第二章(简单线性回归模型)2-3答案
计量经济学 庞皓 第三版课后答案
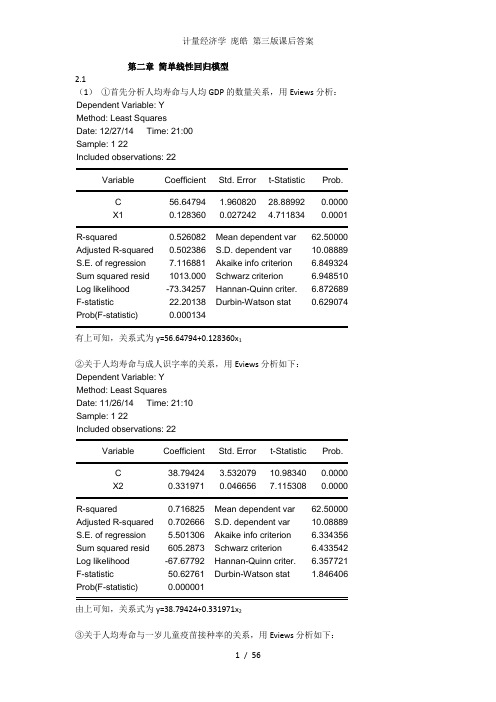
第二章简单线性回归模型2.1(1)①首先分析人均寿命与人均GDP的数量关系,用Eviews分析:Dependent Variable: YMethod: Least SquaresDate: 12/27/14 Time: 21:00Sample: 1 22Included observations: 22Variable Coefficient Std. Error t-Statistic Prob.C 56.64794 1.960820 28.88992 0.0000X1 0.128360 0.027242 4.711834 0.0001R-squared 0.526082 Mean dependent var 62.50000 Adjusted R-squared 0.502386 S.D. dependent var 10.08889 S.E. of regression 7.116881 Akaike info criterion 6.849324 Sum squared resid 1013.000 Schwarz criterion 6.948510 Log likelihood -73.34257 Hannan-Quinn criter. 6.872689 F-statistic 22.20138 Durbin-Watson stat 0.629074 Prob(F-statistic) 0.000134有上可知,关系式为y=56.64794+0.128360x1②关于人均寿命与成人识字率的关系,用Eviews分析如下:Dependent Variable: YMethod: Least SquaresDate: 11/26/14 Time: 21:10Sample: 1 22Included observations: 22Variable Coefficient Std. Error t-Statistic Prob.C 38.79424 3.532079 10.98340 0.0000X2 0.331971 0.046656 7.115308 0.0000R-squared 0.716825 Mean dependent var 62.50000 Adjusted R-squared 0.702666 S.D. dependent var 10.08889 S.E. of regression 5.501306 Akaike info criterion 6.334356 Sum squared resid 605.2873 Schwarz criterion 6.433542 Log likelihood -67.67792 Hannan-Quinn criter. 6.357721 F-statistic 50.62761 Durbin-Watson stat 1.846406 Prob(F-statistic) 0.000001由上可知,关系式为y=38.79424+0.331971x2③关于人均寿命与一岁儿童疫苗接种率的关系,用Eviews分析如下:Dependent Variable: YMethod: Least SquaresDate: 11/26/14 Time: 21:14Sample: 1 22Included observations: 22Variable Coefficient Std. Error t-Statistic Prob.C 31.79956 6.536434 4.864971 0.0001X3 0.387276 0.080260 4.825285 0.0001R-squared 0.537929 Mean dependent var 62.50000Adjusted R-squared 0.514825 S.D. dependent var 10.08889S.E. of regression 7.027364 Akaike info criterion 6.824009Sum squared resid 987.6770 Schwarz criterion 6.923194Log likelihood -73.06409 Hannan-Quinn criter. 6.847374F-statistic 23.28338 Durbin-Watson stat 0.952555Prob(F-statistic) 0.000103由上可知,关系式为y=31.79956+0.387276x3(2)①关于人均寿命与人均GDP模型,由上可知,可决系数为0.526082,说明所建模型整体上对样本数据拟合较好。
计量经济学课后答案第二章 简单线性回归模型

第二章课后答案2.11)设回归模型为: 01i i i Y X u ββ=++其中,Y 为国内生产总值,i X 为地方预算内财政收入对回归模型的参数进行估计,根据回归结果得:i Y = -3.611151+ 0.134582iX (4.161790) (0.003867)t = (-0.867692) (34.80013)2r =0.991810 F=1211.049 S.E.=7.532484 DW=2.0516402)斜率系数的经济意义:国内生产总值每增加1亿元,地方预算内财政收入平均增加0.315亿元。
3)由以上模型可看出,X 的参数估计的t 统计量远大于2,说明GDP 对地方财政收入确有显著影响。
模型在的可决系数为0.991810,说明GDP 解释了地方财政收入变动的99%,模型拟合程度较好。
4)预测点预测:若2005年GDP 为3600亿元,2005年的财政收入预测值为480.884。
区间预测:由X 、Y 的描述统计结果得: 22(1)587.269(121)3793733.66i x x n σ=-=⨯-=∑22()(3600-917.5874)7195337.357f X X -==取α=0.05,f Y 平均值置信度95%的预测区间为:/2f Y t α f X =3600时,480.884 2.228⨯7.5325⨯ 23.61476991 即,2005年财政收入的平均值预测区间为:480.884 23.34796 (457.2692, 504.4988)f Y 个别值置信度95%的预测区间为:/2f Y t α f X =3600,480.884 2.228⨯7.5325⨯ 28.97079 2005年财政收入的个别值预测区间为:480.884 28.97079 (451.91321,509.8548)2.2令Y 为利润额,X 为研究与发展经费研究与发展经费与利润额的相关系数表:设回归模型为:01i i i Y X u ββ=++其中i Y 为利润额,i X 为研究与发展经费。
(完整版)第二章(简单线性回归模型)2-4答案

2.4 回归系数的区间估计和假设检验一、判断题1.如果零假设H 0:B 2=0,在显著性水平5%下不被拒绝,则认为B 2一定是0。
(F )2.k β的置信度为()α-1的置信区间指真实参数落入该区间的概率是()α-1。
(F)3.假设检验为单侧检验还是双侧检验本质上取决于备择假设的形式。
(F )4.回归系数的显著性检验是用来检验解释变量对被解释变量有无显著解释能力的检验。
(T )二、单项选择题1.对回归模型i i 10i u X Y ++=ββ进行检验时,通常假定i u 服从( C )。
A .()2i 0N σ, B .()2n t - C .()20N σ, D .()n t2.用一组有30个观测值的样本估计模型i i 10i u X Y ++=ββ,在0.05的显著性水平下对1β的显著性作检验,则1β显著地不等于零的条件是其统计量大于( D )。
A .()30t 050. B .()30t 0250.) C .()28t 050. D .()28t 0250. 3.回归模型i i i u X Y ++=10ββ中,关于检验010=β:H 所用的统计量)ˆ(ˆ111βββVar -,下列说法正确的是( D )。
A .服从)(22-n χB .服从)(1-n tC .服从)(12-n χ D .服从)(2-n t 4.用一组有30个观测值的样本估计模型后,在0.05的显著性水平上对的显著性作检验,则显著地不等于零的条件是其统计量大于等于( C ) A. B. C. D. 三、简答题1.当α给定后,回归系数2β的置信区间是什么样的?答:总体方差2σ已知时,置信区间为⎥⎥⎦⎤⎢⎢⎣⎡+-∑∑2i 22i2x z xz σβσβˆ,ˆ;总体方差2σ未知则使用2n e 2i2-=∑σˆ估计2σ:①样本容量充分大时,统计量仍服从正态,则置信区间为t t 01122t t t t y b b x b x u =+++1b t 1b t )30(05.0t )28(025.0t )27(025.0t )28,1(025.0F⎥⎥⎦⎤⎢⎢⎣⎡+-∑∑2i 22i 2x z x z σβσβˆˆ,ˆˆ;②样本容量较小时,统计量服从t 分布,则置信区间为⎥⎥⎦⎤⎢⎢⎣⎡+-∑∑2i 222i22x t xt σβσβααˆˆ,ˆˆ 。
(完整word版)应用回归分析,第2章课后习题参考答案汇总(word文档良心出品)

第二章一元线性回归分析思考与练习参考答案2.1 一元线性回归有哪些基本假定?答:假设1解释变量X是确定性变量,丫是随机变量;假设2、随机误差项&具有零均值、同方差和不序列相关性:E( i)=0 i=1,2,…,n2Var (i)=, i=1,2, …,nCov( E £)=0 i 工j i,j= 1,2, …,nCov(X i, i )=0 i=1,2, …,n假设4、&服从零均值、同方差、零协方差的正态分布2i~N(0, ~)i=1,2,…,n2.2考虑过原点的线性回归模型Y i= 0X i+ i i=1,2,…,nn nQ e 八(Y i -Y?)2八(Y i -?i X i)2i』i=1得: f?=M羊Xi)X^0n' (X i Y i)i dn' (X i2)i =1i d2.3 证明(2.27 式),工e i =0 ,工eXi=0。
n nQ=S:(丫-Y?)2=迟(Y i —(f?°+f?X i))2 证明: 1 1其中:丫?=児+叹e=Y-丫?即: I ^(A+AA;-l;) = 0|V^o+/?rVj-T;)A;= 0^e =0 ,乞eX i=0假设3、随机误差项&与解释变量X之间不相关:误差 $ (i=1,2,解:…)n仍满足基本假定。
求仪的最小二乘估计2.4回归方程E (Y ) = 00+ 3X 的参数①,妆的最小二乘估计与最大似然估计在什么条件下等价?给出证明。
答:由于 £ 厂N(0, ~2)i=1,2,…,n所以 Y i =场 + 0X + £~N ( [3D + [3iX i , o 2) 最大似然函数:1 nL( 0, i ,;「2)=二爲 f i (Y i ) =(2=2)』/2exp{——2、 [Y i -( o i o ,X i )]2}2 ynLn{L( o , i ,二2)}= -:帕(2二2)-2、 M -( o i o ,X i )]222<r y使得Ln (L )最大的况,瞬就是肉,0的最大似然估计值。
(完整版)第二章(简单线性回归模型)2-5答案

2.5 回归模型预测一、判断题1.fY ˆ是对个别值f Y 的点估计。
(F ) 2.预测区间的宽窄只与样本容量n 有关。
(F )3.fY ˆ对个别值f Y 的预测只受随机扰动项的影响。
(F ) 4.一般情况下,平均值的预测区间比个别值的预测区间宽。
(F )5.用回归模型进行预测时,预测普通情况和极端情况的精度是一样的。
(F )二、单项选择题1.某一特定的X 水平上,总体Y 分布的离散度越大,即2σ越大,则( A )。
A .预测区间越宽,精度越低B .预测区间越宽,预测误差越小C 预测区间越窄,精度越高D .预测区间越窄,预测误差越大2.在缩小参数估计量的置信区间时,我们通常不采用下面的那一项措施(D )。
A.增大样本容量nB. 预测普通情形而非极端情形C.提高模型的拟合优度D.提高样本观测值的分散度三、多项选择题1.计量经济预测的条件是(ABC )A .模型设定的关系式不变B .所估计的参数不变C.解释变量在预测期的取值已作出预测 D .没有对解释变量在预测期的取值进行过预测 E .无条件2.对被解释变量的预测可以分为(ABC )A.被解释变量平均值的点预测B.被解释变量平均值的区间预测C.被解释变量的个别值预测D.解释变量预测期取值的预测四、简答题1.为什么要对被解释变量的平均值以及个别值进行区间预测?答:由于抽样波动的存在,用样本估计出的被解释变量的平均值fY ˆ与总体真实平均值()f f X Y E 之间存在误差,并不总是相等。
而用fY ˆ对个别值f Y 进行预测时,除了上述提到的误差,还受随机扰动项的影响,使得总体真实平均值()f f X Y E 并不等于个别值f Y 。
一般而言,个别值的预测区间比平均值的预测区间更宽。
2.分别写出()f f X Y E 和f Y 的置信度为α-1的预测区间。
答:()f f X Y E :()⎪⎪⎪⎭⎫ ⎝⎛-+±∑22f 2f i x X X n 1t Y σαˆˆ;f Y :()⎪⎪⎪⎭⎫ ⎝⎛-++±∑22f 2f i x X X n 11t Y σαˆˆ。
计量经济学(庞皓)课后思考题答案

思考题答案第一章绪论思考题1.1怎样理解产生于西方国家的计量经济学能够在中国的经济理论研究和现代化建设中发挥重要作用?答:计量经济学的产生源于对经济问题的定量研究,这是社会经济发展到一定阶段的客观需要。
计量经济学的发展是与现代科学技术成就结合在一起的,它反映了社会化大生产对各种经济因素和经济活动进行数量分析的客观要求。
经济学从定性研究向定量分析的发展,是经济学逐步向更加精密、更加科学发展的表现。
我们只要坚持以科学的经济理论为指导,紧密结合中国经济的实际,就能够使计量经济学的理论与方法在中国的经济理论研究和现代化建设中发挥重要作用。
1.2理论计量经济学和应用计量经济学的区别和联系是什么?答:计量经济学不仅要寻求经济计量分析的方法,而且要对实际经济问题加以研究,分为理论计量经济学和应用计量经济学两个方面。
理论计量经济学是以计量经济学理论与方法技术为研究内容,目的在于为应用计量经济学提供方法论。
所谓计量经济学理论与方法技术的研究,实质上是指研究如何运用、改造和发展数理统计方法,使之成为适合测定随机经济关系的特殊方法。
应用计量经济学是在一定的经济理论的指导下,以反映经济事实的统计数据为依据,用计量经济方法技术研究计量经济模型的实用化或探索实证经济规律、分析经济现象和预测经济行为以及对经济政策作定量评价。
1.3怎样理解计量经济学与理论经济学、经济统计学的关系?答:1、计量经济学与经济学的关系。
联系:计量经济学研究的主体—经济现象和经济关系的数量规律;计量经济学必须以经济学提供的理论原则和经济运行规律为依据;经济计量分析的结果:对经济理论确定的原则加以验证、充实、完善。
区别:经济理论重在定性分析,并不对经济关系提供数量上的具体度量;计量经济学对经济关系要作出定量的估计,对经济理论提出经验的内容。
2、计量经济学与经济统计学的关系。
联系:经济统计侧重于对社会经济现象的描述性计量;经济统计提供的数据是计量经济学据以估计参数、验证经济理论的基本依据;经济现象不能作实验,只能被动地观测客观经济现象变动的既成事实,只能依赖于经济统计数据。
最新第二章(简单线性回归模型)2-1答案

2.1回归分析与回归函数一、判断题1. 总体回归直线是解释变量取各给定值时被解释变量条件期望的轨迹。
(T )2. 线性回归是指解释变量和被解释变量之间呈现线性关系。
( F )3. 随机变量的条件期望与非条件期望是一回事。
(F )4、总体回归函数给出了对应于每一个自变量的因变量的值。
(F )二、单项选择题1.变量之间的关系可以分为两大类,它们是( A )。
A .函数关系与相关关系B .线性相关关系和非线性相关关系C .正相关关系和负相关关系D .简单相关关系和复杂相关关系2.相关关系是指( D )。
A .变量间的非独立关系B .变量间的因果关系C .变量间的函数关系D .变量间不确定性的依存关系3.进行相关分析时的两个变量( A )。
A .都是随机变量B .都不是随机变量C .一个是随机变量,一个不是随机变量D .随机的或非随机都可以4.回归分析中定义的( B )。
A.解释变量和被解释变量都是随机变量B.解释变量为非随机变量,被解释变量为随机变量C.解释变量和被解释变量都为非随机变量D.解释变量为随机变量,被解释变量为非随机变量5.表示x 和y 之间真实线性关系的总体回归模型是( C )。
A .01ˆˆˆt t Y X ββ=+B .01()t t E Y X ββ=+C .01t t t Y X u ββ=++D .01t t Y X ββ=+6.一元线性样本回归直线可以表示为( C )A .i i X Y u i 10++=ββ B. i 10X )(Y E i ββ+=C. i i e X Y ++=∧∧i 10ββ D. i 10X i Y ββ+=∧7.对于i 01i i ˆˆY =X +e ββ+,以ˆσ表示估计标准误差,r 表示相关系数,则有( D)。
A .ˆ0r=1σ=时,B .ˆ0r=-1σ=时,C .ˆ0r=0σ=时,D .ˆ0r=1r=-1σ=时,或8.相关系数r 的取值范围是( D )。
第2章 简单回归模型习题

换言之,ˆ0 对 0 而言是无偏的,ˆ1 对1而言
是无偏的
引理: n 1 (xi x) 0
i 1
n
n
n
n
2 (xi x)( yi y) (xi x)yi ( xi nx) y (xi x)yi
i 1
i 1
i 1
i 1
n
xi yi y ˆ1x ˆ1xi 0
i 1
n
n
xi yi y ˆ1 xi xi x
i 1
i 1
n
n
xi x yi y ˆ1 xi x 2
i 1
i 1
普通最小二乘法的推导
n
xi x yi y
ˆ1 i1 n
xi x 2
i 1 n
在假设前提 xi x 2 0下 i 1
•回归元和OLS残差的样本协方差为零
–代数表示
n
xiuˆi 0
i 1
(xi , yi )
–由OLS的一阶条件得出
n
n1 xi yi ˆ0 ˆ1xi 0
i 1
OLS的操作技巧——OLS统计量的代数性质
•点 x, y 总在OLS回归线上
–代数表示 –可以由
y ˆ0 ˆ1x
n
在简单回归中加入非线性因素——自然对数形式
在简单回归中加入非线性因素——自然对数 形式
“线性”回归的含义
OLS估计量的期望值和方差
–OLS的无偏性 –OLS估计量的方差
OLS的无偏性
–我们首先在一组简单假定的基础上构建OLS 的无偏性。 –假定SLR.1(线性于参数) –在总体模型中,因变量y与自变量x的误差 项u的关系如下:
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
拟合优度的度量
一、判断题
1.当
()∑-2i y y 确定时,()∑-2
i
y y ˆ越小,表明模型的拟合优度越好。
(F ) 2.可以证明,可决系数2R 高意味着每个回归系数都是可信任的。
(F ) 3.可决系数2R 的大小不受到回归模型中所包含的解释变量个数的影响。
(F ) 4.任何两个计量经济模型的2R 都是可以比较的。
(F )
5.拟合优度2R 的值越大,说明样本回归模型对数据的拟合程度越高。
( T )
6.结构分析是2R 高就足够了,作预测分析时仅要求可决系数高还不够。
( F )
7.通过2R 的高低可以进行显著性判断。
(F )
8.2R 是非随机变量。
(F )
二、单项选择题
1.已知某一直线回归方程的可决系数为,则解释变量与被解释变量间的线性相关系数为( B )。
A .±
B .±
C .±
D .± 2.可决系数2R 的取值范围是( C )。
A .2R ≤-1
B .2R ≥1
C .0≤2R ≤1
D .-1≤2R ≤1 3.下列说法中正确的是:( D )
A 如果模型的2R 很高,我们可以认为此模型的质量较好
B 如果模型的2R 较低,我们可以认为此模型的质量较差
C 如果某一参数不能通过显著性检验,我们应该剔除该解释变量
D 如果某一参数不能通过显著性检验,我们不应该随便剔除该解释变量
三、多项选择题
1.反映回归直线拟合优度的指标有( ACDE )。
A .相关系数
B .回归系数
C .样本可决系数
D .回归方程的标准差
E .剩余变差(或残差平方和)
2.对于样本回归直线i 01i ˆˆˆY X ββ+=,回归变差可以表示为( ABCDE )。
A .2
2i i i i ˆY Y -Y Y ∑
∑
(-) (-) B .2
2
1
i
i ˆX X β∑
(-) C .2
2
i
i R
Y Y ∑
(-) D .2
i
i
ˆY Y ∑(-) E .1
i
i
i
i
ˆX X Y Y β∑
(-()-) 3.对于样本回归直线i 01i
ˆˆˆY X ββ+=,ˆσ为估计标准差,下列可决系数的算式中,正确的有( ABCDE )。
A .2i i 2
i
i
ˆY Y Y Y ∑∑(-)(-) B .2i i 2
i
i
ˆY Y 1Y Y ∑∑
(-)-(-)
C.
22
1i i
2
i i
ˆX X
Y Y
β∑
∑
(-)
(-)
D.1i i i i
2
i i
ˆX X Y Y
Y Y
β∑
∑
(-()-)
(-)
E.
2
2
i i
ˆn-2) 1
Y Y
σ
∑
(
-
(-)
4.可决系数2R可表示为(BCE )。
A.2RSS
R=
TSS B.2
ESS
R=
TSS
C.2
RSS
R=1-
TSS
D.2ESS
R=1-
TSS E.2
ESS
R=
ESS+RSS
5. RSS是指(ACDE )。
A.随机因素影响所引起的被解释变量的变差
B.解释变量变动所引起的被解释变量的变差
C.被解释变量的变差中,回归方程不能做出解释的部分
D.被解释变量的总变差与回归平方和之差
E.被解释变量的实际值与回归值的离差平方和
6.回归变差(或回归平方和)是指(BCD )。
A. 被解释变量的实际值与平均值的离差平方和
B. 被解释变量的回归值与平均值的离差平方和
C. 被解释变量的总变差与剩余变差之差
D. 解释变量变动所引起的被解释变量的变差
E. 随机因素影响所引起的被解释变量的变差
四、简答题
1.可决系数与相关系数的联系与区别。
答:联系:在一元回归中,可决系数在数值上等于简单线性相关系数的平方。
区别:①可决系数针对模型而言,说明的是模型中解释变量对被解释变量变差的解释程度,相关系数针对两个变量而言,说明的是两个变量的线性依存程度;②可决系数度量的是不对称的因果关系,相关系数度量的是对称的相关关系;③可决系数具有非负性,相关系数可正可负。
2.可决系数的使用原则。
答:①切勿因2
R的高或低轻易地否定或肯定一个模型;②在样本相同、被解释变量相同的前提下可以比较不同模型的2
R;③2R较高,一是意味着样本回归线对样本数据的拟合程度较高,二是意味着所有解释变量联合起来对被解释变量的影响程度较高。
3、为什么用可决系数2R评价拟合优度,而不是用残差平方和作为评价标准
答:可决系数R2=ESS/TSS=1-RSS/TSS,含义为由解释变量引起的被解释变量的变化占被解释变量总变化的比重,用来判定回归直线拟合的优劣,该值越大说明拟合的越好;而残差平方和与样本容量关系密切,当样本容量比较小时,残差平方和的值也比较小,尤其是不同样本
得到的残差平方和是不能做比较的。
此外,作为检验统计量的一般应是相对量而不能用绝对量,因而不能使用残差平方和判断模型的拟合优度。
五、计算题
1.已知估计回归模型得
i i ˆY =81.7230 3.6541X + 且2X X 4432.1∑
(-)=,2Y Y 68113.6∑(-)=, 求可决系数和相关系数。
答:可决系数:22
12
2
()()
b X X R Y Y -=
-∑∑=23.65414432.1
68113.6
⨯==
相关系数:0.9321r =
==
2.已知相关系数r =,回归方差的估计为2ˆ8σ
=,样本容量n=62。
求:(1)残差平方和;(2)可决系数;(3)总变差。
答:(1)由于22
ˆ2
t
e
n σ
=
-∑,22
ˆ(2)(622)8480t
RSS e n σ=
=-=-⨯=∑。
(2)2220.60.36R r === (3)2
480
750110.36
RSS TSS R ===--。