蚁群算法报告
(完整word版)蚁群算法报告

蚁群算法报告学院:专业:学号:姓名:目录第一部分:蚁群算法原理介绍 (3)1.1蚁群算法的提出 (3)1.2蚁群算法的原理的生物学解释 (3)1.3蚁群算法的数学模型 (3)1.4蚁群算法实现步骤 (5)第二部分:蚁群算法实例--集装箱码头船舶调度模型 (6)2.1集装箱码头船舶调度流程图 (6)2.2算例与MATLAB编程的实现 (6)2.2.1算法实例 (6)2.2.2 Matlab编程 (8)第三章:MATLAB 优化设计工具箱简介 (14)3.1M ATLAB优化工具箱 (14)3.1.1优化工具箱功能: (15)3.2M ATLAB 优化设计工具箱中的函数 (15)3.2.2 方程求解函数 (15)3.2.3最小二乘(曲线拟合)函数 (16)3.2.4 使用函数 (16)3.2.5 大型方法的演示函数 (16)3.2.6 中型方法的延时函数 (16)3.4优化函数简介 (17)3.4.1优化工具箱的常用函数 (17)3.4.2 函数调用格式 (17)3.5模型输入时所需注意的问题 (19)第一部分:蚁群算法原理介绍1.1蚁群算法的提出蚂蚁是地球上最常见、数量最多的昆虫种类之一,常常成群结队地出现于人类的日常生活环境中。
受到自然界中真实蚁群集体行为的启发,意大利学者M.Dorig 。
于20世纪90年代初,在他的博士论文中首次系统地提出了一种基于蚂蚁种群的新型优化算法—蚁群算法}28}(Ant Colony Algorithm, ACA),并成功地用于求解旅行商问题,自1996年之后的五年时间里,蚁群算法逐渐引起了世界许多国家研究者的关注,其应用领域得到了迅速拓宽。
1.2蚁群算法的原理的生物学解释据观察和研究发现,蚂蚁倾向于朝着信息激素强度高的方向移动。
因此蚂蚁的群体行为便表现出了一种信息激素的正反馈现象。
当某条路径上经过的蚂蚁越多,该路径上存留的信息激素也就越多,以后就会有更多的蚂蚁选择它。
蚁群算法及案例分析精选全文

群在选择下一条路径的时
候并不是完全盲目的,而是
按一定的算法规律有意识
地寻找最短路径
自然界蚁群不具有记忆的
能力,它们的选路凭借外
激素,或者道路的残留信
息来选择,更多地体现正
反馈的过程
人工蚁群和自然界蚁群的相似之处在于,两者优先选择的都
是含“外激素”浓度较大的路径; 两者的工作单元(蚂蚁)都
正反馈、较强的鲁棒性、全
局性、普遍性
局部搜索能力较弱,易出现
停滞和局部收敛、收敛速度
慢等问题
优良的分布式并行计算机制
长时间花费在解的构造上,
导致搜索时间过长
Hale Waihona Puke 易于与其他方法相结合算法最先基于离散问题,不
能直接解决连续优化问题
蚁群算法的
特点
蚁群算法的特点及应用领域
由于蚁群算法对图的对称性以
及目标函数无特殊要求,因此
L_ave=zeros(NC_max,1);
%各代路线的平均长度
while NC<=NC_max
%停止条件之一:达到最大迭代次数
% 第二步:将m只蚂蚁放到n个城市上
Randpos=[];
for i=1:(ceil(m/n))
Randpos=[Randpos,randperm(n)];
end
Tabu(:,1)=(Randpos(1,1:m))';
scatter(C(:,1),C(:,2));
L(i)=L(i)+D(R(1),R(n));
hold on
end
plot([C(R(1),1),C(R(N),1)],[C(R(1),2),C(R(N),2)])
蚁群算法
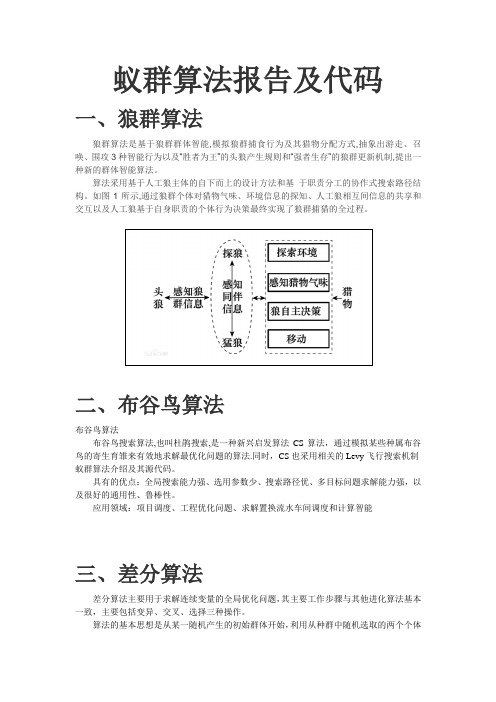
蚁群算法报告及代码一、狼群算法狼群算法是基于狼群群体智能,模拟狼群捕食行为及其猎物分配方式,抽象出游走、召唤、围攻3种智能行为以及“胜者为王”的头狼产生规则和“强者生存”的狼群更新机制,提出一种新的群体智能算法。
算法采用基于人工狼主体的自下而上的设计方法和基于职责分工的协作式搜索路径结构。
如图1所示,通过狼群个体对猎物气味、环境信息的探知、人工狼相互间信息的共享和交互以及人工狼基于自身职责的个体行为决策最终实现了狼群捕猎的全过程。
二、布谷鸟算法布谷鸟算法布谷鸟搜索算法,也叫杜鹃搜索,是一种新兴启发算法CS算法,通过模拟某些种属布谷鸟的寄生育雏来有效地求解最优化问题的算法.同时,CS也采用相关的Levy飞行搜索机制蚁群算法介绍及其源代码。
具有的优点:全局搜索能力强、选用参数少、搜索路径优、多目标问题求解能力强,以及很好的通用性、鲁棒性。
应用领域:项目调度、工程优化问题、求解置换流水车间调度和计算智能三、差分算法差分算法主要用于求解连续变量的全局优化问题,其主要工作步骤与其他进化算法基本一致,主要包括变异、交叉、选择三种操作。
算法的基本思想是从某一随机产生的初始群体开始,利用从种群中随机选取的两个个体的差向量作为第三个个体的随机变化源,将差向量加权后按照一定的规则与第三个个体求和而产生变异个体,该操作称为变异。
然后,变异个体与某个预先决定的目标个体进行参数混合,生成试验个体,这一过程称之为交叉。
如果试验个体的适应度值优于目标个体的适应度值,则在下一代中试验个体取代目标个体,否则目标个体仍保存下来,该操作称为选择。
在每一代的进化过程中,每一个体矢量作为目标个体一次,算法通过不断地迭代计算,保留优良个体,淘汰劣质个体,引导搜索过程向全局最优解逼近。
四、免疫算法免疫算法是一种具有生成+检测的迭代过程的搜索算法。
从理论上分析,迭代过程中,在保留上一代最佳个体的前提下,遗传算法是全局收敛的。
五、人工蜂群算法人工蜂群算法是模仿蜜蜂行为提出的一种优化方法,是集群智能思想的一个具体应用,它的主要特点是不需要了解问题的特殊信息,只需要对问题进行优劣的比较,通过各人工蜂个体的局部寻优行为,最终在群体中使全局最优值突现出来,有着较快的收敛速度。
蚁群优化算法的研究及其应用的开题报告

蚁群优化算法的研究及其应用的开题报告一、研究背景及意义蚁群优化算法(Ant Colony Optimization,简称ACO)是一种基于自然界蚂蚁的行为特性而发展起来的群智能优化算法。
它通过模拟蚂蚁在寻找食物时的集体行为,通过正反馈和信息素等机制进行迭代搜索,最终达到问题最优解的全局优化方法,被广泛运用于组合优化、机器学习、数据挖掘、图像处理、网络计算等领域。
ACO算法在应用过程中存在的核心问题是参数的选择:如何确定信息素的启发式因子、挥发系数、蚁群大小、局部搜索参数等,以及如何在不同的问题中选择合适的参数组合。
因此,对ACO算法的研究不仅可以提高ACO算法在不同领域应用的效率和性能,还可以对其他基于自然界智慧的算法进行改进和优化。
对此,本研究将重点研究ACO算法的自适应参数优化算法及其在不同应用领域的性能评估和优化探究。
二、研究内容和方向1. ACO算法的原理、模型和迭代搜索过程研究;2. 研究ACO算法的参数选择算法,并结合实际问题进行验证和优化;3. 在不同应用领域(如组合优化、机器学习、数据挖掘等)中,探究ACO算法的性能表现及其在问题求解中的优化效果;4. 侧重于自适应参数优化的ACO算法,探究其在各种应用中的适用性、性能表现和求解效果;5. 探究ACO算法在较大规模问题优化中的可行性和效率,并对其进行实际应用。
三、研究方法和技术路线1. 查阅相关文献,深入理解ACO算法的原理、模型和参数选择等关键技术;2. 基于现有研究,设计ACO算法的自适应参数优化算法,并根据不同问题调整和优化参数组合;3. 选择不同领域问题,研究ACO算法的性能表现及其优化效果,并与其他优化算法进行对比分析;4. 将自适应参数优化的ACO算法应用于实际问题中,对ACO算法的可行性和效率进行实验验证,并与其他优化算法进行比较;5. 探究ACO算法在大规模应用中的效率及其应用瓶颈,根据实际问题调整算法优化方案。
四、预期成果及创新之处本研究旨在设计、优化ACO算法的自适应参数选择方案,并将其应用于不同领域中的优化问题,探究ACO算法在不同应用领域中的性能和优化效果。
蚁群算法解决TSP问题实验报告--

智能系统实验报告一、实验题目TSP问题的蚁群算法实现二、实验目的1熟悉和掌握蚁群算法的基本概念和基本思想;2加深对蚁群算法的理解,理解和掌握蚁群算法的各个操作;3理解和掌握利用遗传算法进行问题求解的基本技能。
三、实验原理1、算法来源蚁群算法的基本原理来源于自然界蚂蚁觅食的最短路径原理,根据昆虫学家的观察,发现自然界的蚂蚁虽然视觉不发达,但它可以在没有任何提示的情况下找到从食物源到巢穴的最短路径,并且能在环境发生变化(如原有路径上有了障碍物)后,自适应地搜索新的最佳路径。
2、单个蚂蚁寻找路径正反馈:单个的蚂蚁为了避免自己迷路,它在爬行时,同时也会释放一种特殊的分泌物——信息素(Pheromone),而且它也能觉察到一定范围内的其它蚂蚁所分泌的信息素,并由此影响它自己的行为。
当一条路上的信息素越来越多(当然,随着时间的推移会逐渐减弱),后来的蚂蚁选择这条路径的概率也就越来越大,从而进一步增加了该路径的信息素浓度,这种选择过程称为蚂蚁的自催化过程。
多样性:同时为了保证蚂蚁在觅食的时候不至走进死胡同而无限循环,蚂蚁在寻找路径的过程中,需要有一定的随机性,虽然在觅食的过程中会根据信息素的浓度去觅食,但是有时候也有判断不准,环境影响等其他很多种情况,还有最终要的一点就是当前信息素浓度大的路径并不一定是最短的路径,需要不断的去修正,多样性保证了系统的创新能力。
正是这两点小心翼翼的巧妙结合才使得蚁群的智能行为涌现出来。
3、具体实现需要解决的两个首要问题(1)如何实现单个蚂蚁寻路的过程(2)如何实现信息素浓度的更新四、蚁群算法解决TSP 问题1、 相关变量的表示和计算(1)n 个城市相互之间的几何距离,i j d(2),t i j τ表示在t 时刻在城市i和j路线上残留的信息量,初始值为一个常数C (3)参数ρ表示信息量的保留度(4)在t+1时刻路径i ,j 上的信息量更新公式如下所示11,,,1,,1t t t i j i j i j mt k i ji jk τρττττ+++==+∆∆=∆∑,k 0k k i jQ L τ⎧⎫⎪⎪∆=⎨⎬⎪⎪⎩⎭第只蚂蚁经过i,j 时当不经过时 (5)i,j η表示i 和j 之间路径长度的反比与信息素量相除得到信息素浓度i,j ,1i jd η=(6)每个蚂蚁在当前节点选择可走的下一个点的时候有一个转移概率概率,信息素浓度越高,概率越大,,,s ,s,0k a i j i j k a k i i i j s allowed j allowed P ββτητη∈⎧⎫∈⎪⎪⎪⎪=⎨⎬⎪⎪⎪⎪⎩⎭∑其他(7),αβ参数用来实现对信息素浓度的调节,以实现对算法的优化。
蚁群算法附带数据结果

[代码说明]蚁群算法解决VRP问题[算法说明]首先实现一个ant蚂蚁类,用此蚂蚁类实现搜索。
算法按照tsp问题去解决,但是在最后计算路径的时候有区别。
比如有10个城市,城市1是配送站,蚂蚁搜索的得到的路径是1,3,5,9,4,10,2,6,8,7。
计算路径的时候把城市依次放入派送线路中,每放入一个城市前,检查该城市放入后是否会超过车辆最大载重如果没有超过就放入如果超过,就重新开始一条派送路线……直到最后一个城市放完就会得到多条派送路线这样处理比较简单可以把vrp问题转为tsp问题求解但是实际效果还需要验证。
[作者]Wugsh@2011.12.16wuguangsheng@guangsheng.wu@%}%清除所有变量和类的定义clear;clear classes;%蚁群算法参数(全局变量)global ALPHA; %启发因子global BETA; %期望因子global ANT_COUNT; %蚂蚁数量global CITY_COUNT; %城市数量global RHO; %信息素残留系数!!!global IT_COUNT; %迭代次数global DAry; %两两城市间距离global TAry; %两两城市间信息素global CITYW Ary; %城市货物需求量global VW; %车辆最大载重%===================================================================%设置参数变量值ALPHA=1.0;BETA=2.0;RHO=0.95;IT_COUNT=200;VW=100;%=================================================================== %读取数据并根据读取的数据设置其他参数load data.txt; %从文本文件加载数据city_xy_ary=data(:,2:3); %得到城市的坐标数据CITYW Ary=data(:,4); %得到每个城市的货物需求量CITY_COUNT=length(CITYW Ary); %得到城市数量(包括配送站在内)ANT_COUNT=round(CITY_COUNT*2/3)+1; %根据城市数量设置蚂蚁数量,一般设置为城市数量的2/3%MMAS信息素参数%计算最大信息素和最小信息素之间的比值PBest=0.05; %蚂蚁一次搜索找到最优解的概率temp=PBest^(1/CITY_COUNT);TRate=(1-temp)/((CITY_COUNT/2-1)*temp); %最大信息素和最小信息素之间的比值%信息素的最大最小值开始的时候设置成多大无所谓%第一次搜索完成会生成一个最优解,然后用这个解会重新产生最大最小值Tmax=1; %信息素最大值Tmin=Tmax*TRate; %信息素最小值% 计算两两城市间距离DAry=zeros(CITY_COUNT);for i=1:CITY_COUNTfor j=1:CITY_COUNTDAry(i,j)=sqrt((city_xy_ary(i,1)-city_xy_ary(j,1))^2+(city_xy_ary(i,2)-city_xy_ary(j,2))^2);endend% 初始化城市间信息素TAry=zeros(CITY_COUNT);TAry=TAry+Tmax;%===================================================================%初始化随机种子rand('state', sum(100*clock));%另一种方法%rand('twister',sum(100*clock))%定义蚂蚁mayi=ant();Best_Path_Length=10e9; %最佳路径长度,先设置成一个很大的值tm1=datenum(clock); %记录算法开始执行时的时间FoundBetter=0; %一次搜索是否有更优解产生%开始搜索for i=1:IT_COUNTfprintf('开始第%d次搜索, 剩余%d次',i,IT_COUNT-i);FoundBetter=0; %搜索前先置为没有更优解产生for j=1:ANT_COUNT%蚂蚁搜索一次mayi=Search(mayi);%得到蚂蚁搜索路径长度Length_Ary(j)=get(mayi,'path_length');%得到蚂蚁搜索的路径Path_Ary{j}=get(mayi,'path');%保存最优解if (Length_Ary(j) < Best_Path_Length);Best_Path_Length=Length_Ary(j);Best_Path=Path_Ary{j};%有更优解产生,设置标志FoundBetter=1;endend%有更好解产生,进行2-OPT优化if (FoundBetter == 1)fprintf(' , 本次搜索找到更好解!');Best_Path=opt2(Best_Path);Best_Path_Length=PathLength(Best_Path);end%-------------------------------------------------------------%全部蚂蚁搜索完一次,更新环境信息素TAry=TAry*RHO;%只有全局最优蚂蚁释放信息素dbQ=1/Best_Path_Length;for k=2:CITY_COUNTm=Best_Path(k-1); %上一个城市编号n=Best_Path(k); %下一个城市编号%更新路径上的信息素TAry(m,n)=TAry(m,n)+dbQ;TAry(n,m)=TAry(m,n);end%更新最后城市返回出发城市路径上的信息素TAry(n,1)=TAry(n,1)+dbQ;TAry(1,n)=TAry(n,1);%-------------------------------------------------------------%更新完信息素,进行边界检查Tmax=1/((1-RHO)*Best_Path_Length); %信息素最大值Tmin=Tmax*TRate; %信息素最小值for m=1:CITY_COUNTfor n=1:CITY_COUNTif (TAry(m,n)>Tmax)TAry(m,n)=Tmax;endif (TAry(m,n)<Tmin)TAry(m,n)=Tmin;endendend%-------------------------------------------------------------%换行fprintf('\n');endtm2=datenum(clock); %记录算法结束执行时的时间fprintf('\n搜索完成, 用时%.3f秒, 最佳路径长为%.3f , 派送方案如下::\n\n[1]',(tm2-tm1)*86400,Best_Path_Length);%=================================================================== %输出结果dbW=0;for i=2:CITY_COUNTm=Best_Path(i-1); %上一个城市n=Best_Path(i); %当前城市if (dbW+CITYW Ary(n)>VW) %运送的货物超过限制fprintf(' (满载率: %.1f%%)\n[1]-%d',dbW*100/VW,n);dbW=CITYW Ary(n); %运输的重量等于该城市的需求量else %没有超过限制fprintf('-%d',n);dbW=dbW+CITYWAry(n); %运输的重量加上该城市的需求量endendfprintf(' (满载率: %.1f%%)',dbW*100/VW);fprintf('\n\n');%====== [程序结束]===================================================== %对结果进行2-OPT优化function f=opt2(Line)%数组长度size=length(Line);NewLine=Line; % 返回结果先设置成原来路径Flag=1;while (Flag == 1)Flag=0;for i=1:size-2a=Line(1,1:i); %路径前段b=fliplr(Line(1,i+1:size)); %路径后段倒置c=cat(2,a,b); %新路径%新路径更好就替换if (PathLength(c)<PathLength(NewLine))NewLine=c;Flag=1;fprintf('\n======================= 2-OPT 优化成功! ===');endendend%返回结果f=NewLine;end1 14.5 13.0 0.02 12.8 8.5 0.13 18.4 3.4 0.44 15.4 16.6 1.25 18.9 15.2 1.56 15.5 11.6 0.87 3.9 10.6 1.38 10.6 7.6 1.79 8.6 8.4 0.610 12.5 2.1 1.211 13.8 5.2 0.412 6.7 16.9 0.913 14.8 2.6 1.314 1.8 8.7 1.315 17.1 11.0 1.916 7.4 1.0 1.717 0.2 2.8 1.118 11.9 19.8 1.519 13.2 15.1 1.620 6.4 5.6 1.721 9.6 14.8 1.51 0 0 02 3639 1315 123 4177 2244 134 3712 1399 145 3488 1535 536 3326 1556 457 3238 1229 228 4196 1004 119 4312 790 1110 4386 570 5611 3007 1970 4312 2562 1756 2413 2788 1491 6514 2381 1676 3215 1332 695 5616 3715 1678 6717 3918 2179 6718 4061 2370 2219 3780 2212 3420 3676 2578 5621 4029 2838 2422 4263 2931 2523 3429 1908 2624 3507 2367 4625 3394 2643 8726 3439 3201 3327 2935 3240 2228 3140 3550 2429 2545 2357 5630 2778 2826 2431 2370 2975 4332 1304 2312 12。
(完整word版)蚁群算法报告
蚁群算法报告学院:专业:学号:姓名:目录第一部分:蚁群算法原理介绍 (3)1.1蚁群算法的提出 (3)1.2蚁群算法的原理的生物学解释 (3)1.3蚁群算法的数学模型 (3)1.4蚁群算法实现步骤 (5)第二部分:蚁群算法实例--集装箱码头船舶调度模型 (6)2.1集装箱码头船舶调度流程图 (6)2.2算例与MATLAB编程的实现 (6)2.2.1算法实例 (6)2.2.2 Matlab编程 (8)第三章:MATLAB 优化设计工具箱简介 (14)3.1M ATLAB优化工具箱 (14)3.1.1优化工具箱功能: (15)3.2M ATLAB 优化设计工具箱中的函数 (15)3.2.2 方程求解函数 (15)3.2.3最小二乘(曲线拟合)函数 (16)3.2.4 使用函数 (16)3.2.5 大型方法的演示函数 (16)3.2.6 中型方法的延时函数 (16)3.4优化函数简介 (17)3.4.1优化工具箱的常用函数 (17)3.4.2 函数调用格式 (17)3.5模型输入时所需注意的问题 (19)第一部分:蚁群算法原理介绍1.1蚁群算法的提出蚂蚁是地球上最常见、数量最多的昆虫种类之一,常常成群结队地出现于人类的日常生活环境中。
受到自然界中真实蚁群集体行为的启发,意大利学者M.Dorig 。
于20世纪90年代初,在他的博士论文中首次系统地提出了一种基于蚂蚁种群的新型优化算法—蚁群算法}28}(Ant Colony Algorithm, ACA),并成功地用于求解旅行商问题,自1996年之后的五年时间里,蚁群算法逐渐引起了世界许多国家研究者的关注,其应用领域得到了迅速拓宽。
1.2蚁群算法的原理的生物学解释据观察和研究发现,蚂蚁倾向于朝着信息激素强度高的方向移动。
因此蚂蚁的群体行为便表现出了一种信息激素的正反馈现象。
当某条路径上经过的蚂蚁越多,该路径上存留的信息激素也就越多,以后就会有更多的蚂蚁选择它。
基于蚁群优化算法的TSP问题求解计算智能实验报告

智能计算实验报告学院:班级:学号:姓名:成绩:日期:实验名称:基于蚁群优化算法的TSP问题求解题目要求:利用蚁群优化算法对给定的TSP问题进行求解,求出一条最短路径。
蚁群优化算法简介:蚁群算法是一中求解复杂优化问题的启发式算法,该方法通过模拟蚁群对“信息素”的控制和利用进行搜索食物的过程,达到求解最优结果的目的。
它具有智能搜索、全局优化、稳健性强、易于其它方法结合等优点,适应于解决组合优化问题,包括运输路径优化问题。
TSP数据文件格式分析:本次课程设计采用的TSP文件是att48.tsp ,文件是由48组城市坐标构成的,文件共分成三列,第一列为城市编号,第二列为城市横坐标,第三列为城市纵坐标。
数据结构如下所示:实验操作过程:1、TSP文件的读取:class chengshi {int no;double x;double y;chengshi(int no, double x, double y) {this.no = no;this.x = x;this.y = y;}private double getDistance(chengshi chengshi) {return sqrt(pow((x - chengshi.x), 2) + pow((y - chengshi.y), 2));}}try {//定义HashMap保存读取的坐标信息HashMap<Integer, chengshi> map = new HashMap<Integer,chengshi>();//读取文件BufferedReader reader = new BufferedReader(new (new )));for (String str = reader.readLine(); str != null; str = reader.readLine()) { //将读到的信息保存入HashMapif(str.matches("([0-9]+)(\\s*)([0-9]+)(.?)([0-9]*)(\\s*)([0-9]+)(.?)([0-9]*)")) {String[] data = str.split("(\\s+)");chengshi chengshi = new chengshi(Integer.parseInt(data[0]),Double.parseDouble(data[1]),Double.parseDouble(data[2]));map.put(chengshi.no, chengshi);}}//分配距离矩阵存储空间distance = new double[map.size() + 1][map.size() + 1];//分配距离倒数矩阵存储空间heuristic = new double[map.size() + 1][map.size() + 1];//分配信息素矩阵存储空间pheromone = new double[map.size() + 1][map.size() + 1];for (int i = 1; i < map.size() + 1; i++) {for (int j = 1; j < map.size() + 1; j++) {//计算城市间的距离,并存入距离矩阵distance[i][j] = map.get(i).getDistance(map.get(j));//计算距离倒数,并存入距离倒数矩阵heuristic[i][j] = 1 / distance[i][j];//初始化信息素矩阵pheromone[i][j] = 1;}}} catch (Exception exception) {System.out.println("初始化数据失败!");}}2、TSP作图处理:private void evaporatePheromone() {for (int i = 1; i < pheromone.length; i++)for (int j = 1; j < pheromone.length; j++) {pheromone[i][j] *= 1-rate;}}3、关键源代码(带简单的注释):蚂蚁类代码:class mayi {//已访问城市列表private boolean[] visited;//访问顺序表private int[] tour;//已访问城市的个数private int n;//总的距离private double total;mayi() {//给访问顺序表分配空间tour = new int[distance.length+1];//已存入城市数量为n,刚开始为0n = 0;//将起始城市1,放入访问结点顺序表第一项tour[++n] = 1;//给已访问城市结点分配空间visited = new boolean[distance.length];//第一个城市为出发城市,设置为已访问visited[tour[n]] = true;}private int choosechengshi() {//用来random的随机数double m = 0;//获得当前所在的城市号放入j,如果和j相邻的城市没有被访问,那么加入mfor (int i = 1, j = tour[n]; i < pheromone.length; i++) {if (!visited[i]) {m += pow(pheromone[j][i], alpha) * pow(heuristic[j][i], beta);}}//保存随机数double p = m * random();//寻找随机城市double k = 0;//保存城市int q = 0;for (int i = 1, j = tour[n]; k < p; i++) {if (!visited[i]) {k += pow(pheromone[j][i], alpha) * pow(heuristic[j][i], beta);q = i;}}return q;}城市选择代码:private int choosechengshi() {//用来random的随机数double m = 0;//获得当前所在的城市号放入j,如果和j相邻的城市没有被访问,那么加入mfor (int i = 1, j = tour[n]; i < pheromone.length; i++) {if (!visited[i]) {m += pow(pheromone[j][i], alpha) * pow(heuristic[j][i], beta);}}//保存随机数double p = m * random();//寻找随机城市double k = 0;//保存城市int q = 0;for (int i = 1, j = tour[n]; k < p; i++) {if (!visited[i]) {k += pow(pheromone[j][i], alpha) * pow(heuristic[j][i], beta);q = i;}}return q;}4、算法运行收敛图(即运行到第几步,求得的最优值是多少):run:本次为倒数第100次迭代,当前最优路径长度为41634.60本次为倒数第99次迭代,当前最优路径长度为41514.21本次为倒数第98次迭代,当前最优路径长度为38511.61本次为倒数第97次迭代,当前最优路径长度为38511.61本次为倒数第96次迭代,当前最优路径长度为38511.61本次为倒数第95次迭代,当前最优路径长度为38511.61本次为倒数第94次迭代,当前最优路径长度为37293.07、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、本次为倒数第6次迭代,当前最优路径长度为37293.07本次为倒数第5次迭代,当前最优路径长度为37293.07本次为倒数第4次迭代,当前最优路径长度为37293.07本次为倒数第3次迭代,当前最优路径长度为37293.07本次为倒数第2次迭代,当前最优路径长度为37293.07本次为倒数第1次迭代,当前最优路径长度为37293.07得到的最优的路径长度为: 37293.075、最终求得的最优解的TSP图像:最优路径如下:→1→9→38→31→44→18→7→28→37→19→6→30→43→27→17→36→46→33→15→12→11→23→14→25→13→20→47→21→39→32→48→5→29→2→26→4→35→45→10→42→24→34→41→16→22→3→40→8→1成功生成(总时间:3 秒)实验结果分析:本次通过JA V A语言实现蚁群优化算法,我们发现虽然我们找到了问题的最优解,但是最优解的收敛性并不乐观,并不能求得问题的精确解,并且随着参数的调节运行结果有随机性。
基于蚁群优化算法的TSP问题求解计算智能实验报告
智能计算实验报告学院:班级:学号:姓名:成绩:日期:实验名称:基于蚁群优化算法的TSP问题求解题目要求:利用蚁群优化算法对给定的TSP问题进行求解,求出一条最短路径。
蚁群优化算法简介:蚁群算法是一中求解复杂优化问题的启发式算法,该方法通过模拟蚁群对“信息素”的控制和利用进行搜索食物的过程,达到求解最优结果的目的。
它具有智能搜索、全局优化、稳健性强、易于其它方法结合等优点,适应于解决组合优化问题,包括运输路径优化问题。
TSP数据文件格式分析:本次课程设计采用的TSP文件是att48.tsp ,文件是由48组城市坐标构成的,文件共分成三列,第一列为城市编号,第二列为城市横坐标,第三列为城市纵坐标。
数据结构如下所示:实验操作过程:1、TSP文件的读取:class chengshi {int no;double x;double y;chengshi(int no, double x, double y) {this.no = no;this.x = x;this.y = y;}private double getDistance(chengshi chengshi) {return sqrt(pow((x - chengshi.x), 2) + pow((y - chengshi.y), 2));}}try {//定义HashMap保存读取的坐标信息HashMap<Integer, chengshi> map = new HashMap<Integer,chengshi>();//读取文件BufferedReader reader = new BufferedReader(new (new )));for (String str = reader.readLine(); str != null; str = reader.readLine()) { //将读到的信息保存入HashMapif(str.matches("([0-9]+)(\\s*)([0-9]+)(.?)([0-9]*)(\\s*)([0-9]+)(.?)([0-9]*)")) {String[] data = str.split("(\\s+)");chengshi chengshi = new chengshi(Integer.parseInt(data[0]),Double.parseDouble(data[1]),Double.parseDouble(data[2]));map.put(chengshi.no, chengshi);}}//分配距离矩阵存储空间distance = new double[map.size() + 1][map.size() + 1];//分配距离倒数矩阵存储空间heuristic = new double[map.size() + 1][map.size() + 1];//分配信息素矩阵存储空间pheromone = new double[map.size() + 1][map.size() + 1];for (int i = 1; i < map.size() + 1; i++) {for (int j = 1; j < map.size() + 1; j++) {//计算城市间的距离,并存入距离矩阵distance[i][j] = map.get(i).getDistance(map.get(j));//计算距离倒数,并存入距离倒数矩阵heuristic[i][j] = 1 / distance[i][j];//初始化信息素矩阵pheromone[i][j] = 1;}}} catch (Exception exception) {System.out.println("初始化数据失败!");}}2、TSP作图处理:private void evaporatePheromone() {for (int i = 1; i < pheromone.length; i++)for (int j = 1; j < pheromone.length; j++) {pheromone[i][j] *= 1-rate;}}3、关键源代码(带简单的注释):蚂蚁类代码:class mayi {//已访问城市列表private boolean[] visited;//访问顺序表private int[] tour;//已访问城市的个数private int n;//总的距离private double total;mayi() {//给访问顺序表分配空间tour = new int[distance.length+1];//已存入城市数量为n,刚开始为0n = 0;//将起始城市1,放入访问结点顺序表第一项tour[++n] = 1;//给已访问城市结点分配空间visited = new boolean[distance.length];//第一个城市为出发城市,设置为已访问visited[tour[n]] = true;}private int choosechengshi() {//用来random的随机数double m = 0;//获得当前所在的城市号放入j,如果和j相邻的城市没有被访问,那么加入mfor (int i = 1, j = tour[n]; i < pheromone.length; i++) {if (!visited[i]) {m += pow(pheromone[j][i], alpha) * pow(heuristic[j][i], beta);}}//保存随机数double p = m * random();//寻找随机城市double k = 0;//保存城市int q = 0;for (int i = 1, j = tour[n]; k < p; i++) {if (!visited[i]) {k += pow(pheromone[j][i], alpha) * pow(heuristic[j][i], beta);q = i;}}return q;}城市选择代码:private int choosechengshi() {//用来random的随机数double m = 0;//获得当前所在的城市号放入j,如果和j相邻的城市没有被访问,那么加入mfor (int i = 1, j = tour[n]; i < pheromone.length; i++) {if (!visited[i]) {m += pow(pheromone[j][i], alpha) * pow(heuristic[j][i], beta);}}//保存随机数double p = m * random();//寻找随机城市double k = 0;//保存城市int q = 0;for (int i = 1, j = tour[n]; k < p; i++) {if (!visited[i]) {k += pow(pheromone[j][i], alpha) * pow(heuristic[j][i], beta);q = i;}}return q;}4、算法运行收敛图(即运行到第几步,求得的最优值是多少):run:本次为倒数第100次迭代,当前最优路径长度为41634.60本次为倒数第99次迭代,当前最优路径长度为41514.21本次为倒数第98次迭代,当前最优路径长度为38511.61本次为倒数第97次迭代,当前最优路径长度为38511.61本次为倒数第96次迭代,当前最优路径长度为38511.61本次为倒数第95次迭代,当前最优路径长度为38511.61本次为倒数第94次迭代,当前最优路径长度为37293.07、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、本次为倒数第6次迭代,当前最优路径长度为37293.07本次为倒数第5次迭代,当前最优路径长度为37293.07本次为倒数第4次迭代,当前最优路径长度为37293.07本次为倒数第3次迭代,当前最优路径长度为37293.07本次为倒数第2次迭代,当前最优路径长度为37293.07本次为倒数第1次迭代,当前最优路径长度为37293.07得到的最优的路径长度为: 37293.075、最终求得的最优解的TSP图像:最优路径如下:→1→9→38→31→44→18→7→28→37→19→6→30→43→27→17→36→46→33→15→12→11→23→14→25→13→20→47→21→39→32→48→5→29→2→26→4→35→45→10→42→24→34→41→16→22→3→40→8→1成功生成(总时间:3 秒)实验结果分析:本次通过JA V A语言实现蚁群优化算法,我们发现虽然我们找到了问题的最优解,但是最优解的收敛性并不乐观,并不能求得问题的精确解,并且随着参数的调节运行结果有随机性。
使用蚁群算法进行图像分割报告

使用蚁群算法进行图像分割报告绪论蚁群算法是模拟蚂蚁群体觅食行为的仿生优化算法。
本文利用蚁群算法进行图像分割,提取目标图像的边缘路径,概括来说,是通过一定数量的人工蚂蚁根据图像的灰度值特性自由觅食,在觅食的过程中形成的信息素矩阵即代表了图像的边缘特征信息。
1 本例中蚁群算法的几个要素一幅图像中包括目标、背景、边界和噪声等内容,边缘提取的目的是要找出体现这些内容之间区别的特征量。
区别目标和背景的一个重要的特征是像素灰度,因此选用像素的灰度值作为主要特征。
另外,边界点或噪声点往往是灰度值发生突变的地方,而该点处的梯度体现出这种变化,是反映边界点与背景或目标区域内点区别的重要特征。
因此,在定义可见度因数时,一定要把梯度值作为首要特征。
1.1 确定初始蚂蚁数目蚁群算法是一种随机搜索算法,它通过多个候选解组成群体的进化过程来寻求最优解,在这个进化过程中,既需要每个个体的自适应能力,更需要群体的相互协作,这个相互协作,通过个体之间的信息交流来完成。
蚁群的数量越多,算法的全局搜索能力以及算法的稳定性越高,但是若蚂蚁数目较大,会使大量的曾被搜索过的解上的信息量的变化比较平均,信息正反馈的作用不明显,搜索的随机性虽然得到了加强,但收敛速度减慢,在本例中,蚂蚁数目取为图像像素数的开方值。
1.2 蚂蚁转移概率在蚁群算法的第n步,某一点处的蚂蚁转移到像素点(i,j)的概率主要由该点信息素浓度和能见度因数来决定,其计算公式为【1】:∑Ω∈--=ij j i n j i j i n j i n j i p βαβαητητ)()()()(,)1(,,)1(,)(,其中,i Ω表示蚂蚁k 下一步容许去的城市集合。
)(,n j i p 与1j i,-n τj i ,η成正比,1ji,-n τ为从像素点i ,j 的信息素因数,j i ,η为像素点i ,j 的能见度因数,α,β参数分别反映了蚂蚁在转移过程中,像素点所累积的信息素和像素点的启发信息,在蚂蚁选择转移时的相对重要性。
蚁群算法及算例范文

蚁群算法及算例范文蚁群算法的核心思想是通过模拟蚂蚁在路径选择过程中释放的信息素来寻找到达目标的最优路径。
蚂蚁在觅食过程中会释放一种化学物质(信息素),用于标记已经走过的路径。
当其他蚂蚁经过时,会受到这些信息素的影响,从而倾向于选择已经标记过的路径。
通过这种方式,蚂蚁群体能够找到从巢穴到食物的最短路径。
蚁群算法的算例可以参考旅行商问题(TSP,Traveling Salesman Problem)。
旅行商问题是一种经典的组合优化问题,要求在给定的城市之间找到最短的回路,使得每个城市恰好访问一次。
下面是一个应用蚁群算法解决旅行商问题的算例:1.初始化城市和蚂蚁的信息。
2.随机放置若干蚂蚁在城市中。
3.每只蚂蚁根据当前城市和信息素浓度选择下一个城市。
选择过程可以使用蚂蚁选择概率来确定,概率与信息素浓度和距离有关。
假设蚂蚁A 位于城市B,需要选择下一个城市C,蚂蚁选择概率计算公式如下:p(C)=(τ(B,C)^α)*(η(B,C)^β)/Σ[(τ(B,i)^α)*(η(B,i)^β)]其中τ(B,C)表示城市B到城市C之间的信息素浓度,η(B,C)表示城市B到城市C的适应度(与距离相关),α和β是调节信息素和适应度对蚂蚁选择的相对重要性的参数。
4.更新信息素。
当所有蚂蚁行走完成后,根据蚂蚁走过的路径长度更新信息素浓度。
更新公式如下:Δτ(B,C)=Q/L其中Δτ(B,C)表示城市B到城市C之间的信息素增量,Q是常数,L 是蚂蚁行走的路径长度。
5.重复步骤3和步骤4直到满足终止条件。
通常终止条件可以是达到最大迭代次数或者找到最优路径。
6.输出蚂蚁群体找到的最优路径和路径长度。
蚁群算法通过模拟蚂蚁觅食行为,利用信息素的正反馈机制,能够在很短的时间内找到高质量的解。
它被广泛应用于旅行商问题、资源调度问题、网络优化问题等领域。
蚁群算法人工智能实验报告

人工智能实验报告姓名:学号:班级:实验时间:蚁群算法实验原理:蚂蚁在觅食过程中可以找出巢穴到食物源的最短路径,为什么?(1)信息素(pheromone)(2)正反馈现象:某一路径上走过的蚂蚁越多,则后来者选择该路径的概率就越大。
(3)挥发现象:路径上的信息素浓度会随着时间推进而逐渐衰减。
蚁群算法的缺点:1)收敛速度慢2)易于陷入局部最优改进:1)采用局部优化,设计了三种优化算子。
2)采用蚁群优化算法。
3)其它优化算法实验内容:旅行商问题(TSP,traveling salesman problem):一商人去n个城市销货,所有城市走一遍再回到起点,使所走路程最短。
实验步骤:算法代码:%%蚁群算法的优化计算——旅行商问题(TSP)优化%% 清空环境变量clear allclc%% 导入数据load citys_data.mat%% 计算城市间相互距离n = size(citys,1);D = zeros(n,n);for i = 1:nfor j = 1:nif i ~= jD(i,j) = sqrt(sum((citys(i,:) - citys(j,:)).^2));elseD(i,j) = 1e-4;endendend%% 初始化参数m = 50; % 蚂蚁数量alpha = 1; % 信息素重要程度因子beta = 5; % 启发函数重要程度因子rho = 0.1; % 信息素挥发因子Q = 1; % 常系数Eta = 1./D; % 启发函数Tau = ones(n,n); % 信息素矩阵Table = zeros(m,n); % 路径记录表iter = 1; % 迭代次数初值iter_max = 200; % 最大迭代次数Route_best = zeros(iter_max,n); % 各代最佳路径Length_best = zeros(iter_max,1); % 各代最佳路径的长度Length_ave = zeros(iter_max,1); % 各代路径的平均长度%% 迭代寻找最佳路径while iter <= iter_max% 随机产生各个蚂蚁的起点城市start = zeros(m,1);for i = 1:mtemp = randperm(n); %返回n个[0, n]间的随机元素向量start(i) = temp(1);endTable(:,1) = start;% 构建解空间citys_index = 1:n; %访问1~n这n个城市% 逐个蚂蚁路径选择for i = 1:m% 逐个城市路径选择for j = 2:n %各个蚂蚁都需要访问n-1个城市tabu = Table(i,1:(j - 1)); % 已访问的城市集合(禁忌表)allow_index = ~ismember(citys_index,tabu); %判断citys_index中元素有没有在tabu中出现,出现用1表示,否则用0表示。
基于蚁群算法的聚类分析方法的研究及应用的开题报告

基于蚁群算法的聚类分析方法的研究及应用的开题报告一、研究背景随着现代科技的不断发展,数据量的不断增加,数据分析成为了当前热门的研究方向之一。
其中,聚类分析作为数据挖掘和机器学习领域中的一种重要方法,可以将数据集中的样本划分成若干个不同的类别,并且在同一类别中的样本具有相似的特征,而不同类别之间的样本存在显著差异。
聚类分析方法在市场细分、医学诊断、生物信息学等领域中具有重要应用。
蚁群算法作为一种新兴的优化算法,在优化问题的求解方面具有良好的性能。
蚁群算法源于对蚂蚁觅食行为的研究,它通过模拟蚂蚁在寻找食物时的行为,通过信息交流和趋同行为来寻找问题的最优解。
蚁群算法已经成功地应用于TSP问题、图着色问题、网络路由等领域。
将蚁群算法应用于聚类分析中,将样本等同于蚂蚁,样本之间的相似度等同于蚂蚁之间通过信息素交流所建立的连接关系,利用蚁群算法进行信息素的更新和蚂蚁的移动从而得到聚类结果。
相比于传统的聚类算法,蚁群算法具有更好的鲁棒性、稳定性和有效性,能够处理具有复杂特征的高维数据集。
二、研究目的本文旨在研究基于蚁群算法的聚类分析方法,并将其应用于实际数据集。
具体研究目的如下:1. 综述聚类分析和蚁群算法的相关理论和算法2. 设计基于蚁群算法的聚类分析模型,并验证模型的正确性和有效性3. 对比不同聚类算法在不同数据集下的实验结果,展示蚁群算法的优越性4. 在真实数据集中应用蚁群算法进行聚类分析,并探讨实际应用中的优化措施和注意事项三、研究内容为实现上述研究目的,本文将分以下几个方面进行研究:1. 聚类分析理论概述:对聚类分析的基础理论和算法进行综述,如K-means、层次聚类等2. 蚁群算法理论概述:对蚁群算法的基础理论和算法进行综述,如蚁群优化算法和蚁群聚类算法3. 基于蚁群算法的聚类分析模型设计:设计基于蚁群算法的聚类分析模型,并结合实际数据集验证模型正确性和有效性4. 蚁群算法在聚类分析中的应用:将蚁群算法应用于不同数据集的聚类分析中,并与其他聚类算法进行比较5. 蚁群算法聚类分析的优化措施:探讨蚁群算法在聚类分析中的优化措施,如参数调节、蚁群规模选择等四、研究意义本文的研究结合了蚁群算法和聚类分析两个领域的优势,提出基于蚁群算法的聚类分析模型,并将其应用于实际数据集,探索了蚁群算法在聚类分析中的优越性和实际应用中的注意事项。
《蚁群算法的研究及其在路径寻优中的应用》范文

《蚁群算法的研究及其在路径寻优中的应用》篇一蚁群算法研究及其在路径寻优中的应用一、引言随着现代科技的飞速发展,优化问题在众多领域中显得尤为重要。
路径寻优作为优化问题的一种,其应用广泛存在于物流运输、网络通信、城市交通等多个领域。
蚁群算法作为一种模拟自然界中蚂蚁觅食行为的仿生算法,因其良好的寻优能力和鲁棒性,在路径寻优问题上得到了广泛的应用。
本文将详细研究蚁群算法的原理及其在路径寻优中的应用。
二、蚁群算法的研究1. 蚁群算法的原理蚁群算法是一种模拟自然界中蚂蚁觅食行为的仿生算法。
在寻找食物的过程中,蚂蚁会释放一种特殊的化学物质——信息素,沿着路径寻找食物的过程中留下这种物质。
当其他蚂蚁遇到这条路径时,会被信息素吸引并沿着该路径前进,从而形成一个正反馈机制。
这种正反馈机制使得更多的蚂蚁沿着较短的路径移动,最终达到寻找食物的目的。
2. 蚁群算法的特点蚁群算法具有以下特点:一是分布式计算,多个蚂蚁并行搜索,具有较强的鲁棒性;二是正反馈机制,有利于快速找到最优解;三是通过信息素的传递和更新,能够自适应地调整搜索策略。
这些特点使得蚁群算法在解决复杂优化问题时具有较高的效率和较好的效果。
三、蚁群算法在路径寻优中的应用1. 物流运输路径优化物流运输是路径寻优问题的一个重要应用领域。
通过应用蚁群算法,可以有效地解决物流运输中的路径优化问题。
具体而言,蚁群算法可以根据不同地区的货物需求、运输车辆的容量、道路交通状况等因素,寻找最优的运输路径,从而提高物流运输的效率和降低成本。
2. 城市交通网络优化城市交通网络优化是解决城市交通拥堵问题的有效手段之一。
通过应用蚁群算法,可以优化城市交通网络中的路径选择问题,避免交通拥堵现象的发生。
具体而言,蚁群算法可以通过模拟车辆的行驶行为和交通信号的控制,寻找最优的路径和交通信号控制策略,从而有效地提高城市交通网络的运行效率。
四、蚁群算法的改进及应用展望1. 蚁群算法的改进虽然蚁群算法在路径寻优问题上取得了显著的成果,但仍存在一些不足之处。
蚁群算法研究报告

. . .. 蚁群算法研究报告题目信息工程学院专业计算机科学与技术姓名程亮学号201115068指导教师谭同德2014-6-4目录第一章蚁群算法概述11.1蚁群算法概念11.2蚁群算法原理21.3蚁群算法的特点21.3.1 人工蚁群的特点21.3.2 蚁群的特点31.4蚁群算法的应用31.5算法模型3第二章蚁群算法解决TSP问题42.1 TSP问题描述42.2 基于TSP 问题的蚁群算法模型42.3蚂蚁系统解决TSP问题实现步骤52.4蚂蚁系统解决TSP问题流程图62.5关键代码6参考文献9第一章蚁群算法概述1.1蚁群算法概念蚁群算法(Ant Clony Optimization,ACO)是一种群智能算法,它是由一群无智能或有轻微智能的个体(Agent)通过相互协作而表现出智能行为,从而为求解复杂问题提供了一个新的可能性。
从1991年意大利学者DorigoM等首次提出蚁群算法以来,蚁群算法作为一种自然计算方法,由解决tsP(旅行商)问题开始,从一维静态优化问题到多维动态优化问题,从解决离散域围问题到连续域围,发展到今天已经相对成熟了,应用到了众多的领域,比如说数据挖掘、物流、通信网络、大规模集成电路、网络路由等。
而且这种仿生算法同遗传算法、粒子群算法、免疫算法、神经网络等智能算法相结合的新算法,更好的提高了效率并加强了其在实际问题中的应用。
蚁群算法之所以能引起相关领域研究者的注意,是因为这种求解模式能将问题求解的快速性、全局优化特征以及有限时间答案的合理性结合起来。
其中,寻优的快速性是通过正反馈式的信息传递和积累来保证的。
而算法的早熟性收敛又可以通过其分布式计算特征加以避免,同时,具有贪婪启发式搜索特征的蚁群系统又能在搜索过程的早期找到可以接受的问题解答。
这种优越的问题分布式求解模式经过相关领域研究者的关注和努力,已经在最初的算法模型基础上得到了很大的改进和拓展。
研究蚁群算法的改进方法以及其发展和应用的趋势,为蚁群算法在更多领域有更多的应用价值来说是十分必要的。
蚁群算法及案例分析

蚁群算法原理
自然界中,蚁群的这种寻找路径的过程表现为一种正反馈的过程,与人工蚁群的寻 优算法极为一致。如我们把只具备了简单功能的工作单元视为”蚂蚁”,那么上述寻找 路径的过程可以用于解释人工蚁群的寻优过程。
人工蚁群具有一定的记忆 能力。它能够记忆已经访 问过的节点;另外,人工蚁 群在选择下一条路径的时 候并不是完全盲目的,而是 按一定的算法规律有意识 地寻找最短路径
优良的分布式并行计算机制
易于与其他方法相结合
蚁群算法的 特点
蚁群算法的特点及应用领域
由于蚁群算法对图的对称性以 及目标函数无特殊要求,因此 可以解决各种对称、非对称问 题,线性、非线性问题。 旅行商(TSP)问题 调度问题 图形着色 路径优化
蚁群算法的 应用领域
电力 通信 化工 交通 机器人 冶金 其他领域
自然界蚁群不具有记忆的 能力,它们的选路凭借外 激素,或者道路相似之处在于,两者优先选择的都 是含“外激素”浓度较大的路径; 两者的工作单元(蚂蚁)都 是通过在其所经过的路径上留下一定信息的方法进行间接的 信息传递。
蚁群算法计算步骤
140
160
180
200
Shortest_Length =1.5602e+04
蚁群算法的特点及应用领域
优点 不依赖于所求问题的具体数 学表达式描述,具有很强的 找到全局最优解的优化能力 正反馈、较强的鲁棒性、全 局性、普遍性 缺点 模型普适性不强,不能直接 应用于实际优化问题 局部搜索能力较弱,易出现 停滞和局部收敛、收敛速度 慢等问题 长时间花费在解的构造上, 导致搜索时间过长 算法最先基于离散问题,不 能直接解决连续优化问题
参 数
选 取
TSP算例分析
蚁群算法课程设计报告

计算机学院计算机科学与技术专业《程序设计综合课程设计》报告(2010/2011学年第一学期)学生姓名:学生班级:学生学号:指导教师:2011年1月8日蚁群算法求解TSP问题目录第一章课程设计目的和要求.......................................... - 1 -1.1 程序设计目的................................................ - 1 -1.2 程序设计要求................................................ - 1 - 第二章程序设计内容................................................ - 3 -2.1关于蚁群智能和TSP........................................ - 3 -2.2解决的问题.................................................. - 4 - 第三章详细设计说明................................................ - 5 -3.1模块描述.................................................... - 5 -3.2性能........................................................ - 5 -3.3输入项和输出项.............................................. - 6 -3.4算法........................................................ - 7 -3.5流程逻辑................................................... - 10 -3.6接口....................................................... - 11 -3.7数据存储说明............................................... - 13 -3.8注释设计................................................... - 13 -3.9限制条件................................................... - 14 -3.10测试计划.................................................. - 14 - 第四章程序使用说明............................................... - 15 - 第五章程序设计心得与体会......................................... - 20 - 附录一:参考文献.................................................. - 21 - 附录二:程序清单.................................................. - 22 -第一章课程设计目的和要求1.1 程序设计目的学习C++程序设计不能满足于“懂得了”,满足于了解了语法和能看懂书上的程序,而应当掌握程序设计的全过程,即能独立编写出源程序,独立上机调试程序,独立运行程序和分析结果。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
蚁群算法报告学院:专业:学号:姓名:目录第一部分:蚁群算法原理介绍 (3)1.1蚁群算法的提出 (3)1.2蚁群算法的原理的生物学解释 (3)1.3蚁群算法的数学模型 (3)1.4蚁群算法实现步骤 (5)第二部分:蚁群算法实例--集装箱码头船舶调度模型 (6)2.1集装箱码头船舶调度流程图 (6)2.2算例与MATLAB编程的实现 (6)2.2.1算法实例 (6)2.2.2 Matlab编程 (8)第三章:MATLAB 优化设计工具箱简介 (14)3.1M ATLAB优化工具箱 (14)3.1.1优化工具箱功能: (15)3.2M ATLAB 优化设计工具箱中的函数 (15)3.2.2 方程求解函数 (15)3.2.3最小二乘(曲线拟合)函数 (16)3.2.4 使用函数 (16)3.2.5 大型方法的演示函数 (16)3.2.6 中型方法的延时函数 (16)3.4优化函数简介 (17)3.4.1优化工具箱的常用函数 (17)3.4.2 函数调用格式 (17)3.5模型输入时所需注意的问题 (19)第一部分:蚁群算法原理介绍1.1蚁群算法的提出蚂蚁是地球上最常见、数量最多的昆虫种类之一,常常成群结队地出现于人类的日常生活环境中。
受到自然界中真实蚁群集体行为的启发,意大利学者M.Dorig 。
于20世纪90年代初,在他的博士论文中首次系统地提出了一种基于蚂蚁种群的新型优化算法—蚁群算法}28}(Ant Colony Algorithm, ACA),并成功地用于求解旅行商问题,自1996年之后的五年时间里,蚁群算法逐渐引起了世界许多国家研究者的关注,其应用领域得到了迅速拓宽。
1.2蚁群算法的原理的生物学解释据观察和研究发现,蚂蚁倾向于朝着信息激素强度高的方向移动。
因此蚂蚁的群体行为便表现出了一种信息激素的正反馈现象。
当某条路径上经过的蚂蚁越多,该路径上存留的信息激素也就越多,以后就会有更多的蚂蚁选择它。
这也就是说,在蚂蚁搜寻食物的过程中,对于较短的路径,在单位时间内经过的蚂蚁数量越多,那么该路径上信息激素强度越高。
由于信息激素强度较高,则可以吸引更多的蚂蚁沿相同的路径进行搜索,这又使该路径上的信息激素强度增大。
而对于距离较长的路径,由于单位时间内经过的蚂蚁数量较少,该路径上信息激素强度较低,并且随着信息激素的挥发,该路径信息激素强度逐渐减弱,不再吸引蚂蚁沿这条路径运动。
蚂蚁个体之间就是通过信息激素的间接通信来相互协作形成正反馈,进行路径的最优选择,从而达到搜索食物的目的。
1.3 蚁群算法的数学模型将TSP 问题(traveling salesman problem)作为实例,简单的TSP 描述过程为:假设有n 座城,某个旅者自一城开始,依次经过各城市后回到出发远点,问题就是找到一条距离最小的走法。
假设b i (t)代表t 时位置是i 的蚂蚁数量,Ʈij (t)代表t 时路线((i, j)的所包含的信息量,n 代表TSP 问题的大小,m 则代表蚁群中所有蚂蚁数, 那 么1()n i t m b t ==∑; {|,}ij i i c c C τΓ=⊂则为t 时C 集合里元素(城市)相互连接lij 上的 遗存的信息数量的合集。
在开始时各路线上的信息数量相等, 假设Ʈij(0) =const ,最基本的蚁群算法求解最优是经有向的图断( C,L, Γ)来达到的。
蚂蚁k (k=1,2,...m),运动的过程中,其转移方向是依据每条路线上的信息数量。
我们利用禁忌表tabuk (k =1,2,..., m)来代表蚂蚁k 已经经过的城市,随着tabuk 进化过程变化,集合也做出动态的改变。
在蚂蚁搜索前进的过程,依据各路线上包含的信息以及路线下的启发式信息,用来算出状态转移下的概率。
()k ij P t 代表t 时下蚂蚁k 经城市i 运动到城市j 时的状态转移下的概率。
[][]k 0()()()j allowed ()()k k ij ik ij ij ik s allowed t t P t t t αβαβτητη⊂⎧⎪⎪⎡⎤•=⎣⎦⎨∈⎪⎡⎤•⎣⎦⎪⎩∑否则若 (1)式(1)中,allowedk=C-tabuk 代表k 蚂蚁要到下一个城市时允许选择的元素;α代表信息的启发式的因素,代表运动路线的重要程度,代表了蚂蚁不断地运动积累信息,在后续的蚂蚁移动过程中的作用,它数值较大,说明这个蚂蚁容易于选择别的蚂蚁所走过的路线,这些蚂蚁的协作运动越强;β代表的是期望的启发因素,代表清晰度下的比较的重要程度,反映了蚂蚁在移动中累计的启发式的信息,代表这个蚂蚁在选择路线过程中的重要性,它的数值大,那么这种状态的转移概率,比较与贪心规则相近似;ηik (t)代表是启发式函数:ik ij1t =d η() (2) 式(2)中,d ij 代表的是邻近两个元素之间距离,对于蚂蚁来说,d ij 值越小,那么n ik (t)值就越大,()k ij P t 值也越大。
显然,这个启发式的函数代表的是蚂蚁自城市i 到城市j 的期望度。
如果残留的信息素太多,要使残留的信息素不掩盖启发式的信息,当这个蚂蚁完成一个元素或走完n 个所有的城市,也就是说蚂蚁一个旅程完成,需要更新残留的信息。
这是仿效人类的大脑记忆下的特点提出的信息更新的模式,也就是说我们的大脑存储的新信息后,原先存储的旧的信息会伴随时间的推进,不断被我们逐渐的淡化,到最后甚至是忘记。
因此,t+n 时在路线((i, j)的信息调整规则如下:()(1)()()ij ij ij t n t t τρττ+=-•+∆ (3)1()()m k ij ij k t t ττ=∆=∆∑ (4)式(4.3)中,ρ系数代表的是信息挥发,那么1-ρ因子代表的是信息的残留,为避免信息的过多累积,ρ系数的取值的范围: )0,1;()ij t ρτ∈∆⎡⎣代表这次循环过程中路线(i, j)上信息的增加数量,原先的时间(0)0ij τ∆=,1()mk ij k t τ=∆∑代表的是k 蚂蚁,它旅行过程中在路线(i, j)上的留存下来的信息。
不同的信息更新的模式下,有不同的三种模型,对整体的信息而言,也就是蚂蚁走完一个循环后所有路线上的信息的更新,选择求TSP 时较为准确的模型,于是,选择ant-cycle 模型: ,()0,K (i,j)k K ij Q L t τ⎧⎪∆=⎨⎪⎩若第只蚂蚁在本次循环中经过否则式(4.5)中Q 代表信息素的强度,此强度在一定范围内影响的是算 法收敛快慢,Lk 代表蚂蚁在这次旅程中所走路线的总长度。
1.4蚁群算法实现步骤以TSP 为例,蚁群算法的具体实现步骤如下:1)初始化各参数:令Ʈij (0)=C(C 为常数),ΔƮij =0,迭代次数IT=0,最大迭代次数为IT_M ,计时器t=0,设置α,β,ρ,Q 的值,将m 只蚂蚁随机放在n 个城市上,把蚂蚁k(k=1, 2,...,m)。
目前所处城市设为禁忌表T k 的第一个元素;2)开始循环,蚂蚁k(k=1,2,...,m)根据式((3-2)状态转移概率选择下一城市,并将选择过的城市j 加入到禁忌表T k ,直到禁忌表中包含所有城市n;3)计算蚂蚁k(k=1,2,...,m)遍历所有城市的总路径长度L k ,比较所有蚂蚁找到的路径,选择一条最短路径,根据特定的公式更新路径上的信息素浓度;4)重新迭代,IT =IT+1;5)判断是否满足条件:判断迭代次数IT >_ IT M 且所有蚂蚁选择同一条路径。
满足的话输出最短路径,否则清空禁忌表T k ,跳转到步骤2);6)得到结果,程序结束。
流程图如下:第二部分:蚁群算法实例--集装箱码头船舶调度模型2.1 集装箱码头船舶调度流程图图2.1 集装箱码头船舶调度流程图2.2算例与matlab编程的实现2.2.1算法实例设定种群大小N=5 ,船舶数量vessel Number=8,泊位数量berth Number=3 ,每个泊位上有3台岸桥,岸桥的平均卸货速度为35箱/小时,蚁群算法中α=1,β=2.5,ρ =0.85,COUNTmax=20通过MATLAB编程实现以下:Step 1蚁群初始化,设时间的计数器t=0,初始迭代的次数ITCOUNT=0,Q[i][jl= 0将每个参数进行合理设置。
于此同时,还要设好题中的一些数据、条件以及泊位的条件和船舶载货量,以及模型中最大的岸桥数量等等,还有要按照船舶的载货数量,来算出两个城市间的距离;Step 2可行结点的集合进行初始化,创建一个模型禁忌表,并在禁忌表中方知k只蚂蚁起始的位置,并且将链表的索引设置为s=l;Step 3第k只蚂蚁来说,出发的起始点是Bk,船舶J的选择按照的是状态转移的规律,可以选择的可能性有:①如果船舶的要求在泊位Bk能被满足,那么就将位置(K,J)存在禁忌表中,蚁群算法进行下去;②如果船舶的要求在泊位Bk不能被满足,那么自动选择下一个可供选择的泊位,也就是B k+1,重新回到step 3;将这个过程重复进行,一直到链表满了为止,也就是说全部城市都被旅行过了。
Step 4用得到的信息素来对规则进行更新。
利用各个路线算出船舶等待的时间,并同当前找到的最优解来进行对比,选出本次更优的路线,来更新当前的全局的最优解。
将全部路线上的信息量进行更新,t=t+I, IT COUNT=IT COUNT+l,ΔQ[i][j]=0,清空禁忌表;Step 4假如是k次迭代结束,仍然是没有满足算法条件,那么需要重新开始算法迭代;Step 5假如连续进行迭代IT_COUNTn次以后,如果得出的最优值还是没有明显的改进时,则自适应修改P的值,直达到ρ = ρmin条件后停止修改。
Step 5如果IT_COUNT≤COUNT max,那么重复Step2,如果达到了最大的迭代次数IT_COUNT max,则算法结束。
应用蚁群算法优化得到船舶调度情况泊位1:1号船、6号船泊位2:2号船、7号船、5号船泊位3:3号船、4号船、8号船得到所有船舶在港时间为81.2小时,蚁群算法得到的船舶调度方案有效地缩短了所有船舶的在港时间。
图2.2 基于优先权的先到先服务原则的船舶泊位分布图总体上来看,由于船舶的优先权差距不明显,所以对于吨位差别不是很大的集装箱船舶,集装箱码头调度基本上是根据先来先服务的原则。
因此,通过上述实例验证的调度结果表明:在以先到先服务的原则为前提下,兼顾大船优先调度,可以实现所有船舶在港时间最小的目标。
2.2.2 Matlab编程MaxNc=20AntNum=5%计算船舶到港时间差(城市间距离)LabelMatrix=[0 0 0 -2 -3 3 -4 -4 1 1 1 3 -3 2 1 -3 -1;0 -1 3 -2 -3 -1 0 -1 -2 -1 3 4 0 0 -4 2 -1]%各船舶坐标矩阵X_LabelMatrix=[0 0 0 -2 -3 3 -4 -4 1 1 1 3 -3 2 1 -3 -1]%各船舶x轴坐标矩阵Y_LabelMatrix=[0 -1 3 -2 -3 -1 0 -1 -2 -1 3 4 0 1 -4 2 -1]%各船舶Y轴坐标矩阵mm=max(size(LabelMatrix))%泊位数量DistanceMatrix=zeros(mm);%初始距离矩阵为空矩阵for i=1 :mmforj=l:mmDistanceMatrix(i,j)=sqrt((X_LabelMatrix(1,i)-X_LabelMatrix(1,j))^2+(Y_LabelMatrix(l,i)-Y_LabelMatrix(l,j))^2);%各城市点间距离矩阵endDistanceMatrix %显示距离矩阵%定义其他初始变量R=[0 1.5 1.8 2 0.8 1.5 1 2.5 3 1.7 0.6 0.2 2.4 1.9 2 0.7 0.5 2.2 3.1 0.1]%各船舶的装卸时间,单位hQ=1%初始蚂蚁循环一周释放信息量tao0=Q/100%初始路径上的信息素浓度QV=9%船的装卸时间是9h%给tao矩阵miu矩阵节约值s矩阵赋初值for i=1 :mmfor j=l:mmif i~=js(i,j)=DistanceMatrix(l,i)+DistanceMatrix(l,j)-DistanceMatrix(i,j);%节约值tao(i,j)=tao0;%给路径上信息赋初值miu(i,j)=1/DistanceMatrix(i,j);%miu矩阵endendendfor i=2:mms(l,i)=3/DistanceMatrix(l,i);%这是什么意思,s(i,l)=1 /DistanceMatrix(i,l);endstaomrubest cost=zeros(l,MaxNc)%最优路线长度,每次迭代都会产生一个最优解cost=zeros(MaxNc,AntNum)%路线长度矩阵,每次迭代每只蚂蚁都产生一个路径长度Best_cost=zeros(MaxNc,25)%初始化,最优路径矩阵%开始迭代for Nc=1:MaxNcA_tao=zeros(mm)%各船舶之间的增量矩阵tour=zeros(AntNum,25)%初始路径矩阵为零,每次迭代的每只蚂蚁都产生禁忌表来替换tao%tao矩阵是随着迭代变化的if Nc<10Q=l ,rou=0.3,alpha=2,belta=3,gama=1endif Nc>=10&Nc<40Q=2,rou=0.4,alpha=3,belta=4,gama=2if Nc>40Q=3,rou=O.S,alpha=4,belta=3,gama=3End%迭代参数的变化,动态调整参数for Ant=1:AntNum %蚂蚁数目sumload=0 %初始装载量为0PartNum=1 %产生部分路径的数目cur_pos=1 %初始位置为等泊aa=randperm(mm)%随机置换船舶tabu=[ 1 ] %禁忌表初始为只有船舶的集hh=length(rn) %泊位个数while hh~=0&sumload<=QV%当船舶没有被访问完时继续,当泊位还有空间时继续A=[]p=[]for k=l :hhif sumload+R(rn(k))<=QV %看有没有满足容量约束的点A( l ,k)=1elseA(l,k)=0 %A矩阵记录容量符合的点endendA %输出A矩阵if sum(A)==0%如果没有容量满足约束的点sumload=0%装载量归零cur_pos=1%起始点归一tabu=[tabu,l]%路线重新从一点开始PartNum=PartNum+1 %所用车辆数加一hhelseB=m.*A %记录符合容量约束的实际点C=B(find(B>0)) %去除不符合容量约束的点D=max(size(C)) %符合容量约束的点规模%在满足容量约束的点中选择概率大的点for j=1:Dp(j)=((tao(curios,C(j)))^alpha)*((miu(cur_pos,C(j)))^belta)*(s(cur_pos,C (j))^gama)%计算从cur_pos到C小点的概率的分子endsump=sum(p)%概率公式的分母p=p/sump%到达满足要求的各点的概率r=rand()%产生一个随机数[a,b]=sort(p)%将p矩阵从小打到排列al=rot90(rot90(a))b1=rot90(rot90(b))%将矩阵从大到小排列%轮盘赌策略选择城市if r<max(p)%当随机数小于最大概率时选择概率最大的点curios=C(b I (1))%更新当前点sumload=sumload+R(C(b1(I)))%更新装载量tabu=[tabu,cur}os]%更新禁忌表rn=rn(find(m~=C(b1(1))))%更新备选船舶,去掉了已经选的船舶,相当于禁忌表的功能hh=hh-1if hh==0tabu=[tabu, l ]%给路径最后一个点赋值一,也就是封口endelseif r>=max(p)%当随机数大于最大概率时选择概率次大的点curios=C(b1(2))sumload=sumload+R(C(bl(2)))tabu=[tabu,cur_pos]m=m(find(m~=C(b1(2))))hh=hh-1if hh==0tabu=[tabu,l]endendendendtabu%输出各个蚂蚁的禁忌表,以用来求蚂蚁的cost,(正常情况下会每迭代一次每只蚂蚁输出一个禁忌表)tabu_size=max(size(tabu))%禁忌表的规模for i=1:tabu_sizetour(Ant,i)=tabu( l ,i)end %用tabu里的数据替换tour矩阵里的数据,以记录路径for i=1:(tabu_size-1)cost(Nc,Ant)=cost(Nc,Ant)+DistanceMatrix(tabu(i),tabu(i+1)) %计算禁忌表中路线总长度endcost%输出矩阵endbest_cost(l,Nc)=min(cost(Nc,:))%替换最好距离矩阵的数据[m n]=sort(cost(Nc,:))best tour(Nc,:)=tour(n(1),:)%-记录每一次迭代的最好解的路径%开始更新信息素为下一次迭代准备[q v]=sort(cost(Nc,:))%从小到大排列第Nc次迭代的距离goodAnt 1=tour(v(1), :)%将各个精英蚂蚁的禁忌表矩阵提取出来goodAnt2=tour(v(2),:)goodAnt3=tour(v(3),:)goodAnt4=tour(v(4),:)goodAntS=tour(v(5),: )badAnt=tour(v(AntNum),:)%提取出最差解的矩阵%开始更新城市信息素,采用全局更新策略for i=1 :mmfor j=l :mmif i~=jtao(i,j)=(1-rou)*tao(i,j);endendendtao%首先更新所有路径的信息素,考虑挥发的因素,更新五只精英蚂蚁的信息素tourl=goodAnt1(find(goodAnt 1 >0))%得出除去零点的第一只蚂蚁的路径矩阵for i=1 :(length(tourl)-1)A_tao(tourl(i),tourl(i+1))=A_tao(tourl(i),tourl(i+1))+Q/cost(Nc,v(1))%更新了第一只蚂蚁的路径信息素增量A_tao(tourl(i+1),tourl(i))=A_tao(tourl(i),tourl (i+1))%使得信息素矩阵仍为对称矩阵endA_tao%输出A_tao矩阵tour2=goodAnt2(find(goodAnt2>0))%得出除去零点的第二只蚂蚁的路径矩阵for i:(length(tour2)*1)A_tao(tour2(i),tour2(i+1))=A_tao(tour2(i),tour2(i+l))+Q/cost(Nc,v(2))%更新了第二只蚂蚁的路径信息素增量Aes tao(tour2(i+1),tour2(i))=Aes tao(tour2(i),tour2(i+1))endA tao%再次输出A tao矩阵tour3=goodAnt3(find(goodAnt3>0))%得出除去零点的第三只蚂蚁的路径矩阵for i=1 :(length(tour3)-1)A_tao(tour3(i),tour3(i+1))=Atao(tour3(i),tour3(i+1))+Q/cost(Nc,v(3))%更新了第三只蚂蚁的路径信息素增量A_tao(tour3(i+1),tour3(i))=A_tao(tour3(i),tour3 (i+1))endA_tao%再次输出tao矩阵tour4=goodAnt4(find(goodAnt4>0))%得出除去零点的第四只蚂蚁的路径矩阵for i=1:(length(tour4)-1)A_tao(tour4{i),tour4(i+l))=A_tao(tour4(i),tour4(i+1))+Q/cost(Nc,v(4))%更新了第四只蚂蚁的路径信息素增量A_tao(tour4(i+1),tour4(i))=A_tao(tour4(i),tour4(i+l))endA_ao%再次输出tao矩阵tours=goodAntS(find(goodAntS>0))%得出除去零点的第五只蚂蚁的路径矩阵for i=1 :(length(tour5)-1)A_tao(tour5(i),tour5(i+l))=A_tao(tours(i),tour5(i+l))+Q/cost(Nc,v(5))%更新了第五只蚂蚁的路径信息素增量A_tao(tour5(i+l),tour5(i))=A_tao(tour5(i),tour5(i+1))endA_tao%再次输出tao矩阵%更新糟糕蚂蚁的信息素tour6=badAnt(find(badAnt>0))%得出糟糕蚂蚁的除去零点的路径矩阵for i=1 :(length(tour6)一1)A_tao(tour6(i),tour6(i+1))=A_tao(tour6(i),tour6(i+1))-Qlcost(Nc,v(AntNum)) %更新糟糕蚂蚁的路径信息素增量A_tao(tour6(i+ 1),tour6(i))=AJao(tour6(i),tour6(i+1))endA_tao%最终更新后的信息素矩阵tao=tao+A_tao%更新所有路径的信息素%将信息素限制在mintao和maxtao之间maxtao=SO1rou*(Q/best cost(l,Nc))mintao=maxtao/ 10000for i=1 :mmfor j=l :mmif i==jtao(i,j)=0elseif i~=j&tao(i,j)>=maxtaotao(i,j)=maxtaoelseif i~=j&tao(i,j)<=mintaotao(i,j)=mintaoendendend本文建立的集装箱码头船舶调度优化模型能够比较实际的反映出集装箱码头的调度情况,即当优先权较大的船舶和优先权较小的船在相差较短的一段时间内相继到港,集装箱码头可以根据集装箱码头条件采取大船优先调度的策略;而当船舶先后到达相差时间较大的情况到港,以所有船舶在港时间最短为目标,必然遵循先来先服务的原则,优先调度先行到港的船舶。