自变量选择与逐回归
变量选择与逐步回归
变量选择与逐步回归
1在建立回归模型时,对自变量进行筛选
2选择自变量的原则是对统计量进行显著性检验
(1)将一个或一个以上的自变量引入到回归模型中时,是否使得残差平方和(SSE)有显著地减少。
如果增加一个自变量使SSE的减少是显著的,则说明有必要将这个自变量引入回归模型,否则,就没有必要将这个自变量引入回归模型
确定引入自变量是否使SSE有显著减少的方法,就是使用F统计量的值作为一个标准,以此来确定是在模型中增加一个自变量,还是从模型中剔除一个自变量
3逐步回归:将向前选择和向后剔除两种方法结合起来筛选自变量。
在增加了一个自变量后,它会对模型中所有的变量进行考察,看看有没有可能剔除某个自变量;如果在增加了一个自变量后,前面增加的某个自变量对模型的贡献变得不显著,这个变量就会被剔除;按照方法不停地增加变量并考虑剔除以前增加的变量的可能性,直至增加变量已经不能导致SSE显著减少;在前面步骤中增加的自变量在后面的步骤中有可能被剔除,而在前面步骤中剔除的自变量在后面的步骤中也可能重新进入到模型中。
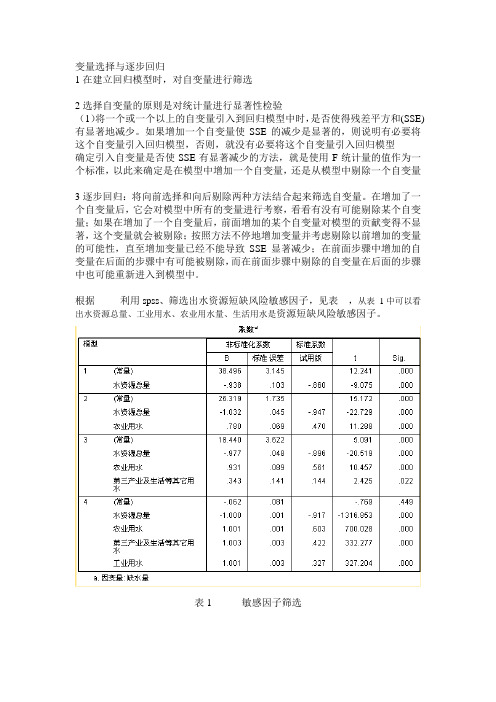
根据利用spss、筛选出水资源短缺风险敏感因子,见表,从表1中可以看出水资源总量、工业用水、农业用水量、生活用水是资源短缺风险敏感因子。
表1 敏感因子筛选。
回归变量的选择与逐步回归

回归变量的选择与逐步回归1 变量选择问题在实际问题中,影响因变量的因素(自变量)很多,人们希望从中挑选出影响显著的自变量来建立回归关系式,这就涉及自变量选择的问题。
在回归方程中若漏掉对因变量影响显著的自变量,那么建立的回归式用于预测时将会产生较大的偏差。
但回归式若包含的变量太多,且其中有些对因变量影响不大,显然这样的回归式不仅使用不方便,而且反而会影响预测的精度。
因而选择合适的变量用于建立一个“最优”的回归方程是十分重要的问题。
选择“最优”子集的变量筛选法包括逐步回归法(Stepwise)、向前引入法(Forward)和向后剔除法。
向前引入法是从回归方程仅包括常数项开始,把自变量逐个引入回归方程。
具体地说,首先,从零模型开始——只含有截距,但不含有预测变量的模型。
然后,在m个自变量中选择一个与因变量线性关系最密切的变量,记为x i,在剩余的m-1个自变量中选择一个变量x i,使得{x i,x i}联合起来二元回归效果最好,在剩下的m-2个自变量中选择一个变量x i,使得{x i,x i,x i}联合起来回归效果最好,如此下去,直至得到“最优”回归方程为止。
向前引入法中的终止条件为:给定显著性水平α,当对某一个将被引入变量的回归系数做显著性检查时,若p-value≥α,则引入变量的过程结束,所得方程为“最优”回归方程。
向前引入法有一个明显的缺点,它是一种贪婪的方法。
就是由于各自变量可能存在着相互关系,因此后续变量的选入可能会使前面已选入的自变量变得不重要。
这样最后得到的“最优”回归方程可能包含一些对因变量影响不大的自变量。
向后剔除法与向前引入法正好相反,首先将全部m个自变量引入回归方程,然后逐个剔除对因变量作用不显著的自变量。
具体地说,首先从回归式m个自变量中选择一个对因变量贡献最小的自变量,如x j,将它从回归方程中剔除;然后重新计算因变量与剩下的m-1个自变量的回归方程,再剔除一个贡献最小的自变量,如x j,依次下去,直到得到“最优”回归方程为止。
第5章逐步回归与自变量选择。

由上式知:尽管1-R2随着变量的增加而减少 , 但由于其前面的系数 n -1 起到制衡作用,
n -p -1 才使R 2随着自变量的增加并不 一定增大。 当所增加的自变量对回 归的贡献很小时, R 2反而可能减少。
浙江财经学院 倪伟才
11
准则2:回归的标准误
回归误差项方差? 2的无偏估计为:??2= 1 SSR n-p-1
引入自变量显著性水平记为: ? 进
剔除自变量显著性水平记为:? 出
要使用逐步回归法的前提: ? 进<? 出
Spss中默认的? 进 =0.05
? 出=0.1
例:用逐步回归法建立例3.1回归方程
练习课本例5.5关于香港股市的研究
练习课本152页的习题浙5江.9财经学院 倪伟才
Stata ,SPSS结果一致(课本例5.1)
④直到未被引入方程的p值>0.05为止。
例:用前进法建立例3.1的 回归方程
浙江财经学院 倪伟才
二、后退法
后退法( backwad )的基本 思想:首先用全部的 p个自变量建立一个回归方程,然后将最不重 要的自变量 一个一个地删除 。
具体步骤:①作 y对全部的p个自变x1,x2,….,xp 的回归②在回归方程中,将 x1,x2,….,xp 对y的 影响最小(最不重要或 p值最大)的自变量剔 除,不妨令 x1;③在② 中的回归方程(已没有 x1 ),将x2,….,xp 对y的影响最小(最不重要 或p值最大)的自变量剔除,④直到回归方程 中,自变量对 y的影响都重要为止。 例:用后退法建立例 3.1回归方程
的增加,SSR能够快速减少,虽然作为除数的
惩罚因子n-p-1也随之减少,但由于SSR减小的速度
自变量的选择与逐步回归实用回归分析ppt课件

§5.2 所有子集回归
准则2 赤池信息量AIC达到最小
设回归模型的似然函数为L(θ,x), θ的维数为p,x为样本,在 回归分析中样本为y=(y1,y2,…yn)′,则AIC定义为:
AIC=-2lnL(θˆ L ,x)+2p 其中θˆ L 是θ的极大似然估计,p 是未知参数的个数。
§5.2 所有子集回归
βˆ p (Xp X p )-1 Xpy
ˆ
2 p
n
1 p
1 SSEp
§5.1 自变量选择对估计和预测的影响
二、自变量选择对预测的影响
关于自变量选择对预测的影响可以分成两种情况: 第一种情况是全模型正确而误用了选模型; 第二种情况是选模型正确而误用了全模型式。
§5.1 自变量选择对估计和预测的影响
(一)全模型正确而误用选模型的情况
性质 1. 在 xj与 xp+1, …,xm的相关系数不全为 0 时,选模型回归系数的 最小二乘估计是全模型相应参数的有偏估计,即
E(ˆ jp ) jp j (j=1,2, …,p)。
§5.1 自变量选择对估计和预测的影响
(一)全模型正确而误用选模型的情况 性质 2. 选模型的的预测是有偏的。 给定新自变量值x0p (x01, x02,, x0m ) ,因变量新值为 y0=β0+β1x01+β2x02+…+βmx0m+ε0 用选模型的预测值为
(ˆ 0p ,ˆ 1p ,,ˆ pp )
全模型的最小二乘参数估计为βˆ m (ˆ 0m ,ˆ 1m ,,ˆ mm )
这条性质说明 D(ˆ jp ) D(ˆ jm ), j 0,1,, p 。
§5.1 自变量选择对估计和预测的影响
(一)全模型正确而误用选模型的情况
《应用回归分析》自变量选择与逐步回归实验报告

《应用回归分析》自变量选择与逐步回归实验报告二、实验步骤:(只需关键步骤)步骤一:对六个回归自变量x1,x2……x6分别同因变量Y建立一元回归模型步骤二:分别计算这六个一元回归的六个回归系数的F检验值。
步骤三:将因变量y 分别与(x1, x2),(x1, x3), …, (x1, x m)建立m-1个二元线性回归方程, 对这m-1个回归方程中x2, x3, …, x m的回归系数进行F 检验,计算 F 值步骤四:重复步骤二。
三、实验结果分析:(提供关键结果截图和分析)1.建立全模型回归方程;由上图结果可知该问题的全模型方程为:Y=1347.986-0.641x1-0.317x2-0.413x3-0.002x4+0.671x5-0.008x62.用前进法选择自变量;从右图上可以看出:依次引入了变量x5、x1、x2最优回归模型为:Y^=874.583-0.611x1-0.353x2+0.637x5最优模型的复决定系数 :R^2=0.996调整后的复决定系数:R^2=0.9953.用后退法选择自变量;从上图上可以看出:依次剔除变量x4、x3、x6最优回归模型为:y^=874.583-0.611x1-0.353x2+0.637x5最优模型的复决定系数 R^2=0.996调整后的复决定系数R^2=0.995最优模型的复决定系数R^2=0.996调整后的复决定系数R^2=0.9954.用逐步回归法选择自变量;从上图上可以看出:依次引入了变量x5、x1、x2最优回归模型为:y^=874.583-0.611x1-0.353x2+0.637x5最优模型的复决定系数 R^2=0.996调整后的复决定系数R^2=0.9955.根据以上结果分三种方法的差异。
前进法和后退法以及逐步回归法的计算结果完全一致,但是在其计算上又有很大的差异,前进法就是当自变量一旦被选入,就永远保留在模型中。
后退法就是反向法,而逐步回归就比后退法更明确,逐步后退回归的方法。
自变量选择与逐回归

自变量选择与逐回归————————————————————————————————作者:————————————————————————————————日期:自变量选择与逐步回归一、全模型和选模型设研究某一实际问题,涉及对因变量有影响的因素共有m 个,由因变量y 和m 个自变量构成的回归模型εββββ+++++=m m x x x y Λ22110称为全模型。
如果从可供选择的m 个变量中选出p 个,由选出的p 个自变量组成的回归模型p pp pp p p p x x x y εββββ+++++=Λ22110称为选模型。
二、自变量选择对预测的影响自变量选择对预测的影响可以分为两种情况考虑,第一种情况是全模型正确而误用了选模型;第二种情况是选模型正确而无用了全模型。
以下是这两种情况对回归的影响。
1、全模型正确而误用选模型的情况性质1,在j x 与m p x x ,,1Λ+的相关系数不全为0时,选模型回归系数的最小二乘估计是全模型相应参数的有偏估计,即jjp jp E βββ≠=)ˆ((p j ,,2,1Λ=) 性质2,选模型的预测是有偏的。
性质3,选模型的参数估计有较小的方差。
性质4,选模型的预测残差有较小的方差。
性质5,选模型的均方误差比全模型预测的方差更小。
性质1和性质2表明,当全模型正确时,而舍去了m-p 个自变量,用剩下的p 个自变量去建立选模型,参数估计值是全模型相应参数的有偏估计,用其做预测,预测值也是有偏的。
这是误用选模型产生的弊端。
性质3和性质4表明,用选模型去作预测,残差的方差比用全模型去作预测的方差小,尽管用选模型所作的预测是有偏的,但得到的预测残差的方差下降了,这说明尽管全模型正确,误用选模型是有弊也有利的。
性质5说明,即使全模型正确,但如果其中有一些自变量对因变量影响很小或回归系数方差过大,丢掉这些变量之后,用选模型去预测,可以提高预测的精度。
由此可见,如果模型中包含了一些不必要的自变量,模型的预测精度就会下降。
应用回归分析,第5章课后习题参考答案

第5章自变量选择与逐步回归思考与练习参考答案自变量选择对回归参数的估计有何影响答:回归自变量的选择是建立回归模型得一个极为重要的问题。
如果模型中丢掉了重要的自变量, 出现模型的设定偏误,这样模型容易出现异方差或自相关性,影响回归的效果;如果模型中增加了不必要的自变量, 或者数据质量很差的自变量, 不仅使得建模计算量增大, 自变量之间信息有重叠,而且得到的模型稳定性较差,影响回归模型的应用。
自变量选择对回归预测有何影响答:当全模型(m元)正确采用选模型(p元)时,我们舍弃了m-p个自变量,回归系数的最小二乘估计是全模型相应参数的有偏估计,使得用选模型的预测是有偏的,但由于选模型的参数估计、预测残差和预测均方误差具有较小的方差,所以全模型正确而误用选模型有利有弊。
当选模型(p元)正确采用全模型(m 元)时,全模型回归系数的最小二乘估计是相应参数的有偏估计,使得用模型的预测是有偏的,并且全模型的参数估计、预测残差和预测均方误差的方差都比选模型的大,所以回归自变量的选择应少而精。
如果所建模型主要用于预测,应该用哪个准则来衡量回归方程的优劣C统计量达到最小的准则来衡量回答:如果所建模型主要用于预测,则应使用p归方程的优劣。
试述前进法的思想方法。
答:前进法的基本思想方法是:首先因变量Y对全部的自变量x1,x2,...,xm建立m 个一元线性回归方程, 并计算F检验值,选择偏回归平方和显着的变量(F值最大且大于临界值)进入回归方程。
每一步只引入一个变量,同时建立m-1个二元线性回归方程,计算它们的F检验值,选择偏回归平方和显着的两变量变量(F 值最大且大于临界值)进入回归方程。
在确定引入的两个自变量以后,再引入一个变量,建立m-2个三元线性回归方程,计算它们的F检验值,选择偏回归平方和显着的三个变量(F值最大)进入回归方程。
不断重复这一过程,直到无法再引入新的自变量时,即所有未被引入的自变量的F检验值均小于F检验临界值Fα(1,n-p-1),回归过程结束。
(整理)自变量选择与逐步回归

自变量选择与逐步回归一、全模型和选模型设研究某一实际问题,涉及对因变量有影响的因素共有m 个,由因变量y 和m 个自变量构成的回归模型εββββ+++++=m m x x x y 22110称为全模型。
如果从可供选择的m 个变量中选出p 个,由选出的p 个自变量组成的回归模型p pp pp p p p x x x y εββββ+++++= 22110称为选模型。
二、自变量选择对预测的影响自变量选择对预测的影响可以分为两种情况考虑,第一种情况是全模型正确而误用了选模型;第二种情况是选模型正确而无用了全模型。
以下是这两种情况对回归的影响。
1、全模型正确而误用选模型的情况性质1,在j x 与m p x x ,,1 +的相关系数不全为0时,选模型回归系数的最小二乘估计是全模型相应参数的有偏估计,即jjp jp E βββ≠=)ˆ((p j ,,2,1 =) 性质2,选模型的预测是有偏的。
性质3,选模型的参数估计有较小的方差。
性质4,选模型的预测残差有较小的方差。
性质5,选模型的均方误差比全模型预测的方差更小。
性质1和性质2表明,当全模型正确时,而舍去了m-p 个自变量,用剩下的p 个自变量去建立选模型,参数估计值是全模型相应参数的有偏估计,用其做预测,预测值也是有偏的。
这是误用选模型产生的弊端。
性质3和性质4表明,用选模型去作预测,残差的方差比用全模型去作预测的方差小,尽管用选模型所作的预测是有偏的,但得到的预测残差的方差下降了,这说明尽管全模型正确,误用选模型是有弊也有利的。
性质5说明,即使全模型正确,但如果其中有一些自变量对因变量影响很小或回归系数方差过大,丢掉这些变量之后,用选模型去预测,可以提高预测的精度。
由此可见,如果模型中包含了一些不必要的自变量,模型的预测精度就会下降。
2、选模型正确而误用全模型的情况全模型的预测值是有偏估计;选模型的预测方差小于全模型的预测方差;全模型的预测误差将更大。
第五章自变量选择与逐步回归

D(e0 p ) D(e0m )
记(
X
X
)1
X X
p q
X X
p p
X
p
X
q
1
X
q
X
q
(
X
p
X
p
)1
ADA
B
B
D
ˆ 的前p 1个分量记为ˆp ,则
cov(ˆp ) 2 (( X p X p )1 ADA)
又 cov( p ) 2 ( X p X p )1, ADA 0
(3)依上法继续进行,到第 s 步,所有的 F ms j F (1, n m s) 为止,则第 s 1 步得到
的方程为最终方程。
三.逐步回归法
前进法与后退法都有各自的不足之处。 前进法的问题是不能反映引进新的自变量后 的变化情况。如某个自变量开始可能是显著 的,当引入其他变量后他变得不显著了,但 没有机会将其剔除。这种只考虑引进,不考 虑剔除的方法是不全面的。
X p ( p ( X p X p )1 X p X q q )
X p p X p ( X p X p )1 X p X q q
而
E(Yˆ)
E
(
X
ˆ
)
(
X
p
,
X
q
)(
p q
)
X pp Xqq
(3)选模型的参数估计有较小的方差,即
D(ˆ jp ) D(ˆ jm ), j 0,1,..., p
y 7.8 8.4 8.7 9 9.6 10.3 10.6 10.9 11.3 12.3 13.5 14.2 14.9 15.9 18.5 19.5 19.9 20.5
回归分析10:自变量的选择(2)

回归分析10:⾃变量的选择(2)⽬录Chapter 10:⾃变量的选择(2)5.2 ⾃变量选择的准则5.2.3 C p 统计量准则C p 统计量准则是从预测的⾓度提出来的⾃变量选择的准则。
对于选模型,定义 C p 统计量为C p =RSS qˆσ2−[n −2(q +1)] ,这⾥ RSS q 是选模型的残差平⽅和,ˆσ2是全模型中 σ2 的最⼩⼆乘估计。
我们按照 C p 统计量越⼩越好的准则选择⾃变量,并称其为 C p 准则。
提出 C p 统计量的想法如下:假设全模型为真,但为了提⾼预测的精度,⽤选模型做预测,因此需要 n 个预测值与期望值的相对偏差平⽅和的期望值(定义为 Γq )达到最⼩。
计算可得:Γqdef=En∑i =1˜y iq −E(y i)σ2=E 1σ2n∑i =1x ′iq ˜βq −x ′i β2=1σ2n∑i =1E x ′iq ˜βq −E x ′iq ˜βq+E x ′iq ˜βq−x ′iβ2=1σ2n∑i =1E x ′iq ˜βq −E x ′iq ˜βq2+E x ′iq ˜βq−x ′iβ2def=1σ2I 1+I 2.其中,第⼀部分 I 1 容易计算:I 1=n∑i =1Ex ′iq ˜βq−Ex ′iq ˜βq2=n∑i =1Varx ′iq ˜βq=σ2n∑i =1x ′iq X ′q X q−1x iq=σ2tr X ′q X q−1n∑i =1xiq x ′iq=(q +1)σ2 .第⼆部分 I 2 可利⽤定理 5.1.1 (1) 的结论和 (4) 的证明过程计算:[()][()]{[()][()]}{[()][()]}()[()]()()[()]I2=n∑i=1E x′iq˜βq−x′iβ2=n∑i=1x′iqβq+B−1Cβt−x′iqβq−x′itβt2=n∑i=1β′tC′B−1x iq−x it C′B−1x iq−x it′βt=n∑i=1β′tC′B−1x iq x′iqB−1C−x it x′iqB−1C−C′B−1x iq x′it+x it x′itβt=β′tC′B−1BB−1C−C′B−1C−C′B−1C+Dβt=β′tM−1βt=(n−q−1)E(˜σ2q)−σ2 .其中M=D−C′B−1C−1。
现代统计分析方法与应用第7章:自变量选择与逐步回归

前面曾提到模型:
y 0 p 1 p x1 2 p x2 pp x p p
对于该模型现将它的残差平方和记为SSEp,当再增加一个新的自变量xp+1 时,相应的残差平方和记为SSEp+1。根据最小二乘估计的原理,增加自变量 时残差平方和将减少,减少自变量时残差平方和将增加。因此有:
是y0的有偏估计。 从预测方差的角度看,根据性质4,选模型的预测方差小于全模型的预 测方差,即:
ˆ ˆ Dy0 p D y0m
2
从均方预测误差的角度看,全模型的均方预测误差为:
ˆ ˆ ˆ E y0m y0 D y0m E y0m E y0
SSEp1 SSEp
又记它们的复判定系数分别为:
R p1 1
2
SSEp 1
R2 1 p
SST SSEp
SST
由于SST是因变量的离差平方和,因而:
R 21 R 2 p p
即当自变量子集在扩大时,残差平方和随之减少,而复判定系数随之增 大 。 如果按残差平方和越小越好的原则来选择自变量子集,或者为提高复相 关系数,不论什么变量只要多取就行,则毫无疑问选的变量越多越好。这 样由于变量的多重共线性,给变量的回归系数估计值带来不稳定性,加上 变量的测量误差积累,参数数目的增加,将使估计值的误差增大。如此构 造的回归模型稳定性差,使得为增大复相关系数R而付出了模型参数估计稳 定性差的代价。
自变量筛选方法

自变量筛选方法
自变量筛选是统计学中一个重要的步骤,用于确定哪些自变量对因变量有显著影响。
以下是几种常用的自变量筛选方法:
1. 逐步回归分析:逐步回归分析是一种常用的自变量筛选方法。
它采用逐步选择的方式,将自变量逐个引入模型,同时根据一定的标准(如对模型的贡献、变量的显著性等)进行筛选。
这种方法有助于避免多重共线性问题,提高模型的解释性和预测能力。
2. 向前选择法:向前选择法也是一种常用的自变量筛选方法。
它从所有自变量中选择对因变量有显著影响的自变量,将其纳入模型中,然后重复这个过程,直到所有显著的自变量都被纳入模型中。
这种方法有助于避免遗漏重要的自变量,但可能会产生多重共线性问题。
3. 向后消除法:向后消除法与向前选择法相反,它首先将所有自变量纳入模型中,然后根据一定的标准(如对模型的贡献、变量的显著性等)逐步排除自变量。
这种方法有助于避免过度拟合问题,但可能会遗漏重要的自变量。
4. 岭回归分析:岭回归分析是一种用于解决多重共线性问题的自变量筛选方法。
它通过对自变量进行正则化处理,减小了自变量之间的相关性,从而避免了多重共线性问题。
岭回归分析在处理大数据集时特别有用。
5. 主成分分析:主成分分析是一种用于降维的自变量筛选方法。
它通过将多个相关联的自变量转化为少数几个不相关的主成分,从而降低了数据集的维
度。
主成分分析有助于提高模型的解释性和预测能力,但可能会遗漏一些重要的自变量。
这些自变量筛选方法各有优缺点,应根据具体情况选择适合的方法。
同时,为了确保模型的准确性和可靠性,应使用多种方法进行自变量筛选,并进行交叉验证和模型评估。
自变量选择和逐步回归分析

y
(X,u)bu
,
逐步回归的数学模型
在新模型 y
(X,u)
bu
中,
bˆu (uRu)1uRy, R I X ( X X )1 X
ˆ(u) ˆ ( X X )1 X ubˆu
残差平方和 Q(u) Q bˆu2 (uRu)
检验新变量的显著性
修正的复决定系数
Rs2
1
(1
Rs2 )
n
n
, s
s :回归方程中参数的个数 。
n : 样本容量,n s。
Rs2 : 复决定系数。 Rs2:修正的复决定系数。
修正的复决定系数最大
设回归方程中原有 r个自变量,后来又增加 了s个自变量,检验这 s个增加的自变量是否 有意义的统计量为
F
Rr2s Rr2 1 Rr2s
全模型与选模型
全模型 因变量y与所有的自变量x1,, xm的回归模型, 称为全模型
y 0 1x1 mxm
选模型 从所有m个变量中所选的p个自变量组成的回归模型 称为选模型.?
y 0 p 1p x1 2 p x2 pp xp p
准则2:C p 统计量达到最小
用选模型
y 0 p 1p x1 2 p x2 pp xp p
数据标准化
Z ij
xij x j
j
, yi
yi y ,
y
i 1,2,, n, j 1,2,, p
x j
1 n
nyi ,
n
n
j
(xij x j )2 , y
( yi y)2
i 1
i 1
标准化数据的模型及回归步骤
数据标准化后模型(1)变为
网络流行度预测中的逐步回归分析方法介绍

网络流行度预测中的逐步回归分析方法介绍随着互联网的发展,网络流行度成为了许多人关注的焦点。
无论是企业还是个人,都需要了解网络流行度的趋势和变化,以便采取相应的措施。
而逐步回归分析方法则是一种常用的预测网络流行度的方法之一。
一、什么是逐步回归分析方法逐步回归分析是一种多元线性回归分析的变体方法。
其核心思想是通过不断迭代的方式,根据自变量的重要性逐步选择进入模型的自变量,从而构建预测模型。
与传统的回归分析方法相比,逐步回归分析方法能够更好地解释变量之间的关系,提高模型的准确度。
二、逐步回归分析方法的步骤1. 数据收集与预处理:首先收集网络流行度的相关数据,并对数据进行预处理,包括去除异常值、处理缺失值等。
为了提高分析的准确性,还需要进行数据标准化处理,以消除不同指标之间的量纲影响。
2. 初步模型构建:在收集和预处理数据后,需要建立一个初步的回归模型。
可以根据经验知识或领域专家的建议,选择一些可能与网络流行度相关的自变量。
3. 自变量选择:逐步回归分析的核心就在于逐步选择自变量。
在初步模型的基础上,通过计算每个自变量的重要性指标,然后选择重要性最高的自变量加入模型中。
这个过程会不断迭代,直到模型中的所有自变量都被选择进去。
4. 模型评估与优化:在自变量选择的过程中,需要对模型进行评估和优化。
可以使用相关系数、均方误差等指标来评估模型的拟合效果,如果模型效果不佳,则可以尝试剔除一些不重要的自变量或者添加新的自变量。
5. 预测与应用:当模型构建完毕后,就可以使用模型来进行网络流行度的预测和分析。
根据输入的自变量数值,可以得到对应的网络流行度数值。
除了预测,逐步回归分析方法还可以通过分析模型中各个自变量的系数大小,来判断不同自变量对网络流行度的贡献程度。
三、逐步回归分析方法的优势和应用场景逐步回归分析方法相较于传统的回归分析方法具有以下优势:1. 自变量选择更加准确:逐步回归分析方法通过逐渐调整模型中的自变量,能够更准确地选择与网络流行度相关的自变量,提高模型的准确度和解释力。
应用回归分析-第5章课后习题参考答案

应用回归分析-第5章课后习题参考答案第5章自变量选择与逐步回归思考与练习参考答案5.1 自变量选择对回归参数的估计有何影响?答:回归自变量的选择是建立回归模型得一个极为重要的问题。
如果模型中丢掉了重要的自变量, 出现模型的设定偏误,这样模型容易出现异方差或自相关性,影响回归的效果;如果模型中增加了不必要的自变量, 或者数据质量很差的自变量, 不仅使得建模计算量增大, 自变量之间信息有重叠,而且得到的模型稳定性较差,影响回归模型的应用。
5.2自变量选择对回归预测有何影响?答:当全模型(m元)正确采用选模型(p元)时,我们舍弃了m-p个自变量,回归系数的最小二乘估计是全模型相应参数的有偏估计,使得用选模型的预测是有偏的,但由于选模型的参数估计、预测残差和预测均方误差具有较小的方差,所以全模型正确而误用选模型有利有弊。
当选模型(p元)正确采用全模型(m元)时,全模型回归系数的最小二乘估计是相应参数的有偏估计,使得用模型的预测是有偏的,并且全模型的参数估计、预测残差和预测均方误差的方差都比选模型的大,所以回归自变量的选择应少而精。
5.3 如果所建模型主要用于预测,应该用哪个准则来衡量回归方程的优劣?C统计量达到最小的准则来衡量回答:如果所建模型主要用于预测,则应使用p归方程的优劣。
5.4 试述前进法的思想方法。
答:前进法的基本思想方法是:首先因变量Y对全部的自变量x1,x2,...,xm建立m个一元线性回归方程, 并计算F检验值,选择偏回归平方和显著的变量(F值最大且大于临界值)进入回归方程。
每一步只引入一个变量,同时建立m-1个二元线性回归方程,计算它们的F检验值,选择偏回归平方和显著的两变量变量(F值最大且大于临界值)进入回归方程。
在确定引入的两个自变量以后,再引入一个变量,建立m-2个三元线性回归方程,计算它们的F检验值,选择偏回归平方和显著的三个变量(F值最大)进入回归方程。
不断重复这一过程,直到无法再引入新的自变量时,即所有未被引入的自变量的F检验值均小于F检验临界值Fα(1,n-p-1),回归过程结束。
应用回归分析,第5章课后习题参考答案

第5章自变量选择与逐步回归思考与练习参考答案自变量选择对回归参数的估计有何影响?答:回归自变量的选择是建立回归模型得一个极为重要的问题。
如果模型中丢掉了重要的自变量, 出现模型的设定偏误,这样模型容易出现异方差或自相关性,影响回归的效果;如果模型中增加了不必要的自变量, 或者数据质量很差的自变量, 不仅使得建模计算量增大, 自变量之间信息有重叠,而且得到的模型稳定性较差,影响回归模型的应用。
自变量选择对回归预测有何影响?答:当全模型(m元)正确采用选模型(p元)时,我们舍弃了m-p个自变量,回归系数的最小二乘估计是全模型相应参数的有偏估计,使得用选模型的预测是有偏的,但由于选模型的参数估计、预测残差和预测均方误差具有较小的方差,所以全模型正确而误用选模型有利有弊。
当选模型(p元)正确采用全模型(m 元)时,全模型回归系数的最小二乘估计是相应参数的有偏估计,使得用模型的预测是有偏的,并且全模型的参数估计、预测残差和预测均方误差的方差都比选模型的大,所以回归自变量的选择应少而精。
如果所建模型主要用于预测,应该用哪个准则来衡量回归方程的优劣?C统计量达到最小的准则来衡量回答:如果所建模型主要用于预测,则应使用p归方程的优劣。
试述前进法的思想方法。
答:前进法的基本思想方法是:首先因变量Y对全部的自变量x1,x2,...,xm建立m个一元线性回归方程, 并计算F检验值,选择偏回归平方和显著的变量(F 值最大且大于临界值)进入回归方程。
每一步只引入一个变量,同时建立m-1个二元线性回归方程,计算它们的F检验值,选择偏回归平方和显著的两变量变量(F值最大且大于临界值)进入回归方程。
在确定引入的两个自变量以后,再引入一个变量,建立m-2个三元线性回归方程,计算它们的F检验值,选择偏回归平方和显著的三个变量(F值最大)进入回归方程。
不断重复这一过程,直到无法再引入新的自变量时,即所有未被引入的自变量的F检验值均小于F检验临界值Fα(1,n-p-1),回归过程结束。
回归分析中的变量选择策略(Ⅰ)

回归分析是一种常用的统计方法,用于研究自变量和因变量之间的关系。
在进行回归分析时,变量的选择策略对结果的准确性和可解释性至关重要。
本文将就回归分析中的变量选择策略展开讨论。
一、理论基础回归分析的理论基础是建立在多元统计学和概率论的基础上的。
在进行回归分析时,需要考虑自变量之间的多重共线性、因变量的非线性关系等问题。
因此,变量选择策略需要综合考虑这些因素,以确保回归模型的稳健性和准确性。
二、变量选择方法在回归分析中,常用的变量选择方法包括前向选择、后向选择、逐步回归和岭回归等。
这些方法各有优缺点,需要根据具体情况进行选择。
前向选择是从一个空模型开始,逐步添加自变量,直到所有自变量都被纳入模型。
这种方法简单直观,但容易产生过拟合的问题。
后向选择则是从包含所有自变量的模型开始,逐步剔除对模型影响较小的自变量,直到找到最优的模型。
这种方法相对前向选择更加稳健,但可能会漏掉一些重要的变量。
逐步回归是前两种方法的结合,既考虑了自变量的增加,又考虑了自变量的减少。
这种方法在实际应用中较为常见。
岭回归是一种正则化方法,通过对参数进行惩罚,可以减少模型的过拟合问题。
在自变量之间存在多重共线性的情况下,岭回归可以更好地应对这一问题。
三、实际应用在实际应用中,变量选择策略需要根据具体问题进行选择。
对于自变量较多的情况,可以采用逐步回归或岭回归等方法来选择最优的变量组合。
对于自变量较少的情况,前向选择和后向选择也是不错的选择。
此外,还可以借助交叉验证、信息准则等方法来评估不同的变量选择策略,以选择最优的模型。
四、总结回归分析中的变量选择策略对模型的准确性和解释性至关重要。
在选择变量时,需要综合考虑自变量之间的关系、模型的稳健性等因素。
不同的变量选择方法各有优缺点,需要根据具体情况进行选择。
在实际应用中,可以结合交叉验证、信息准则等方法来评估不同的变量选择策略,以找到最优的模型。
回归分析中的变量选择策略(十)

回归分析中的变量选择策略回归分析是统计学中一种常用的分析方法,用来探讨自变量和因变量之间的关系。
在进行回归分析时,变量选择是一个十分重要的环节,它决定了模型的准确性和可解释性。
本文将探讨回归分析中的变量选择策略,包括前向选择、逐步回归、岭回归和LASSO回归等方法。
1. 前向选择前向选择是一种逐步选择变量的方法。
它从不包含任何自变量的模型开始,然后逐步添加自变量,直到达到某个停止规则为止。
前向选择的优点在于它很容易实现,并且能够有效地应对多重共线性。
然而,前向选择也有一些缺点,比如可能会产生过拟合的问题,以及对初始自变量的选择比较敏感。
2. 逐步回归逐步回归与前向选择类似,但是它包括了两个阶段:逐步向前和逐步向后。
在逐步向前阶段,模型会逐步添加自变量;而在逐步向后阶段,模型会逐步剔除自变量。
逐步回归的优点在于它能够克服前向选择的一些缺点,比如对初始自变量的选择不敏感。
然而,逐步回归也有一些缺点,比如对于大量自变量的情况下,可能会得到比较复杂的模型。
3. 岭回归岭回归是一种正则化方法,它通过在最小二乘估计中加入L2范数惩罚项来控制模型的复杂性。
因为岭回归可以处理多重共线性的问题,并且能够得到较为稳定的估计结果,所以在实际应用中得到了广泛的应用。
然而,岭回归也有一些缺点,比如模型中的参数可能会被过度惩罚。
4. LASSO回归LASSO回归是另一种正则化方法,它通过在最小二乘估计中加入L1范数惩罚项来控制模型的复杂性。
LASSO回归相较于岭回归来说,具有更强的变量选择能力,能够将一些不重要的自变量系数缩减为零。
因此,LASSO回归在变量选择和稀疏建模方面有很好的表现。
然而,LASSO回归也存在一些问题,比如在存在高度共线性的情况下,可能会随机选择其中之一,并且在解决共线性问题时,可能会产生扭曲。
在实际应用中,选择合适的变量选择策略是非常重要的。
不同的方法适用于不同的数据和问题,研究人员需要根据具体情况来选择合适的方法。
逐步回归
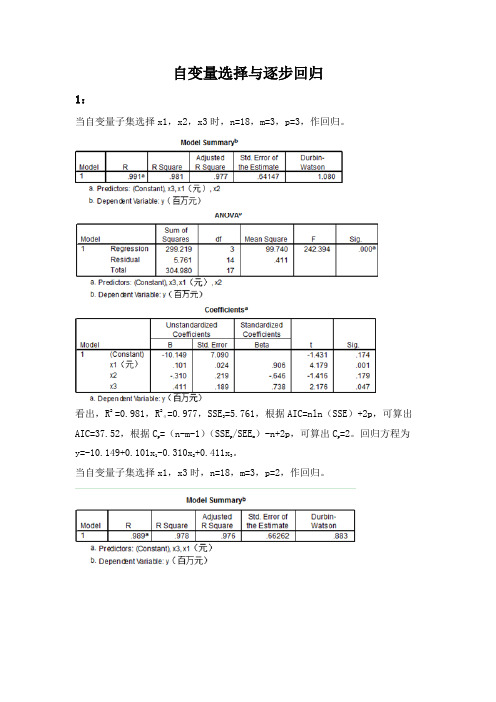
自变量选择与逐步回归1:当自变量子集选择x1,x2,x3时,n=18,m=3,p=3,作回归。
看出,R2 =0.981,R2α=0.977,SSE3=5.761,根据AIC=nln(SSE)+2p,可算出AIC=37.52,根据Cp =(n-m-1)(SSEp/SEEm)-n+2p,可算出Cp=2。
回归方程为y=-10.149+0.101x1-0.310x2+0.411x3。
当自变量子集选择x1,x3时,n=18,m=3,p=2,作回归。
得出:R2 =0.978,R2α=0.976,SSE2=6.586,根据AIC=nln(SSE)+2p,可算出AIC=37.93,根据Cp =(n-m-1)(SSEp/SEEm)-n+2p,可算出Cp=2.005。
回归方程为y=-14.049+0.076x1+0.172x3。
当自变量子集选择x1时,n=18,m=3,p=1,作回归。
得出:R2 =0.973,R2α=0.971, SSE1=8.285,根据AIC=nln(SSE)+2p,可算出AIC=40.06,根据Cp =(n-m-1)(SSEp/SEEm)-n+2p,可算出Cp=4.134。
回归方程为y=-0.821+0.110x。
12:前进法:在Model下拉框中选择前进法Forward,点击Options看到默认的显著性水平为0.05,运行得:从输出结果看到,前进法依次引入了x1,x2,x3,x6,x7,最优模型为y=-2393.975+1.490x1+2.718x2+2.209x3+0.078x6+0.037x7。
复决定系数R2 =0.992,调整的复决定系数R2α=0.991,全模型的复决定系数R2 =0.994,调整的复决定系数R2α=0.991。
后退法:在Model下拉框中选择前进法Backward,点击Options看到默认的显著性水平为0.10,运行得:其中模型1是全模型,从模型2到模型4依次剔除变量x4,x8,x9,最优回归子集模型4的回归方程为:y=-2089.883+1.412x1+2.395x2+2.021x3+0.077x6+0.036x7+0.859x5复决定系数R2 =0.993调整的复决定系数R2α=0.992全模型的复决定系数R2 =0.994,调整的复决定系数R2α=0.991。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
自变量选择与逐步回归一、全模型和选模型设研究某一实际问题,涉及对因变量有影响的因素共有m 个,由因变量y 和m 个自变量构成的回归模型εββββ+++++=m m x x x y 22110称为全模型。
如果从可供选择的m 个变量中选出p 个,由选出的p 个自变量组成的回归模型p pp pp p p p x x x y εββββ+++++= 22110称为选模型。
二、自变量选择对预测的影响自变量选择对预测的影响可以分为两种情况考虑,第一种情况是全模型正确而误用了选模型;第二种情况是选模型正确而无用了全模型。
以下是这两种情况对回归的影响。
1、全模型正确而误用选模型的情况性质1,在j x 与m p x x ,,1 +的相关系数不全为0时,选模型回归系数的最小二乘估计是全模型相应参数的有偏估计,即jjp jp E βββ≠=)ˆ((p j ,,2,1 =) 性质2,选模型的预测是有偏的。
性质3,选模型的参数估计有较小的方差。
性质4,选模型的预测残差有较小的方差。
性质5,选模型的均方误差比全模型预测的方差更小。
性质1和性质2表明,当全模型正确时,而舍去了m-p 个自变量,用剩下的p 个自变量去建立选模型,参数估计值是全模型相应参数的有偏估计,用其做预测,预测值也是有偏的。
这是误用选模型产生的弊端。
性质3和性质4表明,用选模型去作预测,残差的方差比用全模型去作预测的方差小,尽管用选模型所作的预测是有偏的,但得到的预测残差的方差下降了,这说明尽管全模型正确,误用选模型是有弊也有利的。
性质5说明,即使全模型正确,但如果其中有一些自变量对因变量影响很小或回归系数方差过大,丢掉这些变量之后,用选模型去预测,可以提高预测的精度。
由此可见,如果模型中包含了一些不必要的自变量,模型的预测精度就会下降。
2、选模型正确而误用全模型的情况全模型的预测值是有偏估计;选模型的预测方差小于全模型的预测方差;全模型的预测误差将更大。
一个好的回归模型,并不是考虑的自变量越多越好。
在建立回归模型时,选择自变量的基本知道思想是少而精。
丢掉了一些对因变量y 有影响的自变量后,所付出的代价是估计量产生了有偏性。
然而,尽管估计是有偏的,但预测偏差的方差会下降。
另外,如果保留下来的自变量有些对因变量无关紧要,那么,方程中包括这些变量会导致参数估计和预测的有偏性和精度降低。
因此,在建立实际问题的回归模型时,应尽可能剔除那些可有可无的自变量。
三、所有子集回归1、所有子集的数目设在一个实际问题的回归建模中,有m 个可供选择的变量m x x x ,,,21 ,由于每个自变量都有入选和不入选两种情况,这样y 关于这些自变量的所有可能的回归方程就有m 2-1个,这里-1是要求回归模型中至少包含一个自变量,即减去模型中只包含常数项的这一种情况。
如果把回归模型中只包含常数项的这一种情况也算在内,那么所有可能的回归方程就有m 2个。
从另一个角度看,选模型包含的自变量数目p 有从0到m 共有m+1种不同的情况,而对选模型中恰包含p 个自变量的情况,从全部m 个自变量中选p 个的方法共有线性组合p m C 个,因而所有选模型的数目为:m m m m mC C C 210=+++ 。
2、关于自变量选择的几个准则把选模型的残差平方和记为p SSE ,当再增加一个新的自变量1+p x 时,相应的残差平方和记为1+p SSE 。
根据最小二乘估计的原理,增加自变量时残差平方和将减少,减少自变量时残差平方和将增加。
因此有p p SSE SSE ≤+1,它们的负决定系数分别为:SST SSE R p p 1211++-=,SST SSE R p p -=12,由于SST 是因变量的离差平方和,与自变量无关,因而有221p p R R ≥+,即当自变量子集在扩大时,残差平方和随之减少,而复决定系数2R 随之增大。
因此,如果按残差平方和越小越好的原则来选择自变量子集,或者为提高复决定系数,不论什么变量只要多取就行,则毫无疑问选的变量越多越好。
这样由于变量的多重共线性,给变量的回归系数估计值带来不稳定性,加上变量的测量误差积累,参数数目的增加,将使估计值的误差增大。
因此,从数据与模型拟合优劣的直观考虑出发,认为残差平方和SSE 最小的回归方程就是最好的,还曾用负相关系数R 来衡量回归拟合好坏都不能作为选择变量的准则。
准则一:自由度调整复决定系数达到最大。
当给模型增加自变量时,复决定系数也随之逐步增大,然而复决定系数的增大代价是残差自由度的减少,因为残差自由度等于样本个数与自变量个数之差。
自由度小意味着估计和预测可靠性低。
设)1(11122R p n n R a -----=为自由度调整后的复决定系数,其中,n 为样本容量,p 为自变量的个数。
在实际问题的回归建模中,自由度调整复决定系数2a R 越大,所对应的回归方程越好。
则所有回归子集中2a R 最大者对应的回归方程就是最优方程。
从另外一个角度考虑回归的拟合效果,回归误差项2σ的无偏估计为:SSE p n 11ˆ2--=σ,此无偏估计式中也加入了惩罚因子n-p-1,2ˆσ实际上就是用自由度n-p-1作平均的平均残差平方和。
当自变量个数从0开始增加时,SSE 逐渐减小,作为除数的惩罚因子n-p-1也随之减小。
当自变量个数从0开始增加时,2ˆσ先是开始下降然后稳定下来,当自变量个数增加到一定数量后,2ˆσ又开始增加。
这是因为刚开始时,随着自变量个数增加,SSE 能够快速减小,虽然作为除数的惩罚因子n-p-1也随之减小,但由于SSE 减小的速度更快,因而2ˆσ是趋于减小的。
当自变量数目增加到一定程度,应该说重要的自变量基本上都已经选上了,这时在增加自变量,SSE 减少不多,以至于抵消不了除数n-p-1的减小,最终又导致了2ˆσ的增加。
用平均残差平方和2ˆσ和调整的复决定系数作为自变量选元准则实际上是等价的。
因为有22ˆ11σSSTn R a --=,由于SST 是与回归无关的固定值,因而2a R 与2ˆσ是等价的。
2ˆσ小说明模型好,而2ˆσ小2a R 就会大也说明模型好。
准则二:赤池信息量AIC 达到最小。
设模型的似然函数为),(x L θ,θ的维数为p,x 为随即样本,则AIC 定义为:AIC=-2),ˆ(ln x L L θ+2p,其中Lθˆ为θ的极大似然估计;p 为未知参数的个数,式中右边的第一项是似然函数的对数乘以-2,第二项惩罚因子是未知参数个数的2倍。
似然函数越大估计量越好,现在AIC 是死然数的对数乘以-2再加上惩罚因子2p ,因而选择使AIC 达到最小的模型是最优模型。
在回归分析的建模过程中,对每一个回归子集计算AIC ,其中AIC 最小者所对应的模型是最优回归模型。
准则三:p C 统计量达到最小即使全模型正确,仍有可能选模型有更小的预测误差,p C 正是根据这一原理提出来的。
p C =p n SSE SSE m n m p2)1(+---,其中m SSE m n 11ˆ2--=σ为全模型中2σ的无偏估计。
选择使p C 最小的自变量子集,这个自变量子集对应的回归方程就是最优回归方程。
四、前进法前进法的思想是变量由少到多,每次增加一个,直至没有可引入的变量为止。
具体做法是首先将去全部m 个自变量,分别对因变量y 建立m 个一元线性回归方程,并分别计算这m 个一元回归方程的m 个回归系数的F 检验值,记为{}11211,,,m F F F ,选其最大者记为{}112111,,,max m j F F F F =,给定显著性水平α,若)2,1(1-≥n F F j α,则首先将j x 引入回归方程,为了方便,设j x 就是1x 。
接下来因变量y 分别与(21,x x ),(31,x x ),…,(m x x ,1)建立m-1个二元线性回归方程,对m-1个回归方程中m x x x ,,,32 的回归系数进行F 检验,计算F值,记为{}22322,,,m F F F ,选其最大者记为{}223222,,,max m j F F F F =,若)3,1(2-≥n F F j α,则接着将j x 引入回归方程。
依照上述方法接着做下去,直至所有未被引入方程的自变量的F 值均小于αF (1,n-p-1)时为止,这时,得到的回归方程就是最终确定的方程。
每步检验中的临界值αF (1,n-p-1)与自变量数目p 有关,实际使用当中,通常使用显著性p 值作检验。
五、后退法后退法与前进法相反,首先用全部m 个变量建立一个回归方程,然后在这m 个变量中选择一个最不重要的变量,将它从方程中剔除,即把回归系数检验的F 值最小者对应的自变量剔除。
设对m 个回归系数进行F 检验(偏F 统计量),记求得的F 值为{}m m m m F F F ,,,21 ,选其最小者记为{}m m m m m j F F F F ,,,min 21 =,给定显著性水平α,若)1,1(--≤m n F F m j α,则首先将j x 从回归方程中剔除,为了方便,设j x 就是m x 。
接着对剩下的m-1个自变量重新建立回归方程,进行回归系数的显著性检验,项上面那样计算出1-m j F ,如果又有)1)1(,1(1---≤-m n F F m j α,则剔除j x ,重新建立y 关于m-2个自变量的回归方程,依次下去,直至回归方程中所剩余的p 个自变量的F 检验值均大于临界值αF (1,n-p-1),没有可剔除的自变量为止。
这时,得到的回归方程就是最终确定的方程。
六、前进法和后退法的比较前进法和后退法显然都有明显的不足。
前进法可能存在这样的问题,即不能反映引进新的自变量后的变化情况。
因为某个自变量开始可能是显著的,但当引入其他自变量后它变得并不显著了,但是也没有机会将其剔除,即一旦引入,就是“终身制”的,这种只考虑引入,而没有考虑剔除的做法显然是不全面的。
后退法的明显不足是,一开始把全部自变量引入回归方程,这样计算量很大。
如果有些自变量不太重要,一开始就不引入,就可减少一些计算量;再就是一旦某个自变量被剔除,“一棍子就把它打死了”,再也没有机会重新进入回归方程。
如果问题涉及的自变量m x x x ,,,21 是完全独立的(或不相关),那么在取进α=出α时,前进法与后退法所建立的回归方程是相同的。
然而在实际中很难碰到自变量间真正无关的情况,尤其是经济问题中,所研究的绝大部分问题,自变量间都有一定的相关性。
这就会使得随着回归方程中变量的增加和减少,某些自变量对回归方程的影响也会发生变化。
这是因为自变量间的不同组合,由于它们相关的原因,对因变量y 的影响可能大不一样。
如果几个自变量的联合效应对y 有重要作用,但是单个自变量对y 的作用都不显著,那么前进法就不能引入这几个变量,而后退法却可以保留这几个自变量,这是后退法的一个优点。