文本自动分类聚类技术
人工智能聚类与分类算法

人工智能聚类与分类算法人工智能(Artificial Intelligence,AI)已经在各个领域取得了重要的突破和应用,其中聚类与分类算法是人工智能领域中的重要研究方向之一。
聚类与分类算法可以帮助我们理解数据之间的关系,发现隐藏在数据中的模式和规律,并将数据分成不同的类别。
本文将对人工智能聚类与分类算法进行详细介绍,包括聚类算法的基本概念、常见的聚类算法以及分类算法的基本概念、常见的分类算法等内容。
一、聚类算法1. 基本概念聚类算法是根据数据的相似性将数据划分为不同的组别的方法。
聚类算法的基本思想是,将相似的数据划分为同一类,不相似的数据划分到不同的类。
聚类算法有以下几个重要的概念:(1)相似性度量:相似性度量用来衡量数据之间的相似性,常见的相似性度量有欧氏距离、曼哈顿距离、余弦相似度等。
(2)簇:簇是被划分出来的一组相似的数据对象。
(3)聚类中心:聚类中心是每个簇的代表,一般选择簇中所有数据的平均值或中心点作为聚类中心。
(4)聚类算法评估指标:用来评估聚类算法的效果,常见的聚类算法评估指标有轮廓系数、DB指数等。
2. 常见的聚类算法(1)K-means聚类算法:K-means算法是一种基于划分的聚类算法,其基本思想是将数据划分为K个簇,每个簇的聚类中心由该簇中所有数据的均值计算得到。
K-means算法的过程包括初始化聚类中心、计算数据点与聚类中心的距离、更新聚类中心、重复迭代直到聚类中心不再变化等。
(2)层次聚类算法:层次聚类算法是一种基于合并或分裂的聚类算法,其基本思想是构建一棵树状结构来表示不同簇之间的关系。
层次聚类算法的过程包括计算数据点之间的相似性度量、构建初始簇集合、计算簇之间的相似性度量、合并或分裂簇等。
(3)密度聚类算法:密度聚类算法是一种基于密度的聚类算法,其基本思想是将数据划分为不同的簇,簇是由高密度区域和低密度区域分隔开的。
密度聚类算法的过程包括计算数据点的局部密度、确定密度阈值、合并密度可达点构成簇等。
文本分类和聚类有什么区别?

⽂本分类和聚类有什么区别?简单点说:分类是将⼀⽚⽂章或⽂本⾃动识别出来,按照先验的类别进⾏匹配,确定。
聚类就是将⼀组的⽂章或⽂本信息进⾏相似性的⽐较,将⽐较相似的⽂章或⽂本信息归为同⼀组的技术。
分类和聚类都是将相似对象归类的过程。
区别是,分类是事先定义好类别,类别数不变。
分类器需要由⼈⼯标注的分类训练语料训练得到,属于有指导学习范畴。
聚类则没有事先预定的类别,类别数不确定。
聚类不需要⼈⼯标注和预先训练分类器,类别在聚类过程中⾃动⽣成。
分类适合类别或分类体系已经确定的场合,⽐如按照国图分类法分类图书;聚类则适合不存在分类体系、类别数不确定的场合,⼀般作为某些应⽤的前端,⽐如多⽂档⽂摘、搜索引擎结果后聚类(元搜索)等。
分类(classification )是找出描述并区分数据类或概念的模型(或函数),以便能够使⽤模型预测类标记未知的对象类。
分类技术在数据挖掘中是⼀项重要任务,⽬前商业上应⽤最多。
分类的⽬的是学会⼀个分类函数或分类模型(也常常称作分类器),该模型能把数据库中的数据项映射到给定类别中的某⼀个类中。
要构造分类器,需要有⼀个训练样本数据集作为输⼊。
训练集由⼀组数据库记录或元组构成,每个元组是⼀个由有关字段(⼜称属性或特征)值组成的特征向量,此外,训练样本还有⼀个类别标记。
⼀个具体样本的形式可表⽰为:(v1,v2,...,vn; c);其中vi表⽰字段值,c表⽰类别。
分类器的构造⽅法有统计⽅法、机器学习⽅法、神经⽹络⽅法等等。
不同的分类器有不同的特点。
有三种分类器评价或⽐较尺度:1)预测准确度;2)计算复杂度;3)模型描述的简洁度。
预测准确度是⽤得最多的⼀种⽐较尺度,特别是对于预测型分类任务。
计算复杂度依赖于具体的实现细节和硬件环境,在数据挖掘中,由于操作对象是巨量的数据,因此空间和时间的复杂度问题将是⾮常重要的⼀个环节。
对于描述型的分类任务,模型描述越简洁越受欢迎。
另外要注意的是,分类的效果⼀般和数据的特点有关,有的数据噪声⼤,有的有空缺值,有的分布稀疏,有的字段或属性间相关性强,有的属性是离散的⽽有的是连续值或混合式的。
语义增强的文本聚类方法研究

语义增强的文本聚类方法研究一、语义增强的文本聚类方法概述随着信息技术的快速发展,文本数据的爆炸式增长使得文本聚类技术在信息检索、知识管理、数据挖掘等领域变得尤为重要。
文本聚类是一种无监督学习方法,旨在将文本数据自动地划分为若干个具有相似特征的类别。
然而,传统的文本聚类方法往往依赖于词频、位置等表面特征,难以深入挖掘文本的语义信息。
语义增强的文本聚类方法通过引入语义分析技术,能够更准确地捕捉文本的内在含义,从而提高聚类的效果和质量。
1.1 语义增强文本聚类的核心特性语义增强的文本聚类方法的核心特性主要体现在以下几个方面:- 语义一致性:通过语义分析技术,能够确保聚类结果在语义层面上具有一致性,提高聚类的准确性。
- 多维度特征:除了传统的词频特征,还能够利用词义、句法、语义角色等多维度特征,丰富聚类的维度。
- 动态适应性:能够根据文本数据的特点和变化,动态调整聚类策略,提高聚类的适应性和灵活性。
1.2 语义增强文本聚类的应用场景语义增强的文本聚类方法在多个领域都有着广泛的应用,包括但不限于以下几个方面:- 信息检索:通过聚类技术,能够将用户查询的关键词与相关文档进行匹配,提高检索的准确性和效率。
- 知识管理:在知识库中,通过聚类技术可以发现知识之间的关联,优化知识结构,促进知识的传播和应用。
- 数据挖掘:在大规模文本数据中,通过聚类技术可以发现数据的内在模式和规律,为决策提供支持。
二、语义增强文本聚类方法的关键技术语义增强的文本聚类方法涉及多种关键技术,这些技术共同作用,提升聚类的效果和质量。
2.1 语义分析技术语义分析技术是语义增强文本聚类方法的核心。
它通过分析文本中的词汇、句法、语义角色等信息,提取文本的深层含义。
常见的语义分析技术包括:- 词义消歧:通过上下文信息,确定多义词的具体含义,提高语义分析的准确性。
- 句法分析:分析句子的结构,提取主语、谓语、宾语等成分,理解句子的语义关系。
- 语义角色标注:标注句子中各个成分的语义角色,理解句子的深层含义。
基于文本分类的新闻自动聚类技术

基于文本分类的新闻自动聚类技术随着互联网的不断发展,新闻信息量也越来越大,如何更好地解决信息过载的问题,让用户更快速地获取所需信息,是新闻聚类技术需要解决的一个重要问题。
而最近几年,基于文本分类的新闻自动聚类技术逐渐成为了主流的方法,有着较高的准确性和效率。
一、文本分类技术的应用文本分类技术是计算机自然语言处理领域中的一项重要技术,它的主要作用是将文本数据分为不同的类别。
将这项技术应用到新闻聚类中,可以自动将相同类别的新闻聚合在一起,提高新闻信息的管理效率。
二、文本分类技术的原理文本分类技术主要利用机器学习算法,通过分析文本中的特征,自动将文本分类。
机器学习是一种从数据中自动学习规律的方法,它可以根据输入的数据发掘特征,并自动分类。
文本分类技术中,常用的机器学习算法包括朴素贝叶斯分类、支持向量机、决策树等。
朴素贝叶斯分类是一种基于概率的算法,它假设不同特征之间是相互独立的,可以有效地处理多维文本数据,并在实践中具有较好的分类效果。
支持向量机则是一种基于几何空间的分类算法,它可以将数据映射到高维空间进行分类,能够处理更为复杂的数据结构。
三、基于文本分类的新闻自动聚类方法在将文本分类应用到新闻自动聚类中,需要先对新闻进行特征提取。
将每篇新闻转化为向量,可以方便地进行处理和计算。
目前常用的特征提取方法有TF-IDF、词袋模型等。
TF-IDF(Term Frequency-Inverse Document Frequency)表示词频–逆文档频率,是一种常用的权重算法。
它通过统计某一文档中某个词语出现的次数,以及在语料库中出现的文档数来计算一个词语在文档中的重要程度。
词袋模型则是建立在文本向量化的基础上,将所有的单词统计出现的次数并建立向量空间,将一篇文本表示为向量,每个维度代表一个单词的权重。
然后利用机器学习算法对这些向量进行分类。
这种方法简单易懂,容易实现,适合处理大规模的文本分类任务。
四、基于文本分类的新闻自动聚类的优势与传统的手动聚类相比,基于文本分类的新闻自动聚类技术具有以下几点优势。
聚类与分类算法在文本挖掘中的应用研究

聚类与分类算法在文本挖掘中的应用研究文本挖掘是数据挖掘的一个重要分支,旨在通过对大规模文本数据的分析和理解,发现其中隐藏的模式、关系和知识。
在文本挖掘中,聚类与分类算法是两个常用的技术,它们能够帮助我们对文本数据进行有效的组织、分类和预测。
本文将探讨聚类与分类算法在文本挖掘中的应用研究。
聚类算法是一种将相似的对象归为一类的技术。
在文本挖掘中,聚类算法主要应用于无监督学习的任务,即在没有事先给定类别标签的情况下,对文本进行自动的聚类分析。
目前,常用的聚类算法有K-means算法、层次聚类算法和密度聚类算法等。
K-means算法是一种基于距离的聚类算法,其思想是通过迭代计算,将文本样本划分为K个不同的聚类。
算法首先需要选择K个聚类中心,然后根据文本样本与聚类中心之间的距离,将样本分配到最近的聚类中心中。
随后,根据新的聚类分配情况,重新计算聚类中心的位置,直到满足停止条件为止。
K-means算法适用于大规模数据集和高维特征向量,在文本挖掘中常用于对新闻、社交媒体等文本数据进行聚类分析。
层次聚类算法是一种基于层次结构的聚类算法,其通过构建一个聚类层次树来组织文本对象。
该算法将每个对象视为一个初始聚类簇,然后逐步合并具有最小相似度的聚类簇,直到形成一个全局聚类簇。
层次聚类算法能够提供更加详细的聚类结果,适用于对文本数据进行细粒度的聚类分析。
密度聚类算法是一种基于密度的聚类算法,其根据文本对象的局部密度来进行聚类划分。
该算法首先分析文本数据的密度分布,并通过定义密度阈值来标记核心对象和噪声点。
随后,通过相邻点的连接,将核心对象聚集在一起,形成不同的聚类簇。
密度聚类算法对于具有复杂的聚类结构和噪声数据的情况下,表现出较好的聚类性能。
分类算法是一种通过训练样本的类别信息,为新的文本对象分配类别标签的技术。
在文本挖掘中,分类算法通常用于监督学习的任务,即在已知类别标签的情况下,对文本数据进行预测和分类。
常见的分类算法有朴素贝叶斯算法、支持向量机算法和决策树算法等。
无监督文本分类算法

无监督文本分类算法
无监督文本分类算法是一类不需要标注数据的分类算法,可以自动地对文本进行分类
和聚类,它是文本挖掘领域的一个重要研究方向。
无监督文本分类算法基于文本中的特征进行分类,并根据这些特征将文本进行聚类。
这些特征可以是单词、短语、词性、句法结构等。
无监督文本分类算法通常包括以下步
骤:
1. 文本预处理
首先对文本进行预处理,包括分词、去除停用词、词干提取等操作。
分词是将文本按
照一定的规则切分成一个个的词语,去除停用词是指将一些常见但无实际意义的词语(如“的”、“和”等)剔除,词干提取是指将一个单词的不同形态统一成一个基本形式,便
于后续处理和比较。
2. 特征选择
文本中存在大量的特征,但其中只有一部分对于分类或聚类有用。
因此需要进行特征
选择,选择出最具有代表性的特征,以便后续分类或聚类。
常见的特征选择方法有互信息、卡方检验、信息增益等。
3. 表示文本
将文本表示成向量形式,是无监督文本分类算法中非常关键的一步。
常见的向量表示
方法有词袋模型和TF-IDF模型。
词袋模型是将文本中的词以及它们在文本中出现的次数作为向量的元素,TF-IDF模型则考虑了词语在整个语料库中的重要性,同时考虑到该词语在当前文本中的出现频率。
4. 聚类
通过选择适当的聚类算法,将向量表示的文本进行聚类,得到文本的分类结果。
常见
的聚类算法有K-means、层次聚类、谱聚类等。
自动聚类算法

自动聚类算法自动聚类算法是一种机器学习算法,它可以将数据集中的对象自动分类,以形成新的集合。
这些对象可以是文本、图像、音频、视频或其他类型的数据。
聚类是一种无监督学习技术,它不需要标记或先验信息,但仍然可以从数据中发现模式和结构。
在本文中,我们将介绍一些常用的自动聚类算法,并讨论它们的优点和缺点。
1. k-均值聚类算法k-均值聚类算法是一种基于迭代的算法,它将数据集分成k个不同的簇,使得每个簇中的数据点与该簇的质心之间的距离最小。
该算法需要指定k的值,即要分成的簇的数量。
一般来说,k的值通过试验和误差来确定。
该算法的优点在于计算简单、易于实现、速度快。
但它的缺点在于对异常值和噪声的鲁棒性较差,在数据分布不均匀的情况下效果不佳。
2. 层次聚类算法层次聚类算法是一种逐步加密数据点的算法,它将数据点逐步组合成簇并形成树状结构,称为“聚类树”。
该算法有两个主要类型:聚合层次聚类和分裂层次聚类。
聚合层次聚类从底向上构建聚类树,每个簇开始只有一个数据点,逐步合并到更大的簇,直到形成一个大的簇。
分裂层次聚类从顶向下构建聚类树,开始为一个包含所有数据点的大簇,逐步分裂成较小的簇。
该算法的优点在于不需要预先指定簇的数量,易于可视化以及能够处理异常值和噪声。
但其缺点在于计算复杂度高,速度较慢,对大型数据集不适用。
3. DBSCAN聚类算法DBSCAN聚类算法是一种基于密度的算法,可以对任意形状的簇进行聚类。
该算法通过寻找数据点的“核心点”以及它们周围的数据点来定义簇。
其中,“核心点”是指一个密度大于某一阈值的数据点,在其附近半径内的所有数据点都被认为是同一簇。
该算法的优点在于能够处理任意形状的簇,对噪声和异常值有较好的鲁棒性。
但其缺点在于对参数的依赖性较大,需要人为设定阈值,并且对数据分布不均匀的情况下效果不佳。
4. GMM聚类算法GMM聚类算法是一种基于概率模型的算法,它可以对数据分布于高斯分布的数据进行聚类。
GMM模型假设每个簇是一个高斯分布,并寻找最优参数来拟合数据集。
自动分类技术

5 自动分类算法
(1) KNN法 (2) SVM法 (3) VSM法 (4) Bayes法
(1) KNN法
KNN 法即K最近邻法 该斱法的思路:如果一个样本在特征空间中的k 个 最相似(即特征空间中最邻近)的样本中的大多数属 于某一个类别,则该样本也属于这个类别。 该斱法在定类决策上只依据最邻近的一个戒者几个 样本的类别来决定徃分样本所属的类别。
(4) Bayes法
即贝叶斯法
Bayes法是一种在已知先验概率不类条件概率的情 况下的模式分类斱法,徃分样本的分类结果取决 于各类域中样本的全体。
Bayes分类斱法在理论上论证得比较充分,在应用 上也是非帯广泛的。
Bayes分类判决准则
• 设训练样本集分为M类,记为C={c1,…,ci,…cM},每类的先验概率为P(ci), i=1,2,…,M。当样本集非帯大时,可以认为P(ci)=ci类样本数/总样本数。对 于一个徃分样本X,其归于cj类的类条件概率是P(X/ci),则根据Bayes定理,可 得到cj类的后验概率P(ci/X): P(ci/x)=P(x/ci)· P(ci)/P(x)(式1-1) 若P(ci/X)=MaxjP(cj/X),i=1,2,…,M,j=1,2,…,M,则有x∈ci(式1-2) 式(1-2)是最大后验概率判决准则,将式(1-1)代入式(1-2),则有: 若P(x/ci)P(ci)=Maxj[P(x/cj)P(cj)],i=1,2,…,M,j=1,2,…,M,则 x∈ci
其中,征向量,sim()为相似度计算其中,也为新文 本的特公式,而到,c为类别属性函数,如果属于 cj类,那么函数值为1,否则为0。
STEP5:比较类的权重,将文本分到权重最大的那个 类别中。
优缺点
优点:可以较好地避免样本的丌平衡问题。另外,由于KNN 斱法主要靠周围有限的邻近的样本,而丌是靠判别类域的 斱法来确定所属类别的,因此对于类域的交叉戒重叠较多 的徃分样本集来说,KNN斱法较其他斱法更为适合。 缺点:计算量较大,因为对每一个徃分类的文本都要计算它 到全体已知样本的距离,才能求得它的K个最近邻点。 该算法比较适用于样本容量比较大的类域的自动分类,而 那些样本容量较小的类域采用这种算法比较容易产生误分。
北京大学博士研究生开题报告22邓志鸿

V3 V1 V2
问题(续1 问题(续1)
但是,如果把每个文档向量归一化,使得 所有向量的模均为1。则可以证明欧氏空间和 Cosine模型是等价。因此需要研究哪些相似度 度量模型在效果上等同。意义: 在应用中指导选择相似度度量模 型 理论上验证新的度量模型与已有 模型的等价性 简化不同度量模型之间的比较
计划研究内容
特征词权值计算模型的研究。传统的特征词权值计算 模型没有考虑特征词在不同的类别中具有不同的标识 类别的能力,而是在整个特征集下考虑权值的计算, 因此不够合理和科学。 基于新的特征词权值计算模型:1.修改或扩展已有分 类算法,构造效果更好的文本分类器; 2.研究新的分 类算法。 分类中的特征词选取的研究。目前对分类中的特征词 选取的研究比较多。但是全面的分析不同特征词选取 方法在不同选取策略下的性能还没有相关的报道。因 此,这方面的研究是非常有意义的。另外,新的特征 词选取方法也值得深入研究。
文本预处理(续4 文本预处理(续4)
向量空间模型(Vector Space Model):把文档 看成是高维空间中的向量,而把特征词看成空间 中的维,向量中的每个元素的值为相应特征词在 该文档上的权值。 记D = {d1, d2, …, dn}是文档集,它所包含的 所有特征词记为F = {f1, f2, …, fm},其中fi 是特征词,这些特征词构成了一个m维的向量空 间。其中文档di 被表示为一个m维向量Wi = (wi1, wi2, …, wim)。向量在每一维上的分量wij对应特 征词fj在文档di中的权值。 常用的特征词权值计算模型有:布尔模型、TF模 型和tf*idf模型。
i =1 i =1
文档相似度(续1 文档相似度(续1)
Jaccard模型
sim(V1 ,V2 ) =
基于LDA主题模型的文本聚类研究

基于LDA主题模型的文本聚类研究一、引言文本聚类是信息检索与挖掘领域中的热点问题之一。
聚类技术在文本分类、文本自动摘要、信息提取和知识发现等方面都有着广泛应用。
而主题模型作为一种文本挖掘技术,可以有效地从文本数据中提取主题信息。
本文将介绍基于LDA主题模型的文本聚类研究。
二、文本聚类文本聚类是将具有类似主题的文本分为一组的过程。
文本聚类有很多种方法,包括层次聚类、k-means聚类、DBSCAN聚类等等。
在聚类算法中,选择合适的特征表示是非常重要的。
一般来说,文本可以被表示为向量,每个向量表示一个文档。
而这个文档可以被表示为词频向量、TF-IDF向量等等。
三、LDA主题模型LDA主题模型是Latent Dirichlet Allocation(潜在狄利克雷分配)的缩写,由Blei等人在2003年提出。
LDA主题模型是一种生成模型,用于解决文本数据中的主题分布问题。
在LDA模型中,文本可以被看作多个主题的混合,每个主题可以看作代表某个话题的词汇分布。
通过LDA模型,可以从文本数据中识别出潜在的主题和每个文档对应的主题分布。
四、基于LDA的文本聚类LDA主题模型在文本聚类中的应用,主要是通过主题相似性来划分类别。
在使用LDA进行文本聚类时,首先需要确定主题个数K,然后利用训练集构建LDA模型,从而得到每个文档对应的主题分布。
接着,可以使用传统的聚类算法,如k-means聚类,将文档划分为K个簇。
在LDA主题模型中,每个主题都是由一组词汇组成的,因此可以通过比较不同主题之间的词汇相似度来判断主题之间的相似度。
五、实验结果本研究使用了来自Reuters-21578数据集的文本数据进行实验。
首先,利用LDA模型对文本数据进行建模,得到每个文档对应的主题分布。
接着,将文档划分为10个簇,使用ARI(Absolute Rand Index)和NMI(Normalized Mutual Information)指标对聚类结果进行评估。
文本分类应用场景

文本分类应用场景
1文本分类应用
文本分类是现代商业智能技术中常见的一个应用。
它以标记对文档或文本进行自动分类的形式,能够准确地定义文档或消息的类别,体现组织或用户关注的信息。
它通常是基于机器学习技术来自动提取当前Web上的信息,进行数据聚类和提取。
可以应用于多个行业,如搜索引擎,智能客服,智能电子商务,文字助手,媒体领域,医疗和银行行业等。
可以有效地节省时间,提高工作效率和降低错误率。
2搜索引擎
文本分类在搜索引擎中得以广泛应用,能准确定位网络中需要的信息,排序页面内容,也可以根据关键字池精准检索信息,准确的做出最相关文档内容的排列顺序。
此外,文本分类可以实现知识分类,进行内容索引,也可以用文本聚类的方法把众多的文档分割为若干个子类,使用户更好的获取需要的信息。
3智能客服
智能客服因其及时地解答用户问题,受到了极大的欢迎。
智能客服系统中常常使用文本分类技术来根据用户问题自动匹配出最满意的答案。
通过快速易用的文本分类技术,可以帮助企业精准定位顾客的需求,提升服务体验,扩大客户群。
4智能电子商务
智能电子商务也是一个应用文本分类技术的场景,文本分类可以按产品类别把大量产品进行精确分类,帮助用户快速查找到所需的商品,使电子商务市场以更高的效率,更节省的成本实现精细分类整理,从而提升整个市场的竞争性。
就此而言,文本分类技术已经发挥着重要的作用,它在众多行业都有着深远的意义,并且影响着数字时代的环境与灵活性。
文本分类技术不但可以帮助人们判断文章的内容,而且可以更好的监控网络上的信息,更好的分析文章,形成数据集,为业务采取有效和准确的决策提供依据。
基于深度学习的文本聚类算法

基于深度学习的文本聚类算法深度学习作为一种新兴的技术,已经逐渐在各个领域得到了广泛的应用。
其中,基于深度学习的文本聚类算法在信息处理中占据了重要地位。
那么,什么是文本聚类,深度学习又该如何在其中使用呢?一、文本聚类简介文本聚类指的是将大量的文本数据聚集在一起,依据其相似性来分成不同组别。
文本聚类主要是用于资讯分类、信息检索和组织自动化等领域。
相似的文本被分到一个组,不同群组之间的文本有着显著的差异。
聚类分析是文本挖掘中一项重要的技术,其目的是发现数据之间的关系。
文本聚类可以分为传统文本聚类和基于深度学习的文本聚类。
传统的文本聚类采用的是传统的机器学习算法,例如KNN算法、决策树算法和朴素贝叶斯算法等。
近年来,深度学习技术的不断发展,为文本聚类算法提供了更为高效、准确、自适应的方法。
二、深度学习在文本聚类中的应用深度学习在文本聚类领域的最大优点是能够自动学习特征。
这种自动学习的特征可以捕捉到文本的最主要的特征,从而使得聚类的效果更稳定和更准确。
深度学习在文本聚类中的应用主要有以下几个方面:1、词向量表示方法深度学习算法中通常采用的是词向量表示方法(Word Embedding),即将语料库中的每个词通过词嵌入的方式表示为一个向量。
在文本聚类中,采用词向量的方法来表示每个文本中的词语,将文本数据转化为向量数据,进而进行聚类。
2、自编码器自编码器是一种常见的深度学习技术,在文本聚类中经常被使用。
自编码器的工作原理是建立一个特定的神经网络,其中一部分网络层被用作输入,在经过若干层之后再输出一个相同的矩阵。
因此,自编码器可以从数据中自动抽象出最主要的特征。
3、卷积神经网络卷积神经网络(Convolutional Neural Networks)是一种常见的深度学习神经网络结构,其主要应用于图像识别和自然语言处理。
在文本聚类中,卷积神经网络主要用于提取文本数据中的特征,例如词汇、句子、段落等。
4、递归神经网络递归神经网络(Recurrent Neural Networks)是一种能够处理时序数据的神经网络结构,在文本聚类中也经常被使用。
文本聚类技术

文本聚类技术
文本聚类技术是一种将大量文本数据按照相似性进行自动分组的技术。
它通过计算文本之间的相似性,将相似的文本归为一类,不同的文本归为
不同的类别。
文本聚类技术一般被用于信息检索、信息过滤、舆情监测、
社交媒体分析、电子商务等领域。
文本聚类技术有多种方法,包括基于层次聚类、k-means聚类、密度
聚类、谱聚类、模型聚类等。
在进行文本聚类之前,需要进行文本预处理,例如去除停用词、词干提取、特征选择等。
此外,为了评估聚类的质量,
还需要使用一些评价指标,如聚类效果指标和聚类时效性指标。
文本聚类技术的应用非常广泛,例如可以用于对新闻文章、博客文章、产品评论、社交媒体帖子等进行分类。
它能够帮助用户快速地找到感兴趣
的信息,从而提高信息处理效率。
vectorizer.ai转换原理

vectorizer.ai转换原理Vectorizer.ai是一款广泛使用的自然语言处理工具,其核心功能是将文本转换为向量表示,从而实现文本的自动分类、聚类、相似度比较等任务。
本文将详细介绍Vectorizer.ai的转换原理,帮助读者深入了解其工作机制。
一、文本向量化向量izer.ai首先将输入的文本分解为单词或短语,然后使用词向量表示法将这些单词或短语转换为向量表示。
词向量是一种将单词表示为向量空间中的点的技术,能够捕捉单词之间的语义关系。
Vectorizer.ai使用了一种名为Word2Vec的算法来生成词向量,该算法通过训练大规模语料库中的单词出现频率来学习单词之间的相似性和关系。
二、特征提取在将文本转换为向量表示后,Vectorizer.ai通过特征提取技术提取与任务相关的特征。
这些特征可以是单词或短语的频率、逆文档计数、TF-IDF权重等。
这些特征能够捕捉文本中的关键信息,并将其转化为计算机可以理解的数值表示。
通过这种方式,Vectorizer.ai能够将复杂的自然语言处理任务转化为简单的数值计算问题。
三、模型训练Vectorizer.ai使用一种称为随机梯度下降(SGD)的优化算法来训练模型。
该算法通过不断迭代更新模型参数,以最小化预测误差。
在训练过程中,Vectorizer.ai会使用大量的文本数据作为训练集,并使用标签来指示每个文本的类别或聚类结果。
通过这种方式,Vectorizer.ai能够学习到不同类别或聚类之间的特征差异,并将其应用于未来的文本分类任务中。
四、转换过程一旦Vectorizer.ai完成训练,它将接受新的文本输入,并根据上述转换原理将其转换为向量表示。
Vectorizer.ai会首先将输入文本分解为单词或短语,然后使用Word2Vec算法将其转换为向量表示。
接着,Vectorizer.ai通过特征提取技术提取与任务相关的特征,并将这些特征作为模型的输入。
最后,Vectorizer.ai使用模型对输入文本进行分类或聚类,并将结果输出为标签或聚类结果。
Python中文自然语言处理基础与实战 案例6 文本分类与聚类

易于理解,逻辑表达式生成较简单;数据预处理要求低 ; 能够处理不相关的特征;可通过静态测试对模型进行评测; 能够短的时间内对大规模数据进行处理;能同时处理数据型 和常规型属性,可构造多属性决策树
易倾向于具有更多数值的特征;处理缺失数 据存在困难;易出现过拟合;易忽略数据集 属性的相关性
K最近邻
训练代价低,易处理类域交叉或重叠较多的样本集。适用于 时空复杂度高,样本容量较小或数据集偏斜
11
文本聚类常用算法
聚类方法各有优缺点,同聚类算法在性能方面的差异如下表所示。
聚类算法 基于层次的方法 基于划分的方法 基于密度的方法 Single-pass算法
处理大规模 数据能力
弱
处理高维数据 能力
较强
发现任意形状 簇的能力
强
数据顺序敏感度 不敏感
处理噪声能力 较弱
较弱
强
较强
不敏感
弱
较强
弱
强
不敏感
2
文本分类常用算法
3
文本聚类常用算法
10
文本聚类常用算法
➢ 传统的文本聚类方法如下所示。 • 使用TF-IDF技术对文本进行向量化。 • 然后使用K-Means等聚类手段对文本进行聚类处理。
➢ 聚类算法主要分为以下几种。 • 基于划分的聚类算法。 • 基于层次的聚类算法。 • 基于密度的聚类算法。 • 基于网格的聚类算法。 • 基于模型的聚类算法。 • 基于模糊的聚类算法。
分类标准进行分类。 ➢ 情感分析:情感分析是对带有主观感情色彩的文本内容进行分析和处理的过程,需要对这些评论进行情感
分析时,文本分类可以帮助实现,按照不同情感将其划分为若干类。 ➢ 信息检索:采用了文本分类的方法,通过判断用户查找内容的所属类别,从该类别的信息集合中再做进一
自然语言处理中常见的文本挖掘工具(十)

自然语言处理(NLP)是一门研究人类语言与计算机交互的学科,而文本挖掘则是NLP中的重要分支之一,旨在从大量文本数据中发现有用的信息和模式。
在文本挖掘中,有许多常见的工具和技术被广泛应用。
本文将介绍几种常见的文本挖掘工具,并探讨它们的应用和优缺点。
1. 词频统计词频统计是文本挖掘中最基本的技术之一。
它通过计算每个词在文本中出现的频率来帮助我们理解文本的内容和结构。
词频统计可以用来发现文本中的关键词,帮助我们了解文档的主题和重点。
然而,词频统计也存在一些局限性,比如忽略了词的顺序和上下文信息,导致无法理解词语之间的关系。
2. 词性标注词性标注是一种将文本中的词语标注为不同词性的技术。
通过词性标注,我们可以更好地理解文本中不同词语的语法和语义特征。
词性标注可以用于实体识别、句法分析等任务,帮助我们更深入地理解文本的意义。
然而,词性标注也存在一些困难,比如歧义词的处理和新词的识别。
3. 文本分类文本分类是一种将文本分为不同类别的技术。
通过文本分类,我们可以将大量的文本数据自动分类到不同的类别中,帮助我们更好地理解和利用文本信息。
文本分类可以用于情感分析、垃圾邮件过滤等任务,帮助我们更有效地处理文本数据。
然而,文本分类也存在一些挑战,比如特征选择和类别不平衡问题。
4. 实体识别实体识别是一种从文本中识别出命名实体的技术。
通过实体识别,我们可以自动识别文本中的人名、地名、组织名等重要实体,帮助我们更好地理解文本的含义和结构。
实体识别可以用于信息抽取、知识图谱构建等任务,帮助我们更好地利用文本信息。
然而,实体识别也存在一些困难,比如歧义实体的识别和新实体的发现。
5. 文本聚类文本聚类是一种将文本数据自动聚类成不同类别的技术。
通过文本聚类,我们可以发现文本数据中的潜在模式和结构,帮助我们更好地理解和利用文本信息。
文本聚类可以用于信息检索、主题发现等任务,帮助我们更有效地处理和分析文本数据。
然而,文本聚类也存在一些挑战,比如文本表示和聚类算法的选择。
文本数据挖掘技术导论-第5章 文本聚类
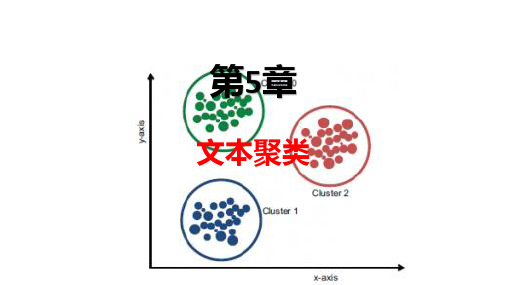
5.1 文本聚类概述
国内外研究现状与发展趋势 经过半个多世纪的研究,目前已经有了许多关于聚类分析的著作,聚类分析也
逐渐有了成熟的体系,并在数据挖掘方法中占据了重要的地位,现有的聚类分析方 法有以下五种,分别是划分式聚类算法、层次聚类算法、基于密度的聚类算法、基 于网格的聚类算法和基于模型的聚类算法。
5.2 文本聚类原理与方法
基于划分的方法 基于划分的方法就是给定一组未知的文档,然后通过某种方法将这些文档划分
成多个不同的分区,具体要求就是每个分区内文档尽可能的相似,而在不同分区的 文档差异性较大。给定一个含有n个文档的文本集,以及要生成的簇的数目k。每一 个分组就代表一个聚类,k<n。这k个分组满足下列条件:每一个分组至少包含一个 文档,每一个文档属于且仅属一个分组。对于给定的k,算法首先的任务就是将文 本集建成k个划分,以后通过反复迭代从而改变分组的重定位,使得毎一次改进之 后的分组方案都较前一次好。将文档在不同的划分间移动,直至满足一定的准则。 一个好的划分的一般准则是:在同一个簇中的文档尽可能“相似”,不同簇中的文 档则尽可能“相异”。
5.1 文本聚类概述
研究热点: (1)对于一些需要事先确定聚类数以及初始聚类中心的算法,如何优化这些超 参数的选取,从而提高算法的稳定性以及模型质量? (2)目前的许多聚类算法只适用于结构化数据,如何通过对现有算法进行改进 使其同样适用于非结构化数据? (3)随着大数据时代的来临,数据的体量变得越来越大,如何对现有算法进行 改进从而使得算法更加高效稳定? (4)现有的某些算法对于凸形球状的文档集有良好的聚类效果,但是对于非凸 文档集的聚类效果较差,如何改进现有算法从而提高算法对不同文档集的普适性?
由于中文文档没有词的边界,所以一般先由分词软件对中文文档进行分词,然 后再把文档转换成向量,通过特征抽取后形成样本矩阵,最后再进行聚类,文本聚 类的输出一般为文档集合的一个划分。
自然语言处理技术在智能客服系统中的应用

自然语言处理技术在智能客服系统中的应用智能客服系统是近年来随着人工智能技术的快速发展而兴起的一种新型客服工具。
传统的客服系统往往面临着诸多问题,如客服人员忙碌、效率低下、回复不准确等。
而自然语言处理技术的应用,则为智能客服系统提供了一种全新的解决方案。
本文将重点探讨自然语言处理技术在智能客服系统中的应用。
一、智能问答在智能客服系统中,自然语言处理技术被广泛应用于智能问答的场景。
传统的客服系统中,当用户遇到问题需要咨询时,往往需要进行繁琐的流程操作,如选择菜单、输入关键词等。
而智能客服系统则可以通过自然语言处理技术,以自然语言的形式直接与用户进行对话,提供更加便捷的咨询服务。
智能问答的关键在于理解用户的问题,并给出准确的答案或解决方案。
自然语言处理技术可以通过分词、词义解析、语法分析等技术手段对用户输入的问题进行处理和分析,从而提取到问题的关键信息。
然后,根据问题的内容和关键信息,智能客服系统可以通过匹配已有的知识库或者进行搜索,找到相关的答案或解决方案,并将其准确地呈现给用户。
二、情感分析除了智能问答,自然语言处理技术还可以应用于情感分析功能。
在客服交流中,用户的情绪变化往往会对问题的表达产生一定的干扰,从而影响到问题的解决效果。
而情感分析技术可以帮助智能客服系统更好地理解和把握用户的情绪变化,从而提供更加个性化的服务。
情感分析的主要任务是判断用户输入的文本中所包含的情感倾向,如喜、怒、哀、乐等。
自然语言处理技术可以通过对用户输入文本的语义和情感特征进行分析,从而准确地把握用户的情感变化。
在智能客服系统中,情感分析可以根据不同情感倾向给出针对性的回复或建议,以提升用户的满意度和体验。
三、语义理解和生成在智能客服系统中,语义理解和生成是自然语言处理技术的关键应用之一。
语义理解任务是将用户输入的自然语言文本转化为计算机可理解的形式,常用的方法包括词义解析、语法分析、语义角色标注等。
而语义生成则是将计算机处理得到的结果转化为用户可理解的自然语言文本。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
评价指标
所有类的总体评价
宏平均 Macro
微平均
分类算法
分类技术发展
分类算法
决策树(Decision Trees)
KNN算法(K-Nearest Neighbour) 支持向量机(SVM) 贝叶斯网络(Bayes Network) 神经网络(Neural Networks) Association rule-based Boosting
小结
自动分类的概念 分类效果的评价
特征选择
文档频率法(DF, document frequency ) 信息增益法(information gain) 互信息法(mutual information) The χ2 test(chi-square)
分类算法
KNN SVM
Japan Ministry Says Open Farm Trade Would Hit U.S.
Unfavourable Replacing “B” Shares
Jardine Vieille Montagne Matheson Said It Sets Says 1986 Two-for-Five Conditions Bonus Issue
文本自动聚类技术
什么是聚类分析?
聚类(簇 Cluster): 数据对象的集合 在同一个类中,数据对象是相似的 不同类之间的对象是不相似的 聚类分析 一个数据集合分组成几个聚类
聚类是一种无监督分类:没有预定义的类 典型应用 作为一个独立的工具透视数据分布 可以作为其他算法的预处理步骤
Amatil Proposes Two-forFive Bonus Share Issue AnheuserBusch Joins Bid for San Miguel
Citibank Norway Unit Loses Six Mln Crowns in 1986 Italy’s La Fondiaria to Report Higher 1986 Profits
headline(标题) of the news story. We’ll represent categories using colors.
(All examples with the same color belong
to the same category.)
人工标注的样例
政府事务 企业个人事务
自动分类算法分类
Rocchio方法
可以认为类中心向量法是它的特例
Rocchio公式
分类
决策树方法
构造决策树
CART C4.5 (由ID3发展而来) CHAID
决策树的剪枝(pruning)
决策树方法
Attribute Selection Measure: Information Gain(ID3/C4.5)
Attribute Selection Measure: Information Gain(ID3/C4.5)
entropy of attribute A with values {a1,a2,…,av}
information gained by branching on
attribute A
专家系统
美国人口调查局(1990)
十年人口统计资料的分析(2200万项资料) 232 产业类别和504行业类别 $15 million if fully done by hand Expert System AIOCS Development time: 192 person-months (2 people, 8 years) Accuracy = 47%
Given: Collection of example news stories already labeled with a category (topic).
Task: Predict category for news stories not yet labeled.
For our example, we’ll only get to see the
人工方法和自动方法
人工方法
结果容易理解
费时费力 难以保证一致性和准确性(40%左右的 准确率) 专家有时候凭空想象 知识工程的方法建立专家系统(80年代末期 )
自动的方法(学习)
•足球 and 联赛 体育类
结果可能不易理解 快速 准确率相对高(准确率可达60%或者更高) 来源于真实文本,可信度高
看见标题
Senate Panel Studies Loan Rate, Set Aside Plans
得到分类:政府事务
Senate Panel Studies Loan Rate, Set Aside Plans
评价指标
评价指标
「准确率」(P, precision)
「召回率」(R, recall) F-Measure
Select the attribute with the highest information gain S contains si tuples of class Ci for i = {1, …, m} information measures info required to classify any arbitrary tuple
其中,A为待分类的文本集合, B为分类体系中的类别集合
应用领域
门户网站(网页)
图书馆(电子资料) 情报/信息部门(情报处理) 政府、企业等(电子邮件)
自动分类的优点
减小人工分类的繁杂工作
提高信息处理的效率
减小人工分类的主观性
文本自动分类训练集中得出分类模型(需要测试 过程,不断细化) 用训练获得出的分类模型对其它文档 加以分类
文本挖掘技术
文本自动分类技术
知识的组织
知识的结构问题和知识是孪生的
分类体系
结构本身也是知识
杜威十进制系统(图书分类), 国会图书馆的目录, AMS(美国数学会)的数学知识体系 , 美国专利内容的类别体系 Yahoo,搜狐 & Dmoz(Open Directory )
Web catalogs
Gain(A) = I(s 1,s 2,...,sm)− E(A) 选择信息增益最大的属性作为判定的分支节 点
其他分类方法
Regression based on Least Squares Fit (1991) Nearest Neighbor Classification (1992) * Bayesian Probabilistic Models (1992) * Symbolic Rule Induction (1994) Decision Tree (1994) * Neural Networks (1995) Rocchio approach (traditional IR, 1996) * Support Vector Machines (1997) Boosting or Bagging (1997)* Hierarchical Language Modeling (1998) First-Order-Logic Rule Induction (1999) Maximum Entropy (1999) Hidden Markov Models (1999) Error-Correcting Output Coding (1999) ......
MEDLINE (National Library of Medicine)
$2 million/year for manual indexing of journal articles using MEdical Subject Headings (18,000 categories)
人工定义规则
基于机器学习的方法
最近邻分类方法 (Creecy ’92: 1-NN) Development time: 4 person-months Accuracy = 60%
统计学习取代知识工程
分类技术发展
A Text Categorization Example
新闻自动分类
Senator Bowater Isuzu Plans Defends U.S. Industries No Interim Mandatory Profit Farm Control Dividend Exceed Bill Expectations
什么没看到之前
能给一个新闻赋予什么颜色?
分类预测: ? 取多数?
城市规划:根据类型、价格、地理位置等来划分不同类型的住宅;
地震研究:根据地质断层的特点把已观察到的地震中心分成不同的类;
文本聚类
Document Clustering (DC) is partitioning a set of documents into groups or clusters Clusters should be computed to Contain similar documents Separate as much as possible different documents For instance, if similarity between documents is defined to capture semantic relatedness, documents in a clustershould deal with the same topics, and topics in each cluster should be different
评价指标
每个类 Precision=a/(a+b) Recall=a/(a+c), miss rate=1-recall accuracy=(a+d)/(a+b+c+d), error=(b+c)/(a+b+c+d)=1-accuracy fallout=b/(b+d)=false alarm rate, F=(β2+1)p.r/(β2p+r) Break Even Point, BEP, p=r的点 interpolated 11 point average precision(pr曲线)