matlab数学实验
实验一matlab环境语法及数学运算(验证性实验-2课时)

实验一Matlab环境语法及数学运算(验证性实验-2课时)一、实验目的:1、熟悉matlab软件的环境语法及简单的数学运算;2、能熟练运用matlab软件进行简单的数学运算;二、实验设备PC机,配置:PIII450/内存128M/显卡TNT32M/硬盘10G以上。
局域网、MATLAB7.0环境、投影仪三、实验原理MATLAB环境是一种为数值计算、数据分析和图形显示服务的交互式的环境。
MATLAB有3种窗口,即:命令窗口(The Command Window)、m-文件编辑窗口(The Edit Window)和图形窗口(The Figure Window),而Simulink另外又有Simulink 模型编辑窗口。
1.命令窗口(The Command Window)当MATLAB启动后,出现的最大的窗口就是命令窗口。
用户可以在提示符“>>”后面输入交互的命令,这些命令就立即被执行。
在MATLAB中,一连串命令可以放置在一个文件中,不必把它们直接在命令窗口内输入。
在命令窗口中输入该文件名,这一连串命令就被执行了。
因为这样的文件都是以“.m”为后缀,所以称为m-文件。
2.m-文件编辑窗口(The Edit Window)我们可以用m-文件编辑窗口来产生新的m-文件,或者编辑已经存在的m-文件。
在MATLAB主界面上选择菜单“File/New/M-file”就打开了一个新的m-文件编辑窗口;选择菜单“File/Open”就可以打开一个已经存在的m-文件,并且可以在这个窗口中编辑这个m-文件。
四、实验内容:1、帮助命令使用 help 命令,查找 sqrt(开方)函数的使用方法;2、矩阵运算(1)矩阵的乘法已知 A=[1 2;3 4]; B=[5 6;7 8];求 A^2*B(2)矩阵除法已知 A=[1 2 3;4 5 6;7 8 9];B=[1 0 0;0 2 0;0 0 3];A\B,A/B(3)矩阵的转置及共轭转置已知 A=[5+i,2-i,1;6*i,4,9-i];求 A.', A'(4)使用冒号选出指定元素已知: A=[1 2 3;4 5 6;7 8 9];求 A 中第 3 行前 2 个元素;A 中所有列第 2,3 行的元素;A 中第 3 列前 2 个元素为:3、多项式求多项式 p(x) = x3 + 2x+ 4的根4、基本绘图命令(1)绘制余弦曲线 y=cos(t),t∈[0,2π](2)在同一坐标系中绘制余弦曲线 y=cos(t-0.25)和正弦曲线 y=sin(t-0.5),t∈[0,2π]5、基本绘图控制绘制[0,4π]区间上的 x1=10sint 曲线,并要求:(1)线形为点划线、颜色为红色、数据点标记为加号;(2)坐标轴控制:显示范围、刻度线、比例、网络线(3)标注控制:坐标轴名称、标题、相应文本;五、实验步骤1、帮助命令使用 help 命令,查找 sqrt(开方)函数的使用方法;SQRT Square root.SQRT(X) is the square root of the elements of X. Complexresults are produced if X is not positive.See also sqrtm.Overloaded functions or methods (ones with the same name in other directories) help sym/sqrt.mReference page in Help browserdoc sqrt2、矩阵运算(1)矩阵的乘法已知 A=[1 2;3 4]; B=[5 6;7 8];求 A^2*BA^2*B =105 122229 266(2)矩阵除法已知 A=[1 2 3;4 5 6;7 8 9];B=[1 0 0;0 2 0;0 0 3];A\B,A/BWarning: Matrix is close to singular or badly scaled.Results may be inaccurate. RCOND = 1.541976e-018.A\B =1.0e+016 *-0.4504 1.8014 -1.35110.9007 -3.6029 2.7022-0.4504 1.8014 -1.3511A/B =1.0000 1.0000 1.00004.0000 2.5000 2.00007.0000 4.0000 3.0000(3)矩阵的转置及共轭转置已知 A=[5+i,2-i,1;6*i,4,9-i];求 A.', A'A.'=5.0000 + 1.0000i 0 +6.0000i2.0000 - 1.0000i 4.00001.0000 9.0000 - 1.0000iA’ =5.0000 - 1.0000i 0 -6.0000i2.0000 + 1.0000i 4.00001.0000 9.0000 + 1.0000i(4)使用冒号选出指定元素已知: A=[1 2 3;4 5 6;7 8 9];求 A 中第 3 行前 2 个元素;A 中所有列第 2,3 行的元素;A 中第 3 列前 2 个元素为:A(3,1:2) =7 8A(2:3,:) =4 5 67 8 9A(1:2,3) =363、多项式求多项式 p(x) = x3 + 2x+ 4的根p=[1 0 2 4];roots(p)ans =0.5898 + 1.7445i0.5898 - 1.7445i-1.17954、基本绘图命令(1)绘制余弦曲线 y=cos(t),t∈[0,2π]t=0:pi/100:2*pi;y=cos(t);plot(t,y)(2)在同一坐标系中绘制余弦曲线 y=cos(t-0.25)和正弦曲线 y=sin(t-0.5),t∈[0,2π]t=0:pi/100:2*pi;y1=cos(t-0.25);y2=sin(t-0.5);plot(t,y1,t,y2)5、基本绘图控制绘制[0,4π]区间上的 x1=10sint 曲线,并要求:(1)线形为点划线、颜色为红色、数据点标记为加号;(2)坐标轴控制:显示范围、刻度线、比例、网络线(3)标注控制:坐标轴名称、标题、相应文本;程序:t=0:pi/100:4*pi;x1=10*sin(t);plot(t,x1,'r-.+')title('t from 0 to 4{\pi}')xlabel('Variable t')ylabel('Variable x1')grid ontext(2,5,'曲线x1=10*sin(t)')legend('x1')六、实验要求利用所学知识,完成上述各项实验内容,并将实验过程和实验步骤和结果写在报告中。
高等数学:MATLAB实验

MATLAB实验
2.fplot绘图命令 fplot绘图命令专门用于绘制一元函数曲线,格式为:
fplot('fun',[a,b]) 用于绘制区间[a,b]上的函数y=fun的图像.
MATLAB实验 【实验内容】
MATLAB实验
由此可知,函数在点x=3处的二阶导数为6,所以f(3)=3为 极小值;函数在点x= 1处的二阶导数为-6,所以f(1)=7为极大值.
MATLAB实验
例12-10 假设某种商品的需求量q 是单价p(单位:元)的函 数q=12000-80p,商 品的总成本C 是需求量q 的函数 C=25000+50q.每单位商品需要纳税2元,试求使销售 利润达 到最大的商品单价和最大利润额.
MATLAB实验
MATLAB实验
MATLAB实验
MATLAB实验
MATLAB实验
MATLAB实验
MATLAB实验
MATLAB实验
MATLAB实验 实验九 用 MATLAB求解二重积分
【实验目的】 熟悉LAB中的int命令,会用int命令求解简单的二重积分.
MATLAB实验
【实验M步A骤T】 由于二重积分可以化成二次积分来进行计算,因此只要
MATLAB实验
MATLAB实验
MATLAB实验
MATLAB实验
MATLAB实验
实验七 应用 MATLAB绘制三维曲线图
【实验目的】 (1)熟悉 MATLAB软件的绘图功能; (2)熟悉常见空间曲线的作图方法.
【实验要求】 (1)掌握 MATLAB中绘图命令plot3和 mesh的使用; (2)会用plot3和 mesh函数绘制出某区间的三维曲线,线型
MATLAB 《数学实验》报告9-Matlab的极限和微分运算

clear syms x F3=x*log(1+x)/sin(x^2) limit(F3,'x',0)
(4) F4
arctan x lim x x
Matlab 命令 结果 F4 = atan(x)/x ans = 0
clear syms x F4=atan(x)/x limit(F4,'x',inf)
clear%dier syms x y2=x*sin(x)*log(x) diff(y2,x)
结果 y2 = x*sin(x)*log(x) ans = sin(x)*log(x)+x*cos(x)*log(x)+sin(x)
(3) y 3
xe x 1 sin x
Matlab 命令 结果 y3 = (x*exp(x)-1)/sin(x) ans = (exp(x)+x*exp(x))/sin(x)-(x*exp(x)-1)/sin(x)^2*cos(x)
1
clear syms x F2=((1+x)/(1-x))^(1/x) limit(F2,'x',0)
F2 = ((1+x)/(1-x))^(1/x) ans = exp(2)
(3) F3
lim
x ln(1 x) 2 x 0 sin x
Matlab 命令 结果 F3 = x*log(1+x)/sin(x^2) ans = 1
x 0
arctan x ; x
结果 = atan(x)/x ans = 1
1
Matlab 命令
clear%µ þ ½· Ú¶ ÖÖ· ¨ syms x f=atan(x)/x limit(f,'x',0)
MATLAB数学实验

实验三 圆周率的计算学号: 姓名:XX一、 实验目的1. 本实验涉及概率论、定积分、三角函数等有关知识,要求掌握计算π的三种方法及其原理。
2. 学习和掌握数学软件MATLAB 的使用方法。
二、 实验内容圆周率是一个极其驰名的数。
从有文字记载的历史开始,这个数就引起了外行人和学者们的兴趣。
作为一个非常重要的常数,圆周率最早是出于解决有关圆的计算问题。
仅凭这一点,求出它的尽量准确的近似值,就是一个极其迫切的问题了。
事实也是如此,几千年来作为数学家们的奋斗目标,古今中外一代又一代数学家为此献出了自己的智慧和劳动。
回顾历史,人们对π的认识过程,反映了数学和计算技术发展情形的一个侧面。
π的研究,在一定程度上反映这个地区或时代的数学水平。
德国数学家康托说:“历史上一个国家所算的圆周率的准确程度,可以作为衡量这个国家当时数学发展水平的指标。
”直到19世纪初,求圆周率的值还是数学中的头号难题。
1. 圆周率的计算方法古人计算圆周率,一般是用割圆法。
即用圆的内接或外切多边形来逼近圆的周长。
Archomedes 用正96边形得到35位精度;刘徽用正3072边形得到5位精度;Ludolph V an Ceulen 用正2^62边形得到了35位精度。
这种基于几何的算法计算量大,速度慢,吃力不讨好。
随着数学的发展,数学家们在进行数学研究时有意无意得发现了许多计算圆周率的公式。
下面挑选一些经典的常用公式加以介绍。
除了这些经典公式外,还有很多其他公式和由这些经典公式衍生出来的公式,就不一一列举了。
1) Machin 公式2391a r c t a n451a r c t a n 16-=π ()121...753arctan 121753--++-+-=--n x x x x x x n n 这个公式由英国天文学教授John Machin 于1706年发现。
他利用这个公式计算到100位的圆周率。
Machin 公式每计算一项可以得到1.4位的十进制精度。
MATLAB数学实验答案(全)

MATLAB数学实验答案(全)第⼀次练习教学要求:熟练掌握Matlab 软件的基本命令和操作,会作⼆维、三维⼏何图形,能够⽤Matlab 软件解决微积分、线性代数与解析⼏何中的计算问题。
补充命令vpa(x,n) 显⽰x 的n 位有效数字,教材102页fplot(‘f(x)’,[a,b]) 函数作图命令,画出f(x)在区间[a,b]上的图形在下⾯的题⽬中m 为你的学号的后3位(1-9班)或4位(10班以上) 1.1 计算30sin limx mx mx x →-与3sin lim x mx mxx →∞-syms xlimit((902*x-sin(902*x))/x^3) ans =366935404/3limit((902*x-sin(902*x))/x^3,inf)//inf 的意思 ans = 0 1.2 cos1000xmxy e =,求''y syms xdiff(exp(x)*cos(902*x/1000),2)//diff 及其后的2的意思 ans =(46599*cos((451*x)/500)*exp(x))/250000 - (451*sin((451*x)/500)*exp(x))/250 1.3 计算221100x y edxdy +??dblquad(@(x,y) exp(x.^2+y.^2),0,1,0,1)//双重积分 ans = 2.13941.4 计算4224x dx m x +? syms xint(x^4/(902^2+4*x^2))//不定积分 ans =(91733851*atan(x/451))/4 - (203401*x)/4 + x^3/12 1.5 (10)cos ,x y e mx y =求//⾼阶导数syms xdiff(exp(x)*cos(902*x),10) ans =-356485076957717053044344387763*cos(902*x)*exp(x)-3952323024277642494822005884*sin(902*x)*exp(x)1.6 0x =的泰勒展式(最⾼次幂为4).syms xtaylor(sqrt(902/1000+x),5,x)//泰勒展式 ans =-(9765625*451^(1/2)*500^(1/2)*x^4)/82743933602 +(15625*451^(1/2)*500^(1/2)*x^3)/91733851-(125*451^(1/2)*500^(1/2)*x^2)/406802 + (451^(1/2)*500^(1/2)*x)/902 +(451^(1/2)*500^(1/2))/500 1.7 Fibonacci 数列{}n x 的定义是121,1x x ==12,(3,4,)n n n x x x n --=+=⽤循环语句编程给出该数列的前20项(要求将结果⽤向量的形式给出)。
(完整word版)Matlab数学实验报告

Matlab 数学实验报告一、实验目的通过以下四组实验,熟悉MATLAB的编程技巧,学会运用MATLAB的一些主要功能、命令,通过建立数学模型解决理论或实际问题。
了解诸如分岔、混沌等概念、学会建立Malthu模型和Logistic 模型、懂得最小二乘法、线性规划等基本思想。
二、实验内容2.1实验题目一2.1.1实验问题Feigenbaum曾对超越函数y=λsin(πx)(λ为非负实数)进行了分岔与混沌的研究,试进行迭代格式x k+1=λsin(πx k),做出相应的Feigenbaum图2.1.2程序设计clear;clf;axis([0,4,0,4]);hold onfor r=0:0.3:3.9x=[0.1];for i=2:150x(i)=r*sin(3.14*x(i-1));endpause(0.5)for i=101:150plot(r,x(i),'k.');endtext(r-0.1,max(x(101:150))+0.05,['\it{r}=',num2str(r)]) end加密迭代后clear;clf;axis([0,4,0,4]);hold onfor r=0:0.005:3.9x=[0.1];for i=2:150x(i)=r*sin(3.14*x(i-1));endpause(0.1)for i=101:150plot(r,x(i),'k.');endend运行后得到Feigenbaum图2.2实验题目二2.2.1实验问题某农夫有一个半径10米的圆形牛栏,长满了草。
他要将一头牛拴在牛栏边界的桩栏上,但只让牛吃到一半草,问拴牛鼻子的绳子应为多长?2.2.2问题分析如图所示,E为圆ABD的圆心,AB为拴牛的绳子,圆ABD为草场,区域ABCD为牛能到达的区域。
问题要求区域ABCD等于圆ABC的一半,可以设BC等于x,只要求出∠a和∠b就能求出所求面积。
数学实验MATLAB第五章

学习方法与建议
学习方法
通过理论学习和实践操作相结合的方式,深入理解MATLAB高级编程技术的原 理和应用。
建议
在学习本章之前,读者应该已经具备一定的MATLAB基础知识和编程经验。同 时,建议读者在学习过程中多进行实践操作,通过编写代码来加深对知识点的 理解和掌握。
02 MATLAB基础知识回顾
数学实验matlab第五章
目 录
• 第五章概述 • MATLAB基础知识回顾 • 数组与矩阵操作 • 数值计算与数据分析 • 程序设计与优化 • 综合应用与案例分析
01 第五章概述
章节内容与目标
内容
介绍MATLAB中的高级编程技术 ,包括脚本和函数编程、数据结 构和算法、面向对象编程等。
目标
通过学习本章,读者应该能够熟 练掌握MATLAB的高级编程技术 ,并能够灵活运用这些技术解决 复杂的数学问题。
运算符与函数
运算符
详细讲解MATLAB中的运算符, 包括算术运算符、关系运算符、 逻辑运算符等。同时介绍运算符
的优先级和结合性。
函数
阐述函数的概念,以及如何在 MATLAB中定义和使用函数。同时 介绍函数的输入和输出参数,以及 函数的返回值。
常用函数
介绍MATLAB中常用的函数,包括 数学函数、字符串处理函数、文件 操作函数等。同时给出函数的语法 和使用示例。
矩阵的乘法
按照矩阵乘法的规则进行运算 ,结果矩阵的维数可能发生变
化。
矩阵的转置
将矩阵的行和列互换,得到转 置矩阵。
矩阵的逆
对于方阵,若其逆矩阵存在, 则可以通过特定的运算求得逆
矩阵。
数组与矩阵的应用举例
线性方程组求解
数据分析与处理
MATLAB数学实验100例题解
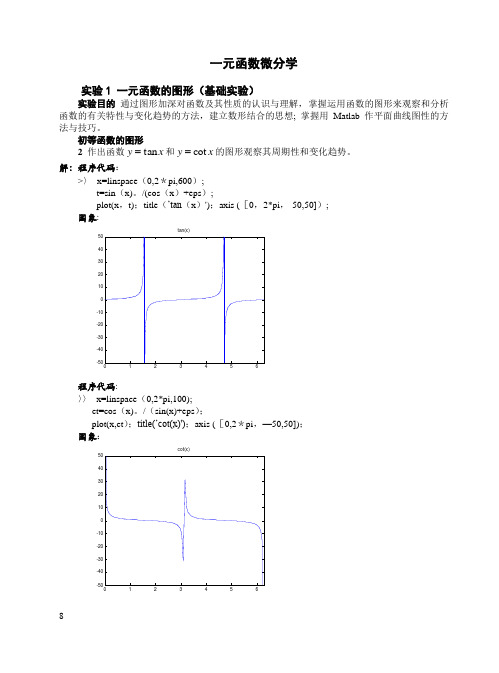
一元函数微分学实验1 一元函数的图形(基础实验)实验目的 通过图形加深对函数及其性质的认识与理解, 掌握运用函数的图形来观察和分析 函数的有关特性与变化趋势的方法,建立数形结合的思想; 掌握用Matlab 作平面曲线图性的方法与技巧。
初等函数的图形2 作出函数x y tan =和x y cot =的图形观察其周期性和变化趋势。
解:程序代码:>〉 x=linspace (0,2*pi,600); t=sin (x)。
/(cos (x )+eps );plot(x ,t);title (’tan (x )');axis ([0,2*pi ,-50,50]); 图象:程序代码: 〉〉 x=linspace (0,2*pi,100); ct=cos (x)。
/(sin(x)+eps ); plot(x,ct );title(’cot(x)');axis ([0,2*pi ,—50,50]); 图象:cot(x)4在区间]1,1[-画出函数xy 1sin =的图形。
解:程序代码:>> x=linspace (-1,1,10000);y=sin(1。
/x ); plot (x,y ); axis ([-1,1,—2,2]) 图象:二维参数方程作图6画出参数方程⎩⎨⎧==t t t y tt t x 3cos sin )(5cos cos )(的图形:解:程序代码:>〉 t=linspace(0,2*pi,100); plot(cos(t ).*cos (5*t ),sin(t )。
*cos(3*t)); 图象:极坐标方程作图8 作出极坐标方程为10/t e r =的对数螺线的图形. 解:程序代码:〉〉 t=0:0.01:2*pi ; r=exp (t/10);polar(log(t+eps ),log (r+eps)); 图象:90270分段函数作图10 作出符号函数x y sgn =的图形。
(完整word)Matlab实验报告
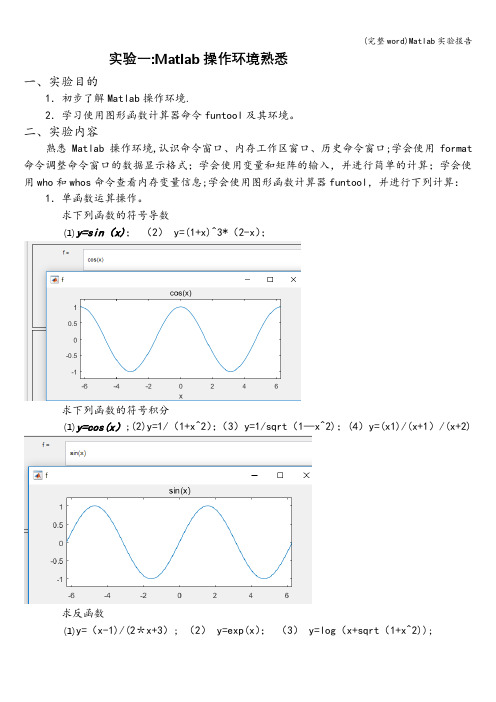
实验一:Matlab操作环境熟悉一、实验目的1.初步了解Matlab操作环境.2.学习使用图形函数计算器命令funtool及其环境。
二、实验内容熟悉Matlab操作环境,认识命令窗口、内存工作区窗口、历史命令窗口;学会使用format 命令调整命令窗口的数据显示格式;学会使用变量和矩阵的输入,并进行简单的计算;学会使用who和whos命令查看内存变量信息;学会使用图形函数计算器funtool,并进行下列计算:1.单函数运算操作。
求下列函数的符号导数(1)y=sin(x);(2) y=(1+x)^3*(2-x);求下列函数的符号积分(1)y=cos(x);(2)y=1/(1+x^2);(3)y=1/sqrt(1—x^2);(4)y=(x1)/(x+1)/(x+2)求反函数(1)y=(x-1)/(2*x+3); (2) y=exp(x);(3) y=log(x+sqrt(1+x^2));代数式的化简(1)(x+1)*(x-1)*(x-2)/(x-3)/(x—4);(2)sin(x)^2+cos(x)^2;(3)x+sin(x)+2*x—3*cos(x)+4*x*sin(x);2.函数与参数的运算操作。
从y=x^2通过参数的选择去观察下列函数的图形变化(1)y1=(x+1)^2(2)y2=(x+2)^2(3) y3=2*x^2 (4) y4=x^2+2 (5) y5=x^4 (6) y6=x^2/2 3.两个函数之间的操作求和(1)sin(x)+cos(x) (2) 1+x+x^2+x^3+x^4+x^5乘积(1)exp(—x)*sin(x) (2) sin(x)*x商(1)sin(x)/cos(x); (2) x/(1+x^2); (3) 1/(x—1)/(x—2); 求复合函数(1)y=exp(u) u=sin(x) (2) y=sqrt(u) u=1+exp(x^2)(3) y=sin(u) u=asin(x) (4) y=sinh(u) u=-x实验二:MATLAB基本操作与用法一、实验目的1.掌握用MATLAB命令窗口进行简单数学运算。
matlab_数学实验_实验报告_数据拟合

数据的分析之数据的拟合一、实验项目:Matlab 数据拟合 二、实验目的和要求1、掌握用matlab 作最小二乘多项式拟合和曲线拟合的方法。
2、通过实例学习如何用拟合方法解决实际问题,注意差值方法的区别。
3、鼓励不囿于固定的模式或秩序,灵活调整思路,突破思维的呆板性,找到打破常规的解决方法。
并在文献检索 动手和动脑等方面得到锻炼。
三、实验内容操作一:Malthus 人口指数增长模型用以上数据检验马尔萨斯人口指数增长模型,根据检验结果进一步讨论马尔萨斯人口模型的改进。
马尔萨斯模型的基本假设是人口的增长率为常数,记为r 。
记时刻t 的人口为()x t ,且初始时刻的人口为x 0,于是得到如下微分方程(0)dx rxdtx x ⎧=⎪⎨⎪=⎩ 需要先求微分方程的解,再用数据拟合模型中的参数。
一、分析有这个方程很容易解出0()*rtx t x e =r>0时,是表示人口箭杆指数规律随时间无限增长,称为指数增长模型。
将上式取对数,可得y=rt+a ,y=lnx ,a=lnx0 二、用matlab 编码t=1790:10:1980;x=[3.9 5.3 7.2 9.6 12.9 17.1 23.2 31.4 38.6 50.2 62.9 76.0 92 106.5 123.2 131.7 150.7 179.3 204.0 226.5]; p=polyfit(t,log(x),1); r=p(1) x0=exp(p(2)) x1=x0.*exp(r.*t); plot(t,x,'r',t,x1,'b')三、结果和图像 0.0214r =0 1.2480016x e =-17801800182018401860188019001920194019601980050100150200250300350操练二:旧车价格预测分析用什么形式的曲线来拟合数据,并预测使用4、5年后的轿车平均价格大致为多少。
matlab数学实验.doc

matlab 数学实验《管理数学实验》实验报告班级姓名实验 1:MATLAB的数值运算【实验目的】(1)掌握 MATLAB 变量的使用(2)掌握 MATLAB 数组的创建,(3)掌握 MA TLAB 数组和矩阵的运算。
(4)熟悉 MATLAB 多项式的运用【实验原理】矩阵运算和数组运算在MA TLAB中属于两种不同类型的运算,数组的运算是从数组元素出发,针对每个元素进行运算,矩阵的运算是从矩阵的整体出发,依照线性代数的运算规则进行。
【实验步骤】(1)使用冒号生成法和定数线性采样法生成一维数组。
(2)使用 MA TLAB 提供的库函数 reshape,将一维数组转换为二维和三维数组。
(3)使用逐个元素输入法生成给定变量,并对变量进行指定的算术运算、关系运算、逻辑运算。
(4)使用 MA TLAB绘制指定函数的曲线图,将所有输入的指令保存为M 文件。
【实验内容】( 1)在 [0,2*pi] 上产生 50 个等距采样数据的一维数组,用两种不同的指令实现。
0:(2*pi-0)/(50-1):2*pi或linspace(0,2*pi,50)( 2)将一维数组A=1:18 ,转换为2×9 数组和 2× 3× 3 数组。
reshape(A,2,9)ans =Columns 1 through 713 5 24 6 789111012131415171618reshape(A,2,3,3) ans(:,:,1) =1 3 52 4 6 ans(:,:,2) =7 9 118 10 12 ans(:,:,3) =13 15 1714 16 18matlab 数学实验( 3)A=[0 2 3 4 ;1 3 5 0],B=[1 0 5 3;1 5 0 5] ,计算数组 A、 B 乘积,计算 A&B,A|B,~A,A==B,A>B 。
A.*Bans=0 0 15 121 15 0 0A&Bans =0 0 1 11 1 0 0A|Bans =1 1 1 11 1 1 1~Aans =1 0 0 00 0 0 1A==Bans =0 0 0 01 0 0 0A>=Bans =0 1 0 11 0 1 0t t ( 4)绘制 y= 0.5 e3 -t*t*sin(t),t=[0,pi] 并标注峰值和峰值时间,添加标题 y= 0.5 e3 -t*t*sint ,将所有输入的指令保存为M 文件。
matlab实验一实验报告

matlab实验一实验报告实验一:Matlab实验报告引言:Matlab是一种强大的数学软件工具,广泛应用于科学计算、数据分析和工程设计等领域。
本实验旨在通过使用Matlab解决实际问题,探索其功能和应用。
一、实验目的本次实验的主要目的是熟悉Matlab的基本操作和常用函数,了解其在科学计算中的应用。
二、实验内容1. 数值计算在Matlab中,我们可以进行各种数值计算,包括基本的加减乘除运算,以及更复杂的矩阵运算和方程求解。
通过编写相应的代码,我们可以实现这些功能。
例如,我们可以使用Matlab计算两个矩阵的乘积,并输出结果。
代码如下:```matlabA = [1 2; 3 4];B = [5 6; 7 8];C = A * B;disp(C);```2. 数据可视化Matlab还提供了强大的数据可视化功能,可以将数据以图表的形式展示出来,更直观地观察数据的规律和趋势。
例如,我们可以使用Matlab绘制一个简单的折线图,来展示某个物体在不同时间下的位置变化。
代码如下:```matlabt = 0:0.1:10;x = sin(t);plot(t, x);xlabel('Time');ylabel('Position');title('Position vs. Time');```3. 图像处理Matlab还可以进行图像处理,包括图像的读取、处理和保存等操作。
我们可以通过Matlab对图像进行增强、滤波、分割等处理,以及进行图像的压缩和重建。
例如,我们可以使用Matlab读取一张图片,并对其进行灰度化处理。
代码如下:```matlabimg = imread('image.jpg');gray_img = rgb2gray(img);imshow(gray_img);```三、实验结果与分析在本次实验中,我们成功完成了数值计算、数据可视化和图像处理等任务。
MATLAB软件与基础数学实验

MATLAB 软件与基础数学实验Saw H.Z实验1 MATLAB 基本特性与基本运算例1-1 求[12+2×(7-4)]÷32的算术运算结果。
>> clear>> s=(12+2*(7-4))/3^2 s = 2例1-2 计算5!,并把运算结果赋给变量y y=1;for i=1:5 y=y*i; end y例1-3 计算2开平方>> s=2^(0.5) s =1.4142 >>例1-4 计算2开平方并赋值给变量x (不显示)查看x 的赋值情况 a=2;x=a^(0.5); x例1-4 设75,24=-=b a ,计算|)tan(||)||sin(|b a b a ++的值。
a=(-24)/180*pi; b=75/180*pi; a1=abs(a); b1=abs(b); c=abs(a+b);s=sin(a1+b1)/(tan(c))^(0.5)例1-5 设三角形三边长为2,3,4===c b a ,求此三角形的面积。
a=4;b=3;c=2; p=(a+b+c)/2;s=(p*(p-a)*(p-b)*(p-c))^(0.5)例1-7 设⎥⎥⎥⎦⎤⎢⎢⎢⎣⎡=101654321A ,⎥⎥⎥⎦⎤⎢⎢⎢⎣⎡-=112311021B ,计算||,,A AB B A +,1-A 。
a=[1,2,3;4,5,6;1,0,1];b=[-1,2,0;1,1,3;2,1,1]; x=a+b; y=a*b; z=norm(a); q=inv(a); x,y,z,q例1-8 显示上例中矩阵A 的第2行第3列元素,并对其进行修改. a=[1,2,3;4,5,6;1,0,1];x=a(2,3);a(2,3)=input('change into=') x,a例1-9 分别画出函数x x y cos 2=和x xz sin =在区间[-6π,6π]上的图形。
Matlab数学实验报告

实验一 Matlab基本操作1.实验课程名称数学实验2.实验项目名称Matlab基本操作3.实验目的和要求了解Matlab的基本知识,熟悉其上机环境,掌握利用Matlab进行基本运算的方法。
4.实验内容和原理内容:三角形的面积的海伦公式为:area=)s-sa--)()(s(csb其中: s=(a+b+c)/2原理:将一般数学问题转化成对应的计算机模型并进行处理的能力。
了解Matlab的基本功能,会进行简单的操作。
5.主要仪器设备计算机与Windows 2000/XP系统;Matlab等软件。
6.操作方法与实验步骤步骤:(1)在M文件编辑窗口输入以下程序,并以文件名”area_helen.m”保存:a= input(‘a=‘) ; b= input(‘b=‘) ; c= input(‘c=‘) ;s= (a+b+c)/2;area=sqrt (s* (s-a) * (s-b) * (s-c))(2)在命令窗口输入文件名“area_helen”,按回车键,即可运行上面的程序,输入三边长,立即可得三角形面积(3)第二题在命令窗口输入b=6;a=3;c=a*b,d=c-2*b(4) 按回车键,即可运行上面的程序7.实验结果与分析<1> a=3; b=4; c=5;时,aera=6 当a为3,b为4,c为5时,s=6,aera=6<2> c= 18,d=6,a为3,b为6时,c=18,d=6实验二 Matlab的数值计算1.实验课程名称数学实验2.实验项目名称Matlab的数值计算3.实验目的和要求了解一些简单的矩阵、向量、数组和多项式的构造和运算方法实例,懂得编写简单的数值计算的Matlab程序。
熟悉一些Matlab的简单程序,会用Matlab的工具箱,懂得Matlab的安装和简单的使用。
4.实验内容和原理内容:从函数表:)1(),5.0(),2( ,0x 1x 021x 1x f(x) 32-⎪⎩⎪⎨⎧≤≤<>+=f f f x x求设)1(),2( ,1211)(2-⎩⎨⎧≤>+=f f x xx x x f 求设 原理:利用矩阵、向量、数组、和多项式的构造和运算方法,用常用的几种函数进行一般的数值问题求解。
数学实验—二次型的MATLAB实验

数学实验——二次型的MATLAB实验
例 1 用正交变换法将二次型 f (x1 ,x2 ,x3 ) 17x12 14x22 14x32 4x1x2 4x1x3 8x2 x3 化为标准形.
数学实验——二次型的MATLAB实验
解 在 MATLAB 命令窗口输入:>>A=[17,-2,-2;-2,14,-4;-2,-4,14]; >>[Q,D]=schur(A) 运行程序后输出:Q= 0.3333 -0.2981 0.8944
解 在 MATLAB 命令窗口输入:>>format rat; >>A=[4,0,0;0,6,4;0,4,6]; 运行程序后输出:A= 4 0 0
064 046
数学实验——二次型的MATLAB实验
在 MATLAB 命令窗口输入:>>d=eig(A) 运行程序后输出:d=
2 4 10 因为 A 的特征值全为正,所以二次型 f (x1 ,x2 ,x3 ) 4x12 6x22 6x32 8x2 x3 是正定的.
0.6667 -0.5963 -0.4472 0.6667 0.7454 0.0000 D= 9 0 0 0 18 0 0 0 18 所作的正交变换为 x Py ,二次型的标准形为 f (x1 ,x2 ,x3 ) 9 y12 18y22 18y32 .
数学实验——二次型的MATLAB实验
例 2 判定二次型 f (x1 ,x2 ,x3 ) 4x12 6x22 6x32 8x2 x3 的正定性.
命令 d=eig(A) [P,D]=eig(A)
[Q,D]=schur(A) format rat
功能 输入 n 阶矩阵 A,运行后以向量的形式输出矩阵 A 的特征值赋给 d 输入 n 阶矩阵 A,运行后输出 A 的特征向量矩阵 P 和由特征值组成的 对角阵 D,使得 P1AP D 输入 n 阶矩阵 A,运行后输出 A 的正交矩阵 Q 和由特征值组成的对 角阵 D,使得 Q1AQ QT AQ D 数据有理化,一般放在最前面
matlab数学实验第三版

matlab数学实验第三版
《MATLAB数学实验第三版》是由作者C. Moler和D. J.
Little合著的一本关于MATLAB编程和数学实验的书籍。
本书旨在帮助读者利用MATLAB进行数学建模和实验,涵盖了MATLAB的基本概念、数值计算、符号计算、绘图、数据分析等内容。
在这本书中,读者将学习如何使用MATLAB进行矩阵操作、线性代数计算、微积分、常微分方程求解、曲线拟合、统计分析等数学实验。
此外,书中还介绍了MATLAB的编程技巧、脚本文件的编写、函数的创建与调用等内容,帮助读者更好地利用MATLAB解决数学问题。
除了数学实验方面的内容,本书还涵盖了工程、物理、生物等领域的实际案例,通过这些案例,读者可以学习如何将MATLAB应用于实际问题的求解和分析中。
总的来说,《MATLAB数学实验第三版》是一本全面介绍MATLAB 数学建模和实验的书籍,适合对MATLAB感兴趣的学生、工程师和科研人员阅读。
通过学习这本书,读者可以掌握MATLAB在数学建模和
实验方面的基本原理和应用技巧,从而更好地应用MATLAB解决实际问题。
MATLAB数学实验6

MATLAB数学实验6实验⼆定积分的近似计算学号:姓名:XX⼀、实验⽬的1.加深理解积分理论中分割、近似、求和、取极限的思想⽅法,了解定积分近似计算的矩阵形法、梯形法与抛物线法。
2.会⽤matlab 语⾔编写求定积分近似值的程序。
3.会⽤matlab 中的命令求定积分。
⼆、实验内容1.定积分近似计算的⼏种简单数值⽅法在许多实际问题中,常常需要计算定积分()baI f x dx =的值。
根据微积分学基本原理,若被积函数()f x 在区间[a,b]上连续,只需要找到被积函数的⼀个原函数()F x ,就可以⽤⽜顿莱布尼兹公式计算。
但在⼯程技术与科学实验中,有⼀些定积分的被积函数的原函数可能求不出来,即使可求出,计算也可能很复杂。
特别地,当被积函数是图形或表格给出时,更不能⽤⽜顿—莱布尼兹公式计算。
因此必需寻求定积分的近似计算⽅法。
⼤多数实际问题的积分需要⽤数值积分⽅法求出近似结果。
数值积分原则上可以⽤多项式函数近似代替被积函数,⽤对多项式的积分结果近似代替对被积函数的积分。
由于所选多项式形式的不同,可以有许多种数值积分⽅法,下⾯介绍最常⽤的⼏种插值型数值积分⽅法。
1)矩形法定积分的⼏何意义是计算曲边梯形的⾯积,如将区间[a,b]n 等分,每个⼩区间上都是⼀个⼩的曲边梯形,⽤⼀个个⼩矩形代替这些⼩曲边梯形,然后把⼩矩形的⾯积加起来就近似地等于整个曲边梯形的⾯积,于是便求出了定积分的近似值,这就是矩形法的基本原理。
假如()f x 在[a,b]上可积,利⽤定积分的定义()()1lim ,nbn n k an k b a I f x dx I I f nξ→∞=-===∑?(2-1)可知当n 充分⼤时,可将n I 视为积分I 的近似值,这⾥k ξ是取⾃第k 个区间[]1,k k x x -中的值。
如果将区间[a,b]n 等分,结点分别记为01...,n a x x x b =<<<=(),,k k b ah f f x h n-==称为积分步长。
matlab数学实验课程设计

matlab数学实验课程设计一、教学目标本课程的目标是让学生掌握MATLAB的基本使用方法,能够利用MATLAB进行数学实验,提高学生的数学建模和计算能力。
具体的教学目标包括:知识目标:使学生了解MATLAB的发展历程、基本功能和应用领域;让学生掌握MATLAB的基本语法、数据类型、运算符、编程技巧等。
技能目标:培养学生利用MATLAB进行数学建模、求解数学问题的能力;使学生能够熟练使用MATLAB进行数据分析、绘图和仿真。
情感态度价值观目标:激发学生对数学实验的兴趣,培养学生的创新精神和团队合作意识;使学生认识到MATLAB在实际生活和科研中的重要性,提高学生运用数学知识解决实际问题的能力。
二、教学内容本课程的教学内容主要包括MATLAB的基本使用方法、编程技巧和数学实验。
具体安排如下:1.MATLAB概述:介绍MATLAB的发展历程、基本功能和应用领域。
2.MATLAB基本语法:讲解MATLAB的数据类型、运算符、编程技巧等。
3.MATLAB数学实验:包括线性方程组求解、函数插值与逼近、数值微积分、常微分方程求解等。
4.MATLAB在实际应用中的案例分析:分析MATLAB在物理学、工程学、经济学等领域的应用实例。
三、教学方法为了提高教学效果,本课程将采用多种教学方法相结合的方式,包括:1.讲授法:讲解MATLAB的基本语法和功能,使学生掌握MATLAB的基本使用方法。
2.案例分析法:分析实际应用案例,使学生了解MATLAB在各个领域的应用。
3.实验法:让学生动手进行数学实验,培养学生的实际操作能力。
4.讨论法:学生进行小组讨论,激发学生的创新思维和团队合作意识。
四、教学资源为了支持本课程的教学,我们将准备以下教学资源:1.教材:《MATLAB教程》或《MATLAB数学实验》。
2.参考书:提供相关的数学实验指导书和论文,供学生参考。
3.多媒体资料:制作课件和教学视频,帮助学生更好地理解MATLAB的使用方法。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
《管理数学实验》实验报告班级姓名实验1:MATLAB的数值运算【实验目的】(1)掌握MATLAB变量的使用(2)掌握MATLAB数组的创建,(3)掌握MA TLAB数组和矩阵的运算。
(4)熟悉MATLAB多项式的运用【实验原理】矩阵运算和数组运算在MA TLAB中属于两种不同类型的运算,数组的运算是从数组元素出发,针对每个元素进行运算,矩阵的运算是从矩阵的整体出发,依照线性代数的运算规则进行。
【实验步骤】(1)使用冒号生成法和定数线性采样法生成一维数组。
(2)使用MA TLAB提供的库函数reshape,将一维数组转换为二维和三维数组。
(3)使用逐个元素输入法生成给定变量,并对变量进行指定的算术运算、关系运算、逻辑运算。
(4)使用MA TLAB绘制指定函数的曲线图,将所有输入的指令保存为M文件。
【实验内容】(1)在[0,2*pi]上产生50个等距采样数据的一维数组,用两种不同的指令实现。
0:(2*pi-0)/(50-1):2*pi 或linspace(0,2*pi,50)(2)将一维数组A=1:18,转换为2×9数组和2×3×3数组。
reshape(A,2,9)ans =Columns 1 through 71 3 5 7 9 11 132 4 6 8 10 12 14Columns 8 through 915 1716 18reshape(A,2,3,3)ans(:,:,1) =1 3 52 4 6ans(:,:,2) =7 9 118 10 12 ans(:,:,3) =13 15 17 14 16 18(3)A=[0 2 3 4 ;1 3 5 0],B=[1 0 5 3;1 5 0 5],计算数组A 、B 乘积,计算A&B,A|B,~A,A= =B,A>B 。
A.*Bans=0 0 15 121 15 0 0 A&Bans =0 0 1 11 1 0 0 A|Bans =1 1 1 11 1 1 1~Aans =1 0 0 00 0 0 1A==Bans =0 0 0 01 0 0 0A>=Bans =0 1 0 11 0 1 0(4)绘制y= 0.53t e -t*t*sin(t),t=[0,pi]并标注峰值和峰值时间,添加标题y= 0.53t e -t*t*sint ,将所有输入的指令保存为M 文件。
a=0.5 b=1/3t=0:0.001:piy=a*exp(b*t)-t.*t.*sin(t) [y_max,t_max]=max(y)t_text=['t=',num2str(t(t_max))] y_text=['y=',num2str(y_max)]max_text=char('maximum',t_text,y_text) tit=['y=a*exp(',num2str(b),'t)-t*t*sin(t)'] hold on plot(t,y,'y.')plot(t(t_max),y_max,'r')text(t(t_max)+0.3,y_max+0.1,max_text)title(tit),xlabel('t'),ylabel('y'),hold off【实验心得与总结】通过这次试验让我了解常用简单函数的功能,学会利用函数解决一些;数值计算和符号计算的实际问题;利用Matlab的help命令查询一些函数的功能。
利用MA TLAB可以让繁琐的计算问题变得更加简单化,如矩阵运算等。
\实验2:MATLAB 绘图【实验步目的】利用MTALAB 画墨西哥帽子,及参数方程的图像 【实验原理】(1)二维绘图命令:plot(x,y)函数(2)三维绘图命令中三维曲线:plot3(x,y,z), (3)利用mesh 函数画三维的网格表面的。
【实验内容】(含参考程序、实验结果及结果分析等)画出函数图形π100)cos(23≤≤⎪⎩⎪⎨⎧===t t z ty t x 。
方程:π100)cos(23≤≤⎪⎩⎪⎨⎧===t t z ty t x 【参考程序】 >> t=0:0.1:4*pi;>> plot3(2*cos(t),t.^3,t) 【实验结果】画出曲面]5.7,5.7[,sin),(2222-∈++==xyxfzyxyx的图像。
方程:(,)[7.5,7.5],[7.5,7.5]z f x y x y=∈-∈-【参考程序】x = -7.5:0.5:7.5;y = x;[xx, yy] = meshgrid(x, y);R = sqrt(xx.^2 + yy.^2) + eps;z = sin(R)./R;surf(xx, yy, z)【实验结果】【实验心得与总结】Matlab的常见错误:Inner matrix dimensions must agree1、因为在Matlab的输入变量是矩阵,参与运算的矩阵维数必须对应,矩阵相应元素的运算必须全部加dot(点),例2中方程如果这样输入:x=2*(cos(t)+t*sin(t)),就会出现该错误.2、mesh函数是用来画三维的网格表面的。
三维空间中的一个点是用(x,y,z)来表示的,mesh就是把这些点之间用网格连接起来。
实验3:MATLAB 微积分问题的计算【实验目的】利用MTALAB 求解二重积分、勒展开式及级数求和。
【实验原理】1.利用int(int(f,x,a,b),y,c,d)函数求二重积分计算累次积分⎰⎰d cbadxdy y x f ),(2.利用泰勒函数taylor (f,n,x,a)来求f(x,y)的n-1阶泰勒展开式k n k k a x k a f x f )(!)()(1)(-∙=∑-=; 3.利用函数symsum(f,k,n1,n2)来求级数的和函数∑=21)(n n k k f【实验内容】(含参考程序、实验结果及结果分析等)求⎰⎰+10122x xydydxx。
【参考程序】 >> syms x y >> z=x*y;>> f=int(int(z,y,2*x,x^2+1),x,0,1) 【实验结果】 f =1/12将f (x )=ln x 展开为幂为(x-2)的5阶泰勒展开式。
【参考程序】 >> syms x n;>> f=(-1)^n*x^(n+1)/(n+1); >> symsum(f,n,1,inf) 【实验结果】ans =log(1+x)-x级数求和)1,1(,1)1(11-∈+-+∞=∑x n x n n n。
【参考程序】>> syms x n;>> f=(-1)^n*x^(n+1)/(n+1); >> symsum(f,n,1,inf) 【实验结果】ans = log(1+x)-x 【实验心得与总结】1、在实验过程中,要是一句程序结束后加了分号,则说明,不要求执行程序时输出执行结果;2、在matlab 中是区别大小写的,如果N 写成n 会出现Undefined function or variable'n'.Undefined function or variable 'n'.的错误提示.实验4: MATLAB 优化计算【实验目的】掌握应用matlab 求解无约束最优化问题的方法【实验原理与方法】 1:标准形式:元函数为其中n R R f X f nR x n→∈:)(min2.无约束优化问题的基本算法一.最速下降法(共轭梯度法)算法步骤: ⑴ 给定初始点n E X ∈0,允许误差0>ε,令k=0; ⑵ 计算()k X f ∇;⑶ 检验是否满足收敛性的判别准则: ()ε≤∇k X f ,若满足,则停止迭代,得点k X X ≈*,否则进行⑷; ⑷ 令()k k X f S -∇=,从k X 出发,沿k S 进行一维搜索, 即求k λ使得: ()()k k k k k S X f S X f λλλ+=+≥0min ;⑸ 令k k k k S X X λ+=+1,k=k+1返回⑵.最速下降法是一种最基本的算法,它在最优化方法中占有重要地位.最速下降法的优点是工作量小,存储变量较少,初始点要求不高;缺点是收敛慢,最速下降法适用于寻优过程的前期迭代或作为间插步骤,当接近极值点时,宜选用别种收敛快的算法..牛顿法算法步骤:(1) 选定初始点n E X ∈0,给定允许误差0>ε,令k=0; (2) 求()k X f ∇,()()12-∇kX f ,检验:若()ε<∇k X f ,则停止迭代,k X X ≈*.否则, 转向(3); (3) 令 ()()k k k X f X f S ∇∇-=-12][(牛顿方向); (4) k k k S X X +=+1,1+=k k ,转回(2).如果f 是对称正定矩阵A 的二次函数,则用牛顿法经过一次迭代 就可达到最优点,如不是二次函数,则牛顿法不能一步达到极值点, 但由于这种函数在极值点附近和二次函数很近似,因此牛顿法的收 敛速度还是很快的.牛顿法的收敛速度虽然较快,但要求Hessian 矩阵要可逆,要计算二阶导数和逆矩阵,就加大了计算机计算量和存储量. 【实验内容】1. 求 f = 2x e xsin -在0<x<8中的最小值与最大值 主程序为wliti1.m: f='2*exp(-x).*sin(x)'; fplot(f,[0,8]); %作图语句 [xmin,ymin]=fminbnd (f, 0,8) f1='-2*exp(-x).*sin(x)';[xmax,ymax]=fminbnd (f1, 0,8) 运行结果:xmin = 3.9270 ymin = -0.0279 xmax = 0.7854 ymax = 0.64482. 对边长为3米的正方形铁板,在四个角剪去相等的正方形以制成方形无盖水槽,问如 何剪法使水槽的容积最大?先编写M 文件fun0.m 如下: function f=fun0(x) f=-(3-2*x).^2*x;主程序为wliti2.m:[x,fval]=fminbnd('fun0',0,1.5); xmax=xfmax=-fval 运算结果为: xmax = 0.5000,fmax =2.0000.即剪掉的正方形的边长为0.5米时水槽的容积最大,最大容积为2立方米.实验5: MATLAB 图论问题计算【实验目的】了解用Matlab 软件求解图论模型及层次分析模型的方法。