第六章语义和符号表
符号表原理介绍(详细)

§6.1 符号表的作用和地位
二、上下文语义的合法性检查的依据 上下文语义的合法性检查的依据 语义的合法性检查
同一个标识符可能在程序的不同地方出现,而有关该符号的属 性是在不同情况下收集的。通过符号表中属性记录可进行相应 上下文的语义检查。 例如: 例如 int i [3][5]; float i[4][2]; int i [3][5]; 1. 2. 首先在符号表中记录i的属性是3×5个整型元素的数组 在分析第二、第三个说明时,通过符号表检查出标识符i的二次 二次 重定义冲突错误 重定义
§6.2 符号的主要属性及作用
(2) 动态存储区 根据变量的局部定义和分程序结构,编译程序设置动态存储区来 适应这些局部变量 局部变量的生存和消亡。局部动态变量 局部动态变量的生存期是定义 局部变量 局部动态变量 该变量的局部范围,即在该定义范围之外此变量已经没存在的必 要。及时撤销时这些单元的分配可以回收,从而提高程序运行时 的空间效率。 对变量存储分配的属性除了存储类别之外还要确定其在所在存储 区的具体位置的属性信息。通常在符号表中存放具体位置的信息 是按该变量的存储区类分别依出现先后的次序(扫描源程序的次 序)排列下相对该存储区表头的相对位移量来表示的。
§6.2 符号的主要属性及作用
(2) 分程序(或复合语句)结构 // 第一层头,定义的局部整型变量a {int a; ; … // 第二层头,定义的局部字符型变量a {char a; ; … // 第三层头 { … {float a; // 第四层头,定义的局部实型变量a ; … // 第四层尾 } …a… // 引用第二层定义的局部字符型变量a // 第三层尾 } // 第二层尾 } // 第一层尾 }
§6.2 符号的主要属性及作用
编译原理课件(刘铭)第6章

本章小结
也就是说标识符是一个没有意义 的字符序列,而名字有确切的意义。 在程序语言中标识符可以是一个变量 的名字或一个函数的名字。
例如 area , 作为标识符,它没有 任何意思,但作为名字,可以表示 变量名或函数名等。
本章小结
3. 符号表的查找
符号表查找算法与该符号表的构造方法 密切相关即有顺序查找、折半查找和杂 凑查找算法。
6.3 符号表的组织
一个编译程序,从词法分析、语法 分析、语义分析到代码生成的整个过程 中,符号表是连贯上下文进行语义检查、 语义处理、生成代码和存储分配的主要 依据,因此符号表的组织直接关系到这 些语义功能的实现和语义处理的时空效 率。
6.3 符号表的组织
符号表的表格形式
名 字 栏 信 息 栏
符号表的作用
符号表的组织
符号表的建立和查找
6.1 符号表的作用与生成期
符号表的作用 符号表用来存放程序语言中出现 的有关标识符的属性和特征。 符号表在整个编译期间的作用归 纳为以下几个方面: 将标识符的名字及属性登录在符号 表中
6.1 符号表的作用与生成期
在分析说明语句时,编译程序根 据说明语句信息将标识符的相应属性 如标识符的类型:实型,整型,布尔 型等;标识符的种属:数组名,变量 名,过程名,函数名等; 标识符的作用 域:全局变量或局部变量等信息登录 到符号表中。
名字栏存放标识符的名字,信息栏存放 名字相关属性。
. . .
. . .
6.3 符号表的组织
符号表的总体组织 1. 编译程序按名字的不同属性构造出多 个符号表。如常量表、变量名表等。 符号表结构相同,表项等长。不便管理。
2. 编译程序把语言中的所有名字组织在 一张符号表中。 符号表便于管理,但表结构复杂且表项 不等长。
c语言 程序符号表

在C语言中,符号表(Symbol Table)是编译器在编译过程中用来存储变量、函数、宏等符号信息的数据结构。
符号表对于编译器的语义分析和代码生成阶段非常重要,它可以帮助编译器识别和解析标识符,并进行类型检查、函数链接等操作。
在C语言的编译器中,符号表通常是一个表格或哈希表结构,其中存储了以下类型的符号信息:
1.变量符号:包括变量的名称、类型、作用域等信息。
2.函数符号:包括函数的名称、参数类型、返回类型等信息。
3.宏定义符号:包括宏的名称、宏的参数和宏的替换文本等信息。
4.其他符号:例如结构体、联合体、枚举等类型的名称和成员信息。
在编译过程中,编译器会根据源代码中的标识符,将其添加到符号表中,并记录相关的符号信息。
同时,编译器还会对符号表中的信息进行验证和更新,以确保类型安全和正确的链接。
需要注意的是,具体的符号表实现方式可能会因编译器而异,但它们的基本原理和功能是相似的。
第六章 语义分析和符号表

FixBody: VariBody:
CaseUnit VariUnits
FixBody
VariBody Next
id CaseType Off
set:
Size Size Size
Kind Kind Kind
BaseType CompType TypeName
file:
pointer:
例有如下的类型定义:
标号部分语义分析原理
设置五种表:LDEC,LDEF,LUSE,SL,PL
LDEC表:(Flag, Label,<Label>); LDEF、LUSE表:(Label); SL表:(kind,LDEFaddr,LUSEaddr); PL表:(LDECaddr,LDEFaddr);
标号的语义分析原理
符号表
符号表的作用:为语义检查和代码生成提供 标识符的语义信息。 标识符的处理思想: 遇到定义性标识符时,在符号表中填写 被定义标识符的符号项; 当遇到使用性标识符时,用该标识符查 符号表求得其属性。
标识符的特点
标识符的作用域:标识符有效的最大程序段 嵌套作用域规则:当存在标识符的嵌套声明 时,最近定义的属性为标识符的当前属性 局部化单位:允许有声明的程序段
标准类型: Size sub: enum: array:
Size Size Size Kind HostType Elems Low Up Leng ElemType
Kind Kind Kind
IndexType
record:
Size Kind FixBody VariBody id FixUnitType Off Next
类型的内部表示
类型的种类:标准、子界、枚举、数组、记录、 集合、文件、指针类型等等。 TypeKind=(intTy,boolTy,charTy,realTy,enumTy, subTy,arrayTy,recordTy,setTy,fileTy,pointerTy)
语义分析和语法制导翻译-编译原理-06-(二)

是语法结构树指针 是名字的表项入口 是数值
id.entry num.val
树构造函数
mknode 建中间结点 mkleaf 建叶结点
生成语法树的属性文法
产生式 S→id:=E 语义规则 S.p:= mknode(':=', mkleaf(id, id.entry), E.p)
E→E1+E2 E.p:= mknode('+', E1.p, E2.p) E→E1*E2 E.p:= mknode('*', E1.p, E2.p) E→ -E1 E→ (E1) E→ id E→ num E.p:= mknode('-', 0, E1.p) E.p:= E1.p E.p:= mkleaf(id, id.entry) E.p:=mkleaf(num,num.val)
翻译模式的设计
D → T { L.in := T.type } L T → int { T.type := integer } T → real { T.type := real } L → { L1.in := L.in } L1 , id { addtype(id.entry, L.in) } L → id { addtype(id.entry, L.in) }
从其兄弟结点和父结点的属性值计算出来的 如:L.in
固有属性(单词属性)
属性的计算
构造语法分析树,填加响应的语义规则 综合属性
自底向上按照语义规则来计算各结点的综
合属性值
继承属性
需要探讨计算次序
例6-3:3*5+4 的
语法树与属性计算
E.val=15 T.val=15 T.val=3 F.val=3 digit.attr=3 *
c语言符号表

C 语言符号表C 语言符号表是一个重要的编译器数据结构,它用于存储和管理程序中的各种符号。
符号是指程序中的变量、函数、常量、类型等具有标识作用的名称。
符号表的作用是在编译过程中,为符号分配内存地址、类型、作用域等属性,并在需要时查找和修改符号的相关信息。
本文将从以下几个方面简述 C 语言符号表的概念、结构、功能和实现方法:符号表的概念和分类符号表的结构和组织方式符号表的功能和操作符号表的实现方法和技术符号表的概念和分类符号表的概念符号表是一种映射关系,它将程序中的符号名称映射到其对应的属性集合。
属性集合包括了符号的内存地址、数据类型、作用域、存储类别、初始化值等信息。
例如,下面的 C 语言代码片段中,定义了一个全局变量globalA,一个静态变量globalB,一个函数funcA和一个主函数main:/*** 全局变量*/int globalA =2022;/*** 静态变量*/static int globalB =2023;int funcA() {int localFuncAValue =13;return0;}int main(int argc, char*argv[]) {int localMainValue =14;return0;}对于这段代码,编译器会为每个符号创建一个符号表项,并填充其属性。
一个可能的符号表如下:符号名称内存地址数据类型作用域存储类别初始化值globalA1000int全局外部2022globalB1004int全局静态2023funcA2000int()全局外部-main3000int(int, char**)全局外部-localFuncAValue-4(%rbp)int局部(funcA)自动-localMainValue-4(%rbp)int局部(main)自动-可以看到,每个符号表项由一个符号名称和一个属性集合组成。
属性集合可以根据不同的编译器设计而有所差异,但一般都包含了上述几个基本属性。
第6章 语义分析(1)
类型的内部表示
为什么需要类型的内部表示?
– 类型是标识符的重要属性; – 类型检查是语义分析的重要部分; – 类型的结构对类型检查很重要;
程序语言的类型
– 基本类型 Integer (int ) Real (float) Bool Char – 构造类型 数组(Array) 结构体(Structure、record) 联合类型(Union、变体记录) – 枚举类型 – 指针类型
联合类型的内部表示
Kind Body unionT y Body: 指向联合体中域定义链表 Size: 所有域的类型的size中最大值;
Body
FieldName FieldType Next
Size
typedef union{ int i; char name[10]; real x; } test;
基本类型的内部表示
Size intPtr Kind
intSize
boolSize realSize
intTy
boolTy realTy
boolPtr realPtr
charPtr
charSize
charTy
数组类型的内部表示
Size
Kind arrayTy
Low
Up
ElemTy
size = sizeof(ElemTy) (Up-Low+1) ElemTy: 指向数组成分类型的指针; array [2..9] of integer; (8, arrayTy, 2, 9, intPtr)
第六章 语义分析
6.1 语义分析概述
6.2 符号表
6.3 类型的语义分析 6.4 声明的语义分析 6.5 程序体的语义分析 么是符号表(Symbol Table)?
编译原理符号表

编译原理符号表1. 引言编译原理是计算机科学领域中一个重要的研究方向,它研究的是将高级语言程序转化为机器语言的过程。
在编译器中,符号表是一种常用的数据结构,用于存储程序中的各种符号及其相关信息。
本文将深入探讨编译原理符号表的概念、作用、设计方法以及常见的符号表实现方式。
2. 符号表的概念和作用2.1 符号表的定义符号表是编译器中用于存储程序中各种符号信息的数据结构。
它一般由编译器自动生成和维护,用于支持语法分析、语义分析和代码生成等编译过程。
2.2 符号表的作用符号表在编译器的各个阶段都发挥着重要的作用:•语法分析阶段:符号表用于识别和存储各种变量、函数和类型的声明信息,以支持后续的语义分析过程。
•语义分析阶段:符号表用于检查变量和函数的引用是否合法,并记录其类型信息和作用域等属性,以支持类型检查和语义约束的验证。
•代码生成阶段:符号表用于存储中间代码和目标代码中的符号引用和符号定义的映射关系,以支持代码生成和目标代码优化等过程。
3. 符号表的设计方法3.1 符号表的数据结构符号表的数据结构通常由符号表项组成,每个符号表项用于存储一个符号及其相关信息。
常见的符号表项包括符号名称、符号类型、作用域、内存地址等。
3.2 符号表的组织方式符号表的组织方式可以有多种选择,常见的包括线性表、哈希表、树和图等。
选择合适的组织方式可以提高符号表的查询效率和插入删除的性能。
3.3 符号表的查询算法符号表的查询算法是指根据给定的符号名称,在符号表中进行查找并返回对应的符号表项。
常见的查询算法有线性搜索、二分搜索和哈希搜索等,选择合适的查询算法可以提高符号表的查询效率。
4. 常见的符号表实现方式4.1 线性表实现线性表实现是符号表最简单的一种实现方式,它可以使用数组或链表来存储符号表项。
线性表实现的优点是简单易懂,缺点是查询效率较低,随着符号表规模的增大,性能下降明显。
4.2 哈希表实现哈希表实现是一种常用的符号表实现方式,它通过哈希函数将符号名称映射到符号表项存储的位置。
第6章 语义分析(2)

– 一般形式 id = type; 一般形式: – 内部表示 内部表示:
建立 type的内部表示; 建立 id的内部表示;
TypePtr
Kind typeKind
6.4 声明的语义分析
变量声明
– 一般形式: type id; 一般形式 – 内部表示 : 建立 type的内部表示;
获取<CurrentLevel, CurrentOffset> 获取 确定存取方式: 确定存取方式 dir/indir 建立 id的内部表示; CurrentOffset += sizeof(type)
语句
… FunNode1
6.4 声明的语义分析
常量声明
– 一般形式 id = number; 一般形式: – 内部表示 内部表示:
建立 number值的内部表示; 建立 number类型的内部表示; 建立 id的内部表示;
TypePtr
Kind constKind
Value
6.4 声明的语义分析
第六章 语义分析
6.1 语义分析概述 6.2 符号表 6.3 类型的语义分析 6.4 声明的语义分析 6.5 程序体的语义分析 6.6 属性文法和动作文法
内容回顾
什么是语义分析? 什么是语义分析
– 建立符号表 建立符号表; – 检查语义错误 检查语义错误;
在何处进行分析? 在何处进行分析
– 声明部分 --- 建立符号表;检查“重复声明”错误 建立符号表;检查“重复声明”错误; – 体部分 --- 查找符号表,检查“有使用无声明”错误和 查找符号表,检查“有使用无声明”
Size
Kind structTy
Body
6.3 类型的语义分析
编译原理_第6章__语义分析和中间代码生成

非终结符T有一个综合属性type,其值为 int或float。语义规则L.in=T.type表示L.in的属性 值由相应说明语句指定的类型T.type决定;属 性L.in被确定后将随语法树的逐步生成而传递 到下边的有关结点使用,这种结点属性称为继 承属性。由此可见,标识符的类型可以通过继 承属性的复写规则来传递。 例如,对输入串int a,b,根据上述的语义 规则,可在其生成的语法树中看到用“→”表 示的属性传递情况,如图6–3所示。
直接生成目标代码 直接生成机器语言或汇编语言形式的目标 代码的优点是编译时间短且无需中间代码到目 标代码的翻译。 生成中间代码 生成中间代码的优点是使编译结构在逻辑 上更为简单明确,特别是使目标代码的优化比 较容易实现。
语义分析时语义检查的分类:
动态语义检查
需要生成相应的目标代码,它是在运行时进行的;
例如,简单算术表达式求值的属性文法如下: 规则 语义规则 (1) S→E print (E.val) (2) E→E(1)+T E.val=E(1).val+T.val (3) E→T E.val=T.val (4) T→T(1)*F T.val=T(1).val*F.val (5) T→T(1) T.val=T(1).val (6) F→(E) F.val=E.val (7) F→i F.val=i.lexval
6.1 概
述
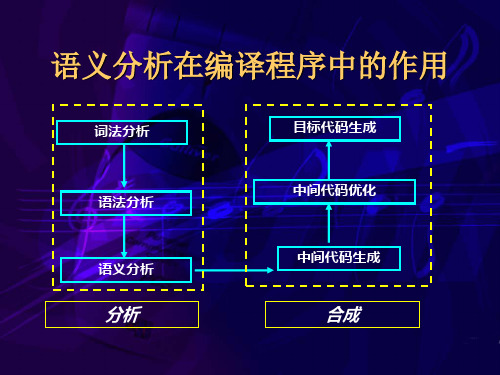
6.1.1 语义分析的概念 一个源程序经过词法分析、语法分析之后,表 明该源程序在书写上是正确的,并且符合程序语言 所规定的语法。但是语法分析并未对程序内部的逻 辑含义加以分析,因此编译程序接下来的工作是语 义分析,即审查每个语法成分的静态语义。如果静 态语义正确,则生成与该语言成分等效的中间代码, 或者直接生成目标代码。
语义分析与符号表

第五章语义分析5.1语义分析基础5.1.1 语义分析内容程序设计语言的语义可分为静态语义和动态语义。
所谓静态语义是指在编译阶段能检查的语义,而动态语义则指只有在目标码的运行阶段才能检查的语义。
如果所有类型均能在编译阶段检查,则称这种语言为强类型语言。
Pascal是强类型语言的一个例子。
在某些语言里变量的类型是可变的,这时类型的语义成为动态语义,因为类型相容问题只能在代码运行时才能检查出来。
语言的静态语义成分越多编译器和解释器的区别会越大,如果都属于动态语义,那么编译器和好的解释器的差别将会变小。
类型在大多数语言里都属于静态语义,而且它是最重要的静态语义,可以说,静态语义问题主要是类型相容的问题。
类型检查主要有以下几种:∙各种条件表达式的类型是不是boolean型?∙运算符的分量的类型是否相容?∙赋值语句的左右部的类型是否相容?∙形参和实参的类型是否相容?∙下标表达式的类型是否为所允许的类型?∙变体记录中表示情形的常量是否为合法类型?∙函数说明中的函数类型和返回值的类型是否一致?等除了上述类型检查外,还要进行如下一些语义检查:∙V[E]中的V是不是变量,而且是数组类型?∙V.i中的V是不是变量,而且是记录类型? i是不是该记录类型中的域名?∙V↑中的V是不是指针或文件变量?∙y+f(....)中的f是不是函数名?形参个数和实参个数是否一致?∙p(....)语句中的p是不是过程名?形参个数和实参个数是否一致?∙每个使用性标识符是否都有相应的声明?在同层内有无标识符被声明多次?∙标号是否有声明?有无重复声明和重复定位错误?有无非法转入错误?∙子界类型中的下界和上界类型是否相容?下界是否小于等于上界?∙ ..........................................一遍扫描的编译器是从源程序的ASC码序列即源语言的字符串序列直接生成目标代码,因此不会有独立的语义分析器。
多遍扫描的编译器,也未必有独立的语义分析器,如果没有,则意味着把语义检查工作分散到编译过程的几个阶段中顺便完成。
第六章(2)符号表的管理

}
} a = 1, b = 1 printf(“a = %d, b = %d\n”, a, b);
}
33
2.在语言程序的局部化单位中,标识符的出现分为定 义性出现和使用性出现。
⑴定义性出现的标识符:局部化单位的声明部分出现 的标识符,其作用是确定该标识符的属性信息,如 名字,类型,存储位置等。一个标识符在一个局部 化单位只能被声明一次。
28
❖对于散列表,新符号的登录是通号表的目的:
判断该符号的存在性; 获取该符号的语义属性. ❖符号表的查找算法:顺序查找、折半查找、杂凑查 找.
30
6.3.3 符号表的局部化处理
一、问题的引出
1.源语言程序的局部化单位 程序中允许有声明的 部分称为一个局部化单位,通常是一个子程序(函数、 过程)或分程序:
19
6.3.1 符号表的建立和查找
一.符号表的初始化 在编译过程中某个时刻,符号表的状态反
映了该时刻被编译的语言程序正被编译的位置 的状态.具体来说主要是反映了在该时刻被编译 的语言程序中可视标识符的状态. 符号表的初始化,在对语言程序开始编译的时刻, 定义建立符号表的初始状态.
20
1.符号表的表长是渐增变化的情况: ❖线性组织和二分法组织的符号表,其表的长度在编译开始时 通常为0,而随着符号的逐步登录,表长增长. ❖按这类方法组织的符号表,其初始化方法只需将表尾推向表
一、符号表的总体组织
符号表的每一项包含两部分:标识符的名字;该名字的信 息。
不同类别的标识符所包含的信息是不同的。 符号表的总体组织既可以采用多表结构,也可以采用单表
结构,也可以二者折中。究竟采用哪种结构并没有统一的规 定,编译程序可根据实际处理语言的需要进行选择。
编译原理第四版课后答案

编译原理第四版课后答案第一章简介1.1 编译原理的定义编译原理是计算机科学中一个重要的领域,它涉及到将高级程序语言转化为机器语言的过程。
编译原理的目标是设计和实现一个能够将源代码转化为机器语言的编译器。
1.2编译器的结构和功能编译器一般包含以下几个部分:词法分析器、语法分析器、语义分析器、中间代码生成器、代码优化器和目标代码生成器。
这些部分协同工作,将源代码转化为可执行的机器语言。
1.3 编译原理的应用编译原理广泛应用于各个领域,如操作系统、数据库、嵌入式系统等。
在这些领域中,编译原理被用于将高级程序语言转化为机器语言,以在计算机上执行。
第二章词法分析2.1 词法分析的基本概念词法分析是编译器中的第一步,它将源代码划分为一个个的词法单元,如标识符、关键字、常量等。
词法分析器通过对源代码进行扫描和解析,生成词法单元的序列。
2.2 正则表达式正则表达式是一种用于描述字符串模式的工具。
在词法分析中,正则表达式常被用于识别和匹配不同的词法单元。
例如,正则表达式[a-z]+可以用来匹配一个或多个小写字母组成的标识符。
2.3 有限自动机有限自动机是一种用于识别和处理正则表达式的工具。
它由状态和转移函数组成,能够根据输入字符的不同改变状态,并最终确定是否接受输入。
有限自动机常被用于实现词法分析器。
第三章语法分析3.1 语法分析的基本概念语法分析是编译器中的第二步,它将词法单元序列转化为一棵语法树。
语法树是一种树形结构,用于表示源代码的语法结构。
语法分析器通过对词法单元序列进行解析和归约,生成语法树。
3.2 上下文无关文法上下文无关文法是用于描述程序语言语法的形式化工具。
它由一个或多个产生式组成,每个产生式包含一个非终结符和一串终结符或非终结符。
上下文无关文法常被用于定义编程语言的语法规则。
3.3 语法分析算法语法分析算法有多种,如递归下降分析、LL(1)分析、LR(1)分析等。
这些算法都是基于上下文无关文法的语法规则进行解析和归约,并生成语法树。
10+8--语义分析与符号表
基本概念
符号表
类型检查
VSL语言的符号表 1/3
符号表元素的数据类型 typedef struct symb { struct symb *next; int type; union { int val; char *text;
/* /* /* /* /*
} val1; union { /* 变量的第一个值 */ int val; /* 对变量取偏移量等 */ struct tac *label; /* 对标号取三地址码 指针 */ } val2 ; } SYMB ; /* 整数常量, 字符串常量和语句标号等也使用 本数据类型, 但是由于没有对其查找的要求, 这些数据将不保存在Hash表中 */ SYMB *symbtab[HASHSIZE] ; /* 符号表 */
静态性质(static):在编译阶段就可以确定的性质, 如:C语言的全 局变量, 类型, 变量和类型的关系,运算和转移指令和函数的入口 地址; 动态性质(dynamic):程序在运行阶段才能确定的性质— 程序在运 行时才能确定的性质,如:C语言的被调用函数的运行环境 (参数、 返回地址、 局部变量和返回值) ;面向对象语言的Virtual Function的动态绑定(binding); 动态性质有相对不变性, 栈式运行环境中, 如: 局部变量和栈顶的 位置关系是不变的; 动态性质必须用其相对不变性实现, 如:函数的调用和被调用转 化为相对不变的调用序列和被调用序列; 语义分析(Semantic Analysis)是编译器前端(front-end)的最后一个 环节, 主要是符号表的建立和类型检查(type checking), 为下一 步中间表示提供必要的上下文相关的信息。
下一个节点 */ 符号的数据类型 */ 变量的第一个值 */ 对整数常数取其值 */ 对变量取其形, 为字符指针 */
6-第六章_语义分析-1-2-3节

2.语义分析程序 2.语义分析程序
为每个产生式,构造一个语义子程序Subi , 为每个产生式,构造一个语义子程序Sub 语义程序包括: 针对每一条产生式) 语义程序包括:⑴ Subi (针对每一条产生式) 公共子程序) ⑵ Comj (公共子程序)
语法分析程序 Par1,Par2…Park 语义 分析 程序 Sub1 Sub2 Ret1,Ret2…Reth
L.in= real L.in= real , , id2 id3
L.in= real id1
语 义 规 则 L.in:=T.type T.type=integer T.type:=real L1.in:=L.in;addtype(id.entry,L.in) ; addtype(id.entry,L.in)
…
Subn 中间代码Leabharlann Com1… Com m
例:E→E1 + E2 入口参数(Par) (Par): .PLACE, 入口参数(Par): E1.PLACE, E2.PLACE (存放E1 、E2 的值的单元地址) 存放E 的值的单元地址) 返回参数(Ret): E.PLACE (存放E值的单元地址) 返回参数(Ret): (存放E值的单元地址) (Ret) 存放 生成中间代码 ( +, E1.PLACE, E2.PLACE, E.PLACE)
例: E → E1 + E2 E .code —— E的中间代码序列 E .val —— E的值 存放E E .PLACE —— 存放E的值的单元地址
说明: 不同的中间代码形式、不同的语言成份, 说明: 不同的中间代码形式、不同的语言成份, 使用的属性不同。 使用的属性不同。
属性 • 综合属性(synthesized attribute) 综合属性(synthesized
编译原理课件-符号表

關鍵字域的組織
符號表的關鍵字域(段)就是符號名稱 等長關鍵字域(段)符號表 不等長關鍵字段符號表---採用關鍵字池的 索引結構。
作用域檢查 作用域和可見性
基本作用域規則(lexical rule) int a;
void Binky(int a) { int a; a = 2; ...
} 作用域檢查實現: 1每個作用域一個獨立的符號表,這些符號表組織成作用域
name:alfa; case kind: object of
constant: (val: integer); variable,procedur: (level, adr, size: integer) end;
例程式說明部分為:
CONST A=35,B=49;
Const(常量)無層次
VAR C,D,E;
VAL:35 VAL:49 LEVEL:LEV LEVEL:LEV LEVEL:LEV LEVEL:LEV LEVEL:LEV+1
ADR:DX ADR:DX+1 ADR:DX+2 ADR: ADR:DX
SIZE:4
…… ……
……
……
名字
類型
層次/值
地址 存儲空間
某編譯器的符號表實例
編譯程序分析第13行時符號表的內容
7.4 符號表
.符號表的作用和地位 .符號的主要屬性及作用 .符號表的組織
符號表的作用和地位-----語義檢查的依據
目標代碼生成階段地址分配的依據
在編譯程式中符號表用來存放語言程式中出現的有 關識別字的屬性資訊,符號表中所登記的資訊在 編譯的不同階段都要用到。
在語義分析中,符號表所登記的內容將用於語義檢 查(如檢查一個名字的使用和原先的說明是否一 致)和產生中間代碼。
计算机编译chapt6

V→Elist]
{ V.place:=getc(Elist.array); V.offset:=Elist.place } 数组元素的宽度W1时, V.offset:=newtemp; emit(*,Elist.place,W,V.offset);
E→V
{ if V.offset=null then E.place:=V.place else begin E.place:=newtemp; emit(=[],V.place[V.offset],-,E.place); end }
2. 语法制导翻译
为每个产生式配上一个语义子程序,在语
法分析过程中,当用一个产生式进行匹配 或归约时,就调用相应的语义程序。
上述语义子程序既可能包含了语义检查,
也可能包含了语义处理,其核心是为了生 成相应的中间代码。
例:语法分析采用自底向上的LR分析法 XAB B的语义值 B A的语义值 YCD A ZXY
(2)两条新的四元式 变址取数 (=[],T1[T],_,X) 相当于X:=T1[T] 变址存数 ([]=,_,X,T1[T]) 相当于T1[T]:=X
(3)语义子程序 V→i { P:=lookup(); if P<>nil then begin V.place:=P; V.offset:=null end else error }
E4.place=d E5.place=t4
(*,t1,4,t2)
(=[], X0[t2],_,t3)
(+,t3,d,t4) (:=,t4,_,a)
Elist.array:记录数组名
Elist.place:记录归约过程中VARPART
的中间结果 Elist.dim:记录当前处理这一维的序号 getc(Elist.array):从内情向量中取数组的 CONSPART limit(Elist.array,k):从内情向量中取数组 第k维的维长
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
值的内部表示
非结构类型值的内部表示:
实型 指针 有序类型:整数形式
有序类型ห้องสมุดไป่ตู้常量表示:
整型常量:ord(N) = N 布尔常量:ord(false)=0, ord(true) = 1 字符常量:ord(C) = ASCⅡ (C) 枚举常量:设有枚举类型(D,A,B),则有
ord(D)=0,ord(A)=1,ord(B)=2 子界常量:设有子界类型C1..C2,则值空间
语义分析和符号表
主要内容: 语义分析概述(必要性、功能、描述方法) 符号表 类型表达式 声明和程序体的语义分析
语义分析的必要性
语法和语义的区别: 语法:关于什么样的字符串才是该语言 在组成结构上合法的程序的法则。 语义:关于结构上合法的程序的意义的 法则。
语义分析的功能
语义种类
静态语义:在编译阶段(从程序文本上)可 以检查的语义。
VariBody:
CaseUnit VariUnits
FixBody VariBody Next
id CaseType Off
set: Size
file: Size
pointer:
Size
Kind Kind
BaseType CompType
Kind TypeName
例有如下的类型定义: at = ARRAY [1..10] OF ARRAY[1..100] OF integer; rt = RECORD x : real ; a : at; CASE u: boolean OF false:(k : integer); true:(y: real; b: boolean) END 构造类型的内部表示。
符号表的实现
用局部符号表实现 proc p:x,y,z
proc p1:x,y1,z1 proc p2:y y,z x,y1,z1,y
proc p3:z,a x,y,a
x,z
符号表的实现
用全局符号表实现 proc p0:x,y proc p1:x,z y proc p2:x1,y1 y x,z
语义分析例子
例有声明如下: CONST pai= 3.14 ; TYPE vector=ARRAY[1..10] OF integer; VAR x, y : real ; r, s : vector ;
设当前层数和可用offset值分别为L和0, 构造标识符 pai, vector, x, y, r 和s 的属性表示。
program p() type at=array[1..100] of array[1..10] of inteter var x:real; a:at; i:integer; proc p1(var a1:at; a2:at) var x:integer; a:real; proc p2(n:integer) var m:1..50; x:real; m,n,x(使用性出现) end a1,a2,x,a,i(使用性出现) end x,a,i(使用性出现)
内部表示(AttributeIR):
常量: TypePtr Kind
Value
类型: TypePtr Kind
Forward
变量: TypePtr Kind Access Level Off
域名*: TypePtr Kind
Off
过函:
TypePtr Kind Level Parm Class
HostType Off Code Size Forward
处理符号表的模块: 定义符号表数据结构 定义符号表上的操作
符号表
符号表的作用:为语义检查和代码生成提供 标识符的语义信息。
标识符的处理思想: ▪ 遇到定义性标识符时,在符号表中填写 被定义标识符的符号项; ▪ 当遇到使用性标识符时,用该标识符查 符号表求得其属性。
标识符的特点
标识符的作用域:标识符有效的最大程序段 嵌套作用域规则:当存在标识符的嵌套声明
动态语义:通过程序的执行才能检查的语 义。
语义的描述
语义形式化方法: 1. 操作语义 2. 指称语义 3. 公理语义 4. 代数语义
语义分析的内容:
类型分析 标识符相关信息
语义分析的功能:
检查语义错误 构造标识符属性表(符号表)
语义分析的实现:
与语法分析相结合
语义分析的功能图示
语法分析树 TokenList
符号表的种类:全局符号表、局部符号表
原则:
▪ 进入一个局部化区时,记录本层符号表的 位置
▪ 遇到定义性标识符时,构造其语义信息, 查本层符号表,若存在,则有重复声明错 误,否则将语义信息填入表中
▪ 遇到一个使用性标识符时,查表(从里层 到外层),查不到则有未定义标识符错 误,否则构造新的TOKEN
▪ 退出一个局部化区时,作废本层符号表
sub: Size Kind HostType Low Up
enum: Size
Kind
Elems Leng
array: Size Kind IndexType ElemType
record: Size Kind FixBody VariBody
FixBody: id FixUnitType Off Next
语义分析
语义定义 自然语言描述规定
符号表 判定
三种内部表示
标识符的内部表示 类型的内部表示 值的内部表示
标识符的内部表示
标识符种类:
常量名、类型名、变量名、函数名、过程名、域名。
TYPE idkind=( consKind, typeKind, varKind,
fieldKind, procKind,funcKind )
为[ord(C1)...ord(C2)]
符号表
标识符的作用: 声明部分:定义了各种对象及对应的属性和 使用规则。 程序体:对所定义的对象进行各种操作。
必要性 Token: $id idname 新表-符号表(种类、类型等信息):
Idname AttributeIR
有关符号表的操作: 添加、作用域删除、查询
时,最近定义的属性为标识符的当前属性 局部化单位:允许有声明的程序段
P: Var x ,y,z x:=0;
Q: Var x,m,n
x:=1; m:=x+1;
y:=x+1;
局部化区入口
Proc p(… Func f(… 形式过/函 p( … f(… Record begin…
标识符处理的原则
类型的内部表示
类型的种类:标准、子界、枚举、数组、记录、
集合、文件、指针类型等等。 TypeKind=(intTy,boolTy,charTy,realTy,enumTy,
subTy,arrayTy,recordTy,setTy,fileTy,pointerTy)
内部表示:(TypeIR)
标准类型: Size Kind