数据模型与决策第7章时序分析与动态预测.ppt
自考数据、模型与决策

高纲1396江苏省高等教育自学考试大纲30447 数据、模型与决策南京大学编江苏省高等教育自学考试委员会办公室I 课程性质、设置目的与要求一、《数据、模型与决策》课程的性质随着社会信息化水平的提高和科学管理意识的普遍增强,人们对如何从数据资料角度进行认识显示出越来越多的兴趣。
数据资料本身并没有什么意义,关键是采用合适的方法对其进行分析和处理,只有这样才能探索客观现象发展变化的内在规律,从而更好地服务于管理决策的需要。
《数据、模型与决策》属于数量性质的课程,侧重于讲解数据资料的搜集、描述、分析和解释,以及管理决策方法和技术方面的知识。
管理决策分为两类,一类是理性决策一类是行为决策。
数据分析与决策模型中,不论是以不确定性为特征的统计决策,还是以确定性为特征的管理科学优化决策,和以策略互动为特征的博弈决策,都可以把它们归结为理性决策范畴。
既然是理性决策,必然会要求建立某种决策准则,然后在既定的准则下通过度量来选择决策方案。
这一过程一方面要对研究的问题进行结构化处理,另一方面也需要有相应的数据资料。
前者是为了能够建立决策模型,后者则是帮助实现计算。
有鉴于此,数据与模型在决策分析中的重要意义不言而喻。
数据与模型除了共同服务于决策分析以外,两者之间也存在密切的关系。
从应用的角度,统计方法比较强调实证性做法,统计分析与决策中,没有大量的、客观准确的数据资料,统计决策分析只能停留在纯理论的状态,无法形成具体的分析结论。
管理运筹优化和博弈决策分析中,虽然不像统计分析那样,需要拥有充足的数据,但是必要的不可控因素比如模型中的有关参数,其数值资料就必须事先给以确定。
尽管现在的企业一般都积累了大量的可供开发利用的数据资料,不过由于这样那样的原因,数据资料本身总会存在不系统、不充分、不完备的情况。
因此,对于背景数据必须经过科学的编辑、处理、汇总和提炼,然后才能用于决策分析。
对此,模型起着重要的转化作用,通过模型化处理,不仅能对数据的价值结构进行改造,而且还能对决策赋以深层次的分析。
供应链协同创新——智能制造与供应链优化方案

供应链协同创新——智能制造与供应链优化方案第一章:供应链协同创新概述 (2)1.1 供应链协同创新的定义与意义 (2)1.2 供应链协同创新的关键要素 (3)第二章:智能制造技术概述 (3)2.1 智能制造技术的概念与分类 (3)2.1.1 智能制造技术的概念 (3)2.1.2 智能制造技术的分类 (3)2.2 智能制造技术在供应链中的应用 (4)2.2.1 供应链管理与智能制造技术的融合 (4)2.2.2 智能制造技术在供应链关键环节的应用 (4)2.2.3 智能制造技术与供应链协同创新的案例分析 (4)第三章:供应链优化策略 (5)3.1 供应链优化策略概述 (5)3.2 供应链设计与优化方法 (5)第四章:智能供应链体系构建 (7)4.1 智能供应链体系架构 (7)4.1.1 数据层 (7)4.1.2 网络层 (7)4.1.3 平台层 (7)4.1.4 应用层 (7)4.2 智能供应链体系构建步骤 (7)4.2.1 明确供应链战略目标 (7)4.2.2 分析供应链现状 (7)4.2.3 设计供应链体系架构 (8)4.2.4 搭建供应链平台 (8)4.2.5 实施供应链智能化改造 (8)4.2.6 建立完善的运维体系 (8)4.2.7 持续优化供应链体系 (8)第五章:供应链数据挖掘与分析 (8)5.1 供应链数据分析方法 (8)5.2 数据挖掘技术在供应链中的应用 (9)第六章:供应链风险管理 (9)6.1 供应链风险类型与识别 (9)6.1.1 引言 (9)6.1.2 供应链风险类型 (9)6.1.3 供应链风险识别方法 (10)6.2 供应链风险防范与应对策略 (10)6.2.1 引言 (10)6.2.2 供应链风险防范策略 (10)6.2.3 供应链风险应对策略 (10)第七章:供应链协同规划与决策 (11)7.1 供应链协同规划方法 (11)7.2 供应链协同决策机制 (12)第八章:供应链协同创新实践案例 (12)8.1 国内外供应链协同创新案例解析 (12)8.1.1 国外案例:亚马逊供应链协同创新实践 (12)8.1.2 国内案例:巴巴供应链协同创新实践 (13)8.2 案例启示与借鉴 (13)第九章:供应链协同创新的政策与法规支持 (14)9.1 政策环境分析 (14)9.1.1 国家层面政策 (14)9.1.2 地方层面政策 (14)9.1.3 行业层面政策 (14)9.2 法规体系建设 (14)9.2.1 法律法规制定 (14)9.2.2 政策法规配套 (14)9.2.3 监管法规完善 (14)9.2.4 国际合作法规 (15)第十章:供应链协同创新的未来发展 (15)10.1 供应链协同创新的发展趋势 (15)10.2 供应链协同创新的挑战与机遇 (15)第一章:供应链协同创新概述1.1 供应链协同创新的定义与意义供应链协同创新是指在供应链管理过程中,各环节主体通过紧密合作、信息共享、资源整合等方式,共同开展技术创新、管理创新、服务创新等活动,以提高供应链整体运作效率、降低成本、增强竞争力的一种新型创新模式。
时间序列分析法范文

时间序列分析法范文1.数据收集:收集时间序列数据,确保数据准确性和完整性。
2.数据可视化:绘制时间序列数据的图表,以便观察其趋势和周期性。
3.时间序列分解:将时间序列数据分解为趋势、周期和随机成分。
趋势部分表示数据的长期变化趋势,周期部分表示数据的循环变化趋势,随机部分表示数据的不规律波动。
4.数据平稳性检验:判断时间序列数据是否具有平稳性,即均值和方差是否稳定。
5.模型拟合:根据数据的特征选择适当的时间序列模型,如AR模型(自回归模型)、MA模型(移动平均模型)或ARMA模型(自回归移动平均模型)。
6.模型检验:利用统计方法对拟合好的模型进行检验,如检查残差序列是否为白噪声序列。
7.模型预测:基于拟合好的模型,对未来的时间序列数据做出预测。
时间序列分析中最常用的模型之一是ARIMA模型(自回归整合移动平均模型)。
ARIMA模型基于时间序列数据的自相关性和移动平均性来做出预测。
ARIMA模型的三个参数分别代表自回归部分的阶数(AR)、差分次数(I)和移动平均部分的阶数(MA),通过对这三个参数的选择和拟合,可以得到最优的模型。
时间序列分析还可以应用于季节性数据的预测。
季节性数据具有明显的周期性,例如每年销售额的变化或每月的气温变化。
对季节性数据进行分析时,需要使用季节性ARIMA模型(SARIMA),该模型结合了ARIMA模型和季节性变化的效应。
在金融领域,时间序列分析可用于股票市场的预测和波动性分析。
例如,可以利用时间序列分析来研究股票市场的趋势,预测未来的股价,并进行风险管理。
时间序列分析的优点包括可以从历史数据中提取有用的信息,预测未来的趋势,并进行风险管理。
它还可以帮助研究人员了解时间序列数据的动态特征和影响因素。
然而,时间序列分析也存在一些局限性,例如对数据平稳性的要求较高,数据的缺失或异常值可能会影响预测结果的准确性。
总之,时间序列分析是一种有效的统计方法,可帮助我们理解和预测随时间变化的数据。
统计预测和决策(2015最全版)..

一、名词解释第一章①预测:根据过去和现在估计预测未来。
②统计预测:属于预测方法研究的范畴,即如何利用科学的统计方法对事物的未来发展进行③定量推测,并计算概率置信区间。
第二章①定性预测:是指预测者依靠熟悉业务知识、具有丰富经验和综合分析能力的人员与专家,根据已掌握的历史资料和直观材料,运用个人的经验和分析判断能力,对事物的未来发展做出性质和程度上的判断,然后再通过一定形式综合各方面的意见,作为预测未来的主要依据。
②主观概率:是人们对根据几次经验结果所做的主观判断的主观判断的量度。
③客观概率:是根据事件发展的客观性统计出来的一种概率。
④相互影响法:是从分析各个事件之间由于相互影响而引起的变化,以及变化发生的概率,来研究各个事件在未来发生的可能性的一种预测方法。
第三章①残差:预测值与真实值的离差②可绝系数:衡量自变量与因变量关系密切程度的指标,表示自变量解释因变量变动的百分百比。
③相关系数:测定拟合优度的指标,相关系数平方等于可绝系数。
④非线性回归预测法:在社会现实经济活动中,很多现象之间的关系并不是线性的,这时就要选配适当类型的曲线,即非线性回归预测。
⑤拟合优度:衡量回归直线拟合效果的指标⑥自相关系数:是衡量同一变量不同时期的数据之间相关程度的指标。
⑦D-W:检验模型是否存在自相关的一个有效方法,其计算公式为:D—W=∑(ui-ui-1)^2/∑ui^2,其中ui=yi-^yi.根据经验D-W统计量在1.5~2.5之间表示没有显著自相关问题。
第四章①不规则变动因素:又称随机变动,它是受各种偶然因素影响所形成的不规则变动。
②趋势外推法:用时间t为自变量,时序数值y为因变量,建立合适的趋势模型,并赋予时间变量t所需要的值,从而得到相应时刻的时间序列未来值。
③图形识别法:通过绘制以时间t为横轴,时序数据为y轴的散点图形,并将其与各种函数曲线模型比较,选择最为合适的模型。
④差分法:利用差分把数据修匀,使非平稳的序列达到平稳序列。
时间序列预测算法-ARIMA算法

时间序列预测算法-ARIMA算法基于时间序列分析的趋势预测算法,主体采⽤ARIMA差分⾃回归移动平均模型,ARIMA算法模型主体包括三⼤部分:AR,I以及MA模型。
其中,每⼀个模型部分都拥有⼀个相关的模型参数—ARIMA(p,d,q)。
算法的基本原理是将⾮平稳时间序列转化为平稳时间序列然后将因变量仅对它的滞后值以及随机误差项的现值和滞后值进⾏回归所建⽴的模型。
在ARIMA(p,d,q)整体模型中,AR是⾃回归模型,对应的模型参数p为⾃回归项数;I为差分模型,对应的模型参数d为使之成为平稳时间序列所做的差分次数(阶数);MA 为滑动平均模型,q为滑动平均项数。
在实际进⾏算法模型的构建时,可以根据ACF⾃相关系数图决定q的取值,PACF偏⾃相关系数图决定p的取值。
1. ⾃回归模型(AR)AR模型是为了建⽴起当前数据特征值与过去历史值之间的关系,实现⽤变量⾃⾝的历史时间数据对⾃⾝进⾏⼀定的时间周期预测,⾃回归模型必须满⾜平稳性的要求,并且必须具有⾃相关性,⾃相关系数⼩于0.5则不适⽤p阶⾃回归过程的公式定义:其中,为当前的值,是常数项,p是阶数,是⾃相关系数,是误差,前⼏天值的⼤⼩。
2. I差分模型I差分模型主要是为了对原始数据进⾏不同书数⽬阶次的差分处理,使得原始数据转变为时间维度上的平稳序列,为后续建⽴AR和MA算法模型奠定基础。
⼀般情况下,采⽤差分阶数最多的是⼀阶或者两阶。
3. 移动平均模型(MA)移动平均模型关注的是⾃回归模型中的误差项的累加,移动平均法能有效地消除预测中的随机波动q阶移动平均过程的公式定义:4. ARIMA算法模型的pq参数的确定PACF,是指偏⾃相关函数,剔除了中间k-1个随机变量x(t-1)、x(t-2)、……、x(t-k+1)的⼲扰之后x(t-k)对x(t)影响的相关程度,可以通过PACF的分布图来选择出p值的最优值⼤⼩。
ACF,⾃相关函数反映了同⼀序列在不同时序的取值之间的相关性。
第8章 时间序列趋势分析

我国年末人口数(万人) 我国人口自然增长率(‰)
某厂职工年平均工资(元/人)
12000
13000
15000……
.
时间序列的构成要素
现象在各时间上的指标数值 时间序列分析的目的
描述现象在过去时间的状态。 分析现象发展变化的规律性。 根据现象的过去行为预测其未来行为。 将相互联系的时间序列进行对比,研究有关现象之 间的联系程度。
4.
不规则变动 (Irregular Variations )
包括随机变动和突然变动。 随机变动—现象受到各种偶然因素影响而呈现出方 向不定、时起时伏、时大时小的变动。 突然变动—战争、自然灾害或其它社会因素等意外 事件引起的变动。影响作用无法相互抵消,影响幅 度很大。 一般只讨论有随机波动而不含突然异常变动的情况。 随机变动与时间无关,是一种无规律的变动,难以 测定,一般作为误差项处理。
8.2.2 长期趋势的测定
长期趋势分析主要是指长期趋势的测定,采用一定的方法
对时间序列进行修匀,使修匀后的数列排除季节变动、循环
.
变动和无规则变动因素的影响,显示出现象变动的基本趋势, 作为预测的依据。
测定长期趋 势的方法
移动平均法 趋势方程拟和法(数学模型法)
.
研究长期趋势的目的和意义
1. 认识和掌握现象随时间演变的趋势和规律,为 制定相关政策和进行管理提供依据;
表8- 2 1981-1998年我国汽车产量数据
年 份
1981 1982 1983 1984 1985 1986 1987 1988 1989
产量(万辆)
17.56 19.63 23.98 31.64 43.72 36.98 47.18 64.47 58.35
应用eviews分析数据和预测
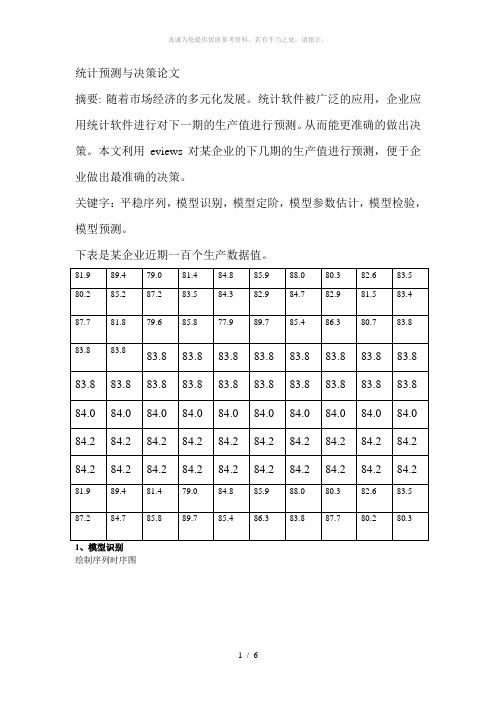
统计预测与决策论文摘要:随着市场经济的多元化发展。
统计软件被广泛的应用,企业应用统计软件进行对下一期的生产值进行预测。
从而能更准确的做出决策。
本文利用eviews对某企业的下几期的生产值进行预测,便于企业做出最准确的决策。
关键字:平稳序列,模型识别,模型定阶,模型参数估计,模型检验,模型预测。
下表是某企业近期一百个生产数据值。
1、模型识别绘制序列时序图7680848892255075100125150175200PRODUCTI ON2模型定阶绘制序列相关图从相关图看出,自相关系数迅速衰减为0,说明序列平稳,但最后一列白噪声检验的Q 统计量和相应的伴随概率表明序列存在相关性,因此序列为平稳非白噪声序列。
模型定阶:由图2-5看出,偏自相关系数在k=3后很快趋于0即3阶截尾,尝试拟合AR (3);自相关系数在k=1处显著不为0,当k=2时在2倍标准差的置信带边缘,可以考虑拟合MA (1)或MA (2);同时可以考虑ARMA (3,1)模型等。
原序列做描述统计分析见图481216207880828486889092Series: PRODUCTION Sample 1 201Observations 201Mean 84.11940Median 84.10000Maximum 91.70000Minimum 76.50000Std. Dev. 2.906625Skewness 0.107191Kurtosis 2.752406Jarque-Bera 0.898321Probability0.638164可见序列均值非0,我们通常对0均值平稳序列做建模分析,所以需要在原序列基础上生成一个新的0均值序列。
这个序列是0均值的平稳非白噪声序列,新序列的描述统计量见图 048121620-8-6-4-22468Series: XSample 1 201Observations 201Mean 2.99e-06Median -0.019400Maximum 7.580600Minimum -7.619400Std. Dev. 2.906625Skewness 0.107191Kurtosis 2.752406Jarque-Bera 0.898321Probability0.6381643模型参数估计(1) 尝试AR 模型。
时间序列分析与预测模型

时间序列分析与预测模型时间序列分析是指对按时间顺序排列的观测数据进行分析的一种方法。
该方法可以帮助我们理解和解释数据的时间相关性,并且可以利用这种相关性进行预测。
时间序列分析在很多领域都有广泛的应用,如经济学、金融学、天气预测等。
1.数据收集:收集包含时间顺序的数据。
这些数据可以是连续的,如每天、每月或每年的数据,也可以是离散的,如每小时或每分钟的数据。
2.数据可视化:绘制时间序列图,将收集到的数据可视化。
通过观察时间序列图,我们可以发现数据的趋势、周期性和季节性。
3.数据平稳性检验:对时间序列数据进行平稳性检验。
平稳性是指数据的均值、方差和自协方差不随时间变化。
平稳性是许多时间序列模型的前提条件。
4.模型拟合:根据时间序列数据的特点选择合适的模型。
常见的时间序列模型包括自回归移动平均模型(ARMA)、自回归集成移动平均模型(ARIMA)和季节性自回归集成移动平均模型(SARIMA)等。
5.模型诊断:对拟合的模型进行诊断检验。
诊断检验可以判断模型是否良好地拟合了数据,并确定是否需要进行模型调整。
6.模型预测:利用已经拟合好的模型进行未来值的预测。
预测可以是单点预测,也可以是预测一段时间内的趋势。
时间序列分析的预测模型可以帮助我们预测未来的趋势,并且可以在实际决策中指导我们采取相应的行动。
例如,我们可以利用时间序列分析预测未来销售量,从而帮助我们制定合适的生产计划和库存策略。
在金融领域,时间序列分析可以帮助我们预测股价的涨跌,从而指导我们的投资决策。
总之,时间序列分析是一种重要的数据分析方法,它可以帮助我们理解和预测按时间顺序排列的数据。
在实际应用中,我们可以根据时间序列数据的特点选择合适的模型,并进行模型拟合和预测。
通过时间序列分析,我们可以获得有关未来趋势的信息,从而在实际决策中作出更准确的预测。
部门数据治理与决策支持平台建设方案

部门数据治理与决策支持平台建设方案第1章项目背景与目标 (3)1.1 部门数据治理现状分析 (4)1.2 决策支持平台建设需求 (4)1.3 项目目标与预期成果 (4)第2章数据治理体系建设 (4)2.1 数据治理框架设计 (5)2.1.1 政策指导 (5)2.1.2 技术支撑 (5)2.1.3 流程优化 (5)2.2 数据治理组织架构 (5)2.2.1 领导小组 (5)2.2.2 数据治理办公室 (5)2.2.3 业务部门 (5)2.2.4 技术支持部门 (6)2.3 数据治理制度与流程 (6)2.3.1 数据治理制度 (6)2.3.2 数据治理流程 (6)2.4 数据质量管理 (6)2.4.1 数据质量控制 (6)2.4.2 数据质量评估 (6)2.4.3 数据质量改进 (6)第四章数据处理与分析技术 (6)4.1 数据预处理与清洗 (7)4.1.1 数据集成 (7)4.1.2 数据清洗 (7)4.1.3 数据转换 (7)4.2 数据挖掘与知识发觉 (7)4.2.1 关联规则分析 (7)4.2.2 聚类分析 (7)4.2.3 决策树分析 (7)4.2.4 机器学习算法 (7)4.3 数据可视化与报表设计 (7)4.3.1 数据可视化 (8)4.3.2 报表设计 (8)4.4 人工智能与大数据技术在决策支持中的应用 (8)4.4.1 智能预测 (8)4.4.2 智能推荐 (8)4.4.3 智能优化 (8)4.4.4 智能分析 (8)第5章决策支持模型与方法 (8)5.1 决策支持模型概述 (8)5.1.2 决策支持模型分类 (9)5.1.3 决策支持模型在部门的应用 (9)5.2 数据驱动的决策支持方法 (9)5.2.1 数据预处理 (9)5.2.2 数据分析方法 (9)5.3 智能决策支持算法 (9)5.3.1 人工神经网络 (10)5.3.2 深度学习 (10)5.3.3 遗传算法 (10)5.4 模型评估与优化 (10)5.4.1 模型评估 (10)5.4.2 模型优化 (10)第6章平台架构设计 (10)6.1 总体架构设计 (10)6.1.1 基础设施层 (11)6.1.2 数据资源层 (11)6.1.3 应用支撑层 (11)6.1.4 业务表现层 (11)6.2 技术架构设计 (11)6.2.1 前端技术 (11)6.2.2 后端技术 (11)6.2.3 数据库技术 (11)6.2.4 中间件技术 (11)6.3 数据架构设计 (12)6.3.1 数据源 (12)6.3.2 数据集成 (12)6.3.3 数据存储 (12)6.3.4 数据处理 (12)6.3.5 数据服务 (12)6.4 应用架构设计 (12)6.4.1 功能模块划分 (12)6.4.2 业务流程设计 (12)6.4.3 系统集成 (12)第7章系统开发与实施 (12)7.1 系统开发方法论 (12)7.1.1 整体规划与分阶段实施 (12)7.1.2 迭代开发与持续优化 (13)7.1.3 风险管理 (13)7.2 系统开发环境与工具 (13)7.2.1 开发环境 (13)7.2.2 开发工具 (13)7.3 系统实施与部署 (13)7.3.1 系统实施流程 (13)7.4 系统测试与验收 (14)7.4.1 系统测试 (14)7.4.2 系统验收 (14)第8章平台功能模块设计 (14)8.1 数据采集与管理模块 (14)8.1.1 数据采集 (14)8.1.2 数据清洗与转换 (15)8.1.3 数据存储与管理 (15)8.2 数据分析与挖掘模块 (15)8.2.1 数据预处理 (15)8.2.2 数据分析 (15)8.2.3 数据挖掘 (15)8.3 决策支持与报告模块 (15)8.3.1 决策支持 (15)8.3.2 报告 (15)8.3.3 报告推送与共享 (15)8.4 用户管理与权限控制模块 (15)8.4.1 用户管理 (16)8.4.2 权限控制 (16)8.4.3 操作日志记录 (16)8.4.4 安全防护 (16)第9章系统安全与运维保障 (16)9.1 系统安全策略与措施 (16)9.1.1 安全策略 (16)9.1.2 安全措施 (16)9.2 数据备份与恢复机制 (17)9.2.1 数据备份策略 (17)9.2.2 数据恢复机制 (17)9.3 系统运维与监控 (17)9.3.1 系统运维 (17)9.3.2 系统监控 (17)9.4 系统升级与维护 (17)9.4.1 系统升级 (17)9.4.2 系统维护 (17)第10章项目实施与评估 (18)10.1 项目实施计划与进度安排 (18)10.2 项目风险管理 (18)10.3 项目评估与优化 (18)10.4 项目总结与经验推广 (19)第1章项目背景与目标1.1 部门数据治理现状分析信息技术的飞速发展,大数据时代已经来临。
(2021年整理)时间序列分析STATA第三课

(完整版)时间序列分析STATA第三课编辑整理:尊敬的读者朋友们:这里是精品文档编辑中心,本文档内容是由我和我的同事精心编辑整理后发布的,发布之前我们对文中内容进行仔细校对,但是难免会有疏漏的地方,但是任然希望((完整版)时间序列分析STATA 第三课)的内容能够给您的工作和学习带来便利。
同时也真诚的希望收到您的建议和反馈,这将是我们进步的源泉,前进的动力。
本文可编辑可修改,如果觉得对您有帮助请收藏以便随时查阅,最后祝您生活愉快业绩进步,以下为(完整版)时间序列分析STATA第三课的全部内容。
(完整版)时间序列分析STATA第三课编辑整理:张嬗雒老师尊敬的读者朋友们:这里是精品文档编辑中心,本文档内容是由我和我的同事精心编辑整理后发布到文库,发布之前我们对文中内容进行仔细校对,但是难免会有疏漏的地方,但是我们任然希望(完整版)时间序列分析STATA第三课这篇文档能够给您的工作和学习带来便利。
同时我们也真诚的希望收到您的建议和反馈到下面的留言区,这将是我们进步的源泉,前进的动力.本文可编辑可修改,如果觉得对您有帮助请下载收藏以便随时查阅,最后祝您生活愉快业绩进步,以下为〈(完整版)时间序列分析STATA第三课> 这篇文档的全部内容。
第三课:ARMA/ARIMA建模及预测核心问题:1,前提:同方差,因此,不用考虑不同时刻变量的离散性;2,建立的是变量分布的均值模型,也就是,随机变量分布的均值所在的位置3,难点在于,时间序列数据建立模型并没有唯一性以quarterly。
dta的数据来说明.这个数据是美国的季度GDP数据,数据从1947年一季度开始,到2012年一季度结束。
研究对象,GDP,存在通货膨胀问题.所以要用GDP平减指数(GDP Deflator)进行矫正,这里是以2005年的美元作为基准的。
所以考察变量是GDP2005,即以2005年的美元作为基准的各季度的GDP真实值.一,一些基本符号:D L F二,建立模型:前期准备:观察时序图相关命令:tsset, tsline/twoway从图上可以看出,GDP2005值呈线性的向右上方倾斜,第一种方法:可以用确定性分析理的方法,使用研究变量对时间变量进行回归即:regress lrgdp date (采用的是最小二乘估计)然后对残差项进行White Noise检验观察此图:特征大值跟大值,小值跟小值,这说明Residual中存在着自相关信息.肯定不是White Noise因此,从这里看出,确定性的方法比较直观,简单,但效果不好,弥补:对残差序列进行回归,建立AR模型,这就是所谓的残差自回归模型.第二种方法BOX —JENKINS 方法,也就是通常所说的ARMA (p,d ) /ARIMA (p,d ,d)建模(采用的是最大似然估计).四大步骤:1、模型识别Identification :决定p 和q2、模型估计Estimation:估计εσθφμ 个),(,个)(,q p 3、模型检验Diagnostic Checking4、模型优化Parsimony1,模型识别Identification 相关命令:ac pac这个图的特征是 ac 值虽然在减小,但其减少类似线性,这时候就要考虑差分了,通常使用的是一阶差分和二阶差分一阶差分 generate growth=lrgdp-L.lrgdp这个时候,growth 就是经济增长率这张图的 ac值快速减少到影音之内,说明在样本中,变量growth显现的是平稳.此时,这张图同时和pac图联合使用,来判定p,qac 图决定是q, pac图决定的是p可以判定,growth的模型是ARMA(1,2)2,模型估计Estimation,命令:ARIMAarima growth, arima(1,0,2)arima lrgdp, arima(1,1,2)关键:如何看懂这个结果,如何写出ARMA的具体方程形式。
物联网数据融合技术 (PPT 136页)

第9章 物联网数据融合技术 ③ 分析能力差。不能实现对影像的有效理解和分析。 ④ 纠错要求。由于底层传感器信息存在不确定性、不完
全性或不稳定性,所以对融合过程中的纠错能力有较高要求。 ⑤ 抗干扰性差。 像元级融合所包含的具体融合方法有代数法、IHS变换、
小波变换、主成分变换(PCT)、K-T变换等。
第9章 物联网数据融合技术
(2) 数据的融合不同于组合,组合指的是外部特性,融 合指的是内部特性,它是系统动态过程中的一种数据综合加 工处理。
(3) 数据的互补过程,数据表达方式的互补、结构上的 互补、功能上的互补、不同层次的互补,是数据融合的核心, 只有互补数据的融合才可以使系统发生质的飞跃。数据融合
第9章 物联网数据融合技术
(4) K-T变换:即Kauth-Thomas变换,又形象地称为“缨 帽变换”。它是线性变换的一种,它能使坐标空间发生旋转, 但旋转后的坐标轴不是指向主成分的方向,而是指向另外的 方向,这些方向与地面景物有密切的关系,特别是与植物生 长过程和土壤有关。因此,这种变换着眼于农作物生长过程 而区别于其他植被覆盖,力争抓住地面景物在多光谱空间的 特征。通过K-T变换,既可以实现信息压缩,又可以帮助解 译分析农业特征,因此,有很大的实际应用意义。目前K-T 变换在多源遥感数据融合方面的研究应用主要集中在MSS与 TM两种遥感数据的应用分析上。
将空间配准的遥感影像数据(或提取的图像特征或模式识别的 属性说明)进行有机合成(如“匹配处理”和“类型变换”等), 以便得到目标的更准确表示或估计。
第9章 物联网数据融合技术
2.数据融合的分类及方法 1) 数据融合的分类 遥感影像的数据融合有三类:像元(pixel)级融合、特征 (feature)级融合、决策(decision)级融合,融合的水平依次从 低到高。 (1) 像元级融合:是一种低水平的融合。 像元级融合的流程:经过预处理的遥感影像数据—数据 融合—特征提取—融合属性说明。
时序网络模型对复杂社会关系的建模与预测

时序网络模型对复杂社会关系的建模与预测引言:社会网络是由大量个体互相联系和互动形成的复杂系统,它是现代社会中最重要的组织形式之一。
研究社会网络对于了解社会关系、预测社会行为和指导社会管理具有重要意义。
时序网络模型是一种基于时间的社会网络分析方法,它可以准确地建模社会关系的演化过程,并能够对未来的社会行为进行预测。
本文将介绍时序网络模型的基本原理和应用,并通过实例阐述其在复杂社会关系的建模与预测中的作用。
一、时序网络模型的基本原理1.1 社会网络的建模方法社会网络可以通过节点和边来描述,节点代表网络中的个体,边代表个体之间的关系。
基于节点和边的描述,可以采用图论和复杂网络理论等方法来对社会网络进行建模。
图论是一种研究节点和边之间关系的数学工具,它可以分析节点的度、聚集系数和中心性等指标来了解节点在网络中的重要程度。
复杂网络理论则可以研究节点之间的联系模式和结构特征,包括小世界网络、无标度网络和社区结构等。
1.2 时序网络模型的特点时序网络模型是一种基于时间的社会网络分析方法,它可以将社会网络中的节点和边与时间序列相结合,准确地描述社会关系的演化过程。
时序网络模型的特点包括:(1)时间序列建模:时序网络模型能够通过时间序列数据对社会关系的演化进行建模,揭示社会网络中节点和边的变化趋势。
(2)动态预测能力:时序网络模型能够基于已有数据对未来的社会行为进行预测,为社会管理和决策提供科学依据。
(3)多维度分析:时序网络模型可以同时考虑节点的属性、关系和时间等多个维度,实现对社会关系的全面分析。
二、时序网络模型的应用场景2.1 社交网络分析社交网络是时序网络模型应用最广泛的领域之一。
通过分析社交网络中的节点和边的演化过程,可以了解社交关系的变化趋势和发展规律。
例如,在微博上的用户关系网络中,可以通过时序网络模型来预测用户之间的转发行为、互动模式和信息传播路径,为营销活动和舆情分析提供决策支持。
2.2 金融风险预测金融系统是一个典型的复杂系统,其中包含了大量的金融机构和个体之间的关系。
时序数据分析方法综述

简单移动平均法对每个观察值都给予先相同的权数,每次计算时间隔都为 确性不同。 加权移动平均法: 是对近期和远期的观察值赋予不同的权重值。 当序列波动较大时, 近期赋予较大的权重,较远时期观察值权重赋予较小值;当序列波动较小时,各期观察 值则相近。当权重值均为 1 时,即为简单移动平均法。但该方法的移动间隔和权数的选 择一般需要通过均方误差预测精度来调整。 (3) 指数平滑法 指数平滑法是加权移动平均法的一种特殊形式,是指观察值越远,权数随时间呈指 数下降。主要有一次指数平滑、二次指数平滑、三次指数平滑等。方法主要表示为:
一、时间序列数据的相关概念
1、 时间序列 { X t , t T } : 指被观察到的依时间为序排列的数据序列。 (A time series is a collection of observations made sequentially in time.) 2、时间序列的特点: (1)时间序列是指同一现象在不同时间上的相继观察值; (2)前后时刻的数据一般具有某种程度的相关性; (3)形式上由现象所属的时间和现象在不同时间上的观察值两部分组成; (4)排列的时间可以是年份、季度、月份或其他任何时间形式。 3、 时间序列的主要成分: 趋势性 (Trend) 、 季节性 (Seasonality) 、 周期性 (Cyclity) 、 随机型(Random) 4、时间序列的分类: (1)平稳序列(stationary series) :基本上不存在趋势的序列, 各观察值基本在某个固定的水平上波动,或虽有波动,但不存在某种规律,其波动可看 成随机。 (2) 非平稳序列 (non-stationary series) :一般包括有趋势的序列,或包括趋势、 季节、周期性的复合型序列。 5、时间序列分析的内涵:依据不同应用背景,时序分析有不同目的: (1)系统描 述:揭示支配时间序列的随机规律; (2)系统预测:通过此随机规律,理解所要考虑的 动态系统,预报未来的事件; (3)干预和决策:通过干预来控制未来事件。 6、时间序列分析的内容: (1)通过对样本的分析研究,找出动态过程的特性; (2) 找到最佳的数学模型; (3)估计模型参数; (4)利用数学模型进行统计预测 7、时间序列数据的特征:时间属性和数据属性 时间属性:时间隐含内在的周期性特征,例如季节的更迭。时间还具有确定型和不 确定性的特征。 数据属性:按照统计尺度分为定性和定量特征;按照参照标准可分为空间和非空间 特征;按变量个数分为单变量和多变量特征。
OneAPM智能运维平台解决方案PPT幻灯片全文

故障根因分析
异常预测
29
2020/2/27
什么是KPI异常检测
KPI(Key Performance Indicator):用于反映服务的健康程度。如:服务请求数、拒绝数、响应时间、流 、订单等 如:服务 CPU、内存、 络、磁盘等 KPI 异常行为:潜在的风险、故障、bugs、攻击...... KPI 异常检测:用于识别 KPI 时序曲线上的异常行为。及早发现风险,防止其发展为故障及时发现故障,进行止损、诊断和修复运维的重要基础
人工智能算法与分析篇
27
2020/2/27
结合领域知识的人工智能算法
人工智能算法
聚类、决策树、随机森林、卷积神经网络
运维领域知识
异常检测、多维分析、根因分析、故障预测
行业运维经验
金融、运营商、互联网、政府、大型企业
AIOps
28
2020/2/27
OneAPM人工智能算法与分析平台
基础数据层
机器学习算法层
17
2020/2/27
与已有ITOM工具的对接
JDBC,SNMP TRAP,Web Service,……
OneAPMAIOps
18
2020/2/27
海量数据处理与存储篇
19
2020/2/27
海量IT数据处理的挑战
数据规模
高并发总量大种类多样格式各异
毫秒级延时秒级处理响应逻辑复杂
实效
20
2020/2/27
降低系统低效对业务的影响多种分散独立监控工具专业化专家型人才业务系统已经发生了什么?被动响应的故障恢复性管理
人工运维
AIOps
5
2020/2/27
什么是AIOps
用户个性化需求满足策略

用户个性化需求满足策略第1章个性化需求概述 (3)1.1 用户个性化需求概念 (3)1.2 个性化需求的重要性 (3)1.3 个性化需求满足的挑战与机遇 (3)第2章用户画像构建 (4)2.1 用户画像基本理论 (4)2.2 用户画像数据采集 (4)2.3 用户画像数据预处理 (4)2.4 用户画像建模方法 (4)2.4.1 基于统计的用户画像建模 (4)2.4.2 基于机器学习的用户画像建模 (5)2.4.3 基于深度学习的用户画像建模 (5)第3章个性化推荐系统 (5)3.1 推荐系统概述 (5)3.2 协同过滤推荐算法 (5)3.3 内容推荐算法 (5)3.4 深度学习在推荐系统中的应用 (6)第4章用户行为分析与预测 (6)4.1 用户行为数据采集 (6)4.2 用户行为特征分析 (7)4.3 用户行为预测方法 (7)4.4 用户留存与流失分析 (7)第5章个性化搜索策略 (8)5.1 个性化搜索概述 (8)5.2 个性化搜索算法 (8)5.3 个性化搜索结果排序 (8)5.4 个性化搜索优化策略 (9)第6章个性化界面设计与交互 (9)6.1 个性化界面设计原则 (9)6.1.1 用户研究 (9)6.1.2 易用性 (9)6.1.3 界面一致性 (9)6.1.4 灵活性与可扩展性 (9)6.1.5 个性化定制 (9)6.2 个性化界面布局与元素 (9)6.2.1 界面布局 (9)6.2.2 色彩与字体 (9)6.2.3 图标与按钮 (10)6.2.4 动效与动画 (10)6.3 个性化交互方式 (10)6.3.1 语音交互 (10)6.3.3 智能推荐 (10)6.3.4 社交互动 (10)6.4 用户体验优化 (10)6.4.1 响应速度优化 (10)6.4.2 交互逻辑优化 (10)6.4.3 信息架构优化 (10)6.4.4 用户反馈机制 (10)第7章大数据与人工智能在个性化需求满足中的应用 (10)7.1 大数据技术概述 (10)7.2 人工智能技术概述 (10)7.3 大数据与人工智能在个性化需求满足中的融合 (11)7.4 应用案例与未来趋势 (11)7.4.1 应用案例 (11)7.4.2 未来趋势 (11)第8章个性化需求满足的伦理与法律问题 (11)8.1 用户隐私保护 (12)8.1.1 隐私权概述 (12)8.1.2 用户隐私信息的收集与使用 (12)8.1.3 用户隐私保护的法律法规及合规要求 (12)8.1.4 用户隐私保护的技术措施与策略 (12)8.2 数据安全与合规性 (12)8.2.1 数据安全概述 (12)8.2.2 数据安全风险与挑战 (12)8.2.3 数据安全法律法规及合规要求 (12)8.2.4 数据安全保护措施与实践 (12)8.3 个性化推荐与广告的法律问题 (12)8.3.1 个性化推荐与广告概述 (12)8.3.2 个性化推荐与广告的法律法规及合规要求 (12)8.3.3 用户权益保护与个性化推荐、广告的界限 (12)8.3.4 个性化推荐与广告的法律风险防范 (12)8.4 伦理与法律风险防范 (12)8.4.1 伦理与法律风险概述 (12)8.4.2 伦理原则与合规要求 (12)8.4.3 伦理与法律风险防范策略 (12)8.4.4 企业社会责任与可持续发展 (13)第9章个性化需求满足的商业模式 (13)9.1 个性化服务商业模式概述 (13)9.2 付费订阅模式 (13)9.3 广告驱动模式 (13)9.4 个性化电商与金融 (13)第10章个性化需求满足的未来展望 (14)10.1 技术发展趋势 (14)10.2 个性化需求满足的行业标准与规范 (14)10.4 个性化需求满足的普及与挑战 (14)第1章个性化需求概述1.1 用户个性化需求概念用户个性化需求,指的是在互联网时代背景下,用户基于个人兴趣、习惯、价值观等特征,对产品或服务提出的独特、定制化的要求。
地下水动态预测模型

第一章综述1.1 动态预报的意义1.1.1 地下水资源的管理提供依据地下水资源的合理开发利用,地下水资源管理目标的实现,从根本上讲,要依靠地下水动态分析及预报的结果.因为只有在合理的动态预报模型下,各种管理模型才具有现实意义和实现的可能。
同时,地下水动态预报也是水资源管理机构发布行政指令或实施技术性措施的科学依据。
1.1.2 为地质灾害的预测与研究提供基本资料近年来,随着人类活动范围的不断扩大,改造自然的加剧,各种地质灾害层出不穷,例如滑坡,崩塌,矿山水害,地震,地面沉陷,地下水污染,土壤盐碱化、沼泽化等,这些地质灾害中,很多与地下水动态有着密切的关系,例如滑坡,地面沉陷,土壤的盐碱化和沼泽化等,另有一些地质灾害,在发生前的预兆中,能在地下水的动态变化中体现出来,例如地震,因此,地下水动态的研究为预防和治理这些灾害提供了基本资料,也是地质灾害预报的一个重要参考方面。
1.1.3 为工农业供水和工程建设提供背景资料当前很多城市和地区的工农业供水持续紧张,影响了当地的经济发展,加强地下水动态的研究,合理开发利用地下水是解决水资源危机的一个重要环节。
此外,同工程设计和施工密切联系的浅层地下水位及其变化趋势与其它工程地质资料一样是城市规划、土地利用、开发的重要资料。
地下水的埋藏和分布情况是地基基础和土力学计算中不可缺少的基本参数,建筑防水设计,抗浮设计,基坑支护设计及施工降水设计等都离不开地下水位资料。
1.1.4 为农业水土工程的实施提供资料众所周知,在我国还有很大面积的中、低产田,其中很多是盐碱地,因此,地下水动态的研究和预报为防制灌区土壤盐碱化,改造中、低产田,合理灌溉和排水提供了重要资料。
1.1.5 为分析水文地质条件提供资料在天然条件下,地下水的动态是地下水埋藏条件和形成条件的综合反应,因此,可以根据地下水的动态特征分析、认识地下水的埋藏条件、水量、水质形成条件和区分不同类型的含水层。
1.1.6 为环境保护提供必要支撑我国以占世界6%的可更新水资源和9%的耕地,养活了占全球22%的人口,其中水利建设发挥了非常重要的作用,但我国水资源形势仍不容乐观。
第二章 线性平稳时间序列模型.ppt

m tm
44
若时间序列是非平稳的,则可先
对序列进行差分运算,然后再建立
ARMA模型,即求和自回归移动平均
模型(Auto Regressive Integrated
Moving Average modek)简称
ARiMA模型
AR, MA
at
Biblioteka ARMA
X
t
ARIMA
xt:0 0 1 0 0
这种状况可用模型概括为:xt 1at1
2019/11/8
40
(3)如果当天的反应是疼痛 0 ,第二天 出现了红肿 1 ,那么:
时间 输入 输出
t :1 2 at: 0 1 xt:0 0
3 45 0 00 1 0 0
这种状况可用模型概括为:xt 0at 1at1
2019/11/8
返回例题
17
例3 北京市最高气温自相关图
2019/11/8
返回例题
18
二、纯随机性检验
(一)纯随机序列的定 义
(二)纯随机性的性质 (三)纯随机性检验
2019/11/8
上一页 下一页 返回本节首页 19
(一)纯随机序列的定义
纯随机序列也称为白噪声序列,它满足 如下两条性质
2019/11/8
ˆ k
~
N (0, 1) n
,k 0
上一页 下一页 返回本节首页 24
2.假设条件
原假设:延迟期数小于或等于m 期的序列 值之间相互独立
H 0:1 2 m 0,m 1
H1:至少存在某个 k 0,m 1,k m
备择假设:延迟期数小于或等于m 期的 序列值之间有相关性
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
2020/10/29
4
第7章时序分析与动态预测
• 二、时间序列的作用与编制
• 3、时间序列的功能
时间序列在经济分析、生产管理、科学研 究、系统控制中,有着许许多多的应用。时 间序列分析的目的主要是即描述、解释和预 测。
• 4、时间序列的编制
时间的长短应一致,变量的内含应一致, 注意空间范围的变化,变量观察的计量单位 要统一起来,统计方法要相同。
表明报告期水平已发展到基期水平的百分之多少或
者多少倍。计算公式
发展速度
报告期水平 基期水平
基期水平的选择不同,发展速度有环比发展速度 和定基发展速度之分。
时间序列中,各个时期发展速度的一般水平叫平 均发展速度。
2020/10/29
9
第7章时序分析与动态预测
• 三、时间序列的对比分析 • 4、增长速度与平均增长速度
2020/10/29
5
第7章时序分析与动态预测
• 三、时间序列的对比分析
• 1、发展水平与平均发展水平
时间序列中的每一项观察值,称为时间序列的水
平,反映客观现象发展变化在各个不同时间上所达 到的状态、规模或水平。
时期序列平均发展水平
X
1 n
n t1
Xt
时点序列平均发展水平
X
(
X1
2
X2
)
f1
(
平均增长量是观察期内各时期增长量的
平均数,主要用以反映现象在观察期内平
均增减变化的情况。平均增长量计算公式
为
平均增长量
逐期增长量之和 逐期增长量个数
累积增长量
时间序列项数 1
2020/10/29
8
第7章时序分析与动态预测
• 三、时间序列的对比分析
• 3、发展速度与平均发展速度
将两个时期的发展水平相除,即得到发展速度,
增长量=报告期水平-基期水平 随着比较对象基期水平的选择不同,增长量 有逐期增长量和累积增长量之分。计算逐期增 长量时,基期水平都选择报告期的前一期水平, 而计算累积增长量,基期水平都选择最初水平 或某一固定时期的水平。
2020/10/29
7
第7章时序分析与动态预测
• 三、时间序列的对比分析
• 2、增长量与平均增长量
X ˆt 1X tkX kt 1 (k(k 1 )1 ) ....1 ..X tk 11
2020/10/29
14
第7章时序分析与动态预测
• 五、长期趋势测定与预测 • 4、长期趋势预测 (2)指数平滑预测
使用当期的实际值和当期的预测值,通过加 权平均以求得时间序列的长期趋势值。
X ˆt 1X t (1)X ˆt
(3)趋势方程预测 先建立趋势方程模型,并运用数学手段将模
型估计出来,然后进行趋势值的预测估计。
2020/10/29
15
第7章时序分析与动态预测
• 六、季节性变动测定与预测
• 1、含义
季节变动是客观现象因受自然条件、人
的经济活动行为、社会风俗习惯等原因的 影响,在一个日历年度内呈现出的周期性 波动,比如游泳池业务秋冬季人流量小春 夏季人流量大,农作物的收获季节会带来 运输和仓储压力的大幅度增加,衣着、燃 料及某些食品的消费总会随一年四季的变 化而波动,节假日商品交易量比平日大等。
• 一、引言
2020/10/29
3
第7章时序分析与动态预测
• 二、时间序列的作用与编制 • 1、含义
按时间顺序排列的现象发展变化的各期观察 序列,就叫时间序列,比如:股票每个交易日 开盘价,商品日成交量,公司历年利润等。
• 2、种类 反映现象在一段时间(周、月、季、年)内
发展变化的结果称之为时期时间序列。只表明 现象在某一时刻所达到的规模、水平和数量状 态的常称为时点时间序列。
X2 f1
2
X3 ) f2 ( f2 fn1
Xn1 2
Xn
)
fn1
n1 t1
Xt
Xt1 2
n1
ft
t1
2X1 2
X2
Xn1
Xn ) 2
n1
1 n 1
Xt 2Xt1
t1
6
第7章时序分析与动态预测
• 三、时间序列的对比分析 • 2、增长量与平均增长量
增长量是时间序列中不同时期的发展水平之 差,用于反映现象在观察期内增加或减少变化 的绝对数量。 增长量的基本计算方法
加法假定 X tT tStC tIt 乘法假定 X t T t S t C t It
2020/10/29
11
第7章时序分析与动态预测
• 五、长期趋势测定与预测 • 1、含义
客观现象由于受到某些决定性因素的作用, 在一段较长时间内,持续向上或向下运动的态势。
• 2、作用 长期趋势是现象运动、发展和变化的基本态
增长速度是增长量与基期水平相比的结 果,可用于反映现象发展变化的相对程度。
平均增长速度是增长速度的平均数,一 般用平均发展速度减1来求得。
平均增长速度=平均发展速度-1
2020/10/29
10
第7章时序分析与动态预测
• 四、时间序列的分解与假定 • 1、时间序列分解
根据时间序列分析的传统理论,可以把 影响时间序列变异的因素划分为:长期趋 势、季节变动、循环变动和不规则变动。 • 2、时序分析假定
第7章时序分析与动态预测
本讲的主要内容: 一、引言 二、时间序列的作用与编制 三、时间序列的对比分析 四、时间序列的分解与假定 五、长期趋势测定与预测 六、季节性变动测定与预测 七、循环变动分析
2020/10/29
1
第7章时序分析与动态预测
• 一、引言
2020/10/29
2
第7章时序分析与动态预测
• 3、长期趋势测定
(1)移动平均法
Y t
1 k
k1 i0
Xti
(2)趋势方程拟合
k
iX t i 1
Y t i1 k
i
i1
根据时间序列动态曲线的变化形状,可以用
相应的函数方程进行模拟,由样本数据估计出
函数方程后,通过该方程求出时间序列各观察
值的趋势值。常用的趋势方程包括:直线方程、 指数方程等。
2020/10/29
13
第7章时序分析与动态预测
• 五、长期趋势测定与预测
• 4、长期趋势预测 时间序列的趋势预测是根据客观存在的长期趋势,
通过拟合趋势方程或模型,以进行时间序列的外推。
(1)移动平均预测 以时间序列中k个时期观察值的平均数,直接作为
下个时期现象的估计值。
X ˆt1Xt Xt1 k.. .Xtk1
势,这种态势不仅存在于过去,而且还可能继续 延伸到未来,通过对时间序列长期趋势分析,可 以帮助人们对现象的前景和将来状况进行预测; 测定长期趋势,把它从时间序列中分离出来,有 助于更好地研究季节变动、循环变动和不规则变 动。
2020/10/29
12
第7章时序分析与动态预测
• 五、长期趋势测定与预测