数学建模优秀论文全国一等奖
2021数学建模国家一等奖论文(B)

2021数学建模国家一等奖论文(B)上海世博会影响力的定量评估摘要本文是一个对上海世博会影响力的定量评估问题,首先我们收集了与世博会有关的数据,如国内来沪旅游人数,国外来沪旅游人数等。
并用灰色预测对相应的数据进行了预处理,然后我们从横向(本届世博对上海的影响)和纵向(本届世博和历届世博的影响比较)两个角度对世博影响力进行了研究,最后还应用了多目标优化模型求出在不同投资增长系数下上海世博对当地旅游经济最大影响力系数。
第一步,我们横向考虑世博会对本地旅游业的影响力,并将该影响分为对旅游经济的影响和对旅游文化的影响两方面。
首先应用本底趋势线模型得出相应数据的本底值,再分别建立对旅游经济和旅游文化的影响力系数模型,然后利用本底值和统计值得出相应的影响力系数,结果表示如下:举办世博影不举办世博影增加的影旅游业时间响力系数响力系数响力系数世博前期 1.18 1 0.18 世博期间 1.58 1 0.58 旅游经济世博后期1.15 1 0.15 世博影响年均值 1.30 1 0.30 旅游文化 1.29 1 0.29 可得出世博期间的世博会对旅游经济影响力系数最大,为1.58。
相比旅游收入的本底值增加了579.39亿元的旅游收入。
而世博对旅游文化的影响力系数为1.29。
第二步,我们纵向考虑上海世博会与历届世博会相比的影响力。
根据收集的历届世博会相关的规模数据,将世博会影响力等级从低到高分为1-5等,从而建立了世博会综合影响力的模糊评价模型。
对历届世博会的影响力做出综合评价并得出了相应的综合影响力系数。
得出的前三名的排名情况如下:举办年份世博会名称综合影响力系数影响力排名2021 上海世博会 4.094134 1 1970 日本万国博览会 3.789834 2 1939 纽约世界博览会3.465383 3 第三步,我们从环保,旅游收入以及后世博效应三个角度对上海世博的影响重新进行了思考。
综合权衡这三个方面因素,我们建立了一个多目标优化的模型。
数学建模全国赛07年A题一等奖论文

关于中国人口增长趋势的研究【摘要】本文从中国的实际情况和人口增长的特点出发,针对中国未来人口的老龄化、出生人口性别比以及乡村人口城镇化等,提出了Logistic、灰色预测、动态模拟等方法进行建模预测。
首先,本文建立了Logistic阻滞增长模型,在最简单的假设下,依照中国人口的历史数据,运用线形最小二乘法对其进行拟合,对2007至2020年的人口数目进行了预测,得出在2015年时,中国人口有13.59亿。
在此模型中,由于并没有考虑人口的年龄、出生人数男女比例等因素,只是粗略的进行了预测,所以只对中短期人口做了预测,理论上很好,实用性不强,有一定的局限性。
然后,为了减少人口的出生和死亡这些随机事件对预测的影响,本文建立了GM(1,1) 灰色预测模型,对2007至2050年的人口数目进行了预测,同时还用1990至2005年的人口数据对模型进行了误差检验,结果表明,此模型的精度较高,适合中长期的预测,得出2030年时,中国人口有14.135亿。
与阻滞增长模型相同,本模型也没有考虑年龄一类的因素,只是做出了人口总数的预测,没有进一步深入。
为了对人口结构、男女比例、人口老龄化等作深入研究,本文利用动态模拟的方法建立模型三,并对数据作了如下处理:取平均消除异常值、对死亡率拟合、求出2001年市镇乡男女各年龄人口数目、城镇化水平拟合。
在此基础上,预测出人口的峰值,适婚年龄的男女数量的差值,人口老龄化程度,城镇化水平,人口抚养比以及我国“人口红利”时期。
在模型求解的过程中,还对政府部门提出了一些有针对性的建议。
此模型可以对未来人口做出细致的预测,但是需要处理的数据量较大,并且对初始数据的准确性要求较高。
接着,我们对对模型三进行了改进,考虑人为因素的作用,加入控制因子,使得所预测的结果更具有实际意义。
在灵敏度分析中,首先针对死亡率发展因子θ进行了灵敏度分析,发现人口数量对于θ的灵敏度并不高,然后对男女出生比例进行灵敏度分析得出其灵敏度系数为0.8850,最后对妇女生育率进行了灵敏度分析,发现在生育率在由低到高的变化过程中,其灵敏度在不断增大。
全国大学生数学建模大赛国家一等奖论文A题

=
− − ( − 1)′
, = 1, 2, · · ·, 210
当逐渐增大,锚链受到的竖直向下方向的合力与支持力之差先逐渐接近于0,
再等于0,直至小于0。当合力小于0时,锚链以海床接触,此时海床提供向上的支持
力,其大小与′ 相等。因此可将小于0 的值都作零处理,故锚链接触海床时,
对于问题二,首先考虑第一个子问题,将风速36/直接代入问题一的模型中,
得出此条件下的吃水深度为0.723,各钢管倾斜角度(度)依次为8.960、9.014、9.068
、9.123,钢桶倾斜角(度)为9.179,锚链链接处的切线方向与海床的夹角(度)为18.414,
游动区域半径为18.80。发现此条件下,水声通讯系统设备的工作效果较差,且锚被
计与应用对海上科学发展有重要意义。
1.2 问题的提出
已知某近浅海传输节点(如图1所示),将浮标视作底面直径2为、高为2、质量
为1000的圆柱体,锚的质量为600,钢管共4节,每节长度为1,直径为50,
每节钢管的质量为10。水声通讯系统安装在一个长为1、外径为30的密封圆
柱形钢桶内,设备和钢桶总质量为100。
Step1: 遍历求解
令吃水深度ℎ的初始值为0.1,以0.0005为单位逐步增加至2。( 浮标高度为2,
完全浸没时吃水深度ℎ则为2 ),记录对应的数据,选取水下物体竖直方向高度和
与海域水深最接近的组别,进一步进行计算,结果如下表所示(具体程序见附录):
表 1: 不同风速的相关结果表
以风速24/的情况为例,绘制游动区域图:
题意的变量临界值。以水深16、系统各部分递推关系式和钢桶与竖直方向夹角小
于5°为约束条件,将多目标优化转化为单目标优化。通过调节决策变量中锚链的型
建模美赛获奖范文

建模美赛获奖范文全文共四篇示例,供读者参考第一篇示例:近日,我校数学建模团队在全国大学生数学建模竞赛中荣获一等奖的喜讯传来,这是我校首次在该比赛中获得如此优异的成绩。
本文将从建模过程、团队合作、参赛经验等方面进行详细介绍,希望能为更多热爱数学建模的同学提供一些借鉴和参考。
让我们来了解一下比赛的背景和要求。
全国大学生数学建模竞赛是由中国工程院主办,旨在促进大学生对数学建模的兴趣和掌握数学建模的基本方法和技巧。
比赛通常会设置一些实际问题,参赛队伍需要在规定时间内通过建立数学模型、分析问题、提出解决方案等步骤来完成任务。
最终评选出的优胜队伍将获得一等奖、二等奖等不同级别的奖项。
在本次比赛中,我们团队选择了一道关于城市交通拥堵研究的题目,并从交通流理论、路网优化等角度进行建模和分析。
通过对城市交通流量、拥堵原因、路段限制等方面的研究,我们提出了一种基于智能交通系统的解决方案,有效缓解了城市交通拥堵问题。
在展示环节,我们通过图表、数据分析等方式清晰地呈现了我们的建模过程和成果,最终赢得了评委的认可。
在整个建模过程中,团队合作起着至关重要的作用。
每个成员都发挥了自己的专长和优势,在分析问题、建模求解、撰写报告等方面各司其职。
团队内部的沟通和协作非常顺畅,大家都能积极提出自己的想法和看法,达成共识后再进行实际操作。
通过团队合作,我们不仅完成了比赛的任务,也培养了团队精神和合作能力,这对我们日后的学习和工作都具有重要意义。
参加数学建模竞赛是一次非常宝贵的经历,不仅能提升自己的数学建模能力,也能锻炼自己的解决问题的能力和团队协作能力。
在比赛的过程中,我们学会了如何快速建立数学模型、如何分析和解决实际问题、如何展示自己的成果等,这些能力对我们未来的学习和工作都将大有裨益。
在未来,我们将继续努力,在数学建模领域不断学习和提升自己的能力,为更多的实际问题提供有效的数学解决方案。
我们也希望通过自己的经验和教训,为更多热爱数学建模的同学提供一些指导和帮助,共同进步,共同成长。
数学建模全国一等奖论文系列(27)

数学建模全国⼀等奖论⽂系列(27)乘公交,看奥运摘要由于可供选择的车次很多,各种车辆的换乘⽅式也很多,为了避免上下⾏站点不⼀样的车次等对路线产⽣的影响,我们以由易到难的思路来完成模型。
⾸先分析⼀辆车可以直接到达的情况,在这其中⼜考虑到环线的特殊性对其单独进⾏判断讨论;由于⼀辆车可使乘客到达⽬的地的可能性太⼩,我们接下来讨论要进⾏⼀次换乘的情况,在这⾥巧妙地利⽤矩阵来判断两辆车是否含有共同站这个思想,避免了⾄少两重循环,使运算速度⼤⼤提⾼;虽然这样就已经能够解决不少的问题,但并不完全,因此我们继续计算换乘两次的乘车路线,经过⼤量的运算,我们发现基本所有的站点间都可以通过换乘两次到达,⾄此对公交线路的讨论基本完成。
对加⼊地铁的讨论与只有公交车时类似,从最简单的两辆地铁换乘的情况开始考虑,由浅⼊深。
论⽂中并没有运⽤⼤量的符号,⽽是⽤⽂字来说明程序的主要步骤,这样可以让不了解程序的读者也清楚地知道模型的思路,⽽且,只要知道起始与终点,利⽤程序就可以计算所有可能路线,并可以在结果中为读者提供路线的相关信息,⽐如路费及所需时间,以供选择。
对于最优的解释,我们除了以时间最少、车费最省为原则,还对时间与车费进⾏了加权平均,⽽权数便是乘客对时间与⾦钱的偏好程度,当输⼊⾃⼰愿⽤1元钱去换多少分钟乘车时间时,程序会根据个⼈的不同喜好,来选择出适合每个⼈的最优路线。
这样将程序⼈性化,可以更符合实际中⼈们的需要。
关键词:公交线路选择最优化矩阵加权平均数组分类讨论⾃主查询问题重述北京是中国的⾸都,是政治、⽂化中⼼,同时也是国际交往的中⼼。
在成功取得2008年第29届夏季奥运会的举办权后,北京市城市建设的步伐将进⼀步加快。
众所周知,可靠的交通保障是成功举办奥运会的关键之⼀,公共客运交通服务系统尤为重要。
在保持公车票价⼀直相对较低的情况下,北京市⼜已经实⾏机动车单双号出⾏,⽬的就是为了⿎励⼈们乘公共汽车出⾏,缓解交通阻塞状况。
全国大学生数学建模竞赛C题国家奖一等奖优秀论文

脑卒中发病环境因素分析及干预摘要本文主要讨论脑卒中发病环境因素分析及干预问题。
根据题中所给出的数据,利用SPSS20 软件进行相关性统计分析,分别对各气象因素进行单因素分析,进而建立后退法线性回归分析模型,得到脑卒中与气压、气温、相对湿度之间的关系。
同时在广泛收集各种资料并综合考虑环境因素,对脑卒中高危人群提出预警和干预的建议方案。
首先,利用SPSS20软件,从患病人群的性别、年龄、职业进行统计分析,得到2007-2010年男性患病人数高于女性,且男性所占比例有逐年下降趋势,女性则有上升趋势,因此,性别比例呈减小趋势。
分析不同年龄段患病人数,得到患病高峰期为75-77岁之间,且青少年比例逐年呈增长趋势,可见患病比例趋于年轻化。
同时在不同的职业中,农民发病人数最多,教师,渔民,医务人员,职工,离退人员的发病人数较少。
其次,由题中所给数据先进行单因素分析,剔除对脑卒中影响不显著的因素,得出气温、气压、相对湿度对脑卒中的影响程度大小,进而采用后退法线性回归分析建立模型,利用SPSS20对数据进行分析,求得脑卒中发病率与气温、气压、相对湿度之间的关系。
即发病率与平均温度成正相关,与最高温度成负相关,发病率与平均气压成正相关,与最低气压成负相关,与平均相对湿度成负相关,与最小相对湿度成正相关。
最后,通过查找资料发现,影响脑卒中的因素有两类,一类是不可干预因素,如年龄、性别、家族史,另一类是可干预因素,如高血压、高血脂、糖尿病、肥胖、抽烟、酗酒等因素。
分析这些因素,建立双变量因素分析模型,并结合问题1和问题2,对高危人群提出预警和干预的建议方案。
关键词脑卒中单因素分析后退法线性回归分析双变量因素分析一问题的重述脑卒中(俗称脑中风)是目前威胁人类生命的严重疾病之一,它的发生是一个漫长的过程,一旦得病就很难逆转。
这种疾病的诱发已经被证实与环境因素,包括气温、湿度之间存在密切的关系。
对脑卒中的发病环境因素进行分析,其目的是为了进行疾病的风险评估,对脑卒中高危人群能够及时采取干预措施,也让尚未得病的健康人,或者亚健康人了解自己得脑卒中风险程度,进行自我保护。
全国数学建模大赛获奖优秀论文.doc

全国数学建模大赛获奖优秀论文者T.L.Satty于代提出了以定性与定量相结合,系统化、层次化分析解决问题的方法,简称AHP。
传统的层次分析法算法具有构造判断矩阵不容易、计算繁多重复且易出错、一致性调整比较麻烦等缺点。
本文利用微软的Excel电子表格的强大的函数运算功能,设置了简明易懂的计算表格和步骤,使得判断矩阵的构造、层次单排序和层次总排序的计算以及一致性检验和检验之后对判断矩阵的调整变得十分简单。
关键词:Excel 层次分析法模型一、层次分析法的基本原理层次分析法是解决定性事件定量化或定性与定量相结合问题的有力决策分析方法。
它主要是将人们的思维过程层次化、,逐层比较其间的相关因素并逐层检验比较结果是否合理,从而为分析决策提供较具说服力的定量依据。
层次分析法不仅可用于确定评价指标体系的权重,而且还可用于直接评价决策问题,对研究对象排序,实施评价排序的评价内容。
用AHP分析问题大体要经过以下七个步骤:⑴建立层次结构模型;首先要将所包含的因素分组,每一组作为一个层次,按照最高层、若干有关的中间层和最低层的形式排列起来。
对于决策问题,通常可以将其划分成层次结构模型,如图1所示。
其中,最高层:表示解决问题的目的,即应用AHP所要达到的目标。
中间层:它表示采用某种措施和政策来实现预定目标所涉及的中间环节,一般又分为策略层、约束层、准则层等。
最低层:表示解决问题的措施或政策(即方案)。
⑵构造判断矩阵;设有某层有n个元素,X={Xx1,x2,x3xn}要比较它们对上一层某一准则(或目标)的影响程度,确定在该层中相对于某一准则所占的比重。
(即把n个因素对上层某一目标的影响程度排序。
上述比较是两两因素之间进行的比较,比较时取1~9尺度。
用表示第i个因素相对于第j个因素的比较结果,则A则称为成对比较矩阵比较尺度:(1~9尺度的含义)如果数值为2,4,6,8表示第i个因素相对于第j个因素的影响介于上述两个相邻等级之间。
数学建模全国赛07年A题一等奖论文

数函 ztrepmoC
拟模态动
测预色灰
型模 citsigoL�字键关
。议建了出提府政给况情口人的国我对针�析 分性理合了行进型模对也时同�点缺优的型模个各了出指别特�价评了行进型模对文本�后最
。大增断不在度敏灵其 �中程过化变的高到低由在率育生在现发 �析分度敏灵了行进率育生女妇对后最 �0588.0 为数系度敏灵其出得析分度敏灵行进 例比生出女男对后然�高不并度敏灵的 θ 于 对量数口人现发�析分度敏灵了行进 θ 子因展发率亡死对针先首�中析分度敏灵在 。义意际实有具更果结的测预所得使 �子因制控入加�用作的素因为人虑考�进改了行进三型模对对们我�着接。高较求要性 确准的据数始初对且并�大较量据数的理处要需是但�测预的致细出做口人来未对以可 型模此。议建的性对针有些一了出提门部府政对还�中程过的解求型模在。期时”利红 口人“ 国我及以比养抚口人�平水化镇城�度程化龄老口人�值差的量数女男的龄年 婚适�值峰的口人出测预�上础基此在。合拟平水化镇城、目数口人龄年各女男乡镇市 年1002出求、合拟率亡死对、值常异除消均平取�理处下如了作据数对并�三型模立建 法方的拟模态动用利文本�究研入深作等化龄老口人、例比女男、构结口人对了为 。入深步一进有没�测预的数总口人了出做是只�素因的类一 龄年虑考有没也型模本�同相型模长增滞阻与。亿 531.41 有口人国中�时年 0302 出得 �测预的期长中合适�高较度精的型模此�明表果结�验检差误了行进型模对据数口人 的年 5002 至 0991 用还时同�测预了行进目数口人的年 0502 至 7002 对�型模测预色灰 )1,1(MG 了立建文本 �响影的测预对件事机随些这亡死和生出的口人少减了为 �后然 。性限局的定一有�强不性用实�好很上论 理�测预了做口人期短中对只以所�测预了行进的略粗是只�素因等例比女男数人生出 、龄年的口人虑考有没并于由�中型模此在。亿 95.31 有口人国中�时年 5102 在出得 �测预了行进目数口人的年 0202 至 7002 对 �合拟行进其对法乘二小最形线用运 �据数史 历的口人国中照依�下设假的单简最在�型模长增滞阻 citsigoL 了立建文本�先首 。测预模建 行进法方等拟模态动、测预色灰、citsigoL 了出提�等化镇城口人村乡及以比别性口人 生出、化龄老的口人来未国中对针�发出点特的长增口人和况情际实的国中从文本
数学建模一等奖论文

2011高教社杯全国大学生数学建模竞赛基于系统综合评价的城市表层土壤重金属污染分析摘要本文针对城市表层土壤重金属污染问题,首先对各重金属元素进行分析,然后对各种重金属元素的基本数据进行统计分析及无量纲化处理,再对各金属元素进行相关性分析,最后针对各个问题建立模型并求解。
针对问题一,我们首先利用EXCEL 和 SPSS 统计软件对各金属元素的数据进行处理,再利用Matlab 软件绘制出该城区内8种重金属元素的空间分布图最后通过内梅罗污染模型:2/12max 22⎪⎪⎭⎫ ⎝⎛+=P P P 平均综,其中平均P 为所有单项污染指数的平均值,max P 为土壤环境中图,由图可以明显地看出各个区内各种元素的污染情况,然后再根据重金属元素污染来源及传播特征进行分析,可以得出工业区及生活区重金属的堆积和迁移是造成污染的主要原因,Cu 、Hg 、Zn 主要在工业区和交通区如公路、铁路等交通设施的两侧富集,随时间的推移,工业区、交通区的土壤重金属具有很强的叠加性,受人类活动的影响较大。
同时城市人口密度,土地利用率,机动车密度也是造成重金属污染的原因。
针对问题三,我们从两个方面考虑建模即以点为传染源和以线为传染源。
针对以点为传染源我们建立了两个模型:无约束优化模型()[]()[]()22y i y x i x m D -+-=,得到污染源的位置坐标()6782,5567;有衰减的扩散过程模型得位置坐标(8500,5500),模型为:u k zu c y u b x u a h u 2222222222-∂∂+∂∂+∂∂=∂∂, 针对以线为传染源我们建立了l c be u Y ∆-+=0模型,并通过线性拟合分析线性污染源的位置。
针对问题四,我们在已有信息的基础上,还应收集不同时间内的样点对应的浓度以及各污染源重金属的产生率。
根据高斯浓度模型建立高斯修正模型,得到浓度关于时间和空间的表达式ut e C C -⋅=0。
国赛数模冲刺必看公交调度一等奖论文
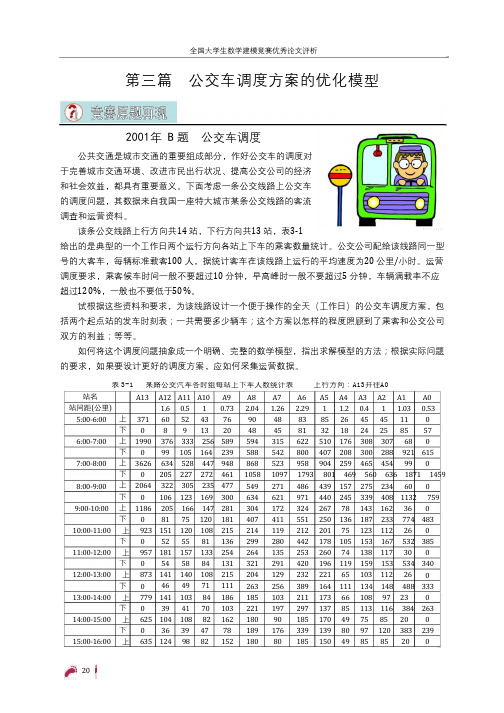
第三篇 公交车调度方案的优化模型2001年 B 题 公交车调度公共交通是城市交通的重要组成部分,作好公交车的调度对 于完善城市交通环境、改进市民出行状况、提高公交公司的经济 和社会效益,都具有重要意义。
下面考虑一条公交线路上公交车 的调度问题,其数据来自我国一座特大城市某条公交线路的客流 调查和运营资料。
该条公交线路上行方向共14 站,下行方向共13 站,表3-1给出的是典型的一个工作日两个运行方向各站上下车的乘客数量统计。
公交公司配给该线路同一型 号的大客车,每辆标准载客100 人,据统计客车在该线路上运行的平均速度为20 公里/小时。
运营 调度要求,乘客候车时间一般不要超过10 分钟,早高峰时一般不要超过5 分钟,车辆满载率不应 超过120%,一般也不要低于50%。
试根据这些资料和要求,为该线路设计一个便于操作的全天(工作日)的公交车调度方案,包 括两个起点站的发车时刻表;一共需要多少辆车;这个方案以怎样的程度照顾到了乘客和公交公司 双方的利益;等等。
如何将这个调度问题抽象成一个明确、完整的数学模型,指出求解模型的方法;根据实际问题 的要求,如果要设计更好的调度方案,应如何采集运营数据。
表3-1某路公交汽车各时组每站上下车人数统计表上行方向:A13开往A0站名 A13A12 A11 A10 A9 0.73 76 A8 2.04 90 A7 1.26 48 A62.29 83 A5 A4 A3 A2 A1 A0 站间距(公里)5:00-6:001.6 0.5 1 1 1.2 0.4 1 1.03 0.53 上 下 上 下 上 下 上 下 上 下371 060 8 52 9 43 13 85 32 26 18 45 24 45 25 11 85 0 57 0 20 48 45 81 6:00-7:00 7:00-8:00 8:00-9:009:00-10:001990376 333 256 99 105 164 3626634 528 447 205 227 272 2064 322 305 235 106 123 169 1186 205 166 147 81 75 120 151 120 108 52 55 81 181 157 133 54 58 84 141 140 108 46 49 71 141 103 84 39 41 70 104 108 82 589 239 948 461 477 300 281 181 215 136 254 131 215 111 186 103 162 78 594 588 868 315 542 523 622 800 958 510 176 308 307 68 407 208 300 288 921 904 259 465 454 99 0615 00 1058 1097 1793 801 469 560 636 1871 1459 549 634 304 407 214 299 264 321 204 263 185 221 180 189 180271 621 172 411 119 280 135 291 129 256 103 197 90 486 971 324 551 212 442 253 420 232 389 211 297 185 339 185439 157 275 234 60 0 0 440 245 339 408 1132 759 267 78 143 162 36 250 136 187 233 774 201 75 123 112 26 178 105 153 167 532 260 74 138 117 30 196 119 159 153 534 221 65 103 112 26 164 111 134 148 488 0 483 0 010:00-11:00 上 923下 0 385 0 11:00-12:00上 957 下 0340 0 12:00-13:00 上 873下 0 333 0 13:00-14:00上 779 173 66 108 97 23 下 0137 85 113 116 384 263 0 14:00-15:00 上 625170 49 139 80 150 49 75 97 120 383 85 85 20 85 20 下 0 36 39 47 82176 80239 015:00-16:00上 63512498 152下36 16:00-17:00 上 1493299 240 199 80 85 135 17:00-18:00 上 2011379 311 230 39 57 88 396 194 497 257 167 108 91 209 404 450 479 694 165 237 85 196 210 441 296 573 108 231 50 339 428 731 586 957 201 390 88 129 80 107 110 353 390 120 208 197 49 335 157 255 251 800 508 140 250 259 61 229 0 下 0557 0 下 0110 118 171 124 107 89 390 253 293 378 1228 793 18:00-19:00 上 691194 53 93 82 22 0 336 0 下 045642250163714348 55 23 43 17 32 14 3 80 46 34 36 24 26 21 2 150 89 131 125 428 19:00-20:00 上 350 89 83 60 59 52 62 5 27 48 22 34 16 30 1 48 64 38 46 28 40 3 47 66 204 37 47 160 27 41 128 11 下 0 63 116 75 108 40 196 77 139 0 20:00-21:00 上 304 72 9 下 0 38 80 84 143 47 117 0 21:00-22:00 上 209 53 55 29 6 下 0 19 0 33 78 63 125 5 92 0 22:00-23:00 上 5 5 3 2 9 1 下 33 58 18 17 27 12 7 9 32 21 表3-1(续) 某路公交汽车各时组每站上下车人数统计表 下行方向:A0 开往A13站名 A0A2 1.56 3 A31 A4 0.442 A5 1.2 A6 A7 A8 1.3 A9 2 A10 A11 A12 A13 站间距(公里) 5:00-6:00 0.97 2.29 0.73 1 1 1 0.5 1.62 上 下 上 下 上 下 上 下 上 下 上 下 上 下 上 下 上 下 上 下 上 下 上 下 上 下 上 下 上 下 上 下 上 下22 0 4 4 4 3 3 3 0 3 0 9 0 2 1 1 6 7 7 5 3 4 2 6:00-7:00 7:00-8:00 795 0 143 70 167 40 84 151 184 420 710 404 756 235 410 155 246 127 199 105 174 102 166 130 219 169 253 305 459 468 737 328 635 138 266 112 186 105 190188 205 455 780 532 827 308 511 206 346 150 238 144 215 133 210 165 238 194 307 404 617 649 109 195 272 849 333 856 162 498 120 320 108 256 92 137 147 343 545 345 529 203 336 150 191 104 175 95 130 93 45 53 75 138 16 40 109 126 444 120 428 76 108 271 2328 380 294 2706 374 266 1556 204 427 156 492 158 274 100 183 59 224 157 224 149 125 80 331 374 354 367 198 199 143 147 107 122 88 45 0 0 265 373 958 153 46 237 376 1167 99 27 136 219 556 8:00-9:00 0 0 9:00-10:00 10:00-11:00 11:00-12:00 12:00-13:00 13:00-14:00 14:00-15:00 15:00-16:00 16:00-17:00 17:00-18:00 18:00-19:00 19:00-20:00 20:00-21:00 21:00-22:000 0 902 0 157 147 103 130 94 276 50 82 59 96 48 68 40 65 43 60 49 78 64 18 154 438 15 128 346 0 59 185 41 847 0 132 48 67 0 48 143 34 706 0 90 118 40 66 12 98 13 0 261 0 70 40 205 97 127 102 136 118 155 152 215 277 401 432 103 104 90 119 36 770 0 97 126 43 59 75 43 209 101 246 141 341 229 549 388 127 42 115 309 15 118 346 19 839 0 133 84 156 48 69 120 112 166 136 253 266 452 416 342 304 147 147 94 0 48 153 54 1110 170 110 1837 260 175 3020 474 330 1966 350 189 73 79 0 0 63 167 95 102 144 425 122 34 162 269 784 205 56 278 448 1249 132 40 246 320 1010 330 96 146 106 248 194 204 150 88 0 0 304 157 494 122 423 48 587 193 399 129 165 59 0 0 934 1016 606 471 787 187 306 153 230 144 243289 690 124 290 87 335 505 143 201 102 146 95 0 0 939 0 223 130 113 107 75 56 86 43 70 40 6717 0 59 155 36 154 398 640 0 126 43 69 13 95 12 0 319 0 43 219 82 90 127 34 636 0 110 73128 4156 98 4219213210712310129022:00-23:00 上下294433551202420468758 359241694247156017335 0108 49 136 公交车调度方案的优化模型*摘要:本文建立了公交车调度方案的优化模型,使公交公司在满足一定的社会效益和获得最大经济效益的前提下,给出了理想发车时刻表和最少车辆数。
高教社杯全国大学生数学建模竞赛获奖论文(精品)

高教社杯全国大学生数学建模竞赛获奖论文(精品)2010高教社杯全国大学生数学建模竞赛编号专用页赛区评阅编号(由赛区组委会评阅前进行编号):赛区评阅记录(可供赛区评阅时使用):评阅人评分备注全国统一编号(由赛区组委会送交全国前编号):全国评阅编号(由全国组委会评阅前进行编号):关于2010年上海世博会影响力的评估——从历史文化交流方面进行讨论摘要本文从各国人民在历史文化方面的交流评估了2010年上海世博会的影响力。
根据题意以及互联网收集到的数据,建立了数学模型并定量估计了上海世博会的影响力,突出上海世博的主题“城市,让生活更美好”的基本理念。
首先,运用灰色聚类法对互联网收集到的数据进行灰类等级划分,再对数据进行无量纲化处理。
其次,建立各灰类白化函数,再对各组数据进行聚类权F运算,进而得出各因素的相应数据。
最后,通过白化函数得到的矩阵和聚类n权运算得到的函数,应用求聚类公式,求得各聚类对象的,,,fd*,LjjLLj,,,jL,1j各灰色聚类系数及结果。
然后应用层次分析法,推导出一种进行加权分析的方法,利用本方法对影响世博会的各个因素进行加权,得出了各个世博城市关于T,通过比较得到上海世博会影影响力的组合权重数据为(0.3634,0.3620,0.2743)响力均高于爱知、汉诺威世博会。
合适的评估体系是本课题的关键。
我们充分利用互联网收集到的数据进行分析及统计,并考虑到方案的可操作性。
通过组合权重数据,得到了三个世博城市关于影响力的权重。
由于此模型不受指数的影响,有很好的灵活性,使得我们可以根据实际情况灵活选取指数,减少模型的工作量,增加模型精度。
关键字:定量估计、层次分析法、灰色聚类法1一、问题重述2010年上海世博会是首次在中国举办的世界博览会。
从1851年伦敦的“万国工业博览会”开始,世博会正日益成为各国人民交流历史文化、展示科技成果、体现合作精神、展望未来发展等的重要舞台。
可以从我们感兴趣的某个侧面,建立数学模型,利用互联网数据,定量评估2010年上海世博会的影响力。
数学建模优秀论文模板[全国一等奖模板]
![数学建模优秀论文模板[全国一等奖模板]](https://img.taocdn.com/s3/m/9babb4dd83d049649a665817.png)
Haozl觉得数学建模论文格式这么样设置版权归郝竹林所有,材料仅学习参考版权:郝竹林备注☆ ※§等等字符都可以作为问题重述左边的。
一级标题所有段落一级标题设置成段落前后间距13磅图和表的标题采用插入题注方式题注样式在样式表中设置居中五号字体Excel中画出的折线表字体采用默认格式宋体正文10号图标题在图上方段落间距前0.25行后0行表标题在表下方段落间距前0行后0.25行行距均使用单倍行距所有段落均把4个勾去掉注意Excel表格插入到word的方式在Excel中复制后,粘贴,word2010粘贴选用使用目标主题嵌入当前Dsffaf所有软件名字第一个字母大写比如E xcel所有公式和字母均使用MathType编写公式编号采用MathType编号格式自己定义农业化肥公司的生产与销售优化方案摘 要 要求总分总 本文针对储油罐的变位识别与罐容表标定的计算方法问题,运用二重积分法和最小二乘法建立了储油罐的变位识别与罐容表标定的计算模型,分别对三种不同变位情况推导出的油位计所测油位高度与实际罐容量的数学模型,运用matlab 软件编程得出合理的结论,最终对模型的结果做出了误差分析。
针对问题一要求依据图4及附表1建立积分数学模型研究罐体变位后对罐容表的影响,并给出罐体变位后油位高度间隔为1cm 的罐容表标定值。
我们作图分析出实验储油罐出现纵向倾斜 14.时存在三种不同的可能情况,即储油罐中储油量较少、储油量一般、储油量较多的情况。
针对于每种情况我们都利用了高等数学求容积的知识,以倾斜变位后油位计所测实际油位高度为积分变量,进行两次积分运算,运用MATLAB 软件推导出了所测油位高度与实际罐容量的关系式。
并且给出了罐体倾斜变位后油位高度间隔为1cm 的罐容标定值(见表1),最后我们对倾斜变位前后的罐容标定值残差进行分析,得到样本方差为4103878.2-⨯,这充分说明残差波动不大。
我们得出结论:罐体倾斜变位后,在同一油位条件下倾斜变位后罐容量比变位前罐容量少L 243。
优秀数学建模论文(全国一等奖)

承诺书我们仔细阅读了中国大学生数学建模竞赛的竞赛规则.我们完全明白,在竞赛开始后参赛队员不能以任何方式(包括电话、电子邮件、网上咨询等)与队外的任何人(包括指导教师)研究、讨论与赛题有关的问题。
我们知道,抄袭别人的成果是违反竞赛规则的, 如果引用别人的成果或其他公开的资料(包括网上查到的资料),必须按照规定的参考文献的表述方式在正文引用处和参考文献中明确列出。
我们郑重承诺,严格遵守竞赛规则,以保证竞赛的公正、公平性。
如有违反竞赛规则的行为,我们将受到严肃处理。
我们参赛选择的题号是(从A/B/C/D中选择一项填写):我们的参赛报名号为(如果赛区设置报名号的话):所属学校(请填写完整的全名):参赛队员(打印并签名) :1.2.3.指导教师或指导教师组负责人(打印并签名):日期:年月日赛区评阅编号(由赛区组委会评阅前进行编号):编号专用页赛区评阅编号(由赛区组委会评阅前进行编号):全国统一编号(由赛区组委会送交全国前编号):全国评阅编号(由全国组委会评阅前进行编号):A题:出版社的资源配置摘要本文根据题目的要求建立了合理的有限资源分配优化模型,我们借助多种数学软件的优势挖掘出大量数据潜在的信息,并将其合理运用,在此基础上,以利润最大为目标,长远发展为原则,制定出信息不足条件下的量化综合评价体系,并为出版社在2006年如何合理有效地分配有限的书号资源提供了最佳的分配方案。
在本文所建立的模型中,我们采取了层次分析法(AHP)、数据统计拟合以及整数线性规划相结合的手段,这样既借鉴了层次分析法综合评价的优势,又克服了该法中主观因素的不确定性,使模型更具有科学性,作出了出版社2006年的分配方案,如下表经过对模型的检验,单从生产计划准确度一项来看,模型所得出的结果就比以往的高,这样就首先保证了出版社获得年度稳定利润的前提,其他几个评价指标也都可以得出相似的结论。
以2006年与2005年生产计划的准确度为例,作比较:2005年的各分社平均生产计划的准确度为0.702006年的各分社平均生产计划的准确度为0.85平均准确度提高约21%从数据的对比中,我们很容易看出本模型具有较高的有效性和合理性。
数学建模优秀论文(精选范文10篇)2021

数学建模优秀论文(精选范文10篇)2021一、基于数学建模的空气质量预测研究本文以某城市为研究对象,通过数学建模方法对空气质量进行预测。
通过收集历史空气质量数据,构建空气质量预测模型。
运用机器学习算法对模型进行训练和优化,提高预测精度。
通过对预测结果的分析,为城市环境管理部门提供决策支持,有助于改善城市空气质量。
二、数学建模在物流优化中的应用本文针对某物流公司配送路线优化问题,运用数学建模方法进行求解。
建立物流配送模型,考虑配送成本、时间、距离等因素。
运用线性规划、遗传算法等优化算法对模型进行求解。
通过对求解结果的分析,为物流公司提供优化配送路线的建议,降低物流成本,提高配送效率。
三、基于数学建模的金融风险管理研究本文以某银行为研究对象,通过数学建模方法对金融风险进行管理。
构建金融风险预测模型,考虑市场风险、信用风险、操作风险等因素。
运用风险度量方法对模型进行评估。
通过对预测结果的分析,为银行提供风险控制策略,降低金融风险,提高银行稳健性。
四、数学建模在能源消耗优化中的应用本文针对某工厂能源消耗优化问题,运用数学建模方法进行求解。
建立能源消耗模型,考虑设备运行、生产计划等因素。
运用优化算法对模型进行求解。
通过对求解结果的分析,为工厂提供能源消耗优化策略,降低能源消耗,提高生产效益。
五、基于数学建模的交通流量预测研究本文以某城市交通流量为研究对象,通过数学建模方法进行预测。
收集历史交通流量数据,构建交通流量预测模型。
运用时间序列分析方法对模型进行训练和优化。
通过对预测结果的分析,为城市交通管理部门提供决策支持,有助于缓解城市交通拥堵。
数学建模优秀论文(精选范文10篇)2021六、数学建模在医疗资源优化配置中的应用本文以某地区医疗资源优化配置问题为研究对象,通过数学建模方法进行求解。
建立医疗资源需求模型,考虑人口分布、疾病类型等因素。
运用线性规划、遗传算法等优化算法对模型进行求解。
通过对求解结果的分析,为政府部门提供医疗资源优化配置策略,提高医疗服务质量。
数学建模优秀论文全国一等奖

基于遗传算法的机组组合问题的建模与求解摘要本文针对当前科技水平不足以有效存储电力的情况下产生的发电机机组组合的问题,考虑负荷平衡、输电线传输容量限制等实际情况产生的约束条件,建立机组组合优化模型,追求发电成本最小。
同时采用矩阵实数编码遗传算法(MRCGA)和穷举搜索算法,利用MATLAB 7.0.1和C++编程,分别对模型进行求解,并对所得结果进行分析比较,以此来帮助电力部门制定机组启停计划。
首先,建立发电成本最小目标函数和各项约束条件的数学表达式。
其中机组空载成本和增量成本之和随该机组发电出力增长呈折线关系,在分析计算时为了简便,本文采用一条平滑的二次曲线来近似代替。
对于问题1,选取相应的约束条件对目标函数进行约束,从而给出优化模型Ⅰ。
由于问题1的求解规模很小,所以采用穷举搜索算法,利用C++编程求解,得到了3母线系统4小时的最优机组组合计划(见表一)。
对于问题2,在优化模型Ⅰ的基础上,增加最小稳定运行出力约束、机组启动和停运时的出力约束以及机组最小运行时间和最小停运时间约束这三个约束条件,建立了优化模型II。
同时采用遗传算法和穷举搜索算法,利用MATLAB和C++编程,分别对模(见表三)。
对于问题3,用IEEE118系统对优化模型II进行测试。
由于求解规模巨大,同样采用遗传算法和穷举搜索算法,利用MATLAB和C++编程,分别对模型进行求解,部分结果如下:作为24小时的最优机组组合计划(见附录)。
最后,我们就模型存在的不足之处提出了改进方案,并对优缺点进行了分析。
关键字机组组合优化模型矩阵实数编码遗传算法穷举搜索算法一、问题的提出当前的科学技术还不能有效地存储电力,所以电力生产和消费在任何时刻都要相等,否则就会威胁电力系统安全运行。
为了能够实时平衡变化剧烈的电力负荷,电力部门往往需要根据预测的未来电力负荷安排发电机组起停计划,在满足电力系统安全运行条件下,追求发电成本最小。
在没有电力负荷损耗以及一个小时之内的电力负荷和发电机出力均不变的前提下,假定所有发电机组的发电成本都是由3部分组成:1.启动成本(Startup Cost),2.空载成本(No load cost),3.增量成本(Incremental Cost)。
精选五篇数学建模优秀论文

精选五篇数学建模优秀论文一、基于深度学习的股票价格预测模型研究随着金融市场的发展,股票价格预测成为投资者关注的焦点。
本文提出了一种基于深度学习的股票价格预测模型,通过分析历史数据,预测未来股票价格走势。
实验结果表明,该模型具有较高的预测精度和鲁棒性,为投资者提供了一种有效的决策支持工具。
二、基于优化算法的智能交通信号控制策略研究随着城市化进程的加快,交通拥堵问题日益严重。
本文提出了一种基于优化算法的智能交通信号控制策略,通过优化信号灯的配时方案,实现交通流量的均衡分配,提高道路通行能力。
实验结果表明,该策略能够有效缓解交通拥堵,提高交通效率。
三、基于数据挖掘的电商平台用户行为分析电商平台在电子商务领域发挥着重要作用,用户行为分析对于电商平台的发展至关重要。
本文提出了一种基于数据挖掘的电商平台用户行为分析模型,通过分析用户购买行为、浏览行为等数据,挖掘用户偏好和需求。
实验结果表明,该模型能够有效识别用户行为特征,为电商平台提供个性化的推荐服务。
四、基于机器学习的疾病预测模型研究疾病预测对于公共卫生管理具有重要意义。
本文提出了一种基于机器学习的疾病预测模型,通过分析历史疾病数据,预测未来疾病的发生趋势。
实验结果表明,该模型具有较高的预测精度和可靠性,为疾病预防控制提供了一种有效的手段。
五、基于模糊数学的农业生产决策支持系统研究农业生产决策对于提高农业效益和农民收入具有重要意义。
本文提出了一种基于模糊数学的农业生产决策支持系统,通过分析农业环境、市场需求等因素,为农民提供合理的生产决策建议。
实验结果表明,该系统能够有效提高农业生产效益,促进农业可持续发展。
精选五篇数学建模优秀论文一、基于深度学习的股票价格预测模型研究随着金融市场的发展,股票价格预测成为投资者关注的焦点。
本文提出了一种基于深度学习的股票价格预测模型,通过分析历史数据,预测未来股票价格走势。
实验结果表明,该模型具有较高的预测精度和鲁棒性,为投资者提供了一种有效的决策支持工具。
全国大学生数学建模竞赛B题全国一等奖论文

全国大学生数学建模竞赛B题全国一等奖论文IMB standardization office【IMB 5AB- IMBK 08- IMB 2C】碎纸片的拼接复原【摘要】破碎文件的拼接在司法物证复原、历史文献修复以及军事情报获取等领域都有着重要的应用。
本文主要解决碎纸机切割后的碎纸片拼接复原问题。
针对第一问,附件1、2分别为沿纵向切割后的19张中英文碎纸片,本文在考虑破碎纸片携带信息量较大的基础上,利用MATLAB对附件1、2的碎纸片图像分别读入,以数字矩阵的方式进行存储。
利用数字矩阵中包含图像边缘灰度这一特征,本文采用贪心算法的思想,在首先确定原文件左右边界的基础上,以Manhattan 距离来度量两两碎纸片边界差异度,利用计算机搜索依次从左往右搜寻最匹配的碎纸片进行横向配对并达成排序目的。
最终,本文在没有进行人工干预,成功地将附件1、2碎纸片分别拼接复原,得到复原图片见附录、,纵切中文及英文结果表分别如下:心思想仍为贪心算法,整体思路为先对209张碎纸片进行聚类还原成11行,再对分好的每行进行横向排序,最后对排序好的各行进行纵向排序。
本文在充分考虑汉字与拉丁字母结构特征差异以及每块碎纸片携带信息减少的基础上,创新地提出一种特征线模型来分别描述汉字及拉丁文字母的特征用于行聚类。
对于行聚类后碎片的横向排序,本文综合了广义Jaccard系数、一阶差分法、二阶差分法、Spearman系数等来构建扩展的边界差异度模型,刻画碎片间的差异度。
对于计算机横向排序存在些许错误的情况,本文给出了人工干预的位置节点和方式。
对于横向排序后的各行,由于在一页纸上,文字的各行是均匀分布的,本文基于各行文字的特征线,在确定首行的位置后,估计出其他行的基准线位置,得到一页的基准线网格,并通过各行基准线在基准线网格上的适配实现纵向的排序。
最终,本文成功的将附件3、4碎纸片分别拼接复原得到复原图片及结果表见附录、、、,同时本文给出了横向排序中人工干预的位置节点和方式。
数学建模国赛一等奖论文

电力市场输电阻塞管理模型摘要本文通过设计合理的阻塞费用计算规则,建立了电力市场的输电阻塞管理模型。
通过对各机组出力方案实验数据的分析,用最小二乘法进行拟合,得到了各线路上有功潮流关于各发电机组出力的近似表达式。
按照电力市场规则,确定各机组的出力分配预案。
如果执行该预案会发生输电阻塞,则调整方案,并对引起的部分序内容量和序外容量的收益损失,设计了阻塞费用计算规则。
通过引入危险因子来反映输电线路的安全性,根据安全且经济的原则,把输电阻塞管理问题归结为:以求解阻塞费用和危险因子最小值为目标的双目标规划问题。
采用“两步走”的策略,把双目标规划转化为两次单目标规划:首先以危险因子为目标函数,得到其最小值;然后以其最小值为约束,找出使阻塞管理费用最小的机组出力分配方案。
当预报负荷为982.4MW时,分配预案的清算价为303元/MWh,购电成本为74416.8元,此时发生输电阻塞,经过调整后可以消除,阻塞费用为3264元。
当预报负荷为1052.8MW时,分配预案的清算价为356元/MWh,购电成本为93699.2元,此时发生输电阻塞,经过调整后可以使用线路的安全裕度输电,阻塞费用为1437.5元。
最后,本文分析了各线路的潮流限值调整对最大负荷的影响,据此给电网公司提出了建议;并提出了模型的改进方案。
一、问题的重述我国电力系统的市场化改革正在积极、稳步地进行,随着用电紧张的缓解,电力市场化将进入新一轮的发展,这给有关产业和研究部门带来了可预期的机遇和挑战。
电网公司在组织电力的交易、调度和配送时,必须遵循电网“安全第一”的原则,同时按照购电费用最小的经济目标,制订如下电力市场交易规则:1、以15分钟为一个时段组织交易,每台机组在当前时段开始时刻前给出下一个时段的报价。
各机组将可用出力由低到高分成至多10段报价,每个段的长度称为段容量,每个段容量报一个段价,段价按段序数单调不减。
2、在当前时段内,市场交易-调度中心根据下一个时段的负荷预报、每台机组的报价、当前出力和出力改变速率,按段价从低到高选取各机组的段容量或其部分,直到它们之和等于预报的负荷,这时每个机组被选入的段容量或其部分之和形成该时段该机组的出力分配预案。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Haozl觉得数学建模论文格式这么样设置版权归郝竹林所有,材料仅学习参考版权:郝竹林备注☆ ※§等等字符都可以作为问题重述左边的。
一级标题所有段落一级标题设置成段落前后间距13磅二级标题设置成段落间距前0.5行后0.25行图和表的标题采用插入题注方式题注样式在样式表中设置居中五号字体Excel中画出的折线表字体采用默认格式宋体正文10号图标题在图上方段落间距前0.25行后0行表标题在表下方段落间距前0行后0.25行行距均使用单倍行距所有段落均把4个勾去掉注意Excel表格插入到word的方式在Excel中复制后,粘贴,word2010粘贴选用使用目标主题嵌入当前Dsffaf所有软件名字第一个字母大写比如E xcel所有公式和字母均使用MathType编写公式编号采用MathType编号格式自己定义公式编号在右边显示农业化肥公司的生产与销售优化方案摘 要 要求总分总 本文针对储油罐的变位识别与罐容表标定的计算方法问题,运用二重积分法和最小二乘法建立了储油罐的变位识别与罐容表标定的计算模型,分别对三种不同变位情况推导出的油位计所测油位高度与实际罐容量的数学模型,运用matlab 软件编程得出合理的结论,最终对模型的结果做出了误差分析。
针对问题一要求依据图4及附表1建立积分数学模型研究罐体变位后对罐容表的影响,并给出罐体变位后油位高度间隔为1cm 的罐容表标定值。
我们作图分析出实验储油罐出现纵向倾斜 14.时存在三种不同的可能情况,即储油罐中储油量较少、储油量一般、储油量较多的情况。
针对于每种情况我们都利用了高等数学求容积的知识,以倾斜变位后油位计所测实际油位高度为积分变量,进行两次积分运算,运用MATLAB 软件推导出了所测油位高度与实际罐容量的关系式。
并且给出了罐体倾斜变位后油位高度间隔为1cm 的罐容标定值(见表1),最后我们对倾斜变位前后的罐容标定值残差进行分析,得到样本方差为4103878.2-⨯,这充分说明残差波动不大。
我们得出结论:罐体倾斜变位后,在同一油位条件下倾斜变位后罐容量比变位前罐容量少L 243。
表 1.1针对问题二要求对于图1所示的实际储油罐,试建立罐体变位后标定罐容表的数学模型,即罐内储油量与油位高度及变位参数(纵向倾斜角度α和横向偏转角度β)之间的一般关系。
利用罐体变位后在进/出油过程中的实际检测数据(附件2),根据所建立的数学模型确定变位参数,并给出罐体变位后油位高度间隔为10cm 的罐容表标定值。
进一步利用附件2中的实际检测数据来分析检验你们模型的正确性与方法的可靠性。
我们根据实际储油罐的特殊构造将实际储油罐分为三部分,左、右球冠状体与中间的圆柱体。
运用积分的知识,按照实际储油罐的纵向变位后油位的三种不同情况。
利用MATLAB 编程进行两次积分求得仅纵向变位时油量与油位、倾斜角α的容积表达式。
然后我们通过作图分析油罐体的变位情况,将双向变位后的油位h 与仅纵向变位时的油位0h 建立关系表达式01.5(1.5)cos h h β=--,从而得到双向变位油量与油位、倾斜角α、偏转角β的容积表达式。
利用附件二的数据,采用最小二乘法来确定倾斜角α、偏转角β的值,用matlab 软件求出03.3=α、04=β α=3.30,β=时总的平均相对误差达到最小,其最小值为0.0594。
由此得到双向变位后油量与油位的容积表达式V ,从而确定了双向变位后的罐容表(见表2)。
本文主要应用MATLAB 软件对相关的模型进行编程求解,计算方便、快捷、准确,整篇文章采取图文并茂的效果。
文章最后根据所建立的模型用附件2中的实际检测数据进行了误差分析,结果可靠,使得模型具有现实意义。
关键词:罐容表标定;积分求解;最小二乘法;MATLAB ;误差分目录1 背景知识 (6)1.1 相关数据 (6)1.2 相关数据 (6)1.3 问题概括 (6)2 问题分析 (7)3 模型假设 (7)4 名词解释和符号说明 (8)4.1 名词解释 (8)4.2 符号说明 (8)5 模型建立与求解 (9)数据预处理 (9)5.1 问题一的分析与求解 (11)5.1.1 问题分析 (11)5.1.2 模型Ⅰ0-1线性规划模型 (11)5.1.3 模型求解 (11)5.2 问题二的分析与求解 (11)5.2.1 问题分析 (11)5.2.2 模型Ⅱ客户满意度最优模型 (12)5.2.3 模型求解 (12)5.3 问题三的分析与求解 (12)5.3.1 问题分析 (12)5.3.2 模型Ⅲ价格波动模型 (12)5.3.3 模型求解 (12)6 误差分析 (13)6.1 误差分析 (13)6.1.1 问题一的误差分析 (13)6.1.2 问题二的误差分析 (13)6.2 灵敏度分析 (13)6.2.1 问题三的误差分析 (13)6.2.2 问题四的误差分析 (13)7 模型评价与推广 (14)7.1 模型优点 (14)7.2 模型缺点 (14)7.3 模型推广 (14)参考文献 (15)附录 (16)附录1 (16)附录2 (16)附录3 (16)附录4 (16)Equation Chapter (Next) Section 1★1问题重述1.1 背景知识1.随着红外仪器技术的发展,更加稳定的电源、信号放大器、更灵敏的光子探测器、微型计算机等的发展使得近红外光谱区作为一段独立的且有独特信息特征的谱区得到了重视和发展。
2.近红外光谱 (Near infrared spectroscopy,NIRS)分析技术是近年来用于制药行业的过程分析技术(Process analytical technology,PAT),可直接对固体药品进行快速、无损检测。
3.样品中的特征吸收峰均来自于片芯和包衣材料,包衣材料与样品均有相同的特征吸收,所以建立的方法对肠溶片包衣厚度建模中的包衣材料定量分析具有专属性。
1.2 相关数据(1) 同一条件下肠溶片片芯、样品及包衣各辅料的近红外光谱肠溶片近红外光谱图。
(2) 近红外检测包衣过程中选取的不同时间点对应的特征吸收值。
(3) 素片、最优包衣和包衣过程15个样本品、10种不同时刻共150样本点的吸收值。
1.3 问题概括1.以肠溶片为研究对象,对近红外光谱的吸收波峰提取有效特征峰。
2.在提取的有效特征峰基础上,对素片、最优包衣和包衣过程三类所有样本点分类。
3.在已经分好类的前提下,对未知某一时刻包衣样本进行识别,以判别包衣厚度是否合适。
Equation Chapter (Next) Section 1★2问题分析总:分:问题分析中不给出结果,摘要中给出如下范例:本题是基于近红外线光谱以此来建立肠溶片最优包衣厚度终点判别,而本题提供了10个时刻和15个样本品共150个样本点的近红外线光谱图。
首先对样本进行划分,针对每个时刻的15个样本,我们将每个时刻的前面10个样本乘以10种时刻共100个样本作为训练集,而每个时刻剩下的5种样本10种时刻共50个样本作为测试集,其次需要通过一种方法对近红外光谱的吸收波峰的训练集和测试集中提取有效特征峰,然后通过聚类分析方法对对素片、最优包衣和包衣过程三类的训练集进行分类。
然后通过未知某一时刻包衣样本即测试集进行识别属于哪一类来检验我们的判别分析方法可行性。
对于问题一,采用主成分分析法针对测试集和训练集进行提取特征峰,为了便于分析,一般情况下提取2到3个主成分即特征峰,但是对于提取特征峰2还是3个,需要分2种情况进行讨论,以此建立模型Ⅰ。
对于问题二,先对每个时刻的所有样品点进行求平均值,得到共10个时刻的样本点,然后针对平均值样本和总体训练集样本,分别采用加权模糊C均值分类法进行分类,通过平均值样本点的分类和总体训练集样本的分类,讨论分2类、3类、4类、5类、6类共5种情况。
然后选取波长范围5407.65-3795.381cm 吸收波值画出每个样本点的折线趋势图进行整体趋势分析,从光谱图的趋势图可以看出,吸收峰的强度与波长的长度成正相关,可以判断出大致的最优包衣厚度是105分钟时刻,以此验证聚类效果,从而建立模型Ⅱ。
对于问题三,在解决问题二的前提下,在已经分好类的前提下,建立模型Ⅲ,对测试集进行验证分类,观察分类效果。
Equation Chapter (Next) Section 1★3模型假设1.所有数据均为原始数据,来源真实可靠。
2.近外红光谱的肠溶片包衣厚度在当前条件下不可测量,只能确定何时包衣厚度合适。
3.样品中的特征峰均来自于片心和包衣材料,不来源于其他物质。
4.包衣材料和样品均有相同的特征吸收。
5.近红外光谱在测量吸收峰时,吸收峰没有其他耗损。
6.素片就是样品的片心,而样品=片心+包衣材料,样品不含其它不相关物质。
Equation Chapter (Next) Section 1★4名词解释和符号说明4.1 名词解释样本点:某一个时刻的各个近红外线所有波长对应的吸收值。
样品点:一个样品对应的所有时刻的各个近红外线所有波长对应的吸收值。
训练集:提取经过波长降序处理的原始数据集X的每时刻前面10个样本共100个样本。
测试集:提取经过波长降序处理的原始数据集X的每时刻剩下的5个样本共50个样本。
平均训练集:训练集的每一时刻的所有样品平均值(10个样本点)4.2 符号说明表 4.1 这是表符号意义对原始数据近红外线波长降序处理和按时刻、素片、最优分组的数据集标准化处理的训练集标准化处理的测试集标准化处理的平均训练集某一个吸收峰的标准差某一个样本点在某一个吸收峰上的值某一个吸收峰的平均值第一有效特征峰原始数据协方差得分向量即有效特征峰矩阵有效特征峰矩阵对原始数据的解释程度有效特征峰对应的特征值训练集的聚类中心测试集的聚类中心平均训练集每个时刻对应隶属度的矩阵训练集每个时刻对应的隶属度矩阵Equation Chapter (Next) Section 1★5模型建立与求解数据预处理在建立模型之前,我们首先对题目提供的数据进行如下预处理:1.单位转换为一致,各种化肥的标准单位为千吨(kt),销售额以及利润标准单位均为万元。
2.表格数据转换将excel表格中的原始数据进行整理,首先将近红外线的波长进行降序处理,再将最优包衣样品放在一起,共150行,分为10个组:分别是15个肠溶片包衣15分钟至120分钟和最优包衣组,按15分钟等差分成的八个组、一个15片素片(未包衣)组和一个15片最优包衣组,经过过降序和分组后的数据集记为X,便于包衣时间段的数据进行趋势分析。
并且,用excel软件分别算出各个组中15个样本数据的均值,用来分析包衣总体趋势。
3.对于题目提供数据:表2(10种农业化肥产量与成本关系表)、表3(每种农业化肥的宣传费用随着销售量变化表)、表4(每种农业化肥的销售额随订购量变化表)、表13(企业向销售部发放计划内销售产品的经费表)以及表14(计划外销售部分销售部向企业缴纳利润表)提供的数据进行多项式拟合,通过做折线图如下:。