数据编码(041440516
错误编码一览表.doc
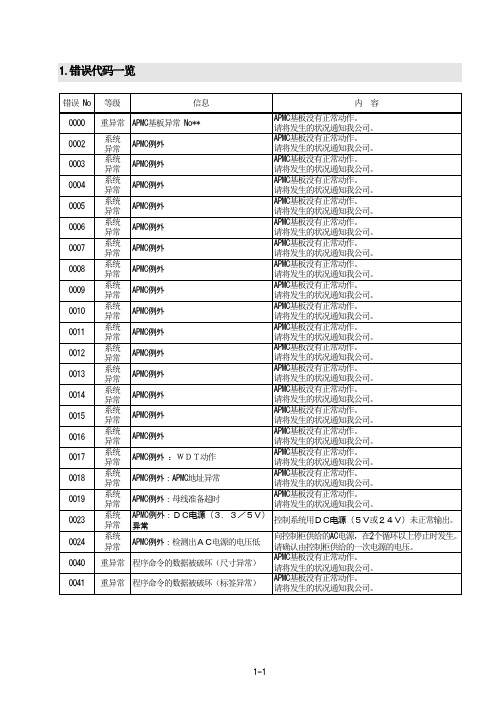
错误 No 0000 0002 0003 0004 0005 0006 0007 0008 0009 0010 0011 0012 0013 0014 0015 0016 0017 0018 0019 0023 0024 0040 0041 等级 信息 内 容 APMC基板没有正常动作。 请将发生的状况通知我公司。 APMC基板没有正常动作。 请将发生的状况通知我公司。 APMC基板没有正常动作。 请将发生的状况通知我公司。 APMC基板没有正常动作。 请将发生的状况通知我公司。 APMC基板没有正常动作。 请将发生的状况通知我公司。 APMC基板没有正常动作。 请将发生的状况通知我公司。 APMC基板没有正常动作。 请将发生的状况通知我公司。 APMC基板没有正常动作。 请将发生的状况通知我公司。 APMC基板没有正常动作。 请将发生的状况通知我公司。 APMC基板没有正常动作。 请将发生的状况通知我公司。 APMC基板没有正常动作。 请将发生的状况通知我公司。 APMC基板没有正常动作。 请将发生的状况通知我公司。 APMC基板没有正常动作。 请将发生的状况通知我公司。 APMC基板没有正常动作。 请将发生的状况通知我公司。 APMC基板没有正常动作。 请将发生的状况通知我公司。 APMC基板没有正常动作。 请将发生的状况通知我公司。 APMC基板没有正常动作。 请将发生的状况通知我公司。 APMC基板没有正常动作。 请将发生的状况通知我公司。 APMC基板没有正常动作。 请将发生的状况通知我公司。
重异常 程序命令的数据被破坏(不能读出) 重异常 APMC基板异常 重异常 APMC基板异常 重异常 APMC基板异常 重异常 APMC基板异常 重异常 APMC基板异常 重异常 APMC基板异常 重异常 程序命令的数据被破坏 (位置数据类型)
计算机编码大全

计算机编码大全从基础的开始最小的单元是位(bit),接着是字节(Byte),一个字节=8位,英语表示是1 byte=8 bits 。
机器语言的单位Byte。
接着是KB,1 KB=1024 Byte; 接着是MB,1 MB=1024 KB; 接着是GB,1 GB=1024 MB ;接着是TB, 1TB=1024 GB。
接着是进制:二进制0和1,8进制0-7,十进制不用说,16进制0-9后面是A,B,C,D,E,F 他们关系如下:Binary Octal Decimal Hex0 0 0 01 1 1 110 2 2 211 3 3 3100 4 4 4101 5 5 5110 6 6 6111 7 7 71000 10 8 81001 11 9 91010 12 10 A1011 13 11 B1100 14 12 C1101 15 13 D1110 16 14 E1111 17 15 F接着是上层建筑字符:字符是各种文字和符号的总称,包括各国家文字、标点符号、图形符号、数字等。
字符集是多个字符的集合,字符集种类较多,每个字符集包含的字符个数不同,常见字符集名称:ASCII字符集、GB2312字符集、BIG5字符集、 GB 18030字符集、Unicode字符集等。
计算机要准确的处理各种字符集文字,需要进行字符编码,以便计算机能够识别和存储各种文字。
ASCII 字符集ASCII(American Standard Code for Information Interchange,美国信息互换标准代码)是基于罗马字母表的一套电脑编码系统,它主要用于显示现代英语和其他西欧语言。
它是现今最通用的单字节编码系统,并等同于国际标准ISO 646。
包含内容:控制字符:回车键、退格、换行键等。
可显示字符:英文大小写字符、阿拉伯数字和西文符号ASCII扩展字符集扩展:表格符号、计算符号、希腊字母和特殊的拉丁符号。
13信息采集代码表_汇总

山东省 山东省 山东省 山东省 山东省 山东省 山东省 山东省 山东省 山东省 山东省 山东省 山东省 山东省 山东省 山东省 山东省 山东省 山东省 山东省 山东省 山东省 山东省 山东省 山东省 山东省 山东省 山东省 山东省 山东省 山东省 山东省 山东省 山东省 山东省 山东省 山东省 山东省 山东省 山东省 山东省 山东省 山东省 山东省 山东省 山东省 山东省
2 2 2 1 2 2 2 2 2 2 1 2 1 2 2 1 2 1 2 2 2 2 1 1 1 2 2 1 2 1 2 2 2 2 2 2 1 2 2 2 2 2 1 2 2 2 2
1990-2-17 1991-6-1 1989-1-2 1988-7-2 1990-1-3 1992-7-4 1991-8-18 1991-6-14 1991-1-1 1991-12-19 1991-7-12 1989-2-20 1991-3-20 1991-4-13 1991-11-18 1991-1-29 1990-2-25 1990-7-16 1990-10-20 1993-10-19 1991-10-13 1991-3-11 1990-7-13 1991-1-28 1991-6-15 1991-5-21 1990-10-4 1990-4-2 1989-10-1 1991-11-14 1992-3-17 1991-3-13 1991-7-29 1992-2-14 1991-11-10 1990-12-26 1990-10-3 1991-4-9 1990-10-28 1990-10-10 1988-2-12 1991-2-8 1990-1-20 1990-11-18 1990-7-6 1988-12-22 1990-7-14
理科 理科 理科 理科 理科 理科 理科 理科 理科 理科 理科 理科 理科 理科 理科 理科 理科 理科 理科 理科 理科 理科 理科 理科 理科 文科 文科 文科 文科 文科 文科 文科 文科 文科 文科 文科 文科 文科 文科 文科 文科 文科 文科 文科 文科 文科 文科
汉字编码表

汉字编码表汉字编码表是指unicode字符集中所包含的汉字及其拼音、笔画等一系列特征信息的列表。
以此表为基础,我们可以方便地在计算机中处理、输入和输出汉字文字。
下面是关于汉字编码表的详细介绍。
一、汉字编码的历史汉字编码的历史可以追溯到计算机问世之初,当时的计算机只能处理英文字符,汉字是不能够被计算机处理的。
为了解决这个问题,人们想出了一种叫做“汉字编码”的方法,将汉字转换为计算机可以识别的数字代码,从而实现汉字文字的输入输出。
汉字编码最早的版本是中国国家标准GB2312,于1980年发布,其中包含了6763个常用汉字,以及682个生僻汉字和符号。
但后来随着社会的发展,汉字数量不断增加,GB2312编码已经无法满足需求,于是便出现了GBK编码、GB18030编码等新版本。
二、汉字编码表的结构汉字编码表通常由三个部分组成:区码、位码和字符描述信息。
区码是汉字编码的一个重要部分,它用于表示汉字所在的区域。
GB2312编码中,共分为94个区,每个区由一组汉字组成,区码范围从A1至F7,每个区包含94个位码,共计8836个字符。
GBK编码中,共分为126个区,其中94个区与GB2312编码相同,另外32个区包含了1600个生僻汉字和符号。
区码范围从81至FE。
GB18030编码共分为257个区,其中126个区与GBK编码相同,另外131个区包含了7万多个汉字。
位码是汉字编码表中的另一个重要部分,它用于表示汉字在所在区中的位置。
每个区包含94个位码,位码范围从A1至FE。
可以看出,位码的数量决定了一个区所能包含的汉字数量,也决定了汉字编码表的容量大小。
字符描述信息的主要包括汉字的拼音、笔画和部首等信息。
其中拼音用于输入法输入汉字,笔画、部首等信息可以用于汉字检索等功能。
三、常用汉字编码表1、GB2312编码表GB2312编码表是最早的汉字编码表,它包含了所有的常用汉字,共6763个。
在GB2312编码表中,区码范围从A1至F7,每个区共计94个位码。
01.数字码序(1-3d)0766.P0121-0140.P1046汉字基本集V186
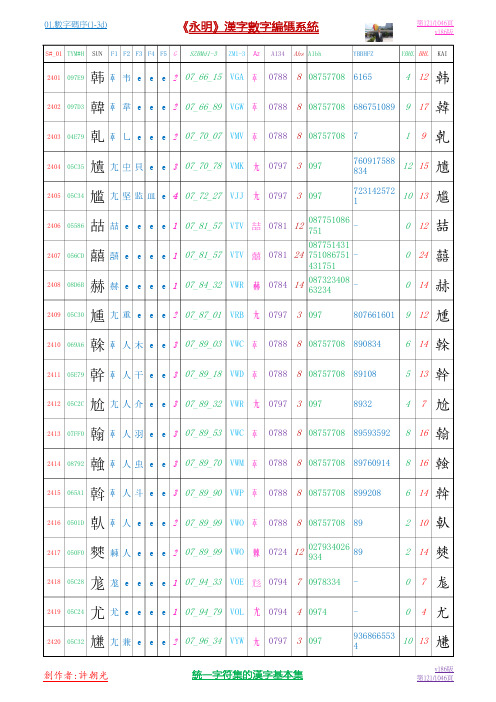
4 12 9 17 1 9
韩 韓 乹 尵 尴 喆 囍 赫 尰 榦 幹 尬 翰 螒 斡 倝 僰 尨 尤 尲
2402 097D3
2403 04E79
2404 05C35
760917588 12 15 834 723142572 10 13 1
2405 05C34
2406 05586
087751086 喆 e e e e 1 07_81_57 VTV 喆 0781 12 751 087751431 囍 e e e e 1 07_81_57 VTV 囍 0781 24 751086751 431751 087323408 赫 e e e e 1 07_84_32 VWR 赫 0784 14 63234 尢 重 e e e 2 07_87_01 VRB 尢 0797 3 097 807661601
統一字符集的漢字基本集
v186版 第122/1046頁
01.數字碼序(1-3d)
《永明》漢字數字編碼系統
F1 F2 F3 F4 F5 G
第123/1046頁 v186版 YBBHFZ
S#_01 TYM#H
SUN
SZBMd1-3
ZM1-3
Az
A134
Ahs A1bh
YBHL BHL
KAI
2441 0622A
4 15 4 15 6 12 6 11 2 8
2443 09EAA
2444 0988A
2445 0804B
2446 0523E
2447 09EA8
088989343 2343 麥 少 e e e 2 08_24_33 CLE 麥 0885 11 65 十 冂 丷 干 犬 5 08_25_04 CMX 十 0888 2 08 十 冂 丷 干 e 4 08_25_18 CMD 十 0888 2 08 十 冂 丷 干 ⻌ 5 08_25_44 CMO 十 0888 2 08 十 具 八 页 e 4 08_28_17 CKF 十 0888 2 08 十 具 八 e e 3 08_28_34 CKW 十 0888 2 08 十 具 八 鳥 e 4 08_28_35 CKQ 十 0888 2 08 十 具 口 匕 e 4 08_28_37 CKR 十 0888 2 08 十 具 心 e e 3 08_28_44 CKO 十 0888 2 08 十 具 e e e 2 08_28_51 CKB 十 0888 2 08 来 贝 e e e 2 08_28_59 CKX 来 0844 7 0480934 十 具 八 頁 e 4 08_28_67 CKF 十 0888 2 08
建设工程造价数据编码规则

建设工程造价数据编码规则
编码示意图
(一)1至4位为规划批准年份代码,指建设工程项目规划立项文件批准年份。
(二)5至8位为行政区划代码,代表建设工程项目所在地的行政区划,具体代码见附表1。
(三)9至10位为工程专业代码;代表建设工程项目所属专业,具体代码见附表2。
(四)11至12位为工程类别代码,代表建设工程项目所属工程类别。
建筑工程、市政公用工程、城市轨道交通工程类别代码由住房和城乡建设部标准定额研究所统一制定。
其他专业工程类别代码由各行业自行制定,交叉行业统一协调制定。
(五)13至14位为工程特征代码,代表建设工程项目工程结构、装置等特征。
建筑工程、市政公用工程、城市轨道交通工程特征代码由住房和城乡建设部标准定额研究所统一制定。
其他专业工程特征代码由各行业自行制定,交叉行业统一协调制定。
(六)15至17位为项目顺序代码,代表建设工程项目收集顺序。
(七)18位为价格类型代码,代表建设工程项目不同阶段造价数据价格类型。
估算为1,概算为2,招标控制价为3,合同价(预算)为4,竣工结算为5。
(八)19至20位为建设工程造价成果文件批准或签订年份的后两位数字。
(九)其中11至14位未分类的代码以0表示。
省(直辖)市(区)。
中国行政区划编码(可查出生地代码)

120223 120225 130000 130100 130101 130102 130103 130104 130105 130107 130108 130121 130123 130124 130125 130126 130127 130128 130129 130130 130131 130132 130133 130181 130182 130183 130184 130185 130200 130201 130202 130203 130204 130205 130207 130208 130223
dm 110000 110100 110101 110102 110105 110106 110107 110108 110109 110111 110112 110113 110114 110115 110116 110117 110200 110228 110229 120000 120100 120101 120102 120103 120104 120105 120106 120110 120111 120112 120113 120114 120115 120116 120200 120221
3.数值型数据的编码PPT

在计算机中可用不同的码制来表示数,常用原码、反码和补码
② 反码
数值型数据的编码
二 原码、反码和补码
③ 补码
三 补码
数值型数据的编码
数值型数据的编码
一、 机器数与真值 二、 原码、反码和补码
数值型数据的编码
一 机器数与真值
计算机内数据采用二进制数的形式,对于带正、负符号的数值 型数据,规定用“0”表示正,用“1”表示负,其他各位仍表示 其数值。这种将符号数码化,并与数字合为一体的机内数表示形式, 称为机器数。
数值型数据的编码
数字编码最简单的物料编码技巧

要点数字编码--最简单的物料编码技巧物料编码是仓储系统对物料的惟一识别代码,它用一组代码来代表一种物料。
物料编码必须是惟一的,也就是,一种物料不能有多个物料编码,一个物料编码不能有多种物料,它们之间的关系是一一对应的。
常见编码形式顺序编码是更简单的一种编码,计算机也可以提供流水编码的功能。
在没有现存的编码可利用的前提下,可以考虑顺序编码,或者称谓流水号编码。
赋义编码顾名思义是赋于编码一定含义。
这种编码常用的是层次码和属性码。
层次码可以表达物料的统计上的卷叠要求;属性码可以表达物料的配置要求。
物料编码的原则唯一性:同一种物料只能对应一个编码,同一编码只能代表一个物料,绝不能出现一个物料多个编码,或多个物料的情况。
可使用性:编码的长度应在6-20之间,不宜过长,否则不易识别规则性:编码应当是按照一定的编码原则编制出来的,并配合对描述进行规范。
可读性:物料编码不一定要求一看就知道是哪种物料,但应当做到一看到物料就能够识别出该物料是属于哪一类的物料,可以考虑采用前段用分类码,后段用顺序码的方式进行编码。
编码的使用者应可以在较短的时间内对编码的方式有大致的了解。
通用性:同一编码原则应能涵盖所有物料,新增加的品种也能够适应可扩展性:编码原则的制定应能考虑公司5-10年内物料的变化趋势。
并且要对不同的情况留有一定的余地。
效率性:编码原则不仅要考虑使用者是否可以较容易地解读,方便记忆和识别,还应当考虑是否有助于提高日常操作的效率。
兼容性:本公司的物料编码应当考虑与主要客户、重要供应商的编码的兼容,这要求要建立一个物料编码对照表,把客户、主要供应商的编码、本公司编码放在一张表内可以自由查询。
对照表综合性:编码原则也应考虑与产品(BOM单)、生产、采购、货仓运作、物料控制、财务、使用软件系统等相关方面的配合使用问题。
例如:在考虑编码时最好全部采用数字,而不要用字母与数字混排,以方便软件系统的使用。
编码误区案例展示一个项目是企业认为其目前的编码体系非常混乱,需要全面整理,重新建立新的编码体系,于是,从产品开发及各业务部门召集8人形成一个编码小组,广泛研究国内外标准零件编号,耗时4个多月,却以失败告终,企业认为涉及方面太多,很难用一套编码把上万中材料清晰地区分开来。
记忆练习数字编码表
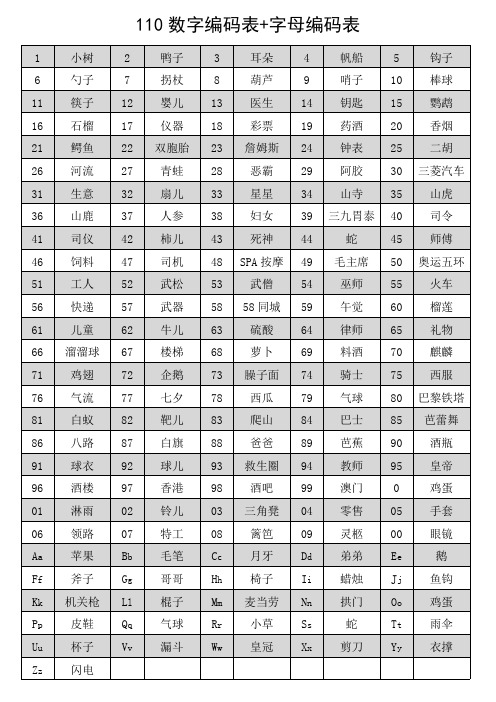
110 数字编码表+字母编码表
1 6 11 16 21 26 31 36 41 46 51 56 61 66 71 76 81 86 91 96 01 06 Aa Ff Kk Pp Uu Zz 小树 勺子 筷子 石榴 鳄鱼 河流 生意 山鹿 司仪 饲料 工人 快递 儿童 溜溜球 鸡翅 气流 白蚁 八路 球衣 酒楼 淋雨 领路 苹果 斧子 机关枪 皮鞋 杯子 闪电 2 7 12 17 22 27 32 37 42 47 52 57 62 67 72 77 82 87 92 97 பைடு நூலகம்2 07 Bb Gg Ll Qq Vv 鸭子 拐杖 婴儿 仪器 双胞胎 青蛙 扇儿 人参 柿儿 司机 武松 武器 牛儿 楼梯 企鹅 七夕 靶儿 白旗 球儿 香港 铃儿 特工 毛笔 哥哥 棍子 气球 漏斗 3 8 13 18 23 28 33 38 43 48 53 58 63 68 73 78 83 88 93 98 03 08 Cc Hh Mm Rr Ww 耳朵 葫芦 医生 彩票 詹姆斯 恶霸 星星 妇女 死神 SPA 按摩 武僧 58 同城 硫酸 萝卜 臊子面 西瓜 爬山 爸爸 救生圈 酒吧 三角凳 篱笆 月牙 椅子 麦当劳 小草 皇冠 4 9 14 19 24 29 34 39 44 49 54 59 64 69 74 79 84 89 94 99 04 09 Dd Ii Nn Ss Xx 帆船 哨子 钥匙 药酒 钟表 阿胶 山寺 三九胃泰 蛇 毛主席 巫师 午觉 律师 料酒 骑士 气球 巴士 芭蕉 教师 澳门 零售 灵柩 弟弟 蜡烛 拱门 蛇 剪刀 5 10 15 20 25 30 35 40 45 50 55 60 65 70 75 80 85 90 95 0 05 00 Ee Jj Oo Tt Yy 钩子 棒球 鹦鹉 香烟 二胡 三菱汽车 山虎 司令 师傅 奥运五环 火车 榴莲 礼物 麒麟 西服 巴黎铁塔 芭蕾舞 酒瓶 皇帝 鸡蛋 手套 眼镜 鹅 鱼钩 鸡蛋 雨伞 衣撑
数字编码表

数字编码表数字编码图片00 望远镜01小树02玲儿03三角凳04轿车05五星06手枪07锄头08溜冰鞋09 猫10 鸡蛋11 帽子12 眼镜13 手帕14 牙刷15 项链16 手套17 背心18 腰带19 坐垫20 鞋鳄鱼21阿姨鸳鸯22双胞胎23 和尚乔丹试管24闹铃二胡25虎柳树26河流27 耳机恶霸28靶子29 酒瓶三轮车30森林鲨鱼31山药扇儿32伞儿咸蛋33仙丹34 山寺35 山谷36 山路37 山鸡伤疤38妇女香蕉39胃药40 司令司仪41蜥蜴42 烧鹅死神43宿舍蛇44柿子45 师父石榴46饲料47 司机48 丝瓜死囚49水饺50 五环武林工人51狐狸52 武二53 午餐乌纱帽五四54乌丝旺旺55火车蜗牛56葫芦57 乌鸡苦瓜58尾巴污垢59蜈蚣60 榴莲老鹰61儿童62 驴儿63 降落伞螺丝64律师65 鹿尿壶蝌蚪66溜溜球楼梯67油漆68 喇叭69 遛狗70 鸡笼71 汽油72 企鹅73 旗杆骑士74棋子西服75积木76 麒麟77 机器78 青蛙79 气球百灵80巴黎白药81军人82 白兔83 芭蕉扇巴士84宝石85 芭蕾舞86 八路搏击87白旗88 爸爸89 棒球90 精灵91 膏药92 孤儿93 僵尸94 狗屎95 酒壶96 骷髅97 香港机关枪98 酒吧99 交警100 毛爷爷1 铅笔2 鸭子3 耳朵4 帆船5 小提琴6 烟斗7 镰刀8 花生9 球拍。
ASCII码表
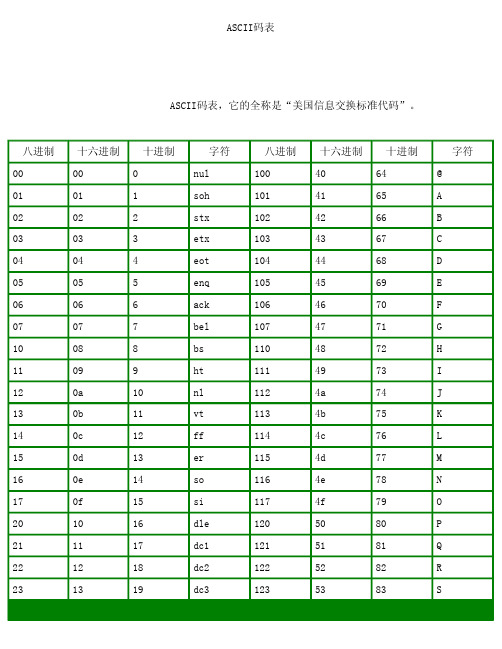
dc4 nak syn etb can em sub esc fs gs re us sp ! " # $ % & ` ( ) * + , .
124 125 126 127 130 131 132 133 134 135 136 137 140 141 142 143 144 145 146 147 150 151 152 153 154 155 156
/nett/a/ASCII.htm(第 1/3 页)2007-8-6 16:04:09
ASCII码表
24 25 26 27 30 31 32 33 34 35 36 37 40 41 42 43 44 45 46 47 50 51 52 53 54 55 56
T U V W X Y Z [ \ ] ^ _ ' a b c d e f g h i j k l m n
/nett/a/ASCII.htm(第 2/3 页)2007-8-6 16:04:09
ห้องสมุดไป่ตู้ ASCII码表
57 60 61 62 63 64 65 66 67 70 71 72 73 74 75 76 77
14 15 16 17 18 19 1a 1b 1c 1d 1e 1f 20 21 22 23 24 25 26 27 28 29 2a 2b 2c 2d 2e
20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46
2f 30 31 32 33 34 35 36 37 38 39 3a 3b 3c 3d 3e 3f
47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63
《数据编码技术》课件

总结词
量子编码利用量子比特的叠加性和纠缠性,可以实现更高效和安全的信息传输和存储。随着量子计算技术的不断发展,量子编码在未来有望成为重要的数据安全保护手段。
详细描述
分布式编码是一种基于分布式计算的数据编码技术,利用多个节点进行数据的协同编码和传输。
1
2
3
游程编码是一种简单的无损数据压缩算法,通过记录连续重复字符的个数来达到压缩数据的目的。
游程编码的优点是简单易实现,压缩速度快。
游程编码的缺点是对连续重复字符较少的文本压缩效果较差。
字典编码是一种基于字典的数据压缩方法,通过将数据中的重复字符串映射到字典中的键来达到压缩数据的目的。
字典编码的优点是能够处理大量重复字符串的数据,压缩效果好。
04
哈夫曼编码的缺点是需要对数据进行统计和排序,编码和解码过程相对复杂。
03
算术编码的缺点是计算复杂度较高,且需要精确的解码器才能正确解码。
01
算术编码是一种将数据表示为实数的方法,通过将数据映射到实数轴上的一个子区间来达到压缩数据的目的。
02
算术编码的优点是能够处理任意长度数据,且具有很好的压缩效果。
总结词:解码速度是衡量数据编码技术实用性的重要指标。
总结词:错误率是衡量数据编码技术可靠性的重要指标。详细描述:错误率是指在传输或存储过程中,解码后的数据与原始数据不一致的比率。错误率越低,说明编码技术的可靠性越高,能够保证数据的准确性和完整性。总结词:影响错误率的因素包括信道噪声、传输错误以及存储介质等。详细描述:信道噪声是影响传输过程中错误率的主要因素,信道噪声越大,传输过程中产生的错误越多。传输错误是由于网络拥堵、丢包等原因导致的传输失败或数据损坏。存储介质的可靠性也会影响数据的错误率,存储介质的寿命和质量直接影响数据的长期保存效果。
国标代码查询表户籍所在地在外省的统一填

杭州市区
0101
桐庐县
0122
淳安县
0127
萧山市
0181
建德市
0182
富阳市
0183
余杭市
0184
临安市
0185
宁波市区
0201
北仑区
0206
镇海区
0211
象山县
0225
宁海县
0226
鄞县
0227
余姚市
0281
慈溪市
0282
奉化市
0283
石化厂
0291
温州市区
0301
瓯海区
0304
洞头县
0322
永嘉县
0324
平阳县
0326
苍南县
0327
文成县
0328
泰顺县
0329
瑞安市
0381
乐清市
0382
嘉兴市区
0401
秀洲区
0411
嘉善县
0421
海盐县
0424
海宁区
0481
平湖市
0482
桐乡市
0483
湖州市区
0501
德清县
0521
长兴县
0522
安吉县
0523
0891
十里坪
0894
舟山市区
0901
定海区
0902
普陀区
0903
岱山县0921ຫໍສະໝຸດ 嵊泗县0922台州市区
1001
椒江区
1002
黄岩区
1003
路桥区
1004
玉环县
1021
数字编码
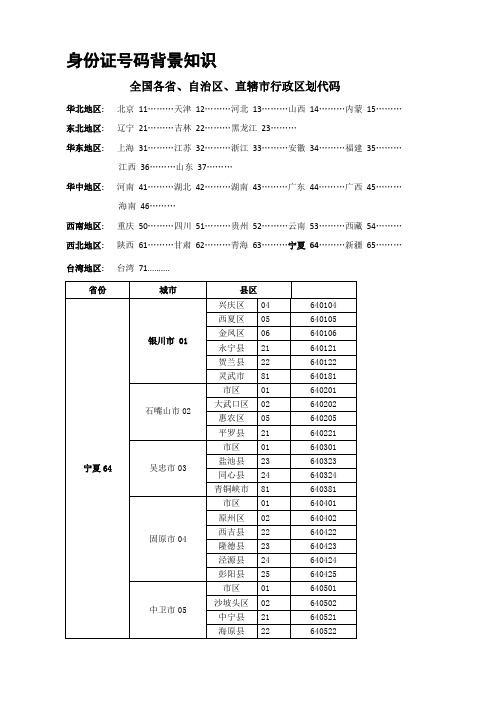
身份证号码背景知识
全国各省、自治区、直辖市行政区划代码
华北地区: 北京11………天津12………河北13………山西14………内蒙15………东北地区: 辽宁21………吉林22………黑龙江23………
华东地区: 上海31………江苏32………浙江33………安徽34………福建35………
江西36………山东37………
华中地区:河南41………湖北42………湖南43………广东44………广西45………
海南46………
西南地区: 重庆50………四川51………贵州52………云南53………西藏54………西北地区:陕西61………甘肃62………青海63………宁夏64………新疆65………台湾地区: 台湾71..........
背景知识:国道编号
我国道路编号由标识加数字组成。
国道 G*** 省道 S*** 县道 X***
国道的编号分为四类:
1.以北京为中心的放射线国道,其编号为G1××,如北京到沈阳的干线公路,编号101国道。
2. 南北纵线,编号为G2××,如锡林浩特到雷州半岛207国道。
3.东西横线,编号为G3××,如上海到聂拉木的318国道。
4.“五纵七横”主干线,以高速公路为主
(1)首都放射线7条,编号为1位,如:G 6 京藏高速(北京-拉萨)(2)南北纵线,编号2位,末尾为单数,如:G85 银昆高速(银川-昆明)(3)东西横线,编号2位,末尾为双数,如:G20 青银高速(青岛-银川)。
ICD疾病编码查询

ICD——10疾病编码查询入门之一ICD——10是疾病和有关健康问题的国际统计分类第十次修订本的符号,在我们使用的电子病历系统中,可以查询ICD——10疾病编码,有的疾病编码只要输入疾病名称,就能查到相应的疾病的ICD——10编码,但是,有时输入疾病全名并不好查,只有输入关键词,在关键词项目中才能查找到你所需要的疾病的ICD——10疾病编码。
所以,我们今天共同来摸索如何使用疾病名称和关键词两种方法来查询ICD——10疾病编码(我今天只是抛砖引玉,还请各位下去多摸索,是否还有其他更方便的方法查找)。
一、输入关键词查找是重点,如“骨折”、“出血”、“脓肿”、“囊肿”、“损伤”、“妊娠”、“炎”及“糖尿病”、“高血压”等等。
如:某部位的骨折,只要输入关键词“骨折”,就能在骨折项中查找到你所需要的与骨折疾病有关的疾病的ICD——10疾病编码。
但是,目前,我还没有掌握骨折部位的“左、右”如何查找,个人认为,可能不分“左、右”,因为,在系统中查不到“左、右骨折”,如股骨颈的骨折,查到的是S72.002,没有左股骨颈的骨折,或右股骨颈的骨折。
下面举例说明:如:尺、桡骨骨干骨折 S52.4051孟氏骨折 S62.0051股骨头骨折 S72.001股骨颈骨折 S72.002股骨干骨折 S72.301股骨干开放性骨折 S72.3150如:某部位的血肿,只要输入关键词“血肿”,就能在血肿项中查找到你所需要的与血肿疾病有关的疾病的ICD——10疾病编码。
如:头皮血肿 S00.002阴囊血肿 S30.202脾血肿 S36.0051肝包膜下血肿 S36.1051腹膜血肿 S36.8052腹膜后腔血肿 S36.8053如:肺部炎症,只要输入关键词“肺炎”,就能在肺炎项中查找到你所需要的与肺炎疾病有关的疾病的ICD——10疾病的编码。
如:麻疹合并肺炎 B05.201+肺炎球菌性肺炎 J13.X01病毒性肺炎 J12.901病毒性肺炎伴流感 J11.051细菌性肺炎 J15.901细菌性支气管肺炎 J15.902新生儿支气管肺炎 J18.005大叶性肺炎 J18.101肺炎 J18.901重症肺炎 J18.953哮喘性肺炎 J44.002过敏性肺炎 J67.901如:糖尿病,只要输入关键词“糖尿病”,就能在糖尿病项中查找到你所需要的与糖尿病有关的疾病的ICD——10疾病的编码。
数据编码(041440516董迎顺)

数据编码姓名__董迎顺__ 学号041440516由于计算机要处理的数据信息十分庞杂,有些数据库所代表的含义又使人难以记忆。
为了便于使用,容易记忆,常常要对加工处理的对象进行编码,用一个编码符合代表一条信息或一串数据。
对数据进行编码在计算机的管理中非常重要,可以方便地进行信息分类、校核、合计、检索等操作。
因此,数据编码就成为计算机处理的关键。
即不同的信息记录应当采用不同的编码,一个码点可以代表一条信息记录。
人们可以利用编码来识别每一个记录,区别处理方法,进行分类和校核,从而克服项目参差不齐的缺点,节省存储空间,提高处理速度。
二进制数字信息在传输过程中可以采用不同的代码,各种代码的抗噪声特性和定时能力各不相同,实现费用也不一样,几种常用的编码方案:单极性码、极性码、双极性码、归零码、双相码、不归零码、曼彻斯特编码、差分曼彻斯特编码、多电平编码、4B/5B编码。
首先介绍两个基本概念:基带信号和频带信号。
基带信号是原始电信号,其频谱从零频附近开始,例如基带话音信号的频率范围为300~3400Hz,基带图像信号的频率范围为0~6MHz。
频带信号是经过调制后的信号,它的特征是携带信息、适合在信道中传输、频谱具有带通形式且中心频率远离零频。
这一节讲述数字数据的基带传输,下一节讲述数字数据的频带传输。
二进制数据采用基带传输时可以采用不同的编码方案,各种编码的抗噪声特性和定时能力各不相同,实现费用也不一样。
数字基带信号的码型设计应遵循以下原则:(1)对于传输频率很低的信道,传输的码型频谱中应不包含直流分量。
(2)可以从基带信号中提取比特定时信号,使得代码具有自定时能力。
(3)基带编码应具有内在检错能力,可以检测传输过程中出现的差错。
(4)码型变换过程应具有透明性,即编码与信源的统计特性无关。
(5)尽量减少基带信号频谱中的高频分量。
这样可以提高信道的频谱利用率,还可以减少串扰。
下面介绍几种常用的编码方案,1. 单极性码在这种编码方案中,只用正的(或负的)电平表示数据。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
数据编码(041440516董迎顺)
数据编码
姓名__董迎顺__ 学号 041440516
由于计算机要处理的数据信息十分庞杂,有些数据库所代表的含义又使人难以记忆。
为了便于使用,容易记忆,常常要对加工处理的对象进行编码,用一个编码符合代表一条信息或一串数据。
对数据进行编码在计算机的管理中非常重要,可以方便地进行信息分类、校核、合计、检索等操作。
因此,数据编码就成为计算机处理的关键。
即不同的信息记录应当采用不同的编码,一个码点可以代表一条信息记录。
人们可以利用编码来识别每一个记录,区别处理方法,进行分类和校核,从而克服项目参差不齐的缺点,节省存储空间,提高处理速度。
二进制数字信息在传输过程中可以采用不同的代码,各种代码的抗噪声特性和定时能力各不相同,实现费用也不一样,几种常用的编码方案:单极性码、极性码、双极性码、归零码、双相码、不归零码、曼彻斯特编码、差分曼彻斯特编码、多电平编码、4B/5B编码。
首先介绍两个基本概念:基带信号和频带信号。
基带信号是原始电信号,其频谱从零频附近开始,例如基带话音信号的频率范围为300~3400Hz,基带图像信号的频率范围为0~6MHz。
频带信号是经过调制后的信号,它的特征是携带信息、适合在信道中传输、频谱具有带通形式且中心频率远离零频。
这一节讲述数字数据的基带传输,下一节讲述数字数据的频带传输。
二进制数据采用基带传输时可以采用不同的编码方案,各种编码的抗噪声特性和定时能力各不相同,实现费用也不一样。
数字基带信号的码型设计应遵循以下原则:
(1)对于传输频率很低的信道,传输的码型频谱中应不包含直流分量。
(2)可以从基带信号中提取比特定时信号,使得代码具有自定时能力。
(3)基带编码应具有内在检错能力,可以检测传输过程中出现的差错。
(4)码型变换过程应具有透明性,即编码与信源的统计特性无关。
(5)尽量减少基带信号频谱中的高频分量。
这样可以提高信道的频谱利用率,还可以减少串扰。
下面介绍几种常用的编码方案,
1. 单极性码
在这种编码方案中,只用正的(或负的)电平表示数据。
例如,在图2-3中我们用+3 V表示二进制数字“0”,而用 0 V表示二进制数字“1”。
单极性码用在电传打字机(TTY)接口以及PC机与TTY兼容的接口中,这种代码需要单独的时钟信号配合定时,否则当传送一长串0或1时,发送机和接收机的时钟将无法同步。
另外单极性码的抗噪声特性也不好,而且这种编码的功率谱中有丰富的低频分量,不能用于基带传输。
2. 极性码
在这种编码方案中,分别用正和负电平表示二进制数“0”和“1”,例如在图2-3中用+3 V表示二进制数字“0”,而用-3V表示二进制数字“1”。
由于这种编码有正负极性的差别,因而抗干扰特性较好,但仍然需要另外的同步信号。
另外,这种二元码中“1”或“0”分别对应某个电平,相邻电平不存在制约关系,没有纠错能力。
3. 归零码
在归零码(Return to Zero,RZ)中,码元中间的信号回归到0电平,因此任意两个码元之间被0电平隔开,与以上仅在码元之间有电平转换的编码方案相比,这种编码方案有更好的噪声抑制特性。
因为噪声对电平的干扰比对电平转换的干扰要强,而这种编码方案是以识别电平转换边来判别“0”和“1”信号的。
图2-3中表示出的是一种双极性归零码。
可以看出,从正电平到零电平的转换边表示码元“0”,而从负电平到零电平的转换边表示码元“1”,同时每一位码元中间都有电平转换,使得这种编码成为自定时的编码。
4. 不归零码
整个码元期间电平保持不变的代码称为不归零码(Not Return to Zero,NRZ)。
图2-3中所示的不归零码的规律是当“1”出现时电平翻转,当“0”出现时电平不翻转,也叫做见一就翻不归零码(NRZ-1)。
这种代码也叫差分码,用于区别数据“1”和“0”的不是电平高低,而是电平是否转换。
NRZ-1用在终端到调制解调器的接口中。
这种编码实现简单而且费用低,但不是自定时的,长串的“0”会使得码流失去同步。
5. 双相码
双相码要求每一比特中都要有一个电平转换,因而这种编码的最大优点是自定时,同时双相码也有检测错误的功能,如果某一位中间缺少了电平翻转,则被认为是违例代码。
6. 双极性码
在双极性编码方案中,信号在正、负、零3个电平之间变化。
一种典型的双极性码就是所谓的信号交替反转编码(Alternate Mark Inversion,AMI)。
在AMI 信号中,数据流中遇到“1”时使电平在正和负之间交替翻转,而遇到“0”时则保持零电平。
双极性是三进制编码方法,脉冲宽度是码元周期的一半,它比二进制编码的抗噪声特性更好,如图2-4a所示。
AMI具有内在的检错能力,当正负脉冲交替出现的规律被打乱时容易识别出来,这种情况叫AMI违例。
AMI编码用在T1线路中。
这种编码方案的缺点是传送长串“0”时会失去位同步信息,对此改进的方案有两种。
一种是3阶高密度双极性码HDB3,这种码流中连续“0”的个数不能大于3,当出现4个连续“0”时用B00V或000V代替,这里B表示正常的信号交替,V表示AMI违例,如图2-4b所示;另一种是双极性6零取代编码B6ZS,即把连续6个“0”用0VB0VB来代替,如图2-4c所示。
HDB3用在E1~E3通信系统中,B6ZS用在贝尔系统的T2标准中。
7. 曼彻斯特编码
曼彻斯特编码(Manchester Code)是一种双相码(或称分相码)。
在图2-3中,我们用高电平到低电平的转换边表示“0”,而用低电平到高电平的转换边表示
“1”,相反的表示也是允许的。
比特中间的电平转换边既表示了数据代码,同时也作为定时信号使用。
曼彻斯特编码用使在以太网中。
8. 差分曼彻斯特编码
差分码又称相对码,在差分码中利用电平是否跳变来分别表示“1”或“0”,分为传号差分码和空号差分码。
传号差分码是输入数据为“1”时,编码波型相对于前一代码电平产生跳变;输入为“0”时,波型不产生跳变。
空号差分码是当输入数据为“0”时,编码波型相对于前一代码电平产生跳变;输入为“1”时,波型不产生跳变。
差分曼彻斯特编码兼有差分码和曼彻斯特编码的特点,与曼彻斯特编码不同的是,这种码元中间的电平转换边只作为定时信号,而不表示数据。
差分曼彻斯特编码用在令牌环网中。
9. 多电平码
这种编码的码元可取多个电平之一,每个码元可代表多个二进制位。
例如,令M=2n,设M=4,则n=2。
若表示码元的脉冲取4个电平之一,则一个码元可表示两个二进制位。
与双相码相反,多电平码的数据速率大于波特率,因而可提高频带的利用率,但是这种代码的抗噪声特性不好,传输过程中信号容易畸变到无法区分。
2B1Q编码是一种4电平码,用在ISDN基本速率接口(BRI)中的U接口,它将2比特组合在一起以电平信号来表示。
编码规则如下:
在曼彻斯特和差分曼彻斯特编码中,每比特中间都有一次电平跳变,因此波特率是数据速率的两倍。
对于100Mb/s的高速网络,如果采用这类编码方法,就需要200M的波特率,其硬件成本是100M波特率硬件成本的5~10倍。
为了提高编码的效率,降低电路成本,可以采用4B/5B编码。
这种编码方法的原理,如图2-5所示。
这实际上是一种两级编码方案。
系统中使用不归零码(NRZ),在发送到传输介质之前要变成见1就翻不归零码(NRZ-I)。
NRZ-I代码序列中“1”的个数越多,越能提供同步定时信息,但如果遇到长串的“0”,则不能提供同步信息。
所以在发送到介质上之前还需经过一次4B/5B编码,发送器扫描要发送的比特序列,4位分为一组,然后按照表2-1的对应规则变换成5位的代码。
表2-1 4B/5B编码规则
5位二进制代码的状态共有32种,在表2-1选用的5位代码中1的个数都不小于2个。
这就保证了在介质上传输的代码能提供足够多的同步信息。
另外还有5B6B、8B/10B等编码方法,其原理是类似的。