数据结构课程设计-文本压缩
数据结构(5)_文件压缩

数据结构实验报告实验名称:文件压缩实验类型:综合性试验班级:20112111学号:2011211107姓名:冯若航实验日期:2003.6.19 下午4:001.问题描述文件压缩①基本要求哈夫曼编码是一种常用的数据压缩技术,对数据文件进行哈夫曼编码可大大缩短文件的传输长度,提高信道利用率及传输效率。
要求采用哈夫曼编码原理,统计文本文件中字符出现的词频,以词频作为权值,对文件进行哈夫曼编码以达到压缩文件的目的,再用哈夫曼编码进行译码解压缩。
●统计待压缩的文本文件中各字符的词频,以词频为权值建立哈夫曼树,并将该哈夫曼树保存到文件HufTree.dat中。
●根据哈夫曼树(保存在HufTree.dat中)对每个字符进行哈夫曼编码,并将字符编码保存到HufCode.txt文件中。
●压缩:根据哈夫曼编码,将源文件进行编码得到压缩文件CodeFile.dat。
●解压:将CodeFile.dat文件利用哈夫曼树译码解压,恢复为源文件。
2.数据结构设计此类问题,应设计文件的数据结构。
* 4 压缩头标记* 1 文件名长度* ns 文件名* 4 源文件长度* 1020 huffman树* 1021~EOF 文件内容赫夫曼树节点的数据结构typedef struct node{long w; //权short p,l,r; //父亲,左孩子,右孩子}HTNODE,*HTNP; //霍夫曼树的结点赫夫曼编码数组元素的数据结构设计typedef struct huffman_code{BYTE len; //长度BYTE *codestr; //字符串}HFCODE; //霍夫曼编码数组元素3.算法设计源代码#define_CRT_SECURE_NO_DEPRECATE#include<stdio.h>#include<string.h>#include<stdlib.h>typedef unsigned int UINT;typedef unsigned char BYTE;typedef struct node{long w; //权short p,l,r; //父亲,左孩子,右孩子}HTNODE,*HTNP; //霍夫曼树的结点typedef struct huffman_code{BYTE len; //长度BYTE *codestr; //字符串}HFCODE; //霍夫曼编码数组元素#define OK 1#define ERROR -1#define UNUSE -1 //未链接节点标志#define CHAR_BITS 8 //一个字符中的位数#define INT_BITS 32 //一个整型中的位数#define HUFCODE_SIZE 256 //霍夫曼编码个数#define BUFFERSIZE 256 //缓冲区大小大小#define UINTSIZE sizeof(UINT)#define BYTESIZE sizeof(BYTE)#define TAG_ZIGHEAD 0xFFFFFFFF //压缩文件头标#define MAX_FILENAME512//函数声明//压缩模块int Compress(char *SourceFilename,char *DestinationFilename);//压缩调用int Initializing(char *SourceFilename,FILE **inp,char *DestinationFilename,FILE **outp); //初始化文件工作环境long AnalysisFiles(FILE *in,long frequency[]);//计算每个不同字节的频率以及所有的字节数int CreateHuffmanTree(long w[],int n,HTNODE ht[]);//生成霍夫曼树int HuffmanTreeCoding(HTNP htp,int n,HFCODE hc[]);//霍夫曼编码int Search(HTNP ht,int n);//查找当前最小权值的霍夫曼树节点并置为占用BYTE Char2Bit(const BYTE chars[CHAR_BITS]);//将一个字符数组转换成二进制数字int Search(HTNP ht,int n);//查找当前最小权值的霍夫曼树节点并置为占用int WriteZipFiles(FILE *in,FILE *out,HTNP ht,HFCODE hc[],char* SourceFilename,long source_filesize);//写压缩文件//解压缩模块int DeCompress(char *SourceFilename,char *DestinationFilename);//解压缩调用int Initializing_Dezip(char *SourceFilename,FILE **inp,char*DestinationFilename,FILE **outp); //为处理解压缩流程初始化文件void ReadHuffmanTree(FILE* in,short mini_ht[][2]);//从待解压缩文件中读取huffman树int WriteDeZipFiles(FILE *in,FILE* out,short mini_ht[][2],long bits_pos,longDst_Filesize); //写解压缩文件void ErrorReport(int error_code);//报错//函数定义//函数实现//压缩int Compress(char *SourceFilename,char *DestinationFilename){FILE *in,*out; //输入输出流int i; //计数变量float Compress_rate; //存放压缩率HFCODE hc[HUFCODE_SIZE]; //存放256个字符的huffman编码HTNODE ht[HUFCODE_SIZE*2-1]; //256个字符的huffman树需要2*256-1=511个节点。
数据结构哈夫曼压缩软件设计实验报告

东北大学信息科学与工程学院数据结构课程设计报告题目哈夫曼压缩软件设计课题组长王健课题组成员张颖刘琪张晓雨专业名称计算机科学与技术班级计1307指导教师杨雷2015 年1月课程设计任务书目录1 课题概述 (4)1.1 课题任务 (4)1.2 课题原理 (4)1.3 相关知识 (4)2 需求分析 (5)2.1 课题调研 (5)2.2 用户需求分析 (5)3 方案设计 (5)3.1 总体功能设计 (5)3.2 数据结构设计 (6)3.3 函数原型设计 (6)3.4 主算法设计 (7)3.5 用户界面设计 (9)4 方案实现 (12)4.1 开发环境与工具 (12)4.2 程序设计关键技术 (12)4.3 个人设计实现(按组员分工)4.3.1 王健设计实现 (12)4.3.2 张颖设计实现 (17)4.3.3 刘琪设计实现 (20)4.3.4 张晓雨设计实现 (22)5 测试与调试 (25)5.1 个人测试(按组员分工) (25)5.1.1 王健测试 (25)5.1.2 张颖测试 (26)5.1.3 刘琪测试 (27)5.1.4 张晓雨测试 (31)5.2 组装与系统测试 (32)5.3 系统运行 (32)6 课题总结 (33)6.1 课题评价 (33)6.2 团队协作 (33)6.3 下一步工作 (33)6.4 个人设计小结(按组员分工) (33)6.4.1 王健设计小结 (33)6.4.2 张颖设计小结 (34)6.4.3 刘琪设计小结 (34)6.4.4 张晓雨设计小结 (34)7 附录A 课题任务分工 (35)A-1 课题程序设计分工 (35)A-2 课题报告分工 (36)附录B 课题设计文档(光盘) (37)B-1源程序代码(*.H,*.CPP) (37)B-2工程与可执行文件) (37)附录C 用户操作手册(可选) (37)C.1 运行环境说明 (37)C.2 操作说明 (37)1 课题概述1.1课题任务采用哈夫曼树求得的用于通信的二进制编码称为哈夫曼编码。
压缩软件(数据结构课程设计)

《数据结构》课程设计实验报告题目:压缩软件(选做题)姓名:学号:指导老师:时间:2015.09.06目录一、设计内容和要求 (3)二、算法思想描述 (3)三、程序结构 (4)四、结果与分析 (5)结果 (5)分析 (9)五、收获与体会 (9)一、设计内容和要求设计内容:压缩软件要求:建立一个文本文件A(可以是C/C++源程序),统计该文件中各字符频率。
首先对各字符进行Huffman编码,将该文件翻译成Huffman编码文件B;然后将Huffman编码文件译码成文件C,并对文件A与C进行比较。
二、算法思想描述1.Huffman编码解码思想:Huffman树是一种加权路径长度最短的二叉树。
编码时,是根据待编码文件中记录的关键字在文件中出现的频率进行编码,每个关键字都对应一个编码,频率较高则编码较短,频率较低则编码较长。
Huffman树解码时,根据记录的关键字的编码对文件进行解码。
具体方法为依次选择权值最小的两个关键字作为左右孩子,其和作为父结点的权值,将其父结点代替两个子结点,再次选择权值最小作为左右孩子,依次进行下去,直到所有的关键字结点都成为叶子结点。
根据创建的Huffman树来确定个关键字的01编码,左孩子为0,右孩子为1。
2.整体算法描述:首先读入待压缩文件,然后对每种字符出现的频度进行统计,以频率作为建立哈夫曼树的权值。
接着建立哈夫曼树,对出现的每种字符进行哈夫曼编码。
此时再读入原文件,逐个字节进行编码,将得到的编码流逐个写入文件。
译码过程:读入被压缩文件,根据哈夫曼树对文件中的字符逐个译码,将译码结果逐个写入文件。
三、程序结构压缩软件的程序流程图压缩软件的函数功能结构图四、结果与分析结果1.界面2.压缩文件3.解压文件4.比较分析1.检查程序的正确性本程序运行时生成两个文件,文件名分别为A.txt 和C.txt 。
当C.txt 和原文件的内容大小一致时,说明程序功能已经实现的,在VC的环境下,二者是相同的,仅文件名的差异。
哈夫曼压缩解压-数据结构设计报告

《数据结构》课程设计数学与应用数学一班胡耕岩 2012214147一、问题分析和任务定义1.1设计任务采用哈夫曼编码思想实现文件的压缩和恢复功能,并提供压缩前后的占用空间之比。
要求(1)运行时的压缩原文件的规模应不小于5K。
(2)提供恢复文件与原文件的相同性对比功能。
1.2问题分析本课题是利用哈夫曼编码思想,设计对一个文本文件(.txt)中的字符进行哈夫曼编码,生成编码压缩文件,并且还可将一个压缩后的文件进行解码还原为原始文本文件(.txt)。
在了解哈夫曼压缩解压缩原理之前,首先让我们来认识哈夫曼树。
哈夫曼树又称最优二叉树,是带权路径长度最小的二叉树。
在文本文件中多采用二进制编码。
为了使文件尽可能的缩短,可以对文件中每个字符出现的次数进行统计。
设法让出现次数多的字符二进制码短些,而让那些很少出现的字符二进制码长一些。
若对字符集进行不等长编码,则要求字符集中任一字符的编码都不是其它字符编码的前缀。
为了确保哈夫曼编码的唯一性,我们可以对它的左右子树的大小给予比较限定,如:左子树的权值小于右子树的权值。
哈夫曼树中的左右分支各代表‘0’和‘1’,则从根节点到叶子节点所经历的路径分支的‘0’和‘1’组成的字符串,为该节点对应字符的哈夫曼编码。
统计字符中每个字符在文件中出现的平均概率(概率越大,要求编码越短)。
利用哈夫曼树的特点:权越大的叶子离根越近,将每个字符的概率值作为权值,构造哈夫曼树。
则概率越大的节点,路径越短。
哈夫曼译码是从二进制序列的头部开始,顺序匹配成共的部分替换成相应的字符,直至二进制转换为字符序列。
哈夫曼用于文件解压缩的基础是在压缩二进制代码的同时还必须存储相应的编码,这样就可以根据存储的哈夫曼编码对压缩代码进行压缩。
总之,该课题的任务应该是首先要打开要压缩的文本文件并读出其字符出现的频率,以其为权值构建哈夫曼树。
其次要找到构建压缩功能的方法,在构建哈夫曼树的基础上进行编码,改变字符原先的存储结构,以达到压缩文件的目的,以外还有存储相应的哈夫曼编码,为解压缩做准备。
数据结构课程设计计划
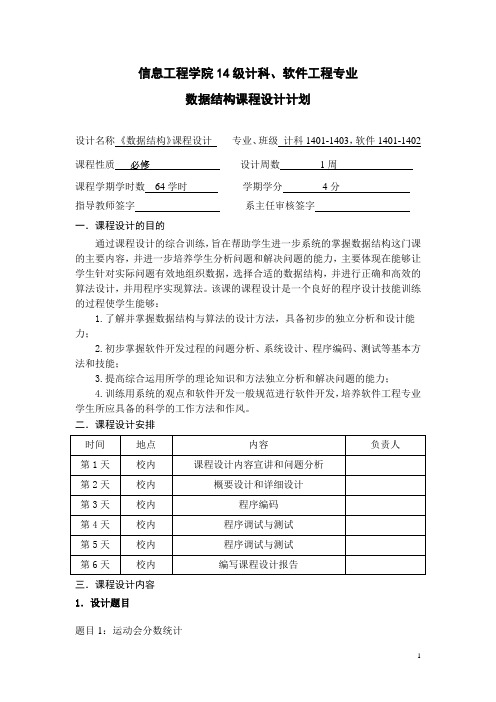
信息工程学院14级计科、软件工程专业数据结构课程设计计划设计名称《数据结构》课程设计专业、班级计科1401-1403,软件1401-1402 课程性质必修设计周数1周课程学期学时数64学时学期学分4分指导教师签字系主任审核签字一.课程设计的目的通过课程设计的综合训练,旨在帮助学生进一步系统的掌握数据结构这门课的主要内容,并进一步培养学生分析问题和解决问题的能力,主要体现在能够让学生针对实际问题有效地组织数据,选择合适的数据结构,并进行正确和高效的算法设计,并用程序实现算法。
该课的课程设计是一个良好的程序设计技能训练的过程使学生能够:1.了解并掌握数据结构与算法的设计方法,具备初步的独立分析和设计能力;2.初步掌握软件开发过程的问题分析、系统设计、程序编码、测试等基本方法和技能;3.提高综合运用所学的理论知识和方法独立分析和解决问题的能力;4.训练用系统的观点和软件开发一般规范进行软件开发,培养软件工程专业学生所应具备的科学的工作方法和作风。
二.课程设计安排三.课程设计内容1.设计题目题目1:运动会分数统计【问题描述】参加运动会有n个学校,学校编号为1……n。
比赛分成m个男子项目,和w个女子项目。
项目编号为男子1……m,女子m+1……m+w。
不同的项目取前五名或前三名积分;取前五名的积分分别为:7、5、3、2、1,前三名的积分分别为:5、3、2;哪些取前五名或前三名由学生自己设定。
(m<=20,n<=20)。
【基本要求】(1) 可以输入各个项目的前三名或前五名的成绩;(2) 能统计各学校总分;(3) 可以按学校编号或名称、学校总分、男女团体总分排序输出;(4) 可以按学校编号查询学校某个项目的情况;可以按项目编号查询取得前三或前五名的学校;(5) 学生自己根据系统功能要求自己设计存储结构,但是要求运动会的相关数据要存储在数据文件中并能随时查询;(6) 输入数据形式和范围:可以输入学校的名称,运动项目的名称;(7) 使用汉字显示。
数据结构课程设计_哈夫曼压缩文件

《数据结构》基于哈夫曼算法的文件压缩程一.总体设计1.目标设计:*实现目标:利用哈夫曼算法编写一个可以对文件进行压缩和解压缩的程序,即可以将指定的文件用哈夫曼算法压缩为一个新的文件,也可以将一个压缩后的文件还原,并可以将压缩或还原后的文件保存到指定位置。
*功能描述:任何文件都可以看作是由字节组成的字节块,将字节看作基本编码单元,一个文件就可以看作是由字节组成的信息串。
对文件中各字节的出现频率进行统计,并以出现频率作为字节的权值,就可以用字节为叶结点构造哈夫曼树,进而构造出各字节的对应哈夫曼编码。
字节编码是一种8位定长编码,将各字节用哈夫曼编码进行重新编码,就有可能使得总的编码长度更短,从而达到压缩的效果。
哈夫曼编码是无损压缩当中最好的方法。
它使用预先二进制描述来替换每个符号,长度由特殊符号出现的频率决定。
常见的符号需要很少的位来表示,而不常见的符号需要很多位来表示。
哈夫曼算法对文件的压缩和解压缩的程序就是将存储源文件的二进制编码通过利用哈夫曼算法译为长度不等的哈夫曼编码,即得到哈夫曼树。
这棵树有两个目的:1.编码器使用这棵树来找到每个符号最优的表示方法,进而存储树实现文件的压缩。
2.解码器使用这棵树唯一的标识在压缩流中每个编码的开始和结束,其通过在读压缩数据位的时候自顶向底的遍历树,选择基于数据流中的每个独立位的分支,一旦一个到达叶子节点,解码器知道一个完整的编码已经读出来了,即通过对哈夫曼树的遍历实现解压过程。
2.框架设计:定义结构体类型变量struct head {}定义函数void compress() /*压缩文件*/{在函数compress内定义变量;读取被压缩文件;建立并打开目标文件;逐字节读入,并进行累加计数,得到各个字节在文件中的出现频率;利用哈夫曼算法构造出字节对应的哈夫曼树;将压缩后的数据写入目标文件,并保存;}定义函数uncompress() /*解压文件*/{在函数uncompress内定义变量;读取需解压文件;建立并打开目标文件;对哈夫曼树进行遍历实现解压;将解压后的数据写入目标文件,并保存;}定义主函数int main(){输入A,压缩文件,调用函数compress;输入B,解压文件,调用函数uncompress;}二.详细设计1、文件的字节频率统计字节共有256个,从0~255,可定义长度为256的频率数组来记录每个字节的出现频率。
数据结构实验报告4文件压缩概要

数据结构与程序设计实验实验报告哈尔滨工程大学实验报告四一、问题描述哈夫曼编码是一种常用的数据压缩技术,对数据文件进行哈夫曼编码可大大缩短文件的传输长度,提高信道利用率及传输效率。
要求采用哈夫曼编码原理,统计文本文件中字符出现的词频,以词频作为权值,对文件进行哈夫曼编码以达到压缩文件的目的,再用哈夫曼编码进行译码解压缩。
统计待压缩的文本文件中各字符的词频,以词频为权值建立哈夫曼树,并将该哈夫曼树保存到文件HufTree.dat 中。
根据哈夫曼树(保存在HufTree.dat 中)对每个字符进行哈夫曼编码,并将字符编码保存到HufCode.txt 文件中。
压缩:根据哈夫曼编码,将源文件进行编码得到压缩文件CodeFile.dat。
解压:将CodeFile.dat 文件利用哈夫曼树译码解压,恢复为源文件。
二、数据结构设计由于哈夫曼树中没有度为1的结点,则一棵树有n个叶子结点的哈夫曼树共有2n-1个结点,可以存储在一个大小为2n-1的一维数组中,而且对每个结点而言,即需知双亲结点的信息,又需知孩子结点的信息,由此可采用如下数据结构。
1.使用结构体数组统计词频,并存储:typedef struct Node{int weight; //叶子结点的权值char c; //叶子结点int num; //叶子结点的二进制码的长度}LeafNode[N];2.使用结构体数组存储哈夫曼树:typedef struct{unsigned int weight;//权值unsigned int parent, LChild, RChild;}HTNode,Huffman[M+1]; //huffman树3.使用字符指针数组存储哈夫曼编码表:typedef char *HuffmanCode[2*M]; //haffman编码表三、算法设计1.读取文件,获得字符串void read_file(char const *file_name, char *ch){FILE *in_file = Fopen(file_name, "r");unsigned int flag = fread(ch, sizeof(char), N, in_file);if(flag == 0){printf("%s读取失败\n", file_name);fflush(stdout);}printf("读入的字符串是: %s\n\n", ch);Fclose(in_file);int len = strlen(ch);。
文件压缩程序设计报告

课程设计报告课程名称:操作系统实验题目:文件压缩程序院系:计算机科学与工程学院班级:姓名:学号:二○一一年七月一日一、需求分析:有两种形式的重复存在于计算机数据中,文件压缩程序就是对这两种重复进行了压缩。
一种是短语形式的重复,即三个字节以上的重复,对于这种重复,压缩程序用两个数字:1.重复位置距当前压缩位置的距离;2.重复的长度,来表示这个重复,假设这两个数字各占一个字节,于是数据便得到了压缩。
第二种重复为单字节的重复,一个字节只有256种可能的取值,所以这种重复是必然的。
给 256 种字节取值重新编码,使出现较多的字节使用较短的编码,出现较少的字节使用较长的编码,这样一来,变短的字节相对于变长的字节更多,文件的总长度就会减少,并且,字节使用比例越不均匀,压缩比例就越大。
编码式压缩必须在短语式压缩之后进行,因为编码式压缩后,原先八位二进制值的字节就被破坏了,这样文件中短语式重复的倾向也会被破坏(除非先进行解码)。
另外,短语式压缩后的结果:那些剩下的未被匹配的单、双字节和得到匹配的距离、长度值仍然具有取值分布不均匀性,因此,两种压缩方式的顺序不能变。
本程序设计只做了编码式压缩,采用Huffman编码进行压缩和解压缩。
Huffman编码是一种可变长编码方式,是二叉树的一种特殊转化形式。
编码的原理是:将使用次数多的代码转换成长度较短的代码,而使用次数少的可以使用较长的编码,并且保持编码的唯一可解性。
根据 ascii 码文件中各 ascii 字符出现的频率情况创建 Huffman 树,再将各字符对应的哈夫曼编码写入文件中。
同时,亦可根据对应的哈夫曼树,将哈夫曼编码文件解压成字符文件.二、概要设计:主程序流程图:压缩过程的实现:压缩过程的流程是清晰而简单的:1. 创建Huffman 树2. 打开需压缩文件3. 将需压缩文件中的每个ascii 码对应的huffman 编码按bit 单位输出生成压缩文件压缩结束。
《数据结构》课程设计

《数据结构》课程设计一、课程目标《数据结构》课程旨在帮助学生掌握计算机科学中基础的数据组织、管理和处理方法,培养其运用数据结构解决实际问题的能力。
课程目标如下:1. 知识目标:(1)理解基本数据结构的概念、原理和应用,如线性表、栈、队列、树、图等;(2)掌握常见算法的设计和分析方法,如排序、查找、递归、贪心、分治等;(3)了解数据结构在实际应用中的使用,如操作系统、数据库、编译器等。
2. 技能目标:(1)能够运用所学数据结构解决实际问题,具备良好的编程实践能力;(2)掌握算法分析方法,能够评价算法优劣,进行算法优化;(3)能够运用数据结构进行问题建模,提高问题解决效率。
3. 情感态度价值观目标:(1)激发学生对计算机科学的兴趣,培养其探索精神和创新意识;(2)培养学生团队合作意识,学会与他人共同解决问题;(3)增强学生的责任感和使命感,使其认识到数据结构在信息技术发展中的重要性。
本课程针对高中年级学生,结合学科特点和教学要求,将目标分解为具体的学习成果,为后续教学设计和评估提供依据。
课程注重理论与实践相结合,旨在提高学生的知识水平、技能素养和情感态度价值观。
二、教学内容《数据结构》教学内容依据课程目标进行选择和组织,确保科学性和系统性。
主要包括以下部分:1. 线性表:- 线性表的定义、特点和基本操作;- 顺序存储结构、链式存储结构及其应用;- 线性表的相关算法,如插入、删除、查找等。
2. 栈和队列:- 栈和队列的定义、特点及基本操作;- 栈和队列的存储结构及其应用;- 栈和队列相关算法,如进制转换、括号匹配等。
3. 树和二叉树:- 树的定义、基本术语和性质;- 二叉树的定义、性质、存储结构及遍历算法;- 线索二叉树、哈夫曼树及其应用。
4. 图:- 图的定义、基本术语和存储结构;- 图的遍历算法,如深度优先搜索、广度优先搜索;- 最短路径、最小生成树等算法。
5. 排序和查找:- 常见排序算法,如冒泡、选择、插入、快速等;- 常见查找算法,如顺序、二分、哈希等。
数据结构实验报告利用Huffman编码对文件进行压缩解压

《数据结构》实验报告利用Huffman编码对文件进行压缩解压学生:XXX学号:XXXXXXXX联系:XXXXXX@(一)基本信息1.实验题目利用Huffman编码对文件进行压缩解压2.完成人(姓名、学号)姓名:XXX 学号:XXXXXXXX3.报告日期2007年12月12日星期二(二)实习内容简要描述1.实习目标学会对树的基本操作学会对文件进行操作利用Huffman编码对文件压缩解压2.实习要求实现最小堆模板类利用最小堆构建Huffman树实现Huffman编码和解码根据用户从键盘输入的报文文本,输出各字符的Huffman编码以及报文的编码根据用户从键盘输入一串报文文本,输出各字符的Huffman编码输出报文的Huffman编码及长度根据输入的Huffman编码,解码输出利用Huffman编码和解码对二进制文件的压缩和解压(三)报告主要内容1.设计思路开发环境:Microsoft Visual C++ 2005设计思路:1.设计Pack类储存字符的权值2.设计MinHeap模板类构建最小堆3.设计ExtBinTree模板类为带权二叉树4.设计Compress模板类以实现文件的压缩解压2.主要数据结构1.MinHeap.h: 头文件,包含MinHeap模板类的类界面以及定义;2.HuffmanTree.h:头文件,包含ExtBinTree模板类以及Compress模板类的类的的类界面以及定义3.main.cpp:调用上述头文件实现相关操作3.主要代码结构主要代码结构为见附件中各文件的代码注释4.主要代码段分析主要代码段分析,见附件中的代码注释(四)实习结果1.基本数据源程序代码行数:约800行完成该实习投入的时间:二十四小时(不包括写实验报告的时间)与其他同学讨论交流情况:感谢刘畅同学对程序的测试2.测试数据设计1.对屏幕输入字符进行Huffman编码2.根据Huffman树非唯一性,虽然和课件上有些许不同,但是还是正确的3.输入字符串:CASTCASTSATATATASA4.输出编码:A:0 C:110 S:111 T:105.输入霍夫曼编码:01110101101106.输出译码:ASATCC7.8.对”实验05.PPT”的压缩操作9.使用0秒(不足一秒按0秒计算),压缩率为56.1755%10.对”实验05.ppt.hfm”(即刚才生成的压缩文件)的解压操作11.使用0秒(不足一秒按0秒计算),解压后文件无异常12.对一个18M的EXE安装包前后进行压缩和解压操作,分别用时10秒和9秒3.测试结果分析A)程序运行的系统资源配置操作系统:Microsoft Windows XP Professional SP2CPU: AMD Athlon 3600+ 2.0GRAM: 1024M DDRII开发环境:Microsoft Visual C++ 2005B)对TXT文档进行压缩和解压后,通过WinMerge检验和原文件无差异C)对MP3和EXE文件压缩和解压后仍能正常使用D)对于中文名字和带有空格的路径均能正确无误识别E)文件名只能小于16个字符(包括后缀名),否则解压会出错(只预留了16个字节用于储存文件名)F)相对于不用文件块读写的程序,效率提高了三倍以上G)具有动态进度条,可以显示当前压缩和解压的进度百分比(当然消耗了一些系统资源)H)出错处理不够充分,特别是cin部分,如果误输入可能会造成死循环(五)实习体会1.实习过程中遇到问题及解决过程A)一开始时候的程序运行很慢,,压缩一个4M左右的文件需要七八秒,后来改用文件块缓存字节来读写后,压缩一个4M的文件只需要两秒左右的时间.本来是只想写一个进度条而已的,后来发现如果只读一个字节就判断一次进度条的话会很消耗系统资源,后来干脆麻烦点用文件块来缓存.不过至于一次缓存多少字节才能达到最好的效果还未知,现在设置的是一次缓存40KB 的数据B)本来一个一个字节读的时候对最后一个字节的操作基本没费什么劲,但是在文件块读写的时候就不是那么清晰明了了,后来经过仔细Debug,才找到错误的所在.许多问题都是这样C)对于中文名和带空格路径,用C++的fstream就不支持,但是C中的FILE*就支持,不知道为什么.还有C++中的fstream的成员函数read返回值很奇怪,不知道如何获取成功读入的项数.改用C中的FILE*文件指针后就解决掉了D)由于这次实验的各个步骤是一环套一环的,在哪里出错很难找得出来,所以这次实验调试消耗的时间特别多.最郁闷的一次错误是发现在取得字符C的第N位函数中,居然把0x40写成了0x30.有时候文件解压出来不对,但是又不清楚是压缩时候错了,还是解压时候错了,然后就要两个函数都要检查一遍.2. 实习体会和收获这次实验最大的特点在于难找错,很锻炼自己的Debug能力(六)自评成绩分数:90 //功能做得较齐全,程序的效率也不错(七)参考文献MSDN还有某网站上树的遍历算法(八)源程序见同一文件夹内.。
《数据结构》课程设计报告

《数据结构》课程设计报告一、课程目标《数据结构》课程旨在帮助学生掌握计算机科学中数据结构的基本概念、原理及实现方法,培养其运用数据结构解决实际问题的能力。
本课程目标如下:1. 知识目标:(1)理解数据结构的基本概念,包括线性表、栈、队列、串、数组、树、图等;(2)掌握各类数据结构的存储表示和实现方法;(3)了解常见算法的时间复杂度和空间复杂度分析;(4)掌握排序和查找算法的基本原理和实现。
2. 技能目标:(1)能够运用所学数据结构解决实际问题,如实现字符串匹配、图的遍历等;(2)具备分析算法性能的能力,能够根据实际问题选择合适的算法和数据结构;(3)具备一定的编程能力,能够用编程语言实现各类数据结构和算法。
3. 情感态度价值观目标:(1)培养学生对计算机科学的兴趣,激发其探索精神;(2)培养学生团队合作意识,提高沟通与协作能力;(3)培养学生面对问题勇于挑战、善于分析、解决问题的能力;(4)引导学生认识到数据结构在计算机科学中的重要地位,激发其学习后续课程的兴趣。
本课程针对高年级学生,课程性质为专业核心课。
结合学生特点,课程目标注重理论与实践相结合,强调培养学生的实际操作能力和解决问题的能力。
在教学过程中,教师需关注学生的个体差异,因材施教,确保课程目标的达成。
通过本课程的学习,学生将具备扎实的数据结构基础,为后续相关课程学习和职业发展奠定基础。
二、教学内容根据课程目标,教学内容主要包括以下几部分:1. 数据结构基本概念:线性表、栈、队列、串、数组、树、图等;教学大纲:第1章 数据结构概述,第2章 线性表,第3章 栈和队列,第4章 串。
2. 数据结构的存储表示和实现方法:教学大纲:第5章 数组和广义表,第6章 树和二叉树,第7章 图。
3. 常见算法的时间复杂度和空间复杂度分析:教学大纲:第8章 算法分析基础。
4. 排序和查找算法:教学大纲:第9章 排序,第10章 查找。
教学内容安排和进度如下:1. 第1-4章,共计12课时,了解基本概念,学会使用线性表、栈、队列等解决简单问题;2. 第5-7章,共计18课时,学习数据结构的存储表示和实现方法,掌握树、图等复杂结构;3. 第8章,共计6课时,学习算法分析基础,能对常见算法进行时间复杂度和空间复杂度分析;4. 第9-10章,共计12课时,学习排序和查找算法,掌握各类算法的实现和应用。
数据结构课程设计报告Huffman编码与文件压缩

数据结构课程设计报告--Huffman编码与文件压缩课程设计报告题目:题目三哈夫曼编码与文件压缩课程名称:数据结构专业班级:计算机科学与技术1003班学号:姓名:鲁辰指导教师:报告日期:2012.09.26计算机科学与技术学院目录1任务书 (4)2 绪言 (5)2.1 课题背景 (5)2.2 课题研究的目的和意义 (5)2.3 国内外概况 (5)2.4 课题的主要研究工作 (5)3 系统设计方案的研究 (6)3.1 系统的控制特点与性能要求 (6)3.2 系统实现的原理 (6)3.2.1 Huffman算法 (6)3.2.2 Huffman编码 (6)3.2.3 压缩过程 (6)3.2.4 解压过程 (7)3.3 系统实现方案分析 (7)3.3.1 实现Huffman编码及压缩所需的变量 (7)3.3.2文件名处理 (9)3.3.3 实现Huffman编码及压缩过程所需要的函数 (10)3.3.4 实现解压缩过程所需要的函数 (13)3.3.5 输入输出 (13)4 基于Huffman编码的文件压缩程序的设计 (14)4.1 主模块功能介绍 (14)5 系统的实现 (15)5.1 目标程序运行截图 (15)5.2 测试及测试数据分析 (15)5.2.1 测试数据 (15)5.2.2 测试数据分析 (16)6 总结与展望 (18)参考文献 (19)附录英文缩写词 (20)1任务书题目三哈夫曼编码与文件压缩☐设计目的:掌握二叉树、哈夫曼树的概念,性质与存储结构,能够利用哈夫曼算法实现哈夫曼编码,并应用于文件压缩,从而提高学生综合运用知识的技能与实践能力。
☐设计内容:分析与设计哈夫曼树的存储结构,实现哈夫曼算法以及编码与译码基本功能,并对任意文本文件利用哈夫曼编码进行压缩得到压缩文件,然后进行解压缩得到解压文件。
有兴趣的同学可以查阅资料实现Lempel-Ziv sliding window压缩方法,并与之比较。
压缩软件课程设计报告

数据结构课程设计报告压缩软件---采用哈夫曼编码技术学号:二○○八年九月三日星期三目录课程设计课题 (3)设计要求及分析 (3)软件开发 (3)类的结构图 (4)程序类的说明 (4)较有特色的函数 (5)测试结果 (6)收获与体会 (7)【一】课程设计课题:压缩软件【二】设计要求及分析:要求:建立一个文本文件A,统计该文件中各字符的频率,对各字符进行Huffman编码,将该文件翻译成Huffman编码文件B,再将Huffman编码文件译码成文件C,并对文件A与C进行比较。
数据压缩理论:数据压缩有2种基本类型:无损压缩和有损压缩,使用无损压缩方法压缩的文件不会丢失任何信息,他与原文件具有可逆性,就是可以通过解压缩的方法恢复原来的数据,通常对文本文件,字处理文件,应用程序等采用这种算法。
有损压缩算法在压缩时回丢失一些信息,压缩后不能完整恢复出原有信息,较多应用于音频,视频图象数据的处理。
哈夫曼树简介:标准ASCII码把每个字符分别用一个7位的二进制数表示,这种方法使用最少的位表示了所有ASCII码中的128个字符,称为等长编码,如果每个字符的使用频率相等,等长编码是空间效率最高的方法。
如果字符出现的频率不同,可以让频率高的字符采用尽可能短的编码,频率低的字符采用稍长的编码,来构造一种不等长编码,则会获得更好的空间效率。
而此处我们所实现的哈夫曼算法,就是一种不等长编码,用于数据的无损压缩。
术语是指用一张特殊的编码表对源字符进行编码。
这张编码表的特殊之处在于,它是根据每一个源字符出现的估算概率而建立起来的,同时保持编码的唯一可解性,这种方法是由美国科学家David.A.Huffman发展起来的。
哈夫曼树是哈夫曼算法的理论描述工具,也称最优二叉树,是一种加权路径长度最短的二叉树。
加权路径长度是指树中所有叶子结点的权值乘上其到根结点的路径长度。
N个叶子结点的哈夫曼树共有2n-1个结点,这个性质将运用于使用数组结构存储哈夫曼树,从根结点开始,左分支结点分配0,右分支结点分配1,沿着树根到各个结点就得到了哈夫曼编码,因为所有被编码的字符都作为叶子结点出现而每个叶子结点路径又是独立的,保障了每个编码都不会四其余码的前缀,这样的编码又称“哈夫曼无重复前缀编码”,这在下面的程序段会应用到。
哈夫曼树压缩软件数据结构课程设计

数据结构课程设计设计题目:哈夫曼树压缩软件姓名:学号:班级:指导老师:一、设计分析 (4)二、算法设计 (5)三、主要模块说明 (6)主界面 (6)int main() (7)bintree.h (8)ceshi.h (16)compress1.h (20)void Decompress() (24)huffmantree.h (26)#if !defined _HEAP_H_ (29)四、运行截图 (33)五、总结 (35)一、设计分析1)课程设计名称及内容课程设计名称:哈夫曼编码的数据压缩/解压程序设计内容:将任意一个指定的文本文件中的字符进行哈夫曼编码,生成一个编码文件(压缩文件);反过来,可将一个压缩文件解码还原为一个文本文件。
2)选择1时:输入一个待压缩的文本文件名称(带路径)。
如:D:\lu\lu.txt统计文本文件中各字符的个数作为权值,生成哈夫曼树;将文本文件利用哈夫曼树进行编码,生成压缩文件。
压缩文件名称=压缩文件时所命的名称.HFM如:D:\lu\lu.COD压缩文件内容=哈夫曼树的核心内容+编码序列(文件存放在软件运行的文件夹下)3) 选择2时:输入一个待解压的压缩文件名称(带路径 )如:D:\lu\lu.COD从文件中读出哈夫曼树,并利用哈夫曼树将编码序列解码;生成(还原)文本文件。
文件名称 =压缩文件名时为解压缩时所命的名字如:D:\lu\***.txt (但是没有实现这一效果,解压时需要建立一个和文件未压缩以前一样的空文件和需要解压文件放在一起)4)选择3时:对输入的字符串进行编码、压缩、解压并对其进行显示。
5)选择0是则退出二、算法设计2.1设计思想:统计字符,得出统计出字符的权值n,建立哈夫曼树,根据哈夫曼树编码对编码进行压缩生成二进制文件,根据哈夫曼树解码生成哈夫曼树,对二进制文件进行解码生成对应文件。
2.2 算法思想:2.2.1输入要压缩的文件首先运行的时候,用户主界面上有菜单提示该如何使用软件,根据菜单提示选择所要执行的项,依次进行,因为各个环节之间有先后顺序。
课程设计文件压缩

课程设计文件压缩一、教学目标本课程的学习目标包括知识目标、技能目标和情感态度价值观目标。
知识目标要求学生掌握文件压缩的基本原理和方法,了解常见的文件压缩格式和工具。
技能目标要求学生能够运用文件压缩工具进行文件的压缩和解压操作,掌握文件压缩的技巧和优化方法。
情感态度价值观目标要求学生培养对信息技术的兴趣和好奇心,提高信息处理的效率和安全性,增强信息共享和交流的能力。
通过本课程的学习,学生将能够了解文件压缩的基本概念和原理,掌握常见的文件压缩格式和工具的使用方法,能够进行文件的压缩和解压操作,并能够根据需要选择合适的压缩工具和策略。
同时,学生将能够提高信息处理的效率和安全性,增强信息共享和交流的能力,培养对信息技术的兴趣和好奇心。
二、教学内容本课程的教学内容主要包括文件压缩的基本原理、常见的文件压缩格式和工具的使用方法以及文件压缩的技巧和优化方法。
具体包括以下几个方面的内容:1.文件压缩的基本原理:介绍文件压缩的原理和过程,包括数据压缩的数学模型和算法。
2.常见的文件压缩格式:介绍常见的文件压缩格式,如ZIP、RAR、7z等,以及它们的优缺点和使用场景。
3.文件压缩工具的使用方法:介绍常见的文件压缩工具,如WinRAR、7-Zip等,以及它们的安装和使用方法。
4.文件压缩的技巧和优化方法:介绍文件压缩的技巧和优化方法,如压缩率的调整、分卷压缩、加密压缩等。
三、教学方法本课程的教学方法采用讲授法、案例分析法和实验法相结合的方式进行。
首先,通过讲授法向学生介绍文件压缩的基本原理和常见的文件压缩格式和工具的使用方法。
然后,通过案例分析法引导学生运用文件压缩工具进行实际操作,解决实际问题。
最后,通过实验法让学生进行文件压缩的实践操作,巩固所学知识和技能。
此外,还可以采用讨论法和学生自主学习法,鼓励学生积极参与课堂讨论,提出问题和建议,促进学生之间的交流和合作,提高学生的自主学习能力和问题解决能力。
四、教学资源本课程的教学资源包括教材、参考书、多媒体资料和实验设备。
数据结构课程设计范例1

一.设计目的数据结构作为一门学科主要研究数据的各种逻辑结构和存储结构,以及对数据的各种操作。
因此,主要有三个方面的内容:数据的逻辑结构;数据的物理存储结构;对数据的操作(或算法)。
通常,算法的设计取决于数据的逻辑结构,算法的实现取决于数据的物理存储结构。
数据结构是信息的一种组织方式,其目的是为了提高算法的效率,它通常与一组算法的集合相对应,通过这组算法集合可以对数据结构中的数据进行某种操作。
在当今信息时代,信息技术己成为当代知识经济的核心技术。
我们时刻都在和数据打交道。
比如人们在外出工作时找最短路径,在银行查询存款、通过互联网查新闻、以及远程教育报名等,所有这些都在与数据发生关系。
实际上,现实世界中的实体经过抽象以后,就可以成为计算机上所处理的数据。
数据结构课程主要是研究非数值计算的程序设计问题中所出现的计算机操作对象以及它们之间的关系和操作的学科。
数据结构是介于数学、计算机软件和计算机硬件之间的一门计算机专业的核心课程,它是计算机程序设计、数据库、操作系统、编译原理及人工智能等的重要基础,广泛的应用于信息学、系统工程等各种领域。
学习数据结构是为了将实际问题中所涉及的对象在计算机中表示出来并对它们进行处理。
通过课程设计可以提高学生的思维能力,促进学生的综合应用能力和专业素质的提高。
通过此次课程设计主要达到以下目的:一、了解并掌握数据结构与算法的设计方法,具备初步的独立分析和设计能力;二、初步掌握软件开发过程的问题分析、系统设计、程序编码、测试等基本方法和技能;三、提高综合运用所学的理论知识和方法独立分析和解决问题的能力;四、训练用系统的观点和软件开发一般规范进行软件开发,培养软件工作者所应具备的科学的工作方法和作风。
二、需求分析2.1选题的意义及背景锻炼我们的编码能力,真正理解数据结构的编码思想,并且锻炼我们的动手能力和成员间的配合,提高程序编写能力。
在信息传递时,希望长度能尽可能短,即采用最短码。
英文文件的压缩和解压缩v-数据结构与算法课程设计报告

题目:名称:英文文件的压缩和解压缩内容:采用哈夫曼编码思想实现文件的压缩和解压缩功能,并提供压缩前后的占用空间之比。
要求:(1)压缩原文件的规模应不小于5K。
(2)提供解压缩后文件与原文件的相同性比较功能。
一、问题分析何任务定义通过阅读并理解这个题目,要求实现对一个大小不小于5KB的英文文件的压缩和解压缩功能。
为了完成这个功能,可以采用哈夫曼编码具体实现。
实现本程序需要解决一下几个问题:1、如何统计英文文件的字符种类数和各类字符的数目,并将各类字符作为哈夫曼树的叶子,数目作为它的权值。
2、如何利用上述的字符数目作为叶子权值建立哈夫曼树。
3、如何对于步骤2建立的哈夫曼树的叶子(字符)进行编码。
4、如何将已知的字符编码应用到英文文件。
5、如何对应经压缩的文件进行解压缩。
首先,给定一个英文文件,如图(1):图(1)解压后的文件:然后再进行字符统计,可以利用ASCII码表的字符与数字一一对应的知识计算出每类字符的数目,把计算出的每类字符放到另一个数组中顺序存储。
利用上述统计出的每类字符及字符数目作为哈夫曼树(数组存储)的叶子结点,把上述数组顺序存储的字符及数目赋给哈夫曼数组前n位,每次选用权值最小和次最小的两个结点构建哈夫曼树,已经选用的就不再此操作了。
建立好哈夫曼树后就是对其叶子进行编码,因为哈夫曼树的结点的度数不是2就是0(叶子),此叶子就是要进行编码的对象,令其左边为0,右边为1,如图(2)0 1图(2)从每个叶子结点开始一直沿着哈夫曼树向上,直到根结点,循环此操作,将每个字符进行编码。
对每个字符编码后,就要对英文文件进行压缩了,再次从英文文件单个单个读出字符,将每个字符对应的编码向另一个文件中写入,此时是利用循环来将字符对应的编码一个个的写入到文件中。
直到文件结束,此时压缩成功。
并可以查看压缩的文件code.txt。
对于一个压缩的文件进行译码,译码的方法就是从压缩文件连续读出0或1,将连续读出的0或1从哈夫曼树的根结点开始一直向下,直到某个叶子结点,将此编码所对应的字符写入另一个文件中,然后在继续读入0或1,利用上述的办法循环写入字符,直到文件结束。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
数据结构课程设计报告实验二:文本文件压缩一、设计要求1、问题描述:根据huffman编码以及二叉树的相关知识实现文本文件的压缩(即将输入的字符串转换为二进制编码)和解压(即将二进制编码转换为字符串)2、输入:文本文件(压缩文件)。
3、输出:压缩文件(文本文件)。
知识点:堆、霍夫曼树、二叉树遍历实际输入输出情况:源文件为文本文件,内容如下:输出的文件是以.zl0010为扩展名的二进制文件,将其用记事本以文本方式打开得到如下文件:解压过程如下:解压获得的文件doc.txt.zl0010.txt比较发现源文件与解压缩后文件内容相同。
一、数据结构与算法描述1.对输入文件的处理创建文件输入流,将源文本文件以二进制方式打开,建立保存每个Byte频率的数组count[256],并通过对文件的第一次遍历,完成对Byte频率的统计。
其中bytecount变量记录输入的字节数,关键代码如下:string filename;//文件名int count[256];//每个字符的频率for(int i=0;i<256;i++)count[i]=0;std::ifstream ifs;//输入流std::cout<<"请输入需要压缩的文件路径"<<std::endl;std::cin>>filename;ifs.open(filename,std::ifstream::binary);if(!ifs){std::cout<<"文件打开错误"<<std::endl;system("pause");exit(0);}char buf;int bytecount=0;//计算总共输入了多少字节std::cout<<"正在计算频率……"<<std::endl;while(!ifs.eof()){ifs.read((char*)&buf,1);/*buf+=128;count[buf]++;*/if(ifs.eof())break;count[(int)buf+128]++;bytecount++;/*std::cout<<(int)buf<<std::endl;*/}2.哈夫曼树的建立及编码过程以第一步中统计的Byte出现频率为每个树节点的权值,进行哈夫曼树的构建,并通过构建的哈夫曼树,获取std::string类型的哈夫曼编码。
关键代码如下:std::cout<<"正在编码……"<<std::endl;BTree tree=HuffmanTree(count,256);string* codes;//保存的是每个字符的编码codes=Getcode(count,256,tree);其中HuffmanTree方法得到以count数组为权值的哈夫曼树,Getcode方法返回的是std::string类的数组,这种编码需要后面进一步处理输出二进制文件。
3.输出压缩文件过程该过程的思路如下:将哈夫曼编码每8位作为一个新的字符,将该字符的ASCII码输出到二进制文件中。
由于在源文件中得到的Bytes是-128到127之间的值,需要建立该域与数组索引0到255间的映射。
将得到的字符串形式的编码进行转换,成为对应该编码的二进制串,因为二进制串在C++语言中无法直接输出,所以先将其转换为Int型,再转为char型进行二进制输出。
以下为该过程的代码:int bstringtoint(const string& str){if(str.size()!=8){std::cout<<"转码错误"<<std::endl;exit(0);}int result=0;for(int i=0;i<8;i++)result+=(str[i]-'0')*pow(2,7-i);return result;}在输出过程中使用一个byteoutcount变量来计算输出的字节数。
以下是输出过程的关键代码,其中ofs变量为输出流:string outbuf;int intbuf;//每个将被输出的字节保存在这里int byteoutcount=0;while(!ifs.eof()){ifs.read((char*)&buf,1);if(ifs.eof())break;outbuf+=codes[(int)buf+128];while(outbuf.size()>=8){intbuf=bstringtoint(outbuf.substr(0,8))-128;ofs.write((char*)&intbuf,1);outbuf.erase(0,8);byteoutcount++;}}还要考虑的一个问题是最后的一个byte可能不到8位,我在这里用0补全8位进行最后一位的输出,关键代码如下:if(!outbuf.empty()){outbuf.append(8-outbuf.size(),'0');intbuf=bstringtoint(outbuf)-128;ofs.write((char*)&intbuf,1);}byteoutcount++;如果仅考虑压缩,该过程到此结束。
而为了进行解压缩,我们必须要在压缩文件中保存字典,在这里我的思路是将计算好的字符频率保存在文件中,而在解压缩时利用他们重新构建哈夫曼树,关键代码如下:for(int i=0;i<256;i++){ofs.write((char*)&count[i],sizeof(int));}//输出字符出现频率,即字典ofs.write((char*)&bytecount,sizeof(int));//输出原文件字节数目,方便解压时使用这样整个压缩过程就结束了4.解压缩过程解压缩过程中利用.zl0010文件中的byte频率重建哈夫曼树,该过程除频率的获取过程外与压缩时相同,关键代码如下:std::cout<<"读取数据……"<<std::endl;for(int i=0;i<256;i++)ifs.read((char*)&count[i],sizeof(int));tree=HuffmanTree(count,256);然后获取压缩时输出的字节数,并保存在bytecount变量中,代码如下:ifs.read((char*)&bytecount,sizeof(int));与压缩过程对应,解压缩时需要将获取的byte转换为string 的编码,并且利用指针对哈夫曼树进行追踪,逐步输出整篇被压缩文本。
主要代码如下:while(!ifs.eof()){ifs.read((char*)&buf,1);if(ifs.eof())break;outbuf=inttobstring((int)buf+128);//std::cout<<outbuf<<std::endl;for(string::iterator it=outbuf.begin();it!=outbuf.end();++it){if(*it=='0')p=p->getleft();else p=p->getright();if (p->getdata()!=-1){bufdata=p->getdata()-128;//std::cout<<p->getdata()<<std::endl;ofs.write((char*)&bufdata,1);p=tree.root;outcount++;}if(outcount==bytecount)break;}if(outcount==bytecount)break;}这样解压缩过程就结束了。
二、分析与探讨1.测试结果分析通过压缩解压缩过程中对.txt 文件和.txt.zl0010.txt文件的对比发现整个过程准确无误,哈夫曼压缩的压缩率对于英文相对较高,可达到50%左右,而对中英混合的文档则不算理想,这个问题的产生主要是因为单纯英文,byte的分布比较集中于0到127之间,而中英混合时则更均匀分布到-128到0之间,考虑到哈夫曼压缩的思想是出现频率高的字符编码较短,如果字符出现频率分布均匀则编码长度无法有较明显区分。
2.算法分析1、建立huffman树的时间复杂性为O(n^2),此时n为256,所以在该过程中时间复杂度为O(1)2、给叶子节点分配二进制码的时间复杂性为O(n*树高)3、输出压缩文件过程的时间复杂性为O(n),其中n为源文件的字符个数。
4、解压缩过程的时间复杂性为O(n),其中n为目标文件的字符个数附录:源代码文件一:treeNode.h#pragma onceclass treeNode{friend class BTree;private:int data;treeNode* left;treeNode* right;public:treeNode(const int& data,treeNode* left,treeNode* right);int getdata(){return data;}treeNode* getleft(){return left;}treeNode* getright(){return right;}};文件二:treeNode.cpp#include"treeNode.h"treeNode::treeNode(const int& data=0,treeNode* left=0,treeNode* right=0) {this->data=data;this->left=left;this->right=right;}文件三:BTree.h#pragma once#include"treeNode.h"#include<string>#include<iostream>class BTree{friend class Huffman;friend std::string* Getcode(int a[],int n,const BTree& HTree);friend int main();private:treeNode* root;public:BTree();void MakeTree(const int& data,BTree& left,BTree& right);//BTree HuffmanTree(int a[],int n);};class Huffman{friend class BTree;friend BTree HuffmanTree(int[],int);private:BTree tree;int weight;public:bool operator<(const Huffman& H) const{return (this->weight)>(H.weight);}};文件四:BTree.cpp(压缩)//coded by cs3_zhanglin//压缩器和解压缩器写在了不同的cpp文件中//两个程序公用treeNode.cpp treeNode.h BTree.h三个文件//这是压缩器#include"BTree.h"#include<queue>#include<math.h>#include<fstream>using std::string;BTree::BTree(){this->root=0;}void BTree::MakeTree(const int& data,BTree& left,BTree& right) {this->root=new treeNode(data,left.root,right.root);left.root=right.root=0;}BTree HuffmanTree(int a[],int n){Huffman* w=new Huffman[n];BTree z,zero;for(int i=0;i<n;i++){z.MakeTree(i,zero,zero);w[i].weight=a[i];w[i].tree=z;}std::priority_queue<Huffman> pq;for(int i=0;i<n;i++){if(w[i].weight!=0)pq.push(w[i]);}Huffman x,y;while(true){x=pq.top();pq.pop();y=pq.top();pq.pop();z.MakeTree(-1,x.tree,y.tree);x.weight+=y.weight;x.tree=z;if(pq.empty()){delete[] w;return z;}pq.push(x);}}bool findcode(const int& goal,treeNode* HTree,string& result) {if(HTree==0)return false;if(HTree->getdata()==goal)return true;if(findcode(goal,HTree->getleft(),result)){result.insert(0,"0");return true;}if(findcode(goal,HTree->getright(),result)){result.insert(0,"1");return true;}return false;}string* Getcode(int a[],int n,const BTree& HTree) {string* code=new string[n];for(int i=0;i<n;i++)code[i]="";for(int i=0;i<n;i++)if(a[i]!=0)findcode(i,HTree.root,code[i]);return code;}int bstringtoint(const string& str){if(str.size()!=8){std::cout<<"转码错误"<<std::endl;exit(0);}int result=0;for(int i=0;i<8;i++)result+=(str[i]-'0')*pow(2,7-i);return result;}string inttobstring(int codeint){string str;while(codeint!=0){if(codeint%2==1)str=str.insert(0,"1");elsestr=str.insert(0,"0");codeint=codeint/2;}if(str.size()!=8)str.insert(0,8-str.size(),'0');return str;}int main()//压缩器{string filename;//文件名int count[256];//每个字符的频率for(int i=0;i<256;i++)count[i]=0;std::ifstream ifs;//输入流std::cout<<"请输入需要压缩的文件路径"<<std::endl;std::cin>>filename;ifs.open(filename,std::ifstream::binary);if(!ifs){std::cout<<"文件打开错误"<<std::endl;system("pause");exit(0);}char buf;int bytecount=0;//计算总共输入了多少字节std::cout<<"正在计算频率……"<<std::endl;while(!ifs.eof()){ifs.read((char*)&buf,1);/*buf+=128;count[buf]++;*/if(ifs.eof())break;count[(int)buf+128]++;bytecount++;/*std::cout<<(int)buf<<std::endl;*/}//for(int i=0;i<256;i++)//{// //std::cout<<i<<':'<<count[i]<<std::endl;//}std::cout<<"正在编码……"<<std::endl;BTree tree=HuffmanTree(count,256);string* codes;//保存的是每个字符的编码codes=Getcode(count,256,tree);/*for(int i=0;i<256;i++){std::cout<<i<<':'<<codes[i]<<std::endl;}*/std::cout<<"正在压缩……"<<std::endl;std::ofstream ofs;//输出流ifs.clear();ofs.open(filename+".zl0010",std::ofstream::out|std::ofstream::binary);for(int i=0;i<256;i++){ofs.write((char*)&count[i],sizeof(int));}//输出字符出现频率,即字典ofs.write((char*)&bytecount,sizeof(int));//输出原文件字节数目,方便解压时使用ifs.seekg(0,std::ifstream::beg);//文件指针回到头部string outbuf;int intbuf;//每个将被输出的字节保存在这里int byteoutcount=0;while(!ifs.eof()){ifs.read((char*)&buf,1);if(ifs.eof())break;outbuf+=codes[(int)buf+128];while(outbuf.size()>=8){intbuf=bstringtoint(outbuf.substr(0,8))-128;ofs.write((char*)&intbuf,1);outbuf.erase(0,8);byteoutcount++;}}if(!outbuf.empty()){outbuf.append(8-outbuf.size(),'0');intbuf=bstringtoint(outbuf)-128;ofs.write((char*)&intbuf,1);}byteoutcount++;std::cout<<"输入"<<bytecount<<"个字节,输出"<<byteoutcount<<"个字节"<<std::endl; double yasuolv=byteoutcount/(double)bytecount;std::cout<<"压缩成功"<<",压缩率是"<<yasuolv*100<<"%"<<std::endl;system("pause");}文件五:BTree.cpp(解压缩)#include"BTree.h"#include<queue>#include<math.h>#include<fstream>using std::string;BTree::BTree(){this->root=0;}void BTree::MakeTree(const int& data,BTree& left,BTree& right){this->root=new treeNode(data,left.root,right.root);left.root=right.root=0;}BTree HuffmanTree(int a[],int n){Huffman* w=new Huffman[n];BTree z,zero;for(int i=0;i<n;i++){z.MakeTree(i,zero,zero);w[i].weight=a[i];w[i].tree=z;}std::priority_queue<Huffman> pq;for(int i=0;i<n;i++){if(w[i].weight!=0)pq.push(w[i]);}Huffman x,y;while(true){x=pq.top();pq.pop();y=pq.top();pq.pop();z.MakeTree(-1,x.tree,y.tree);x.weight+=y.weight;x.tree=z;if(pq.empty()){delete[] w;return z;}pq.push(x);}}bool findcode(const int& goal,treeNode* HTree,string& result) {if(HTree==0)return false;if(HTree->getdata()==goal)return true;if(findcode(goal,HTree->getleft(),result)){result.insert(0,"0");return true;}if(findcode(goal,HTree->getright(),result)){result.insert(0,"1");return true;}return false;}string* Getcode(int a[],int n,const BTree& HTree){string* code=new string[n];for(int i=0;i<n;i++)code[i]="";for(int i=0;i<n;i++)if(a[i]!=0)findcode(i,HTree.root,code[i]);return code;}int bstringtoint(const string& str){if(str.size()!=8){std::cout<<"转码错误"<<std::endl;exit(0);}int result=0;for(int i=0;i<8;i++)result+=(str[i]-'0')*pow(2,7-i);return result;}string inttobstring(int codeint){string str;while(codeint!=0){if(codeint%2==1)str=str.insert(0,"1");elsestr=str.insert(0,"0");codeint=codeint/2;}if(str.size()!=8)str.insert(0,8-str.size(),'0');return str;}int main(){int count[256];int bytecount;char buf;std::ifstream ifs;std::ofstream ofs;string filename;BTree tree;string outbuf;std::cout<<"请输入解压文件路径:"<<std::endl;std::cin>>filename;ifs.open(filename,std::ifstream::binary);ofs.open(filename+".txt",std::ofstream::out|std::ofstream::binary);/*int count[256];*/std::cout<<"读取数据……"<<std::endl;for(int i=0;i<256;i++)ifs.read((char*)&count[i],sizeof(int));tree=HuffmanTree(count,256);//for(int i=0;i<256;i++)//std::cout<<i<<":"<<count[i]<<std::endl;ifs.read((char*)&bytecount,sizeof(int));treeNode* p=tree.root;int outcount=0;int bufdata;std::cout<<"解压缩……"<<std::endl;while(!ifs.eof()){ifs.read((char*)&buf,1);if(ifs.eof())break;outbuf=inttobstring((int)buf+128);//std::cout<<outbuf<<std::endl;for(string::iterator it=outbuf.begin();it!=outbuf.end();++it){if(*it=='0')p=p->getleft();else p=p->getright();if (p->getdata()!=-1){bufdata=p->getdata()-128;//std::cout<<p->getdata()<<std::endl;ofs.write((char*)&bufdata,1);p=tree.root;outcount++;}if(outcount==bytecount)break;}if(outcount==bytecount)break;}std::cout<<"解压成功"<<std::endl;system("pause");}。