数据分析1
数据分析教案1

数据分析教案1标题:数据分析教案1引言概述:数据分析在当今社会已经成为一项重要的技能,无论是在商业领域还是学术领域,数据分析都扮演着至关重要的角色。
因此,学习数据分析成为许多人的必备技能之一。
本文将介绍一份数据分析教案,帮助读者系统学习数据分析的基础知识和技能。
一、数据分析概述1.1 数据分析的定义:数据分析是指通过收集、处理、分析和解释数据,以揭示其中的模式、趋势和关联性,从而为决策提供支持的过程。
1.2 数据分析的重要性:数据分析可以帮助人们更好地理解现象背后的规律,指导决策和行动,提高工作效率和决策的准确性。
1.3 数据分析的应用领域:数据分析广泛应用于市场营销、金融、医疗、教育等领域,帮助企业和组织更好地了解市场需求、优化运营和提升服务质量。
二、数据分析的基础知识2.1 数据类型:数据分析中常见的数据类型包括数值型数据、分类数据和顺序数据,不同类型的数据需要采用不同的分析方法。
2.2 数据采集:数据采集是数据分析的第一步,可以通过问卷调查、实验观察、网络爬虫等方式获取数据。
2.3 数据清洗:数据清洗是数据分析的关键步骤,包括处理缺失值、异常值、重复值等,确保数据的准确性和完整性。
三、数据分析的工具和技能3.1 数据可视化工具:数据可视化是数据分析中常用的方法,可以通过图表、图形等形式将数据呈现出来,帮助人们更直观地理解数据。
3.2 统计分析技能:统计分析是数据分析的基础,包括描述统计、推断统计等方法,可以帮助人们从数据中提取有用信息。
3.3 编程技能:数据分析中常用的编程语言包括Python、R等,具备一定的编程技能可以帮助人们更高效地处理和分析数据。
四、数据分析的方法和模型4.1 描述性统计分析:描述性统计是对数据进行整体性描述和总结的方法,包括均值、中位数、标准差等指标。
4.2 预测性分析:预测性分析是通过历史数据和模型预测未来趋势和结果的方法,包括回归分析、时间序列分析等。
4.3 关联性分析:关联性分析是研究不同变量之间的关联性和影响程度的方法,包括相关系数、卡方检验等。
数据分析教案1

数据分析教案1【数据分析教案1】教案名称:引言:数据分析的重要性与应用领域教学目标:1. 理解数据分析的定义、原理和重要性;2. 掌握数据分析在不同领域的应用案例;3. 培养学生对数据分析的兴趣和实践能力。
教学内容:一、引言1. 数据分析的定义和概念数据分析是指通过收集、整理、加工和解释数据,从中获取有价值的信息和知识的过程。
它是一种基于统计学、数学和计算机科学的跨学科研究领域。
2. 数据分析的重要性数据分析在各个领域都扮演着重要的角色。
它可以帮助企业做出战略决策、提高效率和竞争力;在科学研究中,数据分析可以揭示隐藏的规律和趋势;在医疗领域,数据分析可以辅助诊断和治疗决策等。
二、数据分析的应用案例1. 商业领域案例:某电商平台通过数据分析,发现用户在购买商品时更倾向于选择具有高评分和好口碑的产品。
基于这一发现,平台调整了推荐算法,提高了用户购买率和用户满意度。
2. 科学研究领域案例:天文学家通过对大量观测数据的分析,发现了一颗新的恒星。
这一发现对于研究恒星演化和宇宙起源具有重要意义。
3. 医疗领域案例:医院通过对大量患者的病历数据进行分析,发现了某种疾病的潜在风险因素。
这一发现有助于提前预防和干预,减少患者的发病风险。
4. 社交媒体领域案例:某社交媒体平台通过对用户数据的分析,发现了用户之间的兴趣相似性。
基于这一发现,平台推出了更精准的个性化推荐功能,提高了用户的参与度和留存率。
三、教学方法与学习活动1. 教学方法通过讲解、案例分析和小组讨论等多种教学方法,激发学生的学习兴趣和思维能力。
2. 学习活动a) 学生自主阅读相关文献和案例,进行知识积累;b) 分组讨论,分享自己对数据分析的理解和应用案例;c) 小组展示和讨论,加深对数据分析的理解和应用。
四、教学评估1. 课堂练习:设计一道与数据分析相关的问题,让学生运用所学知识进行解答。
2. 作业:要求学生撰写一篇关于数据分析在自己感兴趣领域的应用案例分析报告。
超市销售数据分析五大方面(一)

超市销售数据分析五大方面(一)引言概述超市销售数据分析是指通过对超市各类商品的销售数据进行收集、整理和分析,以获取对超市运营和销售策略的深入洞察。
本文将从五个方面对超市销售数据进行分析,包括销售趋势分析、商品类别分析、地区销售分析、顾客行为分析和促销效果分析。
通过这些分析,可以帮助超市理解市场需求、优化产品组合、改进运营策略,从而提高销售业绩和顾客满意度。
正文内容一、销售趋势分析1. 分析销售数据的时间性,如按季度、月份或周几的销售额和销售量。
2. 探索销售数据的年度趋势,分析经济周期对销售的影响。
3. 比较不同产品类别的销售增长率,判断市场需求的变化趋势。
4. 分析不同价格段产品的销售情况,找出价格敏感度和消费者品牌偏好。
5. 研究销售额和促销活动之间的关系,评估促销对销售的影响。
二、商品类别分析1. 统计各类商品的销售额和销售量占比,评估各类商品的市场份额。
2. 对比商品类别的销售增长率,发现销售潜力和热门商品。
3. 探究不同商品类别的价格弹性,分析价格调整对销售的影响。
4. 研究商品的季节性销售变化,调整库存和采购策略。
5. 根据商品类别的销售数据,进行促销策略的制定和优化。
三、地区销售分析1. 筛选出具体地区或门店的销售数据,对比不同地区的销售表现。
2. 分析不同地区的销售增长率,了解市场潜力和竞争状况。
3. 考察地区销售的渠道差异,将销售资源和力量加以优化调配。
4. 挖掘不同地区的消费特征,确定地区销售策略的差异化需求。
5. 针对不同地区的销售数据,进行地域性促销活动的制定和执行。
四、顾客行为分析1. 通过购物篮分析,挖掘顾客的购买关联性和消费习惯。
2. 分析顾客购买的时间分布,制定定向性促销活动。
3. 研究不同范围和频次的折扣策略对顾客购买行为的影响。
4. 通过顾客满意度调查,了解顾客对产品和服务的评价和期望。
5. 基于顾客行为分析结果,制定个性化的市场营销策略。
五、促销效果分析1. 收集和分析促销活动的销售数据,评估促销活动的效果。
服装销售数据分析(一)

服装销售数据分析(一)引言概述:服装销售数据分析是一项重要的任务,可以帮助企业了解市场趋势、顾客需求和销售效益。
通过分析销售数据,企业可以制定有效的营销策略,提高销售额和市场竞争力。
本文将从市场规模、顾客画像、热销款式、销售渠道、销售地区等五个大点来进行分析和讨论。
正文:1. 市场规模- 统计过去几年的服装市场销售额,分析销售额的增长趋势。
- 对不同市场细分进行销售数据比较,找出市场份额占比较高的细分市场。
- 分析不同季节对销售额的影响,确定产品季节性需求。
2. 顾客画像- 通过购买记录和客户调研,了解目标顾客的年龄、性别、职业等基本信息。
- 分析不同顾客群体的购买偏好和消费能力,细分目标顾客群体。
- 根据顾客画像进行产品定位和市场定位,满足目标顾客的需求。
3. 热销款式- 分析销售数据,找出热销款式和畅销产品,了解顾客购买偏好。
- 对热销款式进行细分,如男装、女装、童装等,分析各个分类的销售情况。
- 结合时尚趋势和流行元素,预测未来热销款式,为产品设计和采购提供参考。
4. 销售渠道- 了解和分析不同销售渠道的销售额和销售比例,确定主要渠道。
- 分析线上和线下销售渠道的增长趋势,制定线上线下销售平衡策略。
- 研究销售渠道的转化率和客单价等指标,优化销售流程和渠道选择。
5. 销售地区- 利用销售数据,分析不同地区的销售情况,找出销售额高和增长潜力大的地区。
- 考虑地区因素,如气候、文化和消费习惯等,制定地区销售策略和产品调整方案。
- 监测竞争对手在各个销售地区的表现,寻找市场空白和发展机会。
总结:通过服装销售数据分析,企业可以深入了解市场、顾客和产品,并基于数据制定相关策略来提升销售额和市场竞争力。
这些分析包括市场规模、顾客画像、热销款式、销售渠道和销售地区等五个大点,每个大点下面还有多个小点详细阐述。
不断进行数据分析和调整,企业可以更好地把握市场趋势,提高销售效益,实现可持续发展。
数据分析处理 (1)

R (rij ) p p
rij
sij sii s jj
1 n sij ( xai xi )( xaj x j ) n a1
Fi ai1 X 1 ai 2 X 2 aip X p i 1 p
3、求R的特征根及相应的单位特征向量a1,a2,.....ap 4、写出主成分
d 2 ij ( M ) ( X i X j ) 1 ( X i X j )
其中,Xi 为样品的p 个指标组成的向量。
协方差 阵的逆 矩阵
协方差阵定义如下:
(
ij
) p q
1 n 1 n xi xai , x j xaj n a 1 n a 1
1 n ij ( xai xi )( xaj x j ),i, j 1 p, q n 1 a1
例 中国大陆35个大城市某年的10项社会经济统计 指标指标做主成分分析数据见下表。
相关系数矩阵: std = 1.0000 -0.3444 -0.3444 1.0000 0.8425 -0.4750 0.3603 0.3096 0.7390 -0.3539 0.6215 0.1971 0.4039 0.3571 0.4967 0.2600 0.6761 0.1570 0.4689 0.3090 0.8425 0.3603 0.7390 0.6215 0.4039 0.4967 0.6761 0.4689 -0.4750 0.3096 -0.3539 0.1971 0.3571 0.2600 0.1570 0.3090 1.0000 0.3358 0.5891 0.5056 0.3236 0.4456 0.5575 0.3742 0.3358 1.0000 0.1507 0.7664 0.9412 0.8480 0.7320 0.8614 0.5891 0.1507 1.0000 0.4294 0.1971 0.3182 0.3893 0.2595 0.5056 0.7664 0.4294 1.0000 0.8316 0.8966 0.9302 0.9027 0.3236 0.9412 0.1971 0.8316 1.0000 0.9233 0.8376 0.9527 0.4456 0.8480 0.3182 0.8966 0.9233 1.0000 0.9201 0.9731 0.5575 0.7320 0.3893 0.9302 0.8376 0.9201 1.0000 0.9396 0.3742 0.8614 0.2595 0.9027 0.9527 0.9731 0.9396 1.0000
电商数据分析案例(一)

电商数据分析案例(一)引言概述:
电商数据分析在现代商业环境中扮演着重要的角色。
通过对电商平台上的大量数据进行分析,企业可以深入了解消费者行为、市场趋势以及竞争对手情况,从而优化经营策略、提升销售效益。
本文将以一个具体的电商数据分析案例为例,介绍电商数据分析的流程和方法,并详细阐述涉及的五个主要方面。
正文:
1. 数据采集和清洗
- 确定需要分析的数据类型和指标
- 获取电商平台上的数据并进行清洗,去除异常值和重复数据
- 将数据转化为可读取和分析的格式
2. 用户行为分析
- 分析用户的浏览、搜索和购买行为
- 确定用户的消费习惯、偏好和需求
- 利用RFM模型对用户价值进行评估和分类
3. 市场趋势分析
- 分析销售额、销售量和订单数量的变化趋势
- 确定不同产品和类别的销售情况
- 预测未来的市场需求和趋势
4. 竞争对手分析
- 分析竞争对手的产品定价和促销策略
- 比较竞争对手的销售表现和用户评价
- 发现竞争对手的优势和劣势,并制定相应的竞争策略
5. 销售策略优化
- 基于用户行为和市场趋势的分析结果,调整产品定价和促销策略
- 提升用户体验,增加复购和留存率
- 优化供应链和物流,提高配送效率和满意度
总结:
通过本文介绍的电商数据分析案例,可以看出数据分析在电商运营中的重要性。
通过采集、清洗和分析大量的电商数据,企业可以更好地了解用户需求、市场趋势和竞争对手情况,从而优化销售策略并提升经营效果。
电商数据分析将成为未来电商行业中不可或缺的一环。
如何进行数据处理中的空间数据分析(一)

空间数据分析是指在数据处理过程中,对具有地理位置属性的数据进行分析和研究的过程。
随着技术的发展,我们现在能够获取和处理的数据量越来越大,其中很多数据都包含了地理位置信息。
这些地理位置信息的存在,为我们提供了更多的分析和应用的可能性。
本文将讨论如何进行数据处理中的空间数据分析。
一、空间数据的特点和意义空间数据与其他数据相比具有一些独特的特点。
首先,空间数据具有地理位置属性,这使得我们能够将数据与地理信息进行联系和结合,从而获得更全面、更准确的结果。
其次,空间数据通常具有一定的空间自相关性,即附近地区的数据具有一定的相似性。
这个特点使得我们可以通过空间插值方法来填补数据的空缺或缺失值。
最后,空间数据具有一定的空间变异性,即不同地区的数据存在差异性。
这使得我们可以通过空间统计方法来挖掘地理数据中的空间规律和趋势。
对于空间数据分析的意义来说,它不仅可以帮助我们更好地理解和解释地理现象,还可以为环境规划、资源管理、城市规划等领域提供决策支持。
在环境规划中,空间数据分析可以帮助我们了解不同地区的环境质量,从而采取相应的措施进行保护和改善。
在资源管理中,空间数据分析可以指导资源配置和利用,以提高资源利用效率。
在城市规划中,空间数据分析可以帮助我们了解城市的社会经济状况、人口分布等信息,从而为城市的规划和发展提供参考。
二、空间数据分析的方法和技术在进行空间数据分析时,我们可以借助许多方法和技术来获得有关地理数据的更多信息和洞察力。
下面将介绍几种常用的空间数据分析方法和技术。
1. 空间插值空间插值是一种通过已知数据点来推测未知数据点的方法。
在空间数据分析中,空间插值可以用来填充数据的空缺或缺失值。
常用的空间插值方法包括反距离权重插值法、克里金插值法等。
2. 空间统计空间统计是一种通过对地理数据进行统计分析来挖掘地理数据中的空间规律和趋势的方法。
常用的空间统计方法包括点模式分析、聚类分析、地理加权回归等。
3. 空间关联空间关联是一种通过探究地理数据之间的相互关系来预测未来的空间模式的方法。
数据分析-第一章

若样本数据近似于正态分布,在QQ图上这些点近 似地在直线 yx 附近.
茎叶图、箱线图及五数总括
与直方图相比较,茎叶图更能细致地看出数据分 布的结构。 例 某班有31个学生,某门课程的考试成绩如下: 25 45 50 54 55 61 64 68 72 75 75 78 79 81 83 84 84 84 85 86 86 86 87 89 89 89 90 91 91 92 100 做出其茎叶图。
当数据的总体分布为正态分布时,峰 度近似为0;当分布较正态分布的尾部更为 分散时,峰度为正,否则峰度为负。
当峰度为正时,两侧极端数据较多;当 峰度为负时,两侧极端数据较少。
总体的数据特征
设观测数据是由总体X中取出的样本,总体
的分布函数是F( x)。当X为离散分布时,总
体的分布可由概率分布列刻画:
pi P Xxi, i 1,2,.
总体为连续分布时,总体的分布可由 概率密度 f (x)刻画。连续分布中最重要的是 正态分布,它的概率密度 (x) 及分布函数 (x) 分别为
总体的数据特征
(x) 21exp (x22)2
(x) x (t)dt
1.2、数据的分布
数据的数字特征刻画了数据的主要特征,而要对 数据的总体情况作全面的描述,就要研究数据的 分布。对数据分布的主要描述方法是直方图与茎 叶图、数据的理论分布即总体分布。数据分析的 一个重要问题是要研究数据是否来自正态总体, 这是分布的正态性经验的问题。
1.2.1直方图
数据取值范围分成若干区间,区间长度称为组距 ,每个区间上画一矩形,宽度是组距,高度是频 率/组距,每一矩形的面积是数据落入区间的频率 .SAS系统根据样本容量和样本取值范围自动确定 合适的分组方式.PROC CAPABILITY过程可以做 出直方图.
电子商务数据分析的流程(一)

电子商务数据分析的流程(一)引言:电子商务数据分析是一个重要的技术工具,它可以帮助企业理解和掌握电子商务运营的各个方面。
本文将介绍电子商务数据分析的流程,包括数据收集、数据整理、数据清洗、数据分析和数据可视化等五个大点。
正文:一、数据收集1. 确定需要收集的数据类型,如用户行为数据、销售数据、页面访问数据等。
2. 确定数据收集的渠道,如网站统计工具、第三方分析工具等。
3. 配置数据收集工具,包括添加跟踪代码、设置事件触发等。
4. 确保数据收集的准确性和完整性,如检查跟踪代码是否正常、反复验证数据是否准确等。
5. 定期监控数据收集情况,如使用日志分析工具、报警系统等。
二、数据整理1. 将收集到的原始数据进行整理,包括格式的标准化、数据的归类、去重等。
2. 对数据进行标注和注释,以增加数据的可读性和可理解性。
3. 对不完整或缺失的数据进行补充和修复。
4. 将数据划分为不同的维度和指标,以便后续的数据分析。
5. 编写数据整理的文档,包括数据整理的流程、操作方法和结果说明等。
三、数据清洗1. 对数据进行异常值检测和处理,如剔除异常数据、修正错误数据等。
2. 清除重复数据和噪音数据,以减少对后续分析的影响。
3. 处理缺失数据,可以通过填充、插值等方法进行处理。
4. 对数据进行格式转换和规范化,以确保数据的一致性和可比性。
5. 进行合理化和逻辑性检查,通过检查数据之间的关系和一致性来验证数据的有效性。
四、数据分析1. 根据具体的业务问题和需求,选择适当的统计分析方法和模型。
2. 进行数据探索性分析,包括描述性统计、相关性分析等。
3. 进行数据挖掘和预测分析,如聚类、分类、回归等。
4. 进行数据模型的建立和评估,以确定最优的模型。
5. 对分析结果进行解释和总结,提出建议和改进方案。
五、数据可视化1. 利用图表、图形和可视化工具将分析结果展示出来,以便更好地理解和传达。
2. 设计和选择合适的可视化方式,如柱状图、折线图、热力图等。
数据分析实验报告 1

广西大学数据分析实验报告学生姓名:谢丁丁学号:1111100227班级:信科111班完成时间:2014年6月8日实验内容:对数据集advert.sav作回归分析。
这是一个虚拟数据集,目的是研究广告费用和销售量之间的关系。
题意分析:变量之间的关系要么相关、要么不相关。
从学过的知识可知,定量数据的度量方法包括散点图和相关系数。
所以可从这里入手。
实验过程与结果:1、画出散点图:选择菜单“Graph”—散点图……”,出现如下选项卡点击“定义”,出现界面如下,按如下选择:点击确定,即可得所需的散点图。
如下所示:散点图分析:从散点图可看出所画的点大致成一条从左下到右上的直线,由此可初步判断销售量和广告费用成正相关关系。
2、做相关系数分析选择菜单“Analyze”--“Correlate”--“Bivariate”,出现两变量相关分析选项卡。
讲“advert”与“sales”选入Variables列表。
选择相关系数,点击OK,过程和结果如下所示:Person相关系数:相关性Detrended sales Advertising spendingDetrended sales Pearson 相关性 1 .916**显著性(双侧).000N 24 24 Advertising spending Pearson 相关性.916** 1显著性(双侧).000N 24 24 **. 在.01 水平(双侧)上显著相关。
图1Kendall相关系数与Spearman相关系数:相关系数Detrended sales Advertising spendingKendall 的tau_b Detrended sales 相关系数 1.000 .717**Sig.(双侧). .000N 24 24 Advertising spending 相关系数.717** 1.000Sig.(双侧).000 .N 24 24 Spearman 的rho Detrended sales 相关系数 1.000 .889**Sig.(双侧). .000N 24 24 Advertising spending 相关系数.889** 1.000Sig.(双侧).000 .N 24 24 **. 在置信度(双测)为0.01 时,相关性是显著的。
数据分析多选1

数据分析多选11. 客户画像数据是指与客户购买行为相关的,能够反映或影响客户行为的相关信息数据,通常包括()。
*A、客户性别、年龄、地址(正确答案)B、品牌偏好(正确答案)C、购物时间偏好(正确答案)D、商品评价偏好(正确答案)2. 数据分类与处理的作用主要表现为()。
*A、集中、系统地反映客观实际(正确答案)B、确保数据的内容完善和格式统一(正确答案)C、发现规律,实现深度挖掘(正确答案)D、总结客户购物偏好3. 数据逻辑错误包括()。
*A、数据不合理(正确答案)B、数据自相矛盾(正确答案)C、数据不符合规则(正确答案)D、数据格式错误4. 关于时间序列预测法的基本特点,下面描述正确的是() *A、在分析现在、过去、未来的联系时,以及未来的结果与过去、现在的各种因素之间的关系时,效果比较好(正确答案)B、适合预测稳定的、在时间方面稳定延续的过程,适合进行长期预测C、假设事物发展趋势会延伸到未来(正确答案)D、不考虑事物发展之间的因果关系(正确答案)5. 数据采集的方法有()。
*A、数据库采集(正确答案)B、调查问卷采集(正确答案)C、报表采集(正确答案)D、网页数据采集(正确答案)6. 在Excel中,下面关于分类汇总的叙述正确的是() *A、分类汇总前必须按关键字段排序(正确答案)B、进行一次分类汇总时的关键字段只能针对一个字段(正确答案)C、分类汇总可以删除,但删除汇总后排序操作不能撤销(正确答案)D、汇总方式只能是求和7. 电子商务运营体系中,供应链管理涉及多个环节,其中需要重点监控哪些指标()。
*A、采购类指标(正确答案)B、物流类指标(正确答案)C、仓储类指标(正确答案)D、销售类指标8. 下列属于数据采集工具的是() *A、火车采集器(正确答案)B、京东商智(正确答案)C、XMindD、淘数据(正确答案)9. 数据采集的原则有()。
*A、及时性(正确答案)B、有效性(正确答案)C、合法性(正确答案)D、准确性(正确答案)10. 关于数据采集,以下说法正确的是()。
(完整版)数据分析(梅长林)第1章习题答案
第1章 习 题一、习题1。
1解:(1)利用题目中的数据,通过SAS 系统proc univariate 过程计算得到:139.0=x 7.06387S =49.898312=S 0.142众数=51.0g 1-= 08192.5=CV126129.0g 2-=由得到的数据特征可知道,偏度为负,所以呈做偏态,峰度为负,所以均值两侧的极端值较少。
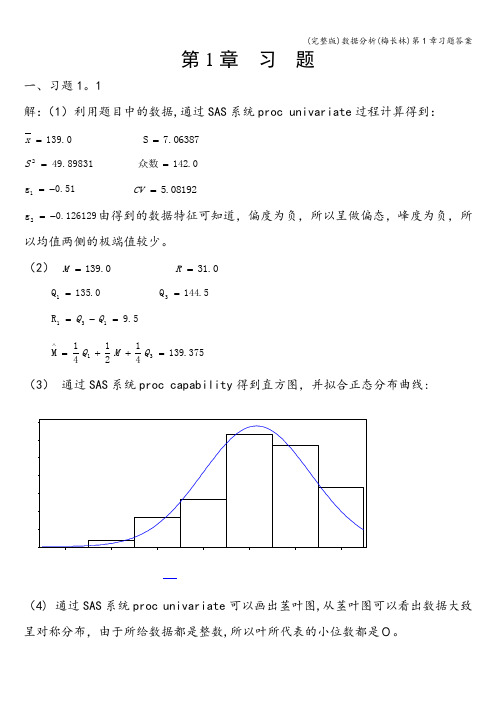
(2) 139.0=M31.0=R0.135Q 1= 5.144Q 3= 5.9R 131=-=Q Q375.139412141M 31=++=∧Q M Q (3) 通过SAS 系统proc capability 得到直方图,并拟合正态分布曲线:(4) 通过SAS 系统proc univariate 可以画出茎叶图,从茎叶图可以看出数据大致呈对称分布,由于所给数据都是整数,所以叶所代表的小位数都是0。
(5) 通过SAS 系统proc univariate 过程计算得到:0.971571W 0=00()H p P W W =≤= 0。
1741取0.05=α,因α>=0.1742p ,故不能拒绝0H ,认为样本来自正态总体分布。
通过画QQ图和经验分布曲线和理论分布函数曲线,从图中可以看出QQ图近似的在一条直线上,经验分布曲线的拟合程度也相当好,所以可以进一步说明此样本来自正态总体分布.Normal Line:Mu=139, Sigma=7.0639x 120125130135140145150155正态分位数-3-2-10123二、习题1.27.8574027=x 1.62568785 S =2.642860982=S0.13721437g 1= 20.6898884=CV -1.4238025g 2=由得到的数据特征可知道,偏度为正,所以呈右偏态,峰度为负,所以均值两侧的极端值较少。
(2)7.636800=M 5.03650=R6.5859 Q 1= 9.3717Q 3= 2.78580R 131=-=Q Q809.7412141M 31=++=∧Q M Q (3)通过SAS 系统proc capability 得到直方图,SAS 系统自动将数据分为中值为4.5,5。
数据分析综合实训报告(1)

数据分析综合实训报告(1)目录数据分析综合实训报告(1) (1)引言 (2)研究背景 (2)研究目的 (3)研究意义 (3)数据分析综合实训的概述 (4)实训内容 (4)实训流程 (5)实训数据来源 (6)数据收集与清洗 (7)数据收集方法 (7)数据清洗步骤 (8)数据清洗工具 (9)数据探索与可视化分析 (10)数据探索方法 (10)数据可视化工具 (11)分析结果与发现 (12)数据建模与预测 (13)数据建模方法 (13)模型选择与评估 (14)预测结果与准确性分析 (14)实训过程中的问题与解决方案 (15)数据收集问题及解决方案 (15)数据清洗问题及解决方案 (17)数据分析问题及解决方案 (18)实训总结与展望 (19)实训成果总结 (19)实训经验分享 (20)实训的不足与改进方向 (20)参考文献 (21)引言研究背景随着信息技术的迅猛发展和互联网的普及,大数据时代已经到来。
在这个时代,海量的数据被不断产生和积累,给我们带来了前所未有的机遇和挑战。
数据分析作为一种重要的技术手段,被广泛应用于各个领域,为决策提供了有力的支持。
数据分析是指通过收集、整理、分析和解释数据,从中发现有价值的信息和规律,以支持决策和解决问题。
它可以帮助我们了解客户需求、市场趋势、产品性能等方面的情况,为企业提供决策依据和战略指导。
同时,数据分析也可以帮助我们发现隐藏在数据背后的规律和趋势,为科学研究和社会发展提供重要的参考。
在当前的社会背景下,数据分析已经成为企业和组织的核心竞争力之一。
通过对大数据的深入挖掘和分析,企业可以更好地了解市场需求,优化产品和服务,提高竞争力。
同时,数据分析也可以帮助企业发现潜在的商机和风险,及时调整战略和决策,降低经营风险。
然而,尽管数据分析在理论和技术上已经取得了很大的进展,但在实践中仍然存在一些挑战和问题。
首先,数据的质量和完整性是数据分析的基础,但由于数据来源的多样性和数据采集的复杂性,数据质量和完整性往往难以保证。
数据分析-第一章-PPT课件

均值 方差
1 n x xi n i 1
1 n 2 S (x x ) i n 1i 1
2
标准差
变异系数
S S
2
S CV100 (%) x
偏度与峰度
偏度与峰度是刻画数据的偏态、尾重程度的度量。它们 与数据的矩有关。数据的矩分为原点矩与中心矩。 k阶原点矩
k E ( x ) 总体中心矩(k阶) k
总G2 4 3
总体数字特征和样本数字特征
根据统计学的结果,样本数字特征是相应的 总体数字特征的矩估计。当总体数字特征存在时 ,相应的样本数字特征是总体数字特征的相合估 计,从而当n较大时,有
1 n k vk xi n i 1
1 k u n ( x x ) k i n i 1
K阶中心矩
s
偏度与峰度
偏度
2 n n u n 3 3 g ( x x ) 1 i 3 3 ( n 1 )( n 2 ) s ( n 1 )( n 2 ) s i 1
2 x 73 . 660 S 15 . 524 S 3 . 940
CV 5 . 349 g 0 . 061 g 0 . 034 1 2
偏度、峰度的绝对值皆较小,可以认为数据是来 自正态总体的样本.
例3
某厂的某种悬式绝缘子机 电破坏负荷试验数据(单 位:吨)分组表示如表, 计算这批分组数据的均值 、方差、标准差、变异系 数、偏度、峰度。 组段 5.5~6.0 6.0~6.5 6.5~7.0 7.0~7.5 7.5~8.0 8.0~8.5 8.5~9.0 9.0~9.5 组中值 5.75 6.25 6.75 7.25 7.75 8.25 8.75 9.25 组频数 4 3 15 42 49 78 50 31
Excel数据分析处理(一)

(4)概率分布分析
概率分布是概率论的基本概念之一,用以表述随机变量取值的概率规律。
二项分布:即重复n次的伯努利试验。在每次试验中只有两种可能的结果
,而且是互相对立的,是独立的,与其它各次试验结果无关,结果事件发 生的概率在整个系列试验中保持不变,则这一系列试验称为伯努力试验。
概率公式: (公式插入函数BINOMDIST)
(公式插入函数HARMEAN) 众数:集合中出现次数最多的数值。 (公式插入函数MODE) 中位数:是指将统计总体当中的各个变量值按大小顺序排列起来,形成一 个数列,处于变量数列中间位置的变量值就称为中位数。当变量值的项数 N为奇数时,处于中间位置的变量值即为中位数;当N为偶数时,中位数 则为处于中间位置的2个变量值的平均数。 (公式插入函数MEDIAN)
建汇总(注意去掉替换当前分类汇总选项)…
(3)显示和隐藏明细数据
点击左边的级别1,2,3…以及利用左侧的+号
3、查找与替换
(1)快速查找
开始编辑查找与选择查找(或者快捷键CTRL+F)
(2)替换
开始编辑查找与选择替换
(3)高级查找与替换
开始编辑查找与选择选择选项(可查找字体、颜色、大小等)
泊松分布:泊松分布适合于描述单位时间(或空间)内随机事件发生的次
数。如某一服务设施在一定时间内到达的人数,电话交换机接到呼叫的次 数,汽车站台的候客人数,机器出现的故障数,自然灾害发生的次数,一 块产品上的缺陷数,显微镜下单位分区内的细菌分布数等等。 概率公式:
(公式插入函数POISSON)
2、文本的输入
一般文本 特殊文本
4、其他的输入
连接符 固定格式输入 等差序列 等比序列 使用数据有效性列表选择数据
数据分析方法(一):对比与对标

数据分析⽅法(⼀):对⽐与对标对⽐是数据分析最基本的⽅法,通过对⽐识别数据差异。
但是对⽐有得失。
在分析过程中,对⽐得当可获得精准结论,但对⽐分析也存在陷阱,⽐如某产品近期销售数据在下滑,想当然得会得出结论此产品受欢迎度在下降,但是查看销售⽐(销售数/DAU)却在上升,所以只是因为DAU下降了。
所以如何去有效对⽐?1、横向、纵向多维度对⽐对⽐的前提是两个事物或统⼀个事物的两个状态,其次必须要有⼀个对⽐的指标或标准(这⾥可称为对⽐的度量)。
对⽐的两事物⼀个是主体,另⼀个是客体。
也就是明确对⽐的三要素:主体、客体和度量。
⽐如⼩明⽐⼩王⾼5cm,就是⼀个最简单的对⽐,这⾥⼩明是主体,⼩王是客体,度量⾝⾼,且⼈们对于⾝⾼这个度量存有共识。
但如果去⼤排档吃⼀碗炒饭50元,可能觉得很贵。
那如果是取希尔顿吃⼀碗炒饭128元可能就不觉得贵,这⾥我们选择了常识作为⽐较的基准,客体也没有问题,问题在于我们所谓的“常识”并⾮所有⼈的“共识”,如果不是共识,就要⾮常谨慎地得出结论,否则就容易从⾃我出发做出判断,影响结论的中肯性。
2、建⽴标准化的对⽐客体和度量就是因为标准可以是认为确定的,所以存在质疑和不确定性。
建⽴标准化的对⽐可以是时间标准、空间标准、特定标准、计划标准。
3、⽐率的对⽐常见的对⽐是⼤⼩的对⽐、数量的对⽐,⽐如销售额的对⽐,⼈数的对⽐,使⽤不同的对⽐指标会得到不同的结论,我们把对⽐标准的选择叫做视⾓,视⾓不同,结论不同。
⽐如上述对⽐⼩明⼩王俩同学,⾝⾼是视⾓事宜,除此之外还有年龄、学习成绩、颜值等等。
在对⽐各种变化的原因时,我们也有各种模型,我们所要做的就是找到合适的对⽐视⾓。
直接描述事物的变量:长度、数量、⾼度、宽度等加⼯后可得到:增速、效率、效益等指标,这才是数据分析时常⽤的。
如下图的AB公司销售额对⽐,虽然A公司销售额总体上涨且⾼于B公司,但是B公司的增速迅猛,⾼于A公司,即使后期增速下降了,最后的销售额还是赶超。
八年级数学下期期末复习专题5(数据的分析 1)

教师姓名学生姓名填写时间学科数学年级八年级教材版本人教版课题名称期末复习专题五(数据的分析1)本人课时统计共()课时上课时间一、选择题(每题3分,共30分)1、已知数据2,3,2,3,5,x的众数是2,则x的值是()A.3 B.2C.2.5D.32、小明五次跳远的成绩(单位:米)是:3.6,3.8,4.2,4.0,3.9,这组数据的中位数是()A.3.9米 B.3.8米 C.4.2米 D.4.0米3、2007年5月份,某市市区一周空气质量报告中某项污染指数的数据是:31 35 31 34 30 32 31,这组数据的中位数、众数分别是()A.32,31 B.31,32 C.31,31 D.32,354、要比较两位同学在五次数学测验中谁的成绩比较稳定,应选用的统计量是()A.平均数B.中位数C.众数D.方差5、筹建中的安徽芜湖核电站芭茅山厂址位于长江南岸繁昌县狄港镇,距离繁昌县县城约17km,距离芜湖市区约35km,距离无为县城约18km,距离巢湖市区约50km,距离铜陵市区约36km,距离合肥市区约99km.以上这组数据17、35、18、50、36、99的中位数为().A.18 B.50 C.35 D.35.56、我市某一周的最高气温统计如下表:最高气温(℃)25 26 27 28天数 1 1 2 3则这组数据的中位数与众数分别是()A.27,28 B.27.5,28 C.28,27 D.26.5,277、某学习小组5位同学参加初中毕业生实验操作考试(满分20分)的平均成绩是16分.其中三位男生的方差为6(分2),两位女生的成绩分别为17分,15分.则这个学习小组5位同学考试分数的标准差为()A.3B.2C.6D.68、某地统计部门公布最近5年国民消费指数增长率分别为8.5%、9.2%、9.9%、10.2%、9.8%,业内人士评论说:“这五年消费指数增长率之间相当平稳”,从统计角度看,“增长率之间相当平稳”说明这组数据( A )比较小A、方差B、平均数C、众数D、中位数9、一家鞋店在一段时间内销售了某种女鞋30双,各种尺码的销售量如下表:尺码/厘米22 22.5 23 23.5 24 24.5 25销售量/双 1 2 5 12 6 3 1如果鞋店要购进100双这种女鞋,那么购进24厘米、24.5厘米和25厘米三种女鞋数量之和最.合适..的是( B ).(A)20双(B)30双(C)50双(D)80双10、甲、乙、丙、丁四位选手各10次射击成绩的平均数都是8环,众数和方差如表,则这四人中水平发挥最稳定的是( B )选手甲I 乙丙丁众数(环) 9 8 8 10方差(环2) 0.035 0.O15 0.025 0.27(A)甲 (B)乙 (C)丙 (D)丁二、填空题:(每小题3分,共30分)11、一组数据35,35,36,36,37,38,38,38,39,40的极差是________。
简单的数据分析(例1)

2、如果他们赛跑,谁跑第一,谁跑最后?
猎豹第一,大象最后。
Hale Waihona Puke 3、你还能提出那些问题?五种动物的最高时速统计图
猫 猎豹 狮子 大象 马
千米/时
A B C D
品种
D C B A
0 5 10 15 20 25 30 35 40 45 50 55数量/箱
品种
纵向条形统计图
横向条形统计图
五种动物的最高时速统计图
猫 猎豹 狮子 大象 马
千米/时 千米/时
鸵鸟每小时 能跑64千米
1、哪几种动物跑得比鸵鸟快?哪几种跑得比它慢?
猎豹、狮子、马 猫、大象
阳光超市上周的销售记录
品牌
数量/箱
A
B 45
C 25
D 10
30
1、你从统计表中知道了哪些信息?
2、你能根据这张统计表绘制一张统计图吗?
2003年6月3~9日矿泉水销售量统计图
数量/箱
2003年6月3~9日矿泉水销售量统计图
数量/箱
数量/箱
55 50 45 40 35 30 25 20 15 10 5 0
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
源程序:
>>
a =
Columns 1 through 19
126 149 143 141 127 123 137 132 135 134 146 142 135 141 150 137 144 137 134
Columns 20 through 38
139 148 144 142 137 147 138 140 132 149 131 139 142 138 145 147 137 135 142
Columns 39 through 57
151 146 129 120 143 145 142 136 147 128 142 132 138 139 147 128 139 146 139
Columns 58 through 60
131 138 149
>>mean(a)
ans =
139
>>median(a)
ans =
139
>>var(a)
ans =
49.8983
>>std(a)
ans =
7.0639
>>skewness(a)
ans =
-0.4972
>> hist(a);title('杨婵201207020226')
>> normplot(a);title('杨婵201207020226')
??? normplot(a);title('杨婵201207020226')
|
Error: The input character is not valid in MATLAB statements or expressions.
>> normplot(a);title('杨婵201207020226')
>> qqplot(a);title('杨婵201207020226')
>>
直方图:
概率分布图:
QQ图:
三均值:
极差:
变异系数:
峰度:
茎叶图:
源程序:function stemleafplot(v,p)
% Plots stem and leaf plot to command window
%
% stemleafplot(v)
% stemleafplot(v,p)
%
% STEMLEAFPLOT plots stem-leaf plots of the input V to the command wi ndow.
% Leaf precision may be defined by the user. Note that inputs will be % rounded to the nearest leaf unit (
/wiki/Stemplot).
%
% INPUT
% V : Array of numerical inputs (NaN values are ignored)
%
% OPTION
% P : Leaf precision (defined as integer power of 10)
% Stem precision (by default) is 10^(P+1).
% P is automatically rounded at the beginning of the function. % Leaf and stem units are printed at the bottom of the graph. % Examples: P = -3 rounds V to the nearest 10^-3 = 0.001
% P = 3 rounds V to the nearest 10^3 = 1000
% [DEFAULT: P = 0]
%
% OUTPUT
% Command window output
%
% EXAMPLES
% % Stem-leaf plot of V with unit precision
% V = 10.*randn(1,50);
% stemleafplot(V)
%
% % Stem-leaf plot of V with precision of 0.1
% V = randn(1,50);
% stemleafplot(V,-1)
%
% % Stem-leaf plot of V with precision of 100
% V = 5000.*randn(1,50);
% stemleafplot(V,2)
%
% Jered Wells
% 01/28/2011
% jered [dot] wells [at] duke [dot] edu
%
% v1.2 (02/14/2012)
%
if ~isnumeric(v); error 'Input V must be numeric'; end
if ~exist('p','var'); p = 0; elseif isempty(p); p = 0; end
if ~isnumeric(p); error 'Input P must be an integer'; end
p = round(p);
% Condition V
v = v(~isnan(v));
v = v(:);
v = roundn(v,p);
% Organize stems and leaves
allstems = floor(v./10^(p+1));
allleaves = round(abs(v./10^p));
nstems = allstems(allstems<0)+1; % Negative stems
nstems = nstems(:);
pstems = allstems(~(allstems<0)); % Positive stems
pstems = pstems(:);
nleaves = allleaves(allstems<0); % Negative leaves
nleaves = nleaves(:);
pleaves = allleaves(~(allstems<0)); % Negative leaves
pleaves = pleaves(:);
dig = ceil(max(log10(abs(allstems))))+1; % Max # of digits in stem form = strcat(['%' num2str(dig+1) 'i']); % Format string for SPRIN TF
% Plot negative stems
if ~isempty(nstems)
for ii = min(nstems(:)):0
strstem = sprintf(form,ii);
if ii==0; strstem(end-1:end) = '-0'; end
strleaves = sprintf('%2i',mod(sort(nleaves(nstems==ii)),10)); s = strcat([strstem ' |' strleaves]);
disp(s)
end % NSTEMS
end % IF
% Plot positive stems
if ~isempty(pstems)
for ii = 0:max(pstems(:))
strstem = sprintf(form,ii);
strleaves = sprintf('%2i',mod(sort(pleaves(pstems==ii)),10)); s = strcat([strstem ' |' strleaves]);
disp(s)
end % PSTEMS
end % IF
% Print out key and units
form = strcat(['%.' num2str(max(0,-p)) 'f']);
s = strcat(['key: 36|5 = ' sprintf(form,36*10^(p+1)+5*10^p)]);
disp(s)
s = strcat(['stem unit: ' sprintf(form,10^(p+1))]);
disp(s)
s = strcat(['leaf unit: ' sprintf(form,10^p)]);
disp(s)
end % MAIN
截图结果:。