定性数据分析-王静龙-第一章
王静龙《非参数统计分析》(1-8章)教案

王静龙《非参数统计分析》(1-8章)教案.引言一般统计分析分为参数分析与非参数分析,参数分析是指,知道总体分布,但其中几个参数的值未知,用统计量来估计参数值,但大部分情况,总体是未知的,这时候就不能用参数分析,如果强行用可能会出现错误的结果。
例如:分析下面的供应商的产品是否合格?合格产品的标准长度为(8.5±0.1),随即抽取n=100件零件,数据如下:表1.18.503 8.508 8.498 8.347 8.494 8.500 8.498 8.500 8.502 8.501 8.491 8.504 8.502 8.503 8.501 8.505 8.492 8.497 8.150 8.496 8.501 8.489 8.506 8.497 8.505 8.501 8.500 8.499 8.490 8.493 8.501 8.497 8.501 8.498 8.503 8.505 8.510 8.499 8.489 8.496 8.500 8.503 8.497 8.504 8.503 8.506 8.497 8.507 8.346 8.310 8.489 8.499 8.492 8.497 8.506 8.502 8.505 8.489 8.503 8.492 8.501 8.499 8.804 8.505 8.504 8.499 8.506 8.499 8.493 8.494 8.490 8.505 8.511 8.502 8.505 8.503 8.782 8.502 8.509 8.499 8.498 8.493 8.897 8.504 8.493 8.494 7.780 8.509 8.499 8.503 8.494 8.511 8.501 8.497 8.493 8.501 8.495 8.461 8.504 8.691经计算,平均长度为cm x 4958.8=,非常接近中心位置8.5cm ,样本标准差为()1047.0112=--=∑=ni i n x x s cm.一般产品的质量服从正态分布,),(~2δμN X 。
定性数据统计分析概要课件

组织文化研究
要点一
总结词
组织文化研究是定性数据统计分析在组织管理领域的运用 ,通过对组织文化的深入了解,提升组织的凝聚力和竞争 力。
要点二
详细描述
组织文化研究关注组织的价值观、行为规范、沟通方式等 方面。通过收集员工反馈、观察组织行为等方法获取数据 ,运用统计分析方法探究组织文化的特点和影响因素。这 有助于组织发现问题、改进管理方式,并培养积极向上的 组织文化,提高员工的工作满意度和忠诚度。
定性数据统计分析概 要课件
目录
• 定性数据统计分析概述 • 定性数据收集方法 • 定性数据分析方法 • 定性数据统计分析软件 • 定性数据统计分析应用案例
01
定性数据统计分析概述
定义与特点
定义
定性数据统计分析是一种基于非数值 型数据的研究方法,通过对数据的内 容、性质、结构和关系进行分析,揭 示数据背后的意义和规律。
特点
定性分析强调对数据的深入理解和主 观解读,注重数据的背景、语境和情 境,能够揭示数据背后的复杂性和多 样性。
目的与意义
目的
定性数据统计分析旨在深入理解数据的意义和内在联系,揭示研究对象的特点 、规律和变化趋势,为决策提供科学依据。
意义
定性分析在社会科学、市场调研、组织研究等领域具有广泛应用,能够帮助研 究者深入探索研究对象,理解复杂的社会现象,为决策提供更加全面和深入的 信息。
访谈法
通过与研究对象进行面对面的交流,收集口头表达的信息。
访谈法是一种常用的定性数据收集方法,通过与研究对象的 直接交流,可以获取他们的观点、感受和经验等深层次的信 息。访谈可以采用开放式或半开放式的问题形式,以便更好 地引导研究对象展开讨论。
如何做定性数据分析报告

如何做定性数据分析报告在当今的信息时代,数据分析在各个领域都扮演着重要的角色,帮助我们更好地了解和解决问题。
定性数据分析作为一种重要的数据分析方法,用于研究人类行为、态度、信念等主观经验方面的数据,对于市场调研、社会研究、心理学等领域都具有重要意义。
本文将介绍如何进行定性数据分析报告的撰写,以帮助读者在实践中更好地应用定性数据分析。
一、确定研究目的和问题在开始进行定性数据分析之前,首先明确研究的目的和问题是十分关键的。
明确目的和问题能够给数据分析提供方向,并将研究结果与原始数据联系起来,从而使分析报告更有针对性和实用性。
在确定研究目的和问题时,可以参考已有的理论框架和相关研究,也可以结合实际情况进行调整和补充。
二、整理和准备数据在进行定性数据分析之前,需要对原始数据进行整理和准备。
首先,对收集到的数据进行适当的整理和分类,例如根据主题、关键词或标签将相关数据归纳到不同的文件夹或子文件夹中。
其次,将数据转化为适合分析的形式,例如将音频录音转录为文字文档,将图片或视频转换为可编辑的格式。
此外,对数据进行初步筛选和去除无效数据,以确保后续分析的准确性和有效性。
三、选择适当的分析方法定性数据分析的目的是理解和识别数据中的模式、趋势和主题,并从中提取有效的信息。
在选择分析方法时,可以根据研究目的和问题来确定适合的方法,例如内容分析、主题分析、情感分析等。
在应用分析方法时,可以结合定量数据或其他数据来源进行综合分析,以提高分析的准确性和可靠性。
四、开展数据分析和解释在进行定性数据分析时,可以采取逐句、逐段或逐条评论的方式,对数据进行分类、编码和归纳。
对数据进行分类时,可以根据主题、意见、观点等方面进行划分,并对每个类别进行适当的描述和解释。
同时,可以对主要观点和发现进行摘要和总结,突出重点和亮点,并提供充分的例证和证据支持。
五、呈现和描述研究结果在定性数据分析报告中,应该清晰、准确地呈现研究结果,包括主要发现、模式和趋势等。
SPSS软件在定性数据分析中的技术处理

SPSS软件在定性数据分析中的技术处理郭梦霞【摘要】SPSS全称为社会科学统计软件包,SPSS软件在数据管理、统计建模、结果报告等方面具有相当大的优势。
本文主要研究的是在做定性数据分析的时候,如何才能利用SPSS软件恰当的进行数据的组织。
本文主要对多变量的列联表、多选项和单变量等三种形式的定性数据统计分析和输入方式进行的深入的研究。
通过本文的研究,希望各个领域、行业当需要进行定性数据分析的时候,通过本文的阅读能够掌握SPSS软件如何进行定性数据分析,方便自己的使用。
%Called the SPSS social science statistical package,SPSS software in data management,statistical modeling,the results report has a big advantage.This paper mainly studies the when doing the qualitative data analysis,how to use SPSS software appropriate for data organization.This article mainly to multivariate contingency table,more options,and the three types of qualitative data such as univariate statistical analysis and input methods of in-depth study.Through the study of this article,I hope each domain, industry when the need for qualitative data analysis,through reading of this article can grasp qualitative data analysis and SPSS software to facilitate their use.【期刊名称】《电子测试》【年(卷),期】2014(000)008【总页数】3页(P106-108)【关键词】社会科学统计;定性数据;单变量;多变量【作者】郭梦霞【作者单位】陕西职业技术学院管理系,陕西西安,710000【正文语种】中文0 引言SPSS 全称为社会科学统计软件包,英文全称为statistical product and service solutions。
定性数据分析论文讲解

2014—2015 学年第一学期《定性数据》期末论文题目不同年级与性别对奖助学金渴望度定性数据分析姓名常XX学号20120623104学院数学与统计学院专业统计专业2014 年12 月18 日不同年级与性别对奖助学金渴望度定性数据分析摘要:定性数据分析是数据分析的一个重要内容,它在实践中有着广泛的应用,如问卷调查、产品检验、医学统计等领域中经常用到列联表的定性数据分析来。
列联表的定性数据分析不2仅可以分析分类特征之间的相互依赖关系,还可以进行2检验、似然比检验、相合性的度量和检验、计算相关系数作相关分析也可以进行一致性与读了性的检验。
本文主要采用2检验、似然比检验、相合性的度量和检验来对不同年级、不同性别的大学生对奖助学金渴望度的独立性、相合性检验,最终得到对奖助学金的渴望度与性别无关、与年级有关。
2关键词列联表2检验似然比检验相合性度量一、问题简述为了解高某校不同年级不同性别的大学生对奖助学的渴望程度,对某校大一年级、大二年级共 80 位同学关于奖助学金的调查,并取其中的年级、性别、渴望度三个指标生成列联表,对列联表做定性数据分析。
二、符号说明22:卡方统计量2ln :似然比统计量U :统计量p :概率:相合性度量统计量三、理论方法理论:列联表一般来说,有二维的r c 列联表,假设将n个个体根据两个属性A和B 进行分类,属性A有r 类:A1, ,A r ,属性B 有c类:B1, ,B c。
n个个体中既属于A i 类又属于B j 类的有n ij 个。
得如下二维的r c列联表:其中,n i j n ij,,i 1, ,r;n j i n ij,j 1, ,c,n n i n j 。
ij如果n 个个体根据三个或三个以上的属性分类,就会有三维或三维以上的列联表,对于高维的列联表一般将其压缩为二维列联表在对数据进行统计分析或对高维列联表进行分层在检验。
方法:对二维表中的数据进行2检验、似然比检验、相合性的度量和检验。
定性数据分析课后答案0001
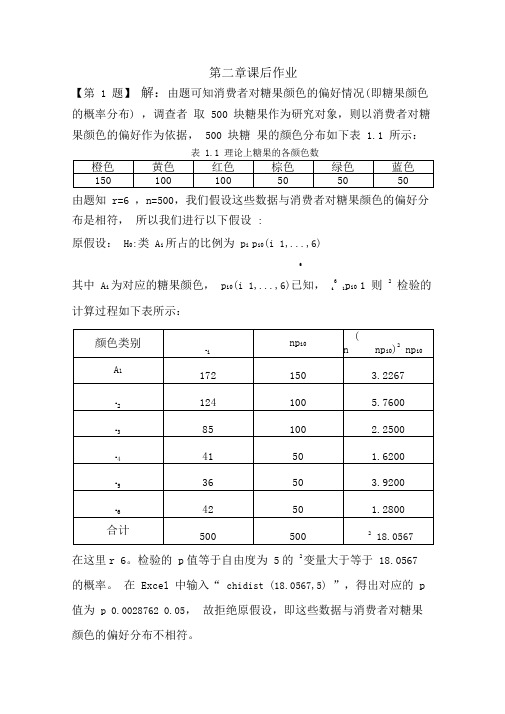
第二章课后作业【第 1 题】解:由题可知消费者对糖果颜色的偏好情况(即糖果颜色的概率分布) ,调查者取500 块糖果作为研究对象,则以消费者对糖果颜色的偏好作为依据,500 块糖果的颜色分布如下表 1.1 所示:表 1.1 理论上糖果的各颜色数由题知r=6 ,n=500,我们假设这些数据与消费者对糖果颜色的偏好分布是相符,所以我们进行以下假设:原假设:H0:类A i所占的比例为p i p i0(i 1, (6)6其中A i为对应的糖果颜色,p i0(i 1,...,6)已知,i61p i0 1 则2检验的计算过程如下表所示:在这里r 6。
检验的p值等于自由度为5的2变量大于等于18.0567 的概率。
在Excel 中输入“ chidist (18.0567,5) ”,得出对应的p 值为p 0.0028762 0.05,故拒绝原假设,即这些数据与消费者对糖果颜色的偏好分布不相符。
【第 2 题】解:由题可知,r=3 ,n=200,假设顾客对这三种肉食的喜好程度相同,即顾客选择这三种肉食的概率是相同的。
所以我们可以进行以下假设:原假设H 0 : p i1(i 1,2,3)0i3则2检验的计算过程如下表所示:在这里r 3。
检验的p值等于自由度为2的2变量大于等于15.72921 的概率。
在Excel 中输入“ chidist (15.72921,2) ”,得出对应的p 值为p 0.0003841 0.05 ,故拒绝原假设,即认为顾客对这三种肉食的喜好程度是不相同的。
【第 3 题】解:由题可知,r=10,n=800,假设学生对这些课程的选择没有倾向性,即选各门课的人数的比例相同, 则十门课程每门课程被选择的概率都相等。
所以我们可以进行以下假设:原假设H 0 : p i 0.1(i 1,2, (10)则2检验的计算过程如下表所示:在这里r 10 。
检验的p值等于自由度为9的2变量大于等于 5.125 的概率。
MassHunter数据分析培训教材 (3)
Sort by Data file/ Type 当调 用多个数据时,可以选择根 据数据类型或者数据名排 列顺序。
3
1.2 方法管理器窗口
Agilent 5977MSD MassHunter 数据分析现场培训教材
这里会显示你当前调用的方法名称,以及方法数据处理的各项参数。
第一章 定性分析
打开软件之前先将数据采集软件光盘(G3336-60065_MassHunter Qualitative Anaylsis DA Software B.06.00 ) X:\DATA\GCMS Pesticide\ 目录下的所有文件夹拷贝到 D:\MassHunter\Data\目录下。此文件夹将包含我们练习 所要使用的所有数据。
ChemStation(化学工作站积分器,主要针对 UV 信号) General(即 MSD Chemstation 里的 RTE 积分器)
6
Agilent 5977MSD MassHunter 数据分析现场培训教材
Universal(即 MSD Chemstation 里的 Chemstation 积分器) MS/MS(第一代少参数积分器,针对液质信号优化过的积分器,不推荐用于 SQ) MS/MS(GC)(第一代少参数积分器,针对气质信号优化过的积分器,不推荐用于 SQ) Agile(默认积分器,第二代少参数积分器,推荐用于 GC 信号)
双击 Qualitative Analysis B.06.00 图标,打开 MassHunter 定性分析软件。
系统将显示“Open Data File”对话框,转到文件夹 D:\MassHunter\Data \GCMS Pesticide 打开一个全扫描的文 件 Pest - 200 - scan.D。
7.定性资料的分析

min nR , nC 1
A 所需组合: 双侧: T A0 T0 例中实际数 单侧:A T A0 T0 A0 T0 0 A T A0 T0 A0 T0 0
按a的数值从小到大排列如下:
(i) |A-T|: (1) 4.0345 (2) 3.0345 (3) 2.0345 (4) 1.0345
1.9655
13
0.089098 (8)
2.9655 16 13 29 14 6 20 2 7 9
16 13 29
0.228686 (9)
3.9655 15 5 20 1 8 9 16 13 29
0.311844 (10)
4.9655 16 4 20 0 9 9 16 13 29
3 6 9
7
20
Pi
第七章
定性资料的分析
一、样本率与总体率的比较
二、两样本率的比较 三、多个率的比较
四、构成比的比较
五、配对设计两样本率的比较 六、似然比检验 七、确切概率法 八、定性资料假设检验的正确应用
样本率与总体率的比较
np>5同时n(1-p)>5,用正态近似检验 :
例7.1 据临床经验,一般的胃溃疡病患者有20%会出 现胃出血症状。某医院观察了304例65岁的胃溃疡病 患者,其中有96例发生胃出血,占31.58%,问老年 患者是否较一般患者易出血?
表7.9 两种检验方法结果比较
荧光抗体法
+ + 160(a) 常规培养法 26(b)
合计
186
合计
5(c)
165
48(d)
74
53
239
H0:两种检验方法的结果相同,即总体B=C; H1:两种检验方法的结果不同,即总体BC。
定性数据分析-王静龙-第一章

作业
自己运用所给数据, 自己运用所给数据,对定性数据进行描述统 计分析
用表、图和数值法 用表、 对不同的定性数据的分布情况进行比较
数值法-离散程度 数值法 离散程度
熵
随机变量ξ的熵 随机变量 的熵
H (ζ ) = − ∑ pi ln pi
i =1
k
熵越大,说明变量ξ分布越离散 熵越大,说明变量 分布越离散 原理:它给出了∑ pi=1的约束前提下,衡量 原理:它给出了 的约束前提下, 的约束前提下 给定的分布与均匀分布的接近程度。 给定的分布与均匀分布的接近程度。均匀分 布最离散,如果给定分布接近均匀分布, 布最离散,如果给定分布接近均匀分布,则 给定分布越离散,此时熵值也越大。 给定分布越离散,此时熵 条形图(与直方图的区别) 圆形图(饼形图 圆形图(饼形图) 排列图(Pareto图) 排列图( 图
绘制 应用
数值法
代表性数值
分布中心 离散程度
数值法-分布中心 数值法 分布中心
名义数据: 名义数据:众数 有序数据: 有序数据:
众数、中位数(更好) 众数、中位数(更好) 百分位数:衡量数据位置,表示相对高低。 百分位数:衡量数据位置,表示相对高低。第 相对高低 50百分位数就是中位数,P百分位数表示至少 百分位数就是中位数, 百分位数表示 百分位数表示至少 百分位数就是中位数 的数据项数小于或等于该数据, 有P%的数据项数小于或等于该数据,且至少 的数据项数小于或等于该数据 有(1-P)%的数据项数大于或等于这个值 。 ) 的数据项数大于或等于这个值
数值法-分布中心 数值法 分布中心
第P百分位数的求法 百分位数的求法
ch3-属性数据分析

上海财经大学统管院
Particulates and Bronchitis
level bronch 频数 |Y |N
| 合计
--------+--------+--------+ H | 42 | 881 | 923 --------+--------+--------+ L | 22 | 517 | 539 --------+---上---海--+财--经--大---学-+统管院
tables agegrp*level*bronch / cmh noprint;
weight n;
run; 注:做Cochran-Mantel-Haenszel检验 表 - level * bronch
2 H N 172 2LY7 2 L N 120 3 H Y 12 3 H N 327 3LY6 3 L N 183
2. 张尧庭 译 离散多元分析:理论与实践,中国统计出版社,1998
版权所有:吴纯杰
上海财经大学统计与管理学院
FREQ(频数)过程--频数表是变量取值分布的描述
PROC FREQ DATA=数据集名;
TABLES 变量;
RUN;
一般是分类变量
PROC FREQ DATA=数据集名;
TABLES 变量*变量 变量*变量 . . ./
title ‘ computing coefficient kappa for two observers’;
tables radiologist_1*radiologist_2 / agree;
weight count; run;
由结果,kappa统计量为0.7881, 表示中等的一致性程度。
报告中的定性数据分析与解释技巧

报告中的定性数据分析与解释技巧
一、引言
描述什么是定性数据,为什么需要对定性数据进行分析和解释。
概述整篇文章的内容和结构。
二、厘定研究目的与问题
在开始进行定性数据分析之前,必须明确研究目的和问题,并将其固化为明确的研究问题。
通过提问和深入讨论的方式,确保研究目的和问题合理合法。
三、准备工作与数据获取
这一部分介绍如何准备工作,选择合适的数据来源和数据收集方法。
同时需要明确研究者的角色和偏好是否可能影响数据的准确性和可信度。
四、编码和分类
在定性数据分析中,编码和分类是基础。
这一部分详细论述如何根据研究目的和问题将数据进行编码和分类,提供一些实用的技巧和方法。
五、模式识别与主题分析
通过模式识别和主题分析,研究者可以发现数据中的潜在模式和主题。
这一部分说明如何进行模式识别和主题分析,引入一些常用的工具和方法。
六、解释和论证
在分析定性数据之后,需要将结果进行解释和论证。
这一部分介绍一些技巧和方法,帮助研究者合理解读和解释结果,并对结果进行有效的论证。
七、结果的可靠性与效度
为了确保结果的可靠性和效度,研究者需要对结果进行验证和确认。
这一部分介绍一些验证的方法和步骤,帮助研究者评估结果的可靠性和效度。
八、结论
对全文进行总结和归纳,重申定性数据分析和解释的重要性,指出可能的不足和改进方向。
通过以上八个小节的展开论述,可以全面且有条理地介绍报告中的定性数据分析与解释技巧。
文章结构紧凑,既有理论分析,又有实践操作,使读者能够全面了解并运用这些技巧,提高研究报告的质量和可信度。
定性数据分析实验

• 以上都是分类数据。数据是枯燥的,但讲 述的问题却是鲜活的。
– 死亡与性别、年龄、所在仓位是否有关? – 如何解释这些关系,与当时人们的价值观念和 对待死亡的态度又有什么联系?
2013-8-9
3
定性数据分析(内容)
• 探索性分析,目的是描述样本特征
– 列联表分析 – 关联性分析
ni E ni E ni i 1
k 2
2
• 卡方统计量的特征
– 值大于0 – 密度函数与自由度有关 – 与横轴围成的面积等于1
2013-8-9
25
统计量(例题分析)
实际频数 期望频数
(fij)
68 75 57 79 32 45 33 31
2013-8-9
ri c j ri c j eij n n n n
2013-8-9 21
一分公司
赞成该方案 反对该方案 合计 68 32 100
二分公司
75 75 120
三分公司
57 33 90
四分公司
79 31 110
合计
279 141 420
例如,第1行和第1列的实际频数为 f11 ,它落在第1行 的概率估计值为该行的频数之和r1除以总频数的个数 n ,即:r1/n;它落在第1列的概率的估计值为该列的频 数之和c1除以总频数的个数 n ,即:c1/n 。根据概率的 乘法公式,该频数落在第1行和第1列的概率应为
2013-8-9
29
2X2列联表
因素X
因素Y x1 y1 y2 列合计
2013-8-9
行合计 x2 b d b+d a+b c+d n
定性数据的统计分析

混合方法研究是一种将定量和定性研究相结合的方法,这种方法可以综
合利用定量和定性的优势,提高研究的全面性和准确性。
感谢您的观看
THANKS
新闻报道内容分析是对新闻
总
报道中的文本内容进行深入
结
分析和解读,以了解新闻事 件的发展趋势和影响。
词
对新闻报道进行分类、
数 据
筛选和整理,确保数据
收
质量。
集
将内容分析结果以图表、 数
报告等形式展示,为企
据 预
业或政府机构提供决策处Fra bibliotek支持。
理
从新闻网站、媒体平台
内 容
等途径收集相关新闻报
分
道。
析
利用文本挖掘技术对新闻报
指非数值型数据,如文字、符号、图片等
分类
按照数据的性质和用途,将定性数据分为类别、顺序、等级和符号等类型
02
定性数据收集方法
访谈法
总结词
通过与研究对象进行面对面的交流,深入了解其观点、态度和经历。
详细描述
访谈法是一种常用的定性数据收集方法,通过与研究对象进行面对面的交流,可以深入了解其观点、态度和经历。 访谈可以采用开放式或半开放式的问题形式,以便获取更具体的信息。访谈过程中应注意建立互信关系,并尊重 被访谈者的隐私和意愿。
03
定性数据分析方法
内容分析法
总结词
内容分析法是一种对文本内容进行客观、系统和定量描述的技术。
详细描述
内容分析法通过对文本内容进行编码、分类和统计,以揭示文本中隐含的意义、 趋势和模式。它广泛应用于新闻媒体、社交媒体、学术文献等领域,帮助研究者 深入了解文本信息的内涵和影响。
主题分析法
数据分析-第一章-PPT课件

均值 方差
1 n x xi n i 1
1 n 2 S (x x ) i n 1i 1
2
标准差
变异系数
S S
2
S CV100 (%) x
偏度与峰度
偏度与峰度是刻画数据的偏态、尾重程度的度量。它们 与数据的矩有关。数据的矩分为原点矩与中心矩。 k阶原点矩
k E ( x ) 总体中心矩(k阶) k
总G2 4 3
总体数字特征和样本数字特征
根据统计学的结果,样本数字特征是相应的 总体数字特征的矩估计。当总体数字特征存在时 ,相应的样本数字特征是总体数字特征的相合估 计,从而当n较大时,有
1 n k vk xi n i 1
1 k u n ( x x ) k i n i 1
K阶中心矩
s
偏度与峰度
偏度
2 n n u n 3 3 g ( x x ) 1 i 3 3 ( n 1 )( n 2 ) s ( n 1 )( n 2 ) s i 1
2 x 73 . 660 S 15 . 524 S 3 . 940
CV 5 . 349 g 0 . 061 g 0 . 034 1 2
偏度、峰度的绝对值皆较小,可以认为数据是来 自正态总体的样本.
例3
某厂的某种悬式绝缘子机 电破坏负荷试验数据(单 位:吨)分组表示如表, 计算这批分组数据的均值 、方差、标准差、变异系 数、偏度、峰度。 组段 5.5~6.0 6.0~6.5 6.5~7.0 7.0~7.5 7.5~8.0 8.0~8.5 8.5~9.0 9.0~9.5 组中值 5.75 6.25 6.75 7.25 7.75 8.25 8.75 9.25 组频数 4 3 15 42 49 78 50 31
毕业论文中的定性研究数据分析

毕业论文中的定性研究数据分析在毕业论文中,定性研究数据分析是非常重要且关键的部分。
通过对定性数据的系统整理、分类和解释,研究者能够深入了解研究现象的本质,并从中提取有价值的结论。
本文将探讨在毕业论文中进行定性研究数据分析的方法和步骤,并提供一些指导性的建议。
一、数据整理和准备在进行定性数据分析之前,研究者需要先对收集到的数据进行整理和准备工作。
首先,对收集到的数据进行初步的整理,将其转录成可供分析的形式,如将访谈录音转录成文字形式。
其次,对数据进行标记和编码,以方便后续的分类和归纳工作。
二、数据分类和编码在数据整理完成后,下一步是对数据进行分类和编码。
根据研究目的和研究问题,将数据按照相似性和主题进行分类。
可以使用一些常见的分类法,如基于主题的分类、基于观察对象的分类等。
同时,对每一类数据进行编码,以便后续的统计和分析工作。
三、数据归纳和总结在数据分类和编码完成后,接下来需要对数据进行归纳和总结。
归纳是指在保留原始数据内容的基础上,找出其中的共性和规律。
这可以通过对每一类数据进行综合和比较分析来实现。
总结是指对归纳的结果进行概括和总结,提炼出研究现象的核心特点和规律。
这需要从整体上把握数据的含义和脉络,并对研究问题进行深入理解。
四、数据解释和验证在数据归纳和总结的基础上,研究者需要对数据进行解释和验证。
解释是指对数据的内在含义和规律进行解读和诠释,以便得出有价值的结论。
验证是指通过引用其他研究数据或理论来核实和支持自己的解释。
这可以增强研究的可信度和说服力。
五、数据讨论和分析最后,研究者需要对数据进行讨论和分析。
在这一步骤中,可以利用一些可视化工具和技术,如绘制图表、制作词云等,以帮助读者更好地理解和理解数据。
同时,通过比较和对比不同数据类别的差异和联系,进行深入的分析和探讨,为论文的结论提供支持和依据。
除了上述步骤,还有一些其他的注意事项和建议需要研究者注意。
首先,要保持独立和客观的态度,尽量避免主观偏见对数据的解读和分析产生影响。
定性数据分析及的使用讲课文档

❖ 质的研究
▪ 质的研究方法是以研究者本人作为研究工具,在自然情境下,采用多 种资料收集方法,对研究现象进行深入的整体性探究,从原始资料 中形成结论和理论,通过与研究对象互动,对其行为和意义建构获得解 释性理解的一种活动。
现在三页,总共六十六页。
质的研究与量的研究的区别
质性研究的意义和适用Βιβλιοθήκη 围现在四页,总共六十六页。
Peer review
Giving feedback
Receiving feedback
help actions
questions general comments giving help criticism suggestions
content evaluation technical
other positive troubleshooting
❖ 通过质性数据,能够让数据具备时间的属性,得 到更富有成效的解释。
❖ 帮助研究者超越最初的成见和框架。
现在九页,总共六十六页。
数据分析方法的比较
量化数据分析
❖ 有一套专门的,标准化 的技巧
❖ 在数据收集和处理之后 开始数据分析
❖ 检验假设
❖ 用数字和统计来测量社 会现象
质性数据分析
❖ 非标准化,通常采用归纳 的方法
定性数据分析及的使用
现在一页,总共六十六页。
汇报内容
1
质性研究
2
定性数据处理和分析
3
NVIVO的使用
4
Q&A
现在二页,总共六十六页。
❖ 量的研究
量的研究VS质的研究
▪ 采取自然科学研究模式,对研究问题或假设,以问卷、量表、测验或实 验仪器等作为研究工具,搜集研究对象有数量属性的资料,经由资料处
定性数据统计分析第1-2章PPT课件

p iP ( a i), i 1 ,2 , ,k
.
12
Gini-Simpson指数
• 基尼-辛卜生指数简称G-S指数
• 随机变量ξ的G-S指数记为G-S(ξ)
k
GS()1 pi2 i1
• G-S指数越小,说明随机变量ξ的分布越集 中; G-S指数越大,则分布越分散。
• 当k=2,p1 p2 0.5时,G-S指数达到最大 值 (11/ k),即均匀分布时指数达到最大(见 附录2)。
– 描述指定时间内,或面积、体积内某一事件出
现的个数的分布,其概率为:
P (X x )x e , 其 中 为 出 现 的 平 均 次 数 x !
.
26
二项分布的统计推断
• 实际中,二项分布和多项分布的参数值未 知,需要通过样本数据估计总体参数。
• 在统计学原理中,可以根据样本比例的抽 样分布,用样本比例估计总体比例的区间, 或用样本比例的差估计总体比例差。
.
5
第一章 定性数据
2、图示法
• 包括条形图、圆形图(表1.4)、排列图等
– 其中的排列图,又叫帕累托图,是按照发生频 率大小顺序绘制的条形图;
• 表示有多少结果是由已确认类型或范畴的原因所造 成;
• 将出现的质量问题和质量改进项目按照重要程度依 次排列而采用的一种图表;
• 可以用来分析质量问题,确定产生质量问题的主要 因素。
– 对于固定的n,随着π趋近0或1,二项分布表现越加偏 斜。
– 对于固定的π ,随着n增加,二项分布更趋近钟形。
.
22
二项分布
• 当n很大时,二项分布趋近于均值 n ,
2 n(1) 的正态分布(近似分布)。
• 原则上,要使二项分布趋近正态分布,要 求期望 n 和 n(1 )都不小于5。
定型属性数据分析答案

定型属性数据分析答案
总体来说,定型属性数据分析是从一组给定的、定型的数据中寻找出有意义的变化的过程。
它的内容包括预先系统地收集、编制、汇总、分析、解释、评价和应用数据。
定型属性数据分析,主要是通过观察和分析定型属性数据,以发现人们没有或者不能及时发现的特定规律,并据此预测未来趋势。
首先,定型属性数据分析需要一个可靠的数据源。
其次,完善而准确的数据收集是必不可少的,以便分析师可以得到准确的数据。
当数据收集完毕后,下一步就是开始进行定型属性数据分析。
这部分的工作主要包括汇总、分析、解释和评价这些数据。
在汇总数据阶段,分析师需要对数据进行归类整理,以便将相关的内容进行比较、联系,从而有效地突出重点,有助于进行更细致的分析。
然后是数据分析,在这个阶段,分析师需要用各种数据分析方法加以探讨,如图表、统计学等,以便找出一些定量数据,这样才能更准确地表述问题。
之后,就是需要对数据进行解释和评价,即对汇总和分析结果进行分解和分析,并与其他数据进行综合分析,从而得出最有价值的认识和结论,为解决实际问题提供有效的指导。
最后,就是分析师需要应用分析结果,实现及时有效地解决实际问题。
总体来说,定型属性数据分析是一个复杂而有趣的课题,需要分析师有较强的数据收集技巧、数据分析常识和应用技巧。
只有把这些知识综合起来,并配合实践,才能更好地运用定型属
性数据分析解决实际问题。
综上所述,定型属性数据分析是一个复杂而有趣的工作,其成功与否取决于分析师对数据的准确收集、有效分析和正确应用。
只有把这三者有效地结合起来,才能得出有价值的结论,为解决实际问题提供有效的指导。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
G − S (ζ ) = 1 − ∑ pi2
i =1
k
G-S指数越大,说明变量ξ分布越离散 指数越大,说明变量 分布越离散 指数越大 原理:如果对 进行两次独立的抽样 当变量ξ的值分 进行两次独立的抽样, 原理:如果对ξ进行两次独立的抽样,当变量 的值分 布比较集中时,两次抽到同一个值xi的概率 i2就大, 布比较集中时,两次抽到同一个值 的概率p 就大, 的概率 ∑ pi2就大,因而 就大,因而G-S布中心
第P百分位数的求法 百分位数的求法
将数据由小到大排序 计算第P百分位数的所在位置 计算第 百分位数的所在位置 p i=( )( n + 1) 100 确定第P百分位数 确定第 百分位数
是整数, 位的数; 不是整数 不是整数, 若i是整数,位于第 位的数;若i不是整数, 是整数 位于第i位的数 向上取整。 将i向上取整。 向上取整
数值法-离散程度 数值法 离散程度
熵
随机变量ξ的熵 随机变量 的熵
H (ζ ) = − ∑ pi ln pi
i =1
k
熵越大,说明变量ξ分布越离散 熵越大,说明变量 分布越离散 原理: 原理:
均匀分布时,所有 均相等 都为1/k. 均相等, 均匀分布时,所有Pi均相等,都为
1 H (ζ ) = − ln( ) k
第一章 定性数据的 数据的描述性统计方法 定性数据的描述性统计方法
定性数据的概念 单个变量的描述统计方法
定性数据
数据的尺度
定类—名义( ):只能计次 定类 名义(Category Scale):只能计次 名义 ): 定序—有序(Ordinal Scale):计次、排序 ):计次 定序 有序( 有序 ):计次、 定距—计数( ):计次 定距 计数(Interval Scale):计次、排序、 计数 ):计次、排序、 加减 定比—计量( ):计次 定比 计量(Ratio Scale):计次、排序、加 计量 ):计次、排序、 减、乘除
则取值的越多,分布越离散,此时熵值也越大。 则取值的越多,分布越离散,此时熵值也越大。
作业
自己运用所给数据, 自己运用所给数据,对定性数据进行描述统 计分析
用表、图和数值法 用表、 对不同的定性数据的分布情况进行比较
图示法
条形图(与直方图的区别) 条形图(与直方图的区别) 圆形图(饼形图 圆形图(饼形图) 排列图(Pareto图) 排列图( 图
绘制 应用
数值法
代表性数值
分布中心 离散程度
数值法-分布中心 数值法 分布中心
名义数据: 名义数据:众数 有序数据: 有序数据:
众数、中位数(更好) 众数、中位数(更好) 百分位数:衡量数据位置,表示相对高低。 百分位数:衡量数据位置,表示相对高低。第 相对高低 50百分位数就是中位数,P百分位数表示至少 百分位数就是中位数, 百分位数表示 百分位数表示至少 百分位数就是中位数 的数据项数小于或等于该数据, 有P%的数据项数小于或等于该数据,且至少 的数据项数小于或等于该数据 有(1-P)%的数据项数大于或等于这个值 。 ) 的数据项数大于或等于这个值
数值法-离散程度 数值法 离散程度
异众比率
众数个数) (n-众数个数)/n 众数个数
从随机变量的角度描述定性数据的离散程度
Gini-Simpson指数 指数 熵(entropy)
数值法-离散程度 数值法 离散程度
Gini-Simpson指数:G-S指数 指数: 指数 指数
随机变量ξ的 随机变量 的G-S指数 指数
数值法-离散程度 数值法 离散程度
熵
随机变量ξ的熵 随机变量 的熵
H (ζ ) = − ∑ pi ln pi
i =1
k
熵越大,说明变量ξ分布越离散 熵越大,说明变量 分布越离散 原理:它给出了∑ pi=1的约束前提下,衡量 原理:它给出了 的约束前提下, 的约束前提下 给定的分布与均匀分布的接近程度。 给定的分布与均匀分布的接近程度。均匀分 布最离散,如果给定分布接近均匀分布, 布最离散,如果给定分布接近均匀分布,则 给定分布越离散,此时熵值也越大。 给定分布越离散,此时熵值也越大。
变量与数据
单个定性数据的描述统计
表格法 大致的分布形状(画像) 大致的分布形状(画像) 图示法 数值法: 数值法:用代表性的数值描述分布特征
原则 低层次数据的描述方法适合高层次数据, 低层次数据的描述方法适合高层次数据, 反之不行
表格法
名义数据
频数频率分布表
有序数据
频数频率分布、 频数频率分布、累积频数频率表