(完整版)X-means:一种针对聚类个数的K-means算法改进
K-MEANS算法(K均值算法)

k-means 算法一.算法简介k -means 算法,也被称为k -平均或k -均值,是一种得到最广泛使用的聚类算法。
它是将各个聚类子集内的所有数据样本的均值作为该聚类的代表点,算法的主要思想是通过迭代过程把数据集划分为不同的类别,使得评价聚类性能的准则函数达到最优,从而使生成的每个聚类内紧凑,类间独立。
这一算法不适合处理离散型属性,但是对于连续型具有较好的聚类效果。
二.划分聚类方法对数据集进行聚类时包括如下三个要点:(1)选定某种距离作为数据样本间的相似性度量k-means 聚类算法不适合处理离散型属性,对连续型属性比较适合。
因此在计算数据样本之间的距离时,可以根据实际需要选择欧式距离、曼哈顿距离或者明考斯距离中的一种来作为算法的相似性度量,其中最常用的是欧式距离。
下面我给大家具体介绍一下欧式距离。
假设给定的数据集 ,X 中的样本用d 个描述属性A 1,A 2…A d 来表示,并且d 个描述属性都是连续型属性。
数据样本x i =(x i1,x i2,…x id ), x j =(x j1,x j2,…x jd )其中,x i1,x i2,…x id 和x j1,x j2,…x jd 分别是样本x i 和x j 对应d 个描述属性A 1,A 2,…A d 的具体取值。
样本xi 和xj 之间的相似度通常用它们之间的距离d(x i ,x j )来表示,距离越小,样本x i 和x j 越相似,差异度越小;距离越大,样本x i 和x j 越不相似,差异度越大。
欧式距离公式如下:(2)选择评价聚类性能的准则函数k-means 聚类算法使用误差平方和准则函数来评价聚类性能。
给定数据集X ,其中只包含描述属性,不包含类别属性。
假设X 包含k 个聚类子集X 1,X 2,…X K ;{}|1,2,...,m X x m total ==(),i j d x x =各个聚类子集中的样本数量分别为n 1,n 2,…,n k ;各个聚类子集的均值代表点(也称聚类中心)分别为m 1,m 2,…,m k 。
k-means论文

对k-means聚类算法的改进研究摘要:本文针对k-means算法对初值的依赖性,基于最小生成树原理选取聚类中心进行聚类。
根据寻找最优初值的思想提出了一种改进的k-means算法,将最小生成树的构造算法之一的卡斯克鲁尔(Kruskal Algorithm)算法以及贪心算法(Greedy Algorithm)的思想引入到k-means算法中。
关键字:k-means算法最小生成树贪心策略一、算法的改进思路的形成无论是原始的k-means算法还是加入了聚类准则函数的k-means算法,都有一个共同的特点,即采用两阶段反复循环过程,算法结束的条件是不再有数据元素被重新分配:1)指定聚类,即指定数据x i到某一个聚类,使得它与这个聚类中心的距离比它到其它聚类中心的距离要近;2)修改聚类中心。
k-means算法中急需解决的问题主要有三个:(l)在k-means算法中,k是事先给定的,这个k值的选定是很难估计的。
很多时候,我们事先并不知道给定的数据集应分成多少类最合适,这也是k-means 算法的一个不足。
有的算法是通过类的自动合并和分裂,得到较为合理的类型数目k,例如ISODALA算法。
关于k-means算法中聚类数目k值的确定,有些根据方差分析理论,应用混合F统计量来确定最佳分类数,并应用了模糊划分墒来验证最佳分类数的正确性。
在文献[26]中,使用了一种结合全协方差矩阵的RPCL算法,并逐步删除那些只包含少量训练数据的类。
而其中使用的是一种称为次胜者受罚的竞争学习规则,来自动决定类的适当数目。
它的思想是:对每个输入而言,不仅竞争获胜单元的权值被修正以适应输入值,而且对次胜单元采用惩罚的方法,使之远离输入值。
(2)在k-means算法中常采用误差平方和准则函数作为聚类准则函数,考察误差平方和准则函数发现:如果各类之间区别明显且数据分布稠密,则误差平方和准则函数比较有效;但是如果各类的形状和大小差别很大,为使误差平方和的值达到最小,有可能出现将大的聚类分割的现象。
一种基于遗传算法的Kmeans聚类算法

一种基于遗传算法的K-means聚类算法一种基于遗传算法的K-means聚类算法摘要:传统K-means算法对初始聚类中心的选取和样本的输入顺序非常敏感,容易陷入局部最优。
针对上述问题,提出了一种基于遗传算法的K-means聚类算法GKA,将K-means算法的局部寻优能力与遗传算法的全局寻优能力相结合,通过多次选择、交叉、变异的遗传操作,最终得到最优的聚类数和初始质心集,克服了传统K-means 算法的局部性和对初始聚类中心的敏感性。
关键词:遗传算法;K-means;聚类聚类分析是一个无监督的学习过程,是指按照事物的某些属性将其聚集成类,使得簇间相似性尽量小,簇内相似性尽量大,实现对数据的分类[1]。
聚类分析是数据挖掘技术的重要组成部分,它既可以作为独立的数据挖掘工具来获取数据库中数据的分布情况,也可以作为其他数据挖掘算法的预处理步骤。
聚类分析已成为数据挖掘主要的研究领域,目前已被广泛应用于模式识别、图像处理、数据分析和客户关系管理等领域中。
K-means算法是聚类分析中一种基本的划分方法,因其算法简单、理论可靠、收敛速度快、能有效处理较大数据而被广泛应用,但传统的K-means算法对初始聚类中心敏感,容易受初始选定的聚类中心的影响而过早地收敛于局部最优解,因此亟需一种能克服上述缺点的全局优化算法。
遗传算法是模拟生物在自然环境中的遗传和进化过程而形成的一种自适应全局优化搜索算法。
在进化过程中进行的遗传操作包括编码、选择、交叉、变异和适者生存选择。
它以适应度函数为依据,通过对种群个体不断进行遗传操作实现种群个体一代代地优化并逐渐逼近最优解。
鉴于遗传算法的全局优化性,本文针对应用最为广泛的K-means方法的缺点,提出了一种基于遗传算法的K-means聚类算法GKA(Genetic K-means Algorithm),以克服传统K-means算法的局部性和对初始聚类中心的敏感性。
用遗传算法求解聚类问题,首先要解决三个问题:(1)如何将聚类问题的解编码到个体中;(2)如何构造适应度函数来度量每个个体对聚类问题的适应程度,即如果某个个体的编码代表良好的聚类结果,则其适应度就高;反之,其适应度就低。
统计分析方法论:K-Means算法

K-Means课前准备下载Anaconda软件。
课堂主题本次课讲解K-Means聚类算法与算法的改进与优化。
课堂目标学习本次课,我们能够达到如下目标:熟知K-Means算法的原理与步骤。
熟知K-Means++算法的原理与初始化方式。
熟知Mini Batch K-Means算法的原理与步骤。
能够选择最佳的值。
知识要点聚类之前我们接触的算法,都是监督学习,即训练数据是包含我们要预测的结果(训练数据中是含有样本的标签)。
我们对含有标签的训练集建立模型,从而能够对未知标签的样本进行预测。
与监督学习对应的,聚类属于无监督学习,即训练数据中是不含有标签的。
聚类的目的是根据样本数据内部的特征,将数据划分为若干个类别,每个类别就是一个簇。
结果为,使得同一个簇内的数据,相似度较大,而不同簇内的数据,相似度较小。
聚类也称为“无监督的分类”。
其样本的相似性是根据距离来度量的。
K-Means算法算法步骤K-Mean算法,即均值算法,是最常见的一种聚类算法。
顾名思义,该算法会将数据集分为个簇,每个簇使用簇内所有样本的均值来表示,我们将该均值称为“质心”。
具体步骤如下:1. 从样本中选择个点作为初始质心。
2. 计算每个样本到各个质心的距离,将样本划分到距离最近的质心所对应的簇中。
3. 计算每个簇内所有样本的均值,并使用该均值更新簇的质心。
4. 重复步骤2与3,直到达到以下条件之一结束:质心的位置变化小于指定的阈值。
达到最大迭代次数。
过程演示下图给出了使用K-Means算法聚类的过程。
优化目标KMeans算法的目标就是选择合适的质心,使得在每个簇内,样本距离质心的距离尽可能的小。
这样就可以保证簇内样本具有较高的相似性。
我们可以使用最小化簇内误差平方和(within-cluster sum-of-squares )来作为优化算法的量化目标(目标函数),簇内误差平方和也称为簇惯性(inertia)。
:簇的数量。
:第个簇含有的样本数量。
K-均值聚类算法

4.重复分组和确定中心的步骤,直至算法收敛;
2.算法实现
输入:簇的数目k和包含n个对象的数据库。 输出:k个簇,使平方误差准则最小。
算法步骤:
1.为每个聚类确定一个初始聚类中心,这样就有K 个初始 聚类中心。
2.将样本集中的样本按照最小距离原则分配到最邻近聚类
给定数据集X,其中只包含描述属性,不包含 类别属性。假设X包含k个聚类子集X1,X2,„XK;各 个聚类子集中的样本数量分别为n1,n2,„,nk;各个 聚类子集的均值代表点(也称聚类中心)分别为m1, m2,„,mk。
3.算法实例
则误差平方和准则函数公式为:
k
2
E p mi
i 1 pX i
单个方差分别为
E1 0 2.52 2 22 2.5 52 2 22 12.5 E2 13.15
总体平均误差是: E E1 E2 12.5 13.15 25.65 由上可以看出,第一次迭代后,总体平均误差值52.25~25.65, 显著减小。由于在两次迭代中,簇中心不变,所以停止迭代过程, 算法停止。
示为三维向量(分别对应JPEG图像中的红色、绿色 和蓝色通道) ; 3. 将图片分割为合适的背景区域(三个)和前景区域 (小狗); 4. 使用K-means算法对图像进行分割。
2 015/8/8
Hale Waihona Puke 分割后的效果注:最大迭代次数为20次,需运行多次才有可能得到较好的效果。
2 015/8/8
例2:
2 015/8/8
Ox y 102 200 3 1.5 0 450 552
数据对象集合S见表1,作为一个 聚类分析的二维样本,要求的簇的数 量k=2。
数据挖掘中的K_means算法及改进

福建电脑2006年第11期数据挖掘中的K-means算法及改进贾磊,丁冠华(武警工程学院研究生队陕西西安710086)【摘要】:从数据挖掘的基本概念入手,逐步深入分析本质,并且对k-means进行探讨,对其中的聚类中心的方法进行了改进。
【关键词】:数据挖掘;k-means算法;聚类中心1.数据挖掘的含义1.1概念:数据挖掘是一个处理过程,它利用一种或多种计算机学习技术,从数据库的数据中自动分析并提取知识。
数据挖掘会话的目的是确定数据的趋势和模式。
它是基于归纳的学习策略,创建的模型是数据的概念概化,概化可表示为树、网络、方程或一组规则的形式。
1.2数据挖掘过程:数据挖掘是一个多步骤过程,包括挖掘数据,分析结果和采取行动,被访问的数据可以存在于一个或多个操作型数据库中、一个数据仓库中或一个平面文件中。
2.K-means算法K-MEANS算法是一个简单而有效的统计聚类技术。
其算法如下:⑴选择一个K值,用以确定簇的总数。
⑵在数据集中任意选择K个实例,它们是初始的簇中心。
⑶使用简单的欧氏距离将剩余实例赋给距离它们最近的簇中心。
⑷使用每个簇中的实例来计算每个簇新的平均值。
如果新的平均值等于上次迭代的平均值,终止该过程。
否则,用新平均值作为簇中心并并重复步骤3-5。
算法的第一步需要我们做出一个初始判断,即认为数据中应表示多少个簇。
下一步,算法任意选择K个数据点作为初始簇中心。
然后,每个实例被放置在与它最相似的簇里,相似性右以以多种方式来定义。
不过,最常使用的相似性度量指标是简单欧氏距离。
举例:我们将两个属性命名为x和y将各个实例映射到x-y坐标系中。
这种映射显示在图中。
第1步,我们必须选择一个K值。
假设我们认为有两个不同的簇。
因此,我们将K设置为2。
该算法任意选择两个点代表初始簇中心。
假设算法选择实例1作为第1个簇中心,选择实例3作为第2簇中心,下一步就是地剩下的实例进行分类。
根据坐标为(x1,y1)的点A与坐标为(x2,y2)的点B之间的欧氏距离公式,为演示算法的工作原理,进行以下的计算。
kmeans聚类算法的算法流程

K-means聚类算法是一种经典的基于距离的聚类算法,它被广泛应用于数据挖掘、模式识别、图像分割等领域。
K-means算法通过不断迭代更新簇中心来实现数据点的聚类,其算法流程如下:1. 初始化:首先需要确定要将数据分成的簇的个数K,然后随机初始化K个簇中心,可以从数据集中随机选择K个样本作为初始簇中心。
2. 分配数据:对于每个数据点,计算它与各个簇中心的距离,将该数据点分配给距离最近的簇,并更新该数据点所属簇的信息。
3. 更新簇中心:计算每个簇中所有数据点的均值,将该均值作为新的簇中心,更新所有簇中心的位置。
4. 重复迭代:重复步骤2和步骤3,直到簇中心不再发生变化或者达到预定的迭代次数。
5. 输出结果:最终得到K个簇,每个簇包含一组数据点,形成了聚类结果。
K-means算法的优点在于简单易实现,时间复杂度低,适用于大规模数据;但也存在一些缺点,如对初始聚类中心敏感,对噪声和离裙点敏感,需要事先确定聚类个数K等。
K-means聚类算法是一种常用的聚类方法,通过迭代更新簇中心的方式逐步将数据点划分为不同的簇,实现数据的聚类分析。
通过对算法流程的详细了解,可以更好地应用K-means算法解决实际问题。
K-means算法是一种非常经典的聚类算法,它在数据挖掘和机器学习领域有着广泛的应用。
在实际问题中,K-means算法可以帮助我们对数据进行分组和分类,从而更好地理解数据的内在规律,为我们提供更准确的数据分析和预测。
接下来,我们将对K-means聚类算法的一些关键要点进行探讨,包括算法的优化、应用场景、以及与其他聚类算法的比较等方面。
1. 算法的优化:在实际应用中,K-means算法可能会受到初始簇中心的选择和迭代次数的影响,容易收敛到局部最优解。
有一些改进的方法可以用来优化K-means算法,例如K-means++算法通过改进初始簇中心的选择方式,来减少算法收敛到局部最优解的可能性;另外,Batch K-means算法通过批量更新簇中心的方式来加快算法的收敛速度;而Distributed K-means算法则是针对大规模数据集,通过并行计算的方式来提高算法的效率。
(完整版)X-means:一种针对聚类个数的K-means算法改进

X-means:一种针对聚类个数的K-means算法改进摘要尽管K-means很受欢迎,但是他有不可避免的三个缺点:1、它的计算规模是受限的。
2、它的聚类个数K必须是由用户手动指定的。
3、它的搜索是基于局部极小值的。
在本文中,我们引入了前两种问题的解决办法,而针对最后一个问题,我们提出了一种局部补救的措施。
根据先前有关算法改进的工作,我们引入了一种根据BIC(Bayesian Information Criterion)或者AIC(Akaike information criterion)得分机制而确定聚类个数的算法,本文的创新点包括:两种新的利用充分统计量的方式,还有一种有效地测试方法,这种方法在K-means算法中可以用来筛选最优的子集。
通过这样的方式可以得到一种快速的、基于统计学的算法,这种算法可以实现输出聚类个数以及他们的参量值。
实验表明,这种技术可以更科学的找出聚类个数K值,比利用不同的K值而重复使用K-means算法更快速。
1、介绍K-means算法在处理量化数据中已经用了很长时间了,它的吸引力主要在于它很简单,并且算法是局部最小化收敛的。
但是它有三点不可避免的缺点:首先,它在完成每次迭代的过程中要耗费大量的时间,并且它所能处理的数据量也是很少的。
第二,聚类个数K值必须由用户自身来定义。
第三,当限定了一个确定的K值时,K-means算法往往比一个动态K值的算法表现的更差。
我们要提供针对这些问题的解决办法,通过嵌入树型的数据集以及将节点存储为充分统计变量的方式来大幅度提高算法的计算速度。
确定中心的分析算法要考虑到泰森多边形边界的几何中心,并且在估计过程的任何地方都不能存在近似的方法。
另外还有一种估计方法,“黑名单”,这个列表中将会包含那些需要在指定的区域内被考虑的图心。
这种方法不仅在准确度上以及处理数据的规模上都表现的非常好,而这个快速算法在X-means 聚类算法当中充当了结构算法的作用,通过它可以很快的估计K值。
一种基于改进的GMM算法的数据丢失预测模型

一种基于改进的GMM 算法的数据丢失预测模型王晖1,姜春茂2(1.哈尔滨师范大学计算机科学与信息工程学院,黑龙江哈尔滨150025;2.福建工程学院计算机科学与数学学院,福建福州350118)摘要:随着云平台上运行任务的数量急剧增加,任务失败的概率也随之增加,数据的丢失是任务失败的主要原因。
如果在任务运行前判断出是否可能发生丢失以及其丢失类型,那么就可以提前采取措施避免或减少损失。
该模型基于谷歌在2019年发布的最新云集群数据,对任务的数据丢失问题进行了深入的研究,针对不同任务属性探究其与数据丢失的相关性,并选用了GMM (Gaussian Mixed Model )算法并将其改进来建立数据丢失预测模型。
经过多种聚类算法的实验比较,改进后的GMM 模型表现出极好的适应性和准确性,能够精准且迅速地在任务运行前判断其发生数据丢失的可能性以及判断其丢失类型。
最后根据预测出的不同数据丢失类型,给出了一定的建议。
关键词:谷歌云集群;任务失败;数据丢失预测;Gaussian Mixed Model 中图分类号:TP301.6文献标识码:A 文章编号:2096-9759(2023)03-0028-07A loss prediction model based on an improved GMM algorithmWANG Hui 1,JIANG Chunmao 2(1.College of Computer Science and Information Engineering,Harbin Normal University,Harbin Heilongjiang 150025,China;2.College of Computer Science and Mathematics,Fujian University of Technology,Fuzhou Fujian,350118,China )Abstract:As the number of tasks running on the cloud platform increases dramatically,the probability of task failure also increases.The loss of data is the main reason for task failure.If the possibility of loss and its type is determined before the task is run,then measures can be taken in advance to avoid or reduce the loss.Based on the latest cloud cluster data released by Google in 2019,this model conducts in-depth research on the problem of task data loss,and explores its correlation with data loss for different task attributes.And the GMM (Gaussian Mixed Model )algorithm was selected and improved to establish a data loss prediction model.After the experimental comparison of various clustering algorithms,the improved GMM model shows excellent adaptability and accuracy,and can accurately and quickly judge the possibility of data loss and the type of loss before the task runs.Finally,according to the different types of data loss predicted,some suggestions are given.Key words:Google Cloud Cluster ;Task failed ;Data Loss Prediction ;Gaussian Mixed?Model0引言随着社会的发展,现如今信息数据几乎呈指数增长。
K-means的优缺点及改进

K-means的优缺点及改进K-means算法是很典型的基于距离的聚类算法,采用距离作为相似性的评价指标,即认为两个对象的距离越近,其相似度就越大。
该算法认为簇是由距离靠近的对象组成的,因此把得到紧凑且独立的簇作为最终目标。
k个初始类聚类中心点的选取对聚类结果具有较大的影响,因为在该算法第一步中是随机的选取任意k个对象作为初始聚类的中心,初始地代表一个簇。
该算法在每次迭代中对数据集中剩余的每个对象,根据其与各个簇中心的距离将每个对象重新赋给最近的簇。
当考察完所有数据对象后,一次迭代运算完成,新的聚类中心被计算出来。
如果在一次迭代前后,J的值没有发生变化,说明算法已经收敛。
1)从N个文档随机选取K个文档作为质心2)对剩余的每个文档测量其到每个质心的距离,并把它归到最近的质心的类3)重新计算已经得到的各个类的质心4)迭代2~3步直至新的质心与原质心相等或小于指定阈值,算法结束具体如下:输入:k,data[n];(1)选择k个初始中心点,例如c[0]=data[0],…c[k-1]=data[k-1];(2)对于data[0]….data[n],分别与c[0]…c[k-1]比较,假定与c[i]差值最少,就标记为i;(3)对于所有标记为i点,重新计算c[i]={ 所有标记为i的data[j]之和}/标记为i 的个数;(4)重复(2)(3),直到所有c[i]值的变化小于给定阈值。
K-means算法的优点是:首先,算法能根据较少的已知聚类样本的类别对树进行剪枝确定部分样本的分类;其次,为克服少量样本聚类的不准确性,该算法本身具有优化迭代功能,在已经求得的聚类上再次进行迭代修正剪枝确定部分样本的聚类,优化了初始监督学习样本分类不合理的地方;第三,由于只是针对部分小样本可以降低总的聚类时间复杂度。
K-means算法的缺点是:首先,在K-means 算法中K 是事先给定的,这个K 值的选定。
融合kmeans聚类与Hausdorff距离的点云精简算法改进

· 60 ·
4) 重复步骤 (2) 和步骤 (3),直到“簇中心”
不再移动。
1.2
Hausdorff 距离是一种描述两组点集之间相似程度
{
[6-7]
, 若 存 在 两 组 数 据 点 A = a a a
{
2 改进的融合kmeans与Hausdorff距离的点
云精简算法
Hausdorff 距离
-0.10
(6)
因此,采样点 pi 的 Hausdorff 距离可以表示为:
H pi = max{hi1hi2hik}
图 1 所示,共 8 171 个点。采用手肘法,以 100 个聚类
Y /m
Hausdorff 距离计算公式如下:
以斯坦福大学兔子点云为例,其原始点云数据如
(7)
该方法通过设定 Hausdorff 距离阈值实现特征点云
Abstract: In the past, the point cloud simplification algorithm integrating K-means clustering and Hausdorff distance needs to set the Hausdorff
distance threshold when the curvature value is too small in the flat region, and the accuracy of curvature estimation is not high in the case of complex model surface. In view of the above problems, we improved the algorithm. Firstly, the determination of K value in K-means clustering was
基于密度最大值的K-means初始聚类中心点算法改进
4 仿真实验分析
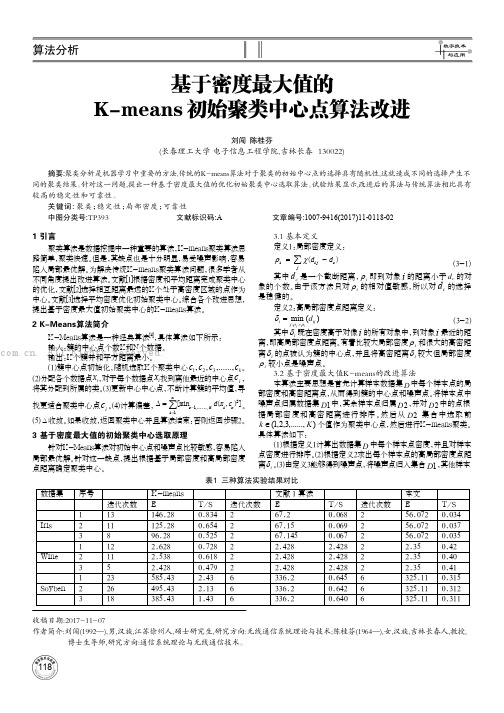
为验证改进算法的有效性,采用国际上的专门用来测试机器学 习算法的UCI数据集中Iris、Wine、Soybean这三组数据进行测试。
较高的稳定性和可靠性。
关键词: 聚类;稳 定性;局 部密度 ;可靠性
中图分类号:TP393
文献标识码:A
文章编号:1007-9416(2017)11-0118-02
1 引言
3.1 基本定义
聚类算法是数据挖掘中一种重要的算法,K-means聚类算法思 路简单,聚类快速。但是,其缺点也是十分明显,易受噪声影响,容易 陷入局部最优解。为解决传统K-means聚类算法问题,很多学者从 不同角度提出改进算法。文献[1]根据密度和平均距离完成聚类中心 的优化,文献[2]选择相互距离最远的K个处于高密度区域的点作为 中心。文献[3]选择平均密度优化初始聚类中心。综合各个改进思想, 提出基于密度最大值初始聚类中心的K-means算法。
博士生导师,研究方向:通信系统理论与无线通信技术。
118
数字技术 与应用
算法分析
表2 三种算法聚类精度(%)
算法 K-means 文献 1 本文
数据集 Iris Wine Soybean Iris Wine Soybean Iris Wine Soybean
最高 88.32 74.32 80.30 87.11 74.02 77.56 91.01 86.02 81.02
T/S 0.834 0.654 0.525 0.728 0.618 0.479 2.43 2.13 1.43
迭代次数 2 2 2 2 2 2 6 6 6
(完整版)数据分析师笔试题目

网易数据分析专员笔试题目一、基础题1、中国现在有多少亿网民?2、百度花多少亿美元收购了91无线?3、app store排名的规则和影响因素4、豆瓣fm推荐算法5、列举5个数据分析的博客或网站二、计算题1、关于简单移动平均和加权移动平均计算2、两行数计算相关系数。
(2位小数,还不让用计算器,反正我没算)3、计算三个距离,欧几里德,曼哈顿,闵可夫斯基距离三、简答题1、离散的指标,优缺点2、插补缺失值方法,优缺点及适用环境3、数据仓库解决方案,优缺点4、分类算法,优缺点5、协同推荐系统和基于聚类系统的区别四、分析题关于网易邮箱用户流失的定义,挑选指标。
然后要构建一个预警模型。
五、算法题记不得了,没做。
反正是决策树和神经网络相关。
1、你处理过的最大的数据量?你是如何处理他们的?处理的结果。
2、告诉我二个分析或者计算机科学相关项目?你是如何对其结果进行衡量的?3、什么是:提升值、关键绩效指标、强壮性、模型按合度、实验设计、2/8原则?4、什么是:协同过滤、n-grams, map reduce、余弦距离?5、如何让一个网络爬虫速度更快、抽取更好的信息以及更好总结数据从而得到一干净的数据库?6、如何设计一个解决抄袭的方案?7、如何检验一个个人支付账户都多个人使用?8、点击流数据应该是实时处理?为什么?哪部分应该实时处理?9、你认为哪个更好:是好的数据还是好模型?同时你是如何定义“好”?存在所有情况下通用的模型吗?有你没有知道一些模型的定义并不是那么好?10、什么是概率合并(AKA模糊融合)?使用SQL处理还是其它语言方便?对于处理半结构化的数据你会选择使用哪种语言?11、你是如何处理缺少数据的?你推荐使用什么样的处理技术?12、你最喜欢的编程语言是什么?为什么?13、对于你喜欢的统计软件告诉你喜欢的与不喜欢的3个理由。
14、SAS, R, Python, Perl语言的区别是?15、什么是大数据的诅咒?16、你参与过数据库与数据模型的设计吗?17、你是否参与过仪表盘的设计及指标选择?你对于商业智能和报表工具有什么想法?18、你喜欢TD数据库的什么特征?19、如何你打算发100万的营销活动邮件。
k-means聚类算法例题

k-means聚类算法例题下面是一个k-means聚类算法的例题:假设有一个包含n个数据点的数据集,数据集中的每个数据点都有两个特征,分别表示为x和y。
现在需要将这些数据点分成k个簇。
1. 随机选择k个数据点作为初始的聚类中心。
2. 计算每个数据点与k个聚类中心的距离,并将其归为距离最近的那个聚类中心。
3. 对于每个聚类,重新计算其聚类中心,即计算该聚类中所有数据点的平均值,并将其作为新的聚类中心。
4. 重复步骤2和3,直到聚类中心不再发生变化或者达到预定的迭代次数。
以下是一个具体的例子:假设我们有以下的数据集:(1, 1), (1, 2), (2, 1), (4, 4), (5, 5), (5, 6)现在假设我们要将这些数据点分为2个簇。
首先,我们随机选择两个数据点作为初始的聚类中心。
假设我们选择(1, 1)和(5, 5)作为初始的聚类中心。
然后,我们计算每个数据点与这两个聚类中心的距离。
例如,对于数据点(1, 1)来说,它与第一个聚类中心的距离为0,与第二个聚类中心的距离为5。
因此,将其归为第一个聚类。
接下来,我们对于每个聚类重新计算其聚类中心。
对于第一个聚类来说,它只包含一个数据点(1, 1),所以其聚类中心为(1, 1);对于第二个聚类来说,它包含两个数据点(1, 2)和(2, 1),所以其聚类中心为(1.5, 1.5)。
然后,我们再次计算每个数据点与新的聚类中心的距离,并将其重新分配到距离最近的聚类中心。
对于数据点(2, 1)来说,它与第一个聚类中心的距离为1.12,与第二个聚类中心的距离为1.12,所以我们将其保持在第二个聚类中。
接着,我们再次重新计算每个聚类的聚类中心。
对于第一个聚类来说,它没有数据点,所以无需重新计算聚类中心;对于第二个聚类来说,它包含两个数据点(1, 2)和(2, 1),所以其聚类中心为(1.5, 1.5)。
我们重复上述步骤,直到聚类中心不再发生变化。
在这个例子中,当我们进行第二轮迭代时,聚类中心没有发生变化,所以我们停止迭代。
k-means聚类算法简介

k-means聚类算法简介k-means 算法是一种基于划分的聚类算法,它以k 为参数,把n 个数据对象分成k 个簇,使簇内具有较高的相似度,而簇间的相似度较低。
1. 基本思想k-means 算法是根据给定的n 个数据对象的数据集,构建k 个划分聚类的方法,每个划分聚类即为一个簇。
该方法将数据划分为n 个簇,每个簇至少有一个数据对象,每个数据对象必须属于而且只能属于一个簇。
同时要满足同一簇中的数据对象相似度高,不同簇中的数据对象相似度较小。
聚类相似度是利用各簇中对象的均值来进行计算的。
k-means 算法的处理流程如下。
首先,随机地选择k 个数据对象,每个数据对象代表一个簇中心,即选择k 个初始中心;对剩余的每个对象,根据其与各簇中心的相似度(距离),将它赋给与其最相似的簇中心对应的簇;然后重新计算每个簇中所有对象的平均值,作为新的簇中心。
不断重复以上这个过程,直到准则函数收敛,也就是簇中心不发生明显的变化。
通常采用均方差作为准则函数,即最小化每个点到最近簇中心的距离的平方和。
新的簇中心计算方法是计算该簇中所有对象的平均值,也就是分别对所有对象的各个维度的值求平均值,从而得到簇的中心点。
例如,一个簇包括以下 3 个数据对象{(6,4,8),(8,2,2),(4,6,2)},则这个簇的中心点就是((6+8+4)/3,(4+2+6)/3,(8+2+2)/3)=(6,4,4)。
k-means 算法使用距离来描述两个数据对象之间的相似度。
距离函数有明式距离、欧氏距离、马式距离和兰氏距离,最常用的是欧氏距离。
k-means 算法是当准则函数达到最优或者达到最大的迭代次数时即可终止。
当采用欧氏距离时,准则函数一般为最小化数据对象到其簇中心的距离的平方和,即。
其中,k 是簇的个数,是第i 个簇的中心点,dist(,x)为X 到的距离。
2. Spark MLlib 中的k-means 算法Spark MLlib 中的k-means 算法的实现类KMeans 具有以下参数。
基于k-means算法改进的短文本聚类研究与实现

文章编号:1009 - 2552(2019)12 - 0076 - 05 DOI:10 13274 / j cnki hdzj 2019 12 016
基于 K ̄means 算法改进的短文本聚类研究与实现
K-means聚类算法簇的个数的研究

K-means聚类算法聚类个数的方法研究摘要:在数据挖掘算法中,K均值聚类算法是一种比较常见的无监督学习方法,簇间数据对象越相异,簇内数据对象越相似,说明该聚类效果越好。
然而,簇个数的选取通常是由有经验的用户预先进行设定的参数。
本文提出了一种能够自动确定聚类个数,采用SSE和簇的个数进行度量,提出了一种聚类个数自适应的聚类方法(SKKM)。
通过UCI数据集的实验,验证了SKKM可以快速的找到数据集中聚类个数。
关键字:K-means算法; 聚类个数; 初始聚类中心;近年来,随着信息技术的发展,特别是云计算、物联网、社交网络等新兴应用的产生,我们的社会正从信息时代步入数据时代。
数据挖掘就是从大量的、不完整的、有噪声的、模糊的数据中通过数据清洗、数据集成、数据选择、数据变换、数据挖掘、数据评估、知识表示等过程挖掘出隐含信息的过程。
目前,数据挖掘已经广泛的应在电信、银行、零售、公共服务、气象等多个行业与领域。
聚类是数据挖掘中一项重要的技术指标,也受到人们的重视,并且广泛的应用在多个领域中[1]。
K均值算法是一种基于划分的聚类算法。
通常是由有经验的用户对簇个数K进行预先设定,一般用户很难确定K的值,K值设定的不正确将会导致聚类算法结果的错误,因此,本文提出了一种SKKM的方法对K值进行确认。
传统的K均值聚类算法中的另外一个缺点就是初始中心点的选取问题,随机选取初始中心点将会导致局部最优解,而不是全局最优解,因此,初始中心点的研究也是聚类算法比较热门的话题。
文献[2]提出了基于划分的聚类算法,该方法对簇的个数并不是自动的获取,而是通过有经验的用户进行设定。
现有的自动确定簇的个数的聚类方法通常需要给出一些参数,然后再确定簇的个数。
如:Iterative Self organizing Data Analysis Techniques Algorithm,该方法在实践中需要过多的对参数进行设定,并且很难应用在高维数据中[3]。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
X-means:一种针对聚类个数的K-means算法改进摘要尽管K-means很受欢迎,但是他有不可避免的三个缺点:1、它的计算规模是受限的。
2、它的聚类个数K必须是由用户手动指定的。
3、它的搜索是基于局部极小值的。
在本文中,我们引入了前两种问题的解决办法,而针对最后一个问题,我们提出了一种局部补救的措施。
根据先前有关算法改进的工作,我们引入了一种根据BIC(Bayesian Information Criterion)或者AIC(Akaike information criterion)得分机制而确定聚类个数的算法,本文的创新点包括:两种新的利用充分统计量的方式,还有一种有效地测试方法,这种方法在K-means算法中可以用来筛选最优的子集。
通过这样的方式可以得到一种快速的、基于统计学的算法,这种算法可以实现输出聚类个数以及他们的参量值。
实验表明,这种技术可以更科学的找出聚类个数K值,比利用不同的K值而重复使用K-means算法更快速。
1、介绍K-means算法在处理量化数据中已经用了很长时间了,它的吸引力主要在于它很简单,并且算法是局部最小化收敛的。
但是它有三点不可避免的缺点:首先,它在完成每次迭代的过程中要耗费大量的时间,并且它所能处理的数据量也是很少的。
第二,聚类个数K值必须由用户自身来定义。
第三,当限定了一个确定的K值时,K-means算法往往比一个动态K值的算法表现的更差。
我们要提供针对这些问题的解决办法,通过嵌入树型的数据集以及将节点存储为充分统计变量的方式来大幅度提高算法的计算速度。
确定中心的分析算法要考虑到泰森多边形边界的几何中心,并且在估计过程的任何地方都不能存在近似的方法。
另外还有一种估计方法,“黑名单”,这个列表中将会包含那些需要在指定的区域内被考虑的图心。
这种方法不仅在准确度上以及处理数据的规模上都表现的非常好,而这个快速算法在X-means 聚类算法当中充当了结构算法的作用,通过它可以很快的估计K值。
这个算法在每次使用K-means算法之后进行,来决定一个簇是否应该为了更好的适应这个数据集而被分开。
决定的依据是BIC得分。
在本文中,我们阐述了“黑名单”方法如何对现有的几何中心计算BIC 得分,并且这些几何中心所产生的子类花费不能比一个单纯的K-means聚类算法更高。
更进一步的,我们还通过缓存状态信息以及估计是否需要重新计算的方法来改善估计方法。
我们已经用X-means算法进行了实验,验证了它的确比猜K值更加科学有效。
X-means 算法可以在人造的或者是真实数据中表现的更好,通过BIC得分机制。
它的运行速度也是比K-means更快的。
2、定义我们首先描述简单的K-means算法应该考虑哪些因素。
通过K-means可以把一定量的数据集分为K个数据子集,这K个数据子集分别围绕着K个聚类中心。
这种算法保持着K个聚类中心不变,并且通过迭代不断调整这K个聚类中心。
在第一次迭代开始之前,K个聚类中心都是随机选取的,算法当聚类中心不再变化的时候返回最佳的结果,在每一次迭代中,算法都要进行如下的动作:1、对于每一个节点向量,找到距离它最近的聚类中心,归入此类。
2、重新评估每一个图心的位置,对于每一个图心,必须是簇的质心。
K-means聚类算法通过局部最小化每个向量到对应图心的距离来实现聚类。
同时,它处理真实数据时是非常慢的。
许多情况下,真实的数据不能直接用K-means进行聚类,而要经过二次抽样筛选之后再进行聚类。
Ester曾经提出了一种可以从树形数据中获得平衡的抽样数据的方法。
Ng和Han曾经提出了一种可以指导概率空间对输入向量的检索模拟模型。
Zhang则提出了一种基于充分统计学的树形模型。
可以被用来异常识别以及快速计算。
然而,这种聚类器是近似的,并且要依靠许多的近似值。
要注意虽然刚开始聚类的聚类中心是随便选取的,但是对于K-means算法来说,这K个聚类中心是实实在在确定了的。
如果你选取了不科学的聚类中心,就有可能影响到最后的聚类结果以及算法的效率。
Bradley和Fayyad讨论了通过二次抽样和平滑数据的方法来更加科学的选取聚类中心。
在本文的剩余部分,我们将会用u j来表示第J个质心,用i表示距离向量i最近的聚类质心,例如说,u i表示在迭代中距离i最近的聚类质心。
D表示输入的数据节点,而D i表示所有距离u i最近的节点集。
R为D中节点的个数,R i为D i中节点的个数。
分布数量是M,高斯协方差矩阵为∑=diag(σ∗σ)3、K值的估计到目前为止,我们所描述的算法是K-means聚类算法的相关步骤,K值是由用户确定的,我们现在要描述X-means算法如何确定K值,通过BIC得分的优劣,通过聚类算法我们不仅仅要得到一些比较合理的聚类中心还要得到一个合理的K值。
首先,我们描述整个确定K值的过程,不要太在意算法的细节。
接下来,我们推导出适用于不同统计模型的测试集。
再然后,我们回到高层的算法描述,显示算法是如何利用黑名单的思想将大量的数据存储在树形的数据集中。
3.1 模型检索本质上,算法的运行过程主要是先给定一个聚类个数的下限,然后不停的用K-means算法进行迭代,直到达到最好的BIC得分的结果,然后返回聚类结果。
迭代算法中主要包括以下动作:X-means:1、改变参数2、改变结构3、如果K大于最高限定的K值则返回结果,否则回到第一步对参数的改变过程很简单,就是传统的K-means收敛的过程。
第二步中改变结构式算法的核心步骤,通过将一个大的聚类一分为二,然后决定新的质心应该出现的地方,我们要通过BIC得分来决定是否对聚类进行分割。
分裂观点1:第一个想法是先选择一个重心,然后再它附近再产生一个重心,然后评价是否两个重心的情况下聚类表现的更好,如果是则分割聚类,如果不是则返回上一步。
这个过程需要在X-means算法聚类的整个过程中反复出现,直到返回最佳的聚类结果,算法的时间复杂度为O(K max)。
但是如果没有得到BIC得分的提高应该怎么办呢,我们就必须对每一个聚类中心都采取这种方式进行处理,所以每一次都需要调用一次K-means算法,也就是说我们在加一个聚类中心的时候需要运行很多次K-means,耗费了太多时间。
分裂观点2:将一个完整的簇分为两个部分,第二个想法用于SPLITLOOP系统,实现高斯混合模型识别。
通过一些启发式的标准来简单的分割完整簇。
分割他们时要调用K-means 算法并且计算分割后的成绩是否比分割之前更好,如果更好的话就返回分割之后的结果,这是一个比较大的改善,因为通过这种方法进行聚类的时间复杂度只有O(Log k)。
不断的改善数据结构,直到X-means算法结束,但是这种思想的问题在于:什么样的启发机制用来分割聚类呢?还有图心应该拥有多大的规模呢?是图心决定了图结构的变化吗?如果只有一个或者是两个簇需要被分割,其他都不需要的话这种算法仍然是科学的吗?我们的解决办法同时考虑了想法一和想法二的优点,同时还避免了他们的缺点,并且我们的解决办法可以在很短时间内实现。
我们将通过一个例子来解释。
图1展示了拥有三个图心的一个稳定的K-means聚类。
每一个图心所拥有的区域边界也在图中展示出来了,对这个图的结构改进的过程如下:首先将每一个簇分为两个孩子簇(图2)。
他们是被距离质心相反方向的两个向量的连线分割开来的。
然后对于每一个父亲簇都运行一次K=2的K-means聚类算法,两个孩子类都要与对方争夺父亲类的聚类区域。
图3表示了三个簇分别的分为两个孩子类的过程。
图4表示所有的簇都已经分为了两个孩子类。
在这个时候,模型的测试机制会对每一对子类进行测试,测试内容包括:两个子类的建模过程是否有证据支撑?还有两个子类是否是由父类平均分配的。
下一节我们会涉及如何用这样的测试集来测试K-means。
根据测试出的结果,删除不符合标准的父亲类以及他们的后代,只有通过了这个过程的父亲类以及他们的孩子类才能留存下来。
另外一方面,没有被现有的图心描述好到的空间将会在增加图心的过程中获得更多的关注。
图5显示了图4经过这种处理之后的情况。
因此我们的搜索空间覆盖了所有的2k种可能的分割设置,并且每个区域的分割是由BIC 得分来确定的。
与上述的想法1以及想法2比较,这种思路可以使得我们自动选择我们的聚类个数的增加量时非常少还是非常多。
通过实际操作我们发现,K-means聚类运行两个聚类个数的时候是对局部最小化准则最不敏感的。
我们在最高限制K值下面将会不断的进行参数改善以及框架改善来得到一个更加科学的K值。
3.2 BIC得分假设我们已经有了一个数据集D以及一些可供选择的模型M j,不同的模型对应了不同的K值。
我们如何才能选择最好的K值呢?我们将要用到后验概率来给模型进行打分。
我们的所有模型都被K-means算法设定。
为了按照统一的标准来设定后验概率,我们使用了以下公式:在这个公式当中l j(D)表示数据针对于第j个模型的对数似然函数,并且取极大似然函数值,p j是模型M j中的参数数量,这个也被叫做Schwarz标准。
这些变化之后的极大似然函数估计要在同一个高斯假设下:节点概率为:节点的对数似然函数为对于n属于1到K中间的数值时,只关注D n数据集中属于n个图心的点,并且插入最大似然函数的估计值。
参数P j就是就是简单的的鞥与K-1个类别的概率、M.K个累心的坐标以及方差的估计值。
为了把这一个图心的公式延伸到所有图心上,我们设定节点的似然函数为节点对于所有图心的相对似然函数值,并且将R替代为所有列入考虑的节点向量。
我们在X-means确定最好的模型时全局的使用BIC公式,而局部的使用图心分割测试。
3.3加速到目前为止,X-means可以用在之前的小型数据上,但是我们都忽略了X-means聚类算法的主要特点,那就是它可以使用在大型数据的分析当中。
对K-means算法的加速:我们以一个简单的K-means算法迭代开始,任务是最终确定哪一个节点属于哪一个质心,通过这种迭代,我们可以计算出所有的质心,并且确定属于节点都是属于哪一个给定的质心,同时确定质心的确定位置。
得出结果之后,我们立刻就会发现,对于一个节点数据集的质心分配与对于一个单独的节点的中心分配过程是一样的,因为我们又足够的数据量作为支撑。
显然,这样做可以节省很多的计算资源,所需要占用的资源往往不比证明一个点的归属问题多多少。
既然kd-tree结构强加了一个分层的数据结构给数据,那么我们就可以很容易的计算它的节点的统计数据在建立他们的时候,对这些节点做一个局部的自然选择。
每一个kd-tree代表一个点集。
这个树形结构同样也有边界,即一个可以包括数据集中所有点的矩形。
另外,这种树形结构有两个指针向量,向量表示每一个父亲节点都被分为了两个子节点。