第二章描述统计
第2章 描述统计:数量方法

第二章
描述统计:数量方法
STAT
4、评价 (1)测度数据的重心位置。
年龄(x) 人数(f) 36 1 A、Mean=38 37 1 离差:2+1=1+2 38 1 B、Mean=38.3333 39 1 离差:2.3333+1.3333+0.3333 40 1( 2) =0.6667+1.66672
STAT
[例]某人早、中、晚购买蔬菜的资料如下,求平均价格。
总金额 价格 数量 3元 xf x =0.26 总数量 数量 11.5斤 f
第二章
描述统计:数量方法
STAT
二、调和平均数(Harmonic Mean ,P35) 1、定义:变量值①倒数②的算术平均数③的倒数④ 。 2、公式推导 ( 1 )变量值: x1 , x2 ,, xn
1 1 1 1 (2)倒数: , ,, 令yi x1 x2 xn xi 1 1 1 1 x x x y 2 n (3)求算术平均数: y 1 x n 111 n n (4)倒数: H “简单调和平均数” 1 x
均值 78.67 77.78
[例2]2000年哈佛大学研究生部6个最大专业录取情况如下:
专业 男性报名人数 录取率(%) 女性报名人数 录取率(%) A 825 62 108 82 B 560 63 25 68 C 325 37 593 34 D 417 33 375 35 E 191 28 393 24 F 373 6 341 7
STAT
第二节
一、概念 1、集中趋势:越靠近中间水平,出现的频数越多,反之亦反。 2、离中趋势:离开并分散在中间水平两侧的趋势。 按年龄分组(岁) 38 39 40 41 42 合计 人数(人) 10 30 70 40 20 170
第二章数值型变量的统计描述

例:某公司五名职员的薪水分别是: 10,100,1000,10000,100000。
10 100 1000 10000 100000 X 22222 5
G 10 100 1000 10000 100000 1000
5
lg 10 lg 100 lg 100000 1 15 G lg ( ) lg ( ) 1000 n 5
统计工作四大步骤之一:分析资料
分析资料:计算有关指标,反映数据的综合特 征, 阐明事物内在联系和规律 (1)统计描述(descriptive statistics):指用统计
指标、统计表、统计图等方法,对资料的数量特 征及其分布规律进行测定和描述 。
(2)统计推断(inferential statistics):指如何根
n 2 n 1 2
2
求:中位数
第1组数:1、4、 3、 2、 3 第2组数: 3、 2、1、 3 第3组数:1、2、 1、 2
(2)频数表法:
适用于样本例数较大的资料(百分位数法)
步骤: ①从小到大计算累计频数和累计频数; ②确定中位数和百分位数所在组段;
③计算中位数M和百分位数PX
i Px= L n x % f L fx
考考你: BUN组段(1)
BUN组段(2)
2.00~2.40 2.40~2.80 2.80~3.20 3.20~3.60
BUN组段(3)
2.00~ 2.40~ 2.80~ 3.20~3.60
2.00~2.30
2.40~2.70 2.80~3.10 3.20~3.50
4、列表划记(数频数):统计各组段内的
例2-3
二、几何均数(geometric mean)
统计学原理(第二章)

数据的计量和类型
一、数据的计量尺度 4.定比尺度:又称为比例尺度或是比较水平, 是对事物之间比值的一种测度,它是最高层 次的测量,可用于参数和非参数统计推断。 它是与定距尺度属于同一层次的一种计量尺 度,但其功能比定距尺度更强一些。
在日常生活中,大多数情况下使用的都是 定比尺度。例如,年龄、收入、某地区每年的 失业人数、罪犯人数等。
数值数据的描述
一、数值数据的 分组
为什么要进行数据的分组?
品质数据的描述
某电脑公司50名销售代表某季度电脑销售量按从小 到大排序如下表:
107 108 108 110 112 112 113 114 115 117 117 117 118 118 118 119 120 120 121 122 122 122 122 123 123 123 123 124 124 124 125 125 126 126 126 127 127 128 128 129 130 131 133 133 134 134 135 139 139 139
204 80.00% 105 41.17%
235 92.16% 51 20%
255 100% 20 7.84%
— 100% —
品质数据的描述
二、品质数据的 图示 1.条形图:是用宽度相同的条形的高度或长 短来表示数据变动的图形,横置的称为带形 图,纵置的称为柱形图(直方图)。
柱形图(直方图)
120 100 80 60 40 20
定类变量、定序变量、 数值型变量(离散变量、连续变量)
第二节 品质数据的描述
一、品质数据的描述 二、数据的类型品质数据的图示 三、品质数据的分布特征描述
品质数据的描述
一、品质数据的 描述 1.频数:是落在某一特定类别(或组)中的 数据的个数。把各个类别及其相应的频数全 部列出来则形成频数分布。
医学统计学-第二章 统计描述

1. 首先对资料作分布类型的判定; 2. 针对分布类型先用合适的指标描述:
均值、标准差;常记录为 X S
中位数、四分位间距; 常录为M(Ql, Qu)
一、集中趋势:用于描述一组计量资料的集中位置, 说明这种变量值大小的平均水平(average)表示。
频 数
身高(cm)
图3.1 某市100名8岁男童身高(cm)的频数分布
(三)频数表的用途:
1.揭示频数的分布特征
频 数
分布 特征
身高(cm)
图3.1 某市100名8岁男童身高(cm)的频数分布
集中趋势
(central tendency)
离散趋势
(tendency of dispersion)
集中趋势与离散趋势结合能全面反映频数的分布特征
2.揭示频数的分布类型
对称 分布
频数 分布
正偏
非对称 分布
负偏
集中部位在中部,两 端渐少,左右两侧的
基本对称,为对称 (正态)分布。
集中部位偏于较小 值一侧(左侧),较大 值方向渐减少,为
正偏态分布。
集中部位偏于较大 值一侧(右侧),较 小值方向渐减少,
为负偏态分布。
(2) 定量资料的描述指标
描述指标: 集中趋势:
累计频数 (4) 1 6 14 31 54 75 89 96 99 100 100
累计频率 (5) 0.01 0.06 0.14 0.31 0.54 0.75 0.89 0.96 0.99 1.00 1.00
频数分布图(frequency distribution figure) :
根据频数分布表,以变量值为横坐标,频数为纵坐 标,绘制的直方图。
第二章 统计数据的描述

第二章统计数据的描述一、填空题:1.统计分组有等距分组与异距分组两大类。
2. 频率是每组数据出现的次数与全部次数之和的比值。
3. 统计分组的关键在于确定组数和组距。
4. 统计表从形式上看,主要由表头(总标题)、横行标题、纵栏标题和数字资料(指标数值)四部分组成。
5. 均值是测度集中趋势最主要的测度指标,标准差是测度离散趋势最主要的测度指标。
6.当平均水平和计量单位不同时,需要用变异系数(离散系数)来测度数据之间的离散程度。
7.众数是一组数据中出现次数最多的变量值。
8.对于一组数据来说,四分位数有 3 个。
二、单项选择题:1. 次数是分配数列组成的基本要素之一,它是指( B )。
A、各组单位占总体单位的比重B、分布在各组的个体单位数C、数量标志在各组的划分D、以上都不对2. 某连续变量数列,其末组为600以上。
又如其邻近组的组中值为560,则末组的组中值为( D )。
A、620B、610C、630D、6403. 变量数列中各组频率的总和应该是( B )。
A、小于1B、等于1C、大于1D、不等于14. 某连续变量数列,其首组为500以下。
又如其邻近组的组中值为520,则首组的组中值为( C )。
A、460B、470C、480D、4905. 在下列两两组合的指标中,哪一组的两个指标完全不受极端数值的影响(D )A、算术平均数和调和平均数B、几何平均数和众数C、调和平均数和众数D、众数和中位数6. 在编制等距数列时,如果全距等于56,组数为6,为统计运算方便,组距应取(D )A、9.3B、9C、6D、107. 一项关于大学生体重的调查显示,男生的平均体重是60公斤,标准差为5公斤;女生的平均体重是50公斤,标准差为5公斤.据此数据可以推断( B) 用变异系数算A、男生体重的差异较大B、女生体重的差异较大C、男生和女生的体重差异相同D、无法确定8. 某生产小组有9名工人,日产零件数分别为10,11,14,12,13,12,9,15,12.据此数据计算的结果是( A ) 众数12 中位数12 平均数12A、均值=中位数=众数B、众数>中位数>均值C、中位数>均值>众数D、均值>中位数>众数9. 按连续型变量分组,最后一组为开口组,下限值为2000。
统计学 第2章 统计数据的描述
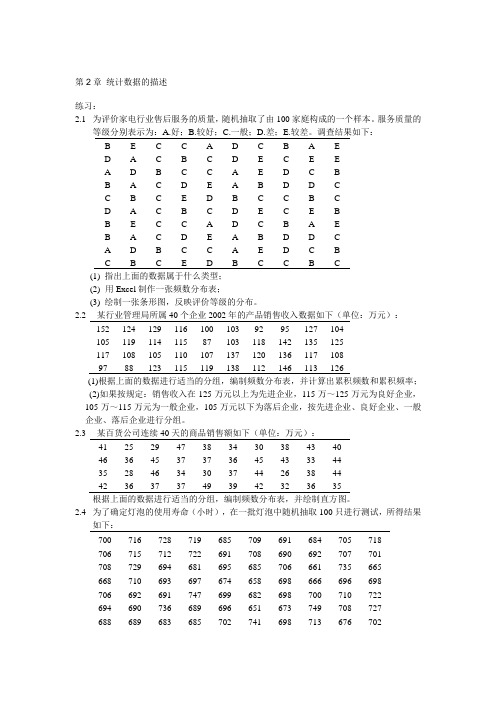
第2章统计数据的描述练习:2.1为评价家电行业售后服务的质量,随机抽取了由100家庭构成的一个样本。
服务质量的等级分别表示为:A.好;B.较好;C.一般;D.差;E.较差。
调查结果如下:B EC C AD C B A ED A C B C DE C E EA DBC C A ED C BB ACDE A B D D CC B C ED B C C B CD A C B C DE C E BB EC C AD C B A EB ACDE A B D D CA DBC C A ED C BC B C ED B C C B C(1) 指出上面的数据属于什么类型;(2)用Excel制作一张频数分布表;(3) 绘制一张条形图,反映评价等级的分布。
2.2某行业管理局所属40个企业2002年的产品销售收入数据如下(单位:万元):152 124 129 116 100 103 92 95 127 104105 119 114 115 87 103 118 142 135 125117 108 105 110 107 137 120 136 117 10897 88 123 115 119 138 112 146 113 126(1)根据上面的数据进行适当的分组,编制频数分布表,并计算出累积频数和累积频率;(2)如果按规定:销售收入在125万元以上为先进企业,115万~125万元为良好企业,105万~115万元为一般企业,105万元以下为落后企业,按先进企业、良好企业、一般企业、落后企业进行分组。
2.3某百货公司连续40天的商品销售额如下(单位:万元):41 25 29 47 38 34 30 38 43 4046 36 45 37 37 36 45 43 33 4435 28 46 34 30 37 44 26 38 4442 36 37 37 49 39 42 32 36 35根据上面的数据进行适当的分组,编制频数分布表,并绘制直方图。
统计学第二章计量资料的统计描述

02
统计数据整理与展示方法
数据清洗与预处理技巧
80%
缺失值处理
根据数据的分布情况和实际背景 ,选择合适的缺失值填充方法, 如均值、中位数、众数等。
100%
异常值处理
采用箱线图、散点图等方法识别 异常值,并根据实际情况选择删 除、替换或保留。
分类
根据测量水平的不同,计量资料可分为离散型和连续型两类。离 散型数据只能取整数值,如人口数、医院床位数等;连续型数据 则可以取实数范围内的任何值,如身高、体重等。
计量资料特点分析
数值性
计量资料以数值形式表示,具有数量化的特点,便 于进行数学运算和统计分析。
连续性
连续型计量资料在实数范围内可以取任意值,数据 分布的连续性使得统计推断更为精确。
06
统计图表在数据可视化中应用
常见统计图表类型介绍
条形图(Bar Chart)
用于展示分类数据之间的比较,横轴表示分类,纵轴表示数量或比例。
折线图(Line Chart)
用于展示时间序列数据或连续性数据的趋势变化,横轴表示时间或类 别,纵轴表示数量或比例。
散点图(Scatter Plot)
用于展示两个变量之间的关系,横轴和纵轴分别表示两个变量,点的 位置表示变量的取值。
一组观察值中出现次数最多的数。
计算方法
应用场景
中位数计算需先将数据排序,然后取中间 位置的数;众数计算则是统计各数值出现 的次数,取出现次数最多的数。
适用于各种类型的数据,尤其适用于偏态 分布数据。中位数和众数对极端值不敏感 ,因此能较好地反映数据的集中趋势。
不同集中趋势指标比较
算术平均数、中位数和 众数都是描述数据集中 趋势的指标,但各有特 点。
第二章 描述性统计分析SPSS应用

萨姆:每周100元又是怎么回事呢? 吉斯莫:那称为众数,是大多数人挣 的工资。 吉斯莫:老弟,你的问题是出在你不 懂平均数、中位数和众数之间的区别。 萨姆:好,现在我可懂了。我……我 辞职!
描述集中趋势的统计量
Mean(均值) Median(中位值) Mode(众值)
(一)均值(定距变量)
定距变量资料分布常用曲线
J形曲线
U形曲线
峰状曲线
对称与不对称曲线
注意:适用于较低测量层次的统计法,也适 用于较高的层次。 图形也同样:饼图主要是用于定类变量 条形图主要是用于定序变量;直方图、折线图 等主要是用于定距变量
练习:城镇自杀率的分组次数分布
自杀率 次数 组中值 向上累积次数
如果只看次数,乙机关已婚者远高于甲机关, 但从百分比来看,甲机关已婚的比例则较大。 频数分布表是不同类别的绝对数量的分布情况, 百分比分布表则是不同类别在总体中的相对数 量分布,因此,百分比分布除具备频数分布的 特点外,还可以十分方便地进行不同总体或不 同类别之间的比较,应用更为广泛。
3. 对比值(ratio):不同类别数值之间的比 值,用x:y的形式表示 如出生性别比为105:100,则表示每出生 100个女孩则有105个男孩出生 某班男女生比率为3:5
你会吗?
2. 对于分组资料:(1)单项数列
根据N/2在累计频数分布中找到中位数所在组, 该组变量值就是Md 。 X f F 3 4 中 位 数 5 6 7 8 9 3 9 25 34 20 7 1 3 12 37 71 91 98 99
10
合计
1 100
100 —
(2)组距数列
按中位数所在组的下限:
统计分析首先要解决的问题,就是寻求
第二章 统计描述习题 医学统计学习题

第二章统计描述习题一、选择题1.描述一组偏态分布资料的变异度,以()指标较好。
A.全距B.标准差C.变异系数D.四分位数间距E.方差2.各观察值均加(或减)同一数后()。
A.均数不变,标准差改变B.均数改变,标准差不变C.两者均不变D.两者均改变E.以上都不对3.偏态分布宜用()描述其分布的集中趋势。
A.算术均数B.标准差C.中位数D.四分位数间距E.方差4.为了直观地比较化疗后相同时点上一组乳腺癌患者血清肌酐和血液尿素氮两项指标观测值的变异程度的大小,可选用的最佳指标是()。
A.标准差B.标准误C.全距D.四分位数间距E.变异系数5.测量了某地152人接种某疫苗后的抗体滴度,宜用()反映其平均滴度。
A.算术均数B.中位数C.几何均数D.众数E.调和均数6.测量了某地237人晨尿中氟含量(mg/L),结果如下:尿氟值:0.2~0.6~ 1.0~ 1.4~ 1.8~ 2.2~ 2.6~ 3.0~ 3.4~ 3.8~频数:7567302016196211宜用()描述该资料。
A.算术均数与标准差B.中位数与四分位数间距C.几何均数与标准差D.算术均数与四分位数间距 E.中位数与标准差7.用均数和标准差可以全面描述()资料的特征。
A.正偏态资料B.负偏态分布C.正态分布D.对称分布E.对数正态分布8.比较身高和体重两组数据变异度大小宜采用()。
A.变异系数B.方差C.极差D.标准差E.四分位数间距9.血清学滴度资料最常用来表示其平均水平的指标是()。
A.算术平均数B.中位数C.几何均数D.变异系数E.标准差10.最小组段无下限或最大组段无上限的频数分布资料,可用()描述其集中趋势。
A.均数B.标准差C.中位数D.四分位数间距E.几何均数11.现有某种沙门菌食物中毒患者164例的潜伏期资料,宜用()描述该资料。
A.算术均数与标准差B.中位数与四分位数间距C.几何均数与标准差D.算术均数与四分位数间距 E.中位数与标准差12.测量了某地68人接种某疫苗后的抗体滴度,宜用()反映其平均滴度。
(完整版)STATA第二章描述性统计命令与输出结果说明

第二章描述性统计命令与输出结果说明上述数据也可以用变量x表示血磷测定值,分组变量group=0表示患者组和group=1表示健康组(如:患者组中第一个数据为2.6,则x=2.6,group=0;又如:健康组中第三个数据为1.98,则x为1.98以及group为1),并假定这些数据已以STATA格式存入ex2a.dta文件中。
计算资料均数,标准差命令summarize,以述资料为例:. summarizeVariable Obs Mean Std. Dev. Min Maxx1 11 4.710909 1.302977 2.6 6.53x2 13 3.354615 1.304368 1.67 5.78Mean 均值;Std.Dev.标准差即:本例中急性克山病患者组的样本数为11,血磷测定值均数为4.711(mg%),相应的标准差为1.303,最小值为2.6以及最大值为6.53;健康组的样本量为13,血磷测定值均数为3.3546,相应的标准差为1.3044,最小值为1.67以及最大值为5.78。
计算资料均数,标准差,中位数,低四分位数和高四分位数的命令summarize 以及子命令detail,仍以述资料为例:. summarize x1 x2,detailx1Percentiles Smallest1% 2.6 2.65% 2.6 3.2410% 3.24 3.73 Obs 1125% 3.73 3.73 Sum of Wgt. 1150% 4.73 Mean 4.710909Largest Std. Dev. 1.30297775% 5.78 5.5890% 6.4 5.78 Variance 1.69774995% 6.53 6.4 Skewness -.081344699% 6.53 6.53 Kurtosis 1.809951x2Percentiles Smallest1% 1.67 1.675% 1.67 1.9810% 1.98 1.98 Obs 1325% 2.33 2.33 Sum of Wgt. 1350% 3.6 Mean 3.354615Largest Std. Dev. 1.30436875% 4.17 4.1790% 4.82 4.57 Variance 1.70137795% 5.78 4.82 Skewness .296394399% 5.78 5.78 Kurtosis 1.875392.结果:Percentiles 显示了从1%到99%的分位数的取值。
第二章统计描述

G ' lg1(
fi lg Xi ) lg1(
1 0.6021 4 0.9031
1 2.709Байду номын сангаас )
fi
40
lg1(67.1282) 48 40
G 1: 48
中位数(median, M)
适合于表达偏态资料、或分布不明的资料的平 均水平,尤其适合于表达只知数据的个数、但 部分较大或较小数据的具体数值未准确知道的 资料的平均水平。
血清总胆固醇 2.5~ 3.0~ 3.5~ 4.0~ 4.5~ 5.0~ 5.5~ 6.0~ 6.5~
7.0~7.5 合计
频数f 1 8 9 23 25 17 9 6 2 1
101
fx 2.75 26 33.75 97.75 118.75 89.25 51.75 37.5 13.5 7.25 478.25
13
174
单侧正常值范围的上限为 1.81
14
188
(mol/L)。
1.69~
4
192
1.93~
4
196
2.17~
1
197
2.42~
2
199
2.66~
0
199
2.90~3.14
1
200
3.四分位数间距(quartile interval, Q)
Q=P75-P25
Q=QU-QL
优缺点:用四分位数间距作为描述数据分布离散 程度的指标,比极差稳定,但仍未考虑到每个数 据的大小,常用于描述偏态频数分布以及分布的 一端或两端无确切数值资料的离散程度。
第1四分位数记作Q1,第2、第3四分位数,分别记作 Q2、Q3;第1百分位数,记作P1。同理,还有第2、第 3、 ···、第99百分位数,分别记作P2、P3、 ···、P99。
(罗良清)统计学(第二版)思考与练习答案:第二章 描述统计(计算题答案)
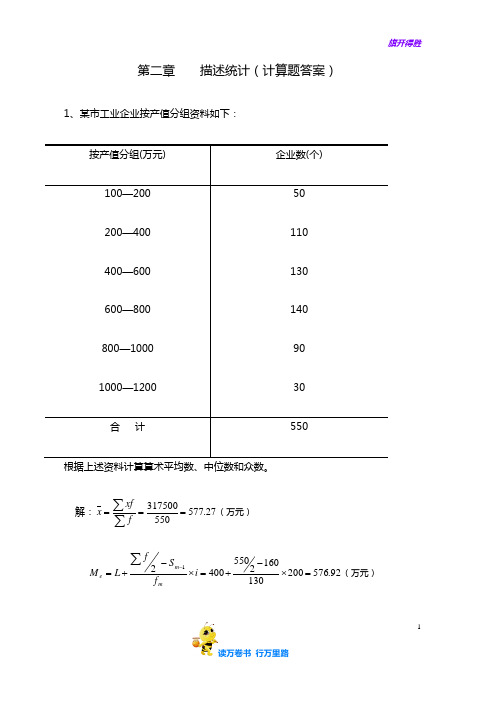
1第二章 描述统计(计算题答案)1、某市工业企业按产值分组资料如下: 按产值分组(万元) 企业数(个)100—200 200—400 400—600 600—800 800—1000 1000—1200 501101301409030合 计 550解:27.577550317500===∑∑f xfx (万元)92.576200130160255040021=⨯-+=⨯-+=-∑i f S fL M m m e (万元)233.6332120=⨯∆+∆∆-=i U M (万元)2、某车间有两个小组,每组都是7人,每人日产量件数如下第一组:20、40、60、70、80、100、120第二组:67、68、69、70、71、72、73若这两组工人每人平均日产量件数都是70件,计算每人日产量的差异指标:①全距;②平均差;③标准差,并比较哪个组的平均数的代表性大?解:大。
第二组的平均数代表性,,件,件件件件件件∴<⋅<⋅<====⋅===⋅=12121221222111702,71.1,662.31,7.25,100σσσσD A D A R R x x D A R D A R Θ3、有两个生产作业班工人按其产品日产量分组的资料如下: 甲组 乙组日产量(件) 工人数(人) 日产量(件) 工人数(人)3 5 7 9 10 13 3 5 64 2 8 12 14 15 16 67331合 计 合 计数代表性大?解:乙组平均数代表性大。
,,件件,件,件,乙甲乙甲乙甲乙甲∴>======σσσσσσV V V V x x Θ%9.22%9.257.22.28.115.84、两种不同的水稻品种分别在5块试验田上试种,其产量资料如下:甲品种 乙品种4 田块面积(亩) 亩产(斤) 田块面积(亩) 亩产(斤)1.2 1.1 1.0 0.9 0.8 1000 950 1100 900 1050 1.2 1.1 1.0 0.9 0.8 136010001250750600合计 合计假定生产条件相同,试研究这两个品种的亩产水平,并确定哪个品种具有较大的推广价值 。
第二章 描述性分析

实验2-4 比率分析(演示)
交叉组下的频数分析
又称为列联表分析,是分析事物(变量)之间的相互影响和 关系。 交叉组下的频数分析的任务
均值:表示所有取值的集中趋势或平均水平。 中位数:变量项数为奇数时,处于中间的变量值;若变量项
数为偶数时,处于中间两位置2个变量的平均值。
众数:出现次数最多的数据。
中位数只有一个,而众数可以有很多个。
方差:各个数据与平均数之差的平方的和的平均值。 标准方差:方差的算术平方根。
第二章 描述性统计 分析
简介
对数据做分析,首要的就是进行描述性分析。
描述性分析包括找出数据中的均值、中位数、众数、方差、四
四分位表、峰度、偏度、频数等。 描述性统计分析的指标通常有:
集中趋势:均值、众数、中位数 离散趋势:最大值/最小值、极差、方差、标准差
分布:偏度、峰度
相关概念
实验2-7 :多选项问题的分析(演示)
操作提示: (1)分析——多重响应——定义响应集——绑定设 置——Байду номын сангаас分法,值1——设置名称——添加——关闭 (2)分析——多重响应——频率——表格——在二分集内—— 按照列表顺序排除——确认
根据收集的样本数据编制交叉表; 在交叉列表的基础上,对两两变量间是否存在一定的相关性进行 分析。
实验2-5(演示)
通常假设两个变量间不存在差异,假设显著性水平为0.05, 如果检验概率P<0.05,则原假设不成立,即两变量间存在差 异;反之,则两变量间不存在差异。
医学统计学统计描述

缺点:仅考虑两端数据的差异,未考虑其它数据的变异情 况,不能全面反映一组资料的离散程度,受样本含量n的 影响较大,且不稳定,易受极端值的影响。
四分位数间距(inter-quartile range)
▪ 定义:把全部变量值值分为四等分的分位数,其
分位数。它是一个位置指标。 Px ▪ 中位数是第50百分位数,用P50表示。 ▪ 第25,第75,第95百分位数记为P25, P75, P95
是统计学上常用的指标。
百分位数(percentile)
▪ 百分位数(percentile)
X%
PX
(100-X)%
▪ 50%分位数就是中位数 ▪ 25%,75%分位数称四分位数(quartile)
方差(variance)
▪ 定义:离均差平方和的均数 ▪ 表示法:总体方差用2表示;样本方差用
S2表示
▪ 计算公式:
▪ 意义: 方差值越大,说明变异程度越大。
▪ 特点:包括了每个变量值与均值的差异,
但该指标的单位为平方。
标准差(standard deviation, sd) :
▪ 定义:方差开平方,取平方根的正值,每
▪ 例 对于某项风险较高的新手术术后的生存 时间进行跟踪,共调查了7人, 6人死亡之 前分别生存了5天、6天、10天、16天、25 天、29天,还有一人术后30天随访时仍存 活。
▪ 本资料属于“开口”资料。
▪ 本例数据已经按从小到大的升序排列,n=7, 为奇数,其中位数为16天。
2. 频数表法(n较大,已编成频数表)
62.05
1 3 1
79.00 72.25
409.75 4.06(mmol / L) 101
统计学第二章描述优秀课件

散点图
60
50
40
james
30
20
均值
0
20
40
60
80
100
no
10
差异( 离散)
score 6 12 18 24 30 36 42 48 54 60
x 27.1
0
20
40
60
80
100
no
中心化( centering)
xxx
no
100
80
60
40
20
0
-20 -10
jamesc
0
10
20
方差
xx2
x2
s2
n1
n1
s2 j
67 .3,sd 2
59 .0
自由度
▪ 计算样本方差时应除以n-1,而不是n
s2 x x 2 n 1 ▪ 这里n-1叫自由度(degree of freedom), 表示样本可自由取值的数目
自由度?
如果某班只有1位学 生,身高为172
如果从某班抽取1位学生 调查其身高为172
四分位数
▪ 观测值按大小顺序排列后,均分为四部分, 处于分界点上的数
• 2/4位置:中位数 • 1/4位置:下四分位数 • 3/4位置:上四分位数
四分位数
▪ 詹姆斯:
Ql 2,2Qu32
▪ 杜兰特:
Ql 2,7Qu36
月薪
从某公司随机抽取13位职工,调查他们的月薪如下:
2000 2600 3500 1800 2500 4800 2800 3000 2200 3300 5200 4600 4000
杜兰特
31 32 25 43 42 29 30 37 18 28 25 25 38 27 28 26 54 33 30 38 31 33 27 51 37 31 36 34 36 24 25 36 27 35 28 26 37 29 29 20 15 26 23 35 42 26 33 24 33 33 28 15 38 30 28 33 30 17 27 33 39 30 28 29 38 41 48 32 32 37 27 36 28 42 43 32 21 30 25 23 40 33 31 27 36 36 48 28 24 33 36 42 29 34 41 46 24 31 19 13 42
描述统计:表格及图形方法

第二章描述统计:表格与图形方法第一节数据的预处理一、数据审核1、准确性审核的对象就登记性误差〔非抽样误差〕采取逻辑检查和计算检查方法·逻辑检查:主要看调查数据的容是否合理,工程之间是否有矛盾的地方,以及与有关数据进展对照,或者检查数据的平衡关系,以暴露逻辑上的矛盾·计算检查:主要是从数字上检查,如各分项之和是否等于总计,计量单位是否适宜,计算方法上是否合理等等2、全面性核对应调查的单位是否有遗漏,应调查的容是否齐全3、及时性即是否按规定的时间获取数据资料二、数据筛选1、当数据中的错误不能予以纠正,或者有些数据不符合调查的要求而又无法弥补时,需要对数据进展筛选2、数据筛选的容〔1〕将*些不符合要求的数据或有明显错误的数据予以剔除〔2〕将符合*种特定条件的数据筛选出来,而不符合特定条件的数据予以剔除3、数据筛选可借助计算机完成三、数据排序1、按一定顺序将数据排列,以发现一些明显的特征或趋势,找到解决问题的线索2、排序有助于对数据检查纠错,以及为重新归类或分组等提供依据3、在*些场合,排序本身就是分析的目的之一4、排序可借助于计算机完成第二节定性数据的图表分析一、频数分布:将统计数据分组后,各组数据出现的次数被称为频数〔次数〕。
把各个组以及相应的频数依一定的次序全部列出来,就形成了频数分布〔次数分布〕1、频率:各组单位数占总体单位总数的比重××定性数据本身就是对事物的一种分类,在列出所分的类别的同时,再列出对应的频数或频率,就形成了分类数据的频数分布。
2、顺序数据的整理(可计算的统计量)〔1〕累积频数:各类别频数的逐级累加。
包括向上累积和向下累积两类。
〔2〕累积频率:各类别频率(百分比)的逐级累加。
包括向上累积和向下累积两类。
&&补充:1>向上累计:从变量值低的组开场,将各组次数〔频率〕逐次向变量值高的组累计,说明*一组上限以下各组的累计次数〔频率〕。
《统计学》2数据的描述

第二章统计数据的描述【说明】(一)统计数据的分类、表达形式1.按数据的计量尺度不同划分•分类数据---列名尺度、定类尺度、名义尺度的计量结果对事物进行分类的结果,数据表现为类别,用文字来表述⏹表现为类别,用文字来表述⏹•顺序数据----定序尺度的计量结果对事物类别顺序的测度⏹数值型数据----定距尺度、定比尺度的计量结果⏹对事物的精确测度⏹结果表现为具体的数值⏹2.按采集方法划分1、观测数据(observational data)2、试验数据(experimental data)3.按时间状况划分•截面数据(cross-sectional data)在相同或者近似相同的时间点上采集的数据⏹描述现象在某一时刻的变化情况⏹•时间序列数据(time series data)在不同时间上采集到的数据⏹描述现象随时间变化的情况⏹(二)数据的表现形式绝对数按其所反映的时间状况不同,划分为:时期数、时点数⏹(计量单位有实物单位、价值单位、复合单位)相对数包括:比例(Proportion)、比率(Ratio)⏹(计量单位有百分比、千分比)统计数据的描述过程一、第一个环节——统计数据的搜集(一)统计数据的来源(渠道)(二)统计数据的搜集方式、方法(三)统计数据的质量要求(评价标准)1. 精度:最低的抽样误差或者随机误差2. 准确性:最小的非抽样误差或者偏差3. 关联性:满足用户决策、管理和研究的需要4. 及时性:在最短的时间里取得并发布数据5. 一致性:保持时间序列的可比性6. 最低成本:以最经济的方式取得数据二、第二个环节——统计数据的整理【重点】数据的整理与显示的基本原则:要弄清所面对的数据类型,因为不同类型的数据,所采取的处理方式和方法是不同的;•对分类数据和顺序数据主要是进行分类整理;•对数值型数据则主要是进行分组整理;•适合于低层次数据的整理和显示方法也适合于高层次的数据;但适合于高层次数据的整理和显示方法并不适合于低层次的数据。
统计学课程2、描述统计学

STAT
实践中的统计学
超市逐渐成为人们的主要购物场所。随着我国加入 WTO,国外的一些大型零售商也在国内的一些城市开设了 连锁超市,这无疑加剧了零售业的竞争态势。2003年,一 家超市面对业界新的形式,除了在硬件设施上加大投入外, 更希望在服务质量上下功夫。为了解顾客对服务质量的要 求,这家超市随机抽取了100名前来购物的顾客,让他们 填写一份简单的调查问卷,对本店的服务质量进行评价。 其中的一个问题是:“你认为本店服务质量如何?请在下 面列出的选项上划‘’”。A.好 B.较好 C.一般 D.较差 E.差
B. 某企业计划规定某种产品成本比上年度降低10%,实际产品成本 降低了14.5%,产品成本降低计划完成程度如何?
解:A :劳动生产率计划完成0030)% 100%
(10025)%
假定130%-125%=5%,即劳动生产率提高了5个百分点。
解:B:
产品成本降低计划完成程度=
部门 计划(万元) 实际(万元) 完成计划(%)
甲
700
735
105
乙
500
450
90
丙
300
345
115
合计 1500
1530
102
STAT
(2)考核进度: 某厂产量资料
全年
实际产量
计划 一季 二季 三季 四季
产量(万吨) 64
12
15.6
18.4
要求:(1)分析该厂生产状况。
(2) 安排第四季度的生产。
指计划执行时起至累计实际完成计划规定止,剩下的时间 即为提前完成任务的时间。
年份 53 54 55 56 57 实际完成(亿) 50 100 80 170 93
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
三、数据的排序
按一定顺序将数据排列,以发现一些明显的
特征或趋势,找到解决问题的线索。
排序有助于对数据检查纠错,以及为重新归
类或分组等提供依据;在某些场合,排序本 身就是分析的目的之一。排序可借助于计算 机完成 。
四、变量计算
变量的计算是指根据研究统计的需要,把已
经录入计算机的数据按照一定的算术表达式 或函数,计算产生一系列新变量并予以保存 的过程。 例1,以“sfgz”为变量名计算“年龄”在50岁以 下性别为“女”的职工的“实发工资”。(“实发 工资”=“基本工资”-“保险” ) 例2,根据农民工的出生年份计算、定类、定序数据的图示—环形图
环形图中间有一个“空洞”,总体中的每一部分数
据用环中的一段表示 环形图与圆形图类似,但又有区别:圆形图只能显 示一个总体各部分所占的比例;环形图则可以同时 绘制多个总体的数据系列,每一个总体的数据系列 为一个环。环形图可用于进行比较研究 。环形图 可用于展示定类和定序的数据。
f=20(10)=200
25 20 15 6 0
f=6(40)=240
10 20 30 40
x
50
90
350 300 250 200 150 100 50 0 1 2 3 µÁ Ï Ð1
f/d
35 25 20 15 6 0
f=20(10)=200
f=6(40)=240
10 20 30 40
x
50
90
三、分组数据的图示
1、直方图
f/d
用矩形的宽度和高度来表 35
示 频 数分 布 的 图 形 ,实 际 上 是 用矩 形 的 面 积 来表示 各 组 的频 数 分 布 。 在 直 角 坐 标 中, 用 横 轴 表 示数据 分 组, 纵 轴 表 示 频 数或频 率 ,各组 与 相 应 的 频数就 形成了一 个矩形 , 即直方 图 (Histogram) 。 分 别 称 为 次 数 直方 图 或 者 百 分率直 方图。
长率
甲校学生的父亲职业
f 110 152 288 550 p 0.200 0.276 0.524 1.000 % 20.0 27.6 52.4 100.0
职业 干部 工人 农民 总数
二、定类数据的图示——条形图、圆形图
条形图是用宽度相同的条形的高度或长短来表示数据变动的图
形;条形图有单式、复式等形式 在表示定类数据的分布时,是用条形图的高度来表示各类别数 据的频数或频率;绘制时,各类别可以放在纵轴,称为条形图, 也可以放在横轴,称为柱形图
350 300 250 200 150 100 50 0 1 2 3
0 50 100 150 200 250 300 350 3
µ Á Ï Ð 1
2
µ Á Ï Ð 1
1
1 2 3
1 2 3
三、定序数据的整理(可计算的指标)
计算指标:频数、累计频数、百分率、累 计百分率 适用于简化定类资料的技术也适用定序资 料,但以下技术适用于定序资料 1. 累计频数:将各类别的频数逐级累加 2. 累计频率:将各类别的频率(百分比)逐 级累加
频数(fi)
1 2 5 10 19 25 17 12 5 3 0 1
频率(Pi)
0.01 0.02 0.05 0.10 0.19 0.25 0.17 0.12 0.05 0.03 0.00 0.01
合计
——
100
——
上下组限重叠分组,恰等于某一组限的数据(如下 表中身高164厘米)归于哪一组? 应该按照“上限不包括在内”的原则处理。这就 是说,164应归于“164—168”这一组,而不应归 于“160—l64”这一组。
X L PR c%b ( )r % i
X L PR c%b ( )r % 77分在全班同学成绩的百分比等级 i
PR=百分比等级 C%b=低于临界组距下限的累积百分比
X=需要计算的原始分数
L=临界组距的下限 i=组距的大小
r%=临界组距的百分比
X L 77 69.5 PR c%b ( )r % 35.0 ( )30% 57.5 i 10
(二)二手数据的审核
适用性审核:弄清楚数据的来源、数据的 口径以及有关的背景材料;确定这些数据 是否符合自己分析研究的需要。
时效性审核:应尽可能使用最新的统计数 据,确认是否必要做进一步的加工整理。
二、数据的筛选
对审核过程中发现的错误应尽可能予以纠正。
当发现数据中的错误不能予以纠正,或者有些 数据不符合调查的要求而又无法弥补时,需要 对数据进行筛选 数据筛选的内容包括: 1.将某些不符合要求的数据或有明显错误的数 据予以剔除 2.将符合某种特定条件的数据筛选出来,而将 不符合特定条件的数据予以剔出
男青年身高按4厘米的间距分组时的频数分布 身高间距(厘米) 组中值 (Xi)
148―152 152―156 156―160 160―164 164―168 168―172 172―176 176―180 180―184 184―188 188―192 192―196 150 154 158 162 166 170 174 178 182 186 190 194
一、定类数据的整理(基本过程)
1.列出各类别; 2.计算各类别的频数; 3.制作频数分布表; 4.用图形显示数据。
可计算的指标:
1.频数:落在各类别中的数据个数 2.比例:某一类别数据占全部数据的比值 3.百分比:指定的比例乘以100. 4.比与比率:性别比、出生率、死亡率、人口自然增
(一)组距分组要点
1.将变量值的一个区间作为一组 2.适合于连续变量 3.适合于变量值较多的情况
必须遵循“不重不漏”的原则;可采用等距分
组,也可采用不等距分组
(二)组距分组的原则
1.分组应使各类别构成之和等于总体
“穷举” “互斥”
2.分组设计应能反映统计总体的分布规律性
统计分组主要是为了能很好地反映统计总体的构 成状况,即反映总体中各单位的分布特征。分组设计 要适应这一要求,必须在分组后使总体单位总数在各 组的分配情况能够反映总体的分布规律性。
1 2 3 4
第三节 定距数据的整理与显示
适用于简化品质数据的技术同样 适用于数值型数据 一、单变量值分组(要点)
1. 将一个变量值作为一组 2. 适合于离散变量 3. 适合于变量值较少的情况 例1 统计某社区家庭户人口数分 布情况。
某社区家庭户人口数统计表
人口数(X)
2 3 4 5 6 7 8
第二节
定类、定序数据的 整理与显示
原始资料杂乱无章,需加整理,才能为人
所用。统计资料的整理,其基础是统计分 组。所谓统计分组.就是按统计研究的目 的和要求,将总体单位或全部调查数据按 一定的标志划分成若干组,使组内差异尽 量小,而组与组之间则有明显差异,从而 使原本杂乱无章的资料有序化,以便为在 统计分析中提炼各种有用信息打下基础。
第一部分:描述统计
第二章 组织数据 第三章 集中趋势的测量 第四章 变异性的测量
第二章 组织数据
数据的预处理
主要内容
定类、定序数据的整理 与显示 定距数据的整理与显示
统计表
第一节
数据的预处理 数据审核 数据筛选 数据排序 变量计算
一、数据的审核
(一)原始数据的审核 逻辑检查:从定性角度,审核数据是否符合 逻辑,内容是否合理,各项目或数字之间有 无相互矛盾的现象。(主要用于对定类数据 和定序数据的审核) 计算检查:检查调查表中的各项数据在计算 结果和计算方法上有无错误。(主要用于对 定距数据的审核)
(六)频数密度计算
男青年身高分组数据表
男青年按身高分组 (厘米) 148―156 156―164 164―168 168―172 172―176 176―180 180―188 188―196
合计
频数
3 15 19 25 17 12 8 1 100
组距
8 8 4 4 4 4 8 8 ——
频数密度
3/8 15/8 19/4 25/4 17/4 12/4 8/8 1/8 ——
有了这一规定,就不会在编制连续变量的数列时 ,发生违背“穷举”与“互斥”这两个基本原则 的情况了。
(五)内插法求百分比等级
成绩 90-99 80-89 70-79 60—69 50—59 40—49 合计 频数 3 4 6 3 2 2 20 百分比 累计频数 15 20 20 17 30 13 15 7 10 4 10 2 100 累计百分比 100 85 65 35 20 10
(四)几个概念
1、 分组数据的最大值与最小值
2、分组数据的真实上限与真实下限
90~94,95~99,100~104 3、 组距:真实上限与真实下限之差 4、组距中位点:一组数据中最居中的数值。 m=(最大值+最小值)/2,
等距分组表的几种形式:
(1)上下组限重叠; (2)上下组限间断
直方图与条形图的区别: ( 1)条形图是用条形的长度 (横置时 )表示各 类别频数的多少,其宽度 ( 表示类别 ) 则是固 定的;直方图是用面积表示各组频数的多少, 矩形的高度表示每一组的频数或百分比,宽 度则表示各组的组距,其高度与宽度均有意 义。 (2)直方图的各矩形通常是连续排列,条形 图则是分开排列。
等距分组与不等距分组在频数分布上的差异 等距分组:各组频数的分布不受组距大小的影
响;可直接根据绝对频数来观察频数分布的特 征和规律。 不等距分组:各组频数的分布受组距大小不同 的影响;各组绝对频数的多少不能反映频数分 布的实际状况,需要用频数密度(频数密度= 频数/组距)反映频数分布的实际状况。