查找不重复值函数方法集锦_chrisfang
excel序列排除重复项的函数

一、介绍excel序列排除重复项的重要性在日常工作中,我们经常需要处理各种各样的数据,其中有一项常见的操作就是对数据序列进行去重处理。
去重操作可以帮助我们清晰地了解数据的真实情况,避免数据重复造成的误解和混乱。
而在excel 中,我们可以利用一些函数来轻松实现对数据序列的去重操作,本文将介绍excel中去重函数的使用方法和注意事项。
二、介绍excel序列去重的常用函数1. 使用“高级筛选”功能excel中的“高级筛选”功能可以帮助我们快速实现对数据序列的去重操作。
具体操作步骤如下:(1) 选择数据序列所在的列,并点击“数据”菜单中的“高级筛选”;(2) 在弹出的对话框中,选择“将筛选结果复制到其他位置”,并在“列表区域”中输入数据序列的区域;(3) 在“条件区域”中选择不同的列,并确保“无重复记录”选项被勾选;(4) 点击确定,即可将去重后的数据序列复制到指定区域。
2. 使用“高级”函数excel中的“高级”函数可以帮助我们实现对数据序列的高级操作,包括去重操作。
具体操作步骤如下:(1) 使用“唯一值”函数唯一值函数可以帮助我们快速实现对数据序列的去重操作,具体操作步骤如下:a. 在空白单元格中输入“=唯一值(数据范围)”;b. 按下回车键,即可得到去重后的数据序列。
(2) 使用“条件格式”函数条件格式函数可以帮助我们根据条件来格式化数据序列,并实现去重操作。
具体操作步骤如下:a. 选择数据序列所在的列,并点击“开始”菜单中的“条件格式”;b. 在弹出的下拉菜单中,选择“突出显示单元格规则”中的“重复值”;c. 在弹出的对话框中,选择要应用格式的范围,并点击确定,即可将重复值突出显示。
三、excel序列去重函数的注意事项1. 数据范围要正确选择在使用excel序列去重函数时,务必确保选择的数据范围是正确的。
如果选择的数据范围不正确,就会导致去重结果不准确。
2. 去重结果要及时核对在使用excel序列去重函数后,务必及时核对去重结果,确保数据的准确性和完整性。
提取单元格不重复值,这组函数公式三秒搞定,你会这样操作吗?

提取单元格不重复值,这组函数公式三秒搞定,你会这样操作吗?在用Excel进行数据统计的时候,我们经常会用表格登记各类数据。
而在一份汇总数据中,会经常出现的一个情况就是,数据中包含许多的重复内容。
这里我们就需要通过各种方法,将表格中唯一的值提取出来。
如上图订单编号可以看的,我们编号数据中有许多红色标记的编号是出现重复的。
这里我们需要将所有的编号去除重复值,单独将唯一的编号提取出来。
类似这样的操作相信对许多同学来说,有通过数据透视表、去重等多种操作来实现。
今天我们就来学习一下,如何利用Excel函数来去重提取唯一的编号。
案例演示:我们通过lookup&countif函数嵌套的方式,这样就能够快速的将有重复的编号,单独提取出来不重复的值。
函数公式:=LOOKUP(1,0/((COUNTIF(F$4:F4,$C$3:$C$12)=0)),$C$3:$C$ 12)函数解析:1、这里我们我们利用lookup函数查询和countif条件计算的函数嵌套用法来实现。
从而实现对唯一的编号值进行提取;2、countif()=0函数在这里是对每一个值进行计数,来确定这个值在表格中是否存在多个值。
我们选择countif函数按F9可以得到Ture或者False下面的10个值。
如下图所示:因为E$4:E4的值在C列编号中是不存在的,所以countif计算的结果都是为0不存在。
就会出现10个Ture的值。
Lookup函数查询值的时候,默认是从第三参数数据区域中从下往上开始查找,所以第一个值提取的结果是324510。
相对应的函数如下:=(COUNTIF(F$4:F4,$C$3:$C$12)=0){TRUE;TRUE;TRUE;TRUE;TRUE;TRUE;TRUE;TRUE;TRUE;TRUE}3、0/COUNTIF()函数段的作用在于用0除以逻辑值,所以这里面的10个TRUE的值用0来除的时候都会显示为0。
选择函数段按F9解析如下图所示:4、如果是重复的值出现,那么重复的值Countif函数会出现False的结果。
excel提取非重复项公式

excel提取非重复项公式摘要:1.介绍Excel 提取非重复项的背景和需求2.详述使用公式实现提取非重复项的方法3.展示具体操作步骤和示例4.说明注意事项和可能的错误处理5.总结并提供进一步学习资源正文:在Excel 中,有时我们需要提取一组数据中的非重复项。
这对于数据清洗和去重操作非常有用。
幸运的是,Excel 内置了函数可以帮助我们实现这个目标。
下面我们将详细介绍如何使用公式来提取非重复项。
首先,我们需要了解如何使用公式来识别重复项。
Excel 中的“IF”函数和“COUNTIF”函数可以用来检查一个单元格是否重复。
具体来说,我们可以使用“IF”函数检查一个单元格是否在一个指定的范围内出现,而“COUNTIF”函数则可以计算一个指定范围内重复出现的单元格的数量。
接下来,我们可以使用“SUM”函数和“IF”函数来提取非重复项。
我们可以将“SUM”函数和“IF”函数嵌套在一起,以便只计算非重复项的总和。
以下是一个具体的操作步骤示例:1.假设我们有一个包含重复项的数据集,我们需要提取其中的非重复项。
2.在一个空白单元格中,输入以下公式:```=SUM(IF(COUNTIF($A$1:$A$10, $A$1:$A$10 & "")=1,$B$1:$B$10, 0))```这个公式将计算$A$1:$A$10 范围内的非重复项的总和。
3.按Enter 键,公式将自动计算结果。
在使用这个公式时,有几个需要注意的地方:- 确保在使用公式时,数据集的范围是正确的。
在这个例子中,我们使用了$A$1:$A$10 和$B$1:$B$10 作为数据的范围。
- 公式中的空字符串("")是为了避免Excel 将公式中的文本视为文本而不是单元格引用。
- 如果需要提取的非重复项在多个列中,可以将公式中的范围扩展到相应的列。
如果遇到错误,可以尝试以下方法进行处理:- 检查公式中的引用是否正确。
干货:统计不重值个数的5种Excel公式解析

干货:统计不重值个数的5种Excel公式解析统计不重复值个数,对新手来说一直是个难题,今天兰色提供3种不同的方法,另外还有让人头痛的多列和条件统计不重复个数的公式,同学们一定要收藏起来备用,用时再查找就很难了。
一、Countif法公式:E3=SUMPRODUCT(1/COUNTIF(A2:A10,A2:A10))原理:逐个统计每个值在区域的总个数,然后用1除,个数2变成1/3,个数为3变成1/3,相同的类加在一起还是值为1。
注意:Countif引用区域只能是区域,不能是数组。
二、Match函数法公式:E4=SUMPRODUCT(N(MATCH(A2:A10,A2:A10,)=ROW(A2:A10)-1))原理:在A列逐个查找自已的位置,返回的行号是否就是现在的行号(如果前面行有,返回的行号肯定小于现在值所在的行数),用N转换成值,然后用Sumproduct函数求和三、Frequency法公式:E7=COUNT(1/FREQUENCY(B2:B10,B2:B10))原理:Frequency函数是统计数字出现的频率,如果第一次出现会返回个数,第二次出现返回0,1/FREQUENCY() 数字还是数字,0转换成错误值。
Count可以统计数字的个数。
注意:只能统计数字四、多列计算不重复个数【例】根据A和B列统计不重复的个数。
只需要用match方法中把区域连接在一起。
=SUMPRODUCT(N(MATCH(A2:A7&B2:B7,A2:A7&B2:B7,0)=ROW(A2:A7)-1))五、根据条件求不重复个数添加条件后再计算唯一值个数就很难了。
【例】要求计算北京A产品出现次数,型号相同只计1次。
公式:E11=SUM(N(MATCH(IF((A2:A8='北京')*(B2:B8='A'),C2:C8),IF((A2:A8='北京')*(B2:B8='A'),C2:C8),0)=ROW(C2:C8)-1))-1原理:先用IF和条件把不符合条件的转换为FALSE,其他的保留原值,然后再套用Match方法计算不重复个数。
查找不重复值的13种绝技

查找不重复值的13种绝技【函数公式法】excel 2010-01-02 11:43:28 阅读74 评论0 字号:大中小不重复筛选方法很多,这里列举下8种函数公式处理方法:方法1=IF(ROW(1:1)>SUM(1/COUNTIF(源数据,源数据)),"",INDEX(A:A,SMALL(IF(COUNTIF(OFFSET($A$2,,,ROW(源数据)-ROW(A$1)),源数据)=1,ROW(源数据)),ROW(1:1))))方法2自定义名称X=T(OFFSET(筛选不重复值!$A$2,SMALL(IF(COUNTIF(OFFSET(筛选不重复值!$A$2,,,ROW(源数据)-ROW(筛选不重复值!$A$1)),源数据)=1,ROW(源数据)),ROW(INDIRECT("1:"&SUM(1/COUNTIF(源数据,源数据)))))-ROW(筛选不重复值!$A$2),))方法3=INDEX(A:A,SMALL(IF(MATCH(源数据,源数据,)=ROW(源数据)-ROW($A$1),ROW(源数据),65536),ROW(源数据)-ROW($A$1)))&""方法4=INDEX(A:A,SMALL(IF(MATCH(源数据,源数据,)=ROW(源数据)-ROW($A$1),ROW(源数据),65536),ROW(1:1)))&""方法5=INDEX(源数据,MATCH(1,1*(COUNTIF($F$1:$F1,源数据)=0),))方法6=INDEX(源数据,MATCH(1,--NOT(COUNTIF($G$1:$G1,源数据)),))方法7=INDEX(源数据,MATCH(1,IF(COUNTIF($H$1:$H1,源数据),,1),))方法8=INDEX(源数据,MATCH(,COUNTIF($I$1:$I1,源数据),)) 最短最好的公式方法9:=OFFSET($A$1,MATCH(,COUNTIF($I$1:I1,源数据),),) 最短最好的公式,这个也不错方法10:=CHAR(SMALL(IF(FREQUENCY(CODE(源数据),CODE(源数据)),CODE(源数据)),ROW(1:1)))方法11:=T(INDEX(A:A,MIN(IF(COUNTIF(L$1:L1,源数据),65536,ROW(源数据)))))方法12:=T(OFFSET(A$1,MATCH(,COUNTIF(M$1:M1,$A$2:$A$19),),))方法13(115楼zqj_824727提供):=LOOKUP(2,1/(COUNTIF($N$1:N1,$A$2:$A$18)=0),源数据)另附普通操作方:高级筛选或者=IF(COUNTIF($A$2:A2,源数据)=1,A2,0),下拉,然后f5,定位公式文本复制粘贴文本。
利用Excel高级函数实现数据去重和重复项查找的高级方法

利用Excel高级函数实现数据去重和重复项查找的高级方法在日常工作和生活中,我们经常需要处理各种各样的数据。
而在处理数据的过程中,数据去重和查找重复项是非常常见的需求。
Excel作为一款功能强大的电子表格软件,提供了一系列高级函数,可以帮助我们实现数据去重和重复项查找的高级方法。
本文将介绍如何利用Excel高级函数实现这两个功能,并分享一些实用的技巧。
一、数据去重在处理大量数据时,经常会遇到重复的数据,为了保证数据的准确性和完整性,我们需要将重复的数据进行去重。
Excel提供了几个常用的高级函数来实现数据去重。
1.1 移除重复数据首先,打开包含数据的Excel文件。
在Excel的数据选项卡中,可以找到“移除重复值”功能。
选择需要去重的数据范围,点击“移除重复值”按钮。
Excel将弹出一个对话框,让你选择需要去重的列。
根据具体需求选择列,点击“确定”按钮。
Excel会自动将重复的数据移除,并保留一条唯一的数据。
这种方法适用于简单的数据去重需求。
1.2 使用高级筛选除了移除重复数据的功能,Excel还提供了高级筛选功能来实现数据去重。
高级筛选功能相对更加灵活,可以根据自定义条件进行数据去重。
首先,选择需要去重的数据范围,点击Excel的数据选项卡中的“高级筛选”按钮。
Excel将弹出一个对话框,让你选择操作的数据范围和筛选的条件。
在“复制到”选项中输入一个空白区域,点击“确定”按钮。
Excel会根据设定的条件进行筛选,并将去重后的数据复制到指定的空白区域中。
这种方法适用于复杂的数据去重需求,可以根据多个条件进行筛选。
二、重复项查找除了去重功能,Excel还提供了多种方法来查找重复项。
无论是查找重复值、查找重复行还是查找重复单元格,都可以利用Excel的高级函数来实现。
2.1 查找重复值在Excel的数据选项卡中,可以找到“条件格式”功能。
选择需要查找重复值的数据范围,点击“条件格式”按钮。
Excel将弹出一个下拉菜单,选择“突出显示单元格规则”,然后选择“重复的值”。
EXCEL如何高速提取去重复信息,一个函数就可以搞定,大家来看看吧

EXCEL如何高速提取去重复信息,一个函数就可以搞定,大家来看看吧HELLO,大家好,我是帮帮,今天跟大家分享一个咱们日常工作经常遇到的问题,提取不重复记录,虽然通过辅助列,功能键实现我们的目的,当然我们更希望一步到位,快捷简单。
【如果大家喜欢帮帮,请点击文章末尾下方的推广广告,在里面找到并关注我,我给表亲们准备了更多更实用的办公软件技巧,期待您的到来】大家请看范例图片,我们现在要提取A列的不重复记录。
选择A列,点击数据选项卡中的删除重复项功能。
选择我们要删除的数据列,点击确定。
\大家看,剩下的数据已经帮我们去重,相信大家都会使用这个功能。
但是这种方法会破坏原表数据,日常工作中,往往我们都采用辅助表来再去重【如果大家喜欢帮帮,请点击文章末尾下方的推广广告,在里面找到并关注我,我给表亲们准备了更多更实用的办公软件技巧,期待您的到来】这里我们采用公式来解决,再C2单元格键入公式,=INDEX(A:A,MIN(IF(COUNTIF($C$1:C1,$A$2:$A$8)=0,ROW($2:$ 8),4^8)))&'',输入完成以后按下CTRL+SHIFT+回车的组合键,转换为数组公式,并向下复制到“出现空值”的单元格,完成操作。
这里我们利用COUNTIF=0作为判断不重复的条件,配合使用MIN函数作为排序的参数。
我们可以理解为INDEX(引用列,MIN(IF (条件,ROW(引用区域的行号),极值行号)))&“”。
大家下来后,自己可以试验一下,这种类型的函数都是属于“套路”,理解掌握以后便能举一反三。
我们再来看两列/多列去重提取数值,如果是按照快捷菜单的方法,需要多次辅助操作来实现。
我们可以再D2处键入公式,=INDIRECT(TEXT(MIN(IF(($A$2:$B$8<>'')*(COUNTIF($D$1:D1,$A$2:$B$8)=0),ROW($2:$8)*1000+COLUMN(A:B),65536001)),'!R0! C000'),0)&'',依然三键组合,形成数组公式,并向下复制,直至“空白”。
不重复个数函数公式

不重复个数函数公式
不重复个数的函数公式有很多种,以下是其中几种常用的方法:
1. 使用COUNTA+UNIQUE函数:这是最简单的方法,首先使用UNIQUE函数提取不重复的数据,然后使用COUNTA函数进行计数。
2. 使用SUMPRODUCT+COUNTIF函数:在不支持UNIQUE函数的版本中,可以使用SUMPRODUCT+COUNTIF函数。
这个公式可以逐个统计每个值在区域的总个数,然后用1除,个数2变成1/3,个数为3变成1/3,相同的类加在一起还是值为1。
3. 使用MATCH函数:在A列逐个查找自已的位置,返回的行号是否就是现在的行号(如果前面行有,返回的行号肯定小于现在值所在的行数),用N转换成值,然后用SUMPRODUCT函数求和。
4. 使用FREQUENCY函数:这个函数是统计数字出现的频率,如果第一次出现会返回个数,第二次出现返回0,1/FREQUENCY() 数字还是数字,0转换成错误值。
Count可以统计数字的个数。
以上是几种常用的不重复个数的函数公式,具体使用哪种方法需要根据实际情况和数据量大小进行选择。
excel中提取不重复值(唯一值)方法大全

excel中提取不重复值(唯一值)方法大全Excel使用过程中,有很多场合都需要获取一组数据的不重复值。
获取不重复值的方法有很多,例如高级筛选法、透视表法、基础操作法和公式法。
本例分别向大家介绍这四种方法如何使用。
工具/原料•Excel高级筛选法获取不重复值:1. 1首先,选中A列的数据区域,选择【数据】-【筛选】-【高级】。
2. 2如下图,选择【将筛选结果复制到其他位置】,选择一个单元格作为存储筛选结果的起始单元格,如B1。
勾选【选择不重复的记录】。
3. 3如上设置后,点击【确定】按钮,B列将返回A列的不重复值也就是唯一值列表。
END数据透视表获取不重复值:1. 1选中数据区域,选择【插入】-【数据透视表】。
2. 2在透视表向导中选择默认设置即可,直接点击【确定】按钮。
3. 3把【姓名】这个字段拖到【行标签】处,透视表中红色框住的部分就是不重复值.END基础操作法获取不重复值:1. 1如果有2007或更高版本的Excel,可以这样操作来获取不重复值:选中A列数据数据区域,选择【数据】—【删除重复项】。
2. 2由于我们的数据包含【姓名】这个标题,所以勾选【数据包含标题】,然后【确定】。
3. 3这时,将弹出提示说明去除了多少个重复值。
A列留下的就是所有不重复的姓名。
END公式法获取不重复值:1.双击B2单元格,输入下面的公式:=INDEX(A$1:A$99,MATCH(0,COUNTIF(B$1:B1,A$1:A$99),0))&"”公式输入完毕后,左手按住Ctrl和Shift,右手按下回车运行公式。
2.将B2的公式下拉就返回了A列姓名的不重复值。
3. 3取得不重复值的公式很多,上面仅仅是其中一例.也可以用INDEX+SMALL+IF+MATCH的经典组合来获取不重复值,有兴趣的读者可以自行百度搜索该用法。
EXCEL中什么函数能够计算不重复数字的个数?比如一列有N个数据,如何得出不重复的个数?

EXCEL中什么函数能够计算不重复数字的个数?比如一列有N 个数据,如何得出不重复的个数?EXCEL中什么函数能够计算不重复数字的个数?比如一列有N个数据,如何得出不重复的个数?假设数据在A1:A10统计不重复的数个数:=SUMPRODUCT(1/COUNTIF(A1:A10,A1:A10))如何在数列中计算不重复的数字个数#include<iostream>using namespace std;int main(){int a[20] = {...}; 初始化数组int count = 1;for(int i=1; i<20; i++){bool flag = true;for(int j=0; j<i; j++){if(a[i] == a[j]){flag = false;break;}}if(flag == true) count++;}cout<<"a列不重复的数字个数为:"<<count<<endl;return 0;}excel 查不重复数据(非数字)的个数用这个你看行不行。
在B列任一格输入=SUM(IF(COUNTIF(A:A,A:A),1/COUNTIF(A:A,A:A),0))按下ctrl + shift + Enterok一列数据中,比如A列有:(11,22,33,11,44,55,77,22)用什么公式可以统计出不重复数字的个数?EXCEL有自带的删除重复项功能。
数据--删除重复项,选择你要删除重复项的列。
任意5个数字组成2个数字排列不重复的或者 3个数字排列不重复Function pl(a As Integer, b As Integer, c As Integer, d As Integer, e As Integer, n As Integer) As StringDim ar(1 To 5) As IntegerDim i As Integer, j As Integer, temp As Integer, k As Integer ar(1) = aar(2) = bar(3) = car(4) = dar(5) = eIf n = 2 ThenFor i = 1 To 5For j = 1 To 5If i <> j Thentemp = ar(i) * 10 + ar(j)pl = pl + Str(temp) + ","End IfNextpl = pl + vbCrLfNextElseIf n = 3 ThenFor i = 1 To 5For j = 1 To 5If i <> j ThenFor k = 1 To 5If i <> j And j <> k And i <> k Thentemp = ar(i) * 100 + ar(j) * 10 + ar(k)pl = pl + Str(temp) + ","End IfNextEnd IfNextpl = pl + vbCrLfNextEnd IfPrint plEnd Functioncall pl(1,2,3,4,5,2)输出:12, 13, 14, 15,21, 23, 24, 25,31, 32, 34, 35,41, 42, 43, 45,51, 52, 53, 54,call pl(1,2,3,4,5,3)输出:123, 124, 125, 132, 134, 135, 142, 143, 145, 152, 153, 154,213, 214, 215, 231, 234, 235, 241, 243, 245, 251, 253, 254,312, 314, 315, 321, 324, 325, 341, 342, 345, 351, 352, 354,412, 413, 415, 421, 423, 425, 431, 432, 435, 451, 452, 453,512, 513, 514, 521, 523, 524, 531, 532, 534, 541, 542, 543, excel怎么统计不重复数据的个数字在B2单元格输入公式=SUMPRODUCT(1/COUNTIF(A2:A8,A2:A8)),即可统计出A列A2:A8单元格区域的不重复值的个数。
excel提取非重复项公式

excel提取非重复项公式摘要:1.Excel提取非重复项的常用方法2.具体操作步骤及公式解释3.注意事项和实用技巧正文:在Excel中,如何提取非重复项是一个常见的问题。
这里,我们将介绍几种常用的方法来帮助你轻松实现这一目标。
1.Excel提取非重复项的常用方法方法一:使用IF公式公式:=IF(ISNUMBER(FIND("," & D222)), LEFT(D222, FIND("," & D222) - 1), D222) & ""方法二:使用COUNTIF公式步骤:a.在D1单元格输入:=COUNTIF(C1:C1, C1)b.按Enter键,查看重复项的数量c.将公式复制到其他单元格,以查看其他区域的重复项方法三:使用INDEX和MATCH公式公式:=IF(ROW() < ROUND(SUM(1/COUNTIF(A1:A10, A1:A10)), 0), INDEX(A1:A10, SMALL(IF(MATCH(A1:A10, A1:A10, 0), ROW(A1:A10), ROW(B1))), "")2.具体操作步骤及公式解释以方法一为例,首先在Excel中选中需要提取非重复项的单元格区域。
然后,在目标单元格中输入上述公式,并按Enter键确认。
接下来,根据需要,可以将公式复制到其他单元格以提取不同区域的非重复项。
方法二的具体操作步骤已在上述文本中详细说明。
方法三的解释:此公式利用了INDEX和MATCH函数的特性,根据单元格内容的重复次数来返回相应的非重复值。
在输入公式后,按Enter键确认,即可得到提取的非重复项。
3.注意事项和实用技巧- 在使用上述方法时,请确保数据区域正确无误,以免影响提取结果。
- 若需要提取的单元格区域包含文本和数字,请将数字和文本分开存放,以免影响提取效果。
Excel提取重复值、不重复值、全部值的函数

Excel提取重复值、不重复值、全部值的函数本文由自已根据网络资料整理,文章源自ExcelHome。
1、从某行中提取定义名称“数量1”:=COUNTA(Sheet2!$B$6:$IV$6)“区域1”:=OFFSET(Sheet2!$B$6,0,0,1,数量1)除定义的名称外,以下(1)至(3)中的公式均为数组公式。
(1)提取有重复的数据【思路】把区域中重复数据的第1个提取出来。
为避免拖动公式超出区域范围时出现的错误,前面加了一个IF函数判断是否超出区域范围。
{=IF(COLUMN(A1)>数量1,"",INDEX(6:6,SMALL(IF((COUNTIF(区域1,区域1)>1)*(MATCH(区域1,区域1,0)=COLUMN(区域1)-1),COLUMN(区域1),256),COLUMN(A1))) & "")}(2)提取没有重复的数据{=IF(COLUMN(A1)>数量1,"",INDEX(6:6,SMALL(IF(COUNTIF(区域1,区域1)=1,COLUMN(区域1),256),COLUMN(A1))) & "")}(3)提取全部数据,重复的只提取一次{=IF(COLUMN(A1)>数量1,"",INDEX(6:6,SMALL(IF(MATCH(区域1,区域1,0)=COLUMN(区域1)-1,COLUMN(区域1),256),COLUMN(A1))) & "")}2、从某列中提取定义名称“数量2”:=COUNTA(Sheet3!$B$7:$B$65536)“区域2”:=OFFSET(Sheet3!$B$7,0,0,数量2)(1)提取有重复的数据{=IF(ROW(A1)>数量2,"",INDEX(B:B,SMALL(IF((COUNTIF(区域2,区域2)>1)*(MATCH(区域2,区域2,0)=ROW(区域2)-6),ROW(区域2),65536),ROW(A1))) & "")}(2)提取没有重复的数据{=IF(ROW(A1)>数量2,"",INDEX(B:B,SMALL(IF(COUNTIF(区域2,区域2)=1,ROW(区域2),65536),ROW(A1))) & "")}(3)提取全部数据,重复的只提取一次{=IF(ROW(A1)>数量2,"",INDEX(B:B,SMALL(IF(MATCH(区域2,区域2,0)=ROW(区域2)-6,ROW(区域2),65536),ROW(A1))) & "")}。
excel 多条件判断不重复的个数

excel 多条件判断不重复的个数【Excel 多条件判断不重复的个数】在Excel 中,我们经常需要根据多个条件来判断某个范围内的数据,并得出不重复的个数。
本文将详细讲解如何利用Excel 的函数和特性,一步一步实现多条件判断下的不重复个数的计算。
第一步:准备数据首先,我们需要准备一组数据用于演示。
假设我们有一个记录学生考试成绩的表格,包含姓名、科目和分数三列。
姓名科目分数张三数学90李四语文85王五英语95张三语文78李四英语88王五数学92我们想要统计每个学生参加的科目数,以及总共有多少个不重复的科目。
第二步:计算学生参加科目数我们可以利用Excel 的条件函数COUNTIFS 来实现多条件下的计数。
COUNTIFS 函数的语法如下:COUNTIFS(range1, criteria1, range2, criteria2, ...)其中,range1、range2 等表示要进行条件判断的范围,criteria1、criteria2 等表示判断条件。
在我们的例子中,我们要统计每个学生参加的科目数,因此,range1 表示姓名列的范围,criteria1 表示当前行的姓名与range1 相匹配;range2 表示科目列的范围,criteria2 表示当前行的科目与range2 相匹配。
假设我们想要计算每个学生参加的科目数的范围是B2:B7,那么我们可以在C2 单元格中输入如下公式,并拖动填充至C7:=COUNTIFS(A2:A7, A2, B2:B7, B2)这样,就可以得到每个学生参加科目数的统计结果了。
姓名科目分数科目数张三数学90 1李四语文85 1王五英语95 1张三语文78 2李四英语88 2王五数学92 2第三步:计算不重复的科目数接下来,我们需要统计不重复的科目数量。
为了实现这个目标,我们可以使用Excel 中的高级筛选功能。
首先,我们需要创建一个独立的区域,用于存储不重复的科目。
excel多条件计数不重复项个数的函数

excel多条件计数不重复项个数的函数在Excel中,可以使用COUNTIFS函数来计数满足多个条件的不重复项的个数。
COUNTIFS函数可以根据指定的多个条件,在给定的范围内统计满足条件的单元格的数量。
COUNTIFS函数的语法如下:COUNTIFS(range1, criteria1, [range2, criteria2], …)其中,range1是要统计的范围,criteria1是与range1中的单元格进行比较的条件。
可以根据需要添加多个范围和条件。
下面以一个示例来说明如何使用COUNTIFS函数进行多条件计数不重复项的个数。
假设有如下的数据表格,包含姓名、性别和年龄三列:姓名,性别,年龄------,------,------张三,男,20李四,女,30王五,男,25李四,女,35张三,男,20王五,男,25现在要计算不重复的性别和年龄的组合的个数。
首先,在一个空白单元格中输入下述公式:=COUNTIFS($B$2:$B$7,B2,$C$2:$C$7,C2)然后,复制这个公式到其他单元格中,即可得到每个组合的个数。
-在这个公式中,范围$B$2:$B$7表示姓名列的范围,$C$2:$C$7表示性别列的范围,B2和C2分别表示要计数的范围内的单元格的条件。
-当计算第一个条件(性别)时,B2和C2分别是男和20,COUNTIFS 函数会统计在性别为男、年龄为20的条件下满足条件的单元格的数量。
-复制这个公式到其他单元格时,B2和C2的相对引用会自动调整为与相应单元格的条件相对应的单元格。
接下来,可以通过使用IF函数来判断一些组合是否已经计数过,从而计算不重复的组合的个数。
假设将上述公式放在单元格D2中,并在E2中输入下述公式来判断一些组合是否已经计数过:=IF(D2>0,1,0)然后,复制这个公式到其他单元格中。
-这个公式中,D2是要判断的组合的个数,当D2大于0时,表示该组合已经计数过,返回1,否则返回0。
Excel中这5种提取不重复值的方法,至少你得会两种吧!

Excel中这5种提取不重复值的方法,至少你得会两种吧!重复值的问题,在Excel中是经常会遇到的一个问题,今天小必老师和大家一起来学习一下关于重复值的提报与标注的几种方法,这几种方法分别如上所示。
下表是列重复的姓名,要求提取不重复的姓名。
具体的操作方法如下:01删除重复项使用删除重复项的功能可以将重复的项目删除掉,保留唯一值。
步骤:行列数据列,单击【数据】-【删除重复项】,在弹出的对话框中单击【确定】,如下图所示:02“高级筛选”功能使用高级筛选的功能也能提取唯一值。
步骤:选中数据列,单击【数据】-【高级】,在弹出的对话框中选择【将筛选结果复制到其他位置】-【复制至】(选择存放的位置)-勾选【选择不重复的记录】-【确定】。
如下图所示:03数据透视表使用数据透视表也可以将唯一值提取出来。
步骤:选中数据区域的任意一单元格,单击【插入】-【数据透视表】,在弹出的对话框中选择【现在位置】,在弹出的对话框中将姓名字段拖放至【行】,然后将透视结果粘贴为广西格式,删除无用的项目即可。
04Power Query使用Power Query也可以完成删除重复项,保留不重复项的效果。
步骤:选中某一上个单元格,单击【数据】-【自表格/区域】,在弹出的对话框中选择【表包含标题】-【确定】,在弹出的对话框中单击【删除列】-【重复项】,然后关闭并上载至指定位置即可。
05公式函数法在C2单元格中输入公式:=IFERROR(LOOKUP(1,0/(COUNTIF(C$1:C1,$A$2:$A$14)= 0),$A$2:$A$14),''),然后按Enter键向下填充至空白即可。
查找不重复值函数方法集锦_chrisfang

内存数组法 (数据源为内 存定义, 最 后查找结果 也为内存数 组ht)tp://clu b.excelho /di spbbs.as p?boardid =3&replyi d=40777 9&id=169 505&pag e=1&skin =0&Star =1
4, 变 化5也是在变 化3的基础 上, 将其中 Countif的用 法替换为 Match的用 法; 如果与 变化2联系起 来, 变化5也 可以看成是 把变化2中的 Lookup用法 替换成了 Index+Matc h的用法。
变 化6也可以看 成是把变化2 中的Lookup 用法替换成 了 Indirect+Mi n的用法。Fra bibliotek方法4:
new_data1= INDEX(A:A, MIN(IF(COU NTIF(A$120 :A120,data_ arr),65536,R OW(data_ar r))))&""
方法4:
CC
CA
AA
AB
BC
变化1: CC CA AA AB BC
注意: 1, 其 中红色A:A 为数据源 data_arr所 在列;
或 用 SUM(N(MAT CH(data_arr ,data_arr,0) =ROW(data _arr)-49))等 方式进行替 换, 例子见变 化1、变化2 。
3, 前 面部分也可 采用 ROWS(data _arr)<=SUM (COUNTIF(d ata_arr,D$6 1:D61))来替 换, 作用为计 算前面已经 取出元素的 个数(含重复 元素), 例子 见变化3。
Excel中提取两列中取不重复(唯一)值之数组公式法图解

Excel中提取两列中取不重复(唯⼀)值之数组公式法图解Excel提取两列中不重复(唯⼀)值之数组公式法将⽤到INDEX、SMALL、IF、ROW、MATCH这⼏个函数Excel2003绿⾊版 EXCEL2003精简绿⾊版 (附excel2003绿⾊⼯具)类型:办公软件⼤⼩:13.3MB语⾔:简体中⽂时间:2012-06-19查看详情⼯具/原料excel 电脑⽅法/步骤我将通过数组公式在d1单元格输⼊数组公式然后向右、向下复制,返回a、b列中不重复的记录match返回⼀个由24个元素组成的数组,元素的位置序号代表a1:a24中单元格从上到下位置顺序,元素的值代表a1:a24中单元格值在a1:a24中⾸次出现的从上到下的位置顺序数,元素数值相同代表出现不⽌⼀次,match的返回值将是这种形式的{1,2,3,1等等⼀共24个},row的返回值是a1:a24中的⾏号组成的数组结果是{1,2,3,4,5,6⼀直到24}等式返回的是逻辑值组成的数组{true,true,true,false等⼀共24个},true代表a1:a24中的值⾸次出现,false代表该位置的值不是⾸次出现将上⼀步骤的等式剪切再剪切板中,然后输⼊if函数,第⼆个参数是row函数,第三个参数是⼀个很⼤的数字然后将剪切板的内容复制到if的第⼀个参数的位置,如图所⽰最后if函数的返回值将是24个数字组成的数组函数,除了9999999,其他的元素值代该位置的值是⾸次出现在a1:a24中,该值同时也是⾏号将上⼀步输⼊的if函数剪切⼀下,然后输⼊small函数,small函数第⼆个参数是row函数,然后将⿏标定位到small第⼀个参数位置粘贴⼀下small函数返回的是在if函数返回值序列中第⼀⼩的元素,整体公式向下复制还会返回第⼆⼩的元素等等将上⼀步的small函数剪切⼀下,然后输⼊index函数,第⼀个参数是相对引⽤的a1到a24,第三个参数是1,第⼆个参数复制⼀下剪切的small函数函数输⼊完成之后按ctrl+shift+回车,然后拖动填充柄向右复制⼀个单元格然后松开⿏标选中d1到e1单元格向下拖动填充柄直到现在公式区域显⽰的就是a1到b24区域中不重复的记录注意事项MATCH($A$1:$A$24,$A$1:$A$24,0)=ROW($A$1:$A$24)要⽤绝对应⽤MATCH($A$1:$A$24,$A$1:$A$24,0)=ROW($A$1:$A$24)意义是⾸次出现位置是否等于⾏号IF(MATCH($A$1:$A$24,$A$1:$A$24,0)=ROW($A$1:$A$24),ROW($A$1:$A$24),9999999) if的第⼆个参数也为数组,返回对应位置的⾏号,对应的位置是逻辑值真以上就是Excel中提取两列中取不重复(唯⼀)值之数组公式法图解,希望能对⼤家有所帮助!。
Excel关于非重复计数的几种计算方法
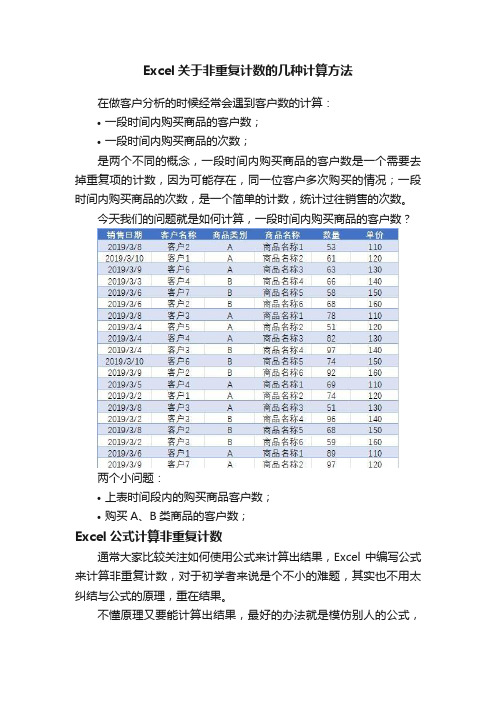
Excel关于非重复计数的几种计算方法在做客户分析的时候经常会遇到客户数的计算:•一段时间内购买商品的客户数;•一段时间内购买商品的次数;是两个不同的概念,一段时间内购买商品的客户数是一个需要去掉重复项的计数,因为可能存在,同一位客户多次购买的情况;一段时间内购买商品的次数,是一个简单的计数,统计过往销售的次数。
今天我们的问题就是如何计算,一段时间内购买商品的客户数?两个小问题:•上表时间段内的购买商品客户数;•购买A、B类商品的客户数;Excel公式计算非重复计数通常大家比较关注如何使用公式来计算出结果,Excel中编写公式来计算非重复计数,对于初学者来说是个不小的难题,其实也不用太纠结与公式的原理,重在结果。
不懂原理又要能计算出结果,最好的办法就是模仿别人的公式,网上搜索一下,就会有很多答案,可以找来几个模仿一下。
我认为有两种公式可以拿来试一试:•SUMPRODUCT+COUNTIFS组合•COUNT+MATCH+ROW组合这两个组合各有特色,SUMPRODUCT组合不用三键的数组公式,但是需要选择好区域,不然会出错;COUNT组合需要用CTRL+SHIFT+ENTER三键数组公式,不用太在意选取区域。
第一个小问题:客户数,相当于没有条件来计算非重复客户计数。
=SUMPRODUCT(1/COUNTIFS(B2:B23,B2:B23))=COUNT(0/( MATCH(B2:B23,B2:B23,)=ROW(1:22)))两个组合都能够计算出正确结果,但是使用SUMPRODUCT要注意数据区域选取。
第二个问题:A、B商品的购买客户数=SUMPRODUCT(($C$2:$C$23=I7)/COUNTIFS($B$2:$B$23,$B$2:$B$23,$C$2:$C$23,$C$2:$C$23))=COUNT(0/(($C$2:$C$23=I 7)*MATCH($B$2:$B$23&$C$2:$C$23,$B$2:$B$23&$C$2:$C$23,) =ROW($1:$22)))根据条件来计算客户的非重复计数:•SUMPRODUCT组合:条件需要添加两次,在“/”左侧添加一次,在COUNTIFS中还需要添加一次。
excel非重复计数函数

excel非重复计数函数
excel计数函数可以在表中统计不重复字段数量,该函数可以从一个或多个字段中搜索唯一的值,并返回其出现的次数,其语法形式为:COUNTIF (range, criteria),其中range表示要搜索的数据范围,criteria表示用于进行搜索的条件,例如,要计算范围A2:A20中符合特定条件的不重复元素数量,可以在别的单元格中输入公式:=COUNTIF (A2:A20,”<>”&A2),这样就可以得到范围A2:A20中符合特定条件的非重复元素的总数。
excel的计数函数是一种很有用的工具,可以帮助我们轻松计算出非重复元素的总数。
它可以处理大型数据集,在需要计算不重复元素总数时特别有用。
同时,excel也提供了其他函数,例如 Count()函数,可以用于计算某一范围内中动态变化的重复值的个数,可以使用这些函数得出较精确的结果。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
3, 变 化1在本质上 没有变化, 只 是更改了 Lookup的查 找参数; 变 化2是将其中 的Countif的 用法替换为 了Match的 用法;
变 化3把 Lookup替换 为了Match, 来作为Index 的行参数; 变化4是在变 化3的基础 上, 将Index 的用法替换 为Offset的 用法, 直接从 数据区域来 定位。
rw: 1 2 3 4 5 6 7
newdata: 1 2 a b
注意: 数组 里没有空值 、false之类 的干扰数值, 或#N/A等错 误值, 否则需 要加条件判 断。
注: 1, 原公 式含义: newdata=L OOKUP(SMA LL(IF(条 件,ROW(IND IRECT("1:"& 总行 数))),ROW(I NDIRECT("1 :"&满足条件 个 数))),ROW(I NDIRECT("1 :"&总行数)), 数据)
非内存数组 (数据源为区 域ht引tp用:/)/clu b.excelho /di spbbs.as p?boardid =102&re plyid=12 5412&id= 103004& page=1& skin=0&S tar=8
如果数据源 为文本
data_arr: CC
CA
AA
CA
如果数据源 为数字(结果 按大小排序)
data1={1;2; false;1;2;4; 5;9;9;17;fal se;false} order=SMAL L(data1,RO W(INDIREC T("1:"&SUM (-ISNUMBER( data1)))))
newdata1=S MALL(IF(FR EQUENCY(or der,order),o rder),ROW(I NDIRECT("1 :"&SUM(-(FREQUENC Y(order,orde r)>0)))))
Frequency+ Match或
Frequency+ Countif的组 合, 虽然感觉 有些舍近求 远, 但也不失 为一种独特 的函数应用 。
3, 变 化1在本质上 没有什么变 化, 只是修改 了Frequency 的参数; 变 化2把Match 的用法替换 成Countif的 用法;
变 化3是把 Frequency放 到了公式前 半部分的判 断当中的用 法, 也使得方 法1增加了 一种变化的 方向。
方法2:
AB
CC
BC
CA
AA
变化1: AB CA CC BC AB
变化2: AB CC BC CA AA
变化3: CC CA AA AB BC
变化4: CC CA AA AB BC
变化5: CC CA AA AB BC
变化6: CC CA AA AB BC
注意: 1, 其 中红色
a$83:a83 为结果公式 位置的上一 位置, 需要根 据公式的实 际位置进行 调整; 这一 组方法的特 点就是以目 前已经得出 的部分查找 结果作为主 公式的"比较 部分"的引用 参数。
4, 如果 数据源包含 #N/A: 增加 定义名称: data_temp =IF(ISNA(M ATCH(data,d ata,)),0,MAT CH(data,dat a,))
修改 公式为: newdata=L OOKUP(SMA LL(IF(data_ temp=rw,r w),ROW(IN DIRECT("1:" &SUM(N(da ta_temp=r w))))),rw,da ta)
2, 公 式中
LOOKUP(2,1
/(COUNTIF(
a$83:a83,da
ta_arr)=0),d ata_arr)部 分, 作用为查 找"数据区域 中"与"目前 已查找出来 的结果中"不 重复元素中 的最后一个 元素。
其 中, 去除重复 元素的算法 利用到了除 法中除数为0 时所返回的 #DIV/0!错 误。 另外, Lookup的第 一个参数2和 后面那个被 除数1都可以 替换为其他 的数字,
方法5: new_data1= IF(ROW(1:1 )>ROUND(S UM(1/COUN TIF(data_arr ,data_arr)), 0),"",INDEX( data_arr,SM ALL(IF(COU NTIF(OFFSE T(A$50,,,RO W(data_arr) 49),data_arr )=1,ROW(d ata_arr)49),ROW(1: 1))))
2, 如果 用“row总” 来表示一, 用“row条件 ”表示满足条 件的data个 数, indirect 部分简写:
newdata=Lo okup(small(i f(条 件,row(1:ro w 总)),row(1:r ow条 件)),row 总,data), 最 后所得内存 数组的行数 为row条件 。
内存数组法 (数据源为内 存定义, 最 后查找结果 也为内存数 组ht)tp://clu b.excelho /di spbbs.as p?boardid =3&replyi d=40777 9&id=169 505&pag e=1&skin =0&Star =1
如果数据源 为文本
data={1;2;1 ;2;"a";"a";"b "} rw=ROW(IN DIRECT("1:" &ROWS(dat a))) newdata= LOOKUP(SM ALL(IF(MAT CH(data,dat a,)=rw,rw), ROW(INDIR ECT("1:"&S UM(N(MATC H(data,data, )=rw))))),rw ,data)
方法1:
CC
CA
AA
AB
BC
变化1: CC CA AA AB BC
变化2: CC CA AA AB BC
变化3: CC CA AA AB BC
注意: 1, 其 中红色49为 data_arr起 始行位置, 需 要根据数据 区域实际位 置进行调整 。
2, 公 式中 SUM(1/COU NTIF(data_a rr,data_arr)) 部分为计算 非重复元素 个数, 可能因 为浮点运算 产生误差, 可 用round函数 取整或+0.1 来进行处理,
3, 如果 数据源包含 空值: 修改 公式为: newdata:=L OOKUP(SMA LL(IF((MATC H(data,data, )=rw)*(data <>""),rw),R OW(INDIRE CT("1:"&SU M(N((MATC H(data,data, )=rw)*(data <>"")))))),r w,data)
变化3的前半 部分我在解 答其他的竞 赛题时想到 了, 后来发现 "开放式竞赛 函数21题" 中梧桐兄在 43楼以及 summer.li nn朋友在下 面这个帖子 中的18楼也 采用了类似 的思路(见方 法2), http://club .excelhom /disp bbs.asp?b oardid=3& replyid=38 3401&id= 165498&p age=1&ski n=0&Star =2
另外, gvntw版主 在"开放式竞 赛函数21题 "的75楼对这 种思路有更 进一步的拓 展, 直接清除 了原公式的 前面判断部 分, 使得公式 更为简化, 具 体可以见方 法4。
方法2: new_data1= IF(ROW(1:1 )>ROUND(S UM(1/COUN TIF(data_arr ,data_arr)), 0),"",LOOKU P(2,1/(COU NTIF(a$83:a 83,data_arr) =0),data_ar r))
order: 1 1 2
newdata1: 1 2 4
注意: 如果 源数据中包 含#N/A等错 误返回值的 话, order公 式之前需要 增加条件判 断。
2
5
4
9
5
17
9
9
17 注: 1, 如果 数据源包含 #N/A: 修改 order定义: order=SMA LL(IF(ISNA (data1),FA LSE,data1) ,ROW(INDIR ECT("1:"&S UM(-ISNUMBER( data1))))), 最后的 newdata1定 义公式不变 。
或 用 SUM(N(MAT CH(data_arr ,data_arr,0) =ROW(data _arr)-49))等 方式进行替 换, 例子见变 化1、变化2 。
3, 前 面部分也可 采用 ROWS(data _arr)<=SUM (COUNTIF(d ata_arr,D$6 1:D61))来替 换, 作用为计 算前面已经 取出元素的 个数(含重复 元素), 例子 见变化3。
方法5:
CC
CA
AA
AB
BC
变化1: CC CA AA AB BC
注意: 1, 这 组方法为 Countif的三 维引用方法, 其中红色 A$50、49 为data_arr 起始行位置, 需要根据数 据区域实际 位置进行调 整。
2, 变 化1改变了 Index和 Offset选取 数据区域的 起始位置。 有些朋友喜 欢使用变化1 这样的 Offset写法, 认为这样不 需要对数据 源区域的起 始位置进行 定位, 简化了 公式。