维特比译码简介
viterbi译码算法详解

viterbi译码算法详解Viterbi译码算法是一种常用的序列解码算法,广泛应用于语音识别、自然语言处理、通信等领域。
本文将详细介绍Viterbi译码算法的原理和步骤,以及它的应用。
Viterbi译码算法是一种动态规划算法,用于在给定观测序列的情况下,求解最可能的隐藏状态序列。
在这个过程中,算法会基于概率模型和观测数据,通过计算每个可能的状态路径的概率,选择概率最大的路径作为输出。
Viterbi译码算法的基本原理是利用动态规划的思想,将问题分解为一系列子问题,并利用子问题的最优解来求解整体问题的最优解。
在Viterbi译码算法中,我们假设隐藏状态的转移概率和观测数据的发射概率已知,然后通过计算每个时刻的最优路径来递推地求解整个序列的最优路径。
具体而言,Viterbi译码算法包括以下步骤:1. 初始化:对于初始时刻t=0,计算每个隐藏状态的初始概率,即P(x0=s)。
2. 递推计算:对于时刻t>0,计算每个隐藏状态的最大概率路径。
假设在时刻t-1,每个隐藏状态的最大概率路径已知,则在时刻t,可以通过以下公式计算:P(xt=s) = max(P(xt-1=i) * P(xi=s) * P(ot=s|xi=s))其中,P(xt=s)表示在时刻t,隐藏状态为s的最大概率路径;P(xt-1=i)表示在时刻t-1,隐藏状态为i的最大概率路径;P(xi=s)表示从隐藏状态i转移到隐藏状态s的转移概率;P(ot=s|xi=s)表示在隐藏状态s的情况下,观测到观测值为s的发射概率。
3. 回溯路径:在最后一个时刻T,选择概率最大的隐藏状态作为最终的输出,并通过回溯的方式找到整个序列的最优路径。
通过上述步骤,Viterbi译码算法可以求解出给定观测序列下的最可能的隐藏状态序列。
这个算法的时间复杂度为O(N^2T),其中N 是隐藏状态的个数,T是观测序列的长度。
Viterbi译码算法在实际应用中有着广泛的应用。
维特比译码算法

维特比(Viterbi)译码算法是一种常用于纠错码解码的动态规划算法,它用于找到给定接收信号中最有可能的发送序列,从而纠正错误。
维特比算法在通信领域和编码理论中广泛应用,特别是在卷积码和循环码等纠错码的解码过程中。
维特比译码算法的基本思想是,在接收到一串含有噪声的数据后,找到最有可能的原始数据序列,以最小化解码错误。
这个算法利用了动态规划的思想,通过逐步迭代地考虑所有可能的状态转移路径,选择最有可能的路径,从而找到最佳的发送序列。
下面是维特比译码算法的基本步骤:
1. **初始化:** 初始化第一个时间步的状态,通常为接收到的第一个数据。
将各个状态的初始路径度量设为接收到的数据与可能发送数据之间的距离(如汉明距离等)。
2. **递归计算:** 对每个时间步,计算到达每个状态的路径度量,考虑从前一个时间步到当前状态的所有可能路径。
选择最小路径度量作为当前状态的路径度量,并记录最佳路径。
3. **回溯:** 在最后一个时间步结束后,通过回溯最小路径度量,找到最佳路径,即最可能的发送序列。
维特比算法适用于许多不同类型的纠错码,包括卷积码、循环码等。
在实际应用中,它可以帮助恢复传输中的错误,提高通信系统的可靠性。
需要注意的是,维特比算法的复杂性会随着状态数和时间步数的增加而增加,因此在实际应用中,可能会通过一些优化策略来减少计
算复杂性,例如利用部分距离计算、并行计算等。
维特比译码算法在通信系统和编码理论中是一个重要的概念,如果你希望了解更多关于维特比算法的详细内容和数学推导,可以参考相关的通信和编码领域的教材和研究论文。
卷积码及维特比译码 notes
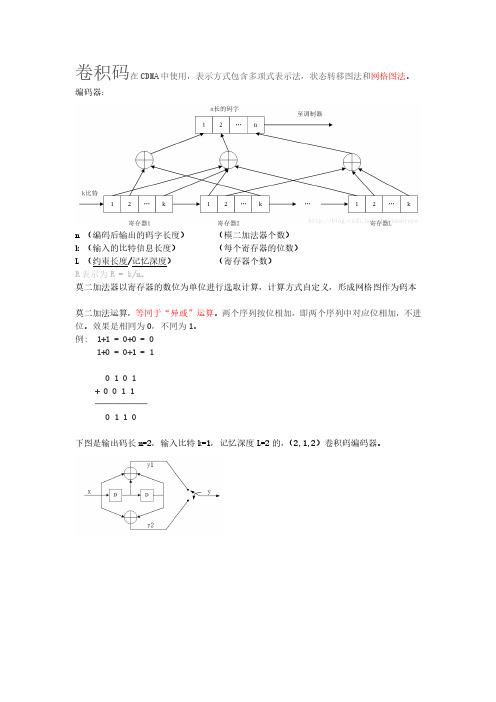
卷积码在CDMA中使用,表示方式包含多项式表示法,状态转移图法和网格图法。
编码器:n (编码后输出的码字长度)(模二加法器个数)k (输入的比特信息长度)(每个寄存器的位数)L (约束长度/记忆深度)(寄存器个数)R表示为R = k/n。
莫二加法器以寄存器的数位为单位进行选取计算,计算方式自定义,形成网格图作为码本莫二加法运算,等同于“异或”运算。
两个序列按位相加,即两个序列中对应位相加,不进位。
效果是相同为0,不同为1。
例: 1+1 = 0+0 = 01+0 = 0+1 = 10 1 0 1+ 0 0 1 1──────0 1 1 0下图是输出码长n=2,输入比特k=1,记忆深度L=2的,(2,1,2)卷积码编码器。
如编码序列“0 1 1 0 0”在图中的序列如下:汉明距离两个二进制数之间进行逐位对比,得到不同的个数如1000,与1100为1,与1110为2,与1111为3维特比算法综合状态之间的转移概率和前一层各状态的概率情况计算出概率最大的状态转换路径,从而推断出隐含状态的序列的情况。
的分支度量(汉明距离)。
其中有两条路径的分支量度为0。
3.寻找最大似然路径 - 译码过程维特比算法的关键点在于,接收机可以使用分支度量和先前计算的路径度量递推地计算当前状态的路径度量。
初始时,状态00代价为0,其它状态代价为正无穷(∞)。
算法的主循环由两个主要步骤组成:首先计算下一时刻监督比特序列的分支度量,然后计算该时刻各状态的路径度量。
路径度量的计算可以认为是一个“加-比-选”的过程1)将分支度量与上一时刻状态的路径度量相加。
2)每一状态比较来自前一时刻状态可达到的所有路径(只有两条这样的路径进行比较)3)每一状态删除其余到达路径,选择最小度量的路径保留(称为幸存路径/存活路径)若进入某个状态的部分路径中,有两条路径的度量值相等,则可以任选其一作为幸存路径。
下图显示了维特比译码的过程。
此例接收到的位序列为11 10 11 00 01 10(偷偷告诉你:这是有误码的信息)此时,产生了具有相同路径度量的四个不同路径,通向这四个状态的任一路径都是可能发送的比特序列(它们都具有度量为2的汉明距离)。
viterbi译码算法详解

viterbi译码算法详解Viterbi译码算法详解Viterbi译码算法是一种在序列估计问题中广泛应用的动态规划算法。
它被用于恢复在一个已知的输出序列中最有可能的输入序列。
该算法最初由Andrew Viterbi在1967年提出,并被广泛应用于各种领域,如语音识别、自然语言处理、无线通信等。
Viterbi译码算法的基本思想是在一个已知的输出序列中寻找最有可能的输入序列。
它通过计算每个可能的输入序列的概率,并选择概率最大的输入序列作为最终的估计结果。
该算法的关键是定义一个状态转移模型和一个观测模型。
状态转移模型描述了输入序列的转移规律,即从一个输入状态转移到另一个输入状态的概率。
观测模型描述了输入序列和输出序列之间的关系,即给定一个输入状态,产生一个输出状态的概率。
在Viterbi译码算法中,首先需要进行初始化。
假设有n个可能的输入状态和m个可能的输出状态,我们需要初始化两个矩阵:状态概率矩阵和路径矩阵。
状态概率矩阵记录了每个时刻每个状态的最大概率,路径矩阵记录了每个时刻每个状态的最大概率对应的前一个状态。
接下来,我们通过递归的方式计算状态概率和路径矩阵。
对于每个时刻t和每个可能的输入状态i,我们计算当前状态的最大概率和对应的前一个状态。
具体的计算方式是通过上一个时刻的状态概率、状态转移概率和观测概率来计算当前时刻的状态概率,并选择其中最大的概率作为当前状态的最大概率。
我们通过回溯的方式找到最有可能的输入序列。
从最后一个时刻开始,选择具有最大概率的状态作为最终的估计结果,并通过路径矩阵一直回溯到第一个时刻,得到整个输入序列的最有可能的估计结果。
Viterbi译码算法的优势在于它能够处理大规模的状态空间和观测空间。
由于使用动态规划的思想,该算法的时间复杂度为O(nmT),其中n和m分别为可能的输入状态和输出状态的数量,T为输出序列的长度。
因此,在实际应用中,Viterbi译码算法能够高效地处理各种序列估计问题。
维特比译码算法

维特比译码算法
维特比译码算法是一种卷积码的译码算法,其基本原理是利用动态规划的方法,通过计算每个状态转移的路径度量值,找到最小路径度量的路径作为幸存路径,从而得到译码输出。
维特比译码算法的复杂度与信道质量无关,其计算量和存储量都随约束长度N和信息元分组k呈指数增长,因此当约束长度和信息元分组较大时并不适用。
为了充分利用信道信息,提高卷积码译码的可靠性,可以采用软判决维特比译码算法。
此时解调器不进行判决而是直接输出模拟量,或是将解调器输出波形进行多电平量化,而不是简单的0、1两电平量化,然后送往译码器。
即编码信道的输出是没有经过判决的“软信息”。
维特比译码原理

维特比译码原理
维特比译码是一种序列鉴别算法,用于解码已被编码的序列。
它主要用于纠错编码和通信领域。
维特比译码基于动态规划的思想,通过计算每个时刻的最大可能性路径来找到最优解码结果。
维特比译码的基本原理如下:
1. 建立状态图:首先根据编码方案的特点,建立一个有向无环状态图,其中每个节点表示一个状态,每个边表示从一个状态转移到另一个状态的转移。
2. 计算到达每个状态的最大概率:从起始状态开始,根据编码的输入序列逐步计算每个状态的到达概率。
对于每个状态,可以通过考虑前一个时刻的所有状态的概率和转移概率来计算到达该状态的最大概率。
3. 选择最大概率路径:在到达最后一个状态时,根据计算得到的最大概率路径,可以通过回溯的方式找到整个序列的最优解码结果。
维特比译码的核心思想是利用动态规划的方法,在计算过程中保存中间结果,以避免重复计算。
通过逐步计算每个状态的最大概率,可以在最后找到最优解码结果。
维特比译码在纠错编码和通信系统中广泛应用,可以有效地解
码受到噪声、干扰和丢失的编码序列,提高通信的可靠性和性能。
卷积码的维特比译码原理及仿真

卷积码的维特比译码原理及仿真摘 要 本课程设计主要解决对一个卷积码序列进行维特比(Viterbi)译码输出,并通过Matlab 软件进行设计与仿真,并进行误码率分析。
实验原理QPSK :QPSK 是英文QuadraturePhaseShiftKeying 的缩略语简称,意为正交相移键控,是一种数字调制方式。
四相相移键控信号简称“QPSK ”。
它分为绝对相移和相对相移两种。
卷积码:又称连环码,是由伊莱亚斯(P.elias)于1955年提出来的一种非分组码。
积码将k 个信息比特编成n 个比特,但k 和n 通常很小,特别适合以串行形式进行传输,时延小。
卷积码是在一个滑动的数据比特序列上进行模2和操作,从而生成一个比特码流。
卷积码和分组码的根本区别在于,它不是把信息序列分组后再进行单独编码,而是由连续输入的信息序列得到连续输出的已编码序列。
卷积码具有误码纠错的能力,首先被引入卫星和太空的通信中。
NASA 标准(2,1,6)卷积码生成多项式为: 346134562()1()1g D D D D D g D D D D D=++++=++++其卷积编码器为:图1.1 K=7,码率为1/2的卷积码编码器维特比译码:采用概率译码的基本思想是:把已接收序列与所有可能的发送序列做比较,选择其中码距最小的一个序列作为发送序列。
如果接收到L 组信息比特,每个符号包括v 个比特。
接收到的Lv 比特序列与2L 条路径进行比较,汉明距离最近的那一条路径被选择为最有可能被传输的路劲。
当L 较大时,使得译码器难以实现。
维特比算法则对上述概率译码做了简化,以至成为了一种实用化的概率算法。
它并不是在网格图上一次比较所有可能的2kL 条路径(序列),而是接收一段,计算和比较一段,选择一段最大似然可能的码段,从而达到整个码序列是一个最大似然值得序列。
下面以图2.1的(2,1,3)卷积码编码器所编出的码为例,来说明维特比解码的方法和运作过程。
卷积码编码和维特比译码的原理、性能与仿真分析

卷积码编码和维特比译码的原理、性能与仿真分析1.引言卷积码的编码器是由一个有k位输入、n位输出,且具有m位移位寄存器构成的有限状态的有记忆系统,通常称它为时序网络。
编码器的整体约束长度为v,是所有k个移位寄存器的长度之和。
具有这样的编码器的卷积码称作[n,k,v]卷积码。
对于一个(n,1,v)编码器,约束长度v等于存储级数m.卷积码是由k个信息比特编码成n(n>k)比特的码组,编码出的n比特码组值不仅与当前码字中的k个信息比特值有关,而且与其前面v个码组中的v*k个信息比特值有关。
卷积码有三种译码方式:序列译码、门限译码和概率译码。
其中,概率译码根据最大似然译码原理在所有可能路径中求取与接收路径最相似的一条路径,具有最佳的纠错性能,维特比译码是概率译码中极重要的一种方式。
序列译码和门限译码则不一定能找出与接收路径最相似的一条路径。
不同于维特比译码,门限译码与序列译码所需的计算量是可变的且对于给定信息分组的最终判决仅仅基于(m+1)个接收分组,而不是基于整个接收序列。
与维特比译码所使用的对数似然量度不同,序列译码所使用的量度为Fano量度。
在接收序列受扰严重的情况下,序列译码的计算量大于维特比译码所需的固定计算量,虽然序列译码要求的平均计算次数通常小于维特比译码。
在采用并行处理的情况下,维特比译码的速度会优于序列译码。
在同样码率和存储级数的条件下,门限译码的性能比维特比译码低大约3dB.维特比译码的数据输出方式有硬判决及软判决两种方式,本文选取生成多项式为561,753的(2,1,8)卷积码对硬判决的性能进行分析,并依据维特比译码的原理以及卷积码的特性,对卷积码编码和维特比译码过程在加性高斯白噪声(AWGN)信道下进行仿真,并且根据仿真结果对维特比译码(硬判决)的结果进行分析。
由于卷积码的生成可以看做一个马尔科夫过程,因此,不同状态间的转移概率对描述这个过程有极关键的作用。
本文则基于MATLAB对不同状态间的转移概率进行求解,从而更准确地分析维特比译码的性能。
卷积码的Viterbi译码设计设计

摘要在数字通信系统中,通常采用差错控制编码来提高系统的可靠性。
自P.Elias 首次提出卷积码编码以来,这一编码技术至今仍显示出强大的生命力。
目前,卷积码已广泛应用在无线通信标准中,如GSM,CDMA2000和IS-95等无线通信标准中。
针对N-CDMA数据传输过程中的误码问题,本文论述了旨在提高数据传输质量的维特比译码器的设计。
虽然Viterbi译码复杂度较大,实现较为困难,但效率高,速度快。
因此本文着重分析和讨论了1/2速率的(2,1,9)卷积码编码和其Viterbi译码算法。
深入研究卷积码编码原理和Viterbi算法原理后,提出了(2,1,9)卷积码编码以及Viterbi算法的初始化、加—比—选和回溯设计方案,运用查表的方法,避免了大量繁琐计算,使得译码简洁迅速,译码器的实时性能良好。
并充分利用TMS320C54X系列DSP芯片,用汇编语言完成了(2,1,9)卷积码编码和Viterbi 译码的程序。
关键词:差错控制编码、卷积码、Viterbi译码、TMS320C54X、DSPAbstractIn digital communication systems, error control coding is usually used to improve system reliability. Since P.Elias put forward the convolutional coding the first time, the coding is still showing strong vitality.,has become widely used in satellite communications, wireless communications and many other communication systemsas a kind of channel coding method. such as GSM, CDMA2000 and has been a wireless communication standards of IS-95.In view of the error problem in the process of N-CDMA data transmission, this paper discusses the aims to improve the quality of data transmission of victor design than the decoder.Although Viterbi decoding complexity is bigger, more difficult to achieve, but high efficiency and fast speed. So this article emphatically analyzed and discussed the 1/2 rate (2,1,9) convolution code coding and its Viterbi decoding algorithm. In-depth study on principle of convolution code coding and Viterbi algorithm, proposed the convolution code coding and Viterbi algorithm (2,1,9) initialization, add - than - choose and back design, using look-up table method, to avoid a large amount of tedious calculation, the decoding and quick, good real-time performance of the decoder. Make full use of the series of TMS320C54X DSP chip, using assembly language to complete the(2,1,9)convolution code coding and Viterbi decoding process.Keywords: error control coding, convolutional code, Viterbi decoding, TMS320C54X目录摘要 (1)Abstract (2)目录 (3)1.绪论 (1)1.1 移动通信及N-CDMA背景 (1)1.2 数字通信概述 (1)1.3 卷积编码与译码的发展 (3)1.4 主要研究工作 (3)2.DSP与CCS简介 (5)2.1 DSP概述 (5)2.1.1 DSP的主要特点 (5)2.1.2 CSSU单元概述 (7)2.2 CCS概述 (8)2.3 本章小结 (8)3.卷积码的理论基础 (9)3.1 卷积码的概述 (9)3.1.1 卷积码基本原理 (9)3.1.2 卷积码的纠错能力 (9)3.1.3 卷积码的表示方法 (10)3.2 Viterbi译码的概述 (11)3.3 本章小结 (14)4.卷积编码的实现 (15)4.1 (2,1,9)卷积码编码 (15)4.1.1 (2,1,9)卷积码编码设计方案 (15)4.1.2 (2,1,9)卷积码编码流程图 (16)4.1.3 (2,1,9)卷积编码程序实现 (16)4.1.4 (2,1,9)的程序仿真 (17)4.2 (2,1,9)卷积码状态转换表 (17)4.2.1 (2,1,9)卷积码状态转换表的设计算法 (18)4.2.2 (2,1,9)卷积码状态转换表的流程图 (18)4.2.3 (2,1,9)卷积码状态表 (18)4.2.4 (2,1,9)卷积码状态表的蝶形结构 (21)4.3 本章小结 (22)5. Viterbi译码的实现 (23)5.1 Viterbi译码基础 (23)5.2 Viterbi译码算法 (23)5.3 变量定义情况 (25)5.4 初始化 (26)5.4.1 初始化流程图 (27)5.4.2 初始化程序仿真 (27)5.5 加-比-选 (28)5.5.1加-比-选流程图 (29)5.5.2加-比-选程序仿真 (30)5.6 回溯 (31)5.6.1 回溯流程图 (32)5.6.2 回溯仿真图 (33)5.7 Viterbi纠错测试 (34)5.8 本章小结 (34)总结 (36)致谢 ............................................................................ 错误!未定义书签。
维特比译码介绍

维特比提出了一种算法:译码器不是在篱笆图上一次就计算和比
较 2Lk 条路径,而是接收一段,就计算、比较一段,从而在每个状 态时,选择进入该状态的最可能的分支。
维特比译码的基本思想:将接收序列 R 与篱笆图上的路径逐分
支地比较,比较的长度一般取 (5~6)mn,然后留下与 R 距离最小的 路径,称为幸存路径,而去掉其余可能的路径,并将这些幸存路径 逐分支地延长并存储起来。
接收序列 R=[10,00,01,00,00,00,00,…]
2015/4/23
杭州电子科技大学通信学院
刘超
16
维特比译码的基本原理
1
S0
1 1
S1
3 2
S2
S3
2
R= 10
00
(2,1,2)码栅格图第二步
2015/4/23
杭州电子科技大学通信学院
刘超
17
维特比译码的基本原理
从第二个时刻起:第二个接收码组 R2=01 进入译码器,从
(2,1,2)码状态转移图(开放型)
编码器状态转移图
2015/4/23
杭州电子科技大学通信学院
刘超
7
卷积码的状态转移图与栅格描述
卷积码的栅格图(篱笆图)
状态图不能反映出状态转移与时间的关系 栅格图/篱笆图:将开放型的状态转移图按时间顺序 级联形成一个栅格图。 编码路径:状态序列σ在栅格图中形成的一条有向路 径。 当有向路径始于全“0”状态S0,又终于S0时,表明此 时编码器又回到全“0”状态,
S2
S2
S3
R= 10
S3
00
01
00
R= 10
00
01
维特比译码详解

维特比译码(Viterbi decoding)是一种用于纠正或还原由信道引起的错误的算法,广泛应用于数字通信、无线通信和数字广播等领域。
该算法基于动态规划的原理,常用于解决卷积编码的译码问题。
以下是维特比译码的详细步骤:
1. **初始化:** 对于每个可能的状态,初始化路径度量(metric)为一个大的值,初始状态路径度量为零。
路径度量表示从初始状态到当前状态的路径上的权重。
2. **逐步前向计算:** 从输入序列的第一个符号开始,对于每个时刻和每个状态,计算经过该状态的路径度量。
这是通过考虑前一个时刻的所有状态,并选择路径度量最小的路径来完成的。
路径度量的更新是通过将前一个时刻的路径度量与相应的转移度量和观测度量相加而完成的。
3. **路径存储:** 对于每个状态,在每个时刻保留路径度量最小的路径。
这些路径构成一个以时间为轴的路径树。
4. **回溯:** 在到达输入序列的末尾后,通过回溯路径树,选择路径度量最小的路径。
这条路径即为最有可能的解码路径。
5. **输出:** 从回溯的路径中提取最终的解码结果。
维特比译码的关键点是在整个过程中维护状态度量,选择具有最小度量的路径。
这种选择基于动态规划的原理,通过逐步计算局部最优解来找到全局最优解。
维特比译码特别适用于卷积编码,其中编码器的状态对应于过去的输入符号。
这种算法在无线通信、数字广播和其他数字通信系统中得到广泛应用,以提高通信系统的可靠性。
动态规划:卷积码Viterbi译码算法

动态规划:卷积码的Viterbi译码算法学院:网研院姓名:xxx 学号:xxx 一、动态规划原理动态规划(dynamic programming)是运筹学的一个分支,是求解决策过程(decision process)最优化的数学方法。
动态规划算法通常用于求解具有某种最优性质的问题。
在这类问题中,可能会有许多可行解,每一个解都对应于一个值,我们希望找到具有最优值的解。
动态规划算法与分治法类似,其基本思想也是将待求解问题分解成若干个子问题,先求解子问题,然后从这些子问题的解得到原问题的解。
与分治法不同的是,适合于用动态规划求解的问题,经分解得到子问题往往不是互相独立的。
若用分治法来解这类问题,则分解得到的子问题数目太多,有些子问题被重复计算了很多次。
如果我们能够保存已解决的子问题的答案,而在需要时再找出已求得的答案,这样就可以避免大量的重复计算,节省时间。
动态规划程序设计是对解最优化问题的一种途径、一种方法,而不是一种特殊算法。
不象搜索或数值计算那样,具有一个标准的数学表达式和明确清晰的解题方法。
动态规划程序设计往往是针对一种最优化问题,由于各种问题的性质不同,确定最优解的条件也互不相同,因而动态规划的设计方法对不同的问题,有各具特色的解题方法,而不存在一种万能的动态规划算法,可以解决各类最优化问题。
二、卷积码的Viterbi译码算法简介在介绍维特比译码算法之前,首先了解一下卷积码编码,它常常与维特比译码结合使用。
(2,1,3)卷积码编码器是最常见的卷积码编码器,在本次实验中也使用了(2,1,3)卷积码编码器,下面介绍它的原理。
(2,1,3)卷积码是把信源输出的信息序列,以1个码元为一段,通过编码器输出长为2的一段码段。
该码段的值不仅与当前输入码元有关,而且也与其之前的2个输入码元有关。
如下图所示,输出out1是输入、第一个编码器存储的值和第二个编码器存储的值逻辑加操作的结果,输出out2是输入和第二个编码器存储的值逻辑加操作的结果。
实验五 维特比译码

实验五维特比译码一、实验题目写一个维特比译码器软件,它接受下列输入:1、以八进制形式给出的码的参数,以及2、接收到的比特流。
二、实验目的1、理解和掌握卷积码的概念;2、掌握维特比译码的方法;三、算法设计四、程序分析min_dist(a,b)函数计算两个码字的汉明重量;num_jinzhi(num,jinzhi,wei)函数将十进制的num转换为进制为jinzhi的wei位数;init_state()函数是对state[ ]矩阵进行初始化操作;G矩阵存储码的参数的二进制形式;xinxi[ ]矩阵存储输入比特流;state[ ]矩阵存储如下表的状态;state 1 2 3 4 5 6 7 8 9 10 11 12 13状态点1 当前寄存器的状态输入为输入为时输出编码值寄存器下一状态输入为1输入为1时输出编码值寄存器下一状态输入为时的汉明距离输入为1时的汉明距离四条路径的汉明距离临时存储解码值当前解码值四条路径的汉明距离状态点2状态点3状态点4五、程序代码主函数:display('编码序列:');xinxi=[1 0 1 0 0 1 1 0 1]% in=0;input_g= '75';str_length=length(input_g);%-----------将输入的char型数字转换成二进制数------------------------% for i=1:str_lengthg_dec=base2dec(input_g,8);%将'75'这个8进制数转换成10进制g=num_jinzhi(g_dec,2,3*str_length);%将10进制数转换成2进制endg; %测试gglobal G;for i=1:str_lengthG_yuanshi(i,1:3)=g(3*i-2:3*i);%将得到的二进制数每三个分成一行endG=G_yuanshi';% ------------------------生成查询表格-----------------------------% state=init_state;% ---------------------以下为编码算法------------------------------ % xinxi_bu0=[xinxi 0 0];xinxi_length=length(xinxi_bu0); %这里的长度实际为补0后的长度state_temp=[0 0]; %初始的状态寄存器里面为00for i=1:xinxi_lengthfor j=1:4 %对应四种状态if isequal(state_temp,state{j,1})if xinxi_bu0(i)==0 %若输入为0code(2*i-1:2*i)=state{j,3};%输出码字state_temp=state{j,4}; %下一状态else if xinxi_bu0(i)==1 %若输入为1code(2*i-1:2*i)=state{j,6};%输出码字state_temp=state{j,7}; %下一状态endendbreak;endendenddisplay('信息编码如下:');code%---------------加入错误编码 (这里仅将第三位出错)---------------------- % code(3)=~code(3);display('出错后的编码:');code%---------------------以下为解码算法--------------------------------- % code_length=length(code); %这里的长度实际为补0后的长度state_temp=[0 0]; %初始的状态寄存器里面为00%计算最初始两个码字四条路径的汉明距离state{1,10}=min_dist(state{1,3},[code(1)code(2)])+min_dist(state{1,3},[code(3) code(4)]);%第一条路径的汉明距离state{2,10}=min_dist(state{1,3},[code(1)code(2)])+min_dist(state{1,6},[code(3) code(4)]);%第二条路径的汉明距离state{3,10}=min_dist(state{1,6},[code(1)code(2)])+min_dist(state{2,3},[code(3) code(4)]);%第三条路径的汉明距离state{4,10}=min_dist(state{1,6},[code(1)code(2)])+min_dist(state{2,6},[code(3) code(4)]);%第四条路径的汉明距离state{1,11}=[0 0];%存放第一条路径的前两个码字state{2,11}=[0 1];%存放第二条路径的前两个码字state{3,11}=[1 0];%存放第三条路径的前两个码字state{4,11}=[1 1];%存放第四条路径的前两个码字for i=1:4state{i,12}=state{i,11};end% for i=3:code_length/2;i=3;while i<=code_length/2temp=[code(2*i-1) code(2*i)]; %下一个码字(2位)%------------四种状态分别输入0/1后得到八种状态,每种可能的距离-----------% for j=1:4state{j,8}=min_dist(temp,state{j,3});%输入0的可能最小距离state{j,9}=min_dist(temp,state{j,6});%输入1的可能最小距离end%--------------------------每种状态所对应的下一编码---------------------% if(state{1,8}+state{1,10})<(state{3,8}+state{3,10}) %第一个状态点的路径选取state{1,12}=[state{1,11} 0];%获得下一个解码else state{1,12}=[state{3,11} 0];endif (state{1,9}+state{1,10})<(state{3,9}+state{3,10})%第二个状态点的路径选取state{2,12}=[state{1,11} 1];else state{2,12}=[state{3,11} 1];endif (state{2,8}+state{2,10})<(state{4,8}+state{4,10})%第三个状态点的路径选取state{3,12}=[state{2,11} 0];else state{3,12}=[state{4,11} 0];endif (state{2,9}+state{2,10})<(state{4,9}+state{4,10})%第四个状态点的路径选取state{4,12}=[state{2,11} 1];else state{4,12}=[state{4,11} 1];end%-------------state{:,13}用来临时存放每条路径的汉明重---------------%state{1,13}=min((state{1,8}+state{1,10}),(state{3,8}+state{3,10}));%第一个状态点在取汉明重量较小的那条路径state{2,13}=min((state{1,9}+state{1,10}),(state{3,9}+state{3,10}));%第二个状态点在取汉明重量较小的那条路径state{3,13}=min((state{2,8}+state{2,10}),(state{4,8}+state{4,10}));%第三个状态点在取汉明重量较小的那条路径state{4,13}=min((state{2,9}+state{2,10}),(state{4,9}+state{4,10}));%第四个状态点在取汉明重量较小的那条路径i=i+1;for j=1:4state{j,10}=state{j,13};%更新state{:,10}state{j,11}=state{j,12};%更新state{:,11}endend%-----------------------判断四组码中的最小距---------------------------% dis_temp=[state{1,10} state{2,10} state{3,10} state{4,10}];index=find(min(dis_temp) == dis_temp);if length(index)>1 %有多条最小路径时的处理方式index=index(1);enddecode_length=length(state{index,12});display('解码如下:')decode=state{index,12}(1:decode_length-2) %%去掉最后面的两个0%-------------------测试解码和原码是否完全相同------------------------% for i=1:decode_length-2test(i)=decode(i) - xinxi(i);enddisplay('检测解码是否正确码字如下'); test子函数:%----------------将十进制的 num转换为进制为jinzhi的wei位数--------------%function out=num_jinzhi(num,jinzhi,wei)% yushu=zeros(1,wei);%为了提高计算速度,提前申请输出数据的内存i=1;shang_pre=num;shang_back=num;while shang_back>=jinzhiyushu(i)=mod(shang_pre,jinzhi);%将10进制数变成二进制数i=i+1;shang_back=fix(shang_pre/jinzhi);shang_pre=shang_back;endyushu(i)=shang_back;for i=1:weiout_yushu(i)=yushu(wei-i+1);%将转换后的结果调整高位在前,低位在后endout=out_yushu;function out=init_state()global G;state=cell(4,7); %创建4*7的数组可以存储不同类型的数据state(:)={[0]};state{1,1}=[0 0];%见教材P164 生成初始状态state{2,1}=[1 0];state{3,1}=[0 1];state{4,1}=[1 1];for i=1:4state{i,2}=0;in=0;% % % 输入0temp=[in state{i,1}];state{i,3}=mod(temp*G,2); %输出值state{i,4}=[in state{i,1}(1)];%下一状态% % % 输入1in=1;state{i,5}=1;temp=[in state{i,1}];state{i,6}=mod(temp*G,2); %输出值state{i,7}=[in state{i,1}(1)];%下一状态endout=state;%--------------------------求两个码字的汉明重量------------------------% function out=min_dist(a,b)min_length=length(a);cnt=0;for i=1:min_lengthif a(i)~=b(i);cnt=cnt+1;endendout=cnt;六、程序运行结果。
matlab维特比译码

维特比(Viterbi)译码是一种用于解码卷积码的算法,常用于通信和数据存储系统。
在MATLAB中实现维特比译码主要涉及以下步骤:定义模型参数:首先,你需要定义卷积码的生成矩阵和转移概率。
初始化路径:为每个可能的起始状态初始化一个路径。
递归计算:对于每个时间步,根据转移概率和接收信号,递归地计算每条路径的概率。
选择最佳路径:在每个时间步,选择具有最大概率的路径作为当前状态。
生成输出:根据最佳路径,生成输出序列。
终止条件:当达到终止状态或达到最大迭代次数时,停止计算。
下面是一个简单的MATLAB代码示例,演示了如何实现维特比译码:matlabfunction [decoded, decoded_path] = viterbi_decoder(received, G, num_states, init_state_prob) % received: 接收信号% G: 生成矩阵% num_states: 状态数% init_state_prob: 初始状态概率num_time_steps = length(received);transition_prob = zeros(num_states, num_states); % 转移概率矩阵% 初始化路径和概率矩阵path = zeros(num_time_steps, num_states);path(:, 1) = init_state_prob;path(:, 1) = path(:, 1) .* ones(size(path(:, 1))); % 设置初始路径prob = zeros(num_time_steps, 1); % 概率矩阵prob(1) = path(1,:) .* log2(init_state_prob); % 初始化概率矩阵% 递归计算for t = 2:num_time_stepsfor i = 1:num_statesfor j = 1:num_statestransition_prob(i,j) = G(:,j) * received(t) .* path(t-1,i); % 计算转移概率endend[~, max_state] = max(prob(t-1) + log2(transition_prob)); % 选择最佳状态path(t,:) = zeros(1, num_states); % 重置路径矩阵path(t, max_state) = 1; % 设置当前路径为最佳状态prob(t) = max_state + log2(prob(t-1) + log2(transition_prob)); % 更新概率矩阵end% 选择最佳路径和生成输出[~, max_time] = max(prob); % 选择具有最大概率的时间步作为终止状态decoded = path(:, max_time); % 生成输出序列end请注意,这只是一个基本的示例,可能需要根据您的具体应用和需求进行调整。
维特比译码的仿真与实现

卷积码的码率越高 ,约束长度越大 ,所需维特比 译码的回溯长度也越长 。我们仍然就上面提出的那 个系统进行 Matlab 仿真 ,在回溯深度为 24 ,48 ,96 时分别观察其误码率曲线 (如图 2) 。可以看出回溯 深度对系统误码率的影响没有判决方式那么严重 ,但 是在误码率为 10 - 3时回溯深度为 24 的情况下所需信 噪比比 48 的情况下大约013 dB左右 ,这也是不可忽 略的 。但是回溯深度为 96 或者更长时相对于回溯深
了广泛地应用 。 本文首先使用 Matlab 分析了在无线高斯信道
中 ,对于维特比译码采用硬判决 、2 比特 、3 比特 、4 比特及 5 比特时的系统性能进行分析比较 ,同时也 分析了在回溯深度分别为 24 、48 和 96 时的系统性 能 ,得出结论 :在 3 比特软判决及回溯深度为 48 时 , 系统的性能达到最佳 。基于这些结论 ,用 Q1900 芯 片来实现卷积编码和维特比译码 ,其性能与仿真结 论一致 。
1 引 言
在无线通信系统中 ,为克服数据传输错误 ,需要 进行差错控制编码 。卷积编码是一种很好的纠错编 码方法 。它充分利用了各组之间的相关性 ,增加的 监督元不仅与本组的信息元有关 ,而且与前面若干 组的信息数字发生关系 ,这就是卷积码的基本想法 。 由于每个校验数字与更多的信息数字有关 ,无论从 理论上还是实际上均已证明其性能优于分组码 。与 卷积码相应的维特比译码算法是加性高斯白噪声 (additive white gaussian noise ,AW GN) 信道下卷积 码的最优译码算法 ,在数据通信和卫星通信中得到
符号软判决维特比译码

符号软判决维特比译码中国科技论文在线////0>.符号软判决维特比译码**郭桂竹, 洪小斌(信息光子学与光通信国家重点实验室 ,北京邮电大学,北京,100876)5 摘要: 介绍符号软判决维特比译码原理 , 分析其性能 , 将其与传统软判决维特比译码对比并进行了仿真 , 符号软判决维特比译码误码率稍高于传统软判决维特比译码 , 但由于其成本低 ,仍有很好的可行性。
关键词:软判决维特比译码;符号软判决维特比译码 ;硬判决维特比译码 ;QPSK中图分类号:G30510soft decision Viterbi decoding based on scalar signalGuo Guizhu, Hong XiaobinState Key Library of Information Photonics and Optical communications,Beijing Unversity ofPosts and Telecommunications, Beijing, 10087615 Abstract: Introduce the principle of symbol soft decision Viterbidecoding algorithm, analyze itsperformance compared with the traditional soft decision Viterbi decoding algorithm. From the result ofsimulation ,we can see that the former has a very little disadvantage than the latter. While the formercan reduce the cost and boost efficiency, leading to a high performance/price ratioKey words: Hard Decision Viterbi Decoding Algorithm; Soft Decision Viterbi Decoding Algorithm;20 QPSK; Symbol Soft Decision Viterbi DecodingAlgorithm ;Quantization0 引言[1]维特比译码算法由维特比 1964 年提出算法实质是最大似然译码, 但它利用了编码[2]网格图的特殊结构, 从而大大降低了计算的复杂性。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
在上例中卷积码的约束长度为N = 3,需要 存储和计算8条路径的参量。由此可见,维 特比算法的复杂度随约束长度N按指数形式 2N增长。故维特比算法适合约束长度较小 (N 10)的编码。
所以,维特比译码的过程可以简单的理解 为:接收端使用相同的网格图,从同一状 态开始猜测发送端可能的编码序列,然后 与接收到的码组比较,其中与接收到的码 组最近的猜测序列即使为译码序列,也就 是码距最小的序列。
设卷积码为(n, k, m) = (3,沿路径每一级有4种状态a, b, c和d。每种状态只有两条路径可以到达。故 4种状态共有8条到达路径。 比较网格图中的这8条路径和接收序列之间 的汉明距离。 比较到达每个状态的两条路径的汉明距离, 将距离小的一条路径保留,也就是幸存路径。 这样,就剩下4条路径了。 继续考察接收序列中的后继的比特,最后得 出总的汉明距离最小的路径,也就是发送序 列。
维特比算法简介
维特比译码是将接收到的序列和所有可能 的发送序列作比较,选择其中汉明距离最 小的序列当作是现在的发送序列的一种算 法。译码器从某个状态出发,每次向右延伸 一个分支,并与接收数字相应分支进行比较, 计算它们之间的距离,然后将计算所得距 离加到被延伸路径的累积距离值中。
对到达每个状态的各条路径的距离累积值 进行比较,保留距离值最小的一条路径, 称为幸存路径,当有两条以上取最小值时, 可任取其中之一。这种算法所保留的路径 与接收序列之间的似然概率为最大,所以 又称为最大似然译码。
假设现在的发送信息位为1101 编码后的发送序列:111 110 010 100 001 011 000 接收序列:111 010 010 110 001 011 000 (红色为 错码) 发送序列的约束长度为N = m + 1 = 3 最后的幸存路径画出的网格图示于下图中,图中粗 线路径是距汉明离最小(等于2)的路径。