epidata软件使用
关于Epidata的使用

EpiData的优点
完全免费软件,占用空间很小,(网址:http:// www.epidata.dk/download.php 界面友好,通俗易懂,只要有电脑基础,均可轻松 自如地操作。 实用性强,直观性强,提高了数据录入速度。 CHK 文件设置中,设置了字段和有效性规则,防止 了异常数据进入数据库。 该数据文件,能转化为大家常用的Excel、SPSS、 SAS、Stata 以及txt纯文本文件等多种数据格式类 型。
新的数据库就是你输入的新名字那个文件
首先打开数据库工具,左键双击 下图标
然后出现以下界面
左键点击文件,再点击打开
打开的是什么?
选择打开的路径。 例如数据库放在桌面,就选择桌面的。
选择桌面的文件夹后出现:
再选择高露洁口腔问卷文件夹
各种表格就在里面了,双击打开后,进行 正常录入。
答案是什么就选择相应的序号
多选的就在选项后面填“0”
保存问题
点击左下角的黑色三角形
出现:
点击“是”,就进行了保存,并且自动跳 到下一条记录。
数据库的合并
左键单击数据输入/输出(D)
按照路径找到你要合并的两个数据文件 然后点击确定
在上图“产生数据库:”后面输 入合并后新的数据库的名字
点击追加,就把后面的数据库2 接上见面的数据库1了
用epidata进行问卷录入的一般过程

用epidata进行问卷录入的一般过程使用epidata进行问卷录入的一般过程如下:1. 下载和安装epidata软件:前往epidata官方网站(2. 创建数据库:打开epidata软件,点击菜单栏中的"数据库"选项,选择“新建数据库”功能。
填写数据库名称、存储位置等相关信息,并点击"确定"按钮来创建新的数据库。
3. 创建表单:在epidata软件中,点击菜单栏中的"表单"选项,选择"新建表单"功能。
根据问卷的需求,填写表单的名称、字段类型、验证条件等相关信息,并点击"确定"按钮来创建新的表单。
4. 添加字段:在表单中,点击"添加字段"按钮,根据问卷的需求,选择合适的字段类型(如文本、数字、日期等),并填写字段的名称和验证条件。
5. 设定表单布局:在表单中,根据问卷的布局需求,调整表单的字段顺序、大小和位置。
6. 开始录入问卷数据:在epidata软件中,点击菜单栏中的"数据输入"选项,选择"手动输入"功能。
按照表单中的字段顺序,逐个录入问卷中的数据,并保存数据。
7. 数据校验和清理:在录入完成后,使用epidata的数据校验和清理功能,检查数据的完整性和一致性。
根据需要,可以使用epidata提供的数据过滤、排序和删除等功能进行数据处理。
8. 数据导出和分析:在epidata软件中,点击菜单栏中的"数据输出"选项,选择"导出数据"功能。
选择合适的导出格式(如Excel、CSV等),设置导出的字段和筛选条件,并导出问卷数据。
导出的数据可用于进一步的数据分析和统计。
以上是使用epidata进行问卷录入的一般过程。
具体的操作步骤可能有所差异,根据软件版本和问卷要求进行适当调整。
建议在使用epidata前,先阅读软件的帮助文档和教程,以便更好地理解和掌握epidata的功能和操作方法。
epidata使用方法

2018/10/30
epidata 软件使用
9
2.1.2 定义变量名(Field Names)
输入的信息要保存在变量中因此需要定义变量名。 一个数据库中录入变量的名称可以根据QES文件 的内容自动创建。 EpiData中命名变量的方式有两种: 1)将第一个单词作为变量名(First word in question is field name) 2)根据规则自动定义变量名(Automatic field names) 执行“文件→选项”命令打开“生成REC文件” (File→Options→Create data file)选项卡。 (1)QES文件字体设置:变量名称的字体及其大 小可以在QES文件显示(Show data form)中设置. 。
2018/10/30
epidata 软件使用
3
2 数据库创建过程
在使用EpiData软件之前,先对该软件中用到的三种 基本的文件类型进行简单介绍: ①.QES文件:调查表文件即数据库结构文件,决定 数据库结构。 ②.REC文件:数据库文件,主要用于存放数据。 ③.CHK文件:核对文件,存放控制数据录入的核对 规则,起质量控制作用。 EpiData由数据库结构文件(.qes),来决定数据库 结构,然后根据该数据库结构文件生成数据文件 (.rec)。
2018/10/30 epidata 软件使用 4
一个最简单的创建数据库的工作至少要包括以下两步: 1、建立调查表文件——根据调查表制作数据库结构文 件即调查表文件(.qes) 2、生成数据库文件——根据调查表文件生成数据库文 件(.rec)。 理论上说,有了数据库文件就可以进行数据录入了,但 是在实际工作中,往往需要对数据录入进行质量控制, 比如对某些字段设置合法值、跳转等等。这些质量 控制工作需要专门的核对文件来完成(.chk)。 因此,在数据库创建过程一般还包括: 3、编写核对程序——即生成数据核对文件(.chk). 在EpiData软件中,在其主界面的上形象的标示出了数 据库创建过程:
Epidata数据库使用方法详细介绍

安装Epidata软件
下载Epidata软件安装包
01
从官方网站或授权下载站点下载最新版本的Epidata软件安装包
。
安装Epidata软件
02
双击安装包,按照安装向导的指示完成软件的安装过程。
启动Epidata软件
03
安装完成后,在桌面或开始菜单中找到Epidata软件图标,双击
05
Epidata在科研中的应用
科研数据管理
数据录入与整理
Epidata支持多种数据录入方 式,如手动输入、文件导入 等,并提供数据整理功能, 如排序、筛选等,方便用户 对数据进行初步处理。
数据质量控制
Epidata提供数据质量检查功 能,可以设定规则对数据进 行自动核查,确保数据的准 确性和完整性。
分析等。
公共卫生管理
EpiData可用于公共卫生管理中的数 据收集、整理和分析,如健康调查、
卫生资源配置等。
临床医学研究
EpiData可用于临床医学研究中的数 据管理和数据分析,如临床试验、病 例对照研究等。
其他领域
EpiData还可应用于社会学、心理学 、教育学等领域的数据管理和数据分 析。
02
03
自定义可视化
Epidata允许用户自定义可视化样式 和布局,以满足个性化的展示需求。 同时,还支持将可视化结果导出为图 片或PDF文件,方便分享和交流。
06
Epidata数据库使用技巧与注意事项
提高数据录入效率
批量导入数据
利用Epidata的数据导入功能,可以一次性导入大量 数据,避免手动逐条录入的繁琐。
按照一个或多个字段对数据进行排 序,升序或降序均可。
epidata数据管理软件录入操作说明
epidata数据管理软件录入操作说明
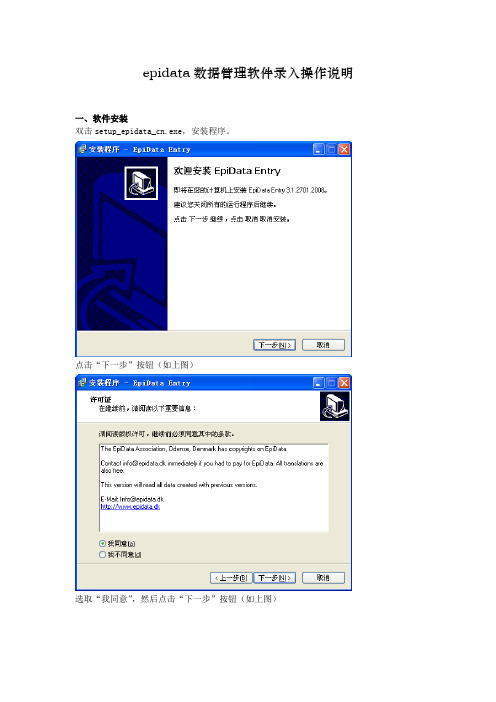
一、软件安装
双击setup_epidata_cn.exe,安装程序。
点击“下一步”按钮(如上图)
选取“我同意”,然后点击“下一步”按钮(如上图)
选择安装路径(默认路径即可),点击下一步安装。
二、数据录入操作步骤
找开epidata软件(如下图),点击打开
1、按“4.数据录入”,或“打开”的图标(如下图),打开PHdata文件夹里扩展名为rec的文件。
其中:
Q1为附件1广东省公共卫生服务均等化中健康教育服务项目调查表(健康教育机构填报)的录入程序;
Q2a为附件2广东省公共卫生服务均等化中健康教育服务项目调查表(乡镇卫生院、村卫生站、社区卫生服务中心、站填报)第一季度用表
Q2b为附件2广东省公共卫生服务均等化中健康教育服务项目调查表(乡镇卫生院、村卫生站、社区卫生服务中心、站填报)第二、三季度用表
2、按上图“打开”按钮,打开Q1.rec文件(如下图)
录入时字符达到设置时位数时自动跳转,或按Enter键跳至下一空格
录入到最后一空格按Enter键时,弹出“确认”窗口,询问“是否将记录存盘”时,点击“是”,将录入的记录保存。
保存后自动进入新一条数据的录入界面,可继续录入下一份调查表。
3、数据录入后,请将文件夹PHdata打包发至aline412@。
文件名改为本市市名和季度。
如“广州市第一季度”即可。
EpiData使用简介

赋值命令
函数 利用出生日期变量数值计算个体年龄命令。 LET AGE=ROUND((TODAY-D1)/365.25) 其中TODAY和ROUND()分别是日期和取整函数,D1为 出生日期变量。 9、终止命令
第四节、数据输入
(在核查文件.chk的控制下,用数据文件.rec实现数据录入。) 方法:单击图中的“数据录入”图标命令,出现对话框后,选 择欲录入的数据文件名.rec,从而可以进行数据录入。
1、输出数据操作 单击图中的导出为SPSS文件,打开对话框,在图中寻找需导出的数据记录文件.rec, 然后单击“打开”按钮,出现对话框(见左下图)后单击OK按钮,出现对话框(见右下 图)后单击OK按钮,输出的数据以指定的文件为名。
三、继续录入数据或修改数据
选择“数据录入/导出”、“数据录入/编辑”,指定欲追加记录 的文件名,即可进行追加记录或修改记录。
从EpiData的操作过程:6个步骤。
制作调查表描述文件.qes
自动生产数据记录文件.rec
建立录入数据质量控制文件.chk
录入数据到数据记录文件.rec中去 浏览数据及统计 对数据记录文件.rec中的数据输出及转换
第二节、基本操作说明
第一步、制作调查表描述文件 (1)新建一个调查表描述文件 单击“文件”、“生成调查表文件(QES文件)”,则自动建立一个名字为 “EpiData文件1”的空的数据描述文件(见下图),数据描述文件的扩展名 为QES,QES是question的缩写。
(2)把空白的“EpiData文件1” 文件存储成想要的文件名(如民意调查.qes) 方法是:单击“文件”、“另存为”命令,弹出一个对话框后,指定新的 文件名(如民意调查.qes ),然后选“保存”即可。
epidata使用.文档

Epidata使用教程之快速入门篇(一)(高手就不要看了)我们为什么使用Epidata?一个是因为Epidata是“免费的数据录入和数据管理软件”,另外最主要的,我想是因为它“简单易学、数据录入功能实用”等特点。
现在的Epidata中文版本是3.1,下载地址。
OK,简单介绍一下,废话少说进入正题。
一、建立调查表文件使用Epidata录入数据的第一步,是先建立数据库。
这时我们需要先写一个后缀是.qes的“调查表文件”,如下图:建立调查表文件这个调查表怎么写呢?看下面的这个例子:1、药物编号({DrugNum}):@####2、患者姓名缩写({Pname}):@_____3、就诊日期({date}):@<yyyy/mm/dd>4、门诊({outp})<Y> 住院({inh}) <Y> 住院病案号({pn}):__________5、性别({sex}):# ①男②女说明:第1句中“药物编号”只是起到提示作用,在由.qes文件生成数据库文件时不编译,就是说在数据库里面它还是显示“药物编号”;后面括号{}里的“DrugNum”,是字段名,当然这个字段(或者说变量)记录的就是药物编号了,用{}定义字段名是Epidata字段命名的一种方式(还有另一种,这里就不说了);再后面的@###:@表示一种对齐方式,先不用管它,后面会讲到;###是用来定义前面那个DrugNum字段的属性的,#代表一位数字,###就代表3位数字,也就是说药物编号最大也就能输入999了,不能再大了;总结第1句的含义:定义了一个字段“药物编号”,字段名是DrugNum,用于记录3位数字形式的数据。
(刚开始有些费劲哈?)第2句:与第1句不同的是,患者姓名缩写肯定是字母了,这里用下横杠“_”来定义。
下横杠“_”是用来定义字符串的,一个字母用一个“_”表示(如果是汉字,要占两个“_”)。
这一句的含义就是:定义了一个字段“患者姓名缩写”,字段名是Pname,用于记录字符形式的数据。
简单实用数据录入、管理软件EpiData软件使用简介

“工作过程工具条”可以指导用户从“1.定义数据” 到“6.数据导出”
Epidata使用前四步曲 程序使用前基本设置
程序菜单语言 解决编辑器中调查表文件乱码的问题 “生成变量名”选项 设置相关文件默认打开程序
程序菜单语言
解决编辑器中调查表文件乱码
“生成变量名”选项
设置相关文件默认打开程序
变量名的要求: 第一个字符一定为字母(A-Z) 之后可含有字母和数字 变量名最多10个字符 变量名不能是中文
2. 变量的设定:变量编码-变量类型
QES文件字段定义
变量类型
字符型:用下划线,_____,最长允许80个 字符,一个中文字占2个字符
数字型:用#号,每位一个#,如##.#,最 长允许14个字符
简单实用数据录入、管理软件
EpiData 软件使用简介
保选
证择
数合
据适
质的
量
数 据
的管
重理
要软
方件
面是
……
统计软件录入数据的弊端
操作不方便 易发生误操作 存在版权的问题
EpiData——免费、易用、够用
主要内容
EpiData基本情况介绍 EpiData使用流程
建立调查表及数据文件生成 添加字段控制 输入数据和数据转出
EpiData数据管理和输入流程
1 建立调查表文件
2 创建数据库
3 建立核查文件
6 输出数据
5 数据库管理
4 录入数据
0 设计“问卷”
一、建立调查表
数据定义是基础性工作,也是关键 性的工作;
在EpiData中表现为建成QES文件
1.建立途径
2. 变量的设定
epidata使用方法汇总

建立调查表文件是建立数据库、实现数据 录入和管理的第一步。 调查表结构文件在编辑器窗口建立
2019/2/26
epidata 软件使用
7
编辑器窗口的使用
1、打开EPDATA 软件,可以单击菜单中的“文 件→生成调查表文件”, 在工作流程栏(Work Process Toolbar)上点击 “建立新的QES文件”, 单击工具栏上的“新记录”按钮 这时窗口中会自动显示一个空白的文档,你可以在这 里输入调查表,也可以把WORD中建立的调查表复 制/粘贴过来再进行编辑。调查表实际上就是数 据录入表格的框架。 编辑完成后,将此调查表文件保存,文件的扩展名统 一为.QES。
2019/2/26 epidata 软件使用 20
2 数值型字段(Numeric Fields)
数值型变量######.##中只能用来接受从0 到9的数字,数值可以是整数也可以是小数。 一个#号代表一位数,用户可以根据需要定 义所需的数值位数,但包括小数点在内最 大为14位。在数据录入过程中和.QES文件 中你可以用圆点(.)或逗号(,)来表示小 数点。一个变量中只允许输入一个小数点, 这意味着,你不能用逗号作为千位的分隔 符(例如:1,000,000)。字符“#”的数目表 示变量的长度,小数点占一位字符。
2019/2/26 epidata 软件使用 8
2、编辑器(Editor)主要功能是创建和编 辑调查表(.QES文件)。这个调查表定义 了数据库结构。编辑器的使用和其它字处 理软件基本一致,由菜单栏,工作流程栏、 工具栏和文本编辑区组成。也可以使用编 辑器处理程序输出的报表,以及编辑 CHECK文件。
2019/2/26 epidata 软件使用 10
EpiData数据管理软件应用教程

第43张
首先选择需定义的变量:
Range,Legal:定义变量输入的合法值
如:输入“1,2” 表示只能输入1或者2; 输入“1-6” 表示可以输入1至6的任何一个 数值; 输入“1-6,99” 表示可以输入1到6的数值或者99; 输入“-inf-5”表示小于等于5;
输入“0-inf”表示大于等于0 。
2013年12月20日5时17分
第18张
7.1.2 记录文件
显示录入界面,存储记录.
2013年12月20日5时17分
第19张
7.1.3 核对文件
建立变量的输入规则, 设置跳转.
2013年12月20日5时17分
第20张
制作数据表文件(1)
1.新建调查表文件 (文件——生成qes文件) qes文件是由一定格式组成的文本文件, 记录了所有需要输入的问题和格式, 类似于电子调查表。
EpiData软件应用
武宁县疾控中心计算机网络技术兴趣小组
2013年12月20日5时17分
第1张
一、 EpiData简介
EpiData是一个免费的数据录入和数据管理软件。 软件具有多种语言版本,如丹麦语、汉语、荷兰语、意大利语、法语、 英语等。 开发者是丹麦欧登塞(Odense,denmark)的一个非盈利性组织。 EpiData的研发工作最早由丹麦的Jens uritsen发起。最初是作为 Funen县开展的“预防意外伤害行动”中的一部分。 1999年末,Jens uritsen、Mark Myatt和Michael 三人组成研发小 组。工作小组希望将EpiData开发成一个简单、易用、独立的应用程序。 这个程序不需要任何专门的数据库系统驱动。他们从社会团体、个人以 及其他捐助者那里得到资金支持,以免费的形式发布这个软件。 软件下载网址:http://www.epidata.dk 或者找度娘索要。
epidata使用教程

epidata使用教程Epidata 是一种开源的电子数据收集工具,可用于设计和管理数据输入表格,并在移动设备上进行数据收集。
以下是Epidata 使用教程的步骤。
1. 下载和安装 Epidata:首先,打开 Epidata 官方网站并下载适用于您操作系统的版本。
安装程序后,打开 Epidata 软件。
2. 创建新项目:在Epidata 的主界面上,选择“新建项目”选项。
给项目命名,并选择所需的表格和字段设置。
您可以自定义表格的名称、列的数量、类型和其他属性。
3. 设计数据输入表格:在创建的项目中,您可以使用 Epidata提供的设计工具来自定义数据输入表格。
通过拖动和放置字段,您可以设置每个字段的属性,例如:文本、日期、数字等。
4. 添加逻辑和验证规则:对于每个字段,您可以添加逻辑约束和验证规则,以确保数据的准确性和一致性。
例如,您可以设置某个字段的取值范围、数据格式要求等。
5. 导入现有数据:如果您已经有现有的数据,可以使用Epidata 的导入功能将其导入到项目中。
确保数据符合表格和字段的规范。
6. 设置移动设备:在移动设备上安装 Epidata Mobile 应用程序,并使用项目的二维码或链接进行登录。
确保设备已与相应的项目成功同步。
7. 进行数据收集:使用移动设备上的 Epidata Mobile 应用程序,输入和记录数据。
根据字段的类型,可以使用键盘、滑块、选择框等不同的输入方式。
8. 数据导出和分析:完成数据收集后,可以将数据导出到Epidata 软件中进行分析和报告。
Epidata 提供了各种数据分析和统计工具,可帮助您有效地了解数据。
请注意,以上步骤仅为Epidata 的基本使用教程。
实际使用中,您可能需要深入了解 Epidata 的更高级功能和设置。
建议参考Epidata 的官方文档和教程以获取更详细的指导和支持。
Epidata软件的使用
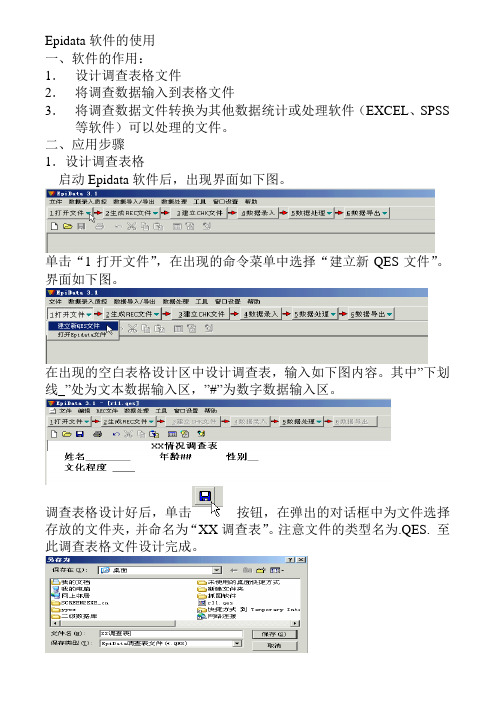
Epidata软件的使用一、软件的作用:1.设计调查表格文件2.将调查数据输入到表格文件3.将调查数据文件转换为其他数据统计或处理软件(EXCEL、SPSS 等软件)可以处理的文件。
二、应用步骤1.设计调查表格启动Epidata软件后,出现界面如下图。
单击“1打开文件”,在出现的命令菜单中选择“建立新QES文件”。
界面如下图。
在出现的空白表格设计区中设计调查表,输入如下图内容。
其中”下划线_”处为文本数据输入区,”#”为数字数据输入区。
调查表格设计好后,单击按钮,在弹出的对话框中为文件选择存放的文件夹,并命名为“XX调查表”。
注意文件的类型名为.QES. 至此调查表格文件设计完成。
2.将调查数据输入到表格文件首先生成数据记录文件,单击“2生成REC文件”选择“生成REC 文件”,如果当前没有打开的文件,则应该先打开文件(应为.QES文件).在弹出的对话框中,可以选择需要的QES文件,并为要生成的REC文件确定存储文件夹或重新命名.当数据记录文件生成后,单击”文件”菜单,选择”打开Epidata文件”命令,找到需要的REC文件(如XX调查表文件),即可显示输入记录的界面了.如下图输入一条记录后,要求确认保存.保存后进入下一条记录的输入.最后当数据记录输入完成后,选择”文件”中”关闭数据表”命令即可退出.3.将调查数据文件转换为其他数据统计或处理软件(SPSS等软件)可以处理的文件。
单击”6数据导出”中选择”导出为SPS文件(SPSS文件)”,在打开的对话中选择要转换的文件,如XX调查表.REC文件,在”导出”对话框中,将文件转换为”XX调查表.sps”文件.单击”确定”按钮.完成数据表向SPSS软件文件的转化.4.在spss软件下使用该数据文件的方法.在Epidata中生成的”XX调查表.sps”文件并不是SPSS的数据文件,所以在SPSS软件中不能直接使用,需要转化成为SPSS的数据文件(.SA V文件).操作方法:启动SPSS软件,选择” open” | “syntax”命令.打开刚生成的”XX调查表.sps”文件.打开文件后出现的窗口中选择”Run”|”All”命令,生成spss数据文件.单击”保存”按钮,保存文件即可.。
Epidata3.0使用手册

Epidata3.0使用手册很详细的应用手册实用软件基本操作足够了Epi Data 3.0软件培训教材Epi Data 3.0软件使用手册中国疾病预防控制中心公共卫生监测与信息服务中心卫生统计研究室北京宣武区南纬路27号4-25电话:(010)***-***** 传真:(010)***-***** Email:mand ... ENDAFTER FILE指定需要在数据文件被关闭时才执行的命令。
参见:BEFORE FILE. 举例:AFTER FILEHELP “Remember to make a backup of the data file!" TYPE=***** END很详细的应用手册实用软件基本操作足够了AFTER RECORD指定一条记录完全录入或修改完成后才执行的命令。
使用AFTER RECORD 可以来检查数据录入的正确性。
如果在AFTER RECORD命令块后面还有GOTO命令,则当前记录不会保存。
下面的例子是要求录入员在数据录入把个人编码作为第一个字段,在记录录完时把个人编码作为最后一个字段以另一个变量重新录入一遍,以进行控制。
如果两个变量的值不相同则给出提示,记录不保存,而且光标移入第一个字段。
举例:AFTER RECORD IF (ID1ID2) THEN HELP "ID1=@ID1 and ID2=@ID2\n\nPlease check the data" TYPE=***** GOTO ID1 EXIT ENDIFIF (ID1 = .) OR (ID2 = .) THENHELP "ID-number must be entered in ID1 and ID2" TYPE=ERROR IF ID1 = . THEN GOTO ID1 ELSEGOTO ID2 ENDIF ENDIF END*****P使光标无条件的跳转到另一个字段。
epidata中文教程
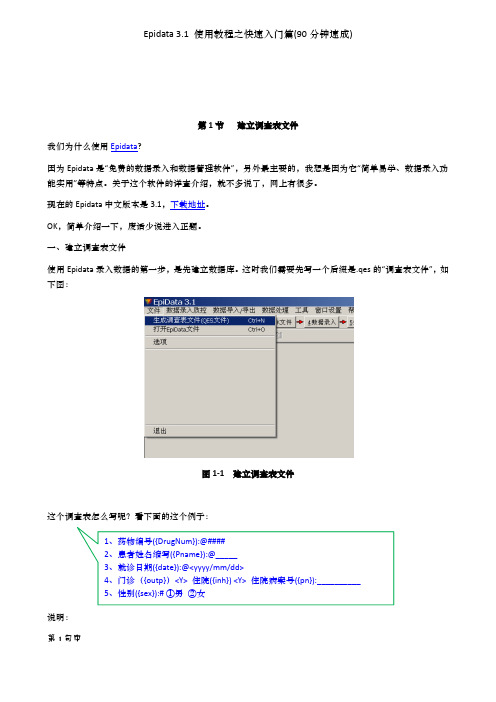
再后面的@###:@表示一种对齐方式,先不用管它,后面会讲到;
###是用来定义前面那个 DrugNum 字段的属性的,#代表一位数字,###就代表 3 位数字,也就是说药物编 号最大也就能输入 999 了,不能再大了;
总结第 1 句的含义:定义了一个字段“药物编号”,字段名是 DrugNum,用于记录 3 位数字形式的数据。(刚
图 1-1 建立调查表文件
这个调查表怎么写呢?看下面的这个例子:
说明: 第 1 句中
1、药物编号({DrugNum}):@#### 2、患者姓名缩写({Pname}):@_____ 3、就诊日期({date}):@<yyyy/mm/dd> 4、门诊({outp})<Y> 住院({inh}) <Y> 住院病案号({pn}):__________ 5、性别({sex}):# ①男 ②女
图 3-5 (Range 和 Legal 这两个命令的作用就是这个) 还记得上一个图中那个“编辑”按钮吗?我们点击它看看里面是什么:
图 3-6 CHK 文件的“编辑”
epidata使用方法解析

2022/8/14
epidata 软件使用
17
2.1.3定义变量标签
变量标签(Variable Labels)变量标签是对一个变 量所含数据内容的描述。在EpiData中,程序会根 据QES文件中,变量编码左侧的解释性文字自动 生成变量标签。如果选择了“文件→选项”中的 “将第一个词作为变量名”(First word in question is field name),则扣除作为变量名的第一个单词后, 自左向右的文字会被作为变量标签。例如:“A1 Age of patient###”,变量名为“A1”,变量标签为 “Age of patient”。中文问题(提示符)虽然不能 不能作为变量名,但是可以自动的作为变量标签。 如果选择了“自动添加字段名”(Automatic field names),则变量名为“A1ageofp”,变量标签为 “A1 Age of patient”。
同时在末尾加上一个数字。例如,前一个 变量的名称为A1,如果没有任何解释性文 字的下一个变量A2。如果前面没有变量, 则默认的变量名为FIELD1。
2022/8/14
epidata 软件使用
16
(7)如果问题(提示符)以数字开头,程 序会自动在数字前插入字母N。例如,“1、 姓名”的变量名会是“N1
EpiData中命名变量的方式有两种: 1)将第一个单词作为变量名(First word in question is
field name) 2)根据规则自动定义变量名(Automatic field names) 执行“文件→选项”命令打开“生成REC文件”
(File→Options→Create data file)选项卡。 (1)QES文件字体设置:变量名称的字体及其大
epidata 使用手册

epidata 使用手册Epidata是一种用于设定、存储和操作流行病数据的计算机软件。
在进行疾病防控、疾病监测等工作时,对于流行病数据的收集和分析具有至关重要的作用。
在使用Epidata软件时,需要一定的操作技能和基本的操作步骤。
下面将对Epidata的使用手册进行介绍,帮助用户更加高效地进行数据分析和处理。
第一步,打开Epidata的主界面。
在计算机上双击Epidata的图标,即可启动该软件。
进入主界面后,可以看到菜单栏、工具栏和数据列表等各个操作组件。
在菜单栏中可以实现数据输入、数据清理、数据管理、数据分析等多种操作。
第二步,建立研究对象。
在Epidata软件中,研究对象通常指流行病学调查中研究的人群或物品等研究单位。
在进行数据录入前,需要先建立研究对象,设置相关的信息,如研究对象编号、名称、地址、联系人信息等。
第三步,设置变量。
在进行数据录入时,需要根据研究对象的不同特点,设置相应的变量。
Epidata软件中,可以使用多种不同的数据类型,包括数字、文本、日期、时间、逻辑等,可根据需要灵活设置。
在设置变量后,还需要设置相应的编辑规则,如数据类型、数据检验、缺失值和超界等,以保证数据录入的准确性和完整性。
第四步,进行数据录入。
在设置好变量后,可以通过Epidata的数据录入功能,开始对研究对象进行数据记录。
在进行数据录入过程中,需要按照事先设定的编辑规则进行数据录入,确保数据的质量和可信度。
第五步,进行数据清理。
数据清理是数据分析的前提,Epidata软件提供了多种数据清理功能,如去除重复值、数据对比、数据修正、数据转换等,以保证数据的准确性和一致性。
第六步,进行数据分析。
在数据清理完成后,可以使用Epidata的数据分析功能,对所采集的数据进行统计分析、比较分析、相关分析、因素分析等,从而得出一些有意义的结论和见解,为研究和预防疾病提供科学依据。
在进行Epidata操作时,还需要注意以下几点:一是备份数据,以防数据丢失或损坏;二是对数据进行正确的分类和命名,以便于数据管理和归档;三是进行操作前先了解相关的操作文档和教程,保证操作准确和高效。
Epdata使用手册

变量标签
变量标签的作用是用来描述变量名的意义。在 EpiData 中,变量标签是根据.QES 文件中的 问题(提示符)自动产生的。 如果选择了将第一个词作为变量名,则这个词不在包括在变量标 签中。中文问题(提示符)虽然不能不能作为变量名,但是可以自动的作为变量标签。 举例: .QES 文件中的“v1 Age of patient ###”将产生变量名为“v1”,而变量标签为“Age of patient”。 如果设置自动产生变量名作为变量名命名规则,则变量名为“v1ageofp”而变量标签为“v1 Age of patient”。
1.选择
选项下的“增加/更改核对文件”
2.在工作程序工具条上直接点击 用户在按上述方法操作后,则出现如图 9 所示窗口,用户在该窗口中选择需要添加核对程 序的数据文件。 在选定数据文件后点击“打开”按钮,则出现如图 10 所示的窗口。用户在该窗口中为数据 文件添加核对程序。在该窗口中,显示的界面与数据录入界面相似。用户可以选择需要添加核 对程序的字段,比如需要给某个字段设置合法值,则用鼠标选择该字段,这时该字段显示为蓝 色,并通过如图 11 所示的窗口进行设置。一些基本的核对程序可以通过在该窗口中设置就可以 实现,比如,合法值范围、跳转、必须录入、自动重复等功能。一些复杂的核对程序需要用户 自己编写,这时可以点击图 11 窗口上的“编辑”按钮,进入如图 12 所示窗口,用户可以在该 窗口中手工写入核对程序。相关核对程序的使用参见本章“常用核对命令”部分内容。
Epidata软件使用

临床研究数据库的建立与数据录入——EpiData软件的使用一、 常见数据库软件简介1.E xcel大多数临床大夫和研究生常用的一种数据库软件,优点:简单易得,界面熟悉。
缺点:数据库用简单表格列出,录入时易串行,发生录入错误;变量类型不清,允许一列内同时存在不同类型的内容(如:字符和数值),影响分析;无法进行双录入核对。
2.S PSS常见的一种数据统计分析软件,也可利用此软件进行录入。
优点:数据库录入完成后即可统计,无需进行格式转换;可指定变量类型、长度、并设置标签。
缺点:数据库用简单表格列出,录入时易录入错误;无法进行双录入核对。
3.E piData因大型流行病学调查需要而产生的一个数据库建立、录入、管理软件。
优点:绿色,自由软件,录入界面简单友好,可指定变量的类型、长度,可简单完成数据库双录入核查,可进行数据库追加、合并操作,数据库可转化各种数据分析软件格式。
缺点:查询功能弱,不带数据分析功能。
由丹麦欧登塞(Odense, Denmark)的一个非盈利组织,即The EpiData Association (http://www.epidata.dk)开发。
EpiData 的工作原理源自DOS 版本的Epi Info 6,但是工作界面为Windows版。
翻译成各国语言:英语、中文、丹麦语、德语、西班牙语、法语、意大利语、荷兰语、挪威语、波兰语、葡萄牙语、罗马尼亚语、俄语、塞尔维亚语、斯洛文尼亚语、阿拉伯语中文最高版本:v3.1 (2008.01更新)EpiData数据库录入、管理步骤1. 建立调查表(QES)2. 创建数据库(REC)3. 建立录入规范文件(CHK)4. 录入数据5. 输出数据(output)理论上,该程序对录入的记录数没有限制。
而实际应用中,记录数最好不要超过200,000~300,000(曾经用250,000 测试过)。
整个录入界面不能超过999行。
对数值或字符串编码进行解释的文字长度最多80个字符,变量名建议控制在8个字符以内,否则可能转出到统计软件时可能出错。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
2013-7-30
epidata 软件使用
5
2.1建立数据库结构文件(Create Questionnaire File)
表 1 工资调查表 A1 编号 A2 姓名 A3 性别(1)男 (2)女 A4 出生日期年 月 日 B1 基本工资 B2 奖金
2013-7-30 epidata 软件使用 6
2.1.1定义变量名
2013-7-30 epidata 软件使用 8
2、编辑器(Editor)主要功能是创建和编 辑调查表(.QES文件)。这个调查表定义 了数据库结构。编辑器的使用和其它字处 理软件基本一致,由菜单栏,工作流程栏、 工具栏和文本编辑区组成。也可以使用编 辑器处理程序输出的报表,以及编辑 CHECK文件。
16
(7)如果问题(提示符)以数字开头,程 序会自动在数字前插入字母N。例如,“1、 姓名”的变量名会是“N1
2013-7-30
epidata 软件使用
17
2.1.3定义变量标签
变量标签(Variable Labels)变量标签是对一个变 量所含数据内容的描述。在EpiData中,程序会根 据QES文件中,变量编码左侧的解释性文字自动 生成变量标签。如果选择了“文件→选项”中的 “将第一个词作为变量名”(First word in question is field name),则扣除作为变量名的第一个单词后, 自左向右的文字会被作为变量标签。例如:“A1 Age of patient###”,变量名为“A1”,变量标签为 “Age of patient”。中文问题(提示符)虽然不能 不能作为变量名,但是可以自动的作为变量标签。 如果选择了“自动添加字段名”(Automatic field names),则变量名为“A1ageofp”,变量标签为 “A1 Age of patient”。
epidata 软件使用 22
2013-7-30
2013-7-30 epidata 软件使用 20
2 数值型字段(Numeric Fields)
数值型变量######.##中只能用来接受从0 到9的数字,数值可以是整数也可以是小数。 一个#号代表一位数,用户可以根据需要定 义所需的数值位数,但包括小数点在内最 大为14位。在数据录入过程中和.QES文件 中你可以用圆点(.)或逗号(,)来表示小 数点。一个变量中只允许输入一个小数点, 这意味着,你不能用逗号作为千位的分隔 符(例如:1,000,000)。字符“#”的数目表 示变量的长度,小数点占一位字符。
2013-7-30 epidata 软件使用 10
(2)REC文件字体设置:更改REC文件变量名称 的字体及其大小。 (3)首字符为汉字变量命名方法:系统不支持中 文作为变量名,在如何生成字段名(How to generate field names)标签中选择定义变量名的方 法。在选择“将第一个单词作为变量名”时,如 第一列为汉字(如去除调查表中的A1,A2,A3等变 量名),则系统自动生成变量名如Field1,field2和 field3,同时REC表中中文文字也不再显示。因此, 建议事先以字母形式定义变量名。 变量名的英文字母是大写(Upper-case)还是小写 (Lower-case)或维持输入时的大小写状态 (Leave as is)也可以在此修改。
epidata 软件使用 11
2013-7-30
(4)首字符为字母的变量命名,系统默认为将自 动将变量编码左侧解释性文字中的第一个单词认 作是变量名(First Word in Question is Field Name)。如果第一个单词的长度超过10个字符, 程序只保留该单词的前10个字符作为变量名。例 如: 1)如果输入:A1 Enter number #### 程序会创建 一个变量名为“A1”的4位整数变量。 2)如果输入:Enter number #### 程序会创建一个 变量名为“Enter”的4位整数变量。此时也可选择 自动定义变量名(Automatic field names)的方式。 3)A1 编号 #### 则变量名为A1 ,注意A1与编号间 要由一空格。
2013-7-30 epidata 软件使用 21
3文本(字符)型字段(Text Fields)
下划线____________定义字符型变量的位数。字 符型变量内可以输入任何字符。该类型变量的最 大长度为80个字符。下划线字符的数目表示变量 的长度。字符型变量允许输入所有字符。变量最 长允许80个字符。如果输入中文,请注意,一个 中文字需占用2个字符。大写字母的字符型变量 (Upper-case Text)<A><A>大写字母的字符型变 量中可以录入任意字符,但程序会自动将录入的 字母转换为大写。变量的长度即“<”和“>”间的 字符数,其中包括大写字母“A”所占的1个字符。 上面例子中,第一个变量的长度为1,第二个变量 的长度为5。
建立调查表文件是建立数据库、实现数据 录入和管理的第一步。 调查表结构文件在编辑器窗口建立
2013-7-30
epidata 软件使用
7
编辑器窗口的使用
1、打开EPIDATA 软件,可以单击菜单中的“文 件→生成调查表文件”, 在工作流程栏(Work Process Toolbar)上点击 “建立新的QES文件”, 单击工具栏上的“新记录”按钮 这时窗口中会自动显示一个空白的文档,你可以在这 里输入调查表,也可以把WORD中建立的调查表复 制/粘贴过来再进行编辑。调查表实际上就是数 据录入表格的框架。 编辑完成后,将此调查表文件保存,文件的扩展名统 一为.QES。
2013-7-30
epidata 软件使用
3
2 数据库创建过程
在使用EpiData软件之前,先对该软件中用到的三种 基本的文件类型进行简单介绍: ①.QES文件:数据库结构文件,决定数据库结构。 ②.REC文件:数据库文件,主要用于存放数据。 ③.CHK文件:核对文件,存放控制数据录入的核对 规则,起质量控制作用。 EpiData由数据库结构文件(.qes),来决定数据库 结构,然后根据该数据库结构文件生成数据文件 (.rec)。
数据录入和数据管理软件
EpiData
2013-7-30
epidata 软件使用
1
1.软件使用简介
1、简介(Introduction) EpiData是一个免费的数据录入和数据管理软件。 由美国CDC(疾病控制中心)和WHO(世界卫 生组织)联合发布的,是一款免费软件。 主要用于数据录入、核对、管理和数据报告。 该软件的功能是建立数字化的调查表格,使收 集的资料信息录入计算机更加方便。该软件不 但可以在数据录入过程中对数据中的错误进行 核对,而且可以在数据录入完成后对数据进行 核对,如双录入的数据核查。
2013-7-30
epidata 软件使用
12
4)当一个变量名已经使用过,再次出现时, 程序会自动添加一个数字,以保证变量名 的唯一性。如有三个A1变量,则自动以 A1,A2,A3命名,并以此类推,建议变量起名 时具有唯一性,以免混淆。选择生成REC文 件中的“更新问题为实际文件名”(Update question to actual field name),这样,即使 创建调查表文件时有重复的变量名,在创 建的数据库中,程序会自动将其更新为其 实际的变量名。
2013-7-30
epidata 软件使用
19
1.自动编码字段<IDNUM>
自动ID号变量(IDNUM)是一个数值型变量, 其值由计算机自动生成。其赋值原则是随 着每一条记录的输入,变量值加1。在数据 录入过程中它的值不能修改,只能自动增 加。该变量的初始值默认为1,但是用户可 以在“文件”菜单的“选项”中的“高级 设置”中进行设置 (File→Options→Advanced→ID number fields→First IDnumber in new data file:1)。 此变量长度为5-18个字符。
2013-7-30
epidata 软件使用
9
2.1.2 定义变量名(Field Names)
输入的信息要保存在变量中因此需要定义变量名。 一个数据库中录入变量的名称可以根据QES文件 的内容自动创建。 EpiData中命名变量的方式有两种: 1)将第一个单词作为变量名(First word in question is field name) 2)根据规则自动定义变量名(Automatic field names) 执行“文件→选项”命令打开“生成REC文件” (File→Options→Create data file)选项卡。 (1)QES文件字体设置:变量名称的字体及其大 小可以在QES文件显示(Show data form)中设置. 。
2013-7-30
epidata 软件使用
4
一个最简单的创建数据库的工作至少要包括以下两步: 1、数据库建立——根据调查表制作数据库结构文件 (.qes) 2、生成数据文件——根据数据库结构文件生成数据库 文件(.rec)。 理论上说,有了数据文件就可以进行数据录入了,但是 在实际工作中,往往需要对数据录入进行质量控制, 比如对某些字段设置合法值、跳转等等。这些质量 控制工作需要专门的核对文件来完成(.chk)。 因此,在数据库创建过程一般还包括: 3、编写核对程序——即生成数据核对文件(.chk). 在EpiData软件中,在其主界面的上形象的标示出了数 据库创建过程:
epidata 软件使用 18
2013-7-30
2.1.4定义变量类型
执行“编辑→字段编辑器”命令 (Edit→Field Pick List), 或者按Ctrl+Q键, 或者在编辑器工具栏(Editor Toolbar)单击 字段编辑器按钮,可以打开变量类型选择 对话框,从中选择适当的变量类型单击 “插入”按钮即可。