基于K―means和布谷鸟算法的流程模型聚类
k-means聚类算法的原理和过程

一、概述k-means聚类算法是一种常用的聚类分析方法,广泛应用于数据挖掘和机器学习领域。
该算法通过迭代的方式将n个数据点分为k个簇,使得同一簇内的点相似度较高,不同簇之间的相似度较低。
本文旨在对k-means聚类算法的原理和过程进行详细介绍,以便读者深入了解该算法的运作机制。
二、k-means聚类算法原理1. 初始质心选择在k-means算法中,首先需要选择k个初始质心作为每个簇的代表点。
初始质心可以通过随机选取数据集中的k个点来确定,也可以使用其他方法如K-means++来选择初始质心。
2. 数据点分配一旦初始质心确定,算法将每个数据点分配到与其最近的质心所代表的簇中。
这一过程可以通过计算每个数据点与各个质心之间的距离,然后将数据点分配到最近的质心所属的簇。
3. 更新质心在数据点分配完成后,每个簇的质心需要重新计算以反映簇中所有数据点的均值位置。
新的质心位置通常是簇中所有数据点的平均值,这一过程反复进行直到质心的位置不再发生变化。
4. 簇内数据点相似度算法的优化目标是使同一簇内的数据点相似度较高,也就是使同一簇内的数据点与其质心的距离最小化。
更新质心的过程是为了最小化簇内数据点与质心之间的距离。
5. 算法收敛k-means算法的终止条件通常是簇内数据点的质心位置不再发生改变,或者达到预设的迭代次数。
三、k-means聚类算法过程k-means聚类算法过程可以概括为以下几个步骤:1. 初始化:根据给定的参数k,随机选择k个数据点作为初始质心。
2. 数据点分配:根据每个数据点与初始质心的距离,将数据点分配到最近的质心所代表的簇中。
3. 更新质心:重新计算每个簇的质心位置,以反映簇中所有数据点的均值位置。
4. 重复步骤2和步骤3,直到满足终止条件。
通常情况下,终止条件是质心位置不再发生变化,或者达到预设的迭代次数。
四、k-means聚类算法的应用k-means聚类算法广泛用于各种领域,包括但不限于:1. 客户分裙分析:通过对客户数据进行聚类分析,可以识别出具有相似特征的客户裙体,为市场营销活动和客户服务提供决策支持。
k-means聚类的基本步骤

k-means聚类的基本步骤
嘿,朋友们!今天咱来聊聊 k-means 聚类的那些事儿哈。
你想啊,这k-means 聚类就好比是给一堆乱七八糟的东西分类整理。
首先呢,咱得确定要分成几类,这就好比你要决定把你的玩具分成几
堆一样。
这可不是随便定的哦,得根据实际情况好好琢磨琢磨。
然后呢,就像给每个东西找个家一样,随机选几个点作为初始的聚
类中心。
这就好像你先随便找几个地方放那几堆玩具。
接下来,就是把每个数据点都归到离它最近的那个聚类中心所属的
类里。
这就好像你把每个玩具都放到离它最近的那堆里去。
哎呀,是
不是挺形象的呀!
这还不算完呢,等都分好类了,还得重新计算每个类的中心。
这就
好比你重新调整一下那几堆玩具的位置,让它们更整齐。
然后再重复上面的过程,一直到这些聚类中心不再变化啦。
这就像
你反复调整玩具堆,直到你觉得满意为止。
你说这 k-means 聚类是不是挺有趣的呀?就像是在玩一个整理的游戏。
而且它用处可大了去了呢!比如说在数据分析里,能帮我们发现
一些隐藏的模式和规律。
你想想看,如果没有k-means 聚类,那面对一大堆杂乱无章的数据,我们得多头疼呀!但有了它,就好像有了一双神奇的手,能把这些乱
麻一样的数据整理得井井有条。
所以说呀,学会 k-means 聚类的基本步骤可太重要啦!咱可不能小
瞧了它,得好好研究研究,把它用在该用的地方,让它发挥出最大的
作用呀!这难道不是很有意义的事情吗?。
基于k-meams算法的聚类模型

图9-1 原始数据
图9-2 聚类结果
根据样本之间的距离或者说是相似性(亲疏性),把较相似、差异较小的样本聚成一类(簇),最后形 成多个类(簇),使同一个类(簇)内部的样本相似度高,不同类(簇)之间差异性高。
k-means算法原理
k-means算法也称为k均值聚类算法,由于其简洁和高效,成为所有聚类算法中使用 最广泛的一种聚类算法。 k-means算法的原理是:给定一个数据点集合和需要的聚类数目k,k由用户指定,k 均值聚类算法根据某个距离函数反复把数据分入k个聚类中。
第二节 k-means算法流程
k-means算法流程
k-means算法的基本步骤如下。 (1)选定要聚类的类别数目k,随机选择k个中心点(质心)。 (2)针对每个样本点,找到距离其最近的中心点(寻找组织),距离同一中心点 最近的点为一个类,这样完成一次聚类。 (3)判断聚类前后的样本点的类别情况是否相同,如果相同,则算法终止,否则 进入下一步。 (4)针对每个类别中的样本点,计算这些样本点的中心点,当作该类的新的中心 点,继续步骤(2)和步骤(3)。
谢谢聆听
THANKS FOR YOUR ATTENTION
k-means算法原理
k-means算法先随机选取k个点作为初始的聚类中心,然后针对每个数据点,计算每个数据点与各个 聚类中心点之间的距离,把每个数据点归为距离它最近的聚类中心点代表的类(簇)。一次迭代结 束之后, 此循环,直到前后两次迭代的类(簇)没有变化。
k-means算法参数选择
某数据集在分类数1到7时,聚类数k和簇内距离平方和的对应关系的手肘图如图9-4 所示。从图9-4可以看到,k=3时,簇内距离平方和的下降率突然变缓,可以考虑选 择k=3作为聚类数量。
布谷鸟搜索改进的k-means聚类算法及其并行化实现

摘要随着计算机和互联网技术的迅速发展,数据量呈爆发式增长,海量数据的高效处理和利用成为当前社会面临的最艰巨任务之一;同时如何高效率、低成本、准确地从现有的海量数据中挖掘出潜在、有用的知识是数据挖掘领域研究面临的一大难题。
以K-means算法为代表的聚类分析是数据挖掘领域最重要的研究方向之一,K-means是一种典型的基于划分方法的聚类算法,具有思路简单、收敛速度快、时间复杂度近似于线性等特点,较适合应用于海量数据的聚类;群体仿生优化算法能够利用群体优势、并行搜索,以全局寻优的方式快速获得优化问题最优解,被认为是目前处理K-means聚类优化问题最行之有效的方法。
当前已有很多学者基于多种不同的群体仿生智能算法对K-means聚类算法进行优化,但现有的K-means聚类改进算法还存在以下两个问题需进一步完善:①聚类过程中的全局寻优能力不够突出,容易陷入局部最优;②在数据量较大时的聚类效率不高,没有充分利用服务器集群优势。
作者所做的主要工作包括:①提出一种新型元启发式基于仿生行为的改进的布谷鸟搜索算法(Quantum-based Adaptive Cuckoo Search,QACS),解决了原始布谷鸟算法搜索步长的自适应性问题,并引入量子运算使该算法的搜索方向具有一定的倾向性。
②针对K-means聚类算法易陷入局部最优的问题,将新算法QACS 与K-means聚类算法相结合,提出了一种新的串行K-means聚类算法(K-means clustering algorithm based on QACS,QACS-KMeans),提高了K-means聚类算法的全局搜索能力;③针对K-means聚类算法在处理较大数据量时效率较低的问题,利用Hadoop分布式平台的MapReduce编程模型实现了对新算法QACS-KMeans 的并行化处理。
通过在虚拟机中搭建的Hadoop伪分布式集群对不同样本数据集分别进行10次准确性实验和效率实验,结果表明:①并行QACS-KMeans新算法聚类的平均准确率在实验所采用的6种UCI标准数据集上,相比原始K-means聚类算法、利用粒子群优化算法(Particle Swarm Optimization, PSO)改进的K-means聚类算法和自适应布谷鸟搜索(Adaptive Cuckoo Search , ACS)改进的K-means聚类算法都有所提高;②并行QACS-KMeans新算法聚类的平均运行效率在实验所采用的5种大小递增的随机数据集上,当数据量较大时,显著优于原始K-means串行算法,稍好于并行PSO-Kmeans算法和并行ACS-KMeans算法。
基于布谷鸟算法的K-means聚类挖掘算法研究的开题报告

基于布谷鸟算法的K-means聚类挖掘算法研究的开题报告一、研究背景和意义随着大数据时代的到来,数据量的不断增加使得数据处理和分析越来越困难。
聚类分析作为一种数据挖掘方法,被广泛应用于大规模数据的分类、分析和挖掘。
K-means聚类算法是一种常见的聚类分析方法,该算法通过将数据集划分为K个类别,使得每个类别内部的数据点之间的距离最小化。
但是,传统的K-means算法结合了随机性和局部最优解,当数据量很大时,算法会陷入局部最优解,导致聚类效果不佳。
布谷鸟算法(Cuckoo Search Algorithm, CSA)是一种模拟鸟巢中蜜蜂覆盖最大问题的优化算法。
该算法具有较强的全局搜索能力和局部搜索能力,其思想与K-means聚类算法相似,两种算法均需要调整两个参数,并寻找最优的解。
本文旨在结合布谷鸟算法和K-means聚类算法的优点,提出一种基于布谷鸟算法的K-means聚类挖掘算法,以提高聚类效果和算法效率,推动数据挖掘研究的发展。
二、研究内容和方法该研究的主要内容为基于布谷鸟算法的K-means聚类挖掘算法的开发和实现。
具体来说,将K-means算法中的初始质心随机选取改为使用布谷鸟算法进行优化,以提高算法的全局搜索能力和局部搜索能力,从而得到更优的聚类效果。
本文的研究方法主要包括以下几个步骤:1. 分析K-means聚类算法和布谷鸟算法的原理和优缺点。
2. 基于布谷鸟算法设计优化初始质心的算法。
3. 实现基于布谷鸟算法的K-means聚类挖掘算法。
4. 对比分析传统K-means算法和基于布谷鸟算法的K-means聚类算法的聚类效果和算法效率。
5. 应用该算法进行数据挖掘实例分析,验证算法的可行性和有效性。
三、预期研究结果预计该研究可以开发出一种基于布谷鸟算法的K-means聚类挖掘算法,并验证该算法的聚类效果和算法效率较传统算法有一定提高。
同时,我们将通过实际数据挖掘实例的分析,探索算法在实际应用中的可行性和有效性。
kmeans聚类算法的算法流程

K-means聚类算法是一种经典的基于距离的聚类算法,它被广泛应用于数据挖掘、模式识别、图像分割等领域。
K-means算法通过不断迭代更新簇中心来实现数据点的聚类,其算法流程如下:1. 初始化:首先需要确定要将数据分成的簇的个数K,然后随机初始化K个簇中心,可以从数据集中随机选择K个样本作为初始簇中心。
2. 分配数据:对于每个数据点,计算它与各个簇中心的距离,将该数据点分配给距离最近的簇,并更新该数据点所属簇的信息。
3. 更新簇中心:计算每个簇中所有数据点的均值,将该均值作为新的簇中心,更新所有簇中心的位置。
4. 重复迭代:重复步骤2和步骤3,直到簇中心不再发生变化或者达到预定的迭代次数。
5. 输出结果:最终得到K个簇,每个簇包含一组数据点,形成了聚类结果。
K-means算法的优点在于简单易实现,时间复杂度低,适用于大规模数据;但也存在一些缺点,如对初始聚类中心敏感,对噪声和离裙点敏感,需要事先确定聚类个数K等。
K-means聚类算法是一种常用的聚类方法,通过迭代更新簇中心的方式逐步将数据点划分为不同的簇,实现数据的聚类分析。
通过对算法流程的详细了解,可以更好地应用K-means算法解决实际问题。
K-means算法是一种非常经典的聚类算法,它在数据挖掘和机器学习领域有着广泛的应用。
在实际问题中,K-means算法可以帮助我们对数据进行分组和分类,从而更好地理解数据的内在规律,为我们提供更准确的数据分析和预测。
接下来,我们将对K-means聚类算法的一些关键要点进行探讨,包括算法的优化、应用场景、以及与其他聚类算法的比较等方面。
1. 算法的优化:在实际应用中,K-means算法可能会受到初始簇中心的选择和迭代次数的影响,容易收敛到局部最优解。
有一些改进的方法可以用来优化K-means算法,例如K-means++算法通过改进初始簇中心的选择方式,来减少算法收敛到局部最优解的可能性;另外,Batch K-means算法通过批量更新簇中心的方式来加快算法的收敛速度;而Distributed K-means算法则是针对大规模数据集,通过并行计算的方式来提高算法的效率。
k-means聚类方法的原理和步骤

k-means聚类方法的原理和步骤k-means聚类方法是一种常用的数据聚类算法,它可以将一组数据划分成若干个类别,使得同一类别内的数据相似度较高,不同类别之间的数据相似度较低。
本文将介绍k-means聚类方法的原理和步骤。
k-means聚类方法基于数据的距离度量,具体而言,它通过最小化各个数据点与所属类别中心点之间的距离来达到聚类的目的。
其基本原理可以概括为以下几点:-定义类别中心点:在聚类开始前,需要预先设定聚类的类别数量k。
根据k的数量,在数据集中随机选取k个点作为初始的类别中心点。
-分配数据点到类别:对于每一个数据点,计算其与各个类别中心点之间的距离,并将其分配到距离最近的类别中。
-更新类别中心点:当所有数据点分配完毕后,重新计算每个类别中的数据点的均值,以此获得新的类别中心点。
-重复分配和更新过程:将新的类别中心点作为参考,重新分配数据点和更新类别中心点,直到类别中心点不再变化或达到预设的迭代次数。
按照上述原理,k-means聚类方法的步骤可以分为以下几个阶段:-第一步,随机选择k个类别中心点。
-第二步,计算每个数据点与各个类别中心点之间的距离,并将其分配到距离最近的类别中。
-第三步,重新计算每个类别中数据点的均值,以此获得新的类别中心点。
-第四步,判断新的类别中心点是否与上一次迭代的中心点相同,如果相同,则结束聚类过程;如果不同,则更新类别中心点,返回第二步继续迭代。
-第五步,输出最终的类别划分结果。
需要注意的是,k-means聚类方法对聚类的初始中心点敏感,不同的初始点可能会导致不同的聚类结果。
为了避免陷入局部最优解,通常采用多次随机初始化的方式进行聚类,然后选取最好的结果作为最终的聚类划分。
综上所述,k-means聚类方法是一种常用的数据聚类算法,它通过最小化数据点与类别中心点之间的距离来实现聚类。
按照预设的步骤进行迭代,最终得到稳定的聚类结果。
在实际应用中,还可以根据具体问题进行算法的改进和优化,以满足实际需求。
基于K-means聚类挖掘智能机器人领域技术创新人才
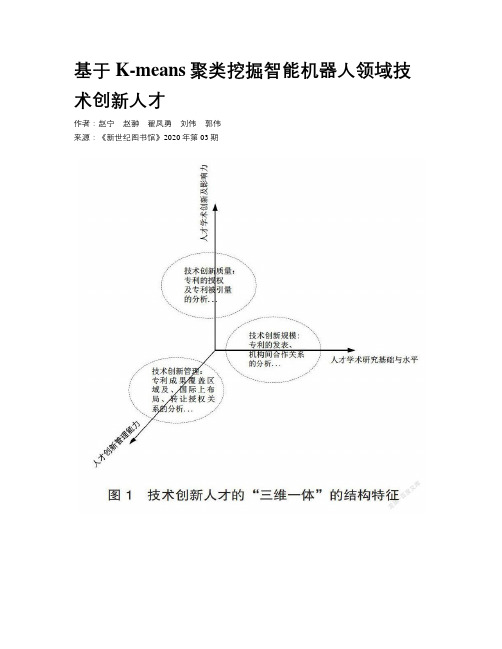
基于K-means聚类挖掘智能机器人领域技术创新人才作者:赵宁赵翀翟凤勇刘伟郭伟来源:《新世纪图书馆》2020年第03期摘要以智能机器人领域为例,借助机器学习的方法挖掘技术创新人才,消除专家分类的主观性。
通过专利信息构建技术创新人才评价指标体系,结合主成分分析、K-means聚类,进行技术创新人才有效分类;利用DWPI手工代码挖掘智能机器人领域对应的创新人员及相应的技术团队成员,对于技术创新人才分类有进一步优化空间。
K-means聚类改进了传统的识别方法,突破人工统计的局限,可以处理数量级更大的数据,对数据挖掘可以进行及时、准确、直观的分析。
关键词专利信息聚类分析技术创新人才 K-means分类号 G252.62DOI 10.16810/ki.1672-514X.2020.03.009Abstract Taking the intelligent robot field as an example, by means of machine learning, the subjectivity of expert classification can be eliminated. The evaluation index system of technological innovation talents is constructed by patent information, and the effective classification of technological innovation talents is carried out by combining principal component analysis and K-means clustering. The corresponding innovation personnel and corresponding technical team members in the field of intelligent robot are mined by DWPI manual code, which has further optimization space for the classification of technological innovation talents. K-means clustering improves the traditional recognition method, breaks through the limitations of artificial statistics. It can deal with larger data of order of magnitude, and can analyze data mining timely, accurately and intuitively.Keywords Patent information. Cluster analysis. Technological innovative talents. K-means.专利作为一种标准化、公开透明、客观化的文献,由于其所载信息贯穿科研流程和活动的不同阶段,对技术发明有详细描述,不仅可以从本质上揭示技术创新能力[1],而且常作为技术创新的重要指标,被嵌入各种技术创新能力量化的评价体系中,以便简化评价流程而得到可靠的评价结果[2]。
kmeans聚类算法流程

kmeans聚类算法流程
Kmeans聚类算法流程
Kmeans聚类算法是一种常用的无监督学习算法,它可以将数据集中的数据分成多个类别,每个类别内部的数据相似度较高,不同类别之间的数据相似度较低。
下面我们来详细介绍一下Kmeans聚类算法的流程。
1. 初始化
我们需要确定聚类的个数k,然后从数据集中随机选择k个数据点作为初始的聚类中心。
这些聚类中心可以是随机选择的,也可以是通过其他算法得到的。
2. 分配数据点
接下来,我们需要将数据集中的每个数据点分配到最近的聚类中心所在的类别中。
这里的距离可以使用欧几里得距离或曼哈顿距离等。
3. 更新聚类中心
在分配完数据点之后,我们需要重新计算每个类别的聚类中心。
具体来说,对于每个类别,我们需要计算该类别内所有数据点的平均值,然后将这个平均值作为新的聚类中心。
4. 重复迭代
接下来,我们需要重复执行步骤2和步骤3,直到聚类中心不再发生变化或达到预定的迭代次数为止。
在每次迭代中,我们需要重新分配数据点和更新聚类中心。
5. 输出结果
我们可以将聚类结果输出,每个类别中的数据点就是一个聚类。
我们可以使用不同的颜色或符号来表示不同的聚类,以便于可视化展示。
总结
Kmeans聚类算法是一种简单而有效的聚类算法,它的流程非常清晰,容易理解和实现。
但是,Kmeans聚类算法也有一些缺点,比如对于非凸形状的聚类效果不佳,对于初始聚类中心的选择比较敏感等。
因此,在实际应用中,我们需要根据具体情况选择合适的聚类算法。
基于自适应布谷鸟搜索算法的K—means聚类算法及其应用

基于自适应布谷鸟搜索算法的K—means聚类算法及其应用作者:杨辉华王克李灵巧魏文何胜韬来源:《计算机应用》2016年第08期摘要:针对原始K-means聚类算法受初始聚类中心影响过大以及容易陷入局部最优的不足,提出一种基于改进布谷鸟搜索(CS)的K-means聚类算法(ACS-K-means)。
其中,自适应CS(ACS)算法在标准CS算法的基础上引入步长自适应调整,以提高搜索精度和收敛速度。
在UCI标准数据集上,ACS-K-means算法可得到比K-means、基于遗传算法的K-means (GA-K-means)、基于布谷鸟搜索的K-means(CS-K-means)和基于粒子群优化的K-means (PSO-K-means)算法更优的聚类质量和更高的收敛速度。
将ACS-K-means聚类算法应用到南宁市青秀区“城管通”系统的城管案件热图的开发中,在地图上对案件地理坐标进行聚类并显示,应用结果表明,聚类效果良好,算法收敛速度快。
关键词:数据挖掘;K-means聚类;布谷鸟搜索算法;数字城管;热图中图分类号:TP391; TP183文献标志码:A0引言随着我国数字化城市管理事业建设的推进,基于城市管理综合数据的智慧城市应用越来越受到重视。
数字城管系统在建设与运行的过程中,不断丰富了城市管理的基础数据,如基础地形图、卫星遥感影像数据、城市管理部件数据、城市管理案件数据等。
这些庞大的城市管理综合数据为数据的空间分析、聚类分析、辅助决策等提供了重要载体。
而如何从海量的城管数据中发掘出有用的信息为城市管理所运用已成为目前智慧城市建设中研究的热点问题之一。
利用数据挖掘技术从城市管理的案件地理数据中发现隐含的有用信息,从时间维度和空间维度分析城市管理问题的高发时段、高发区域,分析城市管理问题的发生、发展等动态变化过程,这在灾害天气频发时进行实时预警、对领导决策提供辅助等方面能起到重要作用。
数据挖掘作为一个热门的多学科交叉应用领域,正在各行各业中扮演着重要的角色。
kmeans聚类步骤

K-means聚类步骤引言K-means聚类是一种常用的无监督学习算法,用于将数据集划分为具有相似特征的不同群组。
它是一种迭代的、基于距离的聚类算法,通过最小化样本点与其所属簇中心点之间的距离来实现数据的聚类。
本文将详细介绍K-means聚类的步骤和原理。
1. 初始化首先,需要选择要生成的簇数k。
簇数k表示最终希望得到的群组数量。
在开始时,需要随机选择k个样本作为初始簇中心点。
这些初始簇中心点可以是从数据集中随机选择的样本,也可以通过其他初始化方法得到。
2. 分配样本到簇接下来,对数据集中的每个样本进行分配操作,将其分配给与其最近的簇中心点所属的簇。
这里使用欧氏距离来度量样本点与簇中心点之间的距离。
具体而言,对于每个样本,计算它与每个簇中心点之间的距离,并将其分配给距离最近的那个簇。
3. 更新簇中心点在将所有样本分配给簇之后,需要更新每个簇的中心点。
对于每个簇而言,计算它包含的所有样本的平均值,并将该平均值作为新的簇中心点。
这一步骤可以通过计算每个维度上的均值来实现。
4. 重复分配和更新步骤接下来,重复执行步骤2和步骤3,直到满足某个停止条件。
常见的停止条件包括:达到最大迭代次数、样本点不再发生变化或者误差减少到一个较小的阈值。
5. 输出结果当停止条件满足时,K-means聚类算法结束。
最终得到k个簇及其对应的中心点。
可以将每个样本所属的簇标记为其群组ID,并将结果输出。
算法优化与改进尽管K-means聚类是一种常用且有效的聚类算法,但它也存在一些局限性和问题。
下面介绍一些常见的优化和改进方法:1. K-means++K-means++是一种改进的初始化方法,在选择初始簇中心点时更加合理和有效。
传统K-means算法在选择初始簇中心点时是随机选择的,可能导致结果不稳定。
而K-means++通过引入概率模型,使得选择的初始簇中心点更具代表性和多样性,从而提高了算法的稳定性和效果。
2. Mini-batch K-means传统的K-means算法需要遍历整个数据集来进行样本分配和簇中心点更新,计算量较大。
kmeans聚类算法的 步骤

一、介绍K-means聚类算法是一种常见的无监督学习算法,用于将数据集划分成多个不相交的子集,从而使每个子集内的数据点都彼此相似。
这种算法通常被用于数据挖掘、模式识别和图像分割等领域。
在本文中,我们将介绍K-means聚类算法的步骤,以帮助读者了解该算法的原理和实现过程。
二、算法步骤1. 初始化选择K个初始的聚类中心,这些聚类中心可以从数据集中随机选择,也可以通过一些启发式算法进行选择。
K表示用户事先设定的聚类个数。
2. 聚类分配对于数据集中的每个数据点,计算其与K个聚类中心的距离,并将其分配到距离最近的聚类中心所属的子集中。
3. 更新聚类中心计算每个子集中所有数据点的均值,将均值作为新的聚类中心。
4. 重复第二步和第三步重复进行聚类分配和更新聚类中心的步骤,直到聚类中心不再发生变化,或者达到预设的迭代次数。
5. 收敛当聚类中心不再发生变化时,算法收敛,聚类过程结束。
三、算法变体K-means算法有许多不同的变体,这些变体可以根据特定的场景和需求进行调整。
K-means++算法是K-means算法的一种改进版本,它可以更有效地选择初始的聚类中心,从而提高聚类的准确性和效率。
对于大规模数据集,可以使用Mini-batch K-means算法,它可以在迭代过程中随机选择一部分数据进行计算,从而加快算法的收敛速度。
四、总结K-means聚类算法是一种简单而有效的聚类算法,它在各种领域都得到了广泛的应用。
然而,该算法也存在一些局限性,例如对初始聚类中心的选择比较敏感,对异常值比较敏感等。
在实际使用时,需要根据具体情况进行调整和改进。
希望本文对读者有所帮助,让大家对K-means聚类算法有更深入的了解。
K-means聚类算法作为一种经典的无监督学习算法,在进行数据分析和模式识别时发挥着重要作用。
在实际应用中,K-means算法的步骤和变体需要根据具体问题进行调整和改进。
下面我们将进一步探讨K-means聚类算法的步骤和变体,以及在实际应用中的注意事项。
k-means聚类算法的一般流程

k-means聚类算法的一般流程下载温馨提示:该文档是我店铺精心编制而成,希望大家下载以后,能够帮助大家解决实际的问题。
文档下载后可定制随意修改,请根据实际需要进行相应的调整和使用,谢谢!并且,本店铺为大家提供各种各样类型的实用资料,如教育随笔、日记赏析、句子摘抄、古诗大全、经典美文、话题作文、工作总结、词语解析、文案摘录、其他资料等等,如想了解不同资料格式和写法,敬请关注!Download tips: This document is carefully compiled by theeditor.I hope that after you download them,they can help yousolve practical problems. The document can be customized andmodified after downloading,please adjust and use it according toactual needs, thank you!In addition, our shop provides you with various types ofpractical materials,such as educational essays, diaryappreciation,sentence excerpts,ancient poems,classic articles,topic composition,work summary,word parsing,copy excerpts,other materials and so on,want to know different data formats andwriting methods,please pay attention!K-Means聚类算法的一般流程详解K-Means聚类算法是一种广泛应用的数据挖掘技术,主要用于无监督学习中的数据分类。
基于布谷鸟算法优化K_means聚类的缺失数据填充算法

学术研究基于布谷鸟算法优化K_means聚类的缺失数据填充算法*林枫1蔡延光1蔡颢2 张丽1(1.广东工业大学自动化学院,广东广州5100062.奥尔堡大学健康科学与工程系,丹麦奥尔堡9920)摘要:针对K_means聚类算法对初始参数较敏感且相对容易出现局部最优解的问题,提出基于布谷鸟算法优化的K_means聚类算法,并将优化后的K_means聚类算法与条件均值填充算法相结合,递归地填充缺失数据。
实验结果表明:与传统算法相比,基于布谷鸟算法优化K_means聚类的缺失数据填充算法具有更好的效果。
关键字:缺失数据;填充;布谷鸟算法;K_means算法中图分类号:TP301 标志码:A 文章编号:1674-2605(2020)06-0003-06 DOI:10.3969/j.issn.1674-2605.2020.06.0030引言数据集在收集与整理过程中,因各种不可控因素导致数据部分属性值缺失,从而对数据质量造成较严重影响且降低数据挖掘效果[1-2]。
因此,为提高数据集的分析效果,对其中缺失数据进行填充是至关重要的。
常用的缺失数据填充方法有回归插补法、聚类插补法、人工神经网络插补法等。
回归分析是一种基于变量间关系的预测性分析方法,广泛应用于各个领域[2]。
回归插补法的基本思想是通过数据中的缺失属性与其余属性的关系建立回归模型,再利用回归模型预测缺失属性的值并进行填充。
卜范玉等利用CFS聚类算法对不完整数据集进行聚类,对降噪自动编码模型进行改进,并根据聚类结果,利用改进的自动编码模型对缺失数据进行填充[3]。
戴明锋等利用logistic回归算法对数据中的缺失属性值进行填充并取得较好成效[4]。
李建更等为解决基因谱的数据缺失问题,提出基于双向核加权回归估计算法,取得较好缺失值填充效果[5]。
在数据挖掘领域,聚类算法是对数据进行分类统计分析的一种经典算法。
它通过度量数据间的相似性对数据进行分类划分,使相同类的数据聚集成一类[6]。
基于自适应布谷鸟优化特征选择的K-means聚类

基于自适应布谷鸟优化特征选择的K-means聚类孙林;刘梦含【期刊名称】《计算机应用》【年(卷),期】2024(44)3【摘要】K-means聚类算法随机确定初始聚类数目,而且原始数据集中含有大量的冗余特征会导致聚类时精度降低,而布谷鸟搜索(CS)算法存在收敛速度慢和局部搜索能力弱等问题,为此提出一种基于自适应布谷鸟优化特征选择的K-means聚类算法(DCFSK)。
首先,为提升CS算法的搜索速度和精度,在莱维飞行阶段,设计了自适应步长因子;为调节CS算法全局搜索和局部搜索之间的平衡、加快CS算法的收敛,动态调整发现概率,进而提出改进的动态CS算法(IDCS),在IDCS的基础上构建了结合动态CS的特征选择算法(DCFS)。
其次,为提升传统欧氏距离的计算精确度,设计同时考虑样本和特征对距离计算贡献程度的加权欧氏距离;为了确定最佳聚类数目的选取方法,依据改进的加权欧氏距离构造了加权簇内距离和簇间距离。
最后,为克服传统K-means聚类目标函数仅考虑簇内的距离而未考虑簇间距离的缺陷,提出基于中位数的轮廓系数的目标函数,进而设计了DCFSK。
实验结果表明,在10个基准测试函数上,IDCS的各项指标取得了较优的结果;相较于K-means、DBSCAN(Density-Based Spatial Clustering of Applications with Noise)等算法,在6个合成数据集与6个UCI数据集上,DCFSK的聚类效果最佳。
【总页数】11页(P831-841)【作者】孙林;刘梦含【作者单位】天津科技大学人工智能学院;河南师范大学计算机与信息工程学院【正文语种】中文【中图分类】TP181【相关文献】1.纹理影像特征选择及K-means聚类优化方法2.基于自适应布谷鸟搜索算法的K-means聚类算法及其应用3.自适应布谷鸟搜索的并行K-means聚类算法4.基于自适应的遗传优化K-means聚类算法的智慧校园网络入侵检测算法设计5.基于自适应果蝇优化算法的K-means聚类因版权原因,仅展示原文概要,查看原文内容请购买。
自适应布谷鸟搜索的并行K-means聚类算法

自适应布谷鸟搜索的并行K-means聚类算法王波;余相君【期刊名称】《计算机应用研究》【年(卷),期】2018(035)003【摘要】针对K-means聚类算法受初始类中心影响,聚类结果容易陷入局部最优导致聚类准确率较低的问题,提出了一种基于自适应布谷鸟搜索的K-means聚类改进算法,并利用MapReduce编程模型实现了改进算法的并行化.通过搭建的Hadoop分布式计算平台对不同样本数据集分别进行10次准确性实验和效率实验,结果表明:a)聚类的平均准确率在实验所采用的四种UCI标准数据集上,相比原始K-means聚类算法和基于粒子群优化算法改进的K-means聚类算法都有所提高;b)聚类的平均运行效率在实验所采用的五种大小递增的随机数据集上,当数据量较大时,显著优于原始K-means串行算法,稍好于粒子群优化算法改进的并行K-means 聚类算法.可以得出结论,在大数据情景下,应用该算法的聚类效果较好.%The original K-means clustering algorithm is seriously affected by initial centroids of clustering and easy to fall into local optima.So this paper proposed an improved K-means clustering based on adaptive cuckoo search,and achieved the parallelization of the improved algorithm using MapReduce programming model.It implemented accuracy experiments and efficiency experiments 10 times respectively on Hadoop platform for every different data sets,the experimental results show that:a)compared with the original K-means algorithm and PSO-Kmeans,the average accuracy of clustering improved in the experiments which test on four UCIstandard data sets;b)tested the average execution efficiency of clustering in the experiments which test on five random incremental data sets,when the amount of data was very large,significantly better than original K-means algorithm,slightly better than PSO-Kmeans.It can be concluded that the algorithm can be applied to large data clustering,and will play a significant effect.【总页数】5页(P675-679)【作者】王波;余相君【作者单位】重庆大学计算机学院,重庆400044;重庆大学计算机学院,重庆400044【正文语种】中文【中图分类】TP301.6【相关文献】1.基于自适应布谷鸟搜索算法的K-means聚类算法及其应用 [J], 杨辉华;王克;李灵巧;魏文;何胜韬2.布谷鸟优化的密度峰值快速搜索聚类算法 [J], 郑虹;周丽媛;韩旭明3.自适应调整的布谷鸟搜索K-均值聚类算法 [J], Wang Rihong;Cui Xingmei;Li Yongjun4.基于改进布谷鸟搜索的k-means算法的离群点检测 [J], 庄丽丽;石鸿雁5.基于布谷鸟搜索改进的聚类算法 [J], 孙伟鹏;孟斌;吴锡生因版权原因,仅展示原文概要,查看原文内容请购买。
请简述k-means算法的流程

请简述k-means算法的流程K-means算法是一种聚类分析方法,用于将数据集分为K个不同的非重叠的簇。
本文将简述K-means算法的流程,并提供相关参考内容。
K-means算法的流程如下:1. 初始化K个簇的中心点:随机选择K个数据点作为初始的中心点。
2. 分配数据点到最近的簇:计算每个数据点与各个簇中心点的距离,将数据点分配到距离最近的簇。
3. 更新簇的中心点:对于每个簇,计算其内部所有数据点的平均位置,将该平均位置作为新的簇中心点。
4. 重复步骤2和步骤3,直到簇的中心点不再变化或达到最大迭代次数。
K-means算法的优化目标是最小化所有数据点与其所分配的簇中心点之间的距离的总和,称为簇内平方和。
算法通过迭代优化簇的中心点,使得簇内平方和最小。
参考内容如下:1. 来自机器学习实战一书(The book "Machine Learning in Action")的描述:K-means算法是一种常见的聚类算法,它使用欧氏距离来度量数据点之间的相似性。
该算法的流程简单明了,通过迭代的方式不断更新簇的中心点,直到达到一定的停止条件。
作者详细介绍了算法的优化目标、算法的实现、停止条件的选择等方面的内容。
2. 来自斯坦福大学机器学习课程(Stanford University Machine Learning course)的讲义:该讲义提供了K-means算法的详细流程图和伪代码,并解释了算法中每个步骤的具体含义和操作。
讲义还介绍了K-means 算法的局限性和改进方法,以及如何处理异常点的情况。
3. 来自维基百科(Wikipedia)的页面:维基百科提供了K-means算法的原理、应用领域、相关算法等方面的详细介绍。
页面中给出了算法的伪代码以及算法复杂度的讨论,还介绍了常用的评估指标和距离度量方法。
4. 来自sklearn官方文档:scikit-learn是一个常用的机器学习库,其中包含了各种聚类算法的实现,包括K-means算法。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
基于K―means和布谷鸟算法的流程模型聚类摘要:流程模型聚类是流程管理领域的一个热门话题。
本文提出一种基于布谷鸟算法的K-means算法,该算法弥补了K-means算法的依赖初始解、易陷入局部最优等缺点。
本文从流程模型结构性能、成本、效率、顾客满意度以及质量等五个方面模拟数据集,并选择权重较高的属性进行试验操作,结果表明算法的具有较高的可行性和有效性。
Abstract:Process model clustering is a hot topic in the field of process management. This paper presents a newK-means algorithm based on cuckoo algorithm,which compensates drawbacks of traditional K-means algorithm,such as relying on initial solution and being easily trapped in local optimums. In this paper,simulated data sets consist of five features (process model structure performance,cost,efficiency,customer satisfaction and quality),but experiments are conducted by only two indicators with higher weight. Experimental results show that the method has relatively higher feasibility and effectiveness.关键词:布谷鸟算法;K-means算法;流程模型聚类Key words:cuckoo algorithm;K-means;process modelclustering0 引言随着流程管理领域关键技术的快速发展以及大型组织或跨国企业拥有越来越多的纷繁复杂的业务流程,建立流程模型库成为一种趋势,而如何对流程模型库进行全面管理和维以及挖掘使用流程模型库成为目前热点问题之一。
对于已聚类的业务流程模型进行流程挖掘,挖掘出更多的模型中隐含的信息,有助于企业领导做出正确的决策,同时用户也可以根据自己的需要进行个性化定制,大大提高了流程模型的使用效率和用户的满意度。
流程模型以求解业务流程相似性的流程模型聚类成为解决流程模型库维护问题的新趋势。
对于业务流程模型聚类的问题,传统的求解方法是利用业务流程模型的结构化组成部分,求解模型相似度,从而进行流程模型聚类。
文献[1]将从标签文本、结构和行为相似三个方面,求解流程相似性。
Dijkman等在文献[2]中提出利用图匹配的流程模型相似性机制。
基于图编辑距离(graph edit distance)比较的结构相似性机制同时考虑了文本相似度和模型拓扑结构[3]。
关于流程行为相似性,相关文献提出了各种流程行为等价的概念,如互模拟等价(bisimulation)[4]、轨迹等价(trace equivalence)[5]等。
但是这些等价概念只能划分出等价和非等价,而不能给出一个量化的值。
为此,专家、学者从不同的角度提出测算方法,Aalst等在文献[6-7]提出基于流程日志的观察行为(observed behavior)方法,Wang等提出基于首要变迁序列(principal transition sequence)的有标志Petri网的行为相似性度量方法[8]。
Jin等提出一种基于流程结构和语义特征进行模型聚类后再检索的机制[9],其目的是为了提高模型检索效率,避免在查询过程中遍历模型库中的每一个流程模型。
这些相似性研究的也为流程模型聚类提供了大量的理论研究。
关于流程模型聚类,文献[10]提出了以业务单据为中心的流程模型聚类,以层次聚类算法进行聚类,进行模型预处理。
K-means算法是由Steihaus、Lloyd、Ball&Hall、J.B.Mac Queen分别于1955年、1957年、1965年、1967年在不同的科学研究领域提出的经典的基于划分的聚类算法,该算法效率较高、容易实施,且易于和其它方法相结合,是成为数据挖掘、机器学习、模式识别和数量统计等领域应用最广的聚类算法之一的主要原因[11]。
布谷鸟(Cuckoo Search,简称CS)算法是由剑桥大学的YANG Xin-she和拉曼工程大学的DEB Suash在文献[12]中提出的一种新的仿生算法,该算法主要基于布谷鸟的巢寄生繁殖机理和莱维飞行(Levy fights)搜索原理两个方面,其主要特点是寻优能力强、随机搜索路径优、参数少、操作简单和易于实现等[13]。
目前,布谷鸟算法已成功应用于无线传感器数据优化[14]、高斯分布[15]、工程优化[16]、嵌入式系统[17]以及结构性软件测试[18]等方面,有效地解决了多种优化问题,由于提出的时间较短,目前还尚未发现将其应用于流程管理领域的文献。
在上述文献中,均是从流程模型的结构部分去考虑流程聚类,但是在实际的应用中,仅仅考虑流程模型的结构或结构性能是远远不够的,还应考虑流程的成本、顾客满意度等等。
本文从流程模型的结构性能、成本、效率、顾客满意度以及质量等五个方面,从数据化的角度对这些指标进行量化,同时提出以一种基于布谷鸟算法的K-means聚类算法进行流程模型聚类。
通过仿真实验,实验结果验证了算法的可行性。
1 K-means算法K-means算法是基于划分的聚类算法。
算法前提是假定数据库中有n个对象以及聚类数目k。
该算法将n个对象划分为k个划分(k?燮n),每个划分代表一个聚类,使得类间对象尽可能不同,类内对象具有较高的相似度。
聚类依据是利用相似度函数,通过距离来衡量,对于kn空间中的向量,一般用的是欧式距离d=‖x-c‖。
K-means聚类算法的过程如下:输入:类数目k以及包含n个对象的数据集X=(x1,x2,x3,…,xn);输出:k个类Zj。
K-means聚类算法的步骤如下:①从数据集中X=(x1,x2,x3,…,xn)中任意选择k 个对象作为初始的聚类中心c1,c2,c3,…,ck;②计算数据集中数据点xi(i=1,2,3,…,n)与上述k个聚类中心的距离cj(j=1,2,3,…,k),若满足‖xi-cj‖<‖xi-cm‖,m=1,2,3,…,k,m≠j,则xi∈Zj;③重新计算中心点c■■,c■■,c■■,…,c■■,公式如下c■■=■■Xi,i=1,2,3,…k (1)④若c■■=c■■,i=1,2,3,…k,则程序终止,算法已经收敛,输出结果,否则,返回步骤②。
在算法执行的过程中,一般会给定一个固定的最大迭代次数,这是为了防止步骤④中不满足条件时会出现无限循环。
2 布谷鸟算法在自然界中,布谷鸟最为人所知的特性就是孵卵寄生性,由于布谷鸟自己并没有孵化能力,所以它们常常将卵放在其他鸟类的巢中,靠其他鸟(义亲)来孵化和养育。
布谷鸟为了减少寄主将它抛弃的可能,布谷鸟产出的卵均是形似寄主的卵。
同时,布谷鸟会移走寄主巢中的一个或多个的卵,以免被寄主发现卵数的增加,同时也可以减少寄主幼鸟的竞争。
如果寄主发现了布谷鸟的卵,则会扔出布谷鸟的卵或者重新选择地方搭建鸟巢[19]。
2.1 布谷鸟算法实现的理想状态根据布谷鸟搜索原理,可以设计出新颖的源自布谷鸟的智能算法,为了模拟鸟巢的产卵的行为,需要假定三种理想的状态:①布谷鸟每次产生一只卵,并随机选择鸟巢位置来孵化;②在随机选择的一组鸟巢中,最优的鸟巢会被保留到下一代;③鸟巢的数量n是固定的,原鸟巢的主人发现外来鸟蛋的概率为Pa.,其中Pa∈[0,1]。
2.2 布谷鸟算法实现的过程在上述三种理想状态的基础上,根据布谷鸟孵化鸟蛋的过程,布谷鸟算法的主要步骤如下:Step1:初始化鸟巢。
目标函数是f(X),X=(x1,x2,x3,…xm)T,随机产生n个鸟巢初始的位置Xi(i=1,2,3…n)。
其中n是表示鸟巢的个数,m表示解空间维数。
Step2:根据目标函数计算每个鸟巢的目标函数值,并得到当前最优解。
Step3:保留上代最优鸟巢位置。
每个鸟巢的主人会通过莱维飞行模式来更新自己的鸟巢的位置,位置更新公式如下:x■■=x■■+?琢.*Levy(?姿)(2)其中,?琢>0为步长大小,且大多数情况下,取?琢=1。
.*为点对点乘法,Levy(?姿)是随机搜索路径,且随机步长符合Levy分布:Levy(?姿)~u=t-?姿,1<?姿?燮3(3)Step4:计算改进后鸟巢的目标函数值,并与改进前的进行比较,按照贪婪法则保留较好的鸟巢。
Step5:产生一个随机数R,R表示鸟巢主人发现外来鸟蛋的可能性并与Pa进行比较,若R>Pa,则随机改变鸟巢位置,得到一组新的鸟巢。
并计算新的鸟巢的目标函数值与当前最优鸟巢进行比较,保留较优解。
Step6:执行上述步骤,直到满足结束条件,并输入最优解。
3 基于布谷鸟算法的K-means聚类算法3.1 适应度函数设计针对于K-means算法对初始值要求很高以及已陷入局部最优的缺点,引入布谷鸟算法可以有效弥补K-means的缺点。
布谷鸟算法根据莱维飞行模式进行位置更新,基于这一基本原理,基于布谷鸟算法的K-means 的适应度函数设计如下:X■■=nj*Y■■-■randi+■+randai+?琢*levy(r)(4)其中,Xi表示鸟巢位置,Yj表示当前类中心即当前鸟巢位置,nj表示当前聚类的个数,k表示聚类数,randi表示随机抽取到其他类的鸟巢,randai表示随机从其他类抽取到当前类的鸟巢,?琢为转移参数,levy(r)为随机搜索路径。
3.2 目标函数设计目标函数设计为使得各类中点到类中心的距离和最短,具体公式如下:d=■‖xi-ci‖(5)其中,xi∈ci。
3.3 算法流程①参数设置:样本数n,聚类数k,转移参数?琢,最大迭代次数T,发现概率Pa。
②初始化:从样本中选出k个点作为聚类中心,作为初始鸟巢位置。
③对各个鸟巢做适应度计算。
④根据公式(2)对每个鸟巢进行位置更新,产生新的鸟巢位置。
同时产生随机数r,r>Pa,则随机改变鸟巢位置。
⑤对每个新产生的鸟巢进行K-means优化操作,将其优化为以改鸟巢为初始值的k均值问题的局部最优解。
⑥产生新一代的鸟巢位置。
⑦判断结束条件,当条件满足时,结束操作并输出结果,否则转入③。
K-means优化策略:①根据布谷鸟算法产生的新的鸟巢,按照数据对象与类中心之间的聚类误差和越小越好,计算出各自分类矩阵U。