高性能计算导论课件-高性能第一章PPT-PPT文档资料
合集下载
高性能计算和高性能计算机.ppt

常用并行库
• 目前的并行库很多,包括PBLAS(Parallel Basic Linear Algebra Subroutines),以及建立在其基础上的LAPACK和 ScaLAPACK,提供了一些线性代数问题的并行求解算法, 如求特征值、最小二乘问题等。LAPACK是为SMP系统优 化的,ScaLAPACK是为DMP系统优化的。大多数高性能计 算系统都提供在本系统上优化的PBLAS、LAPACK、 ScaLAPACK。
共享存储模型
• 特点:
– 一个并行程序由多个共享内存的并行任务组成,数据的交换通过隐含地使 用共享数据来完成。
– 一般仅需指定可以并行执行的循环,而不需考虑计算与数据如何划分,以 及如何进行任务间通信,编译器会自动完成上述功能。
• OpenMP:
– 目前流行的共享内存模型开发标准是OpenMP。 – OpenMP定义了一套编译指导语句,用于指定程序的并行性、数据的共享/
高性能计算和高性能计算机
2007-08-10
目录
• 并行计算概要 • 高性能计算机体系结构 • 并行编程简介 • 高性能计算机群 • 并行计算的应用模式
计算是认识世界的主要手段
实验危险
环境科学
全球气候 污染输运
生物学
药物设计
应用物理
新材料设计 辐射传输 宇宙演化
不可能进行实验
工程
多物理尺度的问题 流体力学(CFD) 结构力学(CAE)
性能分析与预测
• 程序性能分析(profiling)可以帮助用户找到程序中最费 时的部分,从而集中精力进行改进和优化,是改进程 序性能的有效手段
• 传统的性能分析工具一般仅提供子程序级的性能分析 • 但对于高性能程序来说,对于循环程序的性能分析是
数学高性能计算PPT课件

• 采用集中式负载平衡方案,是否存在通信瓶颈?
• 采用动态负载平衡方案,调度策略的成本如何?
第44页/共46页
小 结
• 划分
• 域分解和功能分解
• 通信
• 任务间的数据交换
• 组合
• 任务的合并使得算法更有效
• 映射
• 将任务分配到处理器,并保持负载平衡
第45页/共46页
感谢您的观看。
第46页/共46页
• 划分的任务尺寸是否大致相当。(均衡)
• 若否,分配处理器时很难做到工作量均衡
• 任务数是否与问题尺寸成比例。
• 理想情况下,问题尺寸的增加应引起任务数的增加而不是任务
尺寸的增加
第19页/共46页
第七章 并行算法的一般设计过程
•
7.1 PCAM 设计方法学
•
7.2 划分
•
7.3 通信
•
7.4 组合
• 通过增加任务的粒度和重复计算,可以减少通信成本;
• 保持映射和扩展的灵活性,降低软件工程成本;
第32页/共46页
方法描述 (2)
• 增加粒度:
• 在划分阶段,致力于尽可能多的任务以增大并行执
行的机会。但定义大量的细粒度任务不一定产生一
个有效的算法,因为这有可能增加通信的代价和任
务创建的代价
• 表面-容积效应:通信量比例于子域的表面积,而
第13页/共46页
域分解
• 示例:三维网格的域分解,各格点上计算都是重复的。下图是三种分解方法:
1‐D
2‐D
图7.2
第14页/共46页
3‐D
域分解
• 不规则区域的分解示例:
第15页/共46页
功能分解
• 划分的对象是计算,将计算划分为不同的任务,其出发点不同于域分解;
• 采用动态负载平衡方案,调度策略的成本如何?
第44页/共46页
小 结
• 划分
• 域分解和功能分解
• 通信
• 任务间的数据交换
• 组合
• 任务的合并使得算法更有效
• 映射
• 将任务分配到处理器,并保持负载平衡
第45页/共46页
感谢您的观看。
第46页/共46页
• 划分的任务尺寸是否大致相当。(均衡)
• 若否,分配处理器时很难做到工作量均衡
• 任务数是否与问题尺寸成比例。
• 理想情况下,问题尺寸的增加应引起任务数的增加而不是任务
尺寸的增加
第19页/共46页
第七章 并行算法的一般设计过程
•
7.1 PCAM 设计方法学
•
7.2 划分
•
7.3 通信
•
7.4 组合
• 通过增加任务的粒度和重复计算,可以减少通信成本;
• 保持映射和扩展的灵活性,降低软件工程成本;
第32页/共46页
方法描述 (2)
• 增加粒度:
• 在划分阶段,致力于尽可能多的任务以增大并行执
行的机会。但定义大量的细粒度任务不一定产生一
个有效的算法,因为这有可能增加通信的代价和任
务创建的代价
• 表面-容积效应:通信量比例于子域的表面积,而
第13页/共46页
域分解
• 示例:三维网格的域分解,各格点上计算都是重复的。下图是三种分解方法:
1‐D
2‐D
图7.2
第14页/共46页
3‐D
域分解
• 不规则区域的分解示例:
第15页/共46页
功能分解
• 划分的对象是计算,将计算划分为不同的任务,其出发点不同于域分解;
《高能计算介绍》PPT课件

2021/3/8
18
编译并行程序:
1. openmp paralleled fortran program efc -O2 -tpp2 -fpp -openmp yourprog.f -o yourprog.out
2 .mpi paralleled fortran program efc -O2 -tpp2 yourprog.f -o yourprog.out lmpi
`output1'
prog<input2>output1 \> the same using input file
named `input2'
prog<input2>output1& \> the same `in background'
control-c
\> if cursor does not return: kill task
高性能计算介绍
2021/3/8
1
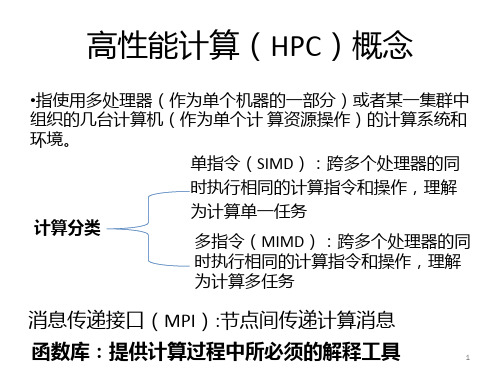
什么是高性能计算?(HPC) 1.高速运算 2.大内存 3.海量存储
2021/3/8
2
常见的高性能计算的实现 1. 多CPU共享内存结构(SGI Altix 3000) 2. 集群(cluster)结构(联想计算集群) 操作系统
Unix, Linux, Windows 并行开发软件
MPI, OpenMP
2021/3/8
3
SGI Altix 3700体系结构
一 系统模块
1.C brick: 32个1.3GHz/3M Intel Itanium2 cpu 2. M brick: 32G内存 3. R brick:路由 4. IX brick:输入/输出 5. D brick: 硬盘扩展(连接1T盘阵)
高性能计算导论课件-高性能计算导论-PPT文档资料

• 作业2:
– 任意选择一个演讲题目,谈谈你对该研究领域的理解 – 长度不限、鼓励原创观点
• 作业提交
– 9月10日,最后一节课上提交打印版
In+Lab@SYSU
3
智能规划
中山大学计算机软件所教授,博士生导师 吉林大学珠海学院计算机科学与技术系主任 中国计算机学会理事 中国计算机教育专业委员会秘书长 姜云飞 教授 中国计算机学会人工智能专业委员会自动推 理学组组长
高性能计算导论
超级计算系 数据科学与计算机学院 中山大学 2019年夏季学期
In+Lab@SYSU
1
课程时间表
In+Lab@SYSU
2
课程作业
• 作业1:
– – – – 写一个高性能计算的综述 定义、起源、分支、应用、最新研究方向等 请做好引用及提供参考文献 A4纸张、单栏、小4号宋体、4页以上
In+Lab@SYSU
4
机器学习辅助的进化计算方法
• • • • • • 詹志辉
副教授
2019年广东省自然科学杰出青年基金获得者 2019年中国高被引学者(计算机科学)入选者 2019年珠江科技新星人才计划项目入选者 2019年中国计算机学会(CCF)优秀博士论文奖 2019年广东省优秀博士学位论文奖 已发表学术论文40多篇,其中IEEE Transactions 等 SCI期刊论文13篇,ESI前1%高被引论文3篇,其中一 篇入选ESI 前0.1% Hot Paper.
李全忠
讲师
In+Lab@SYSU
7
数据密集型视觉计算
• 视觉计算、智能学习、大规模数据处理 • 教育部新世纪优秀人才支持计划入选者,广东省自然科 学杰出青年基金获得者,主持中山大学智能媒体计算实 验室 • 迄今共发表或录用论文70余篇(Proceeding of the IEEE论文1篇,IEEE TPAMI论文4 篇,IEEE TIP论文4 篇,IEEE TCSVT论文4篇,国际会议论文ICCV、CVPR 、NIPS、ACM Multimedia 20余篇) • 香港理工大学,访问教授 • 美国加州大学洛杉矶分校(UCLA),博士后研究员
高性能计算机PPT

目前国际上关于巨型机系统的近期目标(2004年左 目前国际上关于巨型机系统的近期目标(2004年左 近期目标 是开发百万亿次系统,远期目标(2010年前 年前) 右)是开发百万亿次系统,远期目标(2010年前)是开 发千万亿次系统, 发千万亿次系统,表1列出了未来几年国外将推出的先 进巨型机系统. 进巨型机系统.
系统名称 Cray 红色风暴 Cray X1 ( 原 SV2) ) 富 士 HPC2500 通
峰值性能 40万亿次 万亿次
CPU
CPU数量 数量
完成时间
投资方
AMD Opteron 定制MSP 定制
16000个 个
2004年 年
Sandia NSA/DO D 富 士 通 公司 美 国 能 源部 美 国 能 源部 美 国 能 源部 IBM 公 司
52.4万亿次 万亿次
4096个 个
2003年 年
85.1万亿次 万亿次
SPARC64 V
16384个 个
2003年 年
IBM ASCI紫色 紫色
100万亿次 万亿次
Power5
12544个 个
2004年 年
IBM 蓝色行星
150万亿次 万亿次
Power5
16384个 个
2005年 年
IBM 蓝色基因 蓝色基因/L
为占领世界巨型机领域的制高点,夺取信息技术优势, 为占领世界巨型机领域的制高点,夺取信息技术优势,世界各 发达国家,特别是美国和日本,不惜投入大量的人力,物力和财力, 发达国家,特别是美国和日本,不惜投入大量的人力,物力和财力, 发展巨型计算机. 发展巨型计算机.发展巨型机的源动力来自政府行为和市场驱动两 个方面.出于科技发展和国家安全的需要, 个方面.出于科技发展和国家安全的需要,美国能源部的加速战略 计算计划(ASCI),在过去几年中已先后完成了从万亿次到12 ),在过去几年中已先后完成了从万亿次到12万亿 计算计划(ASCI),在过去几年中已先后完成了从万亿次到12万亿 次的4台超级计算机,并计划近期成30万亿次系统,2004年达到 30万亿次系统 年达到100 次的4台超级计算机,并计划近期成30万亿次系统,2004年达到100 万亿次.日本是继美国之后巨型机研究力量最强的国家, 万亿次.日本是继美国之后巨型机研究力量最强的国家,重点研制 大规模并行机和并行向量机, 40万亿次 地球模拟器"系统外, 万亿次" 大规模并行机和并行向量机,除40万亿次"地球模拟器"系统外, 日本计划在2005年研制完成130万亿次的"宇宙模拟器" 2005年研制完成130万亿次的 日本计划在2005年研制完成130万亿次的"宇宙模拟器".另一方 在市场驱动下, 面,在市场驱动下,超级计算机正从科学计算向经济和商业各个领 域扩展,用于商业的超级计算机,其数量急剧增加, 域扩展,用于商业的超级计算机,其数量急剧增加,最高性能已突 破万亿次. 破万亿次.
高性能计算(HPC)PPT课件
如何做好HPC的销售工作之应用 篇
•4、流体力学/分子动力学
主要应用软件:CFD(Ansys、Fluent)工程计算 软件
了解用户研究方向:流体材料、空气动力、 化学反应
了解关键词:并行效果高,动态负载均衡
CPU选型:advanced
内存选型:1、根据CPU
2、需要大内. 存
10
如何做好HPC的销售工作之应用 篇
支持GPGPU 的生物计算软件-GROMACS
支持GPGPU 的生物计算软件-NAMD 支持GPGPU 的生物计算软件-HMMER 支持GPGPU 的生物计算软件-MUMmerGPU
支持GPGPU 的生物计算软件-AxRecon
.
15
.
6
如何做好HPC的销售工作之应用 篇
•1、计算物理
•主要应用软件:VASP 了解用户研究方向:物理计算方向有金属、半导体、绝缘体 了解关键词:Kpoint 4X4X4 8X8X8 CPU选型:advanced 内存选型:1、根据CPU
2、CPU及Kpoint 硬盘选型:I/O量小,SATA 网络选型:跟进Kpoint 软件线性比:高
•5、量子化学 主要应用软件:ADF
了解用户研究方向:物理光谱、分子计算、 材料计算
了解关键词:并行效果高,动态负载均衡
CPU选型:advanced
内存选型:1、根据CPU
2、不需要大内存
硬盘选型:I/O量小,SA. TA
11
如何做好HPC的销售工作之应用 篇
•6、材料计算 主要应用软件:wien2k 了解用户研究方向:材料计算、电导率
.
7
如何做好HPC的销售工作之应用 篇
•2、计算材料
•主要应用软件:Materials Studio
高性能计算导论课件-高性能第一章PPT

divisor = 2; core_difference = 1; sum = my_value; while ( divisor <= number of cores ) {
if ( my_rank % divisor == 0 ) { partner = my_rank + core_difference; receive value from partner core; sum += received value;
:
例子(续)
Core
01
2
my_sum 8 19 7
3
4
15 7
5
67
13 12 14
Global sum 8 + 19 + 7 + 15 + 7 + 13 + 12 + 14 = 95
Core
01
2
my_sum 95 19 7
3
4
15 7
5
67
13 12 14
别急! 还有一个更好 的方法来计算 全局总和
} else { partner = my_rank - core_difference; send my sum to partner core;
} divisor *= 2; core_difference *=2; }
练习3
作为前面问题的另一种解法,可以使用C 语言的位操作来实现树形结构的求全局 总和。为了了解它是如何工作的,写下 核的二进制数编号是非常有帮助的,注 意每个阶段相互合作的成对的核。
求和例子的第二部分——任务 并行
总共有两个任务:一个任务由master核执行,负责接收从其他核传来的 部分和,并累加部分和; 另一个任务由其他核执行, 负责将自己计算得 到的部分和传递给master核。
高性能计算课件

Linux并行程序设计
1
主要内容
MPI 编程基础
MPI 进程 / 进程组 MPI 通信器 MPI 消息 MPI 程序基本结构
MPI 程序编译与运行 MPI 消息传递 高性能计算库函数 大型程序编译
2
MPI 介绍
Message Passing Interface
二、 MPI 消息传递
15
MPI 消息传递
MPI 点对点通信类型
阻塞型和非阻塞型
MPI 消息发送模式
标准模式、缓冲模式、同步模式、就绪模式
MPI 聚合通信
多个进程间的通信
16
阻塞型和非阻塞型通信
阻塞型 (blocking) 和非阻塞型 (non blocking) 通信
C
MPI_Datatype datatype, int dest, int tag, MPI_Comm comm,
MPI_Request *request)
创建一个非阻塞型消息发送请求 参数含义与 MPI_ISEND 相同 该函数并不进行消息的实际发送,只是创建一个请求句柄, 通过 request 返回给用户程序,留待以后实际发送时使用 MPI_SEND_INIT 对应标准的非阻塞型消息发送,相应地有 MPI_BSEND_INIT、MPI_SSEND_INIT、MPI_RSEND_INIT
18
MPI 消息发送模式
MPI 提供四种点对点消息发送模式 标准模式 ( standard mode ) 缓冲模式 ( buffered mode ) 同步模式 ( synchronous mode ) 就绪模式 ( ready mode )
每种发送模式都有相应的阻塞型和非阻塞型函数
1
主要内容
MPI 编程基础
MPI 进程 / 进程组 MPI 通信器 MPI 消息 MPI 程序基本结构
MPI 程序编译与运行 MPI 消息传递 高性能计算库函数 大型程序编译
2
MPI 介绍
Message Passing Interface
二、 MPI 消息传递
15
MPI 消息传递
MPI 点对点通信类型
阻塞型和非阻塞型
MPI 消息发送模式
标准模式、缓冲模式、同步模式、就绪模式
MPI 聚合通信
多个进程间的通信
16
阻塞型和非阻塞型通信
阻塞型 (blocking) 和非阻塞型 (non blocking) 通信
C
MPI_Datatype datatype, int dest, int tag, MPI_Comm comm,
MPI_Request *request)
创建一个非阻塞型消息发送请求 参数含义与 MPI_ISEND 相同 该函数并不进行消息的实际发送,只是创建一个请求句柄, 通过 request 返回给用户程序,留待以后实际发送时使用 MPI_SEND_INIT 对应标准的非阻塞型消息发送,相应地有 MPI_BSEND_INIT、MPI_SSEND_INIT、MPI_RSEND_INIT
18
MPI 消息发送模式
MPI 提供四种点对点消息发送模式 标准模式 ( standard mode ) 缓冲模式 ( buffered mode ) 同步模式 ( synchronous mode ) 就绪模式 ( ready mode )
每种发送模式都有相应的阻塞型和非阻塞型函数
第1讲-高性能计算与高性能计算机

本PPT部分内容来源于国家高性能计算中心(合肥) 2016/3/15 4
并行计算平民化的到来!
每个程序员面临的多核并行计算时代
在单个芯片上内置多个处理单元-“核” 每个处理器视为小型的并行计算机
双核 四核 多核
• 并行计算已经成为必然!
本PPT部分内容来源于国家高性能计算中心(合肥)
通信密集型应用(Network-intensive):
协同工作,网格计算,遥控和远程诊断等。 应用领域:网站、信息中心、搜索引擎、电信、流媒体等。
本PPT部分内容来源于国家高性能计算中心(合肥) 2016/3/15 16
1. 高性能计算的意义(6)
千万亿次超级计算机的应用需求
应用领域
生物医学
应用需求
蛋白质电子态的计算 药物发明中的筛选过程 蛋白质折叠 发动机燃烧模拟和机翼设计模拟 短期天气预报 长期天气预报 局部突发性灾难预报(如洪水、海啸) 完全等离子分析(包括电子结构分析) 核武器数值模拟 天然气燃烧 复合材料的结构分析和功能预测 新材料发明 超新星三维模拟 密码破译 先进武器模拟 2016/3/15
高性能计算与并行程序设计
计算机学院计算机科学与技术系 主讲:陈 蕾 博士/副教授 E-mail: chenlei@
本PPT部分内容来源于国家高性能计算中心(合肥) 2016/3/15
1
为什么要开设这门课程
本课程主要涉及高性能计算和并行程序设计,其核心是 并行技术
澄清对并行计算的认识:
●不是少数人的专利 ●高性能计算随着机群系统、多核处理器的出现将逐渐普及到桌面系统
了解高性能计算的前沿技术发展情况 锻炼基本的资料检索、文献阅读、归纳整理和口头报告的能力 实实在在体验并行软件开发
并行计算平民化的到来!
每个程序员面临的多核并行计算时代
在单个芯片上内置多个处理单元-“核” 每个处理器视为小型的并行计算机
双核 四核 多核
• 并行计算已经成为必然!
本PPT部分内容来源于国家高性能计算中心(合肥)
通信密集型应用(Network-intensive):
协同工作,网格计算,遥控和远程诊断等。 应用领域:网站、信息中心、搜索引擎、电信、流媒体等。
本PPT部分内容来源于国家高性能计算中心(合肥) 2016/3/15 16
1. 高性能计算的意义(6)
千万亿次超级计算机的应用需求
应用领域
生物医学
应用需求
蛋白质电子态的计算 药物发明中的筛选过程 蛋白质折叠 发动机燃烧模拟和机翼设计模拟 短期天气预报 长期天气预报 局部突发性灾难预报(如洪水、海啸) 完全等离子分析(包括电子结构分析) 核武器数值模拟 天然气燃烧 复合材料的结构分析和功能预测 新材料发明 超新星三维模拟 密码破译 先进武器模拟 2016/3/15
高性能计算与并行程序设计
计算机学院计算机科学与技术系 主讲:陈 蕾 博士/副教授 E-mail: chenlei@
本PPT部分内容来源于国家高性能计算中心(合肥) 2016/3/15
1
为什么要开设这门课程
本课程主要涉及高性能计算和并行程序设计,其核心是 并行技术
澄清对并行计算的认识:
●不是少数人的专利 ●高性能计算随着机群系统、多核处理器的出现将逐渐普及到桌面系统
了解高性能计算的前沿技术发展情况 锻炼基本的资料检索、文献阅读、归纳整理和口头报告的能力 实实在在体验并行软件开发
《大学课件:高性能计算》

并行算法
• 针对不同类型和规 模的计算问题,设 计适合的并行算法
• 和并优行化化策技略术。有数据 并行、任务并行、 域分解等。
机器学习
• 深度学习和神经网 络模型的优化和加
• 速 结策 合略 GP。U并行计算 提高训练和推理速 度。
生命科学
• 高性能计算在基因 组学、蛋白质结构 预测和分析、药物 发现等方面的应用。
实时数据
实时数据处理应用,例如股 票交易和地震预警。
实时响应
高性能计算在游戏和虚拟现 实等领域的应用案例。
延迟优化
网络延迟及其对实时数据响 应的影响,以及负载均衡和 缓存优化等方法。
分布式计算系统的设计与实现
分布式计算系统的架构特点,包括分布式任务调度、数据同步和负载均衡等关键技术,以及实战 中的应用案例。
高性能计算
高性能计算是利用先进的技术提高计算速度与效率,被广泛应用于科学研究、 工程分析、大数据处理、机器学习和人工智能等领域。
高性能计算概述
高性能计算的起源与发展历程,性能指标及架构特点,以及各领域中的应用总览。
历史
超级计算机的诞生,国内外 的发展历程。
指标
性能指标与衡量标准,包括 FLOPS、TOPS、PPS等。
应用
在科学、工业、医疗、城市 规划等领域的应用和前景展 望。
并行计算技术介绍
并行计算的原理与分类,分布式存储系统和MapReduce计算模式的概念与应用。
1
并发和并行
概念解释,并行化的基本要素。
并行架构
2
共享存储/消息传递,并发/分布式
内存等架构的原理与特点。
3
分布式存储系统
Google File Syste、使用方法、案例分析。
《高性能计算机讲义》课件

优化策略与工具
阐述如何对应用程序和系统进 行优化,介绍一些优化工具和 策略,如编译器优化、程序分 析等。
最
在这份课件中,你将学习如何理解和应用高性能计算的核心概念,从硬件选 型与优化到并行算法的实现,到性能评估和调试等领域都将得到涵盖,帮助 你更好地掌握这一重要的领域。
3
I/O子系统设计与优化
讲述输入/输出(I/O)子系统的基本组成结构和设计方法,如何优化磁盘I/O性能等。
并行计算基础
并行计算概述
介绍并行计算的概念、分类以及 在高性能计算机中的应用,重点 讲述数据流模型和控制流模型。
并行计算模型
进一步介绍数据流模型和控制流 模型的特点和优势,并描述其在 实际应用场景如何使用。
讨论Hadoop、MapReduce
例和案例,并分析其背后
传算法等。
等开源框架。
的技术、设计和实现方法。
性能评估与调试
性能评估指标
介绍性能评估的一些基本指标, 如吞吐量、响应时间、效率、 可扩展性、可靠性等。
性能调试技巧
总结一些性能调试的技巧和常 用工具,分析性能问题的根本 原因,如内存泄漏、死锁等。
学习目标
详细描述学习高性能计算后可以掌握哪些知识和技能,如何应用这些知识和技能来解决实际 问题。
硬件配置与优化
1
处理器选择与优化
讲解如何选择具有高性能的中央处理器以及如何优化处理器的性能,包括多核处理器的优化 和其他技术。
2
存储器层次与优化
介绍存储器的层次结构、访问时间等基本概念,讨论如何通过编程来最大限度地利用存储器 的性能。
《高性能计算机讲义》 PPT课件
这份课件将带你深入了解高性能计算机的种种奥秘,从处理器的选择到应用 程序的优化,再到性能评估指标的测量,帮助你掌握高性能计算的核心概念。
超性能计算(mpi) ppt课件详解

贵族计算机
• 近年来,集群式系统由于具有以下优点而得到了快速发展
低成本、高性能、短周期,大规模并行,分布式共享内存 平民的超级计算机
• 向量机 (芯片级的并行计算机) • MPP(Massively Parallel Processors)
研制难度逐 渐降底
(主板级的并行计算机)
• Cluster
高性能计算程序设计
课程内容
• 并行计算机与并行算法的基础知识
• MPI程序设计
• OpenMP程序设计
目的:
了解和掌握基本的高性能程序设计编程技术。
参考资料
• • • 《高性能计算并行编程技术—MPI并行程序设计》
都志辉
清华大学出版社
《并行算法实践》 阵国良等 高等教育出版社 《并行计算---结构、算法、编程》 阵国良等 高等教育出版社
4、MPI的语言绑定
MPI不是一门语言,而是一个库,必须和特定的语 言绑定才能进行 MPI_I:C、FORTRAN77 MPI_II:C++、FORTRAN90
5、目前MPI的主要实现
• MPICH: 美国的Argonne国家实验室 /mpi/mpich • CHIMP:
计算系统共有15台曙光W580双路服务器,CPU整体峰值 性能达到3.312万亿次/秒。每台计算节点配臵2颗 IntelXEON E5-2630 2.3G 6C CPU六核CPU,24G DDR3 内存。 GPGPU计算系统共有7台曙光W580I,GPU双精度浮点 峰值达到9.17万亿次/秒。每台GPGPU计算节点配臵2块 Nvidia K20 GPGPU卡。 系统配备1台管理/IO/登陆节点,存储裸容量为2.3TB, 部署曙光Gridview 2.6集群管理系统,用户可通过IP地址 实现Web访问。 系统配臵机房环境管理节点1台,部署曙光IMMS机房环 境管理系统。用户可通过IP地址实现Web访问。 系统配臵1套线速互联的56Gb FDR Infiniband网络。 系统共用9个服务器机柜、1个空调机柜、4个航空电源箱 供电,系统峰值功耗约为28kW。
• 近年来,集群式系统由于具有以下优点而得到了快速发展
低成本、高性能、短周期,大规模并行,分布式共享内存 平民的超级计算机
• 向量机 (芯片级的并行计算机) • MPP(Massively Parallel Processors)
研制难度逐 渐降底
(主板级的并行计算机)
• Cluster
高性能计算程序设计
课程内容
• 并行计算机与并行算法的基础知识
• MPI程序设计
• OpenMP程序设计
目的:
了解和掌握基本的高性能程序设计编程技术。
参考资料
• • • 《高性能计算并行编程技术—MPI并行程序设计》
都志辉
清华大学出版社
《并行算法实践》 阵国良等 高等教育出版社 《并行计算---结构、算法、编程》 阵国良等 高等教育出版社
4、MPI的语言绑定
MPI不是一门语言,而是一个库,必须和特定的语 言绑定才能进行 MPI_I:C、FORTRAN77 MPI_II:C++、FORTRAN90
5、目前MPI的主要实现
• MPICH: 美国的Argonne国家实验室 /mpi/mpich • CHIMP:
计算系统共有15台曙光W580双路服务器,CPU整体峰值 性能达到3.312万亿次/秒。每台计算节点配臵2颗 IntelXEON E5-2630 2.3G 6C CPU六核CPU,24G DDR3 内存。 GPGPU计算系统共有7台曙光W580I,GPU双精度浮点 峰值达到9.17万亿次/秒。每台GPGPU计算节点配臵2块 Nvidia K20 GPGPU卡。 系统配备1台管理/IO/登陆节点,存储裸容量为2.3TB, 部署曙光Gridview 2.6集群管理系统,用户可通过IP地址 实现Web访问。 系统配臵机房环境管理节点1台,部署曙光IMMS机房环 境管理系统。用户可通过IP地址实现Web访问。 系统配臵1套线速互联的56Gb FDR Infiniband网络。 系统共用9个服务器机柜、1个空调机柜、4个航空电源箱 供电,系统峰值功耗约为28kW。
“高性能计算课件PPT教程”

应用案例
探索并行计算软件在科学计 算中的各种应用案例。
数据并行和任务并行的区别
数据并行
探索数据并行的基本原理和应用 场景。
任务并行
介绍任务并行
了解主流的并行计算框架以及将 它们应用到数据并行和任务并行 设计中。
集群计算系统的管理和操作
集群管理技术 系统安装和配置
高性能计算在云计算和大数据场景下的应 用
1
云计算与高性能计算
了解高性能计算在云计算环境下的实现
Map Reduce框架
2
和优化策略。
探索MapReduce框架在大数据处理中的
应用。
3
Hadoop 架构与优化
介绍Hadoop架构和优化技巧,提高大数
机器学习与大数据处理
4
据的处理效率。
探索机器学习在大数据处理中的应用, 如基于Spark的机器学习算法。
2
掌握编译器的原理和使用技巧,提高程
序执行效率。
3
并行化原理
了解多级并行的原理及其在高性能计算 中的应用。
调度器优化
介绍调度器的原理和使用方法,提高系 统的并行计算效率。
并行计算软件设计原则
设计原则
学习并行计算软件设计的基 本原则,如任务分解、通信、 同步等。
主流框架
介绍几种主流的并行计算框 架,如MPI和OpenMP。
并行程序调试
探究并行程序调试的技巧和方法, 如GDB和DDE。
GPU加速计算和异构计算体系 结构
1 CUDA编程模型
学习CUDA并行计算编程模 型和程序设计方法。
2 OpenCL
介绍OpenCL编程模型和异构 计算在高性能计算中的应用 场景。
3 异构计算的挑战
相关主题
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
大多数为传统单核系统编写的程序无法 利用多核处理器 虽然可以在多核系统上运行一个程序的 多个实例,但这样意义不大。例如,在 多个处理器上运行一个喜爱的游戏程序 的多个实例并不是我们需要的。 运行得快!!!
串行问题的处理方法
将串行程序改写为并行程序
编写一个翻译程序来自动地将串行程序 翻译成并行程序
不再继续开发速度更快的单处理器芯片 ,而是开始将多个完整的单处理器放到 一个集成电路芯片上。
对程序员的影响
大多数串行程序是在单个处理器上运行 的,不会因为简单地增加更多的处理器 就获得极大的性能提高
串行程序不会意识到多个处理器的存在 ,它们在一个多处理器系统上运行的性 能,往往与在多处理器系统的一个处理 器上运行的性能相同。
例如,假如有8个核,n=24,24次调用 Compute_next_value获得如下的值:
1,4,3, 9,2,8, 5,1,1, 5,2,7, 2,5,0, 4,1,8, 6,5,1, 2,3,9
例子(续)
当各个核都计算 完各自的 my_sum值后, 将自己的结果值 发送给一个指定 为“master”的 核(主核), master核将收 到的部分和累加 而得到全局总和
非常明显,第一种计算全局总和的方法是对串行求和程序的一般化:将 求和的工作在核之间平分,等到每个核都计算出部分和之后,master简 单地重复串行程序中基本的串行求和。而第二种计算全局总和的方法与 原来的串行程序没有多大关系。
并行程序设计
为什么需要不断提升的性能 为什么需要构建并行系统 为什么需要编写并行程序 怎样编写并行程序
为什么需要不断提升的性能
不断提升的计算能力已经成为许多飞速 发展领域(如科学、互联网、娱乐等) 的核心力量。
随着计算能力的提升,我们要考虑解决 的问题也在增加,下面举些例子
气候模拟
蛋白质折叠
药物发现
能源研究
数据分析
并行程序设计
为什么需要不断提升的性能 为什么需要构建并行系统 为什么需要编写并行程序 怎样编写并行程序
例子
假设我们需要计算n个数的值再累加求和
串行代码:
例子(续)
现在我们假设有p个核,且p远小于n 每个核能够计算大约n/p个数的值并累加 求和,以得到部分和
此处的前缀my_代表每个核都使用自己的私 有变量,并且每个核能够独立于其他核来执 行该代码块
例子(续)
每个核都执行完代码后,变量my_sum中 就会存储调用Compute_next_value获得 的值的和
分析比较
在8个核的情况下,第一种方法中, master核需要执行7次接收操作和7次加 法
第二种方法中,master核仅需要执行3次 接收操和3次加法 第二种方法比第一种方法快2倍!
分析比较(续)
当有更多的核时,两者的差异更大。
在1000个核的情况下,第一种方法需要 999次接收和加法操作,而第二种方法只 需要10次,提高了100倍。
怎么编写并行程序
任务并行
将待解决问题所需要执行的各个任务分配到 各个核上执行.
数据并行
将待解决问题所需要处理的数据分配给各个 核. 每个核在分配到的数据集上执行大致相似的 操作.
例子
15 个问题 300 份试卷
3个助教
数据并行
TA#1
100 exams 100 exams
TA#3
100 exams
பைடு நூலகம்
第一章 为什么要并行计算
为什么需要不断提升的性能 为什么需要构建并行系统 为什么需要编写并行程序 怎样编写并行程序
时代变迁
从1986年到2019年,微处理器的性能以 平均每年50%的速度不断提升
从2019年开始,单处理器的性能提升速 度降低到每年大约20%
一个聪明的解决方案
:
例子(续)
Core my_sum 0 8 1 19 2 7 3 15 4 7 5 13 6 12 7 14
Global sum 8 + 19 + 7 + 15 + 7 + 13 + 12 + 14 = 95
Core my_sum 0 95 1 19 2 7 3 15 4 7 5 13 6 12 7 14
别急! 还有一个更好 的方法来计算 全局总和
更好的并行算法
不要由master核计算所有部分和的累加 工作
将各个核两两结对,0号核将自己的部分 和与1号核的部分和做加法,2号核将自 己的部分和与3号核的部分和做加法,4 号核将自己的部分和与5号核的部分和做 加法,以次类推。
多个处理器求全局总和
非常困难 鲜有突破
更多的问题
尽管我们可以编写一些程序,让这些程序辨识 串行程序的常见结构,并自动将这些结构转换 成并行程序的结构,但转化后的并行程序在实 际运行时可能很低效
一个串行程序的高效并行实现可能不是通过发 掘其中每一个步骤的高效并行实现来获得,相 反,最好的并行化实现可能是通过一步步回溯 ,然后发现一个全新的算法来获得的
与其构建更快、更复杂的单处理器,不如在单 个芯片上放置多个相对简单的处理器。 核( “core” )已经成为中央处理器或者CPU的 代名词。
答案是并行!!!
并行程序设计
为什么需要不断提升的性能 为什么需要构建并行系统 为什么需要编写并行程序 怎样编写并行程序
为什么需要编写并行程序
为什么需要构建并行系统
到目前为止,单处理器性能大幅度提升 的主要原因之一,是日益增加的集成电 路晶体管密度(晶体管是电子开关)
但也有内在的问题
一点物理常识
更小的晶体管=速度更快的处理器 更快的处理器=增大的耗电量 增大的耗电量=增加的热量 增加的热量=不可靠的处理器
解决方案
高性能科学计算理论和方法
教材
主要教材:《并行程序设计导论》
帕切克 美国旧金山大学教授
参考教材
陈国良,中国科学技术大学教授
课程考核
平时表现:包括出勤情况、课堂表现、 课堂练习,占20% 分组报告:课堂将有几次分组讨论作业 ,要求学生分组并完成相应的课后作业 或者编程作业,并在课堂上进行演示, 占40%。 期末考试:课程报告,可以是理论课程 报告,也可以是实践课程报告,占40%