第五章 样本及抽样分布1
曾五一《统计学导论》配套题库【章节题库】第五章 抽样分布与参数估计 【圣才出品】

12.样本均值的抽样标准差 x ,( ).
A.随着样本量的增大而变小 B.随着样本量的增大而变大
5 / 30
圣才电子书 十万种考研考证电子书、题库视频学习平台
C.与样本量的大小无关
D.大于总体标准差
【答案】A
【解析】根据样本均值的抽样分布可知,样本均值抽样分布的标准差 x
D.服从 2 分布
【答案】B
【解析】当 n 比较大时,样本均值的抽样分布近似服从正态分布。题中 n 36 30 为
大样本,因此样本均值的抽样分布近似服从正态分布。
5.估计量的含义是指( )。 A.用来估计总体参数的统计量的名称
2 / 30
圣才电子书 十万种考研考证电子书、题库视频学习平台
圣才电子书 十万种考研考证电子书、题库视频学习平台
第五章 抽样分布与参数估计
一、单项选择题 1.抽样分布是指( )。 A.一个样本各观测值的分布 B.总体中各观测值的分布 C.样本统计量的分布 D.样本数量的分布 【答案】C 【解析】统计量是样本的函数,它是一个随机变量。样本统计量的分布称为抽样分布。
2.根据中心极限定理可知,当样本容量充分大时,样本均值的抽样分布服从正态分布, 其分布的均值为( )。
A.
B. X C. 2
2 D.
n 【答案】A
【解析】根据中心极限定理,设从均值为 ,方差为 2 的任意一个总体中抽取样本量 为 n 的样本,当 n 充分大时,样本均值的抽样分布近似服从均值为 ,方差为 2 n 的正
n
,样本
量越大,样本均值的抽样标准差就越小。
13.在用正态分布进行置信区间估计时,临界值 1.645 所对应的置信水平是( )。 A.85% B.90% C.95% D.99% 【答案】B 【解析】置信水平是指总体参数值落在样本统计值某一区内的概率;而置信区间是指在
5.1 样本均数的抽样分布与抽样误差

第五章 参数估计基础一、样本均数的抽样分布与抽样误差内 容1. 抽样误差和抽样分布2. 样本均数抽样分布和抽样误差1. 抽样误差和抽样分布n误差泛指实测值和真实值之差。
按其产生原因与性质分两 大类:系统误差和随机误差。
抽样误差是一种随机误差。
n抽样误差由于生物固有的个体变异,从某一总体中随机抽取一个样 本,所得样本统计量与相应总体参数往往是有差异的,这种 差异称为抽样误差(sampling error)。
n误差产生的原因n系统误差:由受试对象、研究者、仪器设备、研究方法等确定性 原因造成,有倾向性,可避免。
n随机误差:由多种无法控制的偶然因素引起的,无倾向性,不可 避免。
n抽样误差:产生的根本原因是个体变异、产生的直接原因是抽样。
n抽样分布n由于抽样误差存在,从同一总体中随机抽取若干份样本, 所得样本统计量是不一致的,差异无法避免但其存在一定的分布规律。
n 正态分布总体样本均数抽样分布的电脑试验n假定某年某地所有13岁女生的身高服从总体均数为155.4 cm ,总 体标准差为5.3cm 的正态分布 。
用计算机从该总体中 随机抽样,每次抽取30例组成一份样本,重复抽样100次,计算 每份样本的平均身高。
() 2 155.4,5.3 N 2. 样本均数抽样分布和抽样误差n电脑试验表明,正态分布总体样本均数抽样分布具有以 下特点:n样本均数恰好等于总体均数极其罕见;n样本均数之间存在差异;n样本均数围绕总体均数,中间多、两边少,左右基本对称,呈 近似正态分布;n样本均数间的变异小于原始变量值间的变异。
PERCENT30x MIDPOINT0 . 0 0 . 1 0 . 2 0 . 3 0 . 4 0 . 5 0 . 6 0 . 7 0 . 8 0 . 9 1 . 0 1 . 1 1 . 2 1 . 3 1 . 4 1 . 5 1 . 6 1 . 7 1 . 8 1 . 9 2 . 0 2 . 1 2 . 2 2 . 3 2 . 4 2 . 5 2 . 6 2 . 7 2 . 8 2 . 9 3 . 0 3 . 1 3 . 2 3 . 3 3 . 4 3 . 5 3 . 6 3 . 7 3 . 8 3 . 9 4 . 0 4 . 1 4 . 2 4 . 3 4 . 4 4 . 5 4 . 6 4 . 7 4 . 8 4 . 9 5 . 0n 非正态分布总体样本均数抽样分布的电脑实验n图 (a ) 是正偏峰分布原始数据对应的直方图,用计算机随机抽取 样本量分别为5, 10, 30和50的样本各1000份,计算样本均数并绘 制4个直方图。
抽样与抽样分布(试题及答案)

第五章抽样与抽样分布一、单项选择题(以下每小题各有四项备选答案,其中只有一项是正确的。
)1.抽样推断的主要目的是( )。
A.用统计量来推算总体参数B.对调查单位作深入研究C.计算和控制抽样误差D.广泛运用数学方法[答案] A[解析] 抽样调查是指从总体中按随机原则抽取部分单位作为样本,进行观察研究,并根据这部分单位的调查结果来推断总体,以达到认识总体的一种统计调查方法,因此,抽样推断的主要目的是用已知的统计量来推算未知的总体参数。
2.抽样调查中,无法消除的误差是( )。
A.抽样误差B.责任心误差C.登记误差D.系统性误差[答案] A[解析] 抽样误差是指在遵循了随机原则的条件下,不包括登记误差和系统性误差在内的,用样本指标代表总体指标而产生的不可避免的误差。
3.在其他条件相同的情况下,重复抽样的抽样平均误差和不重复抽样相比,( )。
A.前者一定小于后者B.前者一定大于后者C.两者相等D.前者可能大于,也可能小于后者[答案] B[解析] 以抽样平均数的抽样平均误差为例进行说明:在重复抽样条件下,抽样平均数的平均误差的计算公式:;在不重复抽样条件下,抽样平均数的平均误差的计算公式:。
因为,故。
4.拟分别对甲、乙两个地区大学毕业生在试用期的工薪收入进行抽样调查。
据估计甲地区大学毕业生试用期月工薪的方差要比乙区高出一倍。
在样本量和抽样方法相同的情况下,甲区的抽样误差要比乙区高( )。
A.41.4% B.42.4% C.46.8% D.48.8%[答案] A[解析] 假设乙地区的大学毕业生试用期月工薪的方差为σ2,甲地区的大学毕业生试用期月工薪的方差为2σ2,则:,那么,在样本量和抽样方法相同的,情况下,甲区的抽样误差要比乙区高=41.4%。
5.对某天生产的2000件电子元件的耐用时间进行全面检测,又抽取5%进行抽样复测,资料如表5-1所示。
表5-1耐用时间(小时) 全面检测(支) 抽样复测(支)3000以下3000~4000 4000~5000 50600990230505000以上总计36020018100规定耐用时间在3000小时以下为不合格品,则该电子元件合格率的抽样平均误差为( )。
概率论与数理统计 第5章

n
n
性质2.(分布可加性):若X~2(n1),Y~2(n2),X与 Y独立,则
X + Y~2(n1+n2 )
3、2分布表及有关计算
(1)构成 P{2(n)>λ}=α,已知n, α可查表求得λ; (2)有关计算P 2 (n) 2 (n) 称为上侧α分位数
例5.1 设 X ~ N ( , 2 ) (X1,X2,…,Xn)为X的一个样本,
求(X1,X2,…,Xn)的密度。 解 (X1,X2,…,Xn)为X的一个样本,故
X i ~ N ( , 2 )
n
i 1,2,, n
f ( x1 , x2 ,, xn ) f ( xi )
16 2
解
i 1,2,,16
2 1 16 2 2 P ( X i ) P 8 2 (16) 16 2 16 i 1
2—分布的密度函数f(y)曲线
n/2 1 f ( y) 2 ( n / 2) y 0,
n y 1 2 2
e , y0 y0
2 例5.4 X ~ N ( , ) (X1,X2,X3)为X的一个样本
X 1 X 2 X 3 的分布。 求
(n)为整体记号
2
2 (n) 2 2 查表得 0 ( 25 ) 34 . 382 10) 18.307 .1 0.05 (
1 当n充分大时,近似有 (n ) (u 2n - 1) 2 2
2
练习1. P(2(n)<s)=1-p ∵P(2(n) < s)=1- P(2(n) s )=1-p ∴ P(2(n) s )=p 2 s p (n) 练习2. P(2(11)>s)=0.05,求s
第五章 抽样调查

第二种方案:洛阳市所有小学的名单(第一抽样框), 从中抽取10所学校(抽样单位是学校);被抽中 学校的所有班级名单(第二抽样框),每个学校抽 10个班级,共抽取100个班级。(抽样单位是 班级);被抽中班级的所有学生名单(第三抽样 框),每个班级抽20名学生,共抽取2000名 学生,(抽样单位是学生).
18-30 31-50 50以上 小计 总计
200
缺点 虑其中的几种,不可能做出很细的分类
1. 分层不可能兼顾总体的众多属性,只能考 2. 总体分布变化的最新信息不容易得到,因
而配额的合理性很难保证
3. 主观性很大。如一个访问员会本能地避免 访问难以找到的受访者。
四、滚雪球抽样(Snowball Sampling)
(4)依据从随机数表中选出的数码,到抽样 框中寻找它所对应的元素。 练习: 试用简单随机抽样方法在洛阳师范学院抽取 2000名学生。 请思考:操作的难点是什么?
优点:概率抽样的理想类型,简单易行,误差小。 缺点: 1. 需要为总体每个要素编号,当总体所含个 体的数目太多时采用这种方法费时费力; 2. 总体内分类明显时,这种抽样无法按类别 特征自动分配样本数,若想保证样本的代表性,必 须增大样本量,使工作量增大。
院系——专业——班级——学生
抽样框 抽样单位 院系 专业 班级
第一抽样框:所有院系的名单 第二抽样框:抽中院系的所有专 业名单 第三抽样框:抽中专业的所有班 级名单
第四抽样框:抽中班级的所有学 生名单
学生
四、 抽样的原则
随机原则(random principle):在完全
排除主观上人为选择的前提下,使总体中 每一个单位有相同被抽中的机会。——概 率抽样
第五章 抽样法

抽样的作用
抽样调查能够解决全面调查无法或难以解决的问
题。
抽样调查可以补充和订正全面调查的结果。
抽样调查方法可以用于生产过程中产品质量的检
查和控制。 抽样调查方法可以用于对总体的某种假设进行检 验,以判断这种假设的真伪,决定行动的取舍。
抽样中的几个基本术语
总体(Population):调查研究的事物或现象的全体 个体(Item unit):组成总体的每个元素
一、抽样的概念、特点、作用 二、抽样中的基本术语 (一)总体和样本 (二)参数和统计量 (三)样本容量和样本个数 (四)重复抽样和不重复抽样 (五)概率抽样与非概率抽样 (六)抽样框 三、抽样误差
抽样的概念 特点
(一)概念 抽样调查是按照随机原则从全部研究对象中抽取 一部分单位进行观察,并依据获得的数据对全部研 究对象的数量特征做出具有一定可靠性的估计和判 断.达到对现象总体认识的一种方法. (二)特点 它是按照随机原则从总体中抽取样本。 它是由部分推算整体的一种方法。 它是运用概率估计的方法。 抽样误差可事先计算并加以控制。
抽样中的几个基本术语
X
i 1 N
总体均值
X
i
N
或
X F
i 1 K i
K
i
F
i 1
i
标准差
X
N i 1
i
X
2
N
或
X
K i 1
i K
X Fi
i
2
F
i 1
抽样中的几个基本术语
总体方差
2
( X i X )2
i 1
N
N
或
( X i X ) 2 Fi
《统计学原理》第5章:抽样推断

σ
n )
抽样推断的基本原理
抽样推断的优良标准
设θ 为待估计的总体参数, θ为样本统计量,则 θ的优良标 准为: 1若 E(θ ) =θ ,则称 θ为 θ 的无偏估计量(无偏性)
更有效的估计量(有效性) 2若σθ1 < σθ2,则称θ1为比θ2
3若 越大σθ 越小,则称 θ 为θ 的一致估计量(一 致性)
即中选成分相同但中选顺序不同的视为同一样本
抽样推断的一般问题
抽样组织方式
简单随机抽样 类型抽样 整群抽样 等距抽样 多阶段抽样 多重抽样
抽样推断的一般问题
样本可能数目
按照一定的抽样方法和组织方式,从总体N中抽取n个 单位构成样本,一共可以抽出的不同样本的数量,一般 用M表示. 考虑顺序的不重复抽样 考虑顺序的重复抽样 不考虑顺序的不重复抽样 不考虑顺序的重复抽样
抽样推断的一般问题
全及总体指标:参数 (未知量) 统计推断 样本总体指标:统计量 (已知量)
抽样推断的一般问题
抽样推断的特点 按随机原则抽取样本 运用概率论的理论和方法,用样本指标来推断 总体指标。 推断的误差可以事先计算和控制。
抽样推断的一般问题
抽样推断的应用 无法或 很难进行全面调查而又需要了解 其全面情况时 某些可以采用全面调查的社会经济现象, 也可采用抽样推断。 可用于生产过程的质量控制 进行假设检验
抽样推断的基本原理
抽样推断的优良标准——有效性 中位数的抽样分布
9 8 7 6 5 4 3 2 1 0 -1 45 50 55 60 65 70 75
平均数的抽样 分布
E(x) =
E ( me ) =
e
σx <σm
抽样推断的基本原理
统计学(李荣平)2014-5

P{t>tα(n)}= h(t;n)dt
t (n)
的数tα(n)为t(n)分布的上α分为点。 例:查表求:t0.05(8), t0.95(8)
o
t (n)
第一节 抽样分布
(三)F 分布
设 U ~ 2(n1 ),V ~ 2(n2 ), 且设 U,V 独立,则称随机变量
F U / n1 V / n2
保证质量,规定σ≤0.6mm时,认为生产过程处于良好控制
状态。为此,每隔一定时间抽取20个零件作为一个样本,并
计算样本方差S2。若P{S2≥c } ≤0.01(此时σ=0.6mm),
则认为生产过程失去控制,必须停产检查,问:
(1)C为何值时,S2≥c的概率才小于或等于0.01? (2)若取得的一个样本的标准差S=0.84,生产过程是
第五章 抽样分布与参数估计
主
第一节 抽样分布
要 内
第二节 参数点估计
容
第三节 区间估计
第一节 抽样分布
一、随机样本
总体与个体:试验全部可能的观测值叫总体;试验的 每一个观测值叫个体。
样本容量与样本个数:样本中包含的单位数叫样本容 量;从一个总体中可能抽取多少个样本叫样本个数。
总体容量:总体中所包含的个体数。 有限总体和无限总体:总体容量可数的称有限总体, 不可数的称无限总体。 重置抽样(重复抽样)和无重置抽样(不重复抽样)
X
1 n
n i 1
Xi
为样本均值;称统计量
S 2
1 n1
n i1
(Xi
X )2
为 样本方差 ,称统计量 S
S2
1n
( X X ) 2 为样本标准差 ;统计量
n 1 i1 i
曾五一 应用统计学 第5章

(
)
(
)
2
P =
n1 n
σ 2 ( P ) = P( 1 − P )
二、样本容量与样本个数 1.样本容量。样本集合的大小称为样本容量, 一般用n表示。一般地,样本容量大于30的样 本称为大样本,不超过30的样本称为小样本。 2.样本个数。样本个数又称样本可能数目,它 是指从一个总体中可能抽取多少种样本。样本 个数的多少与抽样方法有关。
Xi = ∑ X ij
j =1 M
M 样本平均是: X=
i =1 j =1
(i = 1,2,L, r )
∑ ∑ X ij rM
r M
= i =1
∑Xi r
r
群间方差是: 2 ∑ (µ i − µ ) 2 δ = R 或者由样本数据估计: −X δ2 r 由于整群抽样都采用不重复抽样的方法,所以样本平均数的标准差是:
四、抽样组织的设计 1.简单随机抽样是基本抽样组织方式 2.类型抽样与整群抽样比较 (1)减小类型抽样中样本平均数标准差的 办法。 (2)减小整群抽样的样本平均数标准差的 办法。
第四节 大数定理与中心极限定理
大数定理:独立同分布的随机变量 X1,X2,…,Xn,…,设它们的平均数 为 µ ,方差为 σ 2 ,即, E ( X i ) = X , σ 2 ( X i ) = σ 2 ,(i=1,2,…)。则对任意的 正数 ε,有: 1 n lim p ∑ X i − µ < ε = 1 n→∞ n i =1
解:样本平均数(平均每次加油量) X = 用样本组间方差代替总体组间方差:
i =1
∑ Xi r
r
=
330 = 33 (公斤) 10
δ2
∑ (X =
2021统计学原理-《统计学》第五章统计量及其抽样分布试题(精选试题)

统计学原理-《统计学》第五章统计量及其抽样分布试题1、智商的得分服从均值为100,标准差为16的正态分布。
从总体中抽取一个容量为n的样本,样本均值的标准差为2,样本容量为____________。
2、样本均值与总体均值之间的差被称作____________。
3、从均值为50,标准差为5的无限总体中抽取容量为30的样本,则抽样分布的超过51的概率为____________。
4、某校大学生中,外国留学生占10%。
随机从该校学生中抽取100名学生,则样本中外国留学生比例的标准差为____________。
5、假设总体服从均匀分布,从此总体中抽取容量为36的样本,则样本均值的抽样分布( )。
A.服从非正态分布B.近似正态分布C.服从均匀分布D.服从x²分布6、从服从正态分布的无限总体中分别抽取容量为4,16,36的样本,当样本容量增大时,样本均值的标准差( )。
A.保持不变B.增加C.减小D.无法确定7、总体均值为50,标准差为8,从此总体中随机抽取容量为64的样本,则样本均值的抽样分布的均值和标准误差分别为( )。
A.50,8B.50,1C.50,4D.8,88、某厂家生产的灯泡寿命的均值为60小时,标准差为4小时。
如果从中随机抽取30只灯泡进行检测,则样本均值( )。
A.抽样分布的标准差为4小时B.抽样分布近似等同于总体分布C.抽样分布的中位数为60小时D.抽样分布近似等同于正态分布,均值为60小时9、假设某学校学生的年龄分布是右偏的,均值为23岁,标准差为3岁。
如果随机抽取100名学生,下列关于样本均值抽样分布描述不正确的是( )。
A.抽样分布的标准差等于3B.抽样分布近似服从正态分布C.抽样分布的均值近似为23D.抽样分布为非正态分布10、从均值为200,标准差为50的总体中抽取容量为100的简单随机样本,样本均值的数学期望是( )。
A.150B.200C.100D.25011、从均值为200,标准差为50的总体中抽取容量为100的简单随机样本,样本均值的标准差是( )。
第五章抽样方法

第三章抽样与抽样调查3.1抽样调查的涵义及原理抽样与抽样调查·抽样的术语(抽样单位、总体、样本、抽样、抽样框、随机原则、总体参数和样本统计量、抽样误差、置信度和置信区间)·大数规律3.2概率抽样概率抽样的地位·简单随机抽样·系统抽样·分层抽样·整群抽样·多段抽样3.3 抽样设计抽样设计的一般程序·样本的产生·样本的大小3.4 非概率抽样偶遇抽样·判断抽样·配额抽样·滚雪球抽样3.5 抽样调查误差及其控制误差及其分类·非抽样误差及其控制·抽样误差及其控制3.6 抽样调查举例“网民知多少?——中国互联网络信息中心全国调查抽样方案设计”一、单项选择题1、分层抽样主要解决的是()A 总体异质性程度较高的问题B 总体同质性程度较高的问题C 总体内所含个体单位数量过大问题D 总体内所含个体单位数量不足问题2、概率抽样中效果最好的抽样方式是( )A 简单随机抽样B 等距抽样C 分层抽样D 整群抽样3、我们日常生活经常使用的简单随机抽样的方法有( )A 自荐B 抽签C 领导点将 D群众推选4、与概率抽样相比较,非概率抽样的缺点是( )A 无法保证样本的代表性 B抽样费时费力 C缺乏目的性 D调查不明确、不深入5、在下列抽样方法中,属于非概率抽样的是( )A 滚雪球抽样B 分层抽样C 整群抽样D 多阶段抽样6、研究者在实际抽样(特别是概率抽样)时,经常是先找到一份近似涵盖所有总体元素的名单,然后从中抽取部分元素,这份名单被称为()A 抽样单元B 总体C 抽样框D 样本7、在定额抽样中确定各层子样本,应采取()A随机抽取 B主观判断C非随机抽取D分层抽样8、总体中某一变量的综合描述叫()A 平均数B 标准差C 参数值D 统计值9、我国对小型工业企业采用的调查方法是()A 全面调查 B抽样调查 C 典型调查 D 重点调查10、从总体中按一定方式抽取出的一部分个体的集合叫()A 抽样框B 样本C 抽样单位D 样本规模11、根据总体的结构比例来分配样本量,由调查员来挑选样本单元这种方法是属于( )A简单随机抽样 B系统抽样 C判断抽样 D配额抽样12、抽样误差是指()A 抽样调查中所存在的误差B 由于抽样的不同方法而产生的误差C 抽样调查中的工作误差D 样本统计值与总体参数值之间存在的误差13、对于概率抽样,下面说法正确的是( )A 样本的结构一定要与总体的结构相一致B 总体中每个单元被抽中的概率一定是相等的C 总体中每个单元被抽中的概率是未知的D总体中每个单元被抽中的概率是已知的14、为提高分层抽样的效率,要求( )A 层内各单元的差异尽可能大B 层内各单元的差异尽可能小C 层内各单元的差异与总体相一致 D各层的差异尽可能相同15、根据正态分布的性质,随机变量落在平均数两侧2个标准差范围内的概率为( )A 68.3%B 90%16、对黑客进行研究,一般先找到几个黑客,然后通过他们的介绍找到新的黑客,这种抽样方法是( )A方便抽样 B配额抽样 C滚雪球抽样 D 判断抽样17、不完全涵盖是指抽样框中( )A 包含了不属于目标总体的单元B 不包含目标总体的某些单元C 时间比较充足,但调查经费较少D 包含了空白的单元18、某省抽选200个村对养羊情况进行整群调查,村内调查对象是( )A成群的羊 B圈养的羊 C 所有住户 D 部分住户19、简单随机抽样是指总体单位( )A 不加任何处理任意抽取样本B 按其某种特征分为若干类型抽取样本C 按一定标志编序按间隔抽取样本D 分为若干群以群体为单位抽取样本20、研究者严格按照随机原则来抽取样本,排除任何事先设定的模式,每一个对象的抽取都是相互独立的,这属于( )A简单随机抽样 B系统抽样 C分层抽样D多段整群抽样21、当需要研究新生事物时,最恰当的调查方法是()A 全面调查B 典型调查C 重点调查D 抽样调查22、当抽样框存在不完全涵盖时,目标总体与调查总体的关系是( )A 目标总体大于调查总体 B目标总体小于调查总体C目标总体等于调查总体 D目标总体、调查总体与抽样框无关23、某大学估计学生的上网人数比例,先用随机的方法抽取10个系,再在每个系中随机抽取20个学生,用这些抽中学生的上网比例来进行估计,这种抽样方法属于( )A 简单随机抽样 B整群抽样 C多阶抽样 D分层抽样24、若欲调查估计某个街区的男女人口比例,采用的方法是按户口册随机抽取200个家庭做样本,用这个样本的比例来推断总体,这种抽样方法属于( )A简单随机抽样 B整群抽样 C多阶抽样 D分层抽样25、抽样框在调查中的作用主要是( )A 确定要调查的范围 B规定各个单元的抽选概率C 避免目标总体的遗漏 D用来代表总体,从中抽选样本26、PPS抽样是一种( )A等概率抽样 B不等概率抽样 C主观概率抽样 D非概率抽样27、由于被调查者拒绝回答而造成的误差属于( )A抽样误差 B 计量误差 C无回答误差 D推断偏差28、以下抽样方法可用于对总体进行推断的是( )A配额抽样 B滚雪球抽样 C判断抽样 D简单随机抽样29、为提高整群抽样的效率,通常要求( )A群内各单元的差异大 B群内各单元的差异小C群内各单元的差异适中 D群内各单元没有差异30、用样本估计值对总体参数进行点估计的理论基础是( )A大数定律 B中心极限定理 C正态分布的原理 D无偏估计的原理31、样本中某一变量的综合描述叫()A 平均数B 标准差C 参数值D 统计值32、由专家有目的地抽选他认为有代表性的样本进行调查,这种方法是属于( )A判断抽样 B滚雪球抽样 C就近抽样 D简单随机抽样33、将总体中所有分子排列并编以序号,然后按计算好的抽样距离依次等距抽样,被称之为()A 分层抽样B 整群抽样C 系统抽样D 多阶段抽样34、下列哪种调查可以较好地推论总体()A 全面调查B 典型调查C 抽样调查D 重点调查35、如果统计量的抽样分布的均值恰好等于被估计的参数之值,那么这一估计便可以认为是()估计。
医药统计学 第五章 抽样分布

3、总体参数(parameter): 总体X 的数字特征即总体的特征 指标。
eg: 、 。
(三)样本(sample):数理统计方法实质上是由局部来推 断整体,即通过一些个体的特征来推断总体的特征。 eg:观察某显像管厂所有显像管的平均寿命。
1、抽样研究(sampling):在实际工作中,所要研究的总 体无论是有限的还是无限的,通常都是采用抽样研究。
抽样:依照一定的规则从总体X 中抽取n个个体,然后对这
些个体进行测试或观察得到一组数据
。
目的:抽样研究的目的是用样本信息推断总体特征。
eg:
从上例的有限总体(浙江省2006年7岁健康男孩)中,按照随机化
原则抽取100名7岁健康男孩,他们的身高值
即为样本。因
此,从总体中抽取样本的过程为抽样,抽样方法有多种。
第四章 抽样分布
数理统计基本概念 抽样分布
学习目的和要求
掌握总体、样本、统计量、标准误等数理统计的基本概
念;查表求 2 分布、t 分布、F分布的临界值及其定理;
熟悉 X 的分布、 2分布、t 分布、F分布定义、性质和应
用。
数理统计的基本任务:
实验或 调查
以概率论为理论基础,通过样本提供的信息,对总 体的统计规律和特征进行估计与推断,其实用性较强。
1、 2分布(chi-square distribution):是指数分布的改进,
尤其当n较大时, 2分布可全面反映随机变量的分布。
eg: 寿命、保险等资料。
定义:设随机变量
为相互独立且服从标准
正态分布N(0,1),则称随机变量
2= X12 + X22 +X32 + … + … +Xn2
第五章《用样本推断总体》复习讲义(解析版)
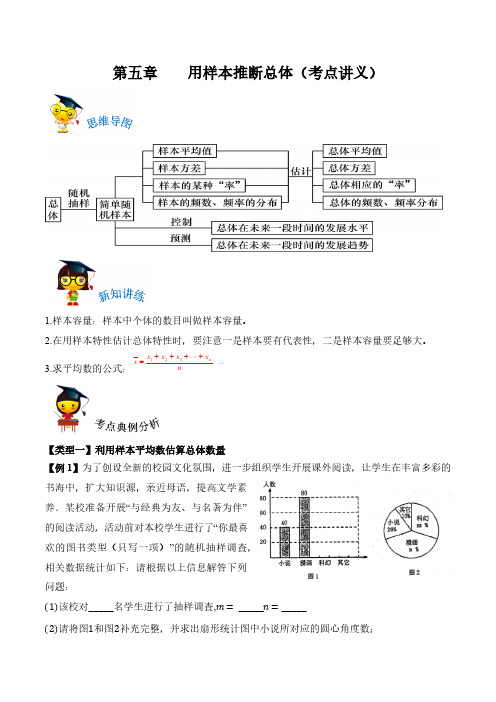
第五章 用样本推断总体(考点讲义)1.样本容量:样本中个体的数目叫做样本容量。
2.在用样本特性估计总体特性时,要注意一是样本要有代表性,二是样本容量要足够大。
3.求平均数的公式:123nx x x x x n++++=L【类型一】利用样本平均数估算总体数量【例1】为了创设全新的校园文化氛围,进一步组织学生开展课外阅读,让学生在丰富多彩的书海中,扩大知识源,亲近母语,提高文学素养.某校准备开展“与经典为友、与名著为伴”的阅读活动,活动前对本校学生进行了“你最喜欢的图书类型(只写一项)”的随机抽样调查,相关数据统计如下:请根据以上信息解答下列问题:(1)该校对_____名学生进行了抽样调查,m = _____n =_____(2)请将图1和图2补充完整,并求出扇形统计图中小说所对应的圆心角度数;(3)已知该校共有学生800人,利用样本数据估计全校学生中最喜欢科幻人数约为多少人?【解析】(1)用其它初一它的百分比即可;(2)用360∘乘以所占得百分比;(3)用样本估计总体.解:(1)20÷10%=200(名).由图1,得n=40,m=100-20-10-40=30答:该校对200名学生进行了抽样调查;m=30,n=40(2)如图:小说对应的圆心角度数为360∘×20%=72∘;(3)800×30%=240.答:全校学生中最喜欢小说的人数约为240名.【对应训练1】为了估计湖里有多少条鱼,小刚先从湖里捞出了100条鱼做上标记,然后放回湖里去.经过一段时间,带有标记的鱼完全混合于鱼群后,小刚又从湖里捞出200条鱼,如果其中15条有标记,那么估计湖里有鱼()A.1333条B.3000条C.300条D.1500条【答案】A【解析】在样本中“捕捞200条鱼,发现其中15条有标记”,即可求得有标记的所占比例,而这一比例也适用于整体,据此即可解答.【对应训练2】我国古代数学名著《九章算术》有“米谷粒分”.粮仓开仓收粮,有人送来谷米1608石,验得其中夹有谷粒.现从中抽取谷米一把,共数得256粒,其中夹有谷粒32粒,则这批谷米内夹有谷粒约是________石.【答案】201【解析】根据256粒内夹谷32粒,可得比例,再乘以1608石,即可得出答案.【解答】解:根据题意,得1608×32=201(石),256∴这批谷米内夹有谷粒约201石.【对应训练3】某山区中学280名学生参加植树节活动,要求每人植3至6棵,活动结束后随机抽查了若干名学生每人的植树量,并分为四种类型,A:3棵;B:4棵;C:5棵;D:6棵,将各类的人数绘制成扇形图(如图1)和条形图(如图2).回答下列问题:(1)这次调查一共抽查了________名学生的植树量;请将条形图补充完整;(2)被调查学生每人植树量的众数是________棵、中位数是________棵;(3)求被调查学生每人植树量的平均数,并估计这280名学生共植树多少棵?【解析】(1)由B类型的人数及其所占百分比可得总人数,总人数乘以D类型的对应的百分比即可求出其人数,据此可补全图形;(2)根据众数和中位数的概念可得答案;(3)先求出样本的平均数,再乘以总人数即可.【解答】(1)这次调查一共抽查植树的学生人数为8÷40%=20(人),D类人数=20×10%=2(人);条形图补充如图:(2)植树4棵的人数最多,则众数是4,共有20人植树,其中位数是第10、11人植树数量的平均数,则中位数是4,(3)x=4×48×562×7=5.3(棵),205.3×280=148(棵).答:估计这3280名学生共植树1484棵.【类型二】用样本估计总体【例2】为了提高学生的综合素养,某校开设了五门第二课堂活动课,按照类别分为:A“剪纸”、B“绘画”、C“雕刻”、D“泥塑”、E“插花”.为了了解学生对每种活动课的喜爱情况,随机抽取了部分同学进行调查,将调查结果绘制成如下两幅不完整的统计图.根据信息,回答下列问题:(1)本次调查的样本容量为________,统计图中的a=________,b=________;(2)通过计算补全条形统计图;(3)该校共有3000名学生,请你估计全校喜爱“雕刻”的学生人数.解:(1)样本容量为1815%=120,a=120×10%=12,b=120×30%=36.故答案为:120;12;36.(2)组频数:120―18―12―30―36=24(人),补全条形统计图如图所示:(3)3000×30120=750(人),答:该校喜爱“雕刻”约有750人.【跟踪训练1】在一个不透明的盒子中装有20个黄、白两种颜色的乒乓球,除颜色外其它都相同,小明进行了多次摸球试验,发现摸到白色乒乓球的频率稳定在0.2左右,由此可知盒子中黄色乒乓球约有…()A.2个B.4个C.18个D.16个【答案】D【跟踪训练2】质检部门从1000件电子元件中随机抽取100件进行检测,其中有2件是次品.试据此估计这批电子元件中大约有________件次品.【答案】20【解析】根据随机抽取100件进行检测,其中有2件是次品,可以计算出这批电子元件中大约有多少件次品.【跟踪训练3】书籍是人类进步的阶梯.为了解学生的课外阅读情况,某校随机抽查了部分学生本学期阅读课外书的册数,并绘制出如下统计图.(1)共抽查了多少名学生?(2)请补全条形统计图,并写出被抽查学生本学期阅读课外书册数的众数、中位数;(3)根据抽查结果,请估计该校1200名学生中本学期课外阅读5册书的学生人数.解:(1)12÷30%=40(名).(2)如图所示,由图知,众数为5,中位数为5.(3)∵抽查的样本中,课外阅读5册书的学生人数占14×100%=35%,40∴估计该校学生课外阅读5册书的学生人数约占35%,∴该校1200名学生中课外阅读5册书的学生人数约为1200×35%=420(人).【类型三】用样本频率估计总体频率【例3】中长跑(男生1000m,女生800m)是河南省某市中招体育考试的必考项目.甲、乙两校为了解本校九年级学生的训练情况,各随机抽取了20名九年级学生的中长跑模拟测试成绩(满分:30分),将成绩进行统计、整理与分析,过程如下:【收集数据】【整理数据】整理以上数据,得到模拟测试成绩x(分)的频数分布表.【分析数据】根据以上数据,得到以下统计量.根据以上信息,回答下列问题:(1)填空:a= ________,b=_________, m=________, n=________;(2)综合上表中的统计量,推断________校学生中长跑成绩更好,理由为________(写出一条即可)(3)若甲、乙两校各有800名学生,请估计两校中长跑模拟测试成绩不低于25分的学生一共有多少名?解:(1)由数据可得,a=7,b=8,m=24.75,n=23.4. 故答案为:7;8;24.75;23.4.(2)甲校学生成绩的平均数比乙校学生成绩的平均数高,且甲校学生成绩的方差比乙校学生成绩的方差小,成绩较稳定.(答案不唯一,合理即可)故答案为:甲.=720(名),(3)(800+800)×1082020答:估计两校中长跑模拟测试成绩不低于25分的学生一共有720名.【跟踪训练】今年是建党100周年,为了让全校学生牢固树立爱国爱党的崇高信念,某校开展了形式多样的党史学习教育活动,八、九年级(各有500名学生)举行了一次党史知识竞答(满分为100分),然后随机各抽取20名同学的成绩进行了收集、统计与分析,过程如下:【收集数据】两个年级抽取的20名同学的成绩如下表:八年级:7968878985598997898998938586899077898379九年级:8688979194625194877194789255979294948598【整理数据】将两个年级的抽样成绩进行分组整理:成绩x(分)50≤x<6060≤x<7070≤x<8080≤x<9090≤x<100八年级113114九年级2a b411【分析数据】抽样的平均数、众数、中位数、方差和优秀率(90分及以上为优秀)如下表:年级统计量平均数众数中位数方差优秀率八年级8589c80.420%九年级859491.5192d请根据以下信息,回答下列问题:(1)填空:a=________,b= ________,c=________,d=________;(2)请估计此次知识竞答中,八年级成绩优秀的学生人数;(3)小李同学认为九年级的整体成绩更好,请从至少两个方面分析其合理性.解:(1)由表中数据可知,九年级落在60≤x<70内的只有62,故a=1;九年级落在70≤x<80内的有71,78,故b=2;八年级成绩按照从小到大的顺序排列后,落在第10,11的数为87,89,∴中位数为88,故c=88;九年级90分及以上的学生有11人,∴九年级的优秀率为1120×100%=55%.故答案为:1;2;88;55%.(2)∵500×20%=100,∴估计此次知识竞答中,八年级成绩优秀的学生人数为100人.(3)九年级抽样成绩的众数,中位数和优秀率均高于八年级,说明九年级平均成绩更高,高分更多,因此九年级整体成绩更好.【类型四】用样本推断总体的实际应用【例4】某运动鞋经销商随机调查某校40名女生的运动鞋号码,结果如下表:鞋的号码35.53636.53737.5人数4616122现在该经销商要进200双上述五种运动鞋,你认为应该怎样进货比较合理?解析:先求出各鞋码所占比例,再乘200,即可得到所需进货数.解:由表中数据可知各鞋码的女生的比例,根据比例进货.需要进35.5码运动鞋:200×440=20(双),需要进36码运动鞋:200×640=30(双)需要进36.5码运动鞋:200×1640=80(双),需要进37码运动鞋:200×1240=60(双)需要进37.5码运动鞋:200×240=10(双)。
极限定理 样本及抽样分布

f ( y)
n =1
n=5 n = 15
O
y
χ 2 (n)分布具有以下性质 分布具有以下性质:
2 χ2 χ2 χ2 (1)如果 1 ~ χ 2 (n1 ), χ2 ~ χ 2 (n2 )且 1 与 2 相互独立 2 χ2 则 1 + χ2 ~ χ 2 (n1 + n2 )
(2)如果 ~ χ (n), 则有 (χ ) = n, D(χ ) = 2n. χ E
1 n E(S ) = E( Xi2 ) − nE( X 2 ) ∑ n − 1 i=1
2
1 σ 2 2 2 2 = ∑(σ + µ ) − n(µ + n ) = σ n − 1 i=1
n 2
第二节 抽样分布
χ2 分布 1、 、
是来自总体N(0,1)的样本,称统计量 的样本, 设X1,X2…Xn是来自总体 , 的样本
1 2 2 (∑ Xi + ∑ X − 2∑ Xi X ) = n − 1 i =1 i =1 i =1 n n n 1 2 2 X = ∑ Xi ⇒ ∑X 2 X = 2 X∑Xi ...X 2 = nX 2 = X + X + = nX= ⇒ ∑Xi n i =1 i =1 i =1
n n n
1 2 2 (∑Xi + nX − 2nX 2 ) = n − 1 i =1
定义5.1 设随机变量序列Y 是常数, 定义5.1 设随机变量序列 1 , Y2 …Yn , a是常数, 是常数 对于任意正数ε, 有
n
lim P { Yn − a < ε } = 1, →∞
则称序列 Y1 , Y2 L Yn ... 依概率收敛于 a , 记为 P Yn → a .
第五章 抽样

Page 18
二、系统抽样(又称机械抽样) 系统抽样的具体步骤是: (1)确定开始抽取人选的位置 (2)计算抽样间距。抽样距离是由总体大小和样 本大小决定的,假设总体所含个体数为N,样本所 含个体数为n,则抽样间距应为K=N/n。 (4)确定抽取元素的方法
Page 19
系统抽样实例 某地区有零售店110户,采用系统抽样方法抽取11户进行 调查。 第一步:将总体调查对象进行编号,即从1号到110号; 第二步:确定抽样距离。调查总体N=110户,所需样本 数n=11户,所以,抽样距离K=10户; 第三步:确定起抽号数。随机地从1-10中抽取一个数作 为抽号; 第四步:确定被抽取单位。从起抽号开始,按照抽样距 离选取样本如果随机抽取了2为起抽号,那么: 2 2+10=12 2+10*2=22 等等 即所抽的样本为编号是2,12,22,32,一直到102共11个 零售店。
Page 17
答案:
(1)确定选出的随机数的位数:由于总体人数为900, 在使用随机数表时,需要有3位数的随机数才能保证所有 人都有被选中的机会; (2)决定从5位数种选择哪几位数字:要从随机数表中从 左到右选取3位数字, (3)确定在表中选择数字的顺序:自下而上选取随机数。 (4)确定开始选择的5位数组起点 (5)处理大于总体规模或重复的随机数
2、“街头拦人”
Page 10
二、配额抽样 配额抽样,是根据某些参数值,确定不同总体类 别中的样本配额比例,然后按比例在各类别中进 行方便抽样。 配额抽样示例
年龄 所得 ¥10,000以 下 ¥10,101以 上 合计 34岁以下 21% 12% 33% 35岁以上 27% 40% 67% 合计 48% 52% 100%
数理统计基本概

第五章 样本及抽样分布从本章开始, 我们将讲述数理统计的基本内容. 数理统计作为一门学科诞生于19世纪末20世纪初, 是具有广泛应用的一个数学分支, 它以概率论为基础, 根据试验或观察得到的数据, 来研究随机现象, 以便对研究对象的客观规律性作出合理的估计和判断.由于大量随机现象必然呈现出它的规律性, 故理论上只要对随机现象进行足够多次观察, 则研究对象的规律性就一定能清楚地呈现出来, 但实际上人们常常无法对所研究的对象的全体(或总体) 进行观察, 而只能抽取其中的部分(或样本) 进行观察或试验以获得有限的数据.数理统计的任务包括: 怎样有效地收集、整理有限的数据资料; 怎样对所得的数据资料进行分析、研究, 从而对研究对象的性质、特点, 作出合理的推断, 此即所谓的统计推断问题, 本课程主要讲述统计推断的基本内容.第一节 数理统计的基本概念内容分布图示★ 引言 ★ 总体与总体分布 ★ 样本与样本分布 ★ 例1★ 例2 ★ 例3 ★ 例4★ 统计推断问题简述★ 分组数据统计表和频率直方图 ★ 例5 ★ 经验分布函数 ★ 例6★ 统计量 ★ 样本的数字特征★ 例7 ★ 例8 ★ 例9 ★ 内容小结 ★ 课堂练习 ★ 习题5-1 ★ 返回内容要点:一、总体与总体分布总体是具有一定共性的研究对象的全体, 其大小与范围随具体研究与考察的目的而确定. 例如, 考察某大学一年级新生的体重情况, 则该校一年级全体新生就构成了待研究的总体. 总体确定后, 我们称总体的每一个可观察值为个体. 如前述总体(一年级新生) 中的每一个个体即为每个新生的体重. 总体中所包含的个体的个数称为总体的容量. 容量为有限的称为有限总体, 容量为无限的称为无限总体.数理统计中所关心的并非每个个体的所有性质, 而仅仅是它的某一项或某几项数量指标. 如前述总体(一年级新生)中, 我们关心的是个体的体重, 进而也可考察该总体中每个个体的身高和数学高考成绩等数量指标.总体中的每一个个体是随机试验的一个观察值, 故它是某一随机变量X 的值,于是, 一个总体对应于一个随机变量X , 对总体的研究就相当于对一个随机变量X 的研究, X 的分布就称为总体的分布函数, 今后将不区分总体与相应的随机变量, 并引入如下定义:定义 统计学中称随机变量(或向量)X 为总体, 并把随机变量(或向量)的分布称为总体分布.注(i) 有时个体的特性很难用数量指标直接描述, 但总可以将其数量化,如检验某学校全体学生的血型, 试验的结果有O 型、A 型、B 型、AB 型4种, 若分别以1,2,3,4依次记这4种血型,则试验的结果就可以用数量来表示了;(ii) 总体的分布一般来说是未知的, 有时即使知道其分布的类型(如正态分布、二项分布等),但不知这些分布中所含的参数等(如p ,,2σμ等).数理统计的任务就是根据总体中部分个体的数据资料对总体的未知分布进行统计推断.二、样本与样本分布由于作为统计研究对象的总体分布一般来说是未知的,为推断总体分布及其各种特征,一般方法是按一定规则从总体中抽取若干个体进行观察,通过观察可得到关于总体X 的一组数值),,,(21n x x x Λ,其中每一i x 是从总体中抽取的某一个体的数量指标i X 的观察值.上述抽取过程为抽样,所抽取的部分个体称为样本.样本中所含个体数目称为样本的容量.为对总体进行合理的统计推断,我们还需在相同的条件下进行多次重复的、独立的抽样观察,故样本是一个随机变量(或向量).容量为n 的样本可视为n 维随机向量),,,(21n X X X Λ,一旦具体取定一组样本,便得到样本的一次具体的观察值),,,(21n x x x Λ,称其为样本值.全体样本值组成的集合称为样本空间.为了使抽取的样本能很好地反映总体的信息, 必须考虑抽样方法,最常用的一种抽样方法称为简单随机抽样, 它要求抽取的样本满足下面两个条件:1. 代表性: n X X X ,,,21Λ与所考察的总体具有相同的分布;2. 独立性: n X X X ,,,21Λ是相互独立的随机变量.由简单随机抽样得到的样本称为简单随机样本, 它可用与总体独立同分布的n 个相互独立的随机变量n X X X ,,,21Λ表示. 显然, 简单随机样本是一种非常理想化的样本, 在实际应用中要获得严格意义下的简单随机样本并不容易.对有限总体, 若采用有放回抽样就能得到简单随机样本,但有放回抽样使用起来不方便, 故实际操作中通常采用的是无放回抽样, 当所考察的总体很大时, 无放回抽样与有放回抽样的区别很小, 此时可近似把无放回抽所得到的样本看成是一个简单随机样本. 对无限总体, 因抽取一个个体不影响它的分布, 故采用无放回抽样即可得到的一个简单随机样本.注: 今后假定所考虑的样本均为简单随机样本, 简称为样本.设总体X 的分布函数为)(x F ,则简单随机样本),,,(21n X X X Λ的联合分布函数为∏==ni i n x F x x x F 121)(),,,(Λ并称其为样本分布.特别地, 若总体X 为连续型随机变量,其概率密度为)(x f ,则样本的概率密度为∏==ni i n x f x x x f 121)(),,,(Λ分别称)(x f 与),,,(21n x x x f Λ为总体密度与样本密度.若总体X 为离散型随机变量,其概率分布为}{)(i i x X P x p ==, x 取遍X 所有可能取值, 则样本的概率分布为,)(},,,{),,,(12121∏======ni i n n x p x X x X x X p x x x p ΛΛ分别称)(i x p 与),,,(21n x x x p Λ为离散总体密度与离散样本密度.三、统计推断问题简述总体和样本是数理统计中的两个基本概念. 样本来自总体,自然带有总体的信息,从而可以从这些信息出发去研究总体的某些特征(分布或分布中的参数). 另一方面,由样本研究总体可以省时省力(特别是针对破坏性的抽样试验而言). 我们称通过总体X 的一个样本n X X X ,,,21Λ对总体X 的分布进行推断的问题为统计推断问题.总体、样本、样本值的关系:总体↙ ↖推断(个体)样本 → 样本值抽样在实际应用中, 总体的分布一般是未知的, 或虽然知道总体分布所属的类型, 但其中包含着未知参数. 统计推断就是利用样本值对总体的分布类型、未知参数进行估计和推断.为对总体进行统计推断, 还需借助样本构造一些合适的统计量, 即样本的函数, 下面将对相关统计量进行深入的讨论.四、分组数据统计表和频数直方图 通过观察或试验得到的样本值,一般是杂乱无章的,需要进行整理才能从总体上呈现其统计规律性. 分组数据统计表或频率直方图是两种常用整理方法. 1. 分组数据表:若样本值较多时,可将其分成若干组,分组的区间长度一般取成相等, 称区间的长度为组距. 分组的组数应与样本容量相适应. 分组太少,则难以反映出分布的特征,若分组太多,则由于样本取值的随机性而使分布显得杂乱. 因此,分组时,确定分组数(或组距)应以突出分布的特征并冲淡样本的随机波动性为原则. 区间所含的样本值个数陈为该区间的组频数. 组频数与总的样本容量之比称为组频率.2. 频数直方图:频率直方图能直观地表示出频数的分布,其步骤如下: 设n x x x ,,,21Λ是样本的n 个观察值.(i) 求出n x x x ,,,21Λ中的最小者)1(x 和最大者)(n x ;(ii) 选取常数a (略小于)1(x )和b (略大于)(n x ),并将区间],[b a 等分成m 个小区间(一般取m 使nm 在101左右): mab t m i t t t i i -=∆=∆+,,,2,1),,[Λ, 一般情况下,小区间不包括右端点.(iii) 求出组频数i n ,组频率i i f nn ∆=,以及),,2,1(,n i tfh i i Λ=∆=(iv) 在),[t t t i i ∆+上以i h 为高,t ∆为宽作小矩形,其面积恰为i f ,所有小矩形合在一起就构成了频率直方图五、经验分布函数样本的直方图可以形象地描述总体的概率分布的大致形态,而经验分布函数则可以用来描述总体分布函数的大致形状。
(完整版)第五章抽样调查习题答案

《统计学》习题五参考答案一、单项选择题:1、抽样误差是指()。
CA在调查过程中由于观察、测量等差错所引起的误差 B人为原因所造成的误差C随机抽样而产生的代表性误差 D在调查中违反随机原则出现的系统误差2、抽样平均误差就是()。
DA样本的标准差 B总体的标准差 C随机误差 D样本指标的标准差3、抽样估计的可靠性和精确度()。
BA是一致的 B是矛盾的 C成正比 D无关系4、在简单随机重复抽样下,欲使抽样平均误差缩小为原来的三分之一,则样本容量应()。
AA增加8倍 B增加9倍 C增加1.25倍 D增加2.25倍5、当有多个参数需要估计时,可以计算出多个样品容量n,为满足共同的要求,必要的样本容量一般应是()。
BA最小的n值 B最大的n值 C中间的n值 D第一个计算出来的n值6、抽样时需要遵循随机原则的原因是()。
CA可以防止一些工作中的失误 B能使样本与总体有相同的分布C能使样本与总体有相似或相同的分布 D可使单位调查费用降低二、多项选择题:1、抽样推断中哪些误差是可以避免的()。
A B DA工作条件造成的误差 B系统性偏差 C抽样随机误差D人为因素形成偏差 E抽样实际误差2、区间估计的要素是()。
A C DA点估计值 B样本的分布 C估计的可靠度D抽样极限误差 E总体的分布形式3、影响必要样本容量的因素主要有()。
A B C EA总体的标志变异程度 B允许误差的大小 C重复抽样和不重复抽样D样本的差异程度 E估计的可靠度三、填空题:1、抽样推断就是根据()的信息去研究总体的特征。
样本2、样本单位选取方法可分为()和()。
重复抽样不重复抽样3、实施概率抽样的前提条件是要具备()。
抽样框4、对总体参数进行区间估计时,既要考虑极限误差的大小,即估计的()问题,又要考虑估计的()问题。
准确性可靠性四、简答题:1、抽样调查与重点调查的主要不同点。
答:第一,选取调查单位的方法不同。
抽样调查是按随机原则抽取调查单位的,重点调查中的重点单位是调查标志值占总体标志总量比重很大的单位,调查单位是明显的;第二,作用不同。
样本及抽样分布1随机样本与直方图

整群随机抽样
定义
将总体分成若干个群或组,然后从每个群或组中 随机抽取一定数量的观察单位组成样本。
优点
便于组织调查,适用于总体数量较小的情况。
ABCD
方法
先对总体进行分群,然后在每个群内进行随机抽 样。
缺点
如果群内差异较大,可能会影响样本的代表性。
03
直方图的绘制步骤
数据收集与整理
收集数据
通过调查、实验或其他方式获取原始数据。
标注信息
在直方图上标注标题、组距、组数等必要信 息。
04
直方图的解读与分析
直方图的形状分析
偏态分析
通过观察直方图的形状,判断数据分布是否对称。如果数据分布不对称,则说明存在偏态。
峰度分析
峰度是描述数据分布形态的统计量,如果峰度值较小,说明数据分布较为平坦;如果峰度值较大,则说明数据分 布较为尖锐。
论文数据支撑
02
在学术论文中,使用随机样本和直方图可以提供有力的数据支
撑,增强论文的说服力和可信度。
学术交流与合作
03
通过共享随机样本和直方图数据,促进学术交流与合作,推动
学科发展。
THANKS
感谢观看
质量改进
通过分析随机样本数据,可以了解产品质量分布和缺陷情况,针对 性地进行质量改进和优化。
持续改进
通过持续收集和分析随机样本数据,可以监测生产过程的持续改进效 果,确保稳定的质量输出。
科学研究与学术论文
实验数据分析
01
在科学实验中,通过收集随机样本数据,绘制直方图,可以对
实验结果进行统计分析,支持科学结论的得出。
数据筛选
去除异常值和缺失值,确保数据质量。
数据排序
第五章抽样检验

(提示:二项分布) 2、用方案(n︱Ac,Re)对一批单位产品不合格数为p的产品
实施计点检验,试计算接收概率L( p) (提示:泊淞分布)
第五章抽样检验
三、计数调整型抽样检验标准 《计数抽样检验程序第1部分:按接受质量限
第五章抽样检验
二、抽样检验原理
1 批质量的描述 2 抽样方案及其类型 3 抽样特性曲线 (OC曲线 ) 4 抽样方案的确定 5 思考题
第五章抽样检验
3 抽样特性曲线 (OC曲线 )
1、 OC曲线 ?设有一批产品N=8,其中不合格品数M=4,抽样方案(4︱2,3),请
问:该批产品经过抽样检验后被判为合格的可能性(或概率L(P=50%))有 多大? 2、OC曲线的影响因素
第五章抽样检验
5、镇江稳润光电公司发光二极管入库抽样检验案例
①确定产品质量特性要求、不合格分类及相应的批质量要求(次抽样) ④组成交验批N(本例N 取10000) ⑤检索GB/T2828获得抽样检验计划 ⑥执行抽样检验计划 备注: GB/T2828.1的表10给出了各字码所对应的一次抽样方案OC曲线
L(p)及其数值表,这些图表也可用于与等效的二次或五次抽样方案。 当然我们也可以用二项分布或帕淞分布进行计算。
第五章抽样检验
GB/T2828.1的OC曲线L(p)及其数值表
•本例查到的“光电参数”抽样方案(200︱1,2)OC曲线特 殊数值表如下:
• 注: GB/T2828.1中各方案的 L(p=AQL)设计在85%~98%之 间
所抽取的样本要能够代表总体,样本的质量特性指标在统计学意义上要能够反 映总体的质量特性指标 ?怎样才能使抽样具备代表性?
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
X1 , X 2 ,
, X 10 是来自总体X 的样本, 求 , X 10 的联合概率密度; , X 10 分别为10块独立工作的电路板
(1) X 1 , X 2 , (2)设X 1 , X 2 , 的概率.
的寿命(以年计),求10块电路板的寿命都大于2
Probability and Statistics
Probability and Statistics
当有限总体包含的个体的总数很大时, 可近 似地将它看成是无限总体. 抛开实际背景,总体就是一堆数,这堆数中 有大有小,有的出现机会多,有的出现的机会少. 因此,用一个概率分布来描述和归纳总结总体是 恰当的. 从这个意义看,总体就是一个分布而其数量 指标就是服从这个分布的随机变量.
成绩分组 [0,60) [60,70) [70,80) [80,90) [90,100] 6 11 16 23 4 人 7班 数 9班 3 8 13 8 5 9 19 29 31 9 合班 合计 60 37 97
Probability and Statistics
从总体中抽取样本可以有不同的抽法,为了能由样 本对总体作出较可靠的推断,就希望样本能很好的 代表总体.这就需要对抽样方法提出一些要求. 最常用的“简单随机抽样”有如下两个要求: 样本具有随机性,即要求总体中每一个个体都有 同等机会被选入样本,这便意味着每一样品xi与总 体X 有相同的分布. 样本要有独立性,即要求样本中每一样品的取 值不影响其他样品的取值,这意味着 X1, X2, …,Xn , 相互独立. 6.简单随机样本:用简单随机抽样方法得到的样本 称为简单随机样本,简称样本。
n左右为佳. 本例分为5组.
Probability and Statistics
160 175 161 156
2.确定组距;
196 178 168 170
164 166 166 157
148 181 162 162
170 162 172 154
极差 样本最大观测值 - 样本最小观测值 组距= = 组数 组数
Probability and Statistics
计算机的诞生与发展,为数据处理提供了 强有力的技术支持,数理统计与计算机的结合 是必然的发展趋势. 学习统计无须把过多时间花在计算上,可以 更有效地把时间用在基本概念、方法原理的正确 理解上. 国内外著名的统计软件包: SAS, SPSS,STAT等,都可以让你快速、简便地进行 数据处理和分析.
直方图 横坐标表示所关心变量 的取值区间,纵坐标表 示频数,这样就得到频 数直方图.若把纵轴改成 频率就得到频率直方图.
9班概率论成绩直方图
频率
60 70 80 90 100
x
Probability and Statistics
例 为研究某厂工人生产某种产品的能力,我 们随机调查了20名工人某天生产的该种产品的 数量,数据如下 160 175 161 156 196 178 168 170 164 166 166 157 148 181 162 162 170 162 172 154
统计学分为两大类:描述统计和推断统计.
点图 1.用图形来显示数据 茎叶图 直方图
Probability and Statistics
2.用数字描述数据集 算术平均值 用来描述数据集中心的度量 中位数 截尾均值 用来描述数据集分散性的度量 方差、标准差 极差
Probability and Statistics
不同的p反映了总体间的差异. 譬如,两 个生产同类产品的工厂的产品总体分布为 X P 0 1 X P 0 1
0.983 0.017
0.915 0.085
显然,第一个工厂的产品质量优于第二个工厂. 实际上,分布中的不合格率是未知的,如何 对之进行估计是统计学要研究的问题.
Probability and Statistics
4.抽样:从总体X中抽取有限个个体对总体进行观察 的取值过程. 5.总体的随机样本:从总体中随机抽取的n个个体的 集合. n 称为样本容量.样本中的个体称为样品. 随机样本具有所谓的两重性:一方面,由于样本是从 总体中随机抽取的,抽取前无法预知它们的数值,因 此,样本是随机变量,用大写字母X1,X2, …,Xn表示; 另一方面,样本在抽取以后经观测就有确定的观测 值,因此,样本又是一组数值,此时,用小写字母x1, x2, …, xn表示是恰当的,它们被称为是样本值;
Probability and Statistics
160 175 161 156
196-148 本例 组距= =9.6,为研究方便,取组距为10. 5
Probability and Statistics
160 175 161 156
196 178 168 170
164 166 166 157
148 181 162 162
170 162 172 154
3.确定组限及组中值;
各组区间端点为 a0 , a0 d a1 , a0 2d a2 , , a0 kd ak , 形成如下的分组区间 (a0 , a1 ],(a1 , a2 ], ,(ak -1 , ak ], 其中a0略小于最小观测值, ak 略大于最大观测值. 本例取a0 =147, a5 =197,于是分组区间为 (147,157],(157,167],(167,177],(177,187],(187,197].
到了十九世纪末二十世纪初,随着近代 数学和概率论的发展,才真正诞生了数理统 计学这门学科.
Probability and Statistics
数理统计学是一门应用性很强的学科. 它是 研究怎样以有效的方式收集、 整理和分析带有 随机性的数据,以便对所考察的问题作出推断和 预测,直至为采取一定的决策和行动提供依据和 建议.
Probability and Statistics
概率论与数理统计是两个有密切联系的学 科,它们都以随机现象的统计规律为研究对象. 但在研究问题的方法上有很大区别: 概率论 —— 已知随机变量服从某分布,寻求 分布的性质、数字特征、及其应用; 数理统计 —— 通过对试验数据的统计分 析,寻找其所服从的分布和数字特征, 从而推断 总体的规律性. 数理统计的核心问题——由样本推断总体
Probability and Statistics
例5.1 考察某厂的产品质量,将其产品只分为合 格品与不合格品,并以0记合格品,以1记不合格 品,则 总体={该厂生产的全部合格品与不合格品} ={由0或1组成的一堆数} 若以 p表示这堆数中1的比例(不合格品率),则 该总体可由一个二点分布表示: X P 0 1- p 1 p
Probability and Statistics
中位数: 将一组数据按照大小顺序排列,如果数据的个 数是奇数,则处于中间位置的一个数是这组数据的 中位数;如果数据的个数是偶数,则处于中间位置 的两个数椐的平均数就是这组数据的中位数;
例如,500 600 600 600 600 750 800 900 2000 3000
650
这组数据的中位数
Probability and Statistics
• 中位数的作用和意义: 中位数也是用来描述数据的集中趋势的,它 是一个位置代表值。如果知道一组数据的中位数, 那么可以知道,小于或大于这个中位数的数据约 各占一半。
Probability and Statistics
2.用数字描述数据集 算术平均值 用来描述数据集中心的度量 中位数 截尾均值 用来描述数据集分散性的度量 方差、标准差 极差 3.五数概括、箱线图
则 X1 , X 2 ,, X n 的联合概率密度为
f * ( x1 , x2 , , xn ) f ( xi ).
i 1 n
Probability and Statistics
例5.3 设总体 X 服从参数为 ( 0) 的指数分布,
x 1 e - , x 0, 其概率密பைடு நூலகம்为f ( x ) 0, 其他.
Probability and Statistics
从历史的典籍中,人们不难发现许多关于 钱粮、户口、地震、水灾等等的记载,说 明人们很早就开始了统计的工作。 但是当时的统计,只是对有关事实的简单 记录和整理,而没有在一定理论的指导下,作 出超越这些数据范围之外的推断。
Probability and Statistics
Probability and Statistics
频数频率分布表 样本数据的整理是统计研究的基础,整理数据的 最常用方法之一是给出其频数分布或频率分布表.
组序 1 2 65 11 18.3% 8 21.6% 19 19.6% 3 75 16 26.7% 13 35.2% 29 29.9% 4 85 23 38.3% 8 21.6% 31 31.9% 5 合计
Probability and Statistics
例5.2 啤酒厂生产的瓶装啤酒规定净含量为640g, 由于随机性,事实上不可能使得所有的啤酒净含量 均为640g,现从某厂生产的啤酒中随机抽取10瓶测 定其净含量,得到如下结果: 641 635 640 637 642 638 645 643 643 639 640 这是一个容量为10的样本的观测值,对应的总体为 该厂生产的瓶装啤酒的净含量. 例5.3 分组样本:
Probability and Statistics
概 率 论 与 数 理 统 计
Key words: • 总体 2 分布 • 个体 t 分布 • 样本 F 分布 • 统计量
Probability and Statistics
现在转入课程的第二部分
数理统计
数理统计的特点是应用面广,分支较多, 社会的发展不断向统计提出新的问题。