离群点挖掘复习过程
离群点的判定

离群点的判定摘要本文首先对离群点进行了定义,离群点(outlier)是指数值中,远离数值的一般水平的极端大值和极端小值。
因此,也称之为歧异值,有时也称其为野值。
深入了解了形成离群点的原因,并建立数学模型来找出一维、n维数据中的离群点,主要利用聚类的离群挖掘法。
针对问题一,考虑到数据的杂乱性,先对数据进行排序,由于在实际生活中我们需要处理的数据量往往比较多,离群点的个数也不确定,就考虑对数据进行分类处理,利用离群值跳跃度比较大的特点,采用斜率比较的方法进行分类,在分类的过程中我们就会很容易的发现离群点。
最后再对完成分类的数据进行分析。
完成分类的数据往往差距更小,可以近似的认为数据服从正态分布,利用正态分布的性质可以找出每类数据中的离群点,这样就找出了数据中所有的离群点。
针对问题二,我们主要采用具体的数据绘制具体的图形来分析存在的离群点,并说明离群点带来的影响。
针对问题三,我们主要利用基于聚类的离群挖掘方法,先利用一趟算法对数据集进行聚类;然后再计算每个簇的离群因子,并按离群因子对簇进行排序,最终确定离群簇,也即确定离群对象。
确定算法以后再利用具体的数据进行检测,看该模型是否可行。
关键词:数据的分类处理聚类的离群挖掘方法(CBOD)一、问题重述A题:离群点的判定离群点(outlier)是指数值中,远离数值的一般水平的极端大值和极端小值。
因此,也称之为歧异值,有时也称其为野值。
形成离群点的主要原因有:首先可能是采样中的误差,如记录的偏误,工作人员出现笔误,计算错误等,都有可能产生极端大值或者极端小值。
其次可能是被研究现象本身由于受各种偶然非正常的因素影响而引起的。
例如:在人口死亡序列中,由于某年发生了地震,使该年度死亡人数剧增,形成离群点;在股票价格序列中,由于受某项政策出台或某种谣传的刺激,都会出现极增,极减现象,变现为离群点。
不论是何种原因引起的离群点对以后的分析都会造成一定的影响。
从造成分析的困难来看,统计分析人员说不希望序列中出现离群点,离群点会直接影响模型的拟合精度,甚至会得到一些虚伪的信息。
大数据管理培训复习材料

⼤数据管理培训复习材料第⼀篇⼤数据概论1.传感器采集的数据主要包括温度、压⼒、转速、声⾳、光线、位置、⽓味、磁场等物理量2.埋点技术的⽬的埋点技术通过在代码的关键部位植⼊统计代码,追踪⽤户的点击⾏为3.Hadoop是处理⼤数据有效技术有效技术4.第三次信息化浪潮的标志是“⼤云物移”5.⼤数据发展的萌芽期是上世纪90年代6.数据的产⽣⽅式经历了从“被动”、“主动”、到“⾃动”的转变7.麦肯锡对⼤数据定义是⼀种规模⼤到在获取、存储、管理、分析⽅⾯⼤⼤超出了传统数据库软件⼯具能⼒范围的数据集合,具有海量的数据规模、快速的数据流转、多样的数据类型和价值密度低四⼤特征8.⼤数据的4V特征是体量⼤、多样性、价值密度低、速度快9.1PB=1024*1024GB10.互联⽹的数据以⾮结构化数据为主11.办公⽂档、⽂本、图⽚、⾳频这些都是⾮结构化的数据第⼆篇数据采集1.传感器数据处理的第⼀步是将电压信号转化为对应的物理量2.企业⾃⾝的APP产品可以通过埋点技术采集⽤户⾏为的数据3.数据采集与业务功能的开发会产⽣冲突4.互联⽹数据的采集依赖爬⾍技术5.互联⽹数据采集后可以应⽤于舆情管理、客户分析、⾏业分析、对⼿分析6.企业采集互联⽹数据不⼀定⾃⼰开发爬⾍程序,可以利⽤第三⽅采集⼯具第三篇数据仓库1.数据仓库的ETL过程包括数据抽取、转换、装载2.数据仓库是⾯向管理的系统,⽽普通数据库是⾯向业务的系统3.数据仓库对数据的访问时只读式的访问4.数据仓库是⾯向主题设计的,⽽普通数据库是⾯向应⽤设计的5.数据仓库的四个特征是⾯向主题的、集成的、随时间变化的、⾮易失的6.数据仓库虽然会⽐普通数据库保留更多的历史数据,但是它也需要根据时间变化删去旧的数据内容7.下⾯两个图中,图2是多维数据库的表现⽅式,更适合于数据仓库的OLAP操作图1 图2产品名称地区销售量冰箱东北 50冰箱西北 60彩电东北 70彩电西北 80空调东北 90空调西北 100 东北西北冰箱 50 60 彩电 70 80 空调 90 1008. 数据仓库的OLAP 操作包括上卷、下钻、切⽚、旋转等操作9. 数据仓库常⽤的模型包括雪花型和星型10. 下图表现的是雪花型的模型设计11. 数据仓库的表会引⼊冗余,也会对源表进⾏物理分割12. 数据仓库元数据的作⽤是描述了数据的结构、内容、键、索引等项内容13. 静态元数据包含名称、描述、格式、数据类型、关系、⽣成时间、来源、索引、类别、域、业务规则等14.动态元数据包含⼊库时间、更新周期、数据质量、统计信息、状态、处理、存储位置、存储⼤⼩、引⽤处等15.数据仓库的运维包含以下⼏部分数据安全管理、数据质量管理、数据备份和恢复16.数据仓库的数据量不断增长,针对增长数据的管理有哪些⽅法利⽤概括技术、对细剖数据的控制、对历史数据的限制、对数据使⽤范围的进⾏限制、将睡眠数据移出。
第9章 离群点检测

图9-5 基于聚类的离群点检测二维数据集
9.2离群点检测
基与聚类的离群点检测挖掘方法如下:
26
9.2离群点检测
基与聚类的离群点检测挖掘方法如下: 表9-1 离群因子表 X 1 1 1 2 2 2 6 2 3 5 5 Y 2 3 1 1 2 3 8 4 2 7 2 OF1 2.2 2.3 2.9 2.6 1.7 1.9 5.9 2.5 2.2 4.8 3.4
9.2离群点检测
21
‒ 结论 • LOF算法计算的离群度不在一个通常便于理解的范围[0,1],而是一 个大于1的数,并且没有固定的范围。而且数据集通常数量比较大, 内部结构复杂,LOF极有可能因为取到的近邻点属于不同数据密度 的聚类簇,使得计算数据点的近邻平均数据密度产生偏差,而得出 与实际差别较大甚至相反的结果。 ‒ 优点 • 通过基于密度的局部离群点检测就能在样本空间数据分布不均匀的 情况下也可以准确发现离群点。
1 2 2 1
18
图9.2 基于密度的局部离群点检测的必要性
9.2离群点检测
19
图9.2中,p1相当于C2的密度来说是一个局部离群点,这就形成了基于密度 的局部离群点检测的基础。此时,评估的是一个对象是离群点的程度,这种“离 群”程度就是作为对象的局部离群点因子(LOF),然后计算 。
reach _ distk ( x, xi ) max{distk ( xi ), dist ( x, xi )}
工作假设H为,假设n个对象的整个数据集来自一个初始的分布模型F,即: H: oi∈F,其中i=1,2,…,n 不和谐检验就是检查对象oi关于分布F是否显著地大(或小)。
9.2离群点检测 基于正态分布的一元离群点检测 • 正态分布曲线特点:N(μ,σ2) • 变量值落在(μ-σ,μ+σ)区间的概率是68.27% • 变量值落在(μ-2σ,μ+2σ)区间的概率是95.44% • 变量值落在(μ-3σ,μ+3σ)区间的概率是99.73%
数据挖掘知识点归纳

知识点一数据仓库1.数据仓库是一个从多个数据源收集的信息存储库,存放在一致的模式下,并且通常驻留在单个站点上。
2.数据仓库通过数据清理、数据变换、数据集成、数据装入和定期数据刷新来构造。
3.数据仓库围绕主题组织4.数据仓库基于历史数据提供消息,是汇总的。
5.数据仓库用称作数据立方体的多维数据结构建模,每一个维对应于模式中的一个或者一组属性,每一个单元存放某种聚集的度量值6.数据立方体提供数据的多维视图,并允许预计算和快速访问汇总数据7.提供提供多维数据视图和汇总数据的预计算,数据仓库非常适合联机分析处理,允许在不同的抽象层提供数据,这种操作适合不同的用户角度8.OLAP例子包括下钻和上卷,允许用户在不同的汇总级别上观察数据9.多维数据挖掘又叫做探索式多维数据挖掘OLAP风格在多维空间进行数据挖掘,允许在各种粒度进行多维组合探查,因此更有可能代表知识的有趣模式。
知识点二可以挖掘什么数据1.大量的数据挖掘功能,包括特征化和区分、频繁模式、关联和相关性分析挖掘、分类和回归、聚类分析、离群点分析2.数据挖掘功能用于指定数据挖掘任务发现的模式,分为描述性和预测性3.描述性挖掘任务刻画目标数据中数据的一般性质4.预测性挖掘任务在当前数据上进行归纳,以便做出预测5.数据可以与类或概念相关联6.用汇总、简洁、精确的表达描述类和概念,称为类/概念描述7.描述的方法有数据特征化(针对目标类)、数据区分(针对对比类)、数据特征化和区分8.数据特征化用来查询用户指定的数据,上卷操作用来执行用户控制的、沿着指定维的数据汇总。
面向属性的归纳技术可以用来进行数据的泛化和特征化,而不必与用户交互。
形式有饼图、条图、曲线、多维数据立方体和包括交叉表在内的多维表。
结果描述可以用广义关系或者规则(也叫特征规则)提供。
9.用规则表示的区分描述叫做区分规则。
10.数据频繁出现的模式叫做频繁模式,类型包括频繁项集、频繁子项集(又叫频繁序列)、频繁子结构。
L O F 离 群 点 检 测 算 法

数据挖掘(五)离群点检测5 异常检测方法异常对象被称作离群点。
异常检测也称偏差检测和例外挖掘。
异常检测的方法:(1)基于模型的技术:首先建立一个数据模型,异常是那些同模型不能完美拟合的对象;如果模型是簇的集合,则异常是不显著属于任何簇的对象;在使用回归模型时,异常是相对远离预测值的对象。
(2)基于邻近度的技术:通常可以在对象之间定义邻近性度量,异常对象是那些远离其他对象的对象。
(3)基于密度的技术:仅当一个点的局部密度显著低于它的大部分近邻时才将其分类为离群点。
(1)统计方法。
统计学方法是基于模型的方法,即为数据创建一个模型,并且根据对象拟合模型的情况来评估它们。
大部分用于离群点检测的统计学方法都是构建一个概率分布模型,并考虑对象有多大可能符合该模型。
离群点的概率定义:离群点是一个对象,关于数据的概率分布模型,它具有低概率。
这种情况的前提是必须知道数据集服从什么分布,如果估计错误就造成了重尾分布。
异常检测的混合模型方法:对于异常检测,数据用两个分布的混合模型建模,一个分布为普通数据,而另一个为离群点。
聚类和异常检测目标都是估计分布的参数,以最大化数据的总似然(概率)。
聚类时,使用EM算法估计每个概率分布的参数。
然而,这里提供的异常检测技术使用一种更简单的方法。
初始时将所有对象放入普通对象集,而异常对象集为空。
然后,用一个迭代过程将对象从普通集转移到异常集,只要该转移能提高数据的总似然(其实等价于把在正常对象的分布下具有低概率的对象分类为离群点)。
(假设异常对象属于均匀分布)。
异常对象由这样一些对象组成,这些对象在均匀分布下比在正常分布下具有显著较高的概率。
优缺点:(1)有坚实的统计学理论基础,当存在充分的数据和所用的检验类型的知识时,这些检验可能非常有效;(2)对于多元数据,可用的选择少一些,并且对于高维数据,这些检测可能性很差。
(2)基于邻近度的离群点检测。
一个对象是异常的,如果它远离大部分点。
数据挖掘——第九章离群点挖掘上课讲义

离群点挖掘(Outlier mining)
离群点挖掘问题由两个子问题构成:。 (1)定义在一个数据集中什么数据是不一致或离群的数据; (2)找出所定义的离群点的有效挖掘方法。离群点挖掘问题
离群点检测方法分类
从使用的主要技术路线角度分类
基于统计的方法 基于距离的方法 基于密度的方法 基于聚类的方法 基于偏差的方法 基于深度的方法 基于小波变换的方法 基于神经网络的方法…
Porkess的定义:离群点是远离数据集中其余部分的 数据
离群点的特殊意义和实用价值
现有数据挖掘研究大多集中于发现适用于大部分数据的 常规模式,在许多应用领域中,离群点通常作为噪音而忽 略,许多数据挖掘算法试图降低或消除离群点的影响。而 在有些应用领域识别离群点是许多工作的基础和前提,离 群点会带给我们新的视角。
生年月、学位和职称作为检测属性。
ቤተ መጻሕፍቲ ባይዱ
序号 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
出生年月 198907 198510 196008 197909 196002 195511 198109 197408 198109 198206 198301 195706 195712 197302 197211 195001 197304 195011 196911
可以概括为如何度量数据偏离的程度和有效发现离群点的 问题。
为什么会出现离群点?
测量、输入错误或系统运行错误所致 数据内在特性所决定 客体的异常行为所致
数据挖掘复习知识点整理
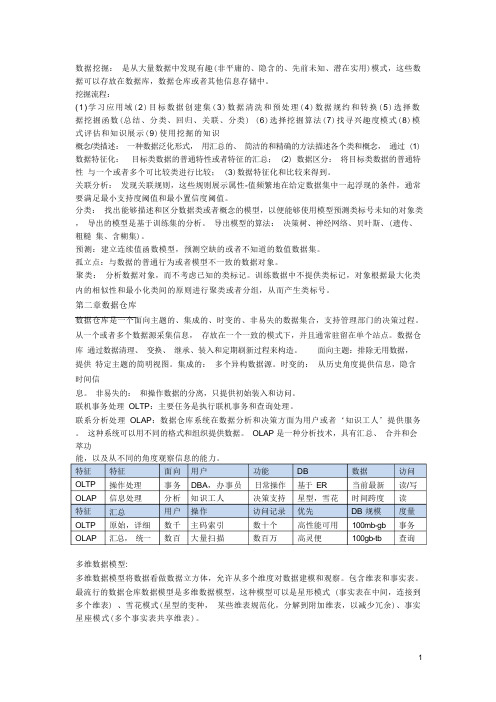
数据挖掘:是从大量数据中发现有趣(非平庸的、隐含的、先前未知、潜在实用)模式,这些数据可以存放在数据库,数据仓库或者其他信息存储中。
挖掘流程:(1)学习应用域(2)目标数据创建集(3)数据清洗和预处理(4)数据规约和转换(5)选择数据挖掘函数(总结、分类、回归、关联、分类) (6)选择挖掘算法(7)找寻兴趣度模式(8)模式评估和知识展示(9)使用挖掘的知识概念/类描述:一种数据泛化形式,用汇总的、简洁的和精确的方法描述各个类和概念,通过 (1) 数据特征化:目标类数据的普通特性或者特征的汇总; (2) 数据区分:将目标类数据的普通特性与一个或者多个可比较类进行比较; (3)数据特征化和比较来得到。
关联分析:发现关联规则,这些规则展示属性-值频繁地在给定数据集中一起浮现的条件,通常要满足最小支持度阈值和最小置信度阈值。
分类:找出能够描述和区分数据类或者概念的模型,以便能够使用模型预测类标号未知的对象类,导出的模型是基于训练集的分析。
导出模型的算法:决策树、神经网络、贝叶斯、(遗传、粗糙集、含糊集)。
预测:建立连续值函数模型,预测空缺的或者不知道的数值数据集。
孤立点:与数据的普通行为或者模型不一致的数据对象。
聚类:分析数据对象,而不考虑已知的类标记。
训练数据中不提供类标记,对象根据最大化类内的相似性和最小化类间的原则进行聚类或者分组,从而产生类标号。
第二章数据仓库数据仓库是一个面向主题的、集成的、时变的、非易失的数据集合,支持管理部门的决策过程。
从一个或者多个数据源采集信息,存放在一个一致的模式下,并且通常驻留在单个站点。
数据仓库通过数据清理、变换、继承、装入和定期刷新过程来构造。
面向主题:排除无用数据,提供特定主题的简明视图。
集成的:多个异构数据源。
时变的:从历史角度提供信息,隐含时间信息。
非易失的:和操作数据的分离,只提供初始装入和访问。
联机事务处理OLTP:主要任务是执行联机事务和查询处理。
联系分析处理OLAP:数据仓库系统在数据分析和决策方面为用户或者‘知识工人’提供服务。
简述离群点检测方法,以及各个方法的优缺点_概述说明

简述离群点检测方法,以及各个方法的优缺点概述说明1. 引言1.1 概述离群点检测是一种数据分析的方法,它旨在识别样本中的异常值。
这些异常值通常与其余的数据点有明显不同的特征或行为。
离群点检测可以应用于各个领域,如金融欺诈检测、网络入侵检测、医学异常检测等。
1.2 文章结构本文将介绍几种常用的离群点检测方法,并对它们的优缺点进行比较。
首先,第二节将详细阐述各种离群点检测方法的原理和过程。
接下来,在第三节和第四节中,我们将分别讨论方法一和方法二的优缺点。
最后,在结论部分,我们将总结各个方法的适用场景和限制。
1.3 目的本文的目标是帮助读者了解不同离群点检测方法之间的差异,并通过对比它们的优缺点来选择合适的方法。
这将有助于研究人员和从业者在实际应用中更好地解决离群点问题,提高数据质量和决策准确性。
2. 离群点检测方法离群点检测是数据挖掘和异常检测领域的一个重要任务,它旨在发现与其他数据点不一致的异常观测值。
在本节中,我们将介绍几种常见的离群点检测方法。
2.1 孤立森林算法(Isolation Forest)孤立森林算法是一种基于树的离群点检测方法。
该方法通过随机选择特征和随机划分来构建一些孤立树,并利用路径长度度量样本的异常值程度。
相比于传统基于距离的方法,孤立森林在处理高维数据上效果更好,并且能够有效地应对大规模数据集。
优点:- 可以有效地处理大规模数据集;- 在处理高维数据时表现较好;- 不受数据分布影响。
缺点:- 对于较小的样本集效果可能不如其他算法;- 对噪声敏感。
2.2 K均值算法(K-means)K均值算法是一种常用的聚类算法,但也可以用于离群点检测。
该方法通过将观测值归类到最近的质心,并计算每个观测值与其所属簇的平均距离,来确定是否为离群点。
如果观测值的平均距离超过了给定的阈值,就将其标记为离群点。
优点:- 简单且易于实现;- 对于有着明显聚类结构的数据集有效。
缺点:- 对初始质心的选择敏感;- 对噪声和孤立样本敏感;- 对数据分布不均匀的情况效果较差。
数据挖掘之5——离群点检测

离群点检测(异常检测)是找出其行为不同于预期对象的过程,这种对象称为离群点或异常。
离群点和噪声有区别,噪声是观测变量的随机误差和方差,而离群点的产生机制和其他数据的产生机制就有根本的区别。
全局离群点:通过找到其中一种合适的偏离度量方式,将离群点检测划为不同的类别;全局离群点是情景离群点的特例,因为考虑整个数据集为一个情境。
情境离群点:又称为条件离群点,即在特定条件下它可能是离群点,但是在其他条件下可能又是合理的点。
比如夏天的28℃和冬天的28℃等。
集体离群点:个体数据可能不是离群点,但是这些对象作为整体显著偏移整个数据集就成为了集体离群点。
离群点检测目前遇到的挑战•正常数据和离群点的有效建模本身就是个挑战;•离群点检测高度依赖于应用类型使得不可能开发出通用的离群点检测方法,比如针对性的相似性、距离度量机制等;•数据质量实际上往往很差,噪声充斥在数据中,影响离群点和正常点之间的差别,缺失的数据也可能“掩盖”住离群点,影响检测到有效性;•检测离群点的方法需要可解释性;离群点检测方法1. 监督方法训练可识别离群点的分类器;但是监督方法检测离群点目前遇到几个困难:1.两个类别(正常和离群)的数据量很不平衡,缺乏足够的离群点样本可能会限制所构建分类器的能力;2.许多应用中,捕获尽可能多的离群点(灵敏度和召回率)比把正常对象误当做离群点更重要。
由于与其他样本相比离群点很稀少,所以离群点检测的监督方法必须注意如何训练和如何解释分类率。
One-class model,一分类模型考虑到数据集严重不平衡的问题,构建一个仅描述正常类的分类器,不属于正常类的任何样本都被视为离群点。
比如SVM决策边界以外的都可以视为离群点。
2.无监督方法正常对象在其中一种程度上是“聚类”的,正常对象之间具有高度的相似性,但是离群点将远离正常对象的组群。
但是遇到前文所述的集体离群点时,正常数据是发散的,而离群点反而是聚类的,这种情形下更适合监督方法进行检测。
聚类分析——离群点分析

聚类分析——离群点分析⼀、什么是离群点分析1、什么是离群点?在样本空间中,与其他样本点的⼀般⾏为或特征不⼀致的点,我们称为离群点。
2、离群点产⽣的原因?第⼀,计算的误差或者操作的错误所致,⽐如:某⼈的年龄-999岁,这就是明显由误操作所导致的离群点;第⼆,数据本⾝的可变性或弹性所致,⽐如:⼀个公司中CEO的⼯资肯定是明显⾼于其他普通员⼯的⼯资,于是CEO变成为了由于数据本⾝可变性所导致的离群点。
3、为什么要对离群点进⾏检测?“⼀个⼈的噪声也许是其他的信号”。
换句话说,这些离群点也许正是⽤户感兴趣的,⽐如在欺诈检测领域,那些与正常数据⾏为不⼀致的离群点,往往预⽰着欺诈⾏为,因此成为执法者所关注的。
4、离群点检测遇到的困难?第⼀,在时间序列样本中发现离群点⼀般⽐较困难,因为这些离群点可能会隐藏在趋势、季节性或者其他变化中;第⼆,对于维度为⾮数值型的样本,在检测过程中需要多加考虑,⽐如对维度进⾏预处理等;第三,针对多维数据,离群点的异常特征可能是多维度的组合,⽽不是单⼀维度就能体现的。
⼆、⼏类离群点检测⽅法1、基于统计分布的离群点检测这类检测⽅法假设样本空间中所有数据符合某个分布或者数据模型,然后根据模型采⽤不和谐校验(discordancy test)识别离群点。
不和谐校验过程中需要样本空间数据集的参数知识(eg:假设的数据分布),分布的参数知识(eg:期望和⽅差)以及期望的离群点数⽬。
不和谐校验分两个过程:⼯作假设和备选假设⼯作假设指的是如果某样本点的某个统计量相对于数据分布的是显著性概率充分⼩,那么我们则认为该样本点是不和谐的,⼯作假设被拒绝,此时备⽤假设被采⽤,它声明该样本点来⾃于另⼀个分布模型。
如果某个样本点不符合⼯作假设,那么我们认为它是离群点。
如果它符合备选假设,我们认为它是符合某⼀备选假设分布的离群点。
基于统计分布的离群点检测的缺点:第⼀,在于绝⼤多数不和谐校验是针对单个维度的,不适合多维度空间;第⼆,需要预先知道样本空间中数据集的分布特征,⽽这部分知识很可能是在检测前⽆法获得的。
(完整版)第9章离群点检测

计算所有对象的离群因子。
图9-5 基于聚类的离群点检测二维数据集
一个离群点。
• r 是距离阈值, α是分数阈值,如果有 则d是一个DB(r, α)离群点。
d ' | dist(d, d ') r
D
9.2离群点检测
17
基于距离的离群点检测:
• 如何计算DB(r, α)-离群点:嵌套循环
对每个对象di(1 i n),计算 与其它对象之间的距离,统计di r-邻域中其它对象的个
9.2离群点检测
23
基与聚类的离群点检测挖掘方法如下:
• 基于对象离群因子法
• 假设数据集D被聚类算法划分为k个簇C={C1,C2,…,Ck},对象p的离群因子 (Outlier Factor)OF1(p)定义为p与所有簇间距离的加权平均值:
•
������������1 ������
=
����������=1
|������������| |������|
∙
������(������,������������
)(9-6)
• 其中,������(������,������������)表示对象p与第j个簇Cj之间的距离。
9.2离群点检测
24
基与聚类的离群点检测挖掘方法如下:
• 两阶段离群点挖掘方法如下:
① 对数据集D采用一趟聚类算法进行聚类,得到聚类结果C={C1,C2,…,Ck}
离群点算法

离群点算法全文共四篇示例,供读者参考第一篇示例:离群点算法(Outlier Detection Algorithm)是一种常见的数据挖掘技术,用于识别数据集中的异常值或离群点。
离群点通常指的是与数据集中的大部分数据分布不同的数据点,可能是错误数据、异常数据或者唯一性数据。
识别和检测离群点可以帮助我们发现数据中的异常情况,进而采取相应的措施进行处理,以保证数据质量和模型准确性。
离群点算法可以分为基于统计方法、基于距离方法、基于密度方法等多种类型。
下面将介绍几种常见的离群点检测算法:1.基于统计方法基于统计方法是通过对数据进行统计分析,判断数据点是否符合某种统计模型来识别离群点。
其中最常用的方法是基于箱线图的离群点检测方法。
箱线图首先计算数据的上四分位数和下四分位数,然后根据四分位数计算出箱线的上下限,超出上下限的数据点被判断为离群点。
2.基于距离方法基于距离方法是通过计算数据点之间的相似性或距离来判断数据点是否为离群点。
其中最常用的方法是LOF(局部离群因子)算法。
LOF 算法通过计算数据点周围邻居数据点的密度与自身密度的比值来判断数据点是否为离群点。
密度比值越小,则数据点越可能是离群点。
3.基于密度方法基于密度方法是通过对数据集进行聚类分析,识别数据集中的高密度区域和低密度区域,从而识别离群点。
其中最常用的方法是DBSCAN(基于密度的空间聚类算法)。
DBSCAN算法通过定义核心对象和边界对象的概念,将数据点划分为核心对象、边界对象和噪声点,从而实现离群点的检测。
除了上述的几种常见离群点检测算法之外,还有一些其他的算法如One-Class SVM、Isolation Forest等也常用于离群点检测。
不同的离群点算法适用于不同的数据场景和问题需求,可以根据实际情况选择合适的算法进行离群点检测。
离群点算法在实际的数据分析和挖掘过程中有着广泛的应用。
在金融领域中,离群点算法可以用于检测信用卡欺诈、异常交易等;在工业生产中,离群点算法可以用于监测设备异常、预测设备故障等;在医学领域中,离群点算法可以用于识别疾病患者的异常生理指标等。
数据挖掘概念与技术(第三版)课后答案——第一章

数据挖掘概念与技术(第三版)课后答案——第⼀章1.1 什么是数据挖掘?在你的回答中,强调以下问题:(a)它是⼜⼀种⼴告宣传吗?(b)它是⼀种从数据库、统计学、机器学习和模式识别发展⽽来的技术的简单转换或应⽤吗?(c)我们提出了⼀种观点,说数据挖掘是数据库技术进化的结果。
你认为数据挖掘也是机器学习研究进化的结果吗?你能基于该学科的发展历史提出这⼀观点吗?针对统计学和模式识别领域,做相同的事。
(d)当把数据挖掘看做知识发现过程时,描述数据挖掘所涉及的步骤。
答:数据挖掘不是⼀种⼴告宣传,它是⼀个应⽤驱动的领域,数据挖掘吸纳了诸如统计学习、机器学习、模式识别、数据库和数据仓库、信息检索、可视化、算法、⾼性能计算和许多应⽤领域的⼤量技术。
它是从⼤量数据中挖掘有趣模式和知识的过程。
数据源:包括数据库、数据仓库、Web、其他信息存储库或动态的流⼊系统的数据等。
当其被看作知识发现过程时,其基本步骤主要有:1. 数据清理:清楚噪声和删除不⼀致数据;2. 数据集成:多种数据源可以组合在⼀起;3. 数据选择:从数据库中提取与分析任务相关的数据;4. 数据变换:通过汇总或者聚集操作,把数据变换和统⼀成适合挖掘的形式;5. 数据挖掘:使⽤智能⽅法或者数据挖掘算法提取数据模式;6. 模式评估:根据某种兴趣度量,识别代表知识的真正有趣的模式。
7. 知识表⽰:使⽤可视化和知识表⽰技术,向⽤户提供挖掘的知识。
1.2 数据仓库与数据库有什么不同?它们有哪些相似之处?答:不同:数据仓库是多个异构数据源在单个站点以统⼀的模式组织的存储,以⽀持管理决策。
数据仓库技术包括数据清理、数据集成和联机分析处理(OLAP)。
数据库系统也称数据库管理系统,由⼀组内部相关的数据(称作数据库)和⼀组管理和存取数据的软件程序组成,是⾯向操作型的数据库,是组成数据仓库的源数据。
它⽤表组织数据,采⽤ER数据模型。
相似:它们都为数据挖掘提供了源数据,都是数据的组合。
第6章-离群点挖掘

10
1.离群点挖掘
• 离群点挖掘的意义
发现与大部分其他对象显著不同的对象,大部分数据挖掘方法都将这种差 异信息视为噪声而丢弃。然而在一些应用中,罕见的数据可能蕴含着更大 的研究价值。
离群点挖掘就是分析数据并及时发现异常,比如:及时发现欺诈行为 ,并采集必要措施,从而避免损失!
1.离群点挖掘
• 离群点挖掘应用
OF 2( P4) relative density( P4, k )
(1 1) / 2 1 1
1
1 yN ( P15, k ) distance(P15, y) 2 2 1 density(P15,k) | N ( P15, k ) | 3 2
欺诈检测 天气预测 公共安全
电子商务
离群点挖掘
入侵检测
医疗
1.离群点挖掘
• 离群点挖掘研究的主要问题
离群点挖掘:就是通过某种方法找出数据集中“与众不同”的数据;
如何度量离群点?远离 群体的点就是离群点?
定义
方法
① 基于统计的方法; ② 基于距离的方法;
③ 基于密度的方法;
④ 基于聚类的方法;
13
1.离群点挖掘
• 离群点挖掘的挑战
数据中有多少离群点? 如何在大规模的数据集中,在无监督的情况下找出离 群点?
15
1.离群点挖掘
离群点 定义
指数据集中与大部分数据“不同”的少部分数 据;
离群点挖 掘意义
少量的数据可能蕴含着重要的研究价值;
离群点挖 掘方法
离群点挖掘=离群点定义+离群点挖掘方法;
离群点挖 掘结果
《数据挖掘》
离群点挖掘
费伦科
《离群点分析》课件

数据输入错误
在数据采集和输入过程中可能 出现错误,导致离群点的产生 。
数据变异
某些情况下,离群点可能是由 于数据分布的自然变异引起的 ,例如生物学或气象学数据中 的随机波动。
数据采集限制
由于数据采集方法的限制,某 些离群点可能被错误地归类为
异常值。
02
离群点检测方法
基于统计的方法
总结词
基于统计的方法利用概率模型或统计 假设来检测离群点。
详细描述
这种方法通常假设数据符合某种概率 分布,然后使用统计测试来识别与该 分布不一致的观测值。例如,使用zscore或标准分数方法来识别离群点。
基于距离的方法
总结词
基于距离的方法通过比较数据点之间的距离来检测离群点。
详细描述
该方法将离群点定义为那些与其他数据点距离超过某个阈值的点。常见的基于 距离的算法包括k-最近邻和DBSCAN聚类算法。
基于密度的离群点检测
总结词
基于密度的方法利用数据点的密度差异来识别离群点。
详细描述
这种方法认为离群点是那些在低密度区域中的点,或者与邻近高密度区域相隔较 远的点。例如,局部异常因子(Local Outlier Factor)是一种常用的基于密度的 方法。
基于聚类的方法
总结词
基于聚类的方法将离群点定义为不属 于任何聚类的点。
VS
详细描述
对于具有趋势性的数据,可以使用插值或 外推的方法填补离群点。这种方法基于数 据的变化趋势,通过预测离群点周围的数 据值来填补缺失值。然而,这种方法可能 引入预测误差,尤其是在数据变化剧烈或 趋势不明显的情况下。
04
案例分析
金融数据中的离群点分析
总结词
金融数据中离群点的识别和处理对于风险管理至关重要。
离群点挖掘研究

收稿日期:2008-04-04;修回日期:2008-06-08作者简介:徐翔(1984-),男,江苏泰州人,硕士研究生,主要研究方向为数据挖掘(mason1200_cn@);刘建伟(1966-),男,新疆石河子人,副教授,博士,主要研究方向为机器学习、非线性控制;罗雄麟(1963-),男,湖南汨罗人,教授,博导,主要研究方向为控制理论与应用、复杂系统检测、控制与优化、模式识别与智能系统、系统工程.离群点挖掘研究徐 翔,刘建伟,罗雄麟(中国石油大学自动化研究所,北京102249)摘 要:随着人们对欺诈检测、网络入侵、故障诊断等问题的关注,离群点挖掘研究日益受到重视。
在充分调研国内外离群点挖掘研究成果的基础上,介绍了数据库领域离群点挖掘的研究进展,并概要地总结和比较了已有的各种离群点挖掘方法,展望了离群点挖掘研究的未来发展方向和面临的挑战。
关键词:离群点;数据挖掘;局部离群点;高维数据;数据流中图分类号:TP 311.13;TP391 文献标志码: A 文章编号:1001-3695(2009)01-0034-07Resear ch on out lier m iningXU Xia ng,LIU J ia n-wei,LU O Xiong-lin(R es earch Institute of Automation,China Univers ity of Petroleum,Beijing 102249,C hina)Abst ract :The problem of out lier m ining a tt racts m ore a nd m ore interest s in research when the resea rch fields of fra ud det ec-t ion,int rus ion det ect ion,fa ult dia gnosis a nd so on receive wide a tt ent ions.This paper presented a s urv ey for the res earch re-s ult s of out lier m ining a t hom e and a broad,a nd based on t his survey,introduced t he research process of outlier m ining in t he a reas of dat abase.It also pres ented a sum m a ry of t he current s ta te of the a rt of t hese techniques,a discuss ion on future re-s ea rch t opics,a nd the cha llenges of t he outlier m ining.Key wo rds:out lier;dat a m ining;local out lier;high-dim ensional da ta;dat a stream 一直以来,人们都比较重视数据集中的离群数据,通常认为这些数据改变了数据集的原有信息或数据产生机理。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
离群点检测的应用领域
电信、保险、银行中的欺诈检测与风险分析 发现电子商务中的犯罪行为 灾害气象预报 税务局分析不同团体交所得税的记录,发现异常模型和趋
势 海关、民航等安检部门推断哪些人可能有嫌疑 海关报关中的价格隐瞒 营销定制:分析花费较小和较高顾客的消费行为 医学研究中发现医疗方案或药品所产生的异常反应 计算机中的入侵检测 应用异常检测到文本编辑器,可有效减少文字输入的错误 ……
通过定义对象的离群程度来给对象打分 ,如都为离群 点的情况下,也还有分高和分低的区别。——离群点得 分(outlier score)或离群因子(Outlier Factor)
离群点检测的挑战和前提
挑战:
数据中有多少离群点? 方法应该是无监督的,就像在干草堆中寻找一根针
前提假设
假定数据集中被认为正常的点数远远超过被认为离群的 点数
由于离群点产生的机制是不确定的,离群点挖掘算法检测 出的“离群点”是否真正对应实际的异常行为,不是由离 群点挖掘算法来说明、解释的,只能由领域专家来解释, 离群点挖掘算法只能为用户提供可疑的数据,以便用户引 起特别的注意并最后确定是否真正的异常。对于异常数据 的处理方式也取决于应用,并由领域专家决策。
离群点挖掘(Outlier mining)
离群点挖掘问题由两个子问题构成:。 (1)定义在一个数据集中什么数据是不一致或离群的数据; (2)找出所定义的离群点的有效挖掘方法。离群点挖掘问题
可以概括为如何度量数据偏离的程度和有效发现离群点的 问题。
为什么会出现离群点?
测量、输入错误或系统运行错误所致 数据内在特性所决定 客体的异常行为所致
(2)全局观点和局部观点
一个对象可能相对于所有对象看上去离群,但它 相对于它的局部近邻不是离群的
例如:身高1.85m对于一般人群是不常见的,但对于职 业篮球运动员不算什么
(3)点的离群程度
某些技术方法是以二元方式来报告对象是否离 群点,即:离群点或正常点
但,这不能反映某些对象比其他对象更加极端偏离群点(Outlier)?
Hawkins的定义:离群点是在数据集中偏离大部分数 据的数据,使人怀疑这些数据的偏离并非由随机因素 产生,而是产生于完全不同的机制。
Weisberg的定义:离群点是与数据集中其余部分不服 从相同统计模型的数据。
Samuels的定义:离群点是足够地不同于数据集中其 余部分的数据。
应用基于统计分布的离群点检测方法依赖于
数据分布 参数分布 (如均值或方差) 期望离群点的数目
(置信度区间)
离群点的概率定义
离群点的概率定义:
离群点是一个对象,关于数据的概率分布模型,它具有 低概率
概率分布模型通过估计用户指定的分布的参数, 由数据创建。
例:如果假定数据具有高斯分布,则基本分布的均值和 标准差可以通过计算数据的均值和标准差来估计,然后 可以估计每个对象在该分布下的概率。
要求存在离群点类和正常类的训练集
半监督的离群点检测方法
训练数据包含被标记的正常数据,但是没有关于离 群点对象的信息
离群点检测中需要处理的问题
(1)用于定义离群点的属性个数
一个对象只有单个属性 一个对象具有多个属性:
可能某个属性异常,某个属性正常 如:对于男生而言,
身高1.6m,体重55kg,这个很正常; 身高1.6m,体重75kg,这个有点离群; 身高1.8m,体重75kg,基本正常。 若对于女生,则三组值可能都不太正常。 所以,定义离群点需要指明如何使用多个属性的值确定一 个对象是否离群?
一部住宅电话的话费由每月200元以内增加到数千元可能 就因为被盗打或其它特殊原因所致;
一张信用卡出现明显的高额消费也许是因为是盗用的卡。
离群点与众不同但具有 相对性:
高与矮,疯子与常人。
类似术语: Outlier mining, Exception mining:异常挖掘、 离群挖掘、例外挖掘和稀有 事件挖掘 。
基于统计的离群点检测
基于统计的离群点检测
这类方法大部分是从针对不同分布的离群点检验 方法发展起来的,通常用户使用分布来拟合数据 集。
假定所给定的数据集存在一个分布或概率模型(例如, 正态分布或泊松分布),然后将与模型不一致(即分布不 符合)的数据标识为离群数据。
基于统计的离群点检测
假定用一个参数模型来描述数据的分布 (如正态分 布)
正常点的数量远远超过离群点的数量,离群点的数量在大 规模数据集中所占的比例较低,小于5%甚至1%
离群点实例
一个人的年龄为-999就可能是由于程序处理缺省数据设置 默认值所造成的 ;
一个公司的高层管理人员的工资明显高于普通员工的工资 可能成为离群点但却是合理的数据(如平安保险公司2007 年 5位高管税后收入超过了1000万元);
Porkess的定义:离群点是远离数据集中其余部分的 数据
离群点的特殊意义和实用价值
现有数据挖掘研究大多集中于发现适用于大部分数据的 常规模式,在许多应用领域中,离群点通常作为噪音而忽 略,许多数据挖掘算法试图降低或消除离群点的影响。而 在有些应用领域识别离群点是许多工作的基础和前提,离 群点会带给我们新的视角。
离群点检测方法分类
从使用的主要技术路线角度分类
基于统计的方法 基于距离的方法 基于密度的方法 基于聚类的方法 基于偏差的方法 基于深度的方法 基于小波变换的方法 基于神经网络的方法…
从类标号(正常或异常)利用的程度分类
无监督的离群点检测方法
在实际情况下,没有提供类标号
有监督的离群点检测方法
离群点挖掘中需要处理的几个问题
(1) 全局观点和局部观点
离群点与众不同,但具有相对性。
(2) 点的离群程度
可以通过定义对象的偏离程度来给对象打分——离群因子 (Outlier Factor)或离群值得分(Outlier Score),即都为离群 点的情况下,也还有分高和分低的区别。
(3) 离群点的数量及时效性