计量经济学计算题解法汇总
计量经济学大题例题

计量经济学大题例题计量经济学大题例题的正文如下:计量经济学大题是考研数学三中一个重要的部分,其中涉及到大量的计算和分析。
下面,我们将通过几个例题来讲解计量经济学大题的解题方法。
例题 1:某公司预计未来两年会有 20% 的增长率,当前股价为10 元。
该公司预计未来三年会有 15% 的增长率,此时股价为 8 元。
假设市场对公司未来的增长前景持乐观态度,请问能否通过公司未来的增长率来判断公司的投资价值?解答:我们可以使用现值公式来解决这道题。
设该公司的未来两年和未来三年的现金流分别为 C1、C2 和 C3,则它们的现值分别为: C1=10×(1+20%)=12.10 元C2=8×(1+15%)=9.39 元C3=10×(1+15%)×(1+20%)=12.31 元因此,现值为 12.10 元的现金流比现值为 9.39 元的现金流更具有投资价值。
例题 2:假设某公司预计未来三年会有 20%、25% 和 30% 的增长率,此时市场对公司未来的增长前景持乐观态度,请问能否通过公司未来的增长率来判断公司的投资价值?解答:与上一个问题类似,我们可以使用现值公式来解决这道题。
设该公司的未来两年和未来三年的现金流分别为 C1、C2 和 C3,则它们的现值分别为:C1=10×(1+20%)=12.10 元C2=8×(1+25%)=9.75 元C3=10×(1+30%)=12.00 元因此,现值为 12.10 元的现金流比现值为 9.75 元的现金流更具有投资价值。
以上两道题是计量经济学大题中比较典型的例题,希望大家能够熟练掌握它们的解题方法。
同时,我们也可以通过不断练习来提高自己的解题能力,从而在考试中取得优异的成绩。
拓展:除了上述例题之外,计量经济学大题还有很多其他类型的例题,例如面板数据模型、自回归移动平均模型等。
下面,我们举一个例子来说明面板数据模型的解题方法。
计量经济学计算题与答案解析

1、根据某城市1978——1998年人均储蓄(y)与人均收入(x)的数据资料建立了如下回归模型x y6843.1521.2187ˆ+-= se=(340.0103)(0.0622)6066.733,2934.0,425.1065..,9748.02====F DW E S R试求解以下问题:(1)取时间段1978——1985和1991——1998,分别建立两个模型。
模型1:x y3971.04415.145ˆ+-= 模型2:x y 9525.1365.4602ˆ+-= t=(-8.7302)(25.4269) t=(-5.0660)(18.4094) ∑==202.1372,9908.0212eR ∑==5811189,9826.0222e R计算F 统计量,即∑∑===9370.4334202.137258111892122eeF ,对给定的05.0=α,查F 分布表,得临界值28.4)6,6(05.0=F 。
请你继续完成上述工作,并回答所做的是一项什么工作,其结论是什么?(2)根据表1所给资料,对给定的显著性水平05.0=α,查2χ分布表,得临界值81.7)3(05.0=χ,其中p=3为自由度。
请你继续完成上述工作,并回答所做的是一项什么工作,其结论是什么? 表1F-statistic 6.033649 Probability 0.007410 Obs*R-squared10.14976 Probability0.017335Test Equation:Dependent Variable: RESID^2 Method: Least SquaresDate: 06/04/06 Time: 17:02 Sample(adjusted): 1981 1998Included observations: 18 after adjusting endpoints Variable Coefficie ntStd. Error t-Statistic Prob. C244797.2 373821.3 0.654851 0.5232 RESID^2(-1)1.226048 0.3304793.7099080.0023RESID^2(-2) -1.405351 0.379187 -3.706222 0.0023 R-squared 0.563876 Mean dependent var 971801.3 Adjusted R-squared 0.470421 S.D. dependent var 1129283. S.E. of regression 821804.5 Akaike info criterion 30.26952 Sum squared resid 9.46E+12 Schwarz criterion 30.46738 Log likelihood -268.4257 F-statistic6.033649 Durbin-Watson stat 2.124575 Prob(F-statistic) 0.0074101、(1)解:该检验为Goldfeld-Quandt 检验。
天津财经大学《计量经济学》(多元例题综合答案).

ˆ 2
2 x y x 2 1 x1 y x1x2
xi X i X
∑X1i=47.5 ∑x1i2=31.83 ∑yix1i=15.28 ∑yi2=7.37 ,
yi Yi Y
∑X2i=19.5 ∑x2i2=7.27
n=10
( 1)对我国 1991~2000 年的消费模型Yi 0 1 X 1i 2 X 2i u i 进行估计
结果表明,当前一期人均居民消费额(X ) 保持不变时,人均国内生产总值( X )每 增加 1 千元,人均居民消费额(Y)平均 增加 0.339 千元;当人均国内生产总值(X ) 保持不变时,前一期人均居民消费额( X ) 每增加 1 千元,人均居民消费额(Y)平均 增加 0.302 千元。
2
1
1
2
ˆ 不是由 0 这样的 检验结果表明,在 95%置信概率下, 1 1 总体产生的,1 显著地不为 0,即变量X 1 对被解释变量的影 响是显著的;也就是说,在 95%的置信概率下,人均国内生 产总值对人 2 0 ˆ 0.302 0 2 2 t 5.298 ˆ 0.057 SE ( 2 ) t0.025 , 7 2.365 t t0.025 , 7
≈0.026
t ,n k 1 t 0.025 ,7 2.365
2
P3.946 E (Y
P 4.007 2.365 * 0.026 E (Y 0) 4.007 2.365 * 0.026 1 0.05
计量经济学习题集及详解答案

第一章绪论一、填空题:1.计量经济学是以揭示经济活动中客观存在的为内容的分支学科,挪威经济学家弗里希,将计量经济学定义为、、三者的结合。
2.数理经济模型揭示经济活动中各个因素之间的关系,用性的数学方程加以描述,计量经济模型揭示经济活动中各因素之间的关系,用性的数学方程加以描述。
3.经济数学模型是用描述经济活动。
4.计量经济学根据研究对象和内容侧重面不同,可以分为计量经济学和计量经济学。
5.计量经济学模型包括和两大类。
6.建模过程中理论模型的设计主要包括三部分工作,即、、。
7.确定理论模型中所包含的变量,主要指确定。
8.可以作为解释变量的几类变量有变量、变量、变量和变量。
9.选择模型数学形式的主要依据是。
10.研究经济问题时,一般要处理三种类型的数据:数据、数据和数据。
11.样本数据的质量包括四个方面、、、。
12.模型参数的估计包括、和软件的应用等内容。
13.计量经济学模型用于预测前必须通过的检验分别是检验、检验、检验和检验。
14.计量经济模型的计量经济检验通常包括随机误差项的检验、检验、解释变量的检验。
15.计量经济学模型的应用可以概括为四个方面,即、、、。
16.结构分析所采用的主要方法是、和。
二、单选题:1.计量经济学是一门()学科。
A.数学B.经济C.统计D.测量2.狭义计量经济模型是指()。
A.投入产出模型B.数学规划模型C.包含随机方程的经济数学模型D.模糊数学模型3.计量经济模型分为单方程模型和()。
A.随机方程模型B.行为方程模型C.联立方程模型D.非随机方程模型4.经济计量分析的工作程序()A.设定模型,检验模型,估计模型,改进模型B.设定模型,估计参数,检验模型,应用模型C.估计模型,应用模型,检验模型,改进模型D.搜集资料,设定模型,估计参数,应用模型5.同一统计指标按时间顺序记录的数据列称为()A.横截面数据B.时间序列数据C.修匀数据D.平行数据6.样本数据的质量问题,可以概括为完整性、准确性、可比性和()。
计量经济学第四章练习题及参考解答

第四章练习题及参考解答4.1 假设在模型i i i iu X X Y +++=33221βββ中,32X X 与之间的相关系数为零,于是有人建议你进行如下回归:ii i i i i u X Y u X Y 23311221++=++=γγαα(1)是否存在3322ˆˆˆˆβγβα==且?为什么? (2)111ˆˆˆβαγ会等于或或两者的某个线性组合吗? (3)是否有()()()()3322ˆvar ˆvar ˆvar ˆvarγβαβ==且? 练习题4.1参考解答:(1) 存在3322ˆˆˆˆβγβα==且。
因为()()()()()()()23223223232322ˆ∑∑∑∑∑∑∑--=iiiii iii iii x x x x x xx y x x y β当32X X 与之间的相关系数为零时,离差形式的032=∑i i x x有()()()()222223222322ˆˆαβ===∑∑∑∑∑∑iiiiiiii xx y x x x x y 同理有:33ˆˆβγ= (2) 111ˆˆˆβαγ会等于或的某个线性组合 因为12233ˆˆˆY X X βββ=--,且122ˆˆY X αα=-,133ˆˆY X γγ=- 由于3322ˆˆˆˆβγβα==且,则 11222222ˆˆˆˆˆY Y X Y X X αααββ-=-=-=11333333ˆˆˆˆˆY Y X Y X X γγγββ-=-=-=则 1112233231123ˆˆˆˆˆˆˆY Y Y X X Y X X Y X X αγβββαγ--=--=--=+- (3) 存在()()()()3322ˆvar ˆvar ˆvar ˆvarγβαβ==且。
因为()()∑-=22322221ˆvarr x iσβ当023=r 时,()()()22222232222ˆvar 1ˆvar ασσβ==-=∑∑iixr x 同理,有()()33ˆvar ˆvar γβ=4.2在决定一个回归模型的“最优”解释变量集时人们常用逐步回归的方法。
计量经济学 课后练习题答案解析
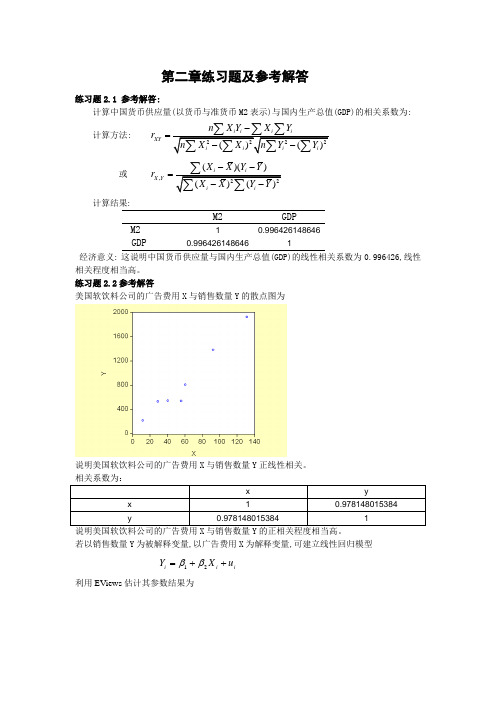
第二章练习题及参考解答练习题2.1 参考解答:计算中国货币供应量(以货币与准货币M2表示)与国内生产总值(GDP)的相关系数为:计算方法: XY n X Y X Y r -=或,()()X Y X X Y Y r --=计算结果:M2GDPM2 10.996426148646GDP0.9964261486461经济意义: 这说明中国货币供应量与国内生产总值(GDP)的线性相关系数为0.996426,线性相关程度相当高。
练习题2.2参考解答美国软饮料公司的广告费用X 与销售数量Y 的散点图为说明美国软饮料公司的广告费用X 与销售数量Y 正线性相关。
相关系数为:说明美国软饮料公司的广告费用X 与销售数量Y 的正相关程度相当高。
若以销售数量Y 为被解释变量,以广告费用X 为解释变量,可建立线性回归模型 i i i u X Y ++=21ββ 利用EViews 估计其参数结果为经t 检验表明, 广告费用X 对美国软饮料公司的销售数量Y 确有显著影响。
回归结果表明,广告费用X 每增加1百万美元, 平均说来软饮料公司的销售数量将增加14.40359(百万箱)。
练习题2.3参考解答:1、 建立深圳地方预算内财政收入对GDP 的回归模型,建立EViews 文件,利用地方预算内财政收入(Y )和GDP 的数据表,作散点图可看出地方预算内财政收入(Y )和GDP 的关系近似直线关系,可建立线性回归模型: t t t u GDP Y ++=21ββ 利用EViews 估计其参数结果为即 ˆ20.46110.0850t tY GDP =+ (9.8674) (0.0033)t=(2.0736) (26.1038) R 2=0.9771 F=681.4064经检验说明,深圳市的GDP 对地方财政收入确有显著影响。
20.9771R =,说明GDP 解释了地方财政收入变动的近98%,模型拟合程度较好。
模型说明当GDP 每增长1亿元时,平均说来地方财政收入将增长0.0850亿元。
(完整word版)计量经济学题库(超完整版)及答案.详解(word文档良心出品)

计量经济学题库计算与分析题(每小题10分)1X:年均汇率(日元/美元) Y:汽车出口数量(万辆)问题:(1)画出X 与Y 关系的散点图。
(2)计算X 与Y 的相关系数。
其中X 129.3=,Y 554.2=,2X X 4432.1∑(-)=,2Y Y 68113.6∑(-)=,()()X X Y Y ∑--=16195.4 (3)采用直线回归方程拟和出的模型为 ˆ81.72 3.65YX =+ t 值 1.2427 7.2797 R 2=0.8688 F=52.99解释参数的经济意义。
2.已知一模型的最小二乘的回归结果如下:i iˆY =101.4-4.78X 标准差 (45.2) (1.53) n=30 R 2=0.31 其中,Y :政府债券价格(百美元),X :利率(%)。
回答以下问题:(1)系数的符号是否正确,并说明理由;(2)为什么左边是iˆY 而不是i Y ; (3)在此模型中是否漏了误差项i u ;(4)该模型参数的经济意义是什么。
3.估计消费函数模型i i i C =Y u αβ++得i i ˆC =150.81Y + t 值 (13.1)(18.7) n=19 R 2=0.81其中,C :消费(元) Y :收入(元)已知0.025(19) 2.0930t =,0.05(19) 1.729t =,0.025(17) 2.1098t =,0.05(17) 1.7396t =。
问:(1)利用t 值检验参数β的显著性(α=0.05);(2)确定参数β的标准差;(3)判断一下该模型的拟合情况。
4.已知估计回归模型得i i ˆY =81.7230 3.6541X + 且2X X 4432.1∑(-)=,2Y Y 68113.6∑(-)=, 求判定系数和相关系数。
5.有如下表数据(1拟合什么样的模型比较合适? (2)根据以上数据,分别拟合了以下两个模型:模型一:16.3219.14P U=-+ 模型二:8.64 2.87P U =- 分别求两个模型的样本决定系数。
计量经济学题库(超完整版)及标准答案

2.已知一模型的最小二乘的回归结果如下:i iˆY =101.4-4.78X 标准差 (45.2) (1.53) n=30 R 2=0.31其中,Y :政府债券价格(百美元),X :利率(%)。
回答以下问题:(1)系数的符号是否正确,并说明理由;(2)为什么左边是iˆY 而不是i Y ; (3)在此模型中是否漏了误差项i u ;(4)该模型参数的经济意义是什么。
13.假设某国的货币供给量Y 与国民收入X 的历史如系下表。
某国的货币供给量X 与国民收入Y 的历史数据年份 X Y 年份 X Y 年份 X Y 1985 2.0 5.0 1989 3.3 7.2 1993 4.8 9.7 1986 2.5 5.5 1990 4.0 7.7 1994 5.0 10.0 1987 3.2 6 1991 4.2 8.4 1995 5.2 11.2 19883.6719924.6919965.812.4根据以上数据估计货币供给量Y 对国民收入X 的回归方程,利用Eivews 软件输出结果为:Dependent Variable: Y Variable Coefficient Std. Error t-Statistic Prob. X 1.968085 0.135252 14.55127 0.0000 C 0.353191 0.5629090.6274400.5444 R-squared0.954902 Mean dependent var 8.258333 Adjusted R-squared 0.950392 S.D. dependent var 2.292858 S.E. of regression 0.510684 F-statistic 211.7394 Sum squared resid2.607979Prob(F-statistic)0.000000问:(1)写出回归模型的方程形式,并说明回归系数的显著性(0.05α=)。
(完整)计量经济学计算题

1、某农产品试验产量Y (公斤/亩)和施肥量X (公斤/亩)7块地的数据资料汇总如下:∑=255iX ∑=3050i Y∑=71.12172ix∑=429.83712i y ∑=857.3122i i y x后来发现遗漏的第八块地的数据:208=X ,4008=Y 。
要求汇总全部8块地数据后进行以下各项计算,并对计算结果的经济意义和统计意义做简要的解释。
(1)该农产品试验产量对施肥量X(公斤/亩)回归模型Y a bX u =++进行估计; (2)对回归系数(斜率)进行统计假设检验,信度为0.05; (3)估计可决系数并进行统计假设检验,信度为0。
05。
解:首先汇总全部8块地数据:87181X X X i i i i +=∑∑== =255+20 =275 n X X i i ∑==81)8(375.348275==2)7(7127127Xx Xi i i i+=∑∑== =1217.71+7⨯27255⎪⎭⎫⎝⎛=1050728712812X X Xi i i i+=∑∑== =10507+202= 109072)8(8128128XX xi ii i+=∑∑== = 10907-8⨯28275⎪⎭⎫⎝⎛=1453.8887181Y Y Y i i i i +=∑∑===3050+400=3450 25.4318345081)8(===∑=n Y Y i i 2)7(7127127Y y Y i ii i +=∑∑== =8371.429+7⨯273050⎪⎭⎫⎝⎛=1337300 28712812Y YY i ii i +=∑∑== =1337300+4002= 14973002)8(8128128Y Y y i i i i +=∑∑== =1497300 -8⨯(83450)2== 9487。
5 )7()7(71717Y X yx Y X i iii ii +=∑∑== ==3122.857+7⎪⎭⎫ ⎝⎛7255⨯⎪⎭⎫⎝⎛73050=114230 887181Y X YX Y X i ii i ii +=∑∑== =114230+20⨯400 =122230)8()8(81818Y X YX y x i ii i ii -=∑∑== =122230-8⨯34。
(完整)计量经济学计算题解法汇总,推荐文档

ui 为随机误差项,并且 E(ui ) 0,Var(ui ) 2 xi2 (其中 2 为常数)。试回答
以下问题: (1)选用适当的变换修正异方差,要求写出变换过程;(2)写出修正异方差 后的参数估计量的表达式。
x 解:(一)原模型: yi b0 b1xi ui (1)等号两边同除以 i ,
(3)在 90%的置信度下,预测当 X=45(百元)时,消费(Y)的置信区间。
(其中 x 29.3 , (x x )2 992.1)
答:(1)回归模型的 R2=0.9042,表明在消费 Y 的总变差中,由回归直线解释的部分占 到 90%以上,回归直线的代表性及解释能力较好。(2 分)
(2)对于斜率项, t
推导出一个 ˆ1 求解的公式:
ˆ1
xy x * y
x2
2
x
两边 ln ˆ1 表示弹性,如果一边则表示绝对量(相对量)的变化引起相对量(绝对量)的
变化。
特例::
R2 1 9 1 (1 0.35) 0.04 ;负值也是有可能的。(4 分) 9 3 1
5、异方差的修正
设消费函数为 yi b0 b1xi ui ,其中 yi 为消费支出, xi 为个人可支配收入,
新模型:
yi xi
b0
1 xi
b1
ui xi
(2)
(2分)
令
yi*
yi xi
, xi*
1 xi
, vi
ui xi
则:(2)变为 yi* b1 b0 xi* vi
(2分)
此时Var(vi )
Var(ui xi
)
1 xi2
( 2 xi2 )
2 新模型i* b1 b0 xi* vi 进行普通最小二乘估计
《计量经济学(第二版)》习题解答(第1-3章)

《计量经济学(第二版)》习题解答第一章1.1 计量经济学的研究任务是什么?计量经济模型研究的经济关系有哪两个基本特征? 答:(1)利用计量经济模型定量分析经济变量之间的随机因果关系。
(2)随机关系、因果关系。
1.2 试述计量经济学与经济学和统计学的关系。
答:(1)计量经济学与经济学:经济学为计量经济研究提供理论依据,计量经济学是对经济理论的具体应用,同时可以实证和发展经济理论。
(2)统计数据是建立和评价计量经济模型的事实依据,计量经济研究是对统计数据资源的深层开发和利用。
1.3 试分别举出三个时间序列数据和横截面数据。
1.4 试解释单方程模型和联立方程模型的概念,并举例说明两者之间的联系与区别。
1.5 试结合一个具体经济问题说明计量经济研究的步骤。
1.6 计量经济模型主要有哪些用途?试举例说明。
1.7 下列设定的计量经济模型是否合理,为什么?(1)ε++=∑=31i iiGDP b a GDPε++=3bGDP a GDP其中,GDP i (i =1,2,3)是第i 产业的国内生产总值。
答:第1个方程是一个统计定义方程,不是随机方程;第2个方程是一个相关关系,而不是因果关系,因为不能用分量来解释总量的变化。
(2)ε++=21bS a S其中,S 1、S 2分别为农村居民和城镇居民年末储蓄存款余额。
答:是一个相关关系,而不是因果关系。
(3)ε+++=t t t L b I b a Y 21其中,Y 、I 、L 分别是建筑业产值、建筑业固定资产投资和职工人数。
答:解释变量I 不合理,根据生产函数要求,资本变量应该是总资本,而固定资产投资只能反映当年的新增资本。
(4)ε++=t t bP a Y其中,Y 、P 分别是居民耐用消费品支出和耐用消费品物价指数。
答:模型设定中缺失了对居民耐用消费品支出有重要影响的其他解释变量。
按照所设定的模型,实际上假定这些其他变量的影响是一个常量,居民耐用消费品支出主要取决于耐用消费品价格的变化;所以,模型的经济意义不合理,估计参数时可能会夸大价格因素的影响。
计量经济学课后习题答案解析汇总

计量经济学练习题第一章导论一、单项选择题⒈计量经济研究中常用的数据主要有两类:一类是时间序列数据,另一类是【 B 】A 总量数据B 横截面数据C平均数据 D 相对数据⒉横截面数据是指【 A 】A 同一时点上不同统计单位相同统计指标组成的数据B 同一时点上相同统计单位相同统计指标组成的数据C 同一时点上相同统计单位不同统计指标组成的数据D 同一时点上不同统计单位不同统计指标组成的数据⒊下面属于截面数据的是【 D 】A 1991-2003年各年某地区20个乡镇的平均工业产值B 1991-2003年各年某地区20个乡镇的各镇工业产值C 某年某地区20个乡镇工业产值的合计数D 某年某地区20个乡镇各镇工业产值⒋同一统计指标按时间顺序记录的数据列称为【 B 】A 横截面数据B 时间序列数据C 修匀数据 D原始数据⒌回归分析中定义【 B 】A 解释变量和被解释变量都是随机变量B 解释变量为非随机变量,被解释变量为随机变量C 解释变量和被解释变量都是非随机变量D 解释变量为随机变量,被解释变量为非随机变量二、填空题⒈计量经济学是经济学的一个分支学科,是对经济问题进行定量实证研究的技术、方法和相关理论,可以理解为数学、统计学和_经济学_三者的结合。
⒉现代计量经济学已经形成了包括单方程回归分析,联立方程组模型,时间序列分析三大支柱。
⒊经典计量经济学的最基本方法是回归分析。
计量经济分析的基本步骤是:理论(或假说)陈述、建立计量经济模型、收集数据、计量经济模型参数的估计、检验和模型修正、预测和政策分析。
⒋常用的三类样本数据是截面数据、时间序列数据和面板数据。
⒌经济变量间的关系有不相关关系、相关关系、因果关系、相互影响关系和恒等关系。
三、简答题⒈什么是计量经济学?它与统计学的关系是怎样的?计量经济学就是对经济规律进行数量实证研究,包括预测、检验等多方面的工作。
计量经济学是一种定量分析,是以解释经济活动中客观存在的数量关系为内容的一门经济学学科。
计量经济学习题与解答4

其中括号内数值为参数标准差。请检验以下零假设:
(1)产出量的资本弹性和劳动弹性是等同的;
(2)存在不变规模收益,即 。
3-14.对模型 应用OLS法,得到回归方程如下:
要求:证明残差 与 不相关,即: 。
3-15.
3-16.考虑下列两个模型:
Ⅰ、
Ⅱ、
要求:(1)证明: , ,
(3)首先计算两人受教育的年数分别为
10.36+0.13112+0.21012=14.452
10.36+0.13116+0.21016=15.816
因此,两人的受教育年限的差别为15.816-14.452=1.364
例2.以企业研发支出(R&D)占销售额的比重为被解释变量(Y),以企业销售额(X1)与利润占销售额的比重(X2)为解释变量,一个有32容量的样本企业的估计结果如下:
(2)针对备择假设H1: ,检验原假设H0: 。易知计算的t统计量的值为t=0.32/0.22=1.468。在5%的显著性水平下,自由度为32-3=29的t分布的临界值为1.699(单侧),计算的t值小于该临界值,所以不拒绝原假设。意味着R&D强度不随销售额的增加而变化。在10%的显著性水平下,t分布的临界值为1.311,计算的t值小于该值,拒绝原假设,意味着R&D强度随销售额的增加而增加。
Statetax
-1.006 (0.40)
-1.004 (0.37)
RSS
4.763e+7
4.843e+7
4.962e+7
5.038e+7
R2
0.349
0.338
0.322
计量经济学(第四版)习题及参考答案解析详细版

计量经济学(第四版)习题参考答案潘省初第一章 绪论1.1 试列出计量经济分析的主要步骤。
一般说来,计量经济分析按照以下步骤进行:(1)陈述理论(或假说) (2)建立计量经济模型 (3)收集数据 (4)估计参数 (5)假设检验 (6)预测和政策分析 1.2 计量经济模型中为何要包括扰动项?为了使模型更现实,我们有必要在模型中引进扰动项u 来代表所有影响因变量的其它因素,这些因素包括相对而言不重要因而未被引入模型的变量,以及纯粹的随机因素。
1.3什么是时间序列和横截面数据? 试举例说明二者的区别。
时间序列数据是按时间周期(即按固定的时间间隔)收集的数据,如年度或季度的国民生产总值、就业、货币供给、财政赤字或某人一生中每年的收入都是时间序列的例子。
横截面数据是在同一时点收集的不同个体(如个人、公司、国家等)的数据。
如人口普查数据、世界各国2000年国民生产总值、全班学生计量经济学成绩等都是横截面数据的例子。
1.4估计量和估计值有何区别?估计量是指一个公式或方法,它告诉人们怎样用手中样本所提供的信息去估计总体参数。
在一项应用中,依据估计量算出的一个具体的数值,称为估计值。
如Y就是一个估计量,1nii YY n==∑。
现有一样本,共4个数,100,104,96,130,则根据这个样本的数据运用均值估计量得出的均值估计值为5.107413096104100=+++。
第二章 计量经济分析的统计学基础2.1 略,参考教材。
2.2请用例2.2中的数据求北京男生平均身高的99%置信区间NS S x ==45=1.25 用α=0.05,N-1=15个自由度查表得005.0t =2.947,故99%置信限为 x S t X 005.0± =174±2.947×1.25=174±3.684也就是说,根据样本,我们有99%的把握说,北京男高中生的平均身高在170.316至177.684厘米之间。
计量经济学习题及参考答案解析详细版

计量经济学(第四版)习题参考答案潘省初第一章 绪论试列出计量经济分析的主要步骤。
一般说来,计量经济分析按照以下步骤进行:(1)陈述理论(或假说) (2)建立计量经济模型 (3)收集数据 (4)估计参数 (5)假设检验 (6)预测和政策分析 计量经济模型中为何要包括扰动项?为了使模型更现实,我们有必要在模型中引进扰动项u 来代表所有影响因变量的其它因素,这些因素包括相对而言不重要因而未被引入模型的变量,以及纯粹的随机因素。
什么是时间序列和横截面数据? 试举例说明二者的区别。
时间序列数据是按时间周期(即按固定的时间间隔)收集的数据,如年度或季度的国民生产总值、就业、货币供给、财政赤字或某人一生中每年的收入都是时间序列的例子。
横截面数据是在同一时点收集的不同个体(如个人、公司、国家等)的数据。
如人口普查数据、世界各国2000年国民生产总值、全班学生计量经济学成绩等都是横截面数据的例子。
估计量和估计值有何区别?估计量是指一个公式或方法,它告诉人们怎样用手中样本所提供的信息去估计总体参数。
在一项应用中,依据估计量算出的一个具体的数值,称为估计值。
如Y就是一个估计量,1nii YY n==∑。
现有一样本,共4个数,100,104,96,130,则根据这个样本的数据运用均值估计量得出的均值估计值为5.107413096104100=+++。
第二章 计量经济分析的统计学基础略,参考教材。
请用例中的数据求北京男生平均身高的99%置信区间NS S x ==45= 用=,N-1=15个自由度查表得005.0t =,故99%置信限为x S t X 005.0± =174±×=174±也就是说,根据样本,我们有99%的把握说,北京男高中生的平均身高在至厘米之间。
25个雇员的随机样本的平均周薪为130元,试问此样本是否取自一个均值为120元、标准差为10元的正态总体? 原假设 120:0=μH备择假设 120:1≠μH 检验统计量()10/2510/25XX μσ-Z ====查表96.1025.0=Z 因为Z= 5 >96.1025.0=Z ,故拒绝原假设, 即 此样本不是取自一个均值为120元、标准差为10元的正态总体。
计量经济学题库(超完整版)及答案.详解

计量经济学题库计算与分析题(每小题10分)1X:问题:(1)画出X 与Y 关系的散点图。
(2)计算X 与Y 的相关系数。
其中X 129.3=,Y 554.2=,2X X 4432.1∑(-)=,2Y Y 68113.6∑(-)=,()()X X Y Y ∑--=16195.4 (3)采用直线回归方程拟和出的模型为t 值 1.2427 7.2797 R 2=0.8688 F=52.99解释参数的经济意义。
2.已知一模型的最小二乘的回归结果如下:i iˆY =101.4-4.78X 标准差 (45.2) (1.53) n=30 R 2=0.31 其中,Y :政府债券价格(百美元),X :利率(%)。
回答以下问题:(1)系数的符号是否正确,并说明理由;(2)为什么左边是iˆY 而不是i Y ; (3)在此模型中是否漏了误差项i u ;(4)该模型参数的经济意义是什么。
3.估计消费函数模型i i i C =Y u αβ++得i i ˆC =150.81Y + t 值 (13.1)(18.7) n=19 R 2=0.81其中,C :消费(元) Y :收入(元)已知0.025(19) 2.0930t =,0.05(19) 1.729t =,0.025(17) 2.1098t =,0.05(17) 1.7396t =。
问:(1)利用t 值检验参数β的显著性(α=0.05);(2)确定参数β的标准差;(3)判断一下该模型的拟合情况。
4.已知估计回归模型得i i ˆY =81.7230 3.6541X + 且2X X 4432.1∑(-)=,2Y Y 68113.6∑(-)=, 求判定系数和相关系数。
5.有如下表数据(1关系?拟合什么样的模型比较合适? (2)根据以上数据,分别拟合了以下两个模型:模型一:16.3219.14P U=-+ 模型二:8.64 2.87P U =- 分别求两个模型的样本决定系数。
7.根据容量n=30的样本观测值数据计算得到下列数据:XY 146.5=,X 12.6=,Y 11.3=,2X 164.2=,2Y =134.6,试估计Y 对X 的回归直线。
计量经济学例题解答

例1(一元线性回归模型) 令kids 表示一名妇女生育孩子的数目,educ 表示该妇女接受过教育的年数。
生育率对教育年数的简单回归模型为:µββ++=educ kids 10(1)随机扰动项µ包含什么样的因素?它们可能与教育水平相关吗?(2)上述简单回归分析能够揭示教育对生育率在其他条件不变下的影响吗?请解释。
解答:(1)收入、年龄、家庭状况、政府的相关政策等也是影响生育率的重要的因素,在上述简单回归模型中,它们被包含在了随机扰动项之中。
有些因素可能与增长率水平相关,如收入水平与教育水平往往呈正相关、年龄大小与教育水平呈负相关等。
(2)当归结在随机扰动项中的重要影响因素与模型中的教育水平educ 相关时,上述回归模型不能够揭示教育对生育率在其他条件不变下的影响,因为这时出现解释变量与随机扰动项相关的情形,基本假设4不满足。
例2(一元线性回归模型) 已知回归模型µβα++=N E ,式中E 为某类公司一名新员工的起始薪金(元),N 为所受教育水平(年)。
随机扰动项µ的分布未知,其他所有假设都满足。
(1)从直观及经济角度解释α和β。
(2)OLS 估计量αˆ和满足线性性、无偏性及有效性吗?简单陈述理由。
βˆ(3)对参数的假设检验还能进行吗?简单陈述理由。
解答:(1)N βα+为接受过N 年教育的员工的总体平均起始薪金。
当N 为零时,平均薪金为α,因此α表示没有接受过教育员工的平均起始薪金。
β是每单位N 变化所引起的E 的变化,即表示每多接受一年学校教育所对应的薪金增加值。
(2)OLS 估计量αˆ和仍满足线性性、无偏性及有效性,因为这些性质的的成立无需随机扰动项βˆµ的正态分布假设。
(3)如果t µ的分布未知,则所有的假设检验都是无效的。
因为t 检验与F 检验是建立在µ的正态分布假设之上的。
例3(一元线性回归模型) 对于人均存款与人均收入之间的关系式t t t Y S µβα++=使用美国36年的年度数据得到如下估计模型,括号内为标准差:)011.0()105.151(067.0105.384ˆtt Y S +=2R =0.538 023.199ˆ=σ(1)β的经济解释是什么?(2)α和β的符号是什么?为什么?实际的符号与你的直觉一致吗?如果有冲突的话,你可以给出可能的原因吗?(3)对于拟合优度你有什么看法吗?(4)检验是否每一个回归系数都与零显著不同(在1%水平下)。
计量经济学部分习题答案解析

第三章 一元线性回归模型P56.3.3 从某公司分布在11个地区的销售点的销售量()Y 和销售价格()X 观测值得出以下结果:519.8X = 217.82Y = 23134543i X =∑ 1296836i i X Y =∑2539512i Y =∑(1)、估计截距0β和斜率系数1β及其标准误,并进行t 检验; (2)、销售的总离差平方和中,样本回归直线未解释的比例是多少? (3)、对0β和1β分别建立95%的置信区间。
解:(1)、设01i i Y X ββ=+,根据OLS 估计量有:()()()11111122222211112=129683611519.8217.820.32313454311519.8N N NNNi i i ii i iii i i i i NNNN i ii i i i i i N Y X Y X N Y X N X NYY XN X YN X N X XN XN X X β=========---==⎛⎫--- ⎪⎝⎭-⨯⨯==-⨯∑∑∑∑∑∑∑∑∑01217.820.32519.851.48Y X ββ=-=-⨯=残差平方和:()()()()222112222220111111122222222010101011111111=225395121NNiii i i NNNNN N ii i i i ii i i i i i N N N N N i i i i i i i i i i i uRSS TSS ESS Y YYYY Y Y Y Y X N N Y X X Y N X X ββββββββββ===============-=---⎛⎫⎛⎫--+=-+ ⎪ ⎪⎝⎭⎝⎭⎛⎫=-++=-++ ⎪⎝⎭=-∑∑∑∑∑∑∑∑∑∑∑∑∑∑()22151.480.32313454320.3251.4811519.8997.20224⨯+⨯+⨯⨯⨯⨯=另解:对()()22211NNiii i i uRSS TSS ESS Y YYY====-=---∑∑∑,根据OLS估计01Y X ββ=-知01+Y X ββ=,因此有()()01011=++i i i Y Y X X X X βββββ--=-,所以()()()()22222211111=N NNNiiii i i i i i u Y Y YY Y YX Xβ=====------∑∑∑∑∑标准差:10.53σ==1β的标准误:()10.026se β=====设原假设和备择假设分别为:01=0H β: 110H β≠: 将原假设带入t 统计量:()()10.02510.3212.31 2.26290.026t t se ββ===>= 即拒绝原假设,认为销售价格()X 显著地解释了销售量()Y 的总体平均变化。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
计量经济学:部分计算题解法汇总
1、求判别系数——R^2
已知估计回归模型得
i i ˆY =81.7230 3.6541X + 且2X X 4432.1∑
(-)=,2Y Y 68113.6∑(-)=,
2、置信区间 有10户家庭的收入(X ,元)和消费(Y ,百元)数据如下表:
10户家庭的收入(X )与消费(Y )的资料
X 20 30 33 40 15 13 26 38 35 43 Y 7 9 8 11 5 4 8 10 9 10
若建立的消费Y 对收入X 的回归直线的Eviews 输出结果如下:
Dependent Variable: Y
var 2
Adjusted R-squared 0.892292 F-statistic 75.5589
8
Durbin-Watson 2.077648 Prob(F-statistic) 0.00002
(1(2)在95%的置信度下检验参数的显著性。
(0.025(10) 2.2281t =,
0.05(10) 1.8125t =,0.025(8) 2.3060t =,0.05(8) 1.8595t =)
(3)在90%的置信度下,预测当X =45(百元)时,消费(Y )的置信区间。
(其中29.3x =,2()992.1x x
-=∑)
答:(1)回归模型的R 2=0.9042,表明在消费Y 的总变差中,由回归直线解释的部分占到90%以上,回归直线的代表性及解释能力较好。
(2分)
家庭收入对消费有显著影响。
(2分)对于截距项,
检验。
(2分)
(3)Y f =2.17+0.2023×45=11.2735(2分)
t0.05
90%置信区间为(11.2735-4.823,11.2735+4.823),即(6.4505,16.0965)。
(2分) 注意:a 水平下的t 统计量的的重要性水平,由于是双边检验,应当减半
3、求SSE 、SST 、R^2等
已知相关系数r =0.6,估计标准误差ˆ8σ=,样本容量n=62。
求:(1)剩余变差;(2)决定系数;(3)总变差。
(2)2220.60.36R r ===(2分)
4、联系相关系数与方差(标准差),注意是n-1
在相关和回归分析中,已知下列资料:
222X Y i 1610n=20r=0.9(Y -Y)=2000σσ∑=,=,,,。
(1)计算Y 对X 的回归直线的斜率系数。
(2)计算回归变差和剩余变差。
(3)
(2)R 2=r 2=0.92=0.81,
总变差:TSS =RSS/(1-R 2)=2000/(1-0.81)=10526.32(2分)
有个疑问
注意:用Eviews 或者是SAS 给出的结果中可以不用查表求t 值,因为用概率求解是同样的结果。
推导出一个1ˆ
β求解的公式:
两边ln 1ˆβ表示弹性,如果一边则表示绝对量(相对量)的变化引起相对量(绝对量)的变
化。
特例::
5、异方差的修正
设消费函数为01i i i y b b x u =++,其中i y 为消费支出,i x 为个人可支配收入, i u 为随机误差项,并且22()0,()i i i E u Var u x σ==(其中2σ为常数)。
试回答以下问题:
(1)选用适当的变换修正异方差,要求写出变换过程;(2)写出修正异方差后的参数估计量的表达式。
解:(一)原模型:01i i i y b b x u =++ (1)等号两边同除以i
x ,
则:(2)变为**10i i i y b b x v =++
(2分)
(二)对**10i i i y b b x v =++进行普通最小二乘估计
(进一步带入计算也可)
6、类似的ML 检验: 检验下列模型是否存在异方差性,列出检验步骤,给出结论。
0112233t t t t t y b b x b x b x u =++++
样本共40个,本题假设去掉c=12个样本,假设异方差由1i x 引起,数值小的一组残差平方和为10.46617RSS E =-,数值大的一组平方和为20.3617RSS E =-。
0.05(10,10) 2.98F =
解:(1)01:; :;t t H u H u 为同方差性为异方差性(2分)
(2)120.46617 1.290.3617
RSS E F RSS E -===-(3分) (3)0.05(10,10) 2.98F =(2分)
(4)0.05(10,10)F F ≤,接受原假设,认为随机误差项为同方差性。
(3分)。