概率统计第七章
概率统计第七章1-2

P(|U|>u1-α/2)=α
φ(x)
U检验
α/2
- u1-αΒιβλιοθήκη 2 u1-α/2接受域α/2
X
否定域
否定域
双侧统计检验
该检验用 u 检验统计量,故称为u 检验。
② H0:μ≤μ0(已知); H1:μ>μ0 (右侧检验) 1) 提出原假设和备择假设: H0:μ≤μ0; H1:μ>μ0, X 0 在H0下有 2) 对统计量: U / n X 0 X , / n / n X 0 X 对给定的α有 { u1 } { u1 } / n / n X 0 X 所以 P( u1 ) P( u1 ) / n / n 3) 故 拒绝条件为U> u1-α
c u u0.05 1.645
由
X 110 4/5
1.645
X 108.648
即区间( ,108.648 ) 为检验的拒绝域 称 X 的取值区间 (108.648,+) 为检验的接受域
四、作出判断
在有了明确的拒绝域后,根据样本观测值 我们可以做出判断: 当 x 108.684 或 u 1.645 时,则拒绝H 0 即接收 H1 ;
H 0 : p 4%
vs
H1 : p 4%
二、选择检验统计量 由样本对原假设进行判断总是通过一 个统计量完成的,该统计量称为检验统计 量。 找出在原假设 H 0 成立条件下,该统计量 所服从的分布。
三、选择显著性水平,给出拒绝域形式 小概率原理中,关于“小概率”的值通常根据实 际问题的要求而定,如取α =0.1,0.05,0.01等, α 为检验的显著性水平(检验水平). 根据所要求的显著性水平α ,描写小概率事件的 统计量的取值范围称为该原假设的拒绝域(否定 域),一般用W表示;一般将 W 称为接受域。 拒绝域的边界称为该假设检验的临界值.
概率论与数理统计第七章-1矩估计法和极大似然估计法

μ1 h1 (θ1 , θ2 , μ j h j (θ1 , θ2 , μk hk (θ1 , θ2 ,
, θk ) , θk ) , θk )
, μk ) , μk ) , μk )
数理统计
从这 k 个方程中解出
θ1 g1 ( μ1 , μ2 , θ j g j ( μ1 , μ2 , θk gk ( μ1 , μ2 ,
数理统计
定义 用样本原点矩估计相应的总体原点矩 ,
用样本原点矩的连续函数估计相应的总体原点矩的 连续函数, 这种参数点估计法称为矩估计法 . 矩估计法的具体做法如下 设总体的分布函数中含有k个未知参数 θ1 , θ2 , 那么它的前k阶矩 μ1 , μ2 ,
, θk ,
, μk , 一般
l xi P{ X xi ;1 , 2 , , k } l E ( X l ) l 1 hl (1 , 2 , , k ) x l p ( x; , , , )dx 1 2 k
2 1
b μ1 3( μ2 μ12 )
于是 a , b 的矩估计量为
总体矩
a A1 3( A2 A12 ) 3 n 2 X ( X X ) , i n i 1
3 n 2 b X ( X X ) n i 1 i
样本矩
数理统计
例2 设总体 X 的均值 μ和方差 σ 2 ( 0) 都存
数理统计
点估计问题的一般提法 设总体 X 的分布函数 F ( x; )的形式为已
知, 是待估参数 . X 1 , X 2 ,, X n 是 X 的一个样 本, x1 , x2 ,, xn 为相应的一个样本值 .
概率论与数理统计第7章

x 0 , x 0 ,x 1 ,x 2 ,
,x n 为 总 体 X
的 一 个 样 本 ,则 未 知 参 数 的 矩 估 计 ˆ _ _ _ _ _ _ _ _ _ _ _ .
这个例子所作的推断已经体现了极大似然法 的基本思想 .
最大似然估计原理:
设X1,X2,…Xn是取自总体X的一个样本,样 本的联合密度(连续型)或联合分布律 (离散型)为
f (x1,x2,… ,xn ; ) .
当给定样本X1,X2,…Xn时,定义似然函数为:
L() f (x1, x2 ,…, xn; )
得
pˆ1Βιβλιοθήκη nn i 1xix
即为 p 的最大似然估计值 .
从而 p 的最大似然估计量为
p ˆ(X1,
1n ,Xn)ni1Xi X
求最大似然估计(MLE)的一般步骤是:
(1) 由总体分布导出样本的联合分布率(或联 合密度);
(2) 把样本联合分布率 ( 或联合密度 ) 中自变
量看成已知常数,而把参数 看作自变量,得到似然 函数L();
要求:领会
2.2 估计量的有效性、相合性, 要求:领会
3.区间估计
3.1 置信区间的概念,
要求:领会
3.2 求单个正态总体均值和方差的置信区间,要求:简单应用
参数估计
现在我们来介绍一类重要的统计推断问题
参数估计问题是利用从总体抽样得到的信息来估计总体 的某些参数或者参数的某些函数.
估计新生儿的体重
1 p
n
pxi (1p)1xi
i1
n
n
xi
n xi
pi1 (1p) i1
n
n
xi
n xi
L(p)pi1 (1p) i1
概率论与数理统计复习7章

( n − 1) S 2 ( n − 1) S 2 = 1 − α 即P 2 <σ2 < 2 χα 2 ( n − 1) χ1−α 2 ( n − 1) ( n − 1) S 2 ( n − 1) S 2 置信区间为: 2 , χα 2 ( n − 1) χ12−α 2 ( n − 1)
则有:E ( X v ) = µv (θ1 , θ 2 ,⋯ , θ k ) 其v阶样本矩是:Av = 1 ∑ X iv n i =1
n
估计的未知参数,假定总体X 的k阶原点矩E ( X k ) 存在,
µ θ , θ ,⋯ , θ = A k 1 1 1 2 µ2 θ1, θ 2 ,⋯ , θ k = A2 用样本矩作为总体矩的估计,即令: ⋮ µ θ , θ ,⋯ , θ = A k k k 1 2 ɵ ɵ ˆ 解此方程即得 (θ1 , θ 2 ,⋯ , θ k )的一个矩估计量 θ 1 , θ 2 ,⋯ , θ k
+∞
−∞
xf ( x ) dx = ∫ θ x θ dx =
1 0
令E ( X ) = X ⇒
θ +1
θ
ˆ = X ⇒θ =
( )
X 1− X
θ +1
2
θ
7.2极大似然估计法
极大似然估计法: 设总体X 的概率密度为f ( x,θ ) (或分布率p( x,θ )),θ = (θ1 ,θ 2 ,⋯ ,θ k ) 为 未知参数,θ ∈ Θ, Θ为参数空间,即θ的取值范围。设 ( x1 , x2 ,⋯ , xn ) 是 样本 ( X 1 , X 2 ,⋯ , X n )的一个观察值:
i =1 n
概率论与数理统计第7章参数估计PPT课件

a1(1, ,k )=v1
1 f1(v1, ,vk )
假定方程组a2(1, ,k ) v2 ,则可求出2 f2(v1, ,vk )
ak (1, ,k ) vk
k fk (v1, ,vk )
则x1 xn为X的样本值时,可用样本值的j阶原点矩Aj估计vj,其中
Aj
1 n
n i1
xij ( j
L(x1, ,xn;ˆ)maxL(x1, ,xn;),则称ˆ(x1, ,xn)为
的一种参数估计方法 .
它首先是由德国数学家
高斯在1821年提出的 ,然而, 这个方法常归功于英国统
Gauss
计学家费歇(Fisher) . 费歇在1922年重新发现了
这一方法,并首先研究了这
种方法的一些性质 .
Fisher
10
极大似然估计是在已知总体分布形式的情形下的 点估计。
极大似然估计的基本思路:根据样本的具体情况
注:估计量为样本的函数,样本不同,估计量不 同。
常用估计量构造法:矩估计法、极大似然估计法。
4
7.1.1 矩估计法
矩估计法是通过参数与总体矩的关系,解出参数, 并用样本矩替代总体矩而得到的参数估计方法。 (由大数定理可知样本矩依概率收敛于总体矩, 且许多分布所含参数都是矩的函数)
下面我们考虑总体为连续型随机变量的情况:
n
它是的函数,记为L(x1, , xn; ) f (xi , ), i 1
并称其为似然函数,记为L( )。
注:似然函数的概念并不仅限于连续随机变量 ,
对于离散型随机变量,用 P {Xx}p(x,)
替代f ( x, )
即可。
14
设总体X的分布形式已知,且只含一个未知参数,
《概率论与数理统计》第七章假设检验.

《概率论与数理统计》第七章假设检验.第七章假设检验学习⽬标知识⽬标:理解假设检验的基本概念⼩概率原理;掌握假设检验的⽅法和步骤。
能⼒⽬标:能够作正态总体均值、⽐例的假设检验和两个正态总体的均值、⽐例之差的假设检验。
参数估计和假设检验是统计推断的两种形式,它们都是利⽤样本对总体进⾏某种推断,然⽽推断的⾓度不同。
参数估计是通过样本统计量来推断总体未知参数的取值范围,以及作出结论的可靠程度,总体参数在估计前是未知的。
⽽在假设检验中,则是预先对总体参数的取值提出⼀个假设,然后利⽤样本数据检验这个假设是否成⽴,如果成⽴,我们就接受这个假设,如果不成⽴就拒绝原假设。
当然由于样本的随机性,这种推断只能具有⼀定的可靠性。
本章介绍假设检验的基本概念,以及假设检验的⼀般步骤,然后重点介绍常⽤的参数检验⽅法。
由于篇幅的限制,⾮参数假设检验在这⾥就不作介绍了。
第⼀节假设检验的⼀般问题关键词:参数假设;检验统计量;接受域与拒绝域;假设检验的两类错误⼀、假设检验的基本概念(⼀)原假设和备择假设为了对假设检验的基本概念有⼀个直观的认识,不妨先看下⾯的例⼦。
例7.1 某⼚⽣产⼀种⽇光灯管,其寿命X 服从正态分布)200 ,(2µN ,从过去的⽣产经验看,灯管的平均寿命为1550=µ⼩时,。
现在采⽤新⼯艺后,在所⽣产的新灯管中抽取25只,测其平均寿命为1650⼩时。
问采⽤新⼯艺后,灯管的寿命是否有显著提⾼?这是⼀个均值的检验问题。
灯管的寿命有没有显著变化呢?这有两种可能:⼀种是没有什么变化。
即新⼯艺对均值没有影响,采⽤新⼯艺后,X 仍然服从)200 ,1550(2N 。
另⼀种情况可能是,新⼯艺的确使均值发⽣了显著性变化。
这样,1650=X 和15500=µ之间的差异就只能认为是采⽤新⼯艺的关系。
究竟是哪种情况与实际情况相符合,这需要作检验。
假如给定显著性⽔平05.0=α。
在上⾯的例⼦中,我们可以把涉及到的两种情况⽤统计假设的形式表⽰出来。
《概率论与数理统计》7

未知参数 , ,, 的函数.分别令
12
k
L(1,,k ) 0,(i 1,2,...,k)
或令
i
ln L(1,,k ) 0,(i 1,2,...,k)
i
由此方程组可解得参数 i 的极大似然估计值 ˆi.
例5 设X~b(1,p), X1, X2 , …,Xn是来自X的一个样本,
求参数 p 的最大似然估计量.
解 E( X ) ,E( X 2 ) D( X ) [E( X )]2 2 2
由矩估计法,
【注】
X
1
n
n i 1
X
2 i
2
2
ˆ X ,
ˆ
2
1 n
n i 1
(Xi
X )2
对任何总体,总体均值与方差的矩估计量都不变.
➢常见分布的参数矩估计量
(1)若总体X~b(1, p), 则未知参数 p 的矩估计量为
7-1
第七章
参数估计
统计 推断
的 基本 问题
7-2
参数估 计问题
(第七章)
点估计 区间估 计
假设检 验问题 (第八章)
什么是参数估计?
参数是刻画总体某方面概率特性的数量.
当此数量未知时,从总体抽出一个样本, 用某种方法对这个未知参数进行估计就 是参数估计.
例如,X ~N ( , 2),
若, 2未知, 通过构造样本的函数, 给出
k = k(A1, A2 , …, A k)
用i 作为i的估计量------矩估计量.
例1 设总体X服从[a,b]上的均匀分布,a,b未知,
X1, X2 , …,Xn为来自总体X的样本,试求a,b的 矩估计量.
解 E(X ) a b , D(X ) (b a)2
《概率论与数理统计》第七章

n
n
ln xi
(4)的极大似然估计量为:ˆ
n
n2 i1
lnX
i
2
i1
第七章 参数估计 ‹#›
例 9 设X~b(1,p), X1,X2,…,Xn是来自X的一个样本, 试求参数p的最大似然估计量
解: 设x1, x2,, xn,是相应于样本X1,X2,…,Xn 的一个样本值,X
的分布律为:
(3)以样本各阶矩A1, ,Ak代替总体各阶矩1,
得各参数的矩估计
ˆi gi(A1, ,Ak ), i 1, , k
, k,
第七章 参数估计 ‹#›
注意:
在实际应用时,为求解方便,也可以用
中心矩 i 代替原点矩i,相应地以样本中心矩Bi 估计 i.
(二)最大似然估计法
最(极)大似然估计的原理介绍
第七章
参数估计
目录/Contents
第1章 随机事件与 2 概率
§ 1 点估计
§3
估计量的评选标准
第七章 参数估计 ‹#›
问题的提出:
在实际进行统计时,有不少总体的(我们关心的某 确定指标)概率分布是已知的。比如
例 1 产品寿命服从的分布
X~
f
(
x)
1
x
e
x0
0
其他
但其中有参数是未知的: θ
n
似然函数 L f xi , 。 i 1
, xn ,
极大似然原理:L(ˆ( x1 ,
,
xn
))
max
L(
).
计算简化方法:
在求L 的最大值时,通常转换为求:lnL 的最大值,
lnL 称为对数似然函数.
利用
概率论与数理统计-第七章

2
= (2π ) (σ ) exp[−
2
2
−
n 2
−
n 2
1 2σ 2
( xi − µ ) 2 ] ∑
i =1
n
n
设总体X~U[a,b],其中 ,b是 例3. 设总体 ,其中a, 是 未知参数。试求a, 的矩估计量 的矩估计量。 未知参数。试求 ,b的矩估计量。 解:E(X)=(a+b)/2, D(X)=(b-a)2/12.
1 n 1 ∑Xi = E(X) = 2 (a +b) n i=1 1 n 2 Xi = E(X 2 ) = D(X) +[E(X)]2 ∑ n i=1 1 1 2 = (b − a) + (a +b)2 12 4
解:白球所占比例p=1/4或3/4. 白球所占比例 或 X:任取 个球中白球的个数,X~B(3, p) 任取3个球中白球的个数 任取 个球中白球的个数,
P( X = 2) = C p (1− p) = 3p (1− p)
2 3 2 2
1 9 , p = 4时 P(X = 2) = 64 p = 3时 P(X = 2) = 27 , 4 64
1 n ˆ (1)µ = X = ∑Xi是 体 值 的 偏 计 ; 总 均 µ 无 估 量 n i=1 1 n ˆ (2)σ 2 = S2 = ( Xi − X )2是 体 差 2的 总 方 σ ∑ n −1 i=1 无 估 量. 偏 计
n −1 2 D(X) = S n 即可解出未知参数的估计量。 即可解出未知参数的估计量。
《概率论与数理统计》课件 第七章 随机变量的数字特征

i 1,2, , 如果 xi pi , 则称 i 1 E( X ) xi pi 为随机变量X的数学期望; i 1
或称为该分布的数学期望,简称期望或均值.
(2)设连续随机变量X的密度函数为p( x),
如果
+
x p( x)dx ,
则称
-
E( X ) xp( x)dx 为随机变量X的数学期望.
5
例2.求二项分布B(n, p)的数学期望.
P(X
k)
n!
k!n
k !
pk
(1
p)nk ,k
1, 2,
, n.
n
解:EX kP{ X k}
k0
n
k
k0
n!
k!n
k !
pk
(1
p)nk
n
np
k 1
k
n 1! 1!n
pk1
k!
(1
p)nk
np[ p (1 p)]n1 np.
特别地,若X服从0 1分布,则EX p.
6
例3. 求泊松分布P( )的数学期望.
注:P( X k) k e , k 1, 2, .
k!
解:EX k k e e
k1
e
k1
k0 k !
k1 k 1 !
k1 k 1 !
ee
e x 1 x 1 x2 1 xn [这里,x ]
当 a 450时,平均收益EY 最大.
28
第二节 方差与标准差
29
引例
比较随机变量X、Y 的期望
X3 4 5 Y1 4 7 P 0.1 0.8 0.1 P 0.4 0.2 0.4
01 2 3 4 5 67
概率与数理统计第7章参数估计习题与答案

第7章参数估计----点估计一、填空题1、设总体X服从二项分布B(N,p),0P1,X1,X2X n是其一个样本,那么矩估计量p?XN.2、设总体X~B(1,p),其中未知参数0p1,X1,X2,X n是X的样本,则p的矩估计为_ 1n in1X i _,样本的似然函数为_in1X i(1p)1Xp__。
i3、设X1,X2,,X n是来自总体X~N(,2)的样本,则有关于及2的似然函数2L(X,X,X n;,)_12 in112e12(X) i22__。
二、计算题1、设总体X具有分布密度f(x;)(1)x,0x1,其中1是未知参数,X1,X2,X为一个样本,试求参数的矩估计和极大似然估计.n解:因E(X ) 1x1a()α1(α1)xdx1x dxαα112a2|xααα12令E(X)X?α?α122X1α?为的矩估计1Xn因似然函数L(x1,x2,x;)(1)(x1x2x)nnnlnLnln(α1)lnX,由αii1 l nLαnα 1inlnX0得,i1n ?的极大似量估计量为(1)αnln Xii12、设总体X服从指数分布f(x)xe,x00,其他,X1,X2,X n是来自X的样本,(1)求未知参数的矩估计;(2)求的极大似然估计.56解:(1)由于1 E(X),令11 X X,故的矩估计为? 1 X(2)似然函数nL(x,x,,x )e12ni nx i 1nlnLnlnxii1 ndlnLnnx0 indi1x ii1故的极大似然估计仍为1 X 。
3、设总体 2 X~N0,, X 1,X 2,,X n 为取自X 的一组简单随机样本,求 2 的极大似然估计;[解](1)似然函数n1 Le i122 x i 2 22n 22en 2x i 2 i 12于是n2nnx2i lnLln2ln2222i1 dlnLn1d224 22n i1 2x i,令 d lnL 2d 2 0,得的极大似然估计:n 122X ini1. 4、设总体X 服从泊松分布P(),X 1,X 2,,X n 为取自X 的一组简单随机样本,(1)求 未知参数估计;(2)求大似然估计. 解:(1)令E(X )X?X ,此为估计。
概率与数理统计第七章

即 , 的估计量分别为
ˆ
1 n 2 2 X X i n i 1
1 n 2 2 ˆX X X i n i 1
7.1.2最大似然法(The method of maximum
likelihood) 最大似然法,也叫极大似然法,它最早是由高 斯所提出的,后来由英国统计学家费歇 (R· A· Fisher)于1922年在其一篇文章中重新提出, 并且证明了这个方法的一些性质.极大似然估计 这一名称也是费歇给的.它是建立在极大似然原 理的基础上的一个统计方法.为了对极大似然原 理有一个直观的认识,我们先来看一个例子.
1 2 n 1 2 n
ˆ( X , X , , X ) 是 的估计量, 估计 的真值,则称 1 2 n ˆ( x , x , , x ) 是 的估计值. 称
1 2 n
本节介绍两个最基本的方法——矩法和极大似然法
7.1.1矩法(The Method of Moments)
k k 设 X 1 ,, X n 是来自总体 X 的样本 , 则 X 1k , X 2 ,, X n
结论: 的估计值为 1 .
当 X 是离散型随机变量时 , 它的分布律设为 p( x; ) P{ X x} , x 是 X 的各可能取值.当 X 是连续型随机变量时,它的概率密度设为 p ( x; ) .称 p ( x; ) 为 X 的概率函数.
定义 6.1.1 设 ( X 1 , X 2 ,, X n ) 是 X 的样本,
问题: 设总体 X 的概率密度为 f ( x, ) ,其中未知参数 的可能取值有两个 ,即 1 和 2 ,但不知道到底哪一个是参数 的真值. 现对总体做了一次观测 ,得到样本值 x0 (如图),问 应该等于 1 还是 2 ?
《概率论与数理统计》课件第七章 参数估计

03
若存在, 是否惟一?
添加标题
1
2
3
4
5
6
对于同一个未知参数,不同的方法得到的估计量可能不同,于是提出问题
应该选用哪一种估计量? 用何标准来评价一个估计量的好坏?
常用标准
(1)无偏性
(3)一致性
(2)有效性
7.2 估计量的评选标准
无偏性
一致性
有效性
一 、无偏性
定义1 设 是未知参数θ的估计量
09
则称 有效.
10
比
11
例4 设 X1, X2, …, Xn 是X 的一个样本,
添加标题
问那个估计量最有效?
添加标题
解 ⑴
添加标题
由于
添加标题
验证
添加标题
都是
添加标题
的无偏估计.
都是总体均值
的无偏估计量.
故
D
C
A
B
因为
所以
更有效.
例5 设总体 X 的概率密度为
关于一致性的两个常用结论
1. 样本 k 阶矩是总体 k 阶矩的一致性估计量.
是 的一致估计量.
由大数定律证明
用切比雪夫不 等式证明
似然函数为
其中
解得参数θ和μ的矩估计量为
2
时
3
令
1
当
6
,故
5
,表明L是μ的严格递增函数,又
4
第二个似然方程求不出θ的估计值,观察
添加标题
所以当
01
添加标题
从而参数θ和μ的最大似然估计值分别为
03
添加标题
时L 取到最大值
02
添加标题
概率与数理统计第7章参数估计习题及答案

第7章参数估计 ----点估计一、填空题1、设总体X 服从二项分布),(p N B ,10P ,n X X X 21,是其一个样本,那么矩估计量pX N.2、设总体)p ,1(B ~X ,其中未知参数01p, X X X n 12,,是X 的样本,则p 的矩估计为_n1i iX n1_,样本的似然函数为_iiX 1n1i X )p 1(p __。
3、设12,,,n X X X 是来自总体),(N ~X 2的样本,则有关于及2的似然函数212(,,;,)n L X X X _2i2)X (21n1i e21__。
二、计算题1、设总体X 具有分布密度(;)(1),01f x x x ,其中1是未知参数,n X X X ,,21为一个样本,试求参数的矩估计和极大似然估计.解:因10101α1α1αdxxdxx x X E a)()()(2α1α2α1α12|a x令2α1α)(XX E XX112α为的矩估计因似然函数1212(,,;)(1)()nn n L x x x x x x ni i X n L 1α1αln )ln(ln ,由ni iX n L 101ααln ln 得,的极大似量估计量为)ln (ni iX n11α2、设总体X 服从指数分布,0()0,xe xf x 其他,n X X X ,,21是来自X 的样本,(1)求未知参数的矩估计;(2)求的极大似然估计.解:(1)由于1()E X ,令11XX,故的矩估计为1X(2)似然函数112(,,,)nii x nn L x x x e111ln lnln 0nii nini ii L n x d Lnnx dx 故的极大似然估计仍为1X。
3、设总体2~0,X N ,12,,,n X X X 为取自X 的一组简单随机样本,求2的极大似然估计;[解] (1)似然函数222112i x ni Le2212222ni i x ne于是2221ln ln 2ln222ni i x n n L22241ln 122n ii d L n x d,令2ln 0d L d,得2的极大似然估计:2211nii X n.4、设总体X 服从泊松分布()P , 12,,,n X X X 为取自X 的一组简单随机样本, (1)求未知参数的矩估计;(2)求的极大似然估计.解:(1)令()E X XX ,此为的矩估计。
概率与数理统计 第七章-1-最大似然估计

定义 对给定的样本值x1 , x2 ,… , xn, 若
存在: qˆ qˆ(x1, x2,L , xn) 使
L(qˆ) max L(q ).
参数q的 取值范围。
q
则称qˆ qˆ(x1, x2,L , xn)为q的最大似然估计值;
定义 对给定的样本值x1 , x2 ,… , xn, 若
存在: qˆ qˆ(x1, x2,L , xn) 使
)
0
求出驻点;
2.
由
dL(q dq
)
0
或
d
ln L(q dq
)
0
求出驻点;
3. 判断并求出最大值点:
qˆ qˆ(x1, x2,L , xn)
即为参数q的最大似然估计值;
qˆ qˆ(X1, X2,L , Xn)
为参数q的最大似然估计量 .
需要注意:
需要注意: ① 当似然函数对未知参数q不可微或由
最大似然估计法的思想:
在一次抽样得到结果x1, x2,…, xn的情 况下, 一般认为这个结果出现的概率:
P{X1= x1, X2 =x2 ,…, Xn = xn} 是最大的。
因此,应该寻找使这个结果出现的可
能性最大的那个qˆ 作为真值q的估计.
下面分别就离散型总体和连续型总体 情形作具体讨论.
设X1, X2,…, Xn是取自总体X的样本, 样本的观察值为x1 , x2 ,… , xn(一次抽样得 到结果) ,其概率为:
概率论与数理统计
张保田 第七章 参数估计
第一节 点估计 二、 最大似然估计法
极大似然法是在总体类型已知条件 下使用的一种参数估计方法 .
它首先是由德国数学家 高斯在1821年提出的 , 然而,这个方法常归功于 英国统计学家费歇 .
概率统计简明教程 第七章 参数估计

222第七章 参数估计统计推断是数理统计的重要内容,它是指在总体的分布完全未知或形式已知而参数未知的情况下,通过抽取样本对总体的分布或性质作出推断.大致可以分为估计问题和假设检验问题两大类. 本章重点介绍参数估计问题,即根据样本对总体分布中所包含的未知参数或总体的数字特征作出数值上的估计.主要内容包括:点估计和区间估计.§1 点估计概述1.1 点估计在许多实际问题中,可以认为总体X 分布的形式是已知的,它只依赖于一个或几个未知参数.如果能对分布中所含的参数作出推断,那么就可以确定总体分布.例如, 已知总体服从正态分布(),1N μ,μ未知,我们的目的是通过样本提供的信息对未知参数μ作出估计,也就是借助于样本对总体作出推断,这类问题就是参数估计问题.点估计问题的一般提法是:设总体X 的分布函数();F x θ类型已知,θ为未知参数,它的可能取值范围Θ是已知的,称Θ为参数空间,即θ∈Θ.这样,我们有一族分布函数(){};:F x θθ∈Θ.如果(){}2;,:,0F x μσμσ-∞<<+∞>是正态分布的分布函数族,其中()2,θμσ=.设12,,,n XX X 是X 的一个样本, 12,,,n x x x 为相应的样本值.我们构造一个统计量()12,,,n X X X θ ,以()12,,,n X X X θ 的值()12,,,n x x x θ 作为参数θ的真实值的估计.习惯上,称223()12,,,n X X X θ 为参数θ的估计量()12ˆ,,,n X X X θ ,称()12,,,n x x x θ 为θ的估计值为()12ˆ,,,n x x x θ .在不致混淆的情况下,估计量与估计值都简称为估计,简记为ˆθ.容易看出,对于不同的样本值来说,由同一个估计量得出的估计值一般是不相同的.在几何上一个数值是数轴上的一个点,用θ的估计值ˆθ作为θ的近似值就像用一个点来估计θ,故称为点估计.如果总体分布中含有k 个未知参数1,,k θθ ,则需要构造k 个统计量()()11212ˆˆ,,,,,,,,n k n X X X X X X θθ 分别作为1,,k θθ 的估计量.例1.1 设总体X 服从参数为λ的泊松分布, 0λ>为未知参数,现有以下样本值3,4,1,5,6,3,8,7,2,0,1,5,7,9,8试求未知参数λ的估计值.解:由于()E X λ=,自然地想到用样本均值11ni i X X n==∑作为λ的估计量,利用样本值得()1341563872015798 4.615x =++++++++++++++=.这样,我们获得了参数λ的估计量ˆX λ=与估计值ˆ 4.6x λ==. 在本例中,对于总体X 的一个样本12,,,n X X X ,()1i X i n ≤≤亦可以作为λ的估计量;同样地,()1X 和()n X 都应该可作为λ的估计量.这样,对于同一个参数,可以有许多不同的点估计;在这些估计中,我们自然地希望挑选一个最“优”的点估计.因此,有必要建立评价估计量优劣的标准.下面介绍几个常用的标准:无偏性、有效性和一致性.1.2 评价估计量的标准1. 无偏性224对于不同的样本值来说,由估计量()12ˆˆ,,,n X X X θθ= 得出的估计值一般是不相同的,这些估计只是在参数θ真实值的两旁随机地摆动.要确定估计量ˆθ的好坏,要求某一次抽样所得的估计值等于参数θ的真实值是没有意义的,但我们希望()ˆE θθ=,这是估计量所应该具有的一种良好性质,称之为无偏性,它是衡量一个估计量好坏的一个标准.定义 1.1 如果未知参数θ的估计量()12ˆˆ,,,n X X X θθ= 的数学期望()ˆE θ存在,且对任意θ∈Θ,都有()ˆE θθ= (1.1) 则称ˆθ是θ的无偏估计量.在科学技术中,称()ˆE θθ-是以ˆθ作为θ估计的系统误差. 无偏估计的实际意义就是无系统误差.例 1.2 设12,,,n X X X 是总体X 的一个样本, 总体X 的k 阶原点矩记为()kk E X μ=,样本原点k 阶矩记为11nkk i i A X n==∑,证明:k A 是k μ的无偏估计量.证明: 12,,,n X X X 是总体X 的一个样本,即12,,,n X X X 与X同分布,因此 ()(),1,2,,k ki k E X E X i n μ=== .即 11()()nk k ik i E A E X nμ===∑ .例1.3 设总体X 的均值μ和方差2σ都存在,证明:未修正样本方差2252211()nii S X X n==-∑不是2σ的无偏估计量.证明: 在第六章第二节中,我们证明了()22E S σ=,因此,修正的样本方差2S =211()1nii X X n =--∑是2σ的无偏估计量,也就是说20S 不是2σ的无偏估计量.我们以后一般取2S 作为2σ的估计量.例 1.4 设总体()X P λ ,12,,,n X X X 是X 的一个样本, 2S 为样本方差,01α≤≤,证明:()21L X S αα=+-是参数λ的无偏估计量.证明:易见()()()2,()E X E X E S D X λλ====,()()()()()211,E L E X E Sαααλαλλ=+-=+-=因此,估计量()21L X S αα=+-是λ的无偏估计.2. 有效性同一个参数可以有多个无偏估计量,那么用哪一个为好呢?设参数θ有两个无偏估计量1ˆθ和2ˆθ,在样本容量n 相同的情况下, 1ˆθ的观测值都集中在θ的真值附近,而2ˆθ的观测值较远离θ的真值,即1ˆθ的方差较2ˆθ的方差小,我们认为1ˆθ较2ˆθ好,由此有如下的定义:定义 1.2 设()1112ˆˆ,,,n X X X θθ= 和()2212ˆˆ,,,n X X X θθ= 都是参数θ的无偏估计量,若对任意θ∈Θ,都有12ˆˆ()()D D θθ≤ (1.2)226且至少存在一个0θ∈Θ使得上式中的不等号成立,则称1ˆθ较2ˆθ有效.例1.5 设12,,,n X X X 是总体X 的一个样本, X 的均值 μ和方差2σ都存在,且20σ>,记11ˆkk i i X kθ==∑,1,,k n = .易见,111ˆ()()kk i i E E X k kkθμμ===⋅=∑,1,,k n = .因此, 这些估计量都是μ的无偏估计量.由于 2222111ˆ()()kk ii D D Xk kkkσθσ===⋅=∑,从而ˆn X θ=最有效.3.一致性无偏性和有效性都是在假设样本容量n 固定的条件下讨论的.由于估计量是样本的函数,它依赖样本容量n ,自然地,我们希望一个好的估计量,当n 越来越大时,它与参数的真值几乎一致,这就是估计量的一致性或称之为相合性.定义1.3 设()12ˆˆ,,,n n X X X θθ= 为参数θ的一个估计量, n 为样本容量,如果对任意θ∈Θ,ˆn θ依概率收敛于θ,即对任意0ε>,有{}ˆlim 1n n P θθε→∞-<= (1.3)则称ˆn θ为参数θ的一致估计量.例 1.6 设总体X 的均值μ和方差2σ都存在,证明:样本均值11ni i X X n==∑是μ的一致估计量.证明:由切比雪夫大数定律可知,对任意0ε>,有22711lim 1ni n i P X nμε→∞=⎧⎫-<=⎨⎬⎩⎭∑因此,11ni i X X n==∑是μ的一致估计量.例1.7 设总体()2,X N μσ ,12,,,n X X X 是总体X 的一个样本,证明: 样本方差2S =211()1nii X X n =--∑是2σ的一致估计量.证明:由于()22211n S n χσ-- ,有 2212(1)n DS n σ-⎡⎤=-⎢⎥⎣⎦,因此, 22422212()11n D S D S n n σσσ⎛⎫-⎡⎤==⎪⎢⎥--⎣⎦⎝⎭.由切比雪夫不等式可知,对任意0ε>,有{}{}42222222120()()(1)P S E S P S D S n σεσεεε≤-≥=-≥≤=-.这样 {}22lim ()0n P S E S ε→∞-≥=,即 {}22lim 1n P S σε→∞-<=, 2S是2σ的一致估计量.§2 矩估计与最大似然估计本节我们介绍两种常用的构造估计量的方法,即矩估计法和最大似然估计法.2.1矩估计法228许多总体的未知参数与总体矩之间存在着函数关系,如在泊松总体()P λ中,它的参数λ就是总体的一阶矩,又如在正态总体()2,X N μσ中(),E X μ=()()222E XE X σ=-⎡⎤⎣⎦.若总体矩存在,我们很自然地想到用样本矩来估计相应的总体矩,从而可以获得未知参数的估计量,这种方法称之为矩估计法.设12,,,n X X X 是总体X 的一个样本,若X 是连续型随机变量,则其概率密度函数为();f x θ;若X 是离散型随机变量,则其分布律为();p x θ,()12,,,k θθθθ= ,θ∈Θ.假设总体X 的k 阶原点矩存在,记()ll E Xμ=,11nlli i AX n==∑,()1,2,,l k = .由辛钦大数定律可知,l A 依概率收敛于l μ,即可以用样本矩替换同阶的总体矩,我们称之为替换原则.替换原则是矩估计法的思想实质,这种方法只需假设总体矩存在,无需知道总体的分布类型.由于l μ依赖于参数12,,,k θθθ ,可设 1121212212(,,,),(,,,),(,,,).k k k k k μθθθμμθθθμμθθθμ=⎧⎪=⎪⎨⎪⎪=⎩将此方程组的解记为1112221212(,,,),(,,,),(,,,).k k kk k θθμμμθθμμμθθμμμ=⎧⎪=⎪⎨⎪⎪=⎩用l A 替换l μ()1,2,,l k = ,得到2291112221212ˆ(,,,),ˆ(,,,),ˆ(,,,).k k k k k A A A A A A A A A θθθθθθ⎧=⎪=⎪⎨⎪⎪=⎩并把它们分别作为参数12,,,k θθθ 的估计量,称之为矩估计量, 矩估计量的观测值称为矩估计值.例2.1 设总体X 的概率密度函数为()()101,;0x x f x θθθ⎧+<<=⎨⎩,,其他.1,θ>-求参数θ的矩估计量.解: ()()111011d 2E X xx θθμθθ++==+=+⎰,解得 11211μθμ-=-,因此, θ的矩估计量为 21ˆ1X Xθ-=-.如果我们获得一组样本观测值,其样本均值为0.65x =,则参数θ的矩估计值为20.651ˆ0.8610.65θ⨯-==-.例2.2 设总体X 的均值μ和方差2σ都存在,且20σ>,又设12,,,n X X X 是总体X 的一个样本,求μ和2σ的矩估计量.解:注意到()()()22E XD XE X =+⎡⎤⎣⎦,由方程组()()12222,.E X E X μμμσμ==⎧⎪⎨==+⎪⎩230解得1μμ=,2221σμμ=-.因此,μ和2σ的矩估计量分别为1ˆA X μ==, 22222211111()nniii i A A X XX X nnσ===-=-=-∑∑.此例表明, 总体X 均值和方差的矩估计量分别是样本均值与样本的二阶中心矩,而不依赖总体X 的分布.2.2 最大似然估计法由于矩估计法只需假设总体矩存在,没有充分利用总体分布提供的信息,为获得更理想的估计,需要引入最大似然估计法,它的一个直观想法是某个随机试验有若干个结果,,A B C 等,如果在一次试验中,出现结果A ,则认为事件A 发生的概率是最大的.例如,一只袋子里有黑白两种外形相同的球,这两种球的数量不详,只知道它们占总数的比例:一种球为10%,另一种球占90%.今从中任抽取一只球,取得白球,一种比较合理的想法是认为袋子里白球的数量较多, 占总数的90%,这就是最大似然估计法的基本思想.我们通过下面的例子说明最大似然估计法的原理.某工厂加工一批产品,现需要估计其不合格品率p ,今从中抽取一个容量为n 的样本值12,,,n x x x ,令1,0,i i X i ⎧=⎨⎩第次取到次品第次取到正品1,2,,i n = ,总体X 的分布律为()()1;1,0,1xxp x p pp x -=-=.取得样本获得观测值的概率为{}()()()1111111122,,,111==---====--∑∑=- nnnniii i x x x x n n x n x P X x X x X x pp pp pp ,()0,11,2,,i x i n == .显然{}1122,,,n n P X x X x X x === 是p 的函231数,记为()L p ,即()()111nnii i i x n x L p pp ==-∑∑=-.由于在一次取样中,样本值12,,,n x x x 出现,我们认为概率()L p 是最大的,选取使得()L p 达到最大的ˆp 作为参数p 的一个估计值,即()(){}ˆm ax p L pL p ∈Θ=.由微积分中求极大点的方法, p 可从方程()d 0d L p p=求出,又由于ln x 是x 的单调增函数,()ln L p 与()L p 在同一个p 处取极大值,p 也可从方程()d ln L p 0dp=求出,()()()11ln ln ln 1nni i i i L p x p n x p ===⋅+--∑∑,()11d ln 0d 1nniii i x n x L p ppp==-=-=-∑∑,解得: 1ˆn ii x pn==∑.容易验证, 1ˆn ii x pn==∑能使得()L p 达到最大,称之为参数p 的最大似然估计值,其对应的统计量称为参数p 的最大似然估计量.下面我们讨论最大似然估计法.设12,,,n X X X 是取自总体X 的一个样本, 12,,,n x x x 为样本值.如果总体X 是离散型的,其分布律为();p x θ,θ为未知参数,θ∈Θ. 样本12,,,n X X X 的联合分布律为232{}()11221,,,;nn n ii P X x X x X x p x θ=====∏ ,容易看出,当样本值12,,,n x x x 固定时上式是参数θ的函数,当θ取固定值时,上式是事件{}1122,,,n n X x X x X x === 发生的概率,记()()()121;,,,;nn ii L L x x x p x θθθ===∏ , (2.1)并称()L θ为样本的似然函数.若样本值12,,,n x x x 的函数()12ˆˆ,,,n x x x θθ=∈Θ 满足()(){}ˆm ax L L θθθ∈Θ=, (2.2)则称()12ˆˆ,,,n x x x θθ= 为θ的最大似然估计值,其相应的统计量()12ˆ,,,n X X X θ 称为θ的最大似然估计量.如果总体X 是连续型的,X 的概率密度为();f x θ,θ为未知参数,θ∈Θ.随机点12(,,,)n X X X 落在点12(,,,)n x x x 的边长为12,,,n x x x ∆∆∆ 的邻域内的概率近似为()1;ni i i fx x θ=∆∏.我们寻找使()1;ni i i f x x θ=∆∏达到最大的()12ˆˆ,,,n x x x θθ= ,但1ni i x =∆∏与它无关,故可取样本的似然函数为()()()121;,,,;nn ii L L x x x f x θθθ===∏ . (2.3)类似地, 若样本值12,,,n x x x 的函数()12ˆˆ,,,n x x x θθ=∈Θ 满足233()(){}ˆm ax L L θθθ∈Θ=则称()12ˆˆ,,,n x x x θθ= 为θ的最大似然估计值,其相应的统计量()12ˆ,,,n X X X θ 称为θ的最大似然估计量.获得样本的似然函数后,为求出未知参数θ的最大似然估计量,可以利用微积分中求函数极值的方法.假设();f x θ或();p x θ关于θ可微,由下面的似然方程()d 0d L θθ=,或对数似然方程()d ln 0d L θθ=,可求出最大似然估计θ.例2.3 设总体(),X P λ 求λ的最大似然估计量.解:似然函数为 ()1!ix ni i eL x λλλ-==∏,对数似然函数为 ()11ln ln ln(!)nni i i i L x n x λλλ===--∑∑ ,令()1d ln 0d nii xL n λλλ==-=∑,求得λ的最大似然估计值为 11nii xx n λ===∑,最大似然估计量为 11ni i X X nλ===∑.234例2.4 总体(),X E λ 求λ的最大似然估计量. 解: 总体X 的概率密度为(),0,0,x e x f x x λλλ-⎧>=⎨≤⎩.似然函数为 ()11niii nx x ni L eeλλλλλ=-=∑==∏,对数似然函数为()1ln ln ni i L n x λλλ==-∑,令()d ln 0d L λλ=,有10nii xnλ=-=∑,因此,λ的最大似然估计值为 11nii nxxλ===∑,最大似然估计量为 1Xλ=.假设总体的分布中含有k 个未知参数12,,,k θθθ ,类似地,写出似然函数()12,,,k L L θθθ= ,求解方程组()01,2,,iL i k θ∂==∂或()ln 01,2,,iL i k θ∂==∂可获得未知参数12,,,k θθθ 的最大似然估计.例2.5 总体()2,,X N μσ 求2,μσ的最大似然估计量.解: 似然函数为 ()()22212211,exp ()22n i n i L x μσμσπσ=⎧⎫=--⎨⎬⎩⎭∑235对数似然函数为()()222211ln ,ln 2ln ()222nii n nL xμσπσμσ==----∑分别求关于2μσ和的偏导数,得以下对数似然方程组()()221222241ln ,1()0,ln ,1()0.22n ii nii L xL n xμσμμσμσμσσσ==⎧∂⎪=-=∂⎪⎨∂⎪=-+-=⎪∂⎩∑∑解上述方程组得2μσ和的最大似然估计值分别为11ˆnii xx nμ===∑ ,2211(),nii x x nσ==-∑因此2μσ和的最大似然估计量分别为ˆX μ=和 2211()nii XX nσ==-∑.最大似然估计具有一个性质:如果ˆθ为总体X 未知参数θ的最大似然估计,函数()μμθ=具有单值反函数()θθμ=,则()ˆˆμμθ=为()μμθ=的最大似然估计.利用此性质,我们可获得例2.5中σ的最大似然估计量为ˆσ==例 2.6 设总体X 服从[]0,θ上的均匀分布,0θ>,求θ的最大似然估计值.解:记()()()()111min ,,,max ,,n n n x x x x x x == .236似然函数为 ()()()11,0,0,n n x x L θθθ⎧<<⎪=⎨⎪⎩其他注意到对于()()10,n x x θ≤≤有 ()()110nnn L x θθ<=≤.因此,取θ的最大似然估计值为()ˆn x θ=.最后我们给出求最大似然估计的一般步骤(有时候它并不适用,如上例):1、写出似然函数)(θL ,即由总体分布导出样本的联合分布律(或联合概率密度);2、令()d 0d L θθ=或()01,2,,iL i k θ∂==∂ ,求出驻点(常转化为求对数似然函数ln ()L θ的驻点:令()d ln 0d L θθ=或()ln 01,2,,iL i k θ∂==∂ );3、求出最大值点;4、求得参数的最大似然估计.§3 区间估计参数的点估计实质是用一个估计值来估计未知参数θ的真值,但估计值只是θ的一个近似值,它本身既没有反映这种近似的精度又没有给出误差的范围,因此,在实际问题的应用中意义有限.例如在一大批产品中,任意取出60件产品,经检验有3件为次品,按点估计的方法,我们获得次品率p的一个估计值为ˆp=0.05,但ˆp 与次品率p 的真值是有误差的,这个误差有237多大,点估计无法给予回答.我们希望给出一个区间()ˆˆ,pp -∆+∆,用它来估计次品率p 的真值,这样就产生了误差∆的大小及用区间()ˆˆ,pp -∆+∆估计次品率p 真值的可靠程度的问题.区间估计解决了上述问题,我们将介绍在区间估计理论中被广泛接受的置信区间.3.1 置信区间定义3.1设1,,n X X 是取自总体X 的一个样本, θ为总体分布中所含的未知参数, θ∈Θ.对于给定的α,01α<<,若存在两个统计量()1,,n X X θθ= 和()1,,n X X θθ= ,使得{}1P θθθα<<=- (3.1)则称随机区间(),θθ是θ的臵信水平为1α-的臵信区间,θ和θ分别称为θ的臵信下限和臵信上限.定义3.1表明置信区间(),θθ包含θ的真值的概率为1α-,它的两个端点是只依赖12,,,n X X X 的随机变量.设12,,,n x x x 为一个样本值,我们获得一个普通的区间()()1212(,,,,,,,)n n x x x x x x θθ 称之为置信区间(),θθ的一个实现,在不致引起误解的情形下,也简称为置信区间.对于一个实现,只有两种可能, 它要么包含θ的真值,要么不包含θ的真值.在重复取样下(各次取样的样本容量均为n ),我们获得许多不同的实现,根据伯努利大数定律,这些不同的实现中大约有100(1α-)%的实现包含θ的真值,而有100α%的实现不包含θ的真值.例 3.1 已知某产品的重量(单位:克)()2,X N μσ,其中8σ=,μ未知,现从中随机抽取9个样品,其平均重量为575.2x =克,试238求该产品的均值μ的臵信水平为95%的臵信区间.解:样本均值11ni i X X n==∑是未知参数μ的较优的点估计,同时有2,X N n σμ⎛⎫ ⎪⎝⎭ , 或()0,1N . 因此,我们构造一个枢轴量U =,选取区间()/2/2,u u αα-,使得/2/21P u u ααα⎧⎫-<<=-⎨⎬⎩⎭,即/2/21P X u X u ααμα⎧-<<+=-⎨⎩.这样我们得到μ的置信水平为1α-的置信区间为/2/2X u X u αα⎛-+ ⎝.由575.2x =,9n =,8σ=,1α-=95%,0.05α=,/2u α=1.96算得/2575.2 1.96569.976x u α-=-⨯=/2575.2 1.96580.424x u α+=+⨯=所以,μ的一个置信区间为()569.976,580.424.从此例可以看出, 寻求未知参数θ的置信区间的步骤为:(1) 选取θ的一个较优的点估计()12ˆˆ,,,n X X X θθ= ,一般是通过239最大似然估计法获得.(2) 以()1ˆˆ,,n X X θθ= 为基础, 寻求未知参数θ的一个枢轴量W ,即()1,,;n W W X X θ= 且W 的分布已知.(3)对于给定的置信水平(与θ无关)1α-,确定两个分位点,a b ,使得(){}1,,;1n P a W X X b θα<<=- .,a b 可通过(){}(){}11,,;,,;2n n P WX X a P W X X b αθθ≤=≥=确定.(4)求出θ的置信区间.3.2 单个正态总体均值与方差的置信区间以下我们将讨论正态总体的均值与方差的置信区间.设()2,X N μσ,12,,,n XX X 是取自总体X 的一个样本.1. 参数μ的置信区间关于参数μ的置信区间,我们分方差2σ已知和2σ未知两种情形. (1) 方差2σ已知的情形例3.1中,我们已经获得了在方差2σ已知的条件下, μ的置信区间为/2/2X u X u αα⎛-+ ⎝,简记为/2X u α⎛± ⎝.(2) 方差2σ未知的情形由于U =σ,又2S 是2σ的无偏估计量,因此,选取240随机变量X T -=.由第六章定理4.1可知(1)T t n - ,对于给定的置信水平1α-,有/2/2(1)(1)1P t n t n ααα⎧⎫--<<-=-⎨⎬⎩⎭,即/2/2(1)(1)1S S P X t n X t n ααμα⎧--<<+-=-⎨⎩,因此,μ的置信水平为1α-的置信区间为/2/2(1)(1)X t n X t n αα⎛--+- ⎝,(3.2)简记为/2(X t n α⎛±- ⎝. 例3.2 假设轮胎的寿命2(,)X N μσ .为估计它的平均寿命,现随机抽取12只,测得它们的寿命为(单位:万千米)4.68 4.85 4.32 4.85 4.615.02 5.20 4.60 4.58 4.72 4.38 4.70 求μ的臵信水平为0.95的臵信区间.解:12n =, 4.7092,x =20.0615s =,1α-=95%,0.05α=,()0.02511 2.2010t =算得μ的置信水平为0.95的置信区间为(()()0.0250.0251111 4.5516,4.8668x t x t ⎛-+= ⎝.2. 参数2σ的置信区间 (1) 均值μ已知的情形 由于()()2,1,2,,i X N i n μσ= ,即()0,1i X N μσ- ,241所以 ()()2221ni i X n μχσ=-∑.我们选取随机变量()2211ni i X μσ=-∑作为枢轴量, 对于给定的置信水平1α-,有()2221/2/2211()()1ni i P n X n ααχμχασ-=⎧⎫<-<=-⎨⎬⎩⎭∑,即()()2221122/21/21.()()n ni i i i X X P n n ααμμσαχχ==-⎧⎫--⎪⎪⎪⎪<<=-⎨⎬⎪⎪⎪⎪⎩⎭∑∑ 因此,2σ的置信水平为1α-的置信区间为()()221122/21/2,()()nnii i i XXn n ααμμχχ==-⎛⎫-- ⎪⎪ ⎪⎪⎝⎭∑∑. (3.3) 我们也得到σ的置信水平为1α-的置信区间为⎝⎭. (3.4) (2) 均值μ未知的情形 由于()()()2222221111nii n S XXn χχσσ=-=-=-∑ ,选取随机变量2χ作为枢轴量,类似地, 我们得到2σ的置信水平为1α-的置信区间为242()()221122/21/2,(1)(1)nn ii i i X X X X n n ααχχ==-⎛⎫-- ⎪ ⎪-- ⎪ ⎪⎝⎭∑∑,即()()2222/21/211,(1)(1)n S n S n n ααχχ-⎛⎫-- ⎪--⎝⎭, 和σ的置信水平为1α-的置信区间为⎛ ⎝⎭, (3.5) 即⎛ ⎝.例3.3 在例3.2中,求2σ的臵信水平为0.95的臵信区间. 解:12n =, 4.7092,x =20.0615s =,()210.6765n s -=1α-=95%,0.05α=,()20.0251121.920χ=,()20.97511 3.816χ=算得2σ的置信水平为0.95的置信区间为(0.03086,0.17728).3.3 两个正态总体均值差与方差比的置信区间设()211,X N μσ ,()222,Y N μσ ,从总体X 和Y 中,分别独立地取出样本12,,,n X X X 和12,,,m Y Y Y ,样本均值依次记为X 和Y ,样本方差依次记为21S 和22S .1. 设21σ和22σ已知,求12μμ-的置信区间243由第六章定理2.2可知()0,1X Y U N μμ---=.对于给定的置信水平1α-,有/2/21X Y P u u ααμμα⎧⎫⎪⎪---⎪⎪-<<=-⎨⎬⎪⎪⎪⎪⎩⎭,即/212/21,P X Y u X Y u ααμμα⎧⎪--<-<-+=-⎨⎪⎩因此,12μμ-的置信水平为1α-的置信区间为//X Y u X Y u αα⎛---+ ⎝. (3.6) 例3.4 分别从()1,4X N μ ,()2,6Y N μ 中独立地取出样本容量为16和24的两样本,已知16.9x =,15.3y =,求12μμ-的臵信水平为0.95的臵信区间.解:16,24n m ==, 16.9x =,15.3y =,1α-=95%,0.05α=, 214σ=22,6σ=,/20.025 1.96u u α==,因此12μμ-的置信水平为0.95的置信区间为()16.915.3 1.9615.3 1.960.214,2.986⎛--⨯-+⨯= ⎝由此可以认为,在置信水平为0.95的情形下12μμ>.2. 设22212σσσ==未知,求12μμ-的置信区间244记()()22122112wn S m S S n m -+-=+-,由第六章定理4.2可知()2X Y T t n m μμ---=+- .以T 为枢轴量,类似地,我们得到12μμ-的置信水平为1α-的置信区间为()()/2/222X Y t n m S X Y t n m S αα⎛--+--++- ⎝(3.7)例3.5 为了估计磷肥对某农作物增产的作用,现选用20块条件大致相同的地块进行对比试验.其中10块地施磷肥,另外10块地不施磷肥,得到单位面积的产量如下(单位:公斤):施磷肥:620, 570, 650, 600, 630, 580, 570, 600, 600, 580; 不施磷肥:560, 590, 560, 570, 580, 570, 600, 550, 570, 550. 设施磷肥的地块的单位面积的产量()21,X N μσ ,不施磷肥的地块的单位面积的产量()22,Y N μσ ,求12μμ-的臵信水平为0.95的臵信区间.解:10n m ==,1α-=95%,0.05α=,600x =,570y =,2164009s =,2224009s =,()()22122211222w n s m s s n m -+-==+-,0.025(18) 2.1010t =.因此,12μμ-的置信水平为0.95的置信区间为60057022 2.101060057022 2.1010⎛--⨯⨯-+⨯⨯⎝(9.23,50.77)=,即我们可以认为磷肥对此农作物增产有作用.2453. 设1μ和2μ已知,求2122σσ的置信区间因为()()212211ni i X n μχσ=-∑,()()222212mi i Y m μχσ=-∑且样本12,,,n X X X 与样本12,,,m Y Y Y 独立,所以有()2211222121(),()nii mii Xm F F n m n Yμσσμ==-=⋅⋅-∑∑ ,对于给定的置信水平1α-,有(){}1/2/2(,),1P F n m F F n m ααα-<<=-,即()22211111222/221/22211()()111,,(,)()()n ni i i i m m i i i i m X m X P F n m F n m n Y n Y ααμμσασμμ==-==⎧⎫--⎪⎪⎪⎪<<=-⎨⎬⎪⎪--⎪⎪⎩⎭∑∑∑∑因此,2122σσ的置信水平为1α-的置信区间为()22111122/21/22211()()11,,(,)()()n ni i i i m mi i i i m X m X F n m F n m n Y n Y ααμμμμ==-==⎛⎫-- ⎪⎪ ⎪--⎪⎝⎭∑∑∑∑. (3.8) 4.设1μ和2μ未知,求2122σσ的置信区间由于()221222211,1S F F n m Sσσ=⋅-- ,对于给定的置信水平1α-,有246(){}1/2/2(1,1)1,11P F n m F F n m ααα---<<--=-,即()222111222/2221/221111,1(1,1)S S P F n m S F n m S αασασ-⎧⎫⎪⎪⋅<<⋅=-⎨⎬----⎪⎪⎩⎭,从而2122σσ的置信水平为1α-的置信区间为()()221122/221/2211,1,11,1S S F n m S F n m S αα-⎛⎫⋅⋅ ⎪ ⎪----⎝⎭. (3.9) 例 3.6 某车间有甲,乙两台机床加工同类零件,假设此类零件直径服从正态分布.现分别从由甲机床和乙机床加工出的产品中取出5个和6个,进行检查,得其直径数据(单位:毫米)为甲: 5.06, 5.08, 5.03, 5.00, 5.07; 乙: 4.98, 5.03, 4.97, 4.99, 5.02, 4.95; 试求22σσ甲乙的臵信水平为0.95的臵信区间.解: 5,6n m ==,1α-=95%,0.05α=,20.00107,s =甲20.00092,s =乙()0.0254,57.39,F =于()()0.9750.025114,50.10685,49.36F F ===,因此22σσ甲乙的置信水平为0.95的置信区间为()0.0010710.001071,0.15738,10.88990.000927.390.000920.1068⎛⎫⋅⋅= ⎪⎝⎭.3.4 单侧置信区间前面讨论的参数θ的置信区间(),θθ是双侧置信区间,即有置信上限247θ和置信下限θ.有时在一些实际问题中,我们只关心参数θ的上限或下限,因此有必要讨论参数θ的单侧置信区间.定义3.2设1,,n X X 是取自总体X 的一个样本, θ为总体分布中所含的未知参数, θ∈Θ.对于给定的α(01α<<),若存在统计量()1,,n X X θθ= 或()1,,n X X θθ= ,使得{}1P θθα>=- (3.10)或{}1P θθα<=- (3.11)则称随机区间(),θ+∞(或(),θ-∞)是θ的臵信水平为1α-的单侧臵信区间,θ称为θ的单侧臵信下限(θ称为θ的单侧臵信上限).求参数θ的单侧置信区间的方法与求θ的置信区间(),θθ的方法是类似的,只需将步骤(3)中的(){}12,,,;n P a W X X X b θ<< 1α=-改为(){}1,,;1n P a W X X θα<=- 或(){}1,,;1n P W X X b θα<=- ,其中,,a b 可通过(){}(){}11,,;,,;n n P W X X a P W X X b θθα≤=≥= 确定.详细的结果看表7.2.例3.7 在例3.2中,求μ的臵信水平为0.95的单侧臵信下限.解:12n =, 4.7092,x =20.0615s =,1α-=95%,0.05α=,()0.0511 1.7960t =算得μ的置信水平为0.95的单侧置信下限为(0.0511 4.5806x t -=.表7.1 正态总体均值,方差的置信区间248表7.2 正态总体均值,方差的单侧置信上、下限249250251习题七( A )1、设总体X 服从参数为N 和p 的二项分布,n X X X ,,,21 为取自X 的一个样本,试求参数p 的矩估计量与极大似然估计量.2,、设n X X X ,,,21 为取自总体X 的一个样本,X 的概率密度为22,0(;)0,xx f x θθθ⎧<<⎪=⎨⎪⎩其它.其中参数0θ>,求θ的矩估计.3、设12,,,n X X X 总体X 的一个样本, X 的概率密度为⎪⎩⎪⎨⎧≤>=--0,0,0,);(1x x ex x f xαλαλαλ其中0>λ是未知参数,0>α是已知常数,求λ的最大似然估计.4、设总体X 服从几何分布 ,10,,2,1,)1()(1<<=-==-p k p p k X P k 试利用样本值n x x x ,,,21 ,求参数p 的矩估计和最大似然估计.5、设总体X 的概率密度为()1;exp ,2x f x σσσ⎧⎫=-⎨⎬⎩⎭0σ>为未知参数, n X X X ,,,21 为总体X 的一样本,求参数σ的最大似然估计.6、证明第5题中σ的最大似然估计量为σ的无偏估计量. 7,、设总体X 的概率密度为()222220;0x x e x f x σσσ-⎧⎪>=⎨⎪⎩,,,其它.,20σ>为未知参数, n X X X ,,,21 为总体X 的一个样本,求参数2σ的的矩估252计量和最大似然估计量.8、设总体),(~2σμN X ,μ已知,σ为未知参数, n X X X ,,,21 为X 的一个样本,∑=∧-=ni i X c 1||μσ, 求参数c ,使∧σ为σ的无偏估计.9、设θˆ是参数θ的无偏估计量,且有0)ˆ(>θD ,试证22)ˆ(ˆθθ=不是2θ的无偏估计量.10、设总体),(~2σμN X ,321,,X X X 是来自X 的样本,试证:估计量32112110351ˆX X X ++=μ;32121254131ˆX XX ++=μ;3213216131ˆX XX ++=μ都是μ的无偏估计,并指出它们中哪一个最有效.11,、设12,,,n X X X 是总体()20,X N σ 的一个样本,20σ>,证明:211ni i X n=∑是2σ的相合估计量.12、设总体X 的数学期望为μ,方差为2σ,分别抽取容量为1n 和2n 的两个独立样本,1X ,2X 分别为两样本均值,试证明:如果,a b 满足1a b +=,则12Y aX bX =+是μ的无偏估计量,并确定,a b ,使得()D Y最小.13、设12,,,n X X X 是总体X 的一个样本, X 的概率密度为();f x θ,0θ>,未知,已知()222nXn χθ,试求θ的置信水平为1α-的置信区间.14、从大批彩色显像管中随机抽取100只,其平均寿命为10000小时,253可以认为显像管的寿命X 服从正态分布.已知均方差40=σ小时,在置信水平0.95下求出这批显像管平均寿命的置信区间.15、设随机地调查26年投资的年利润率(%),得样本标准差(%)15=S ,设投资的年利润率X 服从正态分布,求它的方差的区间估计(置信水平为0.95).16,、从一批钉子中抽取16枚,测得其长度为(单位:厘米)2.14, 2.10, 2.13, 2.15, 2.13, 2.12, 2.13, 2.10, 2.15, 2.12, 2.14, 2.10, 2.13, 2.11, 2.14, 2.11.设钉子的长度X 服从正态分布,试求总体均值μ的置信水平为0.90的置信区间.17、生产一个零件所需时间(单位:秒)),(~2σμN X ,观察25个零件的生产时间得5.5=x ,73.1=s .试求μ和2σ的置信水平为0.95的置信区间.18、产品的某一指标),(~2σμN X ,已知04.0=σ,μ未知.现从这批产品中抽取n 只对该指标进行测定,问n 需要多大,才能以95%的可靠性保证μ的置信区间长度不大于0.01?19、设A 和B 两批导线是用不同工艺生产的,今随机地从每批导线中抽取5根测量其电阻,算得721007.1-⨯=A s ,62103.5-⨯=B s ,若A 批导线的电阻服从),(211σμN ,B 批导线的电阻服从),(222σμN ,求2221σσ的置信水平为0.90的置信区间.20,、从甲乙两个蓄电池厂的产品中分别抽取6个产品,测得蓄电池的容量(A.h)如下:甲厂 140 , 138 , 143 , 141 , 144 , 137;乙厂135 , 140 , 142 , 136 , 138 , 140设蓄电池的容量服从正态分布,且方差相等,求两个工厂生产的蓄电池的容量均值差的95%置信区间.( B )1、设总体X 的概率分别为254其中102θθ⎛⎫<<⎪⎝⎭是未知参数,利用总体X 的如下样本值: 3, 1, 3, 0, 3, 1, 2, 3 求θ的矩估计值和最大似然估计值.2、设()111ˆˆ ,,n X X θθ= 和()221ˆˆ,,n X X θθ= 是参数θ的两个相 互独立的无偏估计量,且方差()()12ˆˆ2D D θθ=,试确定常数,a b ,使得12ˆˆa b θθ+是θ的无偏估计量,且在一切这样的线性估计类中方差最小.3、在测量反应时间中,一心理学家估计的标准差为0.05秒,为了以0.95的置信水平使他对平均反应时间的估计误差不超过0.01秒,应取多大的样本容量.【提供者:路磊】。
概率论与数理统计第七章参数估计
例1. 设总体X的数学期望和方差分别是μ,
σ2 ,求μ , σ2的矩估计量。
E(X )
E( X 2 ) D( X ) [EX ]2 2 2
(3) 写出方程 ln L 0
i1
若方程有解,
求出L(θ)的最大值点 ˆ(x1,x2,..x.n,)
于 是 ˆ ˆ ( X 1 , X 2 , . . . , X n ) 即 为 的 极 大 似 然 估 计 量
例2. 设总体X服从参数λ>0的泊松分布,求 参数λ的极大似然估计量。
例3. 已知某产品的不合格率为p,有简单随机样本 X1 ,X2 ,…, Xn,求p的极大似然估计量。 若抽取100件产品,发现10件次品,试估计p.
ˆ(x1,x2,..x.n,),使得
L (ˆ) m a x L (), (或 L (ˆ) s u p L ())
则 称 ˆ ( x 1 ,x 2 , . . . ,x n ) 为 的 极 大 似 然 估 计 值
称 ˆ ( X 1 ,X 2 ,...,X n ) 为 极 大 似 然 估 计 量
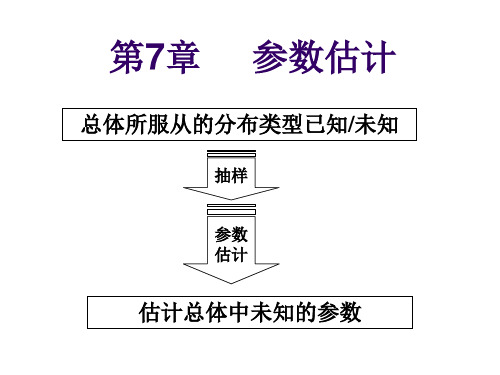
第7章 参数估计
总体所服从的分布类型已知/未知
抽样
参数 估计
估计总体中未知的参数
参数估计 参数估计问题是利用从总体抽样得到的信息
来估计总体的某些参数. 估计新生儿的体重
估计废品率
估计湖中鱼数
§7.1
点估计
设有一个统计总体,总体的分布函数
为 F(x, ),其中为未知参数 (可以是向量) .
概率论与数理统计第七章

估计 为1.68,这是点估计.
估计在区间[1.57, 1.84]内,这是区间估计.
一、点估计概念及讨论的问题
例1 已知某地区新生婴儿的体重X~ N(,2),
, 2未知,
…
随机抽查100个婴儿
得100个体重数据
9, 7, 6, 6.5, 5, 5.2, … 而全部信息就由这100个数组成.
求:两个参数a,b的矩估计
解: 写出方 V E 程 (X a(X )r组 ) ˆˆ2
其 中uˆˆ2Xn1in1(Xi X)2
但是
E
(
X
)
Var ( X )
a
b 2 (b a)2
12
即有
(ab2ba)2 12
X
ˆ
2
由方程组求解出a,b的矩估计:
a ˆX 3 ˆ b ˆX 3 ˆ
其中 ˆ:ˆ2 n 1i n1 ( XiX)2
(4) 在最大值点的表达式中, 用样本值代入 就得参数的极大似然估计值 .
两点说明:
1、求似然函数L( ) 的最大值点,可以应
用微积分中的技巧。由于ln(x)是x的增函
数,lnL( )与L( )在 的同一值处达到 它的最大值,假定是一实数,且lnL( ) 是 的一个可微函数。通过求解所谓“似 然方程”: dlnL() 0
E(X1m)=E(X2m)==E(Xnm)= E(Xm)=am . 根据大数定律,样本原点矩Am作为 X1m,X2m, ,Xnm的算术平均值依概率收敛到均 值am=E(Xm).即:
n 1i n1Xim pE(Xm)am
例1 设总体X的概率密度为
f(x)(1)x,
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
习题七解答1. 设的分布律为,求(1)EX ,(2))1(+-X E ,(3))(2X E ,(4)DX 。
解 由随机变量X所以()1111111(1)01236261243E X =-⨯+⨯+⨯+⨯+⨯= ()11111121210(1)36261243E X -+=⨯+⨯+⨯+⨯+-⨯= ()2111111351014364612424E X =⨯+⨯+⨯+⨯+⨯=22235197()()(())()24372D XE XE X =-=-=另外,也可根据数学期望的性质可得:()()1211133E X E X -+=-+=-+=2.设随机变量X 服从参数为()0>λλ的泊松分布,且已知()()[]232=--X X E ,求λ的值。
解()()[]()()()()()()()()204526526565322222==+-+=+-+=+-=+-=--λλλλX E X E X D X E X E X X E X X EX3. 设X 表示10次独立重复射击命中目标的次数,每次命中目标的概率为0.4,试求2X 的数学期望()2X E 。
解 ()4.0,10~B X所以 ()()4.26.04.010,44.010=⨯⨯==⨯=X D X E 故 ()()()()4.1844.2222=+=+=X E X D X E4. 国际市场每年对我国某种出口商品的需求量X 是一个随机变量,它在[2000,4000](单位:吨)上服从均匀分布。
若每售出一吨,可得外汇3万美元,若销售不出而积压,则每吨需保养费1万美元。
问应组织多少货源,才能使平均收益最大?解 设随机变量Y 表示平均收益(单位:万元),进货量为a 吨Y=()aX a X 33-- a x a x ≥< 则()()()800000014000220001200013200014220004000-+-=+-=⎰⎰a a dxa dx a x Y E aa要使得平均收益()Y E 最大,所以()080000001400022='-+-a a得 3500=a (吨)5. 一台设备由三大部件构成,在设备运转过程中各部件需要调整的概率相应为0.1,0.2,0.3,假设各部件的状态相互独立,以X 表示同时需要调整的部件数,试求X 的数学期望()X E 和方差()X D 。
解 X 的可能取值为0,1,2,3,有()()()()006.03.02.01.03092.03.08.01.03.02.09.07.02.01.02398.03.08.09.07.02.09.07.08.01.01504.07.08.09.00=⨯⨯===⨯⨯+⨯⨯+⨯⨯===⨯⨯+⨯⨯+⨯⨯===⨯⨯==X P X P X P X P所以X 的分布律为()()()()46.06.082.082.0006.03092.02398.01504.006.0006.03092.02398.01504.00222222=-==⨯+⨯+⨯+⨯==⨯+⨯+⨯+⨯=X D X E X E 6. 设X 的密度函数为()xe xf -=21,求(1)()X E ;(2)()2X E 。
解 (1)()⎰∞+∞--=⋅=021dx e x X E x(2)()⎰⎰∞+--∞+∞-==⋅=0222221221dx e x dx e x X E x x注:求解(1)时利用被积函数是奇函数的性质,求解(2)时化简为⎰+∞-02dxe x x 可以看成为是服从参数为1的指数分布随机变量的二阶原点矩。
7. 某商店经销商品的利润率的密度函数为⎩⎨⎧-=0)1(2x 其他10,<<x ,求,DX 。
解 (1)()1012(1)3E X x x dx =⋅-=⎰(2)()122012(1)6E X x x dx =⋅-=⎰故222111()()(())()6318D XE X E X =-=-=8.设随机变量X 的密度函数为()=x f x e - 0>x0 0≤x求()X E 、()X E 2、()X e X E 2-+、()X D 。
解()()()01222x E X xe dx E X E X +∞-====⎰()()()()()()()()22230022022141113321XXx xx x E X e E X E e ee dx e dx E Xx e dx D X E X E X +∞+∞-----+∞-+=+=+=+=+====-=⎰⎰⎰9. 设随机变量()Y X ,的联合分布律为X )(x f EX求()X E 、()Y E 、()Y X E 2-、()XY E 3、()X D 、()Y D 、()Y X ,cov 、Y X ,ρ。
解 关于()5.05.015.00=⨯+⨯=X E()()()()()()()()()()()()()()()()()()()()212121.025.005.0,cov 05.03.05.01.0,cov 3.01.031.0114.0012.0103.0003331.03.025.02221.03.03.03.03.017.003.03.017.0025.05.05.05.05.015.00,22222222-=-==-=⨯-=⋅-==⨯=⨯⨯+⨯⨯+⨯⨯+⨯⨯==-=⨯-=-=-=-==⨯+⨯==⨯+⨯==-==⨯+⨯=Y D X D Y X Y E X E XY E Y X XY E XY E Y E X E Y X E Y D Y E Y E X D X E Y X ρ10. 设随机变量X,Y 相互独立,它们的密度函数分别为()=x f X 022x e -0≤>x x()=y f Y44y e -≤>y y 求()Y X D +。
解 ()2~E X ,所以()41212==X D , ()4~E Y ,所以()161412==Y D ,X,Y 相互独立,所以()()()165=+=+Y D X D Y X D 。
11. 设()Y X ,服从在A 上的均匀分布,其中A 为x 轴、y 轴及直线01=++y x 所围成的区域,求(1)()X E ;(2)()Y X E 23+-;(3)()XY E 的值。
解 先画出A()=y x f , ()A y x ∈,0 其他()()⎰+∞∞-==dy y x f x f X ,()x dy x +=⎰--1220101≤≤-x0 其他()()⎰+∞∞-==dx y x f y f Y ,()y dx y+=⎰--12201 01≤≤-y0 其他()()()()()()()()()121123131231323233112311201010120101=+-===⎪⎭⎫ ⎝⎛-⨯+⎪⎭⎫ ⎝⎛-⨯-=+-=+--=+⋅=-=+⋅=⎰⎰⎰⎰⎰------dx x x dydx xy XY E Y E X E Y X E dy y y Y E dx x x X E x12. 设随机变量()Y X ,的联合密度函数为()=y x f , 212y 10≤≤≤x y 0 其他 求()()()()()()Y D X D Y X E XY E Y E X E ,,,,,22+。
解 先画出区域10≤≤≤x y 的图()()==⎰+∞∞-dy y x f x f X ,⎰=xx dy y 032412 10≤≤x0 其他()()==⎰+∞∞-dx y x f y f Y ,()⎰-=12211212yy y dy y 10≤≤y y 10 1 x其他()()()()1301201200445312151122X E X x x dx E Y y y y dy E XY xy y dydx =⋅==⋅-==⋅=⎰⎰⎰⎰()()()()()()()()()()()()1122222322022222216412115442657563115575E X Y E X E Y x x dx y y y dy D X E X E X D Y E YE Y +=+=⋅+⋅-=⎛⎫=-=-= ⎪⎝⎭⎛⎫=-=-= ⎪⎝⎭⎰⎰13. 设随机变量X,Y 相互独立,且()()()()3,2,1====Y D X D Y E X E ,求()XY D 。
解()()()()()()()()()()()()[]()()()[]()[]()[]()()111113122222222222=⋅-++=-++=⋅-=-=Y E X E Y E Y D X E X D Y E X E Y E X E XY E Y X E XY D14. 设()()4.0,36,25,===Y X Y D X D ρ,求(1)()Y X D +;(2)()Y X D -。
解:(1)()()()()()Y D X D Y D X D Y X D Y X ,2ρ++=+8536254.023625=⋅⨯⨯++=(2)()()()()()Y D X D Y D X D Y X D Y X ,2ρ-+=-3736254.023625=⋅⨯⨯-+=15. 设随机变量相互独立,,,求。
解 ()1,()1;()2,(E X D X E Y D Y ===-= 2(2)2()()21(2)0(2)2()()4115E X Y E X E Y D X Y D X D Y +=+=⨯+-=+=+=⨯+= 16. 验证:当),(Y X 为二维连续型随机变量时,按公式Y X ,)1,1(~N X )1,2(~-N Y )2(),2(Y X D Y X E ++⎰⎰+∞∞-+∞∞-=dydx y x xf EX ),(及按公式⎰+∞∞-=dx x xf EX )(算得的EX 值相等。
这里,),(y x f 、)(x f 依次表示X Y X ),,(的分布密度。
证明 (,)(,)E X x f x y d y d xx f x y d y d x +∞+∞+∞+∞-∞-∞-∞-∞==⎰⎰⎰⎰()xf x dx +∞-∞=⎰17. 设的方差为2.5,利用契比晓夫不等式估计}5.7{≥-EX X P 的值。
解 2(){7.5}7.5D X P X EX -≥≤22.517.522.5== 18. 设随机变量X 和Y 的数学期望分别为-2和2,方差分别为1和4,而相关系数为-0.5,根据切比雪夫不等式估计()6≥+Y X P 的值。
解 ()()()022=+-=+=+Y E X E Y X E()()()()()()3415.02412,=⋅-⨯++=++=+Y D X D Y D X D Y X D Y X ρ所以()()()()()121666062=+≤≥+-+=≥-+=≥+Y X D Y X E Y X P Y X P Y X P 21. 在人寿保险公司里有3000个同龄的人参加人寿保险。