SQLSERVER重要复习资料
《sqlserver数据库》复习提纲
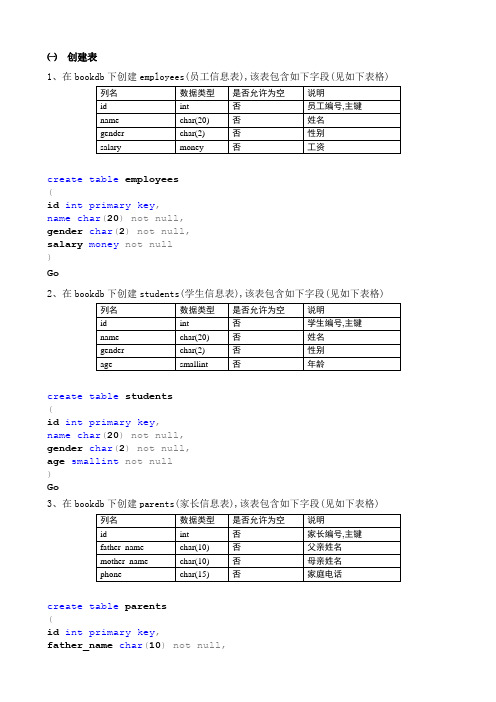
㈠创建表1、在bookdb下创建employees(员工信息表),该表包含如下字段(见如下表格)create table employees(id int primary key,name char(20)not null,gender char(2)not null,salary money not null)Go2、在bookdb下创建students(学生信息表),该表包含如下字段(见如下表格)create table students(id int primary key,name char(20)not null,gender char(2)not null,age smallint not null)Go3、在bookdb下创建parents(家长信息表),该表包含如下字段(见如下表格)create table parents(id int primary key,mother_name char(10)not null,phone char(15)not null)go4、在bookdb下创建teachers(教师信息表),该表包含如下字段(见如下表格)create table teachers(id int primary key,name char(20)not null,gender char(2)not null,subject char(10)not null)go5、在bookdb下创建products(商品表),该表包含如下字段(见如下表格)create table products(pno int primary key,pname char(20)not null,price float not null,num int not null)go6、在bookdb下创建banks(银行储户信息表),该表包含如下字段(见如下表格)(deposit_id int primary key,name char(20)not null,deposit money not null)go㈡ DML操作1.values(118801,'TP4/15','计算机网络','黄丽君','高教出版社',21.80)go2.values(118802,'TP6/15','Linux基础','唐延庆','科学出版社',30.80)go3.values(116,'经贸系','刘莹','女','讲师','1#414')go4.values(119,'服装系','白雪','女','讲师','1#413')go5.在借阅表(borrowing)insert intovalues(113, 445502,'2013-11-11')go6.在借阅表(borrowing)insert into borrowingvalues(114,665544,'2013-10-21')go7.将读者表(readers)中,借书证号为111的职位更改为‘副教授’update readersset position='副教授'where libcardno=111go8.将读者表(readers)中,借书证号为112的职位更改为‘教授’update readersset position='教授'where libcardno=112go9.将图书表(books)中,图书编号为112233的单价更新为16.80update booksset price=16.80where bno=112233go10.将图书表(books)中,图书编号为112233的单价更新为22.80update booksset price=22.80where bno=112233go11.将读者表(readers)中,图书证编号为114的所在地址更新为‘1#323’update readersset address='1#323'where libcardno=114go12.将读者表(readers)中,图书证编号为113的所在地址更新为‘1#123’update readersset address='1#123'where libcardno=113go13.将图书表(books)中,图书编号为118802的图书信息删除delete from bookswhere bno=118802go14.将图书表(books)中,图书编号为118801的图书信息删除delete from bookswhere bno=118801go15.将读者表(books)中,图书证编号为116的读者信息删除delete from readerswhere libcardno=116go16.将读者表(books)中,图书证编号为119的读者信息删除delete from readerswhere libcardno=119go17.将借阅表(borrowing)中,图书证编号为111的借阅信息删除delete from borrowingwhere libcardno=111go18.将借阅表(borrowing)中,图书证编号为114的借阅信息删除delete from borrowingwhere libcardno=114go㈢数据查询1.查询姓李的读者姓名及所在单位select name,company from readerswhere name like'李%'go2.查询图书表(books)中,所有的书名及出版单位select bname,press from booksgo3.查找‘高教出版社’的所有图书,并按价格降序排列select*from bookswhere press='高教出版社'order by price descgo4.查询所有图书的最高单价select max(price)as'最高单价'from booksgo5.查询姓张的读者姓名及所在单位select name,company from readerswhere name like'张%'go6.查询图书表(books)中的所有图书并按图书编号的降序排列select*from booksorder by bno descgo7.查找‘科学出版社’的所有图书where press='科学出版社'8.查询所有图书的平均单价select avg(price)as'平均单价'from booksgo9.查询不同书名的图书名称select distinct bname from booksgo10.查询读者表中性别为‘男’和‘女’的人数各占几个select count(libcardno)as'人数',sex as'性别'from readersgroup by sexgo11.查询日期‘2013-11-11’以后借出的图书名称select bname from books inner join borrowingon books.bno=borrowing.bnowhere borrowing.bordate>'2013-11-11'go12.查询读者表的所有信息,并按图书证号的降序排列select*from readersorder by libcardno descgo13.查询藏书中的价值总额select sum(price)as'藏书价值总额'from booksgo14.查询图书证号为‘113’的老师借阅图书的名称select bname from books inner join borrowingon books.bno=borrowing.bnowhere borrowing.libcardno=11315.查询到目前为止没有借书的读者信息select*from readerswhere libcardno not in(select libcardno from borrowing) go16.查询各出版社图书的最高价格select max(price)as'图书最高价格',press as'出版社名称'from booksgroup by pressgo17.查询借阅了图书编号为‘665544’的借阅者姓名select as'读者姓名'on r.libcardno=b.libcardnowhere b.bno=665544go18.查询没有借阅图书的图书证号select libcardno from readerswhere libcardno not in(select libcardno from borrowing)go19.查询最高图书单价与最低图书单价之间的差值select max(price)-min(price)as'最高单价与最低单价的差值'from books go20.查询单价介于18元和20元之间的图书信息select*from bookswhere price between 18 and 20go21.查询借阅了图书编号为‘112233’的借阅者姓名select as'读者姓名'from readers r inner join borrowing bon r.libcardno=b.libcardnowhere b.bno=112233go22.统计借阅图书的不同图书证号select distinct libcardno from borrowing23.查询图书单价高于平均单价的图书信息select*from bookswhere price>(select avg(price)from books)go24.查询单价介于10元和19元之间的图书信息select*from bookswhere price between 10 and 19go25.查询书名以‘计算机’开头的所有图书及作者select bname,author from bookswhere bname like'计算机%'go26.显示图书表的前两条记录select top 2 *from booksgo27.查询所有借阅了图书的姓名及单位(重复信息不显示)select distinct ,panyfrom readers r inner join borrowing bon r.libcardno=b.libcardno28.查询所有图书的最低单价select min(price)as'最低单价'from booksgo29.查询藏书中各个出版单位的册数、价值总额select press as'出版社名称',count(press)as'出版社册数',sum(price)as'价格总和'from booksgroup by pressgo30.查询图书证号为‘111’的老师借阅图书的名称select bname from bookswhere bno=(select bno from borrowing where libcardno=111) 31.查询图书单价低于平均单价的图书信息select*from bookswhere price<(select avg(price)from books)go32.查询有哪些不重复的图书的名称select distinct bnamefrom books33.查询书名以‘数据库’开头的所有图书及作者select bname,author from bookswhere bname like'数据库%'go34.显示读者表的前两条记录select top 2 *from readersgo35.查询所有借阅了图书的读者姓名及职称(重复信息不显示)select distinct ,r.positionfrom readers r inner join borrowing bon r.libcardno=b.libcardnogo36.查询所有图书的最高单价select max(price)as'最高单价'from booksgo37.查询藏书中各个出版单位的册数、价值总额select press as'出版社名称',count(press)as'出版社册数',group by pressgo38.查询图书证号为‘112’的老师借阅图书的名称select bname from bookswhere bno in(select bno from borrowing where libcardno=112) 39.查询图书单价高于平均单价的图书信息select*from bookswhere price>(select avg(price)from books)go40.统计读者表中职称为‘讲师’的人数select count(position)as'讲师人数'from readerswhere position='讲师'41.查询作者不同的作者人数select count(distinct author)as'不同作者人数'from booksgo42.查询读者表中职称为‘教授’和‘讲师’的人数各占几个select count(position)as'人数',positionfrom readersgroup by positiongo43.查询日期‘2013-11-11’以前借出的图书名称select bname from books inner join borrowingon books.bno=borrowing.bnowhere borrowing.bordate<'2013-11-11'go44.查询读者表的所有信息,并按图书证号的升序排列select*from readersorder by libcardno ascgo45.查询藏书中的价值总额select sum(price)as'藏书价值总额'from booksgo46.查询图书证号为‘112’的老师借阅图书的名称select bname from books inner join borrowingon books.bno=borrowing.bnowhere borrowing.libcardno=11247.查询借书的读者信息select*from readerswhere libcardno in(select libcardno from borrowing)go48.查询各出版社图书的最高价格from booksgroup by pressgo㈣数据完整性1.将图书表(books)的bno和bisbn列设为联合主键,名称为pk_books_bno_bisbnalter table booksalter column bno int not nullgoalter table booksalter column bisbn char(20)not nullgoalter table booksadd constraint pk_books_bno_bisbn primary key(bno,bisbn) go2.在图书表(books)中,添加price列的check约束,规定价格>0alter table booksadd constraint ck_books_price check(price>0)go3.将图书表(books)的bno和bisbn列设为联合主键,名称为pk_books_bno_bisbn alter table booksalter column bno int not nullgoalter table booksalter column bisbn char(20)not nullgoalter table booksadd constraint pk_books_bno_bisbn primary key(bno,bisbn)go4.在读者表(readers)中,添加position列为默认值约束,默认值设为‘讲师’alter table readersadd constraint df_books_position default('讲师')for positiongo5.将读者表(readers)的libcardno列设为主键,名称为pk_readers_libcardnoalter table readersalter column libcardno int not nullgoalter table readersadd constraint pk_readers_libcardno primary key(libcardno) go6.在图书表(books)中,添加company列的默认值约束,默认值为‘信息系’alter table readersadd constraint df_books_company default('信息系')for company goalter table readersalter column libcardno int not nullgoalter table readersadd constraint pk_readers_libcardno primary key(libcardno)go8.将图书表(books)的bno设为唯一性约束alter table booksadd constraint uk_books_bno unique(bno)go9.在读者表(readers)中,添加position列为默认值约束,默认值设为‘副教授’alter table readersadd constraint df_books_position default('副教授')for positiongo10.在图书表(books)中,添加company列的默认值约束,默认值为‘经贸系’alter table readersadd constraint df_books_company default('经贸系')for companygo11.将图书表(books)的bno列设为主键,名称为pk_books_bnoalter table booksalter column bno int not nullgoalter table booksadd constraint pk_books_bno primary key(bno)go12.在图书表(books)中,添加price列的check约束,规定价格>0alter table booksadd constraint ck_books_price check(price>0)go㈤视图、存储过程、函数、触发器、索引、SQL编程1.创建一个名为v_books的视图,其作用是查询图书表(books)中的bno及bname字段;并访问该视图create view v_booksasselect bno,bname from booksgoselect*from v_booksgo2.创建一个名为p_r的存储过程来存储查询读者表(readers)的信息,并运行该存储过程create proc p_rasselect*from readersgogo3.创建一个名为v_readers的视图,其作用是查询读者表(readers)中的name及position字段;并访问该视图create view v_readersasselect name,position from readersgoselect*from v_readers go4.创建一个名为p_bor的存储过程来存储查询借阅表(borrowing)的libcardno及bno信息,并运行该存储过程create proc p_borasselect libcardno,bno from borrowinggop_borgo5.创建一个名为fz()的标量函数,求z*z的值,将z值设为12,运行函数求解create function fz(@z int)returns intasbeginreturn @z*@zendgoselect dbo.fz(12)go6.在读者表(readers)上创建after update触发器,输出信息‘您正在更新读者表的信息!’create trigger tg_readerson readersafter updateasbeginprint('您正在更新读者表的信息!')endgo7.在借阅表(borrowing)的图书证号列上创建一个非聚集索引idx_borrowing_libcardno并按降序排列create nonclustered index idx_borrowing_libcardnoon borrowing(libcardno desc)go8.编写程序,使用while循环,求1到100的和DECLARE @i INT,@sum intSET @i=1SET @sum=0BEGINSET @sum=@sum+@iset @i=@i+1ENDPRINT(@sum)go9.创建一个名为fx()的标量函数,求x*x+1的值,将x值设为2,运行函数求解create function fx(@x int)returns intasbeginreturn @x*@x +1endgoselect dbo.fx(2)go10.在图书表(books)上创建AFTER DELETE触发器,输出信息‘您正在删除图书表中的数据!’create trigger tg_bookson booksafter deleteasbeginprint('您正在删除图书表中的数据!')endgo11.在图书表(books)的编号列上创建一个索引idx_books_bnocreate index idx_books_bnoon books(bno)go12.将借阅表(borrowing)中第一个读者的信息输出(用变量法实现)declare @libcardno intset @libcardno=(select top 1 libcardno from borrowing)select*from readerswhere libcardno=@libcardnogo13.创建一个名为v_readers的视图,其作用是查询读者表(readers)中的libcardno、company及name字段;并访问该视图create view v_readersasselect libcardno,company,name from readersgoselect*from v_readers go14.创建一个名为p_b的存储过程来存储查询图书表(books)的信息,并运行该存储过程asselect*from readersgop_bgo15.创建一个名为fy()的标量函数,求y*y*y的值,将x值设为2,运行函数求解create function fy(@y int)returns intasbeginreturn @y*@y*@yendgoselect dbo.fy(2)go16.在图书表(books)上创建instead of触发器,输出信息‘图书表信息禁止删除!’create trigger tg_bookson booksinstead of deleteasbeginprint('图书表信息禁止删除!')endgo17.在读者表(readers)的编号列上创建一个聚集索引idx_readers_libcardno,并按降序排列create clustered index idx_readers_libcardnoon readers(libcardno desc)go18.编写程序,定义变量@x=3,使用if—else进行判断,@x*@x的运行结果:当结果大于8输出信息“运行结果大于8”,否则输出“运行结果小于8”declare @x intset @x=3if(@x*@x>8)beginprint('运行结果大于>8')endelsebeginprint('运行结果小于<8')endgo访问该视图create view v_borrowingasselect*from borrowinggoselect*from v_borrowinggo20.创建一个名为p_b的存储过程来存储查询图书表(books)的bno及bname字段信息,并运行该存储过程create proc p_basselect bno,bname from booksgop_bgo21.创建一个名为fy()的标量函数,求y*y的值,将x值设为9,运行函数求解create function fy(@y int)returns intasbeginreturn @y*@yendgoselect dbo.fy(9)go22.在图书表(books)上创建instead of update触发器,输出信息‘图书表信息禁止更新!’create trigger tg_bookson booksinstead of updateasbeginprint('图书表信息禁止更新!')endgo23.在读者表(readers)的编号列上创建一个非聚集索引idx_readers_libcardno,并按降序排列create nonclustered index idx_readers_libcardnoon readers(libcardno desc)go24.编写程序,定义变量@x=2,使用if—else进行判断,@x*@x的运行结果:当结果大于8输出信息“运行结果大于4”,否则输出“运行结果小于4”declare @x intset @x=2if(@x*@x>4)print('运行结果大于>4')endelsebeginprint('运行结果小于<4')endgo25.创建一个名为v_books的视图,其作用是查询图书表(books)中的所有字段;并访问该视图create view v_booksasselect*from booksgoselect*from v_booksgo26.创建一个名为p_r的存储过程来存储查询读者表(readers)的company及name字段信息,并运行该存储过程create proc p_rasselect company,name from readersgop_rgo27.创建一个名为fx()的标量函数,求x*x的值,将x值设为4,运行函数求解create function fx(@x int)returns intasbeginreturn @x*@xendgoselect dbo.fx(4)go28.在数据库books上创建drop_table触发器,输出信息‘禁止删除数据库上的表!’create trigger tg_forb_tableon databasefor drop_tableasbeginprint('禁止删除数据库上的表!')29.在图书表(books)的编号列上创建一个聚集索引idx_books_bnocreate clustered index idx_books_bnoon books(bno)go30.将图书表(readers)中第一个图书的信息输出(用变量法实现)declare @bno intset @bno=(select top 1 bno from borrowing)select*from bookswhere bno=@bnogo31.创建一个名为v_readers的视图,其作用是查询读者表(readers)中的所有;并访问该视图create view v_readersasselect*from readersgoselect*from v_readers go32.创建一个名为p_bor的存储过程来存储查询借阅表(borrowing)的信息,并运行该存储过程create proc p_borasselect*from readersgop_borgo33.创建一个名为fz()的标量函数,求z*z*z的值,将z值设为3,运行函数求解create function fz(@z int)returns intasbeginreturn @z*@z*@zendgoselect dbo.fz(3)go34.在读者表(readers)上创建after update触发器,输出信息‘您正在更新读者表的信息!’create trigger tg_readerson readersafter updateasbeginprint('您正在更新读者表的信息!')35.在借阅表(borrowing)的图书证号列上创建一个索引idx_ borrowing _libcardno,并以升序排列create nonclustered index idx_borrowing_libcardnoon borrowing(libcardno asc)go36.编写程序,定义变量@i=1,使用while循环,当@i<10,输出i值,@i每次自增2 DECLARE @i INTSET @i=1WHILE(@i<10)BEGINPRINT(@i)SET @i=@i+2END。
sqlserver知识点培训

提纲:1、SQLServer锁的概念2、SQLServer事物概念3、解决数据库异常膨胀的技术思路4、操作系统崩溃后数据库重新安装的流程5、数据库性能优化6、常见的SQL Server连接失败错误及解决方法7、无法合理使用已建立的索引的错误写法8、常见系统函数9、编写可读性强的代码1. SQLServer锁的概念 (2)1.2并发问题 (2)1.3隔离级别 (3)1.4 SQL Server 中的锁定介绍 (4)1.5阻塞 (6)1.6死锁 (7)将死锁减至最少 (8)2.SQLServer事物概念 (11)2.1事务 (11)2.2显式事务 (11)2.3嵌套事务 (12)2.4事务保存点 (13)2.5调整事务隔离级别 (14)2.6存储过程和触发器中回滚 (14)2.7事务中允许的Transact-SQL 语句 (16)2.8编写有效的事务 (16)3.解决数据库异常膨胀的技术思路 (18)4.操作系统崩溃后数据库重新安装的流程 (19)5. 数据库性能优化体现在哪些方面 (20)5.1数据库性能优化概述 (20)5.2设计联合数据库服务器 (21)5.3数据库设计 (21)5.4查询优化 (22)5.5应用程序设计 (23)5.6优化服务器性能 (25)6.数据库连接失败的情况分析 (27)7.无法合理使用已建立的索引的错误写法有哪些 (29)8.常用系统函数 (31)9. 编写可读性强的代码 (32)1. SQLServer锁的概念1.1锁定Microsoft SQL Server 使用锁定确保事务完整性和数据库一致性。
锁定可以防止用户读取正在由其他用户更改的数据,并可以防止多个用户同时更改相同数据。
如果不使用锁定,则数据库中的数据可能在逻辑上不正确,并且对数据的查询可能会产生意想不到的结果。
虽然SQL Server 自动强制锁定,但可以通过了解锁定并在应用程序中自定义锁定来设计更有效的应用程序1.2并发问题如果没有锁定且多个用户同时访问一个数据库,则当他们的事务同时使用相同的数据时可能会发生问题。
SQL Server 复习

SQL Server 复习一:SQL Server数据库基础1.使用数据库的必要性◆存储大量数据,方便检索和访问◆保持数据信息的一致性、完整性,降低数据冗余◆可以满足应用的共享和安全方面的要求◆通过组合分析,产生新的有用信息2.数据库的发展史◆萌芽阶段——文件系统使用磁盘文件来存储数据◆初级阶段——第一代数据库出现了网状模型、层次模型的数据库◆中级阶段——第二代数据库关系型数据库和结构化查询语言◆高级阶段——新一代数据库“关系-对象”型数据库3.当今常用数据库◆OracleOracle公司的产品“关系-对象”型数据库产品免费、服务收费◆SQL Server针对不同用户群体的五个特殊的版本易用性好◆DB2IBM公司的产品支持多操作系统、多种类型的硬件和设备4.数据库的基本概念P(8)◆数据库就是“数据”的“仓库”◆数据库由表、关系以及操作对象组成◆数据存放在表中5.数据库系统和数据库管理系统◆数据库系统(DBS)是一个实际可运行的软件系统,可以对系统提供的数据进行存储、维护和应用,它是由存储介质、处理对象和管理系统共同组成的集合体数据库管理系统(DBMS)是一种系统软件,有一个互相关联的集合和一组访问数据的程序构成◆数据库由数据库管理系统统一管理,数据的插入、修改和检索都要通过数据库管理系统进行数据库管理员(DBA)在数据库系统中负责创建、监控和维护整个数据库,使数据库能被任何有权限的人有效地使用6.数据冗余和数据完整性数据冗余是指数据库中存在一些重复的数据,数据完整性是指数据库中的数据能够正确反应实际情况,数据库中允许有一些数据冗余,但是要保持数据的完整性为了减少数据冗余最常见的方法是分类存储7.SQL Server 2008管理器7.1连接SQL Server数据库时需注意以下两点◆在连接SQL Server之前,SQL Server的服务必须已启动,可以在操作系统的“服务”项中启动SQL Server 2008的服务◆SQL Server Management Studio 可以连接和管理多个其他计算机上的SQL Server 数据库7.2 SQL Server中的数据库按照用途可以划分为系统数据库和用户数据库两种◆系统数据库是管理和维护SQL Server所必需的数据库,用户数据库是用户自己建立的数据库◆Microsoft SQL Server提供了四个系统数据库Master数据库:记录SQL Server系统的所有系统级别信息,包括如下三点:所有的登录账户和系统配置设置所有其他的数据库及数据库文件的位置SQL Server的初始化信息Tempdb数据库:保存所有的临时表和临时存储过程,以及临时生成的工作表,其他SQL Server每次启动时都重新创建Model数据库:用作在系统上创建的所有数据库的模板Msdb数据库:供SQL Server代理程序调度警报、作业以及记录操作时使用7.3新建一个数据库连接◆步骤P(15)◆SQL Server支持两种身份验证:Windows身份验证和SQL Server身份验证Windows的身份验证是使用当前登录到操作系统的用户账号去登录,而SQLServer身份验证是使用SQL Server中建立的用户账号去登录7.4新建数据库登录名◆步骤P(17)◆给用户赋予操作权限分为两类:第一类是指该用户在服务器范围类能够执行那些操作,这一类权限由固定的服务器角色来确定,可以在“服务器角色中”设置该用户对服务器的操作权限;第二类权限是指该用户对指定的数据库的操作权限,可以在“用户映射”一项中设置特定数据库的权限7.5创建和管理SQL Server数据库一个数据库至少包含一个数据库文件和一个事务日志文件◆数据库文件(Database File):是存放数据库和数据库对象的文件,一个数据库可以有一个或多个数据库文件,只能有一个主数据库,一个数据库文件只属于一个数据库。
SQLServer数据库技术复习

SQLServer数据库技术复习1.SQL Server 2000是⼀个(关系型)的数据库系统。
2.DTS 是⼀个简称,它的全称是(数据传输服务)。
3. SQL Server 2000 采⽤的⾝份验证模式有(Windows⾝份验证模式和混合模式)。
4.SQL 语⾔按照⽤途可以分为三类,是( DML 、DCL 、 DDL)5. 在SELECT语句的WHERE⼦句的条件表达式中,可以匹配0个到多个字符的通配符是(% )6. master 数据库记录了SQL Server 2000的所有系统信息7. 以下那种类型能作为变量的数据类型( C)。
(A)text (B)ntext (C)table (D)image8. 下⾯不属于数据定义功能的SQL语句是:(C )A.CREATE TABLEB.CREATE DATABASEC.UPDATED.ALTER TABLE9. 如果希望完全安装SQL Server,则应选择(典型安装)。
10. 打开要执⾏操作的数据库,应该⽤USE SQL命令?1、下⾯仅存在于服务器端的组件是:( A)A、服务管理器B、企业管理器组件C、查询分析器组件D、导⼊导出组件2、下⾯描述错误的是( B)。
A、每个数据⽂件中有且只有⼀个主数据⽂件。
B、⽇志⽂件可以存在于任意⽂件组中。
C、主数据⽂件默认为 primary⽂件组。
?D、⽂件组是为了更好的实现数据库⽂件组织。
3、SQL Server 2000 企业版可以安装在操作系统上。
(Microsoft Windows 2000 Server )4、下⾯字符串能与通配符表达式[ABC]_a进⾏匹配的是:( C)。
A、BCDEFB、A_BCDC、ABaD、A%a5、下⾯是合法的smallint数据类型数据的是:(C)。
A、223.5B、32768C、-32767D、583456、SQL Server 2000中的数据以页为基本存储单位,页的⼤⼩为( 8KB )。
SQL Server 数据库复习重点

第一章数据库系统概述数据:描述事物的符号记录,是信息的载体,是信息的具体表现形式数据库技术的三个发展阶段:1.人工管理阶段2.文件系统阶段3.数据库系统阶段数据库系统的特点1.数据结构化2.较高的数据共享性3.较高的数据独立性4.数据由DBMS统一管理和控制数据库: 长期储存在计算机内有组织的可共享的数据集合数据库管理系统的功能1.数据定义和操纵功能2.数据库运行控制功能3.数据库的组织,存储和管理4.建立和维护数据库数据库用户1.终端用户2.应用程序员3.数据库管理员数据库的三级结构模型 :外模式:也称子模式或用户模式,是对数据库用户能够看见和使用的局部数据和逻辑结构和特征的描述.一个数据库可以有多个外模式,一个应用程序只能有一个外模式.模式:也称概念模式或逻辑模式.是对数据库中全部数据的逻辑结构和特征的藐视,是所有用户的公共数据视图.一个数据库只有一个模式内模式:也称存储模式或物理模式,是对数据物理结构和存储方式的描述描述,是数据在数据库内部的表示方式,一个数据库只有一个内模式.数据库的两级映像外模式/模式映象:存在于外部级和概念级之间,用于定义外模式和概念模式之间的对应性。
模式/内模式映象:存在于概念级和内部级之间,用于定义概念模式和内模式之间的对应性。
逻辑数据独立性: 应用程序是依据数据的外模式编写的,因而应用程序不必修改,保证了数据与程序的逻辑独立性.即,当数据的逻辑结构改变时,用户程序也可以不变。
物理数据独立性: 当数据库的存储结构改变了,有数据库管理员对模式/内模式映像做相应修改,可以保证模式保持不变,因而应用程序不必修改.实体:客观存在并可以相互区别的事物属性:实体具有的某些特性,通过属性对实体进行描述码: 一个能够唯一标识每一个实体的属性或属性集.实体型:用实体名及其属性名集合来抽象和刻画同类实体.实体集:同类实体的集合联系: ( 1 : 1 ) ( 1 : M ) ( N : M )ER图矩形:实体椭圆:实体的属性菱形:实体间的联系数据模型的元素:1.数据结构:对计算机的数据组织方式和数据之间年联系进行框架性描述的集合,是对数据静态特征的描述2.数据操作:数据库中各记录允许执行的操作集合3.数据完整性约束:关于数据状态变化的一组完整性约束规则的集合,以保证数据的正确性,有效性和一致性.数据模型:层次模型网状模型关系模型关系模型基本概念:关系:一个关系就是一张二维表元组:二维表中行成为元组,每一行是一个元组属性:二维表的列域:属性的取值范围关系模式:对关系的信息结构及语义限制的描述候选码:都能用来唯一标识关系中的元组的多个属性主键:被选中的候选码.主属性:能够成为主键的候选码非主属性: 非候选码外键:不是该关系的主键,却是另一个关系的主键第二章关系数据库关系的性质1.列是同质的2.同关系中不同的列的数据可以同类型,但不能同名3.同关系任意两元组不能完全相同4.同关系列的次序无关紧要5.同关系元组的位置无关紧要6.关系中每个属性必须是单值,不可再分关系的完整性1.实体完整性规则要求关系中的主键不能取空值2.参照完整性规则若属性(或属性组)F是基本关系R的外码,它与基本关系S的主码Ks相对应(基本关系R和S不一定是不同的关系),则对于R中每个元组在F上的值必须为:1)取空值(F的每个属性值均为空值); 2)等于S中某个元组的主码值.外键值受其是主键的表中的值影响.3.用户自定义完整性规则由用户根据实际情况对数据库中的数据内容进行规定.也称域完整性规则关系运算选择运算 : 在关系R中选取满足给定条件的诸元组. 选行σf( R )= { t | t ∈ R ∧ F ( t ) = ‘真’}投影运算 : 在关系R中选择出若干属性列组成新的关系∏ A( R )= { t [ A ] | t ∈ R }连接运算 : 1)等值连接2)自然连接数据依赖: 函数依赖多值依赖连接依赖函数依赖: 如果属性X决定属性Y的值,那么属性Y函数依赖于属性X X-->Y平凡函数依赖: X-->Y 且X包含Y非平凡函数依赖: X-->Y 且X不包含Y完全函数依赖: X-->Y 且 X的任意真子集Z , Z-->Y都不成立.部分函数依赖: X-->Y 且 X的存在真子集Z , Z-->Y成立传递函数依赖: X-->Y , Y-/->X 且 X-->Z关系范式第一范式(1NF):R中每个属性的值域都是不可分的简单数据项的集合.第二范式(2NF):1NF + R中每个非主属性都完全函数依赖于候选码推论:1NF + 唯一主键 = 2NF推论:主关键字是属性的组合可能不是 2NF第三范式(3NF): 2NF + 没有一个非主属性传递函数依赖于候选码推论:1NF + 每个非主属性既不部分也不传递函数依赖候选码BC范式(BCNF): 1NF + 任何非平凡的函数依赖X-->Y,X均包含候选码1.所有非主属性都完全函数依赖于每个候选码2.所有非主属性都完全函数依赖于每个不包含它的候选码3.没有任何属性完全函数依赖于非码的任一组属性第三章数据库设计数据库设计概述--->调查数据需求分析--->数据流图,数据字典概念结构设计--->ER图设计方法和策略1.自顶向下的需求分析2.自底先上的概念设计3.逐步扩张法4.混合策略5.规模适度原则.6个为宜逻辑结构设计-->关系数据模型,用户外模型联系的转换1.1:1联系. 1)联系转为一独立模式.2)联系与其一合并2.1:N联系. 1)联系转为一独立模式.2)联系与N端合并3.N:M联系. 联系产生新的关系模式物理结构设计-->物理结构数据库的实施和运行维护-->满要求的,可持续使用的数据库系统第四章SQL Server基础T-SQL语言的分类:1.数据库定义语言(DDL)CREATE 创建数据库或数据库对象ALTER 修改数据库或数据库对象DROP 删除数据库或数据库对象2.数据操纵语言(DML)INSERT 插入数据UPDATE 修改数据DELETE 删除数据3.数据控制语言(DCL)GRANT 授予权限REVOKE 撤销权限DENY 禁止权限4.数据库查询语言(DQL)SELECT 检索数据第五章数据库的概念和操作数据库具有的三种文件类型1)主数据文件扩展名:mdf2)辅助数据文件扩展名:ndf3)事物日志文件扩展名:ldf逻辑数据库1)master数据库主数据库,记录系统的所有系统级信息2)model数据库为新建的数据库提供模板,包含了所有系统表的结构3)msdb 数据库SQL Server代理程序调度警报作业及记录操作4)tempdb数据库保存所有的临时表和临时存储过程创建数据库CREATE DATABASE database_name[ON [PRIMARY] [<filespec> [,…n]] [,<filegroupspec> [,…n]] ] [LOG ON {<filespec> [,…n]}][FOR LOAD|FOR ATTACH]<filespec>::=([NAME=logical_file_name,]FILENAME=‘os_file_name’[,SIZE=size][,MAXSIZE={max_size|UNLIMITED}][,FILEGROWTH=growth_increment] ) [,…n]修改数据库ALTER DATABASE 数据库名MODIFY FILE(NAME=逻辑文件名,SIZE=文件大小,MAXSIZE=增长限制)ALTER DATABASE 数据库名ADD FILE|ADD LOG FILE(NAME=逻辑文件名,FILE=物理文件名,SIZE=文件大小,MAXSIZE=增长限制)ALTER DATABASE 数据库名REMOVE FILE 逻辑文件名sp_renamedb ‘旧数据库名' , ‘新数据库名'删除数据库DROP DATABASE 数据库名第六章表的操作数据类型1)字符型char(n) 固定长度,自动补空格,MAX:8000varchar(n) 可变长度,超过截断text MAX:231 -12)整型bigint 大整型,( -263 ) - ( 263-1 )int 整型,( -231 ) - ( 231-1 )smallint 短整型,( -215 ) - ( 215-1 )tingyint 微整型,( 0 ) - ( 255 )3)精确数值型decimal(n,m) n:数字的位数m:小数点的位数,右起不能带decimal关键字numeric(n,m) n:数字的位数m:小数点的位数,右起4)近似数值型float(n) n: 1 -- 53real (n)5)日期时间型Datetime 1753年-9999年 , 00:00:00 - 23:59:59.99smalldatetime 1900年-2079年 , 00:00 - 23:59Date 0000年-9999年 , 准确到天数6)货币型Money7)二进制类型binary(n) n+4个字节,自动补足.MAX:8000varbinary 边长image 231 -1个字节8)Unicode字符型Nchar 固定长度 1-2000Nvarchar 可变长度 1-2000Ntext 230-1个字节创建表USE 数据库名GOCREATE TABLE 表格名(列名数据类型NULL / NOT NULL ,列名数据类型CONSTRAINT uk_name/pk_name UNIQUE / PRIMARY KEY ,列名数据类型CONSTRAINT st_name FOREIGN KEY REFERENCES 表名(列名),列名数据类型CHECK( 表达式 ) ,列名数据类型DEFAULT( 默认值 ) ,.......)修改表USE 数据库名GOALTER TABLE 表格名ALTER COLUMN 列名新属性/* 修改属性*/ADD 列名列属性/* 新增列*/DROP COLUMN 列名/* 删除列*/PRIMARY KEY约束UNIQUE约束外键约束CHECK约束DEFAULT约束后期添加约束USE 数据库名GOALTER TABLE 表名ADD CONSTRAINT pk_name PRIMARY KEY( 列名,, )ADD CONSTRAINT uk_name UNIQUE( 列名,, )ADD CONSTRAINT st_name FOREIGN KEY(外键列名) REFERENCES 外表名(主键列名)ADD CONSTRAINT cj_name CHECK( 表达式 )ADD 列名属性 df_name DAFAULT 默认值(表达式) /* 必须新增列 */删除约束USE 数据库名GOALTER TABLE 表名DROP CONSTRAINT pk_nameDROP CONSTRAINT uk_nameDROP CONSTRAINT st_nameDROP CONSTRAINT cj_nameDROP CONSTRAINT df_name插入数据USE 数据库名GOINSERT INTO 表名(列名,列名,...)VALUE(值1,值2,...),(值1,值2,...),......,修改数据USE 数据库名GOUPDATE 表名SET 列名 = ‘值1’WHERE 列名 = ‘值2’删除数据USE 数据库名GODETELE 表名WHERE 表达式删除表USE 数据库名GODROP TABLE 表名第七章数据库查询SELECT查询语法SELECT [DISTINCT] [TOP N] [ * ] select_list [AS / =] [INTO new_table_name ] FROM table_list[ WHERE search_conditions ][ GROUP BY group_by_list ] 分组[ HAVING search_conditions ] 对查询和统计的结果进一步筛选[ ORDER BY order_list [ ASC | DESC ] ] 升降序选择查询查询条件比较运算符: =(等于)、<(小于)、<=(小于等于)、>(大于)、>=(大于等于)、<>(不等于)、!=(不等于)、!<(不小于)、!>(不大于)确定范围 : BETWEEN ? AND ? , NOT BETWEEN ? AND ?确定集合 : IN(‘值1’,‘值2’,...) , NOT IN(‘值1’,‘值2’,...)字符匹配 : LIKE‘_ X % [abc] ’ , NOT LIKE‘_ X % [abc] ’空值 : IS NULL , IS NOT NULL多重条件 : AND , OR , NOT常用通配符% 包含0个或多个字符的字符串- 任何单个字符[] 指定范围内的单个字符聚合函数sum(列名) 返回一个数字列的总和avg(列名) 对一个数字计算平均值min(列名) 返回一个数字,字符或日期列的最小值max(列名) 返回一个数字,字符或日期列的最大值count(列名) 返回一个列的数据项数count(*) 返回找到的行数连接查询内连接SELECT select_listFROM 表1 [INNER] JOIN 表2 ON 表1.列1 = 表2.列2or FROM 表1,表2 WHERE 表1.列1 = 表2.列2自连接SELECT select_listFROM 表1 A INNER JOIN 表1 B ON A.列1 = B.列2外连接SELECT select_listFROM 表1 LEFT/RIGHT/FULL [OUTER] JOIN 表2 ON 表1.列1 = 表2.列2 交叉连接SELECT select_listFROM 表1 CROSS JOIN 表2子查询 : 嵌套了SELECT语句的SELECT语句SOME , ANY , ALL , IN 子查询:测试比较直是否与子查询所返回的全部或部分匹配子查询语句中不能使用image,text,ntext数据类型子查询中不能用ORDER BY 子句集合运算查询UNION联合查询将多个SELECT语句连接起来的查询EXCEPT查询左侧存在而右侧不存在的所有非重复值INTERSECT查询左侧存在且右侧存在的所有非重复值SELECT 学号 FROM 学生表EXCEPT(没选课) | INTERSECT(有选课)SELECT 学号 FROM 选课表第八章T-SQL编程全局变量 :系统提供,预先声明.只能使用,不能修改.前缀:@ @局部变量声明: DECLARE { @loacal_variable date_type } [,...n]赋值: SET / SELECT { @loacal_variable = expression }定义语句块: BEGIN ... END用户自定义函数标量函数格式:CREATE FUNCTION [ owner_name.] function_name /*函数名部分*/ ( [ { @parameter_name [AS] parameter_data_type[ = DEFAULT] } [ ,...n ] ] ) /*形参定义部分*/RETURNS return_data_type /*返回参数的类型*/[ AS ]BEGINfunction_body /*函数体部分*/RETURN expression /*返回语句*/END实例:USE 教学库GOCREATE FUNCTION average(@cn char(4))RETURNS floatAS BEGINDECLARE @aver floatSELECT @aver=( SELECT avg(成绩) FROM 选课表WHERE 课程号=@cn)RETURN @averEND调用:owner_name.function_name(parameter_expression 1…parameter_expression n)内嵌表值函数格式:CREATE FUNCTION [ owner_name.] function_name /*定义函数名部分*/( [ { @parameter_name [AS] parameter_data_type[ = DEFAULT] }[ ,...n ] ] ) /*定义参数部分*/RETURNS table /*返回值为表类型*/[ AS ] RETURN [ (SELECT statement )] /*通过SELECT语句返回内嵌表*/ 实例:USE 教学库GOCREATE FUNCTION st_func(@major char(10)) RETURNS tableAS RETURN( SELECT 学生表.学号, 学生表.姓名,课程号,成绩FROM 学生表,选课表WHERE 专业=@major AND 学生表.学号=选课表.学号)多语句表值函数格式:CREATE FUNCTION [ owner_name.] function_name /*定义函数名部分*/( [ { @parameter_name [AS] parameter_data_type [ = DEFAULT] }[ ,...n ] ] )/*定义函数参数部分*/ RETURNS @return_variable table < table_definition >/*定义作为返回值的表*/[ AS ]BEGINfunction_body /*定义函数体*/RETURNEND实例:CREATE FUNCTION st_score (@no char(7)) RETURNS @score table( xs_no char(7) ,xs_name char(6) ,kc_name char(10) ,cj int ,xf int )AS BEGININSERT into @scoreSELECT s.学号,s.姓名,c.课程名,c.学分,sc.成绩FROM 学生表 s,课程表 c,选课表 sc WHERE s.学号=sc.学号 AND c.课程号=sc.课程号AND s.学号=@noRETURNEND游标的类型T-SQL游标 : 用在T-SQL脚本,存储过程和触发器中,不支持读取多行数据API游标 : 用在OLE DB,ODBC和DB_library中客户游标静态游标 : 只读,总是按照打开游标时的原样显示结果集动态游标 : 滚动游标时动态游标反应的结果集中有所更改只进游标 : 不支持滚动,只支持从头到尾的顺序提取数据键集驱动游标 : 同时具有动态游标和静态游标的特点游标的操作声明游标:DECLARE cursor_name [INSENSITIVE] [SCROLL] CURSORFOR select_statement[FOR {READ ONLY | UPDATE [OF column_name [,...n]]}]例子DECLARE S_Cursor CURSOR FORSELECT * FROM 学生 WHERE 专业='计算机' 打开游标:OPEN { { [GLOBAL] cursor_name } | cursor_variable_name} 例子OPEN S_Cursor GO读取游标:FETCH [[NEXT | PRIOR | FIRST | LAST| ABSOLUTE {n | @nvar}| RELATIVE {n | @nvar}]FROM ]{{[ GLOBAL ] cursor_name } | cursor_variable_name}[INTO @ variable_name [,…n]]例子FETCH NEXT FROM S_ Cursor GO关闭游标:CLOSE { { [GLOBAL] cursor_name } | cursor_variable_name } 例子CLOSE S_Cursor GO释放游标:DEALLOCATE {{[GLOBAL] cursor_name }| cursor_variable_name} 例子DEALLOCATE S_Cursor GO第九章视图和索引视图的优点1.为用户集中数据,简化用户的数据查询和处理2.保证数据的逻辑独立性3.重新定制数据,使得数据便于共享4.数据保密视图的分类标准视图索引视图分区视图视图创建原则1.只能在当前数据库中创建视图2.视图名称必须遵守标识符的规则,且对每一个用户必须唯一3.用户可以在其他视图上建立思路4.用户需要为视图的的每一列指定特定的名称5.不能在视图上定义全文索引定义6.不能创建临时视图,也不能再临时表上创建视图创建语句格式CREATE VIEW [schema_name.]view_name [ (column_name[ ,...n ] ) ][with <view_attribute>[,…n]]AS select_statement[WITH CHECK OPTION]实例USE 教学库GOCREATE VIEW学生_课程_成绩ASSELECT 学生表.学号,姓名,课程表.课程号,课程名,成绩FROM 学生表,选课表,课程表WHERE 学生表.学号=选课表.学号AND 课程表.课程号=选课表.课程号AND 专业='计算机' GO索引 : 加快检索表中数据的方法,用空间换时间优点1.大大加快数据的检索速度2.创建唯一性索引,保证表中每一行数据的唯一性3.加速表和表之间的连接4.显著减少分组和排序的时间聚集索引 : 表格视图中只能有一个. 有序,拼音索引非聚集索引 : 最多可以建立250个,无序,部首索引创建索引CREATE [ UNIQUE ][ CLUSTERED | NONCLUSTERED ] INDEX index_nameON { table_name | view_name } ( column_name [ ASC | DESC ] [ ,...n ] ) [ WITH < index_option > [ ,...n] ] [ ON filegroup ]< index_option > ::= { PAD_INDEX | FILLFACTOR = fillfactor| IGNORE_DUP_KEY | DROP_EXISTING| STATISTICS_NORECOMPUTE }第十章存储过程和触发器过程 : 为了易于修改和扩充,将负责不同功能的语句集中起来而且按照分别独立方式的不同功能语句.存储过程 : 一种独立存储在数据库的对象,可以接受输入参数,输出参数,返回单或多结果,以及返回值,由应用程序通过调用执行.对比SQL语句优势 :1.允许模块化程序设计2.允许更快速的执行3.减少网络流量4.可作为安全机制使用存储过程类型:系统存储过程 : 前缀 sp_本地存储过程 : 前缀 sp_临时存储过程 : 本地临时存储过程: 前缀# 全局临时存储过程: 前缀##远程存储过程扩展存储过程创建格式 :USE database_name GOCREATE [{PROCEDURE | PROC }] procedure_name [:number][{@procedure data_type}[CARYING] [=dafault] [ [OUT[PUT]][,...n}][WITH { PROCEDURE | ENCRYPTION | RECOMPLIE , ENCRYPTION }[ ,...N]][FOR REPLIACATION]As sql_satament[...n]例子use 仓库库存goCREATE PROCEDURE Pname @p_n varchar(20),@average int OUTPUTASSELECT @average = avg(单价) FROM 商品WHERE 商品名称 = @p_nGo执行格式:[[EXEC[URE]] [@return_status = ]procedure_name[;number]{[[@parameter = ] value | [@parameter = ]@varivle[OUTPUT]]}[WITH RECOMPLILE]例子use 教学库goEXECUTE student_avg触发器作用:实现由主键和外键所不能保证的复杂的参照完整性和数据的一致性,有助于强制引用完整性,以便于在添加更新或删除表中行时保留表之间已定义的关系.可执行的操作:1.强制比CHECK约束更复杂的数据的完整性2.使用自定义的错误提醒信息3.实现数据库中多张表的级联修改4.比较数据库修改前后的数据状态5.调用很多的存储过程6.维护非规范化数据触发器的分类1.MDL触发器触发语句:修改数据的INSERT语句,UPDATE语句,DELETE语句结果:如果检测到错误,整个事物即自动回滚AFTER触发器:记录改变完后激活执行,检测错误INSTEAD OF 触发器: 取代原来的操作.2.DDL触发器使用情况:1.数据库里的库架构过数据表架构很重要,不允许修改2.防止数据库或数据表被误操作删除3.在修改某个数据表结构的同时修改另一个数据表相应的结构4.要记录对数据库结构操作的事件创建格式 :CREATE TRIGGER trigger_nameON {table_naem | view}[WITH ENCRYPTION]{ FOR | AFTER | INSTEAD OF}{ [ INSERT ] [ DELETE ] [ UPDATE ] }[NOT FOR REPLICATION ]AS sql_statement[...n]例子:use database_name gocreate trigger trg_name on table_namefor drop_table,alter_tableAsprint ‘名为trg_naem的触发器不允许你执行表的修改,删除’rollback插入表 : inserted 删除表 : deleted删除触发器 : DROP TRIGGER trigger_name第十一章事务与并发控制事务 : 由一系列的操作组成,是数据库的基本逻辑单元,用来保证数据的一致性事务处理原则1.原子性: 原子工作单位,数据修改要么全执行,要么全部执行2.一致性: 执行完成后,数据库从一个状态转变到另一个一致状态3.隔离性: 并行事务的修改必须与其他事务的修改相互独立4.持久性: 完成提交后,对系统产生持久性影响.事务类型1.系统事务: 在执行某些语句时,一条语句就是一个事务2.用户定义事务:在开发应用程序时用BEGIN TRANSACTION语句定义COMMIT : 提交语句,将全部完成的语句明确提交到数据库中ROLLBACK : 回滚语句,事务操作全部回滚,表示事务操作失败一.自动提交事务 : 每一条单独的SQL语句二.显示事务 : 一BENGIN / COMMIT / ROLLBACK TRANSACTION语句定义的事务三.隐士事务 : 在前一个事务完成时新事务隐式开始.与显示事务先相同定义四.批处理事务 : 应用于多个活动结果集中事务处理语句1.定义事务: BENGIN TRANSATION格式:BEGIN { TRAN | TRANSACTION }[ transaction_name | @tran_name_variable ][WITH MARK [‘description’]]2.定义事务: COMMIT TRANSACTION格式:COMMIT [{ TRAN | TRANSACTION }[ transaction_name | @tran_name_variable ] ]3.回滚事务: ROLLBACK TRANSACTION格式:ROLLBACK [ { TRAN | TRANSACTION }[ transaction_name | @tran_name_variable| savepoint_name | @savepoint_variable ] ]4.设保存点; SAVE TRANSACTION例子:DECLARE @t_name CHAR(10)SET @t_name =’add_score’BEGIN TRANSACTION @t_nameUSE 教学库UPDATE 选课表 SET 成绩 = 成绩+5WHERE 课程号=’C003’COMMIT TRAINSACTION @t_name并发控制 : 多个用户同时更新行时,用于保存数据库完整性的各种技术,目的是保证一个用户的工作不会对另一个用户的工作产生不合理影响.并发问题:1.丢失修改2.脏读3.不可重复读4.幻读锁:防止其他事务访问指定资源,实现并发控制的一种手段锁的类型:1.共享锁,允许并发事务读取一个资源,使用时任何其他事务都不能修改数据2.排他锁,防止并发事务对资源进行访问,其他事务不能读取或修改数据.3.更新锁,可读不可写,可以与共享锁共存.使用时自动变为排他锁4.意向共享锁,表示读低层次资源的事务意向,把共享锁放在这些单个资源上意向排他锁,表示修改低层次事务的意向,把排他锁放在这些单个资源上空闲意向排他锁,两种锁的组合,允许并行读取顶层资源的事务的意向,并修改.5.模式锁,保证当前表过索引被另一个会话参考时,不能被删除或修改其结构模式6.大容量更新锁,只允许进程将数据并发的大容量复制到用一个表.解决死锁的方法:1.要求每一个事务将要使用的数据全部加锁,否则不能继续执行2.允许死锁的发生,系统来用某些方式诊断当前系统中是否有死锁的发生第十三章数据库的安全管理安全性:保护数据库以防止不合法用户的访问而造成的数据泄密或破坏设置权限:GRANGT{ ALL [ PRIVILEGES ]}|permission [(column[,...n])][,...n][ON [class :: ]securable]TO principal [,...n][WITH GTANT OPTION ][ AS principal ]例子GRANT INSERT / SELECT / UPDATE ON table_nameTO user_name WITH GRANT OPTION撤销权限 :REVOKE [ GRANT OPTION FOR ]{ [ALL [PRIVILEGES ]]}|permisiion [(column [,...n])][,...n]}[ON[class::] secureable]{ FROM } principal [,..n][CASXADE ] [AS principal]例子REVOKE INSERT / SELECT / UPDATE ON table_nameFROM user_name禁止权限:DENY{ALL [PRIVILEGES]}|permission [(column [,...n])][,...n]}[ON[class::] secureable]TO principal [,..n][CASXADE ] [AS principal]例子DENY INSERT / SELECT / UPDATE ON table_nameTO user_name第十四章数据库的备份和还原备份类型:1.完整数据库备份. 包括事务日志部分2.差异数据库备份. 只备份与上次完整数据库备份发生改变的内容3.事务日志备份. 记录数据库的更改.4.数据库文件或文件组备份.备份语句:BACKUP DATABASE {database_name | @database_name_var}TO< backup_device > [,...n][ WITH[ BLOCKSIZE = { blocksize | @blocksize_variable } ][ [ , ] DESCRIPTION = { 'text' | @text_variable } ][ [ , ] DIFFERENTIAL][ [ , ] EXPIREDATE = { date | @date_var }][ [ , ] PASSWORD = { password | @password_variable } ][ [ , ] FORMAT | NOFORMAT ][ [ , ] { INIT | NOINIT } ]例子:BACKUP DATABASE database_nameTO DISK = ‘E:\backup\database_name.Back’WITH FORMAT / DIFFERENTIAL还原语句:RESTORE DATABASE {database_name | @database_name_var}[FORM<backup_device> [,...n]][WITH[ [ , ] FILE = { backup_set_file_number | @backup_set_file_number } ][ [ , ] KEEP_REPLICATION ][ [ , ] MEDIANAME = { media_name | @media_name_variable } ][ [ , ] MEDIAPASSWORD = { mediapassword | @mediapassword_variable } ] [ [ , ] MOVE 'logical_file_name_in_backup' TO 'operating_system_file_name' ] [ ,...n ][ [ , ] PASSWORD = { password | @password_variable } ][ [ , ] { RECOVERY | NORECOVERY | STANDBY ={standby_file_name | @standby_file_name_var } } ][ [ , ] REPLACE ]]例子:RESTORE DATABASE database_nameFORM DISK= ‘E:\backup\database_name.Back’WITH REPLACE/NORECOVERY/RECOVERY数据库考试范围:一、单选题(每小题2分,共20分)二、填空题(每小题1分,共10分)三、简答题(每小题5分,共15分)四、设计题(共20分)五、综合题(共35分)要求掌握的知识点(在此列出大部分):逻辑独立性、物理独立性;数据库设计的步骤;关系的实体完整性、参照完整性、用户自定义完整性;画E-R图,将E-R图转关系模式;给定语义,写出函数依赖、找出关系的候选码、判断范式、分解关系模式掌握关系代数运算:笛卡尔积、选择、投影、连接SQL语句:select、insert、update、delete语句(以student、course、SC 三个表为例)!理解视图;游标的使用;理解触发器inserted和deleted表;显式事务的三个命令;权限管理:grant、revoke、deny的使用数据库备份类型,备份与还原命令的使用创建存储过程,带输入参数和输出参数!共享锁、排他锁,并发控制带来的数据不一致性;。
SQLSERVER期末复习资料.doc

A.数据共亨D. 65I). DBA5.在SQL 中, 建立表用的命令是( CREATE SCHEMACREATE TABLEC.CREATE VIEW《SQL SERVER 2005》期末复习A一.单项选择题(每小题1分,共10分)1•下列四项中,不属于数据库特点的是(B. 数据完整性C. 数据冗余很高D. 数据独立性高2. 运行命令SELECT ASCII 「Alkk )的结果是(C. 903. SQL Server 装程序创建4个系统数据库,下列哪个不是( )系统数据库。
4. ()是位于用户与操作系统之间的一层数据管理软件,它屈于系统软件,它为用户或应用程 序提供访问数据库的方法。
数据库在建立、使用和维护时由其统一管理.统一控制。
A. DBMSC. DBSD.CREATE TNDEX6. SQL 语言屮,条件年龄BETWEEN 15 AND 35表示年龄在15至35之间,H ( )。
A. 包括15岁和35岁B. 不包括15岁和35岁C. 包括15岁但不包括35岁D. 包括35岁但不包括15岁 7. 下列四项中,不正确的提法是( )。
A. SQL 语言是关系数据幷的国际标准语言B. SQL 语言具有数据定义、杏询、操纵和控制功能C. SQL 语言可以自动实现关系数据廉的规范化D. SQL 语言称为结构查询语言8.在MS SQL Server 中,用來显示数据库信息的系统存储过程是()。
A. sp_dbhelp B .sp_db C. sp_hel pD . sp_helpd b9. SQL 语言中,删除表中数据的命令是()oA. DELETE B. DROP C. CLEAR D.REMOVE 10. SQL 的视图是从()中导出的。
A.基本表 B. 视图 C.皋木表或视图D.数据库 二、判断题(每空1分,共10分)1. '在那遥远的地方’是SQL 中的字符串常量吗?2. '11. 9'是SQL 中的实型常量吗3. select 16%4,的执行结果是:4吗?4.2005. 11.09是SQL 中的日期型常量吗? 5. ¥2005. 89是SQL '|«的货币型常量吗?6. select 25/2的执行结果是:12.5吗?7. '岳飞'>'文天祥’比较运算的结果为真吗?8. 一个表可以创建多个主键吗?9. 创建唯一性索引的列可以有一些重复的值?10. 固定数据库角色:db_datarader 的成员能修改木数据库内表中的数据吗?三、填空题(每空1分,共20分)1. 实体之间的联系类型有三种,分别为一对--、一对多和 _________ o2. 统计平均值的函数是 _______ o3. 语句 select ascii ('D'), char (67)的执行结果是: __ 和 ________ 。
SQLServer数据库基础课程总复习课件

Sdept
所在院系
字符串,长度为20 默认为‘计算机系’
表创建和操作
Create table Student ( Sno char(7) primary key, Sname char(10) not null, Ssex char (2) check(Ssex=‘男’or Ssex=’
女’), Sage int check(Sage between 15 and 45), Sdept varchar(20) default(‘计算机系’) )
表创建和操作
列名 Cno
Cname
Ccredit Semester
Period
Course表结构
说明 课程号
课程名
学分 学期 学时
数据类型
字符串,长度 为10
字符串,长度 为20 整数 整数 整数
约束 主码
非空
取值0~50 取值大于0 取值大于0
表创建和操作
Create table course ( Cno char(10) primary key, Cname varchar(20) not null, Ccredit int check(Scteditbetween 0 and
创建数据库
练习:
1、写出创建产品销售数据库cpxs,初始大小为 10MB,最大为50MB,增长方式为20%;日志文 件名初始为4MB,最大为25MB,增长方式为 5MB,存储路径为
“D:\SQLServer\2012\data”。
create database cpxs on (name=cpxs_dat, 'D:\SQL Server\2012\cpxs_dat.mdf', size=10MB, maxsize=50MB, ) log on (name=cpxs_log, 'D:\SQL Server\2012\cpxs_log.ldf', size=4MB, maxsize=25MB, )
大学SQLServer2000复习资料(辛苦整理)

第一章一、SQL Server 2000 版本:1.企业版(具备所有功能)---作为生产数据库服务器使用。
支持 SQL Server 2000 中的所有可用功能。
2.个人版(安装个人数据库)---一般供移动的用户使用。
3.开发版(适用于我们安装,支持企业版的所有功能)---供程序员用来开发将 SQL Server 2000 用作数据存储的应用程序。
4.标准版(适用于简洁开发)。
---作为小工作组或部门的数据库服务器使用。
注意: 企业版和标准版只能安装在服务器版本的操作系统中,如(2000 Server、NT 4.0 Server 等)。
二、SQL Server 2000 安装组件1.安装数据库服务器(我们选择该组件)---启动SQL SERVER安装程序。
2.安装Analysis Services---在处理OLAP(联机分析处理)多维数据集的计算机上安装Analysis Services。
3.安装English Query---可通过英语查询数据库。
三、目录路径:1.\Program Files\Microsoft SQL Server\MSSQL\Binn---置放程序文件。
包含程序文件及通常不会更改的文件,需要的空间不大。
2.\Program Files\Microsoft SQL Server\MSSQL\Data---置放数据文件。
包含数据库和日志文件、系统日志、备份数据、复制数据所在的目录文件夹,需要的空间大。
3.\Program Files\Microsoft SQL Server\80---置放一些共享工具和com组件。
比如联机丛书、开发工具等组件。
四、自带的系统和示例数据库1.系统数据库a.master 数据库---记录 SQL Server 系统的所有系统级别信息。
它记录所有的登录帐户和系统配置设置。
b.model 数据库---用作在系统上创建的所有数据库的模板。
充当所有数据库的原始模板c.tempdb 数据库---保存所有的临时表和临时存储过程。
SQL Server期末考试复习要点概要

SQL Server期末考试复习要点第1章,关系数据库的基本原理。
理解数据库系统的基本概念,掌握关系数据模型,重点掌握E-R模型的应用,了解关系运算,掌握关系完整性规则,理解关系的规范化。
1.掌握并理解数据、数据库、数据库管理系统的概念,数据库系统的构成和特点;2.掌握现实世界——信息世界——机器世界的“三个世界、两次抽象、两个模型”抽象过程。
3.掌握与概念模型相关的实体、属性、联系等概念,能熟练应用E-R概念和方法解释1:1,1:n,n:m并能举例说明和绘制E-R图。
4.掌握关系数据模型的概念,如关系(表的组成、特征,相关名词术语:元祖(记录,属性(列,字段、属性值,键、主键,外键、主表、从表。
5.三种基本(专门的关系运算:投影、选择、连接。
6.关系的三个完整性规则:实体完整性、参照完整性、域(用户自定义完整性。
7.了解关系规范化方法。
第2章, SQL Server2005基础。
了解SQL Server2005的特性。
了解SQL Server2005产品家族的概况。
了解SQL Server2005工具和实用程序概况。
8.SQL Server2005的五个版本情况。
简易版、工作组版只有32位,后面三个版本都有32位和64位之别。
9.掌握SQL Server Management Studio的功能、组成。
10.重点掌握查询分析器界面组成及使用T-SQL语句查询的操作过程,代码、结果、信息等几个相关窗口和按钮。
11.了解文档和教程的组织方式、使用方法。
12.掌握服务器的启动、停止、关闭等操作方法。
第3章,数据库的创建与管理。
掌握SQL Server2005数据库的基本知识。
重点掌握创建数据库的相关知识和方法。
掌握管理数据库(包括查看数据库信息、备份与还原数据库,分离与附加数据库的相关知识和方法。
13.熟悉数据库的文件和文件组的概念。
14.熟练掌握数据库两种创建方法中涉及的概念、术语。
15.熟练掌握数据库修改语句中几个子句的功能。
SQL Server复习(09)

第一章数据库的原理1、数据库的基本概念(1)数据库是指长期存储在计算机内有组织的、可共享的数据集合储数据和其他数据库对象的操作系统文件,是数据库服务器的主要组件,是数据库管理系统的核心,数据库中的数据按一定的数据模型组织、描述和存储,具有较小的冗余度,较高的数据独立性和易扩展性,并可为各种用户共享(2)数据库管理系统指位于用户与操作系统之间的一层数据管理软件。
数据库在建立、运用和维护时由数据库管理系统统一管理、统一控制。
数据库管理系统使用户能方便地定义数据和操纵数据,并能够保证数据的安全性、完整性、多用户对数据的并发使用及发生故障后的系统恢复功能:(3)数据库系统指在计算机系统中引入数据库后构成的系统,一般由数据库、数据库管理系统(及其开发工具)、应用系统、数据库管理员和用户构成2.3种模型3.关系模型术语关系、元组、属性、码、外码4.关系模型的完整性第三章SQL Server概述企业管理器、服务管理器、查询分析器的作用及使用第四章管理数据库1、数据库对象包括哪些Sql server中数据库对象有:tables、views、stored procedures、user、roles、rules、default、user defined data types、user defined function、full-text catalogs2、事务和事务日志的概念事务就是一个工作单元,该单元的工作要么全部完成,要么全部不完成事务日志记录了对数据库的所有修改。
日志记录了每个事务的开始、对数据库的改变和取消修改的足够信息。
3、操作系统的二种文件形式及特点主数据库文件(Primary Database File)是数据库的起点,每个数据库都仅有一个主数据文件辅助数据库文件(Secondary Database File)是可选的,它们可以存储那些不在主数据文件中的数据和对象。
可以没有可以多个。
事务日志文件保存了用于恢复数据库的全部事务日志信息,至少一个4、使用文件和文件组时,因该考虑哪些事情一个文件或文件组只能用于一个数据库,不能用于多个数据库一个文件只能是某个文件组的成员,不能是多个文件组的成员数据库的数据信息和日志信息不能放在一个文件或文件组中,数据文件和日志文件总是分开的日志文件永远也不能是任何文件组的一部份5、创建数据库使用T ransact-SQL语言创建数据库CREATE DAT ABASE database_name[ON [PRIMARY] [<filespec> [,…n] [,<filegroupspec> [,…n]] ][LOG ON {<filespec> [,…n]}][FOR RESTORE]<filespec>::=([NAME=logical_file_name,]FILENAME=‘os_file_name’[,SIZE=size][,MAXSIZE={max_size|UNLIMITED}][,FILEGROWTH=growth_increment] ) [,…n]<filegroupspec>::=FILEGROUP filegroup_name <filespec> [,…n]6、修改数据库的方法ALTER DA TABASE修改名字?修改文件数目?修改容量?7、删除数据库的方法利用企业管理器删除数据库利用Drop语句删除数据库:Drop语句可以从SQL Server中一次删除一个或多个数据库。
sql server 复习资料

sql server 复习资料SQL Server 复习资料在现代的信息时代,数据库管理系统扮演着至关重要的角色。
而SQL Server作为一种常用的关系型数据库管理系统,其在企业和组织中的应用越来越广泛。
为了更好地掌握SQL Server的知识,我们需要进行系统的学习和复习。
一、SQL Server的基本概念和架构SQL Server是由微软公司开发的一种关系型数据库管理系统。
它采用了客户端/服务器架构,包括数据库引擎、分析服务、报告服务和集成服务等组件。
数据库引擎是SQL Server的核心组件,负责处理数据的存储、检索和管理等任务。
二、SQL Server的安装和配置在使用SQL Server之前,我们需要先进行安装和配置。
安装SQL Server可以通过光盘、网络下载或者虚拟机等方式进行。
在安装过程中,需要选择安装的版本、实例名称、身份验证模式等选项。
配置SQL Server则包括设置数据库文件的位置、内存和CPU的使用等参数。
三、SQL Server的数据库设计和创建数据库设计是SQL Server应用的关键环节。
在设计数据库时,我们需要确定实体、属性和关系等概念,使用ER图或者UML图进行建模。
创建数据库可以通过SQL Server Management Studio工具或者Transact-SQL语句来完成。
四、SQL Server的数据操作和查询SQL Server提供了丰富的数据操作和查询功能。
通过使用SQL语句,我们可以对数据库中的数据进行插入、更新、删除和查询等操作。
常用的SQL语句包括SELECT、INSERT、UPDATE和DELETE等。
此外,SQL Server还支持事务处理和存储过程等高级特性。
五、SQL Server的性能优化和调优为了提高SQL Server的性能,我们需要进行优化和调优。
优化可以从多个方面入手,包括数据库设计、索引优化、查询优化和服务器配置等。
数据库与SQLServer复习提纲

一、名词解释1.事务2.数据库3.函数依赖4.码(键)5.第三范式6.模式7.BC范式8.数据模型9.最小函数依赖集10.关系模式的分解11.属性集X的闭包X+二、填空题1.数据管理技术经历了人工管理、文件系统和数据库系统三个阶段。
2.SQL Server2008数据库分为两种类型:系统数据库和用户数据库。
3.数据独立性包括数据的物理独立性和数据的逻辑独立性。
4.数据库是长期储存在计算机内、有组织的、可共享的大量数据的集合。
5.主键用于保证数据库中数据表的每一个特定实体的记录都是唯一的。
6.数据库中的数据按一定的数据模型组织、描述和储存,具有较小的冗余度、较高的数据独立性和易扩展性,并可为各种用户共享。
7.SQL Server中,权限的各类包括语句权限、对象权限和固定角色隐含权限。
8.触发器是一种特殊类型的存储过程,它不能显式地被调用,它是在指定的表中插入记录、更改记录或者删除记录时被自动激活。
9.计算机系统的安全性问题可分为三大类,即技术安全类、管理安全类和政策法律类。
10.概念结构设计是整个数据库设计的关键。
11.视图是一个虚表,它是从基本表或视图导出的表。
在数据库中,只存放视图的定义,不存放视图的结果。
12.在数据库系统中,定义存取权限称为授权。
13.数据完整性分为实体完整性、域完整性、参照完整性和用户自定义完整性四种类型。
14.数据库系统的发展经历了3个阶段:网状数据库、层次数据库和关系数据库。
15.游标的操作步骤包括声明、处理(提取、删除、修改或推进)、关闭和撤消游标。
16.游标是用于将数据客体数据库中的集合量逐一转换成数据主体(应用程序)中的标量。
17.数据库管理系统是实际存储的数据和用户之间的一个接口,负责处理用户和应用程序存取、操纵数据库的各种请求。
18.如果表的某一列被指定具有NOT NULL属性,则表示该列的值不能为空。
19.聚集索引是指索引项的顺序与表中记录的物理顺序一致的索引组织。
SQL_Server_复习提纲

SQL Server 复习提纲1、了解SQL Server 2005体系结构的4个组成部分;2、SQL Server 2005 的两种数据库类型,系统数据库和用户数据库;系统数据库:master、tempdb、msdb 和model用户实例数据库:如AdventureWorks等3、SQL Server 2005的版本;(6个不同的版本)企业版:功能最齐全、性能最优。
标准版:适合于中小型企业的数据管理。
开发人员版:适合于应用程序开发人员。
工作组版:入门级的数据库产品。
精简版:是一个免费、易用且便于管理的数据库版。
企业评估版:运行时间只有120天。
4、数据库的逻辑结构和物理结构,数据库文件的组成;数据库的逻辑存储结构是指数据库是由哪些性质的信息组成的数据库的物理存储结构是指数据库文件是如何在磁盘上存储的。
一个SQL Server 2005的数据库由多个文件组成。
SQL Server 2005中每个数据库包括主数据库文件(.mdf )、辅助数据库文件(.ndf )和事务日志文件(.ldf )。
一个SQL Server 2005的数据库至少应包含一个主数据库文件和一个事务日志文件。
5、SQL Server 常见的数据类型;(6大类型)(1)字符型: char 、nchar 、varchar(2)数值型 int 、smallint 、float 、real (带有小数的);(3)货币类型:money 、smallmoney ;(4)时间类型:datetime 、smalldatetime ;(5)二进制类型:binary 、varbinary 、image ;(6)其他类型:bit 、XML 、Timestamp 、Uniqueidentifier ,cursor (游标)、sql_variant ;6. 掌握建立数据库的方法;用SQL 语句建立 CREATE DATABASE 数据库名7. 掌握建立表的方法,特别注意用SQL 语句建立约束的方法,6种约束CREATE TABLE 学生表(学号 varchar(11) not null primary key,姓名 varchar(20) not null,性别 char(2) default '男出生日期 smalldatetime,入学日期smalldatetime,院系名称 varchar(20),身份证)create table 选课表(学号 varchar(11) FOREIGN KEY references 学生表(学号),课程号 varchar(6) FOREIGN KEY references 课程表(课程号),分数 int check(分数primary key(学号,课程号)8. 掌握索引的分类及特点,索引的基本操作;索引的分类:索引分为聚集索引和非聚集索引 ▪ 聚集索引(Clustered ):使用表中的一列或多列来排序记录,然后再重新存储在磁盘上,表的物理行顺序和聚集索引中行的顺序一致。
SQLSERVER重要知识点归纳

1,数据模型:由数据结构、数据操作和数据的完整性约束组成。
2,在E-R概念模型中,信息由实体型、实体属性和实体间联系3种概念单元来表示。
3,第一范式(1NF):设R是一个关系模式,如果R中的每个属性都是不可分解的,则称R 是第一范式;第二范式(2NF):如果关系模式R是第一范式,且每个非码属性都完全依赖于码属性,则称R是第二范式;第三范式(3NF):如果关系模式是R第二范式,且没有一个非码属性传递依赖于码,则称R是第三范式。
4,Transact-SQL语句的分类如下所示:○1变量声明Transact-SQL语言可以使用两类变量,局部变量和全局变量。
○2数据定义语言(Data Definition Language,DDL),用来建立数据库及数据库对象,绝大部分以Create开头,如Create Table等○3数据控制语言(Data Control Language,DCL),用来控制数据库组件的存取访问、权限等命令,如GRANT、REVOKE等○4数据操纵语言(Data Manipulation Language,DML),用来操纵数据库中数据的命令,如SELECT、UPDATE等○5流程控制语言(Flow Control Language,FCL),用于控制应用程序流程的语句,如IF、CASE 等。
5,数据类型:整数型:bigint(8个字节,-263~263-1),int(4个字节,-231~231-1),smallint(2个字节,-215~215-1),tingyint(1个字节,0~255);小数数据类型:decimal [(p[,s])] p精度:指定小数点左边和右边可以存储的十进制数字的最大个数。
1~38 s小数位数:0~p之间的值;numeric [(p[,s])]近似数值型:float[(n)] n:1~53 取值范围:-1.79308~1.79308real 取值范围:-3.4038~3.4038字符型(字符常量必须包含在单引号或双引号中):char[(n)]:长度为n个字节的固定长度且非Unicode的字符数据,存储大小为n个字节。
SQL Server数据库(知识点)答案

SQL Server数据库复习资料(知识点)1.数据库、数据库系统、数据库管理系统的概念。
P32.SQL Server2000采用的体系结构。
P163.常见数据库系统的三种模式。
P44.SQL Server 2000 采用的身份验证模式。
P315.SQL Server 2000在安装时创建的数据库。
6.数据库包含的几种文件类型及其作用。
P44-457.文件组的概念和作用。
P43-448.创建、修改、删除表的语句。
CREATE/ALTER/DROP DATEBASE9.主键的概念。
P610.完整性概念。
P711.SQL Server的系统数据类型。
P63-6512.SQL Server采用的通配符。
13.SELECT查询中常用子句TOP、DISTINCT、PERCENT、WHERE、ORDER BY、GROUP BY、HA VING的作用。
P99-10414.连接查询、联合查询。
P105-10615.表间的几种连接类型。
16.聚集索引和非聚集索引的概念。
P8317.SQL Server 2000中的运算和运算符。
P16018.在SQL Server 2000中局部变量和全局变量。
P158-15919.语句块的概念。
20.常用系统函数。
P164-17021.常用聚合函数的使用。
22.视图的概念和作用。
P115-11623.创建、修改、删除视图的语句。
CREATE/ALTER/DROP VIEW24.存储过程的概念和用途。
P18825.常用系统存储过程。
P190-19826.触发器的概念和作用。
P198-19927.触发器的三种类型和两种触发类型。
P210-21128.数据库备份的概念和类型。
P136-13729.事务的概念及相关语句。
P178-17930.批处理的概念。
sqlserver数据库知识点

sqlserver数据库知识点SQL Server数据库知识点:SQL Server是由Microsoft开发的关系型数据库管理系统(RDBMS),广泛用于企业级应用程序开发和数据管理。
以下是SQL Server的一些重要知识点:1. 数据库:SQL Server是基于数据库的软件,数据库是用来保存和管理大量结构化数据的集合。
SQL Server支持多个数据库实例,每个实例可以包含多个数据库。
2. 表和字段:数据库中的数据被组织成表,表由行和列组成。
行代表记录,列代表记录中的数据项。
每个表可以有一个或多个字段,字段定义了表中存储的数据类型。
3. SQL语言:SQL(结构化查询语言)是一种用于管理数据库的标准语言。
SQL Server支持SQL语言,并提供了丰富的SQL命令和功能,用于查询、插入、更新和删除数据库中的数据。
4. 数据库管理:SQL Server提供了一套强大的管理工具,用于创建、备份、还原和维护数据库。
管理员可以通过这些工具监视数据库性能、管理用户权限以及进行数据库优化和调整。
5. 存储过程和触发器:SQL Server支持存储过程和触发器的使用。
存储过程是预编译的代码块,可以在数据库中进行复杂的操作。
触发器是一种特殊的存储过程,当指定的事件发生时自动执行。
6. 索引:索引是用于加快数据访问速度的数据结构。
SQL Server允许在表的一个或多个列上创建索引,以便快速查找和排序数据。
7. 外键和关联:SQL Server支持外键和关联的概念,用于建立表与表之间的关系。
外键定义了两个表之间的引用关系,关联则定义了表之间的连接。
8. 安全性:SQL Server提供了多种安全功能,用于保护数据库中的数据。
可以通过用户权限、角色和加密等方式来限制对数据库的访问和操作。
总结:以上是SQL Server数据库的一些重要知识点。
掌握这些知识,您将能够有效地管理和操作SQL Server数据库,提高应用程序的性能和数据管理的效率。
SQLServer复习要点答案袁瑞萍.doc

12、备份的作类型, 恢复模式对备份的影响,利用sql语句备份和恢复数据库。
二、三、选择判断简答(20题,(10题,20分)10分)(2题,10全部内容全部内容见要点复习要点1、关系数据库的基本概念2、数据库的逻辑结构和物理结构、数据库的分类(各个系统数据库的作用)、用sql语句创建、管理和删除数据库。
3、用sql语句创建、删除、管理表结构;插入、修改、删除表数据;各种约束的创建和作用(主键约束、唯一性约束、检查约束、默认约朿、外键约束),数据完整性的分类和实现。
4、各类数据查询语句(基本查询、分组查询、连接查询、嵌套查询)5、索引的类型和作用,用sql语句创建索引。
6、视图的概念,用sql语句创建、修改和删除视图7、数据库对象的命名规则、局部变量的创建和赋值方法、用户自定义函数的类(大题)型, 各类自定义函数的创建和调用、各种流程控制语句的使用方法8、游标的使用方法(填空)、事务的概念和作用(简答)、使用方法。
(选择)9、各类存储过程的创建和使用方法(不带参数、带输入参数、带输出参数、带返冋值)10、触发器与存储过程的区别和联系(简答),DML触发器的创建和使用11、Sqlserver2005身份验证模式,登录账户、用户、角色的创建和使用方法,权限的授予、拒绝和回收题型:四、综合应用题(本题共11小题,共60分) 现有关系数据库如下: 数据库名:员工管理,包括如下两张表(1)员工表(员工号char (6),姓名char(10),性别char(2),民族char (10)学历char(4),出生日期datetime, .11 作时间datetime,身份证号char(18),部门号char(3))(2)部门表(部门号char (3),部门名称char (20),备注varchar(100))写出或补充完整实现如下功能的sql语句代码:1、创建“员工管理”数据库,包含一个数据文件和一个日志文件,保存在目录D:\data\下。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
第一章:概述SQL Server体系结构:1、主要的服务及其作用四部分组成:数据库引擎(SSDE):是核心服务,负责完成业务数据的存储、处理、查询和安全管理等操作。
分析服务(SSAS):提供多为分析过和数据挖掘功能,可以支持用户建立数据仓库和进行商业智能分析。
报表服务(SSRS):为用户提供了支持Web的企业级的报表功能。
集成服务(SSIS):是一个数据集成平台,可以完成有关数据的提取、转换、加载等。
服务以windows服务程序的形式后台运行。
服务与前台管理工具(management studio)之间的关系:MS是Sql Server提供的一种集成环境,将各种图形化工具和多功能的脚本编辑器组合在一起,完成访问、配置、控制、管理和开发SQL Server 的所有工作,大大方便了技术人员和数据库管理员对SQL Server的各种访问。
2、数据库对象系统数据库有:master、model、msdb,Resource、tempdb。
Master:是最重要的系统数据库。
它记录了SQL Server系统级的所有信息,这些系统级的信息包括服务器配置信息、登录账户信息、数据库文件信息、SQL Server初始化信息等,这些信息影响整个SQL Server系统的运行。
Model:是一个模板数据库。
该系统存储了可以作为模板的数据库对象和数据。
当创建用户数据库时,系统自动把该数据库中的所有信息复制到用户新建的数据库中,使得新建的用户数据库初始状态下具有了与model数据库一致的对象和相关数据,从而简化数据库的初始创建和管理操作。
Msdb:是与SQL ServerAgent服务有关的数据库。
该数据库记录有关作业、警报、操作员、调度等信息,这些信息可以用于自动化系统的操作。
Tempdb:是一个临时数据库,用于存储查询过程中所使用的中间数据或结果。
Resource:是一个很特殊的系统数据库,是一个被隐藏的只读的物理系统数据库,只保存用户实例所需的架构和存储过程。
数据库对象是指存储、管理和使用的不同结构形式。
数据库对象包括:表、视图、同义词、存储过程、函数、触发器、程序集、类型、规则、默认值等。
表:实际用来存储系统数据和用户数据,是整个系统的最核心的数据库对象,是其他大多数数据库对象的基础。
视图:包含了数据库中的视图对象,是数据库中的虚拟表。
视图是建立在表基础之上的数据库对象。
约束:“约束”节点包含约定对象。
约定用于定义应用程序完成特定任务时所用的信息类型。
用户:是指数据库用户,是数据库级的主体。
这些数据库用户对象可以在“用户”节点中找到。
存储过程:节点包含了数据库中存储过程对象的信息。
存储过程是指封装了可重用代码的模块或例程。
触发器:是一种特殊的存储过程,在数据库服务器中发生指定的事件后自动执行。
分为DML触发器和DDL触发器。
3、SQL Server配置管理器可以查看所有服务及其运行状态,可以查看服务的属性,以及启动、停止、暂停、重新启动响应的服务。
第二章sql server版本1·32位版本,64位版本2·服务器版本,专业版本(满足特殊服务)3·服务器版包括企业版和标准版;专业版包括开发人员版、工作组版、WEb版、EXPRESS版、compact版;另外还有企业评估版。
实例sql server允许在一台计算机上多次安装,每一次安装都生成实例。
这种多实例基址,当某实例发生故障时,其他实例依然正常运行并提供数据库服务,确保整个应用系统始终处于正常状态,提高系统可用性。
工作组版本最多可安装16个实例,其他版本最多可安装50个实例。
第一次安装可以使用默认实例,后来的安装需要使用命名实例。
排序规则排序规则指定了表示数据集中每一个字符的位模式,具体内容包括选择字符集、确定数据排序和比较的规则等。
排序规则的主要特征是区分语言、区分大小写、区分重音、区分假名以及区分全角半角。
可以在四个层面设置排序规则,服务器层、数据库层、列层和表达式层。
服务器层的排序规则可以在安装过程中设置的,也是实例的默认排序规则,会自动分派给其他对象。
创建数据库的时候可以使用collate子句来指定数据库的默认排序规则。
创建表的时候也可以用collate子句来指定数据库的默认排序规则。
表达式层次上的排序规则只能在执行语句时设置,并且影响当前结果集的返回方式。
文件夹安装之后sql server有五个文件夹。
即80,90,100,MSAS10.MSSQLSER,MSRS10.MSSQLSERh 和MSSQL10.MSSQLSERVER.80和90文件夹中包含了与先前版本兼容的信息和工具,100文件夹中主要是存储单台计算机上的所有势力使用的公共文件和信息。
服务器选项sql server有60多个服务器选项。
有高级选项,这些选项只有show advanced option 设置为1时,才能对其进行设置。
有些是新设置只有当数据库引擎重新启动之后才能生效。
有些是子配置选项,系统根据需要自动配置。
根据设置后是否立即生效可以讲分为动态选项和非动态选项。
动态选项是设置完选项后,运行reconfidure语句就可生效,非动态选项是设置完选项之后必须停止和重新启动sql server才能起作用。
sp_configuresp_configure系统存储过程可以用来显示和配置服务器的各种选项。
语法格式:sp_configure ‘option_name’,’value’option_name表示服务器的选项名称,value表示服务器选项的设置,默认是控制。
成功执行返回0,否则返回1。
第三章SQL SERVER 2008的数据安全层次第一层:网络设置第二层:登录服务器第三层:登录后进行特定数据库访问或服务器管理第四层:对数据库中特定表或列进行访问1、Windows认证模式:只能使用“windows 身份验证”一种方式混合认证模式:可以使用“windows身份验证”和“SQL Server身份验证”两种方式创建登录名:create login peter with password=’123’修改登录名:alter login peter disable ----不可用Alter login peter enable -----启用删除登录名:drop login peter2、登录名的作用和类型是什么?答:可登录sql server服务器,并对其进行管理的用户。
所有login用户的信息存储在系统表中,是sql server系统级的用户。
windows组或windows用户映射到登录名SQL Server自己的登录名3、服务器角色的作用和类型是什么?答:固定服务器角色是服务器级别的主体,它们的作用范围是整个服务器。
固定服务器角色已经具备了执行指定操作的权限,可以把其他登录名作为成员添加到固定服务器角色中,这样该登录名可以继承固定服务器角色的权限。
Bulkadmin:块数据操作员,拥有执行块操作的权限Dbcreator:数据库创建者,拥有创建数据库的权限Diskadmin:磁盘管理员,拥有修改资源的权限Processadmin:进程管理员,拥有管理服务器连接和状态的权限Securityadmin:安全管理员,拥有执行修改登录名的权限Serveradmin:服务器管理员,拥有修改断点、资源、服务器状态的呢过权限Setupadmin:安装程序管理员,拥有修改连接服务器权限Sysadmin:系统管理员,拥有操作SQL Server 系统的所有权限Public:公共角色,没有预先设定的权限4、什么是数据库用户?数据库用户与登录名之间的关系是什么?答:数据库用户,能够访问、操作数据库的用户,是数据库级的用户服务器登录名属于某组服务器角色;服务器登录名需要于数据库的用户映射后才拥有操作数据库的权限;数据库用户属于某组数据库角色以获取操作数据库的权限。
创建数据库用户:create user peter1 for login peter修改数据库用户:alter user peter1 with name=’petera’修改数据库用户权限:grant(revoke)connect to peter1删除数据库用户:delete user peter1;数据库角色:role 操作同上5、数据库中有哪些特殊的用户?这些用户的作用是什么?答:(1)固定数据库角色。
固定数据库角色是在数据库级别定义的,并且存在于每个数据库中。
db_owner 和db_securityadmin 数据库角色的成员可以管理固定数据库角色成员身份;但是,只有db_owner 数据库的成员可以向db_owner 固定数据库角色中添加权限。
(2)public角色。
每个数据库用户都属于public 数据库角色,当尚未对某个用户授予或拒绝对安全对象的特定权限时,则该用户将继承授予该安全对象的public 角色的权限。
(3)特殊的数据库用户:Dbo:Dbo数据库中的默认用户,拥有在数据库中操作的所有权限,默认情况下,SA登录名在数据库对应的是dbo。
guest用户一个特殊的数据库用户,默认情况下,数据库创建时就包含一个guest 用户。
授予guest 用户的权限由在数据库中没有帐户的用户继承。
6、数据库的默认架构是什么?答:架构是形成单个命名空间的数据库实体的集合,是数据库级的对象,是数据库对象的容器。
每个用户都有一个默认架构,用于指定服务器在解析对象的名称时将要搜索的第一个架构。
可以使用CREATE USER 和ALTER USER 的DEFAULT_SCHEMA 选项设置和更改默认架构。
如果未定义DEFAULT_SCHEMA,则数据库用户将把DBO 作为其默认架构。
Sql server完全限定的对象名称现在包含四部分:server.database.schema.object。
7、为什么要实现用户和架构分离?答:1、多个用户可以通过角色成员身份或Windows 组成员身份拥有一个架构。
这扩展了允许角色和组拥有对象的用户熟悉的功能。
2、极大地简化了删除数据库用户的操作。
3、删除数据库用户不需要重命名该用户架构所包含的对象。
因而,在删除创建架构所含对象的用户后,不再需要修改和测试显式引用这些对象的应用程序。
4、多个用户可以共享一个默认架构以进行统一名称解析。
5、开发人员通过共享默认架构可以将共享对象存储在为特定应用程序专门创建的架构中,而不是DBO 架构中。
8、权限的授予(grant)与回收(revoke)、grant select on table to peter1;Grant control on table to peter1 with grant option;把安全对象BOOK的CONTROL权限授予主体peter1,并且peter1具备授权的权限;下面以peter身份登录,在library数据库下,peter登录用户可对tom授予对BOOK表的任何权限。