医学统计学第二版高等教育出版社课后习题答案
医学统计学选择(全部答案-仅供参考)分析

习题《医学统计学》第二版(七年制临床医学用)(一)最佳选择题1。
描述一组偏态分布资料的变异度,以( )指标较好。
A。
全距 B。
标准差C。
变异系数 D. 四分位数间距E.方差2.用均数和标准差可以全面描述( )资料的特征.A。
正偏态分布 B. 负偏态分布C. 正态分布 D。
对称分布E.对数正态分布3。
各观察值均加(或减)同一数后()。
A. 均数不变,标准差改变B. 均数改变,标准差不变C。
两者均不变 D。
两者均改变E.以上都不对4.比较身高和体重两组数据变异度大小宜采用().A. 变异系数B. 方差C. 极差D. 标准差E.四分位数间距5.偏态分布宜用( )描述其分布的集中趋势。
A。
算术均数 B。
标准差C. 中位数D. 四分位数间距E.方差6。
各观察值同乘以一个不等于0的常数后,( )不变.A.算术均数 B. 标准差C。
几何均数 D. 中位数E.变异系数7。
()分布的资料,均数等于中位数.A. 对数正态 B。
正偏态C. 负偏态 D。
偏态E.正态8。
对数正态分布是一种( )分布.(说明:设X变量经Y=lg X变换后服从正态分布,问X变量属何种分布?)A. 正态B. 近似正态C. 左偏态D. 右偏态E.对称9。
最小组段无下限或最大组段无上限的频数分布资料,可用( )描述其集中趋势。
A. 均数 B。
标准差C。
中位数 D. 四分位数间距E.几何均数10。
血清学滴度资料最常用来表示其平均水平的指标是()。
A。
算术平均数 B。
中位数C。
几何均数 D.变异系数E.标准差11.( )小,表示用该样本均数估计总体均数的可靠性大。
A. CVB. S R E 。
四分位数间距12.两样本均数比较的t 检验,差别有统计学意义时,P 越小,说明( )。
A.两样本均数差别越大B.两总体均数差别越大C.越有理由认为两总体均数不同D.越有理由认为两样本均数不同E 。
越有理由认为两总体均数相同13. 甲乙两人分别从同一随机数字表抽得30个(各取两位数字)随机数字作为两个样本,求得1X 和21S ;2X 和22S ,则理论上( )。
医学统计学(李晓松主编 第2版 高等教育出版社)附录 第3章思考与练习答案

第三章实验研究设计【思考与练习】一、思考题1. 实验设计根据对象的不同可分为哪几类?2. 实验研究中,随机化的目的是什么?3. 什么是配对设计?它有何优缺点?4. 什么是交叉设计?它有何优缺点?5. 临床试验中使用安慰剂的目的是什么?二、案例辨析题“三联药物治疗士兵消化性溃疡”一文中,对2000~2006年在某卫生所采用三联药物治疗的38例消化性溃疡患者进行分析。
内镜检测结果显示,痊愈13人,显效14人,进步7人,无效4人,有效率达89.5%。
据此认为该三联疗法的疗效较好,且由于其价格适中,可在部队卫生所中推广。
该结论是否正确?如果不正确,请说明理由。
三、最佳选择题1. 实验设计的三个基本要素是A. 处理因素、实验效应、实验场所B. 处理因素、实验效应、受试对象C. 受试对象、研究人员、处理因素D. 受试对象、干扰因素、处理因素E. 处理因素、实验效应、研究人员2. 实验设计的三个基本原则是A. 随机化、对照、重复B. 随机化、对照、盲法C. 随机化、重复、盲法D. 均衡、对照、重复E. 盲法、对照、重复3. 实验组与对照组主要不同之处在于A. 处理因素B. 观察指标C. 抽样误差D. 观察时间E. 纳入、排除受试对象的标准4. 为了解某疗法对急性肝功能衰竭的疗效,用12头健康雌性良种幼猪建立急性肝功能衰竭模型,再将其随机分为两组,仅实验组给予该疗法治疗,对照组不给予任何治疗。
7天后观察两组幼猪的存活情况。
该研究采用的是A. 空白对照B. 安慰剂对照C. 实验对照D. 标准对照E. 自身对照5. 观察指标应具有A. 灵敏性、特异性、准确度、精密度、客观性B. 灵敏性、变异性、准确度、精密度、客观性C. 灵敏性、特异性、变异性、均衡性、稳定性D. 特异性、准确度、稳定性、均衡性、客观性E. 灵敏性、变异性、准确度、精密度、均衡性6. 比较两种疗法对乳腺癌的疗效,若两组患者的乳腺癌分期构成不同可造成A. 选择性偏倚B. 测量性偏倚C. 混杂性偏倚D. 信息偏倚E. 失访性偏倚7. 将两个或多个处理因素的各水平进行组合,对各种可能的组合都进行实验,该实验设计方案是A. 随机区组设计B. 完全随机设计C. 析因设计D. 配对设计E. 交叉设计8. 在某临床试验中,将180例患者随机分为两组,实验组给予试验药+对照药的模拟剂,对照给予对照药+试验药的模拟剂,整个过程中受试对象和研究者均不知道受试对象的分组。
医学统计学李晓松主编第2版高等教育出版社附录第3章思考与练习答案.doc

第三章实验研究设计【思考与练习】一、思考题1. 实验设计根据对象的不同可分为哪几类?2. 实验研究中,随机化的目的是什么?3. 什么是配对设计?它有何优缺点?4. 什么是交叉设计?它有何优缺点?5. 临床试验中使用安慰剂的目的是什么?二、案例辨析题“三联药物治疗士兵消化性溃疡”一文中,对2000~2006年在某卫生所采用三联药物治疗的38例消化性溃疡患者进行分析。
内镜检测结果显示,痊愈13人,显效14人,进步7人,无效4人,有效率达89.5%。
据此认为该三联疗法的疗效较好,且由于其价格适中,可在部队卫生所中推广。
该结论是否正确?如果不正确,请说明理由。
三、最佳选择题1. 实验设计的三个基本要素是A. 处理因素、实验效应、实验场所B. 处理因素、实验效应、受试对象C. 受试对象、研究人员、处理因素D. 受试对象、干扰因素、处理因素E. 处理因素、实验效应、研究人员2. 实验设计的三个基本原则是A. 随机化、对照、重复B. 随机化、对照、盲法C. 随机化、重复、盲法D. 均衡、对照、重复E. 盲法、对照、重复3. 实验组与对照组主要不同之处在于A. 处理因素B. 观察指标C. 抽样误差D. 观察时间E. 纳入、排除受试对象的标准4. 为了解某疗法对急性肝功能衰竭的疗效,用12头健康雌性良种幼猪建立急性肝功能衰竭模型,再将其随机分为两组,仅实验组给予该疗法治疗,对照组不给予任何治疗。
7天后观察两组幼猪的存活情况。
该研究采用的是A. 空白对照B. 安慰剂对照C. 实验对照D. 标准对照E. 自身对照5. 观察指标应具有A. 灵敏性、特异性、准确度、精密度、客观性B. 灵敏性、变异性、准确度、精密度、客观性C. 灵敏性、特异性、变异性、均衡性、稳定性D. 特异性、准确度、稳定性、均衡性、客观性E. 灵敏性、变异性、准确度、精密度、均衡性6. 比较两种疗法对乳腺癌的疗效,若两组患者的乳腺癌分期构成不同可造成A. 选择性偏倚B. 测量性偏倚C. 混杂性偏倚D. 信息偏倚E. 失访性偏倚7. 将两个或多个处理因素的各水平进行组合,对各种可能的组合都进行实验,该实验设计方案是A. 随机区组设计B. 完全随机设计C. 析因设计D. 配对设计E. 交叉设计8. 在某临床试验中,将180例患者随机分为两组,实验组给予试验药+对照药的模拟剂,对照给予对照药+试验药的模拟剂,整个过程中受试对象和研究者均不知道受试对象的分组。
医学统计学(高等教育出版社第二版)思考与练习答案

第四章 定量资料的统计描述【习题解析】一、思考题1. 均数、中位数、几何均数三者的相同点是都用于描述定量资料的集中趋势,不同点:①均数用于单峰对称分布,特别是正态分布或近似正态分布的资料;②几何均数用于变量值间呈倍数关系的偏态分布资料,特别是变量经过对数变换后呈正态分布或近似正态分布的资料;③中位数用于不对称分布资料、两端无确切值的资料、分布不明确的资料。
2. 同一资料的标准差不一定小于均数。
均数描述的是一组同质定量变量的平均水平,而标准差是描述单峰对称分布资料离散程度最常用的指标。
标准差大,表示观察值之间变异大,即一组观察值的分布较分散;标准差小,表示观察值之间变异小,即一组观察值的分布较集中。
若标准差远大于均数表明数据离散程度较大,可能为偏态分布,此时应考虑改用其他指标来描述资料的集中趋势。
3. 极差、四分位数间距、标准差、变异系数四者的相同点是都用于描述资料的离散程度。
不同点:①极差可用于描述单峰对称分布小样本资料的离散程度,或用于初步了解资料的变异程度;②四分位数间距可用于描述偏态分布资料、两端无确切值或分布不明确资料的离散程度;③标准差用于描述正态分布或近似正态分布资料的离散程度;④变异系数用于比较几组计量单位不同或均数相差悬殊的正态分布资料的离散程度。
4. 正态分布的特征:①正态曲线在横轴上方均数处最高;②正态分布以均数为中心,左右对称;③正态分布有两个参数,即位置参数μ和形态参数σ;④正态曲线下的面积分布有一定的规律,正态曲线与横轴间的面积恒等于1。
曲线下区间( 2.58, 2.58)μσμσ-+内的面积为95.00%;区间( 2.58, 2.58)μσμσ-+内的面积为99.00%。
5.①通过大量调查证实符合正态分布的变量或近似正态分布的变量,可按正态分布曲线下面积分布的规律制定医学参考值范围;服从对数正态分布的变量,可对观察值取对数后按正态分布法算出医学参考值范围的对数值,然后求其反对数即可;②对于经正态性检验不服从正态分布的变量,应采用百分位数法制定医学参考值范围。
医学统计学课后习题答案(第2版高等教育出版社)

医学统计学课后习题答案(第2版高等教育出版社)第一章绪论1.举例说明总体和样本的概念。
研究人员通常需要了解和研究某一类个体,这个类就是总体。
总体是根据研究目的所确定的所有同质观察单位某种观察值(即变量值)的集合,通常有无限总体和有限总体之分,前者指总体中的个体是无限的,如研究药物疗效,某病患者就是无限总体,后者指总体中的个体是有限的,它是指特定时间、空间中有限个研究个体。
但是,研究整个总体一般并不实际,通常能研究的只是它的一部分,这个部分就是样本。
例如在一项关于2007年西藏自治区正常成年男子的红细胞平均水平的调查研究中,该地2007年全部正常成年男子的红细胞数就构成一个总体,从此总体中随即抽取2000人,分别测的其红细胞数,组成样本,其样本含量为2000人。
2.简述误差的概念。
误差泛指实测值与真实值之差,一般分为随机误差和非随机误差。
随机误差是使重复观测获得的实际观测值往往无方向性地围绕着某一个数值左右波动的误差;非随机误差中最常见的为系统误差,系统误差也叫偏倚,是使实际观测值系统的偏离真实值的误差。
3.举例说明参数和统计量的概念。
某项研究通常想知道关于总体的某些数值特征,这些数值特征称为参数,如整个城市的高血压患病率。
根据样本算得的某些数值特征称为统计量,如根据几百人的抽样调查数据所算得的样本人群高血压患病。
统计量是研究人员能够知道的,而参数是他们想知道的。
一般情况下,这些参数是难以测定的,仅能够根据样本估计。
显然,只有当样本代表了总体时,根据样本统计量估计的总体参数才是合理的。
4.简述小概率事件原理。
当某事件发生的概率小于或等于0.05时,统计学上习惯称该事件为小概率事件,其含义是该事件发生的可能性很小,进而认为它在一次抽样中不可能发生,这就是所谓的小概率事件原理,它是进行统计推断的重要基础。
第二章调查研究设计1.调查研究主要特点是什么?调查研究的主要特点是:①研究的对象及其相关因素(包括研究因素和非研究因素)是客观存在的,不能人为给予干预措施②不能用随机化分组来平衡混杂因素对调查结果的影响。
《医学统计学》第二版习题(五年制临床医学等本科生用)

《医学统计学》第二版习题(五年制临床医学等本科生用)习题(一)单项选择题绪论部分1.观察单位为研究中的()。
A.样本B.全部对象C.影响因素D.个体2.总体是由()。
A.个体组成B.研究对象组成C.同质个体组成D.研究指标组成3.抽样的目的是()。
A.研究样本统计量B.由样本统计量推断总体参数C.研究典型案例研究误差D.研究总体统计量4.参数是指()。
A.参与个体数B.总体的统计指标C.样本的统计指标D.样本的总和5.关于随机抽样,下列那一项说法是正确的()。
A.抽样时应使得总体中的每一个个体都有同等的机会被抽取B.研究者在抽样时应精心挑选个体,以使样本更能代表总体C.随机抽样即随意抽取个体D.为确保样本具有更好的代表性,样本量应越大越好第二章6.各观察值均加(或减)同一数后()。
A.均数不变,标准差改变B.均数改变,标准差不变C.两者均不变D.两者均改变7.比较身高和体重两组数据变异度大小宜采用()。
A.变异系数B.差C.极差D.标准差9.偏态分布宜用()描述其分布的集中趋势。
A.算术均数B.标准差C.中位数D.四分位数间距C.右偏态D.偏态12.对数正态分布是一种()分布。
A.正态B.近似正态C.左偏态D.右偏态14.()小,表示用该样本均数估计总体均数的可靠性大。
A.变异系数B.标准差C.标准误D.极差A.算术平均数B.中位数C.几何均数D.平均数16.变异系数CV的数值()。
A.一定大于1B.一定小于1C.可大于1,也可小于1D.一定比标准差小17.数列8、-3、5、0、1、4、-1的中位数是()。
A.2B.1C.2.5D.0.519.关于标准差,那项是错误的()。
A.反映全部观察值的离散程度B.度量了一组数据偏离平均数的大小C.反映了均数代表性的好坏D.不会小于算术均数20.中位数描述集中位置时,下面那项是错误的()。
的平均水平,用那种指标较好()。
A.平均数B.几何均数C.算术均数D.中位数22.一组变量的标准差将()。
医学统计学参考答案 颜虹第二版

《医学统计学》部分习题参考答案颜虹主编第二版第三章统计描述一、最佳选择题1.C2.A3.D4.B5.E6.E7.C8.D9.C10.C11.A12.D三、计算分析题P53-1素食前X1素食后X2X1-X2平均187.75平均168.25平均19.5中位数179中位数165中位数19标准差33.18885标准差26.79593标准差16.80838方差1101.5方差718.0217方差282.5217 4)第四章常见的概率分布一、最佳选择题1.D2.D3.B4.D5.B6.E7.E8.C9.D10.C11.C三、计算分析题P73-41120124.4 1.15793.8u -==-2125124.40.1578953.8u -==查标准正态分布表得1()( 1.1579)( 1.16)0.123u Φ=Φ-≅Φ-=2()(0.15795)(0.16)1(0.16)10.43640.5636u Φ=Φ≅Φ=-Φ-=-=21()()0.56360.1230.4406u u Φ-Φ=-=该地身高界于120cm 到125cm 范围内的8岁男童比例为44.06%。
20044.06%89()⨯≈人200名8岁男童中身高界于120~125cm 范围的人数约为89人。
P73-5Poisson 0.99967Binominal 0.9998P73-6解:(1)由题意可知,随机误差变量X 服从正态分布,其中μ=2,σ=4。
要求测量误差的绝对值不超过3的概率,即求P P ≤≤≤(X 3)=(-3X 3),作标准化变化132 1.254u --==-2320.254u -==1()( 1.25)0.1056u Φ=Φ-=2()(0.25)1(0.25)10.40130.5987u Φ=Φ-Φ-=-=21()()0.59870.10560.4931u u Φ-Φ=-=即测量误差的绝对值不超过3的概率为0.4931。
(2)根据题意,以Y 表示测量误差的绝对值不超过3,则Y 服从二项分布,其中n=3,0.4931π=,根据题意,至少有1次误差的绝对值不超过3的概率为003033(1)1(0)1(1)10.50690.86975P Y P Y C ππ-≥=-==--=-=P73-7解:根据医学知识可知健康成人血清总胆固醇值过高或过低为异常,故应制定双侧医学参考值范围因为已经假定血清总胆固醇值服从正态分布,故可用正态分布法求该指标的95%医学参考值范围,即 1.96μσ±。
医学统计学参考答案 颜虹第二版
《医学统计学》部分习题参考答案颜虹主编第二版第三章统计描述一、最佳选择题1.C2.A3.D4.B5.E6.E7.C8.D9.C10.C11.A12.D三、计算分析题P53-1素食前X1素食后X2X1-X2平均187.75平均168.25平均19.5中位数179中位数165中位数19标准差33.18885标准差26.79593标准差16.80838方差1101.5方差718.0217方差282.5217 4)第四章常见的概率分布一、最佳选择题1.D2.D3.B4.D5.B6.E7.E8.C9.D10.C11.C三、计算分析题P73-41120124.4 1.15793.8u -==-2125124.40.1578953.8u -==查标准正态分布表得1()( 1.1579)( 1.16)0.123u Φ=Φ-≅Φ-=2()(0.15795)(0.16)1(0.16)10.43640.5636u Φ=Φ≅Φ=-Φ-=-=21()()0.56360.1230.4406u u Φ-Φ=-=该地身高界于120cm 到125cm 范围内的8岁男童比例为44.06%。
20044.06%89()⨯≈人200名8岁男童中身高界于120~125cm 范围的人数约为89人。
P73-5Poisson 0.99967Binominal 0.9998P73-6解:(1)由题意可知,随机误差变量X 服从正态分布,其中μ=2,σ=4。
要求测量误差的绝对值不超过3的概率,即求P P ≤≤≤(X 3)=(-3X 3),作标准化变化132 1.254u --==-2320.254u -==1()( 1.25)0.1056u Φ=Φ-=2()(0.25)1(0.25)10.40130.5987u Φ=Φ-Φ-=-=21()()0.59870.10560.4931u u Φ-Φ=-=即测量误差的绝对值不超过3的概率为0.4931。
(2)根据题意,以Y 表示测量误差的绝对值不超过3,则Y 服从二项分布,其中n=3,0.4931π=,根据题意,至少有1次误差的绝对值不超过3的概率为003033(1)1(0)1(1)10.50690.86975P Y P Y C ππ-≥=-==--=-=P73-7解:根据医学知识可知健康成人血清总胆固醇值过高或过低为异常,故应制定双侧医学参考值范围因为已经假定血清总胆固醇值服从正态分布,故可用正态分布法求该指标的95%医学参考值范围,即 1.96μσ±。
医学统计学第二版高等教育出版社课后习题答案

第一章绪论1.举例说明总体和样本的概念。
研究人员通常需要了解和研究某一类个体,这个类就是总体。
总体是根据研究目的所确定的所有同质观察单位某种观察值(即变量值)的集合,通常有无限总体和有限总体之分,前者指总体中的个体是无限的,如研究药物疗效,某病患者就是无限总体,后者指总体中的个体是有限的,它是指特定时间、空间中有限个研究个体。
但是,研究整个总体一般并不实际,通常能研究的只是它的一部分,这个部分就是样本。
例如在一项关于2007年西藏自治区正常成年男子的红细胞平均水平的调查研究中,该地2007年全部正常成年男子的红细胞数就构成一个总体,从此总体中随即抽取2000人,分别测的其红细胞数,组成样本,其样本含量为2000人。
2.简述误差的概念。
误差泛指实测值与真实值之差,一般分为随机误差和非随机误差。
随机误差是使重复观测获得的实际观测值往往无方向性地围绕着某一个数值左右波动的误差;非随机误差中最常见的为系统误差,系统误差也叫偏倚,是使实际观测值系统的偏离真实值的误差。
3.举例说明参数和统计量的概念。
某项研究通常想知道关于总体的某些数值特征,这些数值特征称为参数,如整个城市的高血压患病率。
根据样本算得的某些数值特征称为统计量,如根据几百人的抽样调查数据所算得的样本人群高血压患病。
统计量是研究人员能够知道的,而参数是他们想知道的。
一般情况下,这些参数是难以测定的,仅能够根据样本估计。
显然,只有当样本代表了总体时,根据样本统计量估计的总体参数才是合理的。
4.简述小概率事件原理。
当某事件发生的概率小于或等于0.05时,统计学上习惯称该事件为小概率事件,其含义是该事件发生的可能性很小,进而认为它在一次抽样中不可能发生,这就是所谓的小概率事件原理,它是进行统计推断的重要基础。
第二章调查研究设计1.调查研究主要特点是什么?调查研究的主要特点是:①研究的对象及其相关因素(包括研究因素和非研究因素)是客观存在的,不能人为给予干预措施②不能用随机化分组来平衡混杂因素对调查结果的影响。
医学统计学第二版高等教育出版社课后习题答案剖析

第一章绪论1.举例说明总体和样本的概念。
研究人员通常需要了解和研究某一类个体,这个类就是总体。
总体是根据研究目的所确定的所有同质观察单位某种观察值(即变量值)的集合,通常有无限总体和有限总体之分,前者指总体中的个体是无限的,如研究药物疗效,某病患者就是无限总体,后者指总体中的个体是有限的,它是指特定时间、空间中有限个研究个体。
但是,研究整个总体一般并不实际,通常能研究的只是它的一部分,这个部分就是样本。
例如在一项关于2007年西藏自治区正常成年男子的红细胞平均水平的调查研究中,该地2007年全部正常成年男子的红细胞数就构成一个总体,从此总体中随即抽取2000人,分别测的其红细胞数,组成样本,其样本含量为2000人。
2.简述误差的概念。
误差泛指实测值与真实值之差,一般分为随机误差和非随机误差。
随机误差是使重复观测获得的实际观测值往往无方向性地围绕着某一个数值左右波动的误差;非随机误差中最常见的为系统误差,系统误差也叫偏倚,是使实际观测值系统的偏离真实值的误差。
3.举例说明参数和统计量的概念。
某项研究通常想知道关于总体的某些数值特征,这些数值特征称为参数,如整个城市的高血压患病率。
根据样本算得的某些数值特征称为统计量,如根据几百人的抽样调查数据所算得的样本人群高血压患病。
统计量是研究人员能够知道的,而参数是他们想知道的。
一般情况下,这些参数是难以测定的,仅能够根据样本估计。
显然,只有当样本代表了总体时,根据样本统计量估计的总体参数才是合理的。
4.简述小概率事件原理。
当某事件发生的概率小于或等于0.05时,统计学上习惯称该事件为小概率事件,其含义是该事件发生的可能性很小,进而认为它在一次抽样中不可能发生,这就是所谓的小概率事件原理,它是进行统计推断的重要基础。
第二章调查研究设计1.调查研究主要特点是什么?调查研究的主要特点是:①研究的对象及其相关因素(包括研究因素和非研究因素)是客观存在的,不能人为给予干预措施②不能用随机化分组来平衡混杂因素对调查结果的影响。
医学统计学第二版钟晓妮课后题答案

医学统计学第二版钟晓妮课后题答案l.统计中所说的总体是指:() [单选题] *A根据研究目的确定的同质的研究对象的全体(正确答案)B随意想象的研究对象的全体C根据地区划分的研究对象的全体D根据时间划分的研究对象的全体E根据人群划分的研究对象的全体2.统计学的主要作用是 : () [单选题] *A使分析更为简单B避免计算出现错误C改善数据质量D克服个体变异的影响E探测随机现象的规律(正确答案)3.关于随机抽样,以下哪一项说法是正确的:() [单选题] *A抽样时应使得总体中的每一个个体都有同等的机会被抽取(正确答案) B研究者在抽样时应精心挑选个体,以使样本更能代表总体C随机抽样即随意抽取个体D为确保样本具有更好的代表性,样本量应越大越好E选择符合研究者意愿的样本4.测量身高、体重等指标的原始资料叫:() [单选题] * A计数资料B计量资料(正确答案)C等级资料D分类资料E有序分类资料5某种新疗法治疗某病患者41人,治疗结果如下:()[单选题] *A计数资料B计量资料C无序分类资料D有序分类资料(正确答案)E数值变量资料6.正态分布曲线的位置参数是: () [单选题] *AαBβC µ(正确答案)DσEχ7.医学统计学的基本内容是: () [单选题] *A统计设计、数据整理与核查、统计描述、统计推断(正确答案)B收集资料、整理资料、设计、统计推断C统计设计、收集资料、统计推断、分析资料D收集资料、整理资料、核对、分析资料E搜集资料、整理资料、分析资料、进行推断8.良好的实验设计,能减少人力、物力,提高实验效率;还有助于消除或减少: () [单选题] *A抽样误差B系统误差(正确答案)C随机误差D责任事故E以上都不对9.以下何者不是实验设计应遵循的原则 : () [单选题] *A对照的原则B随机原则C重复原则D交叉的原则(正确答案)E以上都不对10.对于配对设计的t检验,其检验假设H0是:() [单选题] *A两样本均数相同B两样本均数不同C两总体均数相同D两样本均数不同E配对数据的差值总体均数为0(正确答案)11.某计量资料的分布性质未明,要计算集中趋势指标,宜选择 : () [单选题] * A 算术均数B几何均数C 中位数(正确答案)D 标准差E 变异系数12.各观察值均加(或减)同一数后: () [单选题] *A均数不变,标准差改变B均数改变,标准差不变C两者均不变(正确答案)D两者均改变E以上均不对13.比较某地1990~1997年肝炎发病率宜绘制 : () [单选题] *A直条图B构成图C普通线图(正确答案)D直方图E统计地图14.某厂发生食物中毒,9名患者潜伏期分别为:16、2、6、3、30、2、10、2、24以上(小时),问该食物中毒的平均潜伏期为多少小时? () [单选题] *A 5B 5.5C 6(正确答案)D l0E 1215.比较12岁男孩身高和体重的变异程度大小,宜采用的指标是: () [单选题] * A全距B标准差C方差D变异系数(正确答案)E极差16.对于正态或近似正态分布的资料,描述其变异程度应选用的指标是 : () [单选题] *A变异系数B离均差平方和C极差D 四分位间距E标准差(正确答案)17.以下不属于统计表的基本组成的是:() [单选题] *A.标题B.标目C.线条D.时间(正确答案)E.数字18.某项指标95%医学参考值范围表示的是: () [单选题] *A在此范围“异常”的概率大于或等于95%B 在此范围“正常”的概率大于或等于95%C 在“异常”总体中有95%的人在此范围之外D 在“正常”总体中有95%的人在此范围(正确答案)E 在人群中检测指标有5%的可能超出此范围19.20世纪50年代,发现某省部分地区的居民因长期饮用深井高碘水导致高碘性甲状腺肿,随机抽查得到该地区甲乙两村常住居民的高碘性甲状腺肿患病率,甲村为20.6%,乙村为25.3%,则甲乙两村该病的合计患病率为:() [单选题] *A两村患病率的几何平均数得29.11%B 两村患病率相加得45.9%C 两村患病率相乘得5.21%D 两村患病率的平均数得22.95%E 甲乙两村调查人群中患该病总人数除以调查总人数(正确答案)20.药物A对于治疗普通肺炎的有效率为67.0%,药物B治疗普通肺炎的有效率为65.7%,为了分析A药和B药对于普通肺炎的有效率是否不同,经过两独立样本的t检验计算t值,最后查表得到的P=0.035,那么该研究中最后应该下的研究结论应该是:() [单选题] *A药物A与药物B治疗普通肺炎的有效率相同B 尚不能认为药物A与药物B治疗普通肺炎的有效率相同(正确答案)C 尚不能认为药物A与药物B治疗普通肺炎的有效率不同D 药物A治疗普通肺炎的有效率优于药物BE 无法下结论21.以下属于离散型变量指标的是:() [单选题] *A身高B 体重C 住院病人数D 血液中血红蛋白含量(正确答案)E 某地年降水量22.小概率事件是指:() [单选题] *A统计学上一般把P≤0.05或P≤0.01的事件称为小概率事件(正确答案)B 统计学上一般把P≤0.5或P≤0. 1的事件称为小概率事件C 统计学上一般把P≤0.05或P>0.01的事件称为小概率事件D 统计学上一般把P≤0.25的事件称为小概率事件E 发生概率足够小的事件23.在绘制频数分布表的过程中,组限在每组中: () [单选题] *A只包含下限而不包含上限(正确答案)B 只包含上限而不包含下限C 既包含下限又包含上限D 可自行选择包含上限或下限E 上限和下限均不包含24.以下几幅图中属于正偏态分布的是: ( A ) [单选题]A(正确答案)BC DE25.描述抗体滴度集中趋势适宜用:() [单选题] *A算术均数B 方差C 标准差D 几何均数(正确答案)E 中位数26.算术均数与中位数相比,其特点是:() [单选题] * A不易受极端值的影响B 能充分利用数据的信息(正确答案)C 抽样误差较大D 更适用于偏态分布资料E 更适用于分布不明资料27.医学参考值范围的计算方法主要有:() [单选题] *A百分位数法和估计值法B 百分位数法和正态分布法(正确答案)C 百分位数法和查表法D 正态分布法和查表法E 查表法和公式计算法28.比较两个不同人群的患病率、发病率、死亡率等资料时,为消除其内部构成(如年龄、性别、工龄、病程长短、病情轻重等)对率的影响,可以:()[单选题] *A排除对结果有不良影响的个体B 增大样本量C 采用标准化率(正确答案)D 更改相关数据E 通过统计软件消除影响29.统计学中为了区别个体观察值之间变异的标准差与反映样本均数之间变异的标准差,将后者称为均数的: () [单选题] *A标准值B 标准差C 标准化率D 标准误(正确答案)E 标准方差30.以下变量适合用单侧检验进行分析的是:() [单选题] * A血铅水平(正确答案)B 血压C 呼吸次数D 血红蛋白含量E 3岁男童正常身高3l.统计学中所谓的样本通常是指:() [单选题] *A总体中有代表性的一部分观察单位(正确答案)B可测量的生物性样品C统计量D某一变量的测量值E数据中的一部分观测值32.医学统计学研究的对象是:() [单选题] *A医学中的小概率事件B各种类型的数据C动物和人的本质D疾病的预防与治疗E医学中具有不确定性结果的事物(正确答案)33.关于随机抽样,以下哪一项说法是正确的:() [单选题] *A抽样时应使得总体中的每一个个体都有同等的机会被抽取(正确答案) B研究者在抽样时应精心挑选个体,以使样本更能代表总体C随机抽样即随意抽取个体D为确保样本具有更好的代表性,样本量应越大越好E选择符合研究者意愿的样本34,下列观测结果属于有序数据的是:() [单选题] *A收缩压测量值B脉搏数C住院天数D病情程度(正确答案)E四种血型35.两样本均数比较,其差别有统计学意义是指 :() [单选题] *A两样本均数的差别具有实际意义B两总体均数的差别具有实际意义C两样本和两总体均数的差别都具有实际意义D有理由认为两样本均数有差别E有理由认为两总体均数有差别(正确答案)36.不可完全消除的误差类型是:() [单选题] *A系统误差B 随机误差(正确答案)C 抽样误差D 人为误差E 机械误差37.正态曲线下,横轴上从均数到+∞的面积是:() [单选题] *A 50%(正确答案)B 95%C 97.5%D 99%E 不能确定(与标准差的大小有关)38.6人接种流感疫苗一个月后测定抗体滴度为1:20,1:40,1:80,1:160,1:320,求平均滴度应选用的指标是:() [单选题] *A算术均数B 方差C 标准差D 几何均数(正确答案)E 中位数39.描述两端无确定数值数据的平均水平适宜用:() [单选题] *A算术均数B 方差C 标准差D 几何均数E 中位数(正确答案)40.以下变量中,属于分类变量的是: () [单选题] *A脉搏B血型(正确答案)C肺活量D红细胞计数E血压41.减少抽样误差的有效途径是:() [单选题] *A避免系统误差B控制随机测量误差C增大样本含量(正确答案)D减少样本含量E以上都不对42.样本是总体的 : () [单选题] *A有价值的部分B有意义的部分C有代表性的部分(正确答案)D任意一部分E典型部分43.将计量资料制作成频数表的过程,属于统计工作哪个基本步骤:() [单选题] * A统计设计B收集资料C整理资料D分析资料(正确答案)E以上均不对44.统计工作的步骤正确的是:() [单选题] *A收集资料、设计、整理资料、分析资料B收集资料、整理资料、设计、统计推断C设计、收集资料、整理资料、分析资料(正确答案)D收集资料、整理资料、核对、分析资料E搜集资料、整理资料、分析资料、进行推断45.表示血清学滴度资料平均水平最常计算 :() [单选题] *A算术均数B几何均数(正确答案)C中位数D全距E率46.一种新的治疗方法不能治愈病人,但能延长病人寿命,那么则会发生的情况是 :() [单选题] *A 该病患病率增加(正确答案)B 该病发病率增加C 该病患病率下降D 该病发病率下降E 以上都不对47.计算标化死亡率的目的是:() [单选题] *A 减少死亡率估计的抽样误差B 减少死亡率估计的系统误差C 便于进行不同地区的死亡率比较D 便于进行不同时间的死亡率比较E 消除不同人群内部构成不同的影响(正确答案)48.统计推断的目的是: () [单选题] *A参数估计B假设检验C统计描述D用样本信息推断总体特征(正确答案)E以上均不对49.两样本均数比较时,其无效假设是:() [单选题] * A.两个总体均数不同B.两个样本均数不同C.两个总体均数相同(正确答案)D.两个样本均数相同E.以上均不对50.实验设计的三个基本要素是: () [单选题] *A化学因素、物理因素、研究对象B 研究者、受试对象、效果C 受试对象、背景因素、实验效应D 处理因素、实验效应、受试对象(正确答案)E 干扰因素、实验场所、处理因素。
医学统计学习题及答案

医学统计学试题及答案习题医学统计学第二版五年制临床医学等本科生用一单项选择题1.观察单位为研究中的 d.A.样本B. 全部对象C.影响因素 D. 个体2.总体是由 c .A.个体组成 B. 研究对象组成 C.同质个体组成 D. 研究指标组成3.抽样的目的是b.A.研究样本统计量 B. 由样本统计量推断总体参数C.研究典型案例研究误差 D. 研究总体统计量4.参数是指b .A.参与个体数 B. 总体的统计指标 C.样本的统计指标 D. 样本的总和5.随机抽样,下列那一项说法是正确的 a .A.抽样时应使得总体中的每一个个体都有同等的机会被抽取B.研究者在抽样时应精心挑选个体,以使样本更能代表总体C.随机抽样即随意抽取个体D.为确保样本具有更好的代表性,样本量应越大越好6.各观察值均加或减同一数后 b .A.均数不变,标准差改变B.均数改变,标准差不变C.两者均不变D.两者均改变7.比较身高和体重两组数据变异度大小宜采用 a.A.变异系数B.差C.极差D.标准差8.以下指标中 d可用来描述计量资料的离散程度.A.算术均数B.几何均数C.中位数D.标准差9.偏态分布宜用 c描述其分布的集中趋势.A.算术均数B.标准差C.中位数D.四分位数间距10.各观察值同乘以一个不等于0的常数后, b不变.A.算术均数 B.标准差 C.几何均数D.中位数11. a分布的资料,均数等于中位数.A.对称B.左偏态C.右偏态D.偏态12.对数正态分布是一种 c 分布.A.正态B.近似正态C.左偏态D.右偏态13.最小组段无下限或最大组段无上限的频数分布资料,可用c 描述其集中趋势.A.均数B.标准差C.中位数D.四分位数间距14. c小,表示用该样本均数估计总体均数的可靠性大.A. 变异系数B.标准差C. 标准误D.极差15.血清学滴度资料最常用来表示其平均水平的指标是 c.A. 算术平均数B.中位数C.几何均数D. 平均数16.变异系数CV的数值c .A. 一定大于1B.一定小于1C. 可大于1,也可小于1D.一定比标准差小17.数列8、-3、5、0、1、4、-1的中位数是 b.A. 2B. 1C. 2.5D. 0.519.标准差,那项是错误的D .A.反映全部观察值的离散程度B.度量了一组数据偏离平均数的大小C.反映了均数代表性的好坏D.不会小于算术均数20.中位数描述集中位置时,下面那项是错误的 C.A. 适合于偏态分布资料B.适合于分布不明的资料C.不适合等比资料D.分布末端无确定值时,只能用中位数21. 5人的血清抗体滴度分别为 1:20、1:40、1:80、1:160、1:320.欲描述其抗体滴度的平均水平,用那种指标较好 B.A.平均数 B.几何均数 C.算术均数 D. 中位数22.一组变量的标准差将C .A.随变量值的个数n的增大而增大B.随变量值的个数n的增加而减小C.随变量值之间的变异增大而增大D.随系统误差的减小而减小23.频数表计算中位数要求 D.A.组距相等B.原始数据分布对称C.原始数据为正态分布或近似正态分布D.没有条件限制24.一组数据中20%为3,60%为2,10%为1,10%为0,则平均数为 B.A.1.5 B. 1.9 C. 2.1D. 不知道数据的总个数,不能计算平均数25.某病患者8人的潜伏期如下:2、3、3、3、4、5、6、30则平均潜伏期为 D.A.均数为7天,很好的代表了大多数的潜伏期B.中位数为3天C.中位数为4天D.中位数为3.5天,不受个别人潜伏期长的影响26.某地调查20岁男大学生100名,身高标准差为4.09cm,体重标准差为4.10kg,比较两者的变异程度,结果 D.A. 体重变异度大B.身高变异度较大C.两者变异度相同D.由单位不同,两者标准差不能直接比较27.标准正态分布的均数与标准差分别为 A .A.0与1B.1与0 C.0与0 D.1与128.正态分布有两个参数与 , C 相应的正态曲线的形状越扁平.A.越大 B.越小 C.越大 D.越小29.对数正态分布是一种 D分布.A.正态 B.近似正态 C.左偏态 D.右偏态30.正态曲线下、横轴上,从均数-1.96倍标准差到均数的面积为 D .A.95% B.45% C.97.5% D.47.5%31.标准正态分布曲线下中间90%的面积所对应的横轴尺度的范围是A .A.-1.64到+1.64 B.到+1.64C.到+1.28 D.-1.28到+1.2832.标准误的英文缩写为:BA.S B.SEC. D.SD33.通常可采用以下那种方法来减小抽样误差:CA.减小样本标准差 B.减小样本含量 C.扩大样本含量D.以上都不对34.配对设计的目的:DA.提高测量精度 B.操作方便 C.为了可以使用t检验 D.提高组间可比性35.假设检验,下列那一项说法是正确的BA.单侧检验优于双侧检验B.采用配对t检验还是成组t检验是由实验设计方法决定的C.检验结果若P值大于0.05,则接受H0犯错误的可能性很小D.用u检验进行两样本总体均数比较时,要求方差齐性36.两样本比较时,分别取以下检验水准,下列何者所取第二类错误最小D A. =0.05 B. =0.01C. =0.10 D. =0.2037.统计推断的内容是DA.用样本指标推断总体指标 B.检验统计上的“假设” C.A、B均不是D.A、B均是38.甲、乙两人分别从随机数字表抽得30个各取两位数字随机数字作为两个样本,求得 , , , ,则理论上DA. = , =B.作两样本t检验,必然得出无差别的结论C.作两方差齐性的F检验,必然方差齐D.分别由甲、乙两样本求出的总体均数的95%可信区间,很可能有重叠39.以下参数点估计的说法正确的是CA.CV越小,表示用该样本估计总体均数越可靠B.越小,表示用该样本估计总体均数越准确C.越大,表示用该样本估计总体均数的可靠性越差D.S越小,表示用该样本估计总体均数越可靠40.两样本均数的比较,可用 C .A.方差分析 B.t检验 C.两者均可 D.方差齐性检验41.配伍组设计的方差分析中, 配伍等于 D .A.总- 误差 B.总- 处理 C.总- 处理+ 误差D.总- 处理- 误差42.在均数为μ,标准差为σ的正态总体中随机抽样, B 的概率为5%. A.1.96σB. C. D.43.当自由度 1, 2及显着性水准都相同时,方差分析的界值比方差齐性检验的界值B.A.大 B.小 C.相等 D.不一定44.方差分析中变量变换的目的是D.A.方差齐性化 B.曲线直线化 C.变量正态化 D.以上都对45.下面说法中不正确的是 D .A.方差分析可以用于两个样本均数的比较B.完全随机设计更适合实验对象变异不太大的资料C.在随机区组设计中,每一个区组内的例数都等于处理数D.在随机区组设计中,区组内及区组间的差异都是越小越好46.随机单位设计要求A.A.单位组内个体差异小,单位组间差异大B.单位组内没有个体差异,单位组间差异大C.单位组内个体差异大,单位组间差异小D.单位组内没有个体差异,单位组间差异小47.完全随机设计方差分析的检验假设是 B .A.各处理组样本均数相等 B.各处理组总体均数相等C.各处理组样本均数不相等 D.各处理组总体均数不相等48.完全随机设计、随机区组设计的SS和及自由度各分解为几部分B. A.2,2 B.2,3 C.2,4 D.3,349.配对t检验可用哪种设计类型的方差分析来替代B.A.完全随机设计 B.随机区组设计 C.两种设计都可以 D.AB 都不行50.某病患者120人,其中男性114人,女性6人,分别占95%与5%,则结论为 D .A. 该病男性易得B. 该病女性易得C. 该病男性、女性易患率相等D. 尚不能得出结论51.甲县恶性肿瘤粗死亡率比乙县高,经标准化后甲县恶性肿瘤标化死亡率比乙县低,其原因最有可能是 D .A. 甲县的诊断水平高B. 甲县的肿瘤防治工作比乙县好C. 甲县的老年人口在总人口中所占比例比乙县小D. 甲县的老年人口在总人口中所占比例比乙县大52.已知男性的钩虫感染率高于女性.今欲比较甲乙两乡居民的钩虫感染率,但甲乡人口女多于男,而乙乡男多于女,适当的比较方法是 D.A. 分别进行比较B. 两个率比较的χ2检验C. 不具备可比性,不能比较D. 对性别进行标准化后再比较53.经调查得知甲乙两地的粗死亡率为40/10万,按年龄构成标化后,甲地冠心病标化死亡率为45/10万;乙地为38/10万,因此可以认为B.A. 甲地年龄别人口构成较乙地年轻B. 乙地年龄别人口构成较甲地年轻C. 甲地冠心病的诊断较乙地准确D. 甲地年轻人患冠心病较乙地多55.某部队夏季拉练,发生中暑21例,其中北方籍战士为南方籍战士的2.5倍,则结论为 D .A.北方籍战士容易发生中暑 B.南方籍战士容易发生中暑C.北方、南方籍战士都容易发生中暑 D.尚不能得出结论57.相对比包括的指标有D.A.对比指标 B.计划完成指标 C.关系指标 D.以上都是61.已知某高校学生近视眼的患病率为50%,从该高校随机挑选3名学生,其中2人患近视眼的概率为 B.A.0.125 B. 0.375 C.0.25D. 0.562.某自然保护区狮子的平均密度为每平方公里100只,随机抽查其中一平方公里范围内狮子的数量,若进行100次这样的抽查,其中的95次所得数据应在以下范围内B .A.5~195B.80.4~119.6 C.95~105 D.74.2~125.863. 样本率p的分布正确的说法是:CA.服从正态分布 B.服从分布C.当n足够大,且p和1-p均不太小,p的抽样分布逼近正态分布D.服从t分布A64. 以下说法正确的是:A.两样本率比较可用u检验 B.两样本率比较可用t检验C.两样本率比较时,有 D.两样本率比较时,有65. 率的标准误的计算公式是:DA. B.C.D.66. 以下检验的自由度的说法,正确的是:DA.拟合优度检验时, n为观察频数的个数 B.对一个表进行检验时,C.对四格表检验时, =4 D.若 ,则67.用两种方法检查某疾病患者120名,甲法检出率为60%,乙法检出率为50%,甲、乙法一致的检出率为35%,问两种方法何者为优AA.不能确定 B.甲、乙法一样 C.甲法优于乙法 D.乙法优于甲法68.已知男性的钩虫感染率高于女性.今欲比较甲乙两乡居民的钩虫感染率,适当的方法是:DA.分性别比较 B.两个率比较的检验C.不具可比性,不能比较 D.对性别进行标准化后再做比较69.以下说法正确的是A.两个样本率的比较可用u检验也可用检验AB.两个样本均数的比较可用u检验也可用检验C.对于多个率或构成比的比较,u检验可以替代检验D.对于两个样本率的比较, 检验比u检验可靠70.以下检验方法之中,不属于非参数检验法的是A.A. t检验 B.符号检验 C. Kruskal-Wallis检验D. Wilcoxon检验71.以下对非参数检验的描述哪一项是错误的 D .A.参数检验方法不依赖于总体的分布类型B.应用非参数检验时不考虑被研究对象的分布类型C.非参数的检验效能低于参数检验D.一般情况下非参数检验犯第二类错误的概率小于参数检验72.符合方差分析检验条件的成组设计资料如果采用秩和检验,则 B . A.一类错误增大 B.第二类错误增大 C.第一类错误减小D.第二类错误减小73.等级资料的比较宜用B.A.t检验 B.秩和检验 C.F检验 D.四格表X2检验74.在进行成组设计两样本秩和检验时,以下检验假设正确的是 C . A.H0:两样本对应的总体均数相同 B.H0:两样本均数相同C.H0:两样本对应的总体分布相同 D.H0:两样本的中位数相同75.在进行Wilcoxon配对法秩和检验时,以下检验假设正确的是D.A.H0:两样本对应的总体均数相同 B.H0:两样本的中位数相同C.H0:两样本对应的总体分布相同 D.以上都不正确76.两个小样本比较的假设检验,应首先考虑D.A.t检验 B.秩和检验 C.任选一种检验方法D.资料符合哪种检验的条件77.对于配对比较的秩和检验,其检验假设为.A.样本的差数应来自均数为0的正态总体C B.样本的差数应来自均数为0的非正态总体C.样本的差数来自中位数为0的总体 D.样本的差数来自方差齐性和正态分布的总体78.在配对比较的差数秩和检验中,如果有两个差数为0,则 D .A.对正秩和有0.5和1,对负秩和有-0.5和-1 B.对正秩和有2,对负秩和有-2C.对正秩和有3,对负秩和有-3 D.不予考虑若随机化成组设计资料来自于正态总体,分别采用秩和检验与t检验、u检验,则它们检验效率关系正确的是 D .A.t检验>u检验>秩和检验 B.u检验>秩和检验>t检验C.t检验>秩和检验>u检验 D.t检验,u检验>秩和检验79.配对比较的秩和检验的基本思想是:如果检验假设成立,则对样本来说C.A.正秩和的绝对值小于负秩和的绝对值B.正秩和的绝对值大于负秩和的绝对值C.正秩和的绝对值与负秩和的绝对值不会相差很大D.正秩和的绝对值与负秩和的绝对值相等80.按等级分组资料的秩和检验中,各等级平均秩次为 C .A.该等级的秩次范围的上界 B.该等级的秩次范围的下界C.该等级的秩次范围的上界、下界的均数 D.该等级的秩次范围的上界、下界的之和81.非参数统计应用条件是 D .A.总体是正态分布 B.若两组比较,要求两组的总体方差相等C.不依赖于总体分布 D.要求样本例数很大82.下述哪些不是非参数统计的特点 D .A.不受总体分布的限定 B.多数非参数统计方法简单,易于掌握C.适用于等级资料 D.检验效能总是低于参数检验83.设配对设计资料的变量值为X1和X2,则配对资料的秩和检验 A . A.把X1与X2的差数绝对值从小到大编秩 B.把X1和X2综合从小到大编秩C.把X1和X2综合按绝对值从小到大编秩 D.把X1与X2的差数从小到大编秩84.秩和检验和t检验相比,其优点是A.A.计算简便,不受分布限制 B.公式更为合理 C.检验效能高D.抽样误差小85.配对设计差值的符号秩检验,对差值编秩时,遇有差值绝对值相等时B .A.符号相同,则取平均秩次 B.符号相同,仍按顺序编秩C.符号不同,仍按顺序编秩 D.不考虑符号,按顺序编秩86.配对设计的秩和检验中,其H0假设为 B .A.差值的总体均数为0 B.差值的总体中位数为0 C.μd≠0 D.Md≠087.一组n1和一组n2n2>n1的两个样本资料比较,用秩和检验,有C.A.n1个秩次1,2,...,n1 B.n2个秩次1,2,...,n2C.n1+n2个秩次1,2,...,n1+n2 D.n1-n2个秩次1,2,...,n1-n2 88.成组设计两样本比较的秩和检验中,描述不正确的是C.A.将两组数据统一由小到大编秩 B.遇有相同数据,若在同一组,按顺序编秩C.遇有相同数据,若不在同一组,按顺序编秩D.遇有相同数据,若不在同一组,取其平均秩次89.成组设计的两小样本均数比较的假设检验 D .A.t检验 B.成组设计两样本比较的秩和检验C.t检验或成组设计两样本比较的秩和检验D.资料符合t检验条件还是成组设计两样本比较的秩和检验条件C90.对两样本均数作比较时,已知n1、n2均小于30,总体方差不齐且分布呈偏态,宜用.A.t检验 B.u检验 C.秩和检验 D.F检验91.等级资料两样本比较的秩和检验中,如相同秩次过多,应计算校正uc 值,校正的结果使.A.u值增加,P值减小 B.u值增加,P值增加C.u值减小,P值增加 D.u值减小,P值减小92.符号秩检验Wilcoxon配对法中,秩和T和P值的关系描述正确的是 A . A.T落在界值范围内,则P值大于相应概率B.T落在界值范围上界外,则P值大于相应概率C.T落在界值范围下界外,则P值大于相应概率D.T落在界值范围上,则P值大于相应概率93.配对设计资料的符号秩检验中,如相同秩次过多,未计算校正uc值,而计算u值,不拒绝H0时 A .A.第一类错误增加 B.第一类错误减少 C.第二类错误增加 D.第二类错误减小94.下列 D 式可出现负值.A.∑X— 2 B.∑Y 2—∑Y2/n C.∑Y— 2 D.∑X— Y—95.Y=14+4X是1~7岁儿童以年龄岁估计体重市斤的回归方程,若体重换成国际单位kg,则此方程C .A.截距改变 B.回归系数改变 C.两者都改变D.两者都不改变96.已知r=1,则一定有 C.A.b=1 B.a=1 C.SY. X=0 D.SY. X= SY97.用最小二乘法确定直线回归方程的原则是各观察点B .A.距直线的纵向距离相等 B.距直线的纵向距离的平方和最小C.与直线的垂直距离相等 D.与直线的垂直距离的平方和最小98..直线回归分析中,X的影响被扣除后,Y方面的变异可用指标C 表示.A. B. C. D.99.直线回归系数假设检验,其自由度为C .A.n B.n-1C.n-2 D.2n-1100.应变量Y的离均差平方和划分,可出现D .A.SS剩=SS回 B.SS总=SS剩 C.SS总=SS回 D.以上均可101.下列计算SS剩的公式不正确的是B .A. B. C. D.102.直线相关系数可用D 计算.A. B. C. D.以上均可103.当r=0时, 回归方程中有 D.A.a必大于零 B. a必等于 C.a必等于零 D. a必等于104.可用来进行多元线性回归方程的配合适度检验是:BA.检验 B.检验 C.检验 D.Ridit检验105.在多元回归中,若对某个自变量的值都增加一个常数,则相应的偏回归系数:AA.不变 B.增加相同的常数 C.减少相同的常数 D.增加但数值不定106.在多元回归中,若对某个自变量的值都乘以一个相同的常数k,则:B B.该偏回归系数不变 C.该偏回归系数变为原来的1/k倍D.所有偏回归系数均发生改变 E.该偏回归系数改变,但数值不定107.作多元回归分析时,若降低进入的界值,则进入方程的变量一般会:A A.增多 B.减少 C.不变 D.可增多也可减少108.在下面各种实验设计中,在相同条件下最节约样本含量的是. DA. 完全随机设计B. 配对设计C. 配伍组设计D. 交叉设计109.为研究新药“胃灵丹”治疗胃病胃炎,胃溃疡疗效,在某医院选择50例胃炎和胃溃疡病人,随机分成实验组和对照组,实验组服用胃灵丹治疗,对照组用公认有效的“胃苏冲剂”.这种对照在实验设计中称为D .A. 实验对照B. 空白对照C. 安慰剂对照D. 标准对照110.某医师研究丹参预防冠心病的作用,实验组用丹参,对照组用无任何作用的糖丸,这属于 C.A. 实验对照B. 空白对照C. 安慰剂对照D. 标准对照111.某医师研究七叶一枝花治疗胃溃疡疗效时,实验组服用七叶一枝花与淀粉的合剂,对照组仅服用淀粉,这属于A .A. 实验对照B. 空白对照C. 安慰剂对照D. 标准对照112. 实验设计的三个基本要素是D .A. 受试对象、实验效应、观察指标B. 随机化、重复、设置对照C. 齐同对比、均衡性、随机化D. 处理因素、受试对象、实验效应113. 实验设计的基本原则D .A. 随机化、盲法、设置对照B. 重复、随机化、配对C. 随机化、盲法、配对D. 随机化、重复、设置对照114. 实验设计和调查设计的根本区别是D .A.实验设计以动物为对象B.调查设计以人为对象C.实验设计可随机分组D.实验设计可人为设置处理因素115. 在BC 中,研究者可以人为设置各种处理因素;而在A 中则不能人为设置处理因素.A. 调查研究B. 社区干预试验C. 临床试验D. 实验研究116.在抽样调查中,理论上样本含量大小与C 大小有关.A.样本极差 B.样本变异系数 C.样本方差 D.样本四分位间距117.在计算简单随机抽样中估计总体均数所需样本例数时,至少需要确定 C.A.允许误差 ,总体标准差 ,第二类错误 B.第一类错误 ,总体标准差 ,总体均数C.允许误差 ,总体标准差 ,第一类错误 D.允许误差 ,总体标准差 ,总体均数118.拟用放射免疫法检测某人群5000人血液中流脑特异免疫球蛋白含量,根据文献报道,其标准差约为0.5mg/L,容许误差为0.1mg/L,则按单纯随机抽样,需抽出的样本例数为C 人.A.97 B.95 C.96 D.94119.在抽样调查中,理论上样本含量大小会影响B . A.样本标准差的大小B.总体均数的稳定性C.样本标准差的稳定性 D.样本中位数的大小120.表示 D抽样时均数的抽样误差.A.整群B.系统 C.分层D.简单随机121.我们工作中常采用的几种抽样方法中,最基本的方法为A ;122.操作起来最方便的为 B;123.在相同条件下抽样误差最大的为C ;124.所得到的样本量最小的为D .A.简单随机抽样 B.系统抽样 C.整群抽样D.分层随机抽样125.调查用的问卷中,下面的四个问题中,B 是较好的一个问题.A.你和你的妈妈认为女孩几岁结婚比较好____.B.如果只生1个孩子,你希望孩子的性别是:1.女;2.男;3.随便C.你1个月工资多少_____. D.你一个月吃盐____克.126.原计划调查1000名对象,由于种种非主观和非选择的原因,只调查到600名,这样的调查结果 A.A.可能有偏性,因为失访者太多,可能这些失访有偏性B.不会有偏性,因为这种失访是自然的C.不会有偏性,因为这400名失访者不一定是某一种特征的人D.可能有偏性,因为600名对象不算多127.出生率下降,可使 B .A.婴儿死亡率下降 B. 老年人口比重增加C.总死亡数增加 D. 老年人口数下降128.计算某年婴儿死亡率的分母为 A .A.年活产总数 B. 年初0岁组人口数 C.年中0岁组人口数 D. 年末0岁组人口数129.自然增长率是估计一般人口增长趋势的指标,它的计算是B.A.出生数—死亡数 B. 粗出生率—粗死亡率C.标化出生率—标化死亡率 D. 年末人数—年初人数130.计算某年围产儿死亡率的分母是 C .A.同年妊娠28周以上的妇女数 B. 同年妊娠28周以上出生的活产数C.同年死胎数 + 死产数 + 活产数 D. 同年出生后7天内的新生儿数131.终生生育率是指A.A.一批经历过整个育龄期的妇女一生平均生育的子女数B.一批妇女按某时的生育水平,一生可能生育子女数C.一批经历过整个育龄期的妇女某年的平均活产数D.某年龄段的妇女某年的平均活产数132.年龄别生育率是指D.A.每1000名妇女一生平均生育的子女数B.每1000名妇女按某时的生育水平,一生可能生育子女数C.每1000名妇女某年的平均活产数D.每1000名某年龄段的育龄妇女某年的活产数133.婴儿死亡率是指C.A.0岁死亡率 B. 活产婴儿在生活一年内的死亡概率C.某年不满1岁婴儿死亡数与同年活产总数之比D. 某年不满1岁婴儿死亡数与同年婴儿总数之比134.某病病死率和某病死亡率均为反映疾病严重程度的指标,两者的关系为B.A.病死率高,死亡率一定高 B.病死率高,死亡率不一定高C.青年人口中,病死率高,死亡率也高 D.女性人口中,病死率高,死亡率也高135.总和生育率下降,可使老年人口百分比 A .A.上升 B. 下降 C.毫无关系 D. 以上答案均不对136.观察某种疫苗的预防效果,若第一季度初接种了400人,第二季度初接种了300人,第三季度初接种了100人,第四季度初接种了200人,到年终总结,这1000人中发病者20人,计算发病率的分母应该是 D .A.1000人 B. 400+200/2 人C.400+300+100+200/4人 D. 400+300×3/4 +100×1/2 + 200×1/4 人137.随访观察某种慢性病1000人的治疗结果,第一年死了100人,第二年死了180人,第三年死了144人,则该慢性病的3年生存率的算法为D.A.0.9 + 0.8 + 0.8/3 B. 1–0.10×0.20×0.20C.1–0.10–0.20–0.20 D. 0.90×0.80×0.80138.老年人口一般是指 D .A.50岁及以上的人口 B. 55岁及以上的人口C.60岁及以上的人口 D. 65岁及以上的人口139.在寿命表中,若X岁到X+1岁的死亡概率为1qx,X+1到X+2的死亡概率1qx+1,则X到X+2的死亡概率为 D.A.1qx×1qx+1 B.1-1qx×1qx+1C.1-1qx×1-1qx+1 D.1-1-1qx×1-1qx+1140.卫生统计学中目前常用的计算某年婴儿死亡率的分母是 D.A.年初0岁组人口数 B.年中0岁组人口数 C.年末0岁组人口数D.年出生数。
医学统计学第二版答案

医学统计学第二版答案医学统计学第二版答案【篇一:医学统计学(第六版)课后答案】)第一章绪论一、单项选择题 1. d 2. e 3. d 4. b 5. a 6. d 7. a 8. c 9. e 10. d二、简答题1更容易理解,统计推断则可以使用概率的方式给出结论,两者的重要作用在于能够透过偶然现象来探测具有变异性的医学规律,使研究结论具有科学性。
2能够提高研究效率,并使结果更加准确和可靠,数据整理主要是对数据进行归类,检查数据质量,以及是否符合特定的统计分析方法要求等。
统计描述用来描述及总结数据的重要特征,统计推断指由样本数据的特征推断总体特征的方法,包括参数估计和假设检验。
3 计算参数估计的可信区间、假设检验的p 值得出相互比较是否有差别的结论。
4述样本特征的指标,由样本数据计算得到,参数是描述总体分布特征的5差是生物体的自然变异和各种不可预知因素产生的误差,抽样误差是由于抽样而引起的样本统计量与总体参数间的差异。
6第二章定量数据的统计描述一、单项选择题1. a2. b3. e5. a6. e7. e8. d9. b 10. e二、计算与分析2第三章正态分布与医学参考值范围一、单项选择题1. a2. b3. b4. c5. d6. d7. c8. e9. b 10. a二、计算与分析1 2 [参考答案] 题中所给资料属于正偏态分布资料,所以宜用百分位数法计算其参考值范围。
又因血铅含量仅过大为异常,故应计算只有上限的单侧范围,即95p 。
第四章定性数据的统计描述一、单项选择题1. a2. c3. d4. d5. e7. e8. a9. d 10. e二、计算与分析 1[参考答案] 不正确,因为此百分比是构成比,不是率,要知道男女谁更易患病,需得到1290名职工中的男女比例,然后分别计算男女患病率。
2[参考答案] 不正确,此为构成比替代率来下结论,正确的计算是用各年龄段的死亡人数除各年龄段的调查人数得到死亡率。
医学统计学第二版.doc

习题《医学统计学》第二版(七年制临床医学用)(一)最佳选择题1.描述一组偏态分布资料的变异度,以()指标较好。
A. 全距B. 标准差C. 变异系数D. 四分位数间距E.方差2.用均数和标准差可以全面描述()资料的特征。
A. 正偏态分布B. 负偏态分布C. 正态分布D. 对称分布E.对数正态分布3.各观察值均加(或减)同一数后()。
A. 均数不变,标准差改变B. 均数改变,标准差不变C. 两者均不变D. 两者均改变E.以上都不对4.比较身高和体重两组数据变异度大小宜采用()。
A. 变异系数B. 方差C. 极差D. 标准差E.四分位数间距5.偏态分布宜用()描述其分布的集中趋势。
A. 算术均数B. 标准差C. 中位数D. 四分位数间距E.方差6.各观察值同乘以一个不等于0的常数后,()不变。
A.算术均数 B. 标准差C. 几何均数D. 中位数E.变异系数7.()分布的资料,均数等于中位数。
A. 对数正态B. 正偏态C. 负偏态D. 偏态E.正态8.对数正态分布是一种()分布。
(说明:设X变量经Y=lg X变换后服从正态分布,问X变量属何种分布?)A. 正态B. 近似正态C. 左偏态D. 右偏态E.对称9.最小组段无下限或最大组段无上限的频数分布资料,可用()描述其集中趋势。
A. 均数B. 标准差C. 中位数D. 四分位数间距E.几何均数10.血清学滴度资料最常用来表示其平均水平的指标是()。
A.算术平均数B.中位数C.几何均数D.变异系数E.标准差11.()小,表示用该样本均数估计总体均数的可靠性大。
A. CVB. SC. σXD. RE.四分位数间距12.两样本均数比较的t 检验,差别有统计学意义时,P 越小,说明( )。
A.两样本均数差别越大B.两总体均数差别越大C.越有理由认为两总体均数不同D.越有理由认为两样本均数不同E.越有理由认为两总体均数相同13. 甲乙两人分别从同一随机数字表抽得30个(各取两位数字)随机数字作为两个样本,求得1X 和21S ;2X 和22S ,则理论上( )。
医学统计学(李晓松主编第2版高等教育提高出版社)附录思考与理解练习95%答案解析
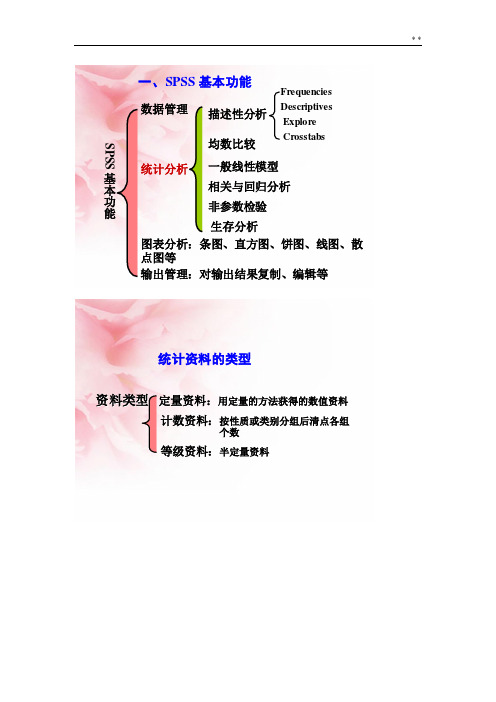
一、SPSS 基本功能SPSS基本功能数据管理统计分析图表分析:条图、直方图、饼图、线图、散点图等输出管理:对输出结果复制、编辑等描述性分析均数比较一般线性模型相关与回归分析非参数检验生存分析FrequenciesDescriptivesExploreCrosstabs 统计资料的类型资料类型定量资料:用定量的方法获得的数值资料计数资料:按性质或类别分组后清点各组个数等级资料:半定量资料定量资料的统计推断正态分布两组均数比较单样本设计t检验配对设计t检验成组设计t检验三组及以上均数比较完全随机设计方差分析随机区组设计方差分析重复测量方差分析析因设计方差分析偏态分布配对设计秩和检验单样本设计秩和检验成组设计秩和检验资料类型定量资料计数资料等级资料统计分析统计描述统计推断相对数总体率的估计假设检验u检验卡方检验4假设检验参数检验非参数检验正态分布等级资料偏态分布资料分布类型未知方差不齐,且不易变换达到齐性数据一端或两端不确定的资料1.参数检验:已知总体分布类型,对未知的总体参数做推断的假设检验方法。
故参数检验依赖于特定的分布类型,比较的是总体参数2.非参数检验:不依赖于总体分布类型、不针对总体参数的检验方法。
故非参数检验对总体的分布类型不做任何要求,不受总体参数的影响,比较的是分布或分布位置。
适用范围广,可适用于任何类型资料 参数检验➢ 优点:资料信息利用充分;检验效能较高 ➢ 缺点:对资料的要求高;适用范围有限 ➢ 优点:适用范围广,可适用于任何类型的资料 ➢ 缺点:检验效能低,易犯Ⅱ型错误 凡适合参数检验的资料,应首选参数检验对于符合参数检验条件者,采用非参数检验,其检验效能低,易犯Ⅱ型错误第一章绪论1.举例说明总体和样本的概念。
研究人员通常需要了解和研究某一类个体,这个类就是总体。
总体是根据研究目的所确定的所有同质观察单位某种观察值(即变量值)的集合,通常有无限总体和有限总体之分,前者指总体中的个体是无限的,如研究药物疗效,某病患者就是无限总体,后者指总体中的个体是有限的,它是指特定时间、空间中有限个研究个体。
医学统计学课后习题答案

### 第一章医学统计中的基本概念#### 一、单向选择题1. 医学统计学研究的对象是答案:E 有变异的医学事件解析:医学统计学旨在研究医学领域中的各种事件和现象,特别是那些存在变异性的医学事件,以揭示其规律和特点。
2. 用样本推论总体,具有代表性的样本指的是答案:E 依照随机原则抽取总体中的部分个体解析:随机抽样可以确保样本的代表性,从而更准确地推论总体特征。
3. 下列观测结果属于等级资料的是答案:D 病情程度解析:等级资料是对事物或现象进行分类的资料,如病情程度通常分为轻度、中度、重度等。
4. 随机误差指的是答案:E 由偶然因素引起的误差解析:随机误差是指由于偶然因素引起的误差,其大小和方向不固定。
5. 收集资料不可避免的误差是答案:A 随机误差解析:随机误差是收集资料过程中不可避免的误差,可以通过增加样本量来减小其影响。
#### 二、简答题常见的三类误差是什么?应采取什么措施和方法加以控制?参考答案:1. 系统误差解析:系统误差是指在收集资料过程中,由于仪器初始状态未调整到零、标准试剂未经校正、医生掌握疗效标准偏高或偏低等原因,可造成观察结果倾向性的偏大或偏小。
控制措施:- 定期检查和校准仪器设备。
- 严格规范实验操作流程。
- 培训操作人员,提高其技术水平。
2. 随机误差解析:随机误差是指由于偶然因素引起的误差,其大小和方向不固定。
控制措施:- 增加样本量,减小随机误差的影响。
- 重复实验,取平均值以减小随机误差。
3. 过失误差解析:过失误差是指由于操作失误、记录错误等原因引起的误差。
控制措施:- 严格规范实验操作流程,减少操作失误。
- 加强数据管理,确保数据准确无误。
### 第二章统计描述#### 一、单项选择题1. 下列指标中,属于集中趋势指标的是答案:B 平均数解析:平均数是描述数据集中趋势的常用指标。
2. 下列指标中,属于离散趋势指标的是答案:D 标准差解析:标准差是描述数据离散程度的常用指标。
卫生统计学第二版习题册方积乾答案与解析

卫生统计学第二版习题册方积乾答案与解析第一章绪论1、统计资料可以分为那几种类型?举例说明不同类型资料之间是如何转换的?答:(1)1定量资料(离散型变量、连续型变量)、2无序分类资料(二项分类资料、无序多项分类资料)、3有序分类资料(即等级资料);(2)例如人的健康状况可分为“非常好、较好、一般、差、非常差”5个等级,应归为等级资料,若将该五个等级赋值为5、4、3、2、1,就可按定量资料处理。
2、统计工作可分为那几个步骤?答:设计、收集资料、整理资料、分析资料四个步骤。
3、举例说明小概率事件的含义。
答:某人打靶100次,中靶次数少于等于5,那么该人一次打中靶的概率≤0.05,即可称该人一次打中靶的事件为小概率事件,可以视为很可能不发生。
第二章调查研究设计1、调查研究有何特点?答:(1)不能人为施加干预措施;(2)不能随机分组;(3)很难控制干扰因素;(4)一般不能下因果结论2、四种常用的抽样方法各有什么特点?答:(1)单纯随机抽样:优点是操作简单,统计量的计算较简便:缺点是当总体观察单位数量庞大时,逐一编号繁复,有时难以做到。
(2)系统抽样:优点是易于理解、操作简便,被抽到的观察单位在总体中分布均匀,抽样误差较单纯随机抽样小:缺点是在某些情况下会出现偏性或周期性变化。
(3)分层抽样:优点是抽样误差小,各层可以独立进行统计分析,适合大规模统计:缺点是事先要进行分层,操作麻烦。
(4)整群抽样:优点是易于组织和操作大规模抽样调查:缺点是抽样误差大。
3、调查设计包括那些基本内容?答:(1)明确调查目的和指标;(2)确定调查对象和观察单位;(3)选释调查方法和技术;(4)估计样本大小;(5)编制调查表;(6)评价问卷的信度和效度;(7)制定资料的收集计划;(8)指定资料的整理与分析计划;(9)制定调查的组织措施。
4、调查表中包含那几种项目?答:(1)分析项目直接整理计算的必须的内容;(2)备查项目保证分析项目填写得完整和准确的内容;(3)其他项目大型调查表的前言和表底附注。
医学统计学李晓松主编第2版高等教育出版社附录第3章思考与练习答案

第三章实验研究设计【思考与练习】一、思考题1. 实验设计根据对象的不同可分为哪几类?2. 实验研究中,随机化的目的是什么?3. 什么是配对设计?它有何优缺点?4. 什么是交叉设计?它有何优缺点?5. 临床试验中使用安慰剂的目的是什么?二、案例辨析题“三联药物治疗士兵消化性溃疡”一文中,对2000~2006年在某卫生所采用三联药物治疗的38例消化性溃疡患者进行分析。
内镜检测结果显示,痊愈13人,显效14人,进步7人,无效4人,有效率达89.5%。
据此认为该三联疗法的疗效较好,且由于其价格适中,可在部队卫生所中推广。
该结论是否正确?如果不正确,请说明理由。
三、最佳选择题1. 实验设计的三个基本要素是A. 处理因素、实验效应、实验场所B. 处理因素、实验效应、受试对象C. 受试对象、研究人员、处理因素D. 受试对象、干扰因素、处理因素E. 处理因素、实验效应、研究人员2. 实验设计的三个基本原则是A. 随机化、对照、重复B. 随机化、对照、盲法C. 随机化、重复、盲法D. 均衡、对照、重复E. 盲法、对照、重复3. 实验组与对照组主要不同之处在于A. 处理因素B. 观察指标C. 抽样误差D. 观察时间E. 纳入、排除受试对象的标准4. 为了解某疗法对急性肝功能衰竭的疗效,用12头健康雌性良种幼猪建立急性肝功能衰竭模型,再将其随机分为两组,仅实验组给予该疗法治疗,对照组不给予任何治疗。
7天后观察两组幼猪的存活情况。
该研究采用的是A. 空白对照B. 安慰剂对照C. 实验对照D. 标准对照E. 自身对照5. 观察指标应具有A. 灵敏性、特异性、准确度、精密度、客观性B. 灵敏性、变异性、准确度、精密度、客观性C. 灵敏性、特异性、变异性、均衡性、稳定性D. 特异性、准确度、稳定性、均衡性、客观性E. 灵敏性、变异性、准确度、精密度、均衡性6. 比较两种疗法对乳腺癌的疗效,若两组患者的乳腺癌分期构成不同可造成A. 选择性偏倚B. 测量性偏倚C. 混杂性偏倚D. 信息偏倚E. 失访性偏倚7. 将两个或多个处理因素的各水平进行组合,对各种可能的组合都进行实验,该实验设计方案是A. 随机区组设计B. 完全随机设计C. 析因设计D. 配对设计E. 交叉设计8. 在某临床试验中,将180例患者随机分为两组,实验组给予试验药+对照药的模拟剂,对照给予对照药+试验药的模拟剂,整个过程中受试对象和研究者均不知道受试对象的分组。
医学统计学第二版习题

)描述其集中趋势。
14.( )小,表示用该样本均数估计总体均数的可靠性大。
A.变异系数 B.标准差 C.标准误 D.极差
15.血清学滴度资料最常用来表示其平均水平的指标是( )。
A.算术平均数 B.中位数 C.几何均数 D.平均数
16.变异系数 CV 的数值( )。
7.比较身高和体重两组数据变异度大小宜采用( )。
网 A.变异系数 B.方差 C.极差 D.标准差
8.以下指标中( )可用来描述计量资料的离散程度。
习 A.算术均数 B.几何均数 C.中位数 D.标准差
9.偏态分布宜用( )描述其分布的集中趋势。
学 A.算术均数 B.标准差 C.中位数 D.四分位数间距
38.甲、乙两人分别从随机数字表抽得 30 个(各取两位数字)随机数字作为两个样本,求得 X 1 ,S12 ,
X
2
,
S
2 2
,则理论上(
)。
A. X 1 = X 2 , S12 =Байду номын сангаасS22
om B.作两样本 t 检验,必然得出无差别的结论 c C.作两方差齐性的 F 检验,必然方差齐 . D.分别由甲、乙两样本求出的总体均数的 95%可信区间,很可能有重叠 j 39.以下关于参数点估计的说法正确的是( )。 t A.CV 越小,表示用该样本估计总体均数越可靠 00 B.σ X 越小,表示用该样本估计总体均数越准确 10 C.σ 越大,表示用该样本估计总体均数的可靠性越差
中 32.标准误的英文缩写为( )。
A.S B.SE C. S
D.SD
X
33.通常可采用以下那种方法来减小抽样误差( )。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
医学统计学第二版高等教育出版社课后习题答案第一章绪论
1.举例说明人口和样本的概念。
研究人员通常需要了解和研究某一类个体,这个类就是总体。
总体是根据研究目的所
确定的所有同质观察单位某种观察值(即变量值)的集合,通常有无限总体和有限总体之分,前者指总体中的个体是无限的,如研究药物疗效,某病患者就是无限总体,后者指总
体中的个体是有限的,它是指特定时间、空间中有限个研究个体。
但是,研究整个总体一
般并不实际,通常能研究的只是它的一部分,这个部分就是样本。
例如在一项关于2021
年西藏自治区正常成年男子的红细胞平均水平的调查研究中,该地2021年全部正常成年
男子的红细胞数就构成一个总体,从此总体中随即抽取2000人,分别测的其红细胞数,
组成样本,其样本含量为2000人。
2.简述误差的概念。
误差一般是指测量值与实际值之间的差值,一般分为随机误差和非随机误差。
随机误
差是指重复观测得到的实际观测值经常在某一值附近无方向波动的误差;最常见的非随机
误差是系统误差,也称为偏差。
正是这种误差使实际观测值偏离了实际值。
3.举例说明参数和统计量的概念。
一项研究通常希望了解人口的一些数字特征,这些特征被称为参数,例如整个城市的
高血压患病率。
根据样本计算的一些数字特征称为统计学,例如根据数百人的抽样调查数
据计算的样本人群中的高血压。
统计是研究人员可以知道的,参数是他们想知道的。
一般
来说,这些参数很难测量,只能通过样本进行估计。
显然,只有当样本代表总体时,根据
样本统计估计的总体参数才是合理的。
4.简述小概率事件原理。
当一个事件的概率小于或等于0.05时,它被用来在统计学中称该事件为低概率事件,这意味着该事件的概率非常小,因此认为不可能在一次采样中发生
是所谓的小概率事件原理,它是进行统计推断的重要基础。
第二章调查研究设计
1.调查研究主要特点是什么?
调查的主要特点是:① 研究对象及其相关因素(包括研究因素和非研究因素)是客
观存在的,不能人为地给出干预措施;② 随机分组不能用来平衡混杂因素对调查结果的
影响。
2.简述勘察设计的基本内容。
①明确调查目的和指标②确定调查对象和观察单位③确定调查方法④确定调查方式⑤
确定调查项目和调查表⑥制定资料整理分析计划⑦制定调查的组织计划。
3.试比较常用的
四种概率抽样方法的优缺点。
(1)简单随机抽样的优点是,平均值(或比率)和标准误差的计算很简单。
缺点是,当整个观测单元的数量较大时,逐个对观测单元进行编号很麻烦,这在实际工作中有时很
难做到。
(2)系统抽样优点是:①易于理解,简便易行②容易得到一个按比例分配的样本,
由于样本相应的顺序号在总体中是均匀散布的,其抽样误差小于单纯随机抽样。
缺点是:
①当总体的观察单位按顺序有周期趋势或单调递增(或递减)趋势,系统抽样将产生明显
的偏性。
但对于适合采用系统抽样的情形,一旦确定了抽样间隔,就必须严格遵守,不能
随意更改,否则可能造成另外的系统误差②实际工作中一般按单纯随机抽样方法估计抽样
误差,因此这样计算得到的抽样误差一般偏大。
(3)分层抽样的优点是:① 减少采样误差:分层后,层内的均匀性增加,因此观
测值的可变性减小,各层的采样误差减小。
就样本含量而言,标准误差通常小于简单随机
抽样、系统抽样和整群抽样的标准误差。
② 便于不同层次采用不同的抽样方法,有利于
调查组织工作的开展。
③ 它还可以在不同层面上进行独立分析。
缺点是:当需要确定的
层数较大时,操作麻烦,在实际工作中难以实现。
(4)整群抽样优点是:便于组织,节省经费,容易控制调查质量;缺点是:当样本
含量一定时,其抽样误差一般大于单纯随机抽样的误差,。
4.常用的非概率抽样方法有哪些?
有偶然抽样、目的抽样、配额抽样、滚雪球抽样等。
简要描述调查问题的顺序。
调查问题顺序安排总原则:①符合逻辑②一般问题在前,特殊问题在后③易答题在前,难答题在后④如果采用封闭式和开放式相结合的问题,一般先设置封闭式问题⑤敏感问题
一般放在最后。
此外,在考虑问题顺序时,还应注意问题是否适合全部调查对象,并采用
跳答的形式安排问题和给出指导语。
第四章定量数据的统计描述
1.均数、中位数、几何均数的适用范围有何异同?
同一点用于描述定量数据的集中趋势。
差异:① 均值用于单峰对称分布,尤其是正
态分布或近似正态分布的数据;② 几何平均用于变量值之间存在多重关系的偏态分布数据,尤其是对数变换后的正态分布或近似正态分布数据;③ 中位数用于两端无精确值的
非对称分布数据和分布不明确的数据。
2.相同数据的标准偏差是否一定小于平均值?
同一资料的标准差不一定小于均数。
均数描述的是一组同质定量变量的平均水平,而
标准差是描述单峰对称分布资料离散程度最常用的指标。
标准差大,表示观察值之间变异
大,即一组观察值的分布较分散;标准差小。
表示观察值之间变异小,即一组观察值的分
布较集中。
若标准差远大于均数表明数据离散程度较大,可能为偏态分布,此时应考虑改
用其他指标来描述资料的集中趋势。
3.极差、四分位数间距、标准差、变异系数的适用范
围有何异同?
同一点用于描述数据的分散性。
差异:① 范围可以用来描述单峰对称分布小样本数
据的分散程度,也可以用来初步了解数据的变化程度;② 四分位间距可用于
描述偏态分布资料、两端无确切值或分布不明确的资料的离散程度③标准差用于描述
正态分布或近似正态分布资料的离散程度④变异系数用于比较几组计量单位不同或均数相
差悬殊的正态分布资料的离散程度。
4.正态分布有哪些基本特征?
① 正态曲线在水平轴上方的平均值处最高② 正态分布以平均值为中心,左右对称③ 正态分布有两个参数,即位置参数μ和形态参数σ④ 正态曲线下的面积分布有一定规律,正态曲线与水平轴之间的面积等于1。
曲线下区间(μ-1点九六σ,μ+1点九六σ)的
面积为95.00%;区间(μ-两点五八σ,μ+两点五八σ)区域为99.00%5.5制定医学参
考值范围时,正态分布法和百分位数法适用于哪些数据?① 通过大量调查,证实了符合
正态分布或近似正态分布的变量可以根据正态分布曲线下面积的规律来制定医学参考值范围。
对于服从对数正态分布的变量,可以取观测值的对数,按照正态分布法计算医学参考
值范围的对数,然后计算反对数② 对于正态性检验后不服从正态分布的变量,应采用百
分位数法制定医学参考值范围。
第五章、定性资料的统计描述
1.应用相对数时应注意什么?
①应有足够的观察单位数;②不能以构成比代替率;③计算观察单位数不等的及格率
的合计率和平均率时,不能简单的把各组率相加求其平均值而得,而应该分别将分子和分
母合计,再求出合计率和平均率;④相对数的比较应注意其可比性,如果内部构成不同,
应计算标准化率;⑤样品率或样品构成比的比较应作检验假设。
2.为什么组成比率不能代替比率?
率是指某现象实际发生数和某时间点或某时间段可能发生该现象的观察单位总数之比,用以说明该现象发生的频率或强度。
构成比是指事物内部某一组成部分观察单位数与同一
事物各组成部分的观察单位总数之比,以说明事物内部各组成部分所占比重,不能说明某
现象发生的频率或强度大小。
3.在计算标准化率时,采用直接法和间接法有什么区别?
如对死亡率的年龄构成标准化,当已知被标化组的年龄别死亡率时,宜采用直接法;
当不知道被标化组的年龄别死亡率,只有年龄别人口数和死亡总数时,可采用间接法。
4.常用的动态系列分析指标是什么?它们的目的是什么?
绝对增长量、发展速度与增长速度、平均发展速度与平均增长速度。
绝对增长是指一定时期内事物和现象增长的绝对价值;发展速度和增长速度是反映一定时期内事物和现象变化速度的相对指标;平均发展速度是指一条链在一定时期内发展速度的平均值,用来解释事物在一定时期内逐年的平均发展速度;而平均增长率是指事物在一定时期内逐年的平均增长率。
5.费率标准化应注意哪些问题?
①仅用于相互间的比较,实际水平应采用未标化率来反映。
②样品的标化率是样品指标,存在抽样误差,若要比较其代表的总体标准化率是否相同,需作假设检验。
③注意直接法和间接法的选用。
④各年龄组若出现明显交叉,或呈非平行变化趋势时,不适合采用标准化法,宜分层比较各年龄组率。
此外,对于因其他条件不同,而非内部构成不同引起的不可比性问题,标准化法难以解决。
第六章总体均值的估计
1、什么是均数的抽样误差?决定均数的抽样误差大小的因素有哪些?抽样研究中,由于同质总体中的个体间存在差异,即个体变异,因而从同一总体中随机抽取若干样本,样本均数往往不等于总体均数,且各样本均数之间也存在差异。
这种由个体变异产生的、随机抽样引起的样本均数与总体均数间的差异称均数的抽样误差。
决定均数抽样误差大小的因素主要为样本含量和标准差。
2、样本均数的抽样分布有何特点?
样本均值的抽样分布特征如下:1。
每个样本的平均值可能不等于总平均值;2.所有样品。