语法与语义分析
编译原理之语法分析与语义分析

编译原理之语法分析与语义分析
语法分析(英语:syntactic analysis,也叫 parsing)是根据某种给定的对由单词序列(如英语单词序列)构成的输⼊⽂本进⾏分析并确定其语法结构的⼀种过程。
语法分析器使⽤由词法分析器⽣成的各个词法单元的第⼀个分量来创建树形的中间表⽰。
语义分析是审查源程序有⽆语义错误,为代码⽣成阶段收集类型信息。
语义分析器(semantic analyzer)使⽤语法树和符号表中的信息来检查源程序是否和语⾔定义的语义⼀致。
它同时也收集类型信息,并把这些信息存放在语法树或符号表中,以便在随后的中间代码⽣成过程中使⽤。
语法和语义分析

2 向前看集 Follow
定义 设文法G[S],非终结符号U的向前看集为 Follow(U)={a︱S * …Ua…, a∈ Vt∪{#}}
即Follow(U)为所有含有U的句型中紧跟在U之 后的终结符号或#组成的集合。 (若紧跟在非终结符号U后面的符号串为空时 ,则视U后面的符号为特殊符号#)
从语法树建立的角度来看,它是根据文法从树根结
点开始,试着自上而下建立一棵语法树,其末端结点
按从左到右的顺序若是给定的句子,则句子得到识别,
表明其结构符合文法,否则不符合文法。
14
文法G[N]:N→D︱ND D→0︱1︱2︱…︱9
分析25是否符合该文法 N
ND D5 2
15
2 自顶向下分析的难点及解决办法
16
对于某个非终结符号有n个规则(n个候选式), 此时要分两种情况 I 首符号不相同
10
例: 文法G[E] E→TE’
E’→+E︱є T→FT’ T’→T︱є F→PF’ F’→*F’︱є P→(E)︱a︱b︱∧
First(E)= First(T)= First(F)= First(P)={(,a,b,∧}
First(E’)={+,є } First(F’)={*,є }
First(T’)={(,a,b,∧,є }
6
例: 文法G[E]:E→E+T︱T
T→T*F︱F F→(E)︱i
E * E
E * E+T Follow(E)={#,+,)}
E * (E)
E * T
E * T+T E * T*F E * (T)
Follow(T)={#,*,+,)}Follow(F)=来自#,*,+,)}7
语言的语法与语义

语言的语法与语义语言是人类社会交流的重要工具,人们通过语言来表达自己的思想、感情和意愿。
而要使用语言进行有效的交流,就需要了解语法和语义这两个重要概念。
本文将从语法和语义的定义、联系以及在语言中的作用等方面进行探讨。
语法是语言的基础结构,是用来组织和规范语言表达的一套规则。
它包括语言的词汇、句法和语法规则等。
语法的作用主要是使语言的表达更为准确和清晰。
在语言中,词汇是构成语法的基本单位,它们通过句法规则被组织成各种形式的句子,从而传递信息。
句法规则决定了不同词汇之间的组合方式和顺序。
例如,在英语中,主语通常位于句子的开头,而谓语动词则紧随其后。
除了语法规则,语义是语言中另一个重要的组成部分。
语义关注的是词汇、短语和句子等在实际意义上所表达的含义。
它研究的是语言的意义和语言符号之间的关系。
语义通过词汇的搭配、短语的语义组合和句子的语义成分等方式来进行表达。
例如,在英语中,我们可以使用不同的词汇来表达相同的意思,如“big”和“large”都可以表示“大”的含义。
此外,语义还研究了词语之间的逻辑关系,如同义词、反义词和上下位词等。
语法和语义在语言中密不可分,相辅相成。
语法提供了语言的框架和结构,使得语言能够被理解和使用。
而语义则赋予了语言以意义和信息,使语言能够表达思想和感情。
一句话要达到有效的交流,既要符合语法的要求,又要传递准确的语义信息。
因此,对于使用者而言,既需要掌握语法规则,又要理解语义含义。
在语言学的研究中,语法和语义也有着各自的分支领域。
语法学主要研究语言的结构和规则,分析语法现象和句法关系,并提出相关的理论和模型,如生成语法和转换生成语法等。
而语义学则注重探究语言的意义和语义关系,研究词义、句义、篇章语义等问题,并通过语义理论来解释这些问题,如逻辑语义学、构式语义学等。
总结起来,语法和语义是语言学中两个至关重要的概念。
语法确保了语言的结构和组织,使语言变得可理解和可使用;而语义则赋予了语言以意义和信息,使语言能够表达思想和感情。
语法 句法中的语义分析 句法中的语义分析 现代汉语课件

设置语境
• 设置语境的方法来加以分析: a.我买了一件毛衣,她又买了一件毛衣。
• (“又”语义指向“她”) b.她已借了一件毛衣,她又买了一件毛衣。
• (“又"语义指向“买") c.她已买了两件毛衣,她又买了一件毛衣。
• (“又”语义指向“一件”) d.她已买了一件皮衣,她又买了一件毛衣。
• (“又”语义指向“毛衣”)
句法关系与语义关系
• 句法关系是句法关系,语义关系是语义关系, 这两者可能一致,也可能不一致。例如: (1)小李吃了/苹果吃了 (2)吃饭了/来人了
• 同一个动词与不同的名词性词语搭配就可 能产生不同的语义关系。
• 例如: (1)吃面条(动作受事)吃大碗(动作工具) 吃食堂(动作处所) 吃大户(动作依据)
• (2)妈妈在包衣服(施事动作受事) 他们在包饺子(施事动作结果) 外头包牛皮纸(处所动作材料) 礼品包小包(受事动作方Байду номын сангаас)
• 同一个名词性词语,与不同的谓词搭配也 可能产生不同的语义关系。
• 例如:买毛衣(动作受事)
织毛衣(动作结果) 打人(动作受事)
来人(动作施事)
语义指向
• 语义指向是指句法结构中的某一成份跟其 他成份之间在语义上的联系。这种语义联 系同句法关系有时一致,有时不一致。
• 例如: (1)月亮渐渐升起来了。 (2)妈妈高兴地点点头。
• 语义指向可以合理地解释句子成份之间的 关系。例如: (1)王冕死了父亲。(王冕的父亲死了) (2)苹果吃了三个。(苹果中的三个吃了) (3)孩子被奶奶抱进了大门。(奶奶抱孩子]进 了大门) (4)奶奶哭瞎了眼睛。(奶奶哭+奶奶的眼睛瞎 了)
语义特征
• 词语中符合某种组合选择的有区别性特征 的最小语义成份就是语义特征。例如,“揉” 这一动词要求与之搭配的受事词语必须具 有[+固体]、[+柔软]这样的语义特征,“衣服 ”、“皮肤”、“面团”同时儿有[+固体]、[+柔 软]这两个语义特征,因此可以同“揉”这一 动词搭配(“揉衣服、揉皮肤、揉面团”),但“ 泉水”不具备[+固体]这一语义特征,“石头”不 具备[+柔软]这语义特征,因此它们不能与动 词“揉”相搭配(“+揉泉水、揉石头")。
编程语言的语法与语义分析

编程语言的语法与语义分析编程语言是程序员用来编写计算机程序的一种人造语言。
它具有自己的语法和语义规则,用以描述计算机程序的结构和行为。
在编写程序时,程序员需要通过语法和语义分析来确保程序的正确性和可靠性。
一、语法分析语法分析是编程语言的第一步,它用于检查程序中的语法错误。
语法是一种规则系统,用于定义编程语言中有效语句和表达式的结构。
通过语法分析,程序员可以确定程序是否符合语法规则。
常见的语法分析方法包括上下文无关文法和词法分析。
1. 上下文无关文法上下文无关文法(Context-Free Grammar)是一种形式化的语言描述工具,用于定义编程语言的语法。
它由一组产生式(Production Rules)组成,每个产生式描述了一个语法结构的生成方式。
通过上下文无关文法,程序员可以将程序按照规定的语法结构进行构造。
例如,C语言中的产生式可以定义为"E -> E + T",表示表达式E的生成方式为"E加T"。
2. 词法分析词法分析(Lexical Analysis)是语法分析的一部分,用于将程序源代码划分为一个个的词法单元(Tokens)。
词法单元是编程语言的最小单位,包括关键字、标识符、操作符等。
通过词法分析,程序员可以检查程序中的词法错误,并将其转化为更易于处理的数据结构。
例如,在C语言中,"for(int i=0; i<10; i++)"可以被词法分析为"for"、"("、"int"、"i"、"="、"0"、";"、"i"、"<"、"10"、";"、"i++"、")"等词法单元。
词法分析、语法分析、语义分析

词法分析、语法分析、语义分析词法分析(Lexical analysis或Scanning)和词法分析程序(Lexical analyzer或Scanner) 词法分析阶段是编译过程的第⼀个阶段。
这个阶段的任务是从左到右⼀个字符⼀个字符地读⼊源程序,即对构成源程序的字符流进⾏扫描然后根据构词规则识别单词(也称单词符号或符号)。
词法分析程序实现这个任务。
词法分析程序可以使⽤lex等⼯具⾃动⽣成。
语法分析(Syntax analysis或Parsing)和语法分析程序(Parser) 语法分析是编译过程的⼀个逻辑阶段。
语法分析的任务是在词法分析的基础上将单词序列组合成各类语法短语,如“程序”,“语句”,“表达式”等等.语法分析程序判断源程序在结构上是否正确.源程序的结构由上下⽂⽆关⽂法描述.语义分析(Syntax analysis) 语义分析是编译过程的⼀个逻辑阶段. 语义分析的任务是对结构上正确的源程序进⾏上下⽂有关性质的审查, 进⾏类型审查.例如⼀个C程序⽚断: int arr[2],b; b = arr * 10; 源程序的结构是正确的. 语义分析将审查类型并报告错误:不能在表达式中使⽤⼀个数组变量,赋值语句的右端和左端的类型不匹配.Lex ⼀个词法分析程序的⾃动⽣成⼯具。
它输⼊描述构词规则的⼀系列正规式,然后构建有穷⾃动机和这个有穷⾃动机的⼀个驱动程序,进⽽⽣成⼀个词法分析程序.Yacc ⼀个语法分析程序的⾃动⽣成⼯具。
它接受语⾔的⽂法,构造⼀个LALR(1)分析程序.因为它采⽤语法制导翻译的思想,还可以接受⽤C语⾔描述的语义动作,从⽽构造⼀个编译程序. Yacc 是 Yet another compiler compiler的缩写.源语⾔(Source language)和源程序(Source program) 被编译程序翻译的程序称为源程序,书写该程序的语⾔称为源语⾔.⽬标语⾔(Object language or Target language)和⽬标程序(Object program or Target program) 编译程序翻译源程序⽽得到的结果程序称为⽬标程序, 书写该程序的语⾔称为⽬标语⾔.中间语⾔(中间表⽰)(Intermediate language(representation)) 在进⾏了语法分析和语义分析阶段的⼯作之后,有的编译程序将源程序变成⼀种内部表⽰形式,这种内部表⽰形式叫做中间语⾔或中间表⽰或中间代码。
语法分析语义成分、语义特征、语义指向

语法分析语义成分、语义特征、语义指向语法分析汉语语法的系统研究始于百年前的《马氏文通》。
学者们一直忙于进行对句法结构中句子成分和词类及句型的分析,即作句法分析,对语义分析和语用分析也涉及一点,大都是不自觉的。
20世纪80年代开始,由于受到国外语法新理论的启发,如生成语法、格语法、功能语法、认知语法,特别是受了符号学的启发,我国学者结合汉语语法研究的实际明确提出了语法研究的三个层面的新理论。
他们认为语法研究应包含句法分析、语义分析和语用分析三方面的内容,应该分清三者并结合起来研究,要加强语义和语用方面的研究,其中对语义方面提出了较多的分析方法。
在吸收了三个层面理论。
但对术语和分析方法没有作定义式说明。
有必要在此对三者作简要的介绍。
句法分析:找出句法结构中的句法成分、指名构成成分的词语类别和词、语、句的整体类型或格式等,也就是对语法单位之间的结构关系和语法单位的类型进行的分析。
语义分析:指出句中动词与有关联的名词语所指事物之间的语义关系,即动作与施事、受事、遇事、工具、时间、处所等关系以及指出其他词语之间的语义关系,如领属、同位、方式等;此外,还包括语义成分、语义指向、语义特征等的分析。
简言之,指语法单位之间的语义关系的分析,实际上是客观事理关系的分析。
语用分析:包括话题和说明、表达重点、语境、省略和倒桩、语气和语调(停顿、重音、句调的升降)等的分析,也就是语言符号与它的使用者、使用环境之间的关系的分析。
下面举几个例子作句法分析:(1)狼咬死了他家的羊。
(带宾主谓句、主动句)主谓动宾中补定中定中(2)狼把他家的羊咬死了。
("把"字句)主谓状中中补(3)他家的羊被狼咬死了。
("被"字句)主谓定中状中定中中补附:这里的"三个层面"也叫"三个平面",指句法、语义、语用,有的学者称"结构、语义、表达"三个方面,有的学者称"语表、语里、语值"小三角。
词法分析、语法分析、语义分析实例解析及实验报告
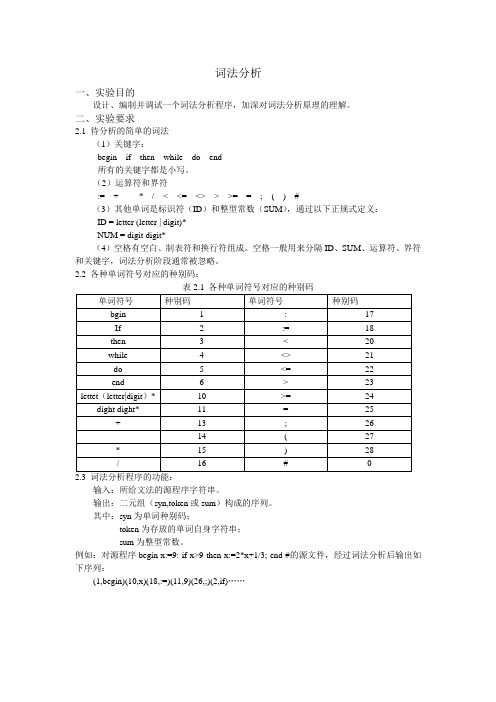
词法分析一、实验目的设计、编制并调试一个词法分析程序,加深对词法分析原理的理解。
二、实验要求2.1 待分析的简单的词法(1)关键字:begin if then while do end所有的关键字都是小写。
(2)运算符和界符:= + - * / < <= <> > >= = ; ( ) #(3)其他单词是标识符(ID)和整型常数(SUM),通过以下正规式定义:ID = letter (letter | digit)*NUM = digit digit*(4)空格有空白、制表符和换行符组成。
空格一般用来分隔ID、SUM、运算符、界符和关键字,词法分析阶段通常被忽略。
2.2 各种单词符号对应的种别码:输入:所给文法的源程序字符串。
输出:二元组(syn,token或sum)构成的序列。
其中:syn为单词种别码;token为存放的单词自身字符串;sum为整型常数。
例如:对源程序begin x:=9: if x>9 then x:=2*x+1/3; end #的源文件,经过词法分析后输出如下序列:(1,begin)(10,x)(18,:=)(11,9)(26,;)(2,if)……标识符(需进一步判断是否为关键字)数字+=+-=-词法分析状态转换图(终结状态右上角*表示多读一个符号)三、词法分析程序的算法思想:算法的基本任务是从字符串表示的源程序中识别出具有独立意义的单词符号,其基本思想是根据扫描到单词符号的第一个字符的种类,拼出相应的单词符号。
3.1 主程序示意图:主程序示意图如图3-1所示。
其中初始包括以下两个方面: ⑴ 关键字表的初值。
关键字作为特殊标识符处理,把它们预先安排在一张表格中(称为关键字表),当扫描程序识别出标识符时,查关键字表。
如能查到匹配的单词,则该单词为关键字,否则为一般标识符。
关键字表为一个字符串数组,其描述如下:Char *rwtab[6] = {“begin ”, “if ”, “then ”, “while ”, “do ”, “end ”,};图3-1(2)程序中需要用到的主要变量为syn,token 和sum 3.2 扫描子程序的算法思想:首先设置3个变量:①token 用来存放构成单词符号的字符串;②sum 用来存放整型单词;③syn 用来存放单词符号的种别码。
语言学中的句法与语义分析

语言学中的句法与语义分析语言学是研究语言的科学,而其中的句法和语义分析则是研究句子语法和含义的学科。
句法和语义分析是语言学研究的重要分支,它们的研究能够从不同角度深入探究语言的结构和运用。
句法分析是指研究句子语法结构的过程,也称为语法分析。
句法分析的目的是通过对句子的成分和结构进行分类和分析,确定句子的基本要素以及它们之间的关系。
句法分析的主要方法是句子成分分析法。
句子成分分析法通过对句子中各个成分进行分类、依据从句意义和结构上建立成分之间的关系的方式,从语法的角度解读句子的结构。
句子成分分为主语、谓语、宾语、表语、定语、状语和补语等,它们各自具有不同的语法特征和语义意义。
主语是句子的核心组成部分,它通常是动作的施事者,主语通常在句子中起主导作用。
谓语是句子的核心所在,它通常表示动作的完成情况,谓语与主语之间必须存在关联关系。
宾语是动作的承受者,通常在句中充当与谓语对应的语法成分,宾语通常是句子的次重要成分。
表语是句子中陈述性名词、形容词或代词,它与主语连词或谓语连用,表达主语的属性或状态。
定语通常修饰名词、代词或数词等,定语在句子中起補充说明的作用。
状语是修饰动词、形容词、副词、句子等成份的语法成分,它通常以副词、介词或子句等表示状语的类型,状语在句子中起修饰作用。
补语是补充说明句子谓语或主语的成分,它通常分为宾补和表补两种类型。
语义分析是指研究句子意义的过程,也称为语义分析。
语义分析的目的是识别句子中所包含的信息、思想或观点,并解读其含义和逻辑关系。
语义分析的主要方法是语义分析法。
语义分析法通过分析句子的成分、词义和上下文等因素,确定句子的含义和语用功能。
语义分析关注语言的实际意义,以及言语交际中的意图和目的。
语义分析的关键是词义分析,词义分析是指解释单词或短语的含义和用法。
词义分析的基础是词汇的知识,它需要考虑到单词组成和语境等多个方面的信息。
在词义分析中,我们会对单词进行分类、归纳和解释。
自然语言处理中的语法与语义分析

自然语言处理中的语法与语义分析自然语言处理(Natural Language Processing,简称NLP)是计算机科学与人工智能领域中的一个重要研究方向,旨在让计算机能够理解、处理和生成自然语言的信息。
而语法与语义分析是NLP中的两个重要组成部分,它们在处理和分析文本的过程中发挥着关键的作用。
本文将重点探讨自然语言处理中的语法与语义分析的概念、技术及应用。
第一节:语法分析语法分析(Syntactic Analysis)是自然语言处理中的一项重要任务,旨在确定一段文本中的各个单词或短语之间的句法关系。
语法分析通常采用上下文无关文法(Context-Free Grammar,简称CFG)来描述和分析句子的结构。
常用的语法分析方法包括依存句法分析和短语结构句法分析。
依存句法分析(Dependency Parsing)是指通过分析句子中词与词之间的依存关系,构建依存树来描述句子的结构。
依存句法分析可以帮助我们理解句子中单词之间的关系,如主谓关系、修饰关系等。
依存句法分析在机器翻译、信息抽取等任务中都有广泛应用。
短语结构句法分析(Phrase Structure Parsing)是指通过分析句子中短语与短语之间的组合关系,确定句子的结构。
短语结构句法分析通常使用上下文无关文法来描述句子的组成结构,常见的方法有基于规则的短语结构分析和基于统计的短语结构分析。
第二节:语义分析语义分析(Semantic Analysis)是自然语言处理中的另一个重要任务,旨在理解和解释句子的含义。
语义分析的主要目标是将自然语言表达转换为形式化的逻辑表示,如一阶逻辑表达式或谓词逻辑表达式,以方便计算机对其进行进一步处理。
常用的语义分析方法包括词义消歧、语义角色标注和语义关系提取等。
词义消歧(Word Sense Disambiguation)是指确定一词在不同上下文中的实际含义的过程。
在自然语言处理中,一个词可能有多种不同的含义,而词义消歧的目标就是准确判断上下文中该词的实际含义,以确保句子的理解和表达的准确性。
编译原理-语法分析

自顶向下的语法分析方法简单直观,易于实现,但可能存在 左递归和回溯的问题。
自底向上的语法分析
01
自底向上的语法分析方法从源代码中的每个符号出发
,逐步归约到文法的起始符号。
02
该方法通常采用LR(0)、SLR(1)、LALR(1)等算法进行
实现。
03
自底向上的语法分析方法可以避免回溯问题,但需要
• 随着人工智能和机器学习技术的不断发展,可以利用这些技术来辅助语法分析 过程,提高语法分析的准确性和效率。例如,可以使用机器学习算法来自动识 别和处理语法规则和歧义问题。
• 另外,随着软件工程和代码质量的重视程度不断提高,对编译器和语法分析器 的要求也越来越高。未来的研究需要更加注重编译器和语法分析器的可维护性 和可扩展性,以满足不断变化的软件需求。
词法分析的算法
自底向上算法
自底向上算法是从源代码的左向右进行扫描,并从下到上构建语法结构。常见 的自底向上算法有预测分析法和移进-规约法。
自顶向下算法
自顶向下算法是从语法结构的顶层开始,向下进行推导,直到找到与源代码相 匹配的语法结构。常见的自顶向下算法有规范分析法和贪婪分析法。
语法分析概述
语法分析是编译过程的核心环节,其任务是将源代码分解成一系列的语法 结构,以便后续的语义分析和代码生成。
自底向上的算法,通过构建归 约表进行移进和规约操作。
LALR(1)算法
扩展的LR(0)算法,能够处理 更广泛的文法,生成更小的归 约表。
03
语义分析
语义分析概述
01
Байду номын сангаас02
03
语义分析是编译过程的 一个阶段,它是在语法
分析之后进行的。
语义分析的主要任务是 检查源代码的语义是否 正确,例如变量是否已 经声明,类型是否匹配
语法分析实验报告

一、实验目的1. 了解语法分析的基本概念和原理。
2. 掌握语法分析的方法和步骤。
3. 提高对自然语言处理领域中语法分析技术的理解和应用能力。
二、实验内容1. 语法分析的基本概念语法分析是指对自然语言进行结构分析,将句子分解成词、短语和句子成分的过程。
通过语法分析,可以了解句子的结构、语义和语用信息。
2. 语法分析方法语法分析方法主要有两种:句法分析和语义分析。
(1)句法分析:句法分析是指根据语法规则,对句子进行分解和组合的过程。
常见的句法分析方法有:词法分析、短语结构分析、句法分析。
(2)语义分析:语义分析是指对句子进行分析,以揭示句子所表达的意义。
常见的语义分析方法有:词汇语义分析、句法语义分析、语用语义分析。
3. 语法分析步骤(1)词法分析:将句子中的单词进行分类,提取词性、词义和词形变化等特征。
(2)短语结构分析:将词法分析得到的词组进行分类,提取短语结构、短语成分和短语关系等特征。
(3)句法分析:根据短语结构分析的结果,将句子分解成句子成分,分析句子成分之间的关系。
(4)语义分析:根据句法分析的结果,分析句子所表达的意义。
三、实验过程1. 实验环境:Python 3.8,NLTK(自然语言处理工具包)。
2. 实验步骤:(1)导入NLTK库。
(2)加载句子数据。
(3)进行词法分析,提取词性、词义和词形变化等特征。
(4)进行短语结构分析,提取短语结构、短语成分和短语关系等特征。
(5)进行句法分析,分解句子成分,分析句子成分之间的关系。
(6)进行语义分析,揭示句子所表达的意义。
四、实验结果与分析1. 词法分析结果实验句子:“我喜欢吃苹果。
”词性标注:我/代词,喜欢/动词,吃/动词,苹果/名词。
2. 短语结构分析结果实验句子:“我喜欢吃苹果。
”短语结构:主语短语(我),谓语短语(喜欢吃苹果)。
3. 句法分析结果实验句子:“我喜欢吃苹果。
”句子成分:主语(我),谓语(喜欢),宾语(吃苹果)。
4. 语义分析结果实验句子:“我喜欢吃苹果。
现代汉语·语法·7(语义)

二、动词与名词的语义关系6 • (二)语义关系的类别 • 1.施事 • 指行为动作的发出者。如: • ⑴小孩儿玩皮球。 • ⑵山坡上长满了青草。 • ⑶钱包被小偷偷走了。
二、动词与名词的语义关系7
• 2.受事 • 行为动作的承受者。如: • ⑴穿衣服。 • ⑵看了两本书。 • ⑶把苹果吃掉了。
二、动词与名词的语义关系8 • 3.系事 • 指系动词联接的对象,系动词指: “是”或“成”“变成”。如: • ⑴这是个陷阱。 • ⑵这里成了鸟的乐园。 • ⑶长安街变成了欢乐的海洋。
五、语义特征5
• 例如语气词“了”表示的是“原来 不这样,现在这样”,即书上所说 的[+推移性],所以与它组合的 词语就必须有[+推移性]的意义。 • ⑴阴天了。(原来不是阴天,现在 阴天了。而且,阴天由晴天转变而 成。)
五、语义特征6
• ⑵星期三了。(原来不是星期三,现 在是,而且星期三由前面的时间发展 而来。) • ⑶大学生了。(原来不是大学生,现 在是了,大学生由小学生、中学生发 展而来。) • ⑷(问:到哪儿了)广州了。
三、定语与中心语的语义关系4 • 3.时属关系 • 人或事物的时间属性,如: • ⑴春天的故事 • ⑵新时代的青年 • ⑶陈年老酒
三、定语与中心语的语义关系5 • 4.从属关系 • 5.隶属关系 • 6.含属关系 • 这几部分都与“领属关系”不好区 别。
三、定语与中心语的语义关系6
• 7.质料关系 • 定语表示的是中心语的质料,如: • ⑴红木家具 • ⑵劣质产品 • ⑶优秀学生
一、语义关系2
例如: a 小王 • 语法: 主语 • 语义: 施事
拿走了 钢笔。 + 述语 + 宾语 + 动作 + 受事
一、语义关系3
•b 狼 把 小羊 • 语法:主语+ 状语 • 语义:施事+把+受事 吃了。 + 述语 + 动作
编程语言的语法与语义分析

编程语言的语法与语义分析编程语言是人与计算机交流的桥梁,它通过一定的语法和语义规则来定义程序的结构和行为。
编程语言的语法和语义分析是对程序进行静态分析和解释的关键过程,它们有助于检测程序中的错误和逻辑问题,并帮助程序员编写出高效、可靠的代码。
一、编程语言的语法分析语法是编程语言中的基本规则,它定义了程序的合法结构和组织方式。
编程语言的语法分析主要包括词法分析和语法分析。
1. 词法分析词法分析是将程序源代码划分为一个个单词(token),并且为每个单词赋予适当的语义。
词法分析器通常通过正则表达式来识别各种单词,如标识符、关键字、操作符等。
它能够去除程序中的空格、注释等无关紧要的字符,并生成一系列有意义的单词流。
2. 语法分析语法分析是在词法分析的基础上进行的,它通过解析单词流,判断程序是否符合语法规则。
语法分析器根据编程语言的文法规定,将单词流转化为一个有层次结构的抽象语法树。
语法分析器可以使用不同的算法,如递归下降法、LR分析法等。
二、编程语言的语义分析语义是编程语言中表达的意义,它描述了程序执行的具体含义和规则。
编程语言的语义分析主要包括类型检查和语义推导。
1. 类型检查类型检查是语义分析中的重要环节,它主要负责检查程序中的数据类型是否合法。
类型检查器可以根据编程语言的类型系统规定,检查变量和表达式的类型是否匹配,以防止类型错误的发生。
通过类型检查可以提前发现一些潜在的编程错误,提高程序的稳定性和可靠性。
2. 语义推导语义推导是根据语法树和类型信息,推导出程序的实际意义和执行流程。
在语义推导的过程中,语义分析器会根据编程语言的语义规则进行符号解析和语义动作,确定变量的作用域、函数的调用关系等。
语义推导有助于程序员理解程序的执行过程,避免逻辑错误和歧义。
三、语法与语义分析的重要性编程语言的语法和语义规则是保证程序正确性和可靠性的基础。
语法分析和语义分析可以帮助程序员发现和解决程序中的错误和问题,提高开发效率。
从语义的角度分析汉语语法

从语义的角度分析汉语语法[摘要]《马氏文通》是中国语法的奠基之作,为中国的语法研究开辟了新的道路。
但是其中模仿拉丁文法的痕迹,对于后来的学者有很大的影响。
随着社会的发展,知识的积累,人们越来越清楚地认识到汉语本身的特点,语义语法的出现就是这种现象的产物。
语义语法是具有中国特色的语法理论,极大地完善了中国语法。
[关键词]语义;形式;语法语言是一种神奇的现象,之所以称之为神奇,是因为它在社会的发展中,发挥了让人难以想象的作用。
因此,语言现象不仅是一种生理现象,更是一种社会现象,是人们的一种重要的交际方式和思维方式,它的本质属性是社会属性,人们利用它来完成各种社会活动,从而促进了人类社会的发展。
语法研究的最终目的是什么?我们为什么花费那么多的精力去研究貌似我们非常熟悉的,并且似乎不用作任何思考就能运用的语言呢?实际上,看上去貌似很简单的语言现象,却浓缩了太多的智慧,我们对自己的语言习以为常,是因为语言在我们的生活中无处不在,它已经融入我们的血液之中。
如果我们换一种语言环境,接触一种我们陌生的语言,我们就会发现语言的智慧和魅力所在了。
就语言研究的目的,目前有代表性的观点有:(1)怎样用有限的格式去说明繁简多方、变化无尽的语句,这应该是语法分析的最终目的,也应该是对于学习的人更为有用的工作。
(吕叔湘《汉语语法分析问题》[1])(2)句子分析的终点是确定句型,但确定句型并不等于完成了析句的全部任务。
句子里复杂的语义关系通过进一步的句法分析加以阐明。
(张斌,胡裕树《句子分析漫谈》[2])(3)语法研究的最终目的就是弄清楚语法形式和语法意义之间的对应关系。
……讲形式的时候能够得到语义方面的验证,讲意义的时候能够得到形式方面的验证。
(朱德熙《语法答问》[3])随着社会的发展,人们对于汉语的认识和研究也越来越深入,语义语法的出现表现出了人们对汉语特点的深刻把握。
作为一种代表了有中国特色的语法理论,语义语法展现出勃勃的生机。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
18
推导与归约&自顶向下与自底向上
推导: 如果a1可直接推导出 a2, a2可直接推导出a3,…… an1可直接推导出an,即存在一个自a1到an的直接推导序 列 + a1 a2 a3 … an-1 an(n>0) 则称a1可推导出an,记作a1 an表示从a1出发经过一步 或若干步,可推导出an,这个推导长度为n-1;
栈 * *( *( * (+ * (+ *( *(*(*( * + + +/ +/ + -
21
四、虚拟机(续一)
Java虚拟机 Java Source
Java Compiler Java Byte Code Java Virtual Machine Operating System Hardware
22
五、递归子程序方法
简单子程序(参见P119图3)
子程序
嵌套子程序(参见P119图4)
1.2运算符栈:存放暂时不能处理的运算符。 2、具体步骤(参P131) 3、框图(参见下页)
31
开始 输入运算符的优先关系
由左至右扫描中缀表达式 运算分量 N 运算符 N Y 退栈 Y error Y Y 左括号( N 右括号) N Y Y 输 出 栈为空 N 当前运算符优 先级大于栈顶 运算符优先级 N 退栈输出 Y 入 栈 Y 入 栈
16
A::=aT1| aT2 | T3 | T4 | …...| Tn且
二、自顶向下分析(续五)
例:文法:G=({a,b,x},{Z,V},Z,P) P: Z::=aV|bZ (1) V::=baZ|x (2) 待分析符号串:bbabaax. 自顶向下分析: Z bZ bbZ bbaV bbabaZ bbabaaV bbabaax
0 *
+ 如果记 a1 a1 ,则 * a1 an 表示自a1出发经过 0步或 若 干步可推导出an, a1 an 意味着a1 = an 或者a1 an
19
推导与归约&自顶向下与自底向上
文 推 归 法 导 约 句子分析 自顶向下 自底向上
20
四、虚拟机
虚拟机:虚拟机不是一台实际的机器,而是为 了便于讨论的一台假设和抽象的计算机。
abc+d-*ef/+g- —
1.运算符出现的先后顺序即代表计算的先后顺序。 2.每次遇到运算符,取左端紧邻的两个(一个)运算分 量作为该运算符号的两个(一个)运算分量
29
六、逆波兰表达式(续三)
中缀表达式—逆波兰表达式
1、定义运算符号的优先级 用自然数来表示运算符的优先级。故也称优先数 1.1常用运算符的优先数关系:
6
一、常用的终结符号集(续四)
P: E::=E+T|T T::=T*F|F F::=i|(E) 则因: E E; * E E+T; * E (E)* Follow(E)={#,+,)};
7
一、常用的终结符号集(续五)
P: E::=E+T|T T::=T*F|F F::=i|(E) 则因: * E F; * E T*F +T; * E F*F; * E (F) Follow(E)={#,+,*,)};
Priority()>Priority()>Priority(*、/) >Priority(+、-)
:表示单目减(负号) (的优先数小于其右边运算符的优先数; (的优先数大于其左边运算符的优先数; )的优先数最低,其不进运算栈,也不进输出区。
30
六、逆波兰表达式(续四)
中缀表达式—逆波兰表达式
直接递归 递归子程序(参见P119图5.6) 间接递归
23
五、递归子程序方法(续一)
例:计算f(n)=n!的函数 function rfact(n:integer):integer; begin if n>1 then rfact:=n*rfact(n-1) else rfact:=1 end;
24
17
推导与归约&自顶向下与自底向上
直接推导、直接归约、推导、归约
直接推导:设有文法G=(VT,VN,S,P),, (VT VN)*, 如果有A——〉P,则称A直接推导出,即: A 其中‘’表示直接推导。 可以称A直接推导出,或者 是A的直接推导。 与推导方向相反,称直接归约到A记作: A
二、自顶向下分析(续一)
例:文法:G=({i,+,-,/,*,(,)},{T,E,F},E,P) P: E::=T|E+T|E-T (1) T::=F|T*F|T/F (2) F::=i|(E) (3) 分析句子(i+i)-i是否符合文法: E E-T E-F E-i T-i F-i (E)-i (E+T)-i (E+F)-i (E+i)-i (T+i)-i (F+i)-i (i+i)-i
符合文法
12
二、自顶向下分析(续二 )
自顶向下分析的难点: 如果规则中含有一条或者多条类似(1)的 规则,则在推导过程中很难确定到底选用 那一条规则,如果采用遍历全部规则的方 法则最明显的缺点就是效率低。
E::=T1| T2 | T3 | T4 | …...| Tn (1)
13
二、自顶向下分析(续二 )
8
一、常用的终结符号集(续六)
3、可选集
定义:设有文法G=(VT,VN,S,P),规则P中 A=::a,则该规则的可选集定义为:
First(a), 当a不为空 Select(A=::a)= Follow(A), 当a为空
9
一、常用的终结符号集(续七)
例如:文法:G=(a,b,c,d, },{S,B},S,P)其中 P: S=::aBc|bB B=::bB|d|
14
二、自顶向下分析(续三 )
2、 当不等于,则对当前输入的符号a,若有 a First() 则可以选用规则A=:: 进行推导,即采用后选式。 3、如果非终结符有n个后选式,即A::=T1| T2 | T3 | T4 | …...| Tn ,则要分(I)(II)两种情况: (I)首符号不相同 对于文法中有规则A::=T1| T2 | T3 | T4 | …...| Tn ,若n个后选 式的首符号均不相同即First(Ti) First(Tj)= (ij) 对于待分析的符号串,如果其第一个符号(即当前的输入 符号)为a,且有a First(Tk),则选择规则A::= Tk进行推导, 即选择后选式Tk。 15
难点解决: 候选式: 如有规则A::=T1| T2 | T3 | T4 | …...| Tn ,
则Ti称为A的后选式。 思路:通过当前的输入字符a来决定对后选式的选择。 方法: 1、首先对文法的每个规则A=:: 求可选集。
First(), 当不为空
Select(A=:: )=
Follow(A), 当为空
实例1:
输出区 a a ab ab abc abc* abc*+ abc*+ abc*+ abc*+d abc*+*
33
实
当前符号 a * ( b + c d
例
) + e / f g
2
输入区 a*(b+c-d)+e/f-g *(b+c-d)+e/f-g (b+c-d)+e/f-g b+c-d)+e/f-g +c-d)+e/f-g c-d)+e/f-g -d)+e/f-g -d)+e/f-g d)+e/f-g )+e/f-g )+e/f-g +e/f-g e/f-g /f-g f-g -g -g -g g
a
运算分量
+
运算符
b
运算分量
27
六、逆波兰表达式(续一)
中缀、前缀、后缀表示法功能等价 共同点: 1、运算符的个数不变; 2、运算分量的次序不变; 后缀表示法的好处: a:无括号,形式简洁; b:运算符的顺序与运算的次序完全相同。
28
六、逆波兰表达式(续二)
逆波兰表达式—中缀表达式
ab+c* abc+* ab * c + — — — (a+b)*c a*(b+c) a*b+c a*(b+c-d)+e/f-g
文法 定义:文法G是一个四元组,G=(VT,VN,S,P),其中 VT为终结符号集,这是个非空有限集。 VN为非终结符号集合,它也是非空有限集。 S为一文法开始符,是一个特殊的非终结符。S VN P是产生式的非空有限集,其中每个产生式(或称规则) 是一序偶(U,x)通常写作U——〉x或U::=x; ——〉( 或::= )意为“由……组成”或“产生”; 字汇表: V=(VT VN) VT VN=
4
一、常用的终结符号集(续二)
P: E::=E+T|T T::=T*F|F F::=i|(E) 则 First(E)={i,(}; First(T*F)={I,(}; First((i))={(}; First(i+i)={i};
5
一、常用的终结符号集(续三)
2、向前看集
定义:设有文法G=(VT,VN,S,P),非终结符号U的向 前看集定义为 Follow(U)={a|S * …Ua…,a VTU{#}} #:非终结符号U后面的符号串为空,则将U后的符号记作特殊 符号#; Follow(U)={所有含有U的句型中紧跟U之后的终结符}U{#} 例如:文法:G=({i,+,*,(,)},{T,E,F},E,P)
入栈
栈顶为( N 栈为空 N 退栈输出