阿里巴巴数据库体系结构的变化与展望
阿里数据库架构变迁与展望

淘宝初创
淘宝初创
淘宝初创
…… Auction Member Apache Search Apache Mod_php4 Apache Mod_php4 Apache Pear DB Mod_php4 Pear DB Mod_php4 Pear DB Pear DB 读 读写 读
MySQL Slave
单元化
OceanBase
新挑战 新机遇 -- 单元化
cdn1 cdn2
。。。
cdnN
按用户分流
中心
接入层 中心服务层 缓存层 数据层
单元1 同步调用 异步消息
接入层 服务层 缓存 层 数据层
单元2
接入层 服务层 缓存 层 数据层
单元N
接入层 服务层 缓存 层 数据层
数据同步
中心备份
单元化
新挑战 新机遇 -- 单元化
复制
MySQL Master
复制
MySQL Slave
淘宝初创
问题: 单机MySQL数据库迅速达到瓶颈 解法: MySQL迁移到Oracle,并逐步升级硬件,到小型机, 高端存储,最终形成IOE 架构
效果:
支撑了淘宝 2004 到 2009 发展高峰
辉煌时代--IOE
辉煌时代--IOE
新挑战 新机遇
全网架构 资源限制, 一个城市已经不能满足需求 容灾,单地域机房风险 AliSQL 分表数量庞大 集群拆分接近极限 业务开发复杂度 路由,关联,聚合,订正
单元化
OceanBase
新挑战 新机遇 -- OceanBase
Query Data 增删改
基线数据 (固态盘)
新挑战 新机遇 -- 单元化
单元化效益 稳定性
阿里巴巴组织结构变革.完美版PPT

企业 部
董事会
CFO蔡崇 信
部
财务 部
CEO马云
法务 部
阿里巴巴2006年核心管理团队
在事业群的管理体系下,子公司 之间不但业务系统、管理系统和 组织文化等方面都将完全打通, 还将形成“你中有我,我中有你” 的一体,把公共的研发资源平台 化
CTO吴 炯
COO李琪
副总裁 曾鸣
副总裁 金建杭
人力资 源
年6月
竞争优势不是凭个子大。我们必须在组织结构上不断尝试和创新,才能摸索出适合互联网 发展的新型企业管理的思路和模式,保持创造力和先进性。阿里的惯例就是把大公司化成 小公司来做,这样才能建立更加创新的机制,才能让更多的年轻人和新同事成长起来,在 “小”环境里让大家有更多机会展示才华和能力。
分是为了更好的合
问题四:
从“One Company”到“One eco-systerm”,这一变化即可看出,阿 里巴巴要从聚合集团式的管理结构向分散矩阵式的结构转变。但“七剑”的 划分仍是以产业形态为依据,注定难以打破“各自为政”“单打独斗的局面 。这对于枝繁叶茂、泛产业链布局的阿里巴巴集团而言,仍然是桎梏和羁绊 ,是不均衡的进化。
问题一:
彼此阿里巴巴集团发展迅速及新出现了阿里云计算业务,集团主体业务的协
同和分享并不能做到完全一体,这在某种程度上构成了资源和决策效率的损 耗。
问题二:商业模式繁杂、高管人才捉襟见肘以及细分领域竞争的加剧( 京东、假货)
问题三:
三家淘系公司在分拆后都取得了快速的发展,接下来摆在管理层面 前的是:在构建整个CBBS业务链上,B2B公司业务结构如何升级和优 化,如何与其他业务打通与融合?由于当时阿里巴巴B2B公司仍是公 众公司,受制于上市公司的业绩压力,这一变革显得难度非常大。同 时,诞生于淘宝内的聚划算业务,从一个小团队,也快速地成长为具 备相当规模的团购平台,成为整个生态链条上的一个重要的业务环节 ,将聚划算升级并完善它与整个体系的关系也摆在了桌面上。
阿里数据仓库解决方案

阿里数据仓库解决方案阿里数据仓库是由阿里巴巴集团自主研发的一套大数据存储与分析解决方案。
随着互联网的发展和大数据的迅猛增长,越来越多的企业开始意识到数据对于业务决策的重要性。
阿里数据仓库作为一种高效、可靠的数据存储和分析平台,为用户提供了全面、深入的数据洞察。
一、架构设计1. 数据采集与存储:阿里数据仓库采用分布式架构,包含数据采集、数据清洗和数据存储三个模块。
其中,数据采集模块负责从各种数据源(如数据库、日志、文件)中获取数据,并对数据进行初步处理。
数据清洗模块用于对采集到的数据进行清洗、转换和去重等操作,确保数据质量。
数据存储模块则将清洗后的数据按照一定的规则进行存储,以便后续的数据分析和挖掘。
2. 数据分析与挖掘:在数据存储模块中,阿里数据仓库提供了多种存储引擎和分区方式,以满足不同用户的数据分析需求。
用户可以通过SQL语言进行数据查询和分析,也可以使用Hadoop的MapReduce框架进行复杂的数据挖掘和计算。
此外,阿里数据仓库还支持实时数据分析,用户可以通过实时流处理技术对不断产生的数据进行实时处理和分析。
3. 数据可视化与应用:阿里数据仓库提供了强大的数据可视化和应用开发功能,用户可以通过简单的拖拽操作,创建丰富多样的数据报表和仪表盘。
同时,阿里数据仓库还支持多种数据应用开发框架,用户可以基于数据仓库构建自己的数据分析应用和业务应用。
二、核心特性1. 高可用性:阿里数据仓库采用分布式架构和容错技术,确保系统在硬件故障、网络故障等情况下仍然可用。
此外,阿里数据仓库还具备自动化的故障恢复和负载均衡机制,提高系统的可用性和稳定性。
2. 高性能:阿里数据仓库在数据存储和分析方面进行了优化,采用了列式存储和压缩算法,提高了系统的存储密度和数据访问速度。
同时,阿里数据仓库还支持并发查询和并行计算,提高系统的处理能力和响应速度。
3. 数据安全:阿里数据仓库采用多层次的数据安全策略,包括数据加密、访问控制和审计跟踪等功能,确保用户的数据得到有效的保护。
《阿里大数据架构》PPT课件

发展空质间量成本
– 技术搭台,业务唱戏 架构搭台,应用唱戏
• 架构永远在随着业务的发展而变更 更多多迁用数–户据 拥抱变
化!
更多功能 提高 收益
精选PPT
3
B2B架构演化过程
WebMacro pojo jdbc
Velocity Ejb
17
网站镜像部署图(国际站)
中供用户
网站运营
海外卖家
精选PPT
18
用户请求处理
Apache
Load Balance (F5, Alteon)
Apache
Jboss
Jboss
Apache
Jboss
Apache
Static Resource
精选PPT
Database Search Engine Cache Storage
基于pojo的Biz层
CompanyObj
业务逻辑方法 数据访问方法
业务层
基于POJO的biz层
数据存储 Oracle数据库
LDAP
精选PPT
BizObj
业务逻辑方法 数据访问方法
MemberObj
业务逻辑方法 数据访问方法
OfferObj
业务逻辑方法 数据访问方法
8
石器时代-中世纪原因
• 表现层仅仅使用模板技术,缺乏MVC框架, 导致大量的servlet配置
19
互联网的挑战
• 流量随着用户量而增加 • 业务的变更频繁 • 用户行为的收集 • 产品角色的细分及调整 • 7 X 24的高可用性
精选PPT
20
单击此处编辑流版量标题激样增式
阿里云新型互联网架构介绍

DevOps 管理
容器服务
• Docker企业版(国内独家) • 支持Kubernates
云效:持续开发持续集成( DevOps ) 的管理软件
Aliware (分布式企业中间件): 大规模验证的 Java 中间件
新型应用 第三方应用 存量IT系统
CSB云服务总线
能力开放运营
用户中心 资源中心
API管理运营 共享服务层
客户和场景:互联网金融生产环境(含大数据) 关键产品:IAAS+大数据+
中间件(含docker)+高级版云盾
平台特性:等保三级,两地三中心 客户和场景:央企,互联网中台+大数据
V2.0 (2016.05)
关键产品:IAAS+大数据+中间件 平台特性:统一运维管理,管控节点压缩
满足生产级可靠性和 安全合规的要求
统一的管理运维系统, 和企业现有IT管理系统 无缝对接
向混合云 平滑演进
飞天平台整体架构
淘宝、天猫、支付宝、高德、菜鸟网络、阿里音乐等事业部 PaaS服务 微服务开发 框架服务 分布式数据 库服务 分布式消息 中间件服务 云服务总线 服务 数据交换服 务 DaaS服务 数据治理服 务 数据开放服 务 数据可视化 服务
解决数据 长效保存 及采集问题
解决数据 规范问题
解决数据 交换及安全问题
解决技术 转化输出问题
飞天平台:由实践锤炼而来
天猫 支付宝
17.5万笔/秒订单
12万笔/秒支付
2017天猫 11.11 购物狂欢节 1682亿元总成交额
阿里云专有云:让每个企业都拥有自己的飞天
专有云 公共云
北京,杭州,上海,青岛 深圳,香港,新加坡
《阿里大数据架构》课件

2
阿里云实时计算引擎
阿里云实时计算引擎是一种实时数据分析和计算平台,提供实时数据处理和实时 智能服务。
3
TensorFlow在阿里的应用
阿里巴巴广泛使用TensorFlow进行机器学习和深度学习,在智能推荐和图像识 别等领域取得了重要成果。
大数据平台管理
阿里巴巴大数据 平台管理的架构
阿里巴巴建立了一套完善 的大数据平台管理架构, 实现了数据的集中管理和 资源的统一调度。
Storm流式计算引擎
Storm是一种分布式的实时流 式计算引擎,用于处理和分析 高速数据流。
Flink在流处理中的应用
阿里巴巴使用Flink进行实时流 处理,通过流计算实现业务实 时监控和分析。
实时智能架构
1
实时智能分析的概念和应用场景
实时智能分析是基于实时数据进行智能挖掘和分析,用于实时推荐、智能广告等 应用。
2 阿里巴巴大数据安全架构设计
阿里巴巴通过建立严格的安全架构和流程,确保数据在收集、存储和处理过程中的安全。
3 阿里云数据加密解决方案
阿里云提供多种数据加密解决方案,保护数据的机密性和完整性,防止数据泄露和篡改。
流处理架构
流处理的定义和应用场景
流处理是一种实时处理数据的 方式,广泛应用于实时推荐、 欺诈检测和实时分析等场景。
数据的写入和读取。
阿里云OSS存储
阿里云对象存储(OSS)是一种安全 可靠、高扩展性的云存储服务,用于 存储和管理大规模的非结构化数据。
HBase列式数据库
HBase是一种分布式、可扩展的列式 数据库,用于存储和查询大规模结构 化数据。
数据安全
1 数据安全的重要性
在大数据时代,数据安全是保护个人隐私和企业利益的关键,需要采取有效的安全措施。
阿里巴巴大型网站架构演变和知识体系

阿里巴巴大型网站架构演变和知识体系之前也有一些介绍大型网站架构演变的文章,例如LiveJournal的、ebay的,都是非常值得参考的,不过感觉他们讲的更多的是每次演变的结果,而没有很详细的讲为什么需要做这样的演变,再加上近来感觉有不少同学都很难明白为什么一个网站需要那么复杂的技术,于是有了写这篇文章的想法,在这篇文章中将阐述一个普通的网站发展成大型网站过程中的一种较为典型的架构演变历程和所需掌握的知识体系,希望能给想从事互联网行业的同学一点初步的概念,文中的不对之处也请各位多给点建议,让本文真正起到抛砖引玉的效果。
架构演变第一步:物理分离webserver和数据库最开始,由于某些想法,于是在互联网上搭建了一个网站,这个时候甚至有可能主机都是租借的,但由于这篇文章我们只关注架构的演变历程,因此就假设这个时候已经是托管了一台主机,并且有一定的带宽了,这个时候由于网站具备了一定的特色,吸引了部分人访问,逐渐你发现系统的压力越来越高,响应速度越来越慢,而这个时候比较明显的是数据库和应用互相影响,应用出问题了,数据库也很容易出现问题,而数据库出问题的时候,应用也容易出问题,于是进入了第一步演变阶段:将应用和数据库从物理上分离,变成了两台机器,这个时候技术上没有什么新的要求,但你发现确实起到效果了,系统又恢复到以前的响应速度了,并且支撑住了更高的流量,并且不会因为数据库和应用形成互相的影响。
看看这一步完成后系统的图示:这一步涉及到了这些知识体系:这一步架构演变对技术上的知识体系基本没有要求。
架构演变第二步:增加页面缓存好景不长,随着访问的人越来越多,你发现响应速度又开始变慢了,查找原因,发现是访问数据库的操作太多,导致数据连接竞争激烈,所以响应变慢,但数据库连接又不能开太多,否则数据库机器压力会很高,因此考虑采用缓存机制来减少数据库连接资源的竞争和对数据库读的压力,这个时候首先也许会选择采用squid 等类似的机制来将系统中相对静态的页面(例如一两天才会有更新的页面)进行缓存(当然,也可以采用将页面静态化的方案),这样程序上可以不做修改,就能够很好的减少对webserver的压力以及减少数据库连接资源的竞争,OK,于是开始采用squid来做相对静态的页面的缓存。
读呗:一张图解密阿里巴巴大数据系统体系架构

读呗:一张图解密阿里巴巴大数据系统体系架构iwangshang / AliData / 2017-06-21摘要:阿里巴巴集团内,数据工程师每天要面对百万级规模的离线数据处理工作,他们是怎样做的?文 / AliData2014年,马云提出,“人类正从IT时代走向DT时代”。
如果说在IT时代是以自我控制、自我管理为主,那么到了DT(Data Technology)时代,则是以服务大众、激发生产力为主。
以互联网(或者物联网)、云计算、大数据和人工智能为代表的新技术革命正在渗透至各行各业,悄悄地改变着我们的生活。
在DT时代,人们比以往任何时候更能收集到更丰富的数据。
IDC 的报告显示:预计到2020年,全球数据总量将超过40ZB(相当于40万亿GB),这一数据量是2011年的22倍!正在呈“爆炸式”增长的数据,其潜在的巨大价值有待发掘。
数据作为一种新的能源,正在发生聚变,变革着我们的生产和生活,催生了当下大数据行业发展热火朝天的盛景。
但是如果不能对这些数据进行有序、有结构地分类组织和存储,如果不能有效利用并发掘它,继而产生价值,那么它同时也成为一场“灾难”。
无序、无结构的数据犹如堆积如山的垃圾,给企业带来的是令人咋舌的高额成本。
在阿里巴巴集团内,我们面临的现实情况是:集团数据存储达到EB级别,部分单张表每天的数据记录数高达几千亿条;在2016年“双11购物狂欢节”的24小时中,支付金额达到了1207亿元人民币,支付峰值高达12万笔/秒,下单峰值达17.5万笔/秒,媒体直播大屏处理的总数据量高达百亿且所有数据都需要做到实时、准确地对外披露……这些给数据采集、存储和计算都带来了极大的挑战。
在阿里内部,数据工程师每天要面对百万级规模的离线数据处理工作。
阿里大数据井喷式的爆发,加大了数据模型、数据研发、数据质量和运维保障工作的难度。
同时,日益丰富的业态,也带来了各种各样、纷繁复杂的数据需求。
如何有效地满足来自员工、商家、合作伙伴等多样化的需求,提高他们对数据使用的满意度,是数据服务和数据产品需要面对的挑战。
阿里的大数据架构课件

OSS对象存储系统
总结词
海量数据、安全可靠、低成本
详细描述
阿里云对象存储系统(OSS)是阿里云提供的一种海量数据存储服务,具有安全可靠、 低成本的特点。它采用分布式架构,能够应对海量数据的存储和访问需求,同时提供数 据加密、权限控制等功能,确保数据的安全性和隐私性。此外,OSS还提供了灵活的计
费方式和成本优化策略,帮助用户降低存储成本。
销售预测
通过分析历史销售数据,预测未来一段时间 内的销售趋势,为库存管理和采购决策提供 依据。
金融风控的数据处理
01
风险评估
对借款人的信用历史、资产负债 表等信息进行综合分析,评估借 款人的信用风险。
02
03
反欺诈检测
信贷决策
通过分析交易数据、用户行为等 数据,检测和预防金融欺诈行为 。
基于借款人的信用评估结果和其 他相关信息,决定是否发放贷款 以及贷款额度。
智能推荐的数据挖掘
个性化推荐
根据用户的兴趣、偏好和行为数据, 为用户推荐个性化的内容和服务。
广告精准投放
通过分析用户的行为和兴趣,将广告 投放到目标用户群体中,提高广告效
果和转化率。
市场细分
基于用户的行为和属性数据,将市场 划分为不同的细分领域,为产品定位
和市场策略提供依据。
07 总结与展望
阿里大数据架构的优势与挑战
02 阿里大数据架构概述
阿里大数据架构的发展历程
起步阶段
阿里早期的大数据架构主要依赖 于开源技术,如Hadoop,用于 处理和分析大规模数据。
升级阶段
随着业务的发展,阿里对大数据 架构进行了升级,引入了更多先 进的技术和解决方案。
领先阶段
目前,阿里的大数据架构已经处 于行业领先地位,为各种业务场 景提供了强大的数据支持。
阿里巴巴组织结构变革课件

变革的阶段和关键事件
关键事件
马云与18位创始人创立阿里巴巴 ,以B2B业务为主。
变革特点
灵活、创新,快速响应市场需求 。
变革的阶段和关键事件
关键事件
淘宝网快速发展,推出支付宝、阿里 云等业务。
变革特点
多元化、跨界整合,形成电商生态圈 。
变革的阶段和关键事件
关键事件
阿里巴巴集团上市,拓展海外市场,投资文化娱乐等领域。
阿里巴巴集团拥有庞大的员工队伍和多元化的业务板块,是全球最具影响力的电子 商务公司之一。
组织结构变革的背景和原因
随着公司规模的扩大和业务范 围的拓展,原有的组织结构已 经无法满足公司发展的需要。
公司需要更加灵活、高效的组 织结构来应对市场变化和竞争 压力,提高公司的运营效率和 创新能力。
组织结构变革是公司发展的必 然选择,也是公司长期稳定发 展的关键因素之一。
优点 灵活性:早期的组织结构相对简单, 能够快速响应市场变化和业务需求。
创新性:由于组织结构相对扁平化, 有利于激发员工的创新精神。
挑战
管理效率:随着业务规模不断扩大, 早期组织结构的管理层级较少,导致 管理效率低下。
资源分配:随着业务线增多,资源分 配成为一大挑战,需要更好地协调和 整合资源。
03
阿里巴巴组织结构变革 课件
目录 CONTENT
• 引言 • 阿里巴巴的早期组织结构 • 阿里巴巴的组织结构变革历程 • 阿里巴巴新的组织结构 • 阿里巴巴组织结构变革的影响和
启示
01
引言
阿里巴巴简介
阿里巴巴集团是中国最大的电子商务公司之一,成立于1999年,总部位于中国杭州 。
公司业务涵盖了B2B、B2C、C2C、云计算等多个领域,是全球最大的电子商务公司 之一。
阿里软件架构规划方案

阿里软件架构规划方案介绍阿里巴巴集团是全球领先的技术驱动型企业,为了支撑公司快速发展和成长,构建一个稳定、高效、可扩展的软件架构是至关重要的。
本文将讨论阿里巴巴软件架构规划方案,包括架构原则、技术栈选择和架构层次等内容。
架构原则阿里巴巴软件架构规划遵循以下原则:1.可靠性:软件架构必须具备高可靠性,能够保证系统的稳定运行。
阿里巴巴将采用分布式架构、容灾备份等技术手段,提高系统的可靠性。
2.可扩展性:软件架构必须具备良好的可扩展性,能够满足业务增长的需求。
阿里巴巴将采用微服务架构、容器化技术等,实现系统的弹性扩展和快速部署。
3.性能优化:软件架构必须具备高性能,能够满足大规模并发访问的需求。
阿里巴巴将采用分布式缓存、负载均衡等技术手段,提升系统的性能。
4.安全性:软件架构必须具备高安全性,能够保护用户和系统的信息安全。
阿里巴巴将采用安全加密、权限管理等技术手段,确保系统的安全性。
技术栈选择阿里巴巴在软件架构规划中选择了一些流行的技术栈,包括但不限于以下几个方面:1.分布式架构:阿里巴巴将采用分布式架构来构建系统,以实现高可用性和可扩展性。
常用的分布式架构包括微服务架构、分布式消息队列、分布式文件系统等。
2.容器化技术:阿里巴巴将采用容器化技术来实现快速部署和弹性扩展。
常用的容器化技术包括Docker、Kubernetes等。
3.大数据技术:阿里巴巴将采用大数据技术来处理海量数据和实现数据分析。
常用的大数据技术包括Hadoop、Spark、Hive等。
4.搜索引擎技术:阿里巴巴将采用搜索引擎技术来实现全文搜索和搜索推荐等功能。
常用的搜索引擎技术包括Elasticsearch、Solr等。
5.缓存技术:阿里巴巴将采用缓存技术来提高系统的性能。
常用的缓存技术包括Redis、Memcached等。
架构层次阿里巴巴软件架构分为以下几个层次:1.用户界面层:用户界面层是用户与系统交互的界面,包括Web界面、移动App界面等。
NoSQL发展历史与阿里巴巴架构演进分析
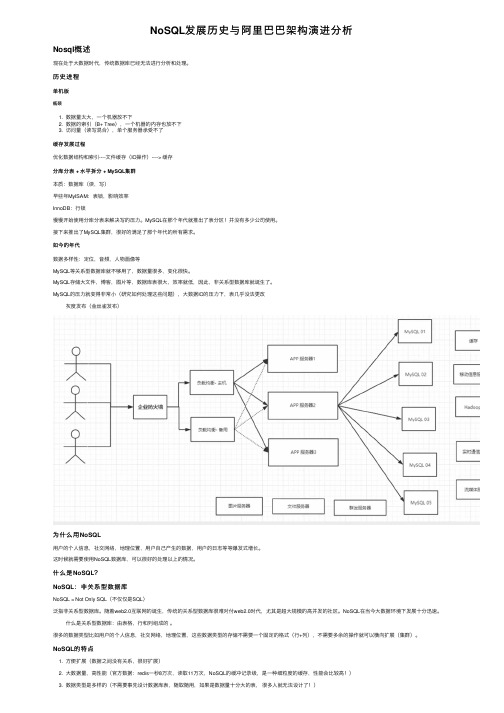
NoSQL发展历史与阿⾥巴巴架构演进分析Nosql概述现在处于⼤数据时代,传统数据库已经⽆法进⾏分析和处理。
历史进程单机版瓶颈1. 数据量太⼤,⼀个机器放不下2. 数据的索引(B+ Tree),⼀个机器的内存也放不下3. 访问量(读写混合),单个服务器承受不了缓存发展过程优化数据结构和索引----⽂件缓存(IO操作)----> 缓存分库分表 + ⽔平拆分 + MySQL集群本质:数据库(读,写)早些年MyISAM:表锁,影响效率InnoDB:⾏锁慢慢开始使⽤分库分表来解决写的压⼒。
MySQL在那个年代就推出了表分区!并没有多少公司使⽤。
接下来推出了MySQL集群,很好的满⾜了那个年代的所有需求。
如今的年代数据多样性:定位,⾳频,⼈物画像等MySQL等关系型数据库就不够⽤了,数据量很多,变化很快。
MySQL存储⼤⽂件,博客,图⽚等,数据库表很⼤,效率就低,因此,⾮关系型数据库就诞⽣了。
MySQL的压⼒就变得⾮常⼩(研究如何处理这些问题),⼤数据IO的压⼒下,表⼏乎没法更改灰度发布(⾦丝雀发布)为什么⽤NoSQL⽤户的个⼈信息,社交⽹络,地理位置,⽤户⾃⼰产⽣的数据,⽤户的⽇志等等爆发式增长。
这时候就需要使⽤NoSQL数据库,可以很好的处理以上的情况。
什么是NoSQL?NoSQL:⾮关系型数据库NoSQL = Not Only SQL(不仅仅是SQL)泛指⾮关系型数据库。
随着web2.0互联⽹的诞⽣,传统的关系型数据库很难对付web2.0时代,尤其是超⼤规模的⾼并发的社区。
NoSQL在当今⼤数据环境下发展⼗分迅速。
什么是关系型数据库:由表格,⾏和列组成的。
很多的数据类型⽐如⽤户的个⼈信息,社交⽹络,地理位置,这些数据类型的存储不需要⼀个固定的格式(⾏+列),不需要多余的操作就可以横向扩展(集群)。
NoSQL的特点1. ⽅便扩展(数据之间没有关系,很好扩展)2. ⼤数据量,⾼性能(官⽅数据:redis⼀秒8万次,读取11万次,NoSQL的缓冲记录级,是⼀种细粒度的缓存,性能会⽐较⾼!)3. 数据类型是多样的(不需要事先设计数据库表,随取随⽤,如果是数据量⼗分⼤的表,很多⼈就⽆法设计了!)4. 传统的RDBMS和NoSQL传统的RDBMS NoSQL结构化组织不仅仅是数据库SQL没有固定的查询语⾔数据和关系都存在单独的表中kv键值对存储,列存储,图形数据库,⽂档存储数据操作员,数据定义语⾔最终⼀致性严格的⼀致性(ACID)CAP定理和 BASE理论(异地多活)基础的事务⾼性能,⾼可⽤,⾼可扩展了解3v+3⾼⼤数据时代的3v: 主要是描述问题的1. 海量Volume2. 多样Variety3. 实时Velocity⼤数据时代的3⾼:主要是对程序的要求1. ⾼并发2. ⾼可扩(⽔平拆分)3. ⾼性能(保证⽤户体验和性能)真正在公司中的实践:NoSQL+RDBMS⼀起使⽤阿⾥巴巴演进分析# 1. 商品的基本信息名称,价格,商家信息关系型数据库就可以解决了。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
MergeServer ChunkServer
应用接口
新挑战 新机遇 -- OceanBase
➢ 基于Paxos的高可用方案
以不可靠部件提供可靠服
小于半数的分区容忍性
较高的可用性(最大35s不可用)
强一致性
角色
异常描述
RootServer
宕机/程序异常退出
UpdateServer
宕机/程序异常退出
➢业务开发复杂度 路由,关联,聚合,订正
OceanBase
新挑战 新机遇 -- OceanBase
Quer y
增删改
Data
基线数据 (固态盘)
修改增量 (内存)
数据存储:多机磁盘 修改增量:单机内存
新挑战 新机遇 -- OceanBase
SQL SQL SQL SQL SQL SQL SQL SQL
新挑战 新机遇 -- 单元化
横跨三年的项目
探索 项目启动
2013-08 2013-05
同城两单元
攻坚 异地双活
2014-11 2014-08
双11洗礼
收尾 多地域,更远距离
2015-08
新挑战 新机遇
➢ 全网架构 资源限制, 一个城市已经不能满足需求 容灾,单地域机房风险
单元化
➢AliSQL 分表数量庞大 集群拆分接近极限
MergeServer
宕机/程序异常退出
ChunkServer
宕机/程序异常退出
主集群不可用
如出现机房断网情况
时间/影响 35S/不可用 25S左右/不可用 1分钟/少量读超时 1分钟/少量读超时 35s/不可用
新挑战 新机遇 -- OceanBase
2010.6 启动
2010
2014.2(v0.5)
2016 --
新机遇新挑战
淘宝初创
淘宝初创
……
ApacheAuction
pache Member
od_phpA4
M
od_php4A
pache
Search
Pear DMB
od_php4Apache
ar DBM
Pe
ar DBMod_php4
Pe
Pear DB
读
读写
读
MySQL Slave
复制
MySQL Master
MergeServer ChunkServer
MergeServer ChunkServer
Root Server
Update Server
MergeServer ChunkServer
基线数据
修改增量
配置管理
MergeServer ChunkServer
MergeServer ChunkServer
无限可能,尽在掌握
无冕之王-- AliSQL
…….
上百组
12年历程回顾
淘宝网创建
应用 Java 化改造
垂直拆分完成
硬件不断升级
第一次双十一 去IOE启动
支付宝完成去IE
2003 2004 2005 2006 2007 2008 2009 2010 2011 2012 2013 2014
引入小型机 引入Oracle
垂直扩展走到了极限 集中式,稳定性的挑战 ➢ 掌控力 闭源的Oracle 封闭的小机/存储
回首往事 –从 IOE 架构走向 AliSQL分布式架构
第一次推动中国数据库产业变革
➢ 获得无限掌控力 数据库限流 -- 第一次自己的命运自己掌握 热点更新优化 -- 定制优化热点商品减库存业务场景 线程池特性优化 -- 定制优化高连接数并发场景 专场7 数据库调优, 阿里巴巴 章颖强
单元内封闭
新挑战 新机遇 -- 单元化
对数据库的挑战及解法
➢中心及各个单元间数据拆分原则
数据买家维度拆分
➢数据质量保障
数据多点写入风险 单Байду номын сангаас间DRC数据复制
数据复制一致性,正确性 保障 专场13 阿里巴巴 钱在晨
新挑战 新机遇 -- 单元化
单元化效益 ➢稳定性
变更范围 故障恢复时间
➢伸缩能力
摆脱机房限制 伸缩规模再次增强
商品库完成去IOE
水平拆分完成 开始尝试MySQL
淘宝全网完成去IOE 支付宝 交易完成OB改造
新挑战 新机遇
➢ 全网架构 资源限制, 一个城市已经不能满足需求 容灾,单地域机房风险
单元化
➢AliSQL 分表数量庞大 集群拆分接近极限
➢业务开发复杂度 路由,关联,聚合,订正
OceanBase
新挑战 新机遇 -- 单元化
复制
MySQL Slave
淘宝初创
问题: ➢ 单机MySQL数据库迅速达到瓶颈
解法: ➢ MySQL迁移到Oracle,并逐步升级硬件,到小型机,
高端存储,最终形成IOE 架构
效果: ➢ 支撑了淘宝 2004 到 2009 发展高峰
辉煌时代--IOE
辉煌时代--IOE
问题: ➢ 扩展性、可用性
V0.1 支持淘宝收藏夹 V0.3 支持广告报表
V0.4 支持SQL
V0.5 支持支付宝交易 V1.0 全新架构发布 V1.0 支持淘宝交易
V1.x 全面覆盖
2011 2012 2013 2014 2015 2016 2017
阿里巴巴数据库体系结构的变化与展望
汇报人:
阿里数据库体系的四个时代
单机房 单个 应用 单机 MySQL
2003 -- 2004
淘宝初创
同城多机房 垂直拆分 商业 IOE
2005 -- 2010
辉煌时代
异地双活 单元化 AliSQL
2011 -- 2015
无冕之王
异地多活 云化 自研OceanBase
中心
接入层
中心服务层
cdn1
cdn2
。。。 cdnN
同步调用
单元1
接入层
异步消息
服务层
单元2
接入层
服务层
按用户分流 单元N
接入层
服务层
数据层
中心备份
数据同步
数据层
数据层
数据层
单元化
新挑战 新机遇 -- 单元化
对应用挑战的及解法
➢延迟同步调用的影响
同一机房0.2ms 同一城市1~5ms 跨城市5ms~100ms 几百次调用吞吐量下降 数据复制延迟问题