序贯决策解析
王则柯博弈论4序贯决策博弈

• 试验表明,在分别判断的情况下(也就是人们不能把这两杯冰 淇淋放在一起比较),人们反而愿意为冰淇淋A多付钱。结果 显示,人们愿意花2.26美元买冰淇淋A,却只愿意用1.66美元 买冰淇淋B。 • 说明:人们在作决策的时候,不是象传统经济学那样判断一个 物品的真正价值,而是根据一些比较容易评价的线索来判断。 • 引申:在送礼物的时候,礼物在它所属的类别里面是不是昂贵 很重要。
n人序贯博弈的博弈树的主要特征
• 对于表达有n个局中人P1,P2,…,Pn参与 的一个序贯博弈的博弈树:
1. 在树的每一个非末端节点上,都只有一个局中人 进行决策; 2. 在树的每一个末端节点上,都指派了一个n维的 “支付”向量p(v)=(p1(v),p2(v),…,p3(v)),这 里v是这个末端节点的相应的策略表达.而1, 2,…n是博弈参与人首次决策的自然顺序。
• 博弈树必须说明在每一个决策节点上相应的局中人能够 采取的所有可能的选择。 • 一些博弈树可能包含“不做任何决策”的决策节点。每一个 决策节点都有至少一条棱从它那里出发往后延伸,但是 没有最大延伸数量的限制。 • 对于不是根的每个节点,只能有来自别的节点的唯一的 棱指向它这个节点。
• 博弈树并不要求每个局中人必须在至少一个非末 端节点上进行决策。即,可能会出现某些局中人 并不在任何一个非末端节点上进行决策的情形。
• 策略组合
• 策略组合星号简示法 : ( U ,{ U’ , * } )2 • 策略组合的节点表示法: ( { U / D }, { U’ / D’ , U’’ / D’’ })8
4-4 倒推法(逆向推导法)
• 在序贯博弈中,由于均衡与结果是两个不同的概 念,所以求解纳什均衡的虚线排除确定法,并不适 用于求解序贯博弈的结果。一般使用倒推法(逆向 推导法)求序贯博弈的结果。
目标规划的序贯式算法

目标规划的序贯式算法序贯式算法的目标规划(SequentialDecisionMaking)是一种智能选择方法,其基本思想是:根据一系列未完成的目标,通过规定的算法,结合当前的信息和状态,来改变未来的局势,从而实现目标的较好达成。
这种方法在自然语言处理、机器学习、社会机器人等领域中被广泛应用。
在目标规划的序贯式算法中,首先求解未完成的目标,然后对这些目标进行序贯决策,以便于在每一步骤中采取最佳的行动,从而最优的实现所需的目标。
它的最大优点是可以适应各种复杂的环境,可以跟踪系统变化,从而提高目标的实现效果。
序贯式算法的目标规划一般分为三步:(1)情况分析;(2)行动规划;和(3)行动执行。
首先,必须进行情况分析,即捕获当前状态,以便于根据当前状态分析与未完成目标相关的未解决问题,以及可能出现的挑战。
其次,必须进行行动规划,即制定一系列有效的行动方案,以最终达到目标。
最后,必须进行行动执行,即根据行动规划,对行动执行进行监督,以及对状态变化和行动进行修正。
序贯式算法的目标规划虽然具有广泛的应用,但也存在一些困难,例如环境的复杂性、目标的不确定性以及行动的决策等等。
因此,在目标规划中需要考虑这些因素,以提高序贯式算法的有效性和准确性。
首先,要针对不确定性环境进行客观评估,即采取有效的预测、解析和预防技术,以减少不确定性带来的影响。
其次,应综合考虑目标和约束,采取全面考虑、量化分析和系统控制分析等方式,以确定最佳的决策,并采取行动。
最后,应综合考虑行动的各个方面,进行全面的总结分析,采取行动原则,从而更好的实现我们的目标。
总之,序贯式算法的目标规划是一种有效的智能选择方法,它可以有效的结合当前的信息和状态,根据未完成的目标和行动原则来进行分析预测,并最终实现目标的达成,从而为其他领域的研究提供有力的支持。
序贯决策 扩散模型

序贯决策扩散模型序贯决策扩散模型是一种用于分析和预测信息传播过程的模型。
它基于人们在接收到信息后做出的决策行为,并通过模拟这一过程来研究信息传播的规律和特点。
在序贯决策扩散模型中,假设信息的传播是一个连续的过程,每个个体在接收到信息后都需要做出决策,决定是否将信息传播给其他人。
这个决策过程是一个序贯的过程,每个个体会根据自己的判断和目标,选择是否传播信息。
我们需要确定信息传播的初始状态。
在现实生活中,信息传播可以从一个人或一组人开始,也可以通过媒体等渠道传播。
在模型中,我们可以假设初始状态为少数人已经接收到信息,并做出了传播的决策。
接下来,我们需要确定每个个体的决策规则。
这个规则可以是基于个体的认知能力、兴趣爱好、社交网络等因素。
个体可能会根据自己的判断和目标,选择将信息传播给自己的朋友、家人或同事。
这个决策过程可以基于个体对信息的看法、信息来源的可信度、传播成本等因素。
在模型中,我们可以通过设定参数来描述个体的决策规则。
例如,我们可以设定一个阈值,当个体认为信息的传播效果超过这个阈值时,才选择将信息传播出去。
我们还可以设定一个传播概率,表示个体传播信息的可能性。
这些参数可以根据实际情况进行调整,以更好地模拟信息传播的过程。
随着时间的推移,信息会逐渐传播到更多的人群中。
每个个体在接收到信息后都会根据自己的决策规则,选择是否将信息传播给其他人。
当所有个体都做出了决策后,下一个时间步骤开始,新的信息传播过程开始。
通过模拟多次信息传播过程,我们可以观察到信息传播的规律和特点。
例如,我们可以研究信息传播的速度、范围和影响力等指标。
我们还可以通过改变个体的决策规则和参数设置,探索不同情况下的信息传播效果。
序贯决策扩散模型在实际应用中具有广泛的意义。
例如,在疫情防控中,我们可以通过这个模型来研究病毒传播的规律,评估各种防控措施的效果。
在营销推广中,我们可以利用这个模型来研究产品信息的传播过程,优化营销策略。
决策理论与方法多属性决策多目标及序贯决策

决策理论与方法多属性决策多目标及序贯决策多属性决策是指在决策过程中考虑多个属性或指标,通过对这些属性进行量化和比较,找出最优选择的决策方法。
在实际决策中,我们常常需要考虑多个属性因素,而这些因素往往是相互矛盾甚至相互制约的。
多属性决策的关键是建立合理的评价指标体系,将不同属性进行量化,再通过合适的决策模型或方法进行计算和比较。
常用的多属性决策模型包括加权法、层次分析法和灰色关联法等。
多目标决策是指在决策过程中存在多个决策目标,且这些目标往往是相互冲突或无法同时达到的。
多目标决策的目标是找到一个最佳的折衷方案,使得各个决策目标能够得到尽可能满足。
多目标决策的关键是建立合理的决策模型,将各个决策目标进行量化和比较,再通过适当的优化方法或规划方法寻找最优解。
常用的多目标决策方法包括线性规划、整数规划、动态规划和遗传算法等。
序贯决策是指在决策过程中需要根据不完全的信息和不确定的环境进行连续的决策,即通过一系列的决策步骤逐渐完善和调整决策方案。
序贯决策的关键是建立适当的决策模型,将决策过程分解为多个连续的阶段,每个阶段根据已有的信息和条件做出决策,并根据反馈信息不断调整和优化决策方案。
常用的序贯决策方法包括马尔可夫决策过程、博弈论和贝叶斯决策等。
在实际应用中,多属性决策、多目标决策和序贯决策往往会相互结合使用。
例如,在制定企业的发展战略时,需要考虑多个因素,如市场需求、竞争环境和资源能力等,这涉及到多属性决策的内容。
同时,为了实现企业的长远目标,需要考虑多个决策目标,如利润最大化、成本最小化和风险最小化等,这也涉及到多目标决策的内容。
而在制定战略的实施方案时,可能需要根据不断变化的市场和竞争环境进行序贯的决策,这涉及到序贯决策的内容。
综上所述,多属性决策、多目标决策和序贯决策是决策理论与方法中常用的三个重要方法。
它们分别从不同的角度和需求出发,帮助人们在复杂和不确定的决策环境中做出最佳决策。
这些方法在实际应用中相互结合,能够提供更全面和准确的决策支持。
第四章序贯决策博弈(博弈论教程-石家庄经济学院,于振英)
2020年9月24日
博弈论第四章
26
第二讲子博弈精炼纳什均衡
第三节 子博弈精炼纳什均衡
➢一、子博弈:针对树型(展开型)博弈 ➢(一)定义 ➢给定n人展开型博弈T(tree),如果博弈S
(sub)满足以下三个条件: ➢1.S博弈树是T博弈树的一枝 ➢2.S不能分割T的信息集
2020年9月24日
博弈论第四章
44
第二讲子博弈精炼纳什均衡
第四节 延伸分析
➢三、子博弈精炼纳什均衡存在的问题
2020年9月24日
第四章序贯决策博弈
9
第一讲方法与解
第二节 分析方法与解
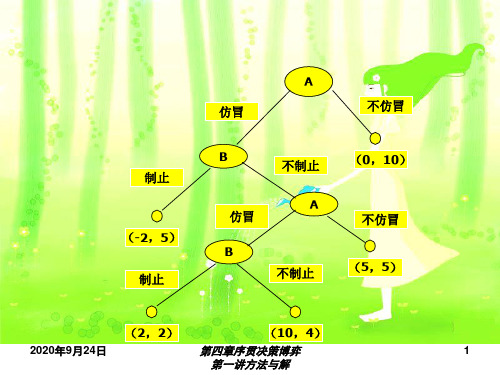
➢一、方法一:虚线排除确定法 ➢(三)策略组合 ➢(进入,{容忍,容忍}) ➢(进入,{容忍,阻挠}) ➢(进入,{阻挠,容忍}) ➢(进入,{阻挠,阻挠})
2020年9月24日
第四章序贯决策博弈
10
第一讲方法与解
第二节 分析方法与解
第四章序贯决策博弈
15
第一讲方法与解
第二节 分析方法与解
➢一、方法一:虚线排除确定法 ➢(五)案例分析 ➢4. (进入,{阻挠,阻挠}) ➢入侵者:进入→不进入,-2→0,存在
单独改变激励 ➢非纳什均衡
2020年9月24日
第四章序贯决策博弈
16
第一讲方法与解
第二节 分析方法与解
➢一、方法一:虚线排除确定法 ➢(五)案例分析 ➢5. (不进入,{容忍,容忍}) ➢进入者:不进入→进入,0→1,存在
➢三、纳什均衡的存在性:库恩定理 ➢完全信息的有限序贯博弈都存在纳 什均衡
2020年9月24日
博弈论第四章
38
序贯均衡定义

序贯均衡定义
序贯均衡是指参与人在选择策略时,根据给定的信念,在每个决策点上选择的策略都是最优的。
具体来说,在博弈中,每个参与人都有自己的信念,即对其他参与人可能采取的策略的预期。
基于这些信念,参与人在每个决策点上都会选择他认为最优的策略。
这种选择过程是序贯的,即每个参与人都是在其他参与人选择策略之后,再根据这些策略选择自己的最优策略。
因此,在序贯均衡中,每个参与人在每个决策点上选择的策略都是最优的,从而形成了一种均衡。
序贯均衡是一种博弈论中的概念,用于描述动态博弈中的均衡状态。
与静态博弈不同,动态博弈中参与人的行动是有先后顺序的,每个参与人在做出决策时都需要考虑其他参与人的行动。
序贯均衡强调的是在动态博弈中,参与人的策略选择应该是一致的,即每个参与人在选择策略时都应该考虑其他参与人的行动,并选择最优的策略。
在实际应用中,序贯均衡可以用于分析各种动态博弈问题,如国际关系、市场竞争、团队合作等。
通过序贯均衡的分析,可以了解参与人在动态博弈中的行为特征和策略选择,从而为实际问题的解决提供理论支持和实践指导。
第四讲 序贯决策博弈

序贯情侣博弈
◆一共八种可能的策略组合:
(足球,{足球,芭蕾}) (足球,{芭蕾,足球}) (足球,{芭蕾,芭蕾}) (足球,{足球,足球}) (芭蕾,{足球,芭蕾}) (芭蕾,{芭蕾,足球}) (芭蕾,{芭蕾,芭蕾}) (芭蕾,{足球,足球})
序贯情侣博弈
◆
(2,1) (0,0)
(-1,-1) (1,2) (足球,{足球,足球}) (2,1) (0,0) (-1,-1) (1,2) (足球,{芭蕾,足球}) (2,1)
不开发
B
开发 (-3,-3)
x
不开发
B
开发
y’
不开发
对抗策略:A开发我不开发,A不开发我 开发——{不开发,开发} ;
不开发策略:不论A开发不开发我不开发 )——{不开发,不开发};
(1,0) (0,1)
(0,0)
策略空间为:{开发,开发}、{开发, 不开发} 、{不开发,开发} (不开发, 不开发}。
(0,0)
(-1,-1) (1,2) (足球,{足球,芭蕾}) (2,1) (0,0) (-1,-1) (1,2) (足球,{芭蕾,芭蕾})
纳什均衡的箭头排除确定法
◆
(2,1) (0,0)
(-1,-1) (1,2) (芭蕾,{足球,足球}) (2,1) (0,0) (-1,-1) (1,2) (芭蕾,{芭蕾,足球}) (2,1)
或行动的具体选择。 ◆纯策略为一个决策规则,它能告诉这个参与人 在每一个可能遇到的决策节点上应当采取的行 动。 ◆在序贯博弈中,一个策略就是一个完整的行动 计划。
策略
◆在进入博弈中,进入者的策略:进入和不进入
。 ◆垄断者的策略:一、不管你怎样,我总是“容 忍”;二、不管你怎样,我总是“对抗”;三 、你进入我“对抗”,你不进入我“容忍”; 四、你进入我“容忍”,你不进入我“对抗” ;即垄断者的四个纯策略:{容忍,容忍}、 { 对抗,对抗}、 {对抗,容忍}、 {容忍,对抗} 。
第九讲(序贯博弈)
反击
• 然而,美军可以通过调整在西德的部署来改变这 个结果。 • 假设美军增加西德的军队,会出现怎样的结果?
增加部署不是为了能打败苏军。 事实上,其数量无法战胜苏军。 同时还会增加美国的开销。 然而,苏军进攻后,如果美军 选择反击,还是能够救援一部 分的部队。这比全军覆没要好。 从左图可以看出,最终结果对 美军来说是变好了。
纳什均衡与子博弈完美均衡
• 再看金雀与蓝鸟的案例:
– 纳什均衡为蓝鸟进入,金雀接受;和蓝鸟不进入,而 金雀威胁展开价格战。 – 通过对扩展式的简化,两个纳什均衡中只有一个是子 博弈完美均衡。即蓝鸟进入,金雀容纳。 – 价格战的威胁是不可信的。
金雀与蓝鸟的收益矩阵:
金雀 如果蓝鸟进 如果蓝鸟进入, 入,就接受 就展开价格战 3,5 -5,2 0,10 0,10
一个商业案例 – 解答
3 PDF 文件使用 "pdfFactory Pro" 试用版本创建
一个商业案例 – 解答
Exercise – 离婚诉讼费
• 琼斯夫人因为先生外遇要与琼斯先生离婚。 根据婚前协定,如果琼斯夫人能够证明她 先生有外遇就能得到10万美元,否则只能 得到5万美元。她的律师只有雇佣私家侦探 才能证明琼斯先生有外遇,所需费用为1万 美元,包含在律师费中。琼斯夫人有两个 选择:无论诉讼结果是什么,都支付2万美 元的律师费用,或者支付诉讼收入的1/3。 • 琼斯夫人该如何选择呢?
序贯博弈有一定的承诺结构commitmentstructure囚徒困境中由于一方在不知道另即谁先做出战略承诺这使序贯博弈拥有一个或多个一方具体会做出怎样的决策下进行的适当子博弈
序贯博弈
• 序贯博弈 (sequential game):
第九讲 序贯博弈
序贯决策

13
1.多阶段决策 多阶段决策
1.3 应用举例
P ( H1 ) = ∑ P ( H1 θ j ) P(θ j )
j =1 3
= 0.4 × 0.4 + 0.3 × 0.2 + 0.32 × 0.4 = 0.34
P (θ1 H1 ) = P ( H1 θ1 ) P (θ1 ) P( H1 ) = 0.4 × 0.4 = 0.471 0.34
0.2 × 0.3 = = 0.177 0.34 = 0.4 × 0.3 = 0.352 0.34
P (θ2 H1 ) =
P ( H1 θ2 ) P (θ2 ) P( H1 ) P ( H1 θ3 ) P(θ3 ) P( H1 )
P (θ3 H1 ) =
14
1.多阶段决策 多阶段决策
1.3 应用举例 试销结果下的后验概率
16
2. 序列决策
有些决策问题, 有些决策问题,在进行决策后又产生一些新情况 需要进行新的决策,接着又有一些新的情况, ,需要进行新的决策,接着又有一些新的情况,有 需要进行新的决策。这样决策、新情况、决策…, 需要进行新的决策。这样决策、新情况、决策 , 就构成一个系列,成为系贯决策。 就构成一个系列,成为系贯决策。 多阶段决策的阶段数是确定的, 多阶段决策的阶段数是确定的,序贯决策的阶段 数是不确定的, 数是不确定的,它依赖于执行决策过程中所出现的 状况。 状况。 决策方法: 决策方法:决策树
20
3. 马尔可夫决策
3.1 马尔可夫决策问题 预测在本质上就是利用预测对象的历史数据去推 知预测对象的未来。 知预测对象的未来。 在经济管理现象中存在一种“无后效性” 在经济管理现象中存在一种“无后效性”,即“ 系统在每一时刻的状态仅仅取决于前一时刻的状态 而与其过去的历史无关。 ,而与其过去的历史无关。” 例如:池塘里有三张荷叶,编号为 , , , 例如:池塘里有三张荷叶,编号为1,2,3,假 设有一只青蛙随机地在荷叶上跳来跳去, 设有一只青蛙随机地在荷叶上跳来跳去,在初始时 它在2号荷叶上 在时刻,它有可能跳到1号或 号荷叶上。 刻,它在 号荷叶上。在时刻,它有可能跳到 号或 号荷叶上, 者3号荷叶上,也有可能原地不动。 号荷叶上 也有可能原地不动。
序贯决策博弈概述

序贯决策博弈:局中人做出策略选 择时知道对手的策略选择。
实验 : 枪手博弈1
三个快枪手相互之间的仇恨到了不可 调和的地步。这天他们三在街上不期而遇, 每个人的手都握住了枪把,一场生死决斗 马上就要开始……
已知这三个人中甲枪法精准,十发八 中;乙的枪法也不错,十发六中,丙的枪 法拙劣,十发四中。假如三个人同时开枪, 决一死战,一枪后谁最后活下来的机会大 一些?
八种策略组合,纳什均衡在哪
该博弈有八种可能的策略组合: ( {足球},{(上)足球,(下)足球} ) ( {足球},{(上)足球,(下)芭蕾} ) ( {足球},{(上)芭蕾,(下)足球} ) ( {足球},{(上)芭蕾,(下)芭蕾} ) ( {芭蕾},{(上)足球,(下)足球} ) ( {芭蕾},{(上)足球,(下)芭蕾} ) ( {芭蕾},{(上)芭蕾,(下)足球} ) ( {芭蕾},{(上)芭蕾,(下)芭蕾} )
实 验 : 枪手博弈2
假设现在三个枪手决定轮流开枪,谁活下 来的机会大一些?
实验:海盗分宝
五个海盗抢到100颗宝石,他们决定按如下方 法来分配:先抽签决定顺序(1,2,3,4,5); 然后先由1号提出分配方案,其余的人进行 表决,当且仅当半数和超过半数的人同意 时,则按1号所提方案分配,否则将1号扔进 大海喂鲨鱼,当1号方案被否决,则由2号提 出分配方案,其余的人进行表决,以此类 推,假定这些海盗都是理性人,问第一个 海盗应提出怎样的分配方案才能获得通过 并使自己的收益最大?
用箭头排除确定法寻找纳什均衡
将以上策略在博弈书中用粗线表示。
将存在单独改变激励的策略用箭头标示。方法如下:
(1)找到第二阶段两根粗线所对应的支付。
(2)比较这两个支付前面的数字,如果大的数字所 对应的那条“树枝”是细的,则男方存在单独偏离 的动机,则男方的策略选择用箭头标示。
如何使用马尔可夫决策过程进行决策(九)

马尔可夫决策过程(MDP)是一种用于建模序贯决策问题的数学框架。
它可以用来解决许多现实世界的问题,比如自动控制、金融、医疗以及机器学习等领域。
MDP的核心思想是基于状态和动作的概率转移,以及对每个状态动作对的奖励值进行优化,从而找到最优的决策策略。
本文将介绍MDP的基本概念和如何使用MDP进行决策。
**1. MDP的基本概念**MDP包括状态空间(S)、动作空间(A)、转移概率(P)、奖励函数(R)和折扣因子(γ)。
状态空间是所有可能的状态的集合,动作空间是所有可能的动作的集合,转移概率描述了在某个状态执行某个动作后转移到下一个状态的概率分布,奖励函数表示在某个状态执行某个动作后所获得的奖励,折扣因子表示未来奖励的折现率。
MDP的目标是找到一个策略(π),使得在每个状态执行对应的动作,最大化长期累积奖励。
**2. 基于MDP的决策过程**MDP的决策过程可以分为两个阶段:学习和执行。
在学习阶段,我们需要通过观察环境和与环境交互来估计状态转移概率和奖励函数,以及学习最优的策略。
在执行阶段,我们根据学习到的策略来进行决策,并根据环境的反馈来不断更新策略。
**3. 使用MDP进行决策**使用MDP进行决策的一般步骤包括:建立环境模型、选择合适的算法、训练模型、评估策略和执行策略。
首先,需要对决策问题进行建模,明确状态空间、动作空间、转移概率和奖励函数。
然后,选择合适的算法来求解MDP,比如值迭代、策略迭代、Q-learning和深度强化学习等。
接下来,使用历史数据来训练模型,通过迭代更新策略,找到最优的决策策略。
在评估策略阶段,可以通过模拟环境或者实际应用中的反馈来评估策略的性能。
最后,在执行阶段,根据学习到的策略来进行决策,并不断更新策略以适应环境的变化。
**4. MDP的应用**MDP在实际应用中有着广泛的应用,比如自动控制、金融、医疗以及机器学习等领域。
在自动控制领域,MDP可以用来设计智能控制系统,根据环境的反馈来调整控制策略。
多阶段决策和序贯决策教材

多阶段决策和序贯决策教材引言多阶段决策和序贯决策是决策理论中重要的概念和方法。
在很多实际应用中,决策问题往往不仅仅是一次性的选择,而是需要在不同阶段进行多次决策,每次决策都受之前决策的影响。
本教材将介绍多阶段决策和序贯决策的基本概念和方法,并提供案例来帮助读者理解和应用这些概念和方法。
多阶段决策多阶段决策是指决策问题中包含多个决策节点的情况。
在每个决策节点,决策者需要面临不同的选择,并根据选择的结果进行下一阶段的决策。
多阶段决策常见于实际生活中的许多问题,比如投资决策、项目管理等。
多阶段决策可以通过决策树来表示。
决策树是一种树状结构,其中每个节点表示一个决策点,每个边表示一个选择。
通过自顶向下的递归过程,从根节点到叶子节点,决策树可以表示整个多阶段决策的过程。
在每个决策节点,决策者根据一定的决策准则选择一个最优的方案。
常用的决策准则包括最大化效益、最小化风险等。
序贯决策序贯决策是多阶段决策的一种特殊形式,它是指在每个决策节点上,决策者只能看到当前状态的信息,并且只做当前状态下最优的决策,无法事先知道所有后续状态的信息。
序贯决策常见于动态环境下的问题,比如控制系统、机器人等。
序贯决策可以通过动态规划来求解。
动态规划是一种递推的算法,通过将问题划分为一系列子问题,并利用子问题的最优解来推导出整个问题的最优解。
在序贯决策中,我们可以定义一个价值函数来表示当前状态的价值,然后利用动态规划算法不断更新和求解价值函数,最终得到最优的决策序列。
案例分析为了帮助读者理解和应用多阶段决策和序贯决策的概念和方法,下面将给出一个案例分析。
假设你是一家餐厅的经理,现在面临一个供应商选择的问题。
你可以选择三个不同的供应商,每个供应商的价格和质量都不同。
此外,每个供应商的产品质量在未来可能会有变化。
你需要决策在当前时间选取哪个供应商,并在之后的时间里根据每个供应商的质量变化重新评估和选择供应商。
这个问题可以通过多阶段决策和序贯决策的方法来解决。
7序贯决策解析

以上各种决策规则都反映了人们对于一种通用的公平的群体决策规则的追求。这种需要是显而易见 的,有集体就有如何公平合理地反映集体意见的问题。50年代,阿罗等人证明了社会选择并不能在完全 符合理性的条件下将个人选择顺序集结为群体的选择顺序,少数服从多数的规则并不能提供一个令人满 意的社会选择顺序。
lim P (n) lim P n1P
n
n
得
1 k 1 k
1
k
1
k
P
1 k 1 k
k
记 1 2 k ,则 P ,且 i 1 i 1
此方程组为稳态方程
第三节 马尔可夫决策
四、马尔可夫应用实例
例6-6 某生产商标 为的产品的厂商为了与另外两个生产同类产品 和 的厂家竞争,有三种可供
第四节 群决策简介
2.委托求解法的步骤
假设成员i知道其他每个成员的效用函数,不知道其他成员设定的权.成员i能够根据其他成员的效用函
数选择权 pij ( j 1,,n),使这些效用函数的组合几乎能够反映成员i的偏好。 (1)设成员i对他委托的小组中各成员的效用 u oj,指定的权系数为 pij ( j 1,,n) ,则成员i的效用
(1)具有有限种状态;
(2)具有马尔可夫性;
(3)转移概率具有平稳性。
第三节 马尔可夫决策
三、稳态概率
称 j
lim
n
Pj( n )
lim P n
xn
j
为稳态概率。
且
决策理论序贯决策分析课件

02
CHAPTER
序贯决策分析基础
序贯决策是在一系列决策过程中,决策者根据每个阶段的环境信息和历史信息,按照一定的顺序和规则进行决策的过程。
序贯决策的定义Байду номын сангаас
序贯决策中的每个决策都有时间顺序,后续决策依赖于先前的决策结果。
时序性
序贯决策中,环境状态和决策后果会随着时间变化而变化。
动态性
在给定条件下,序贯决策的目标是在一系列决策中寻求最优解。
详细描述
VS
优化资源配置和生产流程
详细描述
生产计划决策需要考虑生产资源的配置和生产流程的优化。通过序贯决策分析,企业可以根据市场需求和生产能力制定合理的生产计划,优化资源配置,提高生产效率,降低生产成本。
总结词
协调各个环节实现整体最优
供应链管理决策需要协调各个环节,包括采购、生产、物流等,以实现整体最优。通过序贯决策分析,企业可以综合考虑各个环节的需求和约束,制定合理的供应链管理策略,提高供应链的效率和稳定性。
步骤六
实施与评估:实施决策方案,并根据实施结果进行评估和调整。
动态规划
将多阶段决策问题分解为一系列单阶段问题,通过求解单阶段的最优解,达到求解多阶段问题的最优解。
03
CHAPTER
决策分析方法
不确定型决策分析方法是指在无法预测未来不确定因素的情况下,根据经验、直觉和判断进行决策的方法。
不确定型决策分析方法包括乐观法、悲观法、折中法等,这些方法可以帮助决策者在无法准确预测未来时做出相对合理的决策。
多目标决策分析方法是指在进行决策时,需要考虑多个目标,并权衡这些目标之间的关系,以实现最优的决策结果。
多目标决策分析方法包括层次分析法、多属性效用函数法、优序法等,这些方法可以帮助决策者更好地权衡多个目标之间的关系,从而做出更加全面和科学的决策。
第八章_序贯决策分析

E a 2/H 2 3 0 .4 6 3 0 2 .4 6 ( 2 2 )0 .076
2 .6 ( 2 万 元 )
E a 3/H 2 10 0 .4 6 1 2 0 .46 1 2 0 .462
( 1 万 元 )
θ P(θ)
θ1 0.6 θ2 0.3 θ3 0.1
P(H1︱θ) 0.6 0.2 0.2
P(H2︱θ) 0.3 0.6 0.3
--
P(H3︱θ) 0.1 0.2 0.5
例8.1
如不买此项专利,把这笔费用用在其他方 面,在同样的时期可获利1.1万元。那么, 该公司应该如何决策? (1)是否买专利? (2)如果买专利,是否采取试销办法? (3)如果不试销,应大批生产,中批生产还 是小批生产?如果试销,又应该如何根据 试销结果决定其行动?
--
1
A1
X1=0
4
2
X1=1
5
… X2=0
8
… X2=1
9
a1
a2
(略)
a1
3 a2
A2
A3--
6
7
… A4
【例8.4】
该问题的费
100100100
用矩阵为: Q(qij)232.5 100225
相应的损失矩阵为
97.5 0 0
R(ri j)23
0
0 125
先进行第一次抽样的后验概率计算
3
--
例8.1
❖ 当试销结果为 H1时:
E a 1/H 1 4 0 .8 1 2 0 8 .1 3 ( 3 6 )0 .046
3 .4( 06万 - ---结点元 8 )
E a 2/H 1 3 0 .8 1 3 0 8 .1 3 ( 2 6 )0 .046
序贯博弈纳什均衡

序贯博弈纳什均衡序贯博弈是博弈论中的一种重要形式,指的是参与者在不同时间点依次做出决策的博弈过程。
而纳什均衡则是博弈论中的一个重要概念,指的是在博弈中,各参与者通过选择策略使得自己的收益最大化,并且其他参与者无法通过改变策略获得更好的收益。
本文将从序贯博弈和纳什均衡两个方面展开讨论。
序贯博弈是一种动态博弈形式,参与者在不同时间点做出决策,每个决策都会影响后续的决策和收益。
在序贯博弈中,每个参与者的决策都是基于先前的决策和当前的信息来进行的。
这种博弈形式常见于现实生活中的许多情景,比如商业谈判、国际政治等。
纳什均衡是指在博弈中,每个参与者选择的策略组合使得自己的收益最大化,而其他参与者无法通过改变策略获得更好的收益。
换句话说,纳什均衡是一种稳定状态,任何一个参与者都没有动机单方面改变自己的策略。
纳什均衡是博弈论中的一个核心概念,被广泛应用于经济学、政治学、社会学等领域。
在序贯博弈中寻找纳什均衡是一个复杂而困难的问题。
因为参与者的决策是基于先前的决策和当前的信息,而且每个参与者都在追求自身的最大化收益。
在序贯博弈中,参与者需要考虑对手可能的行动和自己的收益,以及对手对自己的行动的反应,从而做出最优的决策。
为了寻找序贯博弈的纳什均衡,可以使用博弈树来表示博弈的过程和参与者的决策。
博弈树是一个树状结构,每个节点表示一个决策点,每个边表示一个决策的结果。
通过遍历博弈树,可以确定每个参与者的最优策略,并找到纳什均衡。
在博弈树上,每个参与者都有一个决策节点,表示他们在该节点处做出的决策。
每个决策节点有多个子节点,表示参与者在不同决策下的选择。
通过遍历博弈树,可以确定每个参与者的最优策略。
最优策略是指在当前节点下,使得参与者的收益最大化的决策。
当所有参与者都选择了最优策略后,就可以确定博弈的纳什均衡。
纳什均衡是一种稳定状态,任何一个参与者都没有动机单方面改变自己的策略。
在博弈树上,纳什均衡可以通过遍历博弈树,并找到每个参与者的最优策略来确定。
序贯理性

序贯理性
序贯理性的含义
所谓序贯理性,是指每个参与人在其每一
个行动时点上都将重新优化自己的选择, 并且会把自己将来会重新优化其选择这一 点也纳入当前的优化选择当中。
我”、“不犯我”。中国后行,中国的一 个策略就是针对美国的每一个行动制定出 完整的行动计划,这样,中国将有四个策 略,一个策略就是一条完整的行动计划:
1、(不犯美国,犯美国):美国不犯我,
我不犯美国;美国若犯我,我必犯美国; 2、(犯美国,犯美国):美国不犯我,我 就犯美国;美国若犯我,我必犯美国; 3、(不犯美国,不犯美国):美国不犯我, 我不犯美国;美国若犯我,我也不犯美国; 4、(犯美国,不犯美国):美国不犯我, 我就犯美国;美国若犯我,我就不犯美国。
换句话说,一个具备序贯理性的参与人很
清楚自己在每一个需要作出决定的时刻都 需要对已有的决策进行优化,而且在做这 种优化的时候必须把未来需要重新优化的 这一事实考虑在现有的优化决策当中。
显然“悔不当初”不应该出现在生活中。
为什么在生活中难以达到序贯理性呢?
原因是: 1、人们的计算能力是有限的; 2、人们的理性本身也是有限的(比如感情用 事、冲动行事、冒险倾向等)。
一个办法是,妻子承诺一定要选择去歌剧
院。但这种承诺很可能不会被丈夫相信, 或者遭到丈夫的游说。 另一种办法是,妻子会嚷一句“反正我要 去歌剧院”,然后“啪”地挂断了电话, 并且把手机也关上,让丈夫联系不到她, 直到歌剧院上演前几分钟才开机。
妻子这样做是有道理的,因为她通过截断和丈夫 的联系,而明确地表示了自己一定要履行自己的 决定。丈夫虽然很想去看拳击比赛,但是既然他 不想跟太太分开,也担心太太一个人的安全,他 最后不得不满腹委屈地走到歌剧院。 拒绝联系是为了限制不利于自己的信息——因为 博弈局势中,拥有更多信息不一定是好事。 比如盲聋人与正常人狭路相逢,哪一个会让开呢?
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
解决多阶段决策问题的主要方法是决策树方法和动态规划方法,决策树由节点和分支组成,每一条 由树根通往树梢的路线都表示一种决策方案及可能遇到的一种情况。
进行决策分析时,要由树梢往树根依次计算。这种从后到前进行决策分析的方法叫做逆序归纳法。 多阶段决策分析的步骤:
(1)根据具体问题适当划分阶段; (2)确定各阶段的状态变量,寻找各阶段之间的联系; (3)由后到前用逆序归纳法进行决策分析。
利用马氏过程分析系统当前状态并预测未来状态的决策方法,称为马尔可夫决策。
二、马尔可夫链与转移概率矩阵
随机过程X(t)t,T,如果对任意 t1t2tn,ti T,都存在
P x ( t n ) y | x ( t n 1 ) x n 1 x ( t 1 ) x 1 P x ( t n ) y | x ( t n 1 ) x n 1
第六章 序贯决策分析
第一节 多阶段决策
一、多阶段决策问题
在经济活动中,常常遇到这样的决策问题,由于它的特殊性,需要将过程分为若干个相互联系的阶段, 在它的每一个阶段都需要做出决策,从而使整个过程达到最好的活动效果。当各个阶段决策确定后,就组 成了一个决策序列,因而也就决定了整个过程的一条活动路线,这种把一个问题可看作是一个前后关联的 具有链状结构的多阶段过程就称为多阶段决策过程。
(1)具有有限种状态;
(2)具有马尔可夫性;
(3)转移概率具有平稳性。
第三节 马尔可夫决策
三、稳态概率
称 j l n iP m j(n ) l n iP m x n j为稳态概率。
且 l n i P m x n j|x 0 i l n i P m x n j j
图6-2 原决策树
第三节 马尔可夫决策
一、马尔可夫决策问题
决策问题采取的行动已经确定,但将这个行动付诸实践的过程又分为几个时期。在不同的时期,系 统可以处在不同的状态,而这些状态发生的概率又可受前面时期实际所处状态的影响。。其中一种最简 单、最基本的情形,是每一时期状态参数的概率分布只与这一时期的前一时期实际所处的状态有关,而 与更早的状态无关,这就是所谓的马尔可夫链。
3
表6-1 某公司产销新产品的收益矩
为了更正确地了解市场情况,正式投产前可先生产少量产品试销。由于要增添少量生产设备等原因, 试销费需要600元。由于试销前未作广告,顾客对产品不太了解,加之试销量较小,试销结果不很准 确。假设试销结果分为产品受欢迎(H1),一般(H2)和不受欢迎(H3)三种,其准确度(似然分 布矩阵)见表6-2所示。
选择的措施:(1)发放有奖债券;(2)开展广告宣传;(3) 优质售后服务。三种方案分别实施以后,
经统计调查可知,该类商品的市场占有率的转移矩阵分别是
0.80 0.15 0.05 P1 0.20 0.45 0.35
0.30 0.40 0.30
0.90 0.05 0.05 P2 0.10 0.80 0.10
0.10 0.15 0.75
0.90 0.05 0.05 P3 0.10 0.80 0.10
因此我们可以从n步转移矩阵的n 极限取得稳态概率分布
Pn Pn1P
lim P(n) lim Pn1P
n
n
得
1 k 1 k
1
k
1
k
P
1 k 1 k
k
记 1 2 k,则P,且 i 1 i 1
此方程组为稳态方程
第三节 马尔可夫决策
四、马尔可夫应用实例
例6-6 某生产商标为的产品的厂商为了与另外两个生产同类产品和 的厂家竞争,有三种可供
第一节 多阶段决策
三、应用举例
例6-1 离散情况决策分析。某企业考虑是否花费4000元钱从某科研机关购买某项技术然后产销新
Байду номын сангаас
产品。如果买技术,可以进行大批生产(a1),中批生产(a2),或小批生产(a3),可能出现的市
场销售情况也分为畅销(
1)一般(
2)和滞销(
)三种。其收益(利润,元)矩阵如表6-1
则称 X(t)t,T具有马尔可夫性。 条件概率 P x nj|x n 1 i称为转移概率,也称一步转移概率。
各状态之间的转移概率可记为
p11
P
p1k
其中 pij 1 ,对所有i;且 pij 0 ,对所有i,j , j
称P为一步转移概率矩阵。
pk1 pkk
定义:如果随机过程Xt,t0,1,,满足下述性质,则称X t 是一个有限状态的马尔可夫链(Markov)。
第一节 多阶段决策
表6-2 试销结果的准确度
如不买此项技术,把这笔费用用在其他方面,在同样的时期可获利8000元。那么,该公司应 该如何决策?
(1)是否买技术? (2)如果买技术,是否采取试销办法? (3)如果不试销,应大批生产,中批生产还是小批生产?如果试销,又应该如何根据试销结 果决定其行动? 例6-2 连续情形的决策分析。某工厂现有10万元资金可供生产某种产品使用,生产过程有两个方 案可供选择。方案1:每万元资金,每年可产生0.5万元的利润,年产量为2000吨。方案2:每万元资金, 每年可产生0.2万元的利润,年产量为3000吨。每年可用一部分资金采取一种方案生产,另外一部分资 金采取另一种方案进行生产,但一年内不变。假设前一年的利润可作为下一年的资金在两个方案间再行 分配,但一个方案前一年的资金不得在下一年向另一方案转移。那么,为使四年内的总产量最高,该厂 在这四年中应该如何分配资金?
第二节 序贯决策
有些决策问题,在进行决策后又产生一些新情况,需要进行新的决策,接着又有一些新的情况,又需 要进行新的决策。这样决策、情况、决策…,就构成一个序列,这就是序列决策。解决序列问题的有利办 法仍然是决策树。
例6-3 设有某石油勘探队,在一片估计能出油的荒田钻探,可以先做地震试验,然后决定钻井与否。 或者不做地震试验,只凭经验决定钻井与否。做地震试验的费用每次30000元,钻井费用为10000元。若钻 井后出油,这井队可收入40000元;若不出油就没有任何收入。各种情况下出油的概率已估计出,并标在图 6-2上。问钻井队的决策者如何做出决策使收入的期望值为最大。