CAMP和随机因子方法比较
局部外用小分子药物治疗斑秃的研究进展

局部外用小分子药物治疗斑秃的研究进展作者:韩君雅吴维维祝文文方险峰来源:《中国医学创新》2024年第05期【摘要】斑秃(AA)是一种常见的毛囊自身免疫性疾病,外用药物的应用对轻中度AA 具有重要作用。
传统局部外用药物,如糖皮质激素、米诺地尔、局部刺激剂等对于部分患者仍缺乏满意疗效,且长期使用受到副作用的限制。
随着对AA发病机制的进一步了解,酪氨酸蛋白激酶(JAK)抑制剂、磷酸二酯酶抑制剂等小分子药物给斑秃的治疗带来了新的希望。
目前仍需要更多研究证明其有效性及安全性。
【关键词】斑秃外用药物酪氨酸蛋白激酶抑制剂磷酸二酯酶抑制剂Research Progress of Topical Small Molecule Drugs in Treating Alopecia Areata/HAN Junya,WU Weiwei, ZHU Wenwen, FANG Xianfeng. //Medical Innovation of China, 2024, 21(05): -188[Abstract] Alopecia areata (AA) is a common autoimmune disease of hair follicles, the application of topical drugs plays an important role in mild to moderate AA. Traditional topical drugs such as Glucocorticoids, Minoxidil, topical contact irritants, etc. lack satisfactory efficacy for some patients, and long-term use is limited by side effects. With the further understanding of the pathogenesis of AA, small molecule drugs such as JAK inhibitors and phosphodiesterase inhibitors have brought available treatment for alopecia areata. More researches are needed to prove its efficacy and safety.[Key words] Alopecia areata Topical drugs JAK inhibitors Phosphodiesterase inhibitors斑禿(alopecia areata,AA)是一种自身免疫相关的非瘢痕性毛发脱失性疾病,可发生在身体任何有毛发的部位,其发病率占脱发的0.1%~0.2%[1-2],我国AA的患病率为0.27%[3]。
抗血小板药物

• 3、疗效评价:美国和加拿大的多中心临 床研究,采用随机、双盲和安慰剂对照, 对1072例脑卒中后一周至四个月的患者, 进行了长达3年的随防。结果表明安慰剂 组中每年缺血性脑脑卒中、急性心梗或 血管性致死者发生率为15.3%,而噻氯 匹定组为10.8%,显示应用噻氯匹定相 对危险性减少了30.2%。我们自己的研 究亦证实噻氯匹定的疗效由于阿司匹林。
抗血小板药物与缺血性脑血管病
临邑县人民医院
• 缺血性脑血管病的主要发病形式是动脉血 栓形成(脑血栓),动脉血栓形成一般分 为3个时相:1)血小板粘附,2)血小板 释放和聚集,3)凝血机制的活化。由此 可以看出,血小板活化是动脉血栓的起始 因素之一,并在动脉血栓形成的过程中起 着重要的作用。因此抗血小板疗法是防治 缺血性脑血管病的有效措施,是当今公认 的治疗缺血性脑血管病三大有效疗法之一 (t-PA,ASA,StrokeUnite)。
二、抑制血小板激活因子(PAF)药
• 血小板活化因子(Platelet Activating Factor, PAF)最早发现于1966年,因能强烈地激活血 小板而命名。它是一种磷脂,在体内主要由白血 病和血小板产生。随着不断深入的研究,现已证 实它参与多种病理生理过程如动脉血栓形成,急 性炎症,中毒性休克,急性过敏性疾病。它与中 风的关系日益受到重视,动物实验证明它能直接 诱导动脉血栓形成,是血小板活化途径之一。现 已发现的PAF拮抗剂有多种,如银杏叶素、海风 藤酮等,代表药物是银杏叶制剂(EGB)。银 杏叶是一种特异性PAF拮抗剂。应用的范围包括 缺血性脑血管病、脑血管病引起的眩晕及听力障 碍、学习记忆障碍和痴呆。
生物统计名词

一、名词解释因素:将在试验中人为地改变并研究其变化对试验结果的影响的试验条件称为因素。
水平:因素内不同的质量或数量类别为水平。
处理:各种试验材料或方法的通称。
处理组合:多因素试验的处理不是某个因素的某个水平,而是每个因素任意某个水平的组合,我们称之为处理组合。
处理效应:试验处理对所研究的性状所起的增进或减少的作用称为处理效应。
简单效应(主效应):试验因素的水平变化而产生的效应称为简单效应;交互作用效应(互作):不同因素的不同水平搭配组合在一起时除了产生各自的简单效应外,还将产生一些额外的效应,这种额外效应称为交互作用效应。
随机排列:就是在一个重复内,试验方案所规定的每个处理安排在哪一个小区上要排除主观因素的影响,采取随机的方式来确定。
局部控制:是指试验中分范围、分地段地控制非处理因素,使非处理因素对各处理的影响趋于最大程度的一致。
重复:在试验中,将一个处理实施在两个或两个以上的试验单位上。
随机抽样:总体中每个个体均有相等的机会抽作样本的这种抽样方法。
抽样误差:在理论上,我们可以从总体中不断抽取若干个样本,每一样本的平均数不可能恰好等于总体的平均数,它们之间是有一定差异的,这个差异就叫做抽样误差。
唯一差异原则:指在试验中进行比较的各个处理,其区别仅在于各个试验因素的水平之间,其余所有的条件应当完全一致的称为唯一差异原则。
边际效应:指种植在小区或试验地边上的植株因其光照、通风和根系吸收范围等生长条件与中间的植株不同而产生的差异。
生长竞争:指不同处理的相邻小区之间的影响。
准确度:试验中某一性状的观察值与其相应真值接近的程度称为试验的准确度。
精确度:试验中某一性状的重复观察值彼此接近的程度称为试验的精确度。
系统误差:由于试验处理以外其他明显而有规律、有方向的不一致所造成的定向性偏差,称系统误差。
随机误差:由有一些难以控制的偶然因素所造成的无规律、偶然的偏差,称为随机误差。
统计误差,即反映某客观现象的一个量在测量、计算或观察过程中由于某些错误或通常由于某些不可控制的因素的影响而造成的变化偏离标准值或规定值的数量。
【糖尿病足临床进展】基于改善微循环障碍的糖尿病周围神经病变治疗进展

【糖尿病足临床进展】基于改善微循环障碍的糖尿病周围神经病变治疗进展摘要微循环障碍是糖尿病周围神经病变(diabetic peripheral neuropathy, DPN)发生的重要病理生理基础之一。
糖尿病患者血糖控制不佳可导致微血管基底膜增厚、内皮细胞肿胀增生和血管通透性增加等血管结构改变,同时伴有血管舒张功能障碍和血液流变学异常,而微循环的这些变化可通过引发能量代谢障碍、山梨醇积聚和肌醇耗竭及氧化应激异常增高等效应进而造成DPN的发生发展。
前列腺素E1、前列环素衍生物和胰激肽原酶和磷酸二酯酶抑制剂等药物可通过不同机制改善微循环障碍,增加神经组织血流灌注,减轻神经组织缺血缺氧性损伤。
随着经济发展、人口老龄化和人民生活方式的转变,糖尿病等慢性非传染性疾病的发病率大幅增加。
2017年中国疾病预防控制中心流行病学调查显示,中国20岁以上成人糖尿病患病率增长至10.9%,据此可推测我国成年糖尿病患者人数约为1.14亿, 已成为世界糖尿病患者人数最多的国家[1]。
作为糖尿病最常见的慢性并发症之一,糖尿病周围神经病变(diabetic peripheral neuropathy, DPN)的患病率也随之增加,美国流行病学调查显示约半数以上的糖尿病患者将会出现DPN。
2010年上海的一项流行病学调查显示30岁以上2型糖尿病(type 2 diabetes mellitus,T2DM)患者DPN发病率约为61.8%[2],因此,DPN越来越受到人们的关注,对其病因和发病机制的研究变得尤为重要。
关于DPN发病机制目前已经提出了多种学说,如代谢紊乱、微循环障碍、神经营养因子缺乏和免疫损伤因素等,其中微循环障碍在DPN的发生发展中发挥极其关键的作用。
本文就DPN中微循环障碍的表现、微循环障碍在DPN发病机制中的作用及基于改善微循环障碍的DPN治疗进展综述如下。
一、DPN中微循环障碍的表现1.血管结构改变:对轻至重度DPN患者的神经活检研究显示,其神经内膜微血管发生了基底膜厚度增加、周细胞变性和内皮增生等结构变化。
camp计算公式

camp计算公式在计算机科学领域,CAMP是一种常用的计算公式,用于计算某个变量或指标的值。
CAMP即“Computer Algorithm for Mathematical Problems”的缩写,意为“用于数学问题的计算机算法”。
CAMP公式的具体形式如下:CAMP = (P * A * M) / P其中,P代表问题,A代表算法,M代表数学,P代表程序。
根据CAMP公式,我们可以看出,计算CAMP的值需要将问题、算法、数学和程序综合考虑。
其中,问题的重要性和难度(P)越大,算法的效率和复杂度(A)越高,数学的准确性和适用性(M)越强,程序的优化和可读性(P)越好,CAMP的值就越高。
因此,CAMP可以作为评估计算问题解决方案的指标,用于比较不同方案的优劣。
下面,我们以一个实际的例子来说明CAMP的应用。
假设我们需要解决一个线性方程组,如下所示:2x + 3y = 74x - 2y = 1我们可以使用高斯消元法来求解这个方程组。
首先,我们将方程组转化为增广矩阵的形式:[2 3 | 7][4 -2 | 1]然后,通过一系列行变换,将增广矩阵化简为行阶梯形式:[1 3/2 | 7/2][0 7 | 5 ]通过回代法,求解出方程组的解为x = 1, y = 2/7。
接下来,我们来计算这个解的CAMP值。
首先,问题(P)是求解线性方程组,这是一个常见的数学问题。
算法(A)是高斯消元法,这是一种经典的线性代数算法。
数学(M)是线性代数理论和方法。
程序(P)是用于实现高斯消元法的计算机程序。
根据CAMP公式,我们可以计算出CAMP的值:CAMP = (P * A * M) / P = 1 * 1 * 1 / 1 = 1因此,这个解的CAMP值为1。
可以看出,CAMP值为1表示这个解的计算方案在问题、算法、数学和程序四个方面都是合理的、有效的。
如果CAMP值较低,可能意味着计算方案存在问题,需要重新评估和改进。
分子生物学答案

分子生物学答案分子生物学答案一、名词1、鸟枪法(Shotgun method):使用基因组中的随机产生的片段作为模板进行克隆的方法。
使用限制性内切酶将带有目的基因的DNA链切成若干小段,再使用DNA连接酶将其整合到载体的基因中,并使其表达。
2、色氨酸操纵子(tryptophane operon):负责色氨酸的生物合成,当培养基中有足够的色氨酸时,这个操纵子自动关闭,缺乏色氨酸时操纵子被打开,trp基因表达,色氨酸或与其代谢有关的某种物质在阻遏过程(而不是诱导过程)中起作用。
3、酶切图谱(Macrorestriction Map):描述限制性内切酶的酶切点的位置和距离信息的图谱。
4、原位杂交(in situ hybridization):将标记的核酸探针与细胞或组织中的核酸进行杂交,称为原位杂交。
5、结构域(domain):是构成蛋白质三级结构的基本单元,是指生物大分子中具有特异结构和独立功能的区域,是蛋白质生理功能的结构基础,这种相对独立的区域性结构就称为结构域。
6、DNA杂交(Southern blotting):又称为Southern杂交,即用放射性标记的探针与靶DNA进行杂交的技术。
7、基因组文库(genomic library):用限制性内切酶切割细胞的整个基因组DNA,可以得到大量的基因组DNA片段,然后将这些DNA片段与载体连接,再转化到细菌中去,让宿主菌长成克隆。
这样,一个克隆内的每个细胞的载体上都包含有特定的基因组DNA片段,整个克隆群体就包含基因组的全部基因片段总和称为基因组文库(短答案:是指采用基因组克隆的方法,克隆的一套基因组DNA片段。
)8、粘性末端(cos site-carring plasmid):当一种限制性内切酶在一个特异性的碱基序列处切断DNA时,就可在切口处留下几个未配对的核苷酸,叫做粘性末端。
9、一致序列(又称保守序列:conserved sequence):遗传物质里的片段极少发生突变而且在不同生物中广泛存在。
camp试验原理

camp试验原理Camp试验原理Camp试验原理是一种常用于科学研究和实验设计的方法。
它通过对两组或多组实验对象进行不同处理,观察它们之间的差异,从而得出相关结论。
Camp试验原理的应用广泛,涵盖了生物学、医学、心理学等多个领域。
一、Camp试验原理的基本步骤1. 确定实验对象:首先需要明确研究的目标和对象,确定实验需要观察和比较的变量。
2. 设计实验组和对照组:根据研究的目的和假设,将实验对象分为实验组和对照组。
实验组接受特定处理或介入,而对照组则不接受处理。
3. 随机分组:为了排除其他因素的干扰,需要使用随机分组的方法将实验对象分配到实验组和对照组。
4. 进行实验处理:实验组接受特定处理,对照组则保持原样。
处理可以是给予特定药物、施加特定环境条件等。
5. 观察和记录数据:对实验组和对照组进行观察和记录,包括定量和定性的数据。
这些数据可以是生物学指标、心理学问卷调查等。
6. 数据分析和结论:通过对实验数据进行统计分析,比较实验组和对照组之间的差异。
根据分析结果,得出结论并验证研究假设。
二、Camp试验原理的应用举例1. 药物疗效评价:在临床研究中,常使用Camp试验原理评估药物的疗效。
将患者随机分为实验组和对照组,实验组接受药物治疗,对照组接受安慰剂或其他常规治疗。
观察和比较两组患者的症状、生理指标等,来评估药物的治疗效果。
2. 教育干预效果评估:在教育研究中,可以使用Camp试验原理评估教育干预的效果。
将学生随机分为实验组和对照组,实验组接受特定的教育干预措施,对照组接受传统教育。
通过比较两组学生的学习成绩、学习动机等指标,来评估教育干预的效果。
3. 心理学实验设计:在心理学研究中,也常使用Camp试验原理进行实验设计。
例如,研究者可以将被试随机分为实验组和对照组,实验组接受特定的心理干预,对照组不接受干预。
通过观察和比较两组被试的心理指标、行为反应等,来研究特定心理因素对人类行为的影响。
三、Camp试验原理的优缺点1. 优点:a. 可以控制实验条件:通过随机分组和对照组设计,可以控制实验条件,排除其他因素的干扰。
癌基因、抑癌基因、生长因子

癌基因、抑癌基因和生长因子肿瘤的发生是由于细胞的增殖与分化失常所导致的恶性生长现象。
在正常情况下,细胞的增殖受到多种因素的调控,调控失衡可能引起异常的增殖和持续的分裂。
细胞的正常生长与增殖是由两大类基因来调控的,一类是正调节信号,促进细胞生长和增殖,并阻止其发生终未分化,调控失常时表现为肿瘤细胞的恶性生长,现已知多数癌基因(oncogene)起这一作用;另一类为负调节信号,抑制增殖,促进分化、成熟和衰老,最后调亡(apoptosis),抑癌基因(ancer suppressive gene,anti-oncogene)则在这方面发挥作用。
当这两类信号在细胞内产生的效应相互拮抗,维持平衡,对正常细胞的生长、增殖和衰亡进行精确地调控。
当这两类基因中任何一种或它们共同的变化,即有可能引起细胞增殖失控导致肿瘤的发生。
癌基因与抑癌基因的作用机制涉及基因表达调控及细胞分裂,分化过程。
这些生物学效应又与癌基因表达产物——类生长因子多肽及其受体有着极为密切的关系;癌基因可以编码类生长因子多肽及其受体分子,通过细胞内信息传递系统刺激细胞增殖。
由此可见,肿瘤的发生与癌基因、抑癌基因及生长因子三者的功能是密切相关的。
第一节癌基因癌基因最初的定义是指能在体外引起细胞转化、在体内诱发肿瘤的基因。
它是细胞内总体遗传物质的组成部分,人们将这类存在于生物正常细胞基因组中的癌基因称为原癌基因(proto -oncogenes,pro-onc)或称细胞癌基因(Cellular-oncogene,c-onc)。
在正常情况下,这些基因处于静止或低表达的状态,不仅对细胞无害,而且对维持细胞正常功能具有重要作用;当其受到致癌因素作用被活化并发生异常时,则可导致细胞癌变。
癌基因的名称一般用3个斜体小写字母表示,如 myc、 ras、 src等。
一、病毒癌基因肿瘤病毒是一类能使敏感宿主产生肿瘤或使培养细胞转化成癌细胞的动物病毒,根据其核酸组成分为DNA病毒和RNA病毒(即逆转录病毒retrovirus)。
科学网——精选推荐

科学⽹做过16s测序的⼩伙伴们都知道测完之后会拿到⼀份结果报告但这并不代表可以开始写⽂章了看似⼀⼤堆数据图表却不知如何下⼿这是很多⼈头疼的地⽅那么怎样给报告中的数据赋予灵魂让它真正成为对你有帮助的分析呢?今天我们来详细解读下。
⼀⽂扫除困惑⾸先什么是16S rRNA?16S rRNA 基因是编码原核⽣物核糖体⼩亚基的基因,长度约为1542bp,其分⼦⼤⼩适中,突变率⼩,是细菌系统分类学研究中最常⽤和最有⽤的标志。
16S rRNA基因序列包括9个可变区和10个保守区,保守区序列反映了物种间的亲缘关系,⽽可变区序列则能体现物种间的差异。
16S rRNA基因测序以细菌16S rRNA基因测序为主,核⼼是研究样品中的物种分类、物种丰度以及系统进化。
⼆代⾼通量测序原理⽬前⼆代测序是⼀个边合成边测序的过程,使⽤的是荧光可逆终⽌⼦。
每个可逆终⽌⼦的碱基3’端都有⼀个阻断基团,⽽在侧边带有⼀种荧光。
由于有4种不同的碱基(ATCG),因此也会有对应4种不同颜⾊的荧光。
开始扩增每次结合上⼀个碱基,DNA的扩增便会停⽌,此时能收到⼀种荧光信号。
然后放试剂除去阻断基团,进⾏下⼀个碱基的结合,以此类推得到⼀连串的荧光信号组合序列。
⽽根据荧光的颜⾊我们便可以确定每⼀个位点的基因型,即可以得到这⼀段DNA⽚段的序列。
环境样品⾼通量分析需要重复么?在进⾏实验设计前,这是有些⼩伙伴⾯临的⼀个问题。
环境样本由于来源和条件不完全可控,每个样品之间会存在很⼤的差异,即便是相同样本的不同取样时间和部位也会存在⼀定的差异。
基于⾼通量测序主要是为了了解样品的菌群构成和功能分析,以及寻找不同环境之间的差异,包括菌和功能基因以及代谢。
如果仅做单⼀样本,很可能结论只能代表这个单⼀取样样本的信息,⽆法排除不同样本重复之间的差异,也就可能得不到真正代表环境差异的结果。
所以环境样品不仅要重复⽽且还应该以分组⽅式取尽量多的样本以全⾯的代表⼀个环境条件下的各种变异情况。
分子生物学考试复习重点

分子生物学重点1.将外源基因导入的方法常用的基因工程真核细胞包括酵母细胞、动物细胞和植物细胞。
(1)外源基因导入酵母细胞:在对酵母细胞进行外源DNA转化时,一般先需要用酶将其细胞壁消化水解,变成原生质体。
蜗牛消化酶具有纤维素酶、甘露聚糖酶、葡萄糖酸酶以及几丁质酶等,对酵母菌细胞壁有良好水解作用。
原生质体在氯化钙和聚乙二醇存在下,重组DNA能容易地被宿主细胞吸收,转化的原生质体悬浮在营养瓶中,即可再生出新的细胞壁。
(2)外源基因导入动物细胞常用的方法有:1.磷酸钙共沉淀法。
2.DEAE-葡聚糖或聚阳离子,它们能结合DNA并促使细胞吸收;3.脂质体法4.脂质转染法5.电穿孔法6.显微注射法(3)外源基因导入植物细胞常用的方法有:1.转化法2.电穿孔和脂质体法3.显微注射法5.基因枪法4.农杆菌感染法:根瘤农杆菌的Ti质粒上有一段T-DNA ,又称转移DNA,能携带外源基因转移到植物细胞内,并整合到染色体DNA中,因此Ti质粒是目前植物基因工程中最常用的理想的基因载体。
2.核糖体活性中心(核糖体的活性位点)(1)mRNA结合位点(2)P位点(3)A位点(4)肽基转移酶活性位点(转肽酶中心)(5)5SrRNA位点(50S上)(6)E位点(50S上)与氨酰基-tRNA释放有关。
大小亚基在合成中的分工小亚基:对mRNA特殊序列的识别(SD序列)密码子与反密码子的相互作用。
大亚基:AA-tRNA,肽基-tRNA的结合,肽键的形成等。
3.凝胶电泳(操作的主要因素)技术原理流程图目的:分离不同的DNA分子电泳迁移率:电泳分子在电场作用下的迁移速度。
影响迁移率的因素:(1)与电场强度、电泳分子净电荷成正比;(2)与电泳分子的摩擦系数成反比分子摩擦系数为分子大小、极性、介质粘度的函数。
.DNA和RNA在电场中为多聚阴离子,电泳时向正极移动。
速度在于分子大小和构型。
.电泳介质:一般用琼脂糖和聚丙烯酰胺,浓度与所分离的DNA和RNA的大小有关。
camp模型公式

camp模型公式摘要:1.引言2.camp 模型的概念和背景3.camp 模型的公式推导4.camp 模型的应用领域5.结论正文:【引言】在机器学习和数据挖掘领域,聚类算法是一种重要的研究方法。
其中,CAMP(Cluster Analysis by Matrix Programming)模型是一种基于矩阵编程的聚类方法。
本文将详细介绍CAMP 模型的公式及其应用。
【CAMP 模型的概念和背景】CAMP 模型是由我国学者提出的一种聚类方法,它的核心思想是通过矩阵编程来解决聚类问题。
CAMP 模型主要应用于大规模数据的聚类分析,特别适用于高维数据的聚类。
【CAMP 模型的公式推导】CAMP 模型是基于矩阵的,它的基本假设是数据集中存在k 个聚类,每个聚类用一个矩阵表示。
设数据集共有n 个样本,每个样本有d 个特征,则数据集可以表示为X = [x1, x2, ..., xn],其中xi = [x1i, x2i, ..., xdi],i = 1, 2, ..., n。
CAMP 模型的目标是最小化以下目标函数:SC(X, C) = ∑(i, j)∈E[||xi - xj||^2] + λ||C||^2其中,||·||表示矩阵的Frobenius 范数,E 表示样本间距离的矩阵,λ为正则参数。
【CAMP 模型的应用领域】CAMP 模型广泛应用于数据挖掘、机器学习、图像处理、生物信息学等领域。
特别在大规模数据和高维数据的聚类分析中,CAMP 模型具有较好的性能。
【结论】CAMP 模型是一种基于矩阵编程的聚类方法,通过优化目标函数来实现数据的聚类。
基于cAMP信号通路研究miR-7a2对青春期大鼠雄性生殖系统发育的影响
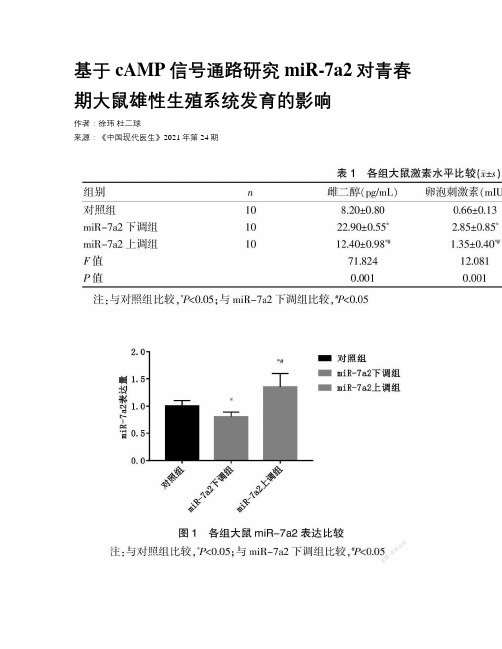
基于cAMP信号通路研究miR-7a2对青春期大鼠雄性生殖系统发育的影响作者:徐玮杜二球来源:《中国现代医生》2021年第24期[摘要] 目的研究基于环磷酸腺苷(cAMP)信号通路分析微小RNA-7a2(miR-7a2)对青春期大鼠雄性生殖系统发育的影响。
方法本研究选取2020年3—10月健康、清洁级Wistar雄性鼠龄3周大鼠30只,随机分为对照组(生理盐水)、miR-7a2上调组(超表达pmcherry-Flag-miR-7a2)、miR-7a2下调组(慢病毒质粒miR-7a2-sh RNA-1),每组各10只。
检测三组激素水平,统计体重、睾丸重量、精子畸变、活动度,观察睾丸形态学,检测cAMP信号通路相关蛋白腺苷酸环化酶(AC)、磷酸二酯酶(PDE)、蛋白激酶(PK)。
结果 miR-7a2上调组miR-7a2表达高于对照组和miR-7a2下调组;miR-7a2下调组miR-7a2表达低于对照组(P<0.05)。
miR-7a2上调组雌二醇、卵泡刺激素水平低于miR-7a2下调组;睾酮水平高于miR-7a2下调组(P<0.05)。
miR-7a2上调组体重、睾丸重量、精子密度高于miR-7a2下调组,精子畸变率低于miR-7a2下调组(P<0.05)。
miR-7a2上调组良好、一般精子活动度高于miR-7a2下调组;不良、死亡精子活动度低于miR-7a2下调组(P<0.05)。
miR-7a2上调组AC蛋白表达低于miR-7a2下调组,PK蛋白表达高于miR-7a2下调组(P<0.05)。
结论 miR-7a2上调能促进青春期大鼠雄性生殖系统发育,其作用机制与cAMP信号通路有关。
[关键词] 环磷酸腺苷;微小RNA-7a2;青春期;生殖系统发育[中图分类号] R691.5 [文献标识码] A [文章编号] 1673-9701(2021)24-0045-05Effect of miR-7a2 on the development of the male reproductive system in adolescent rats based on the cAMP signaling pathwayXU Wei DU ErqiuDepartment of Gynecology, Taizhou Central Hospital in Zhejiang Province (Taizhou University Hospital), Taizhou 318000, China[Abstract] Objective To investigate the effect of microRNA-7a2 (miR-7a2) on the development of the male reproductive system in adolescent rats based on the cyclic adenosine monophosphate (cAMP) signaling pathway. Methods Thirty healthy, clean Wistar male rats aged three weeks from to March to October 2020 were randomly divided into the control group (saline), the miR-7a2 up-regulation group (overexpression of pmcherry-Flag-miR-7a2), and miR-7a2 down-regulation group (lentiviral plasmid miR-7a2-shRNA-1), with ten rats in each group. Hormone levels were detected. The body weight, testicular weight, sperm aberrations,and motility were measured. The testicular morphology was observed. The cAMP signaling pathway-related proteins adenylate cyclase (AC), phosphodiesterase (PDE), and protein kinase (PK) were measured. Results miR-7a2 expression was higher in the miR-7a2 up-regulation group than in the control and miR-7a2 down-regulation groups. miR-7a2 expression was lower in the miR-7a2 down-regulation group than in the control group(P<0.05). Estradiol and follicle-stimulating hormone levels were lower, and testosterone levels were higher in the miR-7a2 up-regulation group than in the miR-7a2 down-regulation group(P<0.05). Body weight, testicular weight, andsperm density were higher, and sperm aberration rate was lower in the miR-7a2 up-regulation group than in the miR-7a2 down-regulation group(P<0.05).The excellent and general sperm motility in the miR-7a2 up-regulation group was higher than that in the miR-7a2 down-regulation group. The poor and dead sperm motility in the miR-7a2 up-regulation was lower than in the miR-7a2 down-regulation group(P<0.05). AC protein expression was lower, and PK protein expression was higher in the miR-7a2 up-regulation group than in the miR-7a2 down-regulation group(P<0.05). Conclusion The up-regulation of miR-7a2 can promote the development of the male reproductive system in adolescent rats, and the mechanism is related to the cAMP signaling pathway.[Key words] Cyclic adenosine monophosphate; microRNA-7a2; Puberty; Reproductive system development近年来研究数据显示,男性精子质量和数量呈下降趋势,前列腺癌、睾丸癌患者人数增加,其受环境分泌物的影响较大[1-2]。
真核基因表达调控的一般规律

(5) mRNA5 ′端非编码区长度对翻译的影响
铁结合调节蛋白
3′
3′
翻译起始因子(eIF2)的调控
2. mRNA稳定性调节
3′端非编码区结构影响其稳定性:重复 AUUUA序列,引起mRNA 不稳定;
蛋白因子的结合可改变mRNA的半衰期.
3.小分子RNA对翻译水平的影响(反义RNA)
真核生物基因多层次表达调控
一. DNA水平的调控* 二. 转录水平的调控----最重要 三. 转录后水平的调控* 四. 翻译水平的调控 五. 翻译后水平的调控*
一. DNA水平的调控
(1) 染色质的丢失 (2) 基因扩增 (3) 基因重排 (4) DNA甲基化 (表达降低, X染色体失活中心) (5) 染色体结构 (常染色质 和 异染色质)
3. 转录后的基因沉默(RNA干涉)
Posttranscriptional gene silencing (PTGS) = RNA interference(RNAi)
1. mRNA的选择性剪接
(1)内含子和外选子的选择
1. mRNA的选择性剪接
(2) 转录终止信号的选择
RNAi (RNA干扰)
去甲基化,转录 失活 甲基化,失活
•常染色质:结构松散, 基因表达
•异染色质:结构紧密, 基因不表达
•有基因表达活性的染 色质DNA对 DNaseⅠ 更敏感,即DnaseⅠ的 敏感性可作为该基因 的转录活性的标志。
二. 转录水平的调控---最重要
转录起始--反式作用因子活性调节 顺式作用元件 和 反式作用因子的相互作用; 以正调控为主
1.线虫、昆虫、哺乳动物、植物和真菌
3.生物学功能:细胞内免疫,阻止外源病毒 和核酸的入侵,阻断逆转作子的作用。
实验统计学中的因子设计与方差分析解析

实验统计学中的因子设计与方差分析解析实验统计学是应用统计学的一个重要分支,它研究的是如何通过实验来获取数据,并通过统计方法对这些数据进行分析和解释。
因子设计与方差分析是实验统计学中的两个重要概念,它们在实验设计和数据分析中起着关键的作用。
一、因子设计因子设计是指在实验中将自变量分为若干个因子,并对每个因子设定不同的水平,以便观察因变量在不同因子水平下的变化情况。
因子设计的目的是确定哪些因子对因变量有显著影响,以及不同因子水平下因变量的差异。
在因子设计中,有两种常见的设计方式:完全随机设计和随机区组设计。
完全随机设计是指将实验对象随机分为若干组,每组只设置一个因子水平。
随机区组设计是指将实验对象分为若干个区组,每个区组内的实验对象设置不同的因子水平。
二、方差分析方差分析是一种常用的统计方法,用于比较两个或多个样本均值之间的差异是否显著。
在因子设计中,方差分析可以用来分析不同因子水平下因变量的差异是否有统计学意义。
方差分析的基本原理是将总方差分解为组内方差和组间方差。
组内方差反映了同一因子水平下因变量的随机误差,组间方差反映了不同因子水平下因变量的差异。
通过计算组内方差和组间方差的比值,可以得到F值,进而判断不同因子水平下因变量的差异是否显著。
在进行方差分析时,需要注意的是要选择适当的方差分析模型。
常见的方差分析模型有单因子方差分析、双因子方差分析和多因子方差分析等。
选择合适的模型可以提高分析的准确性和可靠性。
三、实例分析为了更好地理解因子设计与方差分析的应用,我们以一个实例进行分析。
假设我们想研究不同施肥量对植物生长的影响,我们可以将施肥量作为因子,设置不同的施肥水平,然后观察植物生长的情况。
在实验中,我们随机选择若干个实验对象,并将它们分为不同的施肥组。
然后,在每个施肥组中,我们设置不同的施肥水平,如低施肥量、中施肥量和高施肥量。
最后,我们测量每个施肥组中植物的生长情况,如株高、叶片数量等。
通过方差分析,我们可以比较不同施肥组之间植物生长的差异是否显著。
分子生物学考试知识点研究生

名词解释1、沉默子(silencer):某些基因的负性调节元件,能够同反式因子结合从而阻断增强子及反式激活因子的作用,并最终抑制该基因的转录活性。
2、启动子:是RNA聚合酶特异性识别和结合,并启动转录的特定DNA序列。
至少包括一个转录起始点以及一个以上的功能组件。
3、复制子(replicon):是从一个DNA复制起点开始的DNA复制区域,是独立完成复制的功能单位4、终止子(terminator T):是给予RNA聚合酶转录终止信号的DNA序列。
5、增强子(enhancer):指远离转录起始点、决定基因的时间和空间特异性、增强启动子转录活性的DNA序列。
其发挥作用的方式通常与方向、距离无关。
6、操纵子:每一个由若干个结构基因及其上游的调控序列组成的转录区段,共同组成一个转录单位。
一个操纵子只含一个启动序列(promoter)及数个可转录的编码基因。
7、结构基因:基因中编码RNA或蛋白质的DNA序列。
大多数真核生物结构基因的DNA序列由编码序列和非编码序列两部分组成。
8、重复基因:指染色体上存在多数拷贝基因。
重复基因往往是生命活动最基本,最重要的功能相关的基因。
9、断裂基因:编码序列中间插入的无编码作用的碱基序列。
10、重叠基因:指两个或两个以上的基因共有一段DNA序列,或是指一段DNA序列成为两个或两个以上基因的组成部分。
11、管家基因:在生物体中有些基因的表达在生命的全过程中都是必需的.是维持细胞最低功能所必不可少的基因.在一个生物个体的几乎所有细胞中持续表达,这些基因称为管家基因。
12、跳跃基因(jumping gene):转座子每次移动时携带着转座必需的基因一起在基因组内跃迁,所以转座子又称跳跃基因(jumping gene)。
是那些能够进行自我复制,并能在生物染色体间移动的基因物质。
13、假基因(pseudogene):一种核苷酸序列同其相应的正常功能基因基本相同,但却不能合成出功能蛋白质的失活基因。
阿斯美治疗矽肺的随机对照研究

阿斯美治疗矽肺的随机对照研究目的:探讨阿斯美治疗矽肺的临床疗效。
方法:将我院收治的160例矽肺患者随机分为两组,每组80例,其中对照组采取常规治疗,观察组在常规治疗基础上加用阿斯美治疗,比较两组患者的临床疗效及肺功能改善情况。
结果:观察组治疗总有效率为88.75%,对照组为68.75%,观察组明显高于对照组,两组比较差异显著(P<0.01);观察组与对照组治疗后FEV1%分别为51.20±6.85、46.05±5.29,较治疗前均明显改善(P<0.01),但观察组改善更明显(P<0.01)。
结论:阿斯美治疗矽肺疗效显著,能明显改善患者肺功能,值得临床推广应用。
标签:阿斯美矽肺疗效随机对照矽肺是因长期吸入含游离二氧化硅(SiO2)粉尘引发的以肺组织广泛纤维增生性改变为主的一种慢性全身性疾病,随着病程的进展,患者全身营养状况恶化,极易出现肺感染。
矽肺是我国发病最多的职业病,也是危害最广、最为严重的尘肺病,每年都有大量新生病例。
矽肺具有进行性的特征,一旦发生,即便是脱离粉尘作业,患者肺部纤维化进展仍在继续进行,至中晚期会并发肺结核、肺气肿、自发性气胸、肺源性心脏病等,最终造成呼吸与循环衰竭,部分会产生肺癌[1]。
对于矽肺的治疗目前尚缺乏可靠的治疗方法,常规方法主要为吸氧、控制感染、改善卧位、拍背等,但疗效欠佳。
阿斯美具有镇咳、平喘、祛痰等功效,故应用于矽肺的治疗上效果显著,本研究在常规治疗基础上联合应用阿斯美疗效满意,现分析报告如下。
1. 资料与方法1.1 一般资料将2012年2月~2014年6月来我院就诊的160例矽肺患者随机分为两组,每组80例。
所有患者均符合《尘肺病诊断标准》(GBZ70-2009),小阴影总体密集度至少达到1级,分布范围达到2个肺区,临床表现为呼吸衰弱、呼吸道分泌物增多、痰黏稠不易咳出、胸闷、气促、活动耐力受限等。
所有患者均有生产性粉尘接触史,并经职业、临床表现、x线片等实验室检查确诊。
camp评分生信

camp评分生信近年来,生物信息学领域的研究越来越依赖于计算方法和技术,而Camp 评分作为一种评估蛋白质结构稳定性的方法,也在生信分析中得到了广泛应用。
本文将详细介绍Camp评分生信方法的原理、步骤及实例应用,以期为生物信息学研究者提供实用的分析技巧。
一、引言Camp评分,全称为Coupled amino acid mutation and macroscopic partition function scoring,是一种基于蛋白质序列预测结构稳定性的方法。
在生物信息学领域,蛋白质结构稳定性评估对于预测蛋白质功能、解析突变效应及药物筛选等方面具有重要意义。
因此,掌握Camp评分生信方法对于研究者来说是一门必备技能。
二、Camp评分生信方法的原理概述Camp评分生信方法基于蛋白质序列,通过计算不同氨基酸替换对蛋白质结构稳定性的影响,从而评估蛋白质的稳定性。
该方法主要依赖于两个核心概念:突变分析和宏观分区函数。
1.突变分析:评估单个氨基酸替换对蛋白质稳定性的影响,通常采用点突变实验或计算突变评分。
2.宏观分区函数:对蛋白质序列中的氨基酸进行分组,计算各组在不同温度下的自由能变化,以反映蛋白质在不同温度下的稳定性。
三、Camp评分生信方法的步骤详解1.蛋白质序列输入:获取待评估的蛋白质序列,可从数据库中下载或通过实验测得。
2.氨基酸替换:根据研究目的,选择合适的氨基酸替换策略。
例如,在点突变实验中,可采用随机替换或特定位点替换。
3.计算突变评分:根据氨基酸替换后的蛋白质结构,计算突变评分。
评分越高,说明蛋白质稳定性越差。
4.宏观分区函数计算:对蛋白质序列进行分组,计算各组在不同温度下的自由能变化。
5.分析与预测:根据Camp评分和宏观分区函数的结果,分析蛋白质在不同温度下的稳定性,并为后续研究提供依据。
四、Camp评分生信方法的实例应用以下将以一个实际例子来说明Camp评分生信方法在研究中的应用。
静脉注射咪达唑仑对蛛网膜下腔出血大鼠脑神经炎症和损伤的改善作用及其机制

静脉注射咪达唑仑对蛛网膜下腔出血大鼠脑神经炎症和损伤的改善作用及其机制孟元元1,刘艳1,张华强1,周民1,姚玲玲21 武汉科技大学附属普仁医院麻醉科,武汉430000;2 湖北文理学院附属医院 襄阳市中心医院疼痛科摘要:目的 探讨咪达唑仑(MDZ )对蛛网膜下腔出血(SAH )大鼠脑神经炎症和损伤的改善作用,及其对环腺苷酸(cAMP )/蛋白激酶A (PKA )/环腺苷酸应答元件结合蛋白(CREB )信号通路的调节作用。
方法 取Wistar 大鼠65只,随机分为假手术组10只及造模组55只,造模组通过向枕大池二次注入血液的方法建立SAH 模型,假手术组向枕大池注入等体积生理盐水。
将造模成功的50只SAH 大鼠随机分为SAH 组、MDZ 低剂量组、MDZ 中剂量组、MDZ 高剂量组、MDZ 高剂量+H -89组,每组10只。
MDZ 高、中、低剂量组分别经颈静脉注射0.30、0.15、0.05 mg /kg MDZ ,同时腹腔注射等体积生理盐水;MDZ 高剂量+H -89组经颈静脉注射0.3 mg /kg MDZ ,同时腹腔注射5 mg /kg PKA 抑制剂H -89;SAH 组、假手术组颈静脉及腹腔注射等体积生理盐水;每天1次,连续3 d 。
干预结束后,对大鼠进行神经功能评分;采集静脉血,ELISA 法检测炎症因子肿瘤坏死因子α(TNF -α)、白细胞介素(IL )-1β、IL -6水平;每组随机选取3只大鼠,干/湿法评估脑水含量;剩余大鼠进行SAH 等级评分,HE 染色观察脑组织形态学变化;Western blotting 法检测cAMP /PKA /CREB 通路相关蛋白表达。
结果 与假手术组相比,SAH 组海马区神经元细胞核碎裂、坏死现象,神经功能评分、cAMP 、p -PKA /PKA 、p -CREB /CREB 表达降低,IL -1β、IL -6、TNF -α、脑含水量、SAH 等级评分增加(P 均<0.05);与SAH 组相比,MDZ 高、中、低剂量组神经元损伤有不同程度缓解,神经功能评分、cAMP 、p -PKA /PKA 、p -CREB /CREB 表达增加,IL -1β、IL -6、TNF -α、脑含水量、SAH 等级评分降低(P 均<0.05);与MDZ 高剂量组相比,MDZ 高剂量+H -89组神经元损伤加剧,神经功能评分、cAMP 、p -PKA /PKA 、p -CREB /CREB 表达降低,IL -1β、IL -6、TNF -α、脑含水量、SAH 等级评分增加(P 均<0.05)。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
⎜⎛ rt − (δ − µ + ft )β ⎟⎞
⎜⎛ε t
⎟⎞
ET
⎜ ⎜ ⎜
(rt ft
− (δ −µ
−µ
+
ft )β ) ft
⎟ ⎟ ⎟
=
1 T
∑⎜⎜ ⎜
ε f
t t
ft −µ
⎟ ⎟ ⎟
⎜⎝ ( ft − µ)2 − σ 2
⎟⎠
⎜⎝ ( ft − µ)2 − σ 2 ⎟⎠
(2)
这样,得到广义矩法估计量θˆ = arg min gt (θ )′Wgt (θ ) ,本文编写计算机程序的基本思想是
E[rt ] = δβ
(1)
其中,rt 为 n 项资产 t 时期超出无风险利率的收益率向量,δ 为风险溢价向量, β 是资产收
[ ] 益率对市场因素的敏感度向量,定义为 cov rt , ft σ 2 ( ft 为宏观经济变量的收益率),σ 2
为宏观经济变量收益率的方差 。资产定价模型在实证检验方面,先后经历了时间序列回归、 横截面回归和极大似然估计,和现在流行的广义矩法(GMM)(Hansen,1982; Kan and zhou,1999),由于横截面回归方法忽略了与CAPM相关的样本误差,当收益率和因素呈现条件 同方差分布时,从而会夸大参数估计精度(Suresh ,2000);另外,虽然当收益率和因素服 从独立正态同分布时,极大似然估计能够避免二阶段横截面回归所导致的缺点,但如果独立 正态分布的假设不能得到满足,极大似然估计并不是有效的(Jagannathan和Wang,1998)。 而现实中,资产收益率和宏观经济参数呈现的数据特征为条件异方差、跨期不独立和非正态 分布,在这样的条件下,广义矩估计法更有效,广义矩法(GMM)允许收益率和因素数据特 征为条件异方差,跨期不独立和非正态(Hansen,1996),因此,本文分析使用广义矩估计法 进行参数估计。应用广义矩估计方法,CAPM资产定价模型具有以下几个矩约束:
Abstract: The risk premium, as the core of asset pricing theory, is generally estimated by beta method. Recently, the stochastic discount factor (SDF) is widely used to appraise the risk premium. In this paper, we compare the variance of the estimates of the risk premium under both methods based on asset pricing theories, the generalized method of moments (GMM) and Monte Carlo Simulation with Chinese stock market data, and show that to some extent the SDF method is more efficient than the Beta method for estimating risk premiums.
Key words: Stochastic Discount Factor; GMM; Monte Carlo Simulation
一、引言
资产定价理论是用于解释在未来存在不确定性条件下资产的均衡价格,是现代金融理论 的核心内容,也是近几十年来现代金融理论中发展最快的一个领域。现代资产定价理论的发 展经历了一般均衡理论、投资组合理论、Spanning theorems(跨期理论)、CAPM(资本资产 定价模型)、ICAPM(跨期的资本资产定价模型)、APT(套利定价理论)、期权定价、CCAPM (基于消费的模型)等发展历程。总体上来说,这些资产定价模型并没有发展到完美的阶段, 都存在着某些缺陷:要么虽然理论推导很严密,但要求的假设条件比较严格,与实际的应用
二、文献回顾
在国外学者中,随机折现因子模型的研究以 Kan 和 Zhou (1999),Jagannathan 和 Wang (1998,2002)和 Cochrane(2001)等为代表。首先,Kan 和 Zhou (1999)对比了使用G MM参数估计方法的随机折现因子和使用传统的最大似然法的静态线性 CAPM。实证结果表 明随机折现因子的参数估计的精度很差,它所估计的风险溢价的标准差是上述传统方法的 40 倍,因此 Kan 和 Zhou (1999)认为随机折现因子方法对于风险溢价的是不可靠的。 Jagannathan 和 Wang(2002)通过实证分析,认为 Kan 和 Zhou (1999)得到的结果是错误的, 因为他们忽略了随机折现因子方法与 CAPM 方法所对应的风险溢价不一定相同的事实,错误 在于假设这两种方法的风险溢价取特定的值而且相等,然后比较它们的风险溢价估计量的渐 近方差。Jagannathan 和 Wang(2002)通过实证分析得出:在风险溢价的估计精度方面,两 种方法具有相同的精度,在设定检验能力方面,两种方法近似相同。
∑ α β
= r − δ β β ,其中 r
=1 T
T
rt
t =1
,并估计出相应的标准偏差。
3.2 随机折现因子模型
根据现代金融经济学理论可知,当金融市场上不存在无风险套利机会时,或者在无法取 得大规模无风险套利收益的前提下,可以从单个经济主体的消费选择效用最优化或者在离散 的状态集中,资产价格等于每个状态的报酬的加权平均和的角度,把资产的价格与其未来的 收益可以通过“随机折现因子”联系起来,从而得到基本定价方程(Cochrane 2001)。随机折 现因子的定价方程式推导有两种思路:
E[rt − (δ − µ + ft )β ] = 0n×1
E[(rt − (δ − µ + ft )β ) ft ] = 0n×1 E[ ft − µ ] = 0n×1 E[( ft − µ )2 − σ 2 ] = 0n×1
( ) 其中, 0n×1 是 n 维 0 向量。未知参数向量是 θ = δ , β ′, µ,σ 2 对应的广义约束矩阵
刻证券 i 的损益为 xi,t+1 ,则有:
ct = et − Pi,tψ
ct+1 = et+1 + xi,t+1ψ
单个投资者的期望效用可表示为:
maxU (ct , ct+1 ) = U (ct ) + ( βE ct+1 )
(3)
其中:ct 是 t 时刻的消费,et 是 t 时刻投资人的外来财富;Pi,t 是证券 i 在 t 时刻的价格,
①该文章得到对外经济贸易大学“十五”“211”“中国金融市场的发展与风险防范” 课题(项目号:e12003) 资助
1
存在着差距,如 CAPM、ICAPM、CCAPM;要么虽在实际中的使用较为广泛,较易于理解,但 由于所要求的假设条件较少,但主观个人因素比较大,计算结果会因个人选择的参数不同而 不同,如套利定价理论(Cochrane ,2001)。
随机折现因子方法
与 CAPM 关于风险溢价的实证比较①
娄峰 1
奉立城 2
陈素亮 3
(1. 中国社会科学院数量经济与技术经济研究所
(2. 对外经贸大学国际贸易学院 3.中信实业银行)
【摘要】:本文根据随机折现因子方法的基本理论,结合广义矩阵法和蒙特卡罗模拟,对随机折现因
子方法和传统的CAPM对风险溢价的计算进行实证比较研究。实证结果表明,对于中小样本,随机折现因子 方法比传统的CAPM方法优越:估计量较为精确,误差小;对于大容量样本,这两种方法性能接近;另外,
近几年,随机折现因子模型的出现使对资产定价理论研究有了新的认识,与其他的资产 定价的表达形式相比,随机折现因子模型更具有一般性,更易于理解,而且几乎不对金融数 据作任何限定。在金融市场不允许存在套利机会或者在无法取得大规模无风险套利收益的前 提下,随机折现因子产生并能对经济中所有资产进行定价。这可以被理解为 Arrow-Debreu 一般均衡模型在金融市场上的应用。随机折现因子在特殊情况下可以被线性因素模型所描 述,即成为 CAPM 和多因子模型。对随机折现因子的估算,能将不同形式资产定价模型统一 到一个框架内讨论问题,形成一个可以交流的语言,有利于解决理论上的困惑,同时,也便 于发现理论模型的假设和实际的距离,以及这种距离对理论模型结论的影响,这些对于金融 学界意义重大(张新 2003)。但从目前来看,国内有关随机折现因子模型研究的文献寥寥无 几,国内学者随机折现因子模型在国内的研究及实证还几乎是空白。
在国内,曾志锋(2002)、肖辉,吴冲锋(2004)对随机折现因子模型理论作了一些介 绍,但从目前公开发表的学术论文来看,国内学者还没有对随机折现因子模型的实证作过翔 实研究。
2
三、CAPM模型和随机折现因子模型的基本理论 3.1 CAPM模型
资产定价模型的核心是资产的预期收益率与整体的风险溢价呈现出一定的比例关系,这 种关系可以是线性的,也可以是渐近线性的,所以CAPM表示的资产定价模型可以为
Frank 和 Richard(2005)认为在许多计量经济模型中,矩阵的秩往往决定着模型参数的 识别和估计,只有当矩阵满秩时,模型参数识别的有限性分布才有效,并认为矩阵次级的秩 值不能被拒绝,为了克服矩阵秩的计算缺陷,Frank 和 Richard 提住一种新的方法,并认为 Jagannathan 和 Wang 随机贴现因子的参数的估计可能存在着问题。
鉴于此,本文将详细介绍这种方法,并从计算风险溢价的角度,结合广义矩阵法和蒙特 卡罗模拟,应用我国股票市场上市公司的数据,对随机折现因子方法和传统的CAPM在风险溢 价方面进行实证比较研究。实证结果表明对于中小样本,随机折现因子方法比传统的CAPM 方法优越:估计量较为精确,误差小;对于大容量样本,这两种方法性能接近;另外,随机