单样本标准差检验
单样本t检验的简单例子

单样本t检验的简单例子假设一个教育研究者想要知道某个班级学生的数学成绩是否高于全国平均水平。
全国平均数学成绩为75分。
这个研究者针对这个班级的30名学生进行了数学成绩收集,并获得以下数据:84, 76, 95, 73, 68, 79, 88, 92, 71, 80,74, 69, 90, 85, 82, 77, 66, 72, 78, 70,81, 91, 83, 89, 96, 76, 87, 94, 93, 67现在我们用单样本t检验来判断这个班级的数学成绩是否显著高于全国平均水平(假定总体标准差未知)。
第一步:设置原假设H0 与备选假设H1H0: μ= 75(班级数学成绩等于全国平均水平)H1: μ> 75(班级数学成绩高于全国平均水平)第二步:计算样本平均值和样本标准差样本平均值(X)= (总分) / (样本数) = 2534 / 30 ≈84.47样本标准差(s)= sqrt[Σ(X - X)^2 / (n - 1)] ≈8.96(大致计算)第三步:计算t统计量t = (X-μ) / (s / sqrt(n)) = (84.47 - 75) / (8.96 / sqrt(30)) ≈6.067第四步:确定显著性水平(如α= 0.05)和查询t分布表得到临界值或者通过t分布计算得到对应的p值假定显著性水平α= 0.05,自由度df = n - 1 = 29通过查询t分布表或使用统计工具,得到单尾t临界值为1.699。
我们也可以通过统计工具计算出对应的p值,例如,双尾的p值为0.00002(即非常接近0)。
第五步:做出统计决策由于t统计量6.067远大于临界值1.699,或者双尾的p值显著小于显著性水平0.05,我们拒绝原假设(H0),接受备选假设(H1),即这个班级的数学成绩显著高于全国平均水平。
假设检验与样本数量分析①——单样本Z检验和单样本t检验

X
32.03 + 32.14 + … + 31.87 15
…
1.9 2.0
…
0.029 0.023
…
0.028 0.022
…
0.027 0.022
…
0.0226 0.020
…
0.025 0.020
…
0.024 0.019
…
0.024 0.019
…
0.023 0.018
原假设 (零假设)即上述的可能,符号是H0
备择假设(与原假设对立的假设),符号是H1
如本例:假设外径尺寸 H0:(μ = 32) H1: (μ≠32) 确立检验水准: α——显著水平(通常取α=0.05)
显著水平α是当原假设正确却被拒绝的概率 通常人们取0.05或0.01 这表明,当做出接受原假设的决定时,其正确的可 能性(概率)95% 或99% 概率是0~1之间的一个数,因此小概率就是接近0的 一个数 英国统计家Ronald Fisher 把0.05作为标准,从此0.05 或比0.05小的概率都被认为是小概率
8 作出不拒绝零假设的统计结论,即外径尺寸 均值没有偏离目标Ф 32
<6>
单样本 Z 检验 单样本 t 检验
预备知识
接上页
假设检验的例子(1)
检验 α = 0.05
临界值 临界值
2
=0.025
拒绝范围
1 – α = 95%
不拒绝H0范围
2
=0.025
根据小概率原理,可以先假设总体参数的 某项取值为真,也就是假设其发生的可能 性很大,然后抽取一个样本进行观察,如 果样本信息显示出现了与事先假设相反的 结果(显示出小概率),则说明原来假定 的小概率事件(一次实验中是几乎不可能发 生)在一次实验中居然真的发生了,这是 一个违背小概率原理的不合理现象,因此 有理由怀疑和拒绝原假设;否则不能拒绝 原假设。 在给定了显著水平α 后,根据容量为n的样 本,按照统计量的理论概率分布规律,可 以确定据以判断拒绝和接受原假设的检验 统计量的临界值。 临界值将统计量的所有可能取值区间分为 两个互不相交的部分,即原假设的拒绝域 和接受域。
t检验的计算方法

t检验的计算方法
t检验的计算方法可以分为两种:单样本t检验和配对样本t检验。
1. 单样本t检验:
- 计算样本均值:计算样本数据的均值X。
- 计算标准误差:计算样本数据的标准误差SE,SE=SD/√n,其中SD为样本数据的标准差,n为样本大小。
- 计算t值:计算t值,t=(X-μ)/SE,其中μ为总体均值。
- 查找t分布表:根据自由度(n-1)和所选的α水平,在t
分布表中找到临界值tα/2。
- 判断结果:当|t|>tα/2时,拒绝原假设,认为样本均值与总
体均值不同。
当|t|<=tα/2时,接受原假设,认为样本均值与总
体均值无显著差异。
2. 配对样本t检验:
- 计算差值:计算配对样本的差值d,d=X - Y,其中X和Y
分别为两组配对样本数据。
- 计算差值的均值和标准误差:计算差值的均值d和标准误
差SEd,SEd=SDd/√n,其中SDd为差值的标准差,n为配对
样本大小。
- 计算t值:计算t值,t=d/SEd。
- 查找t分布表:根据自由度(n-1)和所选的α水平,在t
分布表中找到临界值tα/2。
- 判断结果:当|t|>tα/2时,拒绝原假设,认为配对样本均值
存在显著差异。
当|t|<=tα/2时,接受原假设,认为配对样本均
值无显著差异。
如何根据样本例数、均数、标准差进行T-Test和ANOVA

如何根据样本例数、均数、标准差进⾏T-Test和ANOVA⼤家看论⽂的时候经常看到的⼀些实验数据都是以例数、均数、标准差表⽰的。
如果想验证作者的统计结论,只有2组时还可以根据ttest的公式进⾏计算,2组以上进⾏⼿⼯计算就很⿇烦,⽽⼀些常⽤的统计软件好像也没提供这⼀功能。
⼀、⾸先强调⼀点,不管使⽤任何统计分析软件,如果不知道样本量,仅根据均值和标准差是没有办法进⾏T检验和⽅差分析的。
以⽅差分析为例,从最原始的⾓度给出详细理由如下:先看⽅差分析表,⼤家都很熟悉了吧,这⾥就不再介绍原理了。
1.假设共有k组数据,每组分别有n1,n2,n3,…,nk个数据点,每组均值分别为每组数据的标准差分别为S1,S2,S3,…,Sk。
(这⾥的n1,n2,n3,…,nk是不知道的,n总=n1+n2+n3+,…,+nk当然也就不知道了)2.做⽅差分析的最后⼀步是计算F值:其中组间均⽅:组内均⽅:3.再其中组间离差平⽅和:,其中是第j组的组内均数,是总均数;组内离差平⽅和:总的离差平⽅和:SST=SSA+SSE4.对于单组数据标准差结合组内离差平⽅和:,我们尝试计算组内离差平⽅和SSE=S12(n1-1)+ S22(n1-1)+…+ Sk2(nk-1),显然由于不知道n1,n2,n3,…,nk,所以SSE没有办法计算;因此组内均⽅:就更没有办法计算;5.再来看组间离差平⽅和:,⾸先是nj不知道,其次总均数也是不知道的,⽽仅仅根据每组数据的均值和组数k是绝对不可能推出总均数的,所以组间离差平⽅和:SSA就⽆法求得,更不⽤说组间均⽅:MSA了.6.那么是不是可以先捣⿎出总的离差平⽅和:SST=SSA+SSE呢?⼀看就知道了由于缺少总均数,这也是不可能算出来的。
7.更关键的是由于缺少每⼀组的数据个数n1,n2,n3,…,nk,⽅差分析的临界值F1-α就没有办法确定,因为这是与⾃由度有关的。
最后的结论:1. 仅根据均值和标准差是没有办法进⾏T检验和⽅差分析的。
医学统计例题SAS程序

SAS程序 Data ex7; do r=1 to 2; do c=1 to 2; input f@@; output; end; end; cards; 99 5 75 21 ; Proc freq; weight f; tables r*c/chisq expected; Run;
7. 配对四格表资料的 2分析 配对四格表资料的χ
data ex4_2; input x c @@; cards; 3.53 1 2.42 2 2.86 3 0.89 4 4.59 1 3.36 2 2.28 3 1.06 4 4.34 1 4.32 2 2.39 3 1.08 4 2.66 1 2.34 2 2.28 3 1.27 4 3.59 1 2.68 2 2.48 3 1.63 4 3.13 1 2.95 2 2.28 3 1.89 4 3.30 1 2.36 2 3.48 3 1.31 4 4.04 1 2.56 2 2.42 3 2.51 4 3.53 1 2.52 2 2.41 3 1.88 4 3.56 1 2.27 2 2.66 3 1.41 4 3.85 1 2.98 2 3.29 3 3.19 4 4.07 1 3.72 2 2.70 3 1.92 4 1.37 1 2.65 2 2.66 3 0.94 4 3.93 1 2.22 2 3.68 3 2.11 4 2.33 1 2.90 2 2.65 3 2.81 4 2.98 1 1.98 2 2.66 3 1.98 4 4.00 1 2.63 2 2.32 3 1.74 4 3.55 1 2.86 2 2.61 3 2.16 4 2.64 1 2.93 2 3.64 3 3.37 4 2.56 1 2.17 2 2.58 3 2.97 4 3.50 1 2.72 2 3.65 3 1.69 4 3.25 1 1.56 2 3.21 3 1.19 4 2.96 1 3.11 2 2.23 3 2.17 4 4.30 1 1.81 2 2.32 3 2.28 4 3.52 1 1.77 2 2.68 3 1.72 4 3.93 1 2.80 2 3.04 3 2.47 4 4.19 1 3.57 2 2.81 3 1.02 4 2.96 1 2.97 2 3.02 3 2.52 4 4.16 1 4.02 2 1.97 3 2.10 4 2.59 1 2.31 2 1.68 3 3.71 4 ; proc anova; /调用ANOVA过程进行方差分析/ class c; model x=c; means c/lsd; means c/hovtest; run;
生物统计学

1.总体:我们研究的全部对象2.样本:从总体中抽出的一个部分3.方差:4.对立事件:如果事件A1和A2必发生其一,但不能同时发生,我们称事件A1和A2为对立事件。
5.小概率事件:若随机事件的概率很小,例如小于、、,称之小概率事件。
6.小概率事件:原理小概率事件在一次试验中几乎是不会发生的。
若根据一定的假设条件计算出来该事件发生的概率很小,而在一次试验中竟然发生了,则可以认为假设的条件不正确,从而否定假设。
7.抽样分布:从一个已知的总体中,独立随机地抽取含量为 n 的样本,研究所得样本的各种统计量的概率分布。
8.标准正态分布:期望值μ=0,即曲线图象对称轴为Y 轴,标准差σ=1条件下的正态分布,记为N(0,1)。
9.统计推断:根据抽样分布律和概率理论,由样本结果(统计数)来推论总体特征(参数)。
10.单尾测验:否定区位于分布的一尾的测验。
11.备择假设:与零假设相对立的假设称为备择假设。
12.接受区:接受无效假设的区间。
13.数学期望:随机变量Y 或者Y 的函数的理论平均数。
14.点估计:用样本数据所计算出来的单个数值,对总体参数所做的估计称为点估计1.算术平均数的重要特征之一是离均差之和 ( C )A 最小B 最大C 等于零D 接近零2.统计推断过程中,若我们拒绝H0,则 ( C )A 犯错误B 犯错误C 犯错误或不犯错误D 犯错误或不犯错误变数变异程度的度量,对于总体()22i Y N μσ-=∑, 对于样本22()1Y y s n -=-∑。
3.两个平均数的假设测验用测验。
( C )A uB tC u或tD F4.总体参数在区间[L1,L2]内的概率为1-,其中L1和L2在统计上称为( D )A 置信区间 B 区间估计 C 置信距 D 置信限5.下列不是方差分析基本假定的是假定。
( C )A 可加性B 正态性C 无偏性D 同质性6.人口调查中,以人口性别所组成的总体是( C )总体A 正态分布B 对数正态C 二项分布D 指数分布7.下列有关标准正态分布概率公式的计算中错误的是( D )A P(0<U<u)=f (u) -1/2 B P(U>u)=f (-u)C P(| U| > u)= 2 f (-u)D P (u1<U<u2) = f (u1) - f (u2)8.在抽样分布的研究中,当总体标准差σ未知时样本平均数分布服从( B )分布。
第十章 第四节 K-S单样本检验

第四节Kolmogorov-Sirmov单样本检验一、Kolmogorov-Sirmow单样本检验Kolmogorov-Sirmov单样本检验是一种拟合优度性检验。
它的基本原理同Chi-Square检验,但比Chi-Square检验更为精确。
K-S检验是将一组样本值(观察结果)的分布和某一指定的理论分布函数(如正态分布,均匀分布,泊松分布,指数分布)进行比较,确定两者之间的符合程度。
这种检验可以确定是否有理由认为样本的观察结果来自具有该理论分布的总体。
简言之,这种检验包括确定理论分布下的累积频数分布,以及把这种累积频数分布和观察的累积频数分布进行比较(这里的理论分布系指零假设成立时所预期的分布),确定理论分布和观察分布的最大差异点,参照抽样分布并定出这样大的差异是否基于偶然。
这就是说,若观察的结果的确是从理论分布抽取的随机样本,则抽样分布将指出这种观察到的差异程度是否随机出现的。
1二、Kolmogorov-Sirmov单样本检验方法1.K-S单样本检验步骤(1)在数据输入之后,依次单击Analyze→Nonparametric Tests→ 1-Sample K-S →打开One-Sample Kolmogorov-Sirmov Test对话框;(2)在原变量栏选择所要检验的分布到Test Variable List栏;(3)在Test Distribution栏选择理论分布函数复选项:●Normal复选项:如选择此项,则检验变量是否服从正态分布,系统默认;●Uniform复选项:如选择此项,则检验变量是否服从均匀分布;●Poisson复选项:如选择此项,则检验变量是否服从泊松分布;●Exponential复选项:如选择此项,则检验变量是否服从指数分布。
(4)单击“Option”按钮,打开Options对话框:●Statistics栏:在此栏可选择Descriptive复选项,则会输出观测的均值、最小值、最大值、标准差等描述统计;选择Quartiles复选项:则输出观测的四分之一分位数、二分之一分位数和四分之三分位数。
t检验三种类型

t检验三种类型区别:假设检验通常是检验样本对应的总体之间是否有显著性差异⽽关联性检验是检验是否显著相关。
⼀、单样本t检验 1、设计思想: 两个总体,总体A已知;总体B未知,但其样本已知,问题是未知总体B与已知总体A之间有⽆差异?实际上是验证该样本是否就是来⾃这个已知总体A? 2、适⽤: (1)已知⼀个总体和未知总体中的⼀个样本。
(2)样本数据符合正态分布,不符合时应采⽤⾮参检验。
3、SPSS处理解读三步法: ⼆、配对样本t检验 1、设计思想: 配对样本t检验是配对的两组数据相减变成⼀组数据,然后去和已知总体0⽐较,其实就是转化为单样本t检验。
2、适⽤: (1)检测的两组配对数据之间存在相关性⽽不独⽴,这与两独⽴样本设计有着本质的区别。
包括四种配对类型,3种为同体配对,1种异体配对(条件配对)。
(2)两组样本数据配对差值符合正态分布。
3、SPSS处理解读三步法: ⼀般,第⼆步可以忽略。
但从统计学⾓度,这⼀步是为了验证配对数据的⼀致性,⽤于说明实验措施的稳定性。
三、两独⽴样本t检验(A/Btest 背后原理) 1、设计思想:在两个未知的总体中分别抽取⼀个样本,然后⽐较两个总体之间是否有差异?实际是检验两样本所来⾃总体的均值是否相等。
注意:分为「两总体均值检验」和「两总体率值检验」 2、适⽤: (1)独⽴性。
完全随机设计的两样本均值的⽐较。
实践中,两个样本获取只有两种可能:随机分组或按属性分组。
不管哪种,均是保证两组相互独⽴,不受影响。
(2)正态性。
两独⽴样本t检验要求两样本所代表的总体分别服从正态分布N(µ1,σ^2)和N(µ2,σ^2)。
(3)⽅差齐性。
要求两个t分布形态相差不⼤。
即两总体⽅差σ1^2、σ2^2显著性相等。
(ps:若两总体⽅差不满⾜齐性,需要先进⾏变换校正)。
注意:实践中,两个样本的获取只有两种可能:⼀是随机分组,如60只SD⼤⿏,随机分2组,每组30只,分别接受不同的处理,然后⽐较某个计量效应指标;⼆是按照某种属性特征分组,如某班级按照性别分为男⽣组和⼥⽣组,然后⽐较男⼥⽣某门课程的考试成绩差异。
spss均值检验(均数分析单样本t检验独立样本t检验)

在统计学中,我们往往从样本的特性推知随机变量总体的特性。
但由于总体中个体之间存在差异,样本的统计量和总体的参数之间往往会有误差。
因此,均值不相等的样本未必来自不同分布的总体,而均值相等的样本未必来自有相同分布的总体。
也就是说,如何从样本均值的差异推知总体的差异,这就是均值比较的内容。
SPSS提供了均值比较过程,在主菜单栏单击“Analyze”菜单下的“Compare Means”项,该项下有5个过程,如图4-1。
平均数比较Means过程用于统计分组变量的的基本统计量。
这些基本统计量包括:均值(Mean)、标准差(Standard Deviation)、观察量数目(Number of Cases)、方差(Variance)。
Means过程还可以列出方差表和线性检验结果。
[例子]调查了棉铃虫百株卵量在暴雨前后的数量变化,统计暴雨前和暴雨后的统计量,其数据如下:暴雨前 110 115 133 133 128 108 110 110 140 104 160 120 120暴雨后 90 116 101 131 110 88 92 104 126 86 114 88 112该数据保存在“DATA4-1.SAV”文件中。
1)准备分析数据在数据编辑窗口输入分析的数据,如图4-2所示。
或者打开需要分析的数据文件“DATA4-1.SAV”。
图4-2 数据窗口2)启动分析过程在SPSS主菜单中依次选择“Analyze→Compare Means→Means”。
出现对话框如图4-3。
图4-3 Means设置窗口3)设置分析变量从左边的变量列表中选中“百株卵量”变量后,点击变量选择右拉按钮,该变量就进入到因子变量列表“Dependent List:”框里,用户可以从左边变量列表里选择一个或多个变量进行统计。
从左边的变量列表中选中“调查时候”变量,点击“Independent List”框左边的右拉按钮,该变量就进入分组变量“IndependentList”框里,用户可以从左边变量列表里选择一个或多个分组变量。
假设检验-单样本检验
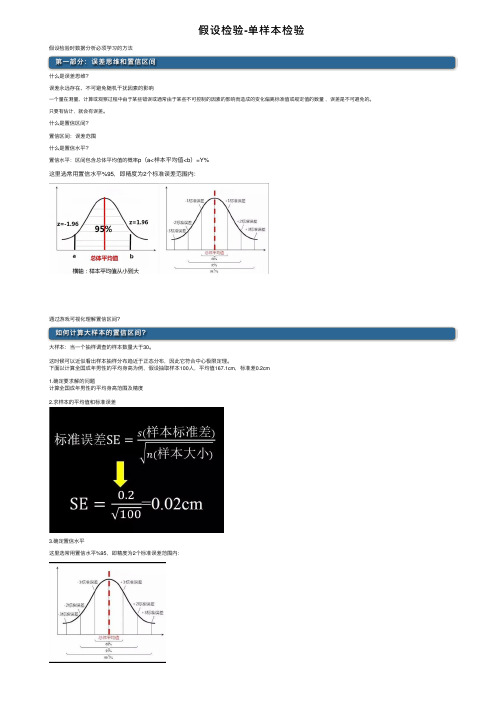
假设检验-单样本检验假设检验时数据分析必须学习的⽅法第⼀部分:误差思维和置信区间什么是误差思维?误差永远存在、不可避免随机⼲扰因素的影响⼀个量在测量、计算或观察过程中由于某些错误或通常由于某些不可控制的因素的影响⽽造成的变化偏离标准值或规定值的数量,误差是不可避免的。
只要有估计,就会有误差。
什么是置信区间?置信区间:误差范围什么是置信⽔平?置信⽔平:区间包含总体平均值的概率p(a<样本平均值<b)=Y%这⾥选常⽤置信⽔平%95,即精度为2个标准误差范围内:通过游戏可视化理解置信区间?如何计算⼤样本的置信区间?⼤样本:当⼀个抽样调查的样本数量⼤于30。
这时候可以近似看出样本抽样分布趋近于正态分布,因此它符合中⼼极限定理。
下⾯以计算全国成年男性的平均⾝⾼为例,假设抽取样本100⼈,平均值167.1cm,标准差0.2cm 1.确定要求解的问题计算全国成年男性的平均⾝⾼范围及精度2.求样本的平均值和标准误差3.确定置信⽔平这⾥选常⽤置信⽔平%95,即精度为2个标准误差范围内:4.求出置信区间上下限的值(1)由于选⽤的样本⼤⼩为100⼤于30符合正态分布,先求出如下图中两块红⾊区域⾯积(概率):(2)通过查z表格查出标准分Z=-1.96(3)求出a和b的值的⽅法:(4)根据中⼼极限定理,样本平均值约等于总体平均值,最终求出a和b的值:结论:当我们选⽤置信⽔平为%95时,求得置信区间为[167.0608,167.1392],即在两个标准误差范围内,全国成年男性的平均⾝⾼为167.0608cm到167.1392cm之间。
5.常⽤置信⽔平及其对应Z值(标准分)如何计算⼩样本的置信区间?⼩样本:当⼀个抽样调查的样本数量⼩于30。
这时候抽样分布符合t分布:在概率论和统计学中,t-分布(t-distribution)⽤于根据⼩样本来估计呈正态分布且⽅差未知的总体的均值。
如果总体⽅差已知(例如在样本数量⾜够多时),则应该⽤正态分布来估计总体均值。
SPSS统计实验单双样本t检验

单样本T检验
班级
期末成
绩
1 87 1 96 1 80 1 90 1 88 1 70 1 67 1 7
2 1 70 1 75 1 86
检验班级1的期末平均成绩是否达到80.
表中可看出均值=80.09,均值大于80
上表是对均值为80的显著性检验:T统计量=0.031,双侧检验P值=0.976大于显著性水平0.05,即表明接受原假设,没有显著性差异。
在95%的置信区间下的取值范围为(-6.50,6.68).综合分析可知班级1的期末平均成绩达到80.
两个样本T检验
班级
期末成
绩
1 87 1 96 1 80 1 90 1 88 1 70 1 67 1 7
2 1 70 1 75
1 86
2 77 2 68 2 65 2 61 2 9
3 2 88 2 80 2 85 2 85 2 80 2 96
计算两个班级期末成绩的平均成绩,标准差,最高分和最低分来比较两个班级间成绩有无明显差异。
两个班级期末成绩的均值为79.95,标准差为10.330,最高分为96,最低分为61,置信区间下限为75.37,上限为84.53。
上表为班级1,2在均值,置信度,标准差、中位数和最大、最小值等各项指标的对比情况:从表中可看出1班与2班的各项指标都很接近,1班略大于2班。
方差齐性检验的F值=0.018,P值=0.895,T检验在方差相等与不等两种情况下的T值都为0.06,P值都为0.952,都大于给定的显著性水平a=0.05,即两个班的成绩没有显著性差异。
实验三基本统计分析与单一样本t检验

本实验的主要发现
实验结果显示,样本均值与已 知总体均值存在显著差异,说 明样本数据与总体数据存在偏 离。
通过单一样本t检验,我们发现 样本数据的标准差较小,说明 样本数据相对集中。
本实验中,样本数据的分布呈 现出正态分布的特点,符合统 计学中的正态分布假设。
对实际应用的启示
在实际应用中,当需要对总体数据进 行推断时,可以采用本实验的方法对 样本数据进行统计分析,以了解样本 数据与总体数据的差异。
样本选取
为了保证实验结果的可靠性,我们选 取了其中50名年龄、性别、体重等特 征相似的受试者作为样本。
使用统计软件进行单一样本t检验
01
软件选择:我们选择了SPSS软件进行统计分析,因为其 功能强大且易于操作。
04
2. 在菜单栏中选择“分析”-“比较均值”-“单一样本t 检验”。
02
实验步骤
05
3. 在弹出的对话框中,将体重作为检验变量,将标准值 设定为某个特定值(例如,正常体重范围的中值)。
实验三基本统计分析与单一样本t 检验
目录
• 引言 • 基本统计概念 • 单一样本t检验的原理 • 单一样本t检验的步骤 • 实验操作与演示 • 结论
01 引言
主题简介
01
基本统计分析与单一样本t检验是 统计学中常用的方法,用于分析 单一样本数据的均值与已知的参 考值或理论值之间的差异。
02
在科学实验、医学研究、社会科 学调查等领域,单一样本t检验被 广泛应用于检验样本均值是否显 著不同于已知的参考值。
实验目的
掌握单一样本t检验 的基本原理和方法。
了解单一样本t检验 在实际问题中的应用 和注意事项。
学习如何使用统计软 件进行单一样本t检 验。
样本方差 样本标准差

样本方差样本标准差样本方差和样本标准差是统计学中常用的两个概念,它们可以帮助我们衡量数据的离散程度和波动程度。
在实际应用中,我们经常需要计算样本的方差和标准差,以便更好地理解数据的分布特征。
本文将详细介绍样本方差和样本标准差的计算方法和应用场景,希望能对读者有所帮助。
首先,让我们来了解一下样本方差的概念。
样本方差是用来衡量一组数据的离散程度的统计量,它的计算公式为,样本方差 = Σ(xi x)² / (n-1),其中xi代表每个数据点,x代表样本的均值,n代表样本容量。
样本方差的计算过程包括两个步骤,首先计算每个数据点与样本均值的差值的平方,然后将所有差值的平方相加并除以样本容量减一。
样本方差的单位是数据点的单位的平方,它的值越大,代表数据的离散程度越大。
接下来,让我们来了解一下样本标准差的概念。
样本标准差是样本方差的平方根,它的计算公式为,样本标准差 = √(Σ(xi x)² / (n-1))。
样本标准差和样本方差一样,都是用来衡量数据的离散程度的统计量,但是样本标准差的单位和数据点的单位一样,它的值越大,代表数据的离散程度越大。
在实际应用中,样本方差和样本标准差经常被用来衡量数据的波动程度。
例如,我们可以用样本标准差来衡量股票价格的波动程度,用样本方差来衡量温度的变化程度。
另外,样本方差和样本标准差还可以用来比较不同数据集的离散程度,帮助我们找出数据的规律和特点。
除了用来衡量数据的离散程度,样本方差和样本标准差还可以用来进行假设检验和推断统计。
在假设检验中,我们可以利用样本方差和样本标准差来计算t值和z值,从而判断样本均值是否显著地不同于总体均值。
在推断统计中,我们可以利用样本方差和样本标准差来计算置信区间,从而对总体参数进行估计。
总之,样本方差和样本标准差是统计学中非常重要的概念,它们可以帮助我们更好地理解数据的离散程度和波动程度。
在实际应用中,我们可以利用样本方差和样本标准差来进行数据分析、假设检验和推断统计,从而得出科学、准确的结论。
方差检验的统计量

方差检验的统计量摘要:一、方差检验的统计量简介1.方差检验的统计量概念2.常见方差检验统计量二、方差检验统计量的计算方法1.方差检验统计量的公式2.计算过程中需要注意的要点三、方差检验统计量的应用场景1.单样本方差检验2.双样本方差检验3.多样本方差检验四、方差检验统计量在实际问题中的优势与局限1.优势2.局限正文:方差检验是一种常见的统计方法,用于检验不同样本均值之间是否存在显著差异。
在进行方差检验时,我们需要计算一些统计量来帮助我们做出决策。
本文将介绍方差检验的统计量及其计算方法、应用场景和优势与局限。
一、方差检验的统计量简介方差检验的统计量是用于衡量样本间差异的统计指标。
常见的方差检验统计量有:方差、均方差、标准差、F统计量等。
二、方差检验统计量的计算方法以双样本方差检验为例,其统计量计算公式为:F = (样本1的均值- 样本2的均值) / (样本1的标准差/ 样本2的标准差)。
计算过程中,需要注意样本数据应满足正态分布、方差齐性的条件,同时要正确选择合适的检验统计量。
三、方差检验统计量的应用场景方差检验统计量广泛应用于单样本、双样本和多样本方差检验。
例如,在教育研究、医学研究、心理学研究等领域,研究者们常使用方差检验统计量来分析不同实验组之间的效果差异。
四、方差检验统计量在实际问题中的优势与局限方差检验统计量的优势在于,它能够直观地反映样本间的差异,计算简单,易于理解和应用。
然而,方差检验统计量也存在局限性,如对总体分布的假设、对样本量的要求等。
此外,当样本量较小时,方差检验统计量的值可能不稳定,从而影响检验结果的准确性。
总之,方差检验统计量是一种实用的统计工具,能够帮助我们分析样本间的差异。
单一样本均值的t检验

95
92
88
92
93
95
89
98
92
注:直接替换“置信水平”和“样本数据”就可得出其他计算结果
(蓝颜色的数据),但是在更换“样本数据”时,需要重新指定一下“
样本数据”所包含的数据,具体方法是:选中“样本数据”及其下面的
数据,点击“插入”→“名称”→“指定”→“首行”→“确定”即可
(这叫“名称引用”)。
举例:有一种新农药防治柑橘红蜘蛛,进行了9个小区的实
验,其防治效果为:95%、92%、88%、92%、93%、95%、89%、98%、92%,与原有使用的一种农药防治效果为90%相比,分析该新农药是否显著优于原有农药。
(置信水平95%)
结果分析:t统计量值为2.5955,大于95%置信水平的t分布差异显著性临界值2.306,所以新农药的防治效果显著高于原有农药的防治效果。
但当置信水平设置为0.99时,t分布临界值为3.355,t统计量值小于这个临界值,所以在该置信水平
下,效果又是不显著的,所以新农药的防治效果显著高于原有农药,但又不是极其显著高于原农药。
另附:t检验的核心思想:
μ
t值越大,样本均值与总体均值的差距越大,那么究竟多大时就认为样本均值不能代表总体均值了呢?一般认为实际算得的t≧ ,即P≦5%时,可以解释为两均值相同的可能性在5%以下,也就是说两者之间差异
μ。
05.0t。
单样本检验的效果量

单样本检验的效果量
单样本检验的效果量常用的是Cohen's d或标准平均差(Standardized Mean Difference),用于衡量两个群体之间的平均差异的效果大小。
这依赖于样本均值之间的差异以及标准差。
计算Cohen's d的公式为:d = (M - μ) / σ
其中,M代表样本均值,μ代表总体均值,σ代表总体标准差。
通常,效果量(Effect Size)的值介于-1至1之间。
效果量为0表示两个群体之间没有差异,大于0表示样本均值高于总体均值,小于0表示样本均值低于总体均值。
效果量越大,差异越显著。
需要注意的是,效果量的解释可能依赖于具体的领域和背景。
一般认为,d<0.2为小效果量,0.2≤d<0.5为中等效果量,d≥0.5为大效果量。
然而,具体领域和背景可能会有所不同。
因此,在报告效果量时,最好提供背景信息和领域内的标准参考来解释其含义。
请注意,计算Cohen's d需要知道总体标准差,但通常情况下我们只能根据样本标准差来估计总体标准差,因此,计算的效果量应视为估计值而非精确值。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
MINITAB协助白皮书本书中有一系列篇章,介绍了 Minitab 统计人员为开发在 Minitab 统计软件的“协助”中使用的方法和数据检查而开展的研究。
单样本标准差检验概述单样本标准差检验用于估计过程的变化性并将变化性与目标值进行比较。
通常,变化性使用方差(也即标准差)进行测量。
现在虽然研制出了许多用于评估总体方差的统计方法,但是每种方法都有各自的优缺点。
用于检验方差的传统卡方检验方法可能是最常用的方法,但它对正态性假设极为敏感,并会在数据呈偏态或重尾分布时生成非常不准确的结果。
同时还研制出了一些其他方法,但是这些方法也有缺点。
例如,有些方法只适用于大样本或呈对称分布的数据(参见附录 A)。
在 Minitab 15 中,我们将使用另一种大样本方法,此方法是从样本方差的扩展卡方近似分布(由 Box 于 1953 年提出)派生的。
这种方法被称作调整自由度 (AdjDF) 方法,对足够大的样本的正态假设不太敏感,已证明能生成比其他方法更准确的置信区间(Hummel、Banga 和Hettmansperger,2005 年)。
不过,Bonett (2006) 最近研制出了经过修订的统计方法,似乎能够提供更准确的近似置信区间。
在本文中,我们将评估 Bonett 方法的性能。
此外,为了规划样本量,我们还研究了与Bonett 的置信区间有关的等效检验程序的功效。
根据我们的研究结果,我们使用 Bonett 方法来在 Assistant 中开展单样本标准差检验。
我们还检查自动执行并在 Assistant Report Card 中显示的以下数据检查,并解释它们对结果造成的影响:∙异常数据∙检验的有效性∙样本量单样本标准差方法Bonett 方法与 AdjDF 方法在 Bonett 方法 (2006) 公布前,对总体方差进行推测的最强大的程序可能莫过于 AdjDF 方法了。
然而,Bonett 公布的结果证明,当从非正态总体提取到大小适中的样本时,Bonett 方法提供接近目标水平的稳定的置信水平。
因此,Bonett 方法可能是对总体的标准差或方差进行推测的优选方法。
目标在对单个总体的方差进行推测时,我们想要比较 Bonett 方法与 AdjDF 方法的性能。
具体来说,当从非正态总体中生成不同大小的样本时,我们想要确定哪种方法将为方差(或标准差)生成更准确的置信区间。
我们比较置信区间是因为 Bonett 方法可直接应用于置信区间。
可以得到与 Bonett 置信区间有关的等效假设检验程序。
不过,为了将我们的研究结果直接与 Bonett (2006) 中发布的结果进行比较,我们检查了置信区间,而不是假设检验。
方法AdjDF 方法和 Bonett 方法都正式在附录 B 中定义。
要比较每种方法的置信区间的准确性,我们进行了下面的模拟。
首先,我们从特性各不相同的分布(如偏态和重尾、对称和重尾以及对称和轻尾分布)中生成了不同大小的随机样本。
对于每个样本量,我们从各个分布中提取了10,000 个重复样本,并使用各种方法为分布的真实方差计算 95%的双侧置信区间。
然后,我们计算出了包含真实方差的 10,000 个区间的比例,称为模拟覆盖概率。
如果置信区间准确无误,则模拟覆盖概率应接近 0.95 的目标范围概率。
此外,我们还计算了与每种方法的置信区间有关的平均宽度。
如果这两种方法的置信区间具有大致相同的模拟覆盖概率,则产生更短间隔(平均而言)的方法更准确。
有关详细信息,请参见附录 C。
结果Bonett 方法通常会产生比 AdjDF 方法更好的覆盖概率和更准确的置信区间。
因此,采用Bonett 方法,方差统计检验产生的类型 I 和类型 II 错误率较低。
因此,Assistant 中的单样本标准差检验将采用 Bonett 方法。
此外,我们的研究结果表明,对于中尾至重尾分布,Bonett 方法需要较大的样本量,以达到准确的目标水平:∙对于正态或轻尾分布,20 个样本量就足够了。
∙对于中度重尾分布,样本量至少应为 80 个。
∙对于重尾分布,样本量至少应为 200 个。
因此,要确保您数据的单样本标准差检验或置信区间结果有效,Assistant 中的数据检查功能可同时评估样本量和数据分布的尾部(参见下文的检验数据检查的有效性)。
理论功效Bonett 方法可直接应用于方差(或标准差)的置信区间。
但是,使用假设检验和置信区间之间的统计关系,我们可以得到一个与 Bonett 的近似置信区间有关的等效检验。
由于无法为此检验提供确切的功效,我们需要得到一个功效。
此外,我们还要评估理论功效对正态性假设的敏感性。
目标我们想要确定我们是否可以使用与 Bonett 置信区间有关的检验的理论功效来评估 Assistant 中的单样本标准差检验的能力和样本量要求。
为此,在对正态和非正态数据进行分析时,我们需要评估这一理论功效是否准确地反映了检验的实际能力。
方法有关使用 Bonett 方法的检验的理论功效,请参见附录 C。
我们进行了模拟,以评估使用Bonett 方法的实际能力水平(我们称之为模拟能力水平)。
首先,我们从前面的研究中所述的分布中生成了不同大小的随机样本:偏态和重尾、对称和重尾以及对称和轻尾分布。
对于每一种分布,我们对每 10,000 个重复样本执行了检验。
对于每种样本量,我们计算了检验的模拟能力,以检测给定的差值,并将其作为此检验对其有重要意义的 10,000 个样本的一部分。
为了比较,我们还使用检验的理论功效计算了对应的能力水平。
如果理论功效对正态性不是那么敏感,正态和非正态数据的理论和模拟能力水平应十分接近。
有关详细信息,请参见附录 D。
结果我们的模拟表明,当样本呈正态或轻尾分布时,使用 Bonett 方法的检验的理论和模拟能力几乎相同。
当样本呈重尾分布时,理论功效可能会采取保守估计,但会高估达到给定能力所需的样本量。
因此,检验的理论功效将确保样本量足够大,无论哪种分布都能够检测到标准差中的实际重要差值。
然而,如果数据呈重尾分布,估计的样本量可能会大于实际需要的样本量,可能会在取样时导致超支。
数据检查异常数据异常数据是非常大或非常小的数据值,也称为异常值。
异常数据会对分析结果产生巨大的影响,并且会影响发现具有重要统计意义的结果的概率,特别是当样本量较小时。
异常数据可以表明数据收集问题或者您正在研究的过程的异常表现引起的问题。
因此,这些数据点往往值得研究,如果可能的话应予以更正。
目标我们想研制一种方法,来检查相对于总体样本而言非常大或非常小并且可能影响分析结果的数据值。
方法我们研制出了一种方法,根据 Hoaglin, Iglewicz, and Tukey (1986) 介绍的用于识别箱线图中的异常值的方法来检查异常数据。
结果如果数据点在分布的下限或上限范围内超过 1.5 倍的四分位范围,Assistant 会将该数据点识别为异常数据点。
上、下四分位范围分别是数据的 25% 和 75%。
四分位范围是两个四分位数之间的差值。
即使有多个异常值,这种方法也应用得很好,因为它可以检测每一个具体的异常值。
检查异常数据时,Assistant 会在 Report Card 中显示以下状态指标:没有异常数据点。
至少有一个异常数据点,可能会对结果产生巨大的影响。
检验的有效性在上面的单样本标准差方法部分,我们发现,Bonett 方法通常提供比 AdjDF 方法更好的结果。
然而,当呈重度重尾分布时,Bonett 方法需要较大的样本量,才能获得准确的结果。
因此,评估检验的有效性的方法必须不仅取决于样本量,还取决于母体分布的尾部重量。
Gel et al. (2007) 研制出了一种检验方法,用于确定样本是否呈重尾分布。
该检验被称为 SJ 检验,结果取决于样本标准差与尾部估计值 J 之比(详见附录 E)。
对于给定的数据样本,我们需要制定一个规则,通过评估数据中的尾部重量来评估 Bonett 方法的有效性。
方法我们通过模拟来研究 SJ 检验的能力,以确定重尾分布。
如果 SJ 检验适用于中等大小的样本,那么它可以为我们区分出重尾和轻尾分布。
有关详细信息,请参见附录 F。
结果我们的模拟表明,当样本足够大时,SJ 检验可用于区分重尾和轻尾分布。
对于中等或大量样本,较小的 p 值表示重度重尾,较大的 p 值表示轻度轻尾。
然而,由于大样本的 p 值往往比小样本的小,我们在确定尾部重量时也会考虑样本量。
因此,我们研制出了一套规则,Assistant 可根据样本量和 SJ 检验的 p 值对每个样本的分布尾部进行分类。
要查看 p 值的具体范围,以及与轻尾、中尾和重尾分布有关的样本量,请参见附录 F。
根据这些结果,Assistant Report Card 将显示以下状态指标,以评估数据的单样本标准差检验(Bonett 方法)的有效性:没有证据表明您的样本呈重尾分布。
您的样本量足够大,可以可靠地检查此条件。
或您的样本呈中度重尾或重尾分布。
不过,您的样本量足够大,可以弥补差值,因此准确的。
您的样本呈中度重尾或重尾分布。
您的样本量不够大,无法弥补差值。
解释结果时应小心。
或您的样本不够大,无法可靠地检查是否有重尾。
解释结果时应小心。
样本量通常情况下,执行统计假设检验可收集证据,以拒绝“无差值”零假设。
如果样本量太小,检验可能无法检测到切实存在的差值,从而导致类型 II 错误。
因此,一定要确保样本量足够大,可以高概率地检测到具有重要意义的实际差值。
目标如果数据没有提供足够的证据来拒绝零假设,我们要确定样本量是否足够大,以便检验能够高概率地检测到所需的实际差值。
尽管规划样本量的目标是确保样本量足够大,可以高概率地检测到重要差值,它们也不应该如此之大,使得无意义的差值高概率地成为具有重要统计意义的差值。
单样本标准差检验的能力和样本量分析基于检验的理论功效。
当数据接近正态分布的尾部或呈轻尾分布时,此功效可提供有用的估计值,但是当数据呈重尾分布时,可能会生成保守的估计值(参见上述单样本标准差方法部分中的理论功效中总结的模拟结果)。
结果当数据未提供针对零假设的足够证据时,Assistant 使用正态近似检验的功效来计算可以用80%和 90%的概率检测到的给定样本量的实际差值。
此外,如果用户提供所需的特定实际差值,Assistant 会采用正态近似检验的功效,计算差值检测概率为 80%和 90%的样本量。
为了帮助解释结果,用于单样本标准差检验的 Assistant Report Card 在检查能力和样本量时,会显示以下状态指标:检验发现标准差与目标值之间的差值,因此能力不是问题。
或能力是足够的。
检验没有发现标准差与目标值之间的差值,但是样本足够大,提供至少的概率来检测给定差值。