分布的拟合与检验的matlab实现
matlab 拟合数据的分布函数

matlab 拟合数据的分布函数Matlab是一种强大的数值计算和数据分析软件,它不仅能够进行各种数值计算和数据处理,还可以进行数据拟合和分布函数的估计。
本文将介绍如何使用Matlab拟合数据的分布函数。
我们需要准备一组数据,这组数据应该是符合某个特定分布的样本数据。
例如,我们可以使用正态分布生成一组样本数据。
假设我们需要生成1000个符合正态分布的随机数,均值为0,标准差为1,可以使用如下代码:```matlabdata = normrnd(0, 1, 1000, 1);```接下来,我们需要选择一个合适的分布函数来拟合这组数据。
Matlab提供了多种分布函数的拟合方法,包括正态分布、指数分布、伽马分布等。
在这里,我们选择正态分布作为例子。
使用Matlab拟合数据的分布函数,可以使用`fitdist`函数。
`fitdist`函数的第一个参数是数据,第二个参数是分布函数的名称。
例如,如果我们要拟合正态分布,可以使用如下代码:```matlabpd = fitdist(data, 'Normal');```这样,我们就得到了拟合后的分布函数对象`pd`。
通过这个对象,我们可以获取拟合后的参数,如均值和标准差,以及进行其他分析。
例如,我们可以使用`pd`对象的`mean`方法获取拟合后的均值,使用`pd`对象的`std`方法获取拟合后的标准差。
代码如下:```matlabmu = pd.mean;sigma = pd.std;```除了均值和标准差,我们还可以使用`pd`对象的其他方法获取更多拟合后的参数信息,例如中位数、偏度、峰度等。
除了获取参数信息外,我们还可以使用`pd`对象进行其他分析。
例如,我们可以使用`pd`对象的`pdf`方法计算拟合后的概率密度函数值。
代码如下:```matlabx = -3:0.1:3;y = pdf(pd, x);```这样,我们就得到了在区间`[-3, 3]`上的概率密度函数值。
分布的拟合与检验的matlab实现

%--------------------------------------------------------------------------% 分布的拟合与检验%--------------------------------------------------------------------------%--------------------------------------------------------------------------% 描述性统计量和统计图%--------------------------------------------------------------------------%读取文件中数据% 读取文件examp02_14.xls的第1个工作表中的G2G52中的数据,即总成绩数据score = xlsread('examp02_14.xls','Sheet1','G2G52';% 去掉总成绩中的0,即缺考成绩score = score(score 0;%计算描述性统计量score_mean = mean(score % 计算平均成绩s1 = std(score % 计算(5.1式的标准差s1 = std(score,0 % 也是计算(5.1式的标准差s2 = std(score,1 % 计算(5.2式的标准差score_max = max(score % 计算样本最大值score_min = min(score % 计算样本最小值score_range = range(score % 计算样本极差score_median = median(score % 计算样本中位数score_mode = mode(score % 计算样本众数score_cvar = std(scoremean(score % 计算变异系数score_skewness = skewness(score % 计算样本偏度score_kurtosis = kurtosis(score % 计算样本峰度%绘制箱线图figure; % 新建图形窗口boxlabel = {'考试成绩箱线图'}; % 箱线图的标签% 绘制带有刻槽的水平箱线图boxplot(score,boxlabel,'notch','on','orientation','horizontal' xlabel('考试成绩'; % 为X轴加标签%绘制频率直方图% 调用ecdf函数计算xc处的经验分布函数值f[f, xc] = ecdf(score;figure; % 新建图形窗口% 绘制频率直方图ecdfhist(f, xc, 7;xlabel('考试成绩'; % 为X轴加标签ylabel('f(x'; % 为Y轴加标签%绘制理论正态分布密度函数图% 产生一个新的横坐标向量xx = 400.5100;% 计算均值为mean(score,标准差为std(score的正态分布在向量x处的密度函数值y = normpdf(x,mean(score,std(score;hold onplot(x,y,'k','LineWidth',2 % 绘制正态分布的密度函数曲线,并设置线条为黑色实线,线宽为2% 添加标注框,并设置标注框的位置在图形窗口的左上角legend('频率直方图','正态分布密度曲线','Location','NorthWest';%绘制经验分布函数图figure; % 新建图形窗口% 绘制经验分布函数图,并返回图形句柄h和结构体变量stats,% 结构体变量stats有5个字段,分别对应最小值、最大值、平均值、中位数和标准差[h,stats] = cdfplot(scoreset(h,'color','k','LineWidth',2; % 设置线条颜色为黑色,线宽为2%绘制理论正态分布函数图x = 400.5100; % 产生一个新的横坐标向量x% 计算均值为stats.mean,标准差为stats.std的正态分布在向量x处的分布函数值y = normcdf(x,stats.mean,stats.std;hold on% 绘制正态分布的分布函数曲线,并设置线条为品红色虚线,线宽为2plot(x,y,'k','LineWidth',2;% 添加标注框,并设置标注框的位置在图形窗口的左上角legend('经验分布函数','理论正态分布','Location','NorthWest';%绘制正态概率图figure; % 新建图形窗口normplot(score; % 绘制正态概率图%--------------------------------------------------------------------------% 分布的检验%--------------------------------------------------------------------------%读取文件中数据% 读取文件examp02_14.xls的第1个工作表中的G2G52中的数据,即总成绩数据score = xlsread('examp02_14.xls','Sheet1','G2G52';% 去掉总成绩中的0,即缺考成绩score = score(score 0;%调用chi2gof函数进行卡方拟合优度检验% 进行卡方拟合优度检验[h,p,stats] = chi2gof(score% 指定各初始小区间的中点ctrs = [50 60 70 78 85 94];% 指定'ctrs'参数,进行卡方拟合优度检验[h,p,stats] = chi2gof(score,'ctrs',ctrs[h,p,stats] = chi2gof(score,'nbins',6 % 指定'nbins'参数,进行卡方拟合优度检验% 指定分布为默认的正态分布,分布参数由x进行估计[h,p,stats] = chi2gof(score,'nbins',6;% 求平均成绩ms和标准差ssms = mean(score;ss = std(score;% 参数'cdf'的值是由函数名字符串与函数中所含参数的参数值构成的元胞数组[h,p,stats] = chi2gof(score,'nbins',6,'cdf',{'normcdf', ms, ss};% 参数'cdf'的值是由函数句柄与函数中所含参数的参数值构成的元胞数组[h,p,stats] = chi2gof(score,'nbins',6,'cdf',{@normcdf, ms, ss};% 同时指定'cdf'和'nparams'参数[h,p,stats] = chi2gof(score,'nbins',6,'cdf',{@normcdf,ms,ss},'nparams',2[h,p] = chi2gof(score,'cdf',@normcdf % 调用chi2gof函数检验数据是否服从标准正态分布% 指定初始分组数为6,检验总成绩数据是否服从参数为ms = 79的泊松分布[h,p] = chi2gof(score,'nbins',6,'cdf',{@poisscdf, ms}% 指定初始分组数为6,最小理论频数为3,检验总成绩数据是否服从正态分布h = chi2gof(score,'nbins',6,'cdf',{@normcdf, ms, ss},'emin',3%调用jbtest函数进行正态性检验randn('seed',0 % 指定随机数生成器的初始种子为0x = randn(10000,1; % 生成10000个服从标准正态分布的随机数h = jbtest(x % 调用jbtest函数进行正态性检验x(end = 5; % 将向量x的最后一个元素改为5h = jbtest(x % 再次调用jbtest函数进行正态性检验% 调用jbtest函数进行Jarque-Bera检验[h,p,jbstat,critval] = jbtest(score%调用kstest函数进行正态性检验% 生成cdf矩阵,用来指定分布:均值为79,标准差为10.1489的正态分布cdf = [score, normcdf(score, 79, 10.1489];% 调用kstest函数,检验总成绩是否服从由cdf指定的分布[h,p,ksstat,cv] = kstest(score,cdf%调用kstest2函数检验两个班的总成绩是否服从相同的分布% 读取文件examp02_14.xls的第1个工作表中的B2B52中的数据,即班级数据banji = xlsread('examp02_14.xls','Sheet1','B2B52';% 读取文件examp02_14.xls的第1个工作表中的G2G52中的数据,即总成绩数据score = xlsread('examp02_14.xls','Sheet1','G2G52';% 去除缺考数据score = score(score 0;banji = banji(score 0;% 分别提取60101和60102班的总成绩score1 = score(banji == 60101;score2 = score(banji == 60102;% 调用kstest2函数检验两个班的总成绩是否服从相同的分布[h,p,ks2stat] = kstest2(score1,score2%分别绘制两个班的总成绩的经验分布图figure; % 新建图形窗口% 绘制60101班总成绩的经验分布函数图F1 = cdfplot(score1;% 设置线宽为2,颜色为红色set(F1,'LineWidth',2,'Color','r'hold on% 绘制60102班总成绩的经验分布函数图F2 = cdfplot(score2;% 设置线型为点划线,线宽为2,颜色为黑色set(F2,'LineStyle','-.','LineWidth',2,'Color','k'% 为图形加标注框,标注框的位置在坐标系的左上角legend('60101班总成绩的经验分布函数','60102班总成绩的经验分布函数',...'Location','NorthWest'%调用kstest2函数进行正态性检验randn('seed',0 % 指定随机数生成器的初始种子为0% 产生10000个服从均值为79,标准差为10.1489的正态分布的随机数,构成一个列向量xx = normrnd(mean(score,std(score,10000,1;% 调用kstest2函数检验总成绩数据score与随机数向量x是否服从相同的分布[h,p] = kstest2(score,x,0.05%调用lillietest函数进行分布的检验% 调用lillietest函数进行Lilliefors检验,检验总成绩数据是否服从正态分布[h,p,kstat,critval] = lillietest(score% 调用lillietest函数进行Lilliefors检验,检验总成绩数据是否服从指数分布[h, p] = lillietest(score,0.05,'exp'。
Matlab中的正态分布拟合技术介绍

Matlab中的正态分布拟合技术介绍正态分布(Normal Distribution)作为统计学中最为重要的概率分布之一,被广泛运用于各类数据的分析与建模中。
而在Matlab中,我们可以利用其强大的数学计算和图形展示功能,实现对数据的正态分布拟合。
本文将介绍Matlab中的正态分布拟合技术,从理论基础、计算方法、示例应用等方面进行详细阐述。
一、理论基础1.1 正态分布概念正态分布,又称高斯分布(Gaussian Distribution),是指随机变量在一定范围内服从的概率分布模式。
其概率密度函数呈钟形曲线,对称分布于平均值处,并由均值mu和标准差sigma两个参数来完全描述。
在Matlab中,我们可以通过命令normpdf(x,mu,sigma)计算给定x处概率密度函数的值。
1.2 正态分布拟合正态分布拟合是指通过一组给定的数据,利用最大似然估计等方法,确定数据的均值和标准差,进而构建满足数据分布的正态分布模型。
拟合过程中,可以使用均方误差(MSE)等指标评估拟合效果。
在Matlab中,我们可以使用命令fitdist(data,'Normal')实现对给定数据的正态分布拟合。
二、计算方法2.1 最大似然估计最大似然估计是一种常用的参数估计方法,其基本思想是寻找一组使得给定数据样本的概率最大化的参数。
在正态分布拟合中,最大似然估计的目标是找到使得样本数据与正态分布之间的差异最小化的参数组合。
Matlab中的fitdist函数采用了最大似然估计的方法进行拟合。
2.2 拟合效果评估拟合效果的评估常常使用均方误差(MSE)来进行度量。
MSE是指拟合模型预测值与实际观测值之间差异的平方平均值。
在Matlab中,可以使用命令mse = immse(data,fitdata)计算给定数据data与拟合数据fitdata之间的均方误差。
三、示例应用我们以某市居民月收入数据为例,展示Matlab中正态分布拟合技术的应用。
正态分布拟合matlab

正态分布拟合matlab在MATLAB中,可以使用 normfit 函数来拟合一组数据到一个正态分布。
normfit 函数会提供正态分布的参数估计,包括均值(mean)和标准差(standard deviation)。
以下是一个使用normfit函数的简单例子:假设有一组数据datadata = randn(1000,1);这会生成一个标准正态分布的随机样本数据使用normfit函数拟合正态分布[mu, sigma] = normfit(data);显示拟合得到的均值和标准差disp(['均值 = ', num2str(mu)]);disp(['标准差 = ', num2str(sigma)]);可以使用normpdf函数生成拟合的正态分布的概率密度函数(PDF)值x = linspace(min(data), max(data), 100);pdf_fitted = normpdf(x, mu, sigma);绘制原始数据的直方图和拟合得到的正态分布曲线histogram(data, 30, 'Normalization', 'pdf');数据的PDF直方图hold on;保持图像,以便在同一图上绘制plot(x, pdf_fitted, 'r', 'LineWidth', 2); 绘制拟合的正态分布曲线hold off; 释放图像在上述代码中,randn 函数生成了一个标准正态分布的随机样本。
在实际操作中,可以使用自己的数据集替换data变量。
normfit函数返回数据集的均值mu和标准差sigma,是正态分布的参数。
我们可以用normpdf函数和这些参数来生成拟合的正态分布的PDF,并将其与原始数据的直方图一起绘制出来。
需要注意的是,确保在使用这些函数之前,的MATLAB环境中已经安装了统计和机器学习工具箱,因为normfit函数是这个工具箱的一部分。
利用Matlab进行统计模型拟合的方法与示例

利用Matlab进行统计模型拟合的方法与示例通过多年的发展,统计模型已经成为了描述和理解现实世界中各种现象的重要工具。
利用统计模型可以通过收集到的数据信息来解决实际问题,同时也可以预测未来的趋势。
Matlab作为一种强大的数值计算和数据处理工具,可以用来进行统计模型的拟合和分析。
本文将介绍一些利用Matlab进行统计模型拟合的方法,并通过一些实例来说明其应用。
首先,为了进行统计模型的拟合,我们需要先了解数据的分布情况。
在现实生活中,很多现象都可以用一些已知的概率分布来描述。
例如,服从正态分布的数据在自然界中非常常见,所以在许多情况下,我们可以假设数据服从正态分布。
如果数据不符合正态分布,我们可以尝试其他的概率分布,如泊松分布、指数分布等。
Matlab提供了丰富的概率分布函数,可以帮助我们判断数据的分布情况。
其次,对于给定的数据集,我们需要选择合适的统计模型来进行拟合。
通常,我们可以通过观察数据的特点来选择适当的模型。
例如,如果数据呈现出线性关系,我们可以选择线性回归模型进行拟合。
如果数据是非线性的,我们可以选择多项式回归模型或者指数回归模型。
此外,还有一些特殊的模型,如逻辑回归模型、广义线性模型等。
在Matlab中,可以使用拟合函数来拟合数据,并根据不同的模型选择合适的拟合算法。
接下来,我们可以利用拟合函数返回的结果来对拟合的模型进行评估。
这是非常重要的一步,因为模型的质量会直接影响到我们的分析结果。
我们可以使用一些统计指标来评估模型的拟合程度,如拟合优度(Goodness of fit)、均方根误差(Root Mean Squared Error)等。
此外,还可以绘制拟合曲线和残差图来直观地观察模型的拟合情况。
这些评估指标和图形化展示在Matlab中都有相应的函数和工具可以使用。
最后,我们可以利用已经拟合好的统计模型进行预测和分析。
预测是统计模型的一个重要应用方向。
通过利用已有的数据信息,我们可以建立一个可靠的模型来预测未来的趋势。
Matlab曲线拟合(cftool)分布拟合(dfittool)

、单一变量的曲线逼近Matlab有一个功能强大的曲线拟合工具箱cftool,使用方便,能实现多种类型的线性、非线性曲线拟合。
下面结合我使用的Matlab R2009b来简单介绍如何使用这个工具箱。
假设我们要拟合的函数形式是y=A*x*x + B*x,且A>0,B>0。
1、在命令行输入数据:》x=[110.3323 148.7328 178.064 202.8258033 224.7105 244.5711 262.908 280.0447 296.204 311.5475];》y=[5 10 15 20 25 30 35 40 45 50];2、启动曲线拟合工具箱》cftool3、进入曲线拟合工具箱界面“Curve Fitting tool”(1)点击“Data”按钮,弹出“Data”窗口;(2)利用X data和Y data的下拉菜单读入数据x,y,可修改数据集名“Data set name”,然后点击“Create data set”按钮,退出“Data”窗口,返回工具箱界面,这时会自动画出数据集的曲线图;(3)点击“Fitting”按钮,弹出“Fitting”窗口;(4)点击“New fit”按钮,可修改拟合项目名称“Fit name”,通过“Data set”下拉菜单选择数据集,然后通过下拉菜单“Type of fit”选择拟合曲线的类型,工具箱提供的拟合类型有:∙Custom Equations:用户自定义的函数类型∙Exponential:指数逼近,有2种类型,a*exp(b*x)、a*exp(b*x) + c*exp(d*x)∙Fourier:傅立叶逼近,有7种类型,基础型是a0 + a1*cos(x*w) + b1*sin(x*w)∙Gaussian:高斯逼近,有8种类型,基础型是a1*exp(-((x-b1)/c1)^2)∙Interpolant:插值逼近,有4种类型,linear、nearest neighbor、cubic spline、shape-preserving∙Polynomial:多形式逼近,有9种类型,linear ~、quadratic ~、cubic ~、4-9th degree ~∙Power:幂逼近,有2种类型,a*x^b、a*x^b + c∙Rational:有理数逼近,分子、分母共有的类型是linear ~、quadratic ~、cubic ~、4-5th degree ~;此外,分子还包括constant型∙Smoothing Spline:平滑逼近(翻译的不大恰当,不好意思)∙Sum of Sin Functions:正弦曲线逼近,有8种类型,基础型是a1*sin(b1*x + c1)∙Weibull:只有一种,a*b*x^(b-1)*exp(-a*x^b)选择好所需的拟合曲线类型及其子类型,并进行相关设置:——如果是非自定义的类型,根据实际需要点击“Fit options”按钮,设置拟合算法、修改待估计参数的上下限等参数;——如果选Custom Equations,点击“New”按钮,弹出自定义函数等式窗口,有“Linear Equations线性等式”和“General Equations构造等式”两种标签。
matlab 对数正态分布拟合

matlab 对数正态分布拟合
对数正态分布是概率统计中的一种重要分布,它具有许多的应用。
在 MATLAB 中我们可以使用拟合工具箱中的 lognfit 函数来对样本数
据进行对数正态分布拟合。
具体操作步骤如下:
首先,我们需要准备一个样本数据。
假设我们有一个数据集 x,
我们可以使用 lognfit 函数来对其进行拟合,代码如下:
```
% 准备样本数据
x = [0.2587 0.6065 0.4711 1.3658 0.0054 0.5037 3.0179 0.1664 0.1144 2.3894];
% 对数正态分布拟合
[mu, sigma] = lognfit(x);
```
运行上述代码后,我们可以得到对数正态分布的两个参数 mu 和sigma。
其中,mu 代表对数正态分布的期望值,sigma 代表对数正态
分布的标准差。
如果我们想要绘制对数正态分布的概率密度函数,可以使用lognpdf 函数,代码如下:
```
% 绘制对数正态分布的概率密度函数
x_values = 0:0.1:4;
y_values = lognpdf(x_values, mu, sigma);
plot(x_values, y_values);
```
上述代码中,我们使用 lognpdf 函数来计算对数正态分布在给
定值处的概率密度值,然后使用 plot 函数来绘制概率密度函数图形。
在 MATLAB 中,对数正态分布拟合和绘制概率密度函数都非常简
单。
通过上述步骤,我们可以快速地对样本数据进行拟合,并且可视化结果,帮助我们更好地理解对数正态分布的特性。
matlab 正态分布拟合

matlab 正态分布拟合MATLAB 正态分布拟合是一种基于数学统计理论,用来估计实际数据与理想正态分布之间的相似度,从而量化描述一组数据的分布特征。
MATLAB 可以使用 fitdist 函数来实现正态分布拟合。
正态分布拟合是基于几何概率理论的,假设一个变量的概率密度函数(PDF)是正态分布的,我们可以使用拟合方法来找到该变量的平均值和标准差。
在 MATLAB 中,fitdist 函数可以用于拟合正态分布,它接受一组数据x,然后返回拟合正态分布的参数 mu 和 sigma,mu 是均值,sigma 是标准差。
如果我们有一组数据x,第一步就是对其进行排序,这样可以确保有序数据的准确性。
接下来,我们可以使用MATLAB 的 fitdist 函数来拟合正态分布。
fitdist 函数接受一个参数,即拟合的分布类型,比如 normal、lognormal、weibull 等。
最后,函数会计算出拟合的参数,并将其作为输出参数返回。
此外,MATLAB 还提供了一种统计检验方法,即 chi-square 测试,它可以用于检验拟合结果是否有效。
chi-square 测试要求检验样本的大小至少是 5 个,并且模型和数据必须是独立的,即模型不能影响数据,而数据也不能影响模型。
如果拟合结果有效,则 chi-square 检验的结果将为 0,如果拟合结果无效,则 chi-square 检验的结果将大于 0。
总的来说,MATLAB 正态分布拟合可以用于估计实际数据与理想正态分布之间的相似度,从而量化描述一组数据的分布特征。
它可以帮助我们更好地分析和研究数据。
MATLAB 的 fitdist 函数可以用于拟合正态分布,并且可以使用 chi-square 测试来检验拟合结果的有效性。
matlab用weibull分布函数拟合曲线

matlab用weibull分布函数拟合曲线Weibull分布函数是一种常用于可靠性分析的概率分布函数,可以用来估计产品的平均故障时间。
在MATLAB中,我们可以使用curve fitting toolbox工具箱中的weibull分布函数进行曲线拟合。
具体步骤如下:1. 导入数据:将需要拟合的数据导入MATLAB中,可以使用xlsread函数读取Excel文件,也可以手动输入数据。
2. 创建拟合曲线对象:可以使用cftool命令打开curvefitting toolbox,选择Weibull分布函数进行拟合,也可以在代码中使用cfit函数创建一个Weibull对象。
3. 设置拟合参数:使用setoptions函数设置拟合参数,包括起点、终点、步长等。
4. 拟合曲线:使用fit函数进行曲线拟合,得到拟合结果。
5. 绘制拟合曲线:使用plot函数绘制拟合曲线,并将图表美化。
下面是MATLAB代码示例:% 导入数据data = xlsread('data.xlsx');% 创建拟合曲线对象weibull_fit = cfit('a*x^b*exp(-x^b/a)', 'a', 'b', 'x');% 设置拟合参数options = fitoptions('Method','NonlinearLeastSquares',...'StartPoint',[1 1],...'Lower',[0 0],...'Upper',[Inf Inf]);% 拟合曲线weibull_result = fit(data(:,1), data(:,2), weibull_fit, options);% 绘制拟合曲线plot(weibull_result, data(:,1), data(:,2)); xlabel('时间');ylabel('概率密度');title('Weibull分布函数拟合曲线');。
matlab 分布曲线拟合

在MATLAB中,可以使用`fit`函数对数据进行分布曲线拟合。
下面是一个简单的示例,演示如何使用MATLAB进行正态分布曲线拟合:
假设有一组数据x,需要拟合正态分布曲线,可以使用以下代码:
```matlab
% 生成一组数据
x = randn(1,1000);
% 拟合正态分布曲线
mu = mean(x); % 计算数据的均值
sigma = std(x); % 计算数据的标准差
y = normpdf(x, mu, sigma); % 计算正态分布的概率密度函数值
% 绘制拟合曲线和数据点
plot(x, y, 'o'); % 绘制数据点
hold on;
plot(x, normpdf(x, mu, sigma), '-'); % 绘制拟合曲线
hold off;
```
在这个示例中,首先生成了一组随机数据x,然后使用`mean`和`std`函数计算数据的均值和标准差。
接下来,使用`normpdf`函
数计算正态分布的概率密度函数值,并将其与数据点一起绘制在图形中。
最后,使用`hold on`和`hold off`命令来在同一图形上绘制拟合曲线和数据点。
需要注意的是,MATLAB还提供了许多其他的分布函数,如`exppdf`、`weppdf`等,可以根据实际需求选择适合的分布函数进行拟合。
同时,也可以使用MATLAB的优化工具箱中的函数来自动选择最佳的参数进行拟合。
matlab 曲线 正态分布拟合

matlab 曲线正态分布拟合摘要:本文将介绍如何使用MATLAB曲线拟合工具箱进行正态分布拟合。
正文:正态分布是一种非常常见的概率分布,广泛应用于各个领域,如统计分析、质量控制、金融分析等。
在MATLAB中,我们可以使用曲线拟合工具箱来拟合正态分布。
本文将介绍如何使用MATLAB进行正态分布拟合,并通过一个实例来说明其应用。
一、正态分布的基本概念正态分布,也被称为高斯分布,其概率密度函数为:f(x) = (1 / sqrt(2 * pi * sigma^2)) * exp(-(x - mu)^2 / (2 * sigma^2))其中,μ是分布的均值,σ是分布的标准差。
正态分布的形状由均值和标准差决定,其概率密度函数在均值两侧对称,且随着与均值的距离增加而递减。
二、使用MATLAB进行正态分布拟合在MATLAB中,我们可以使用曲线拟合工具箱来进行正态分布拟合。
以下是步骤:1. 导入数据:首先,我们需要将数据导入MATLAB。
可以使用load命令导入数据文件,或者使用MATLAB的数据导入功能。
2. 数据预处理:在进行拟合之前,我们需要对数据进行预处理,如去除异常值、对数变换等。
这可以使用MATLAB的统计和数学函数来完成。
3. 正态性检验:在拟合之前,我们需要检验数据是否满足正态分布。
可以使用Kolmogorov-Smirnov检验或者Shapiro-Wilk检验等方法。
如果数据不满足正态分布,我们需要进行数据的转换或者选择其他分布进行拟合。
4. 正态分布拟合:使用MATLAB的fitlm函数进行线性最小二乘法拟合。
fitlm函数会自动选择合适的分布类型,如果数据满足正态分布,则拟合结果为正态分布。
5. 模型评估:评估拟合模型的性能,可以使用R-squared、AIC等指标。
如果模型的性能不佳,可以尝试更换其他分布进行拟合,或者调整数据的预处理方法。
三、实例分析以下是一个使用MA TLAB进行正态分布拟合的实例:1. 导入数据:假设我们有一个数据文件名为"data.txt",内容如下:1.1 1.2 1.3 1.4 1.5 1.6 1.7 1.8 1.92.02.1 2.2 2.3 2.4 2.5 2.6 2.7 2.8 2.93.0...可以使用以下命令导入数据:load data.txt2. 数据预处理:对数据进行排序和计算均值和标准差:sort data ; mu = mean(data) ; sigma = std(data) ;3. 正态性检验:我们可以使用Kolmogorov-Smirnov检验来检验数据是否满足正态分布。
使用MATLAB进行数据拟合的步骤与技巧

使用MATLAB进行数据拟合的步骤与技巧数据拟合是一种通过数学模型来对实验数据进行预测或者揭示隐藏规律的方法。
MATLAB是一个强大的数值计算软件,可以用于进行各种类型的数据拟合。
下面将介绍使用MATLAB进行数据拟合的步骤与技巧。
步骤1:加载数据首先,需要将待拟合的数据导入到MATLAB环境中。
可以通过以下方法加载数据:- 使用CSV文件或其他数据文件导入函数如`csvread`、`xlsread`或`load`。
- 使用MATLAB中的样本数据集,如`load fisheriris`加载鸢尾花数据集。
步骤2:可视化数据为了更好地了解数据的特征和分布情况,可以通过绘制原始数据的散点图来进行可视化分析。
使用`scatter`函数绘制散点图:```matlabscatter(x, y)```其中,x和y是待拟合数据的自变量和因变量。
步骤3:选择合适的模型根据问题的具体要求和数据的分布特点,选择适当的数学模型来拟合数据。
常用的数据拟合模型包括线性回归、多项式回归、指数函数、对数函数等等。
步骤4:拟合数据根据选择的模型,使用MATLAB中的相应函数进行数据拟合。
下面介绍几种常见的拟合方法:- 线性回归:使用`polyfit`函数进行线性回归拟合。
```matlabp = polyfit(x, y, n)```其中,x和y是待拟合数据的自变量和因变量,n是线性回归的阶数。
- 多项式回归:使用`polyfit`函数进行多项式回归拟合。
```matlabp = polyfit(x, y, n)```其中,x和y是待拟合数据的自变量和因变量,n是多项式回归的阶数。
- 指数函数拟合:使用`fit`函数进行指数函数拟合。
```matlabf = fit(x, y, 'exp1')```其中,x和y是待拟合数据的自变量和因变量,'exp1'表示拟合指数函数的模型。
- 对数函数拟合:使用`fit`函数进行对数函数拟合。
正态分布拟合matlab

正态分布拟合 MATLAB介绍正态分布(也称为高斯分布)是统计学中最重要的概率分布之一。
它在自然界和社会科学中广泛应用,因为许多现象都服从正态分布。
在某些情况下,我们可能需要将一组数据与正态分布进行拟合,以便更好地理解和分析数据。
MATLAB是一种功能强大的数值计算和科学编程工具,它提供了各种函数和工具箱来处理和拟合数据。
在本文中,我们将介绍如何使用MATLAB来拟合正态分布。
步骤数据准备首先,我们需要准备一组数据来进行正态分布的拟合。
可以通过以下方式生成一个符合正态分布的随机数向量:mu = 0; % 均值sigma = 1; % 标准差n = 1000; % 数据点数量data = mu + sigma * randn(n, 1);上述代码将生成一个包含1000个符合标准正态分布(均值为0,标准差为1)的随机数的向量。
根据需要,您可以调整均值、标准差和数据点数量。
拟合正态分布接下来,我们使用MATLAB的fitdist函数来拟合正态分布。
这个函数可以根据给定的数据点估计出最佳的正态分布参数。
pd = fitdist(data, 'Normal');上述代码将使用给定的数据点data来拟合一个正态分布,并将结果存储在一个概率分布对象(ProbabilityDistribution object)中。
可视化拟合结果一旦我们拟合了正态分布,我们可以使用MATLAB的pdf函数来计算并可视化该分布的概率密度函数。
x = -4:0.1:4; % x轴范围y = pdf(pd, x); % 计算概率密度plot(x, y);title('正态分布拟合');xlabel('x');ylabel('概率密度');上述代码将在x轴范围内计算并绘制出正态分布的概率密度函数。
您可以根据需要调整x轴范围。
拟合质量评估除了可视化拟合结果,我们还可以使用一些指标来评估拟合质量。
matlab 概率分布拟合

matlab 概率分布拟合
概率分布拟合是指通过对一组观测数据进行统计分析,将其拟合到一个特定的概率分布模型中。
在MATLAB软件中,可以使用统计工具箱(Statistics and Machine Learning Toolbox)来实现概率分布拟合。
首先,我们需要导入观测数据,并选择合适的概率分布模型。
常见的概率分布模型包括正态分布、指数分布、泊松分布等等。
在选择概率分布模型时,可以根据数据的特征、分布形态以及领域知识进行判断。
然后,我们可以使用fitdist函数来对观测数据进行概率分布拟合。
fitdist函数需要输入两个参数,第一个参数为观测数据,第二个参数为所选择的概率分布模型。
该函数会返回一个概率分布对象,其中包含了模型的参数估计值。
最后,我们可以使用概率分布对象的方法来进行各种统计分析。
例如,可以计算概率分布的均值、方差、中位数等等。
也可以生成随机变量,或者计算概率密度、累积分布函数等等。
综上所述,MATLAB软件提供了强大的工具来进行概率分布拟合和相关分析,只需要导入观测数据并选择合适的概率分布模型,即可进行相应的统计分析。
【良心出品】分布的拟合与检验的matlab实现

%--------------------------------------------------------------------------% 分布的拟合与检验%--------------------------------------------------------------------------%--------------------------------------------------------------------------% 描述性统计量和统计图%--------------------------------------------------------------------------%读取文件中数据% 读取文件examp02_14.xls的第1个工作表中的G2G52中的数据,即总成绩数据score = xlsread('examp02_14.xls','Sheet1','G2G52');% 去掉总成绩中的0,即缺考成绩score = score(score 0);%计算描述性统计量score_mean = mean(score) % 计算平均成绩s1 = std(score) % 计算(5.1)式的标准差s1 = std(score,0) % 也是计算(5.1)式的标准差s2 = std(score,1) % 计算(5.2)式的标准差score_max = max(score) % 计算样本最大值score_min = min(score) % 计算样本最小值score_range = range(score) % 计算样本极差score_median = median(score) % 计算样本中位数score_mode = mode(score) % 计算样本众数score_cvar = std(score)mean(score) % 计算变异系数score_skewness = skewness(score) % 计算样本偏度score_kurtosis = kurtosis(score) % 计算样本峰度%绘制箱线图figure; % 新建图形窗口boxlabel = {'考试成绩箱线图'}; % 箱线图的标签% 绘制带有刻槽的水平箱线图boxplot(score,boxlabel,'notch','on','orientation','horizontal')xlabel('考试成绩'); % 为X轴加标签%绘制频率直方图% 调用ecdf函数计算xc处的经验分布函数值f[f, xc] = ecdf(score);figure; % 新建图形窗口% 绘制频率直方图ecdfhist(f, xc, 7);xlabel('考试成绩'); % 为X轴加标签ylabel('f(x)'); % 为Y轴加标签%绘制理论正态分布密度函数图% 产生一个新的横坐标向量xx = 400.5100;% 计算均值为mean(score),标准差为std(score)的正态分布在向量x处的密度函数值y = normpdf(x,mean(score),std(score));hold onplot(x,y,'k','LineWidth',2) % 绘制正态分布的密度函数曲线,并设置线条为黑色实线,线宽为2% 添加标注框,并设置标注框的位置在图形窗口的左上角legend('频率直方图','正态分布密度曲线','Location','NorthWest');%绘制经验分布函数图figure; % 新建图形窗口% 绘制经验分布函数图,并返回图形句柄h和结构体变量stats,% 结构体变量stats有5个字段,分别对应最小值、最大值、平均值、中位数和标准差[h,stats] = cdfplot(score)set(h,'color','k','LineWidth',2); % 设置线条颜色为黑色,线宽为2%绘制理论正态分布函数图x = 400.5100; % 产生一个新的横坐标向量x% 计算均值为stats.mean,标准差为stats.std的正态分布在向量x处的分布函数值y = normcdf(x,stats.mean,stats.std);hold on% 绘制正态分布的分布函数曲线,并设置线条为品红色虚线,线宽为2plot(x,y,'k','LineWidth',2);% 添加标注框,并设置标注框的位置在图形窗口的左上角legend('经验分布函数','理论正态分布','Location','NorthWest');%绘制正态概率图figure; % 新建图形窗口normplot(score); % 绘制正态概率图%--------------------------------------------------------------------------% 分布的检验%--------------------------------------------------------------------------%读取文件中数据% 读取文件examp02_14.xls的第1个工作表中的G2G52中的数据,即总成绩数据score = xlsread('examp02_14.xls','Sheet1','G2G52');% 去掉总成绩中的0,即缺考成绩score = score(score 0);%调用chi2gof函数进行卡方拟合优度检验% 进行卡方拟合优度检验[h,p,stats] = chi2gof(score)% 指定各初始小区间的中点ctrs = [50 60 70 78 85 94];% 指定'ctrs'参数,进行卡方拟合优度检验[h,p,stats] = chi2gof(score,'ctrs',ctrs)[h,p,stats] = chi2gof(score,'nbins',6) % 指定'nbins'参数,进行卡方拟合优度检验% 指定分布为默认的正态分布,分布参数由x进行估计[h,p,stats] = chi2gof(score,'nbins',6);% 求平均成绩ms和标准差ssms = mean(score);ss = std(score);% 参数'cdf'的值是由函数名字符串与函数中所含参数的参数值构成的元胞数组[h,p,stats] = chi2gof(score,'nbins',6,'cdf',{'normcdf', ms, ss});% 参数'cdf'的值是由函数句柄与函数中所含参数的参数值构成的元胞数组[h,p,stats] = chi2gof(score,'nbins',6,'cdf',{@normcdf, ms, ss});% 同时指定'cdf'和'nparams'参数[h,p,stats] = chi2gof(score,'nbins',6,'cdf',{@normcdf,ms,ss},'nparams',2)[h,p] = chi2gof(score,'cdf',@normcdf) % 调用chi2gof函数检验数据是否服从标准正态分布% 指定初始分组数为6,检验总成绩数据是否服从参数为ms = 79的泊松分布[h,p] = chi2gof(score,'nbins',6,'cdf',{@poisscdf, ms})% 指定初始分组数为6,最小理论频数为3,检验总成绩数据是否服从正态分布h = chi2gof(score,'nbins',6,'cdf',{@normcdf, ms, ss},'emin',3)%调用jbtest函数进行正态性检验randn('seed',0) % 指定随机数生成器的初始种子为0x = randn(10000,1); % 生成10000个服从标准正态分布的随机数h = jbtest(x) % 调用jbtest函数进行正态性检验x(end) = 5; % 将向量x的最后一个元素改为5h = jbtest(x) % 再次调用jbtest函数进行正态性检验% 调用jbtest函数进行Jarque-Bera检验[h,p,jbstat,critval] = jbtest(score)%调用kstest函数进行正态性检验% 生成cdf矩阵,用来指定分布:均值为79,标准差为10.1489的正态分布cdf = [score, normcdf(score, 79, 10.1489)];% 调用kstest函数,检验总成绩是否服从由cdf指定的分布[h,p,ksstat,cv] = kstest(score,cdf)%调用kstest2函数检验两个班的总成绩是否服从相同的分布% 读取文件examp02_14.xls的第1个工作表中的B2B52中的数据,即班级数据banji = xlsread('examp02_14.xls','Sheet1','B2B52');% 读取文件examp02_14.xls的第1个工作表中的G2G52中的数据,即总成绩数据score = xlsread('examp02_14.xls','Sheet1','G2G52');% 去除缺考数据score = score(score 0);banji = banji(score 0);% 分别提取60101和60102班的总成绩score1 = score(banji == 60101);score2 = score(banji == 60102);% 调用kstest2函数检验两个班的总成绩是否服从相同的分布[h,p,ks2stat] = kstest2(score1,score2)%分别绘制两个班的总成绩的经验分布图figure; % 新建图形窗口% 绘制60101班总成绩的经验分布函数图F1 = cdfplot(score1);% 设置线宽为2,颜色为红色set(F1,'LineWidth',2,'Color','r')hold on% 绘制60102班总成绩的经验分布函数图F2 = cdfplot(score2);% 设置线型为点划线,线宽为2,颜色为黑色set(F2,'LineStyle','-.','LineWidth',2,'Color','k')% 为图形加标注框,标注框的位置在坐标系的左上角legend('60101班总成绩的经验分布函数','60102班总成绩的经验分布函数',...'Location','NorthWest')%调用kstest2函数进行正态性检验randn('seed',0) % 指定随机数生成器的初始种子为0% 产生10000个服从均值为79,标准差为10.1489的正态分布的随机数,构成一个列向量xx = normrnd(mean(score),std(score),10000,1);% 调用kstest2函数检验总成绩数据score与随机数向量x是否服从相同的分布[h,p] = kstest2(score,x,0.05)%调用lillietest函数进行分布的检验% 调用lillietest函数进行Lilliefors检验,检验总成绩数据是否服从正态分布[h,p,kstat,critval] = lillietest(score)% 调用lillietest函数进行Lilliefors检验,检验总成绩数据是否服从指数分布[h, p] = lillietest(score,0.05,'exp')。
使用MATLAB进行数据拟合的步骤与技巧

使用MATLAB进行数据拟合的步骤与技巧
一、介绍
MATLAB是一种强大的数据处理和数学建模工具,使用它可以进行准
确的数据拟合,提取出有用的特征和模型,最终实现精确的建模和分析。
MATLAB有一个有用的函数库,包括用于线性和非线性拟合的函数,以及
其他用于调整参数和检查数据的函数。
在本文中,我将介绍使用MATLAB
进行数据拟合的一般步骤和技巧,以实现准确的建模分析。
二、步骤
1.准备数据:在进行数据拟合之前,首先要准备数据,这包括将数据
预处理,以及清理由于输入错误或可能存在错误的数据。
同时,我们也可
以使用MATLAB函数进行数据可视化,查看数据的基本分布,以及数据中
有趣的趋势。
2.设置拟合函数:在数据准备完毕后,我们可以使用MATLAB函数对
数据进行拟合,比如拟合一个线性方程或多项式方程。
我们可以使用MATLAB自带的函数,或者使用自定义函数。
3.调整参数:在找到合适的拟合函数后,我们可以使用MATLAB中的
特定函数来调整参数,以使拟合曲线更加拟合数据。
4.检查拟合:使用MATLAB中的函数可以检查拟合的准确性和精确度,并可以评估拟合结果的可靠性。
三、技巧
1.灵活运用自定义函数:在MATLAB中,我们可以使用自定义函数来
进行更有效率的数据拟合。
matlab与分布拟合

综合评述
• 数据检验是本问题中必须做的,但被许多参赛 队所忽略,从而意外成为区分点之一。
• 公平性指标被许多人忽略,反映出对问题本质 认识不到位。效率指标也可以适当精简。
• 优化模型的多样性是本题目最大的亮点,涌现 许多意料之外的解法。
• 入院时间的预测区间完成不好,大部分队没有 置信度概念,不少队给出的区间与当前队长无 关。
• 数据分析做得比较深入的同学,会发现一 条隐含在数据中的关键信息:术前住院时 间过长是当前病床使用效率不高的主要因 素。这样一个关键信息的获得,会使得建 模更有方向感。
第一问
● 主要考核对问题的考虑是否全面,对问题实质的理解是 否到位。评价指标分两类:效率指标和公平性指标。 两类指标可以有各种不同的定义,其合理性是评分依据。
• 抽象来看,本问题可归类于一个通道分类-服 务台共享的多通道随机服务问题,对这样的问 题,排队论中还没有现成的解决方法,可以作 为一个排队论问题加以继续研究。
竞赛中的 几点注意事项
85
86
● 关键词的理解 ● 优化目标
● 基本考点 难点 关键点(区分点) 例:08年A题—数码相机定位
87
● 关键点的清晰化 ● 不断选择 (trade off ) 的过程 ● 现实与理想之间的平衡 ● 大局观 建模思路的顺畅展开
• 在本题所给数据中,各类病人到达人数分别服从不同参 数的Poisson分布,需要进行分布拟合检验及分布参数 提取。
• 由所给数据可以看出,病人术前住院时间是确定的,依 入院时间而定,所以病人住院时间中只有术后住院时间 是随机的,要做拟合检验的也是这一部分时间分布。
• 各类病人术后住院时间分别服从正态分布 、Г分布 或埃 尔朗分布,由于检验方法或检验细节处理不相同,可能 得到以上不同的分布,这是允许的,但若得出服从负指 数分布的结论,则是错误的。也有一些同学不做拟合分 布检验,而是画出直方图,然后以此经验分布作仿真依 据,这样处理也是可以的。
正态分布拟合matlab

正态分布拟合matlab(实用版)目录一、正态分布简介二、正态分布拟合方法三、MATLAB 中正态分布的实现四、MATLAB 中正态分布拟合的步骤五、总结正文一、正态分布简介正态分布,又称为高斯分布(Gaussian distribution),是一种常见的概率分布。
正态分布的概率密度函数具有一种特殊的钟形曲线,其分布的均值(μ)和标准差(σ)决定了分布的形状。
正态分布在自然界和社会科学中的现象很常见,例如人的身高、考试成绩等都近似服从正态分布。
二、正态分布拟合方法拟合正态分布的方法有很多,如极大似然估计、矩估计等。
在 MATLAB 中,我们可以使用曲线拟合工具箱(Curve Fitting Toolbox)来进行正态分布的拟合。
三、MATLAB 中正态分布的实现在 MATLAB 中,可以使用 randn 函数生成标准正态分布(均值为 0,方差为 1)的随机数。
若要生成均值为 a,方差为 b 的非标准正态分布,可以使用 abrandn 函数。
另外,lognrnd 函数可以生成对数正态分布的随机数,而 mvnrnd 函数可以生成多元正态分布的随机数。
四、MATLAB 中正态分布拟合的步骤1.导入数据:将需要拟合的数据导入 MATLAB,可以使用 txtread 等函数将数据保存为矩阵形式。
2.使用曲线拟合工具箱:点击屏幕左下方的 Start 按钮,进入Toolboxes,然后选择 Curve Fitting Tool。
3.导入数据:在 Curve Fitting Tool 中,选择已导入的数据。
4.设置拟合参数:选择 Gaussian 次数为 1,即设置拟合函数为正态分布。
5.开始拟合:点击 Fit 按钮,MATLAB 将自动计算拟合效果,并显示参数。
五、总结通过 MATLAB 可以方便地生成正态分布的随机数,并使用曲线拟合工具箱对数据进行正态分布拟合。
matlab、lingo程序代码10-分布拟合检验

二项分布种子发芽问题:设种子发芽率是80%,每穴播5粒,用X表示发芽的粒数,求X的概率分布。
可能有的穴只发芽1粒,有的发芽3粒,有的发芽4粒……泊松分布葡萄干问题:在蛋糕中添加葡萄干。
把所有葡萄干揉入面团中,按平均每块蛋糕3粒葡萄干计算称量面粉、葡萄干等原料后开始制作蛋糕。
问制做成的蛋糕每块含有的葡萄干数量的概率分布。
有的蛋糕含有3粒葡萄干,有的可能含有5粒,有的可能只有一粒,有的可能没有。
这两个分布有一定的相似性。
有的穴只发芽1粒,有的蛋糕只有一粒葡萄干,有的穴只发芽3粒,有的蛋糕有3粒葡萄干……图形在MATLAB命令控制台输入disttool 可以打开交互式经验分布函数图工具。
当二项分布的参数p=0.5时,概率分布图是对称的发芽率为0.8时,图形为:泊松分布只有一个参数λ,这两个分布,二项分布的np计算得到的数是个最有可能的平均数,相当于泊松分布的平均数λ。
但是从上面的图形来看,控制二项分布的参数n和p得到的概率分布图样子不一样。
奇怪的是,泊松分布图只受制于一个参数λ,这个λ越大图形就越对称越好看:λ=30看来参数比较极端时,都是向着正态分布看齐了。
分布的检验话说很多情形都是泊松分布。
比如单位体积的空气含有的某种微粒的数目、单位面积上坏人的数量的分布、单位时间内来到公共汽车站的乘客数目、单位面积上某种细菌的数量、单位质量的米粒中含有的杂质的数量、单位人群中患有某种特殊疾病的人数,等等,另外还有可以用泊松分布近似的二项分布的各种情况(当n很大,p很小,以至于np<4时可用泊松分布来近似二项分布)。
尽管如此,有些时候也不能断然认为某观测的总体符合泊松分布或者二项分布(或者其他分布,比如正态分布)。
假设已经有一组观测的数据,如何根据这些数据检验是否符合某种分布?使用MATLAB的jbtest函数可以检验大样本(观测值有30个以上)是否符合正态分布,对于小样本数据使用Lilliefors检验。
MATLAB程序设计 资产收益率分布的拟合与检验
资产收益率分布的拟合与检验在统计推断中,通常假定总体服从一定的分布(例如正态分布),然后在这个分布的基础上,构造相应的统计量,根据统计量的分布作出一些统计推断,而统计量的分布通常依赖于总体分布的假设,也就是说总体所服从的分布在统计推断中是至关重要的,会影响到结果的可靠性。
从这个意义上来说,由样本观测数据去推断总体所服从的分布是非常必要的。
指数与基金的收益率,介绍根据样本观测数据拟合总体的分布,并进行分布的检验。
本章主要内容包括:数据的描述性统计,分布的检验,核密度(kernel density)估计。
其中数据的描述性统计又包括均值、标准差、最大值、最小值、极差、中位数、众数、变异系数、偏度和峰度等描述性统计量,以及箱线图、经验分布函数图、频率直方图和正态概率图等统计图;分布的检验主要介绍chi2gof、jbtest、kstest、kstest2、lillietest等函数的用法。
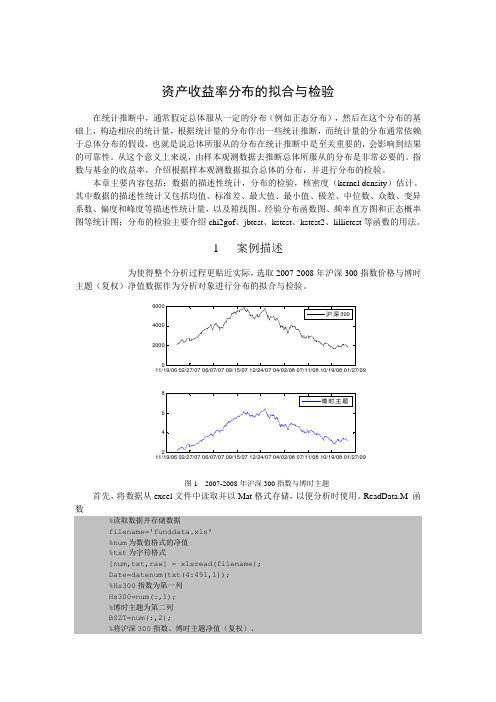
1 案例描述为使得整个分析过程更贴近实际,选取2007-2008年沪深300指数价格与博时主题(复权)净值数据作为分析对象进行分布的拟合与检验。
图1 2007-2008年沪深300指数与博时主题首先,将数据从excel文件中读取并以Mat格式存储,以便分析时使用。
ReadData.M 函数%读取数据并存储数据filename='funddata.xls'%num为数值格式的净值%txt为字符格式[num,txt,raw] = xlsread(filename);Date=datenum(txt(4:491,1));%Hs300指数为第一列Hs300=num(:,1);%博时主题为第二列BSZT=num(:,2);%将沪深300指数、博时主题净值(复权)、%日期数据存储在TestData 中save TestData Hs300 BSZT Date %画图subplot(2,1,1)plot(Date,Hs300,'k');%将时间轴的 数值日期转变为 月/年 格式 dateaxis('x',2) legend('沪深300') subplot(2,1,2)plot(Date,BSZT,'b--');%将时间轴的 数值日期转变为 月/年 格式 dateaxis('x',2) legend('博时主题')2 数据的描述性统计2.1 描述性统计量在进行数据分析之前,先从几个特征数字上认识一下它们,也就是说计算几个描述性统计量,包括均值、标准差、最大值、最小值、极差、中位数、众数、变异系数、偏度和峰度。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
%--------------------------------------------------------------------------% 分布的拟合与检验%--------------------------------------------------------------------------%--------------------------------------------------------------------------% 描述性统计量和统计图%--------------------------------------------------------------------------%读取文件中数据% 读取文件examp02_14.xls的第1个工作表中的G2G52中的数据,即总成绩数据score = xlsread('examp02_14.xls','Sheet1','G2G52');% 去掉总成绩中的0,即缺考成绩score = score(score 0);%计算描述性统计量score_mean = mean(score) % 计算平均成绩s1 = std(score) % 计算(5.1)式的标准差s1 = std(score,0) % 也是计算(5.1)式的标准差s2 = std(score,1) % 计算(5.2)式的标准差score_max = max(score) % 计算样本最大值score_min = min(score) % 计算样本最小值score_range = range(score) % 计算样本极差score_median = median(score) % 计算样本中位数score_mode = mode(score) % 计算样本众数score_cvar = std(score)mean(score) % 计算变异系数score_skewness = skewness(score) % 计算样本偏度score_kurtosis = kurtosis(score) % 计算样本峰度%绘制箱线图figure; % 新建图形窗口boxlabel = {'考试成绩箱线图'}; % 箱线图的标签% 绘制带有刻槽的水平箱线图boxplot(score,boxlabel,'notch','on','orientation','horizontal')xlabel('考试成绩'); % 为X轴加标签%绘制频率直方图% 调用ecdf函数计算xc处的经验分布函数值f[f, xc] = ecdf(score);figure; % 新建图形窗口% 绘制频率直方图ecdfhist(f, xc, 7);xlabel('考试成绩'); % 为X轴加标签ylabel('f(x)'); % 为Y轴加标签%绘制理论正态分布密度函数图% 产生一个新的横坐标向量xx = 400.5100;% 计算均值为mean(score),标准差为std(score)的正态分布在向量x处的密度函数值y = normpdf(x,mean(score),std(score));hold onplot(x,y,'k','LineWidth',2) % 绘制正态分布的密度函数曲线,并设置线条为黑色实线,线宽为2% 添加标注框,并设置标注框的位置在图形窗口的左上角legend('频率直方图','正态分布密度曲线','Location','NorthWest');%绘制经验分布函数图figure; % 新建图形窗口% 绘制经验分布函数图,并返回图形句柄h和结构体变量stats,% 结构体变量stats有5个字段,分别对应最小值、最大值、平均值、中位数和标准差[h,stats] = cdfplot(score)set(h,'color','k','LineWidth',2); % 设置线条颜色为黑色,线宽为2%绘制理论正态分布函数图x = 400.5100; % 产生一个新的横坐标向量x% 计算均值为stats.mean,标准差为stats.std的正态分布在向量x处的分布函数值y = normcdf(x,stats.mean,stats.std);hold on% 绘制正态分布的分布函数曲线,并设置线条为品红色虚线,线宽为2plot(x,y,'k','LineWidth',2);% 添加标注框,并设置标注框的位置在图形窗口的左上角legend('经验分布函数','理论正态分布','Location','NorthWest');%绘制正态概率图figure; % 新建图形窗口normplot(score); % 绘制正态概率图%--------------------------------------------------------------------------% 分布的检验%--------------------------------------------------------------------------%读取文件中数据% 读取文件examp02_14.xls的第1个工作表中的G2G52中的数据,即总成绩数据score = xlsread('examp02_14.xls','Sheet1','G2G52');% 去掉总成绩中的0,即缺考成绩score = score(score 0);%调用chi2gof函数进行卡方拟合优度检验% 进行卡方拟合优度检验[h,p,stats] = chi2gof(score)% 指定各初始小区间的中点ctrs = [50 60 70 78 85 94];% 指定'ctrs'参数,进行卡方拟合优度检验[h,p,stats] = chi2gof(score,'ctrs',ctrs)[h,p,stats] = chi2gof(score,'nbins',6) % 指定'nbins'参数,进行卡方拟合优度检验% 指定分布为默认的正态分布,分布参数由x进行估计[h,p,stats] = chi2gof(score,'nbins',6);% 求平均成绩ms和标准差ssms = mean(score);ss = std(score);% 参数'cdf'的值是由函数名字符串与函数中所含参数的参数值构成的元胞数组[h,p,stats] = chi2gof(score,'nbins',6,'cdf',{'normcdf', ms, ss});% 参数'cdf'的值是由函数句柄与函数中所含参数的参数值构成的元胞数组[h,p,stats] = chi2gof(score,'nbins',6,'cdf',{@normcdf, ms, ss});% 同时指定'cdf'和'nparams'参数[h,p,stats] = chi2gof(score,'nbins',6,'cdf',{@normcdf,ms,ss},'nparams',2)[h,p] = chi2gof(score,'cdf',@normcdf) % 调用chi2gof函数检验数据是否服从标准正态分布% 指定初始分组数为6,检验总成绩数据是否服从参数为ms = 79的泊松分布[h,p] = chi2gof(score,'nbins',6,'cdf',{@poisscdf, ms})% 指定初始分组数为6,最小理论频数为3,检验总成绩数据是否服从正态分布h = chi2gof(score,'nbins',6,'cdf',{@normcdf, ms, ss},'emin',3)%调用jbtest函数进行正态性检验randn('seed',0) % 指定随机数生成器的初始种子为0x = randn(10000,1); % 生成10000个服从标准正态分布的随机数h = jbtest(x) % 调用jbtest函数进行正态性检验x(end) = 5; % 将向量x的最后一个元素改为5h = jbtest(x) % 再次调用jbtest函数进行正态性检验% 调用jbtest函数进行Jarque-Bera检验[h,p,jbstat,critval] = jbtest(score)%调用kstest函数进行正态性检验% 生成cdf矩阵,用来指定分布:均值为79,标准差为10.1489的正态分布cdf = [score, normcdf(score, 79, 10.1489)];% 调用kstest函数,检验总成绩是否服从由cdf指定的分布[h,p,ksstat,cv] = kstest(score,cdf)%调用kstest2函数检验两个班的总成绩是否服从相同的分布% 读取文件examp02_14.xls的第1个工作表中的B2B52中的数据,即班级数据banji = xlsread('examp02_14.xls','Sheet1','B2B52');% 读取文件examp02_14.xls的第1个工作表中的G2G52中的数据,即总成绩数据score = xlsread('examp02_14.xls','Sheet1','G2G52');% 去除缺考数据score = score(score 0);banji = banji(score 0);% 分别提取60101和60102班的总成绩score1 = score(banji == 60101);score2 = score(banji == 60102);% 调用kstest2函数检验两个班的总成绩是否服从相同的分布[h,p,ks2stat] = kstest2(score1,score2)%分别绘制两个班的总成绩的经验分布图figure; % 新建图形窗口% 绘制60101班总成绩的经验分布函数图F1 = cdfplot(score1);% 设置线宽为2,颜色为红色set(F1,'LineWidth',2,'Color','r')hold on% 绘制60102班总成绩的经验分布函数图F2 = cdfplot(score2);% 设置线型为点划线,线宽为2,颜色为黑色set(F2,'LineStyle','-.','LineWidth',2,'Color','k')% 为图形加标注框,标注框的位置在坐标系的左上角legend('60101班总成绩的经验分布函数','60102班总成绩的经验分布函数',...'Location','NorthWest')%调用kstest2函数进行正态性检验randn('seed',0) % 指定随机数生成器的初始种子为0% 产生10000个服从均值为79,标准差为10.1489的正态分布的随机数,构成一个列向量xx = normrnd(mean(score),std(score),10000,1);% 调用kstest2函数检验总成绩数据score与随机数向量x是否服从相同的分布[h,p] = kstest2(score,x,0.05)%调用lillietest函数进行分布的检验% 调用lillietest函数进行Lilliefors检验,检验总成绩数据是否服从正态分布[h,p,kstat,critval] = lillietest(score)% 调用lillietest函数进行Lilliefors检验,检验总成绩数据是否服从指数分布[h, p] = lillietest(score,0.05,'exp')。