金融计量经济第五讲虚拟变量模型和Probit、Logit模型
logit 和probit模型的系数解释 -回复

logit 和probit模型的系数解释-回复主题:logit 和probit 模型的系数解释引言logit 模型和probit 模型是广泛应用于概率统计和经济学中的两个模型,用于解释事件发生的概率与相关因素之间的关系。
本文将详细介绍这两个模型的系数解释,并分析它们在实际应用中的区别和适用场景。
一、logit 模型系数解释logit 模型基于二项逻辑回归的概率模型,适用于事件结果是二元变量(如成功/失败,发生/不发生)的情况。
该模型通过计算事件发生的对数几率来建模,并利用最大似然估计来确定系数的值。
1. 系数的正负logit 模型中的系数是事件发生概率对于自变量的变化的影响大小。
系数的正负代表了自变量与事件发生概率之间的正相关或负相关关系。
正系数意味着自变量的增加会增加事件发生概率,而负系数意味着自变量的增加会减少事件发生概率。
2. 系数的大小logit 模型中,系数的大小代表了自变量单位变化对于事件发生概率的影响程度。
系数越大,自变量的一个单位变化对于事件发生概率的影响就越大。
一般来说,当系数的绝对值大于1时,其影响被认为是显著的。
3. 系数的统计显著性logit 模型使用最大似然估计来确定系数的值,同时也提供了对系数是否显著的统计检验。
当系数的p 值小于显著性水平(通常为0.05或0.01)时,我们可以认为该系数是显著的,即具有统计上的置信度。
二、probit 模型系数解释probit 模型是基于正态分布的概率模型,与logit 模型相似,用于解决二元变量的概率建模问题。
不同的是,probit 模型通过计算事件发生的累积分布函数值来建模,并同样利用最大似然估计来确定系数的值。
1. 系数的正负probit 模型中的系数的解释与logit 模型相同,系数的正负代表了自变量与事件发生概率之间的正相关或负相关关系。
正系数意味着自变量的增加会增加事件发生概率,而负系数意味着自变量的增加会减少事件发生概率。
probit模型与logit模型

probit模型与logit模型2013-03-30 16:10:17probit模型是一种广义的线性模型。
服从正态分布。
最简单的probit模型就是指被解释变量Y是一个0,1变量,事件发生地概率是依赖于解释变量,即P(Y=1)=f(X),也就是说,Y=1的概率是一个关于X的函数,其中f(.)服从标准正态分布。
若f(.)是累积分布函数,则其为Logistic模型Logit模型(Logit model,也译作“评定模型”,“分类评定模型”,又作Logistic regression,“逻辑回归”)是离散选择法模型之一,属于多重变量分析范畴,是社会学、生物统计学、临床、数量心理学、市场营销等统计实证分析的常用方法。
逻辑分布(Logistic distribution)公式P(Y=1│X=x)=exp(x’β)/1+exp(x’β)其中参数β常用极大似然估计。
Logit模型是最早的离散选择模型,也是目前应用最广的模型。
Logit模型是Luce(1959)根据IIA特性首次导出的;Marschark(1960)证明了Logit模型与最大效用理论的一致性;Marley (1965)研究了模型的形式和效用非确定项的分布之间的关系,证明了极值分布可以推导出Logit 形式的模型;McFadden(1974)反过来证明了具有Logit形式的模型效用非确定项一定服从极值分布。
此后Logit模型在心理学、社会学、经济学及交通领域得到了广泛的应用,并衍生发展出了其他离散选择模型,形成了完整的离散选择模型体系,如Probit模型、NL模型(Nest Logit model)、Mixed Logit模型等。
模型假设个人n对选择枝j的效用由效用确定项和随机项两部分构成:Logit模型的应用广泛性的原因主要是因为其概率表达式的显性特点,模型的求解速度快,应用方便。
当模型选择集没有发生变化,而仅仅是当各变量的水平发生变化时(如出行时间发生变化),可以方便的求解各选择枝在新环境下的各选择枝的被选概率。
比较线性模型和Probit模型、Logit模型

研究生考试录取相关因素的实验报告一,研究目的通过对南开大学国际经济研究所1999级研究生考试分数及录取情况的研究,引入录取与未录取这一虚拟变量,比较线性概率模型与Probit模型,Logit模型,预测正确率。
二,模型设定表1,南开大学国际经济研究所1999级研究生考试分数及录取情况见数据表定义变量。
上图为样本观测值。
1.线性概率模型根据上面资料建立模型用Eviews 得到回归结果如图: Dependent Variable: Y Method: Least Squares Date: 12/10/10 Time: 20:38 Sample: 1 97Included observations: 97 Variable Coefficient Std. Errort-StatisticProb.??C SCORER-squared????Mean dependent var Adjusted R-squared ????. dependent var . of regression ????Akaike info criterion Sum squared resid ????Schwarz criterion Log likelihood ????F-statistic Durbin-Watson stat ????Prob(F-statistic)参数估计结果为: iY ˆ+ i SCORE Se=( t=p=预测正确率:Forecast: YF Actual: YForecast sample: 1 97 Included observations: 97Root Mean Squared Error Mean Absolute Error????? Mean Absolute Percentage Error Theil Inequality Coefficient? ?????Bias Proportion???????? ?????Variance Proportion? ?????Covariance Proportion?模型Dependent Variable: Y Method: ML - Binary Logit (Quadratic hill climbing)Date: 12/10/10 Time: 21:38Sample: 1 97Included observations: 97Convergence achieved after 11 iterationsCovariance matrix computed using second derivatives Variable Coefficient Std. Errorz-StatisticProb.??C SCOREMean dependent var ????. dependent var . of regression ????Akaike info criterion Sum squared resid ????Schwarz criterion Log likelihood ????Hannan-Quinn criter. Restr. log likelihood ????Avg. log likelihood LR statistic (1 df) ????McFadden R-squaredProbability(LR stat)Obs with Dep=0 83 ?????Total obs 97Obs with Dep=1 14得Logit 模型估计结果如下p i = F (y i ) =)6794.07362.243(11i x e +--+ 拐点坐标 ,其中Y=+预测正确率Forecast: YF Actual: YForecast sample: 1 97 Included observations: 97Root Mean Squared Error Mean Absolute Error????? Mean Absolute Percentage Error Theil Inequality Coefficient? ?????Bias Proportion???????? ?????Variance Proportion? ?????Covariance Proportion?模型Dependent Variable: Y Method: ML - Binary Probit (Quadratic hill climbing)Date: 12/10/10 Time: 21:40Sample: 1 97Included observations: 97Convergence achieved after 11 iterationsCovariance matrix computed using second derivativesVariable Coefficient Std. Error z-Statistic Prob.??CSCOREMean dependent var ????. dependent var. of regression ????Akaike info criterionSum squared resid ????Schwarz criterionLog likelihood ????Hannan-Quinn criter.Restr. log likelihood ????Avg. log likelihoodLR statistic (1 df) ????McFadden R-squaredProbability(LR stat)Obs with Dep=0 83 ?????Total obs 97Obs with Dep=1 14Probit模型最终估计结果是p i = F(y i) = F+ x i) 拐点坐标,预测正确率Forecast: YFActual: YForecast sample: 1 97Included observations: 97Root Mean Squared ErrorMean Absolute Error?????Mean Absolute Percentage ErrorTheil Inequality Coefficient??????Bias Proportion?????????????Variance Proportion??????Covariance Proportion?预测正确率结论:线性概率模型RMSE= MAE= MAPE=Logit模型 RMSE= MAE= MAPE=Probit模型 RMSE= MAE= MAPE=由上面结果可知线性概率模型的RMSE、MAE、MAPE 均远远大于Logit模型和Probit模型,说明其误差率比Logit模型和Probit模型大很多,所以正确率远远小于Logit模型和Probit模型。
虚拟变量回归模型:计量经济学3

3、虚拟变量的实际应用
(1)虚拟变量可以用于研究制度变迁的影响
如:研究2001年中国加入WTO事件对中国进出 口贸易的影响,可以建立如下方程:
+d 主要贸易伙伴国 GDP+e DWTO
中国的进出口贸易总值 =a b 人民币汇率 c 中国GDP
计量经济学专题:
虚拟变量的回归与Probit模型、 Logit模型
1、虚拟变量的性质
与有明确尺度量化了的变量(GDP、产 量、价格、成本、汇率等)不同,虚拟 变量是一种定性性质的变量,如性别、 种族、国籍等只涉及“是”与“非”两 种状态的变量。 虚拟变量的取值只取0或1。1表示某种性 质出现,0表示某种性质不出现。
(3)对一个普通变量与两个两分虚拟变 量的回归
例:种族及性别差异对薪金的影响。 假定薪金除了受工作年限、性别的影响 之外,还受种族的影响。
yi 1 2 D2i 3D3i xi ui
yi 为某人的工资水平,xi 为工作年限。
yi 1 2 D2i 3D3i xi ui 虚拟变量模型:
白人女性的工资水平:
E( yi D2 0, D3 1) (1 3) xi
yi 1 2 D2i 3D3i xi ui 虚拟变量模型:
其他人种男性的平均工资:
E( yi D2 1, D3 0) (1 2) xi
其他人种女性的平均工资:
Pi P r(Y 1) P r(I i * I i ) F ( I i ) 1 2 1 2
Ii
金融计量经济第五讲虚拟变量模型和Probit、Logit模型

第二节 虚拟被解释变量模型
• 问题1:对于商业银行,企业贷款可能出现违约,也就是说一家企 业贷款后有违约和不违约两种可能,如何甄别?(李萌,2005)
• 问题2:证券投资者在特定时期内的投资选择是买或不买,如何确 定这样的选择?(王冀宁等,2003)
• 问题3:上市公司出现经营问题,可能成为ST、PT,是什么原因导 致这样的结果?
6563.76 1597.98
16.904 16.9416 157.922
0
应用例题2:股息税削减对股价的影响
• 背景资料—2005年6月14日,财政部、税务总局发文,规定对个人投资者从
上市公司取得的股息红利所得,暂减按50%计入个应纳税所得额(红利税从 20%降为10%)。
• 利用事件分析法分析该政策对股价有无显著影响,即政策出台前后股票有无 异常收益。时间窗口为发布日及前后各二天。
E( yi ) P( yi 1) X i
• 但因为
i
1 X
Xi i
当yi 1,其概率为X i 当yi 0,其概率为1 X i
• 模型具有明显的异方差性,故而用模型(5.8)直接进行参数估计 是不合适的。
• 另外,由于要求
E( yi ) P( yi 1) Xi 1
亦
难以达到。
Di 0, 其它季度的数据
, i 2,3,4
• •
原 则模 引型 入若 虚为 拟变量后的y模t 型为:
xt
ut
yt xt 2 D2t 3 D3t 4 D4t ut (5.6)
• 回归模型可视为:
yˆt ˆ ˆxt
一季度
yˆt ˆ ˆxt ˆ2 二季度
yˆt ˆ ˆxt ˆ3 三季度
二、虚拟变量的设置原则
计量经济学虚拟变量模型课件

计量经济学虚拟变量模型
21
1 正常年份 D1i 0 非正常年份
式(5.2)也可表示为
1 非正常年份 D2i 0 正常年份
Y i 0 X 1 i 1 X 2 i 2 X 3 i 3 X i u i (5.3)
其中,X 1i1 ,X 2iD 1i,X 3iD 2i,显然如下等式成立。
X1i X2i X3i
计量经济学虚拟变量模型
3
例如,性别可表现为男或女;人种可表 现为白种人和非白种人;宗教信仰可表 现为教徒和非教徒;政府的经济政策可 表现为改革开放前和改革开放后,如此 等等。
Hale Waihona Puke 计量经济学虚拟变量模型4
显然,这种不同的具体形式是无法直接引 入经济计量模型中去的。但由于这类变量 通常表现为品质、属性、种类的出现或者 未出现,所以我们可以根据质量变量的这 一特征将其数量化。
Y i1 D 1 i2 D 2 i3 X i u i (5.5)
显然模型(5.5)中,解释变量D1,D2和X之间 无完全的多重共线性。可以使用普通最小二乘 法估计式(5.5)的参数。
第五章 虚拟变量模型
在经济计量模型中除了有量的因素外 还有质的因素,质的因素包括被解释变量 为质的因素和解释变量为质的因素。如果 被解释变量为质的因素,主要是逻辑回归 要涉及的内容。
计量经济学虚拟变量模型
1
第一节 虚拟变量的概念与设定
一、虚拟变量的概念 在经济计量分析中, 经常会碰到所建模
型的被解释变量不仅受诸如收入、产量 、价格、 成本、需求、投资等数量变量
(5.4)
计量经济学虚拟变量模型
22
式(5.4)表明模型(5.3)即原模型(5.2)中有 完全的多重共线性,将导致最小二乘估计无 解。我们称该情景为掉入虚拟变量陷阱。所 以,在有截距项的情况下,如果一个质的因 素有多少个特征就引入多少个虚拟变量是行 不通的。
金融计量经济第五讲虚拟变量模型和Probit、Logit模型

• 括号内为t统计值。 • 显然,三季度和四季度与一季度差异并不明显,重 新回归,仅考虑二季度,有结果:
例子:佣金与销售额的关系:
• 模型:
Yi = α1 + β1 xi + β 2 ( xi − x* ) Di + ui 其中 : Yi是销售佣金, X i是销售额, X*是销售额基数值. 若X i > X * , 则Di = 1
• 样本回归函数: ˆ ˆ α +β x
ˆ Yi =
1
1 i
xi < x* xi ≥ x*
D1 = , 0, S < S1 , S ≥ S2 D2 = 0, S < S2
• 工资模型为: • I i = β 0 + β1[ S1 + (1 − D1i − D2i )(Si − S1 )]
+ β 2 [ D2i ( S 2 − S1 ) + D1i ( Si − S1 )] + β 3 D2i ( Si − S 2 ) + ui (5.7)
t t
一季度 ˆ β2 ˆ β3 二季度 三季度 四季度
ˆ ˆ ˆ ˆ y t = α + β xt + β 4
例题:美国制造业的利润—销售额行为 • 模型:利润t = α1 + α 2 D2t + α 3 D3t + α 4 D4t + β (销售)t + ut • 利用1965—1970年六年的季度数据,得结果:
计量经济学logit模型

计量经济学logit模型引言:计量经济学是经济学中的一个重要分支,它运用数学和统计方法来研究经济现象和经济问题。
其中,logit模型是计量经济学中常用的一种模型,它被广泛应用于各个领域,如市场研究、消费者行为分析、医学研究等。
本文将对logit模型进行详细介绍,包括其基本原理、应用场景以及优缺点等。
一、logit模型基本原理logit模型是一种广义线性模型,用于描述两个互斥事件之间的关系。
在logit模型中,我们通常关注的是某个事件发生的概率,即几率(odds)。
几率是指某个事件发生的概率与不发生的概率的比值。
logit模型通过将几率转化为一个线性函数来建模,从而实现对事件发生概率的预测。
logit模型的数学表达式为:log(odds) = β0 + β1X1 + β2X2 + ... + βnXn其中,log(odds)表示对数几率,β0、β1、β2...βn是待估计的系数,X1、X2...Xn是自变量。
通过估计系数,我们可以得到自变量对事件发生概率的影响程度。
二、logit模型的应用场景1. 市场研究:logit模型可以用于预测消费者的购买行为。
通过考察不同因素对购买决策的影响,如价格、品牌、促销活动等,可以帮助企业制定有效的市场营销策略。
2. 消费者行为分析:logit模型可以用于研究消费者在不同选择之间的偏好。
例如,在购买某一产品时,消费者面临多个选择,通过分析消费者的偏好,可以为企业提供产品改进和定价策略的建议。
3. 医学研究:logit模型可以用于预测某种疾病的发生概率。
通过考察与疾病相关的因素,如年龄、性别、家族病史等,可以帮助医生和研究人员进行疾病风险评估和预防措施的制定。
三、logit模型的优缺点1. 优点:(1)适用性广泛:logit模型可以应用于各个领域,对于描述二元事件的概率关系具有较好的表达能力。
(2)结果易解释:logit模型的系数可以解释为自变量对事件发生概率的影响程度,便于理解和解释模型结果。
离散因变量模型(Logit 模型,Probit模型)

yi F ( X i B) i
eZ F(Z) 1 eZ (Z)
模型 yi ( Xi B) i
f
(Z)
F'(Z)
eZ (1 eZ )2
(Z )(1 (Z ))
线性化 pi ( Xi B)
∵
(Z )
eZ 1 eZ
pi ( X i B) eXiB 1 pi 1 ( X i B)
LPM, Probit, Logit
1、 线性概率模型(LPM)
如果选择 F ( XiB) XiB yi X i B i
E( yi Xi ) E( Xi B i ) Xi B yi E( yi X i ) i
P( yi 1 X i ) pi
P( yi 0 Xi ) 1 pi
i 1
ln L
n i 1
yi f i Fi
(1
yi
)
fi (1 Fi
)
X
i
0
求驻点即可。
三、 二元选择模型的显著性检验
1. t 检验 (大样本下用正态分布)
2. 准R2
Pseudo R 2 1 log Lur log Lr
3. 线性约束F检验
0.052 0.873 0.052
-.0050766 -6.326276
-486.509
1.359199 5.373068 1.593967
(3)得到估计式: 注:括号里是p值。
ln( 1
p
p
)
242.4576
0.6771Score
0.4766D1
probit logit 解析表达式

probit logit 解析表达式摘要:1.简介2.probit 和logit 模型的基本概念3.probit 模型的解析表达式4.logit 模型的解析表达式5.结论正文:1.简介在概率论和统计学中,probit 和logit 模型被广泛应用于二元变量的分析,如成功概率、响应概率等。
这两种模型都可以将概率分布转换为连续的线性函数,便于进行参数估计和模型检验。
本篇文章将详细解析probit 和logit 模型的解析表达式。
2.probit 和logit 模型的基本概念Probit 模型是一种基于正态分布的概率模型,它的基本思想是将二元随机变量{Y = 1, Y = 0}的概率密度函数(PDF)转换为连续的线性函数。
Logit 模型则是基于逻辑斯蒂函数的模型,它的基本思想是将二元随机变量{Y = 1, Y = 0}的累积分布函数(CDF)转换为连续的线性函数。
这两种模型都假设观测到的自变量X 与因变量Y 之间存在线性关系。
3.probit 模型的解析表达式对于probit 模型,假设我们有观测到的自变量X 和二元随机变量Y,其中Y 的概率密度函数(PDF)可以表示为:f_Y(y|x) = N(y|μ_y(x), σ_y^2)其中,μ_y(x) 是Y 的期望,σ_y^2 是Y 的方差。
我们可以通过求解累积分布函数(CDF)的逆函数,得到Y 的累积概率:F_Y(y|x) = Phi((y - μ_y(x)) / σ_y)其中,Φ(·) 是标准正态分布的累积分布函数,σ_y 是Y 的标准差。
将F_Y(y|x) 表示为关于x 的线性函数,即可得到probit 模型的解析表达式。
4.logit 模型的解析表达式对于logit 模型,假设我们有观测到的自变量X 和二元随机变量Y,其中Y 的累积分布函数(CDF)可以表示为:F_Y(y|x) = 1 / (1 + exp(-α(x) * (y - β(x))))其中,α(x) 和β(x) 是关于X 的函数,表示logit 模型的参数。
二值因变量模型_14.2Probit和Logit模型

对外经济贸易大学计量经济学I n t r o d u c t i o n t o E c o n o m e t r i c s导论二值因变量模型:Probit和Logit模型Probit和Logit回归在线性概率模型中,y=1 的概率是x 的线性函数:P (y= 1|x) = β0+ β1x在非线性概率模型中:对于β1>0,Pr(y= 1|x)是x的单增函数;010 ≤ P(y= 1|x) ≤ 1 对所有的x都成立。
02我们希望构造一个非线性函数来刻画此概率。
例如一个“S-curve”的函数。
Probit回归用标准正态分布的累积分布函数Φ(z)来建模y=1 的概率。
令z= β+ β1x,那么Probit回归模型的形式为P(y= 1|x) = Φ(β0+ β1x)其中Φ为标准正态分布的分布函数,z= β0+ β1x是probit模型的“z-value” or “z-index”.例如: 假设β= -2, β1= 3, x=0.4, 那么P(y= 1|x=0.4) = Φ(-2 + 3×0.4) = Φ(-0.8)Pr(z≤ -0.8) = 0.2119该函数的“S-shape”满足了我们的需要:对于β1>0,P(y = 1|x ) 是x 的单增函数010 ≤ P(y = 1|x ) ≤ 1 对于所有的x 都成立02为什么要使用标准正态分布的累积分布函数?便于使用–可以查正态分布表的到相关的概率值(在相关的软件中也很容易得到)相对直观的理解:β0+ β1x = z-value01β1对应于x变化一个单位时z-value 的变化02给定x,β0+β1x是预测的z-value 03. probit deny p_irat, r;Iteration 0: log likelihood = -872.0853Iteration 1: log likelihood = -835.6633Iteration 2: log likelihood = -831.80534Iteration 3: log likelihood = -831.79234Probit estimates Number of obs= 2380Wald chi2(1) = 40.68Prob> chi2 = 0.0000 Log likelihood = -831.79234 Pseudo R2 = 0.0462 ------------------------------------------------------------------------------| Robustdeny | Coef. Std. Err. z P>|z| [95% Conf. Interval] -------------+----------------------------------------------------------------p_irat| 2.967908 .4653114 6.38 0.000 2.055914 3.879901 _cons | -2.194159 .1649721 -13.30 0.000 -2.517499 -1.87082 ----------------------------------------------------------------------------P(deny=1|P Iratio)= Φ(-2.19 + 2.97×P/I ratio)(0.16) (0.47)还款收入比前面的系数是正的: 是否符合实际?01标准差的理解和普通的回归一样02 P(deny=1| P Iratio)= Φ(-2.19 + 2.97×P/I ratio )(0.16) (0.47)STATA Example: HMDA data 当P/I ratio 从0.3 增加到0.4:04 P(deny=1| P Iratio =0.4)= Φ (-2.19+2.97×0.4) = Φ (-1.00) =0.159被拒概率的预测值从0.097 升至0.15905概率预测值:03 P(deny=1| P Iratio =0.3)= Φ (-2.19+2.97×0.3) = Φ (-1.30) = 0.097多个自变量的Probit回归模型Pr(Y= 1|X1, X2) = Φ (β0+ β1X1+ β2X2)Φ 是正态分布的累积分布函数.01z= β0+ β1X1+ β2X2是此probit模型的“z-value”或者“z-index”.02β1是固定X2,X1变化一个单位对z-score 的效应。
logit 和probit模型的系数解释

logit 和probit模型的系数解释Logit和Probit模型是通常在二分类问题中使用的统计模型,这些模型的系数表示了解释变量对于被解释变量的影响程度。
在本文中,我将解释Logit和Probit模型的系数含义,并探讨它们在实际应用中的解释。
首先,我们先来了解一下Logit和Probit模型。
这两种模型都属于广义线性模型(Generalized Linear Models,简称GLM),使用类似的数学形式来描述被解释变量与解释变量之间的关系。
对于一个二分类问题,我们希望找到一个函数f(x)来预测被解释变量y=1的概率P(y=1|x),其中x表示解释变量。
Logit模型将被解释变量与解释变量的关系建模为一个logistic函数,它的数学形式是:P(y=1|x) = 1 / (1 + exp(-z))其中,z = β0 + β1*x1 + β2*x2 + ... + βn*xn表示线性预测器,β0,β1,...,βn表示系数。
这些系数可以表示是模型的"回归系数",它们衡量了解释变量在对被解释变量的影响程度上的贡献。
Logit模型中的系数解释是基于"对数几率比"(log odds ratio)的改变来描述的。
具体来说,系数β1的解释是:当其他解释变量保持不变时,若解释变量x1的值增加一个单位,则被解释变量y=1的对数几率(即log odds)将增加β1个单位。
换句话说,系数β1表示了解释变量x1对于预测y=1的概率的影响程度。
如果β1是正的,表示x1的增加会增加预测y=1的概率,而如果β1是负的,则表示x1的增加会减少预测y=1的概率。
Probit模型的数学表达形式与Logit模型略有不同,它使用了标准正态分布的累积分布函数(CDF)来建模被解释变量与解释变量之间的关系:P(y=1|x) = Φ(z)其中,Φ(z)表示标准正态分布的累积分布函数,z的计算方式与Logit模型相同。
probit模型 时间虚拟变量

probit模型时间虚拟变量
probit模型是一种用于建模二分类变量的统计模型。
在probit
模型中,通过引入时间虚拟变量来探究时间对被解释变量的影响。
时
间虚拟变量用于表示观测数据所处的时间段或时间点,并在模型中作
为解释变量。
这样可以对不同时间段或时间点的影响进行比较,并得
出时间对被解释变量的效应。
以一个研究消费者购买行为的probit模型为例,假设我们想探
究广告投放时段对消费者购买产品的影响。
我们可以引入时间虚拟变量,将时间分为若干个时段,比如早晨、上午、下午和晚上,并为每
个时段创建一个对应的虚拟变量,如早晨虚拟变量、上午虚拟变量等。
然后,我们可以将这些时间虚拟变量加入到probit模型中,并
估计每个时间虚拟变量对购买行为的效应。
通过比较不同时间段之间
的效应差异,可以得出时间对购买行为的影响程度。
需要注意的是,为了避免多重共线性,通常会将一个时间虚拟变
量设置为基准组,即将其效应设为0,然后通过比较其他时间虚拟变量的效应与基准组的效应来观察时间的影响。
总而言之,probit模型可以通过引入时间虚拟变量来研究时间对二分类变量的影响。
通过比较不同时间段的效应,可以更好地理解时
间对被解释变量的作用。
logit 和probit模型的系数解释 -回复

logit 和probit模型的系数解释-回复【logit 和probit 模型的系数解释】1. 引言在统计学和经济学中,logit模型和probit模型是两种常见的二元选择模型,它们被广泛应用于解释和预测离散选择的行为。
本文将详细介绍logit 和probit模型的系数解释步骤,并对其应用领域和优缺点进行讨论。
2. 模型背景logit模型和probit模型是建立在二元选择数据上的概率模型。
在这两种模型中,我们假设个体i选择某个选项的概率是一个关于自变量X的非线性函数F(X)的模型,其中F(X)是一个累积分布函数(CDF)。
logit模型和probit模型是两种常见的CDF函数选择,分别使用逻辑函数(logistic function)和正态分布函数(normal distribution function)进行建模。
3. logit模型的系数解释logit模型的系数解释可以通过观察变量系数的大小、正负以及显著性水平来进行。
首先,系数的大小可以表示预测变量在选择行为中的影响程度。
一个正的系数表示该变量与选择行为正相关,即该变量的增加会增加选择某个选项的概率。
一个负的系数表示该变量与选择行为负相关,即该变量的增加会降低选择某个选项的概率。
其次,系数的正负可以表明变量对选择行为的方向性影响。
最后,统计显著性测试可以帮助我们确定该系数是否显著不等于零,即该变量对选择行为的影响是否存在。
4. probit模型的系数解释probit模型的系数解释与logit模型类似。
同样,我们可以通过观察变量系数的大小、正负以及显著性水平来解释系数。
不同的是,probit模型中的系数解释基于正态分布函数的特性。
具体而言,一个正的系数表示该变量的增加会使选择某个选项的概率上升,并且该上升符合正态分布函数的曲线形状。
一个负的系数则说明选择行为概率会下降。
同样,系数的正负可以揭示变量对选择行为的方向性影响。
最后,显著性测试也可以用来确认系数的显著性。
probit logit 解析表达式

probit logit 解析表达式(最新版)目录1.介绍 Probit 和 Logit 模型2.解析 Probit 和 Logit 模型的表达式3.比较 Probit 和 Logit 模型的异同正文Probit 和 Logit 模型是两种常用的概率回归模型,常用于处理二元变量的预测问题。
在这两种模型中,我们都需要解析它们的表达式,以便更好地理解模型的预测机制。
首先,我们来看 Probit 模型。
Probit 模型是一种用于二元响应变量预测的线性模型。
它的表达式可以解析为:Probit(Y=1|X=x) = Φ(β0 + β1X1 + β2X2 +...+ βnXn)其中,Y 代表二元响应变量,X 代表自变量,β0、β1、β2 等为模型参数,Φ为标准正态分布函数的逆函数。
接着,我们看 Logit 模型。
Logit 模型也是一种用于二元响应变量预测的线性模型。
它的表达式可以解析为:Logit(Y=1|X=x) = ln(π1 / π0) = β0 + β1X1 + β2X2 +...+ βnXn其中,Y 代表二元响应变量,X 代表自变量,β0、β1、β2 等为模型参数,π0 和π1 分别为两个类别的概率。
通过比较 Probit 和 Logit 模型的表达式,我们可以发现两者的主要区别在于概率计算的方式。
Probit 模型使用的是标准正态分布函数的逆函数,而 Logit 模型则使用的是对数函数。
此外,Probit 模型的截距项为β0,而 Logit 模型的截距项为 ln(π1 / π0)。
总的来说,Probit 和 Logit 模型都是用于解决二元变量预测问题的有效工具。
比较线性模型和Probit模型、Logit模型
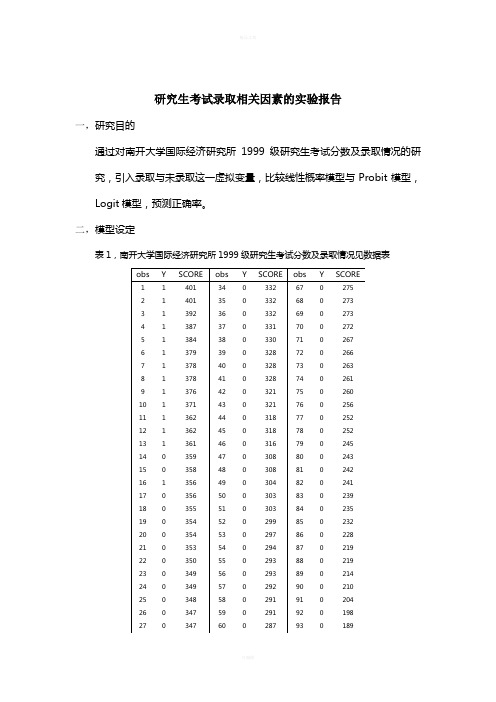
研究生考试录取相关因素的实验报告一,研究目的通过对南开大学国际经济研究所1999级研究生考试分数及录取情况的研究,引入录取与未录取这一虚拟变量,比较线性概率模型与Probit模型,Logit模型,预测正确率。
二,模型设定表1,南开大学国际经济研究所1999级研究生考试分数及录取情况见数据表定义变量SCORE :考生考试分数;Y :考生录取为1,未录取为0。
上图为样本观测值。
1. 线性概率模型 根据上面资料建立模型i i i SCORE B B Y μ++=*21用Eviews 得到回归结果如图:Dependent Variable: Y Method: Least Squares Date: 12/10/10 Time: 20:38Sample: 1 97Included observations: 97VariableCoefficientStd. Error t-Statistic Prob.C -0.847407 0.159663 -5.307476 0.0000 SCORE0.0032970.0005216.3259700.0000R-squared0.296390 Mean dependent var 0.144330 Adjusted R-squared 0.288983 S.D. dependent var 0.353250 S.E. of regression 0.297866 Akaike info criterion 0.436060 Sum squared resid 8.428818 Schwarz criterion 0.489147 Log likelihood -19.14890 F-statistic 40.01790 Durbin-Watson stat0.359992 Prob(F-statistic) 0.000000参数估计结果为: iY ˆ-0.847407+0.003297 i SCORESe=(0.159663)( 0.000521) t=(-5.307476) (6.325970) p=(0.0000) (0.0000)预测正确率:Forecast: YF Actual: YForecast sample: 1 97Included observations: 97Root Mean Squared Error0.294780Mean Absolute Error 0.233437Mean Absolute Percentage Error8.689503Theil Inequality Coefficient 0.475786Bias Proportion 0.000000Variance Proportion 0.294987Covariance Proportion 0.7050132.Logit模型Dependent Variable: YMethod: ML - Binary Logit (Quadratic hill climbing) Date: 12/10/10 Time: 21:38Sample: 1 97Included observations: 97Convergence achieved after 11 iterations Covariance matrix computed using second derivativesVariable Coefficient Std. Error z-Statistic Prob.C-243.7362125.5564-1.9412480.0522SCORE0.679441 0.350492 1.938536 0.0526Mean dependent var 0.144330 S.D. dependent var 0.353250 S.E. of regression 0.115440 Akaike info criterion 0.123553 Sum squared resid 1.266017 Schwarz criterion 0.176640 Log likelihood -3.992330 Hannan-Quinn criter. 0.145019 Restr. log likelihood -40.03639 Avg. log likelihood -0.041158 LR statistic (1 df) 72.08812 McFadden R-squared 0.900282Probability(LR stat) 0.000000Obs with Dep=0 83 Total obs 97Obs with Dep=114得Logit 模型估计结果如下p i = F (y i ) =)6794.07362.243(11i x e +--+ 拐点坐标 (358.7, 0.5)其中Y=-243.7362+0.6794X预测正确率Forecast: YF Actual: YForecast sample: 1 97 Included observations: 97Root Mean Squared Error 0.114244 Mean Absolute Error0.025502Mean Absolute Percentage Error 1.275122Theil Inequality Coefficient 0.153748Bias Proportion 0.000000Variance Proportion 0.025338Covariance Proportion 0.9746623.Probit模型Dependent Variable: YMethod: ML - Binary Probit (Quadratic hill climbing) Date: 12/10/10 Time: 21:40Sample: 1 97Included observations: 97Convergence achieved after 11 iterations Covariance matrix computed using second derivativesVariable Coefficient Std. Error z-Statistic Prob.C-144.456070.19809-2.0578330.0396SCORE0.4028680.196186 2.0535040.0400 Mean dependent var0.144330 S.D. dependent var0.353250 S.E. of regression0.116277 Akaike info criterion0.122406 Sum squared resid 1.284441 Schwarz criterion0.175493Log likelihood-3.936702 Hannan-Quinn criter.0.143872 Restr. log likelihood-40.03639 Avg. log likelihood-0.040585LR statistic (1 df)72.19938 McFadden R-squared0.901672 Probability(LR stat)0.000000Obs with Dep=083 Total obs97Obs with Dep=114Probit模型最终估计结果是p i = F(y i) = F (-144.456 + 0.4029 x i) 拐点坐标(358.5, 0.5)预测正确率Forecast: YFActual: YForecast sample: 1 97Included observations: 97Root Mean Squared Error0.115072Mean Absolute Error 0.025387Mean Absolute Percentage Error 1.216791Theil Inequality Coefficient 0.154476Bias Proportion 0.000084Variance Proportion 0.020837Covariance Proportion 0.979080预测正确率结论:线性概率模型RMSE=0.294780 MAE=0.233437 MAPE=8.689503Logit模型RMSE=0.114244 MAE=0.025502 MAPE=1.275122Probit模型RMSE=0.115072 MAE=0.025387 MAPE=1.216791由上面结果可知线性概率模型的RMSE、MAE、MAPE 均远远大于Logit模型和Probit模型,说明其误差率比Logit模型和Probit模型大很多,所以正确率远远小于Logit模型和Probit模型。
计量经济学(probit,logit,异方差问题)

• 联合概率:
n
f ( yi , xi , )
i 1
• 那样的参数beta是合理的?最大化上面这个 联合概率的。
. #;
• 最大化联合概率实际上就是最大化它的对 数(增函数)
n
L [ yi log G( Xi ) (1 yi ) log(1 G( Xi ))] i 1
. #;
系数估计值的含义
• 但logit和probit不是。
• 应该这样比:
n
n
LPM [n1 glogit ( XB)] [n1 g probit ( XB)]
i 1
log it
i 1
probit
• 对probit来说,g(0)=0.4,对logit来说, g(0)=0.25。
0.4 * probit 0.25* logit
var(u | x1, x2...xk ) E(u2 ) 2
. #;
• 看下面的思路
– 估计原模型,得到残差平方和 uˆi2
– 作下面的回归:
uˆi2 0 1x1 2 x2 ...k xk vi
– 去检验这个回归的系数是不是显著?
1 0,2 0,...,k 0
– 现在再使用普通的F检验或者LM检验。
. #;
异方差问题
• (一)异方差的定义 • (二)异方差的影响 • (三)如何在异方差下求OLS估计值的方
差 • (四)如何检验异方差 • (五)如何估计系数?
– 知道h(x) – 不知道h(x)
. #r(u | x1, x2...xk ) 2
同方差假定意味着条件于解释变量,不可观测误差的方差为常数
rˆ
2 ij
uˆ
2 i
S
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
原始模型:
YX (5.8)
• 其中Y为观测值取1和0的虚拟被解释变量,X为 解释变量。
• 模型的样本形式: yi Xii
(5.9)
• 因为E(i)0
,E所(y以i)Xi
• 令: p i P ( y i 1 ) 1 p i P ( y i 0 )
• 于是有: E ( y i) 1 P ( y i 1 ) 0 P ( y i 0 ) p i
其它季度
1, 三季度
D3
0,
其它季度
• 小心“虚拟变量陷阱”!
精品课件
三、虚拟变量的应用
• 1、在常数项引入虚拟变量,改变截距。
y i0D 1 x 1 i kx k iu i (5.1)
• 对上式作OLS,得到参数估计值和回归模型:
y ˆiˆ0ˆD ˆ1 x 1 i ˆkx ki(5.2)
金融计量经济第五讲
虚拟变量模型和Probit、Logit模 型
精品课件
第一节 虚拟变量的一般应用
一、虚拟变量及其作用 1.定义:取值为0和1的人工变量,表示非量化
(定性)因素对模型的影响,一般用符号D表 示。例如:政策因素、地区因素、心理因素、 季节因素等。 2.作用: ⑴描述和测量定性因素的影响; ⑵正确反映经济变量之间的相互关系,提高模型 的精度; ⑶便于处理异常数据。
yˆt ˆ ˆxt yˆt ˆ ˆxt ˆ2 yˆt ˆ ˆxt ˆ3 yˆt ˆ ˆxt ˆ4
精品课件
一季度 二季度 三季度 四季度
例题:美国制造业的利润—销售额行为
• 模型:利 t 1 润 2 D 2 t 3 D 3 t 4 D 4 t ( 销 ) t u t售
0.503543 0.500354 1.13E+03 1.99E+09 -13241.74 1.648066
Mean dependent var S.D. dependent var Akaike info criterion Schwarz criterion F-statistic Prob(F-statistic)
• 利用1965—1970年六年的季度数据,得结果:
利 t 6 润 6 .3 8 1 88 3 .8D 2 2 9 t 2 2.8 1 D 3 t 7 1.8 8D 4 6 3 t 0 .03 (销 8 )t 3 售 (3.9 (2 ) .0(7 -0 ) .(4 04 .2 5 (8 3 )).33
为不受政策影响、受政策影响和未来有影响三组,
发现股息税削减政策对第二、三组都有显著影响, 且政策出台前二天的股价涨幅较大。 • 说明什么问题? • 政策效应?! • 内幕消息?…
• (用虚拟变量表示时间窗口,同样可以分析事件效应,比 传统的事件分析法要简便。)
• * 2006年10月28-29日南京财大会议论文。
精品课件
例子:佣金与销售额的关系:
• 模型:
Yi 11xi 2(xi x*)Di ui
其中 :Yi是销售佣 ,Xi是 金销售 ,X额 *是销售额基 . 数值 若Xi X*,则Di 1
• 样本回归函数:
Yˆi
ˆ1 ˆ1xi ˆ1ˆ2x*(ˆ1ˆ2)xi
xi x* xi x*
精品课件
附录:Chow检验(邹氏检验)
• (5.2)相当于两个回归模型:
y ˆi ˆ0ˆˆ1x1i ˆkxk i D1 y ˆi ˆ0ˆ1x1i ˆkxk i D0
精品课件
精品课件
• 2、在斜率处引入虚拟变量,改变斜率。
y i0 (D 1 )x 1 i k x k iu i (5.3)
• 作OLS后得到参数估计值,回归模型为:
精品课件
Байду номын сангаас 精品课件
• 3、虚拟变量用于季节性因素分析。
•取
1, 当样本 i季为 度第 的数据 Di 0,其它季度的, i数 2,3据 ,4
• 原模型若为 yt xt ut
• 则引入虚拟变量后的模型为:
y tx t2 D 2 t3 D 3 t4 D 4 t u t (5.6)
• 回归模型可视为:
• 问题1:对于商业银行,企业贷款可能出现 违约,也就是说一家企业贷款后有违约和 不违约两种可能,如何甄别?(李萌, 2005)
• 问题2:证券投资者在特定时期内的投资选 择是买或不买,如何确定这样的选择? (王冀宁等,2003)
• 问题3:上市公司出现经营问题,可能成为 ST、PT,是什么原因导致这样的结果?
量为: 1,
D 0,
t T0 tT 0
• b. 用虚拟变量表示某个特殊时期的影响;
1, D0,
tT1,T2 tT1,T2
• 模型中虚拟变量可放在截距项或斜率处。
精品课件
• 5、分阶段计酬问题。
• 若工作报酬与业务量挂钩,且不同业务量提成比例 不一样(递增),设S1、S2为二个指标临界点
•
D 1 1 0 ,,S S 1 S S 1, S S 2S 2, D 2 1 0 ,, S S S S 2 2
CoefficientStd. Error t-Statistic Prob.
C
3675.349
182.2314
20.16858
0
X1(交易月份)
180.8932
16.8167
10.75675
0
X2(房屋建成年数)
-80.66075
5.523621
-14.60287
0
X3(房屋面积)
3.025509
• Chow检验有二个内容,断点检验和预测检 验。和虚拟变量模型作用有相近之处的是 断点检验(Chow Breakpoint Test)。
• 步骤:在回归分析结果窗口,点 View\Stabiliti Test\Chow Breakpoint Test
• 注:邹氏应是邹至庄。
精品课件
例1:储蓄余额与国民收入的关系
精品课件
例3:应用虚拟变量分析股市的“日 历效应”
• 周内效应 • 周末效应 • 日内效应 • 节日效应
精品课件
离散选择模型(discrete choice models)
• 以虚拟变量为被解释变量的模型被称之为离散选
择模型。
• 离散选择模型除了应用于主要的交通需求问题之
外, 教育及职业的选择、消费者商品的需求, 以
y ˆiˆ0 (ˆD ˆ1 )x 1 i ˆkx ki(5.4)
• 同样可以写成二个模型:
y ˆi ˆ0(ˆˆ1)x1i ˆkxki D1
y ˆi ˆ0ˆ1x1i ˆkxki
D0
• 可考虑同时在截距和斜率引入虚拟变量:
y i 0 0 D i (1 D i 1 ) x 1 i k x k iu i (5.
• CXYE = -1878.817965 + 5.965038605*GMSR + 812.1046287*D1
• 1952—1977: • CXYE = -1066.71 + 5.965*GMSR • 1978—1990: • CXYE = -1878.82 + 5.965*GMSR
精品课件
精品课件
GMSR
虚拟变量用于斜率
• CXYE = -1217.425 + 5.209*GMSR + 1.13*(D1*GMSR)
• 1952—1977: • CXYE = -1217.425 + 6.339*GMSR • 1978—1990: • CXYE = -1217.425 + 5.209*GMSR
后各二天。
• 模型:
R i ti i R M 1 i D 1 t 2 i D 2 3 i D 3 4 i D 4 5 i D 5 u i
• 其中: 表示第i个股票的日收益率, 表示上证A
股指数的R i 日收益率。D1-D5分别是时间RM窗口的虚拟变量。
精品课件
• 复旦大学经济学院的研究生张立早*将普通股分
17.98328
0
D5(城西文教区=1)
2281.312
151.0731
15.10072
0
D6(南岸滨江区块=1)
1870.629
130.4886
14.33557
0
DZ(没有所得税政策=1)
-220.4318
112.711
-1.955726 0.0507
R-squared Adjusted R-squared S.E. of regression Sum squared resid Log likelihood Durbin-Watson stat
• 工资模型为:
• Ii01 [S 1 (1 D 1 i D 2 i)S ( i S 1 )] 2 [D 2 i(S 2 S 1 ) D 1 i(S i S 1 ) ]3 D 2 i(S i S 2 ) u i (5.7
精品课件
D2=1
S0
D1=1
S1
S2
精品课件
• 作OLS得到参数估计值后,三个阶段的报 酬回归模型为: Iˆi ˆ0ˆ1Si, Si S1 Iˆi ˆ0ˆ1S1ˆ2(Si S1), S2Si S1 Iˆi ˆ0ˆ1S1ˆ2(S2S1)ˆ3(Si S2), Si S2
6563.76 1597.98
16.904 16.9416 157.922
0
精品课件
应用例题2:股息税削减对股价的影响
• 背景资料—2005年6月14日,财政部、税务总局发文,
规定对个人投资者从上市公司取得的股息红利所得,暂
减按50%计入个应纳税所得额(红利税从20%降为10%)。
• 利用事件分析法分析该政策对股价有无显著影响,即政 策出台前后股票有无异常收益。时间窗口为发布日及前