(H)图的遍历问题
图的遍历算法

1图的遍历问题在实践中常常遇到这样的问题:给定n个点,从任一点出发对所有的点访问一次并且只访问一次。
如果用图中的顶点表示这些点,图中的边表示可能的连接,那么这个问题就可以表示成图的遍历问题,即从某个顶点出发,沿着某条搜索路径对图中每个顶点各做一次且仅做一次访问。
图的遍历操作和树的遍历操作功能相似,是图的一种基本操作,图的许多其它操作都是建立在遍历操作的基础上。
由于图结构本身的复杂性,所以图的遍历操作也比较复杂,主要表现在以下几个方面:(1) 在图结构中,没有一个确定的首结点,图中任意一个顶点都可以作为第一个被访问的结点。
(2) 在非连通图中,从一个顶点出发,只能够访问它所在的连通分量上的所有顶点,因此,还需要考虑如何选取下一个出发点以访问图中其余的连通分量。
(3) 在图结构中,如果有回路存在,那么一个顶点被访问后,有可能沿回路又回到该顶点。
⑷在图结构中,一个顶点可以和其它多个顶点相连,当这样的顶点访问过后,存在如何选取下一个要访问的顶点的问题。
基于以上分析,图的遍历方法目前有深度优先搜索(DFS)和广度优先搜索(BFS)两种算法。
下面将介绍两种算法的实现思路,分析算法效率并编程实现。
1.1深度优先搜索算法深度优先搜索算法是树的先根遍历的推广,它的实现思想是:从图G的某个顶点V o出发,访问V o,然后选择一个与V o相邻且没被访问过的顶点V i访问,再从V i出发选择一个与V i相邻且未被访问的顶点V j进行访问,依次继续。
如果当前被访问过的顶点的所有邻接顶点都已被访问,贝U退回已被访问的顶点序列中最后一个拥有未被访问的相邻顶点的顶点W,从W出发按同样的方法向前遍历,直到图中所有顶点都被访问。
其递归算法如下:Boolean visited[MAX_VERTEX_NUM]; // 访问标志数组Status (*VisitFunc)(int v); //VisitFunc是访问函数,对图的每个顶点调用该函数void DFSTraverse (Graph G Status(*Visit)(i nt v)){VisitF unc = Visit;for(v=0; vvG.vex num; ++v)visited[v] = FALSE; //访问标志数组初始化for(v=0; v<G .vex num; ++v)if(!visited[v])DFS(G v); //对尚未访问的顶点调用DFS}void DFS(Graph G int v){ //从第v个顶点出发递归地深度优先遍历图Gvisited[v]=TRUE; VisitFunc(v); // 访问第v 个顶点for(w=FirstAdjVex(G ,v); w>=0;w=NextAdjVex(G ,v,w))//FirstAdjVex返回v的第一个邻接顶点,若顶点在G中没有邻接顶点,则返回空(0)。
第15讲图的遍历

V6
V8
V8
V7
V5 深度优先生成树
V8 V1
V2
V3
V4 V5 V6 V7
V8 广度优先生成树
27
例A
B
CD E
F
GH
I
K
J
L
M
A
D
G
LCF
KI E
H M
JB
深度优先生成森林
28
二、图的连通性问题
▪1、生成树和生成森林
▪ 说明
G
▪ 一个图可以有许多棵不同的生成树
KI
▪ 所有生成树具有以下共同特点:
g.NextAdjVex(v, w))
{
if (g.GetTag(w) == UNVISITED)
{
g.SetTag(w, VISITED);
g.GetElem(w, e);
Visit(e);
q.InQueue(w);
}
}}}
24
一、图的遍历 两种遍历的比较
V0
V1 V4
V0
V1 V4
V3
V2 V5
16
一、图的遍历
广度优先遍历序列?入队序列?出队序列?
V1
V2
V3
V1
V4
V5 V6
V7
V8
遍历序列: V1
17
一、图的遍历
广度优先遍历序列?入队序列?出队序列?
V1
V2
V3
V2 V3
V4
V5 V6
V7
V8
遍历序列: V1 V2 V3
18
一、图的遍历
广度优先遍历序列?入队序列?出队序列?
V1
V2
数据结构实验报告图的遍历讲解

数据结构实验报告图的遍历讲解一、引言在数据结构实验中,图的遍历是一个重要的主题。
图是由顶点集合和边集合组成的一种数据结构,常用于描述网络、社交关系等复杂关系。
图的遍历是指按照一定的规则,挨次访问图中的所有顶点,以及与之相关联的边的过程。
本文将详细讲解图的遍历算法及其应用。
二、图的遍历算法1. 深度优先搜索(DFS)深度优先搜索是一种常用的图遍历算法,其基本思想是从一个顶点出发,沿着一条路径向来向下访问,直到无法继续为止,然后回溯到前一个顶点,再选择此外一条路径继续访问。
具体步骤如下:(1)选择一个起始顶点v,将其标记为已访问。
(2)从v出发,选择一个未被访问的邻接顶点w,将w标记为已访问,并将w入栈。
(3)如果不存在未被访问的邻接顶点,则出栈一个顶点,继续访问其它未被访问的邻接顶点。
(4)重复步骤(2)和(3),直到栈为空。
2. 广度优先搜索(BFS)广度优先搜索是另一种常用的图遍历算法,其基本思想是从一个顶点出发,挨次访问其所有邻接顶点,然后再挨次访问邻接顶点的邻接顶点,以此类推,直到访问完所有顶点。
具体步骤如下:(1)选择一个起始顶点v,将其标记为已访问,并将v入队。
(2)从队首取出一个顶点w,访问w的所有未被访问的邻接顶点,并将这些顶点标记为已访问,并将它们入队。
(3)重复步骤(2),直到队列为空。
三、图的遍历应用图的遍历算法在实际应用中有广泛的应用,下面介绍两个典型的应用场景。
1. 连通分量连通分量是指图中的一个子图,其中的任意两个顶点都是连通的,即存在一条路径可以从一个顶点到达另一个顶点。
图的遍历算法可以用来求解连通分量的个数及其具体的顶点集合。
具体步骤如下:(1)对图中的每一个顶点进行遍历,如果该顶点未被访问,则从该顶点开始进行深度优先搜索或者广度优先搜索,将访问到的顶点标记为已访问。
(2)重复步骤(1),直到所有顶点都被访问。
2. 最短路径最短路径是指图中两个顶点之间的最短路径,可以用图的遍历算法来求解。
2022年吉首大学计算机科学与技术专业《数据结构与算法》科目期末试卷A(有答案)

2022年吉首大学计算机科学与技术专业《数据结构与算法》科目期末试卷A(有答案)一、选择题1、下列说法不正确的是()。
A.图的遍历是从给定的源点出发每个顶点仅被访问一次B.遍历的基本方法有两种:深度遍历和广度遍历C.图的深度遍历不适用于有向图D.图的深度遍历是一个递归过程2、用数组r存储静态链表,结点的next域指向后继,工作指针j指向链中结点,使j沿链移动的操作为()。
A.j=r[j].nextB.j=j+lC.j=j->nextD.j=r[j]->next3、算法的计算量的大小称为计算的()。
A.效率B.复杂性C.现实性D.难度4、有六个元素6,5,4,3,2,1顺序入栈,下列不是合法的出栈序列的是()。
A.543612B.453126C.346521D.2341565、下面关于串的叙述中,不正确的是()。
A.串是字符的有限序列B.空串是由空格构成的串C.模式匹配是串的一种重要运算D.串既可以采用顺序存储,也可以采用链式存储6、下列关于无向连通图特性的叙述中,正确的是()。
Ⅰ.所有的顶点的度之和为偶数Ⅱ.边数大于顶点个数减1 Ⅲ.至少有一个顶点的度为1 A.只有Ⅰ B.只有Ⅱ C.Ⅰ和Ⅱ D.Ⅰ和Ⅲ7、下列选项中,不能构成折半查找中关键字比较序列的是()。
A.500,200,450,180 B.500,450,200,180C.180,500,200,450 D.180,200,500,4508、一棵哈夫曼树共有215个结点,对其进行哈夫曼编码,共能得到()个不同的码字。
A.107B.108C.214D.2159、在下述结论中,正确的有()。
①只有一个结点的二叉树的度为0。
②二叉树的度为2。
③二叉树的左右子树可任意交换。
④深度为K的完全二叉树的结点个数小于或等于深度相同的满二叉树。
A.①②③B.⑦③④C.②④D.①④10、在文件“局部有序”或文件长度较小的情况下,最佳内部排序的方法是()。
《图的遍历》练习

写一个程序统计出共有多少颗珍珠肯定不会有中间重量。 【输入格式】
输入文件第 1 行包含两个用空格隔开的整数 N(1<=N<=99)和 M,且 N 为奇数,M 表示 对珍珠进行的比较次数,接下来的 M 行每行包含两个用空格隔开的整数 x 和 y,表示珍珠 x 比珍珠 y 重。 【输出格式】
输出文件仅一行,包含一个整数,表示不可能是中间重量的珍珠的总数 【样例输入】 54
《图的遍历》练习
【问题描述】
1、珍珠(bead)
有 n 颗形状和大小都一致的珍珠,它们的重量都不相同。n 为整数,所有的珍珠从 1 到 n 编号。你的任务是发现哪颗珍珠的重量刚好处于正中间。即在所有珍珠的重量重,该 珍珠的重量列(n+1)/2 位。下面给出将一对珍珠进行比较的办法:
给你一架天平用来比较珍珠的重量,我们可以比出两个珍珠哪个更重一些,在作出一 系列的比较后,我们可以将某些肯定不具备中间重量的珍珠拿走。
每一个栅栏连接两个顶点,顶点用 1 到 500 标号(虽然有的农场并没有 500 个顶点)。一 个顶点上可连接任意多(>=1)个栅栏。所有栅栏都是连通的(也就是你可以从任意一个栅栏到 达另外的所有栅栏)。
你的程序必须输出骑马的路径(用路上依次经过的顶点号码表示)。我们如果把输出的路 径看出是一个 500 进制的数,那么当存在多组解的情况下,输出 500 进制表示法中最小的一 个(也就是输出第一个数较小的,如果还有多组解,输出第二个数较小的...)。输入数据保证 至少有一个解。 【输入格式】
第 1 行:一个整数 F(1<=F<=1024),表示栅栏的数目。 第 2 到 F+1 行:每行两个整数 i,j(1<=i,j<=500),表示这条栅栏连接 i 与 j 号顶点。 【输出格式】 对于每组数据输出应当有 F+1 行,每行一个整数,依次表示路径经过的顶点号。注意数 据可能有多组解,但是只有上面题目要求的第一组解是认为正确的。 【样例输入】 9 12 23
图的遍历操作实验报告

-实验三、图的遍历操作一、目的掌握有向图和无向图的概念;掌握邻接矩阵和邻接链表建立图的存储构造;掌握DFS及BFS对图的遍历操作;了解图构造在人工智能、工程等领域的广泛应用。
二、要求采用邻接矩阵和邻接链表作为图的存储构造,完成有向图和无向图的DFS 和BFS操作。
三、DFS和BFS 的根本思想深度优先搜索法DFS的根本思想:从图G中*个顶点Vo出发,首先访问Vo,然后选择一个与Vo相邻且没被访问过的顶点Vi访问,再从Vi出发选择一个与Vi相邻且没被访问过的顶点Vj访问,……依次继续。
如果当前被访问过的顶点的所有邻接顶点都已被访问,则回退到已被访问的顶点序列中最后一个拥有未被访问的相邻顶点的顶点W,从W出发按同样方法向前遍历。
直到图中所有的顶点都被访问。
广度优先算法BFS的根本思想:从图G中*个顶点Vo出发,首先访问Vo,然后访问与Vo相邻的所有未被访问过的顶点V1,V2,……,Vt;再依次访问与V1,V2,……,Vt相邻的起且未被访问过的的所有顶点。
如此继续,直到访问完图中的所有顶点。
四、例如程序1.邻接矩阵作为存储构造的程序例如#include"stdio.h"#include"stdlib.h"#define Ma*Verte*Num 100 //定义最大顶点数typedef struct{char ve*s[Ma*Verte*Num]; //顶点表int edges[Ma*Verte*Num][Ma*Verte*Num]; //邻接矩阵,可看作边表int n,e; //图中的顶点数n和边数e}MGraph; //用邻接矩阵表示的图的类型//=========建立邻接矩阵=======void CreatMGraph(MGraph *G){int i,j,k;char a;printf("Input Verte*Num(n) and EdgesNum(e): ");scanf("%d,%d",&G->n,&G->e); //输入顶点数和边数scanf("%c",&a);printf("Input Verte* string:");for(i=0;i<G->n;i++){scanf("%c",&a);G->ve*s[i]=a; //读入顶点信息,建立顶点表}for(i=0;i<G->n;i++)for(j=0;j<G->n;j++)G->edges[i][j]=0; //初始化邻接矩阵printf("Input edges,Creat Adjacency Matri*\n");for(k=0;k<G->e;k++) { //读入e条边,建立邻接矩阵 scanf("%d%d",&i,&j); //输入边〔Vi,Vj〕的顶点序号G->edges[i][j]=1;G->edges[j][i]=1; //假设为无向图,矩阵为对称矩阵;假设建立有向图,去掉该条语句}}//=========定义标志向量,为全局变量=======typedef enum{FALSE,TRUE} Boolean;Boolean visited[Ma*Verte*Num];//========DFS:深度优先遍历的递归算法======void DFSM(MGraph *G,int i){ //以Vi为出发点对邻接矩阵表示的图G进展DFS搜索,邻接矩阵是0,1矩阵 int j;printf("%c",G->ve*s[i]); //访问顶点Vivisited[i]=TRUE; //置已访问标志for(j=0;j<G->n;j++) //依次搜索Vi的邻接点if(G->edges[i][j]==1 && ! visited[j])DFSM(G,j); //〔Vi,Vj〕∈E,且Vj未访问过,故Vj为新出发点}void DFS(MGraph *G){int i;for(i=0;i<G->n;i++)visited[i]=FALSE; //标志向量初始化for(i=0;i<G->n;i++)if(!visited[i]) //Vi未访问过DFSM(G,i); //以Vi为源点开场DFS搜索}//===========BFS:广度优先遍历=======void BFS(MGraph *G,int k){ //以Vk为源点对用邻接矩阵表示的图G进展广度优先搜索 int i,j,f=0,r=0;int cq[Ma*Verte*Num]; //定义队列for(i=0;i<G->n;i++)visited[i]=FALSE; //标志向量初始化for(i=0;i<G->n;i++)cq[i]=-1; //队列初始化printf("%c",G->ve*s[k]); //访问源点Vkvisited[k]=TRUE;cq[r]=k; //Vk已访问,将其入队。
图的遍历的实验报告

图的遍历的实验报告图的遍历的实验报告一、引言图是一种常见的数据结构,它由一组节点和连接这些节点的边组成。
图的遍历是指从图中的某个节点出发,按照一定的规则依次访问图中的所有节点。
图的遍历在许多实际问题中都有广泛的应用,例如社交网络分析、路线规划等。
本实验旨在通过实际操作,深入理解图的遍历算法的原理和应用。
二、实验目的1. 掌握图的遍历算法的基本原理;2. 实现图的深度优先搜索(DFS)和广度优先搜索(BFS)算法;3. 比较并分析DFS和BFS算法的时间复杂度和空间复杂度。
三、实验过程1. 实验环境本实验使用Python编程语言进行实验,使用了networkx库来构建和操作图。
2. 实验步骤(1)首先,我们使用networkx库创建一个包含10个节点的无向图,并添加边以建立节点之间的连接关系。
(2)接下来,我们实现深度优先搜索算法。
深度优先搜索从起始节点开始,依次访问与当前节点相邻的未访问过的节点,直到遍历完所有节点或无法继续访问为止。
(3)然后,我们实现广度优先搜索算法。
广度优先搜索从起始节点开始,先访问与当前节点相邻的所有未访问过的节点,然后再访问这些节点的相邻节点,依此类推,直到遍历完所有节点或无法继续访问为止。
(4)最后,我们比较并分析DFS和BFS算法的时间复杂度和空间复杂度。
四、实验结果经过实验,我们得到了如下结果:(1)DFS算法的时间复杂度为O(V+E),空间复杂度为O(V)。
(2)BFS算法的时间复杂度为O(V+E),空间复杂度为O(V)。
其中,V表示图中的节点数,E表示图中的边数。
五、实验分析通过对DFS和BFS算法的实验结果进行分析,我们可以得出以下结论:(1)DFS算法和BFS算法的时间复杂度都是线性的,与图中的节点数和边数呈正比关系。
(2)DFS算法和BFS算法的空间复杂度也都是线性的,与图中的节点数呈正比关系。
但是,DFS算法的空间复杂度比BFS算法小,因为DFS算法只需要保存当前路径上的节点,而BFS算法需要保存所有已访问过的节点。
图的遍历和搜索PPT课件

7
1
2 4
3 5
Dfs: 124356
6
2021/3/12
8
1
2 4
3
6
5
Bfs: 123645
2021/3/12
9
A
B
C
D
E
2021/3/12
10
A
AB
AC
ABC
ACD ACE
ABCD ABCE ACDE ACED
ABCDE ABCDE ACDEC
ACEDC
ABCDEC ABCDEC ACDECB
readln(f,ch1,ch2,ch3); data[ch1,ch3]:=1; data[ch3,ch1]:=1; end; close(f);assign(f,'wjx.out');rewrite(f); end;
2021/3/12
14
procedure main(ch:char;step:integer); var r:char; begin
2021/3/12
3
1
2
3
4
6
5
Dfs: 124563 Bfs: 123465
2021/3/12
4
1 2 4 5 6 3
Dfs: 124563
2021/3/12
5
1
2
3
4
6
5
Bfs: 123465
2021/3/12
6
1
2
3
4
5
6
Dfs: 124356 Bfs: 123645
2021/3/12
2021/3/12
22
一. 递归算法:
图的遍历实验报告

1.问题描述:不少涉及图上操作的算法都是以图的遍历操作为基础的。
试写一个程序,演示在连通的无向图上访问全部结点的操作。
2.基本要求:以邻接表为存储结构,实现连通无向图的深度优先和广度优先遍历。
以用户指定的结点为起点,分别输出每种遍历下的结点访问序列和相应生成树的边集。
3.测试数据:教科书图7.33。
暂时忽略里程,起点为北京。
4.实现提示:设图的结点不超过30个,每一个结点用一个编号表示(如果一个图有n个结点,则它们的编号分别为1,2,…,n)。
通过输入图的全部边输入一个图,每一个边为一个数对,可以对边的输入顺序作出某种限制,注意,生成树的边是有向边,端点顺序不能颠倒。
5.选作内容:(1) .借助于栈类型(自己定义和实现),用非递归算法实现深度优先遍历。
(2) .以邻接表为存储结构,建立深度优先生成树和广度优先生成树,再按凹入表或者树形打印生成树。
1.为实现上述功能,需要有一个图的抽象数据类型。
该抽象数据类型的定义为:ADT Graph{V 是具有相同特性的数据元素的集合,称为顶点集。
R={VR}VR={<v,w> | v ,w v 且P(v,w),<v,w>表示从v 到w 得弧,谓词P(v,w)定义了弧<v,w>的意义或者信息}} ADT Graph2.此抽象数据类型中的一些常量如下:#define TRUE 1#define FALSE 0#define OK 1#define max_n 20 //最大顶点数typedef char VertexType[20];typedef enum{DG, DN, AG, AN} GraphKind;enum BOOL{False,True};3.树的结构体类型如下所示:typedef struct{ //弧结点与矩阵的类型int adj; //VRType为弧的类型。
图--0,1;网--权值int *Info; //与弧相关的信息的指针,可省略}ArcCell, AdjMatrix[max_n][max_n];typedef struct{VertexType vexs[max_n]; //顶点AdjMatrix arcs; //邻接矩阵int vexnum, arcnum; //顶点数,边数}MGraph;//队列的类型定义typedef int QElemType;typedef struct QNode{QElemType data;struct QNode *next;}QNode, *QueuePtr;typedef struct{QueuePtr front;QueuePtr rear;}LinkQueue;4.本程序包含三个模块1).主程序模块void main( ){创建树;深度优先搜索遍历;广度优先搜索遍历;}2).树模块——实现树的抽象数据类型3).遍历模块——实现树的深度优先遍历和广度优先遍历各模块之间的调用关系如下:主程序模块树模块遍历模块#include "stdafx.h"#include<iostream>using namespace std;#define TRUE 1#define FALSE 0#define OK 1#define max_n 20 //最大顶点数typedef char VertexType[20];typedef enum{DG, DN, AG, AN} GraphKind;enum BOOL{False,True};typedef struct{ //弧结点与矩阵的类型int adj; //VRType为弧的类型。
数据结构考试试题

数据结构考试试题一、选择题(每题2分,共20分)1. 在数据结构中,队列是一种______。
A. 线性结构B. 非线性结构C. 树形结构D. 图结构2. 对于长度为n的线性表,在顺序存储结构中,从第i个元素(1≤i≤n)开始,连续做m(1≤m≤n-i+1)个元素的删除操作,需要进行的移动元素次数为______。
A. mB. n-mC. i+m-1D. m+n-m-13. 在二叉树的遍历中,先序遍历的顺序是______。
A. 根左右B. 左右根C. 左根右D. 左右根4. 哈希表的冲突可以通过多种方式解决,其中不是解决冲突的方法是______。
A. 开放寻址法B. 链地址法C. 建立一个公共溢出区D. 二分查找法5. 排序算法中,时间复杂度为O(nlogn)的算法是______。
A. 选择排序B. 冒泡排序C. 快速排序D. 插入排序6. 在图的遍历中,深度优先搜索(DFS)使用的是______。
A. 栈B. 队列C. 哈希表D. 数组7. 堆排序算法中,将堆中的最后一个元素和第一个元素交换,然后重新调整堆的过程称为______。
A. 堆调整B. 堆缩小C. 堆替换D. 堆重建8. 一个长度为n的链表,删除已知第k个元素的时间复杂度是______。
A. O(1)B. O(n)C. O(k)D. O(nk)9. 字符串“Knuth”在一棵二叉查找树中,按照K->n->u->t->h的顺序插入后,使用中序遍历得到的结果是______。
A. hKnuctB. hnKutC. hKnutD. hnuct10. 对于长度为n的数组,如果使用归并排序算法进行排序,其时间复杂度为______。
A. O(n)B. O(n^2)C. O(nlogn)D. O(logn)二、简答题(每题5分,共30分)11. 请简述什么是时间复杂度,并给出最好、最坏和平均时间复杂度的定义。
12. 解释一下什么是平衡二叉树,并说明它在数据结构中的重要性。
图的遍历问题

HUNAN UNIVERSITY数据结构实验报告题目:图的遍历问题学生姓名梁天学生学号************专业班级计科1403指导老师夏艳日期2016.05.14背景网络蜘蛛即Web Spider,是一个很形象的名字。
把互联网比喻成一个蜘蛛网,那么Spider 就是在网上爬来爬去的蜘蛛。
网络蜘蛛是通过网页的链接地址来寻找网页,从网站某一个页面(通常是首页)开始,读取网页的内容,找到在网页中的其它链接地址,然后通过这些链接地址寻找下一个网页,这样一直循环下去,直到把这个网站所有的网页都抓取完为止。
如果把整个互联网当成一个网站,那么网络蜘蛛就可以用这个原理把互联网上所有的网页都抓取下来。
这样看来,网络蜘蛛就是一个爬行程序,一个抓取网页的程序。
在抓取网页的时候,网络蜘蛛一般有两种策略:广度优先和深度优先(如下面这张简单化的网页连接模型图所示,其中A为起点也就是蜘蛛索引的起点)。
深度优先顾名思义就是让网络蜘蛛尽量的在抓取网页时往网页更深层次的挖掘进去讲究的是深度!也泛指: 网络蜘蛛将会从起始页开始,一个链接一个链接跟踪下去,处理完这条线路之后再转入下一个起始页,继续跟踪链接! 则访问的节点顺序为==> A --> B --> E --> H --> I --> C --> D --> F --> K --> L --> G。
深度爬行的优点是:网络蜘蛛程序在设计的时候相对比较容易些;缺点是每次爬行一层总要向"蜘蛛老家" 数据库访问一下。
问问老总有必要还要爬下一层吗! 爬一层问一次.... 如果一个蜘蛛不管3721不断往下爬很可能迷路更有可能爬到国外的网站去,不仅增加了系统数据的复杂度更是增加的服务器的负担。
广度优先在这里的定义就是层爬行,即一层一层的爬行,按照层的分布与布局去索引处理与抓取网页。
则访问的节点顺序为==> A --> B --> C --> D --> E --> F --> G --> H --> I--> K --> L。
图的遍历实验报告

图的遍历实验报告图的遍历实验报告一、引言图是一种常见的数据结构,广泛应用于计算机科学和其他领域。
图的遍历是指按照一定规则访问图中的所有节点。
本实验通过实际操作,探索了图的遍历算法的原理和应用。
二、实验目的1. 理解图的遍历算法的原理;2. 掌握深度优先搜索(DFS)和广度优先搜索(BFS)两种常用的图遍历算法;3. 通过实验验证图的遍历算法的正确性和效率。
三、实验过程1. 实验环境准备:在计算机上安装好图的遍历算法的实现环境,如Python编程环境;2. 实验数据准备:选择合适的图数据进行实验,包括图的节点和边的信息;3. 实验步骤:a. 根据实验数据,构建图的数据结构;b. 实现深度优先搜索算法;c. 实现广度优先搜索算法;d. 分别运行深度优先搜索和广度优先搜索算法,并记录遍历的结果;e. 比较两种算法的结果,分析其异同点;f. 对比算法的时间复杂度和空间复杂度,评估其性能。
四、实验结果与分析1. 实验结果:根据实验数据和算法实现,得到了深度优先搜索和广度优先搜索的遍历结果;2. 分析结果:a. 深度优先搜索:从起始节点出发,一直沿着深度方向遍历,直到无法继续深入为止。
该算法在遍历过程中可能产生较长的路径,但可以更快地找到目标节点,适用于解决一些路径搜索问题。
b. 广度优先搜索:从起始节点出发,按照层次顺序逐层遍历,直到遍历完所有节点。
该算法可以保证找到最短路径,但在遍历大规模图时可能需要较大的时间和空间开销。
五、实验总结1. 通过本次实验,我们深入理解了图的遍历算法的原理和应用;2. 掌握了深度优先搜索和广度优先搜索两种常用的图遍历算法;3. 通过实验验证了算法的正确性和效率;4. 在实际应用中,我们需要根据具体问题的需求选择合适的遍历算法,权衡时间复杂度和空间复杂度;5. 进一步研究和优化图的遍历算法,可以提高算法的性能和应用范围。
六、参考文献[1] Cormen, T. H., Leiserson, C. E., Rivest, R. L., & Stein, C. (2009). Introduction to Algorithms (3rd ed.). MIT Press.[2] Sedgewick, R., & Wayne, K. (2011). Algorithms (4th ed.). Addison-Wesley Professional.。
图的遍历算法实验报告

图的遍历算法实验报告
《图的遍历算法实验报告》
在计算机科学领域,图的遍历算法是一种重要的算法,它用于在图数据结构中
访问每个顶点和边。
图的遍历算法有两种常见的方法:深度优先搜索(DFS)
和广度优先搜索(BFS)。
在本实验中,我们将对这两种算法进行实验,并比较
它们的性能和应用场景。
首先,我们使用深度优先搜索算法对一个简单的无向图进行遍历。
通过实验结
果可以看出,DFS算法会首先访问一个顶点的所有邻居,然后再递归地访问每
个邻居的邻居,直到图中所有的顶点都被访问到。
这种算法在一些应用场景中
非常有效,比如寻找图中的连通分量或者寻找图中的环路。
接下来,我们使用广度优先搜索算法对同样的无向图进行遍历。
通过实验结果
可以看出,BFS算法会首先访问一个顶点的所有邻居,然后再按照距离递增的
顺序访问每个邻居的邻居。
这种算法在一些应用场景中也非常有效,比如寻找
图中的最短路径或者寻找图中的最小生成树。
通过对比实验结果,我们可以发现DFS和BFS算法各自的优势和劣势。
DFS算
法适合用于寻找图中的连通分量和环路,而BFS算法适合用于寻找最短路径和
最小生成树。
因此,在实际应用中,我们需要根据具体的需求来选择合适的算法。
总的来说,图的遍历算法是计算机科学中非常重要的算法之一,它在许多领域
都有着广泛的应用。
通过本次实验,我们对DFS和BFS算法有了更深入的了解,并且对它们的性能和应用场景有了更清晰的认识。
希望通过这篇实验报告,读
者们也能对图的遍历算法有更深入的理解和认识。
图的遍历实验报告

实验五图的基本操作一、实验目的1、使学生可以巩固所学的有关图的基本知识。
2、熟练掌握图的存储结构。
3、熟练掌握图的两种遍历算法。
二、实验内容[问题描述]对给定图,实现图的深度优先遍历和广度优先遍历。
[基本要求]以邻接表为存储结构,实现连通无向图的深度优先和广度优先遍历。
以用户指定的结点为起点,分别输出每种遍历下的结点访问序列。
【测试数据】由学生依据软件工程的测试技术自己确定。
三、实验前的准备工作1、掌握图的相关概念。
2、掌握图的逻辑结构和存储结构。
3、掌握图的两种遍历算法的实现。
四、实验报告要求1、实验报告要按照实验报告格式规范书写。
2、实验上要写出多批测试数据的运行结果。
3、结合运行结果,对程序进行分析。
编程思路:深度优先算法:计算机程序的一种编制原理,就是在一个问题出现多种可以实现的方法和技术的时候,应该优先选择哪个更合适的,也是一种普遍的逻辑思想,此种思想在运算的过程中,用到计算机程序的一种递归的思想。
度优先搜索算法:又称广度优先搜索,是最简便的图的搜索算法之一,这一算法也是很多重要的图的算法的原型。
Dijkstra单源最短路径算法和Prim 最小生成树算法都采用了和宽度优先搜索类似的思想。
其别名又叫BFS,属于一种盲目搜寻法,目的是系统地展开并检查图中的所有节点,以找寻结果。
换句话说,它并不考虑结果的可能位址,彻底地搜索整张图,直到找到结果为止。
以临接链表作为存储结构,结合其存储特点和上面两种算法思想,给出两种遍历步骤:(1)既然图中没有确定的开始顶点,那么可从图中任一顶点出发,不妨按编号的顺序,先从编号小的顶点开始。
(2)要遍历到图中所有顶点,只需多次调用从某一顶点出发遍历图的算法。
所以,下面只考虑从某一顶点出发遍历图的问题。
(3)为了在遍历过程中便于区分顶点是否已经被访问,设置一个访问标志数组visited[n],n为图中顶点的个数,其初值为0,当被访问过后,其值被置为1。
(4)这就是遍历次序的问题,图的遍历通常有深度优先遍历和广度优先遍历两种方式,这两种遍历次序对无向图和有向图都适用。
【判断】图形推理-遍历与图形间关系
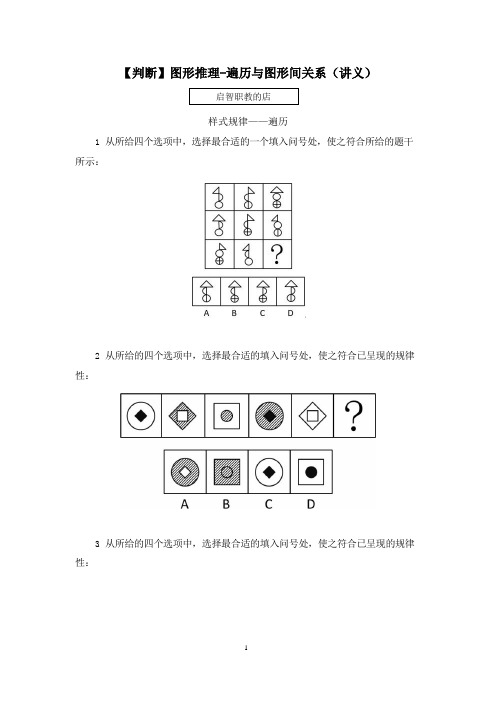
【判断】图形推理-遍历与图形间关系(讲义)启智职教的店样式规律——遍历1.从所给四个选项中,选择最合适的一个填入问号处,使之符合所给的题干所示:2.从所给的四个选项中,选择最合适的填入问号处,使之符合已呈现的规律性:3.从所给的四个选项中,选择最合适的填入问号处,使之符合已呈现的规律性:4.从所给的四个选项中,选择最合适的填入问号处,使之符合已呈现的规律性:图形间关系1.从所给的四个选项中,选择最合适的填入问号处,使之符合已呈现的规律性:2.从所给的四个选项中,选择最合适的填入问号处,使之符合已呈现的规律性:3.把下面的六个图形分为两类,使每一类图形都有各自的共同特征或规律,分类正确的一项是:A.①②⑥,③④⑤B.①③④,②⑤⑥C.①④⑤,②③⑥D.①④⑥,②③⑤4.把下面的六个图形分为两类,使每一类图形都有各自的共同特征或规律,分类正确的一项是:A.①②④,③⑤⑥B.①②⑤,③④⑥C.①③⑤,②④⑥D.①③⑥,②④⑤5.把下面的六个图形分为两类,使每一类图形都有各自的共同特征或规律,分类正确的一项是:A.①④⑥,②③⑤B.①②③,④⑤⑥C.①③⑥,②④⑤D.①③④,②⑤⑥6.把下面的六个图形分为两类,使每一类图形都有各自的共同特征或规律,分类正确的一项是:A.①②③,④⑤⑥B.①②④,③⑤⑥C.①②⑤,③④⑥D.①③④,②⑤⑥7.从所给的四个选项中,选择最合适的一个填入问号处,使之呈现一定的规律性:8.从所给的四个选项中,选择最合适的一个填入问号处,使之呈现一定的规律性:【判断】图形推理-遍历与图形间关系(笔记)【注意】本节课讲解遍历与图形间关系,这些考点对比对称性和数量规律等来说相对没那么高频,但也会考查。
样式规律——遍历什么是遍历?图 1图形特征:相同元素重复出现解题思路:缺啥补啥图 2【注意】遍历:1.含义:遍布经历,每个都出现 1 次。
比如图 1,第一组图出现 1 个圆、1个五角星和 1 个三角形,第二组图出现 1 个三角形和 1 个五角星,“?“处图形应该是圆。
公务员考试备考:图形推理之“遍历”

公务员考试备考:图形推理之“遍历”根据对公务员考试以往历年真题的考情考务分析,判断推理这一模块中,“图形推理”是其必考题型,联考一般是5道题,国考题量稳定在10道题,可见,图形推理很重要。
图形推理说简单也简单,说难也难,但只要熟悉出题的套路,方法运用得当,解题的速度和准确性都是不成问题的。
下面唐山华图教育为大家讲解一种在图形推理类题目中看似很复杂,掌握规律之后实则很简单的题型——“遍历”。
以帮助各位考生在出现这类题目时能够快速准确的找到规律,推出下一个图形是什么。
“遍历”这个词,遍布经历的意思,它经常出现在在计算机领域,表示把所有的节点都访问到,它在我们图形中的作用功能也相同,我们图形中没有节点,但有元素,我们同样需要将出现的元素都访问一遍,下面我们看这样的一个小例子,九宫格的题,先观察,第一行:A、B、C;第二行:B、C、A;第三行:C、A、?;像这样,元素的种类和数量一致,排列和组合的次序不一致时,我们优先考虑遍历,很明显?处应该填入的是C,这就是遍历的解题方法,通俗易懂的四个字:“缺啥补啥”A B CB C AC A ?【例1】从所给的四个选项中,选项最合适的一个填入问号处,使之呈现一定的规律性做图形的题,我们首先要去观察,先识别出题形式九宫格的题,我们说九宫格的题一般先横看,发现这些图形都是用线连接黑圆,白圆,且每行都由三个白圆和三个黑圆构成,且每幅图中圆与线的位置都成三种形式。
再观察,发现内部的排列和组合的次序是不一致的,这个时候我们优先考虑遍历。
为方便描述,我们把九宫格中的图形按行依次用1-9图来表示。
看第一行,1图两个白圆,圆在线的同侧;2图一个黑圆一个白圆,圆在线的两侧;3图两个黑圆,圆在线的端点处,第一行都有三个黑圆三个白圆,且每幅图中圆与线的位置都成三种形式。
第二行,我们来验证规律,4图黑圆白圆,圆在线的端点处;5图两个黑圆,圆在线的同侧;6图两个白圆,圆在线的两侧;发现规律得证。
软件设计师2016年05月上午题(附答案)

软件设计师2016年05月上午题(附答案)●VLIW是(1)的简称。
(1) A.复杂指令系统计算机 B.超大规模集成路由C.单指令流多数据流D.超长指令字●主存与Cache的地址映射方式中,(2)方式可以实现主存任意一块装入Cache中任意位置,只有装满才需要替换。
(2) A.全相联 B.直接映射 C.组相联 D.串并联●如果“2X”的补码是“90H”,那么X的真值是(3)。
(3) A.72 B.-56 C.56 D.111●移位指令中(4)指令的操作结果相当于对操作数进行乘2操作。
(4) A.算术左移 B.逻辑右移 C.算术右移 D.带进位循环左移●内存按字节编址,从A1000H到B13FFH的区域的存储容量为(5)KB。
(5) A.32 B.34 C.65 D.67●以下关于总线的叙述中,不正确的是(6)。
(6) A.并行总线适合近距离高速数据传输B.串行总线适合长距离数据传输C.单总线结构在一个总线上适应不同各类的设备,设计简单且性能很高D.专用总线在设计上可以与连接设备实现最佳匹配●以下关于网络层次与主要设备对应关系的叙述中,配对正确的是(7)。
(7) A.网络层——集线器 B.数据链路层——网桥C.传输层——路由器D.会话层——防火墙●传输经过SSL加密的网页所采用的协议是(8)。
(8) A.HTTP B.HTTPS C.S-HTTP D.HTTP-S●为了攻击远程计算机,通常利用(9)技术检测远程主机状态。
(9) A.病毒查杀 B.端口扫描 C.QQ聊天 D.身份认证●某软件公司参与开发管理系统软件的程序员张某,辞职到另一公司任职,于是该项目负责人将该管理系统软件上开发者的署名更改为李某(接张某工作)。
该项目负责人的行为(10)。
(10)A.侵犯了张某开发者身份权利(署名权)B.不构成侵权,因为程序员张某不是软件著作权人C.只是行使管理者的权利,不构成侵权D.不构成侵权,因为程序员张某现已不是项目组成员●美国某公司与中国某企业谈技术合作,合同约定使用I项美国专利(获得批准并在有效期内),该项目未在中国和其他国家申请专利。
2022年重庆大学计算机科学与技术专业《数据结构与算法》科目期末试卷A(有答案)

2022年重庆大学计算机科学与技术专业《数据结构与算法》科目期末试卷A(有答案)一、选择题1、下列说法不正确的是()。
A.图的遍历是从给定的源点出发每个顶点仅被访问一次B.遍历的基本方法有两种:深度遍历和广度遍历C.图的深度遍历不适用于有向图D.图的深度遍历是一个递归过程2、有一个100*90的稀疏矩阵,非0元素有10个,设每个整型数占2字节,则用三元组表示该矩阵时,所需的字节数是()。
A.60B.66C.18000D.333、以下数据结构中,()是非线性数据结构。
A.树B.字符串C.队D.栈4、在下列表述中,正确的是()A.含有一个或多个空格字符的串称为空格串B.对n(n>0)个顶点的网,求出权最小的n-1条边便可构成其最小生成树C.选择排序算法是不稳定的D.平衡二叉树的左右子树的结点数之差的绝对值不超过l5、向一个栈顶指针为h的带头结点的链栈中插入指针s所指的结点时,应执行()。
A.h->next=sB.s->next=hC.s->next=h;h->next=sD.s->next=h-next;h->next=s6、排序过程中,对尚未确定最终位置的所有元素进行一遍处理称为一趟排序。
下列排序方法中,每一趟排序结束时都至少能够确定一个元素最终位置的方法是()。
Ⅰ.简单选择排序Ⅱ.希尔排序Ⅲ.快速排序Ⅳ.堆排Ⅴ.二路归并排序A.仅Ⅰ、Ⅲ、Ⅳ B.仅Ⅰ、Ⅱ、Ⅲ C.仅Ⅱ、Ⅲ、Ⅳ D.仅Ⅲ、Ⅳ、Ⅴ7、循环队列放在一维数组A中,end1指向队头元素,end2指向队尾元素的后一个位置。
假设队列两端均可进行入队和出队操作,队列中最多能容纳M-1个元素。
初始时为空,下列判断队空和队满的条件中,正确的是()。
A.队空:end1==end2;队满:end1==(end2+1)mod MB.队空:end1==end2;队满:end2==(end1+1)mod (M-1)C.队空:end2==(end1+1)mod M;队满:end1==(end2+1) mod MD.队空:end1==(end2+1)mod M;队满:end2==(end1+1) mod (M-1)8、在下述结论中,正确的有()。
图的建立及输出(图的遍历)

数据结构课程设计题目图的建立及输出学生姓名学号院系专业指导教师二O一O年12 月16 日目录一、设计题目 (2)二、运行环境(软、硬件环境) (2)三、算法设计的思想 (2)3.1邻接矩阵表示法 (2)3.2图的遍历 (4)3.3邻接矩阵的输出 (5)四、算法的流程图 (6)五、算法设计分析 (7)5.1无向网邻接矩阵的建立算法 (7)5.2无向图邻接矩阵的建立算法 (7)5.3图的深度优先遍历 (7)5.4图的广度优先遍历 (8)六、源代码 (8)七、运行结果分析 (14)八、收获及体会 (15)一、设计题目:图的建立及输出*问题描述:建立图的存储结构(图的类型可以是有向图、无向图、有向网、无向网,学生可以任选两种类型),能够输入图的顶点和边的信息,并存储到相应存储结构中,而后输出图的邻接矩阵。
二、运行环境(软、硬件环境)*软件环境:Windows7、 Windows Vista、 Windows Xp等*硬件环境:处理器:Pentium4以上内存容量: 256M以上硬盘容量:40GB 以上三、算法设计的思想1、邻接矩阵表示法:设G=(V,E)是一个图,其中V={V1,V2,V3…,Vn}。
G的邻接矩阵是一个他有下述性质的n阶方阵:1,若(Vi,Vj)∈E 或<Vi,Vj>∈E;A[i,j]={0,反之图5-2中有向图G1和无向图G2的邻接矩阵分别为M1和M2:M1=┌0 1 0 1 ┐│ 1 0 1 0 ││ 1 0 0 1 │└0 0 0 0 ┘M2=┌0 1 1 1 ┐│ 1 0 1 0 ││ 1 1 0 1 │└ 1 0 1 0 ┘注意无向图的邻接是一个对称矩阵,例如M2。
用邻接矩阵表示法来表示一个具有n个顶点的图时,除了用邻接矩阵中的n*n个元素存储顶点间相邻关系外,往往还需要另设一个向量存储n个顶点的信息。
因此其类型定义如下:VertexType vertex[MAX_VERTEX_NUM]; // 顶点向量AdjMatrix arcs; // 邻接矩阵int vexnum, arcnum; // 图的当前顶点数和弧(边)数GraphKind kind; // 图的种类标志若图中每个顶点只含一个编号i(1≤i≤vnum),则只需一个二维数组表示图的邻接矩阵。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
实验六最短路径问题问题描述若用有向网表示某地区的公路交通网,其中顶点表示该地区的一些主要场所,弧表示已有的公交线路,弧上的权表示票价。
试设计一个交通咨询系统,指导乘客以最少花费从该地区中的某一场所到达另一场所。
一、需求分析1.本程序要求从文件中读入有向网中顶点的数量和顶点间的票价的矩阵;2.以用户指定的起点和终点,输出从起点到终点的花费;3.用Dijkstra算法计算点对点的最短路径;4.在Dos界面输出起点到终点的花费。
5.测试数据输入(文件)5-1 10 3 20 -1-1 -1 -1 5 -1-1 2 -1 -1 15-1 -1 -1 -1 11-1 -1 -1 -1 -1(用户)起点0终点4输出18二、概要设计抽象数据类型typedef struct GraphNode //图的结点{int n;Mark m; //节点的状态访问还是未被访问} GraphNode;typedef struct Graph //图{int n;GraphNode * Node;int** edge; //边权信息} Graph;算法思想1、用图结构来存储公交网络信息。
2、用户输入顶点数和边权值,使用邻接矩阵存储边权值。
3、建一个数组D用来存储路径长度。
4、使用Dijkstra算法来计算最短路径长度5、输出最短路径程序的流程输入模块:输入顶点数和边权值,起点和终点。
输出模块:输出最短路径长度。
三、详细设计物理数据类型typedef struct GraphNode //图的节点{int n;Mark m; //是否被访问} GraphNode;typedef struct Graph //图{int n;GraphNode * Node;int** edge; //边权值} Graph;Mark getMark(Graph*G , int i) //返回是否被访问{return G->Node[i].m;}void setMark(Graph*G,int v,Mark m) //标记为已访问{G->Node[v].m=m;}int first(Graph*G , int v) //第一个邻结点{int i;for(i=0 ; i<G->n ; i++)if((G->edge[v][i])!=-1)return i;return i;}int next(Graph*G , int v , int w) //下一个邻结点{int i;for(i=w+1 ; i<G->n ; i++)if((G->edge[v][i])!=-1)return i;return i;}int weight(Graph*G,int v,int w) //返回边权值{return G->edge[v][w];}int minVertex(Graph*G , int *D) ///寻找路径长度最短的那个顶点{int i , v;for(i=0; i<G->n; i++)if(getMark(G,i)==UNVISITED){v=i;break;}for(i++; i<G->n; i++)if(getMark(G,i)==UNVISITED&&((((D[i]<D[v])&&D[i]!=-1)||(D[v]==-1))))v=i;return v;}void Dijkstra(Graph*G , int *D , int s) //Dijkstra算法{int i,v,w;for(i=0; i<G->n; i++){v=minVertex(G,D);if(D[v]==-1) return; //顶点v的路径长度小于0,即还处于初始状态,还未处理任何顶点,返回setMark(G,v,VISITED);for(w=first(G,v); w<G->n; w=next(G,v,w))if((D[w]>(D[v]+weight(G,v,w)))||(D[w]==-1))D[w]=D[v]+weight(G,v,w);}}算法流程输入模块:输入顶点的数量,再输入各条弧(无边相连的权值都置为-1)。
输出模块:输出最短路径长度。
输入输出格式输入:(等待用户输入顶点数和边权值)起点:终点:输出:最短路径:四、测试结果五、源程序#include<iostream>#include<cstdlib>using namespace std;enum Mark {UNVISITED,VISITED};typedef struct GraphNode //图的节点{int n;Mark m; //是否被访问} GraphNode;typedef struct Graph //图{int n;GraphNode * Node;int** edge; //边权值} Graph;Mark getMark(Graph*G , int i) //返回是否被访问{return G->Node[i].m;}void setMark(Graph*G,int v,Mark m) //标记为已访问{G->Node[v].m=m;}int first(Graph*G , int v) //第一个邻结点{int i;for(i=0 ; i<G->n ; i++)if((G->edge[v][i])!=-1)return i;return i;}int next(Graph*G , int v , int w) //下一个邻结点{int i;for(i=w+1 ; i<G->n ; i++)if((G->edge[v][i])!=-1)return i;return i;}int weight(Graph*G,int v,int w) //返回边权值{return G->edge[v][w];}int minVertex(Graph*G , int *D) ///寻找路径长度最短的那个顶点{int i , v;for(i=0; i<G->n; i++)if(getMark(G,i)==UNVISITED){v=i;break;}for(i++; i<G->n; i++)if(getMark(G,i)==UNVISITED&&((((D[i]<D[v])&&D[i]!=-1)||(D[v]==-1)))) v=i;return v;}void Dijkstra(Graph*G , int *D , int s) //Dijkstra算法{int i,v,w;for(i=0; i<G->n; i++){v=minVertex(G,D);if(D[v]==-1) return; //顶点v的路径长度小于0,即还处于初始状态,还未处理任何顶点,返回setMark(G,v,VISITED);for(w=first(G,v); w<G->n; w=next(G,v,w))if((D[w]>(D[v]+weight(G,v,w)))||(D[w]==-1))D[w]=D[v]+weight(G,v,w);}}int main(){Graph* G;int i , j;G=(Graph*)malloc(sizeof(Graph));cin>>G->n; //输入结点数G->Node=(GraphNode*)calloc(G->n,sizeof(GraphNode));for(i=0 ; i<G->n ; i++)G->Node[i].m=UNVISITED; //将所有节点设为未被访问的G->edge=(int **)calloc(G->n,sizeof(int*));if(!G->edge) //若内存未分配成功cout<<"error";for(i=0 ; i<G->n ; i++){G->edge[i]=(int*)calloc(G->n,sizeof(int));if(!G->edge[i]) //若内存未分配成功cout<<"error";}int temp=-1;for(i=0 ; i<G->n ; i++)for(j=0 ; j<G->n ; j++){cin>>temp; //输入边权值if(temp==-1)G->edge[i][j]=9999;elseG->edge[i][j]=temp;}int start , end;cout<<"起点:"<<endl;cin>>start;cout<<"终点:"<<endl;cin>>end;int *D;D=(int *)malloc(G->n*sizeof(int)); //数组D申请空间for(int k=0 ; k<G->n ; k++) //初始化数组DD[k]=G->edge[start][k];Dijkstra(G,D,start);cout<<"最短路径:"<<D[end]<<endl; //输出最短路径长度cout<<endl;system("pause");return 0;}运行结果:。