(5)案例:多重共线性
计量经济学实验五 多重共线性的检验与修正 完成版
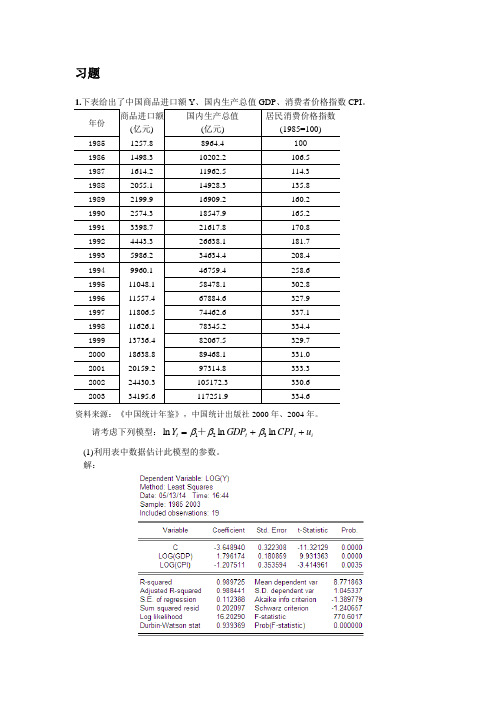
习题1.下表给出了中国商品进口额Y 、国内生产总值GDP 、消费者价格指数CPI 。
年份 商品进口额 (亿元)国内生产总值(亿元)居民消费价格指数(1985=100)1985 1257.8 8964.4 1001986 1498.3 10202.2 106.5 1987 1614.2 11962.5 114.3 1988 2055.1 14928.3 135.8 1989 2199.9 16909.2 160.2 1990 2574.3 18547.9 165.2 1991 3398.7 21617.8 170.8 1992 4443.3 26638.1 181.7 1993 5986.2 34634.4 208.4 1994 9960.1 46759.4 258.6 1995 11048.1 58478.1 302.8 1996 11557.4 67884.6 327.9 1997 11806.5 74462.6 337.1 1998 11626.1 78345.2 334.4 1999 13736.4 82067.5 329.7 2000 18638.8 89468.1 331.0 2001 20159.2 97314.8 333.3 2002 24430.3 105172.3 330.6 200334195.6117251.9334.6资料来源:《中国统计年鉴》,中国统计出版社2000年、2004年。
请考虑下列模型:i t t t u CPI GDP Y ++=ln ln ln 321βββ+ (1)利用表中数据估计此模型的参数。
解:ln 3.6489 1.796ln 1.2075ln t t t Y GDP CPI =--+t= (-11.32) (9.93) (-3.415)20.988770.6.0.1124R F S E ===(2)你认为数据中有多重共线性吗?多重共线性的检验 1)综合统计检验法若 在OLS 法下:R 2与F 值较大,但t 检验值较小,则可能存在多重共线性。
主成分回归多重共线性
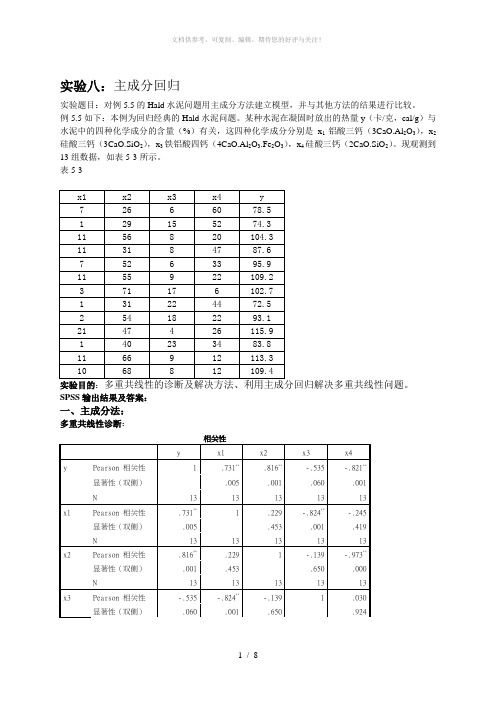
实验八:主成分回归实验题目:对例5.5的Hald水泥问题用主成分方法建立模型,并与其他方法的结果进行比较。
例5.5如下:本例为回归经典的Hald水泥问题。
某种水泥在凝固时放出的热量y(卡/克,cal/g)与水泥中的四种化学成分的含量(%)有关,这四种化学成分分别是x1铝酸三钙(3CaO.Al2O3),x2硅酸三钙(3CaO.SiO2),x3铁铝酸四钙(4CaO.Al2O3.Fe2O3),x4硅酸三钙(2CaO.SiO2)。
现观测到13组数据,如表5-3所示。
表5-3实验目的:SPSS输出结果及答案:一、主成分法:多重共线性诊断:N 13 13 13 13 13 x4 Pearson 相关性-.821**-.245 -.973**.030 1显著性(双侧).001 .419 .000 .924N 13 13 13 13 13**. 在 .01 水平(双侧)上显著相关。
由表可知,x1,x2,x4的相关性都比较大,较接近,所以存在多重共线性主成分回归:解释的总方差成份初始特征值提取平方和载入合计方差的 % 累积 % 合计方差的 % 累积 %1 2.236 55.893 55.893 2.236 55.893 55.8932 1.576 39.402 95.294 1.576 39.402 95.2943 .187 4.665 99.959 .187 4.665 99.9594 .002 .041 100.000 .002 .041 100.000提取方法:主成份分析。
输出结果显示有四个特征根,最大的是λ1=2.236,最小的是λ4=0.002。
方差百分比显示第一个主成分Factor1的方差百分比近56%的信息量;前两个主成分累计包含近95.3%的信息量。
因此取两个主成分就已经足够。
由于前两个主成分的方差累计已经达到95.3%,故只保留前两个主成分。
成份矩阵a成份1 2 3 4x1 .712 -.639 .292 .010x2 .843 .520 -.136 .026x3 -.589 .759 .275 .011x4 -.819 -.566 -.084 .027提取方法:主成分a.已提取了 4 个成份。
实验五多重共线性检验参考案例

实验五 多重共线性检验实验时间: 姓名:学号: 成绩:【实验目的】1、掌握多元线性回归模型的估计、检验和预测;2、掌握多重共线性问题的检验方法3、掌握多重共线性问题的修正方法 【实验内容】1、数据的读取和编辑;2、多元回归模型的估计、检验、预测;3、多重共线性问题的检验4、多重共线性问题的修正 【实验背景】为了评价报账最低工资(负收入税)政策的可行性,兰德公司进行了一项研究,以评价劳动供给(平均工作小时数)对小时工资提高的反应,词研究中的数据取自6000户男户主收入低于15000美元的一个国民样本,这些数据分成39个人口组,并放在表1中,由于4个人口组中的某些变量确实,所以只给出了35个组的数据,用于分析的各个变量的定义如下:Y 表示该年度平均工作小时数;X1表示平均小时工资(美元);X2表示配偶平均收入(美元);X3表示其他家庭成员的平均收入(美元);X4表示年均非劳动收入(美元);X5表示平均家庭资产拥有量;X6表示被调查者的平均年龄;X7表示平均赡养人数;X 8表示平均受教育年限。
μ为随机干扰项,考虑一下回归模型:μβββββββββ+++++++++=87654321876543210X X X X X X X X Y (1) 将该年度平均工作小时数Y 对X 进行回归,并对模型进行简单分析; (2) 计算各变量之间的相关系数矩阵,利用相关系数法分析变量间是否具有多重共线性;(3) 利用逐步回归方法检验并修正回归模型,最后再对模型进行经济意义检验、统计检验。
表5观测组Y X1 X2 X3 X4 X5 X6 X7 X81 2157 2.905 1121 291 380 7250 38.5 2.34 10.52 2174 2.97 1128 301 398 7744 39.3 2.335 10.53 2062 2.35 1214 326 185 3068 40.1 2.851 8.94 2111 2.511 1203 49 117 1632 22.4 1.159 11.55 2134 2.791 1013 594 730 1271057.7 1.229 8.86 2185 3.04 1135 287 382 776 38.6 2.602 10.77 2210 3.222 1100 295 474 9338 39 2.187 1128 2105 2.495 1180 310 255 4730 39.9 2.616 9.39 2267 2.838 1298 252 431 8317 38.9 2.024 11.110 2205 2.356 885 264 373 6489 38.8 2.662 9.511 2121 2.922 1251 328 312 5907 39.8 2.287 10.312 2109 2.499 1207 347 271 5069 39.7 3.193 8.913 2108 2.796 1036 300 259 4614 38.2 2.4 9.214 2047 2.453 1213 397 139 1987 40.3 2.545 9.115 2174 3.582 1141 414 498 1023940 2.064 11.716 2067 2.909 1805 290 239 4439 39.1 2.301 10.517 2159 2.511 1075 289 308 5621 39.3 2.486 9.518 2257 2.516 1093 176 392 7293 37.9 2.042 10.119 1985 1.423 553 381 146 1866 40.6 3.833 6.620 2184 3.636 1091 291 560 1124039.1 2.328 11.621 2084 2.983 1327 331 296 5653 39.8 2.208 10.222 2051 2.573 1197 279 172 2806 40 2.362 9.123 2127 3.263 1226 314 408 8042 39.5 2.259 10.824 2102 3.234 1188 414 352 7557 39.8 2.019 10.725 2098 2.28 973 364 272 4400 40.6 2.661 8.426 2042 2.304 1085 328 140 1739 41.8 2.444 8.227 2181 2.912 1072 304 383 9340 39 2.337 10.228 2186 3.015 1122 30 352 7292 37.2 2.046 10.929 2188 3.01 990 366 374 7325 38.4 2.847 10.630 2077 1.901 350 209 95 1370 37.4 4.158 8.231 2196 3.009 947 294 342 6888 37.5 3.047 10.632 2093 1.899 342 311 120 1425 37.5 4.512 8.133 2173 2.959 1116 296 387 7625 39.2 2.342 10.534 2179 2.959 1116 296 387 7625 39.2 2.342 10.535 2200 2.98 1126 204 393 7885 39.2 2.341 10.6 【实验过程】一、利用Evie ws软件建立年度平均工作小时数y的回归模型。
计量经济学实验五-多重共线性的检验与修正
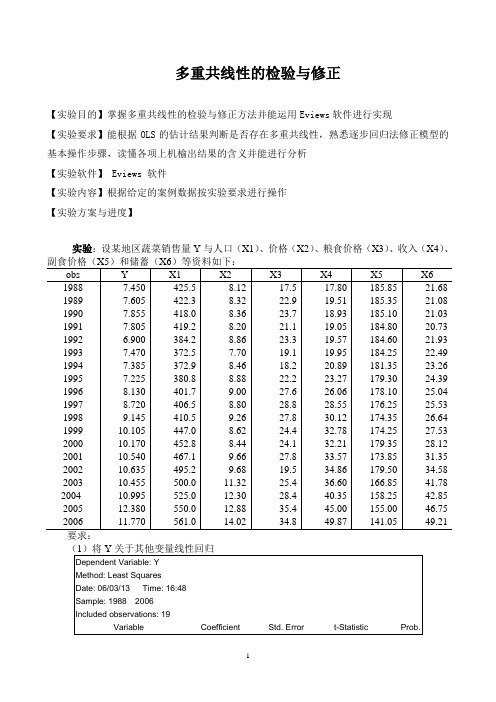
多重共线性的检验与修正【实验目的】掌握多重共线性的检验与修正方法并能运用Eviews软件进行实现【实验要求】能根据OLS的估计结果判断是否存在多重共线性,熟悉逐步回归法修正模型的基本操作步骤,读懂各项上机榆出结果的含义并能进行分析【实验软件】 Eviews 软件【实验内容】根据给定的案例数据按实验要求进行操作【实验方案与进度】实验:设某地区蔬菜销售量Y与人口(X1)、价格(X2)、粮食价格(X3)、收入(X4)、副食价格(X5)和储蓄(X6)等资料如下:obs Y X1 X2 X3 X4 X5 X6 1988 7.450 425.5 8.12 17.5 17.80 185.85 21.68 1989 7.605 422.3 8.32 22.9 19.51 185.35 21.08 1990 7.855 418.0 8.36 23.7 18.93 185.10 21.03 1991 7.805 419.2 8.20 21.1 19.05 184.80 20.73 1992 6.900 384.2 8.86 23.3 19.57 184.60 21.93 1993 7.470 372.5 7.70 19.1 19.95 184.25 22.49 1994 7.385 372.9 8.46 18.2 20.89 181.35 23.26 1995 7.225 380.8 8.88 22.2 23.27 179.30 24.39 1996 8.130 401.7 9.00 27.6 26.06 178.10 25.04 1997 8.720 406.5 8.80 28.8 28.55 176.25 25.53 1998 9.145 410.5 9.26 27.8 30.12 174.35 26.64 1999 10.105 447.0 8.62 24.4 32.78 174.25 27.53 2000 10.170 452.8 8.44 24.1 32.21 179.35 28.12 2001 10.540 467.1 9.66 27.8 33.57 173.85 31.35 2002 10.635 495.2 9.68 19.5 34.86 179.50 34.58 2003 10.455 500.0 11.32 25.4 36.60 166.85 41.78 2004 10.995 525.0 12.30 28.4 40.35 158.25 42.85 2005 12.380 550.0 12.88 35.4 45.00 155.00 46.75 2006 11.770 561.0 14.02 34.8 49.87 141.05 49.21 要求:(1)将Y关于其他变量线性回归Dependent Variable: YMethod: Least SquaresDate: 06/03/13 Time: 16:48Sample: 1988 2006Included observations: 19Variable Coefficient Std. Error t-Statistic Prob.C -1.530260 6.006901 -0.254750 0.8032 X1 0.014649 0.002923 5.012107 0.0003 X2 -0.702775 0.254521 -2.761169 0.0172 X3 0.060321 0.027575 2.187545 0.0492 X4 0.119825 0.036991 3.239290 0.0071 X5 0.018081 0.026022 0.694816 0.5004 X60.0922660.0542651.7003020.1148 R-squared0.986169 Mean dependent var 9.091579 Adjusted R-squared 0.979254 S.D. dependent var 1.717935 S.E. of regression 0.247442 Akaike info criterion 0.322027 Sum squared resid 0.734730 Schwarz criterion 0.669979 Log likelihood 3.940740 F-statistic 142.6067 Durbin-Watson stat2.292164 Prob(F-statistic)0.000000123456-1.5300.0150.7030.0600.120.0180.092t t t t t t t t Y X X X X X X u =+-+++++ (2)经济意义检验:与预期符号相符 (3)方程线性显著性检验由(1)表中的数据可知F 统计量的值为142.6067,查表得0.05(6,1F =3,显然142.6067>0.05(6,12)F =3,说明方程具有线性显著性。
第四章多重共线性实例

表 4.3.3 中国粮食生产与相关投入资料
农业化肥施 粮食播种面 受灾面积 农业机械总
用量 X 1
(万公斤)
积X 2
(千公顷)
X3
(公顷)
动力X 4
(万千瓦)
1659.8
114047 16209.3
18022
1739.8
112884 15264.0
19497
1775.8
108845 22705.3
20913
Yˆ 28259.19 2.240X5
(-1.04) (2.66) R2=0.3064 F=7.07 DW=0.36
• 可见,应选第1个式子为初始的回归模型。
4、逐步回归
将其他解释变量分别导入上述初始回归模型,寻 找最佳回归方程。
C
X1 X2 X3
X4
X5
R2
DW
Y=f(X1)
30868 4.23
0.8852 1.56
t值
25.58 11.49
Y=f(X1,X2)
-43871 4.65 0.67
0.9558 2.01
t值
-3.02 18.47 5.16
Y=f(X1,X2,X3)
-11978 5.26 0.41 -0.19
0.9752 1.53
t值
0.85
19.6 3.35 -3.57
Y=f(X1,X2,X3,X4) -13056 6.17 0.42 -0.17 -0.09
1930.6
110933 23656.0
22950
1999.3
111268 20392.7
24836
2141.5
110123 23944.7
多重共线性的概念实际经济问题中的多重共线性

(3)样本资料的限制 由于完全符合理论模型所要求的样本数据较 难收集,特定样本可能存在某种程度的多重共线 性。 一般经验: 时间序列数据样本:简单线性模型,往往存 在多重共线性。 截面数据样本:问题不那么严重,但多重共 线性仍然是存在的。
具体可进一步对上述回归方程作F检验: 构造如下F统计量
Fj R2 j . /( k 2) (1 R ) /(n k 1)
2 j.
~ F (k 2, n k 1)
式中:Rj•2为第j个解释变量对其他解释变量的回 归方程的决定系数,
若存在较强的共线性,则Rj•2较大且接近 于1,这时(1- Rj•2 )较小,从而Fj的值较大。 因此,给定显著性水平,计算F值,并与 相应的临界值比较,来判定是否存在相关性。
在矩阵表示的线性回归模型 Y=X+ 中,完全共线性指:秩(X)<k+1,即
1 1 X 1 X 11 X 12 X 1n X 21 X 22 X 2n X k1 X k2 X kn
中,至少有一列向量可由其他列向量(不包括第 一列)线性表出。 如:X2= X1,则X2对Y的作用可由X1代替。
二、实际经济问题中的多重共线性
一般地,产生多重共线性的主要原因有以 下三个方面: (1)经济变量相关的共同趋势
时间序列样本:经济繁荣时期,各基本经 济变量(收入、消费、投资、价格)都趋于增 长;衰退时期,又同时趋于下降。
横截面数据:生产函数中,资本投入与劳动力 投入往往出现高度相关情况,大企业二者都大, 小企业都小。
实验五__多重共线性检验参考案例共16页word资料

实验五 多重共线性检验实验时间: 姓名:学号: 成绩:【实验目的】1、掌握多元线性回归模型的估计、检验和预测;2、掌握多重共线性问题的检验方法3、掌握多重共线性问题的修正方法 【实验内容】1、数据的读取和编辑;2、多元回归模型的估计、检验、预测;3、多重共线性问题的检验4、多重共线性问题的修正 【实验背景】为了评价报账最低工资(负收入税)政策的可行性,兰德公司进行了一项研究,以评价劳动供给(平均工作小时数)对小时工资提高的反应,词研究中的数据取自6000户男户主收入低于15000美元的一个国民样本,这些数据分成39个人口组,并放在表1中,由于4个人口组中的某些变量确实,所以只给出了35个组的数据,用于分析的各个变量的定义如下:Y 表示该年度平均工作小时数;X1表示平均小时工资(美元);X2表示配偶平均收入(美元);X3表示其他家庭成员的平均收入(美元);X4表示年均非劳动收入(美元);X5表示平均家庭资产拥有量;X6表示被调查者的平均年龄;X7表示平均赡养人数;X8表示平均受教育年限。
μ为随机干扰项,考虑一下回归模型:μβββββββββ+++++++++=87654321876543210X X X X X X X X Y(1) 将该年度平均工作小时数Y 对X 进行回归,并对模型进行简单分析; (2) 计算各变量之间的相关系数矩阵,利用相关系数法分析变量间是否具有多重共线性;(3) 利用逐步回归方法检验并修正回归模型,最后再对模型进行经济意义检验、统计检验。
表5观测组Y X1 X2 X3 X4 X5 X6 X7 X81 2157 2.905 1121 291 380 7250 38.5 2.34 10.52 2174 2.97 1128 301 398 7744 39.3 2.335 10.53 2062 2.35 1214 326 185 3068 40.1 2.851 8.94 2111 2.511 1203 49 117 1632 22.4 1.159 11.55 2134 2.791 1013 594 730 12710 57.7 1.229 8.86 2185 3.04 1135 287 382 776 38.6 2.602 10.77 2210 3.222 1100 295 474 9338 39 2.187 1128 2105 2.495 1180 310 255 4730 39.9 2.616 9.39 2267 2.838 1298 252 431 8317 38.9 2.024 11.110 2205 2.356 885 264 373 6489 38.8 2.662 9.511 2121 2.922 1251 328 312 5907 39.8 2.287 10.312 2109 2.499 1207 347 271 5069 39.7 3.193 8.913 2108 2.796 1036 300 259 4614 38.2 2.4 9.214 2047 2.453 1213 397 139 1987 40.3 2.545 9.115 2174 3.582 1141 414 498 10239 40 2.064 11.716 2067 2.909 1805 290 239 4439 39.1 2.301 10.517 2159 2.511 1075 289 308 5621 39.3 2.486 9.518 2257 2.516 1093 176 392 7293 37.9 2.042 10.119 1985 1.423 553 381 146 1866 40.6 3.833 6.620 2184 3.636 1091 291 560 11240 39.1 2.328 11.621 2084 2.983 1327 331 296 5653 39.8 2.208 10.222 2051 2.573 1197 279 172 2806 40 2.362 9.123 2127 3.263 1226 314 408 8042 39.5 2.259 10.824 2102 3.234 1188 414 352 7557 39.8 2.019 10.725 2098 2.28 973 364 272 4400 40.6 2.661 8.426 2042 2.304 1085 328 140 1739 41.8 2.444 8.227 2181 2.912 1072 304 383 9340 39 2.337 10.228 2186 3.015 1122 30 352 7292 37.2 2.046 10.929 2188 3.01 990 366 374 7325 38.4 2.847 10.630 2077 1.901 350 209 95 1370 37.4 4.158 8.231 2196 3.009 947 294 342 6888 37.5 3.047 10.632 2093 1.899 342 311 120 1425 37.5 4.512 8.133 2173 2.959 1116 296 387 7625 39.2 2.342 10.534 2179 2.959 1116 296 387 7625 39.2 2.342 10.535 2200 2.98 1126 204 393 7885 39.2 2.341 10.6 【实验过程】一、利用Eviews软件建立年度平均工作小时数y的回归模型。
第五章 多重共线性的概念

3、模型中大量地采用滞后变量 、 滞后变量也易产生多重共线性 滞后变量 例如: 例如:在研究消费函数Y的时候,如果记可支配收入为X ,若在模型
σ2
恰为X1与X2的线性相关系数的平方r2 ∑x ∑x
2 1i 2 2i
(∑ x1i x 2i ) 2
由于 r2 ≤1,故 1/(1- r2 )≥1
完全不共线时, 当完全不共线 完全不共线
r2
=0
ˆ var( β 1 ) = σ 2 / ∑ x12i
1 σ2 ˆ ⋅ > var(β 1 ) = 2 2 x1i 1 − r x12i ∑ ∑
2.
判明存在多重共线性的范围
如果存在多重共线性,需进一步确定究竟由 哪些变量引起。 (1) 判定系数检验法 使模型中每一个解释变量分别以其余解释变 量为解释变量进行回归,并计算相应的拟合优度。 如果某一种回归: Xji=α1X1i+α2X2i+…αLXLi 的判定系数 判定系数较大,说明Xj与其他X间存在共线性 共线性。 判定系数 共线性
(2)逐步回归法 (2)逐步回归法 以Y为被解释变量,逐个引入解释变量,构 成回归模型,进行模型估计。 根据拟合优度的变化决定新引入的变量是否 独立。 如果拟合优度变化显著,则说明新引入的变 如果拟合优度变化显著 量是一个独立解释变量; 如果拟合优度变化很不显著,则说明新引入 如果拟合优度变化很不显著 的变量与其它变量之间存在共线性关系。
β1、 β2已经失去了应有的经济含义,于 是经常表现出似乎反常的现象 似乎反常的现象:例如 β 1 本来 似乎反常的现象
实验五__多重共线性检验参考案例

实验五__多重共线性检验参考案例多重共线性检验是用来检验自变量之间是否存在高度相关性的一种方法。
在回归分析中,如果自变量之间存在高度相关性,会导致回归方程中的相关系数估计值不稳定,难以准确地解释自变量对因变量的影响。
因此,进行多重共线性检验是非常重要的。
下面将以一个案例来说明如何进行多重共线性检验。
假设我们想研究一些城市的房价与以下自变量相关性的影响:房屋面积、房间数量、距离市中心的距离。
我们采集了100个样本,并进行了回归分析。
首先,我们可以查看自变量之间的相关系数矩阵,以判断是否存在高度相关性。
下面是自变量之间的相关系数矩阵:房屋面积房间数量距离市中心的距离房屋面积10.80.2房间数量0.810.1距离市中心的距离0.20.11从相关系数矩阵可以看出,房屋面积和房间数量之间存在高度相关性,相关系数为0.8、这可能意味着两个自变量提供了类似的信息,在回归分析中可能会造成多重共线性的问题。
接下来,我们可以计算自变量的方差膨胀因子(VIF)来进一步检验多重共线性。
VIF是用来度量自变量之间相关度的指标,VIF值越大,说明自变量之间的共线性越强。
计算VIF的公式如下:VIF_i=1/(1-R_i^2)其中,VIF_i表示自变量i的VIF值,R_i^2表示通过其他自变量对自变量i进行回归分析得到的决定系数。
下面是计算三个自变量的VIF值:VIF_房屋面积=1/(1-0.8^2)=1.67VIF_房间数量=1/(1-0.8^2)=1.67VIF_距离市中心的距离=1/(1-0.1^2)=1.01从计算结果可以看出,三个自变量的VIF值都在可接受的范围内,说明它们之间并不存在严重的多重共线性问题。
最后,我们可以绘制自变量对因变量的散点图,以观察它们之间的关系。
如果自变量之间存在高度相关性,会导致散点图中观测点呈现出一种线性的形态。
综上所述,通过相关系数矩阵、VIF值以及散点图的分析,我们可以得出结论:在这个案例中,房屋面积、房间数量和距离市中心的距离之间不存在严重的多重共线性问题,可以继续进行回归分析。
多重共线性案例
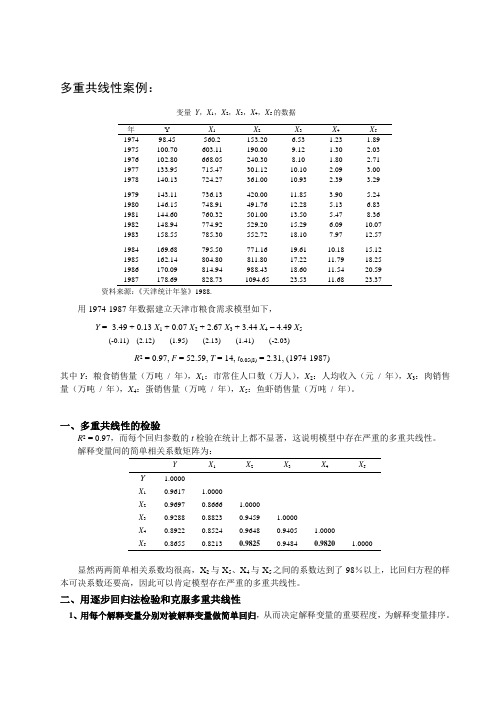
多重共线性案例:变量Y,X1,X2,X3,X4,X5的数据年Y X1X2X3X4X51974 98.45 560.2 153.20 6.53 1.23 1.891975 100.70 603.11 190.00 9.12 1.30 2.031976 102.80 668.05 240.30 8.10 1.80 2.711977 133.95 715.47 301.12 10.10 2.09 3.001978 140.13 724.27 361.00 10.93 2.39 3.291979 143.11 736.13 420.00 11.85 3.90 5.241980 146.15 748.91 491.76 12.28 5.13 6.831981 144.60 760.32 501.00 13.50 5.47 8.361982 148.94 774.92 529.20 15.29 6.09 10.071983 158.55 785.30 552.72 18.10 7.97 12.571984 169.68 795.50 771.16 19.61 10.18 15.121985 162.14 804.80 811.80 17.22 11.79 18.251986 170.09 814.94 988.43 18.60 11.54 20.591987 178.69 828.73 1094.65 23.53 11.68 23.37资料来源:《天津统计年鉴》1988.用1974-1987年数据建立天津市粮食需求模型如下,Y = -3.49 + 0.13 X1 + 0.07 X2 + 2.67 X3 + 3.44 X4– 4.49 X5(-0.11) (2.12) (1.95) (2.13) (1.41) (-2.03)R2 = 0.97, F = 52.59, T = 14, t0.05(8) = 2.31, (1974-1987)其中Y:粮食销售量(万吨/ 年),X1:市常住人口数(万人),X2:人均收入(元/ 年),X3:肉销售量(万吨/ 年),X4:蛋销售量(万吨/ 年),X5:鱼虾销售量(万吨/ 年)。
第四章 多重共线性

多重共线性的定义 产生多重共线性的背景 多重共线性产生的后果 多重共线性的检验 多重共线性的补救措施
第四章 多重共线性
一、多重共线性的定义:案例1 能源消费 多重共线性的定义:案例1
1、完全多重共线性: 、完全多重共线性: 对于 变 量 X 2 , X 3 ,L, X k ,如 果 存在 不全 为零 的数 λ2,λ3, ,λk , 使 L
年份 财政收 农业增 工业增 建筑业 总人口/ 最终消 入CS 加值NZ 加值GZ 增加值 万人 费CUM
1978 1979 1980 1981 1982 1983 1984 1985 1986 1987 1988 1989 1990 1991 1992 1132.3 1146.4 1159.9 1175.8 1212.3 1367 1642.9 2004.8 2122 2199.4 2357.2 2664.9 2937.1 3149.48 3483.37 1018.4 1258.9 1359.4 1545.6 1761.6 1960.8 2295.5 2541.6 2763.9 3204.3 3831 4228 5017 5288.6 5800 1607 1769.7 1996.5 2048.4 2162.3 2375.6 2789 3448.7 3967 4585.8 5777.2 6484 6858 8087.1 10284 138.2 143.8 195.5 207.1 220.7 270.6 316.7 417.9 525.7 665.8 810 794 859.4 1015.1 1415 96259 97542 98705 100072 101654 103008 104357 105851 107507 109300 111026 112704 114333 115823 117171 2239.1 2619.4 2976.1 3309.1 3637.9 4020.5 4694.5 5773 6542 7451.2 9360.1 10556.5 11365.2 13145.9 15952.1
多重共线性产生的原因多重共线性产生的后果多重

根据理论和经验分析,影响粮食生产(Y)的 主要因素有:
农业化肥施用量(X1);粮食播种面积(X2)
成灾面积(X3);
农业机械总动力(X4);
农业劳动力(X5)
已知中国粮食生产的相关数据,建立中国粮食 生产函数:
Y=0+1 X1 +2 X2 +3 X3 +4 X4 +4 X5 +
年份
1983 1984 1985 1986 1987 1988 1989 1990 1991 1992 1993 1994 1995 1996 1997 1998 1999 2000
• 主成分分析的要点是: (1)变量的降维;(2)主成分的解释。
• 在主成分分析中,我们首先应保证所提取的前 几个主成分的累计贡献率达到一个较高的水平 (即变量降维后的信息量须保持在一个较高水 平上),其次对这些被提取的主成分必须都能 够给出符合实际背景和意义的解释(否则主成 分将空有信息量而无实际含义)。
4、变量的显著性检验失去意义
存在多重共线性时
参数估计值的方差与标准差变大
容易使通过样本计算的t值小于临界值, 误导作出参数为0的推断
可能将重要的解释变量排除在模型之外
5、模型的预测功能失效
变大的方差容易使区间预测的“区间”变大, 使预测失去意义。
注意:
除非是完全共线性,多重共线性并不意味 着任何基本假设的违背;
横截面数据:生产函数中,资本投入与劳动 力投入往往出现高度相关情况,大企业二者都大, 小企业都小。
(2)经济变量间存在较密切的关系
• 由于组成经济系统的各要素之间是相互 影响相互制约的,因而在数量关系上也 会存在一定联系。
• 如耕地面积与施肥量都会对粮食总产量 有一定影响,同时,二者本身存在密切 关系。
第5章多重共线性的情形及其处理

记
C=(cij)=(X*′X*)-1 称其主对角线元素VIFj=cjj为自变量xj的方差扩大因子(Variance Inflation Factor,简记为VIF)。根据OLS性质3可知,
var(ˆ j ) cjj 2 / Ljj , j 1,, p
外,除非我们修改容忍度的默认值。
§5.2 多重共线性的诊断
以下用SPSS软件诊断例3.2中国民航客运量一例中的多重共线性问题。
Coeffi ci entsa
Unst andardized Coef f icients
Std.
B
Error
(C onstant ) 450. 909 178. 078
X1
每个数值平方后再除以特征值,然后再把每列数据 除以列数据之和,使得每列数据之和为1,这样就 得到了输出结果6.2的方差比。
再次强调的是线性回归分析共线性诊断中设计 阵X包含代表常数项的一列1,而因子分析模块中 给出的特征向量是对标准化的设计阵给出的,两者 之间有一些差异。
三、 等级相关系数法 (Spearman Rank Correlation )
根据矩阵行列式的性质,矩阵的行列式等于其 特征根的连乘积。因而,当行列式|X′X|≈0时, 矩 阵X′X至少有一个特征根近似为零。反之可以证明, 当矩阵X′X至少有一个特征根近似为零时,X 的列 向量间必存在复共线性,证明如下:
记X =(X0 ,X1,…,Xp),其中 Xi为X 的列向量, X0 =(1,1,…,1)′是元素全为1的n维列向量。 λ是矩阵X′X的一个近似为零的特征根,λ≈0 c=(c0,c1, …,cp)′是对应于特征根λ的单位特征向量,则
第六章:多重共线性

(1)对两个解释变量的模型,采用简单相关系数法
求出X1与X2的简单相关系数r,若|r|接近1,则 说明两变量存在较强的多重共线性。 (2)对多个解释变量的模型,采用综合统计检验 法
若在OLS法下:R2与F值较大,但t检验值较小, 说明各解释变量对Y的联合线性作用显著,但各 解释变量间存在共线性而使得它们对Y的独立作 用不能分辨,故t检验不显著。
(2)R2增加,∣t∣下降, 存在多重共线性.
排除引起多重共线性的变量是克服多重共线最
有效的方法。但是,消除共线变量以后,保留
在模型中变量的经济意义不再仅仅是自身的作 用,也包含了与其共线并被排除变量的作用。
五、克服多重共线的办法 (2)差分法
一般说来,增量间的线性关系弱于总量间的线性 关系。所以,对于时间序列数据,通常将直接的 线性模型转换为差分形式进行估计。
比例1可近似看成比例常数=0.5,比例2则看不出公共的比例常数
五、克服多重共线的办法 (3)改用解释变量的形式
(1)采用相对数变量 例:Q=β 1+β 2Y+β 3P0+β 4P1+μ
改用,Q=β 1+β 2Y+β 3(P0/P1)+μ
需求品的价格除以替代品的价格P0/P1 (2)用被解释变量的滞后值代替解释变量的滞后值 例:消费取决与现期收入和过去收入: Yt=β 0+β 1Xt+β 2Xt-1+……+μ 改用, Yt=β 0+β 1Xt+β 2Yt-1+μ
2、解释变量中含有当期和滞后变量 例如,投资模型 It=β1+β2rt+β3Yt+β4Yt-1+μt It=投资,rt=利率,Yt=当期GDP,Yt-1=上期GDP 而 Y1,……,Yn 自相关(成比例),所以 Yt 与 Yt-1相关
多重共线性(Multi-Collinearity)

i 0 1 1i 2 2i
k ki i
(i=1,2,…,n)
其基本假设之一是解释变量
X,
1
X2,,
X
k
互相独立 。
如果某两个或多个解释变量之间出现了相关性, 则称为多重共线性。
如果存在
c1X1i+c2X2i+…+ckXki=0
i=1,2,…,n
其中: ci不全为0,即某一个解释变量可以用其它解释 变量的线性组合表示,则称为解释变量间存在完全
2
1
x12i 1 r 2
2
x12i
所以,多重共线性使参数估计量的方差增大。
方差扩大因子(Variance Inflation Factor)为1/(1-r2), 其增大趋势见下表:
相关系 0 0.5 0.8 0.9 0.95 0.96 0.97 0.98 0.99 0.999 数平方 方差扩 1 2 5 10 20 25 33 50 100 1000 大因子
多重共线性(Multi-Collinearity)
§2.8 多重共线性
Multi-Collinearity
一、多重共线性的概念 二、多重共线性的后果 三、多重共线性的检验 四、克服多重共线性的方法 五、案例
一、多重共线性的概念
1、多重共线性
• 对于模型
Y X X X
以二元回归模型中的参数估计量ˆ 为例,ˆ 的方差为
1
1
Var(ˆ )
1
ˆ 2
(X X
)1
22
(
ˆ
2
(
x2
2i
)
x2 )( x2 ) ( x
多重共线性分析案例
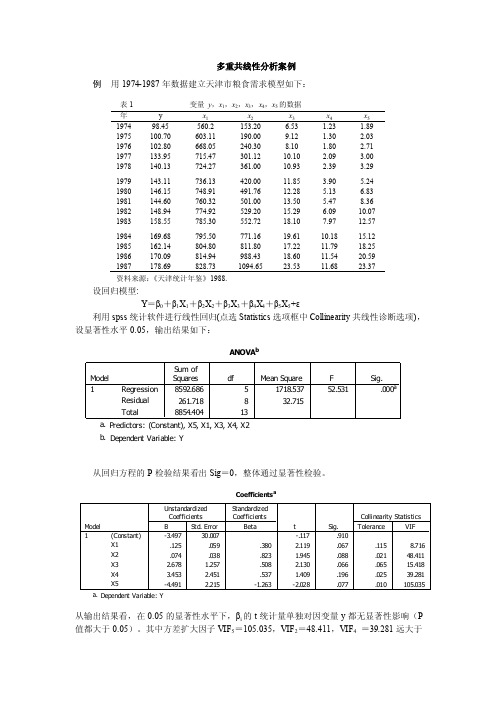
多重共线性分析案例例用1974-1987年数据建立天津市粮食需求模型如下:表1 变量y,x1,x2,x3,x4,x5的数据年y x1x2x3x4x51974 98.45 560.2 153.20 6.53 1.23 1.891975 100.70 603.11 190.00 9.12 1.30 2.031976 102.80 668.05 240.30 8.10 1.80 2.711977 133.95 715.47 301.12 10.10 2.09 3.001978 140.13 724.27 361.00 10.93 2.39 3.291979 143.11 736.13 420.00 11.85 3.90 5.241980 146.15 748.91 491.76 12.28 5.13 6.831981 144.60 760.32 501.00 13.50 5.47 8.361982 148.94 774.92 529.20 15.29 6.09 10.071983 158.55 785.30 552.72 18.10 7.97 12.571984 169.68 795.50 771.16 19.61 10.18 15.121985 162.14 804.80 811.80 17.22 11.79 18.251986 170.09 814.94 988.43 18.60 11.54 20.591987 178.69 828.73 1094.65 23.53 11.68 23.37资料来源:《天津统计年鉴》1988.设回归模型:Y=β0+β1X1+β2X2+β3X3+β4X4+β5X5+ε利用spss统计软件进行线性回归(点选Statistics选项框中Collinearity共线性诊断选项),设显著性水平0.05,输出结果如下:从回归方程的P检验结果看出Sig=0,整体通过显著性检验。
从输出结果看,在0.05的显著性水平下,βi的t统计量单独对因变量y都无显著性影响(P 值都大于0.05)。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
案例分析
一、研究的目的要求
近年来,中国旅游业一直保持高速发展,旅游业作为国民经济新的增长点,在整个社会经济发展中的作用日益显现。
中国的旅游业分为国内旅游和入境旅游两大市场,入境旅游外汇收入年均增长22.6%,与此同时国内旅游也迅速增长。
改革开放20多年来,特别是进入90年代后,中国的国内旅游收入年均增长14.4%,远高于同期GDP 9.76%的增长率。
为了规划中国未来旅游产业的发展,需要定量地分析影响中国旅游市场发展的主要因素。
二、模型设定及其估计
经分析,影响国内旅游市场收入的主要因素,除了国内旅游人数和旅游支出以外,还可能与相关基础设施有关。
为此,考虑的影响因素主要有国内旅游人数2X ,城镇居民人均旅游支出3X ,农村居民人均旅游支出4X ,并以公路里程5X 和铁路里程6X 作为相关基础设
施的代表。
为此设定了如下对数形式的计量经济模型: 23456123456t t t t t t t Y X X X X X u ββββββ=++++++
其中 :t Y ——第t 年全国旅游收入
2X ——国内旅游人数 (万人)
3X ——城镇居民人均旅游支出 (元) 4X ——农村居民人均旅游支出 (元)
5X ——公路里程(万公里) 6X ——铁路里程(万公里)
为估计模型参数,收集旅游事业发展最快的1994—2003年的统计数据,如表4.2所示:
利用Eviews 软件,输入Y 、X2、X3、X4、X5、X6等数据,采用这些数据对模型进行OLS 回归,结果如表4.3:
表4.3
由此可见,该模型9954.02=R ,9897.02
=R 可决系数很高,F 检验值173.3525,明
显显著。
但是当05.0=α时776
.2)610()(025.02=-=-t k n t α,不仅2X 、6X 系数的t 检
验不显著,而且6X 系数的符号与预期的相反,这表明很可能存在严重的多重共线性。
计算各解释变量的相关系数,选择X2、X3、X4、X5、X6数据,点”view/correlations ”得相关系数矩阵(如表4.4):
表4.4
由相关系数矩阵可以看出:各解释变量相互之间的相关系数较高,证实确实存在严重多重共线性。
三、消除多重共线性
采用逐步回归的办法,去检验和解决多重共线性问题。
分别作Y 对X2、X3、X4、X5、X6的一元回归,结果如表4.5所示:
表4.5
按2
R 的大小排序为:X3、X6、X2、X5、X4。
以X3为基础,顺次加入其他变量逐步回归。
首先加入X6回归结果为:
631784.285850632.7639.4109ˆX X Y t ++-=
t=(2.9086) (0.46214) 957152.02
=R
当取05.0=α时,365
.2)310()(025.02
=-=-t k n t
α,X6参数的t 检验不显著,予以剔除,
加入X2回归得
23029761.0194241.6393.3326ˆX X Y t ++-=
t=(4.2839) (2.1512) 973418.02
=R
X2参数的t 检验不显著,予以剔除,加入X5回归得
5390789.10736535.6972.3059ˆX X Y t ++-=
t=(6.6446) (2.6584) 978028.02
=R
X3、X5参数的t 检验显著,保留X5,再加入X4回归得
453221965.362909.13215884.4161.2441ˆX X X Y t +++-=
t=(3.944983) (4.692961) (3.06767)
991445.02=R 987186.02=R F=231.7935 DW=1.952587
当取05.0=α时,447
.2)410()(025.02=-=-t k n t α,X3、X4、X5系数的t 检验都显著,
这是最后消除多重共线性的结果。
这说明,在其他因素不变的情况下,当城镇居民
人均旅游支出3X 和农村居民人均旅游支出4X 分别增长1元时,国内旅游收入t Y 将分别增长4.21亿元和3.22亿元。
在其他因素不变的情况下,作为旅游设施的代表,公路里程5X 每增加1万公里时, 国内旅游收入t Y 将增长13.63亿元。