *lchild,*rchild; /*左右孩子指针*/}BSTNode;typedef BSTNode *BSTree; /*BSTree是二叉排序树的类型*/BSTNode *SearchBST(BSTree T,KeyType key){ /*在二叉排序树T上查找关键字为key的结点,成功时返回该结点位置,否则返回NULL*/if(T==NULL||key==T->key) /*递归的终结条件*/return T; /*若T为空,查找失败;否则成功,返回找到的结点位置*/if(key<T->key)return SearchBST(T->lchild,key);elsereturn SearchBST(T->rchild,key); /*继续在右子树中查找*/}void InsertBST(BSTree *T,int key){ /*插入一个值为key的节点到二叉排序树中*/BSTNode *p,*q;if((*T)==NULL){ /*树为空树*/(*T)=(BSTree)malloc(sizeof(BSTNode));(*T)->key=key;(*T)->lchild=(*T)->rchild=NULL;}else{p=(*T);while(p){q=p;if(p->key>key)p=q->lchild;else if(p->key<key)p=q->rchild;else{printf("\n 该二叉排序树中含有关键字为%d的节点!\n",key);return;}}p=(BSTree)malloc(sizeof(BSTNode));p->key=key;p->lchild=p->rchild=NULL;if(q->key>key)q->lchild=p;elseq->rchild=p;}}BSTree CreateBST(void){ /*输入一个结点序列,建立一棵二叉排序树,将根结点指针返回*/BSTree T=NULL; /*初始时T为空树*/KeyType key;scanf("%d",&key); /*读入一个关键字*/while(key){ /*假设key=0是输入结束标志*/ InsertBST(&T,key); /*将key插入二叉排序树T*/scanf("%d",&key); /*读入下一关键字*/}return T; /*返回建立的二叉排序树的根指针*/ }void ListBinTree(BSTree T) /*用广义表示二叉树*/{if(T!=NULL){printf("%d",T->key);if(T->lchild!=NULL||T->rchild!=NULL){printf("(");ListBinTree(T->lchild);if(T->rchild!=NULL)printf(",");ListBinTree(T->rchild);printf(")");}}}void main(){BSTNode *SearchBST(BSTree T,KeyType key);void InsertBST(BSTree *Tptr,KeyType key);BSTree CreateBST();void ListBinTree(BSTree T);BSTree T;BSTNode *p;int key;printf("请输入关键字(输入0为结束标志):\n");T=CreateBST();ListBinTree(T);printf("\n");printf("请输入欲查找关键字:");scanf("%d",&key);p=SearchBST(T,key);if(p==NULL)printf("没有找到%d!\n",key);elseprintf("找到%d!\n",key);ListBinTree(p);printf("\n");}实验中出现的问题及对问题的解决方案输入数据时,总是不能得到结果,原因是在建立二叉树函数定义中,是对指针的值进行了修改。
typedefstruct在c语言中用法

typedefstruct在c语言中用法在C语言中,typedef struct是一种用来定义结构体的方法,它可以为结构体类型起一个新的类型名,使结构体具有更方便和易用的称呼。
在一些情况下,typedef struct语句可以提高程序的可读性和可维护性。
typedef是C语言中的一个关键字,它可以用来为各种类型定义新的类型名,包括结构体。
而struct是一个关键字,用于定义结构体类型。
结构体是一种自定义的数据类型,它可以包含多个不同类型的数据成员,并可以通过一个名称引用它们。
下面是typedef struct的语法形式:```data_member1;data_member2;...data_memberN;} type_name;```其中,data_member1, data_member2等是结构体的数据成员,它们可以是任何C语言中的合法数据类型,如整数、浮点数、字符、指针等等。
type_name是新定义的结构体类型的名称。
通过typedef struct定义的结构体类型,可以像其他数据类型一样使用,例如声明变量、定义函数参数、定义函数返回值等。
下面是使用typedef struct定义结构体类型的例子:```int x;int y;} Point;```在上面的例子中,我们定义了一个名为Point的结构体类型,它包含两个整型数据成员x和y。
此时,我们就可以像使用其他数据类型一样使用Point类型了,比如声明Point类型的变量:```Point p1;```此时,p1就是一个Point类型的变量,可以使用.操作符访问结构体的成员,例如:```p1.x=10;p1.y=20;```上面的代码给p1的成员x和y分别赋值为10和20。
```struct Nodeint data;Node* next;};```在上面的例子中,首先声明了一个名为Node的结构体类型。
然后在结构体的定义中使用Node* next,表示结构体中的一个成员指向Node类型的指针。
TypedefStruct用法详解

TypedefStruct⽤法详解Typedef Struct ⽤法详解⼀、typedef的⽤法在C/C++语⾔中,typedef常⽤来定义⼀个标识符及关键字的别名,它是语⾔编译过程的⼀部分,但它并不实际分配内存空间。
实例像:typedef int INT;typedef int ARRAY[10];typedef (int*) pINT;typedef可以增强程序的可读性,以及标识符的灵活性,但它也有“⾮直观性”等缺点。
⼆、#define的⽤法#define为⼀宏定义语句,通常⽤它来定义常量(包括⽆参量与带参量),以及⽤来实现那些“表⾯似和善、背后⼀长串”的宏,它本⾝并不在编译过程中进⾏,⽽是在这之前(预处理过程)就已经完成了,但也因此难以发现潜在的错误及其它代码维护问题,它的实例像:#define INT int#define TRUE 1#define Add(a,b) ((a)+(b));#define Loop_10 for (int i=0; i<10; i++)⽤法详解:1. #define 的变体,即 #ifndef,可以防⽌头头⽂件的重复引⽤。
#ifdef和 #define组合,⼀般⽤于头⽂件中,⽤以实现防⽌多个⽂件对此同⼀个头⽂件的重复引⽤.实际使⽤中,即使你的头⽂件暂时没有被多个⽂件所引⽤,为了增加程序可读性,移植性,健壮性等,还是最好都加上。
其⽤法⼀般为:#ifndef <标识>#define <标识>……… // include or define sth.#endif<标识>在理论上来说可以是⾃由命名的,但每个头⽂件的这个“标识”都应该是唯⼀的 to void the definition duplication。
but normallz, 标识的命名规则⼀般是头⽂件名全⼤写,前后加下划线,并把⽂件名中的“.”也变成下划线,如:stdio.h对应的就是:#ifndef _STDIO_H_#define _STDIO_H_……… // include or define sth.#endif1. #define的变体,即#ifdef,可以实现加⼊⾃⼰需要的模块(源⽂件)[例⼦] 在源⽂件中加⼊#ifdef MYSELF_H#include "myself.c"#endif可以实现在源⽂件中加⼊myself.c的代码,将其实现的功能加进来, 即加⼊了myself模块。
大学计算机《数据结构》试卷及答案(十四)

大学计算机《数据结构》试卷及答案一、选择题(24分)1.下列程序段的时间复杂度为( )。
i=0,s=0; while (s<n) {s=s+i ;i++;}(A) O(n 1/2) (B) O(n 1/3) (C) O(n) (D) O(n 2)2.设某链表中最常用的操作是在链表的尾部插入或删除元素,则选用下列( )存储方式最节省运算时间。
(A) 单向链表(B) 单向循环链表 (C) 双向链表(D) 双向循环链表 3.设指针q 指向单链表中结点A ,指针p 指向单链表中结点A 的后继结点B ,指针s 指向被插入的结点X ,则在结点A 和结点B 插入结点X 的操作序列为( )。
(A) s->next=p->next ;p->next=-s ; (B) q->next=s ; s->next=p ;(C) p->next=s->next ;s->next=p ; (D) p->next=s ;s->next=q ;4.设输入序列为1、2、3、4、5、6,则通过栈的作用后可以得到的输出序列为( )。
(A) 5,3,4,6,1,2(B) 3,2,5,6,4,1 (C) 3,1,2,5,4,6 (D) 1,5,4,6,2,35.设有一个10阶的下三角矩阵A (包括对角线),按照从上到下、从左到右的顺序存储到连续的55个存储单元中,每个数组元素占1个字节的存储空间,则A[5][4]地址与A[0][0]的地址之差为( )。
(A) 10 (B) 19 (C) 28 (D) 556.设一棵m 叉树中有N 1个度数为1的结点,N 2个度数为2的结点,……,Nm 个度数为m 的结点,则该树中共有( )个叶子结点。
(A) (B) (C) (D)7. 二叉排序树中左子树上所有结点的值均( )根结点的值。
(A) < (B) > (C) = (D) !=∑=-m i i N i 1)1(∑=m i i N 1∑=m i i N 2∑=-+m i i N i 2)1(18. 设一组权值集合W=(15,3,14,2,6,9,16,17),要求根据这些权值集合构造一棵哈夫曼树,则这棵哈夫曼树的带权路径长度为()。
[数据结构]常见数据结构的typedef类型定义总结
![[数据结构]常见数据结构的typedef类型定义总结](https://img.taocdn.com/s3/m/e6a35f19773231126edb6f1aff00bed5b9f3732f.png)
[数据结构]常见数据结构的typedef类型定义总结⽬录数据结构类型定义:1.线性表线性表(顺序存储类型描述):#define MaxSize 50 //定义线性表的最⼤长度typedef struct {ElemType data[MaxSize]; //顺序表的元素int length; //顺序表的当前长度} SqList; //顺序表的类型定义线性表(动态存储类型描述)#define InitSize 100 //表长度的初始定义typedef struct {ElemType *data; //指⽰动态分配数组的指针int MaxSize,length; //数组的最⼤容量和当前个数} SeqList; //动态分配数组顺序表的类型定义L.data = (ElemType*)malloc(sizeof(ElemType)*InitSize);//初始内存分配2.线性表的链式表⽰单链表的结点类型描述:typedef struct LNode{ //定义单链表结点类型ElemType data; //数据域struct LNode *next; //指针域}LNode,*LinkList;双链表的结点类型描述:typedef struct DNode{ //定义双链表结点类型ElemType data; //数据域struct DNode *prior,*next; //前驱和后继指针}DNode,*DLinkList;静态链表结点类型的描述:#define MaxSize 50 //静态链表的最⼤长度typedef struct { //静态链表结构类型的定义ElemTypen data; //存储数据元素int next; //下⼀个元素的数组下标} SLinkList[MaxSize];3.栈的数据结构顺序栈的数据结构描述#define MaxSize 50typedef struct { //定义栈中元素的最⼤个数ElemType data[MaxSize];//存放栈中元素int top; //栈顶指针} SqStack;链栈的数据结构描述typedef struct Linknode{ElemType data; //数据域struct Linknode *next; //指针域} *LiStack; //栈类型定义4.队列队列的顺序存储类型描述:#define MaxSize 50 //定义队列中元素的最⼤个数typedef struct{ElemType data[MaxSize]//存放队列元素int front,rear;//队头指针和队尾指针} SeQueue;队列的链式存储typedef struct { //链式队列结点ElemType data;struct LinkNode *next;} LinkNode;typedef struct{ //链式队列LinkNode *front, *rear;//队列的队头和队尾指针} LinkQueue;5.⼆叉树⼆叉树的链式存储描述[lchild][data][rchild]typedef struct BiTNode{ElemType data; //数据域struct BiTNode *lchild,*rchild; //左,右指针} BiTNode,*BiTree;线索⼆叉树的存储结构描述:typedef struct ThreadNode{ElemType data; //数据元素struct ThreadNode *lchild,*rchild; //左右孩⼦指针int ltag,rtag; //左右线索标志} ThreadNode,*ThreadTree;6.树,森林双亲表⽰法的存储结构描述如下:#define MAX_TREE_SIZE 100 //树中最多结点数typedef struct{ //树的结点定义ElemType data; //数据元素int parent; //双亲位置域} PTNode;typedef struct { //树的类型定义PTNode nodes[MAX_TREE_SIZE]; //双亲定义int n; //结点数} PTree;孩⼦兄弟表⽰法的存储结构描述如下:typedef struct CSNode {ElemType data; //数据域struct CSNode *firstchild,*nextsibling;//第⼀个孩⼦和右兄弟指针} CSNode,*CSTree;7.图图的邻接矩阵存储结构定义如下#define MaxVertexNum 100 //顶点数⽬的最⼤值typedef char VertexType; //顶点的数据类型typedef int EdgeType; //带权图中边上权值的数据类型typedef struct {vertexType Vex[MaxVertexNum]; //顶点表EdgeType Edge[MaxVertexNum][MaxVertexNum];//邻接矩阵,边表 int vexnum,arcnum; //图的当前顶点数和弧数} MGraph;图的邻接表存储结构定义如下:#define MaxVertexNum 100 //图中顶点数⽬的最⼤值typedef struct ArcNode{ //边表结点int adjvex; //该弧所指向的顶点的位置struct ArcNode *next; //指向下⼀条弧的指针//InfoType info; //⽹的边权值} ArcNode;typedef struct VNode{ //顶点表结点VectexType data; //顶点信息ArcNode *first; //指向第⼀条依附该顶点的弧的指针} VNode,AdjList[MaxVertexNum];typedef struct { //邻接表AdjList vertices; //图的顶点数和弧数int vexnum,arcnum; //ALGraph是以邻接表存储的图类型} ALGraph;图的⼗字链表存储结构定义如下:#define MaxVertexNum 100 //图中顶点数⽬的最⼤值typedef struct ArcNode{ //边表结点int tailvex, headvex; //该弧的头尾结点struct ArcNode *hlink, *tlink; //分别指向弧头相同和弧尾相同的结点 //InfoType info; //相关信息指针}typedef struct VNode{ //顶点表结点VertexType data; //顶点信息ArcNode *firstin, *firstout; //指向第⼀条⼊弧和出弧} VNode;typedef struct {VNode xlist[MaxVertexNum]; //邻接表int vexnum,arcnum; //图的顶点数和弧数} GLGraph; //GLGraph是以⼗字邻接存储的图类型图的邻接多重表存储结构定义如下:#define MaxVertexNum 100 //图中顶点数⽬的最⼤值typedef struct ArcNode{ //边表结点bool mark; //访问标记int ivex,jvex; //分别指向该弧的两个结点struct ArcNode *ilink,*jlink; //分别指向该弧的两个顶点的下⼀条边 //InfoType info; //相关信息指针}typedef struct VNode{ //顶点表结点VertexType data; //顶点信息ArcNode *firstedge; //指向第⼀条依附该顶点的边} VNode;typedef struct{VNode adjmulist[MaxVertexNum]; //邻接表int vexnum,arcnum; //图的顶点数和弧数} AMLGraph; //AMLGraph是以邻接多重表存储的图类型。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
失败:n+1次比较
优缺点
优点:简单,对存储结构、Key之间的关系均无特殊要求 缺点:效率低,当n较大时不宜用
5
§ 9.2.2 二分(折半)查找
适用范围:顺序表、有序 基本思想(分治法)
(1)设R[low..high] 是当前查找区间,首先确定该区间的中点 位置:mid= (low&1..5]
R[1..2]
3
R[2..2]
6 < =
R[7..11]
内部结点 外部结点
>
R[7..8]
9
R[4..5]
R[10..11]
Φ
1
Φ
4
7
R[5..5] Φ
R[8..8] Φ
10
R[11..11]
-1
2 3-4
Φ Φ Φ
5
Φ
6-7
Φ
8
Φ
9-10
Φ
11
Φ
1-2
2-3 4-5 5-6
17
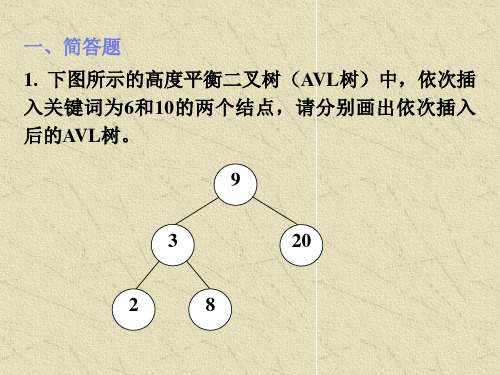
void InsertBST( BSTree *T, KeyType key ) { //*T是根 BSTNode *f, *p=*T; //p指向根结点 while( p ) { //当树非空时,查找插入位置 if ( p->key==key ) return; //树中已有key,不允许重复插入 f=p;// f和p为父子关系, 循环不变量:*parent为*p的双亲 p=( key < p->key ) ? p->lchild; p->rchild; } //注意:树为空时,无须查找 p = (BSTNode *) malloc(sizeof(BSTNode)); p->key=key; p->lchild=p->rchild=NULL; //生成新结点 if ( *T ==NULL ) * T=p; //原树为空,新结点为根 else //原树非空, 新结点作为*f的左或右孩子插入 if ( key < f->key ) f->lchild=p; else f->rchild=p; } //时间为O(h)
存储结构
将R[1..n]均分成b块,前b-1块中结点数为s=⌈n/b⌉ ,最后一块中的结 点数可能小于s,引入索引表标记块。
关键字状态
分块有序:块间有序,块内不一定有序; 例子:n=18,b=3,s=6
最大关键字 22 48 86 起始地址 1 7 13
22 12 13 8
9
20 33 42 44 38 24 48 60 58 74 49 86 53
1
§9.1 基本概念 效率:与存储结构、文件状态(有序、无序)有关 平均查找长度 (ASL) ,即平均的比较次数,作为衡 量查找效率的标准:
ASL i 1 P i Ci
n
Pi:查找第i个结点的概率 Ci:查找第i个结点的比较次数 设Pi=1/n, 1≤i≤n 约定:typedef int KeyType;
} // endwhile
return 0; //当前查找区间为空时失败 }
7
查找过程 判定(比较)树:分析查找过程的二叉树,形态只与结点数相关, 与输入实例的取值无关(为什么?)。例如n=11的形态如下图所示。 1 2 3 4 5 6 7 8 9 10 11 (05,13,19,21,37,56,64,75,80, 88, 92),找21成功,找85失败。
7-8 8-9 10-11 11-
8
时间分析
比较1次:查找R[6] 比较2次:查找R[3]、R{9] 比较3次:查找R[1]、R[4]、R[7]、R[10] 比较4次:查找R[2]、R[5]、R[8]、R[11]
R[1..11] R[1..5]
6 < =
R[7..11]
R[1..2]
§ 9.3.1 二叉查找树(BST)
1.查找(续) 时间 若成功,则走了一条从根到待查节点的路径
5 3 2 4 7 9
若失败,则走了一条从根到叶子的路径?(不一定)
上界:O(h) 分析:与树高相关
①最坏情况:单支树,ASL=(n+1)/2,与顺序查找相同
②最好情况:ASL≈lgn,形态与折半查找的判定树相似 ③平均情况:假定n个keys所形成的n!种排列是等概率的, 则可证明由这n!个序列产生的n!棵BST(其中有的形态相同) 的平均高度为O(lgn),故查找时间仍为O(lgn) 16
§ 9.2.2 二分(折半)查找
算法: int BinSearch( SeqList R, KeyType K ) { int mid, low=1, high=n; while ( low < high ) { //当前查找区间R[low..high]非空 mid= (low+high)/2; //整除 if ( R[mid].key==K )return mid; //成功返回位置mid if ( K<R[mid].key ) //两个子问题求解其中的一个 high=mid-1; //在左区间中查找 else low=mid+1;//在右区间中查找
1 n 1 h n 1 k 1 ASLbs Pi Ci Ci k 2 lg( n 1) 1 lg( n 1) 1 n i 1 n k 1 n i 1
n
最坏时间:查找失败,不超过树高 ⌈lg(n+1)⌉
在链表上可做折半查找吗?
10
§ 9.2.3 分块查找(索引顺序查找)
2
§ 9.2 线性表的查找
对象:用线性表作为表的组织形式。 分类:静态查找、内部查找 方式:顺序查找、二分查找、分块查找 #define n 100//
§9.2.1 顺序查找
基本思想 从表的一端开始,顺序扫描线性表,依次将扫描到的结点的 Key与给定值K进行比较,若当前扫描到结点 Key= K,则查 找成功返回;若扫描完整个表后,仍未找到,则查找失败。 适用范围:顺序表、链表 算法:
3
>
R[7..8]
9
R[4..5]
R[10..11]
1
Φ
R[2..2]
4
Φ
7
R[5..5] Φ
R[8..8] Φ
10
R[11..11]
-1
Φ
2 3-4
Φ Φ
5
Φ
6-7
Φ
8
Φ
9-10 11
Φ
Φ
9
1-2
2-3 4-5 5-6 7-8 8-9 10-11 11-
§ 9.2.2 二分(折半)查找
时间分析
Ch.9 查找
§9.1 基本概念
查找和排序是两个重要的运算 对象:表、文件等。其中每个结点(记录)由多个数据项 构成,假设每个结点有1个能唯一标识该结点的key。 定义:给定1个值K,在含有n个结点的表中找出关键字等于 K的结点,若找到(查找成功),则返回该结点信息或它在 表中的位置;否则(查找失败),返回相关指示信息。 分类: 查找过程中是否修改表?动态查找、静态查找 查找过程是否均在内存中进行?内部查找、外部查找
}
return T;// 返回根指针
}
19
2、BST的插入和生成
举例
输入实例 {10, 18, 3, 8, 12, 2, 7, 3}
10 10
总结:查找过程走了一条从判定树的根到被查结点的路径。 成功:终止于一个内部结点,所需的Key比较次数恰为该结点在 树中的层数;
失败:终止于一个外部结点,所需的Key比较次数为该路径上内 部结点总数。(层数-1)
平均查找长度(ASL): 设n=2h-1, 则树高h=lg(n+1) //不计外部结点的满二叉树 第k层上结点数为2k-1,找该层上每个结点的比较次数为k,在等 概率假设下:
① 若它的左子树非空,则左子树上所有结点的 keys 均小于根 的key
② 若它的右子树非空,则右子树上所有结点的 keys 均大于根 的key
③左右子树又都是二叉查找树
Note:性质1或2中,可以将“﹤” 改为“≤”;或“﹥ ”改 为“≥”
BST性质
二叉查找树的中序序列是一个递增有序序列
13
§ 9.3.1 二叉查找树(BST)
11
§ 9.2.3 分块查找(索引顺序查找)
查找过程(两步查找)
索引表查找:确定块。n较大时用折半查找,n较小时用顺序查找。 块内查找:只能顺序查找。
性能分析
以折半查找确定块
ASL= ASLbs+ASLss=lg(b+1)-1+(s+1)/2≈lg(n/s+1)+s/2
以顺序查找确定块 ASL= ASLss+ASLss=(b+1)/2+(s+1)/2=(s2+2s+n)/(2s)
18
2、BST的插入和生成
生成
算法: 从空树开始,每输入一个数据就调用一次插入算法。 BSTree CreateBST( void ) { BSTree T=NULL; //初始时T为空 KeyType key; scanf( “%d”, &key ); while( key ) { //假设key=0表示输入结束 InsertBST ( &T, key ) ; //将key插入树T中 scanf( “%d”, &key );// 读入下一个关键字
(2)将待查的K值与R[mid]比较,
① K=R[mid].key:查找成功,返回位置mid
② K<R[mid].key:则左子表R[low..mid-1]是新的查找区间 ③ K>R[mid],key:则右子表R[mid+1..high]是新的查找区间
初始的查找区间是 R[1..n],每次查找比较 K和中间点元素,若 查找成功则返回;否则当前查找区间缩小一半,直至当前查找 区间为空时查找失败。 6