模式识别作业2
模式识别第二章

p(x)~N(μ,Σ)
第二章 贝叶斯决策理论
37
等概率密度轨迹为超椭球面
正态分布 Bayes决策
p ( x ) c ( x μ ) T 1 ( x μ ) 2
i
第二章 贝叶斯决策理论
9
分类器设计
判别 函数
分类器是某种由硬件或软件组成的“机器”:
➢计算c个判别函数gi(x)
➢最大值选择
x1
g1
x2
g2
ARGMAX
a(x)
.
.
.
.
.
.
xn
gc
多类识别问题的Bayes最大后验概率决策:gi(x) = P (ωi |x)
第二章 贝叶斯决策理论
10
2.3 Bayes最小错误率决策
根据已有知识和经验,两类的先验概率为:
➢正常(ω1): P(ω1)=0.9 ➢异常(ω2): P(ω2)=0.1 ➢对某一样本观察值x,通过计算或查表得到:
p(x|ω1)=0.2, p(x|ω2)=0.4
如何对细胞x进行分类?
第二章 贝叶斯决策理论
15
Bayes最小错误率决策例解(2)
最小错误 率决策
利用贝叶斯公式计算两类的后验概率:
P ( 1|x ) 2 P P ( ( 1)jp )( p x (x | | 1 )j)0 .9 0 0 ..9 2 0 0 ..2 1 0 .40 .8 1 8
j 1
P ( 2|x ) 2 P P ( ( 2)jp )( p x (x | | 2)j)0 .2 0 0 ..9 4 0 0 ..1 4 0 .1 0 .1 8 2
模式识别作业题(2)

答:不是最小的。首先要明确当我们谈到最小最大损失判决规则时,先验概率是未知的, 而先验概率的变化会导致错分概率变化, 故错分概率也是一个变量。 使用最小最大损 失判决规则的目的就是保证在先验概率任意变化导致错分概率变化时, 错分概率的最 坏(即最大)情况在所有判决规则中是最好的(即最小)。 4、 若 λ11 = λ22 =0, λ12 = λ21 ,证明此时最小最大决策面是来自两类的错误率相等。 证明:最小最大决策面满足 ( λ11 - λ22 )+( λ21 - λ11 ) 容易得到
λ11 P(ω1 | x) + λ12 P(ω2 | x) < λ21 P(ω1 | x) + λ22 P(ω2 | x) ( λ21 - λ11 ) P (ω1 | x) >( λ12 - λ22 ) P (ω2 | x) ( λ21 - λ11 ) P (ω1 ) P ( x | ω1 ) >( λ12 - λ22 ) P (ω2 ) P ( x | ω2 ) p( x | ω1 ) (λ 12 − λ 22) P(ω2 ) > 即 p( x | ω2 ) ( λ 21 − λ 11) P (ω1 )
6、设总体分布密度为 N( μ ,1),-∞< μ <+∞,并设 X={ x1 , x2 ,… xN },分别用最大似然 估计和贝叶斯估计计算 μ 。已知 μ 的先验分布 p( μ )~N(0,1)。 解:似然函数为:
∧Байду номын сангаас
L( μ )=lnp(X|u)=
∑ ln p( xi | u) = −
i =1
N
模式识别第三章作业及其解答
模式识别教学资料-2感知器算法作业

Lecture2作业1,已知类ω1由两个特征向量 0,0 T , 1,0 T 组成,类ω2由两个特征向量 0,1 T , 1,1 T 组成,使用感知器算法,并令w 0=(0,0)T ,设计这两类的线性分类函数。
2,证明:针对线性可分训练样本集,PLA 算法中,当W 0=0,在对分错样本进行了T 次纠正后,下式成立:W f T W f W TW T ≥ T ∙constant3,针对线性可分训练样本集,PLA 算法中,假设对分错样本进行了T 次纠正后得到的分类面不再出现错分状况,定义:R 2=max n x n 2,ρ=min n y n W f TW f x n ,试证明:T ≤R 2ρ2编程作业1,编写一个名为Perce 的函数,用它来实现感知器算法。
函数的输入/输出有:(a )一个N*d 维的矩阵X ,它的第i 行是第i 个数据向量; (b )一个N 维列向量y ,y 的第i 个元素包含了类(-1,1),并且该类与相应的向量相互对应;(c )用向量w_ini 初始化参数向量;并且返回估计参数向量; 假设函数最大迭代次数为10000。
2,(a )产生两个都具有200个二维向量的数据集X1和'1X (注意:在生成数据集之前最好使用命令randn(‘seed ’,0)初始化高斯随机生成器为0(或任意给定数值),这对结果的可重复性很重要)。
向量的前半部分来自均值向量T [-5,0]m1=的正态分布,并且协方差矩阵I =S1。
向量的后半部分来自均值向量T [5,0]m1=的正态分布,并且协方差矩阵I =S1。
其中I 是一个2*2的单位矩阵。
(b )在上述数据集上运用感知器算法,并且使用不同的初始向量初始化参数向量。
(c )测试每一种算法在X1和'1X 上的性能。
(d )画出数据集X1和'1X ,以及分类面。
3,重复第2题的内容,但是实验中要使用数据集X2和'2X (注意:在生成数据集之前最好使用命令randn(‘seed ’,0)初始化高斯随机生成器为0(或任意给定数值),这对结果的可重复性很重要)。
模式识别第二版答案完整版

模式识别(第二版)习题解答
目录
1 绪论
2
2 贝叶斯决策理论
2
j=1,...,c
类条件概率相联系的形式,即 如果 p(x|wi)P (wi) = max p(x|wj)P (wj),则x ∈ wi。
j=1,...,c
• 2.6 对两类问题,证明最小风险贝叶斯决策规则可表示为,若
p(x|w1) > (λ12 − λ22)P (w2) , p(x|w2) (λ21 − λ11)P (w1)
max P (wj|x),则x ∈ wj∗。另外一种形式为j∗ = max p(x|wj)P (wj),则x ∈ wj∗。
j=1,...,c
j=1,...,c
考虑两类问题的分类决策面为:P (w1|x) = P (w2|x),与p(x|w1)P (w1) = p(x|w2)P (w2)
是相同的。
• 2.9 写出两类和多类情况下最小风险贝叶斯决策判别函数和决策面方程。
λ11P (w1|x) + λ12P (w2|x) < λ21P (w1|x) + λ22P (w2|x) (λ21 − λ11)P (w1|x) > (λ12 − λ22)P (w2|x)
(λ21 − λ11)P (w1)p(x|w1) > (λ12 − λ22)P (w2)p(x|w2) p(x|w1) > (λ12 − λ22)P (w2) p(x|w2) (λ21 − λ11)P (w1)
模式识别第二章(线性判别函数法)

2类判别区域 d21(x)>0 d23(x)>0 3类判别区域 d31(x)>0 d32(x)>0
0 1 2 3 4 5 6 7 8 9
x1
d23(x)为正
d32(x)为正
d12(x)为正
d21(x)为正
32
i j 两分法例题图示
33
3、第三种情况(续)
d1 ( x) d2 ( x)
12
2.2.1 线性判别函数的基本概念
• 如果采用增广模式,可以表达如下
g ( x) w x
T
x ( x1 , x 2 , , x d ,1)
w ( w1 , w 2 , , w d , w d 1 ) T
T
增广加权向量
2016/12/3
模式识别导论
13
2.1 判别函数(discriminant function) 1.判别函数的定义 直接用来对模式进行分类的准则函数。
模式识别导论
11
2.2.1 线性判别函数的基本概念
• 在一个d维的特征空间中,线性判别函数的
一般表达式如下
g ( x ) w1 x1 w 2 x 2 w d x d w d 1
g ( x ) w x w d 1
T
w为 加 权 向 量
2016/12/3
模式识别导论
1
d1 ( x ) d3 ( x )
2
3
d2 ( x) d3 ( x)
34
多类问题图例(第三种情况)
35
上述三种方法小结:
当c
但是
3 时,i j
法比
i i
法需要更多
模式识别练习题

2013模式识别练习题一. 填空题1、模式识别系统的基本构成单元包括:模式采集、特征的选择和提取和模式分类。
2、统计模式识别中描述模式的方法一般使用特征矢量;句法模式识别中模式描述方法一般有串、树、网。
3、影响层次聚类算法结果的主要因素有计算模式距离的测度、聚类准则、类间距离阈值、预定的类别数目。
4、线性判别函数的正负和数值大小的几何意义是正负表示样本点位于判别界面法向量指向的正负半空间中,绝对值正比于样本点与判别界面的距离。
5、感知器算法1 ,H-K算法 2 。
(1)只适用于线性可分的情况;(2)线性可分、不可分都适用。
6、在统计模式分类问题中,聂曼-皮尔逊判决准则主要用于某一种判别错误较另一种判别错误更为重要的情况;最小最大判别准则主要用于先验概率未知的情况。
7、“特征个数越多越有利于分类”这种说法正确吗?错误。
特征选择的主要目的是从n个特征中选取最有利于分类的m个特征(m<n),以降低特征维数。
一般在和(C n m>>n )的条件下,可以使用分支定界法以减少计算量。
8、散度J ij越大,说明ωi类模式与ωj类模式的分布差别越大;当ωi类模式与ωj类模式的分布相同时,J ij= 0。
二、选择题1、影响聚类算法结果的主要因素有(B、C、D )。
A.已知类别的样本质量;B.分类准则;C.特征选取;D.模式相似性测度2、模式识别中,马式距离较之于欧式距离的优点是(C、D)。
A.平移不变性;B.旋转不变性;C尺度不变性;D.考虑了模式的分布3、影响基本K-均值算法的主要因素有(ABD)。
A.样本输入顺序;B.模式相似性测度;C.聚类准则;D.初始类中心的选取4、位势函数法的积累势函数K(x)的作用相当于Bayes判决中的(B D)。
A. 先验概率;B. 后验概率;C. 类概率密度;D. 类概率密度与先验概率的乘积5、在统计模式分类问题中,当先验概率未知时,可以使用(BD )。
A. 最小损失准则;B. 最小最大损失准则;C. 最小误判概率准则;D. N-P 判决6、散度J D 是根据( C )构造的可分性判据。
中科院模式识别第二次作业参考答案

4
当 2 3 时,有:
Q( , 0 ) 不存在。
对分布进行归一化,有 P ( x2 ) ~ U (0, 2 ) ,故
P( x )dx
2
2
1
对 P ( x1 ) ,有
p( x1 )dx1
0 0
1
1
e 1x1 dx1 1
因此, 1 1 。
2
1 ( x )2 1 1 x v 2 exp 2 2 nh 2 hn 2 2 hn 2 n 2 hn hn hn nhn hn nhn 1 ( x )2 exp 2 2 2 2 hn 2 2 hn 1 1 ( x )2 1 exp 2 2 2
(c) 用递归公式计算样本均值,每次更新的计算复杂度为: O ( d ) 用递归公式计算样本协方差,每次更新的计算复杂度为: O ( d ) (d) 当样本量非常大,或者样本是边输入边分类的时候,考虑采用递归公式,这是在线分类。 当样本量比较小,可以全部输入之后再分类的时候,考虑采用非递归公式,这是离线分类。
2
2
)1 。
当 1 1, 2 3 时,取得最大值: Q ( , 0 ) 8.52 故,当 3 时, Q( , 0 ) 取得最大值。
1
1 2 x1 2 e (c) 当 4 时,有 P ( x1 , x2 ) 8 0
因此: pn ( x) ~ N ( , hn )
(b) 计算得:
Var [ pn ( x)] Var [
1 nhn
机器学习中的数据挖掘与模式识别(Ⅱ)

机器学习中的数据挖掘与模式识别随着信息时代的到来,大数据已经成为各行各业的重要组成部分。
而机器学习作为大数据处理的关键技术之一,数据挖掘与模式识别更是机器学习中不可或缺的重要环节。
本文将探讨机器学习中的数据挖掘与模式识别,从其定义、应用和发展趋势等多个方面展开论述。
一、数据挖掘与模式识别的定义数据挖掘是指从大量数据中发现并提取先前未知的、有价值的、可理解的模式和信息的过程。
而模式识别则是将目标对象的特征与已知模式相比较,以确定其所属类别或属性的过程。
在机器学习中,数据挖掘与模式识别通常是指利用算法和模型来分析数据、识别模式并做出预测的过程。
二、数据挖掘与模式识别的应用数据挖掘与模式识别在各个领域都有着广泛的应用。
在金融领域,机器学习的数据挖掘能够帮助银行和投资机构发现欺诈行为、预测股市走势以及制定个性化的投资组合。
在医疗领域,数据挖掘和模式识别可以帮助医生分析大量的病例数据,辅助诊断疾病和预测患者的治疗效果。
在电子商务领域,数据挖掘和模式识别可以帮助企业分析用户行为,精准推荐商品,提高销售转化率。
在智能制造领域,数据挖掘和模式识别可以帮助企业提高生产效率,优化生产计划,减少生产成本。
三、数据挖掘与模式识别的发展趋势随着科学技术的不断进步,数据挖掘与模式识别也在不断发展。
一方面,随着大数据技术的普及和成熟,数据挖掘的数据规模越来越大,模式识别的准确性和稳定性也在不断提高。
另一方面,随着人工智能技术的飞速发展,机器学习算法也在不断创新,例如深度学习、强化学习等技术的应用,使得数据挖掘与模式识别的应用领域更加广泛。
未来,数据挖掘与模式识别的发展趋势将更加注重算法的自动化和智能化,以适应大规模数据的处理需求。
同时,数据挖掘与模式识别在医疗健康、智能制造、智能交通等领域的应用前景也将更加广阔。
四、数据挖掘与模式识别的挑战尽管数据挖掘与模式识别有着广泛的应用前景,但是也面临着一些挑战。
首先,随着数据规模的不断增大,数据的质量和可信度成为了一个亟待解决的问题。
模式识别作业

第二章主要内容:几种常见的聚类算法已经所使用的准则函数。
作业1:对如下5个6维模式样本,用最小聚类准则进行系统聚类分析 已知样本如下:x1: 0, 1, 3, 1, 3, 4;x2: 3, 3, 3, 1, 2, 1;x3: 1, 0, 0, 0, 1, 1;x4: 2, 1, 0, 2, 2, 1;x5: 0, 0, 1, 0, 1, 0 第1步:将每一样本看成单独一类,得(0)(0)(0)112233(0)(0)4455{},{},{}{},{}G x G x G x Gx Gx =====计算各类之间的欧式距离,可得距离矩阵(0)D第2步:矩阵(0)D,它是(0)3G 和(0)5G 之间的距离,将他们合并为一类,得新的分类为(1)(0)(1)(0)(1)(0)(0)(1)(0)112233544{},{},{,},{}G G G G G G G G G ====计算聚类后的距离矩阵(1)D 第3步:由于(1)D 它是(1)3G 与(1)4G 之间的距离,于是合并(1)3G 和(1)4G ,得新的分类为(2)(1)(2)(2)(2)(1)(1)1122334{},{},{,}G G G G G G G ===同样,按最小距离准则计算距离矩阵(2)D,得第4步:同理得(3)(2)(3)(2)(2)11223{},{,}G G G G G == 满足聚类要求,如聚为2类,聚类完毕。
系统聚类算法介绍:第一步:设初始模式样本共有N 个,每个样本自成一类,即建立N 类。
G 1(0), G 2(0) , ……,G N (0)为计算各类之间的距离(初始时即为各样本间的距离),得到一个N*N 维的距离矩阵D(0)。
这里,标号(0)表示聚类开始运算前的状态。
第二步:假设前一步聚类运算中已求得距离矩阵D(n),n 为逐次聚类合并的次数,则求D(n)中的最小元素。
如果它是Gi(n)和Gj(n)两类之间的距离,则将Gi(n)和Gj(n)两类合并为一类G ij (n+1),由此建立新的分类:G 1(n+1), G 2(n+1)……第三步:计算合并后新类别之间的距离,得D(n+1)。
模式识别大作业

模式识别大作业(总21页)--本页仅作为文档封面,使用时请直接删除即可----内页可以根据需求调整合适字体及大小--作业1 用身高和/或体重数据进行性别分类(一)基本要求:用和的数据作为训练样本集,建立Bayes分类器,用测试样本数据对该分类器进行测试。
调整特征、分类器等方面的一些因素,考察它们对分类器性能的影响,从而加深对所学内容的理解和感性认识。
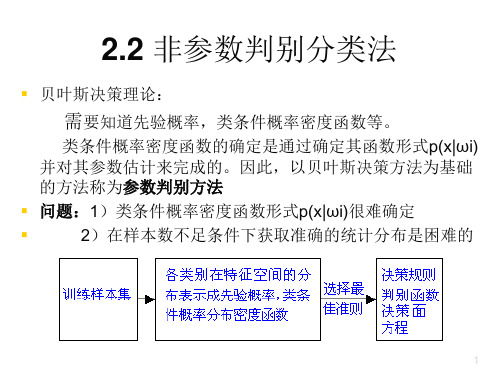
具体做法:1.应用单个特征进行实验:以(a)身高或者(b)体重数据作为特征,在正态分布假设下利用最大似然法或者贝叶斯估计法估计分布密度参数,建立最小错误率Bayes分类器,写出得到的决策规则,将该分类器应用到测试样本,考察测试错误情况。
在分类器设计时可以考察采用不同先验概率(如对, 对, 对等)进行实验,考察对决策规则和错误率的影响。
图1-先验概率:分布曲线图2-先验概率:分布曲线图3--先验概率:分布曲线图4不同先验概率的曲线有图可以看出先验概率对决策规则和错误率有很大的影响。
程序:和2.应用两个特征进行实验:同时采用身高和体重数据作为特征,分别假设二者相关或不相关(在正态分布下一定独立),在正态分布假设下估计概率密度,建立最小错误率Bayes分类器,写出得到的决策规则,将该分类器应用到训练/测试样本,考察训练/测试错误情况。
比较相关假设和不相关假设下结果的差异。
在分类器设计时可以考察采用不同先验概率(如 vs. , vs. , vs. 等)进行实验,考察对决策和错误率的影响。
训练样本female来测试图1先验概率 vs. 图2先验概率 vs.图3先验概率 vs. 图4不同先验概率对测试样本1进行试验得图对测试样本2进行试验有图可以看出先验概率对决策规则和错误率有很大的影响。
程序和3.自行给出一个决策表,采用最小风险的Bayes决策重复上面的某个或全部实验。
W1W2W10W20close all;clear all;X=120::200; %设置采样范围及精度pw1=;pw2=; %设置先验概率sample1=textread('') %读入样本samplew1=zeros(1,length(sample1(:,1)));u1=mean(sample1(:,1));m1=std(sample1(:,1));y1=normpdf(X,u1,m1); %类条件概率分布figure(1);subplot(2,1,1);plot(X,y1);title('F身高类条件概率分布曲线');sample2=textread('') %读入样本samplew2=zeros(1,length(sample2(:,1)));u2=mean(sample2(:,1));m2=std(sample2(:,1));y2=normpdf(X,u2,m2); %类条件概率分布subplot(2,1,2);plot(X,y2);title('M身高类条件概率分布曲线');P1=pw1*y1./(pw1*y1+pw2*y2);P2=pw2*y2./(pw1*y1+pw2*y2);figure(2);subplot(2,1,1);plot(X,P1);title('F身高后验概率分布曲线');subplot(2,1,2);plot(X,P2);title('M身高后验概率分布曲线');P11=pw1*y1;P22=pw2*y2;figure(3);subplot(3,1,1);plot(X,P11);subplot(3,1,2);plot(X,P22);subplot(3,1,3);plot(X,P11,X,P22);sample=textread('all ') %读入样本[result]=bayes(sample1(:,1),sample2(:,1),pw1,pw2);%bayes分类器function [result] =bayes(sample1(:,1),sample2(:,1),pw1,pw2); error1=0;error2=0;u1=mean(sample1(:,1));m1=std(sample1(:,1));y1=normpdf(X,u1,m1); %类条件概率分布u2=mean(sample2(:,1));m2=std(sample2(:,1));y2=normpdf(X,u2,m2); %类条件概率分布P1=pw1*y1./(pw1*y1+pw2*y2);P2=pw2*y2./(pw1*y1+pw2*y2);for i = 1:50if P1(i)>P2(i)result(i)=0;pe(i)=P2(i);elseresult(i)=1;pe(i)=P1(i);endendfor i=1:50if result(k)==0error1=error1+1;else result(k)=1error2=error2+1;endendratio = error1+error2/length(sample); %识别率,百分比形式sprintf('正确识别率为%.2f%%.',ratio)作业2 用身高/体重数据进行性别分类(二)基本要求:试验直接设计线性分类器的方法,与基于概率密度估计的贝叶斯分离器进行比较。
模式识别作业题(2)
=α
∏ p( x | μ ) p( μ )
i =1 i
N
=α
∏
i =1
N
⎡ 1 ⎢ exp ⎢ − 2πσ ⎢ ⎣
( xi − μ )
2σ
2
2
⎤ ⎡ 1 ⎥ ⎢ ⎥ • 2πσ exp ⎢ − 0 ⎥ ⎢ ⎦ ⎣
( μ − μ0 ) ⎤⎥ ⎥ 2σ ⎥ 0 ⎦
2 2
= α exp ⎢ − [⎜
''
⎡ 1 ⎛ N ⎛ 1 1 ⎞ 2 μ + − 2 ⎟ ⎜ 2 2 σ 02 ⎟ 2 ⎜ ⎢ ⎝σ σ ⎝ ⎠ ⎣
2 1 N +C ( x − μ ) ∑ 2 i =1 i
似然函数 μ 求导
∂L( μ ) N = ∑ x -N μ =0 i ∂μ i =1
∧
所以 μ 的最大似然估计: μ =
1 N
∑ xi
i =1
N
贝叶斯估计: p( μ |X)=
p( X | μ ) p( μ )
∫ p( X | μ ) p(μ )du
2 σn =
σ 02σ 2 2 Nσ 0 +σ 2
其中, mN =
1 N
∑x ,μ
i =1 i
N
n
就是贝叶斯估计。
7 略
得证。 3、使用最小最大损失判决规则的错分概率是最小吗?为什么?
答:不是最小的。首先要明确当我们谈到最小最大损失判决规则时,先验概率是未知的, 而先验概率的变化会导致错分概率变化, 故错分概率也是一个变量。 使用最小最大损 失判决规则的目的就是保证在先验概率任意变化导致错分概率变化时, 错分概率的最 坏(即最大)情况在所有判决规则中是最好的(即最小)。 4、 若 λ11 = λ22 =0, λ12 = λ21 ,证明此时最小最大决策面是来自两类的错误率相等。 证明:最小最大决策面满足 ( λ11 - λ22 )+( λ21 - λ11 ) 容易得到
模式识别第2章 模式识别的基本理论(2)
(步长系数 )
33
算法
1)给定初始权向量a(k) ,k=0;
( 如a(0)=[1,1,….,1]T)
2)利用a(k)对对样本集分类,设错分类样本集为yk 3)若yk是空集,则a=a(k),迭代结束;否则,转4) 或 ||a(k)-a(k-1)||<=θ, θ是预先设定的一个小的阈值 (线性可分, θ =0) ( y) a(k 1) a(k) k J p 4)计算:ρ k, J p (a) y y 令k=k+1 5)转2)
1)g(x)>0, 决策:X∈ ω1 决策面的法向量指向ω1的决 策域R1,R1在H的正侧 2) g(x)<0, 决策:X∈ ω2, ω2的决策域R2在H的负侧
6
X g(X) / ||W|| R0=w0 / ||W|| Xp R2: g<0 H: g=0 r 正侧 R1: g>0 负侧
g(X)、 w0的意义 g(X)是d维空间任一点X到决策面H的距离的代数度量 w0体现该决策面在特征空间中的位置 1) w0=0时,该决策面过特征空间坐标系原点 2)否则,r0=w0/||W||表示坐标原点到决策面的距离
否则,按如下方法确定: 1、 2、 3、 m m ln[ P( ) / P( )]
~ ~
w0
1
2
2
1
2
N1 N 2 2
(P(W1)、P(W2) 已知时)
24
分类规则
25
5 感知准则函数
感知准则函数是五十年代由Rosenblatt提出的一种 自学习判别函数生成方法,企图将其用于脑模型感 知器,因此被称为感知准则函数。 特点:随意确定判别函数的初始值,在对样本分类 训练过程中逐步修正直至最终确定。 感知准则函数:是设计线性分类器的重要方法 感知准则函数使用增广样本向量与增广权向量
模式识别大作业
作业1 用身高和/或体重数据进行性别分类(一)基本要求:用和的数据作为训练样本集,建立Bayes分类器,用测试样本数据对该分类器进行测试。
调整特征、分类器等方面的一些因素,考察它们对分类器性能的影响,从而加深对所学内容的理解和感性认识。
具体做法:1.应用单个特征进行实验:以(a)身高或者(b)体重数据作为特征,在正态分布假设下利用最大似然法或者贝叶斯估计法估计分布密度参数,建立最小错误率Bayes分类器,写出得到的决策规则,将该分类器应用到测试样本,考察测试错误情况。
在分类器设计时可以考察采用不同先验概率(如对, 对, 对等)进行实验,考察对决策规则和错误率的影响。
图1-先验概率:分布曲线图2-先验概率:分布曲线图3--先验概率:分布曲线图4不同先验概率的曲线有图可以看出先验概率对决策规则和错误率有很大的影响。
程序:和2.应用两个特征进行实验:同时采用身高和体重数据作为特征,分别假设二者相关或不相关(在正态分布下一定独立),在正态分布假设下估计概率密度,建立最小错误率Bayes 分类器,写出得到的决策规则,将该分类器应用到训练/测试样本,考察训练/测试错误情况。
比较相关假设和不相关假设下结果的差异。
在分类器设计时可以考察采用不同先验概率(如vs. , vs. , vs. 等)进行实验,考察对决策和错误率的影响。
训练样本female来测试图1先验概率vs. 图2先验概率vs.图3先验概率vs. 图4不同先验概率对测试样本1进行试验得图对测试样本2进行试验有图可以看出先验概率对决策规则和错误率有很大的影响。
程序和3.自行给出一个决策表,采用最小风险的Bayes决策重复上面的某个或全部实验。
W1W2W10W20close all;clear all;X=120::200; %设置采样范围及精度pw1=;pw2=; %设置先验概率sample1=textread('') %读入样本samplew1=zeros(1,length(sample1(:,1)));u1=mean(sample1(:,1));m1=std(sample1(:,1));y1=normpdf(X,u1,m1); %类条件概率分布figure(1);subplot(2,1,1);plot(X,y1);title('F身高类条件概率分布曲线');sample2=textread('') %读入样本samplew2=zeros(1,length(sample2(:,1)));u2=mean(sample2(:,1));m2=std(sample2(:,1));y2=normpdf(X,u2,m2); %类条件概率分布subplot(2,1,2);plot(X,y2);title('M身高类条件概率分布曲线');P1=pw1*y1./(pw1*y1+pw2*y2);P2=pw2*y2./(pw1*y1+pw2*y2);figure(2);subplot(2,1,1);plot(X,P1);title('F身高后验概率分布曲线');subplot(2,1,2);plot(X,P2);title('M身高后验概率分布曲线');P11=pw1*y1;P22=pw2*y2;figure(3);subplot(3,1,1);plot(X,P11);subplot(3,1,2);plot(X,P22);subplot(3,1,3);plot(X,P11,X,P22);sample=textread('all ') %读入样本[result]=bayes(sample1(:,1),sample2(:,1),pw1,pw2);%bayes分类器function [result] =bayes(sample1(:,1),sample2(:,1),pw1,pw2);error1=0;error2=0;u1=mean(sample1(:,1));m1=std(sample1(:,1));y1=normpdf(X,u1,m1); %类条件概率分布u2=mean(sample2(:,1));m2=std(sample2(:,1));y2=normpdf(X,u2,m2); %类条件概率分布P1=pw1*y1./(pw1*y1+pw2*y2);P2=pw2*y2./(pw1*y1+pw2*y2);for i = 1:50if P1(i)>P2(i)result(i)=0;pe(i)=P2(i);elseresult(i)=1;pe(i)=P1(i);endendfor i=1:50if result(k)==0error1=error1+1;else result(k)=1error2=error2+1;endendratio = error1+error2/length(sample); %识别率,百分比形式sprintf('正确识别率为%.2f%%.',ratio)作业2 用身高/体重数据进行性别分类(二)基本要求:试验直接设计线性分类器的方法,与基于概率密度估计的贝叶斯分离器进行比较。
模式识别作业_2
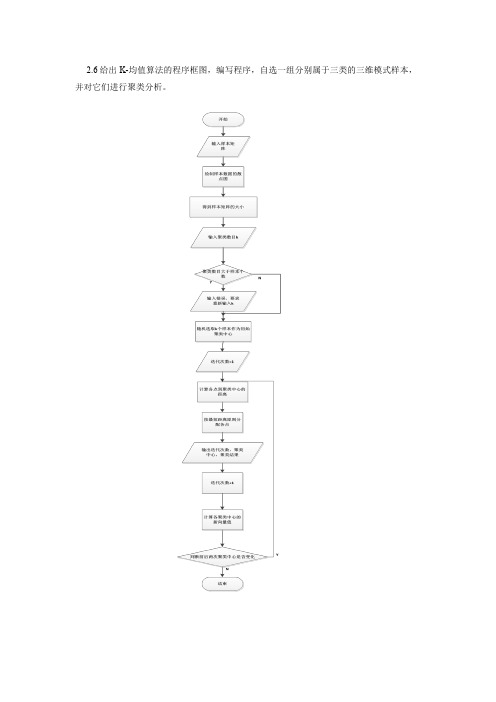
2.6给出K-均值算法的程序框图,编写程序,自选一组分别属于三类的三维模式样本,并对它们进行聚类分析。
MATLAB程序代码clear all;clc;data=input('请输入样本数据矩阵:');X=data(:,1);Y=data(:,2);figure(1);plot(X,Y,'r*','LineWidth',3);axis([0908])xlabel('x');ylabel('y');hold on;grid on;m=size(data,1);n=size(data,2);counter=0;k=input('请输入聚类数目:');if k>mdisp('输入的聚类数目过大,请输入正确的k值');k=input('请输入聚类数目:');endM=cell(1,m);for i=1:kM{1,i}=zeros(1,n);endMold=cell(1,m);for i=1:kMold{1,i}=zeros(1,n);end%随机选取k个样本作为初始聚类中心%第一次聚类,使用初始聚类中心p=randperm(m);%产生m个不同的随机数for i=1:kM{1,i}=data(p(i),:);while truecounter=counter+1;disp('第');disp(counter);disp('次迭代');count=zeros(1,k);%初始化聚类CC=cell(1,k);for i=1:kC{1,i}=zeros(m,n);end%聚类for i=1:mgap=zeros(1,k);for d=1:kfor j=1:ngap(d)=gap(d)+(M{1,d}(j)-data(i,j))^2;endend[y,l]=min(sqrt(gap));count(l)=count(l)+1;C{1,l}(count(l),:)=data(i,:);endMold=M;disp('聚类中心为:');for i=1:kdisp(M{1,i});enddisp('聚类结果为:');for i=1:kdisp(C{1,i});sumvar=0;for i=1:kE=0;disp('单个误差平方和为:');for j=1:count(i)for h=1:nE=E+(M{1,i}(h)-C{1,i}(j,h))^2;endenddisp(E);sumvar=sumvar+E;enddisp('总体误差平方和为:');disp(sumvar);%计算新的聚类中心,更新M,并保存旧的聚类中心for i=1:kM{1,i}=sum(C{1,i})/count(i);end%检查前后两次聚类中心是否变化,若变化则继续迭代;否则算法停止;tally=0;for i=1:kif abs(Mold{1,i}-M{1,i})<1e-5*ones(1,n)tally=tally+1;continue;elsebreak;endendif tally==kbreak;endEnd3.11给出感知器算法程序框图,编写算法程序.MATLAB程序代码clear all;clc;disp('感知器算法求解两类训练样本的判别函数'); Data1=input('请输入第一类样本数据:');Data2=input('请输入第二类样本数据:');W=input('请输入权向量初始值W(1)='); Expand=cat(1,Data1,Data2); ExpandData1=cat(2,Data1,ones(4,1)); ExpandData2=cat(2,Data2.*-1,ones(4,1).*-1); ExpandData=cat(1,ExpandData1,ExpandData2); X=Expand(:,1);Y=Expand(:,2);Z=Expand(:,3);[ro,co]=size(ExpandData);Step=0;CountError=1;while CountError>0;CountError=0;for i=1:roTemp=W*ExpandData(i,:)';if Temp<=0W=W+ExpandData(i,:);disp(W)CounterError=CountError+1;endendStep=Step+1;enddisp(W)figure(1)plot3(X,Y,Z,'ks','LineWidth',2);grid on;hold on;xlabel('x');ylabel('y');zlabel('z');f=@(x,y,z)W(1)*x+W(2)*y+W(3)*z+W(4); [x,y,z]=meshgrid(-1:.2:1,-1:.2:1,0:.2:1);v=f(x,y,z);h=patch(isosurface(x,y,z,v));isonormals(x,y,z,v,h)set(h,'FaceColor','r','EdgeColor','none');。
《模式识别与机器学习》习题和参考答案

(μ i , i ), i 1, 2 ,可得
r (x) ln p(x | w 1) ln p(x | w 2)
d
1
1
(x μ1 ) 1 (x μ1 ) ln 2 ln | |
2
2
2
d
1
1
(x μ 2 ) 1 (x μ 2 ) ln 2 ln | |
(2-15)可简化为
1
gi ( x) (x μi ) 1 (x μi ).
2
(2-17)
将上式展开,忽略与 i 无关的项 x 1x ,判别函数进一步简化为
1
gi (x) ( 1μi ) x μi 1μi .
2
(2-18)
此时判别函数是 x 的线性函数,决策面是一个超平面。当决策区域 Ri 与 R j 相邻时,
190%
(2-13)
最小风险贝叶斯决策会选择条件风险最小的类别,即 h( x) 1 。
3.
给出在两类类别先验概率相等情况下,类条件概率分布是相等对角协方差
矩阵的高斯分布的贝叶斯决策规则,并进行错误率分析。
答:
(1)首先给出决策面的表达式。根据类条件概率分布的高斯假设,可以
得到
p(x | w i )
2
2
2
1
1
1 ||
(x μ1 ) 1 (x μ1 ) (x μ 2 ) 1 (x μ 2 ) ln
2
2
2 ||
1
(μ 2 μ1 ) 1x (μ1 1μ1 μ 2 1μ 2 ).
2
(2-28)
机器学习第二次作业
机器学习第⼆次作业机器学习笔记⼀、机器学习的相关概念模式识别是根据已有知识的表达,针对待识别模式,通过计算机⽤数学技术⽅法来判别所属的类别或是预测对应的回归值。
环境与客体统称为“模式”。
根据任务,模式识别可以分为「分类」和「回归」两种形式。
输⼊待识别模式,经过模式识别模型进⾏计算处理,输出其所属类别或回归值就是模式识别的过程,模式识别模型类似于数学上的\(f(x)\)表达式。
⼀个模式识别模型包含「特征提取」与「分类器」。
机器学习是⼈⼯智能的⼀个分⽀,是通过给定模式识别的初始模型,学习已有的特征知识以不断调整模型参数,最后获得更为准确的模式识别模型的过程,即利⽤机器学习的途径解决⼈⼯智能的问题。
样本是⽤于机器学习的现有知识的集合。
根据真值的给定与否分为「标注的样本」和「未标注的样本」。
机器学习的⽅法根据样本真值的给定与否分为「监督式学习」、「⽆监督式学习」和「半监督式学习」。
近年也出现了新的机器学习⽅法,根据先后累计的多次决策动作判断决策的好坏,称为「强化学习」。
样本根据⽤途的不同还可以分为「训练样本」和「测试样本」。
由于样本的有限性造成样本集合并不能完整表达所有模式,样本⾃⾝携带的噪声也会对模型的判断造成影响,这要求模型具有较好的泛化能⼒。
泛化能⼒是指⼀个模型不仅对训练样本内的模式有判别能⼒,对于训练样本外的模式也要具有决策能⼒。
训练获得的模型泛化能⼒低下则称为过拟合,可以选择复杂度适合的模型或通过加⼊正则项的⽅式提⾼模型的泛化能⼒。
⼆、特征的相关概念特征的定义特征是⽤于区分不同类别模式的可测量的量,具有「辨别能⼒」和「鲁棒性」两个特性。
特征向量是由多个特征构成的列向量,表⽰⼀个模式。
特征空间是特征在空间上的表达⽅式,坐标轴表⽰某⼀个特征,空间中的每个点表⽰⼀个模式,空间原点到点的向量表⽰该模式的特征向量。
特征的相关运算点积\(x \cdot y = x^{T}y = y^{T}x = \sum^{p}_{j=1}{x_{j}y_{j}}\)点积的结果是⼀个标量表达点积是⼀个线性变换⼏何意义:\(x \cdot y = |x||y|cos \theta\)点积为0则表⽰两个向量共线,称为正交向量夹⾓\(cos\theta = \frac{x \cdot y}{|x||y|}\)投影\(x_{y} = |x|cos \theta\)\(x_{y}\)称为x到y上的投影,是x在y⽅向上的长度(标量)投影向量\(x_{y} = |x|cos\theta\frac{y}{|y|}\)\(x_{y}\)称为x在y上的分解,是x在y⽅向上的向量特征的相关性由于每个特征向量表达⼀个模式,因此特征的相关性是度量模式之间是否相似的基础。
模式识别作业第三章2

第三章作业已知两类训练样本为1:(0 0 0 )',(1 0 0)' ,(1 0 1)',(1 1 0)'ω2:(0 0 1)',(0 1 1)' ,(0 1 0)',(1 1 1)'ω设0)'(-1,-2,-2,)1(=W,用感知器算法求解判别函数,并绘出判别界面。
$解:matlab程序如下:clear%感知器算法求解判别函数x1=[0 0 0]';x2=[1 0 0]';x3=[1 0 1]';x4=[1 1 0]';x5=[0 0 1]';x6=[0 1 1]';x7=[0 1 0]';x8=[1 1 1]';%构成增广向量形式,并进行规范化处理[x=[0 1 1 1 0 0 0 -1;0 0 0 1 0 -1 -1 -1;0 0 1 0 -1 -1 0 -1;1 1 1 1 -1 -1 -1 -1];plot3(x1(1),x1(2),x1(3),'ro',x2(1),x2(2),x2(3),'ro',x3(1),x3(2),x3(3),'ro',x4(1),x4(2),x4(3),'ro');hold on; plot3(x5(1),x5(2),x5(3),'rx',x6(1),x6(2),x6(3),'rx',x7(1),x7(2),x7(3),'rx',x8(1),x8(2),x8(3),'rx');grid on; w=[-1,-2,-2,0]';c=1;N=2000;for k=1:N|t=[];for i=1:8d=w'*x(:,i);if d>0w=w;、t=[t 1];elsew=w+c*x(:,i);t=[t -1];end-endif i==8&t==ones(1,8)w=wsyms x yz=-w(1)/w(3)*x-w(2)/w(3)*y-1/w(3);《ezmesh(x,y,z,[ 1 2]);axis([,,,,,]);title('感知器算法')break;else{endend运行结果:w =3]-2-31判别界面如下图所示:!若有样本123[,,]'x x x x =;其增广]1,,,[321x x x X =;则判别函数可写成: 1323')(321+*-*-*=*=x x x X w X d若0)(>X d ,则1ω∈x ,否则2ω∈x已知三类问题的训练样本为123:(-1 -1)', (0 0)' , :(1 1)'ωωω<试用多类感知器算法求解判别函数。
模式识别第二版答案完整版
1. 对c类情况推广最小错误率率贝叶斯决策规则; 2. 指出此时使错误率最小等价于后验概率最大,即P (wi|x) > P (wj|x) 对一切j ̸= i
成立时,x ∈ wi。
2
模式识别(第二版)习题解答
解:对于c类情况,最小错误率贝叶斯决策规则为: 如果 P (wi|x) = max P (wj|x),则x ∈ wi。利用贝叶斯定理可以将其写成先验概率和
(2) Σ为半正定矩阵所以r(a, b) = (a − b)T Σ−1(a − b) ≥ 0,只有当a = b时,才有r(a, b) = 0。
(3) Σ−1可对角化,Σ−1 = P ΛP T
h11 h12 · · · h1d
• 2.17 若将Σ−1矩阵写为:Σ−1 = h...12
h22 ...
P (w1) P (w2)
= 0。所以判别规则为当(x−u1)T (x−u1) > (x−u2)T (x−u2)则x ∈ w1,反
之则s ∈ w2。即将x判给离它最近的ui的那个类。
[
• 2.24 在习题2.23中若Σ1 ̸= Σ2,Σ1 =
1
1
2
策规则。
1]
2
1
,Σ2
=
[ 1
−
1 2
−
1 2
] ,写出负对数似然比决
1
6
模式识别(第二版)习题解答
解:
h(x) = − ln [l(x)]
= − ln p(x|w1) + ln p(x|w2)
=
1 2 (x1
−
u1)T
Σ−1 1(x1
−
u1)
−
1 2 (x2
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
作业一:在一个10类的模式识别问题中,有3类单独满足多类情况1,其余的类别满足多类情况2。
问该模式识别问题所需判别函数的最少数目是多少?答案:将10类问题可看作4类满足多类情况1的问题,可将3类单独满足多类情况1的类找出来,剩下的7类全部划到4类中剩下的一个子类中。
再在此子类中,运用多类情况2的判别法则进行分类,此时需要7*(7-1)/2=21个判别函数。
故共需要4+21=25个判别函数。
作业二:一个三类问题,其判别函数如下:d1(x)=-x1, d2(x)=x1+x2-1, d3(x)=x1-x2-11.设这些函数是在多类情况1条件下确定的,绘出其判别界面和每一个模式类别的区域。
2.设为多类情况2,并使:d12(x)= d1(x), d13(x)= d2(x), d23(x)=d3(x)。
绘出其判别界面和多类情况2的区域。
3. 设d1(x), d2(x)和d3(x)是在多类情况3的条件下确定的,绘出其判别界面和每类的区域。
答案:123作业三:两类模式,每类包括5个3维不同的模式,且良好分布。
如果它们是线性可分的,问权向量至少需要几个系数分量?假如要建立二次的多项式判别函数,又至少需要几个系数分量?(设模式的良好分布不因模式变化而改变。
)答案:如果它们是线性可分的,则至少需要4个系数分量;如果要建立二次的多项式判别函数,则至少需要1025 C 个系数分量。
作业四:用感知器算法求下列模式分类的解向量w :ω1: {(0 0 0)T, (1 0 0)T, (1 0 1)T, (1 1 0)T}ω2: {(0 0 1)T, (0 1 1)T, (0 1 0)T, (1 1 1)T}答案:将属于ω2的训练样本乘以(-1),并写成增广向量的形式。
x①=(0 0 0 1)T,x②=(1 0 0 1)T,x③=(1 0 1 1)T,x④=(1 1 0 1)Tx⑤=(0 0 -1 -1)T,x⑥=(0 -1 -1 -1)T,x⑦=(0 -1 0 -1)T,x⑧=(-1 -1 -1 -1)T第一轮迭代:取C=1,w(1)=(0 0 0 0)T因w T(1)x①=(0 0 0 0)(0 0 0 1)T=0≯0,故w(2)=w(1)+x①=(0 0 0 1) 因w T(2)x②=(0 0 0 1)(1 0 0 1)T =1>0,故w(3)=w(2)=(0 0 0 1)T因w T(3)x③=(0 0 0 1)(1 0 1 1)T=1>0,故w(4)=w(3)=(0 0 0 1)T因w T(4)x④=(0 0 0 1)(1 1 0 1)T=1>0,故w(5)=w(4)=(0 0 0 1)T因w T(5)x⑤=(0 0 0 1)(0 0 -1 -1)T=-1≯0,故w(6)=w(5)+x⑤=(0 0 -1 0)T因w T(6)x⑥=(0 0 -1 0)(0 -1 -1 -1)T=1>0,故w(7)=w(6)=(0 0 -1 0)T 因w T(7)x⑦=(0 0 -1 0)(0 -1 0 -1)T=0≯0,故w(8)=w(7)+x⑦=(0 -1 -1 -1)T因w T(8)x⑧=(0 -1 -1 -1)(-1 -1 -1 -1)T=3>0,故w(9)=w(8)=(0 -1 -1 -1)T因为只有对全部模式都能正确判别的权向量才是正确的解,因此需进行第二轮迭代。
第二轮迭代:因w T(9)x①=(0 -1 -1 -1)(0 0 0 1)T=-1≯0,故w(10)=w(9)+x① =(0 -1 -1 0)T因w T(10)x②=(0 -1 -1 0)(1 0 0 1)T=0≯0,故w(11)=w(10)+x② =(1 -1 -1 1)T因w T(11)x③=(1 -1 -1 1)(1 0 1 1)T=1>0,故w(12)=w(11) =(1 -1 -1 1)T因w T(12)x④=(1 -1 -1 1)(1 1 0 1)T=1>0,故w(13)=w(12) =(1 -1 -1 1)T因w T(13)x⑤=(1 -1 -1 1)(0 0 -1 -1)T=0≯0,故w(14)=w(13)+x⑤ =(1 -1 -20)T因w T(14)x⑥=(1 -1 -2 0)(0 -1 -1 -1)T=3>0,故w(15)=w(14) =(1 -1 -2 0)T因w T(15)x⑧=(1 -1 -2 0)(0 -1 0 -1)T=1>0,故w(16)=w(15) =(1 -1 -2 0)T因w T(16)x⑦=(1 -1 -2 0)(-1 -1 -1 -1)T=2>0,故w(17)=w(16) =(1 -1 -2 0)T因为只有对全部模式都能正确判别的权向量才是正确的解,因此需进行第三轮迭代。
第三轮迭代:w(25)=(2 -2 -2 0);因为只有对全部模式都能正确判别的权向量才是正确的解,因此需进行第四轮迭代。
第四轮迭代: w(33)=(2 -2 -2 1)因为只有对全部模式都能正确判别的权向量才是正确的解,因此需进行第五轮迭代。
第五轮迭代: w(41)=(2 -2 -2 1)因为该轮迭代的权向量对全部模式都能正确判别。
所以权向量即为(2 -2 -2 1),相应的判别函数为123()2221d x x x x =--+ 作业五:编写求解上述问题的感知器算法程序。
程序源码: #include <iostream> using namespace std;int scale; //每个样本的维数,最多支持十维 int W1_N,W2_N; //第一类的个数以及第二类的个数double W1[1000],W2[1000];//第一、二类的所有样本的增广向量 int C;//初始的算法中的C 值double W[10];//初始的算法中的W 向量 int main() {cin>>scale>>W1_N>>W2_N;for(int i=0;i<W1_N*(scale+1);i++){cin>>W1[i];if(i%(scale+1)==2) //转化成增广向量W1[++i]=1;}for(int i=0;i<W2_N*(scale+1);i++){cin>>W2[i];W2[i]=-1*W2[i];if(i%(scale+1)==2) //转化成增广向量W2[++i]=-1;}scale=scale+1;cin>>C;for(int i=0;i<scale;i++)cin>>W[i];bool flag=false;while(!flag){bool flag1=true;for(int i=0;i<W1_N;i++){doubletmp=0.0;for(int j=0;j<scale;j++)tmp+=W1[i*scale+j]*W[j];if(tmp<=0){flag1=false;for(int j=0;j<scale;j++)W[j]=W[j]+W1[i*scale+j];}}for(int i=0;i<W2_N;i++){doubletmp=0.0;for(int j=0;j<scale;j++)tmp+=W2[i*scale+j]*W[j];if(tmp<=0){flag1=false;for(int j=0;j<scale;j++)W[j]=W[j]+W2[i*scale+j];}}if(flag1)flag=true;}cout<<”最后的权向量为:”<<endl;cout<<W[0];for(int i=1;i<scale;i++)cout<<" "<<W[i];cout<<endl;return 0;}程序运行截图:作业六:用多类感知器算法求下列模式的判别函数: ω1: (-1 -1)T ω2: (0 0)Tω3: (1 1)T将模式样本写成增广形式:x ①=(-1-1 1)T ,x ②=(00 1)T ,x ③=(1 1 1)T 取初始值w 1(1)=w 2(1)=w 3(1)=(0 0 0)T ,C=1。
第一轮迭代(k=1):以x ①=(-1 -1 1)T 作为训练样本。
d 1(1)=)1(1T w x ①=(0 0 0)(-1 -1 1)T =0 d 2(1)=)1(2T w x ①=(0 0 0)(-1 -1 1)T =0 d 3(1)=)1(3Twx ①=(0 0 0)(-1 -1 1)T =0因d 1(1)≯d 2(1),d 1(1)≯d 3(1),故w 1(2)=w 1(1)+x ①=(-1 -1 1)T w 2(2)=w 2(1)-x ①=(11 -1)T w 3(2)=w 3(1)-x ①=(11 -1)T第二轮迭代(k=2):以x ②=(0 0 1)T 作为训练样本d 1(2)=)2(1T w x ②=(-1 -1 1)(0 0 1)T =1 d 2(2)=)2(2T w x ②=(1 1 -1)(0 0 1)T =-1 d 3(2)=)2(3Twx ②=(11 -1)(0 0 1)T=-1因d 2(2)≯d 1(2),d 2(2)≯d 3(2),故w 1(3)=w 1(2)-x ②=(-1 -1 0)T w 2(3)=w 2(2)+x ②=(1 1 0)T w 3(3)=w 3(2)-x ②=(1 1 -2)T第三轮迭代(k=3):以x ③=(1 1 1)T 作为训练样本d 1(3)=)3(1T w x ③=(-1 -1 0)(1 1 1)T =-2d 2(3)=)3(2T w x ③=(1 1 0)(1 1 1)T =2 d 3(3)=)3(3Twx ③=(1 1 -2)(1 1 1)T=0因d 3(3)≯d 2(3),故 w 1(4)=w 1(3) =(-1 -1 0)T w 2(4)=w 2(3)-x ③=(0 0 -1)T w 3(4)=w 3(3)+x ③=(2 2 -1)T第四轮迭代(k=4):以x ①=(-1 -1 1)T 作为训练样本d 1(4)=)4(1T w x ①=(-1 -1 0)(-1 -1 1)T =2 d 2(4)=)4(2T w x ①=(0 0 -1)(-1 -1 1)T =-1 d 3(4)=)4(3Twx ①=(2 2 -1)(-1 -1 1)T=-5因d 1(4)>d 2(4),d 1(4)>d 3(4),故 w 1(5)=w 1(4) =(-1 -1 0)T w 2(5)=w 2(4) =(0 0 -1)T w 3(5)=w 3(4) =(2 2 -1)T第五轮迭代(k=5):以x ②=(0 0 1)T 作为训练样本d 1(5)=)5(1T w x ②=(-1 -1 0)(0 0 1)T =0 d 2(5)=)5(2T w x ②=(0 0 -1)(00 1)T =-1d 3(5)=)5(3T wx ②=(2 2 -1)(00 1)T=-1因d 2(5) ≯d 1(5),d 2(5) ≯d 3(5),故w 1(6)=w 1(5)-x ②=(-1 -1 -1) w 2(6)=w 2(5)+x ②=(0 0 0) w 3(6)=w 3(5)-x ②=(2 2 -2)第六轮迭代(k=6):以x ③=(1 1 1)T 作为训练样本d 1(6)=)6(1T w x ③=(-1 -1 -1)(1 1 1)T =-3 d 2(6)=)6(2T w x ③=(0 0 0)(1 1 1)T =0 d 3(6)=)6(3Twx ③=(2 2 -2)(1 1 1)T=2因d 3(6)>d 1(6),d 3(6)>d 2(6),故w 1(7)=w 1(6) w 2(7)=w 2(6) w 3(7)=w 3(6)第七轮迭代(k=7):以x ①=(-1 -1 1)T 作为训练样本d 1(7)=)7(1T w x ①=(-1 -1 -1)(-1 -1 1)T =1 d 2(7)=)7(2T w x ①=(0 0 0)(-1 -1 1)T =0 d 3(7)=)7(3Twx ①=(2 2-2)(-1 -1 1)T=-6因d 1(7)>d 2(7),d 1(7)>d 3(7),分类结果正确,故权向量不变。