hive常用函数参考手册
Hive常用函数大全-字符串函数

Hive常⽤函数⼤全-字符串函数1、字符串长度函数:length(X)(返回字符串X的长度)select length('qwerty') from table--62、字符串反转函数:reverse(X)(返回字符串X反转的结果)select reverse('qwerty') from table--ytrewq3、字符串连接函数:concat(X,Y,...)(返回输⼊字符串连接后的结果,⽀持任意个输⼊字符串连接)select concat('abc','qwe','rty') from table--abcqwerty4、带分隔符字符串连接函数:concat_ws(X,y,Z)(返回输⼊字符串连接后的结果,X表⽰各个字符串间的分隔符)select concat_ws('/','abc','qwe','rty') from table--abc/qwe/rty5、字符串截取函数:substr(X,Y,Z)/substring(X,Y,Z)(返回字符串X从Y位置开始,截取长度为Z的字符串)select substr('qwerty',1,3) from table--qwe6、字符串转⼤写函数:upper(X)/ucase(X)(返回字符串X的⼤写格式)select upper('qwERt') from table--QWERTselect ucase('qwERt') from table--QWERT7、字符串转⼩写函数:lower(X)/lcase(X)(返回字符串X的⼩写格式)select lower('qwERt') from table--qwertselect lcase('qwERt') from table--qwert8、去空格函数:trim(X)(去除X字符串两边的空格)select trim(' qwe rty uiop ') from table--'qwe rty uiop'左边去空格函数:ltrim(X)(去除X字符串左边的空格)select ltrim(' qwe rty uiop ') from table--'qwe rty uiop '右边去空格函数:rtrim(X)(去除X字符串右边的空格)select rtrim(' qwe rty uiop ') from table--' qwe rty uiop'9、正则表达式替换函数:regexp_replace(X,Y,Z)(将字符串X中的符合java正则表达式Y的部分替换为Z:将X中与Y相同的字符串⽤Z替换)select regexp_replace('foobar', 'o|ar', '234') from table--f234234b23410、正则表达式解析函数:regexp_extract(X,Y,Z)(将字符串X按照Y正则表达式的规则拆分,返回Z指定的字符)select regexp_extract('foothebar', 'foo(.*?)bar', 0) from table--foothebarselect regexp_extract('foothebar', 'foo(.*?)bar', 1) from table--theselect regexp_extract('foothebar', 'foo(.*?)bar', 2) from table--bar11、URL解析函数:parse_url(X,Y,Z)(返回URL中指定的部分。
【Hive】hive中的常用日期处理函数

【Hive】hive中的常⽤⽇期处理函数date_format释义:格式化⽇期⽤法:date_format(date,格式)例如:将⽇期格式化为:2020-05-01和2020-05hive (default)> select date_format('2020-05-01 12:00:00','yyyy-MM-dd');_c02020-05-01hive (default)> select date_format('2020-05-01 12:00:00','yyyy-MM');_c02020-05date_add释义:⽇期加法函数,数字为正,则加多少天,若数字为负数,则为减多少天;⽤法:date_add(date,number);例如:将⽇期增加或减少4天;hive (default)> select date_add('2019-05-09',4);_c02019-05-13Time taken: 0.034 seconds, Fetched: 1 row(s)hive (default)> select date_add('2019-05-09',-4);_c02019-05-05Time taken: 0.049 seconds, Fetched: 1 row(s)date_sub释义:⽇期减法函数,数字为正,则减多少天,若数字为负数,则为加多少天⽤法:date_sub(date,number)例如:将⽇期增加或减少4天hive (default)> select date_sub('2019-05-09',4);_c02019-05-05Time taken: 0.04 seconds, Fetched: 1 row(s)hive (default)> select date_sub('2019-05-09',-4);_c02019-05-13Time taken: 0.058 seconds, Fetched: 1 row(s)next_day释义:取该⽇期的下⼀个周⼏的⽇期⽤法:next_day(date,dayofweek)星期⼀到星期⽇的英⽂(Monday,Tuesday、Wednesday、Thursday、Friday、Saturday、Sunday)例如:取5.1后的下⼀个周五hive (default)> select next_day('2020-05-01',"Fri");_c02020-05-08last_day释义:取当⽉的最后⼀天⽇期⽤法:last_day(date)例如:取5⽉的最后⼀天⽇期hive (default)> select last_day('2020-05-01');_c02020-05-31hive (default)> select last_day('2020-04-01');_c02020-04-30datediff释义:⽇期⽐较函数,第⼀个⽇期减去第⼆个时期数字,为正,则前者⼤于后者,为负,则前者⼩于后者;⽤法:datediff(date1,date2)例如:⽐较5⽉1⽇和5⽉5⽇的⼤⼩hive (default)> select datediff('2020-05-01','2020-05-05');_c0-4dayofmonth释义:查询该⽇期在本⽉的第多少天⽤法:dayofmonth(date)例如:5⽉6号在五⽉是第多少天hive (default)> select dayofmonth('2020-05-06');_c06current_date释义:获取当前⽇期hive (default)> select current_date;_c02020-05-14current_timestamp释义:获取当前时间hive (default)> select current_timestamp;_c02020-05-14 10:26:57.613add_months释义:⽇期加⼀个⽉⽤法:add_months(date,number)例如:2020-05-03加⼀个⽉hive (default)> select add_months('2020-05-03',1);_c02020-06-03year释义:获取时间的年份⽤法:year(date)例如:当前⽇期所在的年份hive (default)> select year('2020-05-14 12:00:00');_c02020month释义:获取时间的⽉份⽤法:month(date)例如:当前⽇期所在的⽉份hive (default)> select month('2020-05-14 12:00:00');_c05day释义:获取时间的天⽤法:day(date)例如:获取⽇期中的天hive (default)> select day('2020-05-14 12:00:00');_c014hour释义:获取时间的⼩时⽤法:hour(time) 若时间为空,则取出值为null 例如:获取时间中的⼩时hive (default)> select hour('2020-05-14 12:00:00');_c012minute释义:获取时间的分钟⽤法:minute(time) 若时间为空,则取出值为null例如:获取时间中的分钟hive (default)> select minute('2020-05-14 12:04:50');_c04second释义:获取时间的秒⽤法:second(time) 若时间为空,则取出值为null例如:获取时间中的秒hive (default)> select second('2020-05-14 12:04:53');_c053weekofyear释义:⽇期所在年份的第多少周⽤法:weekofyear(date)例如:当前⽇期是所在年份的第多少周hive (default)> select weekofyear(current_date);_c020to_date释义:转⽇期函数,默认转为yyyy-MM-dd格式⽤法:to_date(time)例如:当前时间转为⽇期格式hive (default)> select to_date(current_timestamp);_c02020-05-14常⽤⽇期需求1.取当⽉第1天--先获取当前⽇期在该⽉份的第n天,然后当前⽇期减去第(n-1)天,则为结果hive (default)> select date_sub('2020-05-14',dayofmonth('2020-05-14')-1);_c02020-05-012.取当⽉第6天--先获取该⽇期在该⽉的第n天,然后当前⽇期减去第(n-1)天,再增加(m-1)天,则为结果hive (default)> select date_add(date_sub('2020-05-14',dayofmonth('2020-05-14')-1),5);_c02020-05-063.查询下⼀个⽉的第⼀天--先获取最后⼀天,然后⽇期+1,则为下⼀⽉第⼀天hive (default)> select date_add(last_day('2020-05-14'),1);_c02020-06-01--先获取今天是当⽉第⼏天,算出当⽉第⼀天,然后加⼀个⽉,则为下⽉第⼀天hive (default)> select add_months(date_sub('2020-05-14',dayofmonth('2020-05-14')-1),1);_c02020-06-014.获取当前⽇期的所在⽉份--⽇期格式化⽅式hive (default)> select date_format('2020-05-14','MM');_c005--直接month获取⽅式hive (default)> select month('2020-05-14');_c055.获取本周⼀的⽇期--先获取下周⼀的⽇期,然后减去7天,则为本周⼀⽇期hive (default)> select date_add(next_day(current_date,"MO"),-7);_c02020-04-276.给出⼀个⽇期计算该⽇期为周⼏--先找⼀个周⼀的⽇期,⽐如我们找的2020-05-04,然后和当前⽇期(2020-05-14)做⽐较,就会得出相差的天数,再⽤pmod获取正余数的函数来获取最后的余数(0-6分别代表周⽇~周六),本实例做+1操作,直接得出周⼏的结果;hive (default)> select pmod(datediff('2020-05-14','2020-05-04') + 1,7);_c04总结在⽇常hive计算中,最常⽤的⽇期函数有5个:date_format:常⽤于处理⽉指标date_add或date_sub:常⽤于处理⽇指标next_day:常⽤于处理周指标last_day:常⽤于处理⽉指标datediff:常⽤于处理⽇指标。
hive高级函数

hive高级函数Hive是一个基于Hadoop的数据仓库解决方案,它使用Hive查询语言(HQL)来处理和分析大型数据集。
Hive提供了许多内置的高级函数,用于对数据进行转换、过滤、聚合等操作。
在本文中,我们将探讨一些常用的Hive高级函数,并讨论它们的用法和应用场景。
一、字符串函数:1. CONCAT:将多个字符串连接在一起。
2. SUBSTRING:返回一个字符串的子串。
3. INSTR:返回一个字符串中第一次出现的指定子串的位置。
4. REPLACE:将一个字符串中的所有指定子串替换为新的子串。
5. TRIM:去除一个字符串两端的空格。
这些字符串函数在数据清洗和转换中非常有用,可以帮助我们从原始数据中提取需要的信息。
二、日期函数:1. TO_DATE:将一个字符串转换为日期格式。
2. YEAR/MONTH/DAY:从一个日期字段中提取年份、月份或日期。
3. DATE_ADD:将指定的时间间隔添加到一个日期字段。
4. DATE_DIFF:计算两个日期之间的天数差。
这些日期函数可以帮助我们对时间序列数据进行分析和计算,如计算每月销售额或计算两个日期之间的间隔。
三、数值函数:1. ROUND:对一个数值字段进行四舍五入。
2. ABS:返回一个数值字段的绝对值。
3. CEIL/FLOOR:对一个数值字段进行向上取整或向下取整。
4. POWER/SQRT:计算一个数值字段的幂或平方根。
这些数值函数在数据分析和统计计算中非常有用,可以帮助我们对数据进行处理和转换。
四、集合函数:1. COUNT:统计一个字段中非空值的数量。
2. SUM:计算一个字段中数值的总和。
3. AVG:计算一个字段中数值的平均值。
4. MAX/MIN:找到一个字段中数值的最大值或最小值。
这些集合函数常用于数据汇总和聚合分析,可以帮助我们计算数据的统计指标和概要信息。
除了上述提到的高级函数,Hive还提供了许多其他的内置函数,如条件函数(CASE WHEN)、窗口函数(OVER)、分组函数(GROUP BY)等。
hive中的常用函数

Hive是一种基于Hadoop的数据仓库工具,用于处理大规模数据集。
以下是Hive中常用的一些函数:
聚合函数:
COUNT:计算行数或非NULL值的数量。
SUM:计算数值列的总和。
AVG:计算数值列的平均值。
MIN:找出数值列的最小值。
MAX:找出数值列的最大值。
字符串函数:
CONCAT:连接两个或多个字符串。
LENGTH:返回字符串的长度。
SUBSTR:截取字符串的子串。
TRIM:去除字符串首尾的空格。
LOWER/UPPER:将字符串转换为小写/大写。
时间日期函数:
YEAR/MONTH/DAY:提取日期字段中的年份/月份/日份。
HOUR/MINUTE/SECOND:提取时间字段中的小时/分钟/秒数。
TO_DATE:将字符串转换为日期格式。
条件函数:
IF/ELSE:根据条件返回不同的值。
CASE WHEN/THEN/ELSE/END:根据多个条件返回不同的值。
数学函数:
ABS:返回数值的绝对值。
ROUND:对数值进行四舍五入。
RAND:生成一个随机数。
EXP:返回指定数值的指数值。
LOG:计算数值的自然对数。
这只是Hive中一些常用的函数示例,实际上Hive提供了更多的函数用于处理数据。
你可以根据具体的需求在Hive官方文档中查找更多详细的函数说明和用法。
hive 正则函数

hive 正则函数一、概述Hive是一个基于Hadoop的数据仓库工具,它提供了SQL查询和数据分析功能,支持大规模数据处理。
在Hive中,正则表达式是非常重要的一种函数,可以用来匹配文本、提取关键字等。
二、Hive中的正则函数1. regexp_replace(string A, string B, string C):将字符串A中符合正则表达式B的部分替换为C。
2. regexp_extract(string A, string B, int C):从字符串A中提取符合正则表达式B的第C个匹配项。
3. regexp_like(string A, string B):判断字符串A是否符合正则表达式B。
4. rlike:同regexp_like。
5. regexp_instr(string A, string B):返回字符串A中符合正则表达式B的第一个匹配项在字符串A中的位置。
6. regexp_substring(string A, string B):返回字符串A中符合正则表达式B的第一个匹配项。
三、使用示例1. 替换字符将“hello world”中所有空格替换为“-”:SELECT regexp_replace("hello world", "\\s+", "-");2. 提取关键字从“2019-01-01 12:34:56”中提取日期:SELECT regexp_extract("2019-01-01 12:34:56", "(\\d{4}-\\d{2}-\\d{2})", 1);3. 判断是否符合条件判断“abc123”是否为数字字母组合:SELECT regexp_like("abc123", "^[a-zA-Z0-9]+$");4. 匹配位置获取“hello world”中“world”的起始位置:SELECT regexp_instr("hello world", "world");5. 提取匹配项从“abc123def456”中提取数字:SELECT regexp_substring("abc123def456", "\\d+");四、注意事项1. 正则表达式必须用双引号括起来。
Hive函数及语法说明

无线增值产品部Hive函数及语法说明版本:Hive 0.7.0.001eagooqi2011-7-19版本日期修订人描述V1.0 2010-07-20 eagooqi 初稿2012-1-4 Eagooqi ||、cube目录⏹函数说明 (2)⏹内置函数 (2)⏹增加oracle函数 (14)⏹增加业务函数 (17)⏹扩展函数开发规范 (19)⏹语法说明 (21)⏹内置语法 (21)⏹增加语法 (28)⏹扩展语法开发规范(语法转换) (29)⏹ORACLE sql 对应的hSQL语法支持 (29)⏹函数说明参考链接:https:///confluence/display/Hive/LanguageManualCLI下,使用以下命令显示最新系统函数说明SHOW FUNCTIONS;DESCRIBE FUNCTION <function_name>;DESCRIBE FUNCTION EXTENDED <function_name>;⏹内置函数数值函数Mathematical Functions集合函数Collection Functions类型转换函数Type Conversion Functions日期函数Date Functions条件判断函数Conditional Functions字符串函数String Functions其他函数Misc. FunctionsxpathThe following functions are described in [Hive-LanguageManual-XPathUDF]:∙xpath, xpath_short, xpath_int, xpath_long, xpath_float, xpath_double, xpath_number, xpath_stringget_json_objectA limited version of JSONPath is supported:∙$ : Root object∙. : Child operator∙[] : Subscript operator for array∙* : Wildcard for []Syntax not supported that's worth noticing:∙: Zero length string as key∙.. : Recursive descent∙@ : Current object/element∙() : Script expression∙?() : Filter (script) expression.∙[,] : Union operator∙[start:end.step] : array slice operatorExample: src_json table is a single column (json), single row table:json{"store":{"fruit":[{"weight":8,"type":"apple"},{"weight":9,"type":"pear"}], "bicycle":{"price":19.95,"color":"red"}},"email":"amy@only_for_json_udf_","owner":"amy"}The fields of the json object can be extracted using these queries:hive> SELECT get_json_object(src_json.json, '$.owner') FROM src_json; amyhive> SELECT get_json_object(src_json.json, '$.store.fruit[0]') FROM src_json;{"weight":8,"type":"apple"}hive> SELECT get_json_object(src_json.json, '$.non_exist_key') FROM src_json;NULL内置聚合函数Built-in Aggregate Functions (UDAF)增加oracle函数增加业务函数扩展函数开发规范提供以下两种实现方式:a继承org.apache.hadoop.hive.ql.exec.UDF类代码包为:package org.apache.hadoop.hive.ql.udf实现evaluate方法,根据输入参数和返回参数类型,系统自动转换到匹配的方法实现上。
hive的date函数

hive的date函数Hive是一个基于Hadoop的数据仓库工具,它提供了一种让用户能够通过类似于SQL的查询语言来进行数据分析和处理的方式。
Hive中内置了很多函数,其中一个非常常用的函数就是`date`函数。
`date`函数主要用于从给定的日期字符串中提取日期部分,并将其返回为日期类型。
这个函数通常在对日期数据进行筛选、聚合或计算的时候使用,它可以帮助用户快速准确地处理日期数据。
Hive中的`date`函数有多种用法,下面列举了一些常见的使用例子和详细说明。
1.提取日期部分:```sqlSELECT date('2022-12-31') FROM table;```这个例子中,`date`函数会从字符串'2022-12-31'中提取出日期部分,并将其返回为日期类型。
结果将是'2022-12-31',即与原字符串相同。
2.根据当前日期获取年月日:```sqlSELECT year(current_date()), month(current_date()),day(current_date()) FROM table;```这个例子中,`year`、`month`和`day`函数会根据当前日期(`current_date()`)获取到对应的年、月、日,并将它们分别返回。
结果将是三个整数,分别代表当前日期的年份、月份和日期。
3.计算指定日期之间的天数差:```sqlSELECT datediff('2022-01-01', '2022-12-31') FROM table;```这个例子中,`datediff`函数会计算出指定日期之间的天数差,并将其返回。
结果将是365,即'2022-12-31'与'2022-01-01'之间相差365天。
4.获取指定日期的星期几:```sqlSELECT dayofweek('2022-12-31') FROM table;```这个例子中,`dayofweek`函数会获取到指定日期的星期几,并将其返回。
hive常用的的函数

hive常用的的函数Hive提供了一种简单的SQL查询语言称为HiveQL,它允许数据工程师、数据分析师和应用程序开发人员查询和管理大规模数据。
以下是Hive中常用的一些函数:1. 字符串函数:`length(string)`: 返回字符串的长度。
`concat(string1, string2, ...)`: 连接两个或多个字符串。
`substr(string, start, length)`: 返回字符串的子串。
`trim(string)`: 去除字符串两端的空格。
`ltrim(string)`: 去除字符串左端的空格。
`rtrim(string)`: 去除字符串右端的空格。
2. 数值函数:`abs(bigint)`: 返回整数的绝对值。
`ceil(double)`: 返回大于或等于给定数字的最小整数。
`floor(double)`: 返回小于或等于给定数字的最大整数。
`round(double, ndigits)`: 返回四舍五入的值,其中ndigits是精度。
`mod(int, int)`: 返回第一个参数除以第二个参数的余数。
3. 日期函数:`current_date()`: 返回当前日期。
`from_unixtime(unix_timestamp[, format])`: 将UNIX时间戳转换为指定格式的日期时间。
`unix_timestamp()`: 将当前日期和时间转换为UNIX时间戳(以秒为单位)。
`date_format(date, format)` or `date_format(timestamp, format)`: 将日期/时间值格式化为指定的字符串格式。
4. 聚合函数:`count(), count(column)`: 计算行数或非NULL值的数量。
`sum(column)`: 计算列的总和。
`avg(column)`: 计算列的平均值。
`min(column)`: 返回列中的最小值。
hive数组函数

hive数组函数ApacheHive是一种开源数据仓库,它提供了一种类SQL的查询语言,称为HiveQL,可以让用户使用Hive中的函数来操作数据。
Hive 中的数组函数可以帮助我们更好地处理数据,从而提高数据分析的效率。
本文将介绍Hive中的一些数组函数,并解释如何使用这些函数。
第一个要介绍的函数是ARRAY_CONTAINS,它可以用于检查数组中是否存在一个特定的值。
它的格式为:ARRAY_CONTAINS(array,value),其中array参数是一个数组,value参数是要搜索的值。
如果数组中存在该值,将返回true,否则将返回false。
例如,如果我们有一个数组【1,2,3,4】,我们可以使用ARRAY_CONTAINS(【1,2,3,4】,3)来检查数组中是否存在值3,它将返回true。
另一个常用的函数是ARRAY_REVERSE,它可以将数组中的元素反转。
它的格式为:ARRAY_REVERSE(array),其中array参数是一个数组。
它将返回一个和原数组相反的新数组。
例如,如果我们有一个数组【1,2,3,4】,我们可以使用ARRAY_REVERSE(【1,2,3,4】)来反转原数组中的元素,将返回【4,3,2,1】。
ARRAY_INDEX函数可以用于获取数组中特定值在数组中的索引位置。
它的格式为:ARRAY_INDEX(array,value),其中array参数是一个数组,value参数表示要查找的值。
它将返回要查找值在数组中的位置,如果没有找到该值,将返回null。
例如,如果我们有一个数组【1,2,3,4】,我们可以使用ARRAY_INDEX(【1,2,3,4】,3)来查找值3在数组中的位置,它将返回2,表示值3在数组中的位置是2。
ARRAY_SIZE函数可以用于获取数组的大小。
它的格式为:ARRAY_SIZE(array),其中array参数是一个数组。
它将返回该数组中元素的数量。
hive函数大全

hive函数大全1.内置运算符1.1关系运算符运算符类型说明A =B 原始类型如果A与B相等,返回TRUE,否则返回FALSEA ==B 无失败,因为无效的语法。
SQL使用”=”,不使用”==”。
A <>B 原始类型如果A不等于B返回TRUE,否则返回FALSE。
如果A或B值为”NULL”,结果返回”NULL”。
A <B 原始类型如果A小于B返回TRUE,否则返回FALSE。
如果A或B值为”NULL”,结果返回”NULL”。
A <=B 原始类型如果A小于等于B返回TRUE,否则返回FALSE。
如果A或B值为”NULL”,结果返回”NULL”。
A >B 原始类型如果A大于B返回TRUE,否则返回FALSE。
如果A或B值为”NULL”,结果返回”NULL”。
A >=B 原始类型如果A大于等于B返回TRUE,否则返回FALSE。
如果A或B值为”NULL”,结果返回”NULL”。
A IS NULL 所有类型如果A值为”NULL”,返回TRUE,否则返回FALSEA IS NOT NULL 所有类型如果A值不为”NULL”,返回TRUE,否则返回FALSEA LIKEB 字符串如果A或B值为”NULL”,结果返回”NULL”。
字符串A与B通过sql 进行匹配,如果相符返回TRUE,不符返回FALSE。
B字符串中的”_”代表任一字符,”%”则代表多个任意字符。
例如:(…foobar‟ like …foo‟)返回FALSE,(…foobar‟ like …foo_ _ _‟或者…foobar‟ like …foo%‟)则返回TUREA RLIKEB 字符串如果A或B值为”NULL”,结果返回”NULL”。
字符串A与B通过java 进行匹配,如果相符返回TRUE,不符返回FALSE。
例如:(…foobar‟rlike …foo‟)返回FALSE,(‟foobar‟rlike …^f.*r$‟)返回TRUE。
hive caldate函数

hive caldate函数Hive是一个基于Hadoop的数据仓库系统,它提供了一个类SQL的接口,使用户可以用常用的SQL语句来操作存储在Hadoop集群中的数据。
Hive中的函数是用来处理数据的重要工具之一,在这里我们将会着重介绍Hive函数中的一个函数——caldate函数。
caldate函数是Hive提供的一个日期函数,它的作用是根据给定的年、月、日参数,返回该日期对应的日期值。
简单来说,就是将给定的年月日转化为Hive中的日期类型。
1. 语法caldate(year, month, day)参数说明:- year:年份,必选参数,整型。
- month:月份,必选参数,整型。
- day:日,必选参数,整型。
返回值类型:- date2. 示例-- 示例1:返回2021年8月23日的日期SELECT caldate(2021, 8, 23);-- 返回结果:2021-08-23需要注意的是,如果给定的年月日不合法,caldate函数会返回NULL。
上面的示例3中,2020年2月29日是一个闰年的特殊情况,因此该示例会返回正确的日期。
caldate函数的使用场景非常广泛,在Hive中,我们常常需要将日期相关的数据进行处理和分析,例如计算某一天的数据量、汇总某段时间内的销售额,等等。
这时我们就需要使用到caldate函数将日期类型转化为标准格式,进而进行统计计算。
下面我们将举一些实际的例子来展示caldate函数的使用场景。
1. 计算一段时间内的销售额SELECT SUM(total_sales)FROM sales_recordWHEREcaldate(year, month, day) BETWEEN '2021-08-01' AND '2021-08-31';在上面的示例中,我们使用了caldate函数将year、month、day转化为了标准的日期类型,然后使用了between关键字来筛选出2021年8月的数据,最后通过SUM函数来计算8月份的总销售额。
hive 工作日函数

hive 工作日函数Hive是一个基于Hadoop的数据仓库系统,提供了类似于SQL的查询语言,它的数据模型是基于键-值对的。
而Hive工作日函数是指Hive中的日期函数,用于获取日期或时间的信息,或者对日期或时间进行计算。
它可以计算工作日,排除节假日等信息,因此在需要进行日期计算的数据仓库场景中非常实用。
在Hive中,常用的日期函数包括year()、month()、day()、quarter()、hour()、minute()和second()等。
而对于工作日函数,常用的有几个:1. next_day(date, day_of_week):返回指定日期之后的第一个day_of_week,其中day_of_week是字符串格式的缩写,如'Mon'、'Tue'等。
这个函数可以用于计算下一个星期几的日期,例如:next_day('2022-03-20', 'Sun')将返回'2022-03-27',即“2022年3月20日后的下一个星期日”。
2. last_day(date):返回指定日期所在月份的最后一天。
例如:last_day('2022-03-25')将返回'2022-03-31',即“2022年3月25日所在月份的最后一天”。
3. datediff(end_date, start_date):返回两个日期之间的天数差距。
例如:datediff('2022-03-31', '2022-03-26')将返回5,即“2022年3月26日到2022年3月31日的天数差距”。
4. add_months(start_date, num_months):返回指定日期加上num_months个月后的日期。
例如:add_months('2022-03-20', 3)将返回'2022-06-20',即“2022年3月20日加上三个月后的日期”。
Hive常用函数大全-数值计算

Hive常⽤函数⼤全-数值计算 11、取整函数:round(X)(遵循四舍五⼊)2select round(3.1415926) from table--33select round(3.5) from table--4452、指定精度取整函数: round(X,Y)(遵循四舍五⼊)6select round(3.14159,3) from table--3.1427select round(3.14123,3) from table--3.141893、向下取整函数: floor(X)10select floor(3.6) from table--311select floor(3.3) from table--312134、向上取整函数: ceiling(X)14select ceiling(3.6) from table--415select ceiling(3.3) from table--416175、取随机数函数: rand(X)(返回⼀个0到1范围内的随机数)18select rand() from table--0.22212132324219206、取随机数函数: rand(X)(重复执⾏结果相同:返回⼀个稳定的随机数序列)21select rand(100) from table--0.684145478237322237、⾃然指数函数: exp(X)(返回e的X次⽅)24select exp(2) from table--e*e25268、以10为底对数函数: log10(X)(返回以10为底的X的对数)27select log10(100) from table--228299、以2为底对数函数: log2(X)(返回以2为底的X的对数)30select log2(8) from table--3313210、对数函数: log(X,Y)(返回以X为底的y的对数:2的3次⽅=8)33select log(2,8) from table--3343511、幂运算函数: pow(X,Y)/power(X,Y)(返回X的Y次幂)36select pow(2,4) from table--16373812、开平⽅函数: sqrt(X)(返回X的平⽅根)39select sqrt(16) from table--4404113、⼆进制函数: bin(X)(返回X的⼆进制表⽰)42select bin(7) from table--111434414、⼗六进制函数: hex(X)(返回X的⼗六进制表⽰)45select hex('ab') from table--6162464715、反转⼗六进制函数: unhex(X)48select hex('6162') from table--ab495016、进制转换函数: conv(X,Y,Z)(将数值X从Y进制转化到Z进制)51select conv(17,10,2) from table--10001525317、绝对值函数: abs(X)(返回X的绝对值)54select abs(-111.9) from table--111.955select abs(111.9) from table--111.9565718、正取余函数: pmod(X,Y)(返回X除以Y的余数)58select pmod(9,4) from table--159select pmod(-9,4) from table--3606119、正弦函数: sin(X)(返回X的正弦值)62select sin(0.8) from table--0.7173560908995228636420、反正弦函数: asin(X)(返回X的反正弦值)65select asin(0.7173560908995228) from table--0.8666721、余弦函数: cos(X)(返回X的余弦值)68select cos(0.9) from table--0.6216099682706644697022、反余弦函数: acos(X)(返回X的反余弦值)71select cos(0.6216099682706644) from table--0.9。
hive和oracle常用函数对照表
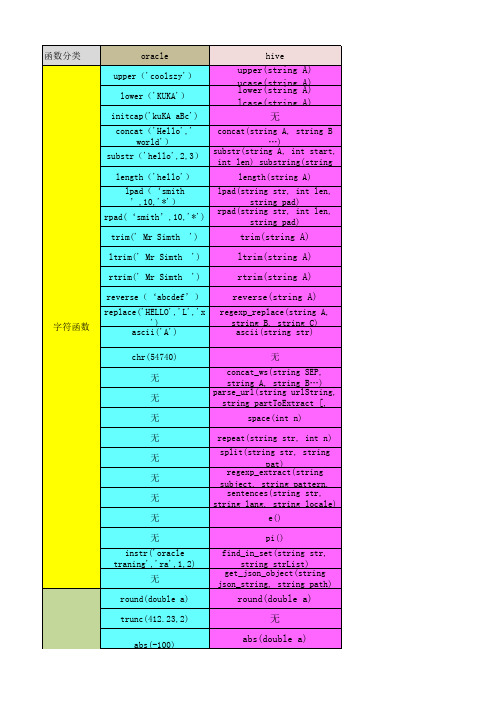
asin(double a) acos(double a) ceil(3.1415927) sin(double a) cos(double a) sqrt(double a) exp(double a) floor(double a) rand(),rand(int seed) ln(double a) log(double base, double a) pow(double a, double p) power(double a, double p) round(double a)round(double a, int d) sign(double a) tan(double a) atan(1) conv(BIGINT num, int from_base, int to_base) positive(int a) positive(double a) negative(int a) negative(double a) pmod(int a, int b) pmod(double a, double b)
删除字符串两端的空格,字符之间的空 格保留 删除字符串左边的空格,其他的空格保 留 删除字符串右边的空格,其他的空格保 留 返回倒序字符串
字符串A中的B字符被C字符替代
返回字符串中首字符的数字值
给出整数,返回对应的字符 链接多个字符串,字符串之间以指定的分 隔符分开。 返回URL指定的部分。parse_url(‘ /path1/p.php?k1=v1 返回指定数量的空格 重复N次字符串 将字符串转换为数组。 通过下标返回正则表达式指定的部分。 regexp_extract(‘foothebar’, ‘ 将字符串中内容按语句分组,每个单词间 以逗号分隔,最后返回数组。 例如 返回e的值 返回pi的值 在一个字符串中搜索指定的字符,返回发现 指定的字符的位置 get_json_object('{"store":{"fruit":[{ "weight":8,"type":"apple"},{"weight":
hive常用函数

hive常用函数Hive一款建立在Hadoop之上的数据仓库分析软件,它为用户提供了一系列的函数,以满足用户的不同需求。
在这里,我们将重点介绍 Hive 中一些常用的函数,希望能够更好的帮助用户使用和熟悉Hive。
### 1.学函数数学函数是 Hive 中的一类经常被使用的函数,它们分为算术运算类函数、随机数类函数、对数类函数、三角函数类函数、取整函数类函数、科学计数法函数等,下面,我们将分别介绍这几类函数的语法以及用法。
####1)算术运算类函数算术运算类函数主要有如下:1. `ABS(x)`:返回x的绝对值2. `EXP(x)`:返回e的x次方3. `MOD(x, y)`:返回x除以y的余数4. `POWER(x,y)`:返回x的y次方5. `ROUND(x,d)`:返回x保留d位小数后的结果6. `LOG(x)`:返回x的自然对数####2)随机数类函数随机数类函数主要有`RAND()`,它用于生成一个0~1之间的随机数。
####3)对数类函数对数类函数主要有`LOG(x, base)` `LOG10(x)`,它们用于返回X的对数,其中base可以自定义,为空时,使用2作为默认值;而`LOG10(x)`则返回以10为底的x的对数。
####4)三角函数类函数三角函数类函数主要有`SIN(x)`,`COS(x)`,`TAN(x)`,它们分别用于返回x的正弦值、余弦值和正切值。
####5)取整函数类函数取整函数类函数主要有`CEIL(x)` `FLOOR(x)`,它们用于返回比x大的最小整数和比x小的最大整数。
####6)科学计数法函数科学计数法函数主要有`ROUND(x,s)`,其中x为一个数字,s代表保留小数点位数,用于表示数字的指数部分,即参数s代表相对于基数10的指数。
### 2.符串函数字符串函数是 Hive 中常用的一类函数,它们分为字符串处理类函数、字符和数值转换类函数、字符集转换类函数、正则表达式类函数等,下面,我们将分别介绍这几类函数的语法以及用法。
hive的table函数参 -回复

hive的table函数参-回复Hive的Table函数参考手册Hive是一个构建在Hadoop上的数据仓库解决方案,通过使用Hive可以方便地进行大数据的处理和分析。
除了常规的SQL语法,Hive还提供了一系列的Table函数,用于对表进行操作和处理。
本文将详细介绍Hive 的Table函数参考手册,并逐步解释每个函数的用法和示例。
1. GROUPING SETSGROUPING SETS函数可以一次聚合多组数据,并将结果放在一个表中返回。
它可以处理多别的级别的汇总数据,是一种高效的数据分析和报表生成工具。
下面是一个使用GROUPING SETS函数的示例:sqlSELECT col1, col2, sum(col3) as totalFROM table1GROUP BY GROUPING SETS((col1, col2), col1, col2);2. CUBECUBE函数用于进行多维度的汇总计算。
它可以生成一个包含所有可能组合的聚合表。
下面是一个使用CUBE函数的示例:sqlSELECT col1, col2, sum(col3) as totalFROM table1GROUP BY CUBE(col1, col2);3. ROLLUPROLLUP函数与CUBE函数相似,但是它只生成一组维度的汇总数据。
下面是一个使用ROLLUP函数的示例:sqlSELECT col1, col2, sum(col3) as totalFROM table1GROUP BY ROLLUP(col1, col2);4. EXTENDED STATSEXTENDED STATS函数用于生成表的统计信息,用于优化查询计划和性能。
它可以为表中的列生成直方图、频率统计和相关性分析等信息。
下面是一个使用EXTENDED STATS函数的示例:sqlANALYZE TABLE table1 COMPUTE STATISTICS EXTENDED;5. LIST BUCKETINGLIST BUCKETING函数用于为表设置桶。
hive里对数指数函数

hive里对数指数函数在Hive中,对数和指数函数是常用的数学函数,它们可以用于处理大量的数据,特别是在统计计算和建模方面。
本文将为大家介绍Hive中对数和指数函数的使用,以及如何在Hive中使用这些函数来进行数据处理和分析。
一、对数函数1.1 ln(x)ln函数是计算以 e 为底的对数,它可以通过以下方式使用:SELECT ln(10);结果将会是:2.3025850929940461.2 log10(x)log10函数是计算以 10 为底的对数,它可以通过以下方式使用:SELECT log10(10);结果将会是:11.3 log2(x)log2函数是计算以 2 为底的对数,它可以通过以下方式使用:SELECT log2(10);结果将会是:3.321928094887362二、指数函数2.1 exp(x)exp函数是计算 e 的 x 次方,它可以通过以下方式使用:SELECT exp(0);结果将会是:12.2 power(x, y)power函数是计算 x 的 y 次方,它可以通过以下方式使用:SELECT power(2, 3);结果将会是:82.3 sqrt(x)sqrt函数是计算 x 的平方根,它可以通过以下方式使用:SELECT sqrt(16);结果将会是:4总结:对数和指数函数在Hive中的使用非常普遍,可以用于很多统计计算和建模的场景中。
本文简单的介绍了Hive中对数函数和指数函数的使用方法,并给出了一些示例。
在实际使用中,我们还应该深入了解其原理和使用方式,以便更好的掌握这些函数的使用。
HIVE常用正则函数(like、rlike、regexp、regexp_replace、r。。。

HIVE常⽤正则函数(like、rlike、regexp、regexp_replace、r。
Oralce中regex_like和hive的regexp对应LIKE语法1: A LIKE B语法2: LIKE(A, B)操作类型: strings返回类型: boolean或null描述: 如果字符串A或者字符串B为NULL,则返回NULL;如果字符串A符合表达式B的正则语法,则为TRUE;否则为FALSE。
B中字符"_"表⽰任意单个字符,⽽字符"%"表⽰任意数量的字符。
hive> select 'football' like '%ba';OKfalsehive> select 'football' like '%ba%';OKtruehive> select 'football' like '__otba%';OKtruehive> select like('football', '__otba%');OKtrueRLIKE语法1: A RLIKE B语法2: RLIKE(A, B)操作类型: strings返回类型: boolean或null描述: 如果字符串A或者字符串B为NULL,则返回NULL;如果字符串A符合JAVA正则表达式B的正则语法,则为TRUE;否则为FALSE。
hive> select 'football' rlike 'ba';OKtruehive> select 'football' rlike '^footba';OKtruehive> select rlike('football', 'ba');OKtrueJava正则:"." 任意单个字符"*" 匹配前⾯的字符0次或多次"+" 匹配前⾯的字符1次或多次"?" 匹配前⾯的字符0次或1次"\d" 等于 [0-9],使⽤的时候写成'\d'"\D" 等于 [^0-9],使⽤的时候写成'\D'hive> select 'does' rlike 'do(es)?';OKtruehive> select '\\';OK\hive> select '2314' rlike '\\d+';OKtrueREGEXP语法1: A REGEXP B语法2: REGEXP(A, B)操作类型: strings返回类型: boolean或null描述: 功能与RLIKE相同hive> select 'football' regexp 'ba';OKtruehive> select 'football' regexp '^footba';OKtruehive> select regexp('football', 'ba');OKtrue语法: regexp_replace(string A, string B, string C)操作类型: strings返回值: string说明: 将字符串A中的符合java正则表达式B的部分替换为C。
hive day函数

hive day函数一、Hive Day函数简介Hive是一个基于Hadoop的数据仓库工具,它提供了类似SQL的查询语言——HiveQL,可以将结构化数据映射到Hadoop分布式文件系统中。
在HiveQL中,Day函数是非常常用的日期函数之一,它可以返回给定日期的天数。
二、Hive Day函数语法Day函数的语法如下:DAY(date)其中,date参数表示要计算天数的日期。
date可以是日期型、时间型或者字符串型。
三、Hive Day函数示例下面给出一些Day函数的示例:1. 返回当前时间的天数SELECT DAY(NOW());2. 返回指定日期的天数SELECT DAY('2021-06-01');3. 返回指定时间戳的天数SELECT DAY(FROM_UNIXTIME(1623585600));四、注意事项在使用Day函数时需要注意以下几点:1. 参数必须为日期型、时间型或者字符串型。
2. 如果参数为字符串型,则必须符合yyyy-MM-dd格式。
3. 如果参数为时间戳,则需要使用FROM_UNIXTIME()函数进行转换。
4. Day函数返回值类型为整型。
五、完整代码示例下面给出一个完整代码示例:```-- 创建测试表CREATE TABLE test_day(id INT,name STRING,date DATE,timestamp BIGINT);-- 插入测试数据INSERT INTO test_day VALUES(1, '张三', '2021-06-01', 1622505600);INSERT INTO test_day VALUES(2, '李四', '2021-06-02', 1622592000);INSERT INTO test_day VALUES(3, '王五', '2021-06-03', 1622678400);-- 查询测试数据并计算天数SELECTid,name,date,timestamp,DAY(date),DAY(FROM_UNIXTIME(timestamp))FROM test_day;```六、总结Day函数是Hive中常用的日期函数之一,它可以返回给定日期的天数。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
函数分类HIVE CLI命令显示当前会话有多少函数可用SHOW FUNCTIONS;显示函数的描述信息DESC FUNCTION concat;显示函数的扩展描述信息DESC FUNCTION EXTENDED concat; 简单函数函数的计算粒度为单条记录。
关系运算数学运算逻辑运算数值计算类型转换日期函数条件函数字符串函数统计函数聚合函数函数处理的数据粒度为多条记录。
sum()—求和count()—求数据量avg()—求平均直distinct—求不同值数min—求最小值max—求最人值集合函数复合类型构建复杂类型访问复杂类型长度特殊函数窗口函数应用场景用于分区排序动态Group ByTop N累计计算层次查询Windowing functionsleadlagFIRST_VALUELAST_VALUE分析函数Analytics functionsRANKROW_NUMBERDENSE_RANKCUME_DISTPERCENT_RANKNTILE混合函数java_method(class,method [,arg1 [,arg2])reflect(class,method [,arg1 [,arg2..]])hash(a1 [,a2...])UDTFlateralView: LATERAL VIEW udtf(expression) tableAlias AS columnAlias(‘,‘ columnAlias)*fromClause: FROM baseTable (lateralView)*ateral view用于和split, explode等UDTF一起使用,它能够将一行数据拆成多行数据,在此基础上可以对拆分后的数据进行聚合。
lateral view首先为原始表的每行调用UDTF,UTDF会把一行拆分成一或者多行,lateral view再把结果组合,产生一个支持别名表的虚拟表。
常用函数Demo:create table employee(id string,money double,type string)row format delimitedfields terminated by‘\t‘lines terminated by‘\n‘stored as textfile;load data local inpath ‘/liguodong/hive/data‘into tableemployee;select*from employee;优先级依次为NOT AND OR select id,money from employee where(id=‘1001‘orid=‘1002‘)and money=‘100‘;cast类型转换select cast(1.5asint);if判断if(con,‘‘,‘‘);hive (default)>selectif(2>1,‘YES‘,‘NO‘);YEScasewhen con then‘‘when con then‘‘else‘‘end(‘‘里面类型要一样)selectcasewhen id=‘1001‘then‘v1001‘when id=‘1002‘then‘v1002‘else‘v1003‘endfrom employee;get_json_objectget_json_object(json 解析函数,用来处理json,必须是json格式)selectget_json_object(‘{"name":"jack","age":"20"}‘,‘$.name‘);URL解析函数parse_url(string urlString,string partToExtract [,string keyToExtract])select parse_url(‘/path1/p.php?k1=v1&k2=v2#Ref1‘, ‘HOST‘) from employee limit 1;字符串连接函数:concat语法: concat(string A, string B…)返回值: string说明:返回输入字符串连接后的结果,支持任意个输入字符串举例:hive>select concat(‘abc‘,‘def’,‘gh‘)from lxw_dual;abcdefgh带分隔符字符串连接函数:concat_ws语法: concat_ws(string SEP, string A, string B…)返回值: string说明:返回输入字符串连接后的结果,SEP 表示各个字符串间的分隔符concat_ws(string SEP, array<string>)举例:hive>select concat_ws(‘,‘,‘abc‘,‘def‘,‘gh‘)from lxw_dual;abc,def,gh列出该字段所有不重复的值,相当于去重collect_set(id)//返回的是数组列出该字段所有的值,列出来不去重collect_list(id)//返回的是数组select collect_set(id)from taborder;求和sum(money)统计列数count(*)select sum(num),count(*)from taborder;窗口函数first_value(第一行值)first_value(money) over (partition by id order by money)select ch,num,first_value(num) over (partition by ch order by num)from taborder;rows between 1 preceding and1 following (当前行以及当前行的前一行与后一行)hive (liguodong)>select ch,num,first_value(num) over (partition by ch order by num ROWS BETWEEN 2 PRECEDING AND CURRENT ROW)from taborder;last_value 最后一行值hive (liguodong)>select ch,num,last_value(num) over (partition by ch)from taborder;lead去当前行后面的第二行的值lead(money,2) over (order by money)lag去当前行前面的第二行的值lag(money,2) over (order by money)``````select ch, num, lead(num,2) over (order by num)from taborder;select ch, num, lag(num,2) over (order by num)from taborder;rank排名rank() over(partition by id order by money)select ch, num, rank() over(partition by ch order by num)as rank from taborder;select ch, num, dense_rank() over(partition by ch order by num)as dense_rank from taborder;cume_distcume_dist (相同值的最大行号/行数)cume_dist() over (partition by id order by money)percent_rank (相同值的最小行号-1)/(行数-1)第一个总是从0开始percent_rank() over (partition by id order by money)select ch,num,cume_dist() over (partition by ch order by num)as cume_dist, percent_rank() over (partition by ch order by num)as percent_rankfrom taborder;ntile分片ntile(2) over (order by money desc)分两份select ch,num,ntile(2) over (order by num desc)from taborder;混合函数select id,java_method("ng,Math","sqrt",cast(id asdouble))as sqrt from hiveTest;UDTFselect id,adidfrom employeelateral view explode(split(type,‘B‘)) tt as adid;explode 把一列转成多行hive (liguodong)>select id,adid>from hiveDemo>lateral view explode(split(str,‘,‘)) tt as adid;正则表达式使用正则表达式的函数regexp_replace(string subject A,string B,string C)regexp_extract(string subject,string pattern,int index)hive>select regexp_replace(‘foobar‘,‘oo|ar‘,‘‘)from lxw_dual;fbhive>select regexp_replace(‘979|7.10.80|8684‘,‘.*\\|(.*)‘,1)from hiveDemo limit 1;hive>select regexp_replace(‘979|7.10.80|8684‘,‘(.*?)\\|(.*)‘,1)from hiveDemo limit 1;。