EXCEL图表技巧-概率纸图
excel概率曲线

excel概率曲线Excel是一款功能强大的电子表格软件,除了可以进行数据处理和计算外,还可以通过绘制概率曲线来展示数据的分布情况。
在本文中,我们将介绍如何使用Excel来绘制概率曲线,并详细解释概率曲线的概念和应用。
一、概率曲线简介概率曲线,又被称为正态分布曲线或高斯曲线,是一种常见的统计图形,用来表示随机变量的概率分布情况。
概率曲线呈钟形曲线,左右对称,最高点位于均值处,标准差决定曲线的宽窄。
利用概率曲线,我们可以更直观地了解数据的分布特征,进行数据分析和预测。
二、绘制概率曲线的步骤1. 准备数据在Excel中,首先需要准备一组数据,可以是实际观测到的数据,也可以是根据某个概率分布函数生成的理论数据。
假设我们选择了一个样本的数据,如下所示:数据: 75, 78, 80, 82, 85, 87, 89, 90, 91, 92, 93, 94, 95, 96, 97, 97, 98, 99, 1002. 计算均值和标准差利用Excel的函数可以方便地计算均值和标准差。
在一个空白单元格中输入“=AVERAGE(A1:A19)”(A1:A19代表你的数据范围),即可得到均值;再在另一个空白单元格中输入“=STDEV(A1:A19)”(A1:A19代表你的数据范围),即可得到标准差。
3. 计算概率密度函数值在Excel中,概率密度函数用公式“=NORM.DIST(x,μ,σ,FALSE)”来表示,其中x为需要计算概率的数值,μ为均值,σ为标准差。
我们可以选择一个合适的范围,如70到100,然后使用公式填充该范围内的每个单元格。
4. 绘制概率曲线选中范围70到100的数据,包括x值和计算出的概率密度函数值。
点击Excel的“插入”选项卡,在“图表”中选择“散点图”,然后选择“散点和线图”。
在弹出的图表中右击空白处,选择“选择数据”,将x值和概率密度函数值分别作为横坐标和纵坐标的数据系列。
点击确定,即可得到概率曲线。
概率纸图的制作方法

0 -0.253347103 -0.524400513
-0.841621234 -1.036433389 -1.281551566
-1.644853627
-2.326347874 -2.575829304
-3.090232306 -3.290526731
20.00% -0.8416212
0
0.40% -2.6520698
30.00% -0.5244005
0
0.60% -2.5121443
40.00% -0.2533471
0
0.70% -2.4572634
50.00%
0
0
0.80% -2.4089155
60.00% 0.2533471
0
0.90% -2.3656181
概率纸 图的制 作方法
1.先假设横 坐标的数值 范围为0~ 100,实际 使用中可以 按情况自行 调整,按下 面的数据作 为自定义坐 标Y轴的数 据。
X轴值取数 值范围的最 小值,累积 分布值就是 累积概率分 布值,网格
值就是用
NORMSINV 函数计算的 达到指定累
积概率值时 的对应数值 。
X轴值
Leq
5.分别设置Y 轴主次网格 值系列的误 差线X为定 值100,其 中的100为X 坐标的最大 最小刻度差 值。
概率纸图
累积概率(%)
0
10 20 30 40 50 60 70 80 90 100
Leq
6.隐藏“Y轴 次网格值” 系列的“数 据标记”, 并显示“Y 轴主网格值 ”系列的“ 数据标志” 为“显示值 ”。
0
26.00% -0.6433454
你这么做Excel的百分比图表,领导会这么说

你这么做Excel的百分⽐图表,领导会这么说
在⽇常的⼯作中,我门看惯了Excel的百分⽐饼图和柱形图,是不是觉得有些乏味和枯燥呢?那
么能不能把Excel的图表换⼀种⽅式来做呢?让我们的图表更美观和直观呢?让我们数据可视化
界⾯更友好呢?
下⾯就让我来教⼤家⼀种Excel的百分⽐图。
Step1:选中案列中的数据插⼊柱状图
选中柱状图【右键】——【选择数据】——【切换⾏/列】
Step2:选中柱状图【右键】——【设置数据系列格式】——【系列重叠】(调⾄100%)
Step3:制作圆环素材【插⼊】——【形状】——【椭圆】(插⼊两个椭圆)
将两个椭圆的⼤⼩分别设置为:【⾼度】:5.5、5.2【宽度】:5.5、5.2
分别设置两个圆的【形状格式】。
如下动图所⽰:
同时选中俩个圆【格式】——【对象对齐】——【⽔平居中】——【垂直居中】
【右键】——【复制】选中⾼的柱状图——【粘贴】——【选择性粘贴】如下动图所⽰:
选中⼩圆填充⾊变为绿⾊如下动图所⽰:
再次选中选中两个圆【复制】然后选中【完成率】的柱状图(就是案例红⾊的柱状图)【粘贴】——【选择性粘贴】如下动图所⽰:
Step4:选中⼩圆的数据列【右键】——【设置数据系列格式】——【填充】——【层叠并缩放】。
如下动图所⽰:
Step5:美化图表
将纵坐标的最⼤值和最⼩值分别设置为:1和0。
如下动图所⽰:
删除横纵坐标轴、⽹格线和标题栏。
如下动图所⽰:
添加⼀个饼图让图形变成圆的。
如下动图所⽰:
请点击此处输⼊图⽚描述请点击此处输⼊图⽚描述
添加⼀个数据标签。
如下动图所⽰:
注:有需要教程原⽂件的朋友可以点击“赞赏”。
Excel绘制海森机率格纸(可编辑修改word版)

海森机率格纸的横向网格线(即纵坐标)均匀分布,可直接由Excel的图表功能自动生成,而纵向网格线(横坐标)需要向图表中添加2或3个系列的XY散点图来完成——实际是使用该系列的值产生矩形波形图,即利用该波形图的“上升沿”和“下降沿”作为纵向网格线,而“高电平”和“低电平”部分与图形边框线重合来实现的。
Excel绘制海森机率格纸
注:现成的Excel文档,在这里。
本文主要介绍利用Excel内置函数和图表功能绘制海森机率格纸的方法。
水文频率计算(适线法)中,采用的海森机率格纸应用的是一种特殊的坐标系统——纵坐标为等间距数学坐标,横坐标为与频率值(下侧概率)的标准正态分布分位数有关。标准正态分布分位数在P=50% 处为零,而海森机率格纸在P = 0.01%时横坐标为零。因此,海森机率格纸横坐标值计算公式可表示为:
图
注:应根据研究对象选择恰当的纵坐标最大值。
2.计算LP(如图1所示)
海森机率格纸中频率P对应的横坐标值LP的计算及填写步骤如下:
(1)在【流量机率格纸数据点】的A5、A6中分别输入0.01→A7、A8中分别输入0.02→依此类推, 在A列后续单元格中输入海森机率格纸的纵向网格线对应的频率值,直至在A233、A234中分别输入99.99;
(2)根据LP的计算方法计算$G$5:$H$36中各单元格的值(即计算X坐标值);
(3)在$I$5:$I$36各单元格中输入0(即Y1坐标,以使曲线与X轴重叠);
(4)在$J$5:$J$36各单元格中输入1000(即Y2坐标,以使曲线与边框线重叠);
(5)$K$5:$K$36各单元格中暂不填写值,后续由程序按以下公式计算:
LP= P‒ 0.01%
(1)
excel 概率分组

excel 概率分组在Excel中,我们可以使用各种函数和工具来进行概率分组,以便更好地理解和分析数据。
以下是一些常见的Excel概率分组方法:1.频率分布表频率分布表是最常见的概率分组方法之一。
它可以帮助我们将数据分成几个组,并显示每个组出现的频率。
在Excel中,我们可以使用以下步骤创建一个频率分布表:步骤1:在Excel工作表上输入数据。
步骤2:选中一个单元格,然后在Excel菜单栏中选择“插入” ->“统计图表”- >“直方图”。
步骤3:在“直方图”对话框中,选择数据范围。
默认情况下,Excel将尝试根据数据范围创建一个合理的组数和数据值。
步骤4:点击“确定”键生成直方图。
步骤5:右键单击直方图然后选择“选择数据”,在“选择数据源”对话框中选择“行”选项卡,然后点击“频率”选项卡。
步骤6:点击“确定”即可生成频率分布表。
2.标准正态分布表标准正态分布表是一个用来计算标准正态分布概率密度的表格。
该表格列出了各种Z值以及相应的概率密度,以便我们可以根据Z值来推断概率。
在Excel中,我们可以使用以下步骤创建标准正态分布表:步骤1:在Excel工作表上输入Z值的范围。
步骤2:在另一个单元格中输入“=标准正态分布的概率密度(Z 值)”。
步骤3:复制这个公式到剩下的单元格中。
步骤4: Excel会计算并显示每个Z值对应的概率密度值。
3.散点图散点图是一种可以帮助我们可视化数据分布的图表类型。
散点图可以显示数据点在X和Y轴的坐标,并显示它们之间的关系。
在Excel 中,我们可以使用以下步骤创建一个散点图:步骤1:在Excel工作表上输入数据。
步骤2:选中数据。
步骤3:在Excel菜单栏中选择“插入” - >“统计图表”- >“散点图”。
步骤4: Excel会自动创建一个散点图。
我们可以通过单击图表并选择“格式化选项卡”来调整图表的样式。
4.箱线图箱线图也是一种常见的概率分组方法。
excel表格百分比数据分析图表的制作教程

excel表格百分比数据分析图表的制作教程Excel中具体该如何制作百分比数据分析图进行数据分析呢?下面是由店铺分享的excel表格百分比数据分析图表制作教程,以供大家阅读和学习。
excel表格百分比数据分析图表的制作教程数据分析图表制作步骤1:数据的收集、录入、表格的设置,最终效果如图所示(对于新手来说,制作表格的过程中,表头是最容易忽略的)数据分析图表制作步骤2:如图所示,选择要进行分析的图据范围。
(对于新手来说,选择定范围的时候最容易把整个表格全选) 数据分析图表制作步骤3:如图所示,点击菜单栏目上的“插入”,选择“饼图”,再选择“三维饼图”,实际工作中,可以自己分析的内容选择相应的图形效果。
数据分析图表制作步骤4:最终生成的效果,如下图1所示。
接下来选择红色框标注位置的“图表布局”,找到如下图2所示的百分比。
数据分析图表制作步骤5:最后一步,修改“图表标题”,把鼠标放到“图表标题”后,单击鼠标左键,录入和表格一致的标题名称。
(对于新手来说这一步也最容易忽略)最终呈现的效果如下图所所示。
统计Excel2013分类所占的百分比的方法①启动Excel2013,选中表格区域,单击菜单栏--插入--表格--数据透视表。
统计Excel2013分类所占的百分比的方法图1 ②选择放置数据透视表的位置,勾选新工作表,确定。
统计Excel2013分类所占的百分比的方法图2 ③在数据透视表字段中勾选姓名、部门和工资,并将工资拖放到下面的值中。
统计Excel2013分类所占的百分比的方法图3 ④右击求和项:工资2,从弹出的右键菜单中选择值字段设置。
统计Excel2013分类所占的百分比的方法图4 ⑤在值显示方式标签中,将方式选为列汇总的百分比。
统计Excel2013分类所占的百分比的方法图5 ⑥利用中文输入法在单元格输入比例两个大字,按tab键退出输入状态。
统计Excel2013分类所占的百分比的方法图6 ⑦最后的效果如下所示:。
excel累积累计概率频率分位值蜡烛柱状图

篇一:《excel做概率分布累积曲线步骤》1. 建立模板.A. 新建EXCEL 文件, 在A1 : A17 单元格内输入数字“0”, 在B1 : B17 单元格内分别输入数字99. 99 ,99. 9 ,99 ,95 ,90 ,80 ,70 ,60 ,50 ,40 ,30 ,20 ,10 ,5 ,1 ,0. 1 ,0.01 。
前者作为横坐标, 代表将来纵轴与横轴的交叉位置, 其数值以后要根据实际情况调整。
后者代表纵轴以百分数表示的概率刻度值。
B. 选择C1 单元后击粘贴函数(见图1 中箭头所指位置) , 待出现粘贴函数菜单后选取统计类的NORMSINV 函数。
C. 出现新的对话框后, 在probability 后输入“B1/ 100”, 然后确定.D.这时C1 单元格内就有了一个函数值, 拖动C1单元格的填充柄(C1 单元格右下角的小黑块) 向下填充, 则C2 : C17 单元格内都自动生成了函数值。
E. 设置C1 : C17 单元格格式, 将其数值的小数位数定为“2”。
2.做草图选中A1 : A17 和C1 : C17 单元格后, 选择图表向导, 按照提示进行:A.在4 步骤之1 中, 选择X、Y 散点图类型中的第一子类型, 后单击下一步;B.在4 步骤之2 中, 确认系列产生在列(点中“列”前面的小圈) , 后单击下一步;C.在4 步骤之3 中, 可暂不做选择, 直接单击下一步;D.在4 步骤之4 , 根据喜好选图表位置, 本文中选“新工作表”, 单击“完成”后草图就算做成了.3. 修图A.首先先去掉图例框、绘图区背景色以及网格线,便于下面的修改;B. 选择数值( Y) 轴, 按鼠标右键弹出菜单后选“坐标轴格式”, 在“坐标轴格式”菜单中做如下设置: ①在“图案”项中将主、次刻度线类型及刻度线标志均选“无”;②在“刻度”项中,最小值选“-3. 72 ”, 最大值选“3. 72 ”,数值( X) 轴交叉于( C) : 选“-3. 72 ” ;C. 选择数据系列, 按鼠标右键弹出菜单后选“数据系列格式”, 在该菜单作如下设置:①将图案中的“数据标记样式”选为短横线作为纵轴刻度线; ②在“数据标志”项中选“显示值”, 然后确定。
Excel绘制海森机率格纸

Excel绘制海森机率格纸注:现成的Excel文档,在这里。
本文主要介绍利用Excel内置函数和图表功能绘制海森机率格纸的方法。
水文频率计算(适线法)中,采用的海森机率格纸应用的是一种特殊的坐标系统——纵坐标为等间距数学坐标,横坐标为与频率值(下侧概率)的标准正态分布分位数有关。
标准正态分布分位数在处为零,而海森机率格纸在时横坐标为零。
因此,海森机率格纸横坐标值计算公式可表示为:(1)其中,为海森机率格纸中的频率P对应的横坐标值;为频率P对应的标准正态分布分位数;为频率对应的标准正态分布分位数。
标准正态分布分位数可用Excel内置函数NORM.S.INV(P)(返回标准正态累积分布函数的反函数,精度)直接计算。
在Excel中绘制海森机率格纸的要点:海森机率格纸的横向网格线(即纵坐标)均匀分布,可直接由Excel的图表功能自动生成,而纵向网格线(横坐标)需要向图表中添加2或3个系列的XY散点图来完成——实际是使用该系列的值产生矩形波形图,即利用该波形图的“上升沿”和“下降沿”作为纵向网格线,而“高电平”和“低电平”部分与图形边框线重合来实现的。
下面以某站流量频率计算为例,介绍海森机率格纸在Excel中的绘制方法。
一、数据准备1.新建Excel工作簿→将工作表【Sheet1】重命名为【流量机率格纸数据点】→按以下格式布局表格:(1) 合并A1:N1区域,并输入标题:“海森机率格纸参数配置”;(2) 合并A2:B2区域,并输入栏目:“纵坐标范围”;(3) C2中输入栏目:“最小值”,D2中输入参数:0;(4) F2中输入栏目:“最大值”,G2中输入参数:1000;(5) 合并A3:D3区域,并输入主列标题:“机率格纸网格线”;(6) 在A4、B4、C4、D4中分别输入子列标题:“频率”、“至P=50%处水平距离”、“X坐标”、“Y坐标”;(7) 按照(5)、(6)的操作在设置F3:K4的格式及参数,如图1所示。
如何在Excel中制作百分比图表?
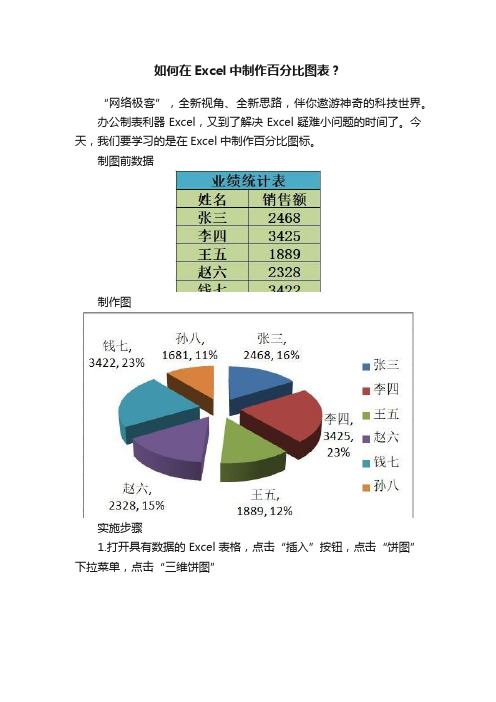
如何在Excel中制作百分比图表?
“网络极客”,全新视角、全新思路,伴你遨游神奇的科技世界。
办公制表利器Excel,又到了解决Excel疑难小问题的时间了。
今天,我们要学习的是在Excel中制作百分比图标。
制图前数据
制作图
实施步骤
1.打开具有数据的Excel表格,点击“插入”按钮,点击“饼图”下拉菜单,点击“三维饼图”
2.点击“选择数据”按钮
3.选定姓名和销售额数据,单击“确定”按钮
4.右击饼图,选择“添加数据标签(B)”
5.添加数据标签后,继续右击饼图,点击“设置数据标签格式(B)”
6.勾选“百分比(P)”选项,则出现百分比图标。
是否还有更加简便的方法,,欢迎大家留言讨论。
利用Excel软件绘制正态概率纸的方法_图文(精)

,
偏差O-,能够直观地分析出工序的过程能力,求出工序的过程能力指数Cr值或Cm值.并且还可咀估计工序的不合格品率。因此,利用正态概率纸分析工序的方法,具有多功能的优点(参阅文献『1]):
利用正态概率纸分析工序,有着直观、简单、快速和易于掌握等诸多优点,在生产现场中使用备受欢迎,但由于它是一种图算法,精度相对较差,然而在现场使用其精度也已足够。如能提高正态概率纸本身的绘制精度,将有助于弥补正态概率纸的这一缺点。
O779960265070—2462800一m588000
0849970275O80—2413000—0528l∞
08899.80
288090
—2373200-0478200
09299_蛐
309—2333400-04】83∞
095999I312—205
3600
一0368400
09999j2316300一l88
由公式2得,△X=00唧5即误
差在原始数据的小数点后第四位。
正态概率纸是一种图算法,精确度要求不高,故这样的精确
(0135%)
‘3
o
(23%)
+2o
(15.1I%)
(15.眠)
t
2.娼)
一2
o
【013蛐)
一3
o
(o.003%)一4
o
度已足够可以满足要求。◇
参考文献:[1】1
量堆先:正态概率纸的用造.《中国质
为0.38。
6.修改行高(建立纵坐标)。(1)单击选中表格的第2行,然后单击鼠标右键选“行高”,在弹出的“行高”对话框里填人“表2”中行高的第一个数据11.3,将行,
表2
然后单击鼠标右键选“行高”,在弹出的“行高”对话框里填人“表2”中行高的第二个数据7_3,将此行的行高改为7_3。
应用excel软件实现海森概率格纸的绘制

较繁琐ꎬ 因此也采用海森概率格纸ꎮ 虽然 P ̄III 型
Excel 软件具有简单易操作和兼容性强的特点ꎬ
∫
收稿日期: 2019 ̄06 ̄27
基金项目: 广西自然科学基金(2018GXNSFAA294087) ꎬ 桂林理工
大学 2019 年度本科教学建设与改革项目( jxzh201915)
作者简介: 邓 欢(1979—) ꎬ 女ꎬ 讲师ꎮ
L = Q - 1 (0 01% ) - Q - 1 ( P)
probabilityꎬ 即 Q ( P) = NORM S INV(1 - P) ꎮ 于
-1
P = 99 99% 时ꎬ x = - 3 719ꎮ 绘 制 通 过 ( 0 01% ꎬ
3 719) 和 (99 99% ꎬ - 3 719 ) 两 点 的 直 线ꎬ 为 便
于理解ꎬ 将之平移至图 1B 中ꎬ 曲线上其他各点均
可移到 这 条 直 线 上ꎮ 例 如 图 1 A 曲 线 上 的 a 点ꎬ
坐标为( 50 % ꎬ 0 ) ꎬ 因纵坐标分格不变ꎬ 可 作 过
a 点的水平线与图 1 B 中的直线相交于 b 点ꎬ b 点
坐标与 P = 0 01 % 的距离 L 为:
Q( x) =
的部位ꎬ 同时这也不便于采用目估适线法判断其与
∫
∞
x
1 - x22
e dx ꎬ - ∞ < x < + ∞ (1)
2π
式中ꎬ x—随机变量值ꎻ Q( x) —标准化正态随机变
经验点据拟合的好坏程度ꎮ 为了方便和精确绘制曲
量 X 的超过制概率ꎬ 也称超过制累积频率ꎬ 水文上
线ꎬ 以及分析计算ꎬ 需要设计一种坐标纸ꎬ 使频率
变量与其超过制累积频率呈非线性ꎬ 水文频率曲线
excle做概率累计曲线粒度 (1)

excel做概率分布累积曲线步骤绝对详细的用excel做概率分布累积曲线的好东西,是我一步一步的摸索出来的,热的哦,有问题也可以发消息我解答的。
1. 建立模板建立模板. A. 新建EXCEL 文件, 在A1 : A17 单元格内输入数字“0”, 在B1 : B17 单元格内分别输入数字99. 99 , 99.9 ,99 ,95 ,90 ,80 ,70 ,60 ,50 ,40 ,30 ,20 ,10 ,5 ,1 ,0. 1 ,0. 01 。
前者作为横坐标, 代表将来纵轴与横轴的交叉位置, 其数值以后要根据实际情况调整。
后者代表纵轴以百分数表示的概率刻度值。
B. 选择C1 单元后击粘贴函数(见图1 中箭头所指位置) , 待出现粘贴函数菜单后选取统计类的NORMSINV 函数。
C. 出现新的对话框后, 在probability 后输入“B1/ 100”, 然后确定. D.这时C1 单元格内就有了一个函数值, 拖动C1单元格的填充柄(C1 单元格右下角的小黑块) 向下填充, 则C2 : C17 单元格内都自动生成了函数值。
E. 设置C1 : C17 单元格格式, 将其数值的小数位数定为“2”。
2.做草图 2.做草图选中A1 : A17 和C1 : C17 单元格后, 选择图表向导, 按照提示进行: A.在4 步骤之1 中, 选择X、Y 散点图类型中的第一子类型, 后单击下一步; B.在4 步骤之2 中, 确认系列产生在列(点中“列”前面的小圈) , 后单击下一步; C.在4 步骤之3 中, 可暂不做选择, 直接单击下一步; D.在4 步骤之4 , 根据喜好选图表位置, 本文中选“新工作表”, 单击“完成”后草图就算做成了. 3. 修图 A.首先先去掉图例框、绘图区背景色以及网格线,便于下面的修改; B. 选择数值( Y) 轴, 按鼠标右键弹出菜单后选“坐标轴格式”, 在“坐标轴格式” 菜单中做如下设置: ①在“图案” 项中将主、次刻度线类型及刻度线标志均选“无” ; ②在“刻度”项中,最小值选“-3. 72 ”, 最大值选“3. 72 ”,数值( X) 轴交叉于( C) : 选“-3. 72 ” ; C. 选择数据系列, 按鼠标右键弹出菜单后选“数据系列格式”, 在该菜单作如下设置: ①将图案中的“数据标记样式”选为短横线作为纵轴刻度线; ②在“数据标志”项中选“显示值”, 然后确定。
excel中的概率统计非常好的精选

数理统计实验1Excel基本操作1.1 单元格操作1.1.1单元格的选取Excel启动后首先将自动选取第A列第1行的单元格即A1(或a1)作为活动格,我们可以用键盘或鼠标来选取其它单元格.用鼠标选取时,只需将鼠标移至希望选取的单元格上并单击即可.被选取的单元格将以反色显示.1.1.2选取单元格范围(矩形区域)可以按如下两种方式选取单元格范围.(1) 先选取范围的起始点(左上角),即用鼠标单击所需位置使其反色显示.然后按住鼠标左键不放,拖动鼠标指针至终点(右下角)位置,然后放开鼠标即可.(2) 先选取范围的起始点(左上角),即用鼠标单击所需位置使其反色显示.然后将鼠标指针移到终点(右下角)位置,先按下Shift键不放,而后点击鼠标左键.1.1.3选取特殊单元格在实际中,有时要选取的单元格由若干不相连的单元格范围组成的.此类有两种情况.第一种情况是间断的单元格选取.选取方法是先选取第一个单元格,然后按住[Ctrl]键,再依次选取其它单元格即可.第二种情况是间断的单元格范围选取.选取方法是先选取第一个单元格范围,然后按住[Ctrl]键,用鼠标拖拉的方式选取第二个单元格范围即可.1.1.4公式中的数值计算要输入计算公式,可先单击待输入公式的单元格,而后键入=(等号),并接着键入公式,公式输入完毕后按Enter键即可确认..如果单击了“编辑公式”按钮或“粘贴函数”按钮,Excel将自动插入一个等号.提示:(1) 通过先选定一个区域,再键入公式,然后按 CTRL+ENTER 组合键,可以在区域内的所有单元格中输入同一公式.(2) 可以通过另一单元格复制公式,然后在目标区域内输入同一公式.公式是在工作表中对数据进行分析的等式.它可以对工作表数值进行加法、减法和乘法等运算.公式可以引用同一工作表中的其它单元格、同一工作簿不同工作表中的单元格,或者其它工作簿的工作表中的单元格.下面的示例中将单元格 B4 中的数值加上 25,再除以单元格 D5、E5 和 F5 中数值的和.=(B4+25)/SUM(D5:F5)1.1.5公式中的语法公式语法也就是公式中元素的结构或顺序.Excel 中的公式遵守一个特定的语法:最前面是等号(=),后面是参与计算的元素(运算数)和运算符.每个运算数可以是不改变的数值(常量数值)、单元格或区域引用、标志、名称,或工作表函数.在默认状态下,Excel 从等号(=)开始,从左到右计算公式.可以通过修改公式语法来控制计算的顺序.例如,公式=5+2*3的结果为 11,将 2 乘以 3(结果是 6),然后再加上 5.因为Excel 先计算乘法再计算加法;可以使用圆括号来改变语法,圆括号内的内容将首先被计算.公式=(5+2)*3的结果为21,即先用 5 加上 2,再用其结果乘以 3.1.1.6单元格引用一个单元格中的数值或公式可以被另一个单元格引用.含有单元格引用公式的单元格称为从属单元格,它的值依赖于被引用单元格的值.只要被引用单元格做了修改,包含引用公式的单元格也就随之修改.例如,公式“=B15*5”将单元格 B15 中的数值乘以 5.每当单元格 B15 中的值修改时,公式都将重新计算.公式可以引用单元格组或单元格区域,还可以引用代表单元格或单元格区域的名称或标志.在默认状态下,Excel 使用 A1 引用类型.这种类型用字母标志列(从 A 到IV ,共 256 列),用数字标志行(从 1 到 65536).如果要引用单元格,请顺序输入列字母和行数字.例如,D50 引用了列 D 和行 50 交叉处的单元格.如果要引用单元格区域,请输入区域左上角单元格的引用、冒号(:)和区域右下角单元格的引用.下面是引用的示例.1.1.7工作表函数Excel 包含许多预定义的,或称内置的公式,它们被叫做函数.函数可以进行简单的或复杂的计算.工作表中常用的函数是“SUM”函数,它被用来对单元格区域进行加法运算.虽然也可以通过创建公式来计算单元格中数值的总和,但是“SUM”工作表函数还可以方便地计算多个单元格区域.函数的语法以函数名称开始,后面是左圆括号、以逗号隔开的参数和右圆括号.如果函数以公式的形式出现,请在函数名称前面键入等号(=).当生成包含函数的公式时,公式选项板将会提供相关的帮助.使用公式的步骤:A. 单击需要输入公式的单元格.B. 如果公式以函数的形式出现,请在编辑栏中单击“编辑公式”按钮.C. 单击“函数”下拉列表框右端的下拉箭头.D. 单击选定需要添加到公式中的函数.如果函数没有出现在列表中,请单击“其它函数”查看其它函数列表.E. 输入参数.F. 完成输入公式后,请按 ENTER 键.1.2 几种常见的统计函数1.2.1均值Excel计算平均数使用AVERAGE函数,其格式如下:AVERAGE(参数1,参数2,…,参数30)范例:AVERAGE(12.6,13.4,11.9,12.8,13.0)=12.74如果要计算单元格中A1到B20元素的平均数,可用 AVERAGE(A1:B20).1.2.2 标准差计算标准差可依据样本当作变量或总体当作变量来分别计算,根据样本计算的结果称作样本标准差,而依据总体计算的结果称作总体标准差.(1)样本标准差Excel 计算样本标准差采用无偏估计式,STDEV 函数格式如下:STDEV (参数1,参数2,…,参数30)范例:STDEV (3,5,6,4,6,7,5)=1.35如果要计算单元格中A1到B20元素的样本标准差,可用 STDEV(A1:B20).(2)总体标准差Excel 计算总体标准差采用有偏估计式STDEVP 函数,其格式如下:STDEVP (参数1,参数2,…,参数30)范例:STDEVP (3,5,6,4,6,7,5)=1.251.2.3 方差方差为标准差的平方,在统计上亦分样本方差与总体方差.(1)样本方差S 2=1)(2--∑n x x iExcel 计算样本方差使用VAR 函数,格式如下:VAR (参数1,参数2,…,参数30)如果要计算单元格中A1到B20元素的样本方差,可用 VAR(A1:B20). 范例:VAR (3,5,6,4,6,7,5)=1.81(2)总体方差S 2=n x x i ∑-2)(Excel 计算总体方差使用VARP 函数,格式如下:VARP (参数1,参数2,…,参数30)范例:VAR (3,5,6,4,6,7,5)=1.551.2.4 正态分布函数Excel 计算正态分布时,使用NORMDIST 函数,其格式如下:NORMDIST (变量,均值,标准差,累积)其中:变量(x ):为分布要计算的x 值;均值(μ):分布的均值;标准差(σ):分布的标准差;累积:若为TRUE ,则为分布函数;若为FALSE ,则为概率密度函数.范例:已知X 服从正态分布,μ=600,σ=100,求P {X ≤500}.输入公式=NORMDIST (500,600,100,TRUE )得到的结果为0.158655,即P {X ≤500}=0.158655.1.2.5 正态分布函数的反函数Excel 计算正态分布函数的反函数使用NORMINV 函数,格式如下:NORMINV (下侧概率,均值,标准差)范例:已知概率P =0.841345,均值μ=360,标准差σ=40,求NORMINV 函数的值.输入公式=NORMINV (0.841345,360,40)得到结果为400,即P{X≤400}=0.841345.注意:(1) NORMDIST函数的反函数NORMINV用于分布函数,而非概率密度函数,请务必注意;(2) Excel 提供了计算标准正态分布函数 NORMSDIST(x),及标准正态分布的反函数 NORMSINV(概率).范例:已知X~N(0,1), 计算(2)Φ=P{X<2}.输入公式=NORMSDIST(2)得到0.97725,即(2)Φ=0.97725.范例:输入公式=NORMSINV(0.97725) ,得到数值2.若求临界值uα(n),则使用公式=NORMSINV(1-α).1.2.6t分布Excel计算t分布的值(查表值)采用TDIST函数,格式如下:TDIST(变量,自由度,侧数)其中:变量(t):为判断分布的数值;自由度(v):以整数表明的自由度;侧数:指明分布为单侧或双侧:若为1,为单侧;若为2,为双侧.范例:设T服从t(n-1)分布,样本数为25,求P(T>1.711).已知t=1.711,n=25,采用单侧,则T分布的值:=TDIST(1.711,24,1)得到0.05,即P(T>1.711)=0.05.若采用双侧,则T分布的值:=TDIST(1.711,24,2)得到0.1,即()1.7110.1P T >=.1.2.7 t 分布的反函数Excel 使用TINV 函数得到t 分布的反函数,格式如下:TINV (双侧概率,自由度)范例:已知随机变量服从t (10)分布,置信度为0.05,求t 205.0(10).输入公式=TINV(0.05,10)得到2.2281,即()2.22810.05P T >=.若求临界值t α(n ),则使用公式=TINV(2*α, n ).范例:已知随机变量服从t (10)分布,置信度为0.05,求t 0.05 (10).输入公式=TINV(0.1,10)得到1.812462,即t 0.05 (10)= 1.812462.1.2.8 F 分布Excel 采用FDIST 函数计算F 分布的上侧概率1()F x -,格式如下:FDIST(变量,自由度1,自由度2)其中:变量(x ):判断函数的变量值;自由度1(1n ):代表第1个样本的自由度;自由度2(2n ):代表第2个样本的自由度.范例:设X 服从自由度1n =5,2n =15的F 分布,求P (X >2.9)的值.输入公式=FDIST(2.9,5,15)得到值为0.05,相当于临界值α.1.2.9 F 分布的反函数Excel 使用FINV 函数得到F 分布的反函数,即临界值12(,)F n n α,格式为:FINV(上侧概率,自由度1,自由度2)范例:已知随机变量X 服从F (9,9)分布,临界值α=0.05,求其上侧0.05分位点F 0.05(9,9).输入公式=FINV(0.05,9,9)得到值为3.178897,即F 0.05(9,9)= 3.178897.若求单侧百分位点F 0.025(9,9),F 0.975(9,9).可使用公式=FINV(0.025,9,9)=FINV(0.975,9,9)得到两个临界值4.025992和0.248386.若求临界值F α(n 1,n 2),则使用公式=FINV(α, n 1,n 2).1.2.10 卡方分布Excel 使用CHIDIST 函数得到卡方分布的上侧概率1()F x -,其格式为:CHIDIST(数值,自由度)其中:数值(x ):要判断分布的数值;自由度(v ):指明自由度的数字.范例:若X 服从自由度v =12的卡方分布,求P (X >5.226)的值.输入公式=CHIDIST(5.226,12)得到0.95,即1(5.226)F-=0.95或(5.226)F=0.05.1.2.11卡方分布的反函数Excel使用CHIINV函数得到卡方分布的反函数,即临界值2()nαχ.格式为:CHIINV(上侧概率值α,自由度n)范例:下面的公式计算卡方分布的反函数:=CHIINV(0.95,12)得到值为5.226,即20.95(12)χ=5.226.若求临界值2αχ(n),则使用公式=CHIINV(α, n).1.2.12泊松分布计算泊松分布使用POISSON函数,格式如下:POISSON(变量,参数,累计)其中:变量:表示事件发生的次数;参数:泊松分布的参数值;累计:若TRUE,为泊松分布函数值;若FALSE,则为泊松分布概率分布值.范例:设X服从参数为4的泊松分布,计算P{X=6}及P{X≤6}.输入公式=POISSON(6,4,FALSE)=POISSON(6,4,TRUE)得到概率0.104196和0.889326.在下面的实验中,还将碰到一些其它函数,例如:计算样本容量的函数COUNT,开平方函数SQRT,和函数SUM,等等.关于这些函数的具体用法,可以查看Excel 的关于函数的说明,不再赘述.2 区间估计实验计算置信区间的本质是输入两个公式,分别计算置信下限与置信上限.当熟悉了数据输入方法及常见统计函数后,变得十分简单.2.1 单个正态总体均值与方差的区间估计:2.1.1 σ2已知时μ的置信区间 置信区间为22x u x u αα⎛⎫-+ ⎝. 例1 随机从一批苗木中抽取16株,测得其高度(单位:m )为:1.14 1.101.13 1.15 1.20 1.12 1.17 1.19 1.15 1.12 1.14 1.20 1.231.11 1.14 1.16.设苗高服从正态分布,求总体均值μ的0.95的置信区间.已知σ =0.01(米).步骤:(1)在一个矩形区域内输入观测数据,例如在矩形区域B3:G5内输入样本数据.(2)计算置信下限和置信上限.可以在数据区域B3:G5以外的任意两个单元格内分别输入如下两个表达式:=average(b3:g5)-normsinv(1-0.5*α)*σ/sqrt(count(b3:g5))=average(b3:g5)+normsinv(1-0.5*α)*σ/sqrt(count(b3:g5))上述第一个表达式计算置信下限,第二个表达式计算置信上限.其中,显著性水平α和标准差σ是具体的数值而不是符号.本例中,α =0.05, 0.01σ=,上述两个公式应实际输入为=average(b3:g5)-normsinv(0.975)*0.01/sqrt(count(b3:g5))=average(b3:g5)+normsinv(0.975)*0.01/sqrt(count(b3:g5))计算结果为(1.148225, 1.158025).2.1.2 σ2未知时μ的置信区间置信区间为22((x t n x t n αα⎛⎫--+- ⎝. 例2 同例1,但σ未知.输入公式为:=average(b3:g5)-tinv(0.05,count(b:3:g5)-1)*stdev(b3:g5)/sqrt(count(b3:g5))=average(b3:g5)-tinv(0.05,count(b:3:g5)-1)*stdev(b3:g5)/sqrt(count(b3:g5))计算结果为(1.133695, 1.172555).2.1.3 μ未知时σ2的置信区间: 置信区间为 2222122(1)(1),(1)(1)n n n n s s ααχχ-⎛⎫ ⎪-- ⎪-- ⎪⎝⎭. 例3 从一批火箭推力装置中随机抽取10个进行试验,它们的燃烧时间 (单位:s)如下:50.7 54.9 54.3 44.8 42.2 69.8 53.4 66.1 48.1 34.5试求总体方差2σ的0.9的置信区间(设总体为正态).操作步骤:(1)在单元格B3:C7分别输入样本数据;(2)在单元格C9中输入样本数或输入公式=COUNT(B3:C7);(3)在单元格C10中输入置信水平0.1.(4)计算样本方差:在单元格C11中输入公式=VAR(B3:C7)(5)计算两个查表值:在单元格C12中输入公式=CHIINV(C10/2,C9-1),在单元格C13中输入公式=CHIINV(1-C10/2,C9-1)(6)计算置信区间下限:在单元格C14中输入公式=(C9-1)*C11/C12(7)计算置信区间上限:在单元格C15中输入公式=(C9-1)*C11/C13.当然,读者可以在输入数据后,直接输入如下两个表达式计算两个置信限:=(count(b3:c7)-1)*var(b3:c7)/chiinv(0.1/2, count(b3:c7)-1)=(count(b3:c7)-1)*var(b3:c7)/chiinv(1-0.1/2, count(b3:c7)-1)2.2 两正态总体均值差与方差比的区间估计2.2.1 当σ12 = σ22 = σ2但未知时μ1-μ2的置信区间置信区间为 ()1212211(2)w x y t n n S n n α⎛⎫-±+-+ ⎪ ⎪⎝⎭.例4 在甲,乙两地随机抽取同一品种小麦籽粒的样本,其容量分别为5和7,分析其蛋白质含量为甲:12.6 13.4 11.9 12.8 13.0乙:13.1 13.4 12.8 13.5 13.3 12.7 12.4蛋白质含量符合正态等方差条件,试估计甲,乙两地小麦蛋白质含量差μ1-μ2所在的范围.(取α=0.05)实验步骤:(1)在A2:A6输入甲组数据,在B2:B8输入乙组数据;(2)在单元格B11输入公式=AVERAGE(A2:A6),在单元格B12中输入公式=AVERAGE(B2:B8),分别计算出甲组和乙组样本均值.(3)分别在单元格C11和C12分别输入公式=VAR(A2:A6),=VAR(B2:B8),计算出两组样本的方差.(4)在单元格D11和D12分别输入公式=COUNT(A2:A6),=COUNT(B2:B8),计算各样本的容量大小.(5)将显著性水平0.05输入到单元格E11中.(6)分别在单元格B13和B14输入=B11-B12-TINV(0.025,10)*SQRT((4*C11+6*C12)/10)*SQRT(1/ 5+1/7)和=B11-B12+TINV(0.025,10)*SQRT((4*C11+6*C12)/10)*SQRT(1/ 5+1/7)计算出置信区间的下限和上限.2.2.2μ1和μ2未知时方差比σ21/σ22的置信区间置信区间为22 112221221212211,(1,1)(1,1)s ss F n n s F n nαα-⎛⎫⎪⎪----⎪⎝⎭.例5有两个化验员A、B,他们独立地对某种聚合物的含氯量用相同的方法各作了10次测定.其测定值的方差分别是SA=0.5419,SB=0.6065.设σ2A和σ2B分别是A、B所测量的数据总体(设为正态分布)的方差.求方差比σ2A/σ2B的 0.95置信区间.操作步骤:(1)在单元格B2,B3输入样本数,C2,C3输入样本方差,D2输入置信度.(2)在B4和B5利用公式输入=C2/(C3*FINV(1-D2/2,B2-1,B3-1))和=C2/(C3*FINV(D2/2,B2-1,B3-1))计算出A组和B组的方差比的置信区间上限和下限.2.3 练习题1. 已知某树种的树高服从正态分布,随机抽取了该树种的60株林木组成样本.样本中各林木的树高资料如下(单位:m)22.3, 21.2, 19.2, 16.6, 23.1, 23.9, 24.8, 26.4, 26.6, 24.8, 23.9, 23.2,23.3, 21.4, 19.8, 18.3, 20.0, 21.5, 18.7, 22.4, 26.6, 23.9, 24.8, 18.8,27.1, 20.6, 25.0, 22.5, 23.5, 23.9, 25.3, 23.5, 22.6, 21.5, 20.6, 25.8,24.0, 23.5, 22.6, 21.8, 20.8, 19.5, 20.9, 22.1, 22.7, 23.6, 24.5, 23.6,21.0, 21.3, 22.4,18.7, 21.3, 15.4, 22.9, 17.8, 21.7, 19.1, 20.3, 19.8 试以0.95的可靠性,对于该林地上全部林木的平均高进行估计.2. 从一批灯泡中随机抽取10个进行测试,测得它们的寿命(单位:100h)为:50.7,54.9,54.3,44.8,42.2,69.8,53.4,66.1,48.1,34.5.试求总体方差的0.9的置信区间(设总体为正态).3. 已知某种玉米的产量服从正态分布,现有种植该玉米的两个实验区,各分为10个小区,各小区的面积相同,在这两个实验区中,除第一实验区施以磷肥外,其它条件相同,两实验区的玉米产量(kg)如下:第一实验区: 62 57 65 60 63 58 57 60 60 58第二实验区: 56 59 56 57 60 58 57 55 57 55试求出施以磷肥的玉米产量均值和未施以磷肥的玉米产量均值之差的范围(α=0.05)3假设检验实验实验内容:单个总体均值的假设检验;两个总体均值差的假设检验;两个正态总体方差齐性的假设检验;拟合优度检验.实验目的与要求:(1)理解假设检验的统计思想,掌握假设检验的计算步骤;(2)掌握运用Excel进行假设检验的方法和操作步骤;(3)能够利用试验结果的信息,对所关心的事物作出合理的推断.3.1 单个正态总体均值μ的检验3.1.1σ2已知时μ的U检验例1 外地一良种作物,其1000m2产量(单位:kg)服从N(800, 502),引入本地试种,收获时任取5块地,其1000m2产量分别是800,850,780,900,820(kg),假定引种后1000m2产量X也服从正态分布,试问:=800kg 有无显 (1)若方差未变,本地平均产量μ与原产地的平均产量μ0著变化.=800kg高.(2)本地平均产量μ是否比原产地的平均产量μ0=800kg低.(3)本地平均产量μ是否比原产地的平均产量μ0操作步骤:(1)先建一个如下图所示的工作表:(2)计算样本均值(平均产量),在单元格D5输入公式=AVERAGE(A3:E3);(3)在单元格D6输入样本数5;(4)在单元格D8输入U检验值计算公式=(D5-800)/(50/SQRT(D6);(5)在单元格D9输入U检验的临界值=NORMSINV(0.975);(6)根据算出的数值作出推论.本例中,U的检验值1.341641小于临界值1.959961,故接受原假设,即平均产量与原产地无显著差异.(7)注:在例1中,问题(2)要计算U检验的右侧临界值:在单元格D10输入U 检验的上侧临界值=NORMSINV(0.95).问题(3)要计算U检验的下侧临界值,在单元格D11输入U检验下侧的临界值=NORMSINV(0.05).3.1.2σ2未知时的t检验例2某一引擎制造商新生产某一种引擎,将生产的引擎装入汽车内进行速度测试,得到行驶速度如下:250 238 265 242 248 258 255 236 245 261254 256 246 242 247 256 258 259 262 263该引擎制造商宣称引擎的平均速度高于250 km/h,请问样本数据在显著性水平为0.025时,是否和他的声明抵触?操作步骤:(1)先建如图所示的工作表:(2)计算样本均值:在单元格D8输入公式=AVERAGE(A3:E6);(3)计算标准差:在单元格D9输入公式=STDEV(A3:E6);(4)在单元格D10输入样本数20.(5)在单元格D11输入t检验值计算公式=(D8-250)/(D9/(SQRT(D10)),得到结果1.06087;(6)在单元格D12输入t检验上侧临界值计算公式=TINV(0.05, D10-1). 欲检验假设H0:μ=250;H1:μ>250.已知t统计量的自由度为(n-1)=20-1=19,拒绝域为t>t025.0=2.093.由上面计算得到t检验统计量的值1.06087落在接收域内,故接收原假设H0.3.2 两个正态总体参数的假设检验3.2.1当σ12 = σ22 = σ2但未知时12μ-μ的检验在此情况下,采用t检验.例试验及观测数据同11.2中的练习题3,试判别磷肥对玉米产量有无显著影响?欲检验假设H0:μ1=μ2;H1:μ1>μ2.操作步骤:(1)建立如图所示工作表:(2)选取“工具”—“数据分析”;(3)选定“ t-检验:双样本等方差假设”.(4)选择“确定”.显示一个“t-检验:双样本等方差假设”对话框;(5)在“变量1的区域”输入A2:A11.(6)在“变量2的区域”输入B2:B11.(7)在“输出区域”输入D1,表示输出结果放置于D1向右方的单元格中.(8)在显著水平“α”框,输入0.05.(9)在“假设平均差”窗口输入0.(10)选择“确定”,计算结果如D1:F14显示.得到t值为3.03,“t单尾临界”值为1.734063.由于3.03>1.73,所以拒绝原假设,接收备择假设,即认为使用磷肥对提高玉米产量有显著影响.3.2.2σ21与σ22已知时12μ-μ的U检验例3 某班20人进行了数学测验,第1组和第2组测验结果如下:第1组: 91 88 76 98 94 92 90 87 100 69第2组: 90 91 80 92 92 94 98 78 86 91已知两组的总体方差分别是57与53,取α =0.05,可否认为两组学生的成绩有差异?操作步骤:(1)建立如图所示工作表:(2)选取“工具”—“数据分析”;(3)选定“z-检验:双样本平均差检验”;(4)选择“确定”,显示一个“z-检验:双样本平均差检验”对话框;(5)在“变量1的区域”输入A2:A11;(6)在“变量2的区域”输入B2:B11;(7)在“输出区域”输入D1;(8)在显著水平“α”框,输入0.05;(9)在“假设平均差”窗口输入0;(10)在“变量1的方差”窗口输入57;(11)在“变量2的方差”窗口输入53;(12)选择“确定”,得到结果如图所示.计算结果得到z=-0.21106(即u统计量的值),其绝对值小于“z双尾临界”值1.959961,故接收原假设,表示无充分证据表明两组学生数学测验成绩有差异.3.2.3两个正态总体的方差齐性的F检验例5羊毛在处理前与后分别抽样分析其含脂率如下:处理前:0.19 0.18 0.21 0.30 0.41 0.12 0.27处理后:0.15 0.13 0.07 0.24 0.19 0.06 0.08 0.12问处理前后含脂率的标准差是否有显著差异?欲检验假设H 0:σ21=σ22; H1:σ21≠σ22.操作步骤如下:(1)建立如图所示工作表: (2)选取“工具”—“数据分析”; (3)选定“F-检验 双样本方差”.(4)选择“确定”,显示一个“F-检验:双样本方差”对话框; (5)在“变量1的区域”输入A2:A8. (6)在“变量2的区域”输入B2:B9. (7)在显著水平“α”框,输入0.025. (8)在“输出区域”框输入D1. (9)选择“确定”,得到结果如图所示.计算出F 值 2.35049小于“F 单尾临界”值 5.118579,且P(F<=f)=0.144119>0.025,故接收原假设,表示无理由怀疑两总体方差相等.4 拟合优度检验拟合优度检验使用统计量221()ki i i i n np np χ=-=∑, (11.1) i i n np k 其中为实测频数,为理论频数,为分组数。
Excel绘制海森机率格纸的方法(水文)

Excel绘制海森机率格纸的方法(水文)Excel 绘制海森机率格纸的方法(水文)水文频率计算中采用的海森机率格纸是一种特殊的坐标系统,其纵坐标为均匀分格的常规数学坐标,横坐标与频率值(下侧概率)的标准正态分布分位数有关。
由于标准正态分布分位数在P =50%处为零,而海森机率格纸在P =0.01%时的横坐标值为零,因此海森机率格纸横坐标值计算公式可表示为:P P U U L +-=%01.0 (1)式(1)中,L P 为海森机率格纸中频率P 对应的横坐标值;U P 为频率P 对应的标准正态分布分位数;U 0.01%为频率P =0.01%对应的标准正态分布分位数。
标准正态分布分位数可以用Excel 软件中的内置函数NORMSINV (P )直接计算,结果的精度可达到±3×10-7。
函数NORMSINV 为返回累积标准正态分布对应的自变量,该函数的详细说明和用法可参考Excel 软件的帮助。
一、海森机率格纸纵向网格线的绘制海森机率格纸的横向网格线为均匀分布,可直接由Excel 软件的图表功能自动生成,而纵向网格线不能直接由Excel 软件的图表功能自动生成,因为海森机率格纸要求的纵向网格线是不均匀的。
纵向网格线的绘制可以通过向图表中添加一个系列的XY 散点图来完成,下面以某站流量频率计算用海森机率格纸的绘制为例进行介绍,具体方法如下:1、设置纵坐标的最大值与最小值(如图1所示)新建Excel工作簿,将工作表“Sheet3”重命名为“流量机率格纸数据点”。
在本工作表D2单元格中输入“1800”,设置纵坐标最大值为1800,在D3单元格中输入“0”,设置纵坐标最小值为0。
注意:针对不同的研究对象,应选择合适的纵坐标最大值。
图12、计算海森机率格纸中频率P对应的横坐标值L P(如图1所示)(1)在“流量机率格纸数据点”工作表A6、A7单元格中分别输入“0.01”,在A8、A9单元格中分别输入“0.02”……,依此类推,在A列后续单元格中输入海森机率格纸纵向网格线对应的频率值,直至最后在A234、A235单元格中分别输入“99.99”。
excel中的概率统计

数理统计实验1Excel基本操作1.1单元格操作1.1.1单元格的选取Excel启动后首先将自动选取第A列第1行的单元格即A1(或a1)作为活动格,我们可以用键盘或鼠标来选取其它单元格.用鼠标选取时,只需将鼠标移至希望选取的单元格上并单击即可.被选取的单元格将以反色显示.1.1.2选取单元格范围(矩形区域)可以按如下两种方式选取单元格范围.(1) 先选取范围的起始点(左上角),即用鼠标单击所需位置使其反色显示.然后按住鼠标左键不放,拖动鼠标指针至终点(右下角)位置,然后放开鼠标即可.(2) 先选取范围的起始点(左上角),即用鼠标单击所需位置使其反色显示.然后将鼠标指针移到终点(右下角)位置,先按下Shift键不放,而后点击鼠标左键.1.1.3选取特殊单元格在实际中,有时要选取的单元格由若干不相连的单元格范围组成的.此类有两种情况.第一种情况是间断的单元格选取.选取方法是先选取第一个单元格,然后按住[Ctrl]键,再依次选取其它单元格即可.第二种情况是间断的单元格范围选取.选取方法是先选取第一个单元格范围,然后按住[Ctrl]键,用鼠标拖拉的方式选取第二个单元格范围即可.1.1.4公式中的数值计算要输入计算公式,可先单击待输入公式的单元格,而后键入=(等号),并接着键入公式,公式输入完毕后按Enter键即可确认..如果单击了“编辑公式”按钮或“粘贴函数”按钮,Excel将自动插入一个等号.提示:(1) 通过先选定一个区域,再键入公式,然后按 CTRL+ENTER 组合键,可以在区域内的所有单元格中输入同一公式.(2) 可以通过另一单元格复制公式,然后在目标区域内输入同一公式.公式是在工作表中对数据进行分析的等式.它可以对工作表数值进行加法、减法和乘法等运算.公式可以引用同一工作表中的其它单元格、同一工作簿不同工作表中的单元格,或者其它工作簿的工作表中的单元格.下面的示例中将单元格 B4 中的数值加上25,再除以单元格 D5、E5 和 F5 中数值的和.=(B4+25)/SUM(D5:F5)1.1.5公式中的语法公式语法也就是公式中元素的结构或顺序.Excel 中的公式遵守一个特定的语法:最前面是等号(=),后面是参与计算的元素(运算数)和运算符.每个运算数可以是不改变的数值(常量数值)、单元格或区域引用、标志、名称,或工作表函数.在默认状态下,Excel 从等号(=)开始,从左到右计算公式.可以通过修改公式语法来控制计算的顺序.例如,公式=5+2*3的结果为 11,将 2 乘以 3(结果是 6),然后再加上 5.因为Excel 先计算乘法再计算加法;可以使用圆括号来改变语法,圆括号内的内容将首先被计算.公式=(5+2)*3的结果为21,即先用 5 加上 2,再用其结果乘以 3.1.1.6单元格引用一个单元格中的数值或公式可以被另一个单元格引用.含有单元格引用公式的单元格称为从属单元格,它的值依赖于被引用单元格的值.只要被引用单元格做了修改,包含引用公式的单元格也就随之修改.例如,公式“=B15*5”将单元格 B15 中的数值乘以 5.每当单元格 B15 中的值修改时,公式都将重新计算.公式可以引用单元格组或单元格区域,还可以引用代表单元格或单元格区域的名称或标志.在默认状态下,Excel 使用 A1 引用类型.这种类型用字母标志列(从 A 到 IV ,共 256 列),用数字标志行(从 1 到 65536).如果要引用单元格,请顺序输入列字母和行数字.例如,D50 引用了列 D 和行 50 交叉处的单元格.如果要引用单元格区域,请输入区域左上角单元格的引用、冒号(:)和区域右下角单元格的引用.下面是引用的示例.1.1.7工作表函数Excel 包含许多预定义的,或称内置的公式,它们被叫做函数.函数可以进行简单的或复杂的计算.工作表中常用的函数是“SUM”函数,它被用来对单元格区域进行加法运算.虽然也可以通过创建公式来计算单元格中数值的总和,但是“SUM”工作表函数还可以方便地计算多个单元格区域.函数的语法以函数名称开始,后面是左圆括号、以逗号隔开的参数和右圆括号.如果函数以公式的形式出现,请在函数名称前面键入等号(=).当生成包含函数的公式时,公式选项板将会提供相关的帮助.使用公式的步骤:B. 如果公式以函数的形式出现,请在编辑栏中单击“编辑公式”按钮 .C. 单击“函数”下拉列表框 右端的下拉箭头.D. 单击选定需要添加到公式中的函数.如果函数没有出现在列表中,请单击“其它函数”查看其它函数列表.E. 输入参数.F. 完成输入公式后,请按 ENTER 键.1.2 几种常见的统计函数1.2.1 均值Excel 计算平均数使用AVERAGE 函数,其格式如下:AVERAGE (参数1,参数2,…,参数30)范例:AVERAGE (,,,,)=如果要计算单元格中A1到B20元素的平均数,可用 AVERAGE(A1:B20).1.2.2 标准差计算标准差可依据样本当作变量或总体当作变量来分别计算,根据样本计算的结果称作样本标准差,而依据总体计算的结果称作总体标准差.(1)样本标准差Excel 计算样本标准差采用无偏估计式,STDEV 函数格式如下:STDEV (参数1,参数2,…,参数30)范例:STDEV (3,5,6,4,6,7,5)=如果要计算单元格中A1到B20元素的样本标准差,可用 STDEV(A1:B20).(2)总体标准差Excel 计算总体标准差采用有偏估计式STDEVP 函数,其格式如下:STDEVP (参数1,参数2,…,参数30)范例:STDEVP (3,5,6,4,6,7,5)=1.2.3 方差方差为标准差的平方,在统计上亦分样本方差与总体方差.(1)样本方差S 2=1)(2--∑n x x iExcel 计算样本方差使用VAR 函数,格式如下:VAR (参数1,参数2,…,参数30)如果要计算单元格中A1到B20元素的样本方差,可用 VAR(A1:B20).范例:VAR (3,5,6,4,6,7,5)=(2)总体方差S 2=n x x i ∑-2)(Excel 计算总体方差使用VARP 函数,格式如下:VARP (参数1,参数2,…,参数30)范例:VAR (3,5,6,4,6,7,5)=1.2.4 正态分布函数Excel 计算正态分布时,使用NORMDIST 函数,其格式如下:NORMDIST (变量,均值,标准差,累积)其中:变量(x ):为分布要计算的x 值;均值(μ):分布的均值;标准差(σ):分布的标准差;累积:若为TRUE ,则为分布函数;若为FALSE ,则为概率密度函数.范例:已知X 服从正态分布,μ=600,σ=100,求P {X ≤500}.输入公式=NORMDIST (500,600,100,TRUE )得到的结果为,即P {X ≤500}=.1.2.5 正态分布函数的反函数Excel 计算正态分布函数的反函数使用NORMINV 函数,格式如下:NORMINV (下侧概率,均值,标准差)范例:已知概率P =,均值μ=360,标准差σ=40,求NORMINV 函数的值.输入公式=NORMINV (,360,40)得到结果为400,即P {X ≤400}=.注意:(1) NORMDIST 函数的反函数NORMINV 用于分布函数,而非概率密度函数,请务必注意;(2) Excel 提供了计算标准正态分布函数 NORMSDIST(x),及标准正态分布的反函数 NORMSINV(概率).范例:已知X~N(0,1), 计算(2)Φ=P {X <2}.输入公式=NORMSDIST(2)得到,即(2)Φ=.范例:输入公式=NORMSINV ,得到数值2.若求临界值u α(n ),则使用公式=NORMSINV(1-α).1.2.6 t 分布Excel 计算t 分布的值(查表值)采用TDIST 函数,格式如下:TDIST (变量,自由度,侧数)其中:变量(t ):为判断分布的数值;自由度(v ):以整数表明的自由度;侧数:指明分布为单侧或双侧:若为1,为单侧;若为2,为双侧.范例:设T 服从t (n-1)分布,样本数为25,求P (T >).已知t =,n =25,采用单侧,则T 分布的值:=TDIST,24,1)得到,即P (T >)=.若采用双侧,则T 分布的值:=TDIST,24,2) 得到,即()1.7110.1P T >=. 1.2.7 t 分布的反函数Excel 使用TINV 函数得到t 分布的反函数,格式如下:TINV (双侧概率,自由度)范例:已知随机变量服从t (10)分布,置信度为,求t 205.0(10).输入公式=TINV,10) 得到,即()2.22810.05P T >=.若求临界值t α(n ),则使用公式=TINV(2*α, n ).范例:已知随机变量服从t (10)分布,置信度为,求 (10).输入公式=TINV,10)得到,即 (10)= .1.2.8 F 分布Excel 采用FDIST 函数计算F 分布的上侧概率1()F x -,格式如下:FDIST(变量,自由度1,自由度2)其中:变量(x ):判断函数的变量值;自由度1(1n ):代表第1个样本的自由度;自由度2(n ):代表第2个样本的自由度.范例:设X 服从自由度1n =5,2n =15的F 分布,求P (X >的值.输入公式=FDIST,5,15)得到值为,相当于临界值α.1.2.9 F 分布的反函数Excel 使用FINV 函数得到F 分布的反函数,即临界值12(,)F n n α,格式为:FINV(上侧概率,自由度1,自由度2)范例:已知随机变量X 服从F (9,9)分布,临界值α=,求其上侧分位点(9,9).输入公式=FINV,9,9)得到值为,即(9,9)= .若求单侧百分位点(9,9),(9,9).可使用公式=FINV,9,9)=FINV,9,9)得到两个临界值和.若求临界值F α(n 1,n 2),则使用公式=FINV(α, n 1,n 2).1.2.10 卡方分布Excel 使用CHIDIST 函数得到卡方分布的上侧概率1()F x -,其格式为:CHIDIST(数值,自由度)其中:数值(x ):要判断分布的数值;自由度(v ):指明自由度的数字.范例:若X 服从自由度v =12的卡方分布,求P (X >的值.输入公式=CHIDIST,12)得到,即1(5.226)F -=或(5.226)F =.1.2.11 卡方分布的反函数Excel 使用CHIINV 函数得到卡方分布的反函数,即临界值2()n αχ.格式为:CHIINV (上侧概率值α,自由度n )范例:下面的公式计算卡方分布的反函数:=CHIINV,12)得到值为,即20.95(12)χ=.若求临界值2χ(n),则使用公式=CHIINV(α, n).1.2.12 泊松分布计算泊松分布使用POISSON 函数,格式如下:POISSON(变量,参数,累计)其中:变量:表示事件发生的次数;参数:泊松分布的参数值;累计:若TRUE ,为泊松分布函数值;若FALSE ,则为泊松分布概率分布值. 范例:设X服从参数为4的泊松分布,计算P {X =6}及P {X ≤6}.输入公式=POISSON(6,4,FALSE)=POISSON(6,4,TRUE)得到概率和.在下面的实验中,还将碰到一些其它函数,例如:计算样本容量的函数COUNT ,开平方函数SQRT ,和函数SUM ,等等.关于这些函数的具体用法,可以查看Excel 的关于函数的说明,不再赘述.2 区间估计实验计算置信区间的本质是输入两个公式,分别计算置信下限与置信上限.当熟悉了数据输入方法及常见统计函数后,变得十分简单.2.1 单个正态总体均值与方差的区间估计:2.1.1 ?2已知时?的置信区间 置信区间为22x u x u αα⎛⎫-+ ⎝. 例 1 随机从一批苗木中抽取16株,测得其高度(单位:m )为: .设苗高服从正态分布,求总体均值μ的的置信区间.已知σ =(米).步骤:(1)在一个矩形区域内输入观测数据,例如在矩形区域B3:G5内输入样本数据.(2)计算置信下限和置信上限.可以在数据区域B3:G5以外的任意两个单元格内分别输入如下两个表达式:=average(b3:g5)-normsinv*α)*σ/sqrt(count(b3:g5))=average(b3:g5)+normsinv*α)*σ/sqrt(count(b3:g5))上述第一个表达式计算置信下限,第二个表达式计算置信上限.其中,显着性水平α和标准差σ是具体的数值而不是符号.本例中,? =, 0.01σ=,上述两个公式应实际输入为=average(b3:g5)-normsinv*sqrt(count(b3:g5))=average(b3:g5)+normsinv*sqrt(count(b3:g5))计算结果为(, ).2.1.2 ?2未知时?的置信区间置信区间为22((x t n x t n αα⎛⎫--+- ⎝. 例2 同例1,但σ未知.输入公式为:=average(b3:g5)-tinv,count(b:3:g5)-1)*stdev(b3:g5)/sqrt(count(b3:g5)) =average(b3:g5)-tinv,count(b:3:g5)-1)*stdev(b3:g5)/sqrt(count(b3:g5)) 计算结果为(, ).2.1.3 ?未知时?2的置信区间:置信区间为 2222122(1)(1),(1)(1)n n n n s s ααχχ-⎛⎫ ⎪-- ⎪-- ⎪⎝⎭. 例3 从一批火箭推力装置中随机抽取10个进行试验,它们的燃烧时间 (单位:s)如下:试求总体方差2σ的的置信区间(设总体为正态).操作步骤:(1)在单元格B3:C7分别输入样本数据;(2)在单元格C9中输入样本数或输入公式=COUNT(B3:C7);(3)在单元格C10中输入置信水平.(4)计算样本方差:在单元格C11中输入公式=VAR(B3:C7)(5)计算两个查表值:在单元格C12中输入公式=CHIINV(C10/2,C9-1),在单元格C13中输入公式=CHIINV(1-C10/2,C9-1)(6)计算置信区间下限:在单元格C14中输入公式=(C9-1)*C11/C12(7)计算置信区间上限:在单元格C15中输入公式=(C9-1)*C11/C13.当然,读者可以在输入数据后,直接输入如下两个表达式计算两个置信限:=(count(b3:c7)-1)*var(b3:c7)/chiinv2, count(b3:c7)-1)=(count(b3:c7)-1)*var(b3:c7)/chiinv2, count(b3:c7)-1)2.2 两正态总体均值差与方差比的区间估计2.2.1 当?12 =??22 =??2但未知时?1-?2的置信区间置信区间为 ()1212211(2)wx y t n n S n n α⎛⎫-±+-+ ⎪ ⎪⎝⎭. 例4 在甲,乙两地随机抽取同一品种小麦籽粒的样本,其容量分别为5和7,分析其蛋白质含量为甲:乙:蛋白质含量符合正态等方差条件,试估计甲,乙两地小麦蛋白质含量差μ1-μ2所在的范围.(取α=)实验步骤:(1)在A2:A6输入甲组数据,在B2:B8输入乙组数据;(2)在单元格B11输入公式=AVERAGE(A2:A6),在单元格B12中输入公式=AVERAGE(B2:B8),分别计算出甲组和乙组样本均值.(3)分别在单元格C11和C12分别输入公式=VAR(A2:A6),=VAR(B2:B8),计算出两组样本的方差.(4)在单元格D11和D12分别输入公式=COUNT(A2:A6),=COUNT(B2:B8),计算各样本的容量大小.(5)将显着性水平输入到单元格E11中.(6)分别在单元格B13和B14输入=B11-B12-TINV,10)*SQRT((4*C11+6*C12)/10)*SQRT(1/ 5+1/7)和=B11-B12+TINV,10)*SQRT((4*C11+6*C12)/10)*SQRT(1/ 5+1/7)计算出置信区间的下限和上限.2.2.2?1和??未知时方差比σ21/σ22的置信区间置信区间为22 11 2221221212211,(1,1)(1,1)s ss F n n s F n nαα-⎛⎫⎪⎪----⎪⎝⎭.例5有两个化验员A、B,他们独立地对某种聚合物的含氯量用相同的方法各作了10次测定.其测定值的方差分别是SA=,SB=.设σ2A和σ2B分别是A、B所测量的数据总体(设为正态分布)的方差.求方差比σ2A/σ2B的置信区间.操作步骤:(1)在单元格B2,B3输入样本数,C2,C3输入样本方差,D2输入置信度.(2)在B4和B5利用公式输入=C2/(C3*FINV(1-D2/2,B2-1,B3-1))和=C2/(C3*FINV(D2/2,B2-1,B3-1))计算出A组和B组的方差比的置信区间上限和下限.2.3练习题1. 已知某树种的树高服从正态分布,随机抽取了该树种的60株林木组成样本.样本中各林木的树高资料如下(单位:m), , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , ,, , , , , , , ,试以的可靠性,对于该林地上全部林木的平均高进行估计.2. 从一批灯泡中随机抽取10个进行测试,测得它们的寿命(单位:100h)为:,,,,,,,,,.试求总体方差的的置信区间(设总体为正态).3. 已知某种玉米的产量服从正态分布,现有种植该玉米的两个实验区,各分为10个小区,各小区的面积相同,在这两个实验区中,除第一实验区施以磷肥外,其它条件相同,两实验区的玉米产量(kg)如下:第一实验区: 62 57 65 60 63 58 57 60 60 58第二实验区: 56 59 56 57 60 58 57 55 57 55试求出施以磷肥的玉米产量均值和未施以磷肥的玉米产量均值之差的范围(α=)3假设检验实验实验内容:单个总体均值的假设检验;两个总体均值差的假设检验;两个正态总体方差齐性的假设检验;拟合优度检验.实验目的与要求:(1)理解假设检验的统计思想,掌握假设检验的计算步骤;(2)掌握运用Excel进行假设检验的方法和操作步骤;(3)能够利用试验结果的信息,对所关心的事物作出合理的推断.3.1单个正态总体均值μ的检验3.1.1?2已知时μ的U检验例1 外地一良种作物,其1000m2产量(单位:kg)服从N(800, 502),引入本地试种,收获时任取5块地,其1000m2产量分别是800,850,780,900,820(kg),假定引种后1000m2产量X也服从正态分布,试问:=800kg 有无显着变化. (1)若方差未变,本地平均产量μ与原产地的平均产量μ0(2)本地平均产量μ是否比原产地的平均产量μ=800kg高.0=800kg低.(3)本地平均产量μ是否比原产地的平均产量μ0操作步骤:(1)先建一个如下图所示的工作表:(2)计算样本均值(平均产量),在单元格D5输入公式=AVERAGE(A3:E3);(3)在单元格D6输入样本数5;(4)在单元格D8输入U检验值计算公式=(D5-800)/(50/SQRT(D6);(5)在单元格D9输入U检验的临界值=NORMSINV;(6)根据算出的数值作出推论.本例中,U的检验值小于临界值,故接受原假设,即平均产量与原产地无显着差异.(7)注:在例1中,问题(2)要计算U检验的右侧临界值:在单元格D10输入U检验的上侧临界值=NORMSINV.问题(3)要计算U检验的下侧临界值,在单元格D11输入U检验下侧的临界值=NORMSINV.3.1.2?2未知时的t检验例2某一引擎制造商新生产某一种引擎,将生产的引擎装入汽车内进行速度测试,得到行驶速度如下:250 238 265 242 248 258 255 236 245 261254 256 246 242 247 256 258 259 262 263该引擎制造商宣称引擎的平均速度高于250 km/h,请问样本数据在显着性水平为时,是否和他的声明抵触操作步骤:(1)先建如图所示的工作表:(2)计算样本均值:在单元格D8输入公式=AVERAGE(A3:E6);(3)计算标准差:在单元格D9输入公式=STDEV(A3:E6);(4)在单元格D10输入样本数20.(5)在单元格D11输入t检验值计算公式=(D8-250)/(D9/(SQRT(D10)),得到结果;(6)在单元格D12输入t检验上侧临界值计算公式=TINV, D10-1).欲检验假设H0:μ=250;H1:μ>250.已知t统计量的自由度为(n-1)=20-1=19,拒绝域为t>t025.0=.由上面计算得到t检验统计量的值落在接收域内,故接收原假设H0.3.2两个正态总体参数的假设检验3.2.1当?12 =??22 =??2但未知时12μ-μ的检验在此情况下,采用t检验.例试验及观测数据同中的练习题3,试判别磷肥对玉米产量有无显着影响欲检验假设H0:μ1=μ2;H1:μ1>μ2.操作步骤:(1)建立如图所示工作表:(2)(3)选定“ t-检验:双样本等方差假设”.(4)选择“确定”.显示一个“t-检验:双样本等方差假设”对话框;(5)在“变量1的区域”输入A2:A11.(6)在“变量2的区域”输入B2:B11.(7)在“输出区域”输入D1,表示输出结果放置于D1向右方的单元格中.(8)在显着水平“α”框,输入.(9)在“假设平均差”窗口输入0.(10)选择“确定”,计算结果如D1:F14显示.得到t值为,“t单尾临界”值为.由于>,所以拒绝原假设,接收备择假设,即认为使用磷肥对提高玉米产量有显着影响.3.2.2σ21与σ22已知时12μ-μ的U检验例3 某班20人进行了数学测验,第1组和第2组测验结果如下:第1组: 91 88 76 98 94 92 90 87 100 69第2组: 90 91 80 92 92 94 98 78 86 91已知两组的总体方差分别是57与53,取α =,可否认为两组学生的成绩有差异操作步骤:(1)建立如图所示工作表:(2)选取“工具”—“数据分析”;(3)选定“z-检验:双样本平均差检验”;(4)选择“确定”,显示一个“z-检验:双样本平均差检验”对话框;(5)在“变量1的区域”输入A2:A11;(6)在“变量2的区域”输入B2:B11;(7)在“输出区域”输入D1;(8)在显着水平“α”框,输入;(9)在“假设平均差”窗口输入0;(10)在“变量1的方差”窗口输入57;(11)在“变量2的方差”窗口输入53;(12)选择“确定”,得到结果如图所示.计算结果得到z=(即u统计量的值),其绝对值小于“z双尾临界”值,故接收原假设,表示无充分证据表明两组学生数学测验成绩有差异.3.2.3 两个正态总体的方差齐性的F检验例5 羊毛在处理前与后分别抽样分析其含脂率如下: 处理前: 处理后:问处理前后含脂率的标准差是否有显着差异 欲检验假设H 0:σ21=σ22; H 1:σ21≠σ22.操作步骤如下:(1)建立如图所示工作表:(2)选取“工具”—“数据分析”; (3)选定“F-检验 双样本方差”. (4)选择“确定”,显示一个“F-检验:双样本方差”对话框; (5)在“变量1的区域”输入A2:A8. (6)在“变量2的区域”输入B2:B9. (7)在显着水平“α”框,输入. (8)在“输出区域”框输入D1. (9)选择“确定”,得到结果如图所示.计算出F 值小于“F 单尾临界”值,且P(F<=f)=>,故接收原假设,表示无理由怀疑两总体方差相等.4 拟合优度检验拟合优度检验使用统计量221()ki i i i n np np χ=-=∑, i i n np k 其中为实测频数,为理论频数,为分组数。
excel中的概率统计(非常好的资料)

数理统计实验1Excel基本操作1.1 单元格操作1.1.1单元格的选取Excel启动后首先将自动选取第A列第1行的单元格即A1(或a1)作为活动格,我们可以用键盘或鼠标来选取其它单元格.用鼠标选取时,只需将鼠标移至希望选取的单元格上并单击即可.被选取的单元格将以反色显示.1.1.2选取单元格范围(矩形区域)可以按如下两种方式选取单元格范围.(1) 先选取范围的起始点(左上角),即用鼠标单击所需位置使其反色显示.然后按住鼠标左键不放,拖动鼠标指针至终点(右下角)位置,然后放开鼠标即可.(2) 先选取范围的起始点(左上角),即用鼠标单击所需位置使其反色显示.然后将鼠标指针移到终点(右下角)位置,先按下Shift键不放,而后点击鼠标左键.1.1.3选取特殊单元格在实际中,有时要选取的单元格由若干不相连的单元格范围组成的.此类有两种情况.第一种情况是间断的单元格选取.选取方法是先选取第一个单元格,然后按住[Ctrl]键,再依次选取其它单元格即可.第二种情况是间断的单元格范围选取.选取方法是先选取第一个单元格范围,然后按住[Ctrl]键,用鼠标拖拉的方式选取第二个单元格范围即可.1.1.4公式中的数值计算要输入计算公式,可先单击待输入公式的单元格,而后键入=(等号),并接着键入公式,公式输入完毕后按Enter键即可确认..如果单击了“编辑公式”按钮或“粘贴函数”按钮,Excel将自动插入一个等号.提示:(1) 通过先选定一个区域,再键入公式,然后按CTRL+ENTER 组合键,可以在区域内的所有单元格中输入同一公式.(2) 可以通过另一单元格复制公式,然后在目标区域内输入同一公式.公式是在工作表中对数据进行分析的等式.它可以对工作表数值进行加法、减法和乘法等运算.公式可以引用同一工作表中的其它单元格、同一工作簿不同工作表中的单元格,或者其它工作簿的工作表中的单元格.下面的示例中将单元格B4 中的数值加上25,再除以单元格D5、E5 和F5 中数值的和.=(B4+25)/SUM(D5:F5)1.1.5公式中的语法公式语法也就是公式中元素的结构或顺序.Excel 中的公式遵守一个特定的语法:最前面是等号(=),后面是参与计算的元素(运算数)和运算符.每个运算数可以是不改变的数值(常量数值)、单元格或区域引用、标志、名称,或工作表函数.在默认状态下,Excel 从等号(=)开始,从左到右计算公式.可以通过修改公式语法来控制计算的顺序.例如,公式=5+2*3的结果为11,将 2 乘以3(结果是6),然后再加上5.因为Excel 先计算乘法再计算加法;可以使用圆括号来改变语法,圆括号内的内容将首先被计算.公式=(5+2)*3的结果为21,即先用 5 加上2,再用其结果乘以3.1.1.6单元格引用一个单元格中的数值或公式可以被另一个单元格引用.含有单元格引用公式的单元格称为从属单元格,它的值依赖于被引用单元格的值.只要被引用单元格做了修改,包含引用公式的单元格也就随之修改.例如,公式“=B15*5”将单元格B15 中的数值乘以5.每当单元格B15 中的值修改时,公式都将重新计算.公式可以引用单元格组或单元格区域,还可以引用代表单元格或单元格区域的名称或标志.在默认状态下,Excel 使用A1 引用类型.这种类型用字母标志列(从A 到IV ,共256 列),用数字标志行(从 1 到65536).如果要引用单元格,请顺序输入列字母和行数字.例如,D50 引用了列D 和行50 交叉处的单元格.如果要引用单元格区域,请输入区域左上角单元格的引用、冒号(:)和区域右下角单元格的引用.下面是引用的示例.1.1.7工作表函数Excel 包含许多预定义的,或称内置的公式,它们被叫做函数.函数可以进行简单的或复杂的计算.工作表中常用的函数是“SUM”函数,它被用来对单元格区域进行加法运算.虽然也可以通过创建公式来计算单元格中数值的总和,但是“SUM”工作表函数还可以方便地计算多个单元格区域.函数的语法以函数名称开始,后面是左圆括号、以逗号隔开的参数和右圆括号.如果函数以公式的形式出现,请在函数名称前面键入等号(=).当生成包含函数的公式时,公式选项板将会提供相关的帮助.使用公式的步骤:A. 单击需要输入公式的单元格.B. 如果公式以函数的形式出现,请在编辑栏中单击“编辑公式”按钮 .C. 单击“函数”下拉列表框 右端的下拉箭头.D. 单击选定需要添加到公式中的函数.如果函数没有出现在列表中,请单击“其它函数”查看其它函数列表.E. 输入参数.F. 完成输入公式后,请按 ENTER 键.1.2 几种常见的统计函数1.2.1均值 Excel 计算平均数使用A VERAGE 函数,其格式如下:A VERAGE (参数1,参数2,…,参数30)范例:A VERAGE (12.6,13.4,11.9,12.8,13.0)=12.74如果要计算单元格中A1到B20元素的平均数,可用 A VERAGE(A1:B20).1.2.2 标准差计算标准差可依据样本当作变量或总体当作变量来分别计算,根据样本计算的结果称作样本标准差,而依据总体计算的结果称作总体标准差.(1)样本标准差Excel 计算样本标准差采用无偏估计式,STDEV 函数格式如下:STDEV (参数1,参数2,…,参数30)范例:STDEV (3,5,6,4,6,7,5)=1.35如果要计算单元格中A1到B20元素的样本标准差,可用 STDEV(A1:B20).(2)总体标准差Excel 计算总体标准差采用有偏估计式STDEVP 函数,其格式如下:STDEVP (参数1,参数2,…,参数30)范例:STDEVP (3,5,6,4,6,7,5)=1.251.2.3 方差方差为标准差的平方,在统计上亦分样本方差与总体方差.(1)样本方差S 2=1)(2--∑n x x iExcel 计算样本方差使用V AR 函数,格式如下:V AR (参数1,参数2,…,参数30)如果要计算单元格中A1到B20元素的样本方差,可用 V AR(A1:B20).范例:V AR (3,5,6,4,6,7,5)=1.81(2)总体方差S 2=n x x i ∑-2)(Excel 计算总体方差使用V ARP 函数,格式如下:V ARP (参数1,参数2,…,参数30)范例:V AR (3,5,6,4,6,7,5)=1.551.2.4 正态分布函数Excel 计算正态分布时,使用NORMDIST 函数,其格式如下:NORMDIST (变量,均值,标准差,累积)其中:变量(x ):为分布要计算的x 值;均值(μ):分布的均值;标准差(σ):分布的标准差;累积:若为TRUE ,则为分布函数;若为FALSE ,则为概率密度函数.范例:已知X 服从正态分布,μ=600,σ=100,求P {X ≤500}.输入公式=NORMDIST (500,600,100,TRUE )得到的结果为0.158655,即P {X ≤500}=0.158655.1.2.5 正态分布函数的反函数Excel 计算正态分布函数的反函数使用NORMINV 函数,格式如下:NORMINV (下侧概率,均值,标准差)范例:已知概率P =0.841345,均值μ=360,标准差σ=40,求NORMINV 函数的值.输入公式=NORMINV (0.841345,360,40)得到结果为400,即P {X ≤400}=0.841345.注意:(1) NORMDIST 函数的反函数NORMINV 用于分布函数,而非概率密度函数,请务必注意;(2) Excel 提供了计算标准正态分布函数 NORMSDIST(x),及标准正态分布的反函数 NORMSINV(概率).范例:已知X~N(0,1), 计算(2)Φ=P {X <2}.输入公式=NORMSDIST(2)得到0.97725,即(2)Φ=0.97725.范例:输入公式=NORMSINV(0.97725) ,得到数值2.若求临界值u α(n ),则使用公式=NORMSINV(1-α).1.2.6 t 分布Excel 计算t 分布的值(查表值)采用TDIST 函数,格式如下:TDIST (变量,自由度,侧数)其中:变量(t ):为判断分布的数值;自由度(v ):以整数表明的自由度;侧数:指明分布为单侧或双侧:若为1,为单侧;若为2,为双侧.范例:设T 服从t (n-1)分布,样本数为25,求P (T >1.711).已知t =1.711,n =25,采用单侧,则T 分布的值:=TDIST(1.711,24,1)得到0.05,即P (T >1.711)=0.05.若采用双侧,则T 分布的值:=TDIST(1.711,24,2)得到0.1,即()1.7110.1P T >=. 1.2.7 t 分布的反函数Excel 使用TINV 函数得到t 分布的反函数,格式如下:TINV (双侧概率,自由度)范例:已知随机变量服从t (10)分布,置信度为0.05,求t 205.0(10).输入公式=TINV(0.05,10)得到2.2281,即()2.22810.05P T >=.若求临界值t α(n ),则使用公式=TINV(2*α, n ).范例:已知随机变量服从t (10)分布,置信度为0.05,求t 0.05 (10).输入公式=TINV(0.1,10)得到1.812462,即t 0.05 (10)= 1.812462. 1.2.8 F 分布Excel 采用FDIST 函数计算F 分布的上侧概率1()F x -,格式如下:FDIST(变量,自由度1,自由度2)其中:变量(x ):判断函数的变量值;自由度1(1n ):代表第1个样本的自由度;自由度2(2n ):代表第2个样本的自由度.范例:设X 服从自由度1n =5,2n =15的F 分布,求P (X >2.9)的值.输入公式=FDIST(2.9,5,15)得到值为0.05,相当于临界值α.1.2.9 F 分布的反函数Excel 使用FINV 函数得到F 分布的反函数,即临界值12(,)F n n α,格式为:FINV(上侧概率,自由度1,自由度2)范例:已知随机变量X 服从F (9,9)分布,临界值α=0.05,求其上侧0.05分位点F 0.05(9,9).输入公式=FINV(0.05,9,9)得到值为3.178897,即F 0.05(9,9)= 3.178897.若求单侧百分位点F 0.025(9,9),F 0.975(9,9).可使用公式=FINV(0.025,9,9)=FINV(0.975,9,9)得到两个临界值4.025992和0.248386.若求临界值F α(n 1,n 2),则使用公式=FINV(α, n 1,n 2).1.2.10 卡方分布Excel 使用CHIDIST 函数得到卡方分布的上侧概率1()F x -,其格式为:CHIDIST(数值,自由度)其中:数值(x ):要判断分布的数值;自由度(v ):指明自由度的数字.范例:若X 服从自由度v =12的卡方分布,求P (X >5.226)的值.输入公式=CHIDIST(5.226,12)得到0.95,即1(5.226)F -=0.95或(5.226)F =0.05.1.2.11 卡方分布的反函数Excel 使用CHIINV 函数得到卡方分布的反函数,即临界值2()n αχ.格式为:CHIINV (上侧概率值α,自由度n )范例:下面的公式计算卡方分布的反函数:=CHIINV(0.95,12)得到值为5.226,即20.95(12)χ=5.226.若求临界值2αχ(n),则使用公式=CHIINV(α, n). 1.2.12 泊松分布计算泊松分布使用POISSON 函数,格式如下:POISSON(变量,参数,累计)其中:变量:表示事件发生的次数;参数:泊松分布的参数值;累计:若TRUE ,为泊松分布函数值;若FALSE ,则为泊松分布概率分布值. 范例:设X服从参数为4的泊松分布,计算P {X =6}及P {X ≤6}.输入公式=POISSON(6,4,FALSE)=POISSON(6,4,TRUE)得到概率0.104196和0.889326.在下面的实验中,还将碰到一些其它函数,例如:计算样本容量的函数COUNT ,开平方函数SQRT ,和函数SUM ,等等.关于这些函数的具体用法,可以查看Excel 的关于函数的说明,不再赘述.2 区间估计实验计算置信区间的本质是输入两个公式,分别计算置信下限与置信上限.当熟悉了数据输入方法及常见统计函数后,变得十分简单.2.1 单个正态总体均值与方差的区间估计:2.1.1?2已知时?的置信区间 置信区间为22x u x u αα⎛⎫-+ ⎝. 例1 随机从一批苗木中抽取16株,测得其高度(单位:m )为:1.14 1.10 1.131.15 1.20 1.12 1.17 1.19 1.15 1.12 1.14 1.20 1.23 1.11 1.14 1.16.设苗高服从正态分布,求总体均值μ的0.95的置信区间.已知σ =0.01(米).步骤:(1)在一个矩形区域内输入观测数据,例如在矩形区域B3:G5内输入样本数据.(2)计算置信下限和置信上限.可以在数据区域B3:G5以外的任意两个单元格内分别输入如下两个表达式:=average(b3:g5)-normsinv(1-0.5*α)*σ/sqrt(count(b3:g5))=average(b3:g5)+normsinv(1-0.5*α)*σ/sqrt(count(b3:g5))上述第一个表达式计算置信下限,第二个表达式计算置信上限.其中,显着性水平α和标准差σ是具体的数值而不是符号.本例中,? =0.05, 0.01σ=,上述两个公式应实际输入为=average(b3:g5)-normsinv(0.975)*0.01/sqrt(count(b3:g5))=average(b3:g5)+normsinv(0.975)*0.01/sqrt(count(b3:g5))计算结果为(1.148225, 1.158025).2.1.2 ?2未知时?的置信区间置信区间为22((x t n x t n αα⎛⎫--+- ⎝. 例2 同例1,但σ未知.输入公式为:=average(b3:g5)-tinv(0.05,count(b:3:g5)-1)*stdev(b3:g5)/sqrt(count(b3:g5))=average(b3:g5)-tinv(0.05,count(b:3:g5)-1)*stdev(b3:g5)/sqrt(count(b3:g5))计算结果为(1.133695, 1.172555).2.1.3 ?未知时?2的置信区间:置信区间为 2222122(1)(1),(1)(1)n n n n s s ααχχ-⎛⎫ ⎪-- ⎪-- ⎪⎝⎭. 例3 从一批火箭推力装置中随机抽取10个进行试验,它们的燃烧时间 (单位:s)如下:50.7 54.9 54.3 44.8 42.2 69.8 53.4 66.1 48.1 34.5试求总体方差2σ的0.9的置信区间(设总体为正态).操作步骤:(1)在单元格B3:C7分别输入样本数据;(2)在单元格C9中输入样本数或输入公式=COUNT(B3:C7);(3)在单元格C10中输入置信水平0.1.(4)计算样本方差:在单元格C11中输入公式=V AR(B3:C7)(5)计算两个查表值:在单元格C12中输入公式=CHIINV(C10/2,C9-1),在单元格C13中输入公式=CHIINV(1-C10/2,C9-1)(6)计算置信区间下限:在单元格C14中输入公式=(C9-1)*C11/C12(7)计算置信区间上限:在单元格C15中输入公式=(C9-1)*C11/C13.当然,读者可以在输入数据后,直接输入如下两个表达式计算两个置信限:=(count(b3:c7)-1)*var(b3:c7)/chiinv(0.1/2, count(b3:c7)-1)=(count(b3:c7)-1)*var(b3:c7)/chiinv(1-0.1/2, count(b3:c7)-1)2.2 两正态总体均值差与方差比的区间估计2.2.1当?12 =??22 =??2但未知时?1-?2的置信区间置信区间为()122(2) x y t n n Sα⎛-±+-⎝.例4在甲,乙两地随机抽取同一品种小麦籽粒的样本,其容量分别为5和7,分析其蛋白质含量为甲:12.6 13.4 11.9 12.813.0乙:13.1 13.4 12.8 13.5 13.3 12.7 12.4蛋白质含量符合正态等方差条件,试估计甲,乙两地小麦蛋白质含量差μ1-μ2所在的范围.(取α=0.05)实验步骤:(1)在A2:A6输入甲组数据,在B2:B8输入乙组数据;(2)在单元格B11输入公式=A VERAGE(A2:A6),在单元格B12中输入公式=A VERAGE(B2:B8),分别计算出甲组和乙组样本均值.(3)分别在单元格C11和C12分别输入公式=V AR(A2:A6),=V AR(B2:B8),计算出两组样本的方差.(4)在单元格D11和D12分别输入公式=COUNT(A2:A6),=COUNT(B2:B8),计算各样本的容量大小.(5)将显着性水平0.05输入到单元格E11中.(6)分别在单元格B13和B14输入=B11-B12-TINV(0.025,10)*SQRT((4*C11+6*C12)/10)*SQRT(1/ 5+1/7)和=B11-B12+TINV(0.025,10)*SQRT((4*C11+6*C12)/10)*SQRT(1/ 5+1/7)计算出置信区间的下限和上限.2.2.2 ?1和??未知时方差比σ21/σ22的置信区间置信区间为 22112221221212211,(1,1)(1,1)s s s F n n s F n n αα-⎛⎫ ⎪ ⎪---- ⎪⎝⎭ . 例5 有两个化验员A 、B ,他们独立地对某种聚合物的含氯量用相同的方法各作了10次测定.其测定值的方差分别是S A =0.5419,S B =0.6065.设σ2A 和σ2B 分别是A 、B 所测量的数据总体(设为正态分布)的方差.求方差比σ2A /σ2B 的 0.95置信区间.操作步骤: (1)在单元格B2,B3输入样本数,C2,C3输入样本方差,D2输入置信度.(2)在B4和B5利用公式输入=C2/(C3*FINV(1-D2/2,B2-1,B3-1))和=C2/(C3*FINV(D2/2,B2-1,B3-1))计算出A 组和B 组的方差比的置信区间上限和下限.2.3 练习题1. 已知某树种的树高服从正态分布,随机抽取了该树种的60株林木组成样本.样本中各林木的树高资料如下(单位:m)22.3, 21.2, 19.2, 16.6, 23.1, 23.9, 24.8, 26.4, 26.6, 24.8, 23.9, 23.2, 23.3, 21.4, 19.8, 18.3,20.0, 21.5, 18.7, 22.4, 26.6, 23.9, 24.8, 18.8, 27.1, 20.6, 25.0, 22.5, 23.5, 23.9, 25.3, 23.5,22.6, 21.5, 20.6, 25.8, 24.0, 23.5, 22.6, 21.8, 20.8, 19.5, 20.9, 22.1, 22.7, 23.6, 24.5, 23.6,21.0, 21.3, 22.4,18.7, 21.3, 15.4, 22.9, 17.8, 21.7, 19.1, 20.3, 19.8试以0.95的可靠性,对于该林地上全部林木的平均高进行估计.2. 从一批灯泡中随机抽取10个进行测试,测得它们的寿命(单位:100h)为:50.7,54.9,54.3,44.8,42.2,69.8,53.4,66.1,48.1,34.5.试求总体方差的0.9的置信区间(设总体为正态).3. 已知某种玉米的产量服从正态分布,现有种植该玉米的两个实验区,各分为10个小区,各小区的面积相同,在这两个实验区中,除第一实验区施以磷肥外,其它条件相同,两实验区的玉米产量(kg)如下:第一实验区:62 57 65 60 63 58 57 60 60 58第二实验区:56 59 56 57 60 58 57 55 57 55试求出施以磷肥的玉米产量均值和未施以磷肥的玉米产量均值之差的范围(α=0.05)3假设检验实验实验内容:单个总体均值的假设检验;两个总体均值差的假设检验;两个正态总体方差齐性的假设检验;拟合优度检验.实验目的与要求:(1)理解假设检验的统计思想,掌握假设检验的计算步骤;(2)掌握运用Excel进行假设检验的方法和操作步骤;(3)能够利用试验结果的信息,对所关心的事物作出合理的推断.3.1 单个正态总体均值μ的检验3.1.1 2已知时μ的U检验例1 外地一良种作物,其1000m2产量(单位:kg)服从N(800, 502),引入本地试种,收获时任取5块地,其1000m2产量分别是800,850,780,900,820(kg),假定引种后1000m2产量X也服从正态分布,试问:(1)若方差未变,本地平均产量μ与原产地的平均产量μ=800kg 有无显着变化.0=800kg高.(2)本地平均产量μ是否比原产地的平均产量μ0=800kg低.(3)本地平均产量μ是否比原产地的平均产量μ0操作步骤:(1)先建一个如下图所示的工作表:(2)计算样本均值(平均产量),在单元格D5输入公式=A VERAGE(A3:E3);(3)在单元格D6输入样本数5;(4)在单元格D8输入U检验值计算公式=(D5-800)/(50/SQRT(D6);(5)在单元格D9输入U检验的临界值=NORMSINV(0.975);(6)根据算出的数值作出推论.本例中,U的检验值1.341641小于临界值1.959961,故接受原假设,即平均产量与原产地无显着差异.(7)注:在例1中,问题(2)要计算U检验的右侧临界值:在单元格D10输入U检验的上侧临界值=NORMSINV(0.95).问题(3)要计算U检验的下侧临界值,在单元格D11输入U 检验下侧的临界值=NORMSINV(0.05).3.1.2?2未知时的t检验例2某一引擎制造商新生产某一种引擎,将生产的引擎装入汽车内进行速度测试,得到行驶速度如下:250 238 265 242 248 258 255 236 245 261254 256 246 242 247 256 258 259 262 263该引擎制造商宣称引擎的平均速度高于250 km/h,请问样本数据在显着性水平为0.025时,是否和他的声明抵触?操作步骤:(1)先建如图所示的工作表:(2)计算样本均值:在单元格D8输入公式=A VERAGE(A3:E6);(3)计算标准差:在单元格D9输入公式=STDEV(A3:E6);(4)在单元格D10输入样本数20.(5)在单元格D11输入t检验值计算公式=(D8-250)/(D9/(SQRT(D10)),得到结果1.06087;(6)在单元格D12输入t检验上侧临界值计算公式=TINV(0.05, D10-1).欲检验假设H0:μ=250;H:μ>250.1已知t统计量的自由度为(n-1)=20-1=19,拒绝域为t>t=2.093.由上面计算得到t.0025检验统计量的值1.06087落在接收域内,故接收原假设H0.3.2 两个正态总体参数的假设检验μ-μ的检验3.2.1当?12 =??22 =??2但未知时12在此情况下,采用t检验.例试验及观测数据同11.2中的练习题3,试判别磷肥对玉米产量有无显着影响?欲检验假设:μ1>μ2.H0:μ1=μ2;H1操作步骤:(1)建立如图所示工作表:(2)选取“工具”—“数据分析”;(3)选定“t-检验:双样本等方差假设”.(4)选择“确定”.显示一个“t-检验:双样本等方差假设”对话框;(5)在“变量1的区域”输入A2:A11.(6)在“变量2的区域”输入B2:B11.(7)在“输出区域”输入D1,表示输出结果放置于D1向右方的单元格中.(8)在显着水平“α”框,输入0.05.(9)在“假设平均差”窗口输入0.(10)选择“确定”,计算结果如D1:F14显示.得到t值为3.03,“t单尾临界”值为1.734063.由于3.03>1.73,所以拒绝原假设,接收备择假设,即认为使用磷肥对提高玉米产量有显着影响.3.2.2σ21与σ22已知时12μ-μ的U检验例3 某班20人进行了数学测验,第1组和第2组测验结果如下:第1组:91 88 76 98 94 92 90 87 100 69第2组:90 91 80 92 92 94 98 78 86 91已知两组的总体方差分别是57与53,取α =0.05,可否认为两组学生的成绩有差异?操作步骤:(1)建立如图所示工作表:(2)选取“工具”—“数据分析”;(3)选定“z-检验:双样本平均差检验”;(4)选择“确定”,显示一个“z-检验:双样本平均差检验”对话框;(5)在“变量1的区域”输入A2:A11;(6)在“变量2的区域”输入B2:B11;(7)在“输出区域”输入D1;(8)在显着水平“α”框,输入0.05;(9)在“假设平均差”窗口输入0;(10)在“变量1的方差”窗口输入57;(11)在“变量2的方差”窗口输入53;(12)选择“确定”,得到结果如图所示.计算结果得到z=-0.21106(即u统计量的值),其绝对值小于“z双尾临界”值1.959961,故接收原假设,表示无充分证据表明两组学生数学测验成绩有差异.3.2.3两个正态总体的方差齐性的F检验例5羊毛在处理前与后分别抽样分析其含脂率如下:处理前:0.19 0.18 0.21 0.30 0.41 0.12 0.27处理后:0.15 0.13 0.07 0.24 0.19 0.06 0.08 0.12问处理前后含脂率的标准差是否有显着差异?欲检验假设H0:σ21=σ22;H1:σ21≠σ22.操作步骤如下:(1)建立如图所示工作表:(2)选取“工具”—“数据分析”; (3)选定“F-检验 双样本方差”. (4)选择“确定”,显示一个“F-检验:双样本方差”对话框; (5)在“变量1的区域”输入A2:A8. (6)在“变量2的区域”输入B2:B9. (7)在显着水平“α”框,输入0.025. (8)在“输出区域”框输入D1. (9)选择“确定”,得到结果如图所示.计算出F 值2.35049小于“F 单尾临界”值5.118579,且P(F<=f)=0.144119>0.025,故接收原假设,表示无理由怀疑两总体方差相等.4 拟合优度检验拟合优度检验使用统计量221()ki i i i n np np χ=-=∑, (11.1) i i n np k 其中为实测频数,为理论频数,为分组数。
excle做概率累计曲线粒度 (1)
excel做概率分布累积曲线步骤绝对详细的用excel做概率分布累积曲线的好东西,是我一步一步的摸索出来的,热的哦,有问题也可以发消息我解答的。
1. 建立模板建立模板. A. 新建EXCEL 文件, 在A1 : A17 单元格内输入数字“0”, 在B1 : B17 单元格内分别输入数字99. 99 , 99.9 ,99 ,95 ,90 ,80 ,70 ,60 ,50 ,40 ,30 ,20 ,10 ,5 ,1 ,0. 1 ,0. 01 。
前者作为横坐标, 代表将来纵轴与横轴的交叉位置, 其数值以后要根据实际情况调整。
后者代表纵轴以百分数表示的概率刻度值。
B. 选择C1 单元后击粘贴函数(见图1 中箭头所指位置) , 待出现粘贴函数菜单后选取统计类的NORMSINV 函数。
C. 出现新的对话框后, 在probability 后输入“B1/ 100”, 然后确定. D.这时C1 单元格内就有了一个函数值, 拖动C1单元格的填充柄(C1 单元格右下角的小黑块) 向下填充, 则C2 : C17 单元格内都自动生成了函数值。
E. 设置C1 : C17 单元格格式, 将其数值的小数位数定为“2”。
2.做草图 2.做草图选中A1 : A17 和C1 : C17 单元格后, 选择图表向导, 按照提示进行: A.在4 步骤之1 中, 选择X、Y 散点图类型中的第一子类型, 后单击下一步; B.在4 步骤之2 中, 确认系列产生在列(点中“列”前面的小圈) , 后单击下一步; C.在4 步骤之3 中, 可暂不做选择, 直接单击下一步; D.在4 步骤之4 , 根据喜好选图表位置, 本文中选“新工作表”, 单击“完成”后草图就算做成了. 3. 修图 A.首先先去掉图例框、绘图区背景色以及网格线,便于下面的修改; B. 选择数值( Y) 轴, 按鼠标右键弹出菜单后选“坐标轴格式”, 在“坐标轴格式” 菜单中做如下设置: ①在“图案” 项中将主、次刻度线类型及刻度线标志均选“无” ; ②在“刻度”项中,最小值选“-3. 72 ”, 最大值选“3. 72 ”,数值( X) 轴交叉于( C) : 选“-3. 72 ” ; C. 选择数据系列, 按鼠标右键弹出菜单后选“数据系列格式”, 在该菜单作如下设置: ①将图案中的“数据标记样式”选为短横线作为纵轴刻度线; ②在“数据标志”项中选“显示值”, 然后确定。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
20.00% -0.8416212
0
0.40% -2.6520698
30.00% -0.5244005
0
0.60% -2.5121443
40.00% -0.2533471
0
0.70% -2.4572634
50.00%
0
0
0.80% -2.4089155
60.00% 0.2533471
0
0.90% -2.3656181
0
0.07% -3.1946511
1.00% -2.3263479
0
0.08% -3.1559068
5.00% -1.6448536
0
0.09% -3.1213891
10.00% -1.2815516
0
0.20% -2.8781617
15.00% -1.0364334
0
0.30% -2.7477814
右端点值 累计频率(%) 作图值
45
6.90% -1.4832801
50
27.60% -0.5947658
55
48.30% -0.0426256
60
65.50% 0.39885507
65
82.80% 0.94629136
70
93.10% 1.48328013
75
99.99% 3.71901649
99.99% 99.90% 99.00%
70.00% 0.52440051
0
2.00% -2.0537489
80.00% 0.84162123
0
3.00% -1.8807936
85.00% 1.03643339
0
4.00% -1.7506861
90.00% 1.28155157
0
6.00% -1.5547736
95.00% 1.64485363
0
87.00% 1.12639113
0
88.00% 1.17498679
0
89.00% 1.22652812
0
91.00% 1.34075503
0
92.00% 1.40507156
0
93.00% 1.47579103
0
94.00% 1.55477359
0
96.00% 1.75068607
0
97.00% 1.88079361
99.99% 3.71901649
0
13.00% -1.1263911
0
14.00% -1.0803193
0
16.00% -0.9944579
0
17.00% -0.9541653
0
18.00% -0.9153651
0
19.00% -0.8778963
0
22.00% -0.7721932
0
24.00% -0.7063026
0
72.00% 0.58284151
0
74.00% 0.64334541
0
76.00% 0.70630256
0
78.00% 0.77219321
0
81.00% 0.8778963
0
82.00% 0.91536509
0
83.00% 0.95416525
0
84.00% 0.99445788
0
86.00% 1.08031934
选择已显示 出的数据标 志值,在“ 数据标志格 式》对齐》 标志位置” 中设置“靠 左”。
3.719016485
3.290526731 3.090232306
概率纸图
2.575829304 2.326347874
1.644853627 1.281551566
累积概率(%)
1.644853627
1.281551566 1.036433389 0.841621234
80.00% 70.00% 60.00% 50.00% 40.00% 30.00% 20.00%
累积概率
20.00% 10.00%
5.00%
1.00%
0.10%
0.01% 0
10
20
30
40
50
60
70
80
90
100
Leq
8.这样概率 纸已做好, 只要将下列 数据作为一 个新的系列 加入到图表 中就完成 了,请注意 概率纸不能 反映100%的 概率,所以 用99.99%代 替。
Y轴次网格
Y轴主网格 请继续往下
累积分布值 值
累积分布值 值
阅读
0
0.02% -3.5400838
0.01% -3.7190165
0
0.03% -3.4316144
0.05% -3.2905267
0
0.04% -3.3527948
0.10% -3.0902323
0
0.06% -3.2388801
0.50% -2.5758293
概率纸 图的制 作方法
1.先假设横 坐标的数值 范围为0~ 100,实际 使用中可以 按情况自行 调整,按下 面的数据作 为自定义坐 标Y轴的数 据。
X轴值取数 值范围的最 小值,累积 分布值就是 累积概率分 布值,网格
值就是用
NORMSINV 函数计算的 达到指定累
积概率值时 的对应数值 。
X轴值
Leq
5.分别设置Y 轴主次网格 值系列的误 差线X为定 值100,其 中的100为X 坐标的最大 最小刻度差 值。
概率纸图
累积概率(%)
0
10 20 30 40 50 60 70 80 90 100
Leq
6.隐藏“Y轴 次网格值” 系列的“数 据标记”, 并显示“Y 轴主网格值 ”系列的“ 数据标志” 为“显示值 ”。
0
7.00% -1.475791
99.00% 2.32634787
0
8.00% -1.4050716
99.50% 2.5758293
0
9.00% -1.340755
99.90% 3.09023231
0
11.00% -1.2265281
99.95% 3.29052673
0
12.00% -1.1749868
0
99.92% 3.15590676
0
99.93% 3.19465105
0
99.94% 3.23888012
0
99.96% 3.35279478
0
99.97% 3.4316144
0
99.98% 3.5400838
2.按上面的 两组网格值 数据作2个 XY散点图系 列。
累积概率(%)
5
4
3
2
1
0
-1 0
0
48.00% -0.0501536
0
52.00% 0.05015358
0
54.00% 0.10043372
0
56.00% 0.15096922
0
58.00% 0.20189348
0
62.00% 0.30548079
0
64.00% 0.35845879
0
66.00% 0.41246313
0
68.00% 0.4676988
-0.71947 -1.71947 -2.71947 -3.71947
0
4.隐藏坐标Y 轴、图例, 并显示坐标 X轴的主要 网格线。
概率纸图
Y轴主网格值 Y轴次网格值
10 20 30 40 50 60 70 80 90 100
Leq
概率纸图
累积概率(%)
0 10 20 30 40 50 60 70 80 90 100
-3.719016485 0
7.隐藏“Y轴 主网格值” 系列的“数 据标记”。 并单选每一 个显示的数 据标志,在 公式编辑栏 中用公式对 指定单元格 进行链接, 不要显示的 就删除。
99.99%
10 20 30 40 50 60 70 80 90 100 Leq
概率纸图
99.90%
99.00%
95.00% 90.00%
0
98.00% 2.05374891
0
99.10% 2.36561813
0
99.20% 2.40891555
0
99.30% 2.45726339
0
99.40% 2.51214433
0
99.60% 2.65206981
0
99.70% 9
0
99.80% 2.87816174
0
99.91% 3.12138915
概率纸图
累积概率
95.00% 90.00%
80.00% 70.00% 60.00% 50.00% 40.00% 30.00% 20.00%
10.00% 5.00%
1.00%
0.10%
0.10%
0.01% 0
10
20
30
40
50
60
Leq
60
70
80
90
100
0.524400513 0.253347103
0 -0.253347103 -0.524400513
-0.841621234 -1.036433389 -1.281551566
-1.644853627
-2.326347874 -2.575829304
-3.090232306 -3.290526731
0
26.00% -0.6433454
0
28.00% -0.5828415