数学模型5-2决策树
数据建模与应用作业指导书

数据建模与应用作业指导书第1章数据建模基础 (2)1.1 数据建模的概念与意义 (2)1.2 数据建模的流程与步骤 (3)1.3 常见数据建模方法 (3)第2章数据预处理 (4)2.1 数据清洗 (4)2.1.1 缺失值处理:针对数据集中的缺失值,采用填充、删除或插值等方法进行处理。
(4)2.1.2 异常值检测与处理:通过统计分析、箱线图等方法识别数据集中的异常值,并采用合理的方式进行处理。
(4)2.1.3 重复数据处理:对数据集中的重复数据进行识别和删除,避免对后续分析产生影响。
(4)2.1.4 数据类型转换:对数据集中的数据类型进行统一和转换,保证数据的一致性。
42.2 数据整合与转换 (4)2.2.1 数据集成:将来自不同来源的数据进行合并,形成统一的数据集。
(5)2.2.2 数据变换:对数据集中的数据进行规范化、标准化等变换,消除数据量纲和尺度差异的影响。
(5)2.2.3 特征工程:基于业务需求,提取和构造具有代表性的特征,提高模型功能。
(5)2.2.4 数据归一化与标准化:对数据集中的数值型数据进行归一化或标准化处理,降低数据分布差异的影响。
(5)2.3 数据规约 (5)2.3.1 特征选择:从原始特征集中选择具有较强预测能力的特征,降低数据维度。
(5)2.3.2 主成分分析:通过线性变换,将原始数据投影到低维空间,实现数据降维。
(5)2.3.3 聚类分析:对数据进行聚类,识别数据集中的潜在模式,为特征选择和降维提供依据。
(5)2.3.4 数据压缩:采用编码、哈希等方法对数据进行压缩,减少存储和计算负担。
(5)2.4 数据可视化 (5)2.4.1 分布可视化:通过直方图、散点图等展示数据集中各特征的分布情况。
(5)2.4.2 关系可视化:利用热力图、相关性矩阵等展示特征之间的关系。
(5)2.4.3 聚类可视化:通过散点图、轮廓图等展示数据聚类结果。
(5)2.4.4 时间序列可视化:采用折线图、面积图等展示时间序列数据的变化趋势。
数学建模分类

数学建模分类
一、基于数学规划的建模方法
1. 线性规划模型
2. 整数规划模型
3. 二次规划模型
4. 非线性规划模型
5. 动态规划模型
6. 最优化问题建模
二、基于统计分析的建模方法
1. 线性回归模型
2. 逻辑回归模型
3. 主成分分析模型
4. 马尔可夫模型
5. 时间序列模型
6. 方差分析模型
三、基于图论的建模方法
1. 最短路径模型
2. 最小生成树模型
3. 拓扑排序模型
4. 最大流模型
5. 最小费用流模型
6. 图着色问题建模
四、基于优化方法的建模方法
1. 遗传算法模型
2. 蚁群算法模型
3. 粒子群优化模型
4. 模拟退火模型
5. 遗传规划模型
6. 蚁群优化模型
五、基于随机过程的建模方法
1. 马尔可夫链模型
2. 随机游走模型
3. 泊松过程模型
4. 随机差分方程模型
5. 随机微分方程模型
6. 随机优化问题建模
六、基于决策分析的建模方法
1. 决策树模型
2. 神经网络模型
3. 支持向量机模型
4. 贝叶斯网络模型
5. 人工智能模型
6. 多目标决策问题建模。
李航-统计学习方法-笔记-5:决策树
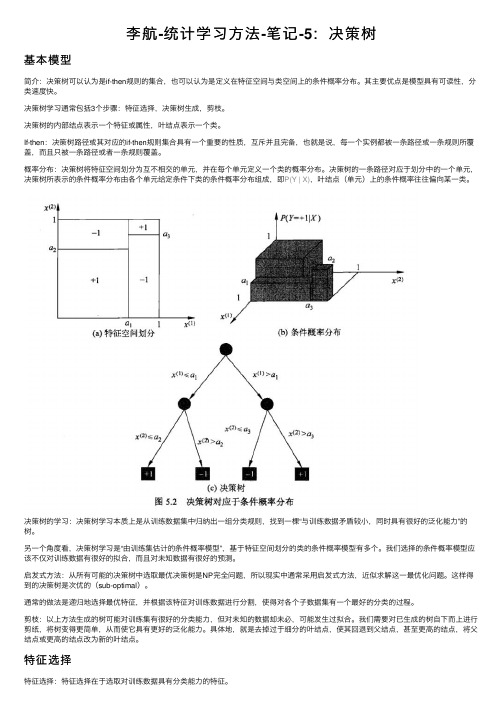
李航-统计学习⽅法-笔记-5:决策树基本模型简介:决策树可以认为是if-then规则的集合,也可以认为是定义在特征空间与类空间上的条件概率分布。
其主要优点是模型具有可读性,分类速度快。
决策树学习通常包括3个步骤:特征选择,决策树⽣成,剪枝。
决策树的内部结点表⽰⼀个特征或属性,叶结点表⽰⼀个类。
If-then:决策树路径或其对应的if-then规则集合具有⼀个重要的性质,互斥并且完备,也就是说,每⼀个实例都被⼀条路径或⼀条规则所覆盖,⽽且只被⼀条路径或者⼀条规则覆盖。
概率分布:决策树将特征空间划分为互不相交的单元,并在每个单元定义⼀个类的概率分布。
决策树的⼀条路径对应于划分中的⼀个单元,决策树所表⽰的条件概率分布由各个单元给定条件下类的条件概率分布组成,即P(Y | X),叶结点(单元)上的条件概率往往偏向某⼀类。
决策树的学习:决策树学习本质上是从训练数据集中归纳出⼀组分类规则,找到⼀棵“与训练数据⽭盾较⼩,同时具有很好的泛化能⼒”的树。
另⼀个⾓度看,决策树学习是“由训练集估计的条件概率模型”,基于特征空间划分的类的条件概率模型有多个。
我们选择的条件概率模型应该不仅对训练数据有很好的拟合,⽽且对未知数据有很好的预测。
启发式⽅法:从所有可能的决策树中选取最优决策树是NP完全问题,所以现实中通常采⽤启发式⽅法,近似求解这⼀最优化问题。
这样得到的决策树是次优的(sub-optimal)。
通常的做法是递归地选择最优特征,并根据该特征对训练数据进⾏分割,使得对各个⼦数据集有⼀个最好的分类的过程。
剪枝:以上⽅法⽣成的树可能对训练集有很好的分类能⼒,但对未知的数据却未必,可能发⽣过拟合。
我们需要对已⽣成的树⾃下⽽上进⾏剪纸,将树变得更简单,从⽽使它具有更好的泛化能⼒。
具体地,就是去掉过于细分的叶结点,使其回退到⽗结点,甚⾄更⾼的结点,将⽗结点或更⾼的结点改为新的叶结点。
特征选择特征选择:特征选择在于选取对训练数据具有分类能⼒的特征。
决策论

。
5
二.收集信息拟定方案
目标明确以后,首先应该通过调查研究收集与目标有关的详细信息,并 根据所收集的信息对未来进行科学预测,以确知决策人所可能会面临的决策 环境。在预测的基础上,即可以着手拟定方案。拟定方案必须遵循两个基本 原则,一是整体详尽性,二是相互排斥性。对于比较复杂的决策问题,方案 的拟定还可以分两个阶段进行,即先进行大胆设想,然后再进行精心设计。
9
5.2.1 悲观法(Max Min 准则)
悲观法也叫小中取大准则,其特点是从最不利的情况出发,找出可能
出现的最差状态,然后在最不利的情况下选择最好的方案。其决策过程是 :首先从每一个方案中选择一个最小收益值,然后再从这些最小收益值所 代表的方案中选择一个收益值最大的方案作为备选方案,即所谓“小中取 大”。这是一种保守的决策方法,其实质也就是当面临多种情况时人们所 采取的“从最坏处着想向最好处努力”一种思维方法。 按照这种方法,上述例子应选择的方案就是滞销状态下的小批量生产 。
5.2.4 平均法(等可能准则)
这种决策方法是假定每一种市场状态出现的可能性是相同的,因而可以 把每一个方案在各种不同状态下的收益值加以平均,取其最大者为决策方案 ,计算公式如下。容易算出,引例中各方案的平均收益值分别为:40、46.7 和50。显然,应取大批量生产方案为最优方案。
xi
x
j 1
例5-1 某企业准备上马某一种产品的生产,根据预测, 未来的市场状态有三种情况,即畅销、一般和滞销。因此, 准备采用三种相应的生产方案,即大批量生产、中等批量生 产和小批量生产。每一方案在每一市场状态下的收益值如表5 -1所示,问企业应如何决策。
表5-1 生产批量决策表 生产方案 收益值(万元) 畅销 一 般 滞 销 小批量生产 50 40 30 中等批量生产 80 50 10 大批量生产 120 60 -30
招标采购案例分析2_真题(含答案与解析)-交互

招标采购案例分析2(总分100, 做题时间90分钟)试题一1.政府投资的某工程,某监理单位承担了该工程施工招标代理和施工监理任务,该工程采用无标底公开招标方式选定施工单位。
工程实施中发生了下列事件:事件1:工程招标时,A、B、C、D、E、F、G共七家投标单位通过资格预审,并在投标截止时间前提交了投标文件。
评标时,发现A投标单位的投标文件虽加盖了公章,但没有投标单位法定代表人签字,只有法定代表人授权书中被授权人的签字(招标文件中对是否可由被授权人签字没有具体规定);B投标单位的投标报价明显高于其他投标单位的投标报价,分析其原因是施工工艺落后造成的;C投标单位将招标文件中规定的工期380天作为投标工期,但在投标文件中明确表示如果中标,合同工期按定额工期400天签订;D投标单位投标文件中的总价金额汇总有误。
事件2:经评标委员会评审,推荐G、F、E投标单位为前3名中标候选人。
在中标通知书发出前,建设单位要求监理单位分别找G、F、E投标单位重新报价,以价格低者为中标单位。
按原投标价签订施工合同后,建设单位与中标单位再次以新报价签订协议书,作为实际履行合同的依据。
监理单位认为建设单位的要求不妥,并提出了不同意见,建设单位最终接受了监理单位的意见,确定G投标单位为中标单位。
问题1.分别指出事件1中A、B、C、D投标单位的投标文件是否有效?说明理由。
2.事件2中,建设单位的要求违反了招标投标有关法规的哪些具体规定?SSS_TEXT_QUSTI该题您未回答:х该问题分值: 201.事件1中A、B、C、D投标单位的投标文件是否有效的判断:(1)A单位的投标文件有效。
理由:招标文件对此没有具体规定,签字人有法定代表人的授权书。
(2)B单位的投标文件有效。
理由:招标文件中对高报价没有限制。
(3)C单位的投标文件无效。
理由:没有响应招标文件的实质性要求(或:附有招标人无法接受的条件)。
(4)D单位的投标文件有效。
理由:总价金额汇总有误属于细微偏差(或:明显的计算错误允许补正)。
决策树

• 风险决策问题的直观表示方法的图示法。因为图的形状 像树,所以被称为决策树。 • 决策树的结构如下图所示。
1
状态节点
概率分枝 4 概率分枝 5
结果节点
2
方案分枝
结果节点
1 方案分枝 决策结点 3 概率分枝 状态节点 7 结果节点 概率分枝 6 结果节点
2Leabharlann 决策树所用图解符号及结构:
6
例一
• A1、A2两方案投资分别为450万和240 万,经营年限为5年,销路好的概率为 0.7,销路差的概率为0.3,A1方案销 路好、差年损益值分别为300万和负60 万;A2方案分别为120万和30万。
7
决策过程如下:画图,即绘制决策树
• A1的净收益值=[300×0.7+(-60)×0.3] ×5-450=510 万 • A2的净收益值=(120×0.7+30×0.3)×5-240=225万 • 选择:因为A1大于A2,所以选择A1方案。 • 剪枝:在A2方案枝上打杠,表明舍弃。
12
最后比较决策点1的情况: • 由于点③(719万元)与点②(680万元) 相比,点③的期望利润值较大,因此取 点③而舍点②。这样,相比之下,建设 大工厂的方案不是最优方案,合理的策 略应采用前3年建小工厂,如销路好,后 7年进行扩建的方案。
13
课后练习 • 1. 从甲地到乙地有两条行军路线,其中Ⅰ号路线是 通道没有桥梁,Ⅱ号路线中间有一座桥。如果Ⅱ号路 线桥梁被损坏可折返走Ⅰ号路线或用船摆渡通过。现 已知走Ⅰ号路所需时间4小时,Ⅱ号路桥好需2小时, 桥好的概率为0.7。船渡情况如下表 • 请用决策树方法选择最优行军路线。
8
多阶段决策
常用风控模型指标体系

常用风控模型指标体系摘要:一、引言二、风险控制模型的概述三、常用风控模型的指标体系1.信用评分模型2.风险矩阵模型3.决策树模型4.神经网络模型5.支持向量机模型四、总结正文:一、引言在我国金融行业中,风险控制是至关重要的环节。
为了有效管理金融风险,各种风控模型被广泛应用。
这些模型通常包括一系列指标,用于评估潜在风险和制定相应的防控措施。
本文将为您介绍常用的风控模型指标体系。
二、风险控制模型的概述风险控制模型是金融机构为了识别、评估和管理潜在风险而采用的一种方法。
这些模型通常包括数据收集、特征工程、模型训练、模型评估和优化等步骤。
通过这些模型,金融机构可以更加精确地衡量风险,从而制定相应的政策和措施。
三、常用风控模型的指标体系以下是五种常用的风控模型及其指标体系:1.信用评分模型信用评分模型主要通过评估借款人的信用历史、还款能力、负债状况等因素来预测其违约概率。
常用的信用评分指标包括:- 逾期次数- 逾期天数- 负债水平- 收入水平- 信用历史长度2.风险矩阵模型风险矩阵模型是一种基于概率论的风险评估方法,通过构建风险矩阵来描述不同风险事件的发生概率和损失程度。
常用的风险矩阵指标包括:- 概率- 损失程度- 风险价值- 预期损失3.决策树模型决策树模型是一种基于树结构的分类与回归模型,通过选择最优特征进行分割,递归地构建树结构。
常用的决策树指标包括:- 信息增益- 基尼指数- 剪枝- 树深度4.神经网络模型神经网络模型是一种模拟人脑神经元结构的计算模型,通过学习输入与输出之间的非线性关系来进行预测。
常用的神经网络指标包括:- 激活函数- 损失函数- 学习率- 迭代次数- 隐藏层数5.支持向量机模型支持向量机模型是一种基于统计学习理论的分类与回归模型,通过找到最优决策边界来最小化误差。
常用的支持向量机指标包括:- 核函数- 最大间隔- 误分类代价- 支持向量- 训练误差四、总结在金融行业中,风控模型是评估和管理风险的重要工具。
决策树例题经典案例python

决策树例题经典案例python摘要:1.决策树概述2.决策树例题:经典案例3.Python 在决策树中的应用4.决策树例题:Python 代码实现5.总结正文:1.决策树概述决策树是一种常见的机器学习方法,它通过一系列的问题来对数据进行分类或者预测。
决策树可以看作是一个问题树,每个内部节点表示一个特征,每个分支代表一个决策规则,每个叶子节点代表一个分类或预测结果。
2.决策树例题:经典案例假设我们有一个数据集,包含以下几个特征:性别、体重、是否购买运动鞋。
我们希望通过这些特征来预测一个人是否会购买运动鞋。
这就是一个典型的决策树应用场景。
3.Python 在决策树中的应用Python 中有很多库可以用来实现决策树,其中最常用的是scikit-learn。
scikit-learn 提供了决策树分类器(DecisionTreeClassifier)和决策树回归器(DecisionTreeRegressor)两种工具。
4.决策树例题:Python 代码实现下面我们通过一个简单的例子来展示如何使用Python 实现决策树。
首先,我们需要导入必要的库:```pythonimport numpy as npfrom sklearn.datasets import load_irisfrom sklearn.model_selection import train_test_splitfrom sklearn.tree import DecisionTreeClassifierfrom sklearn.metrics import accuracy_score```接下来,我们加载数据集并进行预处理:```pythoniris = load_iris()X = iris.datay = iris.target```然后,我们将数据集分为训练集和测试集:```pythonX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)```接着,我们创建一个决策树分类器实例:```pythonclf = DecisionTreeClassifier()```最后,我们用训练集训练模型,并在测试集上进行预测:```pythonclf.fit(X_train, y_train)y_pred = clf.predict(X_test)```模型的准确率可以通过以下代码计算:```pythonaccuracy = accuracy_score(y_test, y_pred)print("Accuracy: {:.2f}%".format(accuracy * 100))```5.总结本篇文章通过一个简单的例子介绍了如何使用Python 实现决策树。
机器学习中的五种回归模型及其优缺点

机器学习中的五种回归模型及其优缺点1.线性回归模型:线性回归模型是最简单和最常用的回归模型之一、它通过利用已知的自变量和因变量之间的线性关系来预测未知数据的值。
线性回归模型旨在找到自变量与因变量之间的最佳拟合直线。
优点是简单易于实现和理解,计算效率高。
缺点是假设自变量和因变量之间为线性关系,对于非线性关系拟合效果较差。
2.多项式回归模型:多项式回归模型通过添加自变量的多项式项来拟合非线性关系。
这意味着模型不再只考虑自变量和因变量之间的线性关系。
优点是可以更好地拟合非线性数据,适用于复杂问题。
缺点是容易过度拟合,需要选择合适的多项式次数。
3.支持向量回归模型:支持向量回归模型是一种非常强大的回归模型,它通过在数据空间中构造一个最优曲线来拟合数据。
支持向量回归模型着眼于找到一条曲线,使得在该曲线上离数据点最远的距离最小。
优点是可以很好地处理高维数据和非线性关系,对离群值不敏感。
缺点是模型复杂度高,计算成本也较高。
4.决策树回归模型:决策树回归模型将数据集划分为多个小的决策单元,并在每个决策单元中给出对应的回归值。
决策树由一系列节点和边组成,每个节点表示一个特征和一个分割点,边表示根据特征和分割点将数据集分配到下一个节点的规则。
优点是容易理解和解释,可处理离散和连续特征。
缺点是容易过度拟合,对噪声和离群值敏感。
5.随机森林回归模型:随机森林回归模型是一种集成学习模型,它基于多个决策树模型的预测结果进行回归。
随机森林通过对训练数据进行有放回的随机抽样来构建多个决策树,并利用每个决策树的预测结果进行最终的回归预测。
优点是可以处理高维数据和非线性关系,对噪声和离群值不敏感。
缺点是模型较为复杂,训练时间较长。
总之,每种回归模型都有其独特的优点和缺点。
选择适当的模型取决于数据的特点、问题的要求和计算资源的可用性。
在实际应用中,研究人员需要根据具体情况进行选择,并对模型进行评估和调整,以获得最佳的回归结果。
最新国家开放大学《安全系统工程》复习资料

安全系统工程复习资料(新增)一、单项选择题1.故障原因是指导致系统、元件等形成故障类型的(A),造成系统、元件发生故障的原因。
A.过程与机理B.致因元素C.条件D.单元2.致命度分析的目的在于评价每种故障类型的危险程度,通常采用(A)来评价故障类型的危险度。
A.概率-严重度B.概率-相关度C.数理统计D.概率统计3.事故树的(B)分析是在已经确定各基本事件发生概率的基础上,计算顶上事件发生概率,并依此进行各基本事件概率重要度分析和临界重要度分析。
A.定性B.定量C.数理D.概率4.安全评价是一个运用安全系统工程原理和方法,辨识和评价(D)中存在的风险的过程。
A.系统、结构B.组织、工程C.组织、结构D.系统、工程5.安全评价的分类方法很多,按照实施阶段不同分为三类:安全预评价、安全验收评价、(D)。
A.安全评估评价B.安全现实评价C.安全核查评价D.安全现状评价6.安全评价方法分类的目的是为了根据安全评价(B)选择适用的评价方法。
A.目标B.对象C.方向D.内容7.危险性在一定的条件下发展成为事故,所造成的后果受两个因素影响,一个是发生事故的(C),另一个是发生事故造成后果的严重程度。
A.可能性B.必然性C.概率D.机率8.在生产活动中,每人每年死亡概率的数量级为(B),是极其危险的,是绝对不能接受的。
A.10-1B.10-2C.10-3D.10-49.层次分析法的特点是在对复杂的决策问题的本质(C)及其内在关系等进行深入分析的基础上,利用较少的定量信息使决策的思维过程数学化,从而为多目标、多准则或无结构特性的复杂决策问题提供简便的决策方法。
A.影响机制B.影响层次C.影响因素D.影响内容10.安全预测按按所应用的原理分:(B)、灰色理论预测、黑色理论预测。
A.红色理论预测B.白色理论预测C.绿色理论预测D.蓝色理论预测11.德尔菲法是一种广为适用的方法,它既可以用于科技预测,也可以用于(A)、经济预测。
交通分析习题课(运筹学)

习 题第二章 线性规划习题2-1 某桥梁工地需集合料3万立方米,集合料含量为:粘土含量不大于0.8%,细沙含量在5%~8%之间,粗沙含量在60%~70%之间,砾石含量在20%~30%之间,现有材料数量及单价如下表所示。
问如何配料才能使集合料的总成本费用最低?(试列出数学模型)。
2—2 将下列线性规划问题化成标准型:① 42154m ax x x x S ++=s.t.⎪⎪⎪⎩⎪⎪⎪⎨⎧≥≥+-≤-+≤+++=+0,,,843104480334304432143432432121x x x x x x x x x x x x x x x② 4321343m in x x x x S --+=s.t.⎪⎪⎪⎩⎪⎪⎪⎨⎧≤≥≤+-≥++=-+≤+0,0,8434040403213242132141x x x x x x x x x x x x x 2—3 用图解法求解下列线性规划问题:2152m ax x x S +=s.t.⎪⎪⎩⎪⎪⎨⎧≥≤+≤≤0,8234212121x x x x x x(答案:19=*S ,()T X 3,2=*。
)2—4 用单纯形法求解下列线性规划问题 ① 321834m in x x x S ++=s.t.⎪⎩⎪⎨⎧≥≥+≤+0,,5223213231x x x x x x x(答案:15=*S ,T X ),0,5,0(=*。
) ② 432132m ax x x x x S -++=s.t. ⎪⎪⎩⎪⎪⎨⎧≥=+++=++=++0,,,1022052153243214321321321x x x x x x x x x x x x x x (答案:15=*S ,T X )0,2/5,2/5,2/5(=*。
)第三章 特殊类型的线性规划习题3-1用表上作业法求解以下运输问题。
3-2某市区交通愿望图有三个始点和三个终点,始点发生的出行交通量a i ,终点吸引的交通量b j 及始终点之间的旅行费用如下所示。
决策树模型在临床研究数据分析中的应用

·临床研究规范·决策树模型在临床研究数据分析中的应用沈范玲子1王瑞平1,2(1. 上海中医药大学公共健康学院上海 201203;2. 上海市皮肤病医院临床研究与创新转化中心上海 200443)摘要决策树模型是一种有监督的机器学习方法,分类规则通常采取IF-THEN形式,分析结果常以树形图呈现,具有可解释性强、易于理解的优势,在灾害预测、环境监测、临床诊疗决策等领域均有广泛的应用。
本文从决策树模型概念入手,介绍了决策树模型的一般构建步骤、分类与回归树(classification and regression tree, CART)决策树模型在临床研究数据分析中的应用,并应用SPSS软件示例CART决策树模型的构建过程和实现方法,以期为临床研究者采用决策树模型进行数据分析提供参考。
关键词决策树临床研究 CART算法 SPSS软件中图分类号:G304; R-3 文献标志码:C 文章编号:1006-1533(2024)05-0014-05引用本文沈范玲子, 王瑞平. 决策树模型在临床研究数据分析中的应用[J]. 上海医药, 2024, 45(5): 14-18.Application of decision tree modeling in clinical research data analysisSHEN Fanlingzi1, WANG Ruiping1,2(1. School of Public Health, Shanghai University of Traditional Chinese Medicine, Shanghai 201203, China;2. Clinical Research & Innovation Center, Shanghai Skin Disease Hospital, Shanghai 200443, China)ABSTRACT Decision tree model is a supervised machine learning method and its classification rules usually take the form of IF-THEN, the analysis results are often presented in the form of tree diagrams, with the advantages of solid interpretability and ease understanding, and it has been widely used in the fields of disaster prediction, environmental monitoring, clinical diagnosis and treatment decision-making. This article starts from the concept of decision tree model, introduces the general construction steps of decision tree model, the application of classification and regression tree (CART) decision tree model in the analysis of clinical research data, and the construction process and realization method of CART decision tree model using the SPSS software example, so as to provide a better solution for clinical researchers to use decision tree model for data analysis.KEY WORDS decision trees; clinical research; CART algorithm; SPSS software临床医学研究中,在探讨多个自变量和因变量之间关系时,常采用多元线性回归、logistic回归、Cox回归分析、广义线性模型等经典统计分析方法。
职场中的五个最佳决策模型

职场中的五个最佳决策模型在职场中,做出明智的决策是成功的关键之一。
然而,由于信息不完全、不确定性和复杂性等因素的存在,决策常常是具有挑战性的。
为了帮助职场人士更好地应对各种决策情境,下面将介绍五个最佳的决策模型。
1. SWOT分析模型SWOT分析模型是一种常用的决策工具,它帮助人们评估一个组织或个人在内外环境中的优势和劣势,并确定机会和威胁。
SWOT代表着组织的优势(Strengths)、劣势(Weaknesses)、机会(Opportunities)和威胁(Threats)。
通过将这些因素结合起来,SWOT分析模型能够帮助决策者制定出符合自身条件和环境的最佳决策方案。
2. 决策树模型决策树模型以树状图的形式,将决策问题的各种可能情况和相应的决策及结果进行展示。
在决策树中,每个节点代表一个决策或结果,分支表示可能的选项或情况。
通过分析决策树的各个分支和结果的概率,决策者可以评估不同决策方案的风险和潜在回报,并做出理性的选择。
3. 边际成本-边际效益分析模型边际成本-边际效益分析模型是为了帮助决策者在资源有限的情况下,评估不同决策方案的成本与效益之间的关系。
该模型通过比较每个决策方案带来的额外成本和额外效益,以确定最佳的决策方案。
在职场中,决策者可以通过边际成本-边际效益分析模型来评估不同项目的投资回报率,从而做出投资决策。
4. BCG矩阵模型BCG矩阵模型是一种用来评估和管理组织产品组合的工具。
该模型将产品分为四个不同的象限:明星、现金奶牛、问题儿童和瘦狗。
明星产品具有高市场份额和高增长率,是组织的收入和利润主要来源。
现金奶牛产品市场份额高,但增长缓慢,能够为组织提供稳定的现金流。
问题儿童产品市场份额低,但增长潜力大,需要进一步投资和发展。
瘦狗产品市场份额低且增长缓慢,可能需要考虑是否放弃。
通过使用BCG矩阵模型,决策者能够更好地分析和决策产品组合的发展方向。
5. 六顶思考帽模型六顶思考帽模型是由爱德华·德·博诺设计的,通过将不同颜色的思考帽子来代表不同的思维角色和方式。
管理学基础(第四版)第五章决策习题及答案

第五章决策一、单项选择题1.决策所涉及的问题一般与()。
A.将来有关B.过去有关C.现在有关D.过去、现在、将来都有关2.现代组织活动的成功与否关键在于()。
A.信息的准确及时B.是否作了充分的调查C.决策的正确与否D.组织内部的管理质量3.()旨在实现组织内部各环节活动的高度协调和资源的合理使用,以提高经济效益和管理效率。
A.战略决策B.管理决策C.业务决策D.确定性决策4. 合理决策必须具备的三个条件不包括()。
A.目标合理B.可靠的信息情报C.有限合理、经济性D.决策结果满足预定目标的要求5. 战略决策主要是谋求()。
A.组织目标的实现B.从两个以上的可行方案中选择一个最佳方案C.组织内部条件、外部环境和目标三方面的动态均衡D.组织工作的正确指导6.决策方案的后果有多种,每种都有客观概率,这属于()。
A.不确定型决策B.非程序化决策C.战术决策 D.风险型决策7.决策的定量方法是()。
A.依靠人们的知识、经验和判断能力来进行决策的方法B.运用数学方法,建立数学模型来进行决策的方法C.确定型、不确定型和风险型决策的方法D.一系列科学的处理过程8.决策树的构成要素是()。
A.概率枝、方案枝、决策点、状态结点B.方案、概率、期望值、自然状态C.决策点、方案枝、概率枝、自然状态D.方案、决策点、概率、状态结点9.对某种自然状态概率为“1”的决策是()。
A.风险型B.确定型C.程序化D.非程序化10.某企业生产某种产品,固定成本为160 000元,单位变动成本为10 000元,每台售价12 000元,该产品的盈亏平衡点是()。
A.14台B.12.5台C. 7.3台 D.80台11. 决策过程的第一步是()。
A.确定目标B.发现问题C.搜集信息D.调查研究、分析情报资料、找出问题12. 不确定型决策和风险型决策的主要区别在于()。
A.风险的大小B.可控程度C.能否确定客观概率 D.环境的稳定性13.管理决策主要应由()作出。
实验5 建立决策树并进行分类

实验5 建立决策树并进行分类实验目的通过使用SPSS对数据集进行分析并建立决策树,学会建立决策树的数据处理过程和方法,从而深入地理解分类的一般过程和基本原理,以及如何利用决策树分类解决现实的问题。
实验内容1、建立决策树2、使用决策树对未知类别的数据(集)进行类别预测分析实验条件1.操作系统:Windows XP SP22.SPSS13。
1实验要求1、现有1000位顾客个人信息,主要包括性别、地址、收入、婚姻状况、教育程度、职业等信息(保存在顾客.xls文件中),数据表的结构如下图所示:请你运用SPSS统计分析软件分析数据,并将实验步骤和结果记录到实验报告单上。
(1)以顾客.xls作为训练数据集,收入、职业、年龄为测试属性,是否购买自行车为类别属性,分别选择四种分类方法建立决策树,记录准确率最高的分析结果。
(2)使用分类规则预测预测1.xls中数据所属的类别(是否购买自行车)。
(3)对分类结果和预测结果进行分析。
2、现有2646位顾客的年龄、收入、信用卡数、教育程度、车贷数、信用等级信息(保存在tree_credit.sav中),请你运用SPSS统计分析软件分析数据,并将实验步骤和结果记录到实验报告单上。
(1)分别选择四种分类方法建立决策树,记录准确率最高的分类析果。
(2)使用分类规则预测tree.sav中数据所属的类别(信用等级)。
(3)对分类结果和预测结果进行分析。
实验步骤及指导1、建立决策树第一步:数据准备,将待处理的数据输入或导入SPSS中,本例将顾客.xls导入SPSS 中。
第二步:建立决策树(1)选择统计分析[Statistics]菜单,选聚类分析[Classify]中的树状分析[Classification Tree...]项,弹出树状分析[Classification Tree]对话框,从对话框左侧的变量列表中分别选择类别属性和测试属性进入右侧类别属性[Dependent Variable]和测试属性[Independent Variable]框中。
决策树模型的使用教程(七)

决策树模型的使用教程决策树模型是一种用于分类和回归分析的机器学习算法,它将数据集分成更小的子集,直到每个子集中的数据点属于同一类别或具有相似的特征。
决策树模型简单易懂,适用于处理大型数据集,并且可以解释性较好。
在本文中,我们将介绍决策树模型的基本概念、构建方法和实际应用。
1. 基本概念决策树模型由节点、边和叶子组成。
节点表示数据集中的一个特征或属性,边表示特征的取值,叶子表示数据点所属的类别或回归结果。
决策树的构建过程是一个递归的过程,从根节点开始,根据特征的取值将数据集分成更小的子集,直到满足停止条件为止。
2. 构建方法构建决策树模型的主要方法有ID3、和CART。
其中,ID3算法使用信息增益来选择特征,算法使用信息增益比来选择特征,CART算法则使用基尼系数来选择特征。
在实际应用中,通常会根据数据集的特点选择合适的算法。
3. 实际应用决策树模型在实际应用中有着广泛的应用。
例如,在医疗诊断中,可以利用决策树模型根据患者的症状和检查结果来判断疾病类型;在金融风控中,可以利用决策树模型来预测客户的信用风险;在电商推荐系统中,可以利用决策树模型根据用户的行为来推荐商品。
4. 模型评估对于决策树模型,通常会使用交叉验证来评估模型的性能,以及剪枝来避免过拟合。
此外,还可以使用AUC、准确率、召回率等指标来评估模型的性能。
5. 实现方式在实际使用中,可以使用Python的sklearn库来实现决策树模型。
首先,需要加载数据集,然后使用决策树算法来构建模型,最后使用训练好的模型对新数据进行预测。
6. 注意事项在使用决策树模型时,需要注意的是特征选择、剪枝、处理缺失值和处理过拟合等问题。
此外,在处理连续型特征时,通常会使用二分法来进行处理。
综上所述,决策树模型是一种简单且实用的机器学习算法,它在分类和回归分析中有着广泛的应用。
通过本文的介绍,相信读者对决策树模型有了更深入的了解,希望读者能够在实际应用中灵活运用决策树模型,取得更好的效果。
第五章 决策树-2016-ID3CART《统计学习方法》课件

决策树算法
与决策树相关的重要算法包括:
CLS, ID3,C4.5,CART
算法的发展过程
Hunt,Marin和Stone 于1966年研制的CLS学习系统,用于学习单个概 念。
1979年, J.R. Quinlan 给出ID3算法,并在1983年和1986年对ID3 进行了 总结和简化,使其成为决策树学习算法的典型。
1、模型构建(归纳) 通过对训练集合的归纳,建立分类模型。
2、预测应用(推论) 根据建立的分类模型,对测试集合进行测试。
决策树
决策树是一种典型的分类方法
首先对数据进行处理,利用归纳算法生成可读的规则和 决策树,
然后使用决策对新数据进行分析。
本质上决策树是通过一系列规则对数据进行分类的过程。
决策树
通过比较、总结、概括而得出一个规律性的结论。 归纳推理试图从对象的一部分或整体的特定的观察中获
得一个完备且正确的描述。即从特殊事实到普遍性规律 的结论。 归纳对于认识的发展和完善具有重要的意义。人类知识 的增长主要来源于归纳学习。
决策树和归纳算法
归纳学习由于依赖于检验数据,因此又称为检验学习。 归纳学习存在一个基本的假设:
逻辑问题生成,每个树节点只有两个分枝,分别包括学习实例的正例 与反例。
决策树算法
计数 年龄 收入 学生 信誉
64 青 高 否
良
64 青 高 否
优
128 中 高 否
良
60 老 中 否
良
64 老 低 是
良
64 老 低 是
优
64 中 低 是
优
128 青 中 否
良
64 青 低 是
良
132 老 中 是
良
决策树预测股价原理

决策树预测股价原理
决策树预测股价的原理主要基于历史数据的分析和学习,通过建立决策树模型来预测未来的股价走势。
首先,需要收集历史股价数据,包括开盘价、收盘价、最高价、最低价等信息。
这些数据将用于训练决策树模型,以识别出影响股价走势的关键因素。
接下来,利用这些数据,通过一定的算法和模型训练,生成决策树。
决策树的每个节点代表一个特征或属性,而每个分支则代表对某个特征的决策或选择。
通过不断分割数据集,最终形成一棵由多个节点和分支组成的决策树。
在构建决策树的过程中,需要对数据进行预处理和特征工程。
例如,对连续型数据需要进行离散化处理,将连续的数值转换为离散的区间;对分类型数据需要进行独热编码(one-hot encoding),将分类标签转换为机器学习算法能够理解的格式。
此外,还需要选择合适的特征和算法,以便训练出精度较高的决策树模型。
一旦训练好了决策树模型,就可以用于预测未来的股价走势。
根据决策树的规则和结构,对未来数据进行输入,然后按照决策树的路径进行预测。
预测结果可以是未来股价的走势、买卖信号等。
需要注意的是,决策树预测股价的精度和可靠性受到多种因素的影响,包括数据的质量和数量、特征选择和工程、算法的选择和参数设置等。
因此,在实际应用中,需要进行充分的测试和验证,以确保预测结果的准确性和可靠性。
决策树模型的交叉验证方法与使用技巧(五)

决策树模型的交叉验证方法与使用技巧决策树模型是机器学习中常用的一种模型,它通过对数据集进行分割,逐步构建树形结构,从而进行分类或回归预测。
在实际应用中,为了保证模型的泛化能力和预测准确性,需要对模型进行验证和优化。
交叉验证是一种常用的验证方法,通过将数据集划分成训练集和测试集,多次重复进行模型训练和验证,从而得到更稳定和可靠的评估结果。
本文将介绍决策树模型的交叉验证方法及使用技巧。
1. 交叉验证方法在使用决策树模型进行建模时,为了评估模型的性能,常常需要将数据集划分成训练集和测试集。
然而,单次划分的训练集和测试集可能并不能很好地代表整个数据集的特征,从而导致评估结果不够准确。
为了解决这一问题,交叉验证方法应运而生。
常用的交叉验证方法包括 k 折交叉验证和留一交叉验证。
在 k 折交叉验证中,数据集被划分成 k 个大小相似的互斥子集,每次选择其中一个子集作为测试集,剩下的 k-1 个子集作为训练集进行模型训练和验证。
在留一交叉验证中,每次只留下一个样本作为测试集,其余样本作为训练集进行验证。
通过多次重复交叉验证,可以得到更为稳定和可靠的评估结果。
2. 交叉验证的使用技巧在进行决策树模型的交叉验证时,需要注意一些使用技巧,以确保评估结果的准确性和稳定性。
首先,要注意数据集的划分。
在进行 k 折交叉验证时,需要确保每个子集中都包含各类别样本的代表性,以避免由于样本分布不均匀而导致评估结果偏差。
在进行留一交叉验证时,需要注意留一样本的选择,以保证代表性和随机性。
其次,要注意模型参数的选择。
决策树模型有多个参数可以进行调节,如树的深度、分裂节点的最小样本数等。
在交叉验证中,可以通过网格搜索等方法寻找最优的参数组合,以提高模型的泛化能力和预测准确性。
最后,要注意评估指标的选择。
在进行交叉验证时,可以选择多个评估指标进行模型性能的评估,如准确率、召回率、F1 值等。
综合考虑多个评估指标,可以更全面地评估模型的性能。
《数据科学与大数据技术》第5章 数据分析与计算

表5.1 客户贷款情况表
图5.5是利用上述历史数据训练出来的一个决策树。利用该决策树,金 融机构就可以根据新来客户的一些基本属性,决定是否批准其贷款申请。比 如某个新客户的年龄是中年,拥有房产,我们首先访问根节点Age,根据该 用户的年龄为中年,我们应该走中间那个分支,到达是否拥有房产的节点 “Own_House”,由于该客户拥有房产,所以我们走左边那个分支,到达叶 子节点,节点的标签是“Yes”,也就是应批准其贷款申请。
(3)应用阶段的主要任务是使用分类器,对新数据进行分类。
5.2.4 K最近邻(KNN)算法
KNN(K-Nearest Neighbors)算法是一种分类算法。它根据某个数据 点周围的最近K个邻居的类别标签情况,赋予这个数据点一个类别。具体的 过程如下,给定一个数据点,计算它与数据集中其他数据点的距离;找出距 离最近的K个数据点,作为该数据点的近邻数据点集合;根据这K个最近邻所 归属的类别,来确定当前数据点的类别。
当决策树出现过拟合现象时,可以通过剪枝减轻过拟合。剪枝分为预 先剪枝和后剪枝两种情况。
5.2.3 朴素贝叶斯方法
贝叶斯分类,是一类分类算法的总称。该类算法都以贝叶斯定理为基 础。
1.贝叶斯定理
P(B|A)表示在事件A已经发生的前提下,事件B发生的概率,称为事件 A发生情况下,事件B发生的“条件概率”。
图5.6 KNN算法实例
在KNN算法中,可用的距离包括欧式距离、夹角余弦等。一般对于文本 分类来说,用夹角余弦计算距离(相似度),比欧式距离更为合适。距离越 小(距离越近),表示两个数据点属于同一类别的可能性越大。
KNN分类算法的应用非常广泛,包括协同过滤推荐(Collaborative Filtering)、手写数字识别(Hand Written Digit Recognition)等领 域。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
什么函数具有上述性质?可以证明,唯有对数函数具有上述性质。
两类(p+, p-)情形
按年龄分三组(青384,中256,老384) 青128买,256不买。
中256买,0不买。
老256买,128不买。
高160买,128不买。
中160买,192不买。
低192买,64不买。
按学生分两组(是480,否544)
是416买,64不买。
否224买,320不买。
优160买,192不买。
良480买,192不买。
按收入分三组(高128,中192,低64) 高0买,128不买。
中64买,128不买。
低64买,0不买。
按学生分两组(是128,否256)
是128买,0不买。
否0买,256不买。
按信誉分两组(优128,良256)
优64买,64不买。
良64买,192不买。
按收入分两组(中256,低128)
中192买,64不买。
低64买,64不买。
按学生分两组(是256,否128)
是192买,64不买。
否64买,64不买。
按信誉分两组(良256,优128)
良256买,0不买。
优0买,128不买。
增益比率定义为,
如果一个划分T将数据集S分成两个子集
和S。
则分割后的Gini指标是
2
1
S2: 年龄>27.5 (2高,7低)。